







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexGoogle выпустила экспериментальную модель искусственного интеллекта DiffusionGemma, в которой при генерации текста используется принципиально иной подход по сравнению с моделями, на которых работает большинство современных чат-ботов.






Источник изображений: blog.google
Вместо того, чтобы генерировать слово за словом в строгой последовательности, она создаёт за один раз целый блок текста и продолжает его дорабатывать, пока он не станет читаемым. Основное преимущество DiffusionGemma в том, что приоритетом для неё является скорость, даже за счёт некоторой потери качества конечного результата. Модель опубликована с открытым исходным кодом под лицензией Apache 2.0 и ориентирована на разработчиков и исследователей, а не обычных пользователей.
Ответ на запрос пользователей она начинает с набора случайных токенов — шумного, нечитаемого текста, который за несколько проходов превращается в осмысленный. Это позволяет существенно увеличить скорость по сравнению с традиционными вариантами: на ускорителе Nvidia H100 генерируются по 1000 токенов в секунду, а на потребительской видеокарте — по 700 токенов в секунду.
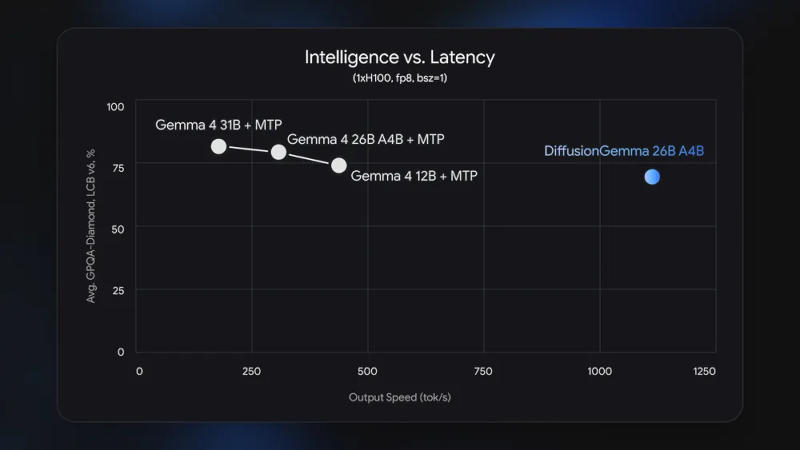
Google DiffusionGemma имеет архитектуру «смеси экспертов» (Mixture-of-Experts), то есть при размере 26 млрд параметров одновременно активными остаются лишь 3,8 млрд; для работы модели требуются около 18 Гбайт видеопамяти. За один шаг она генерирует 256 токенов, и все они взаимодействуют внутри блока. Это даёт модели глобальное представление о результатах, а не строго линейное.
Она хорошо подходит для задач на структурирование или выполнение правил: её можно использовать для заполнения недостающих фрагментов кода, работы с форматами вроде JSON, решения сложных логических задач и обработки математических закономерностей. Видя блок токенов сразу, она может исправлять противоречия в одном цикле генерации, а не ждать, когда ошибку исправит более поздний токен.

Но есть у неё существенный минус. Ответы Google DiffusionGemma по качеству уступают ответам Gemma 4 – пользователь получает скорость в ущерб точности. Поэтому Google позиционирует проект как экспериментальный — он разработан для сценариев, при которых скорость ответа важнее совершенства. Например, для работы приложений ИИ в реальном времени, для встроенных помощников по написанию текста или кода и других быстрых итеративных рабочих процессов. Заменой моделей семейств Gemma и Gemini она быть не может.
Источник:





