С тех пор как Advanced Micro Devices и ATi превратились в одну компанию, у ценителей процессоров AMD и графических карт Radeon ни разу не было возможности собрать компьютер из комплектующих любимого производителя, не поступившись быстродействием в одном из ключевых аспектов — CPU или GPU. Два года тому назад AMD, вооруженная архитектурой Zen, совершила триумфальное возвращение на рынок центральных процессоров, но печальная примета вновь сбылась. Марка Radeon с тех пор и вплоть до настоящего момента переживает свои худшие времена. И началось это гораздо раньше — после Radeon R9 Fury X на чипе Fiji графическое подразделение AMD уже не смогло породить устройство, готовое наравне соревноваться с решениями NVIDIA за мантию самого производительного игрового GPU, да и в нижних ценовых эшелонах позиции «красных» слабеют год от года.

Но теперь, решив вопрос с центральными процессорами, AMD набралась сил для атаки на рынок дискретных графических карт. Сегодня мы представляем обзор ускорителей Radeon RX 5700 и Radeon RX 5700 XT, с помощью которых AMD намеревается потеснить NVIDIA из рыночной ниши, которую оккупировали младшие модели серии GeForce RTX — 2060 и 2070. Причем на этот раз главная ставка AMD сделана не на передовой техпроцесс 7 нм, по которому выпускают чип Navi, а на абсолютно новую логику RDNA, которая пришла на смену GCN — архитектуре с без малого восьмилетним стажем. RDNA должна решить проблемы, которые помешали чипам Polaris и Vega в полную силу выступить против конкурирующего кремния Pascal и Turing, а затем — если первый опыт будет удачным — она откроет дорогу ускорителям AMD к борьбе за титул абсолютного чемпиона.
Трудно удержаться от аналогий с архитектурой Zen, которой удалось за пару лет перевернуть рынок центральных процессоров, да и в истории ATi есть примеры революционных преобразований. И все-таки какие обстоятельства побудили разработчиков Radeon 5000-й серии отказаться от проверенной архитектуры GCN в пользу совершенно иного решения и что такого в RDNA, чтобы на рынке дискретных GPU опять возникла интенсивная конкуренция? Попробуем разобраться в этих вопросах, а затем приступим к долгожданным тестам Radeon RX 5700 и Radeon RX 5700 XT.
⇡#Новая архитектура RDNA
В первые годы GCN, которая дебютировала вместе с ускорителями Radeon HD 7970 еще в конце 2011 года, графические процессоры AMD, по большому счету, совершенно не уступали продуктам NVIDIA на чипах Kepler по энергоэффективности и быстродействию. Однако переход к архитектуре Maxwell, а затем Pascal позволил конкурентам AMD радикально нарастить производительность в 3D-рендеринге, оставаясь в границах прежнего резерва мощности. GCN тем не менее всегда держала паритет с чипами NVIDIA по массиву вычислительных блоков, однако колоссальный резерв теоретического быстродействия, которым отличаются продукты AMD, целиком раскрывается только в расчетах общего назначения — не удивительно, ведь GCN и была задумана как решение для задач GP-GPU в противовес предшествующей архитектуре TeraScale, ориентированной преимущественно на игры.
Для рынка дискретных видеокарт определяющее значение имеет показатель быстродействия на рубль, а не на ватт мощности, поэтому экономный кошелек нередко голосует именно за «красных». Тем не менее, коль скоро чипы GCN с определенного момента утратили возможность настолько эффективно транслировать терафлопсы расчетной производительности в быстродействие 3D-приложений, для того, чтобы поддерживать накал борьбы, видеокартам Radeon требуются более крупные чипы, чем те, которыми довольствуется NVIDIA. А в погоне за локальными победами в той или иной ценовой нише AMD раз за разом принуждала GPU работать на грани оптимальной зоны тактовых частот и питающего напряжения. В результате AMD уже давно не претендует на корону абсолютного быстродействия, да и в нижних категориях производительности NVIDIA было легче придать видеокарте такие характеристики, чтобы оправдать, как правило, более высокую розничную цену.

Благодаря архитектуре Turing NVIDIA совершила очередной скачок в энергоэффективности, и теперь стало совершенно ясно, что дальше AMD уже не может ехать по накатанным рельсам. Кроме того, архитектура GCN, несмотря на постоянные оптимизации и попытки консервативной переработки, которые происходили в каждом новом поколении кремния, не располагает такими новаторскими функциями, как аппаратное ускорение трассировки лучей и обработки данных методом машинного обучения. Однако AMD было не так-то просто отказаться от наследия GCN в пользу совершенно новой микроархитектуры. Свою роль сыграл и вероятный дефицит бюджета R&D в те годы, когда комапния работала едва ли не в убыток из-за плачевного положения дел на рынке центральных процессоров, и неудачное партнерство с полупроводниковым контрактором GlobalFoundries, который сперва аннулировал все планы по запуску линии 10 нм, а затем и вовсе прекратил работу над любыми новыми узлами после 14 нм FinFET.
Пространство для маневра наверняка ограничено и союзом с производителями консолей, для которых AMD разработала целую серию SoC с графическим ядром архитектуры GCN. NVIDIA по всем этим причинам чувствует себя более свободно и не стесняется проводить резкие изменения в архитектуре GPU. Неспроста ее то и дело обвиняют в том, что современные игры, рассчитанные на Direct3D 12 и Vulkan, из рук вон плохо работают на старых GPU архитектуры Kepler и Maxwell, — все дело в том, как сильно Pascal и Turing отличаются от прошлых итераций «зеленого» кремния.
Однако для ускорителей Radeon все-таки настал судьбоносный момент. Как утверждает AMD, над принципами архитектуры RDNA компания работала в течение восьми лет и последняя, в отличие от GCN, глубоко уходящей корнями в задачи GP-GPU, всецело сфокусирована на быстродействии 3D-приложений. Это еще совсем не значит, что RDNA не подходит для вычислений общего назначения, но место в этой нише по-прежнему будет занято существующими и, наверняка, грядущими продуктами на основе GCN. AMD последовала успешному примеру NVIDIA и отныне собирается поддерживать два отдельных направления архитектуры GPU — RDNA для игровых ускорителей и GCN для серверов и рабочих станций.
⇡#Легче и быстрее: Compute Unit графического процессора в GCN и RDNA
Для того чтобы понять фундаментальные различия между RDNA и GCN, сперва придется освежить в памяти основные принципы массивно-параллельных вычислительных процессоров, которыми являются GPU, и конкретику их реализации в чипах AMD, начиная с Tahiti — самого первого кристалла на основе GCN.
Львиную долю каждого современного GPU занимает массив шейдерных ALU. AMD называет их потоковыми процессорами, NVIDIA — ядрами CUDA, но, в сущности, и тот и другой блок выполняет одну функцию — арифметические операции над вещественными (с плавающей точкой) или целочисленными данными. Но сила GPU заключается в том, каким образом организована совместная работа шейдерных ALU. 3D-рендеринг и масса вычислительных задач иного рода подразумевает выполнение однотипных действий над массивом разных операндов, поэтому вычислительные блоки внутри чипа группируются так, чтобы одна инструкция могла занять в одно и то же время несколько ALU, а данные поступают на обработку в виде нескольких потоков (threads). Группа из 32 потоков в терминологии NVIDIA называется warp, GCN оперирует группами по 64 потока под названием wavefront. Соответственно, каждая инструкция warp’a или wavefront’а позволяет выполнить необходимую операцию над 32 или 64 операндами (последние мы будем далее называть рабочими единицами — work items).
Основным строительным блоком архитектуры GCN является Compute Unit (CU) — именно его, а вовсе не отдельные ALU можно считать аналогом ядра центральных процессоров, поскольку только CU целиком обладает способностью декодировать и отправлять инструкции на исполнение.
Compute Unit содержит 64 т. н. векторных ALU, разделенных на четыре блока SIMD (Single Instruction Multiple Data). И хотя wavefront’ы в архитектуре GCN состоят как раз из 64 потоков, каждый SIMD обрабатывает собственный wavefront параллельно с другими SIMD’ами, а поскольку в каждом SIMD’е есть всего лишь 16 ALU, для выполнения одной инструкции ему необходимо четыре такта — это ключевая черта архитектуры GCN, определяющая немало сильных и слабых сторон данной архитектуры. Другая важная особенность состоит в том, что векторный планировщик в CU всего один, и для того, чтобы загрузить все четыре SIMD работой, они получают собственные инструкции поочередно.
Для того чтобы запустить CU с нуля, требуется потратить четыре такта, а в течение трех первых часть ALU будет простаивать. Но у подобной логики есть и другой изъян. Все дело в том, что далеко не каждая инструкция требует полной загрузки 16 векторных ALU в течение четырех тактов. Wavefront’ам свойственно ветвиться, и в этот момент получается так, что часть рабочих единиц включает одну операцию, а часть — другую. SIMD должен проходить «ветки» в два приема, независимо от того, сколько векторных ALU при этом будет бездействовать. Кроме того, CU всегда требует не меньше четырех wavefront’ов для максимальной загрузки ALU — условие, которое по тем или иным причинам может кратковременно нарушаться.
Чтобы снизить влияние этих факторов и адаптировать GPU к операциям с меньшим количеством потоков, создатели архитектуры RDNA совершили переход от 64-поточных к 32-поточным wavefront’ам. CU теперь содержит два SIMD’a по 32 векторных ALU, и каждый SIMD снабжен отдельным планировщиком. CU архитектуры RDNA рассчитан на исполнение двух инструкций в течение одного такта, в то время как CU чипов GCN исполняет четыре инструкции в течение четырех тактов.
Заметим, что, поскольку wavefront в то же время стал в два раза уже, старая и новая архитектуры являются эквивалентными по терафлопсам на один CU — ни о каком удвоении пропускной способности тут речи не идет. Тем не менее RDNA действительно обязана проявить высокую эффективность в задачах с «легкопоточной» нагрузкой, и на этом все плюсы реорганизации CU далеко не заканчиваются. Так, благодаря отдельным планировщикам, обслуживающим собственные SIMD’ы, и одновременной отдаче двух инструкций каждый такт, RDNA характеризуется пониженной латентностью исполнения индивидуальных инструкций. И наконец, у RDNA есть еще одно, не столь очевидное достоинство. Как и в GCN, SIMD здесь не привязан к единственному wavefront’у — каждый раз, когда планировщик дает инструкцию на исполнение, она может быть выбрана из нескольких wavefront’ов (вплоть до 10 на каждый SIMD в GCN и 20 в RDNA). Но количество потоков, находящихся в рабочем пуле отдельно взятого CU, в результате уменьшилось с 2560 до 1280 — это значит, что в кешах теперь находятся менее разнородные данные и их объем используется более экономно.
Тем не менее темп исполнения одной инструкции в четыре такта, свойственный GCN, был изначально установлен не без веских оснований. Пока инструкция «бегает» на SIMD в течение четырех тактов, CU может дождаться получения данных, необходимых для следующей инструкции, — например, из оперативной памяти, обращение к которой происходит целую вечность по меркам внутренней логики GPU. Архитектура RDNA, напротив, пролетит через инструкции wavefront’а, пока не столкнется с необходимостью ожидания данных. Конечно, SIMD в этот момент может переключиться на один из 19 других wavefront’ов, но возможно и альтернативное решение проблемы. RDNA допускает работу со старым, 64-поточным форматом wavefront’а. В таком режиме инструкция широкого wavefront’а отдается на исполнение в два приема, и в период отработки за два такта латентность в ожидании отсутствующих данных эффективно маскируется.
Широкие и узкие wavefront’ы могут сосуществовать в пределах рабочего пула одного SIMD без необходимости в смене контекста, однако специфику выбора между тем или иным форматом — существуют ли в ISA архитектуры RDNA инструменты, определяющие ширину wavefront’а, или это является решением драйвера — AMD не раскрывает. Прим. от 09.08.2019: ширину wavefront'a определяет компилятор. Вычислительные шейдеры обычно компилируются в формате Wave32, пиксельные — Wave64. Как бы то ни было, устоявшиеся приложения GP-GPU, тщательно оптимизированные с расчетом на особенности GCN, равно как и игровые шейдеры, скомпилированные в машинном коде (Shader Intrinsics), наверняка нуждаются в ревизии, чтобы извлечь из RDNA максимально высокую эффективность.
Функция Rapid Packed Math, которая появилась в графических процессорах Vega, перекочевала и в RDNA. За счет нее чипы AMD могут выполнять операции над данными половинной точности (FP16 или INT16) с удвоенным темпом по сравнению с FP32 или INT32. На уровне Compute Unit'а принцип действия Rapid Packed Math таков, что два операнда FP16/INT16 объединяются в одной рабочей единице wavefront'a. Последний в таком случае эффективно увеличивается вдвое, но инструкция требует для исполнения такое же количество тактов: четыре в GCN и один в RDNA. GCN может задавать произвольный темп обработки данных двойной точности (FP64) в соответствии с предназначением конкретного чипа — от 1/2 до 1/16 по отношению к FP32. В большинстве потребительских видеокарт AMD пропускная способность FP64 равна 1/16, но есть примечательные исключения — такие, как ускорители на чипах Hawaii (Radeon R9 290/390 и Radeon R9 290/390X) и Radeon VII, у которых соотношение между FP64 и FP32 установлено на уровне 1/4. Сохранилась ли в RDNA такая гибкость, мы пока не знаем, но судя по предварительным тестам, конкретно Radeon RX 5700 и Radeon RX 5700 XT обрабатывают FP64 в темпе 1/16.
⇡#Скалярные ALU в GCN и RDNA
Помимо векторных SIMD, которые обслуживает собственный планировщик, в каждом Compute Unit’е графических процессоров AMD — как GCN, так и RDNA — существует двойной скалярный конвейер, который обслуживает собственная логика декодирования и отправки инструкций. Одна часть скалярного блока выполняет операции условного ветвления в коде шейдерных kernel'ов и некоторые типы синхронизации. Другая представляет собой полноценное целочисленное ALU, открывающее альтернативный путь исполнения для инструкции wavefront’а — на тот случай, когда все из 32 или 64 рабочих единиц содержат однородные данные, и можно смело заменить их единственной операцией вместо того, чтобы делать одну и ту же работу несколько десятков раз подряд.
В GCN скалярный блок может быть использован в течение каждого такта, но только одновременно с тем из четырех SIMD, к которому подошла очередь единого векторного планировщика. В RDNA скалярных блоков два, а поскольку четырехтактная ротация SIMD’ов ушла в прошлое, они способны принимать инструкцию на исполнение каждый такт, причем параллельно векторной инструкции соседнего SIMD’а, что дополнительно усиливает параллелизм в чипах AMD.
⇡#Блоки специального назначения (SFU)
Третий тип исполнительных блоков, который присутствует в Compute Unit’е GCN и RDNA, предназначен для т. н. операций специального назначения. Под этим термином скрываются тригонометрические функции, которые нередко используются при 3D-рендеринге. В рамках GCN блок SFU представляет собой отдельный SIMD, который состоит из четырех ALU, привязан к каждому из основных векторных SIMD’ов и служит в качестве резервного пути исполнения инструкции wavefront’а — для этого требуется 16 тактов, в течение которых векторный SIMD вынужден бездействовать.
В RDNA используется похожая организация SFU: с каждым из двух векторных SIMD ассоциирован SFU, в который входят 8 ALU. Таким образом, тригонометрические операции чип RDNA тоже исполняет в темпе 1/4 от стандартных векторных инструкций. Но есть одно ключевое отличие: из общих ресурсов векторный SIMD и SFU имеют только порт планировщика, а в остальном оперируют независимо друг от друга. Чтобы CU мог загрузить SFU, векторный SIMD должен пропустить лишь один такт, а в течение трех следующих, пока SFU отрабатывает свою инструкцию, SIMD готов принимать и исполнять инструкции в стандартном режиме. Вот еще один источник параллелизма и в конечном счете более высокой фактической производительности в пересчете на терафлопс, который сулит графическим процессорам AMD архитектура RDNA.
⇡#Переработанная структура кешей
Как мы уже писали выше, исполнение инструкций с темпом в один такт, на который рассчитана архитектура RDNA, делает ее уязвимой для задержек исполнения, вызванных ожиданием данных, а значит, чип Navi особенно требователен к организации стека памяти — от внутренних кешей Compute Unit’а до интерфейса оперативной памяти. Ведь даже чипы GCN, для которых характерна латентность исполнения инструкции в четыре такта (включая «Вегу» с чрезвычайно высокой ПСП, которую обеспечивает память HBM2), нуждаются в доступе к данным на коротком расстоянии и значительно выигрывают от разгона RAM. К счастью, создатели RDNA не обошли стороной этот момент и полностью преобразили структуру памяти графического процессора.

Преобразования не обошли стороной ни один уровень стека памяти графического процессора. Ближайшее хранилище к SIMD'ам — векторные регистры общего назначения (vGPR, Vector General Purpose Registers) — в RDNA увеличилось сразу в четыре раза: с 256 до 1024 регистров на один SIMD. В то же время и скалярных регистров стало 2560 вместо 800. Но это лишь первый пункт длинного списка усовершенствований.
Отдельные CU в составе GCN и RDNA сгруппированы по несколько штук и пользуются несколькими типами разделяемых ресурсов — таких как 32-килобайтный кеш инструкций и скалярный кеш объемом в 16 Кбайт. Однако если в чипах GCN эти хранилища были общими для четырех (а впоследствии трех) CU, то в RDNA группа связанных CU, называемая Workgroup Processor, уменьшена до двух участников, а конкуренция за общие ресурсы в результате ослабевает.
Хранилище LDS (Local Data Store), которое представляет собой наиболее быстрый тип памяти после регистров векторных SIMD, теперь тоже стало общим для двух CU и увеличилось в объеме в два раза — с 64 до 128 Кбайт. Кроме того, количество потоков на отдельно взятый CU при работе с 32-поточными wavefront’ами в RDNA вдвое меньше, чем в GCN, а значит меньше конкуренция и за пространство LDS: GCN запускает вплоть до 10 wavefront'ов на один SIMD, а RDNA — вплоть до 20, но SIMD'ов стало два вместо четырех, и общее количество потоков изменилось с 2560 на 1280. 64-килобайтное хранилище GDS (Global Data Share), к которому имеют доступ wavefront'ы шейдерного kernel'а, работающие на любых CU графического процессора, сохранило прежний объем в 64 Кбайт.
