|
Опрос
|
реклама
Быстрый переход
OpenAI обновила самую популярную LLM для ChatGPT, сделав её более удобной и приятной в общении
25.06.2026 [09:41],
Анжелла Марина
Компания OpenAI выпустила обновление для своей модели GPT-5.5 Instant, используемой в чат-боте ChatGPT. Разработчики заявляют, что новая версия стала лучше понимать сложные запросы и адаптировать ответы под конкретные задачи. 
Источник изображения: xAI Изначально представленная 5 мая модель GPT-5.5 Instant уже подвергалась доработкам, направленным на снижение количества избыточных эмодзи и улучшение читаемости текстов. Предыдущие правки, внесённые несколько недель назад, должны были сделать общение более естественным, а практическую помощь — более структурированной, избавив ответы от чрезмерной длины и излишнего использования маркированных списков. Текущее обновление смещает фокус, по словам разработчика, на более «приятный» диалог, повышая вовлечённость пользователя в процесс взаимодействия с ИИ. Платные подписчики сервиса получат доступ к новой версии GPT-5.5 Instant сегодня. Для пользователей бесплатного тарифа изменения станут доступны днём позже. OpenAI представила свой дебютный чип Jalapeno — он сулит удешевление работы ChatGPT
24.06.2026 [17:56],
Сергей Сурабекянц
Сегодня OpenAI сообщила о готовности первых образцов специализированного чипа Jalapeno для запуска уже обученных ИИ-моделей (инференса) и начале его тестирования. Компания рассчитывает получить дополнительное конкурентное преимущество за счёт адаптации оборудования под свои продукты. Чип создан в партнёрстве с Broadcom. По словам главы Broadcom Хока Тана (Hock Tan), он позволит сэкономить до 50 % ресурсов по сравнению с типичными графическими процессорами. 
Источник изображения: OpenAI В октябре OpenAI объявила о партнёрстве с Broadcom для разработки ускорителей, оптимизированных для работы с её моделями искусственного интеллекта. По словам OpenAI и Broadcom, новые чипы были разработаны с нуля в рекордно короткие сроки и способны обеспечить производительность на ватт энергии, которая «значительно превосходит современные аналоги» в инференсе. Финальные версии чипов будут использоваться в крупных дата-центрах Microsoft и других партнёров OpenAI, начиная с конца этого года. Чипы призваны повысить производительность ИИ-моделей за счёт уменьшения объёма передаваемых данных. Они разработаны с учётом особенностей использования вычислительных ресурсов, памяти и сетевого оборудования, наиболее важных для высококлассных моделей ИИ. Следующая версия Jalapeno запланирована на 2028 год. Партнёры не исключают появления в будущем чипов, рассчитанных на другие рабочие нагрузки. Тан ожидает, что OpenAI и Broadcom смогут превзойти его предыдущий прогноз по развёртыванию чипов искусственного интеллекта общей мощностью 1,3 ГВт в следующем году. «Мы хотим верить, что сможем добиться лучших результатов, потому что спрос очень высок», — заявил он. Глава подразделения аппаратного обеспечения OpenAI Ричард Хо (Richard Ho), отказался раскрыть механизм взаиморасчётов с Broadcom, отметив, что финансовые соглашения будут окончательно согласованы после полного выполнения заказа на чипы. Тан также отказался от комментариев, но подтвердил, что Broadcom создала механизм финансирования разработки чипов совместно с инвестиционными компаниями Apollo Global Management и Blackstone. C начала этого года OpenAI привлекла уже $122 млрд инвестиций для поддержки своих дорогостоящих проектов по разработке чипов, центров обработки данных и привлечению талантливых сотрудников. Затраты на разработку и выпуск собственных чипов увеличат и без того огромные расходы убыточного стартапа на физическую инфраструктуру для поддержки ИИ. Акции Broadcom после анонса процессора OpenAI выросли на 1,6 % до $386,25. С начала года они подорожали почти на 10 %. ИИ-агента OpenAI Codex уличили в порче SSD пользователей — он активно записывает лишние данные
24.06.2026 [14:06],
Павел Котов
У современных SSD ограниченный объём циклов записи, по исчерпании которого повышается вероятность выхода твердотельного накопителя из строя. И сейчас OpenAI пытается исправить некорректную реализацию логирования, из-за которой у пользователей сокращается срок службы SSD, что наносит их владельцам материальный ущерб. 
