







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание

Опрос
|
реклама
Самое интересное в новостях
HOWTO: как установить и настроить собственный ИИ на игровом ПК
⇡#Как художник художникуНет ничего проще: в основное поле для ввода (Prompt) впишем для начала одно-единственное слово «robot».  Оставим поле Negative prompt пустым, не будем трогать другие параметры, только ползунок Batch size (размер пакета) передвинем вправо до упора — чтобы получать сразу восемь картинок с различными затравками (seed) одновременно: так проще будет выбирать достойную дальнейшей обработки заготовку. Дальше следует нажать на огромную оранжевую кнопку Generate — и, если всё было сделано должным образом, через некоторое время Stable Diffusion визуализирует полученную подсказку.  За ходом процесса можно наблюдать в терминальном окне, где запущена сама система, — там будет появляться детальная информация о времени, затраченном на загрузку рабочих параметров, и даваться оценка продолжительности работы. 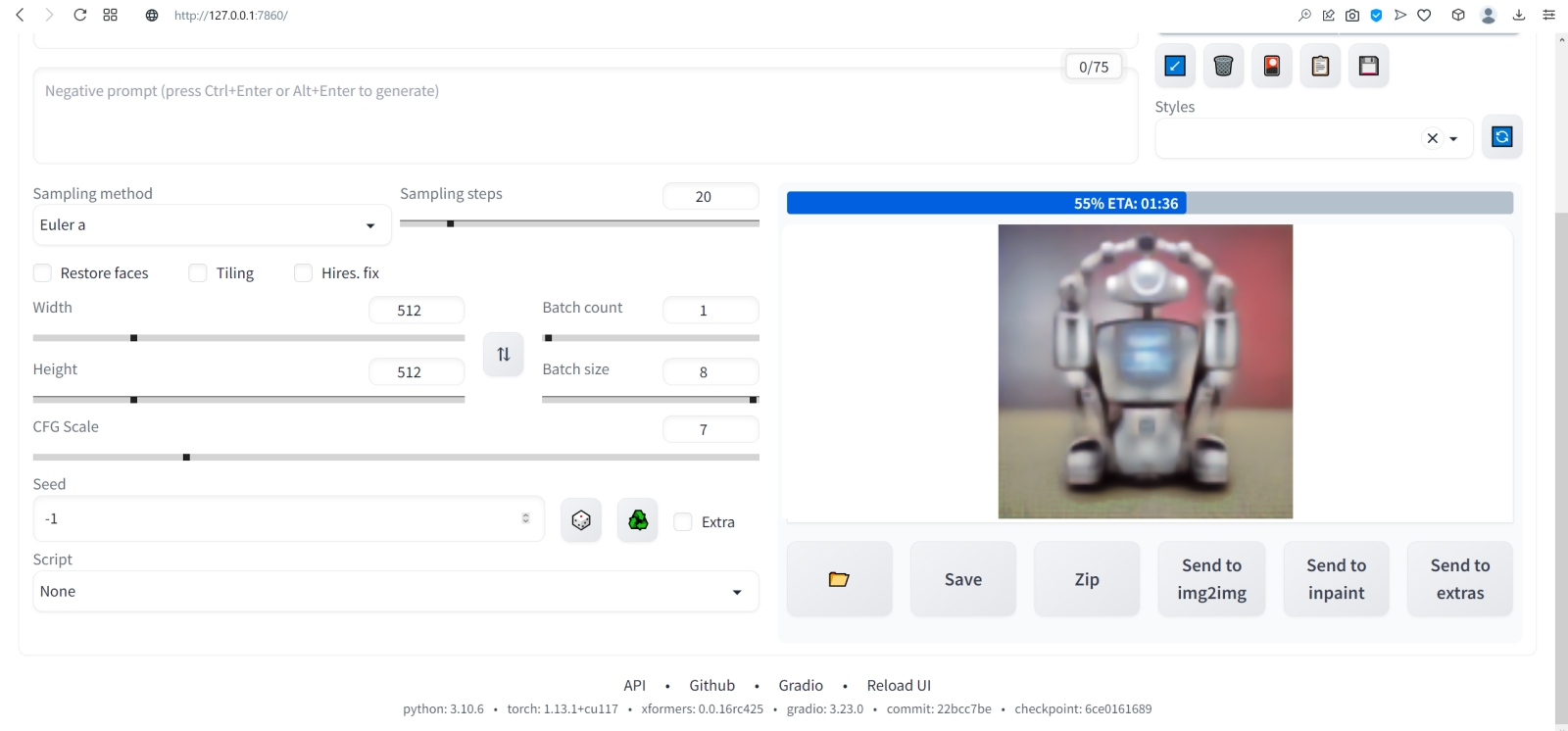 Ту же оценку можно видеть на фоне ползущей вправо синей полоски прогресса и в графическом веб-интерфейсе. Там же — для справки — система демонстрирует некоторые промежуточные результаты процесса диффузии: как из исходного «белого щума» постепенно проявляется ожидаемое изображение. 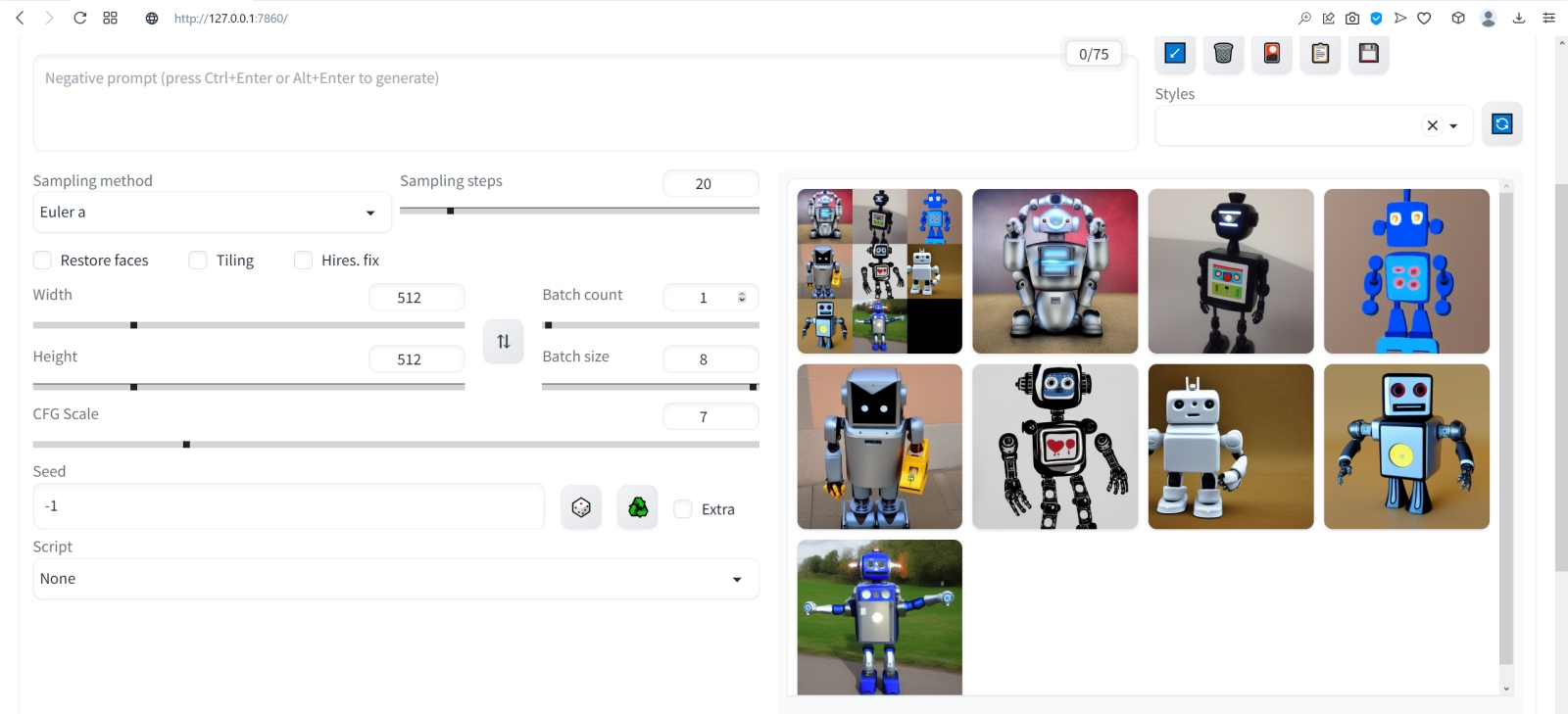 М-да. Результаты не то чтобы разочаровывают — скорее, не впечатляют. Роботы в этих фигурках вполне угадываются, но какие-то они… невыразительные, что ли. Нельзя ли как-нибудь повысить качество выдачи? 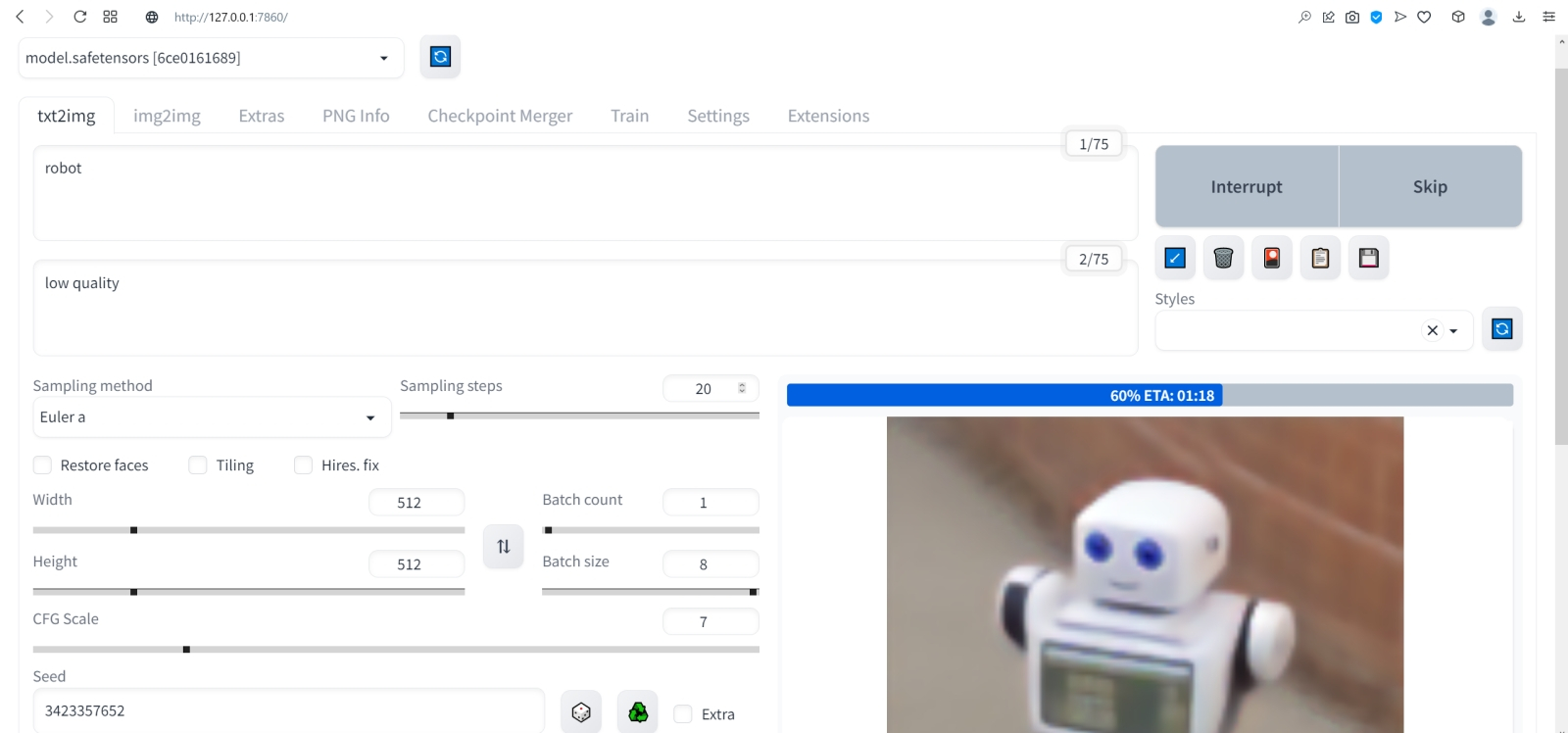 Можно и даже нужно: вся прелесть ИИ-преобразования текста в картинки заключается как раз не в самом рисовании роботом неких образов по заданной подсказке, а в том, насколько разнообразными и порой неожиданными могут быть плоды его трудов — в зависимости от приложенных оператором мыслительных усилий. Для начала задействуем поле Negative prompt, вписав туда то, чего не хочется видеть в итоговой картинке, а именно — low quality. Далее нажмём на зелёный треугольник из стрелочек, напоминающий условное обозначение вторичной переработки: это позволит зафиксировать случайно подобранную системой затравку (seed; в данном случае — 3423357652) для последующих генераций, что сделает оценку влияния вводимых нами параметров на итоговую картинку более наглядным.  Кстати, в домашнем каталоге Stable Diffusion есть теперь папка output, в которой хранятся результаты: сами картинки по отдельности (txt2img-images) и обзорные сборки пакетных генераций (txt2img-grids). Внутри этих папок изображения помещаются в помеченные текущей датой подкаталоги. 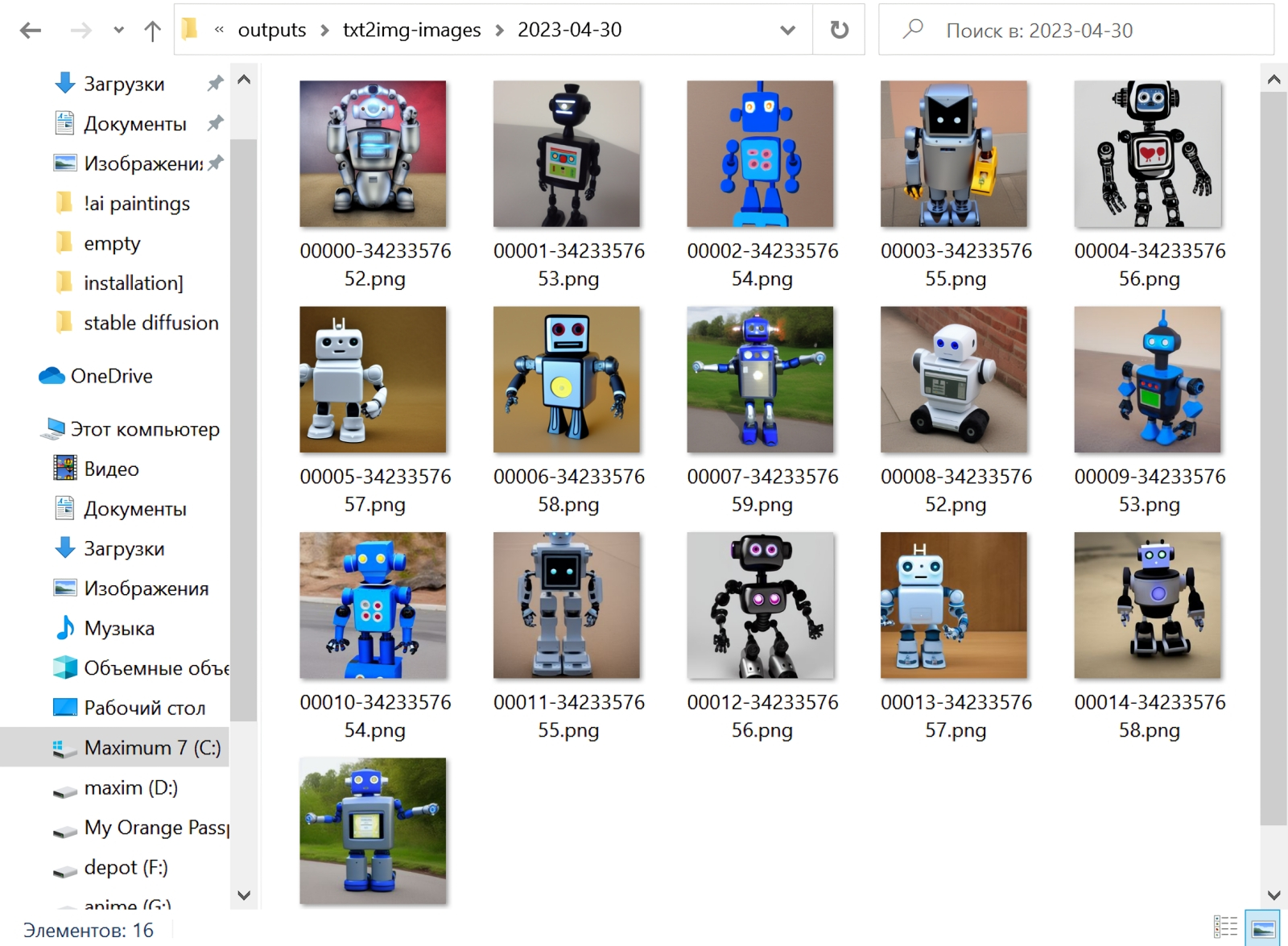 Как можно видеть, уже простейшая негативная подсказка сделала изображения более выразительными. Обратите внимание, как система именует их по умолчанию: сперва идёт сквозной номер генерации за текущую дату, далее через дефис — использованная для создания данной картинки затравка (seed). То есть здесь первому изображению в первом пакете (00000-3423357652) соответствует первое во втором (00008-3423357652) и т. д.  