







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Tiger Lake: архитектура процессоров Intel Core одиннадцатого поколения
В начале сентября компания Intel представила одиннадцатое поколение мобильных процессоров Intel® Core™, которое до этого было известно под именем Tiger Lake. И этот анонс стал очень важной вехой для компании, поскольку в этих процессорах нашла воплощение критическая масса инноваций. Проще говоря, Tiger Lake представляют собой нечто большее, чем простое добавление дополнительных ядер или увеличение тактовых частот. В этом поколении Intel сделала существенные шаги сразу по многим направлениям, которые затронули и микроархитектуру, и техпроцесс. Глобальная задача, которую компания хотела решить выпуском Tiger Lake, была очень проста: она хотела сделать процессор, который стал бы следующим после Ice Lake шагом в развитии 10-нм продуктов. Однако с учётом того, что к моменту выхода Tiger Lake в распоряжении Intel появился улучшенный 10-нм техпроцесс, эта задача решилась автоматически. Поэтому попутно перед инженерами были поставлены некоторые дополнительные и более сложные цели. И конечном итоге Tiger Lake стал не просто обновлённым Ice Lake, в котором проведена работа над ошибками. Фактически у Intel получилось сделать новый процессорный дизайн и провести в нём довольно масштабные нововведения. 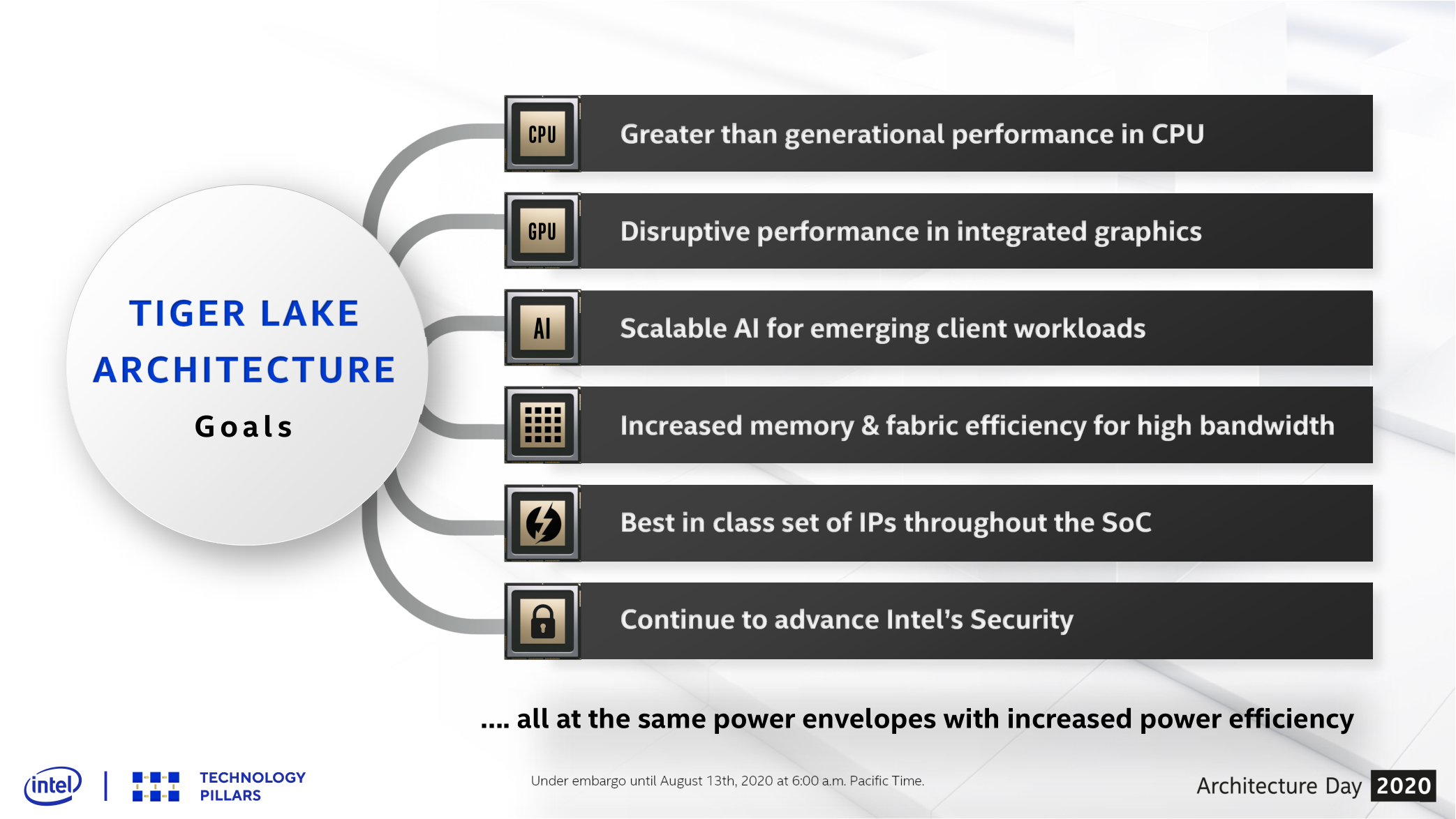 В текущей реализации Tiger Lake собрано четыре ядра с кодовым именем Willow Cove и графическое ядро на базе 96 исполнительных устройств с архитектурой Xe-LP. Всё это выпускается с применением улучшенных 10-нм технологических норм, которые получили собственное название SuperFin. При этом, в отличие от предшественника, Tiger Lake нацелен на то, чтобы охватить все классы мобильных процессоров с тепловым пакетом от 7 до 65 Вт, а кроме того, он способен предложить заметно лучшую удельную производительность в пересчёте на ватт и к тому же приносит новые мультимедийные и ИИ-возможности.  Рассказать про это всё в двух словах вряд ли возможно, поскольку перемены слишком значительны, поэтому в рамках партнёрского проекта с Intel мы решили сделать отдельную статью, где ключевые улучшения будет описываться максимально подробно. Технологический процесс с 10-нм нормами компания Intel эксплуатирует уже довольно давно, но в основном для производства чипов, ориентированных на мобильный сегмент (помимо мобильных процессоров по 10-нм техпроцессу выпускаются также ПЛИС семейства Intel Agilex™). При этом применяемая технология непрерывно развивается и уже достигла определённой зрелости. Именно оптимизация 10-нм техпроцесса и служит базисом дизайна Tiger Lake: появление на свет данного чипа – во многом результат внедрения технологии, которая у Intel называется термином 10 нм SuperFin. Речь идёт о новой версии 10-нм техпроцесса первого поколения, но Intel утверждает, что обновление довольно существенно и эффект от него сродни переходу на следующую ступень производственных норм. Чтобы наглядно проиллюстрировать это утверждение, Intel указывает, что по сравнению с прошлой версией 10-нм техпроцесса SuperFin обеспечивает рост производительности транзисторов примерно на 17-18 %. А это, в свою очередь, сравнимо с тем эффектом, который был получен за четыре последовательных обновления 14-нм техпроцесса (традиционно обозначаемых плюсами) в течение последних нескольких лет. В конечном итоге появление добавки SuperFin в названии 10-нм техпроцесса выливается в более широкий диапазон тактовых частот и напряжений, а также потенциально лучшую плотность расположения транзисторов на кристалле, которая достигается с применением того же самого производственного оборудования. Все улучшения, которые даёт SuperFin, основываются на двух принципиальных изменениях в дизайне полупроводникового кристалла – они сделаны в слоях металлических соединений и в конструкции самих транзисторов. Что касается металлических соединений, то на более низких уровнях Intel ввела в обиход новый барьерный материал, который позволил сократить толщину изолирующего слоя и протяжённость межслойных проводников, что в конечном итоге снизило их сопротивление примерно на 30 % и позволило нарастить скорость и точность передачи сигналов между металлическими слоями, а новая конструкция затворов