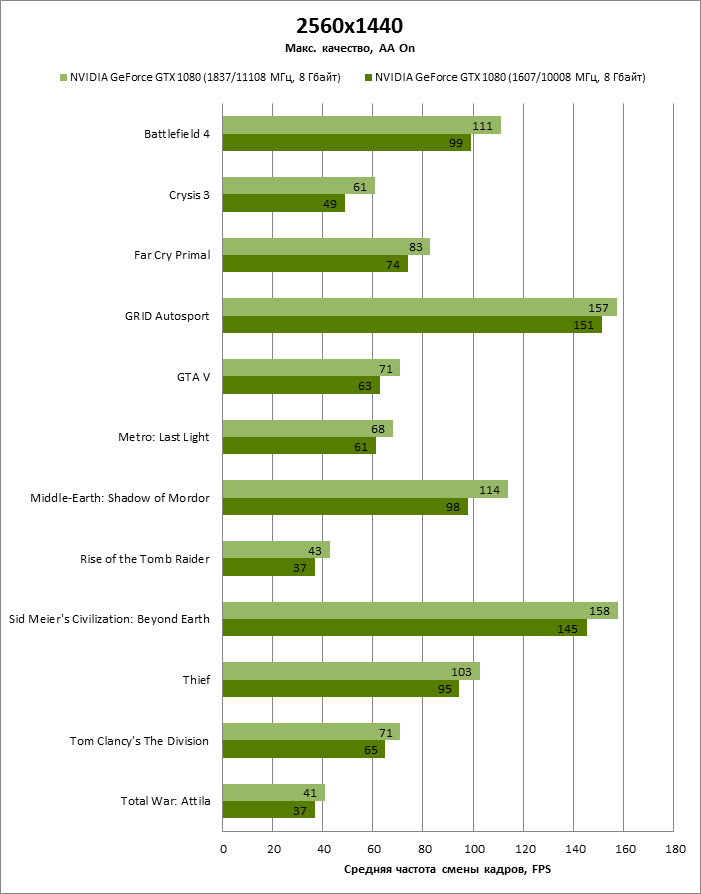Седьмого мая на мероприятии в Остине NVIDIA представила первый игровой видеоадаптер на базе GPU с архитектурой Pascal, который в то же время является первым GPU в массовой продаже, произведенным по норме 16 нм. На тот момент NVIDIA раскрыла только базовые характеристики нового флагмана и приблизительные оценки производительности в сравнении с топовыми продуктами предыдущего поколения. Сегодня истекает эмбарго на публикацию обзоров видеокарты, и мы рады поделиться с читателями как результатами нашего собственного тестирования, так и весьма подробной информацией о GeForce GTX 1080 и архитектуре Pascal в целом.
⇡#Введение: долгая дорога от 28 к 16 нм
Появление такого продукта по меркам компьютерной индустрии задержалось настолько, как вряд ли кто-либо мог предположить в то время, как с конвейера тайваньской фабрики TSMC сошли первые крупные микросхемы стандарта 28 нм, в свою очередь сменившие GPU с размером транзистора 40 нм.
Как известно, TSMC и GlobalFoundries рассматривались как подрядчики по производству графических процессоров по норме 20 нм, но GlobalFoundries в свое время отказалась от планов ввести в строй соответствующую линию, а конвейер 20 нм на TSMC рассчитан в первую очередь на компактные чипы с небольшим энергопотреблением и не обеспечивает экономически приемлемых параметров (по выходу годных кристаллов и току утечки) для процессоров, включающих несколько миллиардов транзисторов.
По слухам, NVIDIA планировала использовать стандарт 20 нм для производства GPU семейства Maxwell на определенном этапе, но в итоге данная линейка за все время своего существования производилась по норме 28 нм. Единственным исключением для Maxwell стала система на чипе Tegra X1, содержащая сравнительно компактное графическое ядро. AMD также официально заявляла, что инженеры компании успели поиграть с первыми образцами кремния стандарта 20 нм от TSMC, но ранее согласованные планы на массовое производство были свернуты – пусть даже ценой выплаты неустойки в 33 млн. долларов.
Сам по себе техпроцесс 20 нм не является принципиально ущербным с точки зрения производства крупных микросхем, как показывает пример других продуктов, выпущенных TSMC на данном узле: процессора SPARC M7, (включает свыше 10 млрд. транзисторов – больше, чем в каком-либо GPU на сегодняшний день) и FPGA-чипов Virtex (вплоть до 20 млрд. транзисторов). Но с экономической точки зрения обоим разработчикам дискретных GPU было целесообразно дождаться входа в строй производства по норме 14/16 нм с технологией FinFET, которая специально направлена на уменьшение токов утечки в полупроводниковых кристаллах.
TSMC применяет для новых GPU NVIDIA на базе архитектуры Pascal уже второе поколение данного техпроцесса – 16FF+ (FinFet Plus), которое по официальной информации характеризуется вдвое более высокой плотностью размещения транзисторов по сравнению с техпроцессом 28HPM (наиболее скоростным вариантом узла 28 нм на TSMC) и может обеспечить либо на 65% более высокие тактовые частоты, либо снижение мощности в размере 70%. Графическим процессорам все это сулит колоссальный рывок в их пользовательских характеристиках.
⇡#NVIDIA GP104 – первый игровой GPU на архитектуре Pascal
GeForce GTX 1080 – флагман «тысячной» серии игровых видеокарт NVIDIA – построен на базе GPU GP104 – второго по старшинству чипа в линейке Pascal. Хотя более крупный кристалл GP100 уже был представлен ранее в составе ускорителя вычислений Tesla P100, в потребительские продукты он придет намного позже (коль скоро первые партии Tesla P100 NVIDIA будет поставлять избранным организациям, а в OEM-каналах ускоритель появится в первом квартале 2017 года).
P104 в сравнении с P100 почти вдвое меньше по числу транзисторов и площади кристалла. Если же отталкиваться от линейки Maxwell, то новый чип занимает промежуточное положение между GM204, который NVIDIA использует в GeForce GTX 970/980, и GM200 (GeForce GTX 980 Ti и GTX 980 TITAN X) как по «физическим» параметрам кристалла, так и по количеству ядер CUDA и текстурных модулей.
Конфигурация back-end’а GP104 безошибочно определяет его позицию как последователя GM204, поскольку он также комплектуется 256-битной шиной памяти, разделенной между восемью контроллерами, и 64 блоками ROP.
С точки зрения компоновки вычислительных блоков GPU архитектура Pascal в реализации GP104 точно следует принципам, заложенным в Maxwell. Вся вычислительная логика сосредоточена в структурах под названием Graphics Processing Cluster (GPC) – их четыре в данном процессоре. Внутри GPC находится пять Stream Multiprocessors, каждый из которых включает 128 ядер CUDA, 8 текстурных модулей и секцию кэша L1, которая увеличена с 24 до 48 Кбайт сравнительно с Maxwell. Каждый GPC также включает единственный Polymorph Engine (Raster Engine на диаграмме), выполняющий первоначальные стадии рендеринга: определение граней полигонов, проекция и отсечение невидимых пикселов (здесь также есть специфические оптимизации, о которых будет рассказано ниже).
⇡#GeForce GTX 1080: технические характеристики, цена
Главное достижение техпроцесса 16 нм здесь выражается в тактовых частотах, которые выросли почти вдвое относительно GeForce GTX 980: базовая частота – 1607 МГц, Boost Clock – 1733 МГц (т.к. последняя является усредненной частотой в типичных приложениях, GTX 1080 способен кратковременно разгоняться до более высоких значений – нам предстоит выяснить на практике, насколько более высоких). Впрочем, NVIDIA сообщает, что столь серьезный прирост частот нельзя целиком отнести на счет прогрессивного техпроцесса, и создателям пришлось тщательно поработать над схемотехникой чипа с тем, чтобы какое-либо из «слабых» соединений не создавало бутылочное горлышко, ограничивающее общий частотный потенциал.
| NVIDIA GeForce GTX 980 | NVIDIA GeForce GTX 980 Ti | NVIDIA GeForce GTX TITAN X | NVIDIA GeForce GTX 1080 |
|---|
| Графический процессор |
| Кодовое название |
GM204 |
GM200 |
GM200 |
GP104 |
| Число транзисторов, млн |
5200 |
8000 |
8000 |
7200 |
| Техпроцесс, нм |
28 |
28 |
28 |
16 |
| Тактовая частота, МГц: Base Clock / Boost Clock |
1126/1216 |
1000/1076 |
1000/1089 |
1607/1733 |
| Число ядер CUDA |
2048 |
2816 |
3072 |
2560 |
| Число текстурных блоков |
128 |
176 |
192 |
160 |
| Число ROP |
64 |
96 |
96 |
64 |
| Оперативная память |
| Разрядность шины, бит |
256 |
384 |
384 |
256 |
| Тип микросхем |
GDDR5 SDRAM |
GDDR5 SDRAM |
GDDR5 SDRAM |
GDDR5X SDRAM |
| Тактовая частота, МГц (пропускная способность, Мбит/с на линию) |
1753 (7012) |
1753 (7012) |
1753 (7012) |
1250(10000) |
| Объем, Мбайт |
4096 |
6144 |
12288 |
8192 |
| Шина ввода/вывода |
PCI Express 3.0 x16 |
PCI Express 3.0 x16 |
PCI Express 3.0 x16 |
PCI Express 3.0 x16 |
| Производительность |
| Вычислительная мощность шейдерных ALU, FP32 |
4612 |
5632 |
6144 |
8228 |
| Производительность FP32/FP64 |
1/32 |
1/32 |
1/32 |
1/32 |
| Вывод изображения |
| Интерфейсы (макс разрешение@частота кадров, Гц) |
HDMI 2.0, DisplayPort 1.2, DL-DVI |
HDMI 2.0, DisplayPort 1.2, DL-DVI |
HDMI 2.0, DisplayPort 1.2, DL-DVI |
HDMI 2.0b, DisplayPort 1.3/1.4, DL-DVI |
| TDP, Вт |
160 |
250 |
250 |
180 |
| Розничная цена на момент выпуска (рекомендованная для США, без налогов), $ |
549 |
649 |
999 |
599/699 (54 990 руб.) |
В итоге, пиковая производительность GTX 1080 в GFLOPS с одинарной точностью (FP32) существенно превышает таковую как у GTX 980 Ti, так и даже у GTX TITAN X. В играх сравнение GTX 1080 с TITAN X может оказаться даже более выгодным, так как последний в графических приложениях практически не имеет преимуществ над GTX 980 Ti, если не брать в расчет объем RAM в 12 Гбайт.
Расчеты двойной точности (FP64) процессор GP104 выполняет на скорости 1/32 от FP32 – в этом он наследует чипам второго и последующего эшелонов семейства Maxwell. Архитектура Pascal также может выполнять операции FP16 с удвоенной производительности относительно FP32, в то время как Maxwell выполняет их на такой же скорости
По энергопотреблению GeForce GTX 1080 относится к тому же классу, как и GeForce GTX 980 – 180 Вт. Опираясь на эти данные и заявленную производительность в TFLOPS для GTX 980 и GTX 1080, мы получаем прирост энергоэффективности Pascal в 63% по сравнению с Maxwell.
Объем RAM составляет 8 Гбайт типа GDDR5X – объем, который ранее был прерогативой видеокарт AMD на базе GPU Hawaii, обладающих 512-битной шиной памяти.
Как и Maxwell, GeForce GTX 1080 обладает наиболее широкой среди GPU на рынке поддержкой новых функций рендеринга в стандарте DirectX 12 (feature level 12_1).
Видеокарта поступает в продажу сегодня по рекомендованной цене $599 для рынка США (без налога на продажи) 54 990 рублей — для России. Более высокую цену ($699) получила версия GTX 1080 под названием Founder’s Edition, представляющая собой референсный образец, который выпускает сама NVIDIA. Данный факт уже вызвал определенное непонимание в массах, и в отдельном разделе статьи мы расскажем, почему NVIDIA поступила таким образом. Но сперва изучим более подробно архитектуру GeForce GTX 1080.