Добавим определённости в то, какими именно нам хочется видеть изображаемых роботов. В позитивные подсказки вместо просто «robot» напишем «fighting robot, shiny steel», а в негативные — один из стандартных нежелательных наборов контекстуальных терминов (undesired content prompt): «lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name». Гораздо интереснее, не правда ли?  Общее правило в искусстве составления подсказок (promptsmithing, по аналогии со златокузнечным делом — goldsmithing) таково: всё, что точно должно присутствовать на картинке, прописывается в позитивные подсказки; всё, чего там ни при каких условиях не должно появляться, — в негативные; прочее отдаётся на откуп ИИ-художнику. При этом следует помнить, что чем ближе то или иное слово к началу подсказки, тем значительнее оно повлияет на итоговую картинку. Вообще, широта возможностей при составлении подсказок открывает огромный простор для экспериментаторства. В сообществе text2image-энтузиастов выработано уже немало схем (которые в любом случае следует подвергать конструктивному сомнению) их структурирования — например, такая: Subject, Medium, Style, Artist, Website, Resolution, Additional details, Color, Lighting (т. е. объект, среда, стиль, художник, веб-сайт, разрешение, дополнительные детали, цветовая палитра, освещение). Попробуем обогатить нюансами нашу исходную подсказку, выстроив слова в ней следующим образом (перевод строки в интерфейсе AUTOMATIC1111 просто игнорируется обработчиком текста, что позволяет использовать его для пущей наглядности): fighting robot, digital painting, hyperrealistic, by Viktor Vasnetsov, trending on ArtStation, extremely high details, sharp focus, depth of field, futuristic, stunningly beautiful, dystopian, iridescent shiny steel, cinematic lighting, dynamic lighting, sparks and flashes Негативную подсказку оставим прежней. Не следует удивляться появлению ссылки на Васнецова: Stable Diffusion при обучении ознакомили с работами множества художников, так что их имена в подсказке оказывают влияние на общий стиль изображения — пусть даже сам этот реальный художник в своей практике сражающихся роботов не писал. Упоминание известного среди мастеров и поклонников цифровых художеств сайта ArtStation тоже не случайно: популярные на нём (trending) работы в целом имеют весьма определённую стилистику, и её система машинного обучения тоже вполне успешно ухватывает. Ещё одна деталь: квадратные изображения Stable Diffusion 1.5 генерирует лучше всего (в том смысле, что генерация эта порождает минимум артефактов вроде искажённых пропорций человеческих тел или нарушений перспективы), поскольку обучалась на картинках с разрешением 256 × 256 и 512 × 512 пикселов. Однако AUTOMATIC1111 позволяет на страх и риск пользователя менять эти размеры, в том числе получая изображения альбомной или книжной ориентации, а не только квадратные. Базовая модель Stable Diffusion 1.5 не очень уверенно справляется с прямоугольниками (другие чекпойнты делают это лучше, плюс есть ещё целый ряд трюков, но об этом позже), но всё же в размере 512 × 768 пикселов должна выдавать более или менее приемлемый результат. Сдвинем поэтому ползунок «Height» на позицию 768 (или можно просто набрать это число вручную в соответствующем окошке) — и насладимся уже более впечатляющим результатом. 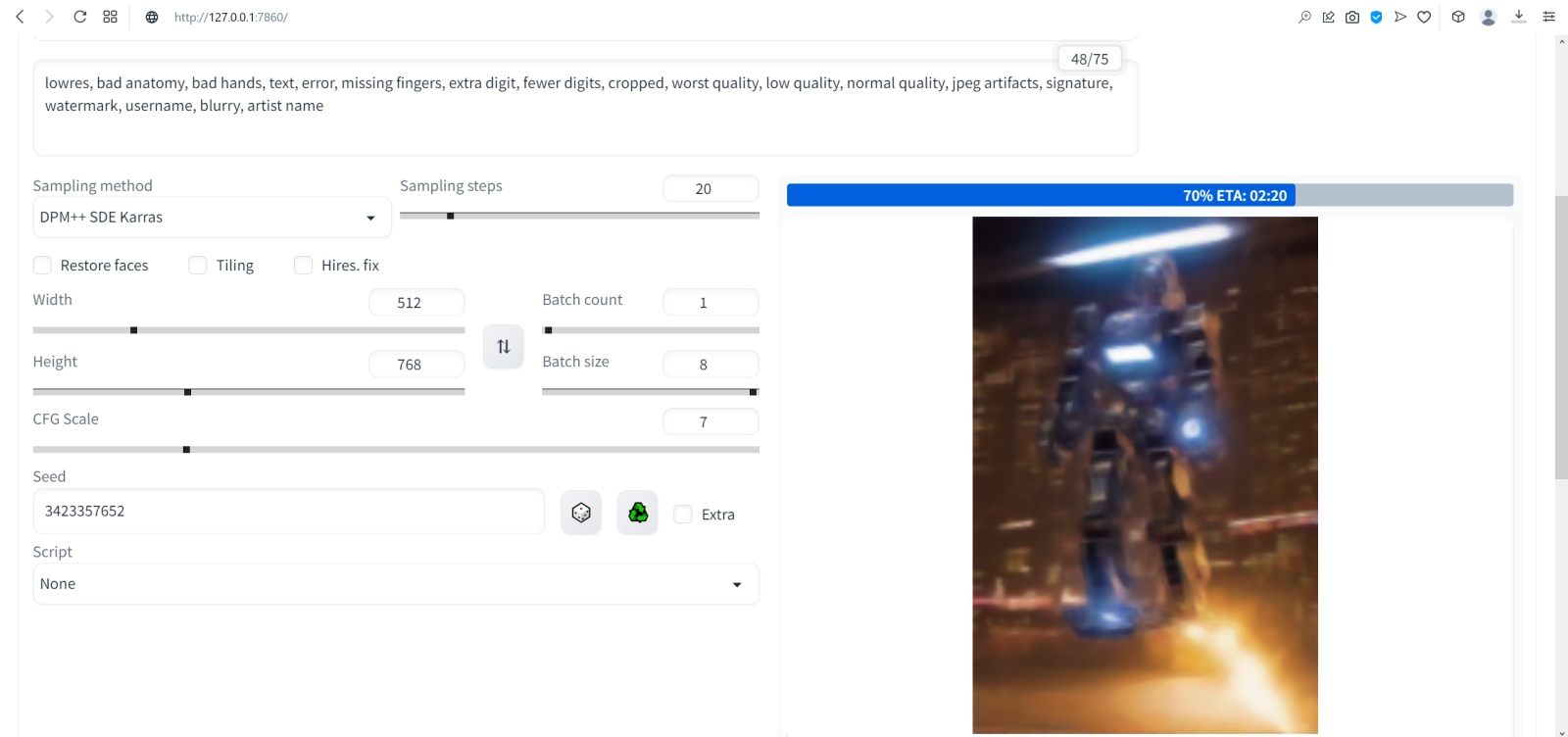 Продолжим изучать органы управления AUTOMATIC1111, обратив внимание на выпадающее меню Sampling method, где по умолчанию выбрано «Euler a». Как уже упоминалось, работа диффузионной генеративной модели заключается в поэтапном вычитании из исходного образа (квадрата или прямоугольника, заполненного «белым шумом») другого шума, уже упорядоченного (predicted noise), — специальным образом сгенерированного на основе текстовой подсказки. Непосредственно процесс снижения уровня шума (denoising) называется также сэмплингом (sampling), поскольку на каждом этапе последовательного снижения зашумлённости картинки получается новый её образчик (sample) — и, собственно, сколько именно шагов на этом пути будет пройдено, контролирует параметр Sampling steps. Для большинства чекпойнтов достаточно 20-30 шагов.  А вот то, каким именно образом модель решает, сколько шума и на каких именно участках надо оставить на картинке на каждом этапе, и определяется методом сэмплинга; говоря математическим языком — тем или иным методом градиентного спуска. Наиболее простой и быстрый (но и дающий менее выразительные с художественной точки зрения результаты) — это уже использованный нами Euler (см. схема Эйлера). Другие сэмплеры могут давать более интересные и/или более сложные результаты с бóльшим или меньшим учётом различных фрагментов подсказки — здесь нет ни единого рецепта, ни общего правила, что считать более предпочтительным. Однако, поменяв Euler на более «продвинутый», хотя и требующий большего времени на исполнение сэмплер DPM++ SDE Karras (Каррас — фамилия одного из авторов оригинальной статьи, где описан целый ряд таких методов), мы ровно с теми же самыми позитивной и негативной подсказками и с той же затравкой (seed) получим в целом более живописные изображения.  Продолжаем усложнять позитивную подсказку: уж слишком получающиеся роботы трансформерообразны, — добавим здравый элемент стимпанка: fighting robot, Разве не хорошо? Особенно вон те двое, что играют в чехарду (как раз здесь проявляется самотворчество цифрового художника: в заданной нами подсказке ничего ни про двух роботов, ни про их взаимное расположение не говорилось). Правда, становятся очевидными артефакты вертикальной композиции, прежде всего — отъединённые конечности. Чтобы бороться с этим, есть разные способы.  Попробуем для начала переставить стили (указание на художника и сайт) в конец, а заодно убрать «ретрофутуризм» как термин из подсказок — слишком уж невнятно определён, может сбивать модель с толку, — и добавим больше подразумеваемых им деталей: янтарно светящиеся лампы, бронзовые трубки, медные зубчатые колёса, хромированные цепи, циферблаты слоновой кости, вентили эбенового дерева: fighting robot, in ancient alien ruins, digital painting, hyperrealistic, extremely high details, sharp focus, depth of field, steampunk, stunningly beautiful, iridescent shiny metal, amber neon tubes, brass pipes, copper gears, chrome chains, ivory dials, ebony valves, cinematic lighting, dynamic lighting, sparks and flashes, by Viktor Vasnetsov, trending on ArtStation Вот это поворот! Деталей стало явно больше.  