Источник изображения: Dima Solomin / unsplash.com Один из разработчиков, который активно пользуется сервисом OpenAI Codex подсчитал, что за 21 день работы на его SSD были записаны около 37 Тбайт данных, что примерно соответствует 640 Тбайт в год. Если участь, что у вышедшего в 2025 году SSD Samsung 9100 PRO объёмом 1 Тбайт ресурс записи составляет 600 Тбайт, получается, что гарантированный объём исчерпывается менее чем за год. Пользователи OpenAI Codex вывели формулу экономического ущерба, который причиняет сервис их SSD. Он оказывается равен числу Тбайт записанных данных × (цена SSD / ресурс SSD в Тбайт). Исходя из этой формулу при усреднённом ценнике $200 за накопитель лишний объём записанных 37 Тбайт данных обходится в $12,33, хотя сам OpenAI Codex насчитал пострадавшему ущерб в $38,64, исходя из стоимости его 2-терабайтного Samsung 990 NVMe. На уровне всех США объём ущерба с мая по июнь исчисляется миллионами долларов, говорят пользователи приложения. В OpenAI знают о проблеме, подтвердил представитель компании, и уже ведётся работа по её устранению. Сервис Codex записывает такие значительные объёмы данных, чтобы впоследствии инженеры компании могли легче диагностировать проблемы, но система стала проявлять на диске бо́льшую активность, чем ожидалось. Жалобы на некорректную работу приложения поступают в OpenAI через GitHub уже не первый месяц, компания уже проделала некоторую работу, но проблема пока не решена окончательно. OpenAI встроит в ChatGPT голосовую модель Bidi 1 — она может говорить и слушать одновременно
23.06.2026 [16:49],
Павел Котов
OpenAI намерена превратить ChatGPT в суперприложение, и сейчас в разработке находится очередная масштабная модернизация. Важнейшим компонентом обновления станет помощник программиста OpenAI Codex и инструменты агентов искусственного интеллекта. Кроме того, в приложении обнаружена двунаправленная аудиомодель GPT Bidi 1, призванная улучшить голосовые функции ChatGPT. 
Источник изображения: BoliviaInteligente / unsplash.com Название Bidi, как сообщается, означает «двунаправленный механизм» (bidirectional design), позволяющий ИИ слушать пользователя и одновременно говорить. Упоминания Bidi 1 обнаружены ещё на прошлой неделе — в коде модель характеризуется как «значительный скачок в интеллекте» и «голосовой интерфейс нового поколения». Bidi 1 будет доступна в списке выбора моделей наравне со стандартными и расширенными опциями; при её выборе значок «пузыря» становится жёлтым. 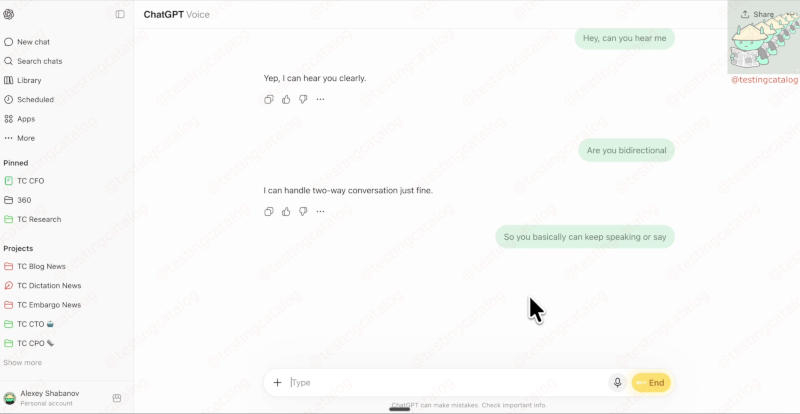
Источник изображения: x.com/testingcatalog Новая модель уже начала развёртываться в приложениях некоторых пользователей, и официального её выхода можно ожидать на текущей неделе, утверждают авторы ресурса TestingCatalog. Она поддерживает простые и естественные подтверждения, например, простое «окей», когда пользователь делает паузу или замедляет разговор, не прерывая его. Она также умеет переключаться между задачами на лету: модель можно попросить посчитать до десяти, прервать, чтобы изменить счёт — и та адаптируется. Важнейшим изменением станет то, что модель сохраняет нить всего разговора, не теряя предыдущего контекста, что было слабым местом ChatGPT. Она не пытается забить длительные паузы своими ответами. Bidi 1 можно рассматривать как возможность для OpenAI сократить разрыв между шагнувшими далеко вперёд текстовыми моделями и устаревшими голосовыми функциями. Компания делает ставку на то, что основным интерфейсом для большинства пользователей станет голос, а не текст. Официального анонса Bidi 1 пока не было, и подробной информации о новой GPT 5.6 разработчик пока не представил. OpenAI запустила инициативу Patch the Planet, чтобы помочь разработчикам открытого ПО в поиске ошибок
23.06.2026 [10:46],
Владимир Мироненко
OpenAI объявила о запуске инициативы Patch the Planet по исправлению ошибок в программном обеспечении с открытым исходным кодом в партнёрстве с компаниями в сфере кибербезопасности Trail of Bits, HackerOne и Calif. Цель состоит в том, чтобы оказать индивидуальную поддержку как можно большему количеству проектов с открытым исходным кодом для повышения их безопасности и долгосрочной устойчивости. 
Источник изображения: Mika Baumeister/unsplash.com «Patch the Planet — это масштабная интернет-инициатива, призванная помочь программному обеспечению с открытым исходным кодом опередить инструменты поиска ошибок, созданные искусственным интеллектом, — заявил гендиректор и соучредитель Trail of Bits Дэн Гуидо (Dan Guido). — Но это также попытка помочь сообществу разработчиков программного обеспечения с открытым исходным кодом увидеть преимущества, а не только недостатки инструментов для поиска ошибок, созданных ИИ». По словам руководителя отдела кибербезопасности OpenAI Фуада Матина (Fouad Matin), проект Patch the Planet нацелен на максимальную эффективность с точки зрения использования токенов, чтобы снизить нагрузку на сопровождающих open source-проекты, включая оценку кодовой базы, проверку потенциальных отчётов, создание патчей и их внедрение. «Мы хотим компенсировать затраты, будь то токены или рабочая сила, чтобы фактически исправить как можно больше ошибок в программном обеспечении», — добавил он. Также компания субсидирует использование сканера безопасности Codex Security, который находится в стадии предварительного тестирования с начала этого года, как для открытого, так и для частного кода «на сумму в 20 трлн токенов». Сообщается, что в Patch the Planet уже участвуют более 30 проектов с открытым исходным кодом, и ещё больше находятся в стадии подключения. По словам OpenAI и Trail of Bits, уже за первую неделю проект выявил сотни ошибок и позволил выпустить десятки патчей. Объявление OpenAI об инициативе поступило после того, как ее конкурент Anthropic закрыл доступ к передовым моделям Fable 5 и Mythos 5 из-за опасений администрации Трампа по поводу возможности их использования злоумышленниками в ущерб интересам национальной безопасности. OpenAI также представила в понедельник улучшенную версию ИИ-модели GPT-5.5-Cyber для поиска уязвимостей в ПО, которая набирает 85,6 % в бенчмарке CyberGym, что является улучшением по сравнению с предыдущей версией GPT-5.5-Cyber. Для сравнения, Mythos 5 от Anthropic набрала в этом бенчмарке 83,8 %. ChatGPT «по собственной воле» стал генерировать изображения интимного и насильственного характера
19.06.2026 [08:28],
Павел Котов
Последняя публичная версия чат-бота с искусственным интеллектом ChatGPT оказалась способной генерировать изображения деликатного характера или сцены насилия в ответ на простой запрос, установили исследователи из британской компании Mindgard. 