Не менее грандиозные изменения произошли на следующих уровнях стека памяти RDNA: 16-килобайтный кеш L1 в пределах отдельно взятого CU теперь считается кешем нулевого уровня, а попутно инженеры AMD увеличили его ассоциативность с 4 до 32 каналов (а это, в свою очередь, значительно влияет на процент попаданий в кеш) и нарастили вдвое пропускную способность дороги к векторным ALU. Место старого L1 в иерархии памяти RDNA теперь занимает громадный 128-килобайтный кеш, доступный десяти Compute Unit’ам, с 16-канальной ассоциативностью. Он должен снять значительную часть нагрузки с кеша L2, ведь последний обошелся без значительных изменений после предыдущей итерации в чипах Vega: при 16-канальной ассоциативности и объеме в 4 Мбайт кеш L2 чипа Navi связан, с одной стороны, с каждой секцией L1, а с другой — посредством шины Infinity Fabric — с контроллерами RAM и uncore-компонентами SoC (блоками DMA для коммуникации между дискретными GPU, кодеком видеопотока и т. д.).
И наконец, в дополнение к очередной оптимизации алгоритмов компрессии цвета, RDNA допускает передачу сжатых данных по тем участкам конвейера рендеринга, где в GCN было разрешено только движение «сырых» данных. Шейдерные программы могут считывать и записывать компрессированный цвет не только в RAM, но и в кеш-память L1 и L2 (шейдерам в Polaris и Vega было позволено только чтение). Также возможна передача сжатого цвета из L2 в контроллер дисплея.
⇡#GCN vs RDNA vs Turing
Дополнение 18.07.2019
Чип Navi стал кульминацией крупнейших преобразований, которые AMD когда-либо совершала в логике своих графических процессоров после перехода от принципов VLIW к скалярной архитектуре Graphics Core Next почти восемь лет тому назад. RDNA акцентировала достоинства GCN и устранила ее главные недостатки. Однако для того, чтобы оценить RDNA по достоинству, нельзя обойтись без сравнения с тем, чего достиг за это время второй дуополист рынка дискретных GPU. Но перед тем как сделать свои выводы, мы направили AMD массу вопросов о подробностях работы RDNA, которым нет ответа в скудной документации Navi, да и про GCN еще не все известно с исчерпывающей точностью. К сожалению, AMD оказалась не настолько открытой к сотрудничеству с прессой, как того хотелось бы, и в итоге мы решили опубликовать сравнение RDNA с Turing исходя из той неполной информации, которой уже располагаем. Без подтверждения от AMD наши выкладки не застрахованы от ошибок, но в отдельных аспектах архитектуры, которые заставляют нас сомневаться (таких, например, как параллельная отправка инструкций на скалярные и векторные ALU), мы опираемся на вполне обоснованные гипотезы. NVIDIA, с другой стороны, помогла разобраться в том, как работают ее графические процессоры, и за анализ Turing мы полностью ручаемся.
Глубокая ревизия, которой AMD подвергла свою графическую архитектуру, изрядно похожа на то, что сделала NVIDIA в чипах Maxwell (а затем продолжила в Turing), изменив соотношение между исполнительной и управляющей логикой и сократив набор ALU, подчиненных каждому планировщику. Ключевая особенность GCN — исполнение wavefront’a из 64 рабочих единиц за 4 такта — ушла в прошлое, и в целом графический процессор теперь настроен на то, чтобы извлекать параллелизм из легкопоточной нагрузки, нежели большого количества wavefront’ов, которые необходимы GCN для эффективной работы. Однако если сравнивать Navi именно с Turing, то NVIDIA по-прежнему располагает во многих отношениях более сильной и гибкой архитектурой. О принципах работы чипов Turing и особенностях, которые отличают новые графические процессоры NVIDIA от предыдущих итераций — Maxwell и Pascal — мы уже подробно написали в первой части нашего обзора GeForce RTX 2080 Ti, но сейчас не помешает краткое резюме. К тому же, с тех пор нам стали известны некоторые подробности о Turing, которые поначалу не были освещены настолько хорошо.
Аналогом Compute Unit’а в чипах NVIDIA является SM — потоковый мультипроцессор (Streaming Multiprocessor). Начиная с Maxwell, инженеры NVIDIA делят SM на четыре секции с различным числом вычислительных блоков внутри (в зависимости от конкретной реализации в том или ином GPU) и пришли к тому, что в Turing секция SM содержит 16 шейдерных ALU (CUDA-ядер). Последние, по большому счету, выполняют ту же функцию, что один SIMD из 16 ALU в GCN, однако это лишь поверхностное сходство.
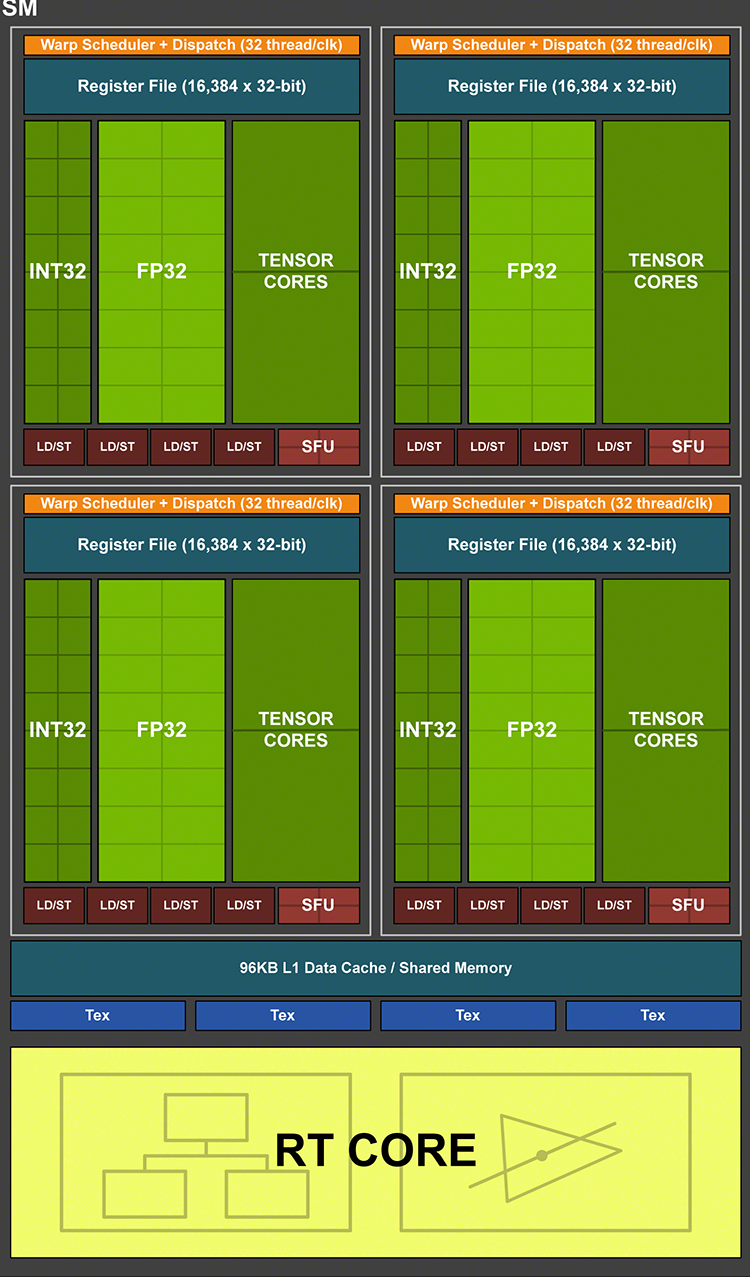
Потоковый мультипроцессор архитектуры Turing
В процессорах Volta и Turing отделили пути данных для операций над целыми числами внутри CUDA-ядер от арифметики с плавающей запятой — таким образом количество независимых ALU внутри SM эффективно удвоилось. Работа планировщиков и выдача инструкций у NVIDIA тоже организована совершенно по-другому. В каждой секции SM находится собственный планировщик, который за такт отправляет на исполнение одну инструкцию warp’a — группы из 32 потоков. Блоку 16 шейдерных ALU нужно два такта, чтобы ее выполнить, а во втором такте планировщик остается свободен. Нечетные такты планировщика могут быть заняты отправкой инструкций — обязательно из другого warp’а — на 16 целочисленных ALU (или другие типы исполнительных блоков, которые мы пока не упоминали), поэтому теоретическая пропускная способность Turing при полной загрузке целочисленными расчетами и операциями с плавающей точкой также увеличивается в два раза по сравнению с исключительно дробной или исключительно целочисленной арифметикой.
Помимо FP- и INT-ALU в каждой секции SM есть блок из четырех ALU специального назначения (SFU), предназначенных для выполнения тригонометрических операций. Одну инструкцию warp’а SFU выполняет за восемь тактов, но занимает только один такт планировщика для инициализации. В наборе инструкций процессоров Turing появились скалярные операции, а значит — есть и скалярные ALU, но их количество и специфику получения инструкций NVIDIA предпочитает держать в секрете.
Среди других исполнительных блоков секции SM есть два тензорных ядра, которые рассчитаны на единственный тип операций — FMA (Fused Multiply Add), — а в качестве операндов принимают матрицы чисел с плавающей запятой. Подобные вычисления используются при обработке данных нейросетями (inference) — как в фирменном алгоритме масштабирования DLSS. Но за пределами машинного обучения у тензорных блоков есть еще одно применение — на них Turing выполняет операции с вещественными числами половинной точности (FP16). В младших чипах Turing — TU116 и TU117 — заменой тензорных ядер является блок из 32 специализированных ALU, однако и в том, и в другом случае результат один: инструкция warp’а над операндами FP16 выполняется за один такт — вдвое быстрее операций стандартной точности.
Общими компонентами SM за пределами четырех секций являются четыре TMU (блока фильтрации текстур) и один блок трассировки лучей. Пара CUDA-ядер для операций двойной разрядности (FP64) присутствуют в Turing для совместимости с кодом, содержащим высокоточные расчеты.
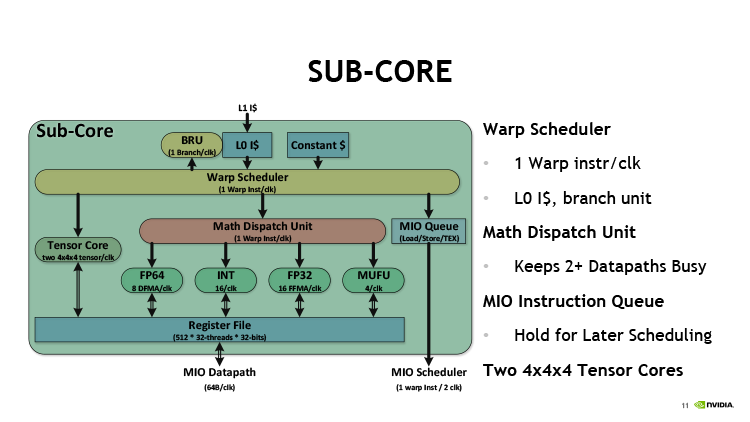
Секция SM архитектуры Volta
Таким образом, секция SM способна оперировать четырьмя типами инструкций — арифметика с вещественными числами одинарной точности (на CUDA-ядрах FP32), с целыми (INT32), с вещественными половинной точности (FP16) и тригонометрические операции (SFU). Однако конкуренция исполнительных блоков за такты планировщика позволяет параллельно загрузить только три типа исполнительных блоков из четырех: благодаря тому, что FP32- и INT32-инструкции бегают на своих ALU по два такта, а SFU — по восемь, возможны различные комбинации между ними. Кроме того, клиентами планировщиков являются еще и блок ветвлений, а также группа блоков load/store. Чтобы задействовать какой-либо из них, в этот такт планировщик не может отдать инструкцию для исполнения на шейдерных ALU. Кстати, архитектура GCN обходит последнее ограничение за счет большого числа портов планировщика (за такт он может отдать вплоть до пяти инструкций различного типа) — запросы к памяти и ветвление выполняются параллельно с выдачей инструкций векторным и скалярным ALU.
Расчеты пропускной способности, которую развивает SM графических процессоров Turing, приведены в таблице для сравнения с GCN и RDNA. Заметим, что мы не пытались охватить абсолютно все сочетания инструкций, которые возможны в рассмотренных архитектурах, а выкладки для GCN и RDNA основаны на предположении, что скалярные блоки действительно обладают отдельным планировщиком и могут получать инструкции параллельно векторным SIMD’ам. Пропуск тактов ALU, который в чипах NVIDIA могут вызывать операции load/store, тоже не берется во внимание. Все, что нам было нужно, это оценить пиковое быстродействие при работе с тем или иным форматом данных: FP32, INT32, FP16, а также тригонометрические операции. А с учетом темпа исполнения медленных инструкций мы взяли за временной интервал пропускной способности восемь тактов GPU — таким образом в таблице остается меньше дробных чисел.
| Compute Unit (GCN 5 поколения) | Compute Unit (RDNA) | Streaming Multiprocessor (Turing) |
|---|
| Исполнительные блоки |
4 × векторных SIMD16;
4 × векторных SIMD4 SFU;
1 × скалярное ALU;
4 × TMU (блока фильтрации текстур).
|
2 × векторных SIMD32;
2 × векторных SIMD8 (SFU);
2 × скалярных ALU;
4 × TMU (блока фильтрации текстур).
|
4 × секции 16 ALU (FP32);
4 × секции 16 ALU (INT32);
4 × секции 4 SFU;
? × скалярных ALU;
4 × секции 2 тензорных ядрер (или 4 × секции 32 FP16 ALU);
2 × ALU (FP64);
1 × RT-ядро; 4 × TMU (блока фильтрации текстур).
|
| Пропускная способность, инструкций за 8 тактов |
8 × FP32 (64 раб. ед.) +
8 × скалярных
ИЛИ
8 × FP16 (2 × 64 раб. ед.)
+ 8 × скалярных
ИЛИ
4 × 1/2 SF FP32 (64 раб. ед.)
+ 8 × скалярных
|
16 × FP32 (32 раб. ед.) +
16 × скалярных
ИЛИ
16 × FP16 (2 × 32 раб. ед.) +
16 × скалярных
ИЛИ
12 × FP32 (32 раб. ед.) +
4 × SF FP32 (32 раб. ед.) +
16 × скалярных
|
16 × FP32 (32 раб. ед.) +
16 × INT32 (32 раб. ед.)
ИЛИ
32 × FP16 (32 раб. ед.)
ИЛИ
4 × (3 + 1/2) FP32 (32 раб. ед.) +
4 × (3 + 1/2) INT32 (32 раб. ед.) +
4 × SF FP32 (32 раб. ед.)
|
|
8 × FP32 (64 раб. ед.) +
16 × скалярных
ИЛИ
8 × FP16 (2 × 64 раб. ед.) +
16 × скалярных
ИЛИ
6 × FP32 (64 раб. ед.) +
2 × SF FP32 (64 раб. ед.) +
16 × скалярных
|
| Пропускная способность, операций за 8 тактов |
512 × FP32/INT32 +
8 скалярных
ИЛИ
1024 × FP16/INT16 +
8 скалярных
ИЛИ
128 × SF FP32 +
8 скалярных
|
512 × FP32/INT32 +
16 скалярных
ИЛИ
1024 × FP16/INT16 +
16 скалярных
ИЛИ
384 × FP32/INT32 +
128 × SF FP32 +
16 × скалярных
|
512 × FP32 +
512 × INT32
ИЛИ
1024 × FP16
ИЛИ
448 × FP32 +
448 × INT32 +
128 × SF FP32
|
Так что же получилось в итоге? RDNA, да и GCN тоже, совершенно не уступает Turing по расчетному быстродействию в операциях FP32/INT32, FP16/INT16 или SFU, когда графический процессор больше ничем не занимается. Кроме того, тригонометрические операции SFU в RDNA теперь не заставляют отдыхать векторные SIMD’ы, хотя их присутствие в шейдерном коде все-таки сильнее бьет по общей пропускной способности, чем в Turing. Ключевое различие между современными архитектурами AMD и NVIDIA на уровне темпа исполнения инструкций — это параллельные операции над целыми и вещественными числами, которые возможны на полной скорости в Turing, но не в GCN и RDNA. Для шейдерного кода современных игр это совсем немаловажный фактор и одна из причин, наряду с RT-ядрами, которые позволяют чипам NVIDIA эффективно выполнять трассировку лучей в реальном времени.
Впрочем, за пределами столь ресурсоемких и специфических задач, как Ray Tracing, достойным соперником RDNA после многолетнего отставания в игровой сфере можно считать и предыдущую архитектуру NVIDIA — Pascal, — которая не обладает возможностью удвоить быстродействие за счет параллельной работы целочисленных и вещественно-численных ALU. Как мы уже не раз отметили, решающее значение имеют не терафлопсы, а способность GPU эффективно распоряжаться своими вычислительными ресурсами — в этом вопросе критерием истины будет практика.
⇡#Графический процессор Navi 10
Наиболее крупной структурой в организации компонентов чипа Navi является Shader Engine. В составе Navi 10 их два — каждый содержит по 20 CU и массив конвейеров растеризации (ROP). Таким образом, полнофункциональная версия Navi 10 включает 2560 шейдерных ALU и 160 блоков фильтрации текстур. Среди чипов прошлого поколения можно безошибочно назвать аналог подобной конфигурации — это старший чип семейства Polaris. Только Polaris, несмотря на две ревизии после его дебюта в составе Radeon RX 480, все-таки не дорос до 40 CU.