А если вовсе отказаться от двух последних строк в поле позитивной подсказки? Пожалуй, это отсутствие заёмного стиля — само по себе стиль оригинальной Stable Diffusion 1.5 при работе с довольно развёрнутым текстовым вводом: несколько сумбурный, зато высокодетализированный. ⇡#Комбинируя комбинатораНе раз уже мы называли используемый с AUTOMATIC1111 чекпойнт «v-1-5-pruned-emaonly.safetensors» (переименованный, напомним, в «model.safetensors») базовым. Значит, должны быть и какие-то не-базовые, производные? Так и есть: на основе изначальной модели Stable Diffusion 1.5 (только в версии pruned, без emaonly) энтузиасты производят дотренировку, прогоняя через систему — тем же путём, что пропутешествовали исходные миллиарды картинок, — ещё несколько сотен, или тысяч, или на сколько у них хватит терпения и вычислительных мощностей. Картинки эти, соответствующим образом подобранные и аннотированные, расширяют горизонты восприятия, если так можно выразиться, модели: она начинает значительно чаще выдавать изображения в стимпанковской стилистике без дополнительных подсказок, или лучше начинает рисовать фэнтезийных эльфов (базовый чекпойнт в ответ на подсказку «elf» c большой вероятностью изобразит помощника Санты в зелёном колпачке, а не горделивого обитателя зачарованных лесов), или ещё каким-то образом модифицирует результаты своей генерации. 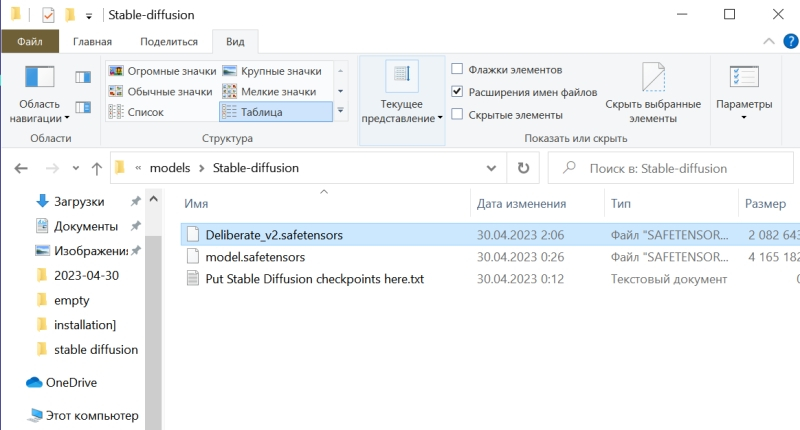 Чего ради стоит возиться с чекпойнтами, мы покажем на примере одной из наиболее популярных сегодня доработок Stable Diffusion 1.5 под названием Deliberate v.2. Загрузить этот файл в формате .safetensors логичнее всего со страницы данного проекта на уже знакомом нам репозитории Hugging Face, после чего надо поместить дотренированную модель в ту же папку, где уже находится базовая, — model.safetensors. На сей раз переименовывать ничего не требуется. 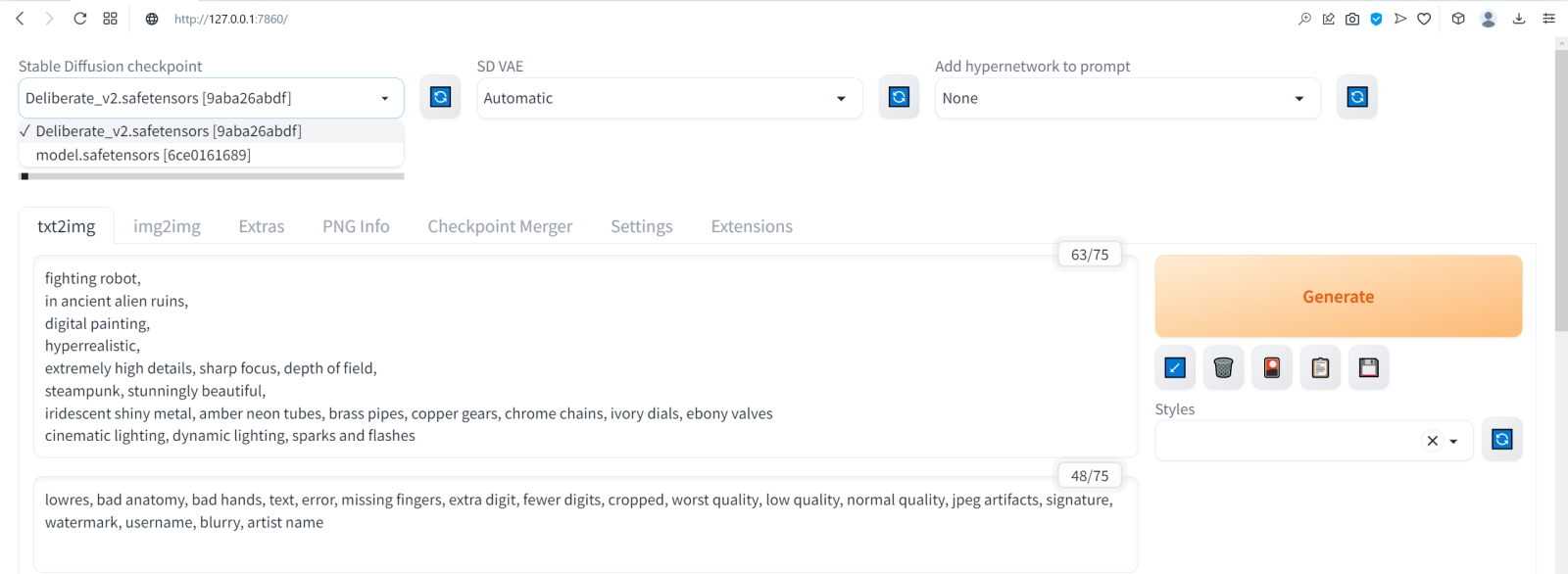 Перезапускать систему целиком (закрывать окно терминала и запустить webui-user.bat заново) не надо: достаточно нажать на синюю кнопку с белыми полукруглыми стрелочками у выпадающего меню Stable Diffusion checkpoint, затем открыть это меню, активировать появившуюся опцию Deliberate_v2.safetensors — и снова нажать на Generate.  Небо и земля! Фигуры роботов стали куда более статичными, но проработка и взаимосогласованность деталей определённо улучшились. В этом сила производных (от базовой модели) чекпойнтов: они позволяют с меньшими усилиями — со стороны конечного пользователя — получать более эстетически привлекательные изображения с теми же подсказками и затравками, чем ванильная Stable Diffusion 1.5. 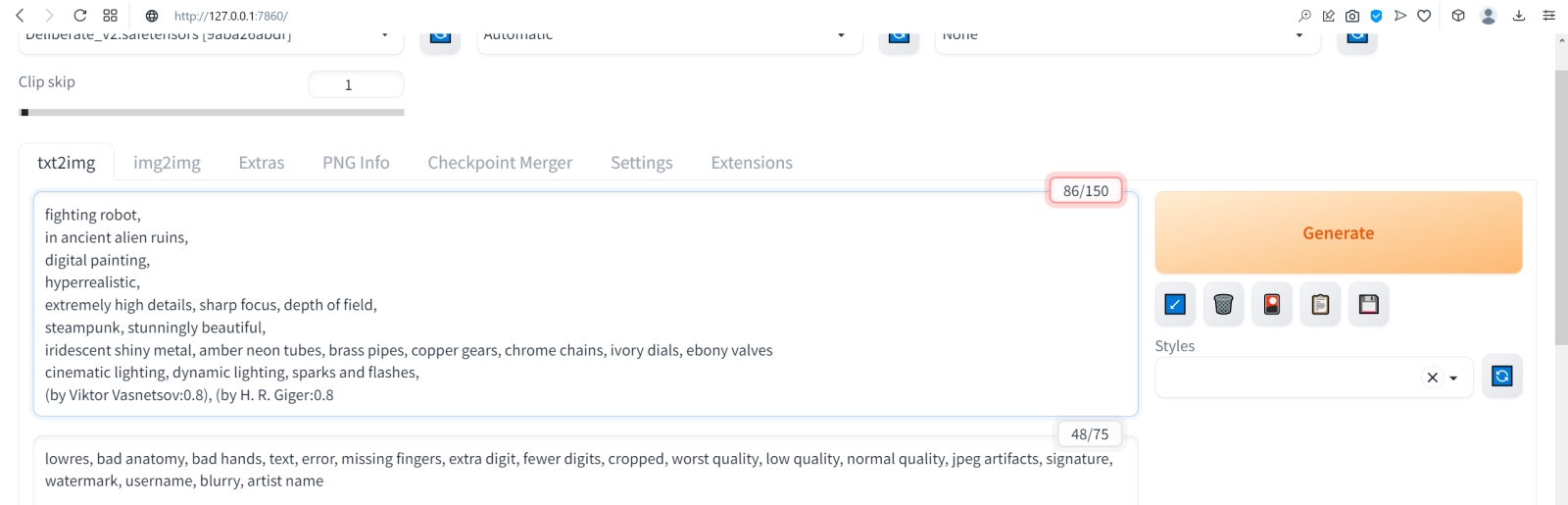 А теперь попробуем вернуть художников (сайт пока всё-таки упоминать не станем: понятие стиля для него в целом более размыто, чем для индивидуальных живописцев). Самой последней строкой в поле позитивных подсказок укажем: (by Viktor Vasnetsov:0.7), (by H. R. Giger:0.9) Кстати, если забыть закрыть одну из скобок, система предупредит о возможной ошибке: число параметров генерации (в правом верхнем углу соответствующего окошка; в данном примере — 86/150) окажется обведено тревожной красноватой рамочкой.  