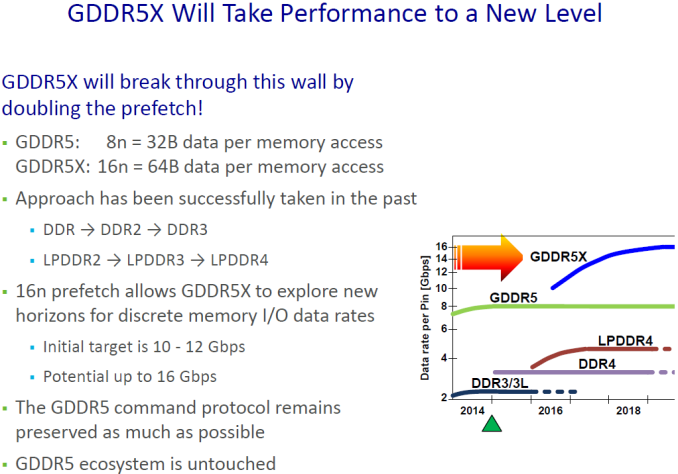
⇡#GDDR5X
Мы переходим к еще одной особенности GeForce GTX 1080, которая сделала эту модель первой в своем роде – поддержке памяти GDDR5X. В этом качестве GTX 1080 какое-то время будет единственным продуктом на рынке, поскольку уже известно, что GeForce GTX 1070 будет укомплектован стандартными чипами GDDR5. В сочетании с новыми алгоритмами компрессии цвета (об этом также чуть позже) высокая ПСП (пропускная способность памяти) позволит GP104 более эффективно распоряжаться имеющимися вычислительными ресурсами, чем это могли себе позволить продукты на базе чипов GM104 и GM200.
JEDEC выпустила финальные спецификации нового стандарта лишь в январе текущего года, а единственным производителем GDDR5X на данный момент является компания Micron. На 3DNews не было отдельного материала, посвященного этой технологии, поэтому мы кратко опишем те нововведения, которые приносит GDDR5X, в данном обзоре.
Протокол GDDR5X имеет много общего с GDDR5 (хотя электрически и физически те и другие чипы различаются) – в отличие от памяти HBM, которая представляет собой принципиально другой тип, что делает делает практически неосуществимым сосуществование с интерфейсом GDDR5(X) в одном GPU. По этой причине GDDR5X называется именно так, а не, к примеру, GDDR6.
Одно из ключевых различий между GDDR5X и GDDR5 состоит в возможности передачи четырех бит данных на одном цикле сигнала (QDR – Quad Data Rate) в противоположность двум битам (DDR – Double Data Rate), как это было во всех предшествующих модификациях памяти DDR SDRAM. Физические же частоты ядер памяти и интерфейса передачи данных располагаются приблизительно в том же диапазоне, что у чипов GDDR5.
А чтобы насытить данными возросшую пропускную способность чипов, в GDDR5X применяется увеличенная с 8n до 16n предвыборка данных (prefetch). При 32-битном интерфейсе отдельного чипа это означает, что контроллер за один цикл доступа к памяти выбирает уже не 32, а 64 байта данных. В итоге результирующая пропускная способность интерфейса достигает 10-14 Гбит/с на контакт при частоте CK (command clock) 1250-1750 МГц – именно эту частоту показывают утилиты для мониторинга и разгона видеокарт – такие, как GPU-Z. По крайней мере, сейчас в стандарт заложены такие показатели, но в будущем Micron планирует достигнуть чисел вплоть до 16 Гбит/с.
Следующее преимущество GDDR5X состоит в увеличенном объеме чипа – с 8 до 16 Гбит. GeForce GTX 1080 комплектуется восемью чипами по 8 Гбит, но в дальнейшем производители графических карт смогут удвоить объем RAM по мере появления более емких микросхем. Как и GDDR5, GDDR5X допускает использование двух чипов на одном 32-битном контроллере в так называемом clamshell mode, что в результате дает возможность адресовать 32 Гбайт памяти на 256-битной шине GP104. Кроме того, стандарт GDDR5X помимо равных степени двойки описывает объемы чипа в 6 и 12 Гбит, что позволит варьировать общий объем набортной памяти видеокарт более «дробно» – например, оснастить карту с 384-битной шиной RAM чипами на суммарные 9 Гбайт.
Вопреки ожиданиям, которые сопровождали первую информацию о GDDR5X, появившуюся в открытом доступе, энергопотребление нового типа памяти сравнимо с таковым у GDDR5 либо лишь немного превышает последнее. Чтобы компенсировать возросшую мощность на высоких значениях пропускной способности, создатели стандарта снизили питающее напряжение ядер с 1,5 В, стандартных для GDDR5, до 1,35 В. Кроме того, стандарт в качестве обязательной меры вводит управление частотой чипов в зависимости от показателей температурного датчика. Пока неизвестно, насколько новая память в действительности зависима от качества теплоотвода, но не исключено, что мы теперь чаще будем видеть на видеокартах системы охлаждения, обслуживающие не только GPU, но и чипы RAM, в то время как производители карт на базе GDDR5 в массе своей пренебрегают этой возможностью.
Может возникнуть впечатление, что переход с GDDR5 на GDDR5X был несложной задачей для NVIDIA в силу родства данных технологий. К тому же, GeForce GTX 1080 комплектуется памятью с наименьшей пропускной способностью, определенной стандартом – 10 Гбит/с на контакт. Однако практическая реализация нового интерфейса сопряжена с рядом инженерных трудностей. Передача данных на столь высоких частотах потребовала тщательной разработки топологии шины данных на плате с целью минимизировать наводки и затухание сигнала в проводниках.
Результирующая пропускная способность 256-битной шины в GeForce GTX 1080 составляет 320 Гбайт/с, что несущественно меньше скорости 336 Гбайт/с, которой характеризуется GeForce GTX 980 Ti (TITAN X) с его 384-битной шиной GDDR5 при 7 Гбит/с на контакт.
⇡#Улучшенная компрессия цвета
Архитектура Pascal привнесла новые алгоритмы дельта-компрессии цвета наряду с компрессией 2:1, которую используют предыдущие семейства GPU NVIDIA (которая также была сделана более эффективной в Pascal). В целом, смысл дельта-компрессии состоит в том, чтобы обнаружить группы соседних пикселов, слабо отличающихся по цвету, и кодировать их цвет в виде опорного (reference) значения и отступлений от последнего (собственно, дельта). В Pascal появился алгоритм 4:1, работающий на еще более тонких градиентах, а также комбинированный режим 8:1, позволяющий взять два блока, сжатых по схеме 4:1 и отобразить в виде опорного значения и дельты между ними – что в итоге обеспечивает восьмикратное сжатие данных.
В сравнении GeForce GTX 980 и GTX 1080 эти меры обеспечивают эффективное увеличение ПСП на 20% поверх 40%, которые принес новый тип памяти с итоговым результатом в 70%. На скриншотах из Project: CARS фиолетовой заливкой отмечены пикселы, подвергшиеся компрессии на GPU семейств Maxwell и Pascal.
Теперь мы закончили с описанием общих архитектурных особенностей GeForce GTX 1080 и переходим к более специфическим функциям. Помимо улучшенной производительности, которую обеспечила более прогрессивная производственная норма и новый тип памяти, Pascal принес массу нововведений, заслуживающих обстоятельного рассказа.
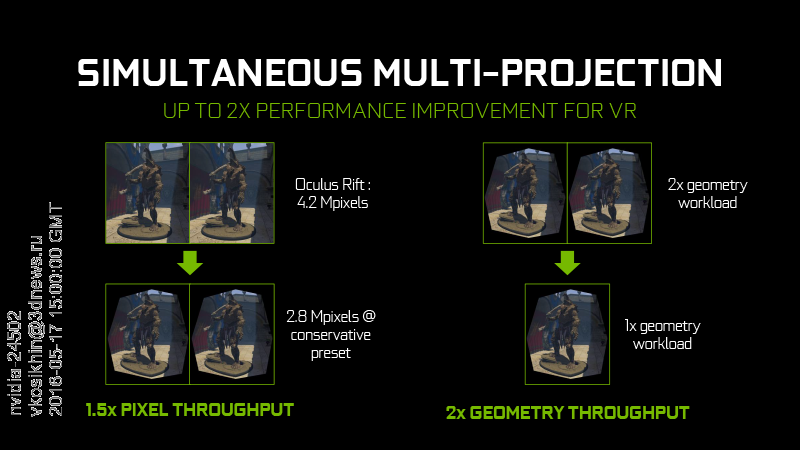
⇡#Simultaneous Multi-Projection
Выше мы отметили, что NVIDIA внесла определенные модификации в блок обработки геометрии GPU. SMP в Pascal представляет собой расширенный вариант данной функции, ранее внедренный в Maxwell. GPU NVIDIA предыдущего поколения могли одновременно проецировать геометрию сцены на перпендикулярные плоскости, составляющие куб, – это используется для формирования вокселов в технологии глобального освещения VXGI (более подробно об этом вы можете прочитать в обзоре GeForce GTX 980).
Теперь PolyMorph Engine может создавать одновременно вплоть до 16 проекций (viewport’ов), размещенных произвольным образом, и сфокусированных на одной или двух точках, сдвинутых по горизонтальной оси относительно друг друга. Данные преобразования выполняются исключительно в «железе», и не вызывают снижения производительности как такового.
У этой технологии есть два вполне предсказуемых применения. Первое – это шлемы VR. За счет двух центров проекции Pascal может создавать стерео-изображение за один проход (впрочем, речь идет только о геометрии – GPU по-прежнему придется совершить вдвое больше работы, чтобы выполнить растеризацию текстур в двух кадрах).
Кроме того, SMP позволяет на уровне геометрии выполнять компенсацию искажения картинки, которую вносят линзы шлема. Для этого изображения для каждого глаза формируется четырьмя отдельными проекциями, которые затем склеиваются в плоскость с применением фильтра пост-обработки. Таким образом не только достигается геометрическая точность итогового изображения, но и снимается необходимость в обработке 1/3 пикселов, которые в противном случае все равно были бы потеряны при финальной коррекции стандартной плоской проекции под кривизну линз.
Единственная оптимизация для VR, которой обладал Maxwell, состояла в том, что периферические зоны изображения, которые компрессируются наиболее сильно для вывода через линзы, могли рендериться с пониженным разрешением, что давало экономию пропускной способности лишь на 10-15%.
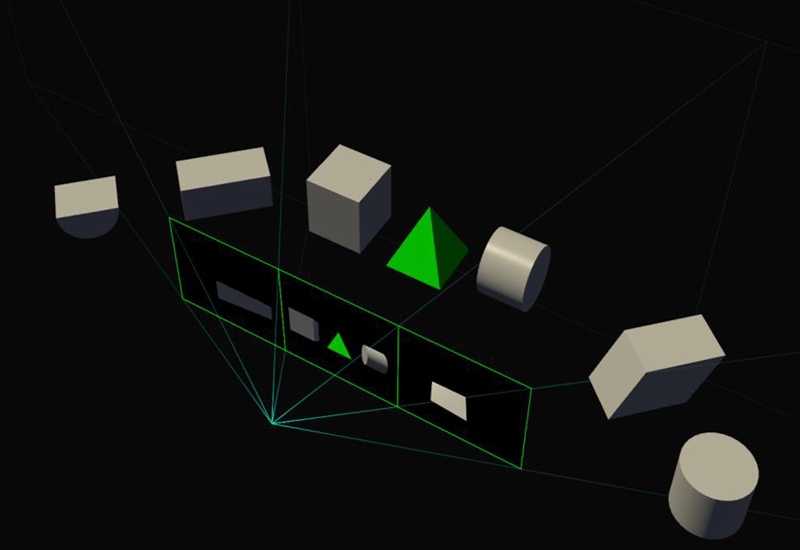
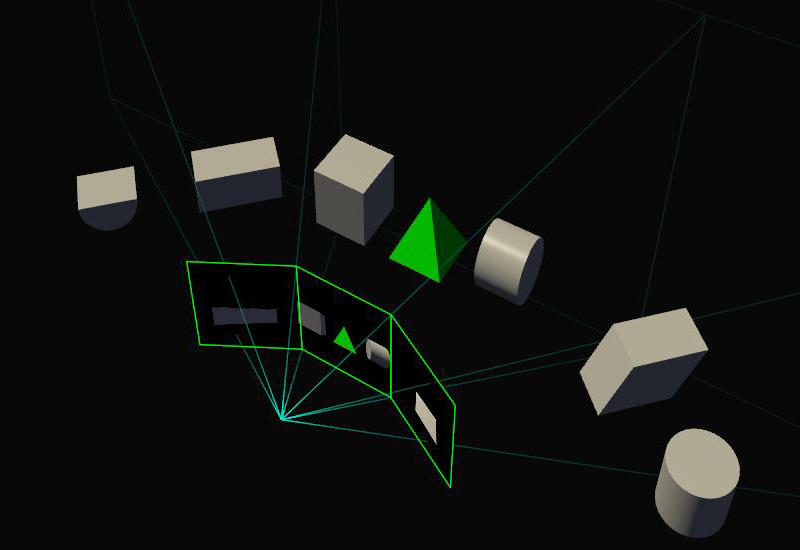
Следующая область, в которой востребована функция SMP, – это мультимониторные конфигурации. Без SMP изображение на нескольких состыкованных дисплеях представляет собой плоскость с точки зрения GPU, и выглядит геометрически корректно при условии, что экраны перед зрителем выстроены в линию, но стыковка под углом уже не выглядит корректно – как если бы вы просто согнули в нескольких местах большую фотографию. Не говоря уже о том, что в любом случае зритель видит именно плоское изображение, а не окно в виртуальный мир: если повернуть голову к боковому экрану, объекты в нем останутся растянутыми, так как виртуальная камера по-прежнему смотрит в центральную точку.