Однако между Polaris и Navi можно обнаружить существенные различия, выходящие за пределы внутренней организации Compute Unit’ов, которую мы обсуждали до сих пор, — начиная с того, что Navi досталось вдвое больше ROP: 64 вместо 32. Это совершенно необходимое изменение back-end’a GPU в свете того, что от RDNA ожидается повышенная эффективность в 3D-рендеринге, — считается, что Polaris избегал «пузырей», возникающих при ожидании отработки ROP, попросту за счет общего недостатка эффективной загрузки шейдерных ALU.
Впечатляющий пиксельный филлрейт, который развивают 64 конвейера растеризации, сочетается с поддержкой оперативной памяти типа GDDR6. Navi 10, как и старший Polaris, обходится 256-битной шиной RAM, но высокая пропускная способность GDDR6 (14 Гбит/с на контакт) гарантирует необходимую более эффективной архитектуре скорость доступа к данным. Полная ревизия стека памяти, которую провели инженеры AMD в чипе Navi, заканчивается поддержкой удаленных коммуникаций по шине PCI Express четвертого поколения. Впрочем, увидеть PCI Express 4.0 в деле на первых порах позволит только собственная платформа AMD с процессорами Ryzen 3000-й серии, а Navi 10 в любом случае не сможет загрузить настолько быстрый канал связи с CPU.

Front-end графического конвейера представлен блоками обработки геометрических примитивов. Создатели Navi изменили его топологию таким образом, что часть стадий геометрической логики, включая растеризатор, осталась в пределах Shader Array или, как раньше называли этот блок, Compute Engine (познакомьтесь еще с одним термином архитектуры чипов AMD) — структуры, объединяющей половину всего содержимого Shader Engine. А общий геометрический процессор вынесен за пределы Shader Array, поближе к командным процессорам ACE (Asynchronous Compute Engine), распределяющим потоки шейдерных вычислений между Compute Unit’ами. Всего Navi 10 может получить вплоть до четырех геометрических примитивов, прошедших стадию фильтрации невидимых поверхностей за такт — как Vega. Однако напомним, что в составе полностью функционального чипа Vega на 60 % больше шейдерных ALU и блоков фильтрации текстур, так что пропорция между мощностью геометрического front-end’a и основных ресурсов, обеспечивающих текстурирование и работу шейдерных kernel’ов, в Navi явно более выгодная.
Каким образом AMD поступила с альтернативным конвейером NGG (Next Generation Geometry), мы не можем сказать с полной уверенностью. Vega за счет NGG умеет отсекать невидимые треугольники на ранних стадиях рендеринга и может принять до семнадцати примитивов за такт, чтобы отдать на растеризацию четыре. Условием для этого являются Primitive Shaders — высокоэффективные программы, заменяющие ряд операций в конвейере стандартных графических API (доменные и геометрические шейдеры). Поначалу AMD собиралась активировать примитивные шейдеры на уровне компилятора, но затем по невыясненным причинам отказалась от этой идеи. Ни в игровых движках, ни в виде расширений API прямая поддержка NGG так и не появилась спустя без малого два года жизни Vega на рынке игровых ускорителей. Однако слайды, посвященные RDNA, говорят, что Navi тоже способна отсекать невидимые полигоны «с помощью шейдеров»: восемь на входе и четыре на выходе. Согласно неофициальным, но вполне респектабельным источникам, это и есть следующая версия NGG, которая на этот раз задействована в драйвере и не требует ответных усилий со стороны API и графических движков.
Прим. от 29.07.2019
Судя по результатам профилировки игр с помощью свежей версии Radeon GPU Profiler, блок NGG в чипах Navi действительно запущен, и большая часть вычислений проходит через него, нежели стандартный геометрический конвейер. В дополнение к тому, что примитивные шейдеры используются для отбраковки невидимых поверхностей, ожила и другая функция NGG — шейдеры поверхности (Surface Shaders), которые по решению компилятора заменяют часть шейдерной цепочки, вовлеченной в тесселяцию (Vertex Shaders и Hull Shaders) до того, как данные попадают в собственно тесселятор — блок фиксированной функциональности. Теперь понятны комментарии AMD к топологии разделов GPU, связанных с геометрией, и их обновленная номенклатура. В архитектуре GCN под термином Geometry Processor подразумевается весь геометрический конвейер, кроме растеризатора, повторяющий модель программирования Direct3D. И напротив, в RDNA блок с тем же названием занимается общими этапами работы, а преобладающая часть действий до и после тесселяции распределена по блокам Primitive Unit, находящимся внутри каждого Shader Array.
Как бы то ни было, AMD все-таки не нашла возможности включить NGG на ускорителях архитектуры GCN: между тем, как эта опция реализована в Vega и Navi, явно есть какие-то существенные различия, о которых разработчики предпочитают не говорить. В будущем для NGG может найтись другая работа, помимо эффективной фильтрации невидимых полигонов — среди прочего, генерация карт теней, рендеринг с неравномерным разрешением или с нескольких точек обзора, — но эти функции уже наверняка потребуют эксплицитной поддержки в приложениях или API.
NVIDIA предлагает свою альтернативу стандартной последовательности шейдерных этапов, которая обрабатывает геометрию в рамках распространенных графических API — комбинацию Mesh Shaders и Task Shaders, о которых мы писали в обзоре архитектуры Turing. В конечном счете, и NGG, и то, что сделала NVIDIA, преследуют одну и ту же цель — ускорить ранние стадии рендеринга, но достигают ее разными путями. NGG заменяет проблемные порции геометрического конвейера, свойственного Direct3D, на лету перекодируя старый тип шейдеров в новый — то есть, выполняет прежнюю работу более эффективно. Напротив, Mesh Shaders и Task Shaders позволяют расширить возможности рендеринга благодаря управляемой генерации геометрических деталей прямо на GPU силами шейдерных ALU (в отличие от грубой настройки параметров тесселятора). Mesh Shaders сейчас доступны через расширения к Direct3D 12 и Vulkan, но уже движутся к полноправной интеграции в интерфейс программирования Microsoft. Как знать, быть может инновации NVIDIA и нераскрытые возможности NGG в конце концов объединятся под зонтиком одной программной функции, что побудит разработчиков игр применять их более активно.
Драйвер Navi автоматически включает и тайловый рендеринг, появившийся в графических процессорах Vega, для того, чтобы сократить обращения к оперативной памяти и удержать данные, необходимые для растеризации и шейдеров, в пределах кеша L2.
Что касается упомянутых блоков ACE (Asynchronous Compute Engine), то и они научились новым трюкам. В RDNA доступна такая функция, как Asynchronous Compute Tunneling (ACT). Она оперирует на уровне очередей инструкций, которые драйвер видеокарты получает от графического API, — в отличие от preemption и других методов, работающих на уровне wavefront’ов и отдельных цепочек данных для векторных ALU (к примеру, Direct3D 12 поддерживает одну очередь для рендеринга и несколько для неграфических расчетов). Благодаря ACT графический процессор способен мгновенно приостановить прием дальнейших инструкций из очередей, имеющих низкий приоритет, ради того, чтобы закончить критически важную работу из другой очереди. Главной целью подобных оптимизаций, разумеется, является VR. Разработчики «железа» продолжают уделять шлемам виртуальной реальности повышенное внимание, несмотря на то, к какому плачевному состоянию сегодня пришла эта, когда-то перспективная, идея.

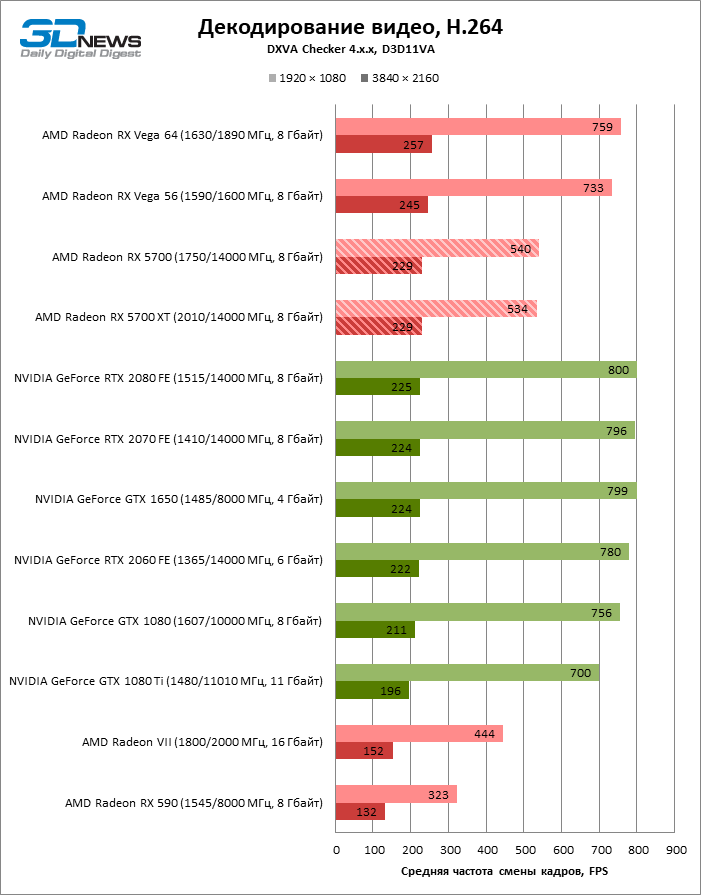
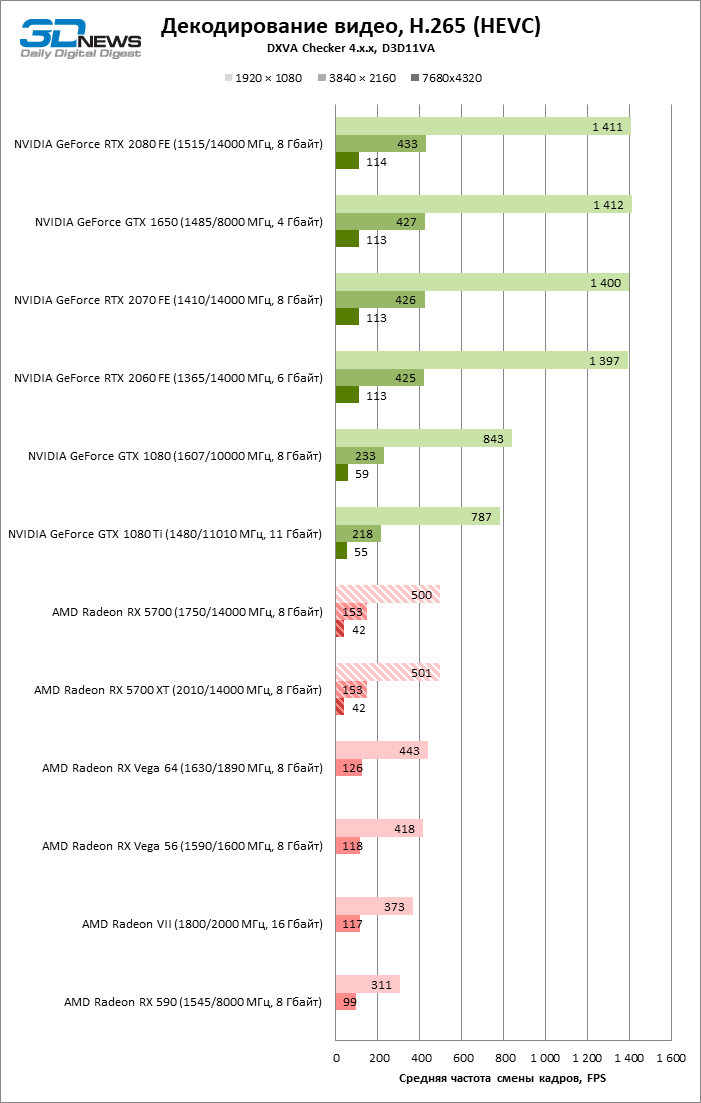
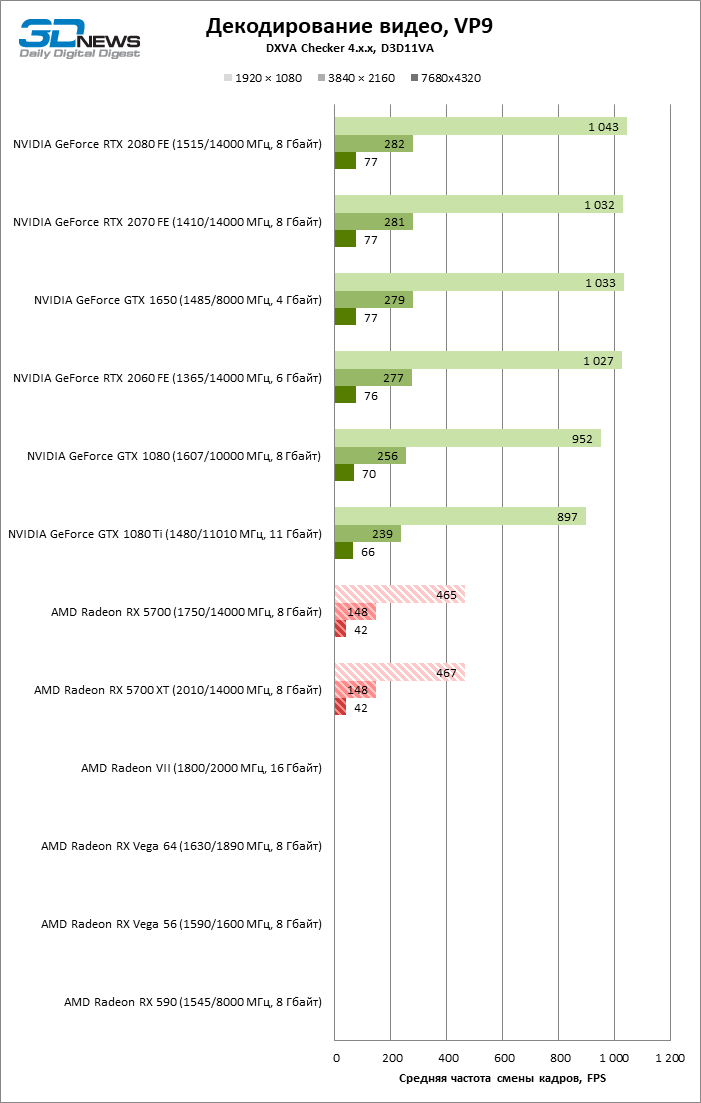
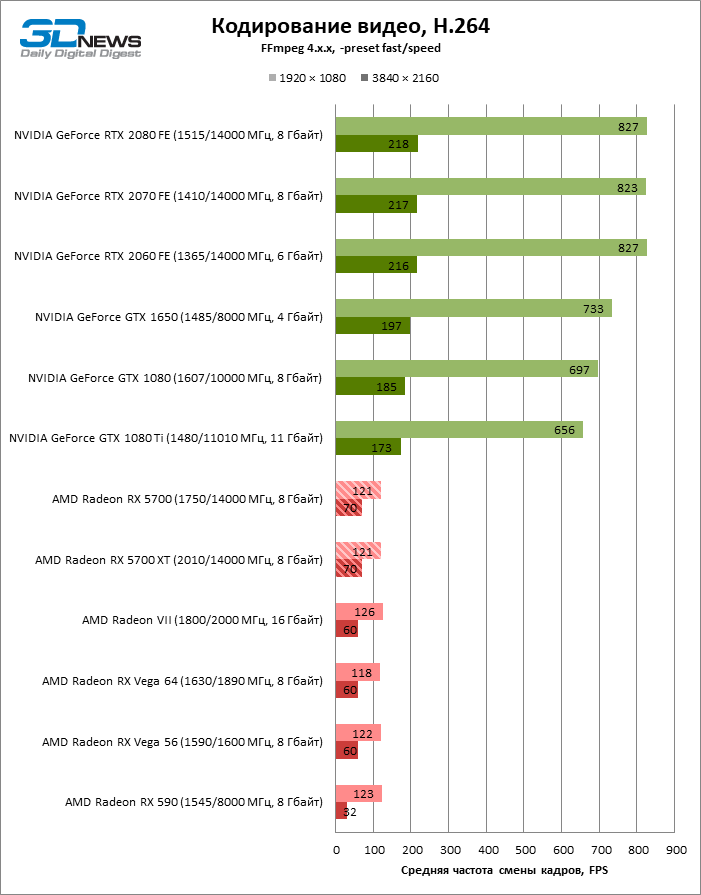
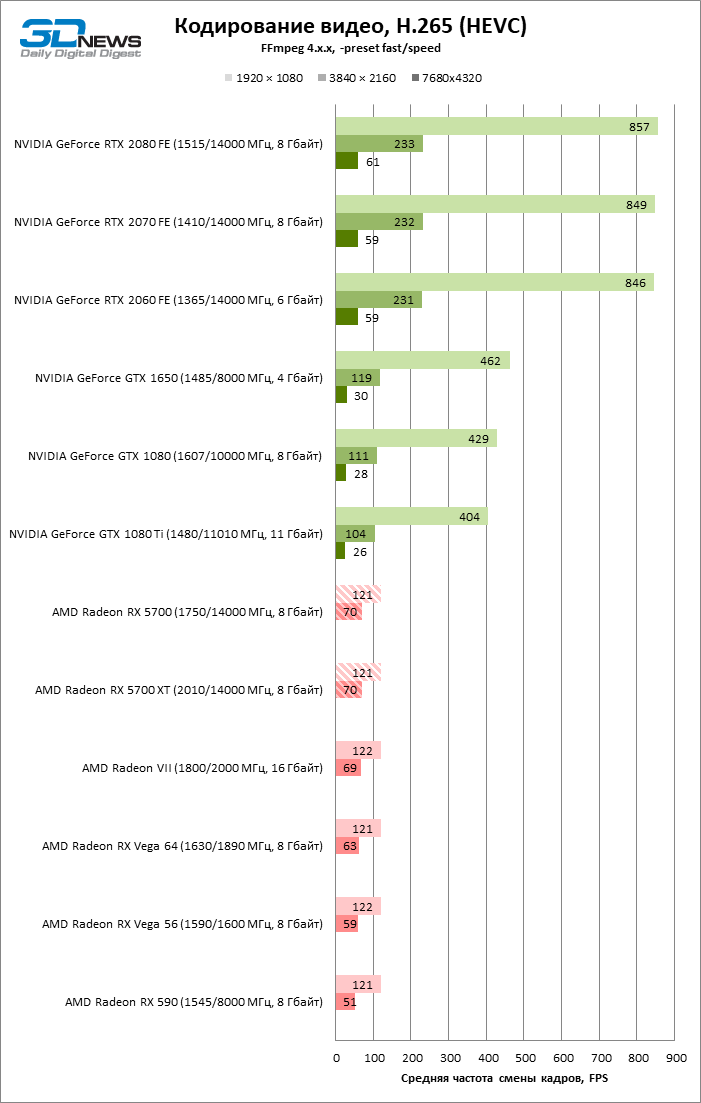
AMD наконец-то обратила должное внимание и на uncore-часть кристалла GPU, а именно блоки фиксированной функциональности, выполняющие кодирование и декодирование видео — UVD (Unified Video Decoder) и VCE (Video Coding Engine). Еще в чипах Polaris компания обещала внедрить аппаратную поддержку стандарта VP9, который используют для компрессии видео стриминговые сервисы — в первую очередь, YouTube. Но в действительности и все три поколения Polaris, и Vega, так и не научились декодировать VP9 без помощи шейдерных ALU — это все еще лучше, чем софтверная обработка на CPU, вот только браузеры «гибридное» декодирование VP9 поддерживают неохотно. Чип Navi 10, как и APU семейства Raven Ridge до него, умеет обрабатывать VP9 полностью в железе, а заодно AMD увеличила пропускную способность обоих компонентов видеодвижка — и на декодирование, и на кодирование потока. Radeon RX 5700 и RX 5700 XT обязаны декодировать видео трех основных стандартов (H.264, HEVC и VP9) при разрешении вплоть до 8К с кадровой частотой 24–30 FPS. Расчетное быстродействие при кодировании достигает 360 FPS в 1080p и 60–90 FPS в режиме 4К: в зависимости от стандарта — H.264 или HEVC.