Имя Ханса «Рюди» Гигера известно немногим, однако стилистика его работ в жанре фантастического реализма знакома каждому, кто видел хотя бы пару кадров из культового фильма «Чужой», для которого именно этот художник разработал и образ ксеноморфа, и общий дизайн. Что же касается скобочек и цифр внутри, то это принятый в AUTOMATIC1111 способ изменения значимости (относительного веса) конкретной подсказки. По умолчанию любая из них имеет условный вес 1; если просто заключить подсказку в круглые скобки, это будет соответствовать приданию ей веса 1,1 (т. е. она станет более значимой для генерации данного изображения, чем соседние), а если нужно установить какой-то иной вес, его указывают явно после двоеточия. Обычно стоит избегать весов менее 0,5 (по причине пренебрежимо малого влияния таких подсказок на итоговую картинку) и более 1,5 (результат может оказаться графически непредсказуемым), но в любом случае это ещё одна степень свободы опосредованного искусственным интеллектом творчества — которой энтузиасты охотно пользуются. Выставив для стилей обоих этих художников невысокие веса, мы избежим чрезмерного влияния их на итоговую картинку (роботизированный Чужой в сарафане уж точно не появится здесь), но живости и индивидуальности ей, безусловно, прибавим. 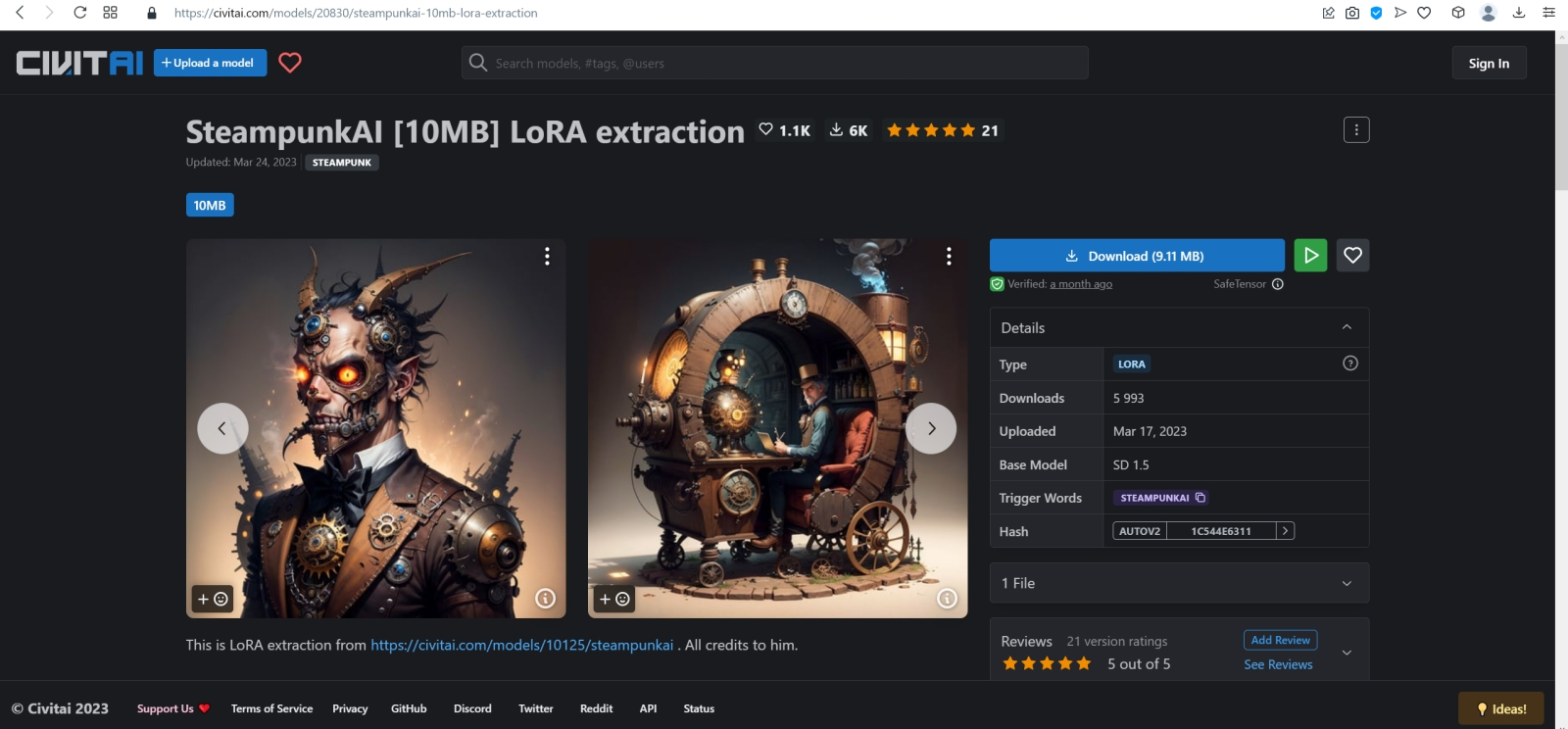
Источник: скриншот сайта civitai.com Помимо полноценных дотренированных чекпойнтов, известны и другие методы обучения генеративной модели text2image определённой стилистике или рисованию новых объектов, не входивших в первичную тренировочную базу. Один из таких методов — LoRA (low-rank adaptation of large language models, низкоуровневая адаптация LLM), что подразумевает внедрение дополнительных обучаемых нейронных слоёв в уже готовые (натренированные в ходе создания базовой модели) блоки трансформеров. Как это реализуется математически — для нас в данном случае принципиального значения не имеет; важно понимать, как этим пользоваться. Вот, к примеру, на сайте Civitai.com, открытом репозитории множества ресурсов для энтузиастов text2image-генераций, имеется LoRA под названием SteampunkAI. Она создана на основе чекпойнта, специально дообученного для рисования в соответствующем стиле, и может применяться с любым другим чекпойнтом, обеспечивая вполне узнаваемую и зрелищную стилистику. Чтобы скачать соответствующий файл в формате .safetensors, достаточно нажать на длинную синюю кнопку на правой стороне веб-страницы. 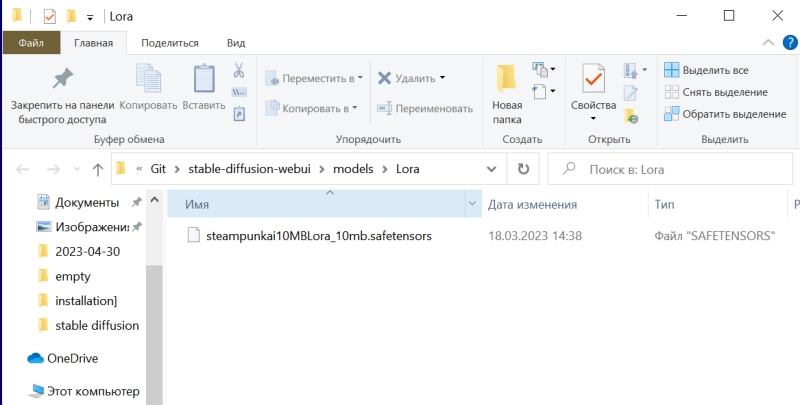 А поместить полученный файл, steampunkAI10MBLora_10mb (да, он занимает всего около 10 Мбайт — разительный контраст с чекпойнтом!) нужно будет в специально для того предназначенный каталог models\Lora. 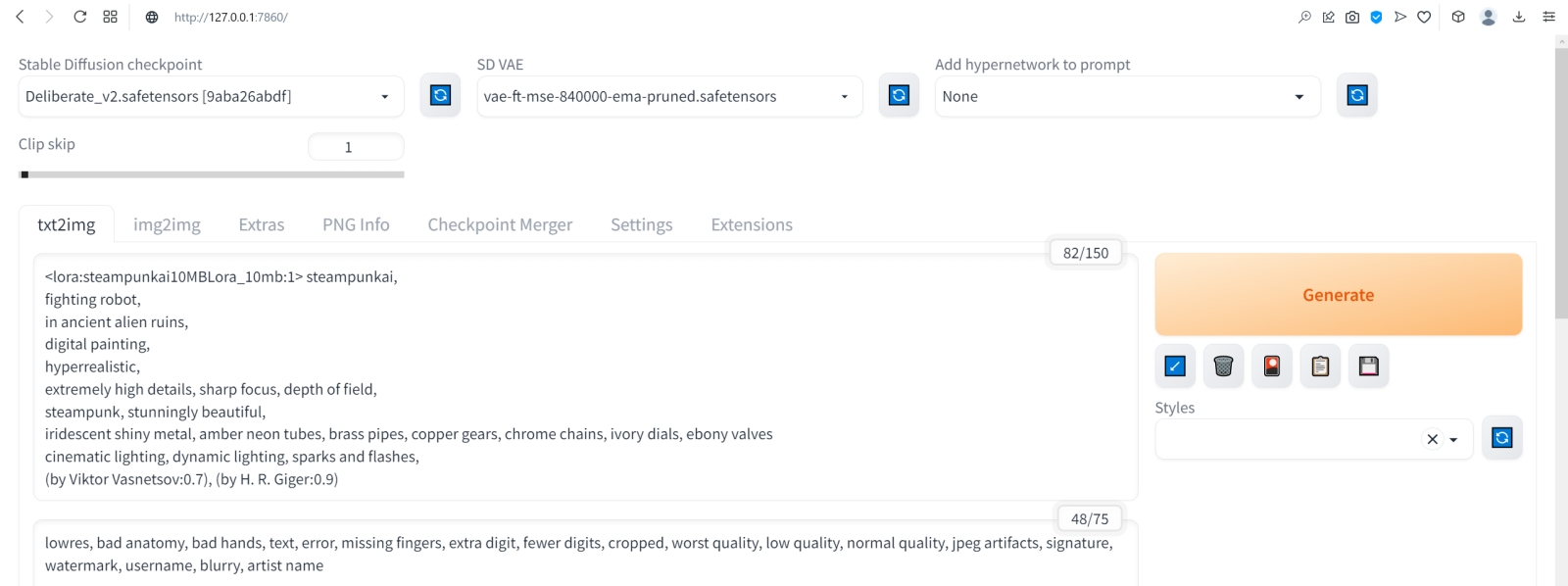 Для активации LoRA служит особая команда в треугольных скобках с указанием точного её наименования и условного веса (который в зависимости от желания оператора может быть и меньше, и больше единицы): <lora:steampunkai10MBLora_10mb:1> steampunkai, fighting robot, in ancient alien ruins, digital painting, hyperrealistic, extremely high details, sharp focus, depth of field, steampunk, stunningly beautiful, iridescent shiny metal, amber neon tubes, brass pipes, copper gears, chrome chains, ivory dials, ebony valves, cinematic lighting, dynamic lighting, sparks and flashes, (by Viktor Vasnetsov:0.7), (by H. R. Giger:0.9) Негативная подсказка по-прежнему неизменна.  