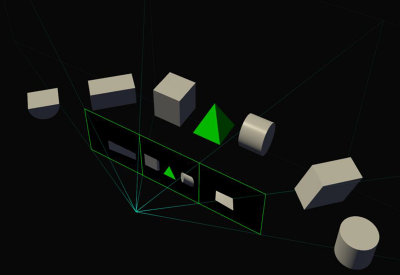
Gропорции корректны из точки наблюдателя
|
|
|
|
С помощью SMP драйвер видеокарты может получить информацию о физическом расположении нескольких экранов с тем, чтобы проецировать изображение для каждого из них через собственный viewport, что в конечном счете функционально приближает мультимониторную сборку к полноценному «окну».
⇡#Новые функции программирования для графики и вычислений
Архитектура Maxwell уже обладает наиболее широкой среди GPU на рынке поддержкой новых функций рендеринга в стандарте DirectX 12 (feature level 12_1). Pascal добавляет к этому арсеналу еще несколько опций, также имеющих потенциал для применения в сфере VR.
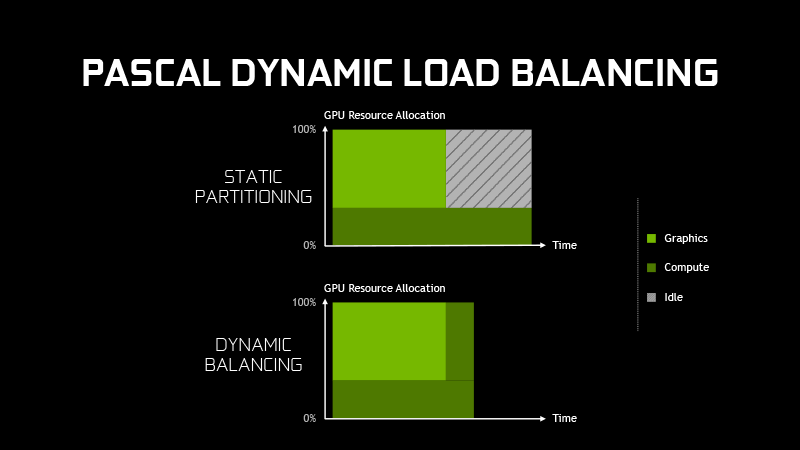
Async Compute – одна из возможностей DirectX 12, ранее свойственная только процессорами AMD на архитектуре GCN, позволяет динамически распределять ресурсы GPU между графической и вычислительной нагрузкой с тем, чтобы освободившиеся после завершения одной из задач ресурсы можно было немедленно бросить на оставшуюся задачу.
Pascal добавляет к этому возможность прерывания (preemption) цепочки операций в процессе растеризации пикселов в проекции отдельного треугольника. В неграфических вычислениях, помимо стандартной функции прерывания на потоковом (thread) уровне, Pascal обеспечивает прерывание на уровне отдельных инструкций. Промежуточный результат прерванной задачи может быть выгружен в оперативную память ускорителя, чтобы продолжить работу в последствии с того же места.
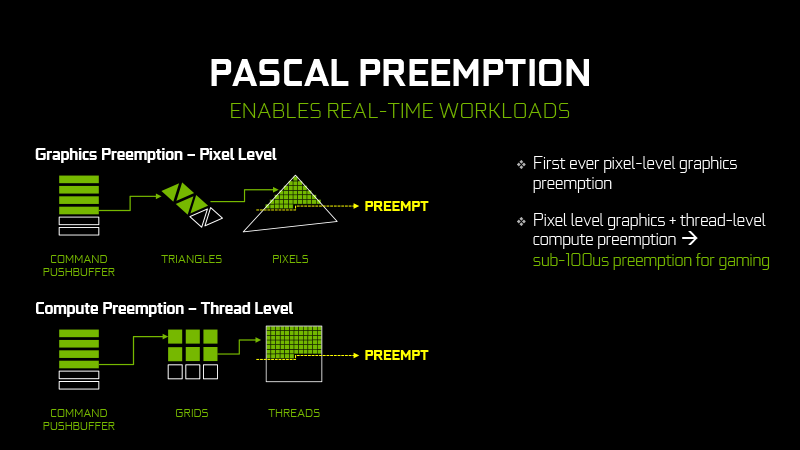
Прерывание позволяет снизить латентность в ситуациях, когда она является критичным фактором. Например, при выполнении операции Async Time Warp. Последняя технология используется в шлемах виртуальной реальности для компенсации задержки ввода, вызываемой рассинхронизацией частоты смены кадров в конвейере рендеринга с частотой обновления дисплея. Когда GPU «понимает», что кадр не успеет сформироваться до начала следующего цикла обновления, а человек при этом двигает головой, лучше прервать рендеринг, взять последний готовый кадр и деформировать изображение в соответствии с движением головы. Благодаря прерыванию задач с более высокой точностью Pascal может отодвинуть начало Time Warp как можно ближе к надвигающемуся обновлению экрана, дабы картинка была изменена в соответствии с наиболее последней информацией о положении головы.
В целом, NVIDIA оценивает, что если при рендеринге в одно окно GTX 1080 в 1,7 раза производительнее GTX 980, то в среде VR разница возрастает до 2,7 раза.
Переработанный интерфейс SLI
В то время как AMD в конфигурациях из нескольких GPU перешла на синхронизацию по шине PCI Express, NVIDIA по-прежнему использует в SLI отдельный интерфейс. Однако от публичного внимания ускользнул тот факт, что при достаточно высоких разрешениях экрана GPU NVIDIA также обмениваются частью данных посредством PCI Express. Это говорит о том, что в такой форме, которая была реализована в предшествующих архитектурах NVIDIA, SLI уже исчерпала лимит своей пропускной способности. Насколько нам известно, он составляет 1 Гбайт/с, чего уже недостаточно для обмена кадрами в разрешении 3840х2160 с частотой 60 Гц.
Но вместо того, чтобы полностью перейти на PCI Express, в Pascal переработали существующий интерфейс. Традиционно, видеокарта NVIDIA обладает двумя соединениями SLI, которые работают одновременно для связи GPU с его соседями в тройной или четверной конфигурации, но для передачи данных в двухпроцессорной связке используется только один канал. Использовать два канала в тандеме GPU – самый очевидный путь увеличения производительности, и в Pascal произошло именно это.
NVIDIA также выпустила специальный мостик, существующий в нескольких версиях различной длины, который обладает улучшенными физическими характеристиками для работы интерфейса на повышенной с предыдущих 400 МГц до 650 МГц частоте. Ранее выпущенные мостики также могут быть автоматически разогнаны при условии, что обеспечивают достаточно качественный сигнал. В частности, для этого годятся жесткие мостики с подсветкой, выпускаемые некоторыми производителями видеокарт. Впрочем, последние не имеют двойного разъема для соединения двух GPU, поэтому новый фирменный мостик остается единственным решением, рекомендованным для разрешений класса 5К и мультимониторных конфигураций.

Естественно, системы с тремя и четырьмя GPU не могут использовать двойное соединение. Более того, NVIDIA официально отказалась от поддержки SLI с более, чем двумя GPU в Pascal, поскольку масштабирование производительнсти в последних исторически было довольно ограниченным. Хотя для энтузиастов остается лазейка: на грядущей веб-страничке NVIDIA можно будет скачать файл Enthusiast Key и затем установить в прошивку каждой видеокарты, чтобы разблокировать данную функцию.
NVIDIA также прокомментировала ситуацию с поддержкой множественных GPU в DirectX 12. Существуют три режима: MDA (Multi Display Adapter) и LDA (Linked Display Adapter) в вариациях Implicit и Explicit. Режим MDA обеспечивает наибольшую гибкость за счет того, что приложение самостоятельно адресует отдельные GPU, которых может быть сколь угодно много, и даже с различными характеристиками и от различных производителей.

Режим LDA в целом предназначен для одинаковых или похожих GPU и позволяет, среди прочего, объединить оперативную память последних в общий пул (в то время как в DX11 драйвер отображает сборку SLI/CrossFire как одну видеокарту с объемом памяти, равным таковому у каждого из компонентов сборки). При этом, разумеется, данные, запрошенные из памяти соседнего GPU, передаются по сравнительно медленной шине PCI Express.
LDA Explicit также позволяет разработчику использовать любое количество графических процессоров, но, в отличие от MDA, здесь задействуются мостики SLI. В варианте Implicit синхронизацией GPU занимается драйвер видеокарты – таким образом SLI работала в эпоху, предшествующую DirectX 12.
⇡#Новые возможности вывода изображения
NVIDIA расширила возможности выделенного декодера, совместимого со стандартом HEVC (H.265), который впервые появился в GeForce GTX 960. Pascal теперь поддерживает декодирование видеопотока с глубиной цвета 10/12 бит на канал, а также появилась возможность кодирования в HEVC (также с 10-битным цветом).
Увеличенная глубина цвета используется для отображения более широкого цветового пространства по сравнению со стандартным sRGB, и расширенного динамического диапазона яркости (HDR) – на экранах ТВ, которые физически обладают такими характеристиками и поддерживают интерфейс HDMI 2.0b, впервые внедренный в GPU от NVIDIA. Компьютерные мониторы смогут принимать метаданные HDR по интерфейсу DisplayPort 1.4, который будет финализирован в будущем, но также уже поддерживается в Pascal.
Pascal готов к поддержке формата 8К: при использовании двух кабелей DP 1.3 достижимо разрешение вплоть до 7680x4320 при частоте 60 Гц.
⇡#Fast Sync
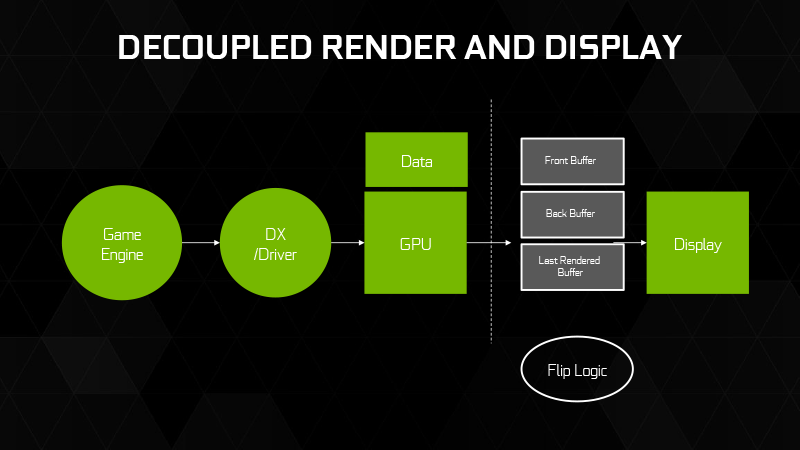
И еще одно нововведение, которое Pascal получил на уровне драйвера: еще один режим вертикальной синхронизации в дополнение к Adaptive Sync и G-Sync, которые NVIDIA представила ранее – Fast Sync. В сущности, этот режим ничем не отличается от тройной буферизации, которая доступна в API OpenGL, но отсутствует в DirectX. Мы когда-то писали о том, как это работает, в обзоре технологии G-Sync.
