|
Опрос
|
реклама
Быстрый переход
OpenAI снова отложила выпуск «феноменальной» открытой ИИ-модели
12.07.2025 [11:31],
Павел Котов
OpenAI уже второй раз за это лето откладывает выпуск открытой модели искусственного интеллекта, сообщил генеральный директор компании Сэм Альтман (Sam Altman). Изначально планировалось выпустить модель на следующей неделе, но теперь было принято решение перенести релиз на неопределённый срок для проведения дополнительного тестирования на предмет безопасности. 
Источник изображения: Zac Wolff / unsplash.com «Нам нужно время, чтобы провести дополнительные проверки в области безопасности и потенциально высоких рисков. Сколько времени это займёт — пока не знаем. Мы верим, что сообщество создаст на базе этой модели отличные проекты, но после установки весовых коэффициентов изменить их уже будет невозможно. Это для нас новый опыт, и мы хотим сделать всё как следует», — написал Альтман в соцсети X. Выпуск открытой модели от OpenAI — одно из самых ожидаемых событий в сфере ИИ этим летом наряду с релизом GPT-5 от той же компании. В отличие от GPT-5, открытую модель можно будет скачать и запускать локально. Оба проекта должны продемонстрировать, что OpenAI остаётся ведущей ИИ-лабораторией Кремниевой долины. Сделать это становится всё труднее — в разработку собственных решений миллиарды долларов инвестируют xAI, Google DeepMind и Anthropic. Ожидается, что новая открытая модель OpenAI будет обладать аналогичными способностями к рассуждению, что и модели серии «o» из текущего ассортимента компании. OpenAI рассчитывает, что её проект станет лучшим среди всех доступных на рынке открытых ИИ-моделей. В июне, когда Альтман впервые сообщил о задержке, он отметил, что разработчикам удалось достичь «неожиданного и поразительного результата», однако подробностей тогда не привёл. «С точки зрения возможностей мы считаем эту модель феноменальной. Но планка для открытых проектов у нас высокая, и, по нашему мнению, нужно ещё время, чтобы убедиться: мы выпускаем продукт, которым действительно можем гордиться», — заявил накануне вице-президент OpenAI по исследованиям и руководитель проекта по разработке открытой модели Эйдан Кларк (Aidan Clark). Ранее также сообщалось, что руководство OpenAI обсуждало возможность подключения открытой модели к облачной инфраструктуре компании для обработки сложных запросов, однако будет ли реализована такая функция в финальной версии — пока неизвестно. Huawei откроет исходный код языка программирования Cangjie для конкуренции с Java и Swift по всему миру
02.07.2025 [13:18],
Павел Котов
Huawei Technologies объявила о намерении 30 июля открыть исходный код созданного в компании языка программирования Cangjie. Это очередная мера в стремлении Huawei добиться технологической самодостаточности — вчера стало известно, что Huawei сделала открытыми ряд своих ИИ-моделей. 
Источник изображения: huawei.com Открытый исходный код позволит сторонним разработчикам вносить изменения в работу программной платформы, устранять обнаруженные проблемы или расширять возможности языка программирования. Cangjie, получивший название в честь легендарного персонажа китайской мифологии, с которым связывают изобретение иероглифов, предназначается для «полного анализа сценариев», отмечает Huawei. Язык поддерживает функции искусственного интеллекта и безопасности, что делает его пригодным для написания широкого спектра приложений — в первую очередь для платформы HarmonyOS Next, выступающей как альтернатива Android. Huawei вела разработку Cangjie около пяти лет, предварительная версия Cangjie дебютировала в июне прошлого года. Язык позиционируется как конкурент Java, который используется в разработке для Google Android, и Swift, на котором пишут приложения для Apple iOS. Cangjie быстро завоевал популярность в сообществе разработчиков, и уже через несколько недель после его выхода были написаны более 10 000 тестовых версий приложений. В октябре прошлого года язык стал доступен для всех разработчиков HarmonyOS — на нём были написаны приложения для китайской службы доставки Meituan и платформы электронной коммерции JD.com. В III квартале Meituan намеревается выпустить приложение для курьеров, также написанное на Cangjie. Huawei приняла решение открыть исходный код Cangjie, наращивая усилия по выстраиванию собственной экосистемы ПО в условиях американских санкций. Сейчас HarmonyOS 5 работает на более чем 40 моделях устройств, в экосистеме зарегистрированы более 8 млн разработчиков, доступны более 30 000 приложений, рассказали в компании. Новый план Huawei по «захвату мира»: компания открыла исходный код своих ИИ-моделей
