







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
HOWTO: как установить и настроить собственный ИИ на игровом ПК
Энтузиасты, что жаждали бы запустить на домашнем ПК большую языковую модель (large language model, LLM) современного уровня, сталкиваются с принципиальной проблемой: их машинам остро не хватает видеопамяти. Дело в том, что плотная многослойная нейронная сеть, к работе которой в конечном итоге сводится LLM, выдаёт некий результат в ходе взвешенного суммирования огромного количества — десятков и сотен миллиардов — операндов. Чтобы производить такие — сравнительно несложные, но чрезвычайно массированные — расчёты за разумное время, необходимо свести к минимуму задержки при передаче сигналов между вычислительными узлами и памятью, с которой те оперируют.  Безусловно, аргумент этот чисто количественный. Законы природы не запрещают применять для эмуляции нейронной сети исключительно центральный процессор с его 4, 8 или 16 ядрами и оперативную память DRAM. Но поскольку вычисления непосредственно в памяти в рамках классической x86-архитектуры не реализуются, потери времени при переносе небольших (обработанных считаными единицами, максимум первыми десятками ядер) пакетов данных между ЦП и ОЗУ оказываются попросту несуразными. И это проблема любых подобных вычислений: к примеру, Stable Diffusion — нейросетевая модель с открытым исходным кодом для создания изображений по текстовым описаниям — при запуске на ПК без дискретного графического адаптера генерирует простейшие картинки за многие десятки минут, тогда как на компьютере даже с не самой современной видеокартой — за пару-тройку минут максимум, а с какой-нибудь NVIDIA RTX 4080 — и вовсе за секунды. LLM ещё более требовательны как к доступному числу физических вычислителей, способных автономно и параллельно производить взвешенные суммирования (для чего почти идеально подходят ядра CUDA), так и к объёму напрямую связанной с ними памяти (при использовании дискретного графического адаптера) — видеопамяти. Для запуска и эксплуатации больших языковых моделей активно применяются специализированные видеокарты — с гигантскими объёмами VRAM в десятки гигабайт на каждой, объединённые сверхскоростными мостами (NVLink, если речь идёт о продуктах NVIDIA) в кластеры из 4 или 8 единиц. 
Пара A100, соединённых мостами NVLink (источник: NVIDIA) Число рабочих параметров для LLM GPT-3.5, что легла в основу первого общедоступного ChatGPT, — 175 млрд. Если каждый из этих параметров кодировать 16-разрядным числом («представление с плавающей запятой половинной точности»; тип данных float16, т. е. по 2 байта на число), то только для одновременного размещения всех их в памяти — в видеопамяти, подчеркнём! — той потребуется более 320 Гбайт. Вот, собственно, и главная причина, по которой запустить ChatGPT на домашнем ПК невозможно в принципе. Да, известен целый ряд разрабатываемых энтузиастами менее требовательных к аппаратной части LLM-проектов, наиболее перспективным среди которых можно считать Alpaca — в вариантах модели с 7, 13 и 30 млрд входных параметров. Однако качество генерируемого ею текста откровенно расстроит завсегдатаев чатов с ChatGPT (и тем более GPT-4): настолько оно не соответствует успевшим уже сформироваться у них высоким стандартам, заданным свежайшими продуктами OpenAI. Казалось бы, если выдавать адекватно воспринимаемый человеком текст для большой языковой модели настолько сложно — точнее, требует таких существенных аппаратных ресурсов, — то что уж говорить о создании изображений! Однако не тут-то было: упомянутая чуть выше Stable Diffusion в наиболее актуальных своих версиях нуждается в ГП NVIDIA как с минимум 4 Гбайт видеопамяти — либо AMD с 8 Гбайт и более. Так что даже далеко не самый современный игровой ПК вполне способен стать вместилищем для бота-художника, готового создавать практически любые изображения по вашему запросу — стоит лишь приложить немного усилий. Собственно, тому, что и как именно делать для установки, запуска и (самой базовой) тонкой настройки Stable Diffusion, и посвящён настоящий киберпрактикум. ⇡#Предварительные замечанияБесспорно, лучше прочих из сравнительно широко доступных видеокарт для машинного преобразования текста в картинки подойдут новейшие NVIDIA RTX 4080 и 4090, в первую очередь по причине внушительного объёма их VRAM — 16 и 24 Гбайт соответственно. Объём ОЗУ компьютера и производительность его ЦП принципиального значения не имеют, но лучше всё-таки ориентироваться на 8 Гбайт DRAM как минимум и хотя бы на четырёхъядерный процессор — такое «железо» позволит быстрее производить служебные вычисления, необходимые для подготовки к собственно генерации изображений. Однако «лучшее» вовсе не значит «единственно возможное». Все процедуры, описанные ниже, были проделаны и все изображения сгенерированы на не самом, мягко говоря, свежем игровом ПК, повидавшем многие виды: с ЦП Intel Core i7-2600K (это не опечатка: именно 2600, а не 12600), с 16 Гбайт ОЗУ и дискретным адаптером на основе ГП NVIDIA GeForce GTX 1070 (8 Гбайт VRAM). На системном SSD была развёрнута актуальная версия Windows 10; для её идейной наследницы Windows 11 все рекомендации и указания почти наверняка можно будет использовать без изменений. 