транзисторов позволяет носителям заряда перемещаться быстрее. На верхних уровнях Intel перешла на использование новых конденсаторов SuperMIM (металл — изолятор — металл), которые за счёт изменений в составе диэлектрика получили пятикратное увеличение ёмкости по сравнению с ранее применяемыми конденсаторами без изменения занимаемой ими площади. Это стало важным улучшением для оптимизации схем питания, в которых стало возможным использовать более низкие напряжения и менять их с большей точностью и частотой. Данный технологический прорыв Intel объясняет внедрением новых методов осаждения диэлектриков с высокой диэлектрической проницаемостью, позволяющих получать слои с толщиной менее 0,1 нм и комбинировать различные материалы между собой.  Попутно в самих транзисторах нашёл применение улучшенный FinFET-дизайн третьего поколения, характеризующийся увеличенным шагом между затворами и некими усовершенствованиями в техпроцессе, за счёт которых произошло снижение сопротивления канала открытого транзистора. Имея в виду именно эти изменения, Intel говорит об увеличении производительности транзисторов на 17-18 %.  Техпроцесс 10 нм SuperFin мог бы получить название 10 нм++, однако в последний момент Intel решила отказаться от этой терминологии во избежание путаницы, так как в какой-то момент она стала употреблять обозначение 10 нм+, имея при этом в виду всё те же нормы 10 нм++. Теперь же схема наименований упростилась. «Чистокровный» 10-нм техпроцесс – это тот процесс, по которому производится Ice Lake; 10 нм SuperFin – это улучшенный техпроцесс для Tiger Lake; а процессоры Cannon Lake, по всей видимости, следует считать выпущенными по предварительной «бета»-версии 10-нм технологии. Кстати говоря, Intel уже успела анонсировать и следующую после 10 нм SuperFin версию техпроцесса – она будет называться 10 нм Enhanced SuperFin. ⇡#Микроархитектура ядер Willow Cove Новая микроархитектура вычислительных ядер процессоров Tiger Lake получила название Willow Cove. Она является дальнейшим развитием микроархитектуры Sunny Cove, которая впервые появилась в мобильных процессорах Ice Lake. Intel утверждает, что по сравнению с прошлыми ядрами новые вычислительные ядра могут обеспечить прирост производительности на 10-20 %, однако это утверждение, по всей видимости, относится не к показателю IPC (числу исполняемых за такт инструкций), а к обобщённой интегральной производительности, на которую оказывает влияние, в частности, и рост тактовой частоты.  В действительности же похоже, что микроархитектурных различий между Willow Cove и Sunny Cove не так много. По крайней мере, сама Intel указывает лишь на улучшения, связанные с изменением подсистемы кеш-памяти. В остальном перемены сводятся к появлению новых технологий обеспечения безопасности, а также к минорным изменениям в наборе поддерживаемых векторных инструкций. А это значит, что в программных алгоритмах, которые не чувствительны к латентности и объёму кеш-памяти второго и третьего уровня, каких-то заметных невооружённым глазом различий в производительности при одинаковой тактовой частоте у Willow Cove и Sunny Cove нет. Однако это не должно стать поводом для разочарования. Появившаяся в процессорах Ice Lake чуть более года назад микроархитектура Sunny Cove стала очень серьёзным шагом вперёд по сравнению с Skylake – она одномоментно подняла удельную производительность ядер Intel на величину порядка 18 %. И это значит, что подобное серьёзное преимущество перед микроархитектурой Skylake унаследовано и в Willow Cove. 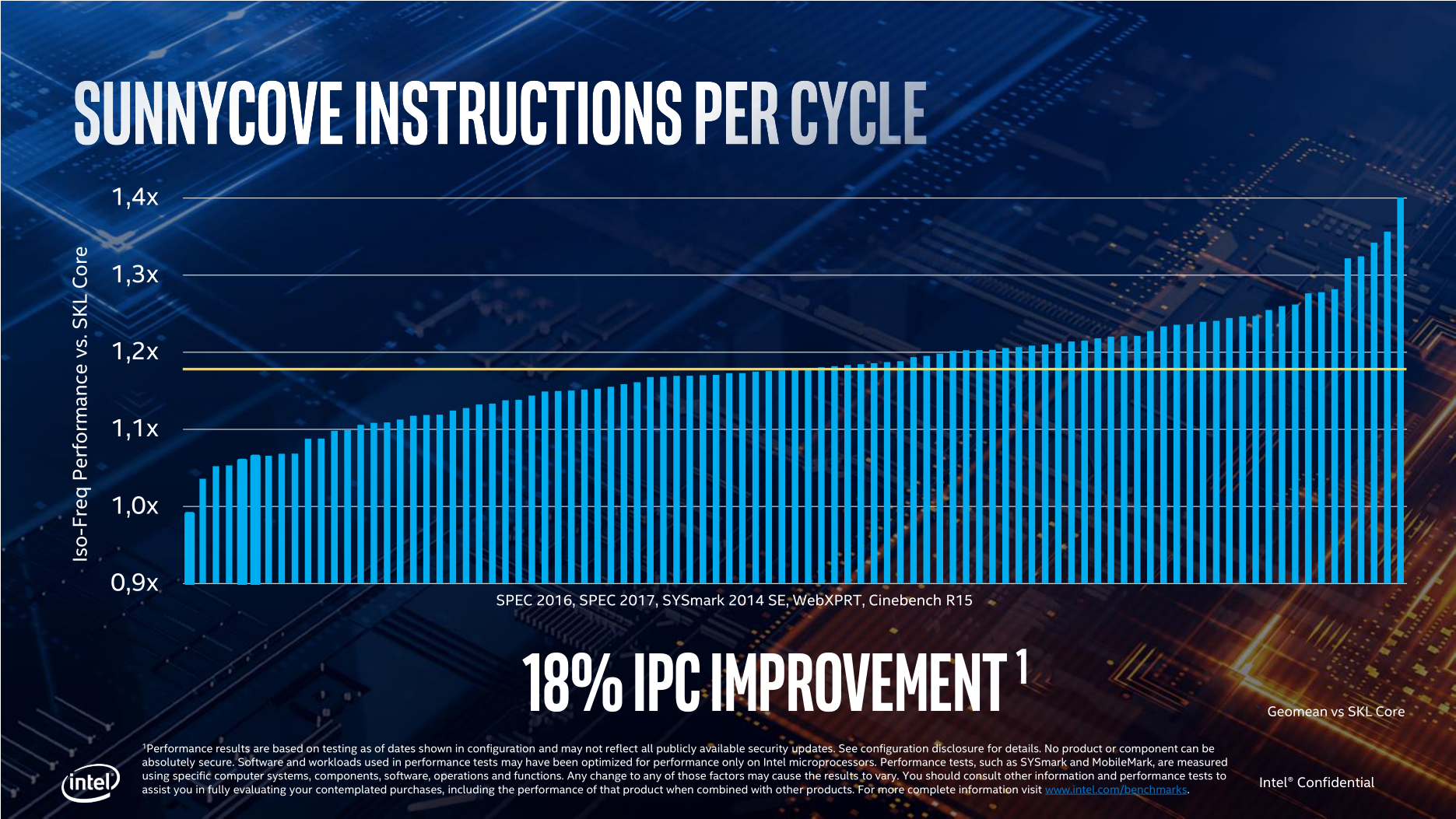
Среднее преимущество Sunny Cove перед Skylake на одинаковой тактовой частоте – 18 % В Sunny Cove улучшения затронули все части исполнительного конвейера, но тем не менее этот дизайн скорее похож на усовершенствованную версию Skylake, чем на кардинальную переработку прошлой микроархитектуры. Во входной части конвейера Sunny Cove улучшения затронули алгоритмы предварительной выборки инструкций и предсказания ветвлений, которые были перебалансированы с прицелом на нагрузки, свойственные ПК. Вместе с тем увеличился в объёме кеш микроопераций, объём которого вырос с 1500 до 2250 записей. Кроме того, обновлённый кеш микроопераций теперь получил возможность выдавать в очередь на исполнение по шесть микроопераций за такт, в то время как классические декодеры в Sunny Cove работают с тем же темпом, что и ранее, – по пять микроопераций за такт. 