01.07.2025 [16:59],
Павел Котов
Huawei открыла исходные коды своих моделей искусственного интеллекта. Эта мера, уверены эксперты, поможет ей даже в условиях американских санкций выстраивать экосистему в области ИИ и расширять свою деятельность за рубежом. Об этом сообщает CNBC.  Накануне китайский технологический гигант объявил об открытии исходных кодов моделей ИИ серии Pangu и ряда технологий рассуждающего ИИ. Аналогичные решения всё чаще принимают и другие китайские компании — в тот же день Baidu перевела в разряд открытых свою большую языковую модель Ernie. Тем самым Huawei пытается закрепиться не только как разработчик собственно моделей, но и как игрок, присутствующий на всех этапах разработки ИИ и пытающийся преодолеть введённые США ограничения на экспорт чипов для систем ИИ. За последние годы Huawei превратилась из разработчика телекоммуникационных решений в технологического гиганта, охватившего программные и аппаратные средства для разработки ИИ, указывают опрошенные CNBC эксперты. Этот тезис подтвердила и сама Huawei, упомянувшая «стратегию экосистемы Ascend», призванную ускорить внедрение ИИ в «нескольких тысячах отраслей». Под маркой Ascend компания, в частности, выпускает ИИ-ускорители, которые в Китае считаются альтернативой оборудованию Nvidia — сама же Nvidia лишена возможности поставлять в страну свою передовую продукцию. Будучи открытыми, ИИ-модели Pangu выступят для разработчиков и предприятий стимулом использовать и другие продукты компании. Если Baidu, например, разрабатывает большие языковые модели общего назначения, Huawei занимается специализированными системами, в том числе для правительственных структур, финансового сектора и производства. По общему уровню ПО компания может уступать таким игрокам как DeepSeek и Baidu, но ей и не нужно состязаться с ними напрямую — её целью является скорее продажа оборудования. Huawei призвала разработчиков, корпоративных клиентов и исследователей по всему миру загружать и использовать её открытые продукты и оставлять на них отзывы, чтобы она могла улучшать свои модели. В перспективе компания намеревается наладить поставки ИИ-ускорителей и в другие страны. Hugging Face выпустила человекоподобного робота HopeJR всего за $3000
31.05.2025 [17:38],
Павел Котов
Платформа для разработчиков в области искусственного интеллекта Hugging Face выпустила двух новых человекоподобных роботов — проекты с открытым исходным кодом получили названия HopeJR и Reachy Mini. 
Источник изображений: Hugging Face HopeJR — полноразмерный человекоподобный робот, конструкция которого имеет 66 степеней свободы, то есть он может осуществлять 66 независимых движений, в том числе ходить и двигать руками. Reachy Mini — настольная машина, которая умеет двигать головой, говорить и слушать; она предназначена для тестирования приложений на основе искусственного интеллекта. Точных сроков поставки этих роботов в Hugging Face не назвали. Соучредитель и генеральный директор компании Клем Деланг (Clem Delangue), однако, уточнил в интервью TechCrunch, что к концу года компания планирует отгрузить хотя бы несколько единиц. В настоящее время все желающие приобрести роботов могут оставить заявку в списке ожидания. HopeJR будет стоить около $3000 за единицу, а Reachy Mini — в пределах от $250 до $300 в зависимости от пошлин.  «Важным аспектом является то, что у этих роботов открытый исходный код. Любой может собрать их, перестроить, понять, как они работают, и они доступны по цене, так что в сфере робототехники не будут доминировать несколько крупных игроков с опасными системами — "чёрными ящиками"», — отметил руководитель компании. Hugging Face пришла в это направление деятельности, поглотив стартап по разработке человекоподобных роботов Pollen Robotics. Компания заинтересовалась этой областью уже несколько лет назад. В 2024 году она представила пакет открытых моделей ИИ LeRobot для создания роботов, а в 2025 году выпустила обновлённую версию программируемого манипулятора SO-101, разработанную при участии французской компании The Robot Studio. Hugging Face также расширила объёмы данных для обучения LeRobot, добавив при поддержке стартапа Yaak обучающие массивы для беспилотного транспорта. К 50-летию Microsoft Билл Гейтс опубликовал «самый крутой код, который когда-либо писал»
03.04.2025 [16:18],
Павел Котов
Завтра, 4 апреля, корпорация Microsoft будет праздновать 50-летие. В честь этого события её основатель Билл Гейтс (Bill Gates) опубликовал исходный код интерпретатора Altair BASIC, который определил истоки компании. 
