







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Задача на триллион
В 2024-м же Nvidia представила первые литографированные для неё на предприятиях TSMC серверные графические процессоры архитектуры Blackwell, что содержали 208 млрд полевых транзисторов, а микроэлектронщики уже рассуждают, когда же удастся преодолеть технологически (да и психологически) значимый рубеж в один триллион этих мельчайших элементов полупроводниковой вычислительной логики на одном же чипе, пусть и не монолитном. Для чего, однако, гнаться за столь умопомрачительной плотностью транзисторов? Если не брать в расчёт присущее настоящим инженерам и учёным бескорыстное стремление прорваться за границы уже известного в неведомое (само по себе благородное, но чем дальше, тем более затратное — и потому нуждающееся в основательном финансовом подкреплении со стороны государств, деловых структур, а то и тех и других разом), всё упирается в банальную экономику. Чем больше логических контуров — скомпонованных из тех самых транзисторов — уместится на чипе, тем более сложные задачи тот способен будет решать; а заодно и тем меньше времени затратит, чтобы справиться с ныне актуальными. Особенно важно это в эпоху революции искусственного интеллекта, который никак не выберется из виртуального пространства, — в том смысле, что все сколько-нибудь востребованные нейросети сегодня эмулируются в памяти классических компьютеров на полупроводниковой элементной базе, построенных по архитектурным принципам, что заложил ещё Джон фон Нейман (John von Neumann). Простые арифметические операции, умножение и сложение, к которым по большей части — хотя и не всегда — сводится вся эта эмуляция, выполняются тем быстрее, чем меньше выходит задержка при переносе данных из памяти на процессор (чтобы произвести означенные вычисления) и обратно (чтобы сохранить промежуточный результат). А поскольку операции эти великолепно распараллеливаются — благо складывать и умножать приходится неимоверное количество чисел в каждом слое глубокой нейросети (учтём, что число параметров в актуальных ИИ-моделях уже превышает триллион), — то чем больше физических (микро)ядер на едином чипе одновременно трудятся над ними, тем лучше. Разумеется, такого рода задачи не составит труда распределить между разнесёнными в пространстве процессорами со сравнительно малым числом транзисторов, но необходимость гонять данные по длинным шинам межсоединений неизбежно увеличит латентность — и тем самым катастрофически снизит производительность работы нейросетей. 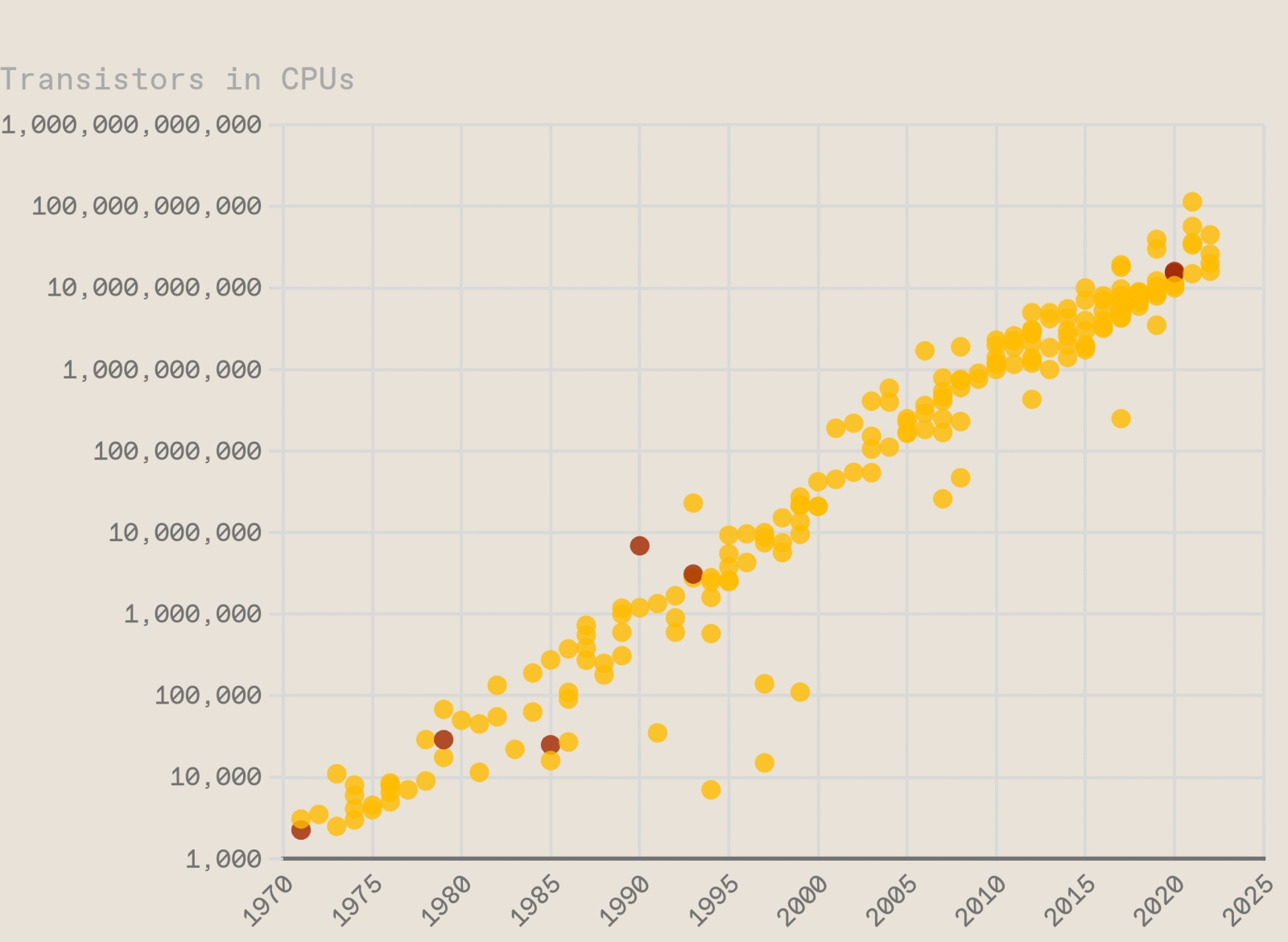