В целом результат очень хорош, проработка деталей фантастическая, но какими-то эти роботы враз стали… статичными, что ли. И резко однотипными. Однако и с этой напастью ИИ-энтузиасты научились бороться, применяя такое сильнейшее шаманство, как clip skip. Сейчас поясним, что это значит.  Но сперва слегка подкорректируем интерфейс AUTOMATIC1111. В настройках — Settings — веб-интерфейса надо открыть раздел User interface, и в нём — окошечко Quicksettings list. Это перечисление того, какие элементы управления будут вынесены на самый верх заглавной страницы интерфейса. Изначально там был единственный параметр, sd_model_checkpoint, — именно его наличие сделало доступным выпадающее меню, в котором мы поменяли model.safetensors на Deliberate_v2.safetensors. 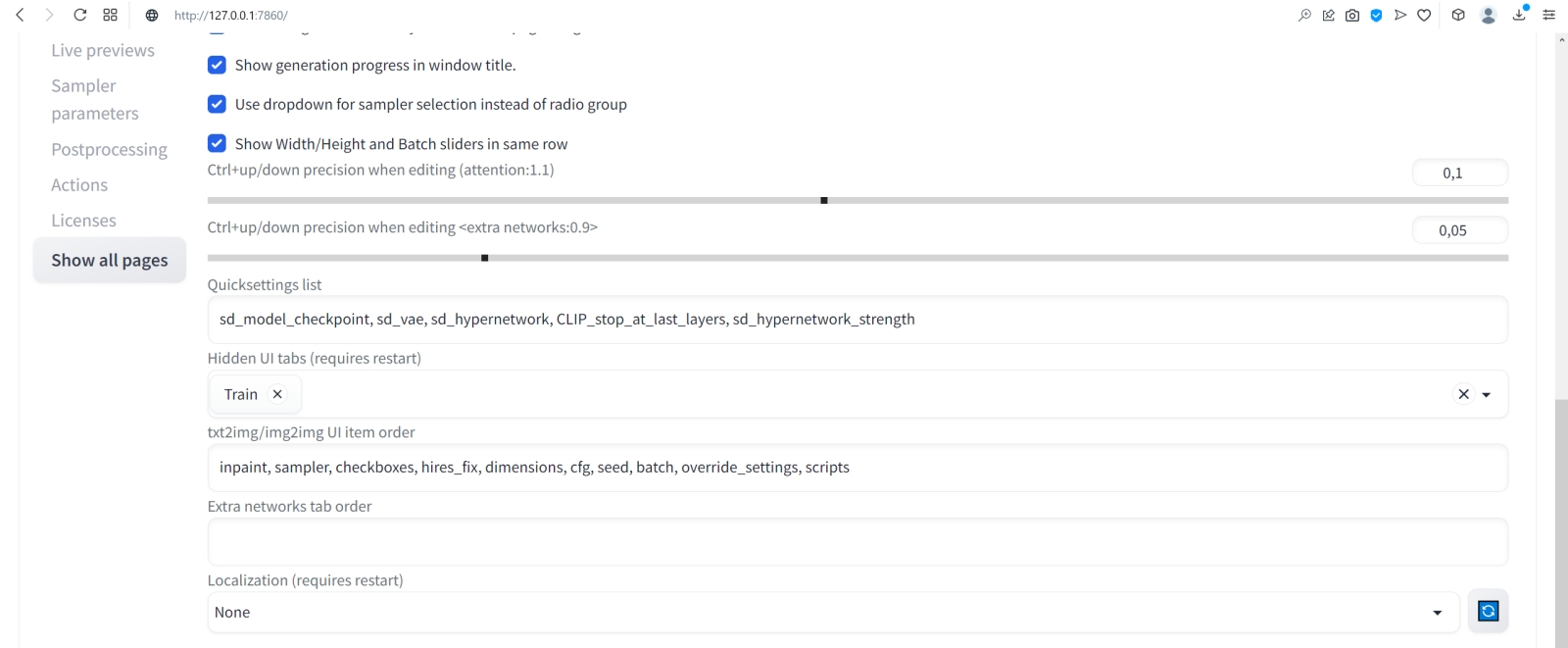 Добавим туда через запятую sd_vae, sd_hypernetwork, CLIP_stop_at_last_layers, sd_hypernetwork_strength (начиная с версии 1.2.0 AUTOMATIC1111 добавление это производится из выпадающего меню: достаточно начать набирать наименование желаемого параметра, и список предлагаемых опций будет автоматически сужаться). 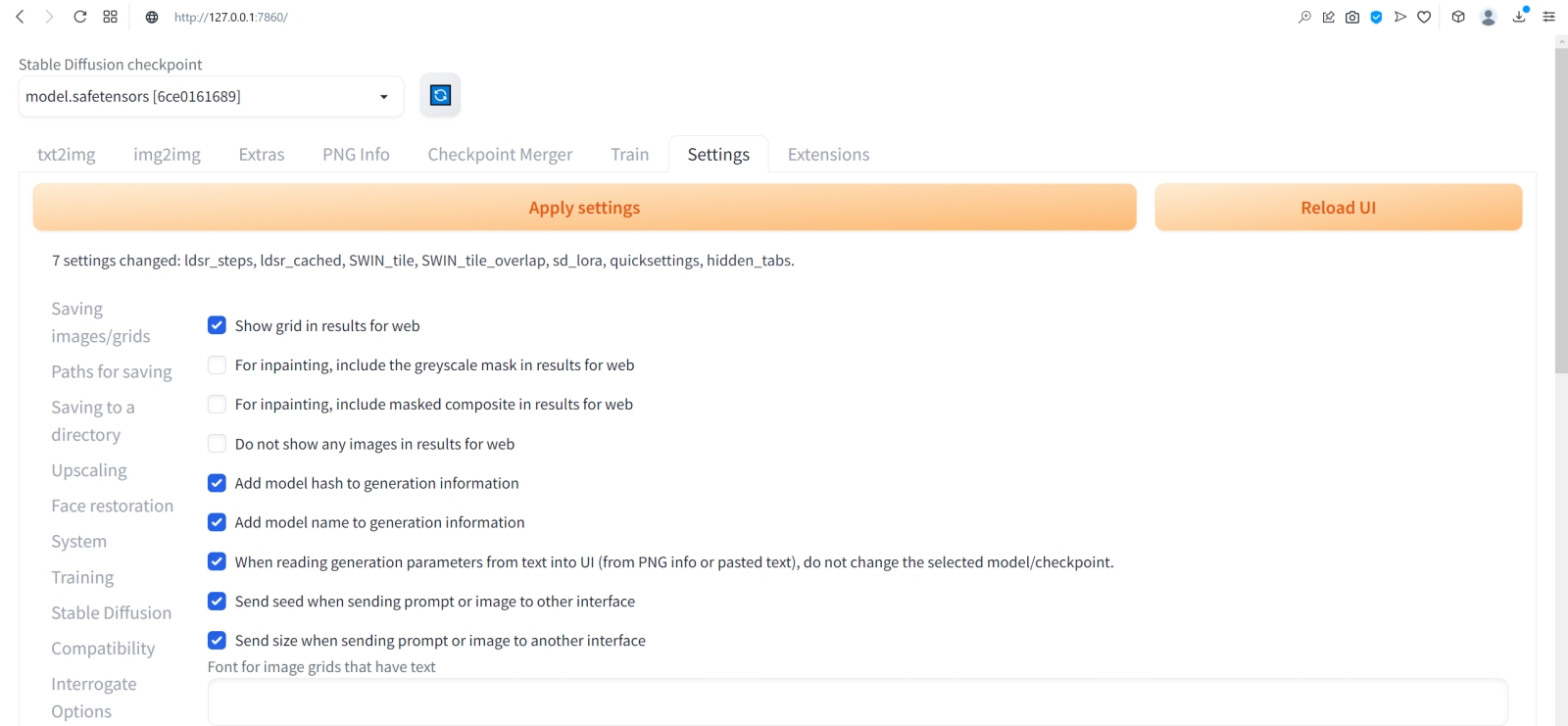 Прописав нужные параметры, вернёмся прокруткой в начало страницы и нажмём огромную оранжевую кнопку Apply settings, а затем — соседнюю с ней Reload UI. 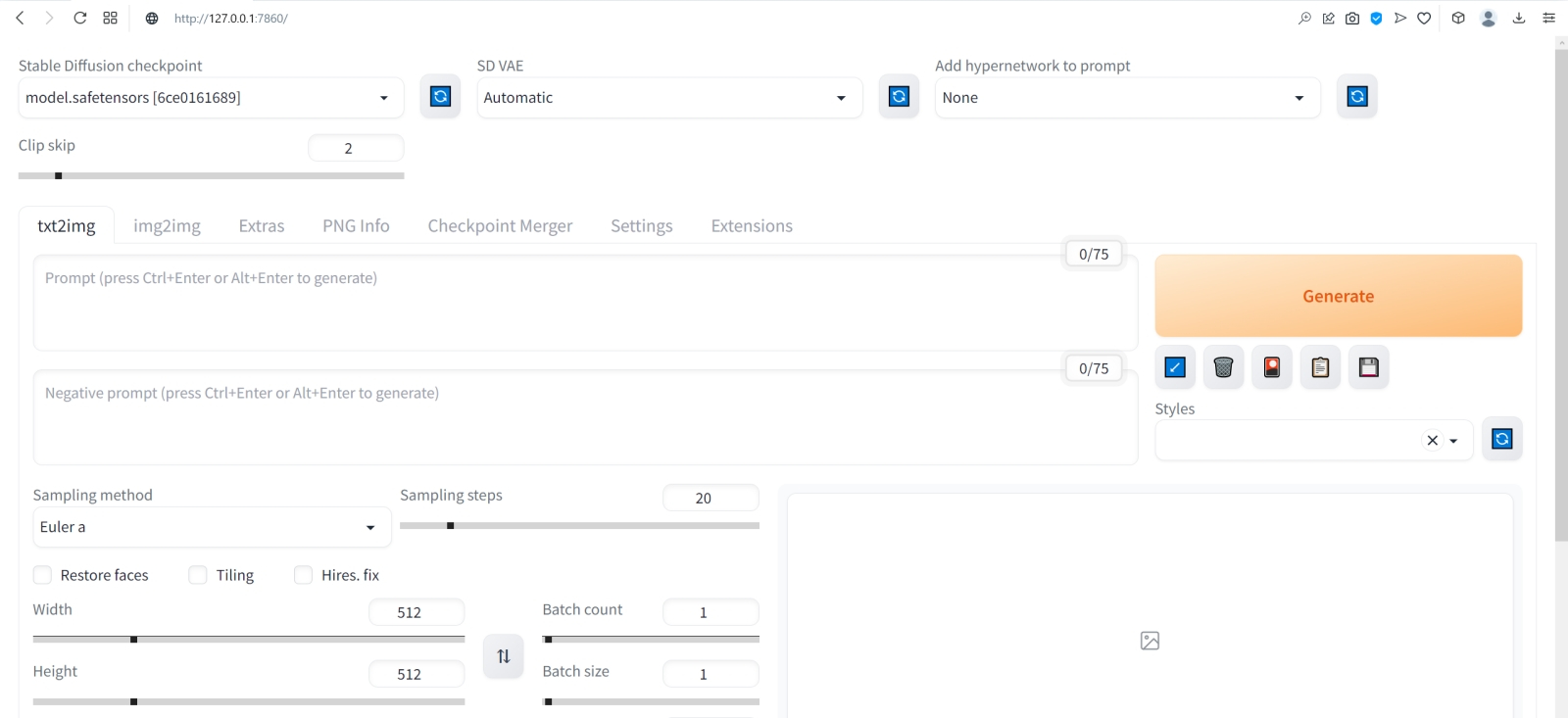 После возврата на заглавную страницу веб-интерфейса (вкладка txt2img) убеждаемся, что верхняя её часть теперь содержит два дополнительных выпадающих меню (SD-VAE, Add hypernetwork to prompt) и ползунок — собственно Clip skip. Вот его-то и следует передвинуть в позицию 2. Но с какой целью? После запуска генерации картинки первым в работу вступает CLIP — построенный на трансформерах кодировщик текста в токены, которые используются в дальнейшем уже собственно диффузионной моделью, чтобы «убрать ненужный шум» с заготовки будущего изображения. Как и полагается такому кодировщику, он сам представляет собой многослойную нейросеть (для Stable Diffusion 1.5 — 12 слоёв), на каждом из которых, грубо говоря, производится дополнительная конкретизация подсказки. Скажем, невозможно изобразить «дом вообще», как концептуальную идею: модели необходимо определиться со стилистикой (будет ли это фото, реалистичный тщательный рисунок, стилизация из детской книжки, беглый набросок и т. п.), общими параметрами (этажность, форма крыши, наличие/отсутствие трубы), цветом, числом видимых окон и дверей и ещё множеством параметров. Хорошо, если подсказка детальная: «дом ведьмы» уже значительно сузит пространство выбора вариантов, но всё равно оставит значительный простор для (нет, не воображения, — у современных ИИ его всё ещё нет) псевдослучайного комбинирования вариантов, возникших на основе обучения модели. Ещё раз: это очень грубое описание, поскольку, как и всякая многослойная плотная нейросеть, работа CLIP принципиально не интерпретируема на внутреннем уровне и представляет собой по сути «чёрный ящик». Так вот, на финальном шаге CLIP должна передать диффузионной модели достаточно подробные указания (в виде набора токенов), какая именно картинка должна скрываться в очередном заполненном «белым шумом» прямоугольнике. И чем лучше система натренирована на сравнительно