Рабочие сборки Python для Windows 7 доступны, к примеру, на GitHub (источник: скриншот сайта github.com) С Windows 7 ситуация сложнее (поскольку нужная версия языка Python для неё официально не поддерживается), а для пользователей ОС с ядром Linux путь к финальной настройке генеративной модели для преобразования текста в картинки окажется даже короче — ибо в большинстве популярных дистрибутивов значительная часть необходимого ПО уже исходно предустановлена. Впрочем, в рамках настоящего киберпрактикума вопросы установки Stable Diffusion на других ОС затрагиваться не будут: sapienti sat. Свободного пространства на системном накопителе потребуется как минимум 20 Гбайт, однако с учётом того, что изображения по умолчанию сохраняются внутрь каталога установки, чем больше на диске места, тем лучше. А как насчёт видеокарт AMD — годятся ли они для запуска Stable Diffusion? Практика показывает, что да, вполне, — однако придётся совершить несколько дополнительных шагов в ходе установки и настройки системы, да и в целом производительность при переводе текста в изображения тут будет ниже, чем у сопоставимых по классу графических адаптеров NVIDIA. Основная причина — в том, что сама система преобразования текстовых подсказок в картинку при написании опиралась на ряд проприетарных возможностей, реализованных в ядрах CUDA как на уровне «железа», так и в созданных для него ИИ-ориентированных программных библиотеках. Учитывая, что на мировом рынке дискретной графики NVIDIA доминирует с долей 88% (данные JPR за III кв. 2022 г.), разработчиков трудно упрекнуть здесь в безосновательной избирательности. Впрочем, по слухам, сама Microsoft (ныне фактически владеющая половиной OpenAI, создательницы ChatGPT) сегодня активно сотрудничает с AMD по вопросу оптимизации графических продуктов последней — как раз для решения связанных с ИИ задач. Вполне вероятно поэтому, что следующее поколение дискретной графики AMD будет лучше подходить для преобразования текста в картинки (и в видео, кстати, но это уже и вовсе особая история). 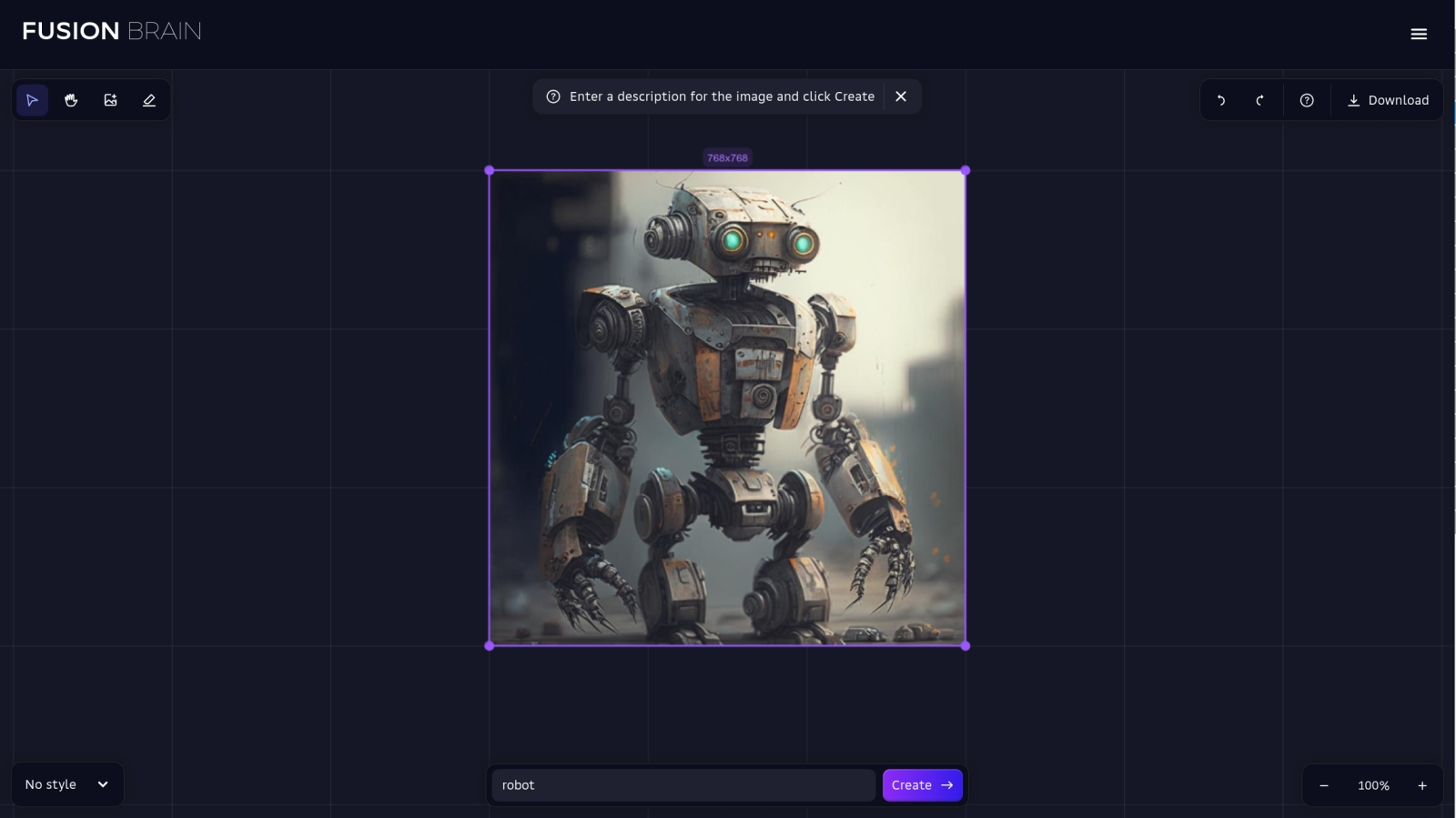
Так представляет себе робота доступная онлайн-модель Kandinsky 2.1 (источник: скриншот сайта fusionbrain.ai) А можно ли генерировать изображения со Stable Diffusion вообще в отсутствие подходящего ПК под рукой? Да, разумеется! Онлайн совершенно бесплатно (а порой, хотя бы в ограниченных пределах, и анонимно, т. е. без требования непременной предварительной регистрации) доступен целый ряд действующих инсталляций: Stable Diffusion Playground, mage.space, Stable Diffusion Online, Dezgo и ещё множество, обнаружить которые через любой поисковик не составит труда (едва ли не единственная отечественная разработка среди них — модель Kandinsky 2.1). Понятно, что на пользователя, в особенности не имеющего возможности заплатить за визуализацию своих текстовых описаний, такие сайты накладывают немало ограничений: это и скудость выбора параметров генерации, и невозможность совершенствовать полученную базовую картинку, и кое-где даже принудительное наложение метки сайта (watermark) на готовое изображение. Кроме того, очереди на бесплатную генерацию на популярных сайтах могут быть довольно длинными. Но если очень-очень надо получить хоть какой-то визуальный образ на основе возникшего в голове сочетания слов, доступные онлайн модели — неплохое начало. Другой вариант, тоже онлайновый, — задействовать Google Colab, бесплатную платформу, что позволяет каждому обладателю учётной записи Google разворачивать в облаке корпорации так называемые блокноты (Python notebooks) для исполнения кода, написанного на языке Python. Поскольку локальная инсталляция Stable Diffusion тоже, по сути, сводится к установке на ПК среды Python и ряда специализированных скриптов на этом языке, практически всё, что возможно проделать с этой моделью на вашем компьютере, доступно и после развёртывания её в Colab. Соответствующих инструкций в Сети имеется в избытке, однако следует помнить: только платным пользователям Colab (10 долл. США в месяц и более — причём оплата картой, да) доступно исполнение блокнота на физическом серверном ГП NVIDIA A100 с его великолепной ИИ-производительностью. В противном же случае скорость генерации изображений вряд ли будет намного выше, чем на видавшем виды локальном игровом ПК. ⇡#…Но Git установить обязанВ понимании рядового пользователя установка ПО на компьютер сводится к скачиванию и запуску инсталляционного файла — после чего в системе оказывается развёрнута вожделенная программа или целая платформа; как правило, уже в виде исполняемого бинарного файла (часто с рядом дополнительных файлов — служебных библиотек, конфигурационных и пр.). У программистов, особенно ориентированных на ПО с открытым исходным кодом, подход иной: если есть программа, написанная на некоем языке, и свободно доступная среда для исполнения кода на этом же языке, к чему городить огород с бинарниками? Проще запускать программы в этой же самой среде и горя не знать. Как раз такому принципу в целом и следует логика установки Stable Diffusion. 
А такое изображение робота — предел возможностей для бесплатных и анонимных посетителей mage.space (источник: скриншот сайта mage.space) Для начала на локальном ПК необходимо развернуть клиент Git. Git — это распределённая система контроля версий (version control system, VCS); платформа не безусловно необходимая, но до чрезвычайности полезная для множества независимых программистов, совместно и исключительно добровольно трудящихся над многочисленными проектами ПО с открытым кодом. Главное достоинство VCS — в том, что никакая информация из неё бесследно не исчезает (если не прикладывать к тому особых усилий), т. е. любое внесённое в код исправление не затирает прежнего состояния соответствующего фрагмента листинга программы. Более того, Git не отслеживает такие изменения и не ведёт им тщательный учёт по отдельности (в отличие от других популярных VCS, таких как Subversion, Bazaar, CVS и пр.), но после каждого коммита (отправки пользователем со своего локального ПК исправленной версии кода в облако Git) создаёт моментальную копию — снэпшот (snapshot) — всех файлов данного проекта. Впрочем, красоту и практичность этого решения в полной мере оценят лишь программисты; рядовому же пользователю, просто желающему запустить Stable Diffusion на своём ПК, важно понимать, что загруженный через Git проект останется заведомо работоспособным именно в той версии, в которой его впервые установят. И что любые последующие изменения и дополнения — пока они не «втянуты» через тот же Git на локальный ПК — никак на работе уже инсталлированной системы не отразятся. В век подспудных фоновых автообновлений, частенько приводящих к внезапным кардинальным переменам в интерфейсах и функциональных возможностях привычных приложений, это дорогого стоит. 