Вкратце, задача тройной буферизации в том, чтобы отделить процесс рендеринга новых кадров в конвейере GPU от сканирования изображения из кадрового буфера за счет того, что видеокарта может создавать новые кадры со сколь угодно высокой частотой, записывая их в два сменяющихся кадровых буфера. При этом содержимое самого последнего кадра с частотой, кратной частоте обновления экрана, копируется в третий буфер, откуда монитор может его забрать без разрывов картинки. Таким образом, кадр, который попадает на экран, в момент начала сканирования всегда содержит последнюю информацию, которую произвел GPU.
Тройная буферизация наиболее полезна для мониторов с частотой обновления экрана 50-60 Гц. При частотах 120-144 Гц, как мы уже писали в статье, посвященной G-Sync, включение вертикальной синхронизации уже, в принципе, увеличивает латентность несущественно, но Fast Sync уберет ее до минимума.
Если вы задаетесь вопросом, как Fast Sync соотносится с G-Sync (и ее аналогом Free Sync от AMD – но это чисто теоретический вопрос, т.к. NVIDIA поддерживает только свой вариант), то G-Sync снижает латентность в ситуации, когда GPU не успевает произвести новый кадр к моменту начала сканирования, а Fast Sync – напротив, снижает латентность, когда частота обновления кадров в конвейере рендеринга выше частоты обновления экрана. К тому же, эти технологии могут работать совместно.
⇡#GeForce GTX 1080 Founder’s Edition: конструкция
Этим пышным именем теперь называется референсная версия GeForce GTX 1080. Начиная с GeForce GTX 690 NVIDIA уделяет большое внимание тому, в какой форме их новые продукты выходят на рынок. Референсные образцы современных видеокарт под маркой GeForce далеки от своих невзрачных предшественников, оснащавшихся сравнительно неэффективными и шумными системами охлаждения.
GeForce GTX 1080 Founder’s Edition вобрал в себя лучшие черты дизайна видеокарт Kepler и Maxwell: алюминиевый кожух турбины, крыльчатка кулера, изготовленная из малошумного материала, и массивная алюминиевая рама, придающая жесткость конструкции и снимающая тепло с микросхем RAM.
В составе GTX 1080 присутствуют одновременно два компонента, которые периодически то появляются, то пропадают из референсных видеокарт NVIDIA – радиатор GPU с испарительной камерой и задняя пластина. Последняя частично демонтируется без отвертки, дабы обеспечить приток воздуха кулеру соседней видеокарты в режиме SLI.

Помимо своей представительской функции, референсный образец видеокарты нужен для того, чтобы конечные производители видеокарт могли закупать его – в данном случае у NVIDIA – и удовлетворять спрос, пока не будут готовы устройства оригинального дизайна на том же GPU. Но в этот раз NVIDIA планирует сохранять референсную версию в продаже на протяжении всего срока жизни модели и распространять, среди прочего, через свой официальный сайт. Так мотивирована на $100 более высокая цена GTX 1080 FE по сравнению с рекомендованными для всех остальных $599. В конце концов, Founder’s Edition не выглядит и не является дешевым продуктом.
В то же время, видеокарта имеет референсные частоты, ниже которых, как обычно, не опустится ни один производитель карт оригинального дизайна. Не идет речи и о каком-либо отборе GPU для GTX 1080 FE по разгонному потенциалу. Стало быть, во всей массе реализаций GeForce GTX 1080 могут оказаться и более дорогие. Но какое-то время Founder’s Edition будет преобладающей и даже единственной версией флагманского Pascal, что автоматически повышает его розничные цены на $100 сверх «рекомендации» NVIDIA.
GeForce GTX 1080 Founder’s Edition: плата
NVIDIA утверждает, что достоинства Founder’s Edition не ограничиваются внешним видом. Хотя четырехфазный преобразователь напряжения на плате не в силах чем-либо удивить после видеокарт с 10-фазными (и это не предел) VRM, которые в разное время прошли через нашу лабораторию, здесь применяются высококачественные компоненты и эффективная схемотехника, в совокупности обеспечивающие стабильное питание и платформу для оверклокинга GPU и RAM.

⇡#Тестовый стенд, методика тестирования
| Конфигурация тестовых стендов |