Источник изображения: gatesnotes.com «Прежде чем появились Office, Windows 95, Xbox или ИИ, был Altair BASIC. В 1975 году Пол Аллен (Paul Allen) и я создали Microsoft, потому что мы верили в свою идею компьютера на каждом столе и в каждом доме. Пять десятилетий спустя Microsoft продолжает изобретать новые способы сделать жизнь проще, а работу — более продуктивной. Заниматься этим 50 лет — огромное достижение, и у нас бы не получилось сделать это без таких невероятных лидеров как Стив Балмер (Steve Ballmer) и Сатья Наделла (Satya Nadella), а также тех, кто работал в Microsoft на протяжении многих лет», — написал в своём блоге основатель Microsoft. Он написал для компании немало кода, что отчасти способствовало её успеху в разработке ПО и сделало её одной из самых дорогих в мире. Но Altair BASIC он назвал «самым крутым кодом, который я когда-либо писал». Источником вдохновения для этого проекта послужил номер журнала Popular Electronics за январь 1975 года — на его обложке был компьютер Altair 8800, побудивший Гейтса заняться разработкой ПО. Он и Аллен обратились в выпустившую компьютер компанию MITS (Micro Instrumentation and Telemetry Systems) и предложили интерпретатор языка программирования BASIC для этой модели. Этот продукт позволил бы большому числу пользователей с лёгкостью создавать собственные программы, но Гейтсу и Аллену потребовались несколько месяцев, чтобы добиться этого результата. Altair BASIC стал первым продуктом, который Гейтс и Аллен разработали для новой компании, тогда называвшейся Micro-Soft, а от дефиса они избавились позже. Исходный код занимает 157 страниц — его можно скачать (PDF) и распечатать. OpenAI пообещала выпустить открытую рассуждающую ИИ-модель в ближайшие месяцы
01.04.2025 [16:34],
Павел Котов
«В ближайшие месяцы» OpenAI намерена выпустить открытую большую языковую модель искусственного интеллекта — она станет первой со времён GPT-2. Об этом говорится на специальной странице на сайте компании; здесь же размещена форма, которую предлагается заполнить «разработчикам, исследователям и всему сообществу». 
Источник изображения: Growtika / unsplash.com «Мы рады сотрудничеству с разработчиками, исследователями и сообществом, чтобы собрать мнения и сделать эту модель максимально полезной. Если вы заинтересованы дать обратную связь команде OpenAI, сообщите нам об этом [через форму] ниже», — говорится на сайте OpenAI. Дополнительно собрать отзывы и показать прототипы модели компания хочет на мероприятиях, которые проведёт сама. Первое через несколько недель пройдёт в Сан-Франциско, за ним последуют встречи в Европе и Азиатско-Тихоокеанском регионе. OpenAI приходится всё активнее отбивать атаки конкурентов, в том числе китайской DeepSeek, которые выпускают открытые модели ИИ. Конкуренты позволяют сообществу использовать эти системы как для экспериментов, так и в коммерческих целях. Значительные средства в разработку моделей семейства Llama вложила Meta✴✴ — в марте эти модели набрали более 1 млрд загрузок. Большую базу пользователей быстро собрала DeepSeek. «[Лично я считаю,] нам нужно выработать другую стратегию в отношении открытого исходного кода. Эту точку зрения в OpenAI разделяют не все, и сейчас это нашим приоритетом не является. [В будущем] мы станем выпускать лучшие модели, но наше лидерство станет меньшим, чем в предыдущие годы», — рассказал ранее глава OpenAI Сэм Альтман (Sam Altman). Новая открытая модель будет поддерживать функцию рассуждений, добавил он накануне в соцсети X. Компания проведёт все стандартные проверки, как перед выпуском коммерческих моделей, и ряд дополнительных, учитывая, что после выпуска пользователи начнут её дорабатывать самостоятельно. Развёртывать её будут крупные компании и правительственные учреждения, считает господин Альтман. Разработчики открытого ПО объявили партизанскую войну сборщикам данных для ИИ
28.03.2025 [11:22],
Павел Котов
Боты, которые массово собирают данные с веб-страниц для обучения и работы моделей искусственного интеллекта, становятся всё более ощутимой проблемой для владельцев сайтов. Некоторые разработчики начали давать отпор этим системам оригинальными способами, которые могут показаться наивными или ироничными, но во многих случаях они работают. 