Источник изображения: BoliviaInteligente / unsplash.com Специалисты британского стартапа Mindgard, который занимается поиском уязвимостей в системах ИИ, нашли способ, как заставить ChatGPT создавать изображения с недопустимым содержимым, немного изменив некий широко распространённый запрос, первоначально разработанный для получения результатов юмористического характера. Особенно тревожным оказалось то, что в запросе не указывается тематика изображений, и ИИ «по собственной воле» создаёт явно недопустимые кровавые и деликатные изображения. В одном случае это был мужчина с серьёзной травмой головы, в другом — окровавленная женщина, на которой был минимум одежды. На изображениях присутствовали взрослые люди, чьи образы были сгенерированы ИИ, но, как показали предыдущие исследования Mindgard, ChatGPT можно обманным путём заставить создавать дипфейки реальных обнажённых людей, подставляя их лица. Не исключается, что ИИ способен создавать картинки ещё более шокирующего содержания, если исследователи потратят на эту задачу больше времени. Результаты работы ChatGPT отражают данные, которые использовались в его разработке и обучении — генерируемый ИИ недопустимый контент «имеет связи с реальными изображениями и реальным миром», подчёркивают эксперты. Результаты своей работы специалисты Mindgard раскрыли компании OpenAI в мае, но в ответ получили отписку. Когда инцидент был предан огласке, разработчик всё-таки отреагировал. «Изучив эту тенденцию, мы ввели дополнительные меры защиты от запросов такого рода. <..> Мы также сочетаем автоматизированные системы и проверку человеком для выявления и блокировки вредоносных материалов», — заявил представитель OpenAI и добавил, что в системах компании имеется многоуровневая защита, предназначенная для предотвращения показа пользователям изображений, нарушающих её политику. Исследователи, однако, обратили внимание, что и после внесения изменений ChatGPT в ответ на проблемный запрос по-прежнему выдавал вызывающий опасения контент. Содержание запроса по понятным причинам не раскрывается. Настоящая проблема в том, указывают эксперты, что модели ИИ не понимают, как люди, что они создают, и чего разработчики просят их не делать. «Модели не понимают намерений. Они не понимают контекста. Они не понимают принципов, правильного и неправильного», — напоминают учёные. Поэтому внедрение защитных механизмов и средств их обхода — это «игра в кошки-мышки»: по мере совершенствования одних более изощрёнными становятся и другие. Соруководитель Gemini Ноам Шазир покидает Google и переходит в OpenAI
18.06.2026 [12:08],
Владимир Фетисов
Вице-президент Google по инженерии и один из руководителей подразделения по разработке ИИ-моделей Gemini Ноам Шазир (Noam Shazeer) объявил о своём уходе из компании. Свою карьеру Шазир продолжит в OpenAI. 
Источник изображения: BoliviaInteligente / unsplash.com «Рад сообщить, что присоединяюсь к OpenAI, и с нетерпением жду возможности поработать с выдающейся командой этой компании. <…> Было непросто принять решение об уходе. Я невероятно горжусь потрясающей командой Google и всем, что мы создали вместе. Для меня было честью и удовольствием работать со всеми вами», — написал Шазир в своём аккаунте в социальной сети X. Уход Шазира из Google произошёл менее чем через два года после его возвращения в компанию. В 2021 году Шазир вместе со своим коллегой Даниэлем Де Фрейтасом (Daniel De Freitas) покинули Google, чтобы основать стартап Character.AI. В августе 2024 года оба инженера вернулись в Google и стали частью подразделения DeepMind. Переход Шазира в OpenAI подчёркивает, что ожесточённая борьба за лучших специалистов в сфере ИИ стала одним из ключевых факторов конкуренции технологических компаний. Новость об уходе Шазира появилась через несколько недель после запуска новых ИИ-продуктов Google, таких как модель Gemini 3.5 Flash и ИИ-агент Gemini Spark. Чистые убытки OpenAI выросли в восемь раз в прошлом году и достигли $38,5 млрд
16.06.2026 [10:59],
Алексей Разин
Многие стартапы длительное время остаются убыточными, но OpenAI с такой скоростью наращивает свои затраты, что разрыв между выручкой и убытками растёт пугающими темпами. По итогам прошлого года компания выручила всего $13,05 млрд, а её чистые убытки достигли $38,5 млрд. 