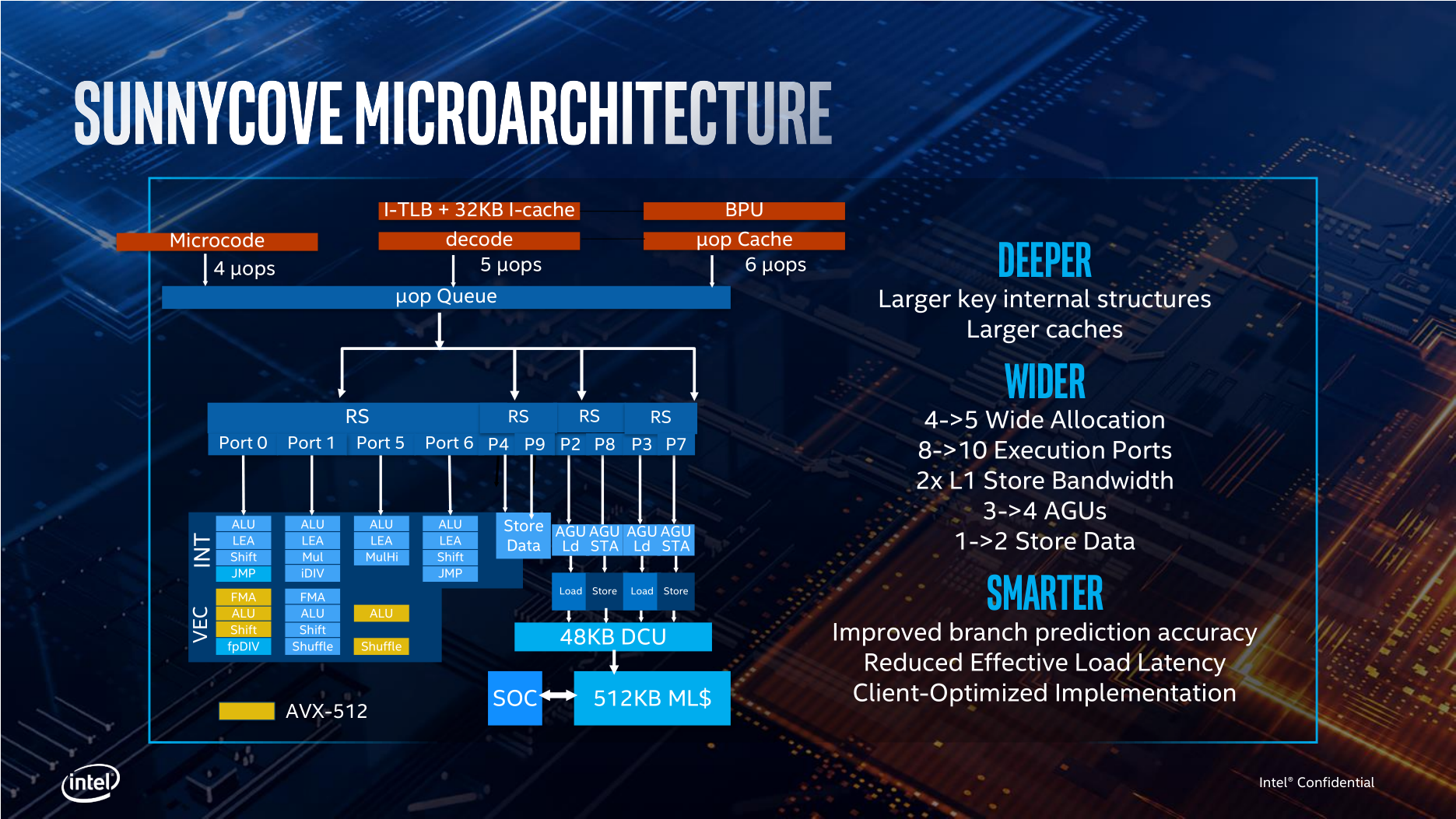 Далее, более чем в полтора раза была увеличена глубина очереди переупорядочивания инструкций, что должно поспособствовать более эффективной загрузке исполнительных устройств. А сам исполнительный домен Sunny Cove получил два дополнительных порта, что сделало возможным отправлять на исполнение по десять микроопераций за такт вместо восьми в микроархитектуре Skylake. Благодаря этому в Sunny Cove стало больше на один блок генерации адресов и на один блок сохранения данных, и в конечном итоге это конвертируется в удвоение пропускной способности L1-кеша данных при записи, который к тому же в новых ядрах вырос в объёме в полтора раза. Хотя, как было сказано выше, никаких качественных изменений в микроархитектуре при переходе от Sunny Cove к более новому дизайну Willow Cove не произошло, для наращивания производительности были задействованы другие ресурсы, которые всё равно положительно повлияли на интегральный показатель производительности процессоров Tiger Lake. В первую очередь ускорение было достигнуто теми средствами, которые предоставил усовершенствованный техпроцесс 10 нм SuperFin. Благодаря улучшению свойств транзисторов и применению при проектировании полупроводникового кристалла новых библиотек, Intel смогла увеличить эффективность дизайна ядер Willow Cove. Это вылилось, с одной стороны, в снижение тепловыделения, а с другой – в увеличение частотного диапазона. И то и другое отлично прослеживается при знакомстве с составом модельного ряда. Если процессоры Ice Lake, производимые по прошлой версии 10-нм техпроцесса, были ограничены максимальной частотой 4,1 ГГц, то представители нового семейства Tiger Lake оказались способны брать в турборежиме частоты вплоть до 4,8 ГГц. Подобный рост прослеживается и в базовых частотах: например, у чипов с тепловым пакетом 28 Вт они выросли с 2,3 до 3,0 ГГц. Причём, вероятно, потолок ещё не достигнут. Intel планирует расширять модельный ряд своих передовых мобильных процессоров, и, скорее всего, вместе с расширением рамок теплового пакета позднее будут достигнуты и более высокие частотные рубежи. 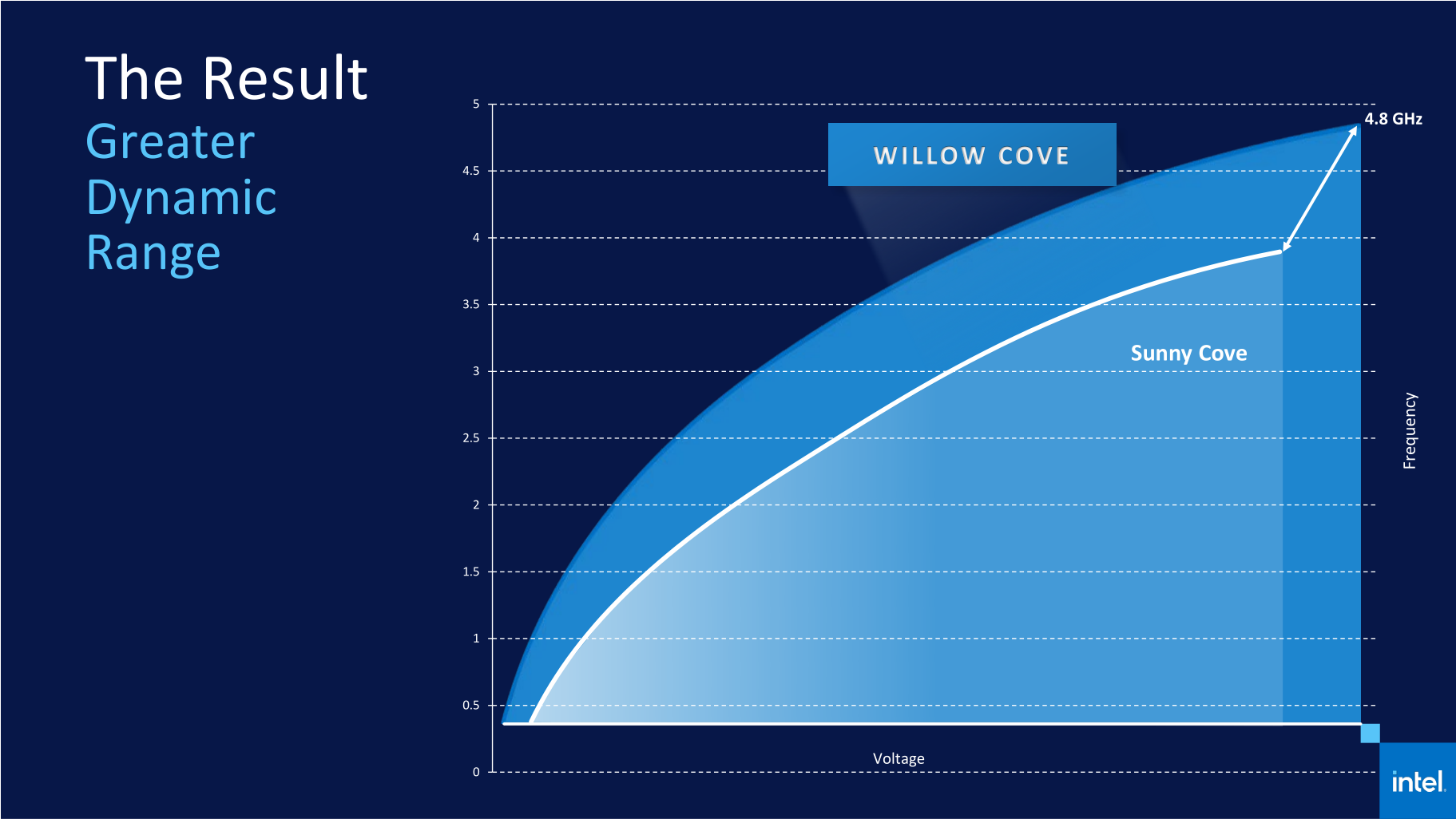 В пользу повышения производительности новых процессоров играет не только тактовая частота, но и новая схема кеш-памяти, изменения в которой на самом деле очень значительны. Кеш второго уровня в Tiger Lake увеличился по сравнению с Ice Lake в два с половиной раза, и его объём теперь достиг 1,25 Мбайт на ядро. В процессорах Skylake, напомним, объём L2-кеша составлял всего 256 Кбайт на ядро. Такое расширение кеш-памяти существенно поднимает вероятность нахождения необходимых данных в непосредственной близости от процессора. Правда, обычно в росте ёмкости кеша есть и обратная сторона – у него возрастают задержки. Но если судить по той информации, которую обнародовала компания Intel, латентность L2-кеша Tiger Lake составляет 14 тактов, и это лишь на один такт больше латентности L2-кеша в процессорах предыдущего поколения и всего на два такта превышает латентность L2-кеша Skylake. Выглядит такое очень впечатляюще: кратное увеличение объёма кеша сопровождается ростом задержки всего на единицы процентов. И более того, вместе с этим кеш второго уровня в Tiger Lake стал не инклюзивным. Претерпела значительные изменения в Tiger Lake и кеш-память третьего уровня. Её объём вырос в полтора раза, и теперь на каждое ядро выделяется не по 2, а по 3 Мбайт L3-кеша. Однако при этом у нового кеша снизилась ассоциативность. Четырёхъядерный Ice Lake обладал L3-кешем объёмом до 8 Мбайт с 16-кратной ассоциативностью, в то время как в четырёхъядерном Tiger Lake кеш третьего уровня имеет объём 12 Мбайт со степенью ассоциативности 12. Эти два изменения работают разнонаправленно в смысле вероятности нахождения нужных процессору данных в кеш-памяти, но зато дают существенный выигрыш в энергопотреблении, плюс позволяют увеличенному кешу работать с довольно небольшой латентностью. В конечном итоге Intel считает, что L3-кеш Tiger Lake, который также является не инклюзивным, в рабочих нагрузках должен проявлять себя лучше по сравнению с кеш-памятью Ice Lake.