Источник изображения: Ticka Kao / unsplash.com Атаке веб-сканера сегодня может подвергнуться любой сайт. Иногда сайты даже теряют работоспособность, но сильнее прочих страдают разработчики ПО с открытым кодом: на сайтах таких проектов выкладываются материалы для скачивания, но ресурсов у них меньше, чем у коммерческих проектов. Проблема в том, что ИИ-боты игнорируют директивы файлов robot.txt, в которых указываются запрещённые для сканирования разделы. В январе разработчик открытого ПО Се Ясо (Xe Iaso) опубликовал в блоге «крик о помощи», рассказав о неподобающих действиях AmazonBot. Этот бот неустанно бил по Git-серверу разработчика, устраивая настоящие DDoS-атаки. Он игнорировал директивы robot.txt, менял IP-адреса, подменял значения строки User agent и прибегал к другим уловкам. В итоге Ясо разработал программу Anubis, которая проводит проверку подключающихся к серверу Git клиентов — она блокирует ботов, но пропускает браузеры, которыми пользуются люди. Проект Anubis был опубликован на GitHub 19 марта, и всего за несколько дней он собрал 2000 звёзд, 20 участников и 39 форков. Успех программы указывает, что случай Ясо не уникален: на агрессивное поведение ИИ-ботов указал основатель и гендиректор платформы SourceHut Дрю ДеВолт (Drew DeVault), которому приходится от 20 % до 100 % рабочего времени тратить на защиту от веб-сканеров. Администратору проекта Linux Fedora Кевину Фензи (Kevin Fenzi) в какой-то момент пришлось полностью заблокировать Бразилию, а разработчик KDE Plasma Никколо Венеранди (Niccolò Venerandi) однажды временно заблокировал все китайские IP-адреса. В январе анонимный разработчик под ником Aaron выпустил решение под названием Nepenthes в честь кувшиночника — насекомоядного растения. Система заманивает ИИ-ботов в «лабиринт» бесполезного контента, заставляя их сканировать чушь. Аналогичное решение недавно представила Cloudflare — оно получило более очевидное название AI Labyrinth. Эта система подключается, когда боты не соблюдают директиву «no crawl», — в результате они попусту тратят время и ресурсы. Дрю ДеВолт вообще призвал бойкотировать все новомодные ИИ-инструменты, в том числе большие языковые модели, генераторы изображений и GitHub Copilot. Едва ли это случится в действительности, поэтому разработчикам открытого ПО приходится подключать смекалку. DeepSeek обновила открытую модель V3, улучшив её навыки программирования
25.03.2025 [12:59],
Владимир Мироненко
DeepSeek выпустила обновление ИИ-модели V3, получившее название V3-0324, которое, как сообщается, предоставляет лучшие возможности для программирования, одновременно устанавливая новые стандарты точности и эффективности, пишет Bloomberg. Обновление было опубликовано на платформе Hugging Face без официального анонса. 
Источник изображения: Solen Feyissa/unsplash.com Открытая ИИ-модель DeepSeek V3 была представлена в конце прошлого года. Модель построена на архитектуре Mixture of Experts (MoE, набор экспертов) с общим количеством параметров 671 млрд и 37 млрд параметров, активируемых на каждый токен. Как сообщила тогда компания, на обучение DeepSeek V3 ушло $5,5 млн, что значительно ниже расходов других технологических компаний, таких как OpenAI, на обучение аналогичных моделей. Спустя несколько недель DeepSeek выпустила открытую рассуждающую модель R1, которая, несмотря на скромный бюджет на разработку, превзошла ИИ-модель o1 от компании OpenAI в некоторых бенчмарках по ряду ключевых показателей. В январе 2025 года приложение DeepSeek опередило ИИ-чат-бот ChatGPT и вышло на первое место в рейтинге самых популярных бесплатных приложений в интернет-магазине Apple App Store в США. Достижения китайского стартапа вызвали вопросы у инвесторов по поводу обоснованности громадных затрат американских компаний на разработку ИИ-технологий, что привело к обрушению ИИ-рынка, в результате которого его участники столкнулись со значительным падением акций. В частности, лидер рынка Nvidia потеряла за день $593 млрд рыночной стоимости, что было крупнейшим однодневным падением в истории фондового рынка. Выход DeepSeek запустил тренд на открытый исходный код в сфере ИИ
24.03.2025 [17:36],
Владимир Мироненко
Китайские игроки ИИ-рынка, от крупных, таких как Baidu, до более мелких, таких как Manus AI, всё чаще прибегают к использованию в своих проектах модели лицензирования ПО с открытым исходным кодом, пишет CNBC. 