Эмпирическая зависимость количества транзисторов на единичном чипе от времени неплохо аппроксимируется прямой линией (на логарифмическом графике), так что, если продержавшаяся несколько десятилетий тенденция сохранится и далее, триллион транзисторов на одном процессоре инженеры сумеют уместить даже раньше 2035 года (источник: IEEE Spectrum) ⇡#Когда мельчить полезноЕщё в конце 2022 г., когда ChatGPT только начинал завоёвывать нынешнюю оглушительную популярность, представители подразделения Intel под названием Components Research Group предсказали, выступая на IEEE International Electron Devices Meeting, что к 2030 году плотность транзисторов на чипах просто-таки обязана будет вырасти десятикратно. Если учесть, что на тот момент максимальное значение этого показателя для серийных микросхем уже практически достигало 100 млрд, речь как раз шла об одном триллионе транзисторов на кристалл. К тому, похоже, дело и движется: весной 2024-го Nvidia представила самый мощный свой чип для серверных ускорителей Blackwell B200 на 208 млрд транзисторов, а год спустя Apple вывела на рынок персональные компьютеры на ARM-процессорах собственной разработки M3 Max с общим числом транзисторов 184 млрд, — правда, здесь это число приходится на два раздельных чипа, упакованных в единый корпус и соединённых высокопроизводительной шиной обмена данными. Важно подчеркнуть, что простота (на базовом операционном уровне) ИИ-вычислений — один из главных стимулов для микропроцессорной индустрии осваивать всё более миниатюрные производственные нормы. В среднем для «классических», алгоритмических задач, которые решаются по большей части центральными процессорами, многоядерность имеет не самое первостепенное значение — важен сам по себе рост скорости выполнения однопоточных операций при переходе от более крупного техпроцесса к менее масштабному. Производительность же генеративных нейросетей, что эмулируются в памяти фон-неймановских компьютеров, грубо говоря, прямо пропорциональна количеству транзисторов, которые расположены на кремниевой пластине под крышкой корпуса выполняющего ИИ-расчёты специализированного процессора (по традиции их продолжают называть «графическими», хотя уже в ходу термины «тензорный» или просто «нейропроцессор») — в предположении, что цифровой образ такой нейросети целиком умещается в быстрой оперативной (видео)памяти, избавляясь тем самым от дополнительных задержек на многократную частичную подгрузку-выгрузку этого образа из постоянной памяти в оперативную и обратно. Соответственно, львиную долю доступных для организации логических вычислений транзисторов логично организовывать в сравнительно простые аппаратные ядра (CUDA, в случае Nvidia, или их аналоги), и тогда действительно выходит, что чем таких ядер внутри процессора больше, тем пропорционально больше ИИ-операций он способен производить за единицу времени. Если бы не существовало технологических ограничений на этапе литографирования современных микросхем, нейрочипы наверняка становились бы с каждым поколением всё крупнее, ведь наращивать площадь для увеличения общего числа транзисторов на кристалле явно должно обходиться дешевле, чем миниатюризировать производственные нормы. Но ограничения эти, увы, существуют. 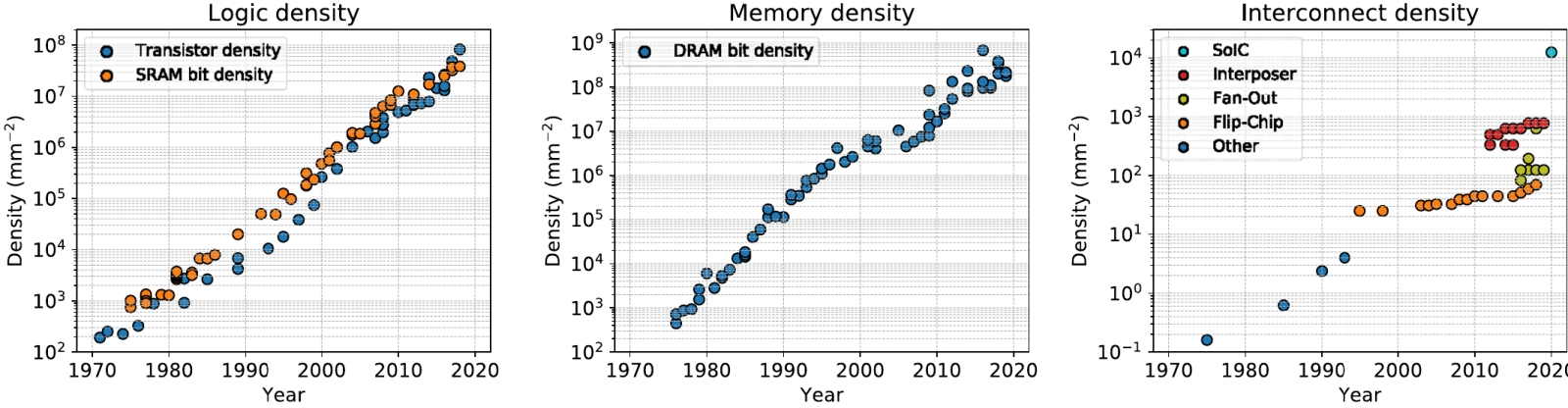