Для большинства пользователей размеры кеш-памяти обычно не являются той характеристикой, на которую обращают пристальное внимание, хотя AMD своим примером и подводит общественность к мнению, что большой кеш хорош для игровых нагрузок. Тем не менее Intel парирует, что изменение структуры, алгоритмов и размеров кеш-памяти – скорее технологический вопрос. По крайней мере, при изменении структуры кеш-памяти в Tiger Lake на первом месте стояла не погоня за дополнительными процентами производительности, а оптимизация дизайна полупроводникового кристалла с точки зрения компоновки для улучшения рассеивания тепловой мощности. Впрочем, Intel при работе над новыми микроархитектурами всегда проводит тщательный анализ в том числе и производительности при различных сценариях нагрузки, поэтому логично ожидать, что подсистема кеш-памяти с каждой новой итерацией дизайна становится лучше и эффективнее. Одним из ключевых нововведений в микроархитектуре Ice Lake стало добавление поддержки расширений системы команд AVX-512 и в первую очередь подмножества инструкций AVX512 VNNI, направленного на ускорение работы нейронных сетей и алгоритмов глубокого обучения. В процессорах Tiger Lake эта функциональность полностью сохранилась, плюс добавилась поддержка некоторого количества новых команд из этого множества. Стоит напомнить, что процессоры, нацеленные на серверные системы и HEDT, поддерживают команды AVX-512 уже несколько лет. Но теперь Intel решила начать широкомасштабное внедрение этих инструкций и в массовом сегменте тоже. Пока количество реальных программ, которые интересны массовому пользователю и способны использовать AVX-512, исчисляется единицами. Но в то же время среди них уже начали появляться реально интересные для обычных пользователей инструменты. В качестве примера можно привести программные продукты Topaz AI, предназначенные для ретуширования и улучшения качества видео и фотографий, – они работают на процессорах с поддержкой AVX-512 несоизмеримо лучше. 
Примеры приложений, использующих ИИ К инструкциям AVX-512 существует разное отношение в сообществе. Например, создатель Linux Линус Торвальдс (Linus Torvalds) недавно говорил, что AVX-512 достойны мучительной смерти, поскольку их исполнение приводит к снижению частоты ядра, а реализация их поддержки бессмысленно транжирит транзисторный бюджет, который в действительности мог быть пущен на более полезные вещи. Однако стратегия Intel остаётся неизменной. Компания считает, что пользователи любых платформ должны в конечном итоге получать доступ к единому набору команд, и инструкции AVX-512 уже отлично зарекомендовали себя в высокопроизводительных вычислениях. Поэтому массовые мобильные системы в конечном итоге должны обрести поддержку AVX-512, несмотря на то, что их присутствие в процессорах класса Tiger Lake пока не приносит явных преимуществ. В конце концов, за ИИ-алгоритмами будущее, и они постепенно будут распространяться всё шире и шире, а поддержка AVX-512 рано или поздно станет ощутимым козырем и для мобильных систем. Руководствуясь этой логикой, Intel, начиная с Ice Lake, вдобавок к AVX-512 развивает в своих мобильных процессорах отдельный дополнительный ИИ-блок – GNA (Gaussian Neural Accelerator), предназначенный для решения фоновых задач вроде шумоподавления или распознавания речи при крайне невысоком энергопотреблении. В процессоры Tiger Lake попала уже вторая версия этого блока, которая может выполнять 1 млрд операций вывода в секунду при потреблении 1 мВт или до 38 млрд операций в секунду при потреблении до 38 мВт. 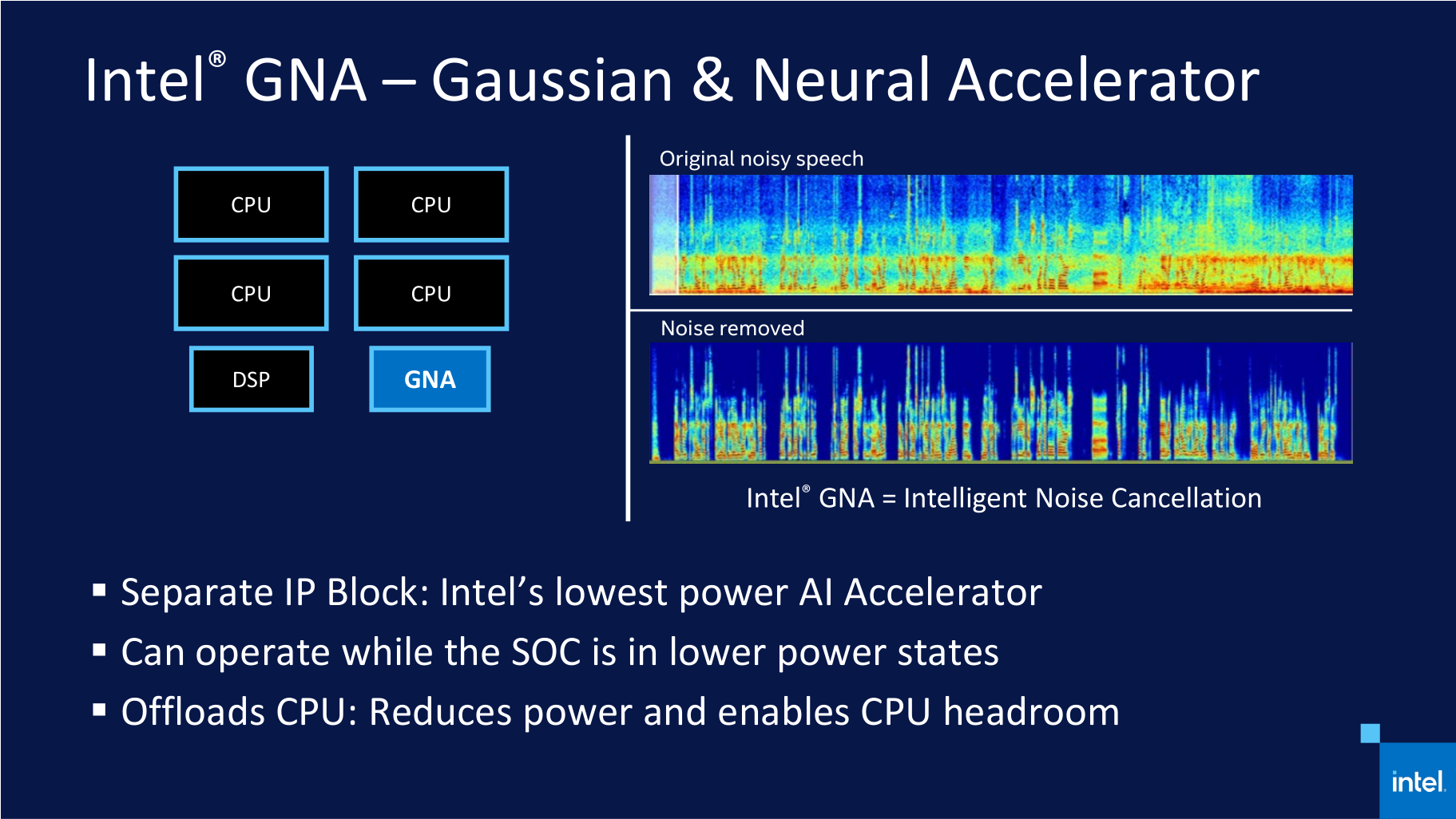 Для взаимодействия со всеми специфическими ИИ-инструментами, имеющимися в процессорах Ice Lake и Tiger Lake, Intel предлагает разработчикам ПО специальные библиотеки – Intel DL Boost или более универсальную модель OneAPI. Тем самым сегодняшняя ситуация в корне отличается от того, как происходило внедрение AVX/AVX2, поскольку сейчас Intel побеспокоилась не только об аппаратной реализации, но и о лёгкости задействования новых возможностей разработчиками программ. Это должно ускорить переход на использование AVX-512 и GNA в общеупотребительном ПО. ⇡#Технология Control-Flow Enforcement Technology Нашумевшая история с уязвимостями, которые дают возможность проводить результативные атаки на процессоры Intel по побочному каналу, заставила компанию пересмотреть подходы к средствам безопасности, которые имеются в современных процессорах. Результаты этого пересмотра воплотились в Tiger Lake в добавлении в микроархитектуре технологии CET (Control-Flow Enforcement Technology), которая трассирует команды передачи управления (вызовы функций, возвраты и переходы) и не допускает запуска исполнения нежелательного кода. В состав CET входит две методики: Shadow Stacks (теневые стеки) и Indirect Branch Tracking (косвенное отслеживание ветвлений).  