Источник изображения: Unsplash, Zac Wolff Об этом стало известно из официальных финансовых документов, на которые ссылаются ресурсы Financial Times и Where’s You Ed At. Приводится и отчётность стартапа за 2024 год, позволяя понять динамику изменения показателей OpenAI. По итогам 2024 года компания выручила $3,7 млрд, при этом чистые убытки ограничились $5,09 млрд. На исследования и разработки за период было направлено $7,81 млрд, а в совокупности с прочими расходами сумма выросла до $12,48 млрд. Операционные убытки составили $8,78 млрд, и только отнесение их части на капитал неконтролирующих акционеров позволило сократить чистые убытки до $5,09 млрд. Итоги 2025 года в целом иллюстрируют развитие бизнеса OpenAI, но вместе с выручкой ($13,07 млрд) выросли и чистые убытки — до $38,53 млрд, причём их исходная сумма достигла $60,35 млрд, просто не вся она была отнесена на баланс компании. Так называемая «себестоимость выручки» выросла с $2,65 до $7,5 млрд по сравнению с 2024 годом. Расходы на исследования и разработки достигли $19,18 млрд, маркетинговые расходы выросли более чем в пять раз до $5,73 млрд. Общая сумма затрат достигла $34 млрд, операционные убытки составили $20,92 млрд. К концу года компания подошла с активами на сумму $50 млрд, примерно половина из них номинировалась в денежных средствах. В 2025 году SoftBank выплатила OpenAI $867 млн за предоставление услуг, в случае с Microsoft сумма выплаты составила $303 млн. Сама OpenAI заплатила Microsoft весомые $10,59 млрд за услуги в сфере разработки и исследований. Скорее всего, эти затраты были связаны с обучением ИИ-моделей OpenAI на аппаратной инфраструктуре Microsoft. В общей сложности, последняя получила от OpenAI в прошлом году $17,2 млрд. По состоянию на конец года задолженность OpenAI перед Microsoft достигала $3,64 млрд. Операционные убытки в размере $38,5 млрд по итогам прошлого года — это не тот показатель, который позволяет OpenAI хвастать перед инвесторами в ожидании IPO. Не исключено, что финансовая отчётность стартапа скрывает ещё немало информации, заставляющей вернуться к рассуждениям на тему «ИИ-пузыря». Маск проиграл Альтману в суде ещё раз — иск xAI к OpenAI о краже коммерческих тайн отклонён
16.06.2026 [05:09],
Алексей Разин
На этой неделе стартап xAI Илона Маска (Elon Musk), который теперь входит в состав вышедшей на IPO компании SpaceX, потерпел ещё одно поражение в суде в противостоянии с OpenAI. Суд отклонил претензии xAI в части предполагаемой попытки OpenAI получить доступ к коммерческой тайне истца путём переманивания одного из разработчиков чат-бота Grok. 
Источник изображения: Unsplash, Levart_Photographer Речь идёт о бывшем старшем разработчике Сюэчэне Ли (Xuechen Li), который работал в xAI с 2024 по 2025 годы, и якобы готовился передать OpenAI коммерческие секреты, связанные с разработкой ИИ-бота Grok. Истец строил свою линию на презентации, которую Ли предоставил OpenAI в момент, когда этот стартап пытался переманить его из xAI. Он указал на свой опыт предыдущей работы, сославшись на владение методом обучения ИИ-моделей с подкреплением и пост-обучения. По мнению xAI, по состоянию на июль 2025 года ChatGPT отставал в сфере комплексных суждений от Grok, а потому для OpenAI было важно получить в свой штат специалиста с профильными компетенциями. Судья Рита Линь (Rita Lin) отклонила иск xAI, исходя из суждения, что демонстрация навыков и опыта предыдущей работы является обычной частью собеседования при найме кандидатов на работу, и преследовать на этом основании всех работодателей было бы неразумно. По мнению судьи, представителям xAI не удалось доказать, что OpenAI склоняла инженера Ли к раскрытию коммерческой тайны стартапа, и что инженеры самой OpenAI были осведомлены о способности Ли раскрыть подобную информацию. OpenAI заявила в суде, что Сюэчэнь Ли никогда не работал в компании, а сама она никогда не получала коммерческих секретов xAI. По словам представителей OpenAI, компания просто не нуждается в заимствовании разработок xAI, поскольку последняя проигрывает конкурентную борьбу и не может справиться с оттоком кадров. Непосредственно Ли свою причастность к попыткам передать OpenAI коммерческую тайну xAI отрицает, бывший работодатель преследует его в суде по отдельному иску. Генпрокуроры нескольких штатов США запустили проверку в отношении OpenAI
13.06.2026 [11:12],
Павел Котов
Коалиция генеральных прокуроров нескольких американских штатов начала масштабную проверку в отношении компании OpenAI, сообщает газета The Wall Street Journal со ссылкой на анонимный источник. 