В обновленном контроллере дисплея Navi реализованы дополнения к интерфейсам HDMI и DisplayPort, которых тоже не было в чипах Polaris и Vega. HDMI повысили с версии 2.0 до 2.0b, а это означает поддержку HDR. Выходы DisplayPort, в свою очередь, получили функцию DSC (Display Stream Compression) — это опциональный метод кодирования в стандарте 1.4, обеспечивающий сжатие данных без потери качества, заметной человеческому глазу. За счет DSC можно добиться трехкратного увеличения пропускной способности интерфейса, а значит подключать одним кабелем мониторы с таким разрешением и частотой смены кадров, для которых раньше был нужен двойной канал или цветовая субдискретизация (chroma subsampling), вызывающая неизбежное падение качества изображения. Интерфейсу DisplayPort 1.4 в сочетании с DSC 1.2a доступно разрешение 4К при частоте 120 Гц или 5К 60 Гц (и то, и другое — одновременно с HDR).
Разумеется, Navi поддерживает и технологию FreeSync 2 в комбинации с широким цветовым охватом и HDR — посредством DisplayPort или, в зависимости от доброй воли производителя телевизора, HDMI. В официальные спецификации HDMI адаптивную частоту обновления добавила версия 2.1, но первым GPU с таким интерфейсом Navi не стал, да и соответствующие телевизоры появились на рынке лишь полгода тому назад.

Однако все те нововведения, которые вобрал в себя чип Navi 10, не достались бесплатно с точки зрения компонентного бюджета. Старший Polaris при такой же конфигурации основных вычислительных блоков обходится скромными 5,7 млрд транзисторов, а для того, чтобы построить Navi 10, понадобилось уже 10,3 млрд — так много места занимает дополнительная управляющая логика и разбухшая система кешей. Неудивительно, что AMD оставит архитектуру GCN для ускорителей неграфических расчетов, ведь всю эту площадь можно попросту забить шейдерными ALU, которым GCN всегда найдет работу в GP-GPU. Для того чтобы эффективно задействовать ресурсы чипа в играх, с такими жертвами волей-неволей приходится мириться. Графические процессоры NVIDIA тоже набирали вес с каждым поколением, а ведь масштаб изменений в архитектуре RDNA можно сравнить одновременно с двумя крупнейшими переходами, которые совершил конкурент, — от Kepler к Maxwell и от Pascal к Turing.
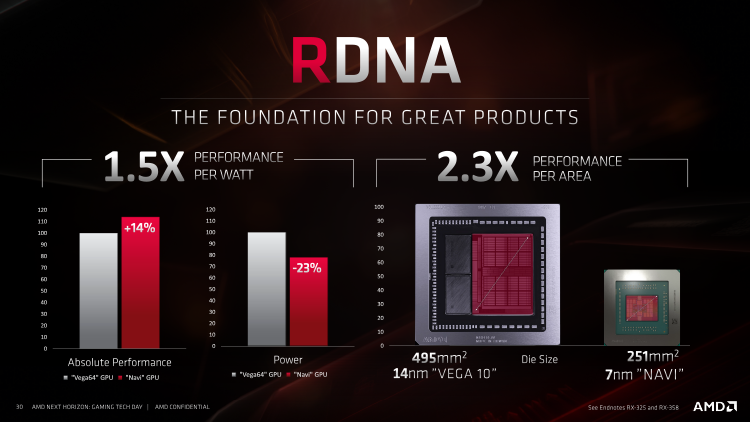
Во всяком случае, техпроцесс 7 нм позволяет упаковывать дополнительные транзисторы намного компактнее, чем при норме 14 нм. Площадь Navi 10 составляет 251 мм2 — немногим больше, чем у Polaris 10/20, а плотность компонентов возросла на 67 %. Куда важнее то, что в играх Navi 10 сулит повысить удельное быстродействие на площадь чипа в 2,3 раза по сравнению с Vega 10, а быстродействие на ватт — на 48 %. Если суммировать информацию из официальных слайдов, посвященных Navi, львиную долю выигранной мощности AMD относит именно на счет архитектуры RDNA, в то время как отдельно взятая смена технологической нормы с 14 на 7 нм дала только 11 %. Свой вклад в энергоэффективность внесла и схемотехника кристалла — в этой части команда Radeon позаимствовала лучшие методы у создателей Ryzen.
⇡#Radeon RX 5700 и Radeon RX 5700 XT: технические характеристики, цены
AMD создала на основе графического процессора Navi 10 сразу два устройства, к выпуску которых приурочена очередная смена модельной номенклатуры. Имена новинок вызывают в памяти старинные ускорители Radeon HD 5000, снискавшие на геймерском рынке того времени большой успех. Кто знает, руководствовалась ли AMD именно этим намерением, но история трехзначных модельных номеров для видеокарт AMD закончилась, а вот буквенные индексы, различающие устройства на основе одного и того же GPU, вернулись в дело после многолетнего отсутствия.
Старшая модель Radeon RX 5700 оснащена полностью функциональным чипом Navi 10, который включает 40 модулей CU и, соответственно, 2560 векторных ALU вместе с 160 блоками фильтрации текстур. В свою очередь, младшая версия Radeon располагает 36 CU, а число векторных ALU и текстурников сокращено до 2306 и 144 соответственно. Таким образом, Radeon RX 5700 является аналогом Radeon RX 580 и Radeon RX 590 по конфигурации основных вычислительных ресурсов, а Radeon RX 5800 XT в этом плане представляет собой то, чем не суждено было стать любым ускорителям на чипах Polaris.

Однако для того, чтобы сделать предварительные оценки быстродействия Radeon RX 5700 и Radeon RT 5700 XT, нужно принять во внимание не только общую ширину вычислительного конвейера, но и тактовые частоты GPU. В описании новинок AMD использует модель, введенную ускорителями Vega и Radeon VII: есть базовая частота (Base Clock), до которой GPU отступает при чрезвычайно энергоемкой нагрузке, и есть Boost Clock — максимальный уровень автоматического разгона, на который можно рассчитывать в типичных приложениях.
В дополнение к этим параметрам AMD ввела еще одну метрику тактовой частоты — Game Clock, соответствующую минимальному авторазгону в особо требовательных играх. Таким образом, числа, которыми оперирует AMD, делают сравнение ускорителей Radeon с продуктами NVIDIA по одним лишь тактовым частотам совершенно бесполезным занятием. У «зеленых» тоже есть понятие Boost Clock, но применительно к видеокартам GeForce оно означает среднюю гипотетическую частоту в играх, а вовсе не минимум и максимум автоматического разгона.
Кроме того, у Radeon RX 580 и прочих моделей на чипах Polaris характеристика Boost Clock означает попросту пиковую частоту, которой в принципе разрешено достигнуть графическому процессору. В спецификациях Radeon RX 5000-й серии пиковая частота не приводится. В каком-то смысле она по-прежнему существует — как крайняя точка кривой частоты-напряжения, — но GPU под достаточно легкой нагрузкой может выходить за ее пределы. Однако именно пиковой частотой манипулируют программные инструменты для разгона «красных» GPU, включая утилиту WattMan в панели управления драйвером AMD, поэтому на графиках с результатами тестов мы приводим именно ее — как единственный твердый индикатор быстродействия. У NVIDIA, напротив, якорем для разгона остается базовая частота, в то время как Boost Clock и пиковая частота постоянно плавают вместе с графиком функции, управляющей тактовыми частотами и напряжением питания GPU, в зависимости от текущей температуры чипа.
Однако это было лишь необходимое отступление для того, чтобы предотвратить возможные претензии к маркировке видеокарт на тестовых диаграммах. Насколько велика теоретическая вычислительная мощность Radeon RX 5700 и Radeon RT 5700 XT по сравнению с видеокартами на чипах Polaris и Vega, исходя из максимальной частоты, которую сообщают паспортные данные (Boost Clock)? По «голым» терафлопсам Radeon RX 5700 XT ненамного уступает Radeon RX Vega 56 (7 %), а Radeon RX 5700, в свою очередь, лишь на 12 % превосходит ближайшую видеокарту прошлого поколения — Radeon RX 590. Кроме того, Vega располагает огромным массивом блоков фильтрации текстур — от 224 до 256 в зависимости от конкретной версии графического процессора.

Но не будем забывать, что архитектура RDNA обещает увеличить игровое быстродействие на 25 % по сравнению с GCN. Кроме того, благодаря 64 конвейерам растеризации, включенным в back-end чипа Navi 10, обе новые модели легко превосходят и ускорители на чипах Vega, и тем более Polaris по пиксельному филлрейту.
Последнее обстоятельство отлично сочетается с высокой пропускной способностью шины памяти, которую обеспечили чипы GDDR6. Несмотря на сравнительно узкую 256-битную шину Radeon RX 5700 и Radeon RX 5700 XT не уступают в ПСП Radeon RX Vega 56 с памятью HBM2. Прибавьте к этому более эффективные алгоритмы компрессии данных и развитую систему кешей — пожалуй, доступ к RAM уж точно не будет сдерживать быстродействие Navi 10, как происходит в чипах Vega первого поколения, всегда нуждающихся в дополнительной ПСП для того, чтобы обслужить громадный массив шейдерных ALU.
Впрочем, ни одно из перечисленных устройств по скорости работы с RAM нельзя поставить рядом с Radeon VII: за счет четырех стеков HBM2 последний развивает головокружительную ПСП в 1 Тбайт/с. К тому же память HBM и HBM2 является более энергоэффективным решением по сравнению с GDDR6, и об этом не стоит забывать, когда заходит речь о потребляемой мощности той или иной видеокарты. У Radeon RX 5700 и Radeon RX 5700 XT на долю чипов памяти (и тепловые потери регуляторов напряжения) приходится 30 и 45 Вт из полной мощности платы.
По паспортным значениям TDP младшая и старшая модификации Radeon RX 5700 занимают позиции Radeon RX 580 и Radeon RX 590 — 185 и 225 Вт соответственно. Это, как ни странно для поверхностного взгляда, чрезвычайно позитивный индикатор, вызывающий уверенность в потенциале архитектуры RDNA, ведь Navi 10 не только работает на значительно более высоких частотах по сравнению с чипами Polaris 20 и Polaris 30, но и содержит на 80 % больше транзисторов.
Тем не менее главные соперники, с которыми предстоит столкнуться в тестах видеокартам AMD — GeForce RTX 2060 и GeForce RTX 2070, характеризуются более низким энергопотреблением, которое составляет 160 и 175 Вт соответственно. В пользу новинок играет более высокая теоретическая производительность массива шейдерных ALU, но опять-таки исход противостояния целиком зависит вовсе не от «голых» терафлопсов, а от того, насколько умело та или иная архитектура способна транслировать их в быстродействие графических приложений.
| Производитель | AMD |
|---|
| Модель |
Radeon RX 580 |
Radeon RX 590 |
Radeon RX Vega 56 |
Radeon RX Vega 64 |
Radeon VII |
Radeon RX 5700 |
Radeon RX 5700 XT |
Radeon RX 5700 XT Anniversary Edition |
| Графический процессор |
| Название |
Polaris 20 XT |
Polaris 30 XT |
Vega 10 XL |
Vega 10 XT |
Vega 20 XL |
Navi 10 PRO |
Navi 10 XT |
Navi 10 XT |
| Микроархитектура |
GCN 4-го поколения |
GCN 4-го поколения |
GCN 5-го поколения |
GCN 5-го поколения |
GCN 5-го поколения |
RDNA |
RDNA |
RDNA |
| Техпроцесс, нм |
14 нм FinFET |
12 нм FinFET |
14 нм FinFET |
14 нм FinFET |
7 нм FinFET |
7 нм FinFET |
7 нм FinFET |
7 нм FinFET |
| Число транзисторов, млн |
5 700 |
5 700 |
12 500 |
12 500 |
13 200 |
10 300 |
10 300 |
10 300 |
| Тактовая частота, МГц: Base Clock / Boost Clock |
1 257/1 340 |
1 469/1 545 |
1 156/1 471 |
1 247/1 546 |
1 400/1 750 |
1 465/1 725 |
1 605/1 905 |
1 680/1 980 |
| Число шейдерных ALU |
2 304 |
2 304 |
3 584 |
4 096 |
3 840 |
2 304 |
2 560 |
2 560 |
| Число блоков наложения текстур |
144 |
144 |
224 |
256 |
240 |
144 |
160 |
160 |
| Число ROP |
32 |
32 |
64 |
64 |
64 |
64 |
64 |
64 |
| Оперативная память |
| Разрядность шины, бит |
256 |
256 |
2 048 |
2 048 |
4 096 |
256 |
256 |
256 |
| Тип микросхем |
GDDR5 SDRAM |
GDDR5 SDRAM |
HBM2 |
HBM2 |
HBM2 |
GDDR6 SDRAM |
GDDR6 SDRAM |
GDDR6 SDRAM |
| Тактовая частота, МГц (пропускная способность на контакт, Мбит/с) |
2 000 (8 000) |
2 000 (8 000) |
800 (1 600) |
945 (1 890) |
1000 (2 000) |
1 750 (14 000) |
1 750 (14 000) |
1 750 (14 000) |
| Объем, Мбайт |
4 096/8 192 |
8 192 |
8 096 |
8 096 |
16 192 |
8 096 |
8 096 |
8 096 |
| Шина ввода/вывода |
PCI Express 3.0 x16 |
PCI Express 3.0 x16 |
PCI Express 3.0 x16 |
PCI Express 3.0 x16 |
PCI Express 3.0 x16 |
PCI Express 4.0 x16 |
PCI Express 4.0 x16 |
PCI Express 4.0 x16 |
| Производительность |
| Пиковая производительность FP32, GFLOPS (из расчета максимальной указанной частоты) |
6 175 |
7 119 |
10 544 |
12 665 |
13 440 |
7 949 |
9 754 |
10 138 |
| Производительность FP64/FP32 |
1/16 |
1/16 |
1/16 |
1/16 |
1/4 |
1/16 |
1/16 |
1/16 |
| Производительность FP16/FP32 |
1/1 |
1/1 |
2/1 |
2/1 |
2/1 |
2/1 |
2/1 |
2/1 |
| Пропускная способность оперативной памяти, Гбайт/с |
256 |
256 |
410 |
484 |
1024 |
448 |
448 |
448 |
| Вывод изображения |
| Интерфейсы вывода изображения |
DL DVI-D, DisplayPort 1.3/1.4, HDMI 2.0b |
DL DVI-D, DisplayPort 1.3/1.4, HDMI 2.0b |
DisplayPort 1.4, HDMI 2.0b |
DisplayPort 1.4, HDMI 2.0b |
DisplayPort 1.4, HDMI 2.0b |
DisplayPort 1.4, HDMI 2.0b |
DisplayPort 1.4, HDMI 2.0b |
DisplayPort 1.4, HDMI 2.0b |
| TBP/TDP, Вт |
185 |
225 |
210 |
295 |
300 |
185 |
225 |
235 |
| Розничная цена (США, без налога), $ |
4 Гбайт: 199; 8 Гбайт: 229 (рекоменд. в момент выхода) |
279 (рекоменд. в момент выхода) |
399 (рекоменд. в момент выхода) |
499 (рекоменд. в момент выхода) |
699 (рекоменд. в момент выхода) |
349 (рекоменд.) |
399 (рекоменд.) |
449 (рекоменд.) |
| Розничная цена (Россия), руб. |
4 Гбайт: 13 449; 8 Гбайт: 15 299 (рекоменд. в момент выхода) |
18 990 (рекоменд. в момент выхода) |
НД |
НД |
НД |
25 499 (рекоменд.) |
29 499 (рекоменд.) |
НД |
На этот вопрос нам ответят результаты тестов, а вот NVIDIA уже увидела в новых «Радеонах» потенциал для конкуренции. Компания из Санта-Клары не собирается поздравлять AMD с технологическим прорывом, как они в свое время сделали в ответ на запуск центральных процессоров Ryzen Threadripper. Вместо этого NVIDIA перетряхнула серию видеокарт GeForce RTX 20. Теперь в дополнение к GeForce RTX 2060, который продается по рекомендованной цене в $349, на рынке появится GeForce RTX 2060 с приставкой SUPER, оцененный в $399. Производство GeForce RTX 2070 будет прекращено, а его место займет SUPER-версия по той же рекомендованной цене в $499.