|---|
| CPU |
Intel Core i7-5960X @ 4 ГГц (100x40) |
| Материнская плата |
ASUS RAMPAGE V EXTREME |
| Оперативная память |
Corsair Vengeance LPX, 2133 МГц, 4x4 Гбайт |
| ПЗУ |
Intel SSD 520 240 Гбайт + Crucial M550 512 Гбайт |
| Блок питания |
Corsair AX1200i, 1200 Вт |
| Система охлаждения CPU |
Thermalright Archon |
| Корпус |
CoolerMaster Test Bench V1.0 |
| Монитор |
NEC EA244UHD |
| Операционная система |
Windows 10 Pro X64 |
| ПО для GPU AMD |
?AMD Radeon Software Crimson Edition 16.5.2.1 |
| ПО для GPU NVIDIA |
365.19 WHQL (368 для GeForce GTX 1080) |
Энергосберегающие технологии CPU во всех тестах отключены. В настройках драйвера NVIDIA в качестве процессора для вычисления PhysX выбирается CPU. В меню драйвера AMD настройка Tesselation переводится из состояния AMD Optimized в Use application settings.
| Бенчмарки: синтетические |
|---|
| Программа |
Настройки |
Полноэкранное сглаживание |
| 1920x1080/2560x1440 |
3840x2160 |
| 3DMark |
Тест Fire Strike (не Extreme) |
– |
– |
| Бенчмарки: игры |
|---|
| Игра (в порядке даты выхода) |
API |
Настройки |
Полноэкранное сглаживание |
| 1920x1080/2560x1440 |
3840x2160 |
| Crysis 3 + FRAPS |
DirectX 11 |
Макс. качество. Начало миссии Post Human |
MSAA 4x |
Выкл. |
| Metro: Last Light, встроенный бенчмарк |
Макс. качество |
SSAA 4x |
| Battlefield 4 + FRAPS |
Макс. качество. Начало миссии Tashgar |
MSAA 4x + FXAA |
| Thief, встроенный бенчмарк |
Макс. качество |
SSAA 4x + FXAA |
| GRID Autosport, встроенный бенчмарк |
MSAA 4x |
MSAA 4x |
| Middle-Earth: Shadow of Mordor, встроенный бенчмарк |
Макс. качество |
Не поддерживается |
| Sid Meier's Civilization: Beyond Earth, встроенный бенчмарк |
MSAA 4x |
SMAA T2X |
| Total War: Attila, встроенный бенчмарк |
Макс. качество |
MSAA 4x |
| GTA V, встроенный бенчмарк |
Макс. качество |
MSAA 4x + FXAA |
| Rise of the Tomb Raider, встроенный бенчмарк |
DirectX 12 |
Макс. качество, DirectX 12, без VXAO (не поддерживается в DX12) |
SSAA 4x |
| Far Cry Primal, встроенный бенчмарк |
DirectX 11 |
Макс. качество |
SMAA |
| Tom Clancy's The Division, встроенный бенчмарк |
DirectX 11 |
Макс. Качество, без HFTS (поддерживается только в GPU NVIDIA) |
SMAA 1x High |
| Бенчмарки: вычисления, декодирование видео |
|---|
| Программа |
Настройки |
| LuxMark 3.1 X64 |
Сцена Hotel Lobby (Complex Benchmark) |
| Sony Vegas Pro 13 |
Бенчмарк Sony для Vegas Pro 11, продолжительность – 65 с, рендеринг в XDCAM EX, 1920х1080@24p |
| CompuBench CL Desktop Edition X64, Ocean Surface Simulation |
– |
| CompuBench CL Desktop Edition X64, Particle Simulation – 64K |
– |
| SiSoftware Sandra 2016, Scientific Analysis |
Open CL, FP32/FP64 |
| DXVA Checker |
Decode benchmark. H.264, H.265. Файлы 1920х1080p (битрейт видео ~3000 Кбит/с), 3840x2160p (битрейт видео ~7500 Кбит/с). Microsoft H264 Video Decoder, Microsoft H265 Video Decoder, ускорение на аппаратном кодеке GPU (DXVA2) |
⇡#Участники тестирования
В тестировании приняли участие следующие видеокарты:
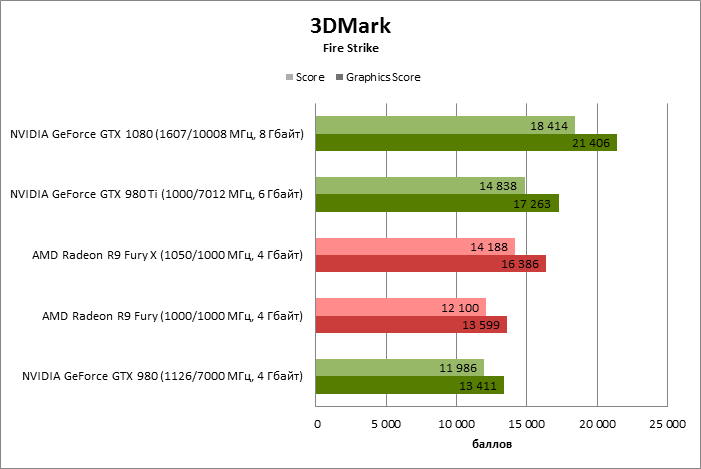
⇡#Производительность: 3DMark
| 3DMark |
|---|
|
NVIDIA GeForce GTX 1080 (1607/10008 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 Ti (1000/7012 МГц, 6 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
AMD Radeon R9 Fury X (1050/1000 МГц, 4 Гбайт) |
| 3DMark Score |
18 414 |
11 986 |
14 838 |
12 100 |
14 188 |
| Graphics Score |
21 406 |
13 411 |
17 263 |
13 599 |
17 263 |
|
|
|
|
|
|
|
NVIDIA GeForce GTX 1080 (1607/10008 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 Ti (1000/7012 МГц, 6 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
AMD Radeon R9 Fury X (1050/1000 МГц, 4 Гбайт) |
| 3DMark Score |
100% |
65% |
81% |
66% |
77% |
| Graphics Score |
100% |
63% |
81% |
64% |
81% |
⇡#Производительность: игры
⇡#1920x1080, 2560х1440
| 1920х1080 (AA) |
|---|
|
Полноэкранное сглаживание |
NVIDIA GeForce GTX 1080 (1607/10008 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 Ti (1000/7012 МГц, 6 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
AMD Radeon R9 Fury X (1050/1000 МГц, 4 Гбайт) |
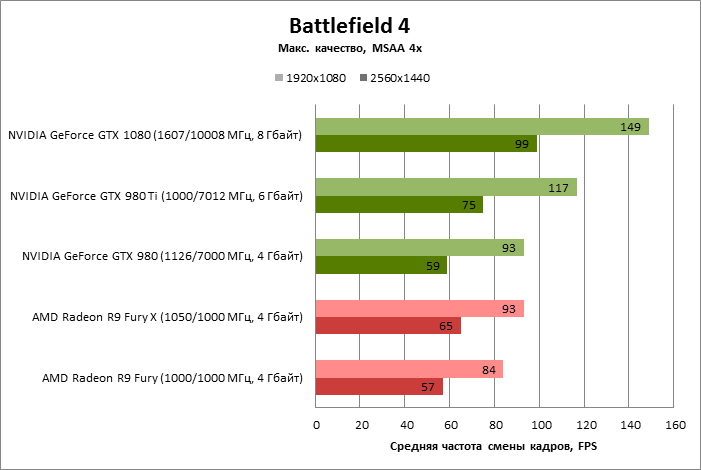