Источник изображения: BoliviaInteligente / unsplash.com Накануне, 12 июня, разработчику ChatGPT вручили повестку с требованием предоставить документы, касающиеся широкого спектра её деятельности и влияния на пользователей: материалы, связанные с рекламой, привлечением и удержанием пользователей, а также обработкой потребительских и медицинских данных. Генпрокуроры также запросили информацию о деятельности, связанной с несовершеннолетними и пожилыми людьми, моделями глубокого обучения и внутренней политикой компании. Власти США пока проведение проверки не подтвердили. Представитель OpenAI, однако, заявил: «Искусственный интеллект — новая и мощная технология, и мы каждый день работаем над тем, чтобы безопасно и со всей ответственностью обеспечивать людей его преимуществами. Мы всерьёз относимся к опасениям, выраженным генеральными прокурорами штатов, и намерены в конструктивном ключе сотрудничать с их ведомствами». В минувший понедельник, 8 июня, OpenAI в закрытом формате подала заявку на первичное публичное размещение акций (IPO) в США. Компания может выйти на биржу в сентябре при оценке до $1 трлн. Аудитория ChatGPT достигла миллиарда пользователей — быстрее любого сервиса в истории
12.06.2026 [13:25],
Павел Котов
По итогам мая аудитория сервиса OpenAI ChatGPT достигла 1 млрд пользователей в месяц, пишет CNBC со ссылкой на статистику аналитической компании Sensor Tower. Это рекордный темп: предыдущий рекордсмен в лице «Google Карт» сумел набрать аудиторию в 1 млрд пользователей лишь за пять лет. 
Источник изображения: BoliviaInteligente / unsplash.com Ещё в феврале OpenAI сообщила, что совокупная аудитория ChatGPT на всех платформах составляла 900 млн пользователей в месяц, и добавила, что шестикратно обгоняет конкурента, который идёт вторым в рейтинге. Следующими по популярности, гласит статистика Sensor Tower, идут Google Gemini, китайская ByteDance Doubao и её международный вариант Dola, а также считающийся главным конкурентом чат-бот Anthropic Claude. Годовой рост аудитории ChatGPT по итогам мая составил 62 %, а Claude и Meta✴✴ AI показали рост на 640 % и 973 % соответственно — конкуренты активно повышают качество своих сервисов, отмечают эксперты. Репутация ChatGPT не идеальна. После того, как у Anthropic возник конфликт и Пентагоном, OpenAI заняла место конкурента в качестве оборонного подрядчика в области искусственного интеллекта, чем навлекла на себя гнев общественности: только 28 февраля, на следующий день после заключения контракта, число удалений ChatGPT подскочило на 295 %. Негативная динамика лидера отрасли сыграла в пользу Anthropic, чьё приложение чат-бота Claude в те же выходные взлетело на верхушку рейтинга Apple App Store, впервые обогнав ChatGPT. А сейчас OpenAI и Anthropic готовятся выйти на биржу. Но едва ли этический аспект окажет ощутимое влияние на развитие технологий ИИ и на успех лидеров отрасли — признаков замедления эксперты не наблюдают. Anthropic недавно предупредила, что бесконтрольное развитие ИИ представляет угрозу; папа римский Лев XIV предупредил о растущем неравенстве и проблемах безопасности из-за ненасытного спроса на ИИ в мире; американские выпускники стали освистывать каждое публичное упоминание ИИ из-за опасений, что он может вытеснить человека с рынка труда. Недавно проведённый опрос среди 12 000 специалистов по работе с клиентами показал, что 74 % респондентов постоянно пользуются ИИ в работе, и это на 23 п.п. выше, чем год назад; более 40 % регулярно применяющих ИИ работников признались, что экономия рабочего времени достигает одного дня в неделю. «Хотя отрицательное отношение к ИИ <..> несомненно, растёт, потребители всё чаще используют эти платформы и полагаются на них», — заключили в Sensor Tower. ChatGPT может подешеветь — OpenAI собирается усилить борьбу с Anthropic
11.06.2026 [16:11],
Павел Котов
OpenAI рассматривает возможность резко снизить цены на услуги в области искусственного интеллекта в стремлении переманить клиентов у своего основного конкурента — Anthropic, сообщила The Wall Street Journal со ссылкой на информированные источники. 
Источник изображения: Mariia Shalabaieva / unsplash.com Ещё одна причина для OpenAI рассматривать понижение цен на свои услуги — ожидание, что Anthropic сделает это первой. Сейчас разработчик ChatGPT предлагает потребителям три тарифных плана с оплатой $8, $20 и $100 в месяц за доступ к флагманской модели ИИ GPT-5.5. Anthropic взимает по $17 в месяц при годовой подписке Claude Pro и по $100 за подписку Claude Max. В минувший понедельник OpenAI официально подала заявку на первичное публичное размещение акций (IPO) в комиссию по ценным бумагам и биржам (SEC) США, а незадолго до этого аналогичный шаг совершила Anthropic. 28 мая Anthropic в статусе частной компании завершила очередной раунд финансирования при оценке $965 млрд — OpenAI в марте получила оценку в $852 млрд. Тем временем вышедшее в ноябре 2022 года приложение ChatGPT в мае 2026 года вышло на ежемесячную аудиторию в 1 млрд пользователей. Для сравнения, предыдущий рекорд по скорости набора аудитории поставил сервис «Google Карты», который шёл к своему миллиарду пользователей около пяти лет. OpenAI может выпустить GPT-5.6 уже в этом месяце — и она будет «значительно лучше» GPT-5.5
11.06.2026 [12:43],
Владимир Фетисов
Конкуренция в сфере ИИ продолжает обостряться, о чём свидетельствует ускоренный график выпуска новых ИИ-моделей крупных разработчиков. Хотя флагманская модель OpenAI GPT-5.5 была выпущена в апреле, компания, похоже, уже готова к очередному обновлению платформы. 
Источник изображения: Mariia Shalabaieva/unsplash.com По данным источника, OpenAI может выпустить GPT-5.6 в этом месяце. В сообщении сказано, что главный научный эксперт OpenAI Якуб Пахоцки (Jakub Pachocki) отправил сотрудникам письмо, в котором говорилось, что GPT-5.6 будет «значительно лучше» GPT-5.5. Нынешняя флагманская модель OpenAI уже может похвастаться высокой скоростью обработки запросов и понимания целей пользователей. Вероятно, в GPT-5.6 эти показатели станут ещё выше. В пользу предположения о скором появлении новой ИИ-модели свидетельствует и то, что в этом месяце OpenAI должна обновить своего ИИ-бота ChatGPT. Источник также раскрыл некоторые подробности касательно выхода OpenAI на биржу. Компания недавно подала в Комиссию по ценным бумагам и биржам США документы, необходимые для проведения первичного размещения акций. По данным источника, гендиректор OpenAI Сэм Альтман (Sam Altman) уведомил сотрудников о том, что компания может выйти на биржу «в течение следующего года», но окончательное решение может зависеть от сложившейся ситуации. По словам Альтмана, если ИИ в компании достигнет точки, когда система сможет обновлять себя самостоятельно, «то технологии и мир могут измениться удивительным образом, и в это время могут быть веские причины оставаться частной компанией». Однако OpenAI приходится тратить много времени на ИИ-инфраструктуру. В этих условиях выход на биржу может стать для компании оптимальным решением. Visa открыла ИИ-агентам OpenAI возможность оплачивать покупки от имени пользователей
11.06.2026 [10:51],
Владимир Мироненко
Visa объявила на форуме Visa Payments Forum в Сан-Франциско о партнёрстве с OpenAI, в рамках которого её платежная сеть будет интегрирована в нейросеть ChatGPT, что позволит ИИ-агентам совершать покупки в магазинах и завершать транзакции от имени пользователей. Финансовые условия сотрудничества пока неизвестны, как и размер комиссий, которые должны будут платить за услугу продавцы или покупатели. 
Источник изображения: CardMapr.nl/unsplash.com Пользователи ChatGPT смогут подключить свои платёжные карты Visa к платформе ChatGPT. При этом OpenAI будет отвечать за предоставление агентам возможности просматривать, оценивать варианты и совершать покупки, в то время как Visa будет управлять авторизацией и отслеживать транзакции, чтобы упредить потенциальное мошенничество. Visa сообщила, что система позволит пользователям устанавливать ограничения на то, как агент тратит их деньги, например, ограничивать расходы, типы доступных для покупки маркетплейсов и требовать подтверждения перед совершением определённых покупок. Для обработки платежей Visa будет использовать токенизированные учётные данные и авторизацию в режиме реального времени. «По мере того, как агенты ИИ становятся активными участниками экономики, Visa сосредоточена на обеспечении доверия, безопасности и бесперебойности транзакций», — заявил Джек Форестелл (Jack Forestell), директор по продуктам и стратегии Visa. Он сообщил, что что Visa будет рассматривать споры, используя те же основные правила, что и для любой другой транзакции: действительно ли потребитель намеревался совершить покупку, и правильно ли продавец оформил транзакцию. Изменения могут произойти, добавил он, если и намерение потребителя, и обработка транзакции продавцом были выполнены правильно, но «что-то произошло посередине, что вызвало проблему». «Именно поэтому мы меняем всю нашу систему токенов и процесс сбора данных с помощью Visa Intelligent Commerce, чтобы гарантировать, что эта проблема не возникнет», — сказал Форестелл. Банки и продавцы выразили обеспокоенность по поводу использования ИИ для совершения покупок, поскольку агенты могут потратить больше, чем хотели бы пользователи, или совершить покупки, которые клиенты впоследствии оспорят. Особенную обеспокоенность у банков вызывает то, что чётко не определено, кто будет нести ответственность за мошенничество, если агент использует счёт держателя карты. Как отметило агентство Associated Press, платёжная система Mastercard также внедряет функции покупок с использованием ИИ в свою платёжную сеть, но в меньшем масштабе. В частности, Mastercard объявила, что ИИ-агенты смогут приобретать услуги от имени бизнеса. Например, если кофейня захочет запустить рекламную кампанию в рамках выхода нового продукта, она сможет предоставить ИИ-агенту право приобретать услуги у веб-провайдеров и рекламных агентств. ChatGPT начал рекомендовать поддельные магазины мошенников — пользователи лишились денег
10.06.2026 [13:44],
Павел Котов
ChatGPT стал предлагать пользователям ссылки на запущенные мошенниками поддельные интернет-магазины и рассказывать о товарах, которые никогда не существовали, сообщила газета The Guardian со ссылкой на сервис по обнаружению мошенничества Ask Silver. 
Источник изображения: Andras Vas / unsplash.com Пользователи ChatGPT при попытке поиска переходили по ссылкам на ресурсы, которые выглядели как интернет-магазины популярных бредов, таких как производитель обуви и аксессуаров Russell & Bromley и сеть магазинов товаров для дома Dunelm. Те, кто делал на этих поддельных сайтах заказы, теряли свои деньги, а их платёжные данные становились достоянием злоумышленников. Одной из причин инцидента стало то, что бренд Russell & Bromley перестал существовать как самостоятельный розничный продавец — в январе он перешёл под внешнее управление и был поглощён компанией Next. Образовавшуюся пустоту заполнили мошенники, потому что люди продолжают искать оригинальный сайт бренда. В ходе атак мошенники реализовали методику «отравления искусственного интеллекта», при которой злоумышленники публикуют в интернете не соответствующую действительности информацию и страницы, копирующие дизайн легитимных ресурсов. Большие языковые модели индексируют эти мошеннические сайты, непреднамеренно способствуя противоправной деятельности и выдавая подделки за оригинал. Людям не следует доверять рекомендациям только потому, что они исходят от чат-бота с ИИ, предупреждают эксперты: преступники быстро адаптируются к новым технологиям и используют все каналы, способные привести к ним потенциальных жертв. Признаки мошенников остаются теми же. Это огромные скидки, странные адреса сайтов, неверная контактная информация и запросы на банковские переводы. Эксперты рекомендуют другими способами устанавливать адреса розничных продавцов, а не полагаться на ссылки, которые генерирует ИИ. OpenAI удалила часть ссылок на сайты, на которые поступили жалобы, но проблема не исчезла: люди всё чаще пользуются ИИ, а значит, требуются более надёжные средства защиты потребителей. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