Источник: скриншот сайта git-scm.com Итак, для загрузки Git для Windows следует воспользоваться репозиторием на сайте самой платформы. 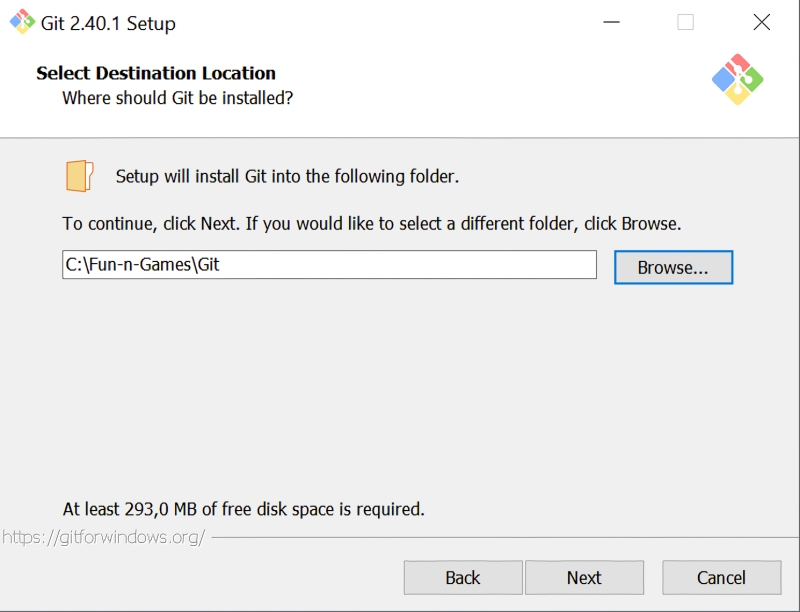 По завершении закачки инсталлятора надо его запустить — и пройти стандартную процедуру установки, раз за разом нажимая кнопку Next. Практически повсеместно достаточно будет лишь подтвердить параметры, предлагаемые инсталлятором по умолчанию. Возможно, для начала вам захочется поменять целевой каталог установки (самое первое окно) 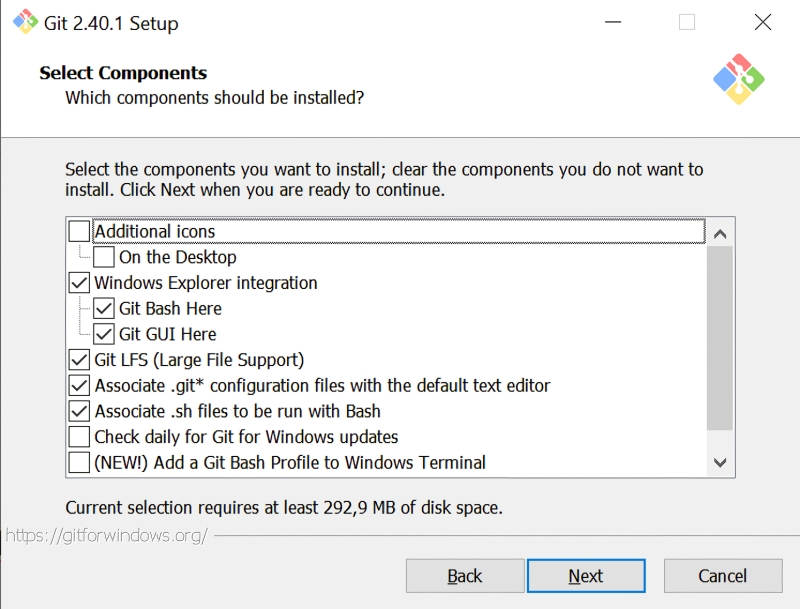 В окне «Select Components» необходимо будет удостовериться, что опция интеграции с «Проводником» Windows активна, равно как и две опции более низкого уровня — «Git Bash Here» и «Git GUI Here». Предпоследняя окажется крайне полезна как раз для удобной и быстрой загрузки с Git проекта, позволяющего запускать графический интерфейс для взаимодействия со Stable Diffusion. 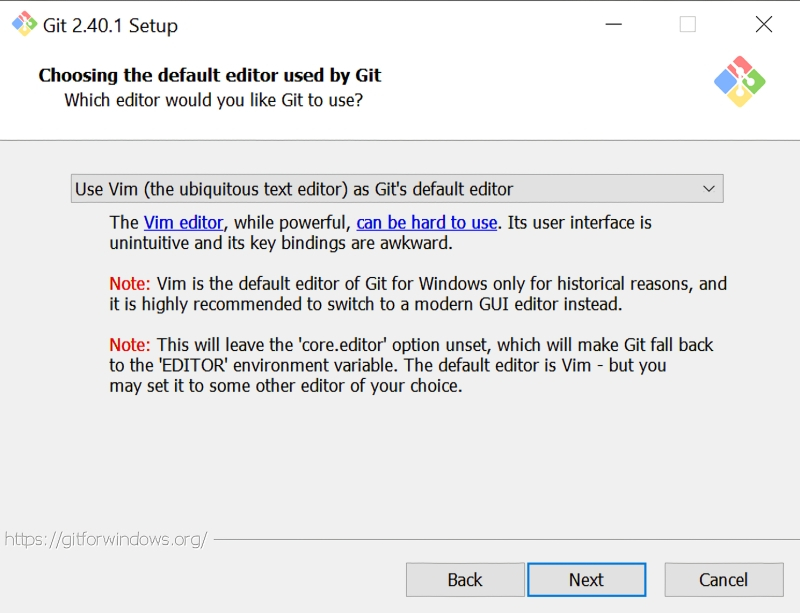 Программисты-олдфаги оценят изощрённый юмор разработчиков платформы: в окне «Choosing the default editor used by Git» по умолчанию выбран Vim — известный и заслуженный, но крайне противоречивый текстовый редактор; из мира не Linux даже, а стародавнего ещё UNIX (точнее, BSD). Не ввязываясь в дискуссию о плюсах и минусах различных редакторов эпохи исключительно текстовых компьютерных терминалов, отметим, что далёкому от этих материй пользователю (особенно пользователю Windows) имеет смысл выбрать в этом окне что-то менее остросюжетное, хотя бы банальный Notepad. 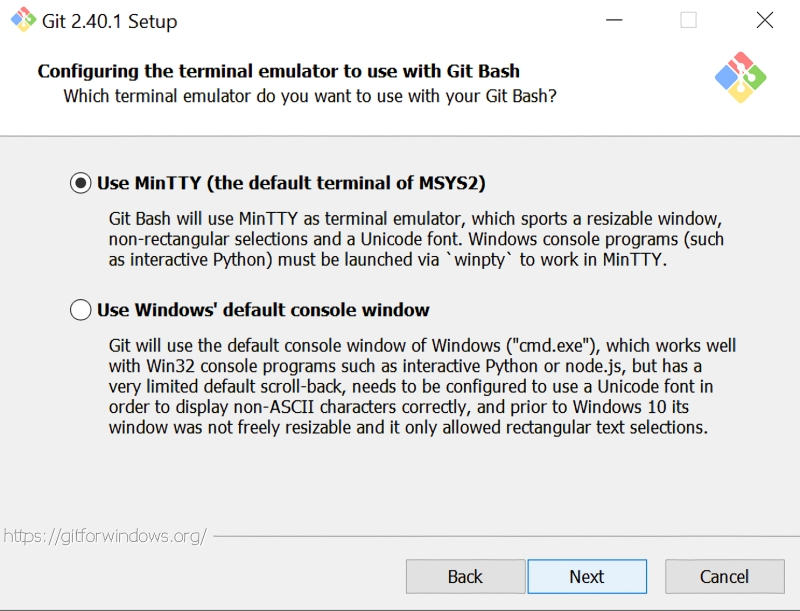 Ещё один момент: в окне «Configuring the terminal emulator to use with Git Bash» из предлагаемых опций лучше выбрать MiniTTY. Это не принципиальный вопрос, и консольное окно Windows по умолчанию тут вполне сгодится, — но из соображений лучшей совместимости (с Unicode-шрифтами прежде всего) MiniTTY всё-таки предпочтительнее.  По завершении инсталляции в «Проводнике» Windows следует открыть папку, в которую Git был установлен, и, удерживая курсор мыши в пределах этого окна (не имеет значения, на каком именно файле), нажать на правую кнопку. Откроется меню, в котором — благодаря тому, что напротив опций «Git Bash Here» и «Git GUI Here» в ходе инсталляции были проставлены галочки, — появятся две новых соответствующих строчки. Нужно навести курсор на «Git Bash Here» и нажатием теперь уже левой кнопки мыши запустить тот самый терминал MiniTTY, о котором шла речь буквально только что.  Именно из этого терминала пользователь и отдаёт команды Git — в частности, на закачку интересующих его проектов. «Закачка» в терминах этой платформы — «клонирование», т. е. создание локальной копии расположенного онлайн кода, поэтому требуемая команда выглядит следующим образом: git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui AUTOMATIC1111 — это и есть название интересующего нас проекта веб-интерфейса для работы со Stable Diffusion. Это именно веб-интерфейс: доступ к нему производится через браузер; по умолчанию только с локального ПК, но при желании можно открыть его и для внешних пользователей — правда, вероятно, придётся повозиться с настройками брандмауэра на своём маршрутизаторе. Это, пожалуй, наиболее популярный на сегодня интерфейс для работы со Stable Diffusion: хотя имеются и другие подобные проекты, широта возможностей контроля над процессом генерации и множество доступных плагинов делают AUTOMATIC1111 отличным инструментом для экспериментирования. ⇡#Внимание: модель!Интерфейс установлен, пользователь перед компьютером есть, — самое время загрузить собственно Stable Diffusion, т. е. модель на основе машинного обучения для преобразования текста в графический образ (text-to-image model), написанную на языке Python. К ней впервые предоставил свободный доступ 22 августа 2022 г. сам же её разработчик — компания Stability.ai, специализирующаяся на развитии генеративных ИИ с открытым кодом. В основе Stable Diffusion лежит латентная диффузия: изначально в качестве базы для каждого нового изображения генерируется мешанина разноцветных точек на основе достаточно большого целого числа — «затравочного зерна» (seed), или попросту затравки, на основе которой работает псевдослучайный алгоритм такой генерации и которая в дальнейшем, совместно с текстом подсказки и другими параметрами, определяет конечный вид готового изображения. Не вдаваясь в детали, поясним, как происходит обучение таких моделей: на вход нейросети подаётся некое изображение и его достаточно полное текстовое описание. Затем система зашумляет исходную картинку, последовательно добавляя к ней разноцветные точки в псевдослучайном, но генерируемом по вполне детерминистическому алгоритму порядке (гауссовский шум) на основе набора токенов, связанных с описывающими картинку терминами, — и снова пропускает через нейросеть полученный результат. Несколько десятков итераций спустя изображение превращается — на взгляд человека — в совершенно бесструктурную мешанину разноцветных пикселей. Однако для самой системы в этом хаосе закодирована исходная картинка — просто скрытая под напластованиями множества шумовых слоёв, наложенных известным ей образом. Можно даже сказать, что в каком-то смысле исходная картинка заархивирована, — вот только для обратного процесса потребуется не линейный алгоритм разархивации, а та же самая нейронная сеть. Проведя много таких операций обучения — желательно десятки и даже сотни тысяч для каждого текстового термина, — нейросеть с обратным распространением ошибок формирует на входах своих перцептронов такие веса, что позволяют «разархивировать» картинки из шума по ключевым словам, проходя весь путь в обратном порядке. А именно: взяв прямоугольник, заполненный «белым шумом», и известный системе текстовый термин, слой за слоем удалять с картинки случайные пикселы в определённом порядке — и получать запрашиваемое изображение. Почти как ваятель удаляет лишние, на его взгляд, фрагменты мрамора с глыбы, открывая в итоге таившуюся там скульптуру. Аналогия эта вполне адекватна: как из двух идентичных каменных блоков можно изваять совершенно разные статуи, так и две затравочных картинки с «белым шумом», сгенерированным на основе одного и того же seed, в ответ на различные текстовые подсказки породят совершенно несхожие между собой изображения. 
Источник: скриншот сайта huggingface.co Сама модель Stable Diffusion версии 1.5 (сегодня есть уже и более поздние проекты самой Stability.ai, и аналоги за авторством других разработчиков, однако на данный момент именно эта пользуется наибольшей популярностью в кругах энтузиастов text2image-активности) доступна — опять-таки бесплатно, без SMS и регистрации — на репозитории онлайн-сообщества ИИ-кодеров Hugging Face. 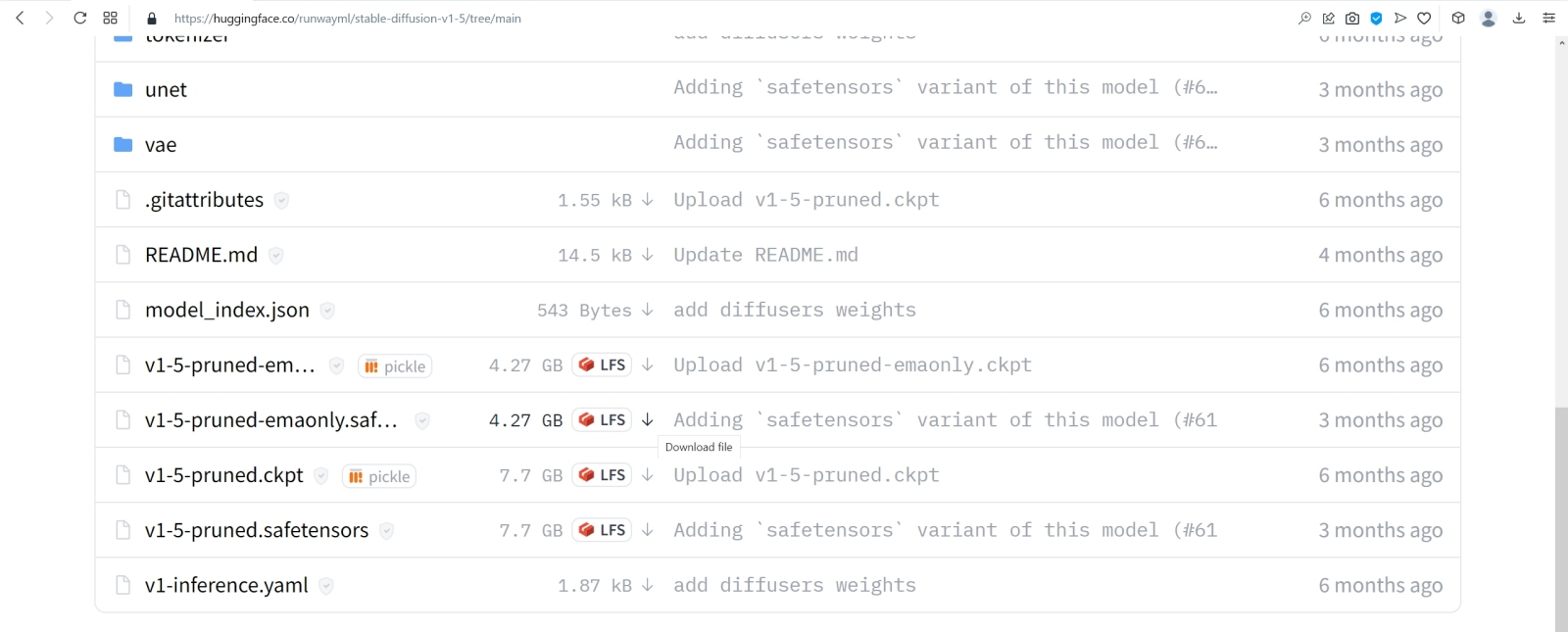
Источник: скриншот сайта huggingface.co Чтобы загрузить эту модель, следует перейти на вкладку Files в веб-интерфейсе её странички на репозитории, чуть прокрутить вниз — и нажать на не самую приметную стрелочку с подчёркиванием, стоящую справа от букв «LFS» в строке, что начинается с «v-1-5-pruned-emaonly.safetensor». Как только при наведении на стрелочку всплывёт окошко с мелкой надписью «Download file» — можно нажимать и запасаться терпением: файл занимает несколько гигабайтов. Почему среди прочих вариантов представления Stable Diffusion лучше выбирать именно этот? Первое соображение — размер: версия без «emaonly» тянет на 7,7 Гбайт, а выбранная нами — менее чем на 4,3 Гбайт. Для дальнейшей тренировки модели (натаскивания её на новых изображениях; тех, что не вошли в исходный пул обучения в 2,3 млрд аннотированных картинок) лучше подойдёт более полный и весомый вариант, но в ходе генерации по текстовым подсказкам разница между «pruned» и «pruned-emaonly» пренебрежимо мала. Но, может быть, более крупный файл модели позволит получать, исходя из той же самой текстовой подсказки, изображения лучшего качества? Не совсем так; но, чтобы обосновать этот тезис, придётся немного углубиться в технические детали. Для начала сам термин pruned (англ. «обрезанный», «упрощённый») указывает на некоторую потерю информации в этой версии модели по сравнению с полной, полученной в Stability.ai после обработки тех самых 2,3 млрд изображений. По сути, итог обучения нейросети — это определённый набор весов на входах каждого перцептрона каждого из её слоёв. Некоторые из этих весов могут оказаться с высокой точностью равными нулю, а поскольку нейросеть высчитывает взвешенные суммы (произведение текущего значения аргумента и веса на данном входе данного перцептрона), умножение на почти ноль тоже даст в результате почти ноль. Иными словами, в pruned-версии все «почти нули» ниже некоторого порога величины заменены самыми обычными нулями, так что при формировании картинки по готовой модели разница между «урезанным» и полным вариантами практически неприметна. 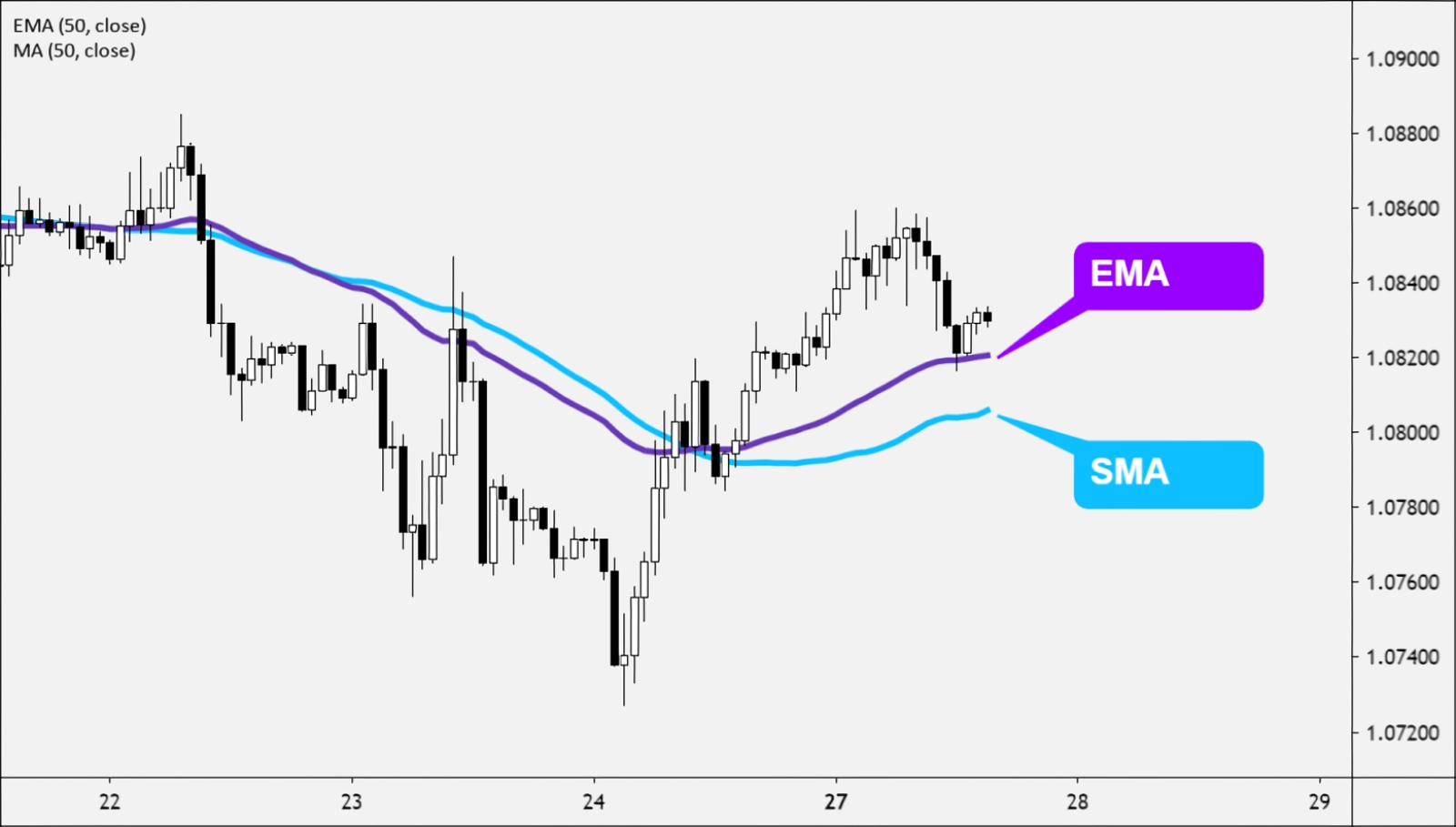
Наглядная демонстрация разницы между экспоненциально взвешенным скользящим средним (EMA) и простым, или арифметическим, скользящим средним (SMA) на примере динамики биржевых котировок за определённое время (источник: BabyPips) Можно пойти и ещё дальше, применив к pruned-набору весов операцию вычисления экспоненциально взвешенного скользящего среднего (exponential moving average, EMA). Хорошо известная онлайн-трейдерам, эта операция представляет собой по сути свёртку: выявление главного тренда в динамике изменения некоего параметра за счёт сглаживания случайных флуктуаций в ряду наблюдений. Способов вычислять скользящее среднее известно немало; метод именно экспоненциального взвешивания привлекателен тем, что недавние наблюдения получают здесь больший вес по сравнению с более ранними. Иными словами, EMA позволяет усреднять длинные ряды наблюдений (для рассматриваемых моделей — весов на входах перцептронов) с упором на самые последние, ближние к стадии формирования финального результата. Здесь подходит такой наглядный пример: студент за время обучения получает различные оценки (за сессионные экзамены и зачёты, за активность на коллоквиумах, лабораторные работы и т. п.), и в конце концов сдаёт госэкзамены. Так вот, итоги госэкзаменов можно рассматривать как финальные веса ИИ-модели на завершающем этапе её обучения. Однако на эти оценки может влиять огромное количество факторов: внезапное недомогание, чрезмерное волнение и пр. Поэтому о реальном прилежании студента и уровне накопленных им за период обучения знаний гораздо больше скажет EMA всех его прежних оценок вплоть до госэкзаменационных — с упором, конечно, на наиболее близкие к ним по времени. Потому что первая, к примеру, сессия была давно, и предметы, за которые на ней выставлялись оценки, для практической работы выпускника вуза, скорее всего, не будут иметь большого значения. Интересующихся математическими подробностями отсылаем к оригинальной статье сотрудников OpenAI, впервые предложивших EMA-оптимизацию набора весов для моделей глубокого обучения. Здесь же важно, что для практических пользовательских приложений файлы моделей pruned-emaonly оптимальны по соотношению занимаемого дискового пространства (равно как и требуемого для закачки времени, кстати) и качества получаемого результата. Более того, они, по оценкам энтузиастов, креативнее исходных, с несвёрнутыми наборами весов, — причина этого станет яснее, когда мы дойдём до рассмотрения параметра Clip skip в настройках AUTOMATIC1111. Если браться за дообучение Stable Diffusion (за создание текстовых инверсий, LoRA и за прочее высокоуровневое шаманство, которое в рамках настоящего киберпрактикума мы рассматривать не станем) — тогда решительно необходимой окажется именно полная, pruned-модель. 
Если задействовать на различных сайтах одни и те же модели для генерации образов (Stable Diffusion 1.5 в данном случае), и результаты буду выходить схожими (источник: скриншот сайта dezgo.com) Ещё один важный момент: рекомендуется всегда — особенно если интересная модель попадётся вам на, скажем так, не самых заслуживающих доверия сайтах — отдавать предпочтение версии с расширением .safetensors. Дело в том, что стандартный формат, в котором хранятся веса натренированной модели, pickle (расширения .ckpt, .pkl и пр.), небезопасен, поскольку допускает исполнение стороннего — потенциально вредоносного — кода. Это, по сути, машиночитаемый бинарный файл; набор инструкций, указывающих, с каким перцептроном в каком слое нейросети какие веса использовать при обработке входящего сигнала, — а не таблица с самими этими весами и соответствующими связями: та вышла бы чрезмерно громоздкой). Как сообщает официальная документация, «модуль pickle имплементирует двоичные протоколы для сериализации и десериализации структуры объектов Python», т. е. устанавливает связи между различными объектами. В частности — позволяет при определённых условиях запускать сторонний код, написанный на Python, в том числе содержащий инструкции прямого исполнения — вроде eval или exec. Вот почему в среде энтузиастов машинного обучения в применении к моделям с открытым кодом всё большее распространение получает простейший формат сериализации .safetensors — безопасный, обеспечивающий ускоренную загрузку весов модели в память и более быстрое получение результата на системах с несколькими графическими процессорами. ⇡#Подползая к роботамЗагруженный файл модели v-1-5-pruned-emaonly.safetensors надо поместить в специально предназначенную для моделей папку внутри установочного каталога Stable Diffusion: /models/Stable-diffusion. Изначально она пуста, если не считать текстового файла нулевой длины с говорящим наименованием «Put Stable Diffusion checkpoints here» — «чекпойнтами» как раз и называют файлы с натренированными на определённым наборе картинок весами для данной нейросети.  Для корректной работы системы по умолчанию требуется, чтобы базовый чекпойнт — тот, что будет сразу загружаться в память при запуске Stable Diffusion, — носил название «model», однако, помимо него, в этой папке может располагаться сколько угодно чекпойнтов. Поэтому следует либо переименовать «v-1-5-pruned-emaonly.safetensors» в «model.safetensors», либо сохранить прямо здесь же его копию с таким именем. 
Источник: скриншот сайта python.org Чекпойнт в формате файла сериализации для структуры объектов Python есть — а как же сам язык программирования Python? В Windows 10 его исходно, разумеется, нет, но он свободно доступен для загрузки с официального сайта. Главное — обращать пристальное внимание на выбираемую версию, а именно 3.10.6: следует загружать файл установщика для 64-битных систем — python-3.10.6-amd64.exe (проще всего найти «3.10.6» на странице через Ctrl+F). Дело в том, что разработка Stable Diffusion 1.5 (и, в меньшей степени, AUTOMATIC1111) велась именно на этой версии языка с поддержкой PyTorch — фреймворка, специально созданного для ускорения расчётов по части задач машинного обучения на современных графических адаптерах. И в целом следует помнить, что программы на Python не лучшим образом исполняются на любых иных (включая более свежие) его версиях, чем те, которыми пользовались их разработчики.  В ходе установки Python 3.10.6 на самом первом экране инсталляции потребуется поставить галочку напротив строки «Add Python 3.10 to PATH» — чтобы у Windows не возникало проблем с поиском соответствующих исполняемых файлов. Прочие опции в последующих окнах можно оставить нетронутыми. 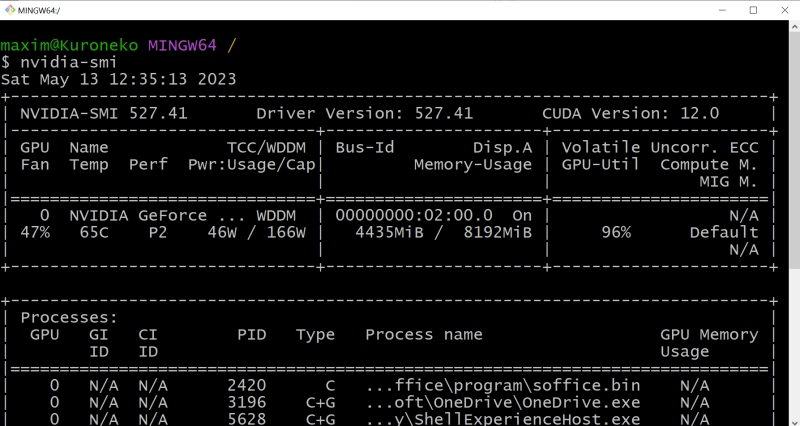 Да, и кстати: хорошо бы на всякий случай установить самые свежие из доступных драйверов для используемого графического адаптера, а заодно и CUDA Toolkit с сайта NVIDIA. Лишним не будет, поскольку обеспечиваемая этим пакетом поддержка инструкций xFormers позволяет Stable Diffusion и схожим text2image-моделям эффективнее использовать видеопамять. Чтобы узнать, имеется ли уже в системе CUDA Toolkit и какова текущая версия драйверов, следует выполнить из командной строки Windows команду nvidia-smi И если позиция «CUDA Version» в выдаче отсутствует либо номер этой версии меньше 11.7, имеет смысл скачать и проинсталлировать новую. 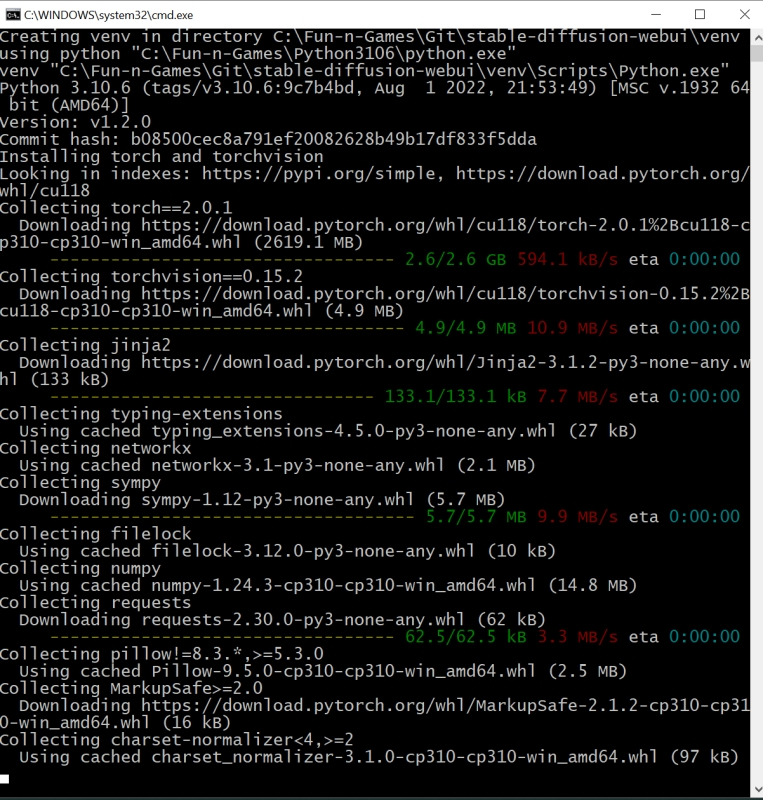 И вот, собственно, волнительный момент: первый запуск Stable Diffusion 1.5 с базовым чекпойнтом на вашем локальном ПК! Для этого теперь, когда всё необходимое ПО закачано и подготовлено, в «Проводнике», где открыт каталог stable-duffusion-webui, нужно дважды щёлкнуть левой кнопкой мыши по файлу webui-user.bat. Откроется окно терминала, в котором будут появляться служебные сообщения о производимых системой операциях. Сперва ей потребуется произвести ряд донастроек программного окружения, так что первый запуск может потребовать 5-10 минут, — но в дальнейшем всё будет происходить значительно быстрее. 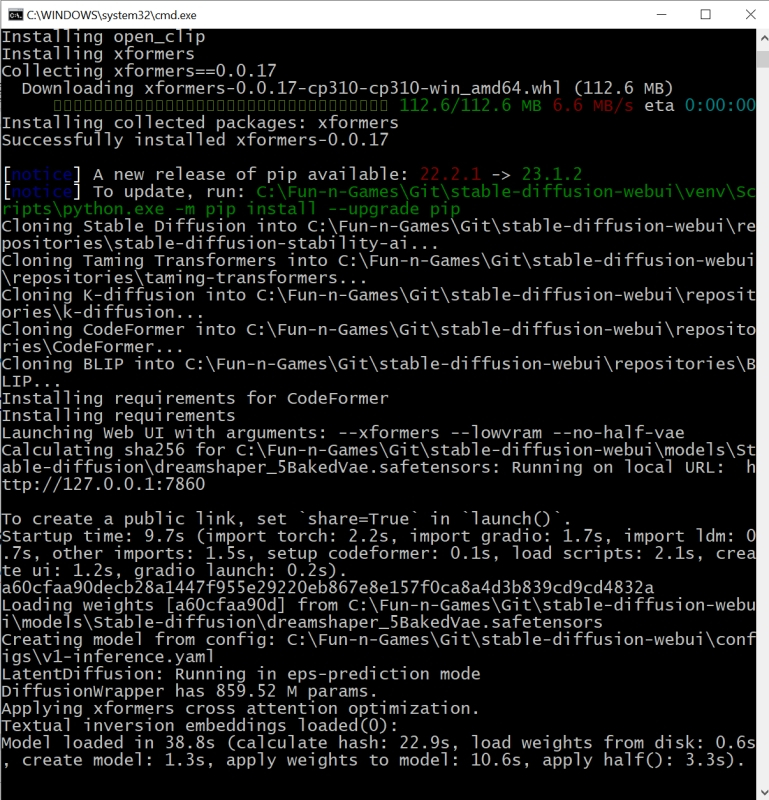 Обратите внимание, что в ходе установки система сообщает об обнаружении новой версии pip — и сразу же предлагает прямую ссылку для её установки. В принципе, это не обязательный момент, но pip — служебный пакет для управления зависимостями между пакетами (Python package manager), и как раз его — в отличие от рекомендованной версии самого Python — обновить лишним не будет. 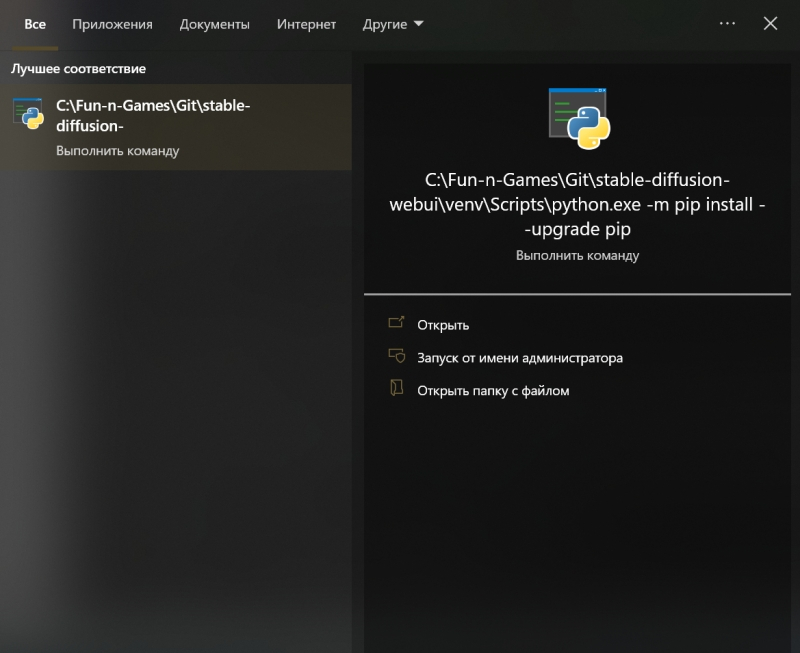 Скопировав прямо из терминального окна соответствующую команду (разумеется, точный путь до исполняемого файла будет зависеть от того, в какой каталог на данном ПК установлен Stable Diffusion), достаточно просто вставить её в системное поле поиска, что располагается слева на панели управления Windows 10/11, и нажать на «Enter». 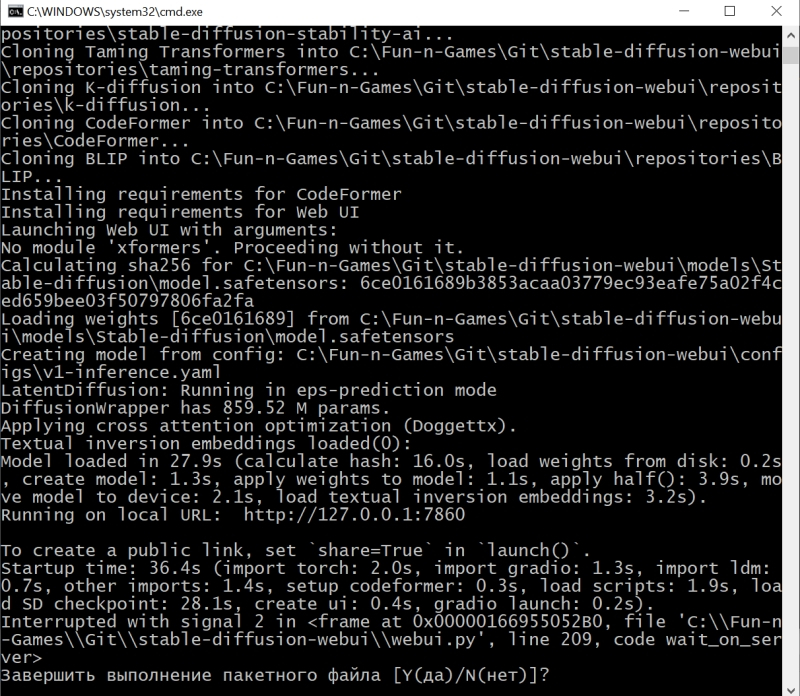 Итак, модель Stable Diffusion установлена и запущена. Можно уже приступать к рисованию? Почти: осталось лишь произвести тонкую настройку производительности, чтобы оптимизировать работу системы в дальнейшем. Остановим пока что работу пакета, нажав в активном терминале (открывшемся, напомним, после запуска файла webui-user.bat из «Проводника») клавиши «Ctrl» и «C» одновременно, а затем после появления подсказки введя «y» с подтверждающим «Enter». Окно терминала закроется после этого автоматически.  Обратимся снова к «Проводнику» и откроем уже знакомый файл с параметрами запуска webui-user.bat для редактирования: для этого нужно, подведя к нему курсор, нажать на правую кнопку мыши, а в появившемся меню выбрать опцию «Изменить». 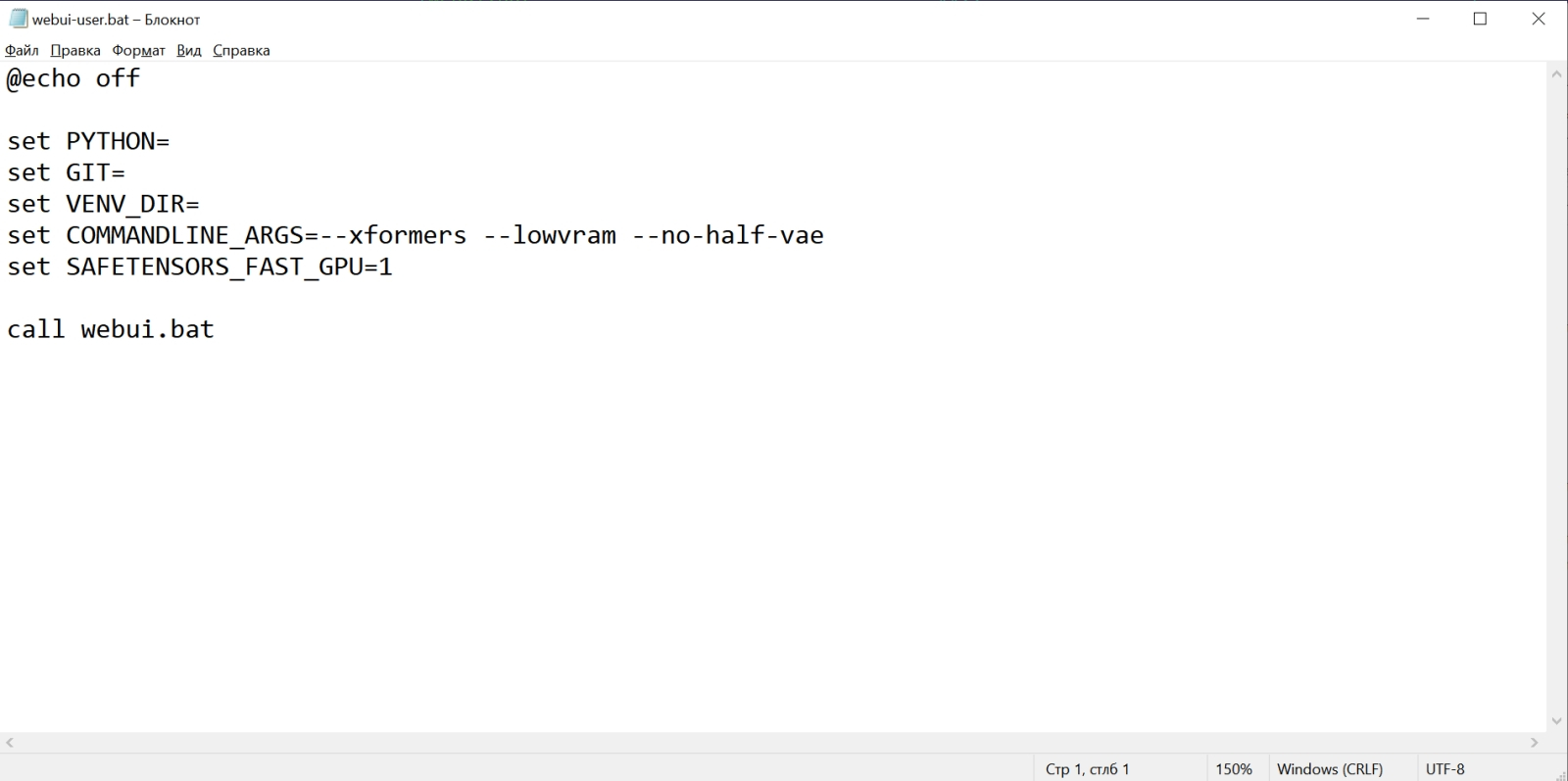 Вот так должен выглядеть webui-user.bat после редактирования. Здесь добавлены аргументы командной строки --xformers --lowvram --no-half-vae а также установлено значение переменной SAFETENSORS_FAST_GPU=1 Кратко поясним, что здесь к чему. Xformers — точнее, xFormers, — это инструментарий для ускорения ИИ-вычислений, производимых с участием трансформеров, что применяются практически во всех современных диффузионных моделях — преобразователях текстовых подсказок в изображения, не исключая и Stable Diffusion. Навскидку на GTX 1070 указание аргумента --xformers при запуске системы ускоряет при прочих равных получение результата едва ли не вдвое. Правда, имеются основания утверждать, что xFormers добавляют изрядно стохастики в генеративный процесс, так что воспроизвести однажды полученную картинку с теми же стартовыми параметрами (затравка-seed, чекпойнт, CFG, подсказки и пр.) со стопроцентной точностью уже не удастся. В любом случае владельцам графических адаптеров менее чем с 12 Гбайт видеопамяти применять xFormers, скорее всего, придётся, поскольку этот инструментарий за счёт оптимизации вычислений ощутимо снижает объём используемой VRAM — и тем самым делает возможной дальнейшую ИИ-обработку полученных картинок внутри Stable Diffusion, включая до- и перерисовку, увеличение масштаба с наращиванием детализации и т. п. Смысл --lowvram куда более очевиден: это указание системе на то, что видеопамяти в её распоряжении немного. В перечне доступных оптимизаций AUTOMATIC1111 указаны и этот параметр, и не так сильно сказывающийся на производительности (но зато и более требовательный к объёму памяти) --medvram. В отношении --lowvram приговор разработчиков лаконичен: «Devastating for performance». При использовании --medvram модель не загружается в видеопамять вся, а разбивается на три блока, каждый из которых подтягивается в VRAM последовательно, по мере необходимости, но целиком; --lowvram же дробит наиболее объёмистый из этих модулей на ещё более мелкие фрагменты, тем самым позволяя (теоретически; лично не проверялось) трансформировать текстовые подсказки в изображения даже на ГП с 2 Гбайт видеопамяти, — но ценой заметного увеличения времени работы. 