Графики поступательного, год от года, роста плотности логических элементов и конструктивно схожих с ними ячеек SRAM (слева), ячеек памяти DRAM (в центре) и межсоединений на полупроводниковом кристалле (справа) выглядели бы весьма органично согласованными, если бы не пара тонких моментов. Во-первых, масштаб по вертикали (логарифмический, в обратных квадратных миллиметрах) для всех трёх графиков разный: от 102 до 108, от 102 до 109 и от 10−1 до 104 соответственно. Во-вторых, с середины 1990-х плотность межсоединений явно начала расти куда более сдержанными темпами, чем первые две величины (источник: IEEE Spectrum) Речь идёт, как уже, наверное, догадались знакомые с нашим почти трёхлетней давности материалом «Зачем нужны чиплеты, или Как вдохнуть новую жизнь в „закон Мура“ за пределами 3 нм» читатели, о достигнутом микропроцессорной индустрией пределе площади проекции фотомаски на заготовку — reticle limit, — что составляет около 800 мм2. Более того, для самых перспективных фотолитографов серии High-NA EUV — с применением анаморфической оптики, которая за счёт неосесимметричного (по перпендикулярным направлениям) увеличения обеспечивает предельно допустимое разрешение лишь по одному из измерений, — эта эффективная площадь грозит сократиться приблизительно вдвое. Потому, увы, остаётся только один путь наращивать число транзисторов под корпусной крышкой готового процессора — умещать как можно большее их число на одну субмикросхему (чиплет), а затем соединять эти чиплеты короткими и сверхширокими шинами для минимизации задержек при переносе данных между ними внутри логически единого кристалла. Это, бесспорно, компромиссный вариант: в физически цельном чипе с тем же количеством транзисторов, что и в составном, электрические импульсы всё равно распространялись бы с меньшими задержками. Но без концептуальной переделки самой схемы EUV-литографа (с отказом от оловянной плазмы в качестве источника фотонов нужной длины волны и от сложной системы металлических зеркал, что фокусируют получаемый поток рентгеновского по сути излучения) монолитный полупроводниковый кристалл под фотомаску площадью намного более 800 мм2 имеющимися сегодня средствами не создать, а переход к иному методу EUV-генерации потребует титанических капиталовложений и многих лет, если не пары-тройки десятилетий, для доведения лабораторного прототипа до стадии готовой к серийной эксплуатации промышленной установки. Так что за неимением гербовой ИТ-индустрия продолжает писать на простой — и, как показывает практика, неплохо со своими задачами справляется. ⇡#CoWoS изволите?