| Battlefield 4 |
MSAA 4x + FXAA |
149 |
93 |
117 |
84 |
93 |
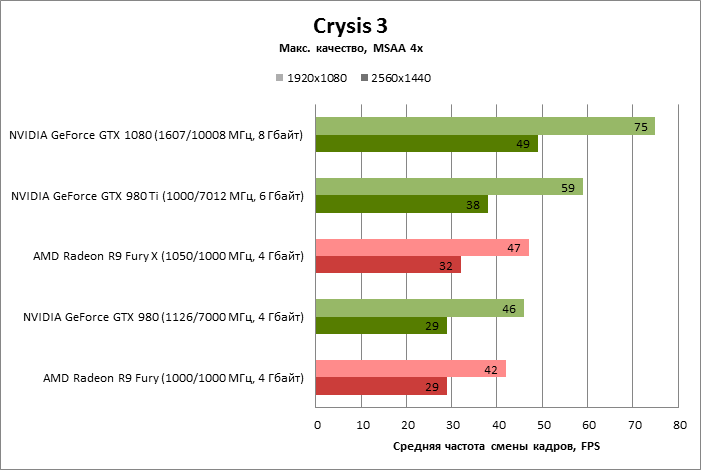
| Crysis 3 |
MSAA 4x |
75 |
46 |
59 |
42 |
47 |
| Far Cry Primal |
SMAA |
102 |
64 |
79 |
63 |
69 |
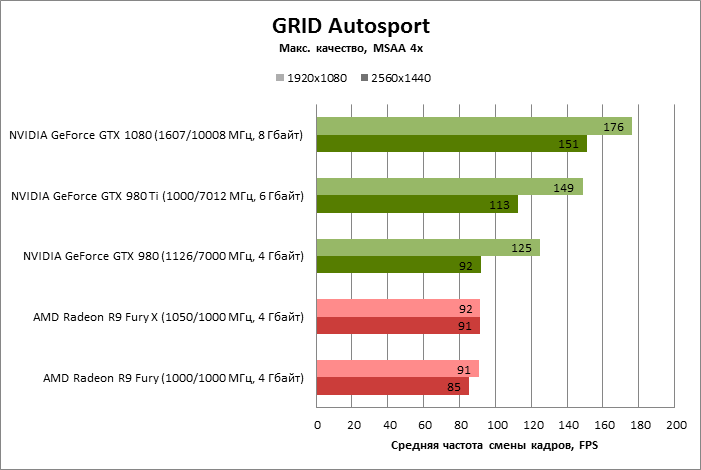
| GRID Autosport |
MSAA 4x |
176 |
125 |
149 |
91 |
92 |
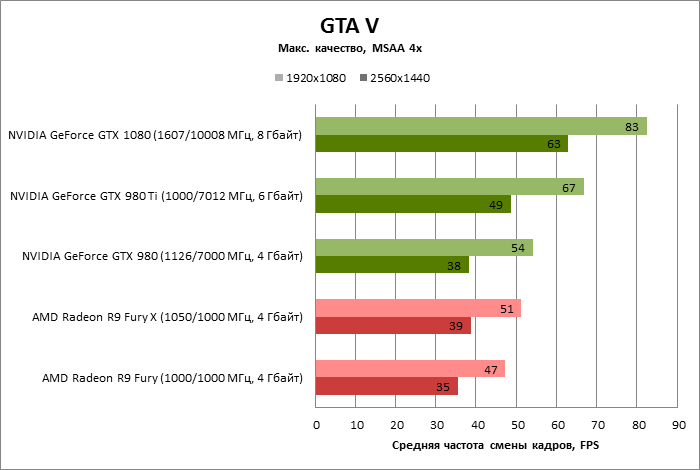
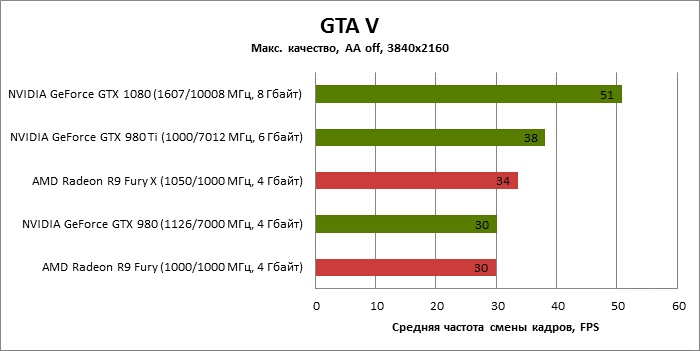
| GTA V |
MSAA 4x + FXAA |
83 |
54 |
67 |
47 |
51 |
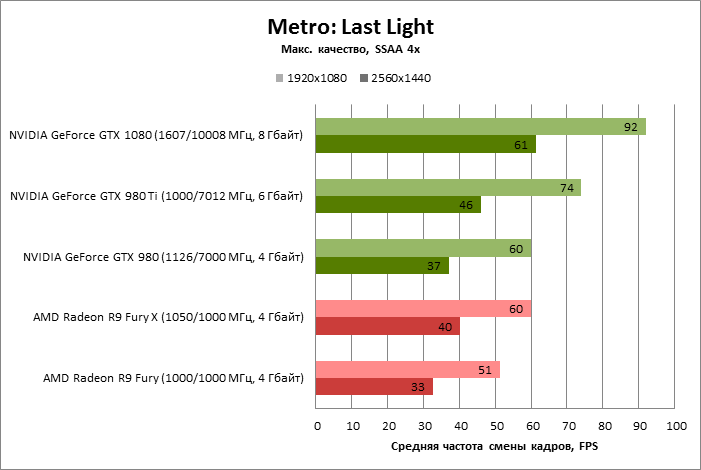
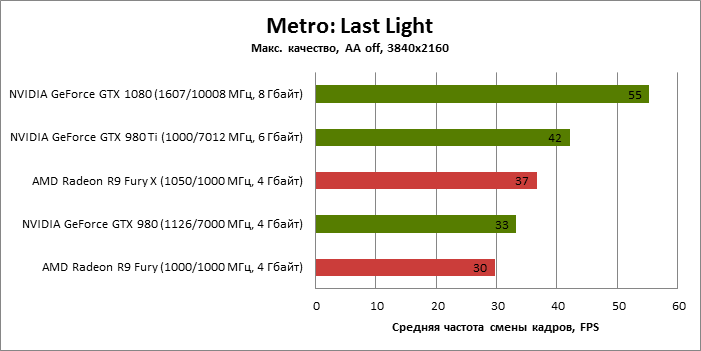
| Metro: Last Light |
SSAA 4x |
92 |
60 |
74 |
51 |
60 |
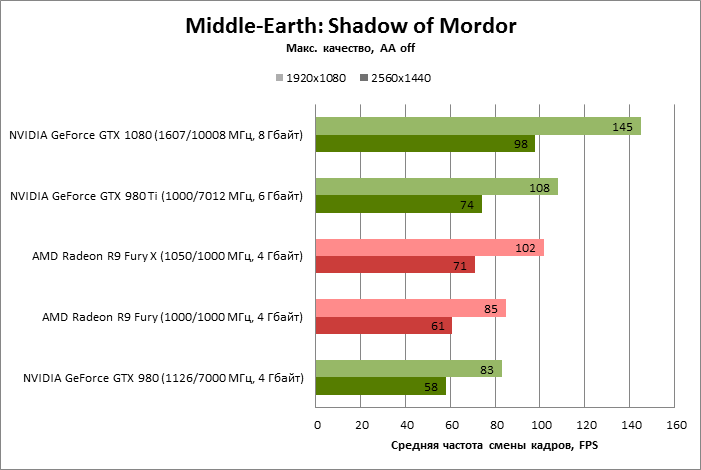
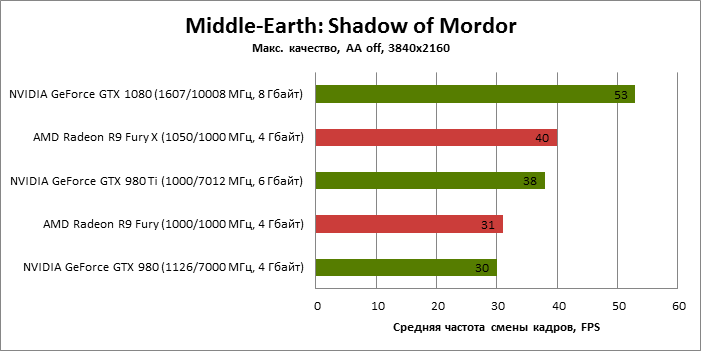
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
145 |
83 |
108 |
85 |
102 |
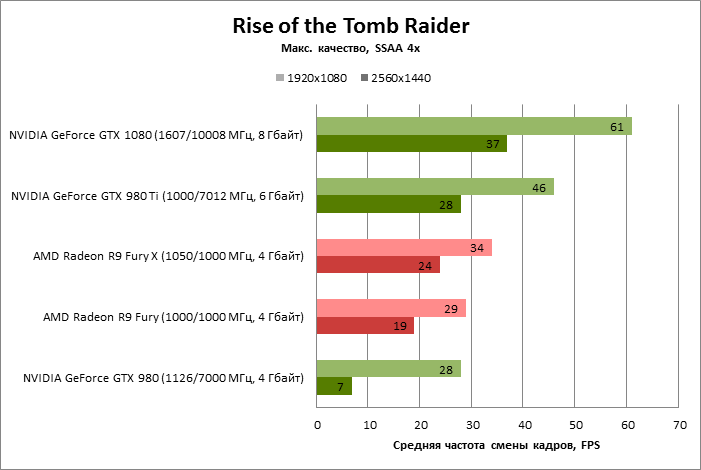
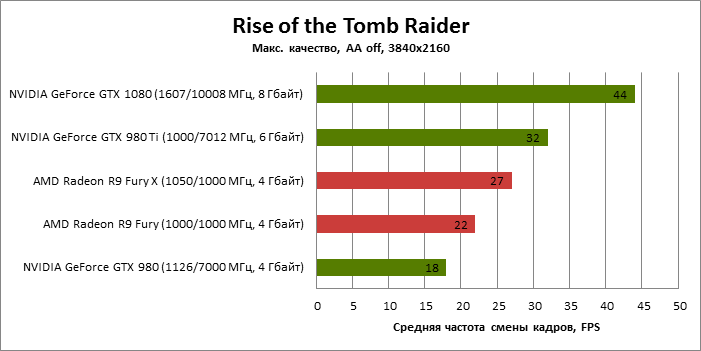
| Rise of the Tomb Raider |
SSAA 4x |
61 |
28 |
46 |
29 |
34 |
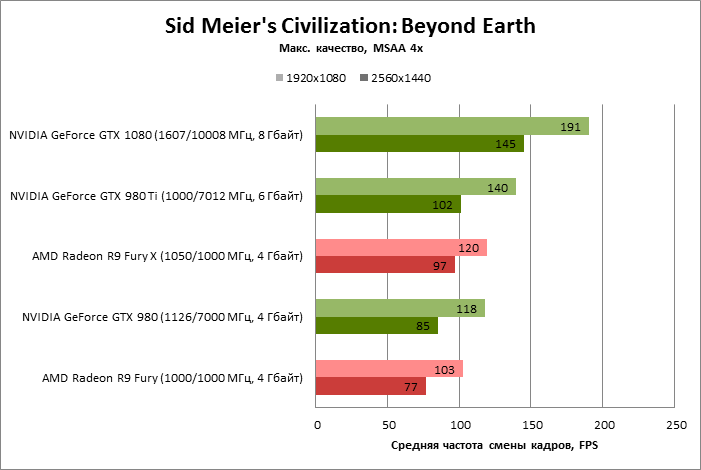
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
191 |
118 |
140 |
103 |
120 |
| Thief |
SSAA 4x + FXAA |
126 |
87 |
105 |
86 |
100 |
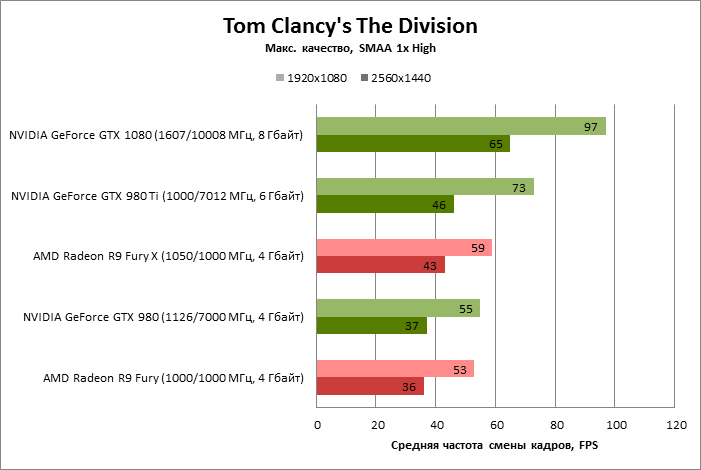
| Tom Clancy's The Division |
SMAA 1x High |
97 |
55 |
73 |
53 |
59 |
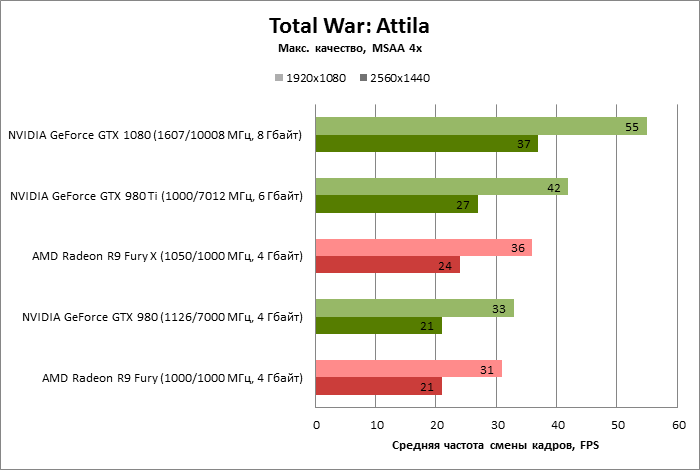
| Total War: Attila |
MSAA 4x |
55 |
33 |
42 |
31 |
36 |
|
|
|
|
Полноэкранное сглаживание |
NVIDIA GeForce GTX 1080 (1607/10008 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 Ti (1000/7012 МГц, 6 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
AMD Radeon R9 Fury X (1050/1000 МГц, 4 Гбайт) |
| Battlefield 4 |
MSAA 4x + FXAA |
100% |
62% |
79% |
56% |
62% |
| Crysis 3 |
MSAA 4x |
100% |
61% |
79% |
56% |
63% |
| Far Cry Primal |
SMAA |
100% |
63% |
77% |
62% |
68% |
| GRID Autosport |
MSAA 4x |
100% |
71% |
84% |
52% |
52% |
| GTA V |
MSAA 4x + FXAA |
100% |
66% |
81% |
57% |
62% |
| Metro: Last Light |
SSAA 4x |
100% |
65% |
80% |
56% |
65% |
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
100% |
57% |
74% |
59% |
70% |
| Rise of the Tomb Raider |
SSAA 4x |
100% |
46% |
75% |
48% |
56% |
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
100% |
62% |
73% |
54% |
63% |
| Thief |
SSAA 4x + FXAA |
100% |
69% |
84% |
69% |
79% |
| Tom Clancy's The Division |
SMAA 1x High |
100% |
57% |
75% |
55% |
61% |
| Total War: Attila |
MSAA 4x |
100% |
60% |
76% |
56% |
65% |
| Макс. |
|
|
71% |
84% |
69% |
79% |
| Среднее |
|
|
62% |
78% |
57% |
64% |
| Мин. |
|
|
46% |
73% |
48% |
52% |
| 2560x1440 (AA) |
|---|
|
Полноэкранное сглаживание |
NVIDIA GeForce GTX 1080 (1607/10008 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 Ti (1000/7012 МГц, 6 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
AMD Radeon R9 Fury X (1050/1000 МГц, 4 Гбайт) |
| Battlefield 4 |
MSAA 4x + FXAA |
99 |
59 |
75 |
57 |
65 |
| Crysis 3 |
MSAA 4x |
49 |
29 |
38 |
29 |
32 |
| Far Cry Primal |
SMAA |
74 |
45 |
55 |
48 |
54 |
| GRID Autosport |
MSAA 4x |
151 |
92 |
113 |
85 |
91 |
| GTA V |
MSAA 4x + FXAA |
63 |
38 |
49 |
35 |
39 |
| Metro: Last Light |
SSAA 4x |
61 |
37 |
46 |
33 |
40 |
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
98 |
58 |
74 |
61 |
71 |
| Rise of the Tomb Raider |
SSAA 4x |
37 |
7 |
28 |
19 |
24 |
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
145 |
85 |
102 |
77 |
97 |
| Thief |
SSAA 4x + FXAA |
95 |
58 |
72 |
61 |
73 |
| Tom Clancy's The Division |
SMAA 1x High |
65 |
37 |
46 |
36 |
43 |
| Total War: Attila |
MSAA 4x |
37 |
21 |
27 |
21 |
24 |
|
|
|
|
Полноэкранное сглаживание |
NVIDIA GeForce GTX 1080 (1607/10008 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 Ti (1000/7012 МГц, 6 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
AMD Radeon R9 Fury X (1050/1000 МГц, 4 Гбайт) |
| Battlefield 4 |
MSAA 4x + FXAA |
100% |
60% |
76% |
58% |
66% |
| Crysis 3 |
MSAA 4x |
100% |
59% |
78% |
59% |
65% |
| Far Cry Primal |
SMAA |
100% |
61% |
74% |
65% |
73% |
| GRID Autosport |
MSAA 4x |
100% |
61% |
74% |
56% |
60% |
| GTA V |
MSAA 4x + FXAA |
100% |
61% |
77% |
56% |
61% |
| Metro: Last Light |
SSAA 4x |
100% |
61% |
75% |
53% |
65% |