Чем хороша ИИ-генерация изображений на специализированных сайтах, так это отсутствием необходимости заботиться об установке и настройке системы (источник: скриншот сайта clipdrop.co) Иными словами, с --lowvram система заработает практически на любом ПК, более или менее заслуживающем называться «игровым», почти гарантированно. Но едва первые изображения получены, есть смысл поменять в конфигурационном файле этот параметр на --medvram и, перезапустив Stable Diffusion, произвести генерацию заново; и если всё получится — оставить всё именно в таком виде. Например, для используемой в настоящем киберпрактикуме системы с GTX 1070 базовая генерация с параметром --lowvram занимает 28-35% от доступных 8 Гбайт видеопамяти, тогда как с --medvram — уже 68-75%, причём выигрыш во времени, что уходит на создание одной картинки, не превышает 25-30%. Счастливым же обладателям видеокарт с VRAM 12 Гбайт и более ни один из этой пары оптимизационных параметров не пригодится. Параметр --no-half-vae — ещё одна оптимизация, дающая системе указание не использовать формат половинной точности (16 бит для 32-разрядных компьютеров) представления данных с плавающей запятой для работы VAE (вариационного автокодировщика; смысл его в том, чтобы снижать размерность пространства задаваемых модели параметров почти без потери информации о них). Строго говоря, такой формат в полной мере поддерживают лишь наиболее новые поколения ГП NVIDIA — Pascal, Volta, Ampere, — так что пользователям более ранних видеокарт имело бы смысл применять разом две оптимизации: и указанную нами --no-half-vae, и более глобальную --no-half (относится уже не к одному только VAE, а к базовому чекпойнту в целом). Однако, как показывает практика, в отсутствие --no-half даже на сравнительно старых ГП Stable Diffusion работает вполне уверенно, тогда как без --no-half-vae частенько выдаёт чёрные прямоугольники вместо сгенерированных картинок. Речь, подчеркнём ещё раз, идёт именно о GeForce GTX 2000-й серии и более ранних: для актуальных RTX 3000-го и 4000-го семейств в аргументах командной строки внутри .bat-файла не имеет смысла указывать параметры оптимизации — разве только --xformers. Ещё одна дописанная нами в этот файл строка SAFETENSORS_FAST_GPU=1 тоже направлена на ускорение работы системы. Здесь использована та особенность формата .safetensors, что представленные в нём веса модели оказывается возможно загрузить напрямую в видеопамять, минуя этап первоначальной подгрузки в основное ОЗУ.  Собственно, всё: сохранив изменения в webui-user.bat и закрыв его, снова запускаем этот файл двойным щелчком — и наблюдаем, как система (уже с оптимизированными параметрами) приходит в рабочее состояние. После появления надписи «Running on local URL» самое время открыть в браузере новую вкладку и набрать в ней адрес, по которому доступен веб-интерфейс AUTOMATIC1111, — http://127.0.0.1:7860. 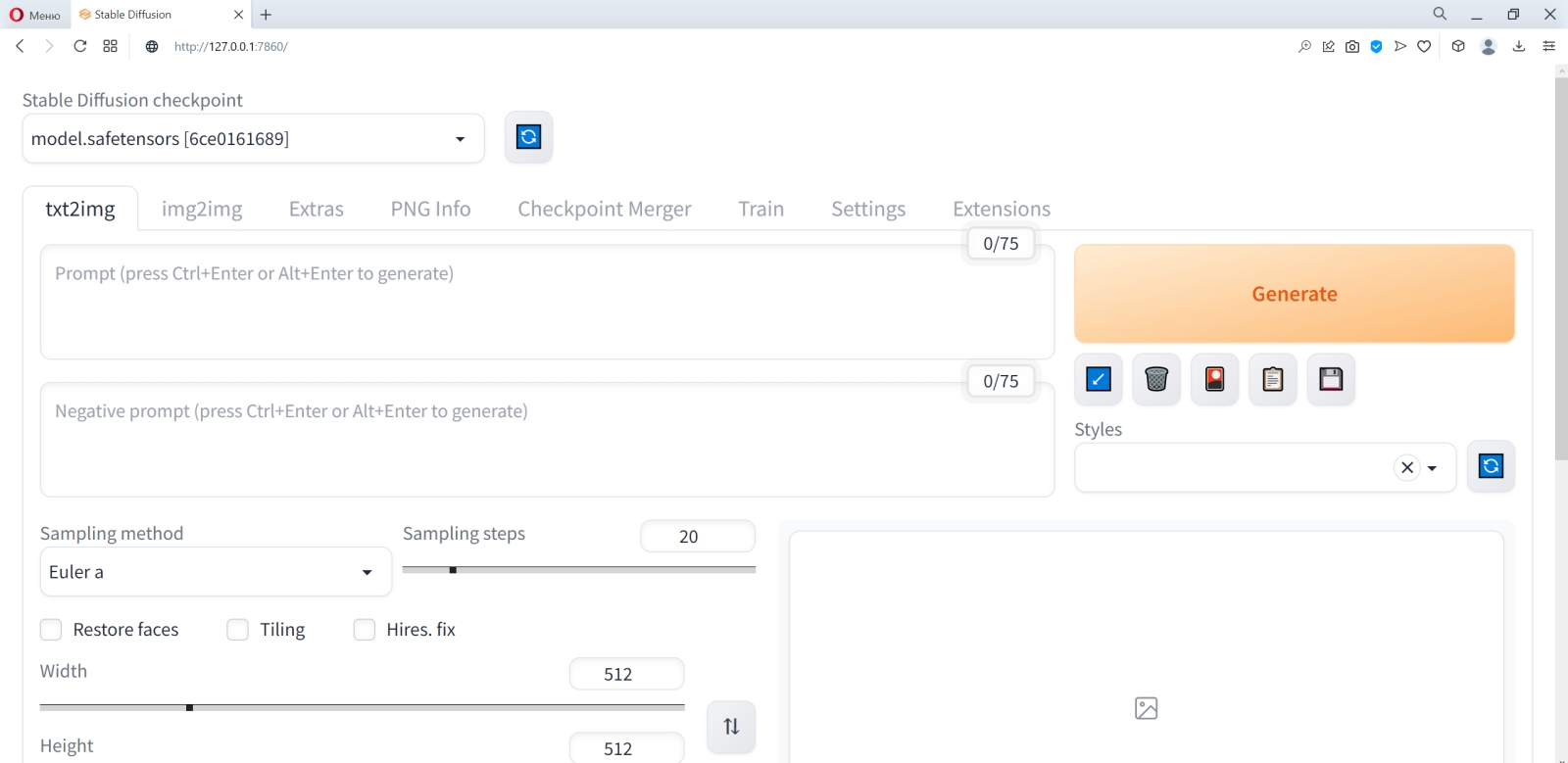 Вот примерно так он и выглядит изначально. Наконец-то пришла пора приниматься за творчество! Точнее, за побуждение ИИ к изобразительному действию путём выдачи ему текстовых подсказок.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