Принципиальное отличие составленной из чиплетов, но логически всё же единой микросхемы от многопроцессорной, к примеру, сборки, обычной для высоконагруженных серверов (когда два и более ЦП — а вдобавок порой и ГП, соединённых NVlink, — работают над решением одной и той же задачи совместно) заключается в протяжённости, ширине и способе физической реализации шины данных, что сопрягает отдельные части сборной системы. Для минимизации задержек необходимо сделать эту шину, с одной стороны, как можно более широкой (многоканальной), с другой — как можно менее длинной. Отдельная тема — величина электрической проводимости выбранного для формирования такой шины проводника, особенно с учётом уже приближающейся к единицам квадратных нанометров площади ширины его сечения: классическая медь перестаёт по мере дальнейшей миниатюризации устраивать микроэлектронщиков, — на смену ей прочат графен, рутений, тонкоплёночные полуметаллы и другие материалы. Но пока эти изыскания актуальны лишь для межсоединений внутри физически единых микросхем, — межчиплетные шины всё-таки продолжают изготавливать в том числе и фотолитографическим методом по старому доброму дамасскому процессу. 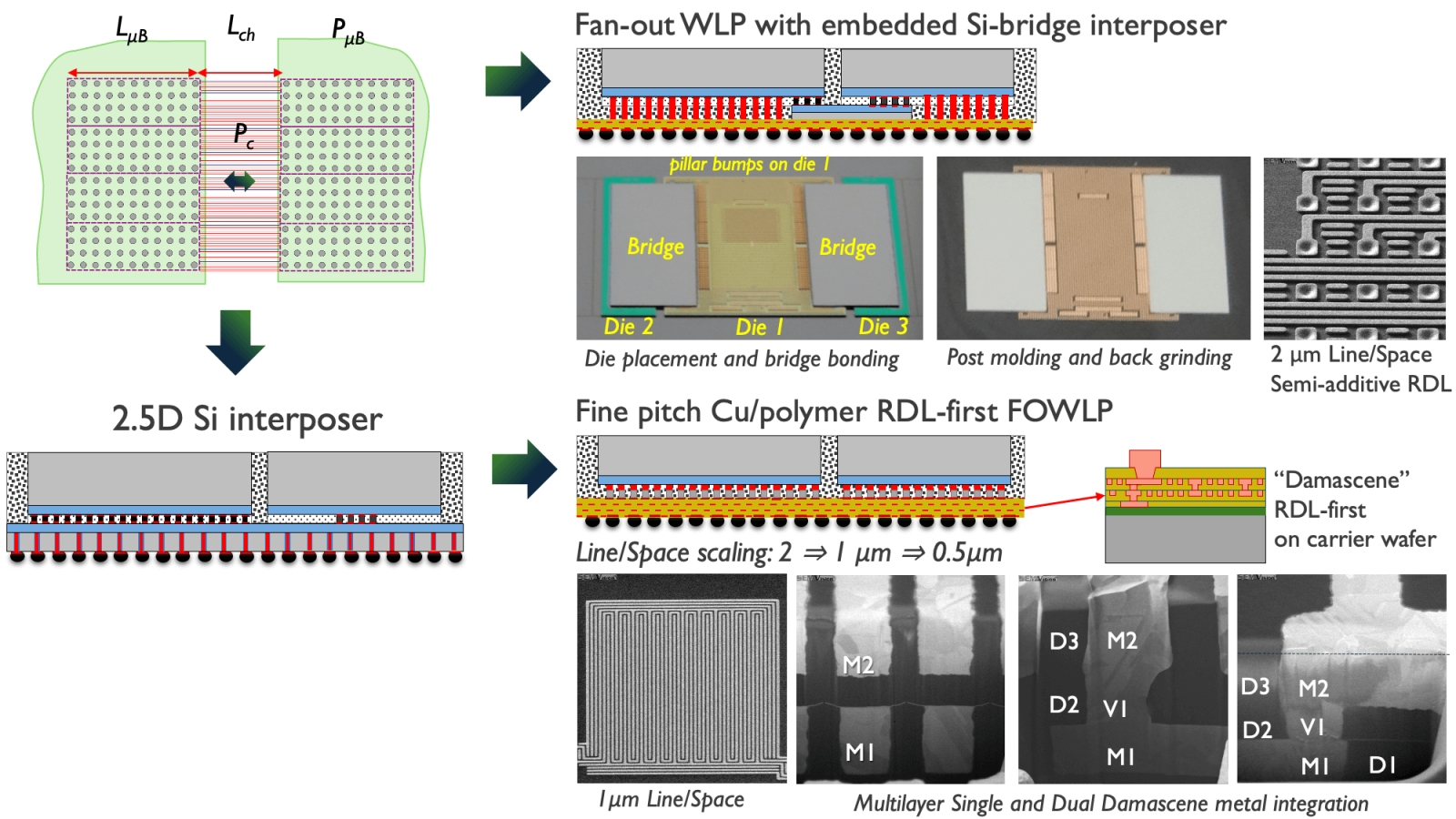
Интеграция чиплетов посредством кремниевой подложки — классика, однако в Imec разрабатывают и другие, более перспективные (в смысле снижения себестоимости и сложности обработки) соединения на перераспределяющих слоях (redistribution layer, RDL) органических полимеров, переложенных сверхтонкими медными листочками (источник: Imec) Один из наиболее распространённых способов организации чиплетов в логически единую микросхему — «двух с половиной мерное соединение через общую подложку», 2.5D interposer technology. Чаще всего подложка кремниевая — как раз из тех соображений, что с кремнием современная микроэлектроника умеет работать лучше, чем с каким бы то ни было иным материалом, в том числе и по части литографирования на нём токоведущих дорожек. Но в качестве субстрата в принципе допустимо использовать и стекло, и слоистый пластик, и различные органические полимеры, — сами проводники всё равно остаются пока что исключительно медными. Геометрически 2.5D-соединения могут довольно заметно различаться: исходно широко применяли непосредственное размещение чиплетов с крайне малым зазором (50 мкм и менее) на единой подложке, внутри которой прокладывали медные шины, а уже чиплеты с подложкой сопрягали через точечные контакты (microbumps) характерными размерами в десятки микрон с аналогичной протяжённости зазорами между ними. Другой вариант — вместо общего для всего составного чипа дополнительного слоя кремния, который и толщину конструкции увеличивает, и эффективность теплоотвода снижает, применять мостики (bridges) из прошитых медными шинами узких кремниевых пластин, которые располагают встык между чиплетами. Отсюда, собственно, остаётся всего