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
100% |
59% |
76% |
62% |
72% |
| Rise of the Tomb Raider |
SSAA 4x |
100% |
19% |
76% |
51% |
65% |
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
100% |
59% |
70% |
53% |
67% |
| Thief |
SSAA 4x + FXAA |
100% |
62% |
76% |
64% |
77% |
| Tom Clancy's The Division |
SMAA 1x High |
100% |
57% |
71% |
55% |
66% |
| Total War: Attila |
MSAA 4x |
100% |
57% |
73% |
57% |
65% |
| Макс. |
|
|
62% |
78% |
65% |
77% |
| Среднее |
|
|
56% |
75% |
58% |
67% |
| Мин. |
|
|
19% |
70% |
51% |
60% |

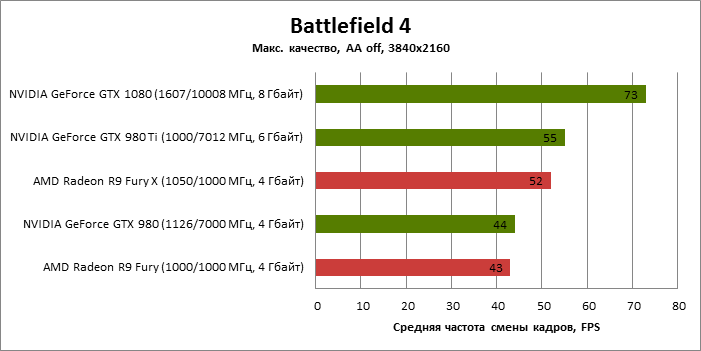
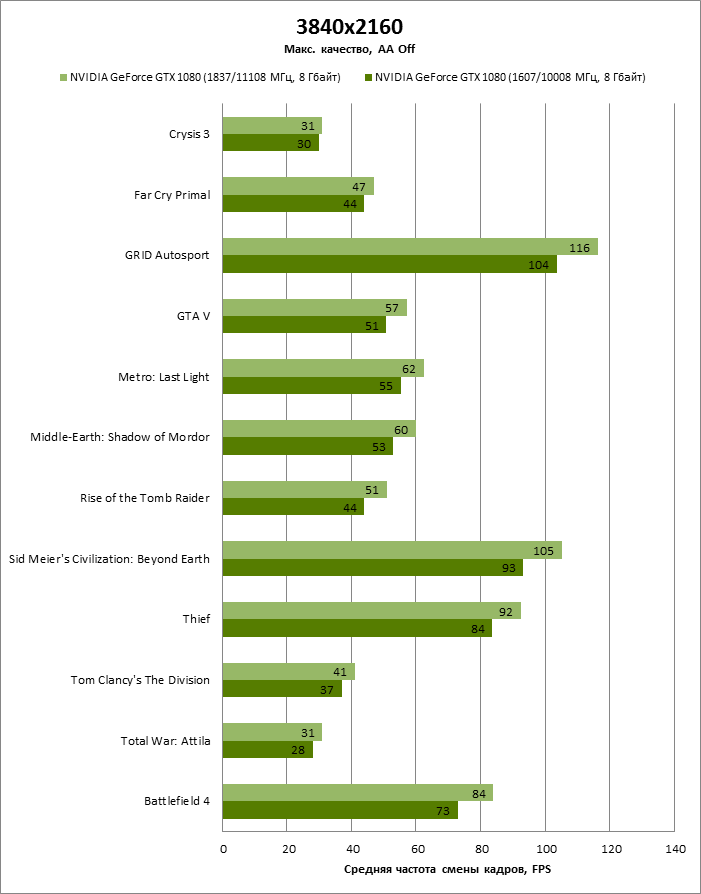
⇡#3840x2160
| 3840x2160 (AA Off) |
|---|
|
Полноэкранное сглаживание |
NVIDIA GeForce GTX 1080 (1607/10008 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 Ti (1000/7012 МГц, 6 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
AMD Radeon R9 Fury X (1050/1000 МГц, 4 Гбайт) |
| Battlefield 4 |
MSAA 4x + FXAA |
73 |
44 |
55 |
43 |
52 |
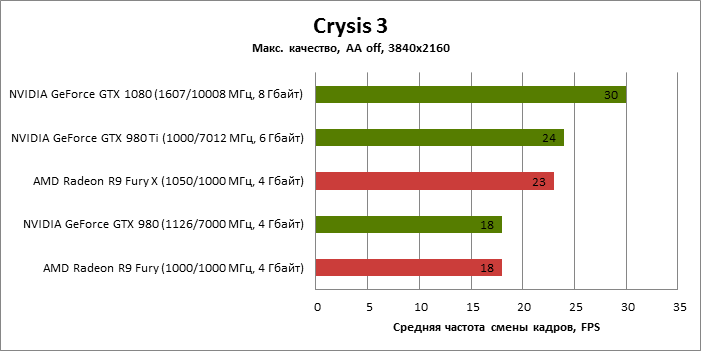
| Crysis 3 |
MSAA 4x |
30 |
18 |
24 |
18 |
23 |
| Far Cry Primal |
SMAA |
44 |
26 |
33 |
29 |
34 |
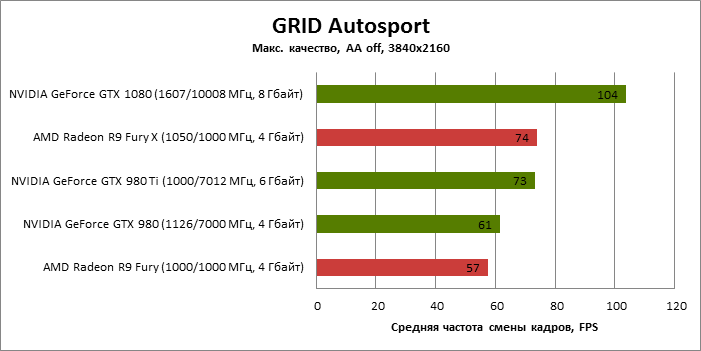
| GRID Autosport |
MSAA 4x |
104 |
61 |
73 |
57 |
74 |
| GTA V |
MSAA 4x + FXAA |
51 |
30 |
38 |
30 |
34 |
| Metro: Last Light |
SSAA 4x |
55 |
33 |
42 |
30 |
37 |
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
53 |
30 |
38 |
31 |
40 |
| Rise of the Tomb Raider |
SSAA 4x |
44 |
18 |
32 |
22 |
27 |
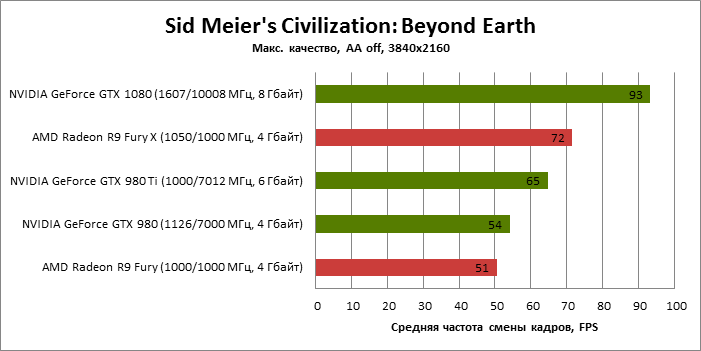
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
93 |
54 |
65 |
51 |
72 |
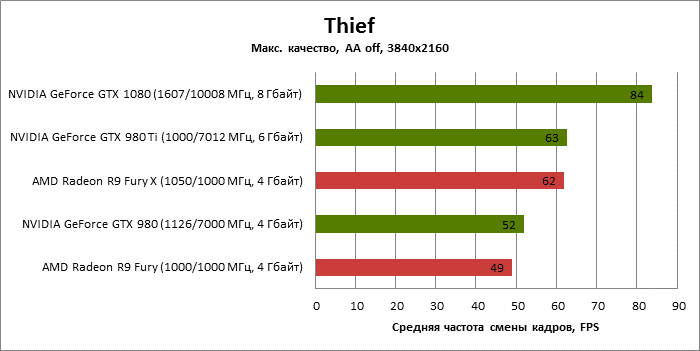
| Thief |
SSAA 4x + FXAA |
84 |
52 |
63 |
49 |
62 |
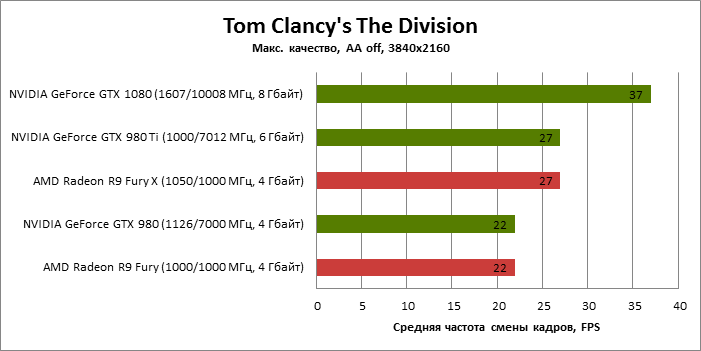
| Tom Clancy's The Division |
SMAA 1x High |
37 |
22 |
27 |
22 |
27 |
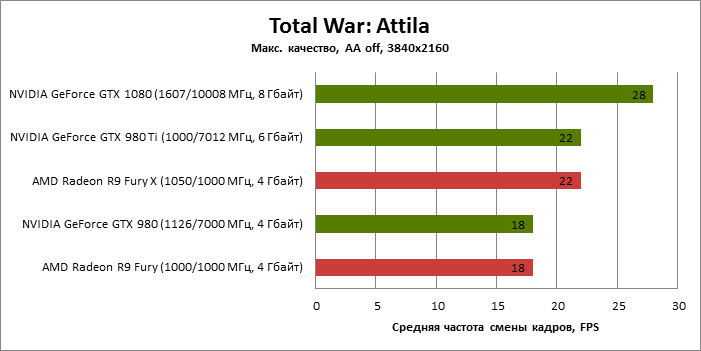
| Total War: Attila |
MSAA 4x |
28 |
18 |
22 |
18 |
22 |
|
|
|
|
Полноэкранное сглаживание |
NVIDIA GeForce GTX 1080 (1607/10008 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 Ti (1000/7012 МГц, 6 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
AMD Radeon R9 Fury X (1050/1000 МГц, 4 Гбайт) |
| Battlefield 4 |
MSAA 4x + FXAA |
100% |
60% |
75% |
59% |
71% |
| Crysis 3 |
MSAA 4x |
100% |
60% |
80% |
60% |
77% |
| Far Cry Primal |
SMAA |
100% |
59% |
75% |
66% |
77% |
| GRID Autosport |
MSAA 4x |
100% |
59% |
71% |
55% |
71% |
| GTA V |
MSAA 4x + FXAA |
100% |
59% |
75% |
59% |
66% |
| Metro: Last Light |
SSAA 4x |
100% |
60% |
76% |
54% |
66% |
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
100% |
57% |
72% |
58% |
75% |
| Rise of the Tomb Raider |
SSAA 4x |
100% |
41% |
73% |
50% |
61% |
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
100% |
58% |
69% |
54% |
77% |
| Thief |
SSAA 4x + FXAA |
100% |
62% |
75% |
58% |
74% |
| Tom Clancy's The Division |
SMAA 1x High |
100% |
59% |
73% |
59% |
73% |
| Total War: Attila |
MSAA 4x |
100% |
64% |
79% |
64% |
79% |
| Макс. |
|
|
64% |
80% |
66% |
79% |
| Среднее |
|
|
58% |
74% |
58% |
72% |
| Мин. |
|
|
41% |
69% |
50% |
61% |
⇡#Производительность: вычисления
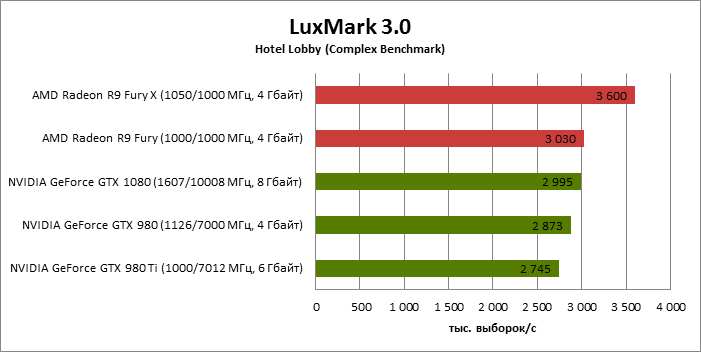
⇡#Luxmark 3.0: Hotel Lobby (Complex Benchmark)
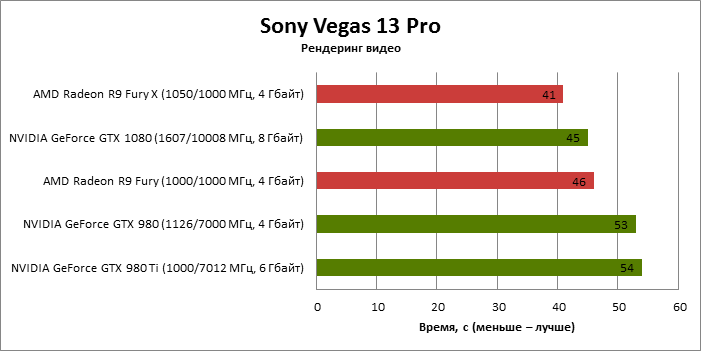
⇡#Sony Vegas Pro 13
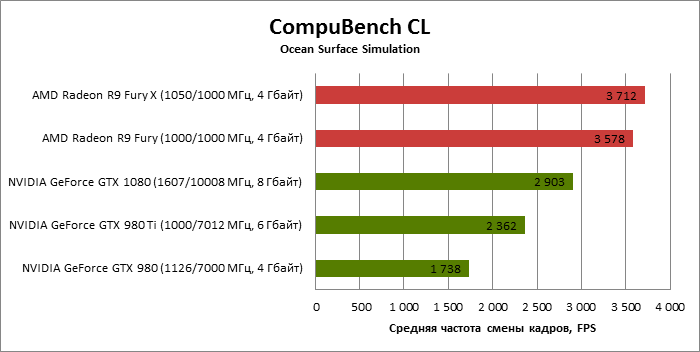
⇡#CompuBench CL: Ocean Surface Simulation
⇡#CompuBench CL: Particle Simulation
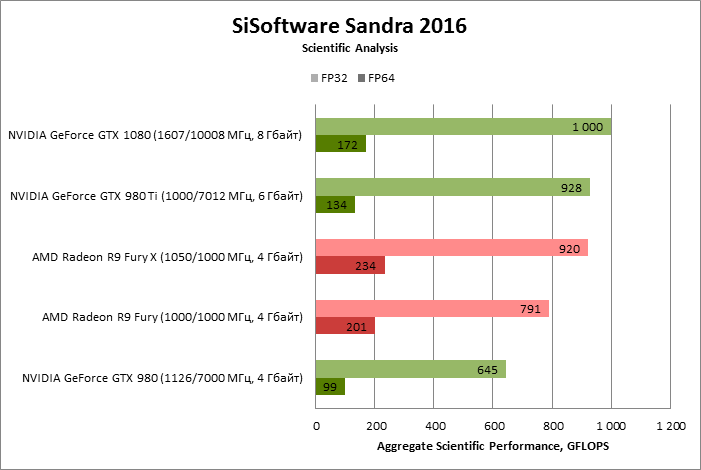
⇡#SiSoftware Sandra 2016: Scientific Analysis
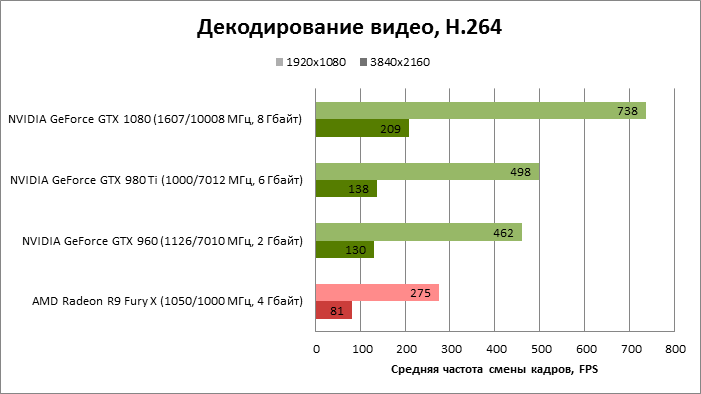
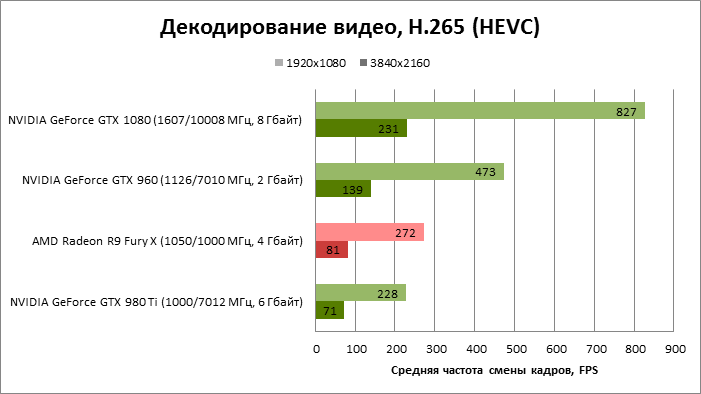
⇡#Декодирование видео (DXVA Checker, Decode Benchmark)
⇡#Тактовые частоты, энергопотребление, температура, разгон
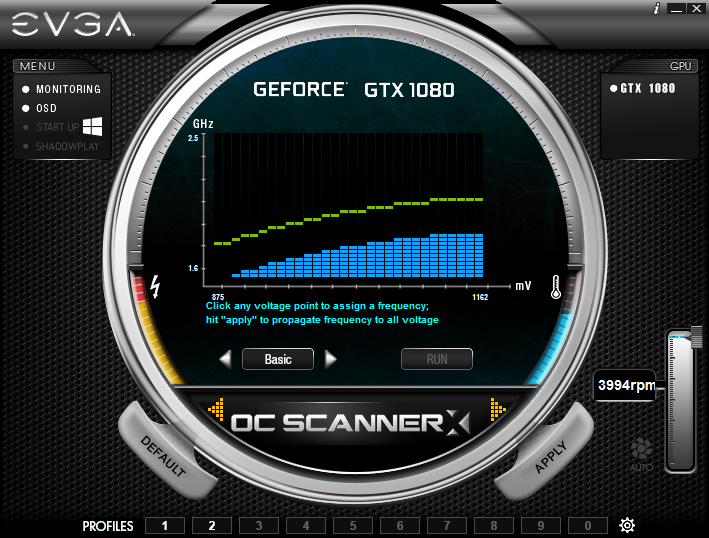
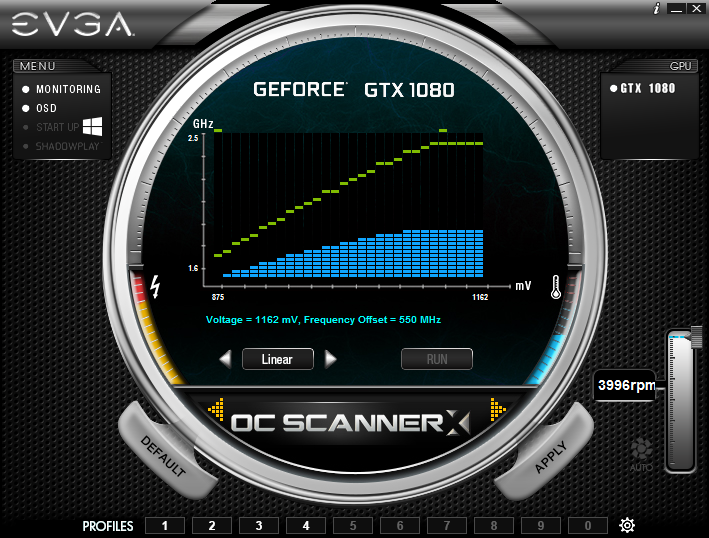
В Pascal обновилась до следующей, третьей, версии фирменная NVIDIA технология для управления частотой и разгона – GPU Boost. Здесь есть единственное лежащее на поверхности изменение: возможность вручную модифицировать кривую соотношения частоты и напряжения питания графического процессора. В специальной бета-версии утилиты EVGA PrecisionX доступны три варианта управления кривой.