узком наборе изображений — а как раз этим нередко страдают «авторские» чекпойнты, — тем более однотипные картинки она станет выдавать при различных затравках (seed). Что, собственно, хорошо иллюстрирует только что полученная нами галерея практически паспортных фотокарточек квазистимпанковских роботов. Да, каждая из них детально проработана, но именно все разом они явно демонстрируют некую перетренированность используемой диффузионной модели. Скорее всего, это вина не чекпойнта Deliberate, а узкотематической LoRA, так что, поиграв с её значимостью (поменяв «:1» внутри треугольных скобок на «:0.7» для начала), можно было бы сгладить негативный эффект. Но мы поступим иначе, задав Clip skip = 2, т. е. заставив систему прерывать формирование структуры инструкций для диффузионной модели за шаг до исходно намеченного финала. Это словно бы несколько собьёт генератор токенов с толку — и во множестве случаев как раз предпоследний, а не финально вылизанный набор инструкций для ИИ-рисования и породит подлинно привлекательную на человеческий взгляд картинку. В качестве самостоятельного упражнения попробуйте и другие варианты Clip skip, вплоть до максимально возможного, — результат вас не на шутку удивит. 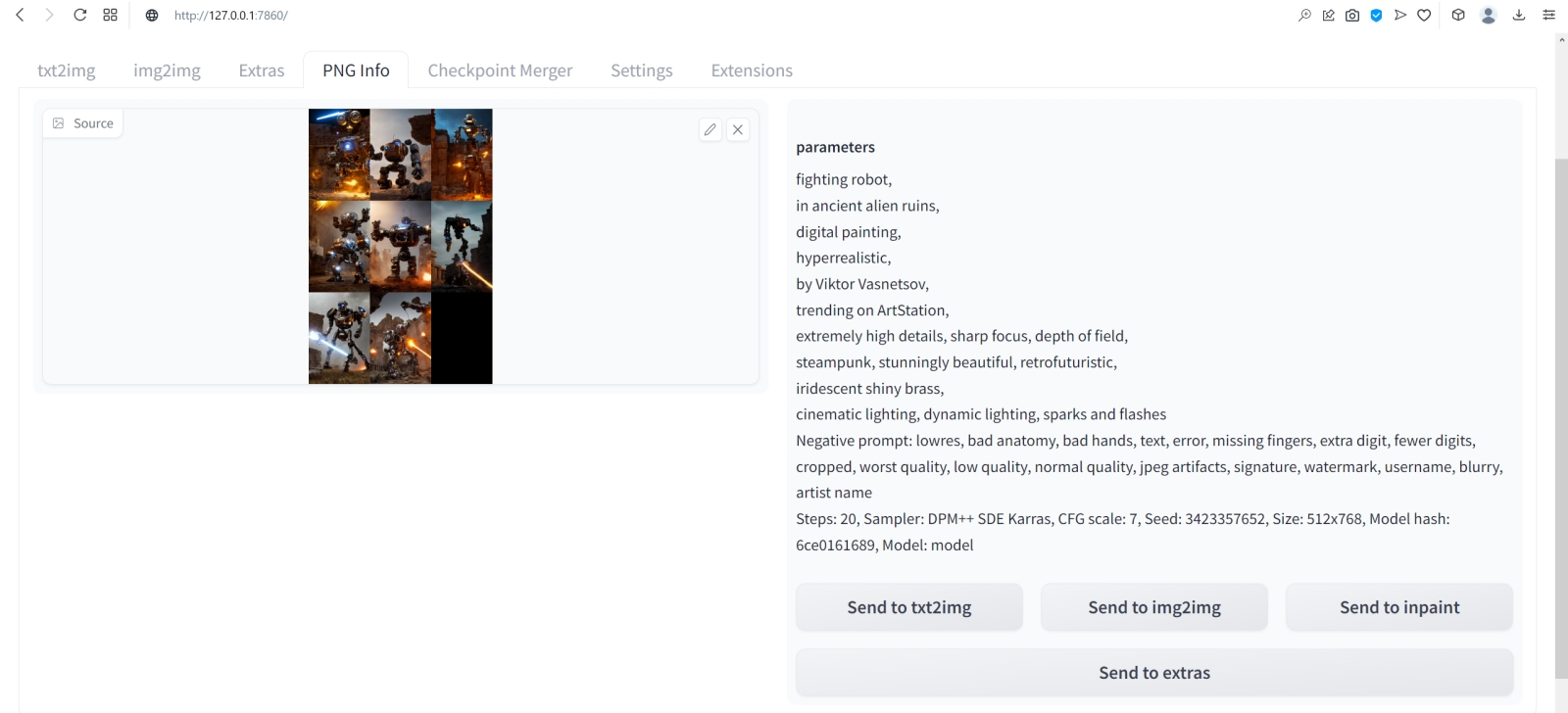 Практическое отступление: после перезагрузки интерфейса пропали все наши подсказки и настройки во вкладке txt2img. Можно, конечно, восстановить их вручную по предыдущим записям — но зачем, если AUTOMATIC1111 помещает все важнейшие данные прямо в генерируемые картинки; в поля текстовых комментариев, предусмотренные стандартами PNG и JPEG? Обратите внимание на вкладку PNG Info в веб-интерфейсе: при переходе на неё появляется область для загрузки изображений. Поместим туда (просто перетащив мышкой) из окна «Проводника» Windows, в котором открыта папка txt2img-grids, последнюю из сгенерированных картинок в формате PNG — и справа появится вся информация, сохранённая в её метаданных. Теперь достаточно нажать на «Send to txt2img», чтобы все использованные для генерации данной картинки подсказки и параметры, вплоть до Seed, оказались на своих местах. Надо лишь только вернуть Batch size значение 8 — иначе будет сгенерирована не подборка, как всё время до сих пор, а только единичная картинка с исходной затравкой. В подборке же у каждой последующей картинки затравка (seed), напомним, отличается от предыдущей на единицу.  Итак, запускаем генерацию вновь с прежними параметрами (восстановленными через PNG Info), но с clip skip = 2. Ну вот, разительный контраст! Разнообразие явно увеличилось, а где-то даже и динамика появляется. 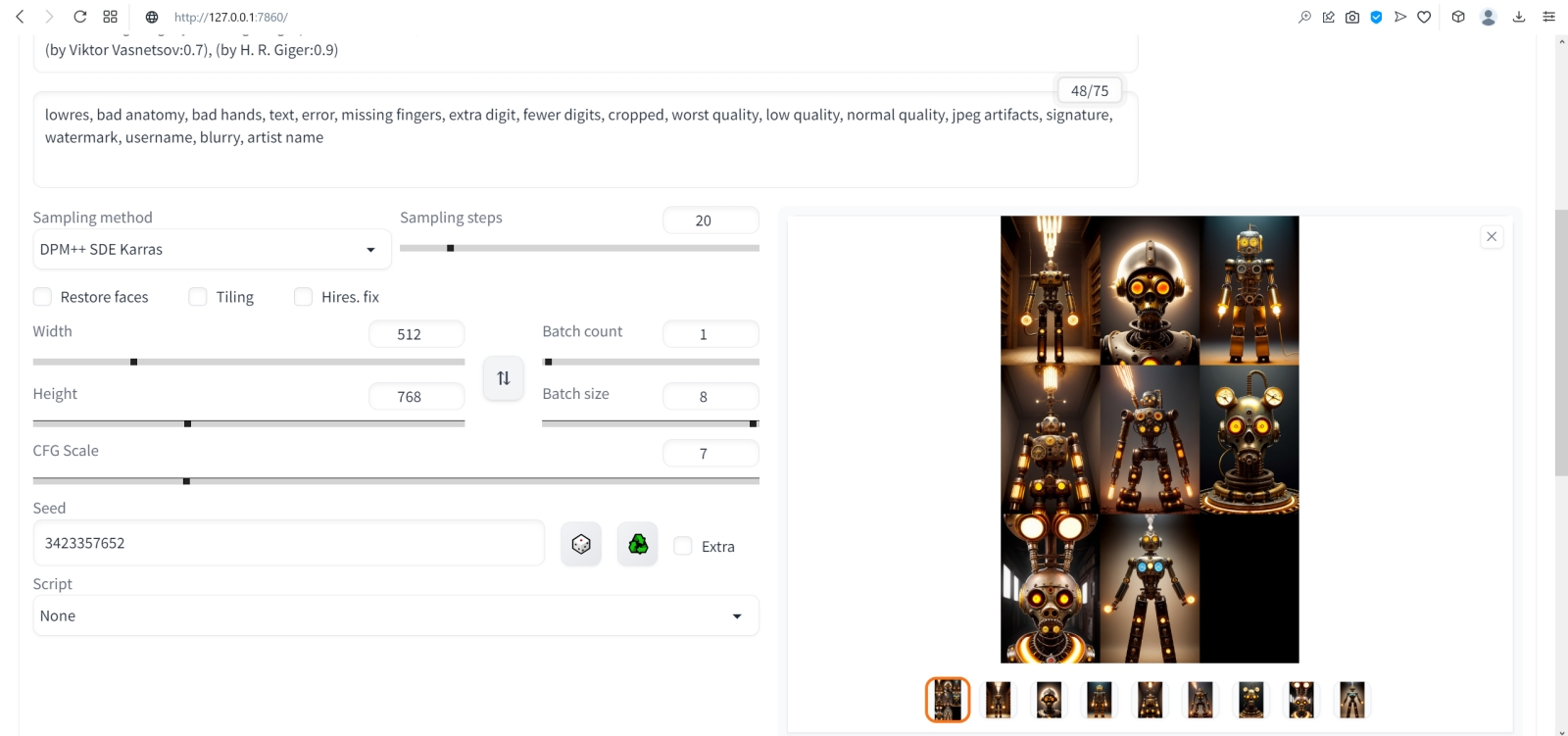 А что если перевести изображение из книжного формата в альбомный? Вертикальная композиция человекоподобной сущности всё-таки подразумевает некую портретность, соседствующую со статичностью, тогда как растянутая по ширине картинка может предоставить больше простора для динамики. Для простой перемены местами размерностей (чтобы вместо 512 × 768 пикселей стало 768 × 512) достаточно нажать на кнопку со стрелочками «вверх» и «вниз» рядом с ползунками Height и Width. Попробуем сгенерировать так.  Очень неплохо! Но простор для улучшения всё ещё есть.  