В рамках методики теневых стеков процессор отслеживает возвраты из функций, для чего создаёт в каком-то месте памяти второй, «теневой» стек адресов возврата и сверяет адреса каждый раз, когда происходит переход по команде выхода из подпрограммы. В случае несовпадения адресов выявляется атака и предпринимаются действия по её нейтрализации. Эта методика может работать без внесения каких-либо изменений в исходный код, однако требует от программиста предусмотреть обработку исключений, возникающих, когда адреса возврата не сходятся друг с другом. Вторая методология – косвенное отслеживание ветвлений – несколько сложнее в реализации, но и решает другую задачу – проверяет правильность переходов при выполнении соответствующих команд и вызовах функций. В данном случае программист должен предварительно расставить в коде специальные маркеры возможных мест, куда может происходить передача управления, и, если процессор не увидит эти маркеры при исполнении кода после взятия перехода, сработает защита. Графика – это, вероятно, та сфера, в которой Tiger Lake получил наиболее серьёзные улучшения. Ещё бы, ведь он стал первым процессором на рынке, в который попало принципиально новое графическое ядро двенадцатого поколения, известное по собирательному названию Xe. Более того, это ядро к тому же получило весьма значительный вычислительный ресурс. В то время как GPU процессоров Ice Lake состоял из 64 исполнительных блоков одиннадцатого поколения, в Tiger Lake число исполнительных блоков выросло до 96 штук. К этому нужно прибавить повышенные частоты, которые новая графика смогла получить благодаря новым транзисторам 10 нм SuperFin. В то время как GPU в процессорах Ice Lake работал на частоте 1100 МГц, в имеющихся на рынке версиях Tiger Lake частота графики достигла отметки 1350 МГц. А в будущих моделях процессоров с ослабленными ограничениями по тепловому пакету эта частота имеет шанс стать ещё выше. По крайней мере, в дискретной видеокарте Iris Xe MAX с аналогичной архитектурой частота GPU достигла величины 1650 МГц. 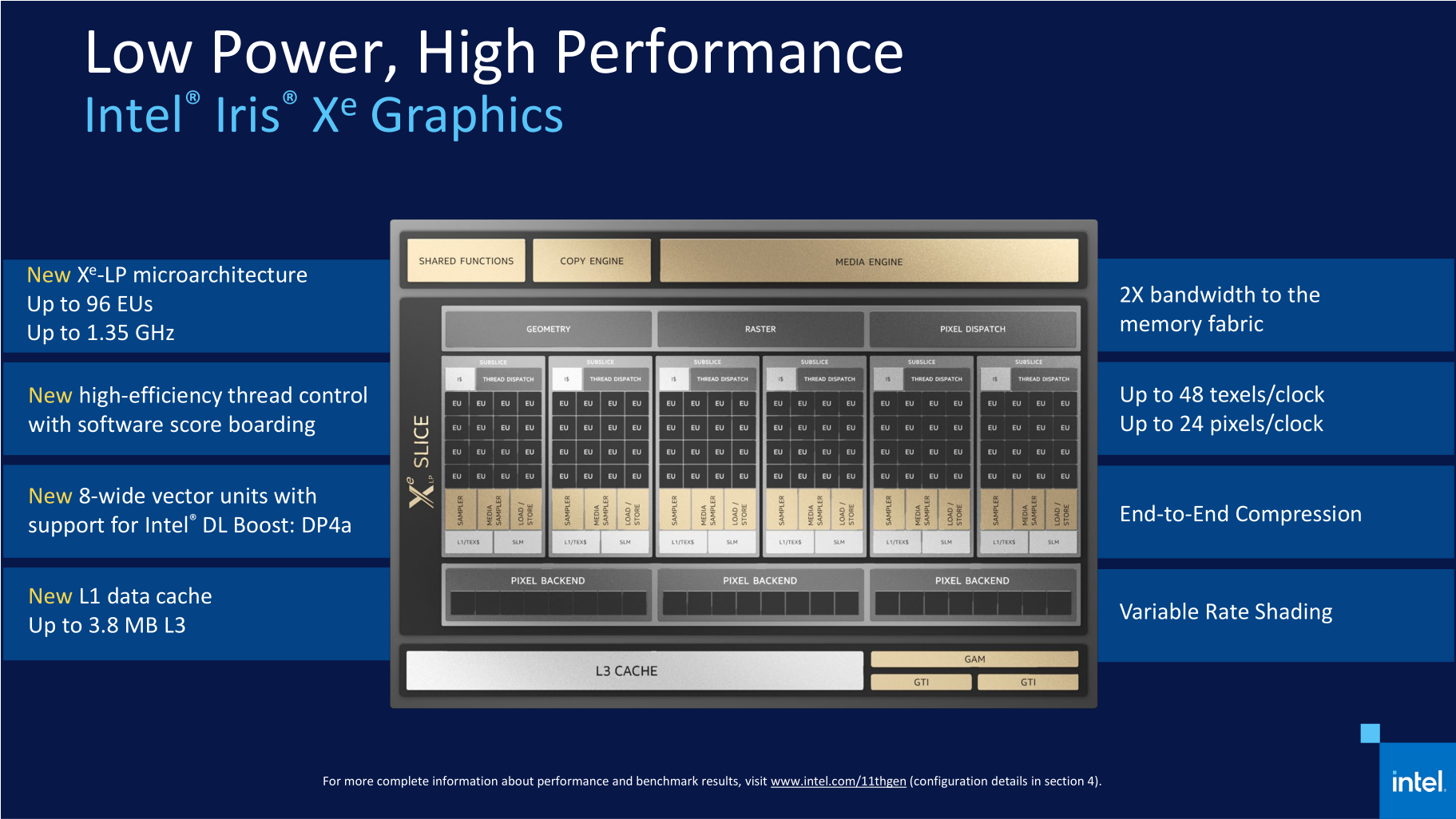 Исполнительные блоки графических ядер Intel в своей основе используют ALU (Arithmetic Logic Units – «арифметически-логические устройства»). Такие устройства предназначены для выполнения фиксированного набора математических операций над целыми числами или числами с плавающей запятой, а также для вычислений некоторых сложных функций, например тригонометрических. В графических ядрах одиннадцатого поколения, которые использовались в процессорах Ice Lake, каждый из 64 исполнительных блоков содержал внутри себя по восемь ALU, четыре из которых предназначались для целочисленной и вещественной арифметики, а другие четыре – для вещественной арифметики и сложных функций. В графической архитектуре Xe-LP эта схема поменялась. В новой версии GPU каждый исполнительный блок имеет в своём составе по десять ALU. Восемь из них – устройства для арифметических операций с целыми числами и числами с плавающей запятой, а оставшиеся два – для сложных функций. Кроме того, новые исполнительные блоки научились спариваться для решения комплексных задач, что позволяет бросать на выполнение каких-то вычислительных потоков удвоенный набор ALU. Также стоит отметить, что в арифметических устройствах в архитектуре Xe-LP добавилась поддержка восьмибитных целых чисел и набора инструкций DP4a для работы с ними, что востребовано в задачах ИИ. Отдельный шаг, направленный на повышение скорости работы графики, касается реализации в Tiger Lake собственного L3-кеша объёмом 3,8 Мбайт для GPU, который подключён к общей внутрипроцессорной кольцевой шине. Причём, так как мощное графическое ядро нуждается в более интенсивном потоке данных, разработчики попутно расширили саму кольцевую шину, которая используется процессором. Фактически речь идёт об удвоении её пропускной способности за счёт совмещения двух колец, которые в сумме поддерживают двунаправленную пересылку двух пар 32 байт данных каждый такт. Intel утверждает, что по скорости графики Tiger Lake превосходит предшественника где-то вдвое. Этот прирост складывается из нескольких частей. Увеличение количества исполнительных блоков с 64 до 96 штук даёт примерно полуторакратное увеличение производительности, рост частоты добавляет ещё примерно 25 %. Оставшиеся проценты производительности приносит L3-кеш и увеличение числа ALU внутри вычислительного блока. Иными словами, внедрение в мобильных процессорах графического ядра Xe-LP – действительно очень большой шаг вперёд, который ставит Tiger Lake на одну ступень с лучшими в отрасли образцами встроенных GPU. 