Basic – простой сдвиг частот, соответствующих каждому напряжению (то же самое делает ползунок тактовой частоты GPU в любой аналогичной программе). Опция Linear позволяет установить зависимость между частотой и напряжением в виде линейной функции. С другой стороны, можно выбрать абсолютно произвольные значения для каждой пары значений частота/напряжение. Наконец, можно отправить систему в длительный процесс тестирования, и в результате оптимальная кривая для конкретного экземпляра видеокарты будет построена автоматически.
Для того, чтобы оценить оверклокерский потенциал нашего образца GeForce GTX 1080, мы воспользовались стандартными средствами из арсенала EVGA PrecisionX – предварительно повысили до предела ограничители температуры и мощности GPU (последний имеет запас вплоть до 120%), добавили напряжения с помощью соответсвтующего ползунка и запустили систему охлаждения на полную скорость.
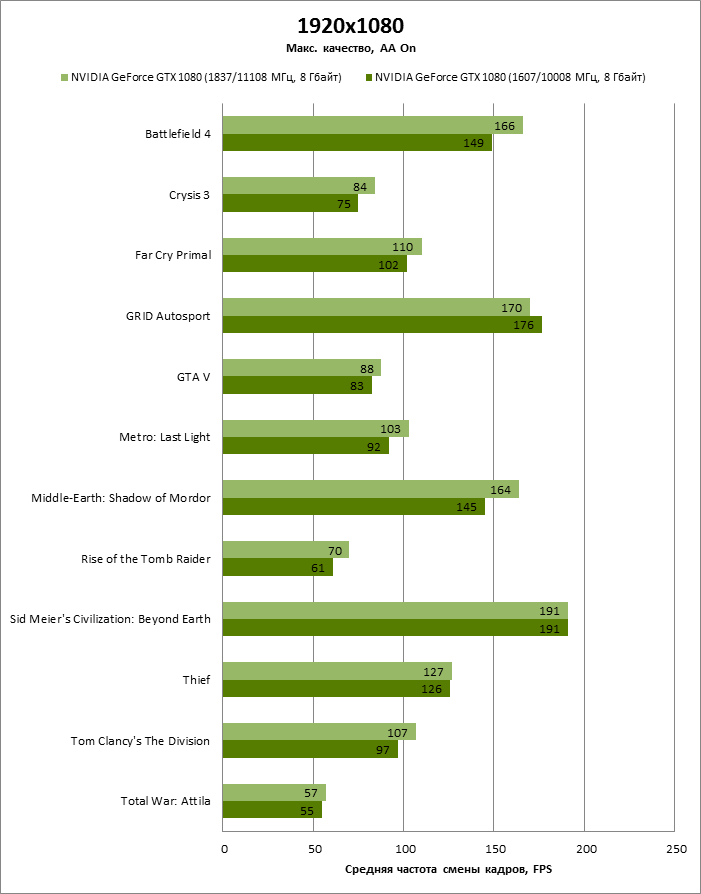
В штатном режиме напряжение на GP104 не превышает 1,05 В, а частота достигает 1860 МГц. Разгон позволил добавить 230 МГц к базовой часоте ядра, а предельные напряжение и частота увеличились до 1,093 и 2126 МГц соответственно. Эффективную частоту видеопамяти удалось поднять на 1,1 ГГц.
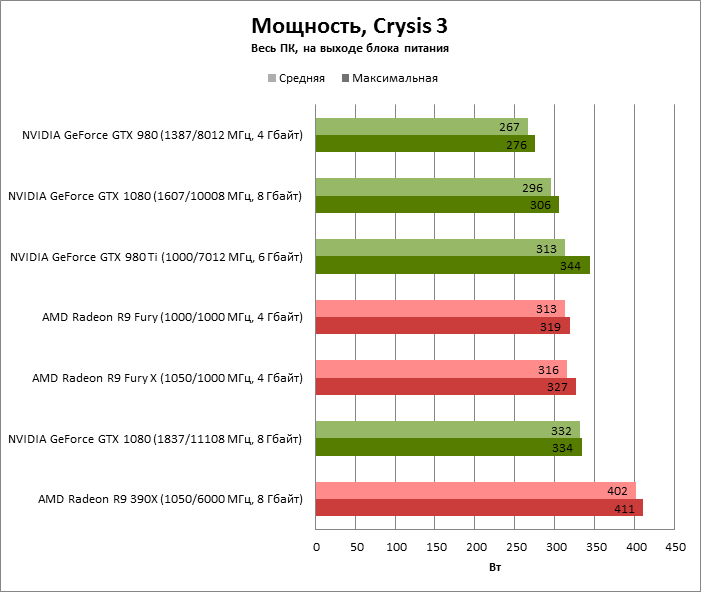
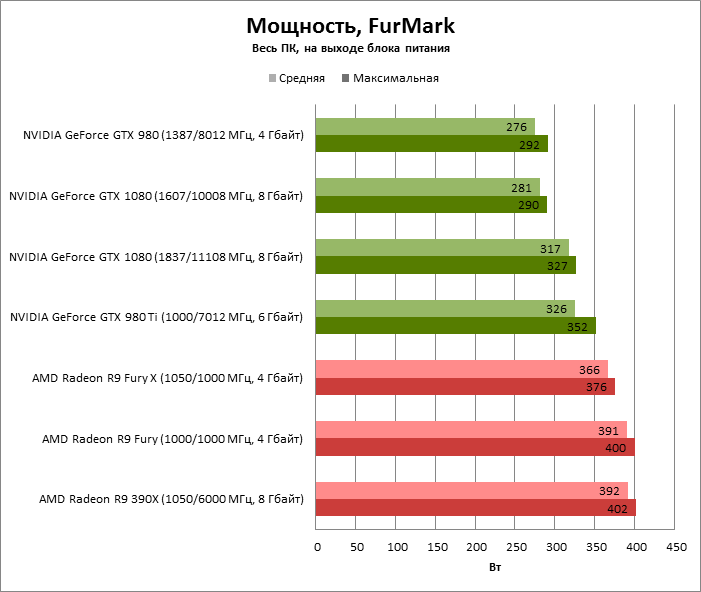
По среднему энергопотреблению в 3D-игре GeForce GTX 1080 лишь на 17 Вт отличается от GeForce GTX 980 Ti и братии видеокарт на базе GPU Fiji.
В FurMark 45 разница между бывшим и действующим флагманами NVIDIA оценивается уже в 45 Вт, а ускорители AMD уже не в состоянии скрыть свой аппетит, на фоне которого выгодно выделяется 16-нанометровый GPU.
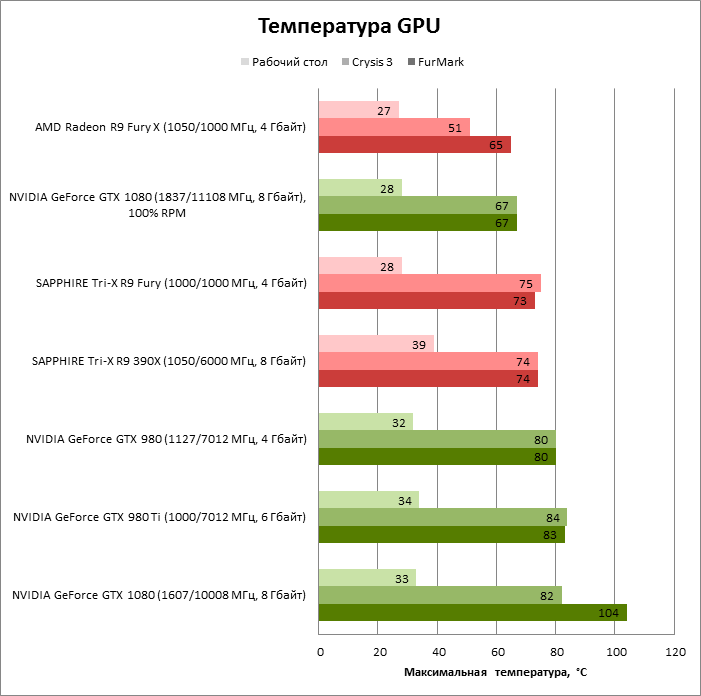
GPU Boost стремится поддерживать температуру GP104 в рамках 82 °С, что вполне соответствует целевой температуре чипов из предыдущего поколения.
⇡#Производительность: разгон
*В Middle-Earth: Shadow of Mordor полноэкранное сглаживание не поддерживается
*В Middle-Earth: Shadow of Mordor полноэкранное сглаживание не поддерживается
⇡#Выводы
От флагманского продукта на базе GPU новой архитектуры всегда ожидается, что он превзойдет рекорды, установленные предшественниками – как в линейке того же производителя, так и его конкурентов. Но в данном случае произошло намного более важное событие, ведь GeForce GTX 1080 представляет первый дискретный GPU на пользовательском рынке, произведенный по норме 16 нм – NVIDIA GP104. Более крупный процессор семейства Pascal – GP100 – обрел физическую форму раньше, и хотя начать производство сразу двух весьма крупных и изощренных GPU по новаторской технологии – само по себе серьезное достижение, пока еще продукты на GP100 очень далеки от широкого распространения вообще и от появления в игровых компьютерах в частности.
Вторая важнейшая особенность GeForce GTX 1080 состоит в поддержке GDDR5X. Пока микросхемы типа HBM остаются прерогативой GPU верхнего эшелона, память GDDR5X обеспечила пространство для развития более компактных процессоров с 256-битной и более узкими шинами памяти. Хотя NVIDIA сделала наиболее консервативный выбор в диапазоне частот, которую предлагает стандарт GDDR5X, GTX 1080 получил свое распоряжение пропускную способность, для которой ранее требовалась шина разрядностью 384 бит.
GP104 стал первым представителем архитектуры Pascal, с которым познакомится массовый пользователь, и в этом качестве GeForce GTX 1080 – чрезвычайно успешный запуск для NVIDIA. По сравнению с GeForce GTX 980 Ti новый флагман предлагает, в среднем, на 32% более высокую производительность в рамках совсем другого теплового пакета. Не менее впечатляет и частотный потенциал GPU: даже в штатном режиме GTX 1080 охватывает частоты свыше 1,8 ГГц, а 2 ГГц – вполне достижимая цель для оверклокинга при воздушном охлаждении.
В итоге, среди игровых видеоадаптеров GeForce GTX 1080 пока не знает себе равных. И, судя по тому, что нам известно о планах NVIDIA и AMD на данный момент, он будет наслаждаться этим положением еще по меньшей мере до конца текущего года. В вычислительных задачах картина не столь предсказуема, и позиции AMD по-прежнему сильны в нагрузке, которая хорошо ложится на архитектуру GCN. Кроме того, возможность выполнять расчеты двойной точности в Pascal столь же рудиментарна, как в Maxwell.
Что касается функциональных возможностей GTX 1080, то в архитектуре Pascal NVIDIA развила все сильные стороны своих предшествующих продуктов. Pascal обладает наиболее полной поддержкой функций рендеринга, представленных в DirectX 12. Видеокарта подготовлена к новой волне экранов с интферейсами DisplayPort 1.3/1.4 и расширенным динамическим диапазоном. Выделенный кодек форматов H.264/H.265 стал еще более мощным, чем в Maxwell. Отдельного внимания заслуживает тесная интеграция GPU со средой VR и мультимониторными системами, которую принес обновленный блок обработки геометрии в Pascal.
Фактически, новый флагман NVIDIA лишен каких-либо очевидных недостатков с точки зрения пользователя. Более того, если рассматривать запуск GeForce GTX 1080 ретроспективе, то это один из самых удачных продуктов, произведенных компанией из Санта-Клары за последние годы, установивший весьма высокую планку для любых будущих соперников и последователей.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex