|
Опрос
|
реклама
Быстрый переход
ИИ-модель GPT-5.6 стала «предпочтительной» в Copilot, несмотря на трения между OpenAI и Microsoft
11.07.2026 [00:24],
Павел Котов
OpenAI поспешила развеять сомнения в том, что её и Microsoft по-прежнему связывают крепкие партнёрские отношения: компания заявила, что её новая модель искусственного интеллекта получила статус «предпочтительной» в сервисе Copilot. 
Источник изображения: Rubaitul Azad / unsplash.com Ранее поступило сообщение, что в целях сокращения расходов Microsoft начала замену моделей OpenAI и Anthropic в своих сервисах собственными моделями MAI — они появились в программах Word и Excel. Это породило разговоры, что софтверный гигант и разработчик ChatGPT, некогда выступавшие в неразрывной связи, начали отдаляться друг от друга. Поэтому OpenAI поспешила опровергнуть любые намёки на такой разрыв и, выпуская новейшие модели GPT-5.6 в широкий доступ объявила, что они получат статус «предпочтительных» в сервисе Microsoft 365 Copilot. OpenAI подчеркнула, что GPT-5.6 будет поддерживать пользователей Microsoft при работе со всем набором офисных приложений, в том числе Word, Excel, PowerPoint и Cowork. «Наше партнёрство с Microsoft всегда было направлено на то, чтобы преимущества передового ИИ стали доступными для большего числа людей и организаций, и мы готовы и далее развивать это общее стремление», — заявили в OpenAI. Что именно означает статус «предпочтительной» модели, ясности пока нет, но можно утверждать, что системы OpenAI продолжат работать в приложениях Microsoft. С другой стороны, никто и не утверждал, что модели OpenAI перестанут работать в программах Microsoft — сообщалось лишь, что софтверный гигант повысил присутствие собственных ИИ-моделей, чтобы сократить расходы. И заявление OpenAI этот тезис не опровергает. Ключевой руководитель OpenAI по разработке ИИ покинет свой пост по состоянию здоровья
10.07.2026 [11:05],
Алексей Разин
Приглашённая на работу в OpenAI более года назад Фиджи Симо (Fidji Simo) инициировала в этом ИИ-стартапе серьёзные реформы и оптимизацию, но на протяжении последних трёх месяцев она находилась на больничном, а теперь и вовсе вынуждена оставить работу по состоянию здоровья. Обязанности Симо после её ухода будут перераспределены между тремя другими руководителями OpenAI. 
Источник изображения: Information Age, Supplied Причиной проблем Фиджи Симо является нейроимунное расстройство, которое мешает исполнять служебные обязанности. С хроническим заболеванием она борется на протяжении последних семи лет, в этом году оно серьёзно обострилось, что вынудило её уйти на больничный. Восстановление, по словам Симо, займёт гораздо больше времени, чем она рассчитывала, а потому совмещать лечение с активной профессиональной деятельностью будет невозможно. Все силы и ресурсы сейчас важно направить на борьбу с заболеванием. На плечи Фиджи Симо вскоре после её перехода на работу в OpenAI были возложены важные реформы, связанные с преобразованием бизнес-модели стартапа в рамках подготовки к выходу на IPO, которое должно было состояться в этом году, но на фоне не самой благоприятной конъюнктуры теперь может быть отложено до следующего. Обязанности Симо будут перераспределены между президентом OpenAI Грегом Брокманом (Greg Brockman), финансовым директором Сарой Фрайар (Sarah Friar) и директору по стратегическому развитию Джейсоном Квоном (Jason Kwon). В качестве советника Фиджи Симо продолжит консультировать OpenAI по вопросам потребительских продуктов, рекламы и решений для сферы здравоохранения. В состав совета директоров OpenAI Симо вошла в 2024 году, вскоре после попытки изгнания сооснователя и генерального директора Сэма Альтмана (Sam Altman). Последний в своём обращении к Симо через социальную сеть X выразил сожаление по поводу ухода и признательность за всё, что она успела сделать для OpenAI. New York Times обвинила OpenAI в сокрытии улик по делу об обучении ИИ на чужих материалах