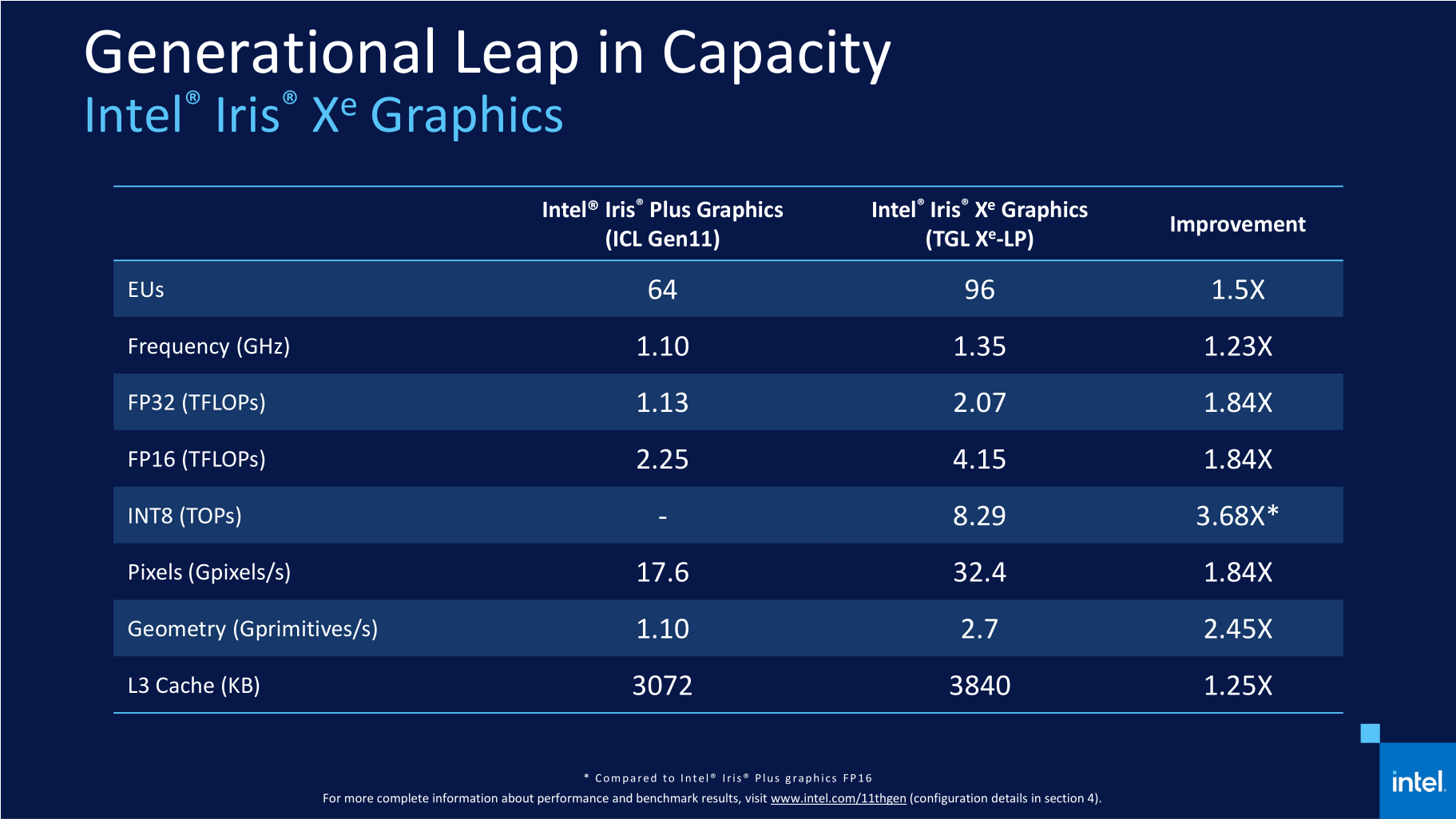 Но в дополнение к сказанному стоит упомянуть и про другие нововведения в графике Tiger Lake, которые касаются медиадвижка – здесь Xe-LP тоже есть чем похвастать. Во-первых, в Tiger Lake появилась аппаратная поддержка декодирования видео в формате AV1. Во-вторых, Intel удвоила пропускную способность аппаратного кодирования и декодирования всех популярных форматов видео. Это стало возможно благодаря реализации 12-битного видеоконвейера, который к тому же получил полноценную поддержку HDR и видео в разрешении 8K60.  Попутно расширились и возможности графического ядра по поддержке дисплеев, в котором появилось четыре независимых дисплейных порта с поддержкой разрешений 4K. Благодаря этому Tiger Lake сможет обеспечить подключение мониторов по DisplayPort 1.4, HDMI 2.0, Thunderbolt™ 4 и USB4 Type-C, причём одновременно, если у пользователя действительно возникнет желание или потребность работать с четырьмя дисплеями. При этом каждый конвейер отображения поддерживает HDR10, 12-битную глубину цвета и может обеспечить работу дисплеев с частотой обновления вплоть до 360 Гц. 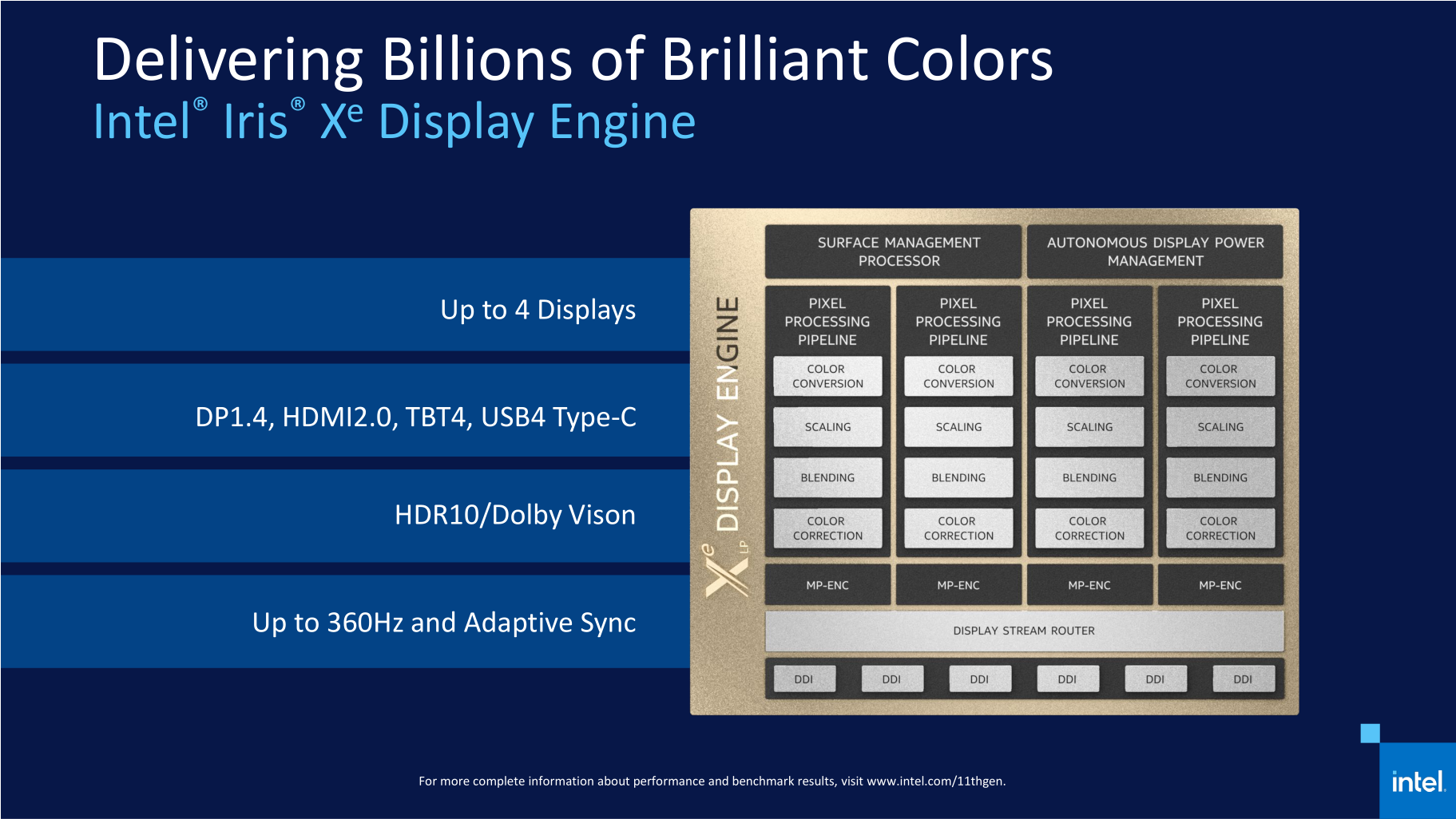 ⇡#Поддержка LPDDR5-5400, PCI Express 4.0 и Thunderbolt 4 Наряду с изменениями в микроархитектуре вычислительных и графического ядер, улучшения были внесены и в ту часть Tiger Lake, которая называется SoC и по сути представляет собой логику северного моста чипсета, интегрированную внутрь процессора. И в первую очередь здесь следует отметить появление поддержки более быстрых типов памяти. В то время как в процессорах Ice Lake контроллер памяти мог работать лишь с LPDDR4-3733, в Tiger Lake появилась поддержка LPDDR4X-4266, которой может быть установлено до 32 Гбайт. Совместимость процессора с DDR4-3200 при этом сохранилась, и в этом случае поддерживается до 64 Гбайт памяти. Попутно Intel отмечает, что в контроллер памяти уже заложена поддержка LPDDR5, однако на данный момент такие модули памяти не прошли валидацию, поэтому реальных устройств на базе Tiger Lake с этой разновидностью памяти пока не будет. Однако это не значит, что они не появятся в будущем. И судя по всему, к их появлению уже всё готово, и память класса LPDDR5-5400 может заработать даже совместно с существующей версией кремния Tiger Lake. Говоря о контроллере памяти нового мобильного процессора Intel, нельзя не упомянуть, что в нём Intel реализовала технологию TME (Total Memory Encryption). Благодаря ей мобильное устройство может хранить все данные в памяти в зашифрованном виде, что обеспечивает аппаратную защиту от многих видов атак. Подобные защитные механизмы становятся всё более популярны, особенно с учётом того, что их применение почти не влияет на производительность. Однако возможно в устройствах на базе Tiger Lake технология TME будет применяться исключительно совместно с vPro® – набором средств безопасности платформ Intel, которые обычно реализуются в компьютерах для бизнес-сегмента. Вместе с улучшенным контроллером памяти Tiger Lake получил контроллер PCI Express 4.0, став таким образом первым мобильным процессором с поддержкой этого скоростного интерфейса. Использовать шину PCIe 4.0 разработчик предлагает для подключения высокоскоростных NVMe SSD — для этой цели в процессоре имеется четыре выделенных линии, так что системы, построенные на Tiger Lake, вполне могут сопрягаться с новейшими высокопроизводительными накопителями класса Samsung 980 PRO или WD Black SN850. В то же время некоторые производители мобильных систем при желании смогут задействовать эту скоростную шину для подключения дискретных графических ускорителей как самой Intel, так и сторонних производителей. Также нельзя не упомянуть, что Tiger Lake стал первой точкой внедрения интерфейса Thunderbolt 4. Фактически Thunderbolt 4 является расширением стандарта USB4, поэтому в новых мобильных процессорах поддерживаются и USB4-порты. Возможности Tiger Lake позволяют реализовать в мобильной системе до четырёх портов с пропускной способностью 40 Гбит/с. Как предполагается самой Intel, один из таких портов должен подходить, в частности, и для быстрой зарядки аккумулятора мобильного устройства. В настоящее время модельный ряд процессоров Tiger Lake включает в себя процессоры с числом вычислительных ядер не более четырех, которые рассчитаны на работу в рамках тепловых пакетов 15 или 28 Вт. 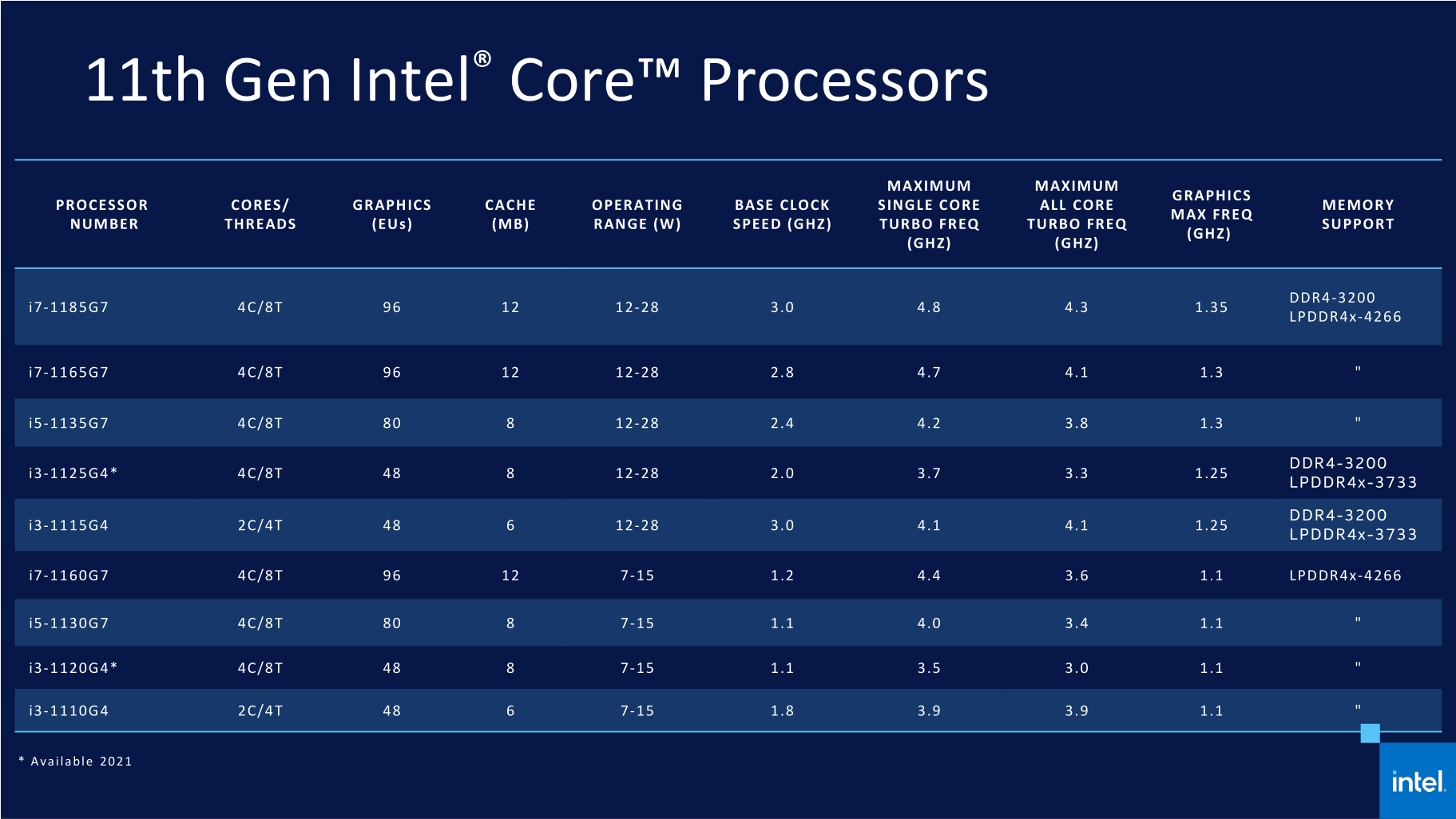 Но это далеко не всё. В соответствии с изначально обозначенным планом множество этих процессоров будет расширяться за счёт более мощных процессоров. Ожидается как минимум ещё два группы CPU: процессоры с 35-Вт тепловым пакетом, ориентированные на более высокие частоты, и процессоры с 45-Вт пакетом, которые получат шести- и восьмиядерные конфигурации. Их анонс ожидается в ближайшее время. Одиннадцатое поколение процессоров Core – это не только мобильные Tiger Lake. Вскоре на рынке появятся также и настольные процессоры Core с таким же номером поколения, но это будут уже не представители семейства Tiger Lake, а несколько иные чипы, которые известны под кодовым именем Rocket Lake. Однако в действительности между Tiger Lake и Rocket Lake существует довольно близкое родство, и, скорее всего, к одному поколению они отнесены не просто так. И на этом нужно остановиться несколько подробнее. Но вначале напомним, что десктопные Core одиннадцатого поколения должны появиться на рынке в течение первого квартала наступающего года, они придут на смену имеющимся процессорам Comet Lake, но сохранят совместимость с разъёмом LGA1200 и материнскими платами, в которых сейчас работают процессоры Core десятого поколения (Comet Lake). Микроархитектура вычислительных ядер процессоров Rocket Lake названа Cypress Cove, и это – ещё одно имя, которое добавляется к ряду Sunny Cove и Willow Cove. Однако в действительности Cypress Cove – не совсем шаг вперёд, а, скорее, наоборот, потому что эта микроархитектура будет представлять собой портированную на старый 14-нм техпроцесс архитектуру Sunny Cove, которая в мобильном сегменте соответствует процессорам Ice Lake. Но в то же время процессоры Rocket Lake всё-таки ближе к Tiger Lake, потому что в них найдёт применение графическая архитектура Xe-LP, которая является принадлежностью наиболее современных мобильных процессоров. Для десктопной реализации она так же, как и Cypress Cove, будет перенесена на 14-нм технологические рельсы, но сути это не меняет – Rocket Lake вполне можно считать десктопным переложением Tiger Lake, адаптированным под 14-нм техпроцесс.  С выпуском Rocket Lake компания Intel рассчитывает заметно увеличить производительность своих предложений в настольном сегменте. В секторе мобильных решений переход на микроархитектуру Sunny Cove в своё время поднял показатель IPC процессоров Ice Lake на 18 % по сравнению с предшественниками. Примерно такой же прирост производительности произойдёт, очевидно, и при переходе от Comet Lake к Rocket Lake. Кроме того, отдельным плюсом внедрения ядер Cypress Cove в десктопах станет появление поддержки набора инструкций AVX-512 в массовых настольных системах, ведь это позволит получить дополнительный и весьма весомый прирост производительности в задачах, задействующих ИИ-алгоритмы и использующих набор технологий Deep Learning Boost. С учётом сложности ядер Sunny Cove и из-за увеличения необходимого для их реализации транзисторного бюджета в сравнении с обычными для десктопов ядрами Skylake максимальные версии Rocket Lake смогут получить лишь восемь вычислительных ядер. И в этом отношении десктопные процессоры не смогут превзойти Tiger Lake, в семействе которых вскоре тоже появятся восьмиядерники. Однако в отличие от мобильных собратьев энергетическая эффективность, к сожалению, не станет козырем Rocket Lake – их тепловой пакет прогнозируется на уровне уже обычной для десктопной платформы Intel величины 125 Вт. Зато встроенный в ожидаемые настольные процессоры северный мост получит все необходимые для современного процессора интерфейсы. Контроллер памяти сможет официально поддерживать модули DDR4-3200, в то время как контроллер PCI Express будет наделён совместимостью с PCIe 4.0. Попутно Intel добавит ему линий, что позволит подключать напрямую к CPU не только графический ускоритель, но и твердотельный накопитель, для которого будет выделено четыре собственных линии. Таким образом, суммарное число поддерживаемых процессором линий PCIe 4.0 достигнет 20. Что касается встроенного графического ядра, то переход в Rocket Lake на графическую архитектуру Xe-LP с применяемой сейчас в десктопных процессорах Comet Lake графики поколения 9.5 должен обеспечить качественный скачок в производительности. По всей видимости, в графическом ядре настольных CPU будут использоваться графические ядра с 32 исполнительными блоками, но этого окажется достаточно для роста производительности встроенного GPU по сравнению с существующими десктопными процессорами как минимум в полтора раза. Кроме того, не следует забывать о поддержке в Xe-LP аппаратного кодирования и декодирования более широкого набора форматов видео, о 12-битном цвете и прочих достоинствах. Также встроенным в Rocket Lake графическим ядром должны поддерживаться трёхмониторные конфигурации с разрешением 4K60 или пары дисплеев с разрешением 5K60 и подключением через DisplayPort 1.4a (с HBR3) или HDMI 2.0b. ⇡#Вместо заключения: что будет дальше В настоящее время положение Intel на рынке выглядит далеко не таким выигрышным, каким оно было несколько лет тому назад. Компании пришлось столкнуться с ожесточённой конкуренцией со стороны AMD, плюс некоторые крупные партнёры Intel начинают поглядывать в сторону архитектуры ARM. На всё это накладываются производственные трудности и задержки с освоением тонких технологических процессов. И даже передовые процессоры Tiger Lake, о которых шла речь в этом материале, хотя и являются во многом революционными, на самом деле попадают в сложную конкурентную среду, в которой их успех отнюдь не очевиден. Однако у Intel есть вполне конкретный план, каким образом она может ответить на все вызовы, с которой ей пришлось столкнуться. Самое главное: Intel твёрдо уверена, что сможет отстоять свои позиции на производственном фронте. Компания не намерена уходить от своей привычной модели бизнеса и собирается и дальше оставаться производителем чипов полного цикла – от проекта до воплощения в кремнии и серийного производства. Intel готова признать, что временно лидерство в освоении новейших техпроцессов было утрачено, но фундаментальные усовершенствования в строении транзисторов, такие как SuperFin, в сочетании с новыми технологиями упаковки чипов, которые компания активно разрабатывает в последнее время, должны дать ей возможность в будущем предлагать продукты, не уступающие решениям конкурентов. И в скором времени мы должны увидеть, как сочетание этих методик преобразит предложения компании. Основополагающая стратегия, которой Intel собирается придерживаться впредь, базируется на двух столпах. Первый в компании называют дезагрегацией, то есть декомпозицией крупных монолитных полупроводниковых конструкций на множество мелких чиплетов, соединённых в одно целое с помощью высокоскоростных каналов связи и упакованных в единый чип с применением различных технологий. Второй обозначается как xPU и представляет собой диверсификацию архитектур чипов с широким применением специализированных кремниевых конструкций. В течение последних месяцев Intel устами своих руководителей высшего звена последовательно рассказывает о преимуществах дезагрегированного дизайна. Его основным плюсом выступает то, что он даёт большую гибкость для смешивания различных чиплетов в одной упаковке. А ещё он позволяет перейти к полупроводниковым кристаллам с меньшей площадью, производить которые и проще, и выгоднее. Кроме того, распределение функций по чиплетам даёт Intel разнообразные варианты по привлечению сторонних подрядчиков для выпуска тех или иных компонентов процессоров, на что компании, судя по всему, придётся опираться в течение ближайших лет, пока она в полной мере не отладит собственные технологические процессы. Intel, несомненно, продолжит фокусироваться на разработке и производстве центральных процессоров, однако попутно значительные усилия начнут пригласиться и в смежных областях: в разработке графических процессоров с архитектурой Xe, в создании различных специализированных ускорителей ИИ, а заодно и в развитии модельного ряда ПЛИС. И хотя все эти решения интересны сами по себе, Intel считает, что в перспективе на рынке возникнет потребность в каких-то объединённых решениях, где идеологически различные аппаратные вычислительные ресурсы могли бы комбинироваться в единое целое. Даже сейчас процессоры Tiger Lake уже содержат в себе классические вычислительные ядра, графическое ядро и специализированный ускоритель GNA. И дальше подобные составные решения будут становиться сложнее и функциональнее, причём для их создания как раз и начнёт применяться дезагрегированный многочиплетный подход. Но настоящая магия подобных решений создаётся за счёт использования специализированного программного обеспечения Intel oneAPI. За этим названием скрывается открытая и унифицированная модель программирования, которая должна] облегчить разработчикам написание программного кода, использующего преимущества различных чипов Intel. Основная идея oneAPI состоит в том, что разработчики программных продуктов должны абстрагироваться от аппаратного уровня, доверив задачу выбора подходящих ускорителей и оптимизации кода под них на заранее созданные Intel универсальные инструменты. Иными словами, Intel хочет воплотить в жизнь дезагрегированный подход вместе со сменой всей парадигмы разработки и оптимизации ПО, и это – весьма амбициозный план, за выполнением которого следить будет как минимум нескучно.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