Источник изображения: Solen Feyissa/unsplash.com Тренд на использование открытого исходного кода для ИИ-моделей был инициирован китайским стартапом DeepSeek, выпустившим в начале года рассуждающую модель R1, бросив вызов американскому доминированию на рынке ИИ и обрушив акции ведущих технологических компаний. Также у инвесторов возникли вопросы по поводу огромных расходов компаний на разработку больших языковых моделей, поскольку DeepSeek добился успеха с гораздо меньшими затратами. По словам ряда аналитиков, наиболее значительным влиянием успеха DeepSeek на рынок стало ускорение внедрения ИИ-моделей с открытым исходным кодом. «Успех DeepSeek доказывает, что стратегии с открытым исходным кодом могут привести к более быстрым инновациям и широкому внедрению», — сообщила Вэй Сан (Wei Sun) из Counterpoint Research, отметив, что модель DeepSeek внедрили многие организации. 16 марта Baidu представила новую версию своей базовой ИИ-модели Ernie 4.5, а также новую рассуждающую модель Ernie X1, сделав их бесплатными для индивидуальных пользователей. Также Baidu планирует в конце июня выпустить серию моделей Ernie 4.5 с открытым исходным кодом. Эксперты отметили, что переход Baidu на открытый исходный код представляет собой более широкий сдвиг китайского ИИ-рынка, подразумевающий собой отказ от бизнес-стратегии, которая фокусируется на проприетарном лицензировании программного обеспечения. Лиан Цзе Су (Lian Jye Su), главный аналитик исследовательской и консультативной группы технологий Omdia, подчеркнул, что Baidu всегда придерживалась проприетарной бизнес-модели и выступала против открытого исходного кода, но такие компании, как DeepSeek, доказали, что Open Source-модели могут быть такими же конкурентоспособными и надёжными, как проприетарные.  DeepSeek R1 распространяется по лицензии MIT, которую Counterpoint описывает как одну из самых доступных и широко распространённых с открытым исходным кодом, допускающей неограниченное использование, модификацию и распространение ПО, в том числе в коммерческих целях. Хотя сама ИИ-модель DeepSeek бесплатна, стартап взимает плату за использование API, который позволяет интегрировать модели и их возможности в приложения других компаний. Однако её ценник рекламируется как гораздо более доступный по сравнению с последними предложениями OpenAI и Anthropic, чьи модели считаются «закрытыми», поскольку их наборы данных и алгоритмы недоступны широкой публике. Помимо Baidu, другие китайские технологические гиганты тоже стали предлагать Open Source-модели. Alibaba Cloud заявила в прошлом месяце, что открывает исходный код своих ИИ-моделей для генерации видео, в то время как Tencent выпустила в начале марта пять новых ИИ-моделей с открытым исходным кодом с возможностью преобразования текста и изображений в 3D-визуализацию. Этой тенденции также следуют небольшие фирмы в сфере ИИ. Китайская компания Manus AI, недавно представившая ИИ-агента, который, как утверждается, превосходит Deep Research от OpenAI, заявила, что перейдет на открытый исходный код. Zhipu AI, один из ведущих стартапов Китая в области ИИ, в этом месяце объявил на платформе WeChat, что 2025 год станет «годом открытого исходного кода». Рэй Ванг (Ray Wang), главный аналитик и основатель Constellation Research, сообщил ресурсу CNBC, что компании были вынуждены пойти на это после выпуска DeepSeek своих ИИ-моделей. «Поскольку DeepSeek бесплатный, никакие другие китайские конкуренты не смогут взимать плату за то же самое. Чтобы конкурировать, им придется перейти на модели бизнеса с открытым исходным кодом», — сказал Ванг. Тим Ванг (Tim Wang), управляющий партнёр технологического хедж-фонда Monolith Management, назвал происходящее на рынке ИИ «моментом Android», имея в виду, что когда Google сделала исходный код своей операционной системы доступным для всех, это способствовало инновациям и развитию экосистемы приложений, отличных от Apple. Вышел бесплатный графический редактор GIMP 3.0 — первое крупное обновление за семь лет
18.03.2025 [15:55],
Павел Котов
Вышла финальная версия бесплатного графического редактора GIMP (GNU Image Manipulation Program) 3.0 — он пришёл на смену GIMP 2.10, который появился в 2018 году. Программа получила множество заметных улучшений. 
Источник изображения: gimp.org Основной целью проекта GIMP 3.0 стала капитальная переработка пользовательского интерфейса программы, но появились и новые возможности. Переход на библиотеку GTK3 GUI помог улучшить механизмы масштабирования интерфейса на экранах высокого разрешения — в GIMP 2.10 это иногда было проблемой. Улучшились поддержка тёмной темы, эффекты движения и анимации интерфейса; усовершенствована поддержка планшетов; обновлённая программа получила нативную поддержку графической платформы Wayland на системах Linux. Разработчики усовершенствовали работу со слоями, цветом и текстом, расширился набор поддерживаемых форматов. Новую раскраску получил Вильбер (Wilber) — маскот GIMP. В новой версии редактора отпала необходимость постоянно изменять размер доступной рабочей области — можно смело рисовать за пределами холста, потому что программа сама подстроит его размер. Программа появилась в 1995 году. Семейство редакторов GIMP 1.X оставалось актуальным восемь лет; GIMP 2.X продержался долгих 20 лет; сейчас разработчики GIMP намереваются выпускать текущие обновления чаще — уже в течение года должен появиться GIMP 3.2. Новые функции с обновлениями будут появляться в более скромных объёмах, но пользователи смогут начинать работать с ними раньше. Google выпустила Gemma 3 — самую мощную модель ИИ для запуска на одной видеокарте
12.03.2025 [12:23],
Павел Котов
Google выпустила открытую модель искусственного интеллекта Gemma 3 — это новый представитель семейства моделей, на основе которых разработчики смогут создавать приложения, способные запускаться локально на рабочих станциях или даже смартфонах. Поддерживаются 35 языков, есть функции анализа текста, изображений и коротких видеороликов. 
Источник изображений: blog.google Google охарактеризовала Gemma 3 как «лучшую в мире модель для одного ускорителя» и заверила, что она демонстрирует результаты лучше, чем конкуренты от Meta✴✴, DeepSeek и OpenAI при работе на одной видеокарте; она оптимизирована для оборудования Nvidia и других ИИ-ускорителей. Обновился компонент анализа видео — теперь он поддерживает записи высокого разрешения и отличную от квадратной форму кадра; фильтр безопасности входных и выходных изображений ShieldGemma 2 реагирует на картинки деликатного характера и материалы с изображением жестокости. 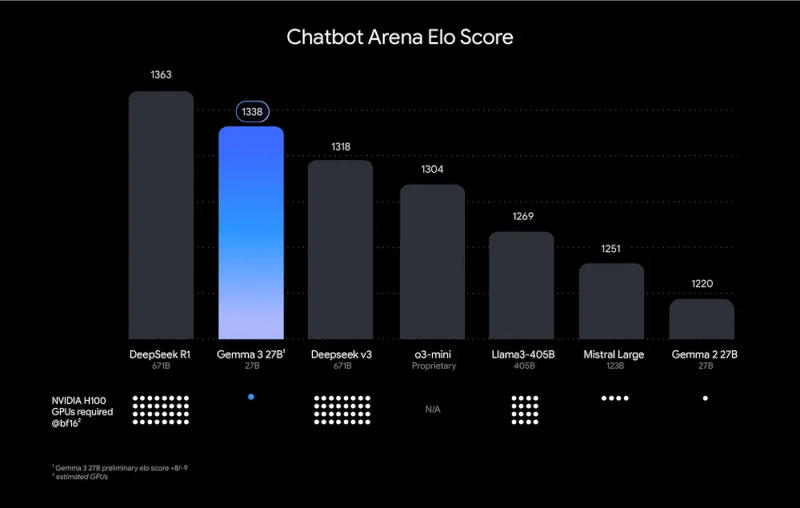 У Google это открытая модель ИИ уже третьего поколения, но потенциал этого направления помогла раскрыть китайская DeepSeek — её проекты продемонстрировали, что существует спрос на ИИ-решения с относительно невысокими системными требованиями. У Gemma 3 отмечаются значительные познания в области технических дисциплин, и Google провела дополнительное тестирование на возможность нецелевого использования модели, например, для создания вредных веществ — вероятность сбоя защитных механизмов в компании оценили как невысокую. Открытая лицензия Gemma 3 на деле является ограниченной: Google указала, для чего её разрешено использовать. Новая модель доступна, в частности, в Google Cloud. В рамках академической программы можно подать заявку на получение кредитов на сумму $10 000, если она будет использоваться в исследовательских целях. Alibaba представила «думающую» ИИ-модель QwQ-32B, которая лучше DeepSeek R1
06.03.2025 [13:07],
Владимир Мироненко
Китайская компания Alibaba Group Holding представила модель QwQ-32B на основе искусственного интеллекта (ИИ) с открытым исходным кодом со способностью к рассуждениям, которая, по словам разработчиков, превосходит DeepSeek R1 по быстродействию в ряде областей, используя гораздо меньше ресурсов. 
Источник изображения: Alibaba Group Holding После этого анонса акции Alibaba выросли на 7,5 % на торгах в Гонконге, что является самым большим внутридневным ростом почти за две недели. Новая ИИ-модель Alibaba имеет 32 млрд параметров и превосходит DeepSeek R1 с 671 млрд параметров в таких областях, как математические вычисления, написание программного кода и решение общих вопросов. По словам команды разработчиков, меньшее количество параметров позволяет модели работать с меньшими требованиями к вычислительным ресурсам, что способствует её более широкому внедрению. Для повышения производительности модели рассуждений разработчики использовали обучение с подкреплением. Аналогичный подход использовала DeepSeek при разработке модели R1. Alibaba также заявила, что QwQ-32B превосходит модель OpenAI o1-mini с 100 млрд параметров. QwQ-32B доступна на Hugging Face, крупнейшей в мире платформе для ИИ-моделей с открытым исходным кодом. Протестировать её работу можно и через чат-бота Qwen. Там она представлена в списке моделей под названием QwQ-32B-Preview. Ранее Alibaba объявила о планах инвестировать более 380 млрд юаней ($52 млрд) в облачные вычисления и инфраструктуру ИИ в течение следующих трёх лет, что является крупнейшим проектом в сфере ИИ, который когда-либо финансировался одной частной компанией в Китае. Глава Alibaba Эдди Ву (Eddie Wu) заявил, что ключевой задачей компании является разработка ИИ общего назначения (Artificial General Intelligence, AGI), который он определил как рубеж, на котором ИИ сможет достичь 80 % человеческих возможностей. Alibaba снова ударила по OpenAI — вышел бесплатный ИИ-генератор реалистичных видео Wan 2.1
26.02.2025 [13:25],
Павел Котов
Китайский гигант в области электронной коммерции Alibaba сделал общедоступной разработанную им модель искусственного интеллекта для создания видео и статических изображений Wan 2.1. Этим шагом компания создала условия для её массового развёртывания и способствовала усилению конкуренции в области ИИ. 
Источник изображения: Alibaba Публикация ИИ-моделей с открытым исходным кодом — распространённый шаг в отрасли ИИ; одним из наиболее заметных игроков здесь стал стартап DeepSeek. Alibaba выпустила четыре варианта Wan 2.1: T2V-1.3B, T2V-14B, I2V-14B-720P и I2V-14B-480P — эти модели генерируют видео и статические картинки по текстовому запросу или по образцу, которым может служить изображение. Обозначения «1.3B» и «14B» указывают, что эти варианты содержат соответственно 1,3 млрд и 14 млрд параметров. Младшей модели T2V-1.3B для работы требуется всего 8,19 Гбайт видеопамяти, что делает её совместимой со многими потребительскими видеокартами. Разработчики заявляют, что эта модель может сгенерировать пятисекундный ролик в 480р на GeForce RTX 4090 примерно за 4 минуты (без оптимизаций). Модели доступны для пользователей по всему миру на платформах HuggingFace и ModelScope (входит в Alibaba Cloud) для академических, исследовательских и коммерческих целей. Последнюю версию модели ИИ для генерации видео Alibaba представила в январе — первоначально она называлась Wanx, впоследствии её переименовали в Wan. Проект получил высокую оценку в тестах Vbench, предназначенных для генераторов видео — в частности, она стала лидером по критерию взаимодействия объектов. Накануне Alibaba также выпустила предварительный вариант рассуждающей модели QwQ-Max, которая впоследствии также будет опубликована как проект с открытым кодом. В ближайшие три года компания намеревается вложить не менее 380 млрд юаней ($52 млрд) в поддержку облачных вычислений и инфраструктуры ИИ. «Небольшой, но искренний прогресс»: DeepSeek откроет для всех пять ИИ-репозиториев
21.02.2025 [17:47],
Владимир Мироненко
Китайский стартап DeepSeek объявил, что на следующей неделе сделает код своих моделей доступным для всех пользователей, подтвердив свою приверженность открытому исходному коду для технологий ИИ. 
Источник изображения: Solen Feyissa/unsplash.com Компания сообщила в соцсети X, что откроет исходный код пяти репозиториев, назвав это «небольшим, но искренним прогрессом», которым она делится «с полной прозрачностью». «Эти скромные строительные блоки в нашем онлайн-сервисе были задокументированы, развёрнуты и проверены на практике в производственной среде», — говорится в публикации DeepSeek. DeepSeek выпустила в прошлом месяце Open Source-модель DeepSeek R1 со способностью к размышлению, способную соперничать с ИИ-системами американских компаний по производительности, хотя на её создание ушло гораздо меньше средств. Это заставило инвесторов более критично относиться к отчётам разработчиков в сфере ИИ о затратах на развёртывание новых моделей. Приверженность DeepSeek открытому исходному коду отличает её от большинства фирм в сфере ИИ в Китае, которые, как и их американские конкуренты, предпочитают предлагать на рынке модели с закрытым исходным кодом, пишет Reuters. Основатель DeepSeek Лян Вэньфэн (Liang Wenfeng) сообщил в интервью китайским СМИ в июле прошлого года, что компания не считает коммерциализацию своих моделей ИИ приоритетом, и что открытый исходный код может стать своего рода «мягкой силой». «Когда другие следуют за вашими инновациями, это даёт глубокое чувство выполненного долга», — сказал Лян. Репозитории с открытым исходным кодом предоставят инфраструктуру для поддержки моделей ИИ, которыми DeepSeek уже публично поделилась, на основе существующих фреймворков Open Source-моделей. Ранее на этой неделе DeepSeek представила новый алгоритм Native Sparse Attention (NSA), разработанный для повышения эффективности обучения и инференса ИИ-моделей при обширном контексте. Чат-бот DeepSeek является самым популярным в Китае с 22,2 млн ежедневных активных пользователей по состоянию на 11 января, по данным Aicpb.com, что превышает 16,95 млн пользователей китайской платформы Douban. Основатель Pebble возобновит выпуск легендарных смарт-часов — у них будет экран E-Ink и открытое ПО
28.01.2025 [11:03],
Владимир Мироненко
Эрик Мигиковски (Eric Migicovsky), основавший 13 лет назад фирму по производству смарт-часов Pebble, которая впоследствии была продана компании Fitbit, а та — компании Google, решил возобновить производство легендарного носимого устройства. В ответ на его просьбу Google согласилась открыть исходный код Pebble OS и теперь Мигиковски создает компанию, чтобы продолжить с того места, на котором он остановился. 
Источник изображения: Pebble По словам предпринимателя, суть Pebble заключается в нескольких моментах. Смарт-часы должны быть необычными и забавными, и ощущаться как гаджет в важном смысле. Новые часы будут отображать уведомления, позволять управлять музыкой с помощью кнопок, обладать продолжительной автономностью и «не пытаться делать слишком много». Мигиковски решил не повторять прошлые ошибки и теперь будет владеть новой фирмой единолично, не занимая деньги у инвесторов, которые смогут воспользоваться своей властью и изменить компанию по своему усмотрению. Мигиковски заработал достаточно много денег на продаже в прошлом году компании Automattic своего стартапа, разработчика приложения для обмена сообщениями Beeper, а также будучи инвестором в Y Combinator, и их хватит на единоличный запуск нового проекта. У новой компании будет другое название, поскольку Google владеет торговой маркой Pebble. Сейчас с Мигиковски работает несколько сотрудников, занятых неполный рабочий день. Они размещают лист ожидания и подписку на новости на сайте RePebble. Как только у компании появится название и доступ ко всему ПО Pebble, она начнёт поставки новых носимых устройств, которые будут выглядеть, ощущаться и работать как прежние Pebble. 
Источник изображения: GSMArena.com С тех пор, как фирма Pebble прекратила существование, многое изменилось. На рынке смарт-часов лидируют Google, Apple и Samsung, предлагая носимые устройства, которые тесно связаны с другими гаджетами их экосистемы. Но, как утверждает Мигиковски, с момента появления Pebble не было ничего похожего на Pebble. «Из тех возможностей, которые я хочу от гаджета, например, хорошего экрана на основе электронной бумаги, длительного времени работы от батареи, хорошего и простого пользовательского опыта, невозможности взлома, просто ничего нет», — говорит он. Доказательством реальности своих планов предприниматель считает то, что до сих пор пользуется часами Pebble. Мигиковски также планирует стать частью более широкого сообщества разработчиков с открытым исходным кодом Pebble OS. Всё созданное компанией ПО будет с открытым исходным кодом. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