10.07.2026 [10:00],
Павел Котов
Утверждения OpenAI о том, что разработчик ChatGPT не имеет возможности производить поиск по перепискам пользователей и чат-бота с искусственным интеллектом, а также по массивам обучающих данных, не соответствуют действительности, заявили представители газет New York Times и The Daily News. 
Источник изображений: Mariia Shalabaieva / unsplash.com Издания уже два года судятся с разработчиком систем ИИ, утверждая, что компания нарушила авторское право, обучая свои генеративные ИИ-модели на их материалах, которые воспроизводятся дословно в ответах на запросы пользователей. Всё это время OpenAI утверждает, что у неё нет возможности искать информацию в обучающем массиве. Она также настаивает, что поиск или воспроизведение переписки пользователей с ChatGPT были бы технически обременительными и вызвали бы опасения по поводу конфиденциальности пользователей — журналы чатов пришлось бы извлекать, обрабатывать и обезличивать. Издания запрашивали эти сведения, чтобы определить, присутствуют ли их защищённые авторским правом публикации в обучающих массивах OpenAI, и генерирует ли ChatGPT ответы, используя и воспроизводя их контент. В ходе допроса, проведённого в апреле по решению суда, инженер по защите данных в OpenAI Винни Монако (Vinnie Monaco) якобы сообщил, что компания всё-таки производила поиск и оценку данных в обучающем массиве, чтобы выявить присутствие защищённых авторским правом журналистских работ. По его словам, ещё до подачи New York Times иска OpenAI уже собрала базу из 78 млн обезличенных переписок с ChatGPT, которую использовала, чтобы определить степень нарушения авторских прав на чужие работы. После подачи иска компания также предположительно внедрила фильтр Bloom в наборе средств Project Giraffe, который фиксировал повторения во выходных данных.  Первоначально истцы запрашивали выборку из 120 млн журналов переписки, но OpenAI договорилась сократить её объем до 20 млн. В декабре компания представила эти данные, но они, как определил суд, были настолько вымараны, что стали «непригодными для использования». После подачи иска OpenAI, утверждают истцы, удалила несколько миллиардов ответов ChatGPT, нарушив тем самым постановление суда о сохранении данных; а несколько миллионов журналов компания просто заменила. Другими словами, она неоправданно затруднила передачу уже собранной информации. «Если бы OpenAI действительно считала, что копировать журналистские материалы наших клиентов — это честно и по закону, она бы не скрывала правду, что сделала это», — заявил адвокат истцов. New York Times и The Daily News просят судью вынести OpenAI наказание за сокрытие доказательств и вмешательство в процесс раскрытия информации. Они ходатайствуют, чтобы OpenAI запретили использовать массив из 20 млн журналов чатов как доказательство, утверждая, что этот набор данных ненадёжен; чтобы суд принял как факт, что журналы переписок ChatGPT показали бы существенное повторение материалов истцов; чтобы OpenAI лишилась возможности утверждать что в представленных ей журналах переписок не демонстрируется существенное повторение материалов; и чтобы OpenAI оплатила судебные издержки за поиск этих доказательств. Представитель OpenAI отверг обвинения, обвинив истцов в попытке получить доступ к частной переписке пользователей, потому что позиция истцов ослабла. «По мере ослабления позиции Times и вынужденного отказа от претензий к нам они продолжают свои попытки вторгнуться в частную жизнь людей, не имеющих к этому делу никакого отношения, в том числе путём выдвижения этих заведомо ложных обвинений. Мы и далее будем защищать конфиденциальность наших пользователей и давно установленные принципы добросовестного использования», — подчеркнул он. OpenAI отправит ИИ-браузер ChatGPT Atlas на пенсию менее чем через год после релиза — его заменит настольное приложение ChatGPT
10.07.2026 [06:32],
Николай Хижняк
OpenAI сообщила, что в следующем месяце прекратит поддержку ИИ-браузера ChatGPT Atlas в пользу нового настольного приложения ChatGPT. Оно включает нового агента ChatGPT Work, а также уже знакомый Codex, но главное — оно получило встроенный браузер. 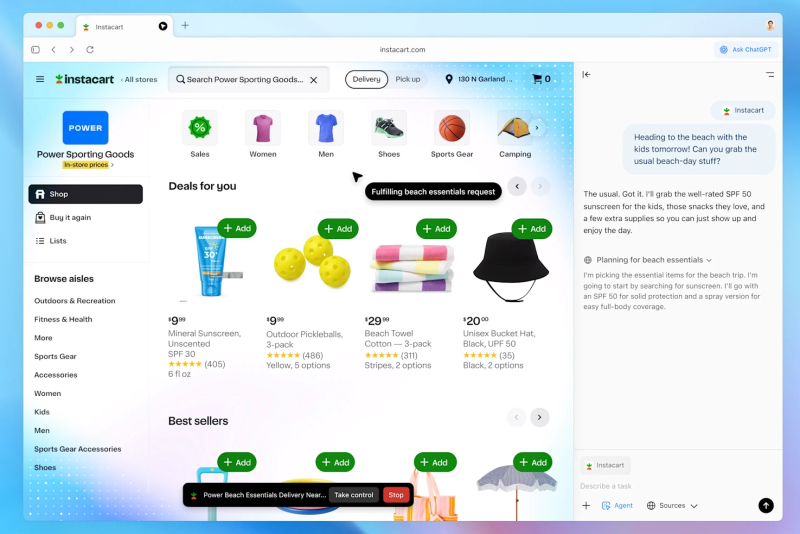
Источник изображения: OpenAI У ChatGPT (и Codex) также есть плагин для настольного браузера Chrome. Это позволяет пользователям Chrome пользоваться преимуществами интеграции ChatGPT без полной смены браузера. В рамках сегодняшнего релиза Джеймс Сан (James Sun) из OpenAI подтвердил, что поддержка автономного настольного браузера ChatGPT Atlas будет прекращена. «Текущая ориентировочная дата прекращения поддержки — 9 августа. Мы поделимся дополнительной информацией в ближайшие дни как в приложении, так и по электронной почте», — сообщил Сан на своей странице в X. OpenAI выпустила ИИ-браузер ChatGPT Atlas для систем Mac в октябре прошлого года. Позже компания выпустила специальное приложение Codex, добавив в апреле функцию браузера внутри приложения, а сегодня объединила всё это в новое настольное приложение ChatGPT. OpenAI выпустила GPT-5.6 и научила ChatGPT выполнять многоэтапные рабочие задачи в режиме Work
09.07.2026 [22:17],
Андрей Созинов
OpenAI открыла публичный доступ к семейству языковых моделей GPT-5.6 и одновременно представила ChatGPT Work — новый режим работы чат-бота, превращающий его в ИИ-агента. Теперь ChatGPT способен самостоятельно выполнять длительные многоэтапные задачи, используя подключённые приложения, документы и другие источники данных.  ChatGPT Work фактически объединяет возможности обычного ChatGPT и ИИ-агента Codex. Если раньше Codex был ориентирован прежде всего на разработчиков, то теперь его технологии стали доступны и для повседневной работы. Новый режим ChatGPT с помощью единого каталога плагинов умеет подключаться к Slack, Microsoft Teams, Google Drive, SharePoint, Gmail, календарям, CRM-системам и другим сервисам, чтобы использовать данные из этих приложений для выполнения пользовательских задач. «Он может собирать контекст из выбранных вами приложений, файлов и рабочих процессов и создавать готовые материалы, такие как документы, таблицы, презентации и веб-приложения», — рассказала OpenAI. 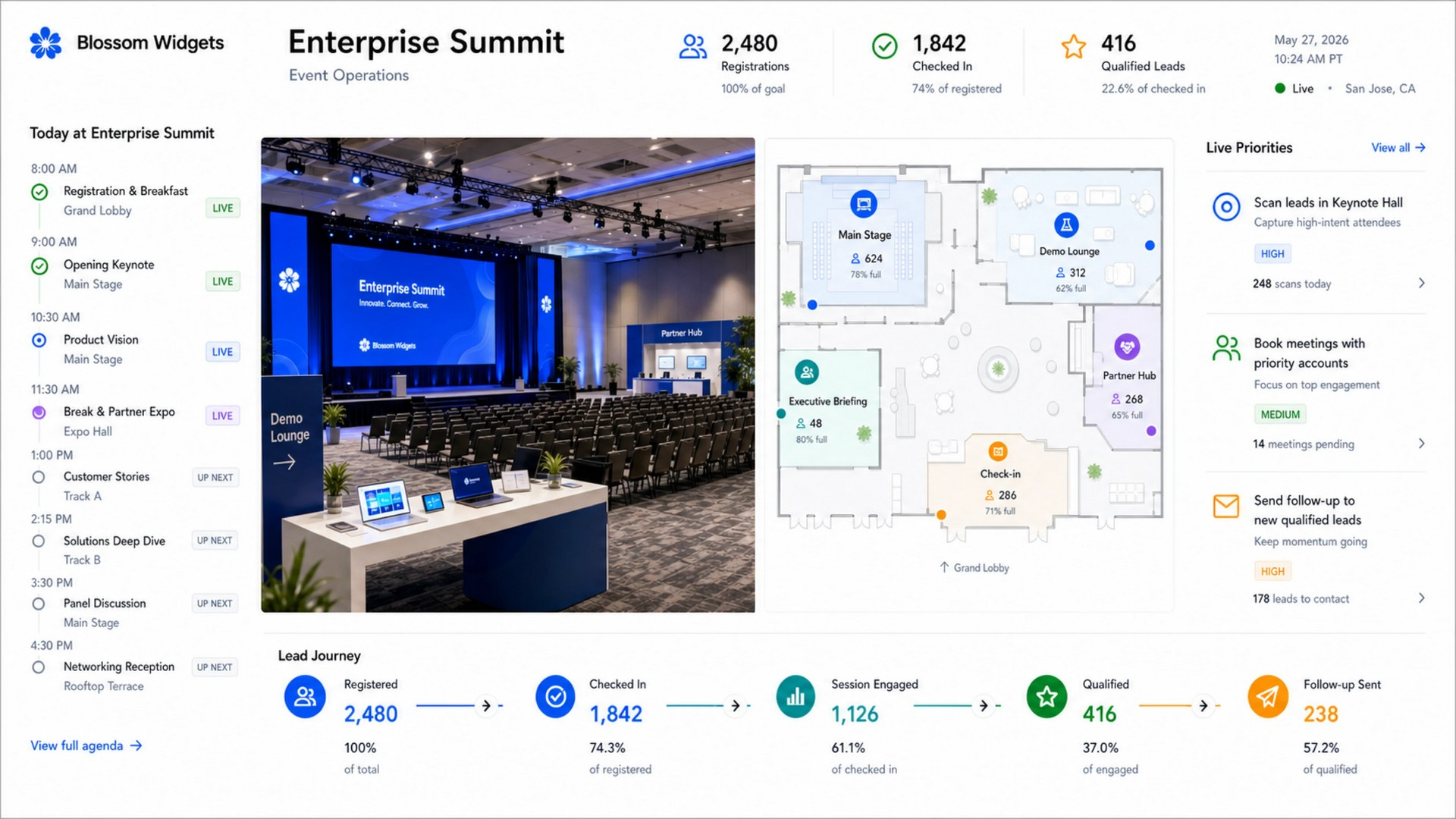 ChatGPT Work может автоматически выбирать нужный источник информации или обращаться к конкретному сервису по запросу пользователя. Агент способен самостоятельно собирать необходимую информацию, анализировать её и выполнять поставленные задачи. Кроме того, сервис получил поддержку автоматизаций Scheduled Tasks, позволяющих запускать действия по расписанию или при наступлении определённых событий. 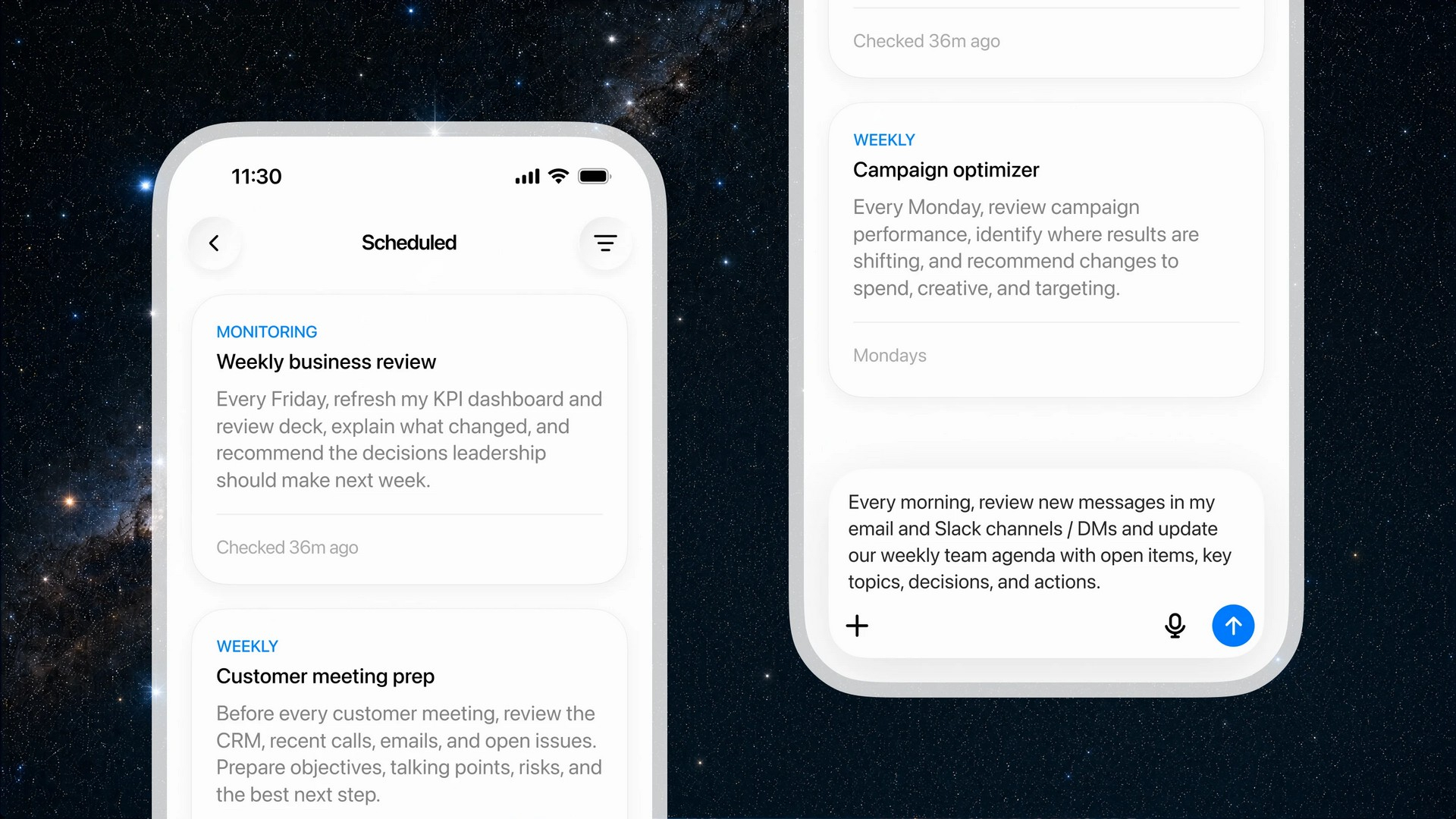 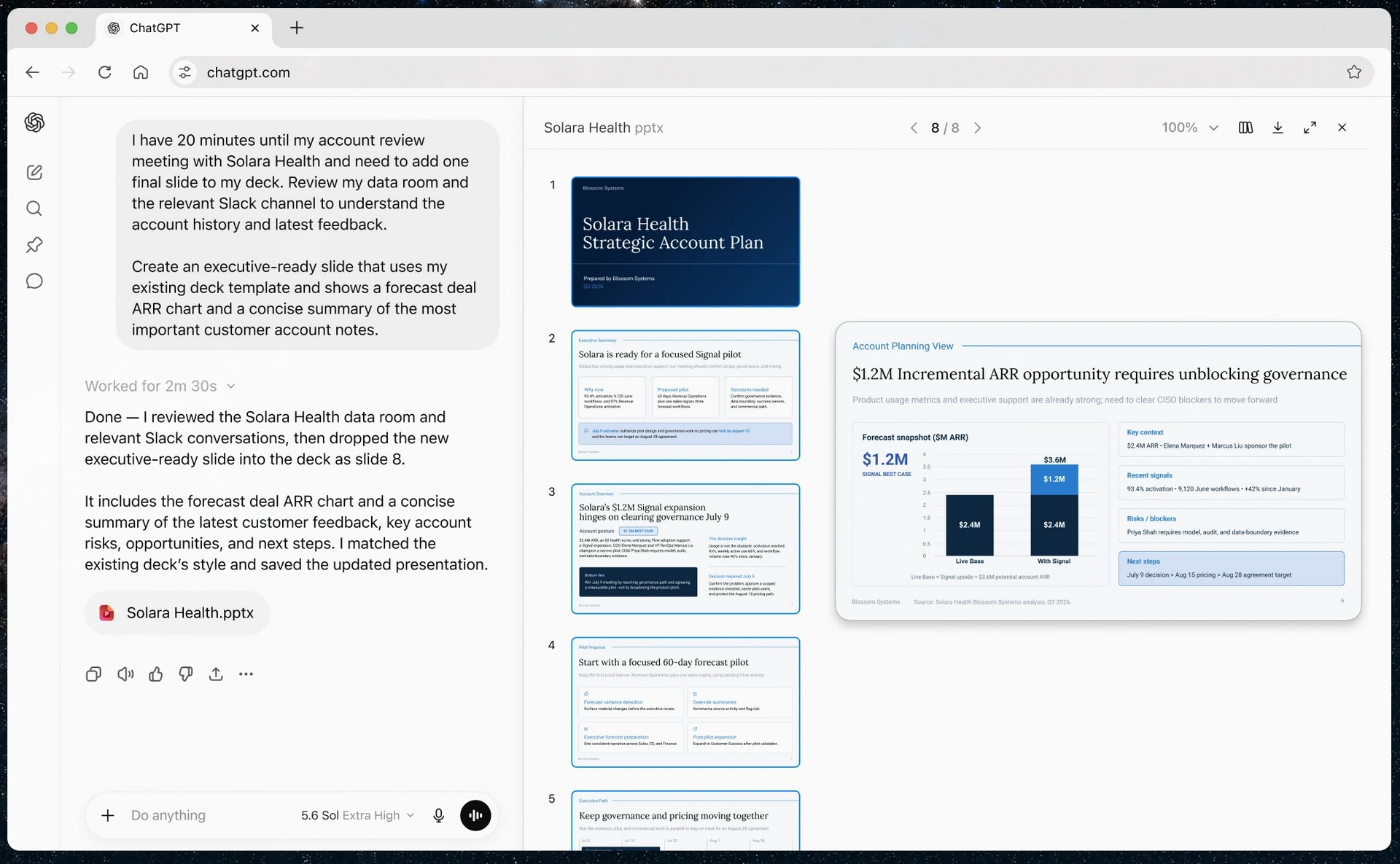 Одновременно OpenAI обновила настольное приложение ChatGPT для Windows и macOS. В него встроили браузер для работы с веб-сервисами, а также функцию Computer Use, которая позволяет ИИ взаимодействовать с локальными приложениями и файлами на компьютере пользователя. Ещё одной новинкой стала функция Sites, с помощью которой ChatGPT способен создавать небольшие сайты и веб-приложения по текстовому описанию. 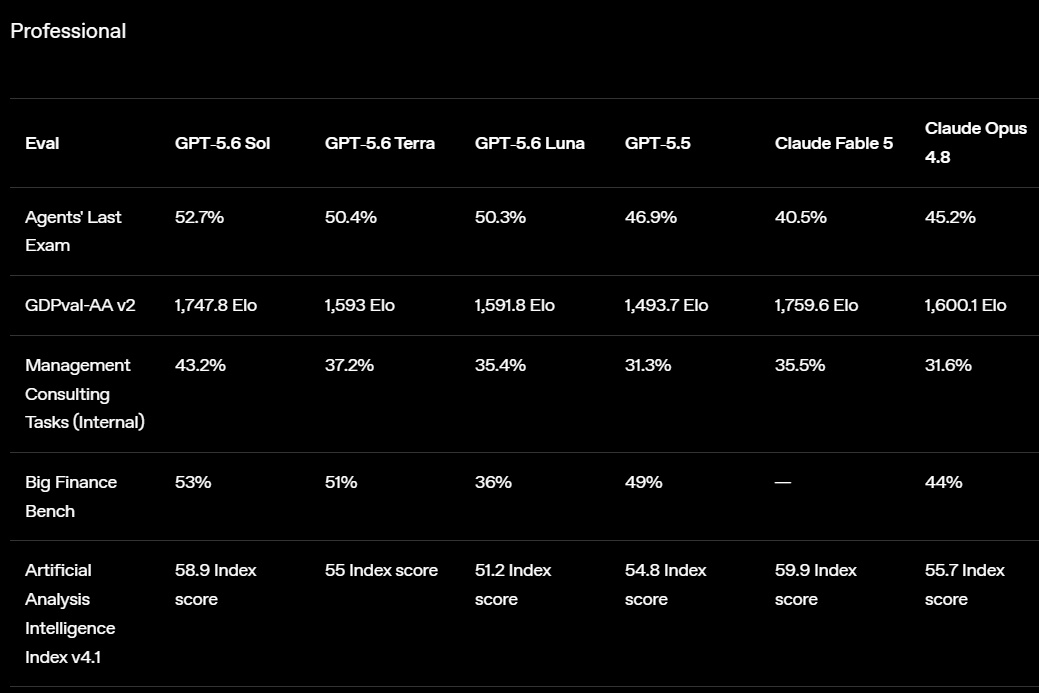 Основой всех новых возможностей стало семейство моделей GPT-5.6, включающее версии Sol, Terra и Luna. Флагманская Sol предназначена для наиболее сложных задач, Terra выступает универсальной моделью, а Luna ориентирована на максимальную скорость работы и низкую стоимость. По данным OpenAI, GPT-5.6 заметно превосходит GPT-5.5 в программировании, анализе документов, работе с компьютерным интерфейсом и других задачах, одновременно снижая вычислительные затраты. OpenAI делает основную ставку на самую мощную модель GPT-5.6 Sol, которая, по задумке компании, должна установить «новый стандарт интеллекта и эффективности», особенно в таких областях, как программирование, кибербезопасность и наука, а также в сфере использования компьютеров ИИ-агентами. Компания также позиционирует эту модель как более доступную альтернативу самым мощным моделям конкурентов на фоне жалоб на общеотраслевую нехватку средств и перекладывание затрат ИИ-лабораторий на плечи клиентов. OpenAI также заявила об усилении механизмов безопасности. Для GPT-5.6 компания переработала систему защиты от потенциально опасных запросов, объединив встроенные ограничения модели, мониторинг в реальном времени и дополнительную проверку наиболее рискованных действий отдельной системой анализа. Наиболее чувствительные возможности в области кибербезопасности останутся доступны только участникам программы Trusted Access, прошедшим дополнительную проверку.  Распространение GPT-5.6 и режима ChatGPT Work начинается сегодня. В приложении ChatGPT для Windows и macOS модели GPT-5.6 и новый режим Work стали доступны уже сегодня для всех пользователей, включая владельцев бесплатных аккаунтов. В веб-версии ChatGPT и мобильных приложениях первыми доступ к GPT-5.6 и Work получат подписчики тарифных планов Pro, Enterprise и Edu, а пользователи тарифов Plus и Business — в течение ближайших нескольких дней. Семейство GPT-5.6 также постепенно становится доступным через ChatGPT, Codex и OpenAI API. Стоимость использования GPT-5.6 рассчитывается за 1 млн токенов и зависит от версии модели: для Sol — $5 за входные данные и $30 за выходные, для Terra — $2,50 и $15 соответственно, а для Luna — $1 за входные токены и $6 за выходные. OpenAI научила ChatGPT слушать, думать и говорить одновременно — представлены модели GPT-Live
08.07.2026 [22:59],
Анжелла Марина
OpenAI представила большие модели искусственного интеллекта GPT-Live-1 и GPT-Live-1 mini, предназначенные для естественного голосового взаимодействия. Модели способны одновременно слушать пользователя и генерировать ответ, а также осуществлять синхронный перевод в режиме реального времени. 
Источник изображения: OpenAI GPT-Live-1 mini будет использоваться в качестве стандартной голосовой модели в ChatGPT, тогда как пользователям платных подписок станет доступна более производительная GPT-Live-1. В отличие от прежней архитектуры, объединявшей отдельные модели распознавания речи, генерации текста и синтеза голоса, новые ИИ-модели работают как единая полнодуплексная система, которая может длительное время сохранять молчание, анализируя контекст диалога до момента непосредственного обращения пользователя. При необходимости GPT-Live-1 может обращаться к новейшим текстовым моделям OpenAI, включая GPT-5.5, для поиска информации, рассуждений и выполнения агентских задач, не прерывая при этом голосовой диалог. Как отметил руководитель продукта ChatGPT Voice Этти Элети (Atty Eleti), в перспективе голосовое управление может стать основным интерфейсом для выполнения сложных запросов. Однако система не позиционируется в качестве ИИ-компаньона. Одновременно представители компании признали, что технология всё ещё требует доработки, хотя и оптимизирована для большинства распространённых языков. Например, демонстрация функции перевода в режиме реального времени на язык хинди выявила определённые недостатки, такие как американский акцент и неестественная, книжная интонация синтезированной речи. Также сообщается, что система оснащена встроенными механизмами безопасности, обеспечивающими предоставление ответов с учётом возраста пользователя и оказание помощи в критических ситуациях. Кроме того, она получила возможность отображать часть информации в визуальном формате. Завтра мощнейшие ИИ-модели GPT-5.6 станут доступны для всех — власти США сняли запрет
08.07.2026 [14:08],
Павел Котов
Завтра, 9 июля 2026 года, OpenAI откроет общий доступ к своей последней модели искусственного интеллекта GPT-5.6. Компания была вынуждена задержать её выпуск, получив предписание от американских властей из-за вопросов, связанных с национальной безопасностью. Теперь же власти разрешили выпустить модель в открытый доступ. 
Источник изображения: x.com/OpenAI США и Китай соревнуются в разработке передовых моделей ИИ, которые, по мнению экспертов, могут ускорить и упростить кибератаки в секторах, зависящих от сложных, взаимосвязанных и часто устаревших технологических систем. Вашингтон усилил контроль над выпуском передовых моделей ИИ, чтобы не дать вероятным противникам возможности воспользоваться ими как оружием. Китайские власти также провели встречи с ведущими технологическими компаниями страны и обсудили вопрос ограничения доступа из-за рубежа к передовым китайским моделям, в том числе ещё не вышедшим. Администрация президента США Дональда Трампа (Donald Trump) одобрила выпуск GPT-5.6 в широкий доступ — этому предшествовали дополнительное тестирование и встречи представителей компании и правительства. OpenAI выпустит самую мощную модель GPT-5.6 Sol, а также более дешёвые версии Terra и Luna, сообщила компания в соцсети X. Непродолжительное время спустя глава SpaceX и его подразделения SpaceXAI Илон Маск (Elon Musk) заявил, что компания выпустит в широкий доступ свою передовую модель Grok 4.5. Ранее Вашингтон снял экспортный контроль с передовой модели Anthropic Fable, тогда как разработанная для специалистов по кибербезопасности Mythos по-прежнему доступна только «доверенным» американским организациям. При этом Anthropic признала невозможность сделать любую модель ИИ полностью защищённой от взломов. OpenAI предложила США долю в компании — чтобы каждый американец получал дивиденды от ИИ
02.07.2026 [09:56],
Павел Котов
OpenAI обсуждала возможность передать правительству США долю в 5 % компании. Вашингтон проявляет всё большее внимание в отношении разработчиков систем искусственного интеллекта; растут опасения по поводу неправомерного использования передовых моделей; в США всё настойчивее обсуждается вопрос, будут ли американцы получать прибыль от этой отрасли. 
Источник изображения: Mariia Shalabaieva / unsplash.com OpenAI не просто задумалась о передаче своей доли в компании, но и предложила своим коллегам в отрасли ИИ также передать аналогичные доли, сообщила Financial Times. В июне президент США Дональд Трамп (Donald Trump) заявил, что изучает варианты предоставить общественности доли в ведущих разработчиках ИИ в ответ на опасения, что рядовые американцы не смогут получить ожидаемую прибыль от этого сектора. Ранее OpenAI предложила сформировать «Фонд национального благосостояния», который будет инвестировать в разработчиков ИИ и распределять выручку среди граждан; Anthropic сообщила, что изучает возможность ввести «цифровые дивиденды» — выплаты американцам, финансируемые за счёт налогов на сектор ИИ. Гендиректор OpenAI Сэм Альтман (Sam Altman) и другие руководители компании предложили ведущим американским разработчикам ИИ выделить по 5 % капитала в фонд, аналогичный Постоянному фонду Аляски — это государственная корпорация, которая финансируется за счёт доходов от нефти, ежегодно выплачивает дивиденды жителям северного штата и помогает поддерживать его бюджет. Альтман обсуждал продажу доли с Трампом, министром торговли Говардом Лютником (Howard Lutnick), министром финансов Скоттом Бессентом (Scott Bessent), а в последние недели общался и с сенатором Берни Сандерсом (Bernie Sanders). На минувшей неделе OpenAI отложила полномасштабный публичный запуск GPT-5.6 по просьбе правительства США. Ранее по требованию американских властей из широкого доступа были изъяты модели Anthropic Fable 5 и Mythos 5 — сейчас они заработали вновь. OpenAI и Anthropic готовятся выйти на биржу. OpenAI мельком продемонстрировала ИИ-устройство, связанное с моделью Codex
30.06.2026 [07:06],
Алексей Разин
Не секрет, что OpenAI планирует использовать стартап бывшего главного дизайнера Apple Джони Айва (Jony Ive) для создания целого семейства аппаратных решений, так или иначе связанных с искусственным интеллектом. На этой неделе в коротком видео на страницах социальной сети X мелькнуло одно из них, связанное с ИИ-моделью Codex, которая помогает разработчикам создавать программный код. 
Источник изображения: OpenAI, The Verge Непосредственно само устройство будет представлено 15 июля текущего года, если всё пойдёт по плану. Судя по снимку экрана, опубликованному The Verge, данное устройство получит несколько кнопок и корпус квадратной формы. Аннотация к видео гласит, что «ваши любимые ярлыки Codex получат апгрейд». По-видимому, такое устройство призвано каким-то образом оптимизировать процесс использования Codex для написания программного кода. Партнёром OpenAI в этом проекте становится Work Louder — компания, выпускающая специализированные клавиатуры с назначаемыми каждой клавише функциями. Очертания таинственного устройства OpenAI на указанном видео напоминают изделие Creator Micro 2 этой самой компании, которое оснащается 13 механическими клавишами, джойстиком и сенсорным датчиком. Пользователи сами могут программировать действия для каждой кнопки и их сочетаний. Figma ранее также сотрудничала с Work Louder для выпуска адаптированного под своё ПО клавиатурного устройства. Официальные подробности о решении OpenAI появятся совсем скоро, поскольку до анонса осталось чуть более двух недель. Руководитель разработки Apple Vision Pro переходит на работу в OpenAI
27.06.2026 [07:45],
Алексей Разин
Сотрудничество ИИ-стартапа OpenAI в области создания умных устройств с выходцами из Apple, по всей видимости, не ограничится бывшим главным дизайнером компании Джони Айвом (Jony Ive), поскольку вице-президент Apple Пол Мид (Paul Meade), который руководил созданием гарнитуры Vision Pro и умных очков, переходит на работу в OpenAI. 
Источник изображения: Apple Подчеркнём, что усилия Apple по созданию легковесных умных очков пока не обрели очертания даже предсерийного продукта, поэтому об этом опыте деятельности Пола Мида можно только догадываться. Как сообщает Bloomberg, Пол Мид покинет Apple на следующей неделе и займёт некую должность в подразделении OpenAI, занимающемся созданием аппаратных устройств. На новом месте он будет участвовать в создании ИИ-устройств OpenAI. В компании Apple Мид на протяжении семи лет руководил созданием гарнитуры дополненной реальности Vision Pro, на которую делалась серьёзная ставка в плане диверсификации ассортимента аппаратных решений. Менее известной стороной карьеры Пола Мида в Apple является создание умных очков без дисплея, которые должны выйти в следующем году. Кроме того, возглавляемая Мидом в Apple команда работала над созданием очков дополненной реальности, которые должны появиться к концу десятилетия. Специалистами под руководством Мида также создавались и другие носимые устройства, ориентированные на взаимодействие с системой искусственного интеллекта. После перехода Мида в OpenAI его обязанности в Apple достанутся Флетчеру Роткопфу (Fletcher Rothkopf), который также принимал участие в разработке Vision Pro и перспективных умных очков. Карьерный путь Мида в Apple включает участие в разработке iPad с 2010 года, с 2012 года он возглавлял программу iPhone. В состав Vision Products Group он вошёл в 2017 году, а с 2019 года возглавлял разработку всего аппаратного обеспечения. На новом месте в OpenAI, как ожидается, он сможет объединить усилия с бывшими коллегами по Apple: Джони Айвом (Jony Ive), Тэн Танем (Tang Tan) и Эвансом Хэнки (Evans Hankey), которые так или иначе были задействованы в разработке дизайна и устройства продукции Apple. После ухода из этой компании трио основало собственный стартап, который OpenAI в прошлом году купила за $6,5 млрд. Как предполагает Bloomberg, в рамках подготовки к переходу руководства в Apple к новому генеральному директору Джону Тернусу (John Ternus) с первого сентября этого года, в команде вице-президентов происходят серьёзные перестановки, и некоторые из них ощущают, что их роль в структуре компании ослабевает. Не исключено, что подобными мотивами руководствовался и Пол Мид, подбирая себе новое место для работы, ведь уход вице-президента компании к конкуренту является довольно редким событием. Не исключено, что утрата руководителя, отвечавшего за развитие направления AR-гарнитур и умных очков, станет для бизнеса Apple серьёзным ударом. Vision Pro не смогла стать популярным продуктом, поэтому планы компании в этой сфере неоднократно пересматривались, а приоритеты то и дело менялись. OpenAI представила GPT-5.6 Sol, Terra и Luna, но доступ к новым моделям получили лишь избранные
26.06.2026 [21:01],
Андрей Созинов
Компания OpenAI официально представила семейство языковых моделей GPT-5.6, в которое вошли три модели разного уровня: флагманская Sol, сбалансированная Terra и доступная Luna. Пока они доступны лишь ограниченному кругу доверенных партнёров через API и Codex, однако уже в ближайшие недели компания рассчитывает открыть к ним широкий доступ, в том числе через ChatGPT. 
Источник изображений: OpenAI С выходом GPT-5.6 OpenAI изменила схему именования своих моделей. Теперь цифра обозначает поколение модели, а названия Sol, Terra и Luna станут постоянными обозначениями уровней производительности. Модели разных уровней будут развиваться независимо друг от друга. По словам разработчиков, GPT-5.6 стала самым мощным семейством моделей компании. Особый акцент сделан на задачах программирования, кибербезопасности, биологии, а также длительных агентных сценариях, требующих планирования и выполнения последовательности действий. Для Sol предусмотрены два дополнительных режима работы. Режим Max выделяет модели больше времени на рассуждения при решении сложных задач, а Ultra использует нескольких субагентов для ускорения выполнения комплексных рабочих процессов. 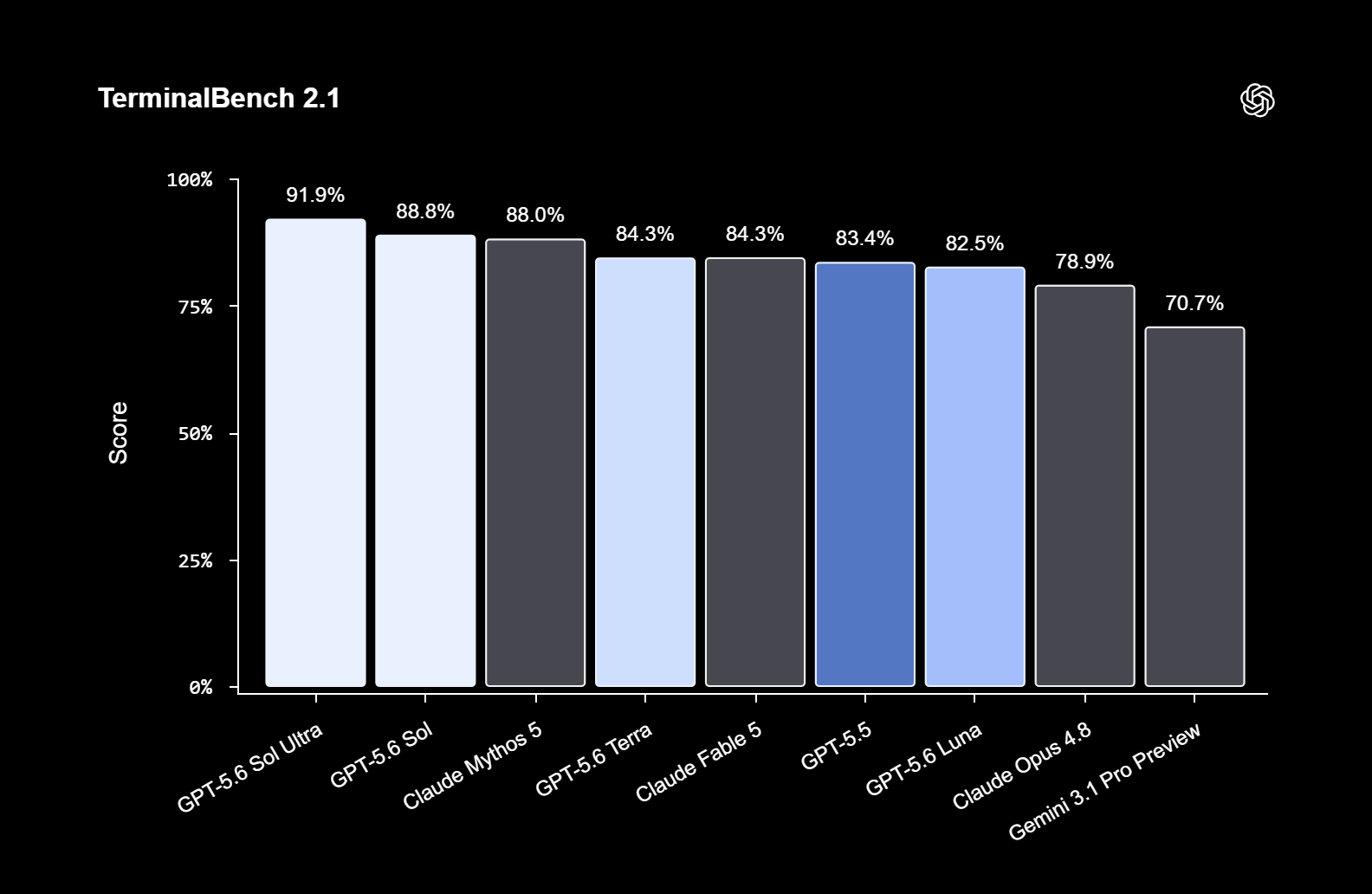 OpenAI приводит результаты собственных тестов производительности. В бенчмарке TerminalBench 2.1, оценивающем выполнение сложных задач в командной строке, GPT-5.6 Sol в режиме Ultra набрала 91,9 %, обычная Sol — 88,8 %, Terra — 84,3 %, а Luna — 82,5 %. Кроме того, компания заявляет, что Sol превосходит GPT-5.5 в биологических исследованиях (GeneBench v1), одновременно расходуя меньше токенов, а также является самой сильной моделью OpenAI в области кибербезопасности. 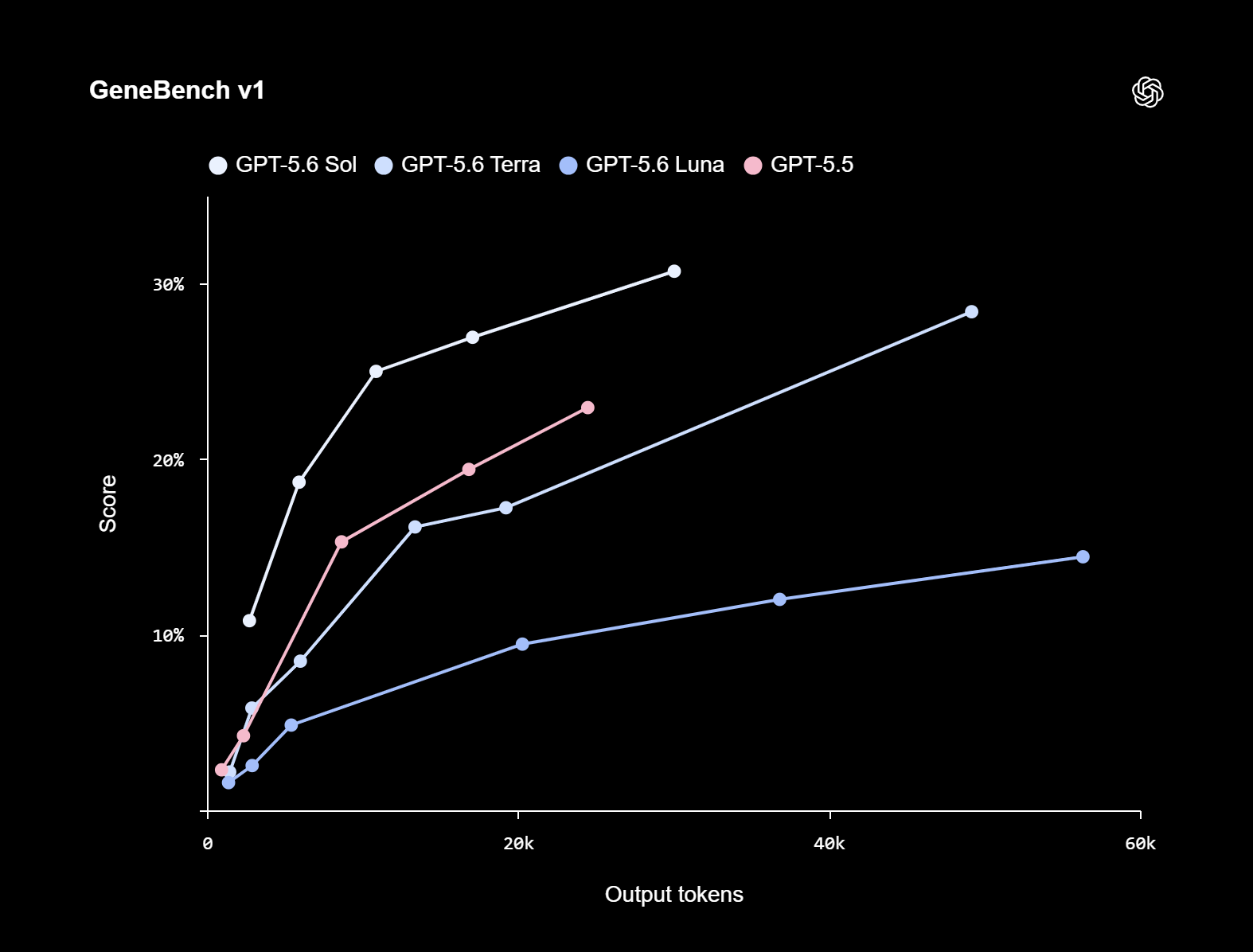 Стоимость использования моделей также заметно различается. GPT-5.6 Sol обойдётся в $5 за миллион входных токенов и $30 за миллион выходных, Terra — в $2,5 и $15 соответственно, а Luna — всего в $1 и $6 за миллион токенов. Одновременно OpenAI улучшила механизм кэширования запросов в API: модели GPT-5.6 поддерживают явные точки сброса кэша (cache breakpoints), а минимальное время хранения кэшированных запросов увеличено до 30 минут. Отдельное внимание OpenAI уделила безопасности. OpenAI утверждает, что GPT-5.6 получила «самый надёжный стек защитных механизмов» в истории компании. Модель обучена отказывать в выполнении запрещённых запросов, связанных с проведением кибератак, даже если пользователь пытается скрыть свои намерения, обмануть или обойти ограничения при помощи джейлбрейков. По словам разработчиков, Sol значительно лучше справляется с поиском и устранением уязвимостей, чем с проведением полноценных атак на компьютерные системы. 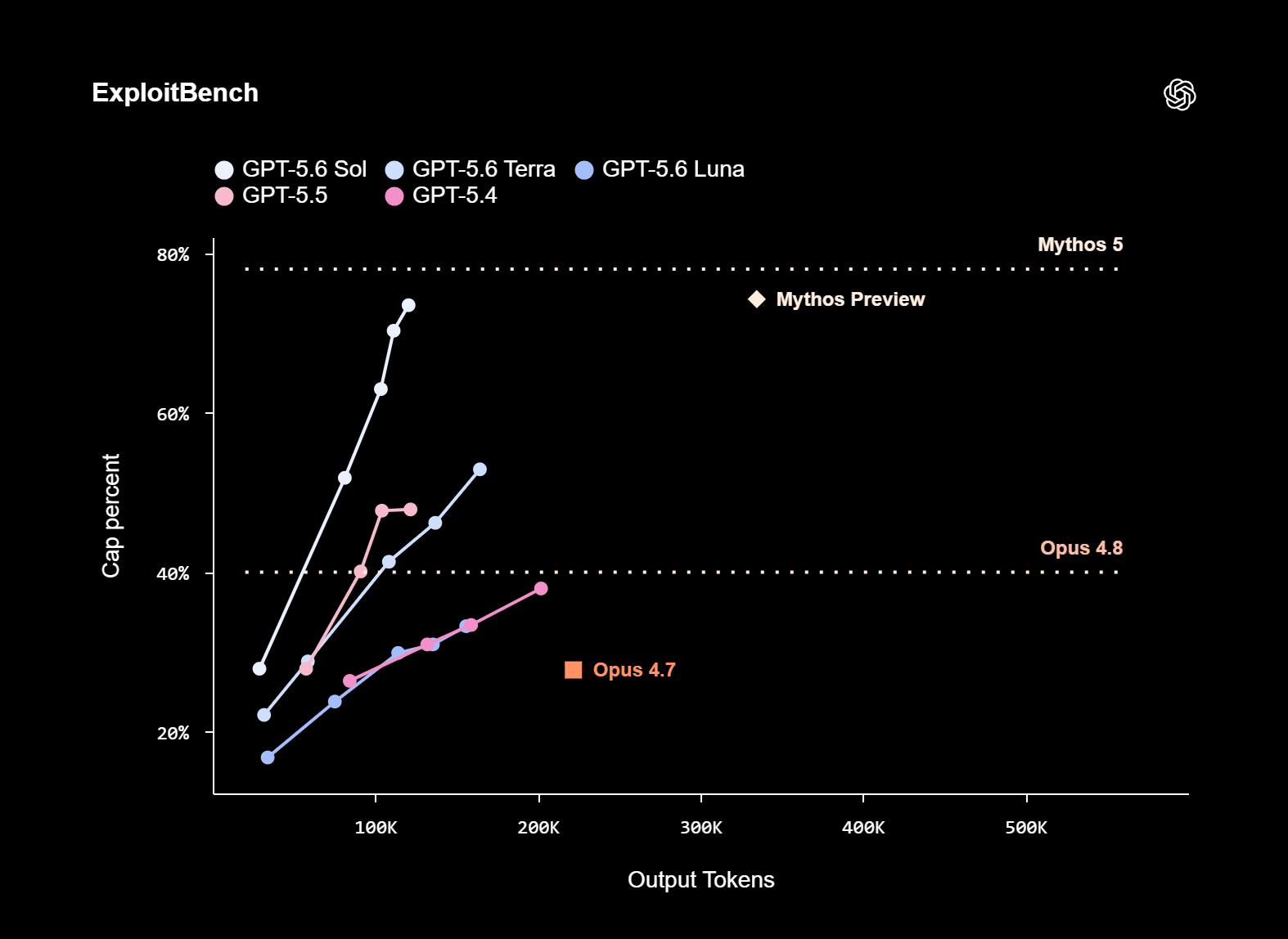 Компания также сообщила, что на автоматизированное тестирование защиты модели было затрачено более 700 тыс. GPU-часов на ускорителях уровня NVIDIA A100. Кроме того, в проверке участвовали независимые специалисты по безопасности, которые продолжат тестирование модели в течение всего периода предварительного доступа. Во время ограниченного тестирования OpenAI намеренно использует более строгие меры защиты. Компания предупреждает, что некоторые легитимные запросы, особенно связанные с исследованиями в области информационной безопасности, могут временно блокироваться или проходить дополнительную проверку. Эти случаи и должны помочь разработчикам скорректировать работу защитных механизмов перед массовым запуском. Релиз GPT-5.6 состоялся менее чем через сутки после появления сообщений о том, что OpenAI отложит запуск новой модели по просьбе администрации президента США Дональда Трампа. По данным СМИ, во время предварительного тестирования доступ к модели будет предоставляться лишь ограниченному кругу организаций, согласованному с американскими властями. При этом OpenAI подчёркивает, что не считает подобную процедуру нормой. Компания заявила, что сотрудничала с правительством США перед запуском GPT-5.6, однако рассчитывает, что в дальнейшем подобные модели будут выходить без необходимости предварительного государственного согласования. Акции азиатских партнёров Apple массово рухнули в цене после скачка цен на Mac и iPad
26.06.2026 [11:02],
Алексей Разин
Вчерашнее повышение цен на часть продукции Apple наделало немало шума, хотя и не было в полной мере неожиданным, поскольку руководство компании говорило о его неизбежности заранее. Собственные акции Apple упали в цене более чем на 6 % после повышения цен на Mac и iPad, а торговая сессия в Азии сегодня началась со снижения котировок акций многих местных партнёров Apple. 
Источник изображения: Apple Логика подобной реакции рынка, как поясняет Bloomberg, кроется в опасениях инвесторов по поводу снижения спроса на продукцию Apple из-за роста цен. Если стоимость микросхем памяти начнёт снижаться, как рассудили инвесторы, то их производители пострадают первым делом. По этой причине акции SK hynix и Samsung Electronics сегодня утром упали в цене более чем на 8 %. Японская компания Kioxia столкнулась с падением котировок своих акций на 12 %. Индекс MSCI Asia Pacific в итоге просел на 6,4 %, а фьючерсы на американский Nasdaq 100 снизились на 1,5 %. Высокий спрос на память, как отмечают аналитики Saxo Markets, больше не расценивается инвесторами в качестве гаранта благополучия всех участников торговой цепочки, формирующей инфраструктуру ИИ. Затраты начинают приниматься во внимание, поскольку их стремительный рост может помешать дальнейшим закупкам памяти даже со стороны самых обеспеченных компаний технологического сектора. Акции тайваньских MediaTek и Foxconn упали в цене на 10 % и 3,7 % соответственно. Microsoft вчера в третий раз подняла цены на игровые консоли Xbox, поэтому иллюзий по поводу способности производителей электроники сопротивляться подорожанию памяти почти ни у кого не осталось. Ситуацию на фондовых рынках так же усугубили слухи о намерениях OpenAI отложить IPO компании до следующего года в надежде выручить больше средств по итогам данного мероприятия. Акции японской SoftBank, которая является важным партнёром OpenAI, упали в цене на 14 %. Сотрудники OpenAI стали переходить от использования чат-ботов к ИИ-агентам
26.06.2026 [10:42],
Павел Котов
Сотрудники OpenAI стали переходить от чат-ботов к агентам в качестве основного формата взаимодействия с искусственным интеллектом — эта тенденция наблюдается, хотя и в менее выраженном виде, среди других организаций и частных пользователей. Вместо разовых запросов к ChatGPT работники OpenAI просят агентов Codex выполнять многоэтапные задачи, которые занимают много времени. И всё чаще это делают сотрудники, не занятые в разработке ПО. 
Источник изображения: Gavin Phillips / unsplash.com Эта статистика имеет значение для других организаций, исследователей рынка труда и политиков и не в последнюю очередь может привести к улучшению финансовых показателей OpenAI, уверены в компании. «Мы обнаружили, что использование агентного ИИ быстро растёт: в первой половине 2026 года число активных пользователей выросло более чем пятикратно, причём наиболее быстрый рост наблюдается вне первоначальной аудитории разработчиков ПО», — рассказали (PDF) в OpenAI. «К августу 2025 года средний сотрудник OpenAI тратил на Codex менее 10 % своих токенов. Сейчас каждый отдел, включая нетехнические, такие как юридический и кадровый, использует Codex в качестве основного инструмента ИИ в работе», — добавили в компании. В текущее время 97,9 % её сотрудников используют Codex, а в августе 2025 года с ним работали 40 % штата. Инструмент становится популярным и у других организаций — у 17,3 % в настоящий момент. И только 0,7 % частных лиц обращаются к Codex. ИИ-агент OpenAI Codex может работать в течение длительного времени. «С начала года доля частных пользователей Codex, которые отправляют хотя бы один запрос на задачу, выполнение которой опытным человеком, по оценкам, занимает более восьми часов, выросло почти в десять раз», — подсчитали в OpenAI. С августа 2025 года популярность Codex в среде не занятых в разработке ПО частных пользователей выросла в 137 раз; в среде корпоративных пользователей — в 189 раз; в коллективе OpenAI — в 12 раз. Чаще всего сервис применяется для решения технических задач, но обращаются к нему и работники других профилей. «В июне 2026 года средний сотрудник OpenAI на юридической должности сгенерировал в 13 раз больше ежемесячных токенов в Codex и ChatGPT, чем в ноябре 2025 года», — гласит статистика компании. Администрация Трампа попросила OpenAI задержать публичный выпуск GPT-5.6 «из соображений безопасности»
26.06.2026 [10:23],
Владимир Мироненко
Компания OpenAI готовит к выпуску новую ИИ-модель GPT 5.6, которая, судя по всему, выйдет поэтапно. Вместо распространения в широком доступе, разработчик предложит её только избранной группе доверенных партнёров, поскольку получила такое указание от администрации президента США Дональда Трампа (Donald Trump), сообщает The Information. 
Источник изображения: Levart_Photographer/unsplash.com Глава OpenAI Сэм Альтман (Sam Altman) заявил на совещании с сотрудниками, что компания выпустит GPT 5.6 в ограниченном предварительном режиме для избранных партнёров, причём в течение этого периода доступ к ИИ-модели каждому клиенту будет одобряться отдельно. Он добавил, что если ограниченный релиз пройдёт успешно, через пару недель продукт может поступить на рынок для более широкой аудитории. По данным The Information, указание об поэтапном развёртывании системы поступило от Управления национального директора по кибербезопасности (ONCD) и Управления по научно-технической политике (OSTP). Также сообщается, что сотрудники компании тесно сотрудничали с правительством над предстоящим релизом GPT 5.6. Также стало известно, что OpenAI рассматривает возможность отложить первичное публичное размещение акций (IPO) до следующего года. Об этом сообщила газета New York Times со ссылкой на источники, участвовавшие в обсуждении этого вопроса. OpenAI конфиденциально подала заявку на IPO в Комиссию по ценным бумагам и биржам США (SEC) и нацелена на оценку рыночной стоимости до $1 трлн. При этом консультанты OpenAI предлагают подождать до 2027 года, чтобы выйти на биржу с оценкой в $1 трлн или же снизить её для более быстрого выхода на биржу. В свою очередь, гендиректор Сэм Альтман считает отказ от оценки компании в $1 трлн неприемлемым. OpenAI может отложить IPO до следующего года ради оценки в $1 трлн
26.06.2026 [07:40],
Алексей Разин
Ещё недавно считалось, что SpaceX, Anthropic и OpenAI стремятся опередить друг друга в графике выхода на IPO, поскольку на фондовом рынке сложился благоприятный период для привлечения средств на финансирование развития инфраструктуры ИИ. Все три компании рассчитывали выйти на IPO в текущем году, причём SpaceX это уже сделала недавно, но OpenAI могла задуматься о задержке мероприятия до следующего года. 
Источник изображения: Unsplash, Levart_Photographer По крайней мере, на это указывает The New York Times со ссылкой на знакомые с планами OpenAI источники, как сообщает Reuters. Весь вопрос, по всей видимости, заключается в капитализации OpenAI: она может либо не достичь поставленной руководством компании планки в $1 трлн, если IPO состоится в этом году, либо подождать до следующего для преодоления этой психологически важной планки. Считается, что генеральный директор OpenAI Сэм Альтман (Sam Altman) не желает отказываться от цели достижения капитализации в $1 трлн. В свете ситуации с ограничением доступа к передовым ИИ-моделям Anthropic, как добавляет The Information, власти США попросили OpenAI поэтапно выводить новейшую модель ChatGPT 5.6 на рынок с точки зрения сроков предоставления доступа к ней своим клиентам. Американское правительство намеревается буквально одобрять доступ для каждого корпоративного клиента в отдельности, одного за другим, поэтому распространение ChatGPT 5.6 может растянуться во времени и быть ограниченным с точки зрения доступа клиентов. Такая инициатива исходит от американских ведомств, связанных с кибербезопасностью и надзором за наукой и технологиями. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