один шаг от «двух с половиной мерности» к подлинному 3D: вместо того чтобы располагать чиплеты рядом и соединять их пусть даже совсем неширокими промежуточными коннекторами, есть смысл свести протяжённость этих самых коннекторов и вовсе практически к нулю — поместив один чиплет на другой и обеспечив их соединение прямыми точечными контактами. О том, как именно микроэлектронщики это делают и какие сложности здесь приходится преодолевать, мы уже рассказывали в материале «Трудный штурм микроскопических высот: как чиплеты выходят в третье измерение». Напомним только, что если соединения «микрозернью» обеспечивают зазоры между контактами около 30, 10, в лучшем случае 5 мкм (а для современных сверхминиатюрных техпроцессов это чересчур много, чтобы создать по-настоящему высокоплотную межчиплетную шину обмена данными), то более технически совершенные — но и дорогостоящие — методы размещения заранее подготовленных микросхем на только что литографированной пластине (die-to-wafer bonding), а также комбинации двух комплементарных пластин для образования уже практически готовых — только разрезать и упаковать — 3D-чипов (wafer-to-wafer bonding) — позволяют сократить зазоры между соседними контактами и до 200 нм, и до 100 нм, а в обозримой перспективе — и до нескольких десятков нанометров. 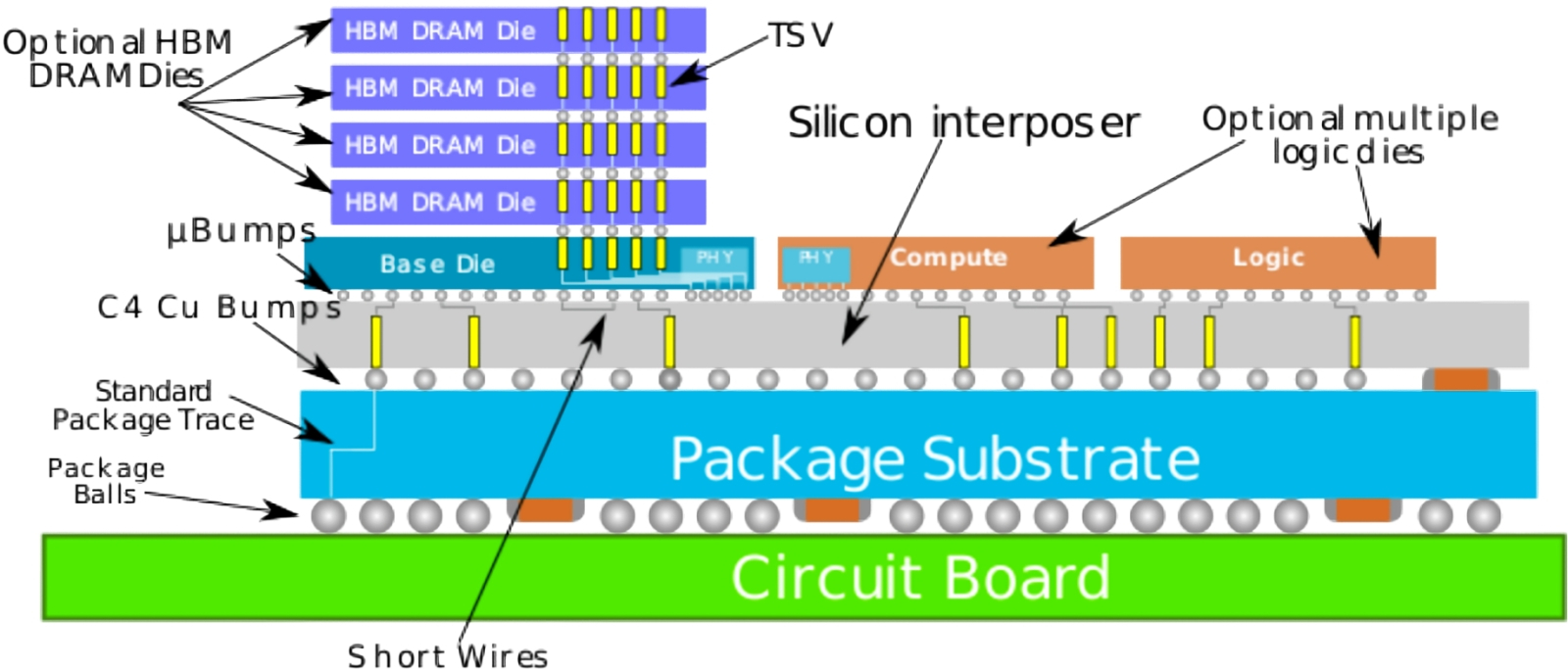
Схема организации гибридного составного чипа в рамках архитектуры CoWoS-S (источник: TSMC) Ещё в 2021 г. пятое поколение разработанной тайваньской TSMC гибридной технологии мультичиплетной интеграции CoWoS-S (Chip-on-Wafer-on-Substrate with Si interposer – «монтаж микросхемы на кремниевую подложку на субстрате с кремниевым промежуточным слоем») позволило практически втрое увеличить эффективную площадь проекции фотомаски: с 830 до примерно 2500 мм2. Имеется в виду обратный пересчёт количества транзисторов (на всех «этажах» в совокупности, ясное дело), которые умещаются на данном кристалле, — в ту площадь, что занимала бы необходимая для их совместного экспонирования одиночная фотомаска. Там, правда, всё даже несколько сложнее: для логических контуров эффективная площадь маски выросла не так уж сильно, до 1200 мм2, — тогда как основной вклад в увеличение сделали по-настоящему многослойные «кубики» сверхскоростной оперативной памяти HBM, смонтированные на том же составном кристалле. По аналогичному принципу эффективную площадь проецируемой на заготовку фотомаски потенциально можно сделать и вшестеро больше физически допустимой, однако опять-таки благодаря соседству на общей гибридной микросхеме «небоскрёбов» HBM-модулей и логических чиплетов куда более скромной этажности. Но считать это каким-то жульничеством со стороны микроэлектронщиков было бы некорректно: оперативная память в непосредственном соседстве с вычислительной логикой, соединённая с той сверхширокой шиной данных с минимальными задержками, — это ведь как раз то, что остро необходимо для решения современных ИИ-задач на фон-неймановских вычислителях. Так что, если вожделенный триллион транзисторов на кристалле будет достигнут прежде всего за счёт уплотнения DRAM-структур, а не логических контуров, дисквалифицировать такой рекорд никто не станет. ⇡#Доработки (не) напильникомПонятно, что выложить на условный стол составной микрочип, все чиплеты и HBM-модули которого в сумме содержат триллион транзисторов, для микроэлектронной индустрии — не самоцель: гораздо важнее на каждом этапе продвижения к этому (психологически в первую очередь) значимому рубежу добиваться заметного повышения производительности получаемых микросхем на реальных приложениях. А в этом плане любое сокращение латентности сигналов, что перемещаются внутри такого чипа, — уже достойный шаг. Для сокращения же латентности инженеры то и дело предлагают практические решения, напрямую не связанные с ростом плотности транзисторов ни в каком из доступных им трёх измерений: так, фирменная технология TSMC «система на составных микросхемах», system on integrated chips, SoIC, — не путать с «системой-на-кристалле», SoC! — реализует гетерогенную интеграцию многоэтажных чипов посредством сквозных вертикальных соединений, through-silicon-via (TSV), а не точечных контактов — микрозерни. Уже сам переход к протравленным в кремниевых (или иных) подложках каналам от выступающих за пределы этих подложек контактных «зёрнышек» сокращает путь распространения электрического сигнала, причём в зависимости от задачи современные технологии позволяют создавать TSV самой разной протяжённости — от десятков и сотен микрометров (для КМОП-датчиков изображений, в которых такого рода соединения изначально и появились) до 5-нм и даже более коротких «шпеньков» для подвода питания с тыльной стороны микросхем, backside power delivery, или PowerVia в терминологии Intel. 
Различные варианты TSV — ещё и не самые миниатюрные, — доступные сегодня в микроэлектронике (источник: Imec) Правда, как уже наверняка догадался внимательный читатель, скорость прогресса по этому направлению дальнейшего развития микроэлектроники ограничивает чрезвычайно важный фактор — экономический. По мере того, как TSV становятся ýже и протяжённее, растёт себестоимость их изготовления: глубокие каналы дольше требуется протравливать (а увеличенное время изготовления чипа на станке, загруженном заказами едва ли не год-полтора вперёд, оборачивается удорожанием такой микросхемы просто потому, что другие партии в это время вынуждены дожидаться своей очереди), наносить необходимые в ходе этого процесса слои материалов на стенки узкого колодца выходит сложнее и дороже, а формируемый в итоге в том же самом канале слой токоведущей меди обязан быть равномерным и строго расчётной толщины по всей немалой своей высоте, — чего и добиться в технологическом плане непросто, и на совесть проконтролировать чрезвычайно трудно. По этой причине составные чипы с TSV обходятся дорого не только на этапе собственно изготовления: для них требуется специализированное контрольно-измерительное оборудование, а его, в свою очередь, тоже нужно где-то сделать (и явно крайне ограниченной по количеству партией, что автоматически задирает себестоимость), а потом обслуживать и т. д. Словом, для широкого распространения такого рода микросхем остро необходим предельно широкий рынок сбыта, объёмы которого позволят удерживать цену каждой единицы предлагаемого заказчикам товара в разумных пределах, — и с этой точки зрения составные чипы с TSV и сегмент ИИ-вычислений попросту созданы один для другого. Добавим сюда и другую проблему, в целом для микроэлектронной отрасли освещённую нами в сравнительно недавнем материале «Старость — не радость (и для кремния тоже)»: глубокие узкие каналы, что пронизывают некрупные в общем-то кремниевые кристаллы на манер перфорации, вовсе не придают тем прочности. Чем больше отношение глубины TSV-колодца к его диаметру, тем сильнее оказывается механическое напряжение за счёт стягивания (tensile stress), которому вещества, осаждаемые на стенки канала в процессе изготовления чипа, подвергают соседний с таким колодцем участок кремниевой подложки. А поскольку масштабы тут уже даже не микро-, а нанометровые, напряжение это (проявляющее себя в деформации кристаллической решётки) напрямую начинает сказываться на мобильности свободных зарядов в толще полупроводника — организованного, напомним, фотолитографическими средствами на всё той же кремниевой основе, — и на рабочих характеристиках соседних транзисторов соответственно. По этой причине микроэлектронщикам приходится при проектировании гибридных микросхем отгораживать вокруг TSV-каналов «зоны отчуждения» (keep-out zones), в которых не рекомендуется размещать логические элементы микросхем. Выходит, хотя в целом освоение третьего измерения ведёт к очевидному кратному наращиванию числа транзисторов под крышкой упаковки CoWoS-кристаллов, темпы этого прироста не так велики, как хотелось бы, потому что приходится располагать на каждом «этаже» несколько меньше транзисторов, чем это было бы возможно для классической планарной микросхемы той же площади. Мало того: медный слой внутри узких длинных колодцев и окружающий те кремний обладают неодинаковой, мягко говоря, теплопроводностью, что при неизбежном нагреве чипа в ходе работы лишь усиливает накапливающиеся в его толще напряжения, а поскольку перфорация тончайших кремниевых пластин TSV-каналами вынужденно неравномерная (межчиплетные контакты группируются во вполне определённых зонах), это добавляет инженерам-проектировщикам головной боли. 
Схема организации подвода питания с тыльной стороны микросхем (слева) и микрофотография сечения такого чипа (источник: Imec) Вполне вероятно, что уже в какой-то обозримой перспективе TSV внутри логически единых кристаллов заменит кремниевая фотоника — и в целом, возможно, оптоэлектронные системы окажутся в итоге более экономически выгодным «железом» именно для ИИ-вычислений, — но пока CoWoS и подобные ей технологии продолжают торжествовать в этой области. Бесспорно, здесь крайне велика роль набранной уже генеративной отраслью инерции: да, экстенсивная работа по совершенствованию освоенных ранее технологий обходится дорого и обеспечивает не слишком впечатляющий прирост производительности на каждом очередном этапе, но зато здесь возможно более или менее уверенно планировать как спрос со стороны заказчиков, так и сроки освоения этих самых этапов. Если же сейчас бросить всё и вложиться в развитие откровенно сырых пока, пусть и чрезвычайно перспективных, направлений модификации «железа», есть риск и потребности рынка в новых партиях ИИ-вычислителей вовремя не удовлетворить, и неверно оценить необходимое для уверенного запуска новинок в серию время. За гибридными электронно-фотонными вычислительными системами, впрочем, остаётся то невероятно привлекательное (как раз в самом приземлённом, коммерческом плане) преимущество, что с уверенным их освоением сама задача «достичь порога в 1 триллион транзисторов на кристалле» может потерять актуальность. Судите сами: если пяток высокопроизводительных серверных графических чипов вроде упоминавшегося уже B200 на 208 млрд транзисторов связать в единую систему оптическими интерконнекторами — а у фотонного способа передачи информации задержки несопоставимо меньше, чем у электронного, — они вполне смогут работать (после определённого доведения до ума программного обеспечения) как единая логическая микросхема на тот самый триллион транзисторов — причём сигнал между соседними её ГП-блоками будет проходить едва ли не быстрее, чем с одного конца каждого такого блока в отдельности до его же другого. Более того, сотни серверов в стойках внутри общего машинного зала смогут действовать по сути как единый нейровычислитель, да ещё и с неимоверным объёмом высокоскоростной оперативной памяти (также подключённой по фотонным каналам), — перспективы в плане дальнейшего усложнения ИИ-моделей это открывает практически неоглядные. Так что, вполне вероятно, именно кремниевая фотоника и гибридные системы позволят однажды снять с повестки дня саму «задачу на триллион транзисторов», — правда, есть шанс, что обойдётся такое решение, с учётом стоимости всех лабораторных разработок и последующего доведения их до серийно изготавливаемых коммерческих систем, даже не в один триллион долларов. ⇡#Материалы по теме
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