Поиграем снова с порядком расположения подсказок: <lora:steampunkai10MBLora_10mb:1> steampunkai, fighting robot, in ancient alien ruins, iridescent shiny metal, amber neon tubes, brass pipes, copper gears, chrome chains, ivory dials, ebony valves, steampunk, stunningly beautiful, digital painting, hyperrealistic, extremely high details, sharp focus, depth of field, cinematic lighting, dynamic lighting, sparks and flashes, (by Viktor Vasnetsov:0.7), (by H. R. Giger:0.9) Выходит вполне достойно.  Следующий шаг — оптимизация негативной подсказки. Стандартный набор отрицаний, который мы применяли до сих пор, хорош своей относительной универсальностью, но всё же он не охватывает всего возможного круга недочётов, могущих возникнуть при преобразовании текста в изображение — особенно в ходе рисования роботов. Более универсальное решение даёт так называемая текстовая инверсия (textual inversion), ещё одна, наряду с LoRA, разновидность частной доработки генеративной модели. С уже знакомого сайта Huggingface скачаем ставшим привычным способом текстуальную инверсию Bad prompt, поместим её в файл в папку Git\stable-diffusion-webui\embeddings. Обратите внимание: не в \stable-diffusion-webui\models, где располагаются каталоги для самих моделей и LoRA, а на одном уровне с \models. 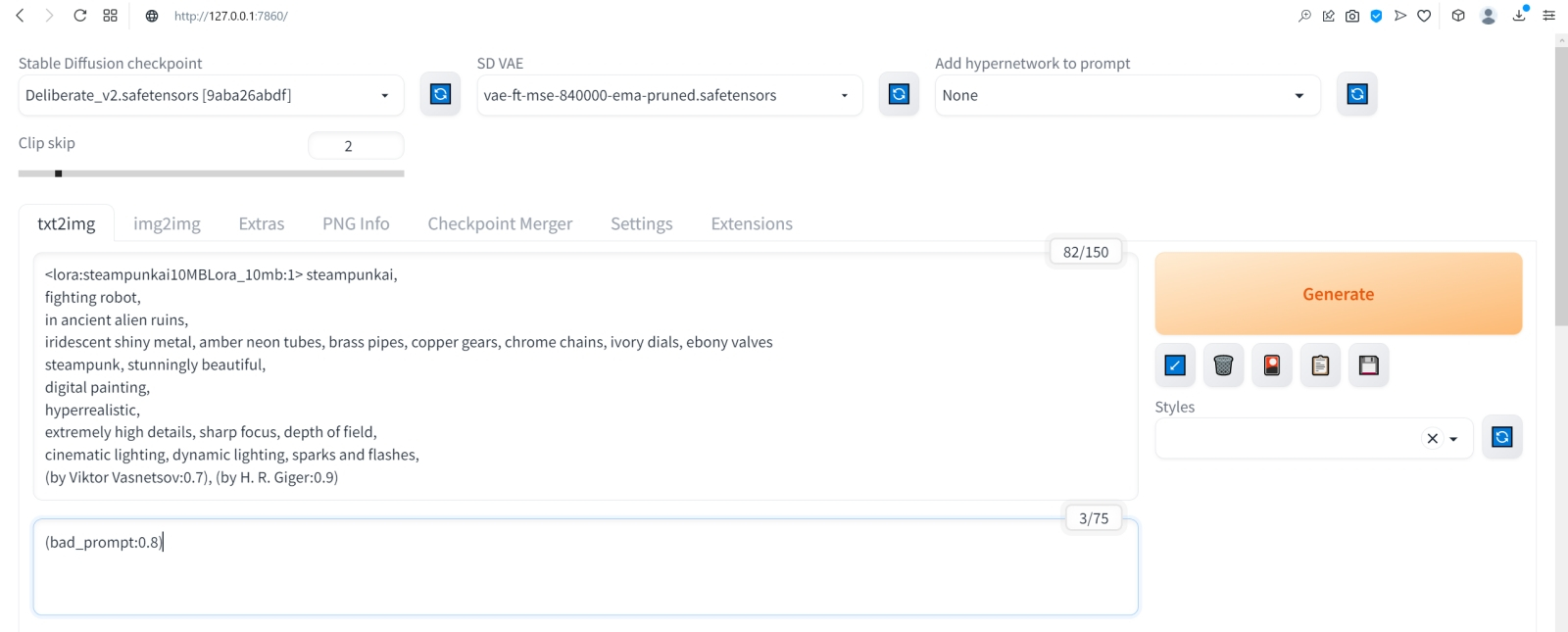 А в поле негативной подсказки вместо всего того, что там было, поместим теперь вызов текстовой инверсии с параметром значимости 0,8: (bad_prompt:0.8)  И вот это уже совершенно другое дело! Но тем не менее всё это — лишь начало, самые первые этапы погружения в бездонную глубину мира диффузных моделей для преобразования текста в изображения. Возможностей для дальнейшего совершенствования картинок Stable Diffusion и AUTOMATIC1111 предлагают немало: это и перерисовка отдельных фрагментов полученной картинки, и укрупнение её до других форматов (скажем, из квадратной заготовки можно сделать прямоугольную — так, что вновь сгенерированные элементы будут дополнять уже имевшиеся бесшовно), и почти неограниченное увеличение в размерах, и создание многофигурных композиций по шаблону, и ещё многое, многое другое… И, что самое главное, для освоения всего этого великолепия достаточно лишь простенького игрового ПК, минимальных навыков в установке ПО и — вот это существенный момент — титанического усердия. Но у тех, кто осилил настоящий киберпрактикум до самого конца, оно, вне всякого сомнения, имеется. Надеемся получить обратную связь от читателей, взявших на себя труд установить и запустить Stable Diffusion на локальном ПК или в Google Colab либо поднаторевших в работе с веб-сайтами для рисования картинок по текстовым подсказкам. В планах у нас дальнейшее углубление в тему — в частности, освоение расширения изображения (outpaint), перерисовки его отдельных фрагментов (inpaint), масштабирования (upscale), выявления текстовых подсказок из готовых картинок, не содержащих метаданных (interrogate), рисования по шаблонам (ControlNet) и ещё многое другое. Интересно было бы знать, с какими затруднениями и ограничениями на тропе ИИИИ (ИИзобразительного ИИскусства) вы успели уже столкнуться. Оставляйте ваши комментарии, попытаемся разобраться вместе!
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