Сейчас мы не будем уделять повышенное внимание техническим характеристикам обновленных видеокарт NVIDIA — это мы оставим для полноценного обзора, как только тестовые образцы попадут к нам в руки. Пока достаточно сказать, что GeForce RTX 2060 SUPER комплектуется чипами с расширенной конфигурацией активных вычислительных блоков и восемью вместо шести гигабайт оперативной памяти. В то же время GeForce RTX 2070 SUPER представляет собой совершенно иную видеокарту на основе GPU более высокого ранга (TU104 вместо TU106) и фактически является урезанной версией GeForce RTX 2080.
Оперативная реакция NVIDIA заставила AMD снизить розничные цены Radeon RX 5700 и Radeon RX 5700 XT, не дожидаясь выпуска на рынок. Вместо $379 и $449, на которые AMD рассчитывала изначально, новинки появятся в продаже за $349 и $399 соответственно. Таким образом, обе модификации Radeon RX 5700 теперь не превышают по цене GeForce RTX 2060 SUPER. Но означает ли это паритет по быстродействию, мы сможем выяснить только тогда, когда получим доступ к первым образцам обновленных «Тьюрингов».
⇡#Radeon RX 5700 и Radeon RX 5700 XT: конструкция
Как уже было в случае Polaris, а затем и Vega, новые ускорители AMD появятся на рынке в форме референсных карт, но останавливаться на этом этапе производитель не планирует. В отличие от Radeon VII, который навсегда останется привязан к референсному дизайну, устройства на чипе Navi предназначены для массового рынка. Как только AMD насытит первую волну спроса, обязательно придет очередь партнерских решений с модифицированными PCB и системами охлаждения.
И тем не менее перед эталонными образцами Radeon RX 5700 и Radeon RX 5700 XT стоит немаловажная задача — продемонстрировать достоинства кремния Navi перед видеокартами прошлого поколения с процессорами архитектуры GCN. Раньше AMD не раз критиковали за пренебрежительное отношение к дизайну и конструкции референсных устройств. Даже Radeon VII, в котором SAPPHIRE под руководством AMD проделала серьезную работу над ошибками, не лишен очевидных изъянов (выражающихся в высоком уровне шума под нагрузкой).
Референсные варианты Radeon RX 5700, на первый взгляд, застрахованы от повторения прошлых ошибок сравнительно низким уровнем энергопотребления. Уж если из Radeon RX Vega 56 и Vega 64 удалось сделать качественное устройство (с поправкой на шум турбинного кулера), то из обеих версий Radeon RX 5700 производитель и подавно сможет.
Как бы ни обстояли дела с эффективностью охлаждения, с эстетической точки зрения к двум ускорителям на чипе Navi не может возникнуть ни малейших претензий. AMD отошла от агрессивного и грубоватого дизайна Radeon VII и старших модификаций Vega — в каждой мелочи здесь чувствуется забота и внимание. Видеокарты упакованы в цельнометаллический корпус, под которым, по всей видимости, лежит одна и та же PCB. Однако Radeon RX 5700 и Radeon RX 5700 XT отличает форма и текстура кожуха системы охлаждения: у старшей модели поверхность рифленая, а у младшей — гладкая и матовая. Кроме того, обратная поверхность текстолита Radeon RX 5700 XT покрыта защитной металлической пластиной, которая отсутствует у Radeon RX 5700. И наконец, под красным логотипом Radeon на борту XT есть ряд светодиодов (как в наше время обойтись без такого украшения), а у «простого» Radeon RX 5700 он нанесен красной краской.
Независимо от того, как выглядит алюминиевый кожух Radeon RX 5700 и Radeon RX 5700 XT, внутри него скрывается одна и та же система охлаждения. Главную роль в задаче отвода тепла от чипа Navi играет радиатор с медной испарительной камерой, а в качестве термоинтерфейса вместо термопасты используется тонкая графитовая прокладка. По всей видимости, это тот же самый материал, который AMD опробовала на Radeon VII — Hitachi TC-HM03. По теплопроводности графитовая прокладка превосходит даже лучшие термопасты: 40–90 Вт/(м·K) у TC-HM03 против 12,5 Вт/(м·K) у излюбленного оверклокерами состава Thermal Grizzly Kryonaut. Тем не менее, как уже продемонстрировали эксперименты с Radeon VII, качественная термопаста и графитовая прокладка одинаково хороши для охлаждения GPU, поскольку толщина последней нивелирует преимущество в теплопроводности. Вернуть стандартный термоинтерфейс Radeon RX 5700 на место после демонтажа кулера уже невозможно — прокладка разрывается на части. Но не беда, подпружиненные винты достаточно сильно прижимают радиатор к кремнию графического процессора, чтобы размазать тонким слоем обычную термопасту.
Не столь горячие компоненты PCB — чипы оперативной памяти GDDR6 и ключи регулятора напряжения — сначала отдают тепло массивной алюминиевой раме, нависающей над всей площадью печатной платы, но в конечном счете тоже являются клиентами основного радиатора, т.к. рама и подошва испарительной камеры припаяны друг к другу.
Единственное функциональное различие, которое мы нашли в кулерах Radeon RX 5700 и Radeon RX 5700 XT, — дополнительный «огрызок» ребер в хвостовой части рамы XT, который отсутствует в младшей видеокарте. Но эта деталь лишь создает иллюзию более крупного радиатора, чем есть на самом деле, и не принимает в охлаждении реального участия: турбину кулера окружает воздуховод, который собирает весь поток в сторону испарительной камеры.
⇡#Печатная плата
Как мы и предполагали при внешнем осмотре, Radeon RX 5700 и Radeon RX 5700 XT основаны на одной и той же PCB — у младшей модели даже остался разъем для подключения светодиодов. AMD лишь удалила часть компонентов из регулятора напряжения Radeon RX 5700, как обычно поступают с младшими моделями. Однако, на какую из двух плат ни посмотри, VRM здесь чрезвычайно мощный и эффективный — все как любит AMD.
Для питания GPU предусмотрена шести- или семифазная схема под управлением ШИМ-контроллера IR35217 от International Rectifier. Микросхемам памяти GDDR6 выделена еще одна фаза питания, для управления которой AMD решила использовать второй экземпляр IR35217. Такой же чип применяется во всех достаточно производительных видеокартах AMD, начиная с Radeon RX 480 и заканчивая Radeon VII (и, кажется, нигде больше). В открытый доступ документация на IR35217 не выложена, но известно, что он может непосредственно контролировать вплоть до восьми фаз регулятора напряжения.
Ключи и драйвер в каждой фазе VRM графического процессора на референсных платах Navi заменяет однокомпонентное решение FDMF3170 производства ON Semiconductor. Такая микросхема пропускает ток вплоть до 70 А, а значит при максимальном напряжении питания, какое BIOS ускорителей разрешает подать на кристалл GPU, регулятор напряжения осилит вплоть до 588 Вт мощности. Интегрированные фазы (power stages) такого номинала мы раньше видели только на платах Radeon VII и GeForce RTX 2080 Ti, а, к примеру, референсные видеокарты NVIDIA на чипе TU106 (GeForce RTX 2060, RTX 2060 SUPER и RTX 2070) обходятся шестью фазами по 55 А. Но дело вовсе не в доступной мощности — до предела собственного VRM графический процессор Navi не дойдет даже при экстремальном оверклокинге. Просто такие сборки, как FDMF3170, отличаются чрезвычайно низкими тепловыми потерями. Несмотря на то, что кулер референсных вариантов Radeon RX 5700 и Radeon RX 5700 XT и на вид, и в действительности (как мы скоро выясним) довольно слабый, а под общим радиатором GPU нагревает компоненты VRM, их температура под нагрузкой не превышает 70 °C.
Кстати, для того, чтобы в этом убедиться, не пришлось монтировать под радиатор термопары: как и Vega, новые ускорители отдают температурные показания VRM через API, в результате их можно увидеть в GPU-Z (и температуру чипов RAM тоже). А вот мониторинг энергопотребления по-прежнему рудиментарный. AMD не регистрирует общий ток, протекающий по линиям 12 В с помощью шунтов, как это делает NVIDIA. Те числа, которые показывает GPU-Z и оверклокерские программы, рассчитаны по току на выходе MOSFET'ов графического процессора, и, соответственно, отражают потребляемую мощность ядра GPU без учета остальных компонентов, у которых есть собственные VRM — контроллера дисплея, шины оперативной памяти и самих чипов GDDR6, — не говоря уже о вентиляторе и тепловых потерях на преобразование напряжения. Но оверклокерам Radeon RX 5700 и XT наверняка понравятся: VRM абсурдно мощный, жесткого лимита энергопотребления по-прежнему нет, и все температуры перед глазами. Что точно не понравится, так это пустующие площадки для резервной микросхемы и переключателя BIOS. По какой-то причине эта, прежде неотъемлемая, черта высокопроизводительных моделей Radeon исчезла сначала у Radeon VII, а теперь и у Navi.
AMD прибегла к услугам двух поставщиков для сборки массива RAM: младшая версия Radeon RX 5700 укомплектована микросхемами Micron с маркировкой 9GA77 D9WCW, а у XT чипы Samsung K4Z80325BC-H14. И те, и другие работают с пропускной способностью 16 Гбит/с. Внешние интерфейсы Radeon RX 5700 и Radeon RX 5700 XT представлены типичным набором для современных высокопроизводительных ускорителей — три выхода DisplayPort и единственный HDMI.
⇡#Новые функции Radeon Software
Читатели, осилившие подробный анализ RDNA и графического процессора Navi 10, могли заметить, что на предыдущей странице отсутствует раздел, который непременно должен быть в рецензии на GPU совершенно новой архитектуры, — дополнительные функции рендеринга. Однако это вовсе не упущение со стороны автора обзора. Navi не располагает никакими новыми возможностями за пределами джентльменского набора Feature Level 12_1 в рамках Direct3D 12 и тех немногочисленных проприетарных функций, которые видеокарты AMD приобрели еще в эпоху GCN. Благо, альтернативный шейдерный конвейер для обработки геометрии (Next Generation Geometry), по каким-то причинам заблокированный в чипах Vega, наконец-то ожил и не требует активации со стороны API и графических движков.
В одном аспекте видеокарты нового поколения даже сделали шаг назад по сравнению с набором аппаратных функций, которыми располагают Polaris и Vega: несколько ускорителей Radeon RX 5700 или Radeon RX 5700 XT больше нельзя собрать в массив CrossFire. AMD не говорит, почему — в силу чисто программного ограничения или отсутствия возможности на аппаратном уровне, — но CrossFire на новых «Радеонах» действительно не работает, хотя в предварительной версии ПО такую опцию оставили по недосмотру разработчиков. Придется смириться с тем, что рендеринг при помощи нескольких GPU в играх постепенно отмирает. Приложения, написанные под Direct3D 12, все еще могут использовать несколько графических процессоров в эксплицитном режиме, не полагаясь на драйвер, но нам пока известна лишь единственная игра, которая умеет так делать — это уже далеко не свежий проект Ashes of the Singularity.
Кремний Navi лишен специализированных блоков фиксированной функциональности для трассировки лучей — это AMD запланировала в следующей версии RDNA (да и тогда на первых порах будут реализованы лишь «избранные эффекты»). Аналога тензорных ядер, которые применяются в отдельных играх для масштабирования кадра при помощи нейросети (DLSS, Deep Learning Super Sampling), в чипах AMD тоже нет. Однако функции, которые пока что не по силам железу AMD, может взять на себя ее программное обеспечение. Компания не исключает того, что рано или поздно Navi приобретет софтверную реализацию Ray Tracing'а — как чипы NVIDIA архитектуры Pascal и младшие «Тьюринги» в составе GeForce GTX 1650 и GTX 1660 (Ti), — а перспективная альтернатива DLSS существует уже сегодня.
AMD предлагает разработчикам игр пакет ПО с открытым исходным кодом FidelityFX, который содержит алгоритмы пост-обработки изображения: CAS (Contrast-Adaptive Sharpening) и LPM (Luma Preserving Mapping). Название технологии говорит само за себя: CAS увеличивает четкость отдельных фрагментов изображения на основании локального контраста. В зонах с низким контрастом он усиливается, а высококонтрастных участков и световых ореолов, которым лишняя четкость только вредит, алгоритм избегает. FidelityFX предназначен, в первую очередь, для того, чтобы компенсировать издержки современных алгоритмов полноэкранного сглаживания (таких, как вездесущий TAA и его предшественник FXAA), в той или иной степени размывающих картинку — насколько сильно, зависит от специфики реализации в конкретной игре. Кроме того, опционально CAS могут применять для высококачественного масштабирования кадра из низкого в высокое разрешение. Шейдеры FidelityFX требуют прямой интеграции в графический движок, но о поддержке инициативы AMD объявили несколько крупных софтверных команд, а две игры его уже используют — Rage 2 и World War Z. Заметим, что код FidelityFX не привязан к чипам AMD и совместим с GPU любых производителей.

В драйвере для видеокарт 5000-го семейства, помимо нескольких менее значительных нововведений, появилась функция на основе CAS под аббревиатурой RIS (Radeon Image Sharpening). Как и родительская технология, она позволяет восстановить детали, размытые полноэкранным сглаживанием, а если совместить RIS с масштабированием изображения на GPU, получается аналог DLSS. Пока ничего не можем сказать про качество картинки, обработанной RIS, по сравнению с DLSS — в немногочисленных случаях реализации последнего есть образцы и превосходного, и отвратительного качества: мы когда-то исследовали этот вопрос вBattlefield V, Final Fantasy XV и Metro Exodus, а затем в Shadow of the Tomb Raider. Зато известно, что драйвер AMD выполняет масштабирование с минимальной потерей быстродействия — а DLSS, между прочим, нет, пусть в конечном счете позволяет сэкономить много FPS по сравнению с честным рендерингом в целевом разрешении. Но главное, метод AMD не нуждается в адаптации под конкретную игру и активируется прямо в панели управления Radeon Settings.
Впрочем, в данный момент на RIS тоже наложен ряд ограничений: AMD успела внедрить поддержку API Direct3D 9, 12 и Vulkan, но игры, созданные под все еще чрезвычайно популярный интерфейс Direct3D 11, будут охвачены лишь в следующих версиях. RIS не совместим с высоким динамическим диапазоном (HDR). И наконец, технология пока доступна только первым обладателям видеокарт 5000-й серии, хотя со временем придет на ускорители Vega. А вот модели семейства Radeon RX 400/500 могут и не дождаться RIS, т.к. алгоритмы FidelityFX опираются на возможность исполнять операции FP16 в удвоенном темпе, которой лишены чипы Polaris.
Radeon Anti-Lag (RAL) — другая опция пакета Radeon Software, которой AMD уделяет повышенное внимание. Компания утверждает, что переключатель, появившийся в панели управления драйвером, способен сократить задержку между действиями пользователя и реакцией игры на экране — вплоть до разницы в 31 %. Принцип работы RAL легко разгадать по ограничениям этой технологии: она совместима только с играми под API Direct3D 9 и 11 и, по всей видимости, просто уменьшает длину очереди кадров (Context Queue в терминологии Microsoft), которые центральный процессор может подготовить для рендеринга на GPU в программном графическом конвейере. В сценариях, ограниченных производительностью видеокарты, очередь кадров увеличивается вплоть до трех по умолчанию или, если требует приложение, больше. Таким образом обеспечивается непрерывная загрузка графического процессора и постоянный темп рендеринга, но есть и побочный эффект в виде задержки реакции на ввод, ведь Direct3D не позволяет выбросить из очереди заранее спланированные кадры. Однако RAL не может стать универсальным лекарством от лагов: к примеру, если быстродействие игры сдерживается возможностями центрального, а не графического процессора, короткая очередь кадров (или ее полное отсутствие) делает бутылочное горлышко CPU только уже. Результат зависит от конфигурации компьютера и особенностей игры. Тем не менее, переключатель RAL в панели управления видеокартой открывает доступ к настройке параметра Direct3D, который раньше на видеокартах AMD можно было изменить только при помощи стороннего ПО (например, утилиты RadeonPro), и геймеры могут на собственном опыте выяснить, нужно ли пользоваться этой функцией или лучше оставить длину очереди кадров в покое. RAL, само собой, не привязан к ускорителям на чипах Navi и работает как на старых, так и на новых видеокартах. У NVIDIA аналогичная опция называется Maximum Pre-Rendered Frames.

⇡#Тестовый стенд, методика тестирования
| Тестовый стенд |
|---|
| CPU |
Intel Core i9-9900K (4,9 ГГц, 4,8 ГГц в AVX, фиксированная частота) |
| Материнская плата |
ASUS MAXIMUS XI APEX |
| Оперативная память |
G.Skill Trident Z RGB F4-3200C14D-16GTZR, 2 × 8 Гбайт (3200 МГц, CL14) |
| ПЗУ |
Intel SSD 760p, 1024 Гбайт |
| Блок питания |
Corsair AX1200i, 1200 Вт |
| Система охлаждения CPU |
Corsair Hydro Series H115i |
| Корпус |
CoolerMaster Test Bench V1.0 |
| Монитор |
NEC EA244UHD |
| Операционная система |
Windows 10 Pro x64 |
| ПО для GPU AMD |
| Все видеокарты |
AMD Radeon Software Adrenalin 2019 Edition 19.7.1 |
| ПО для GPU NVIDIA |
| Все видеокарты |
NVIDIA GeForce Game Ready Driver 431.16 |
| Синтетические тесты 3D-графики |
|---|
| Тест |
API |
Разрешение |
Полноэкранное сглаживание |
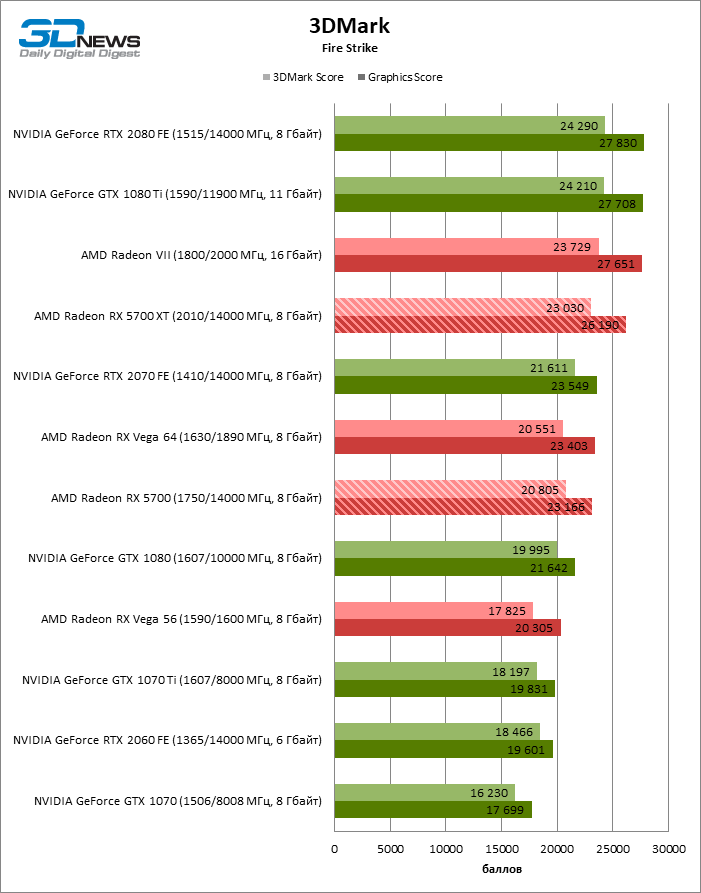
| 3DMark Fire Strike 1.1 |
DirectX 11 (feature level 11_0) |
1920 × 1080 |
Выкл. |
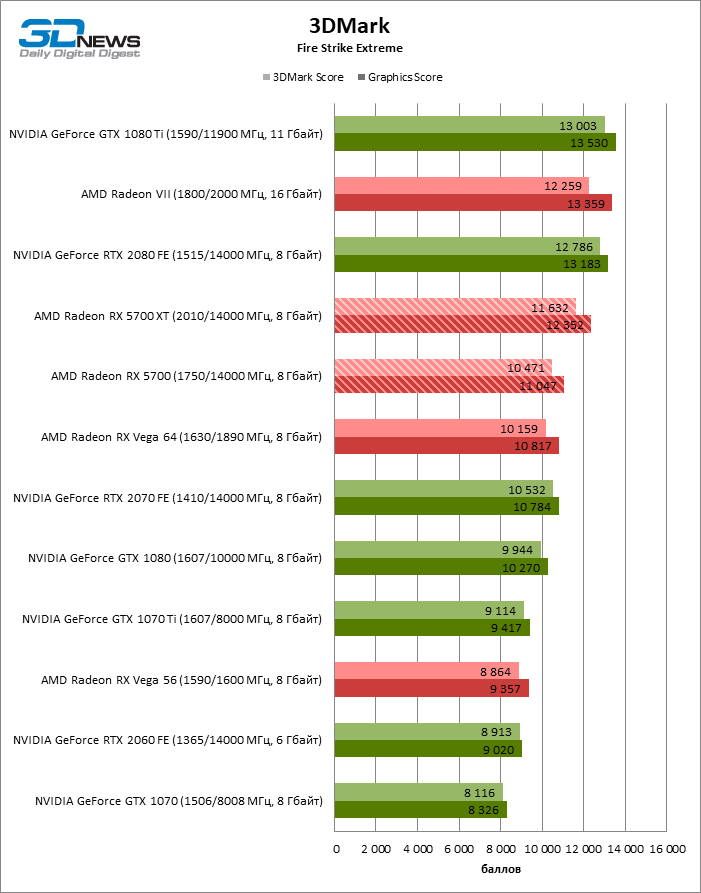
| 3DMark Fire Strike 1.1 Extreme |
2560 × 1440 |
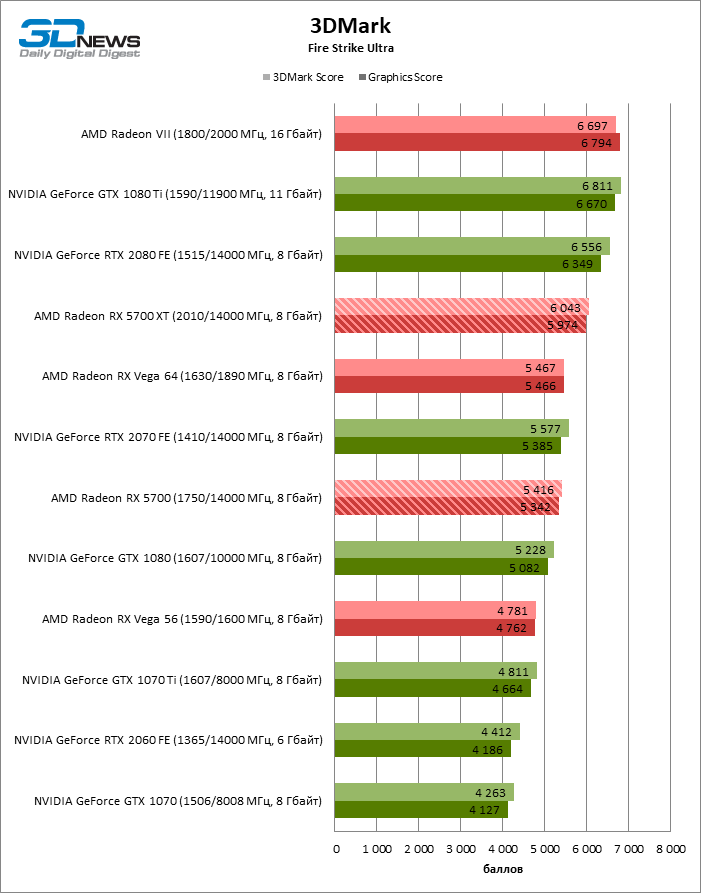
| 3DMark Fire Strike 1.1 Ultra |
3840 × 2160 |
| 3DMark Time Spy 1.1 |
DirectX 12 (feature level 11_0) |
2560 × 1440 |
| 3DMark Time Spy Extreme 1.1 |
3840 × 2160 |
| Игровые тесты |
|---|
| Игра (в порядке даты выхода) |
API |
Настройки, метод тестирования |
Полноэкранное сглаживание |
| 1920 × 1080 / 2560 × 1440 |
3840 × 2160 |
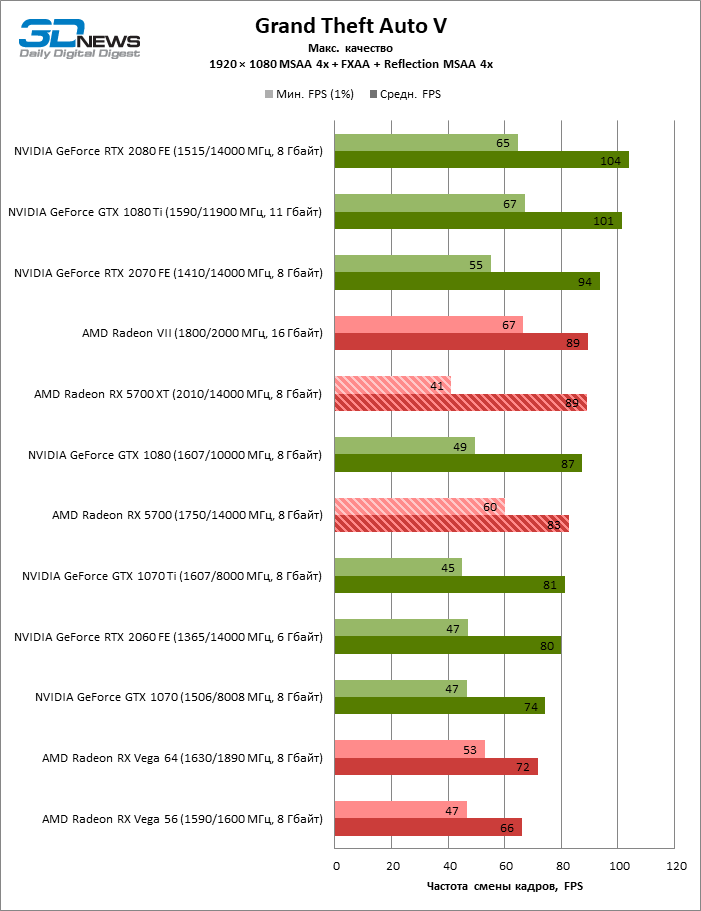
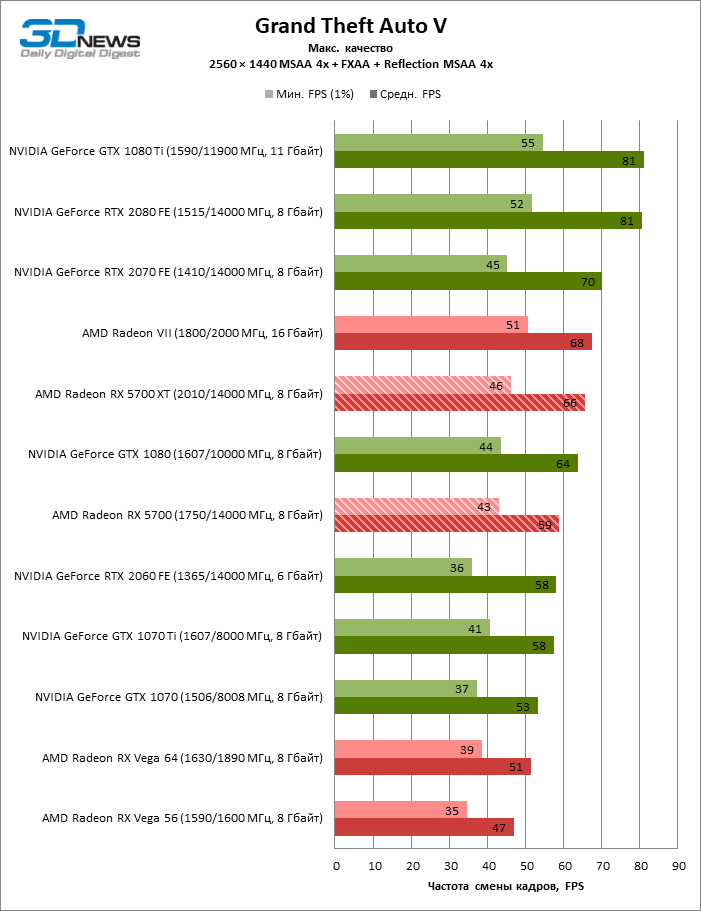
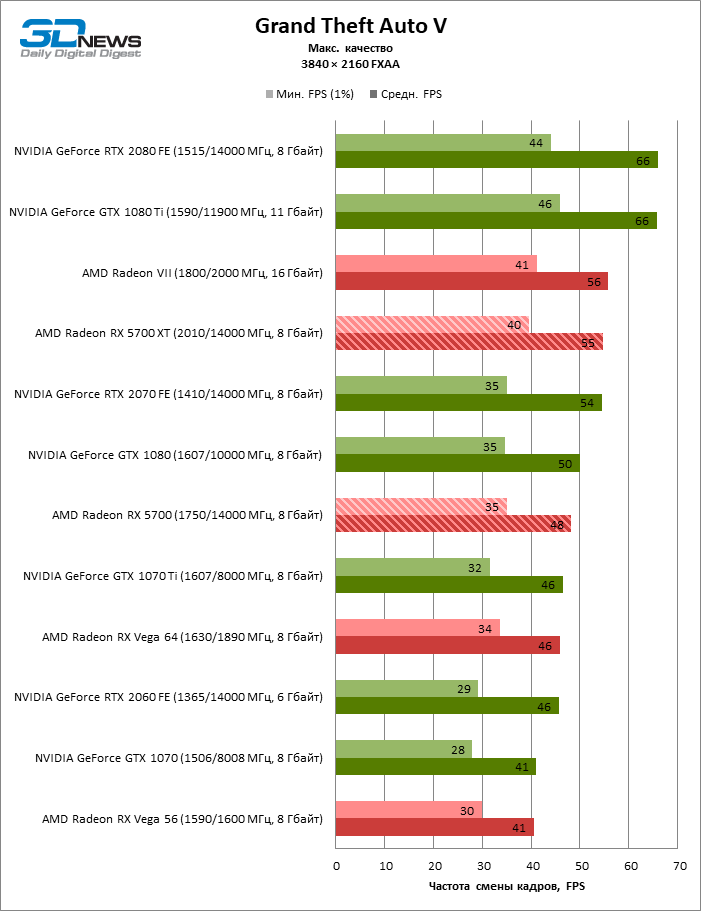
| Grand Theft Auto V |
DirectX 11 |
Встроенный бенчмарк. Макс. качество графики |
MSAA 4x + FXAA + Reflection MSAA 4x |
FXAA |
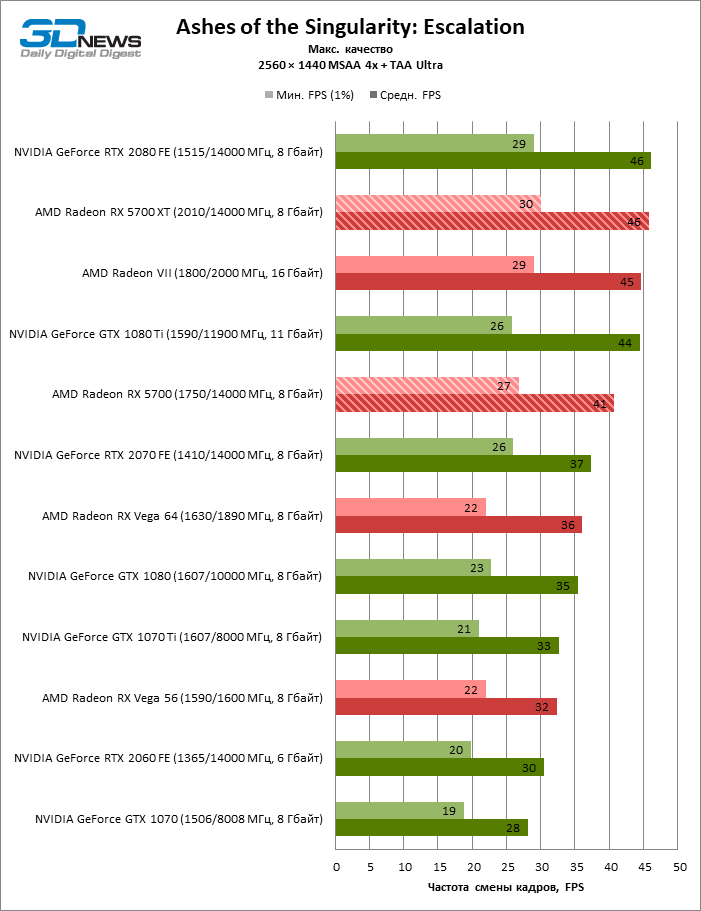
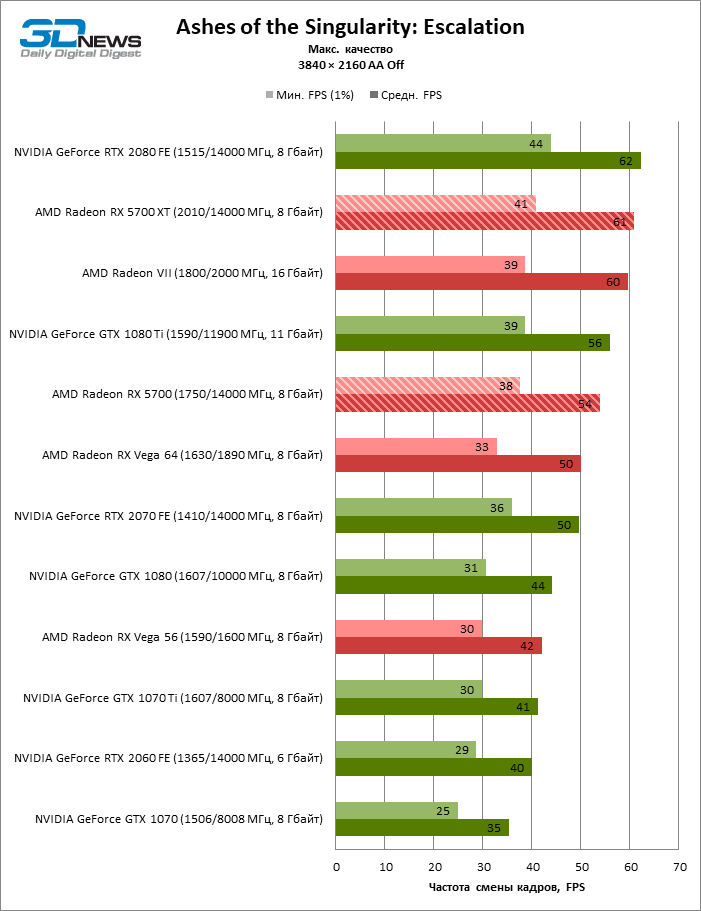
| Ashes of the Singularity: Escalation |
Vulkan |
Встроенный бенчмарк. Макс. качество графики |
MSAA 4x + TAA Ultra |
Выкл. |
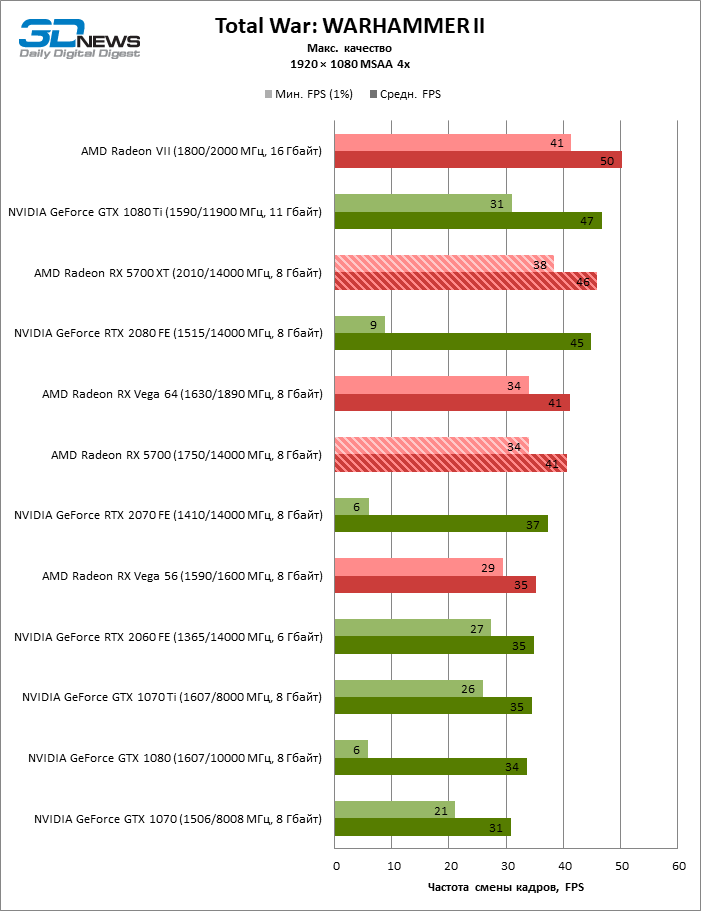
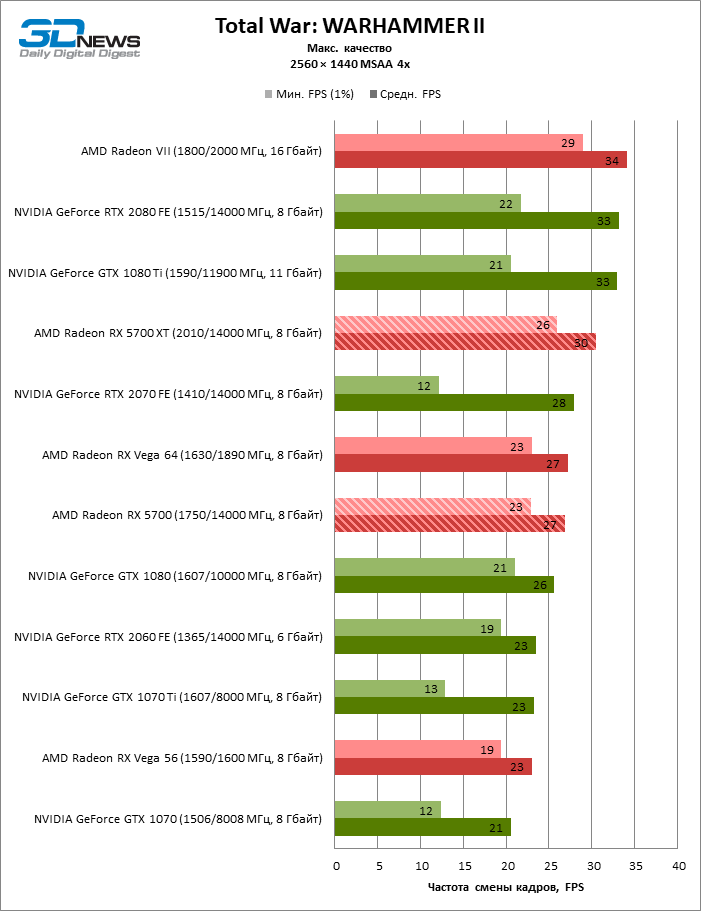
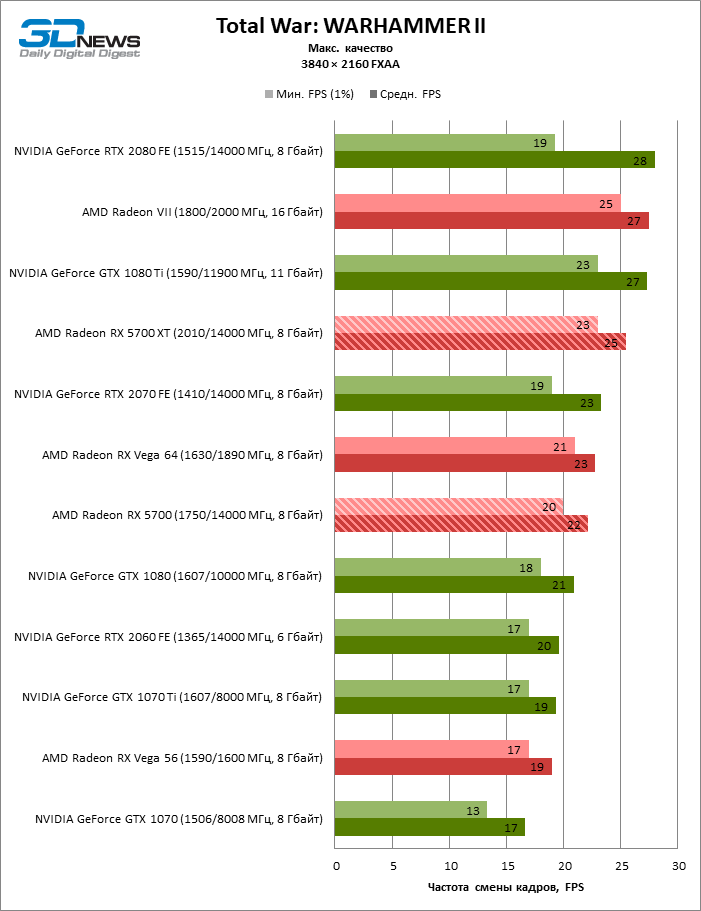
| Total War: WARHAMMER II, встроенный бенчмарк |
DirectX 12 |
Встроенный бенчмарк (Battle Benchmark). Макс. качество графики |
MSAA 4x |
FXAA |
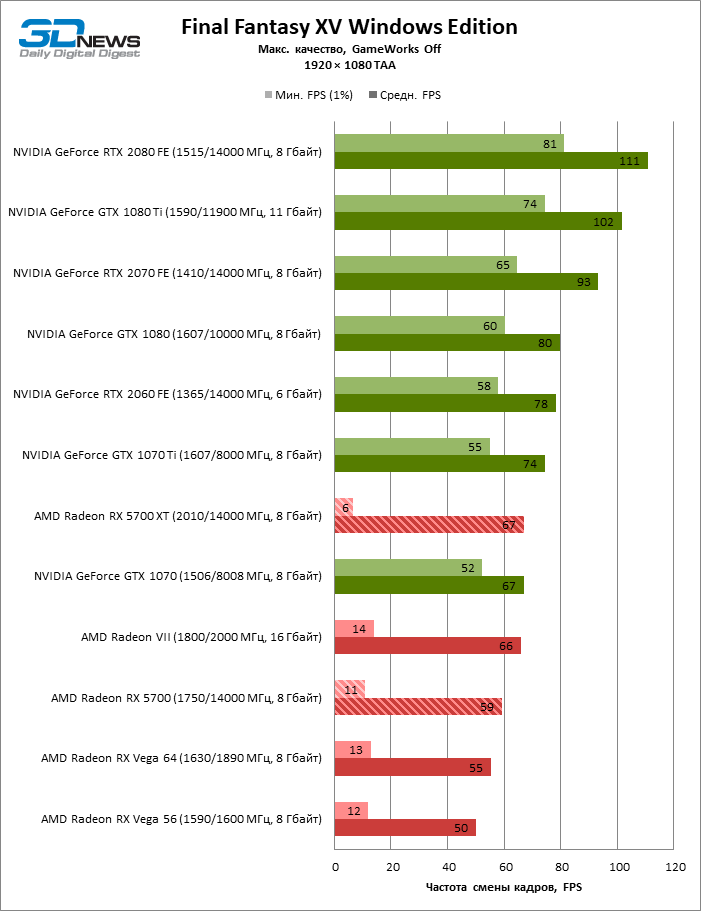
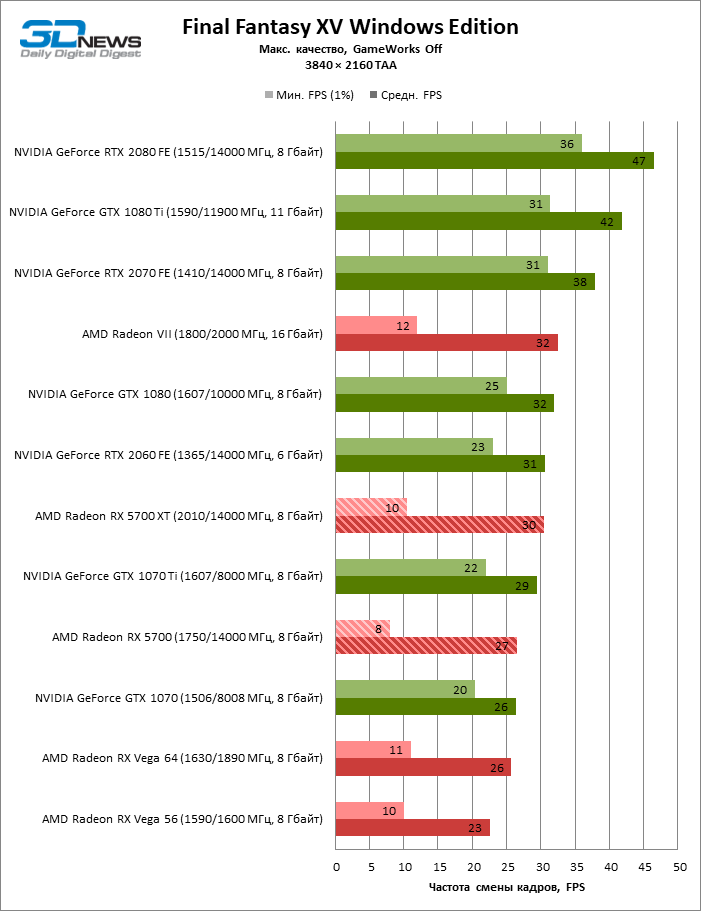
| Final Fantasy XV Windows Edition |
DirectX 11 |
Встроенный бенчмарк + OCAT. Макс. качество графики. NVIDIA GameWorks выкл., DLSS выкл. |
TAA |
TAA |
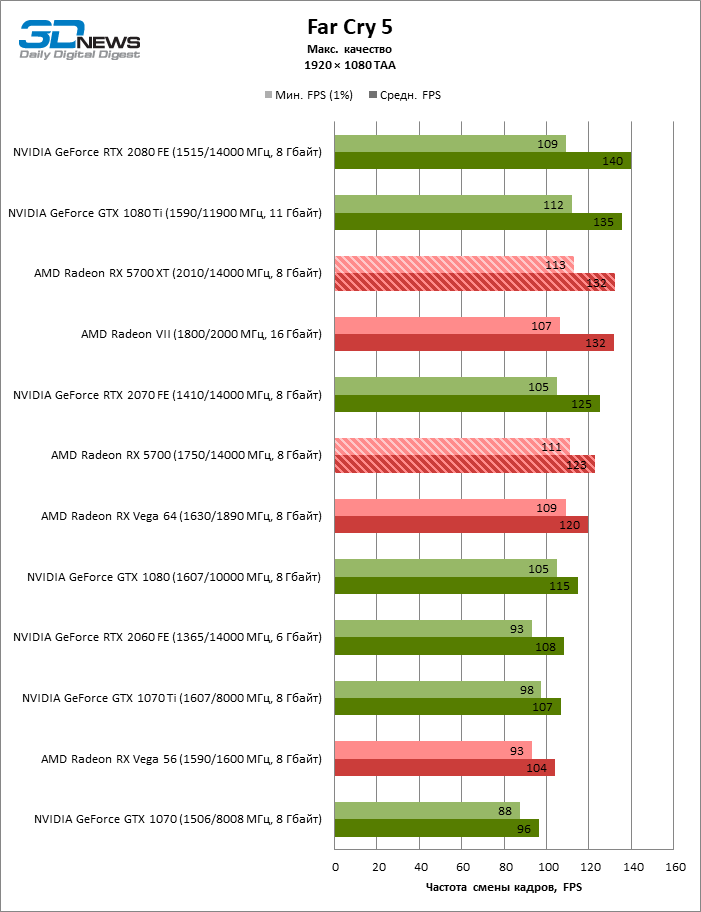
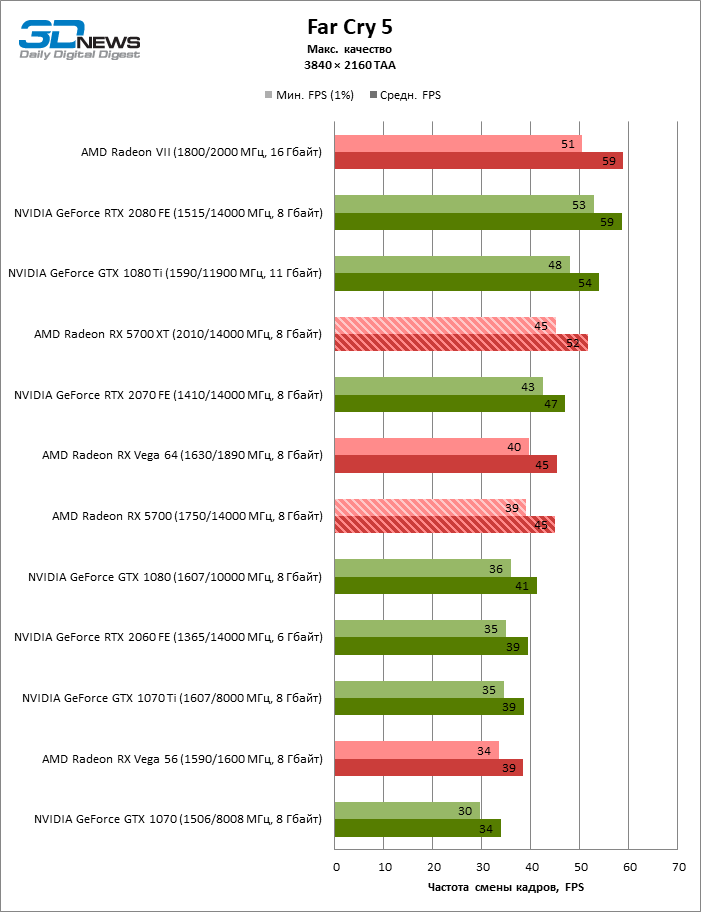
| Far Cry 5 |
DirectX 11 |
Встроенный бенчмарк. Макс. качество графики |
TAA |
TAA |
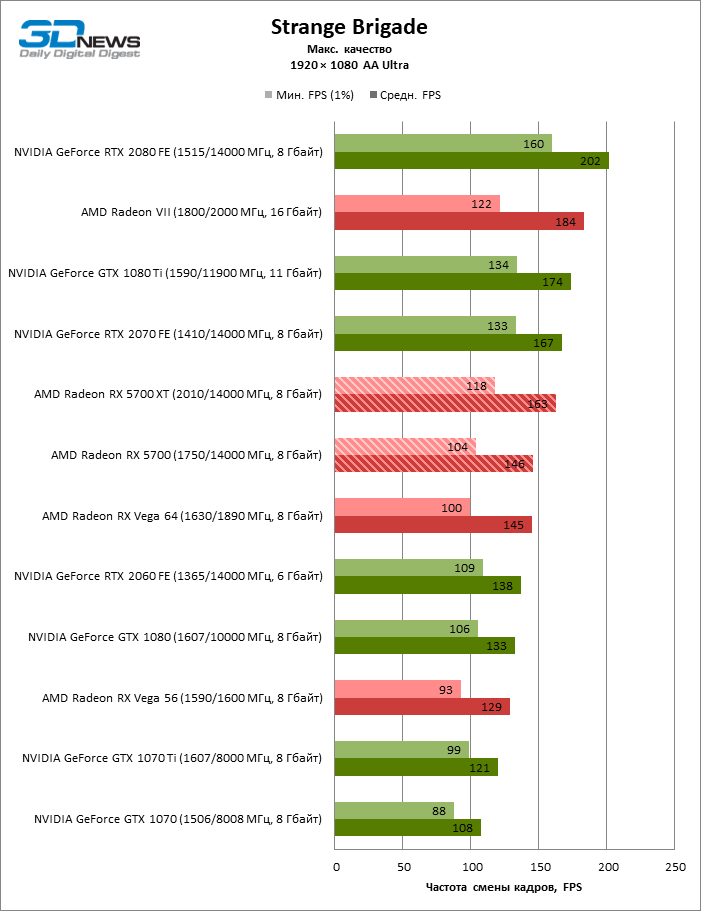
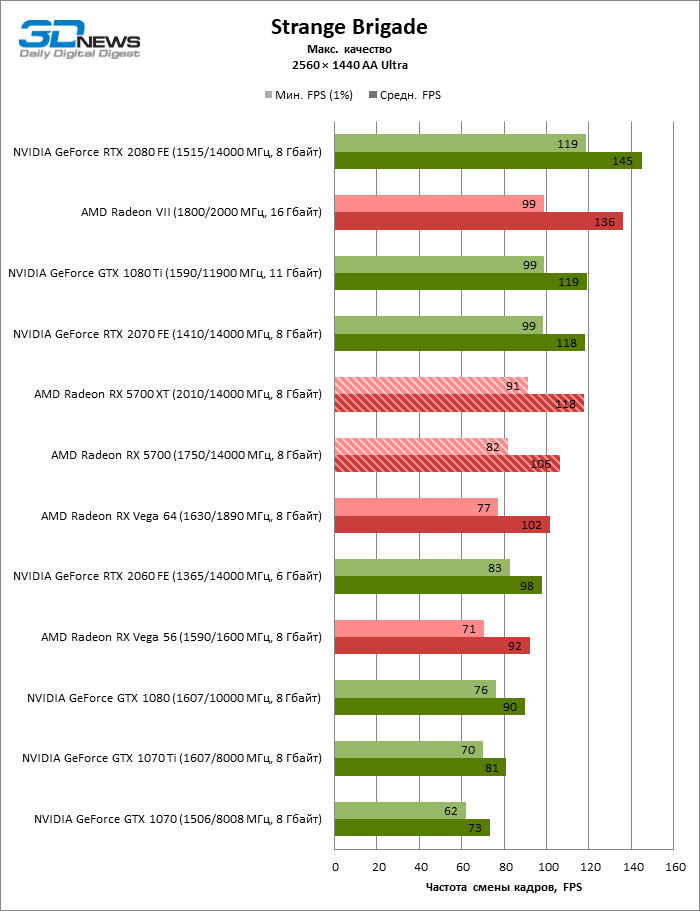
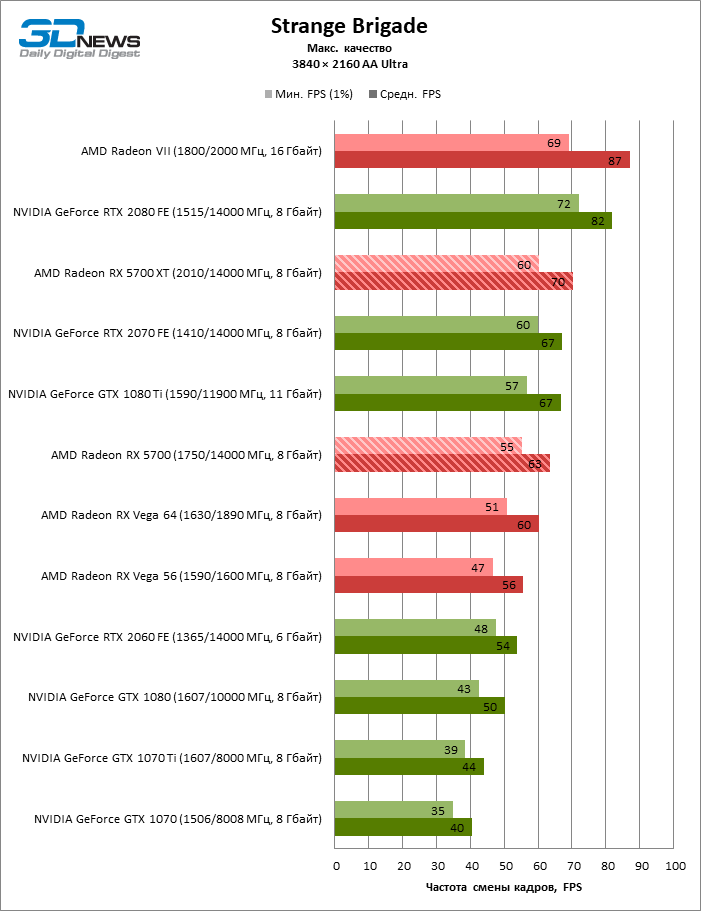
| Strange Brigade |
Vulkan |
Встроенный бенчмарк. Макс. качество графики |
AA Ultra |
AA Ultra |
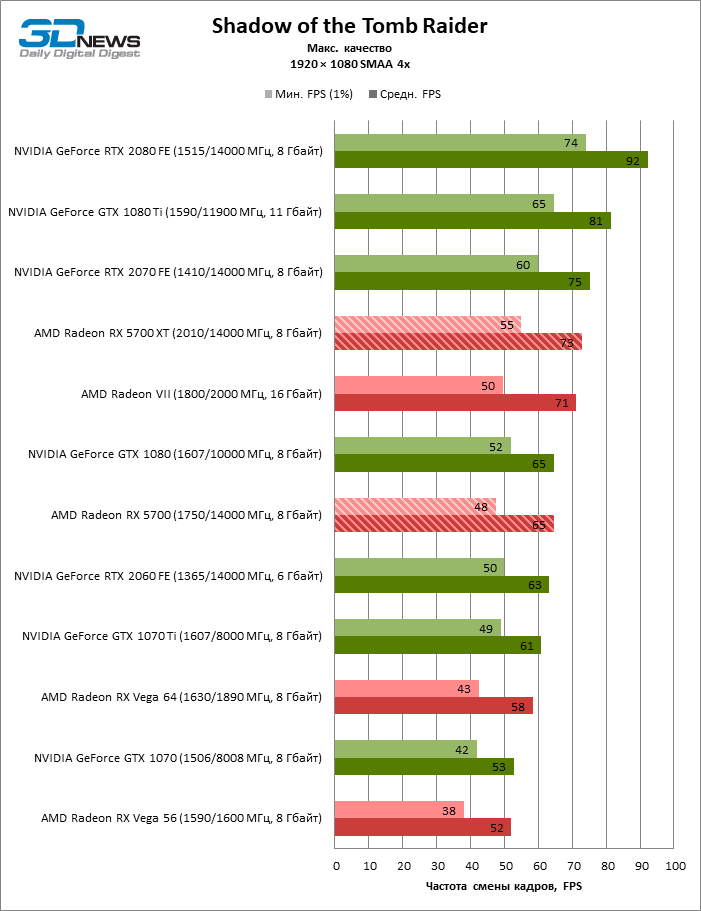
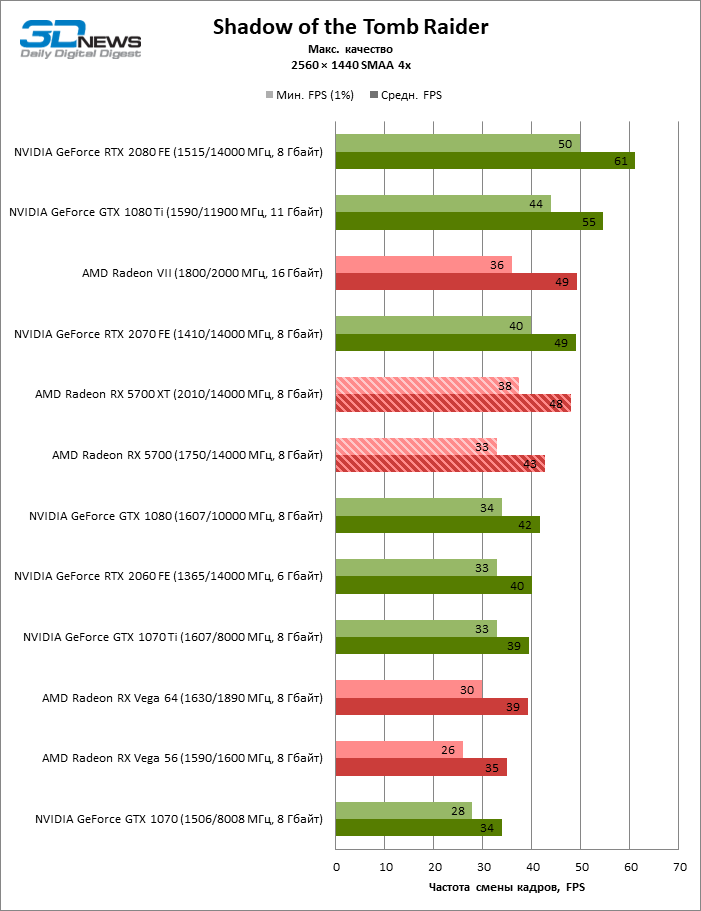
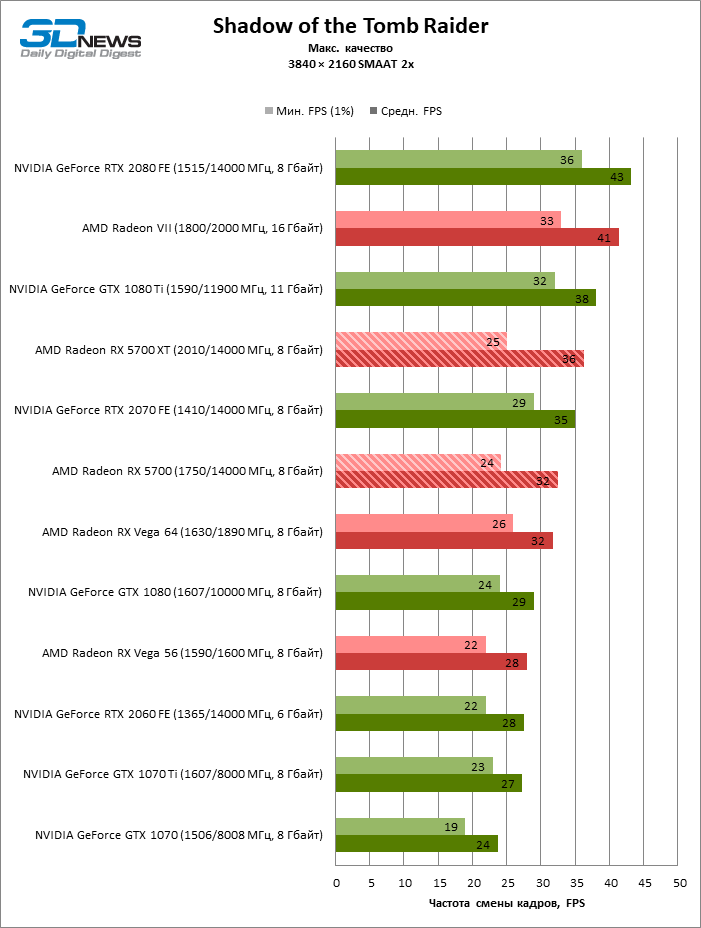
| Shadow of the Tomb Raider |
DirectX 12 |
Встроенный бенчмарк. Макс. качество графики |
SMAA 4x |
SMAAT 2x |
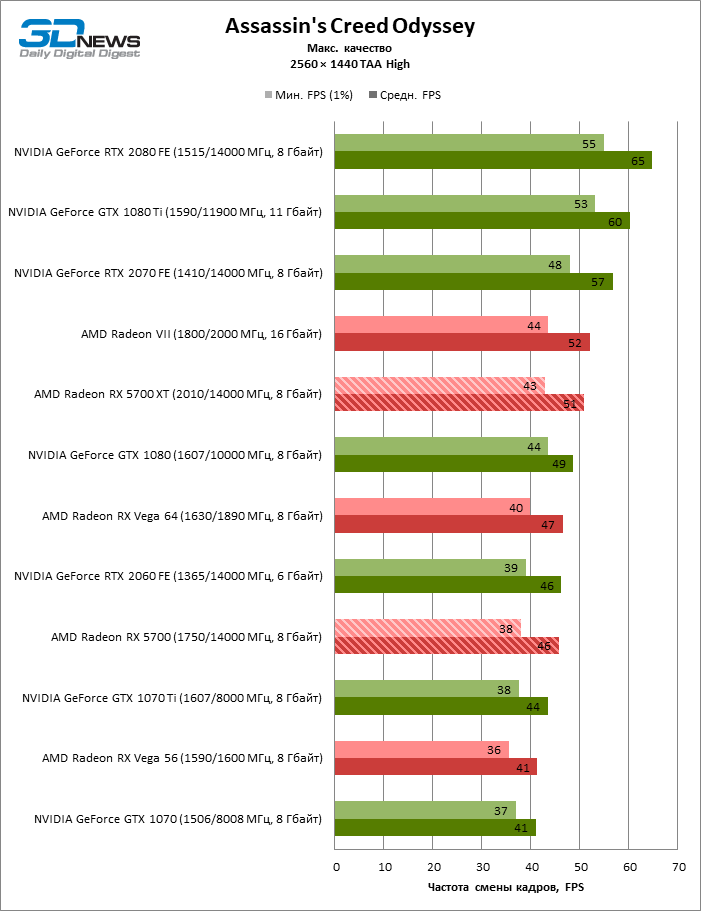
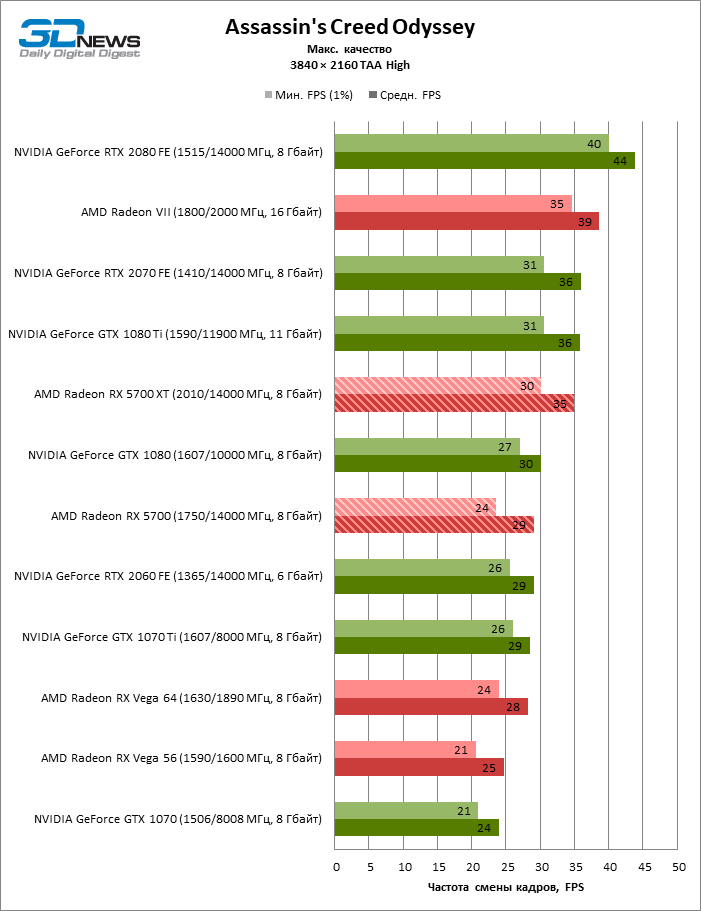
| Assassin's Creed Odyssey |
DirectX 11 |
Встроенный бенчмарк. Макс. качество графики |
AA High (TAA) |
AA High (TAA) |
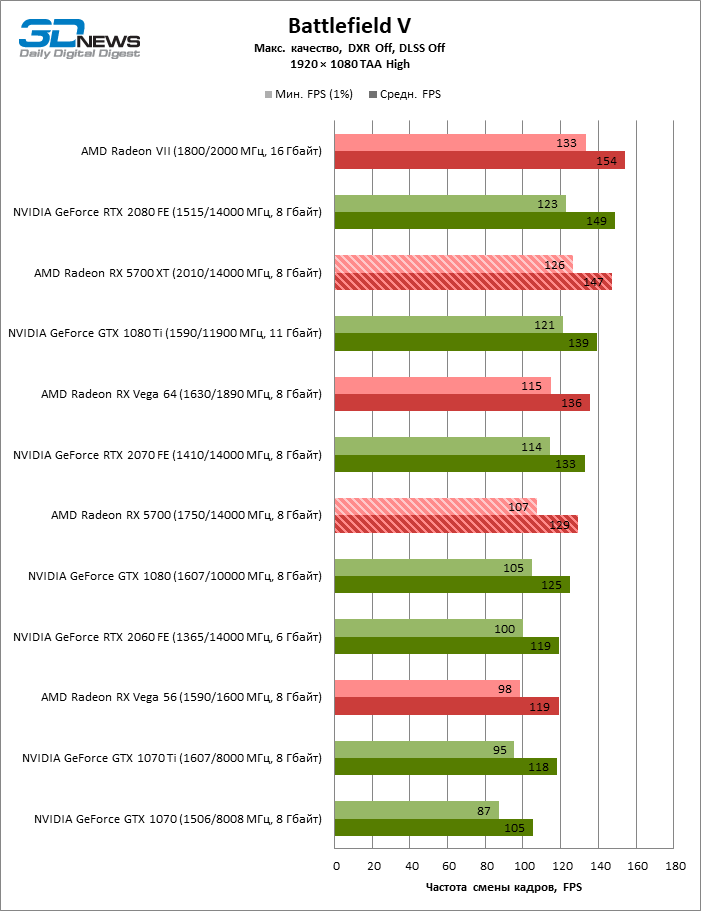
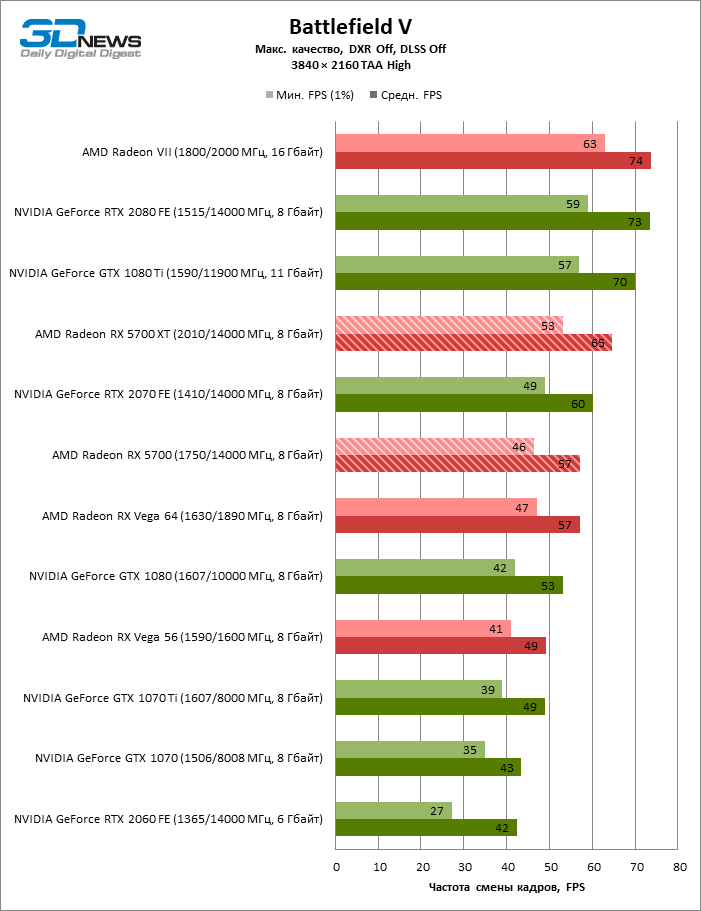
| Battlefield V |
DirectX 12 |
OCAT, миссия Liberte. Макс. качество графики. DXR выкл., DLSS выкл. |
TAA High |
TAA High |
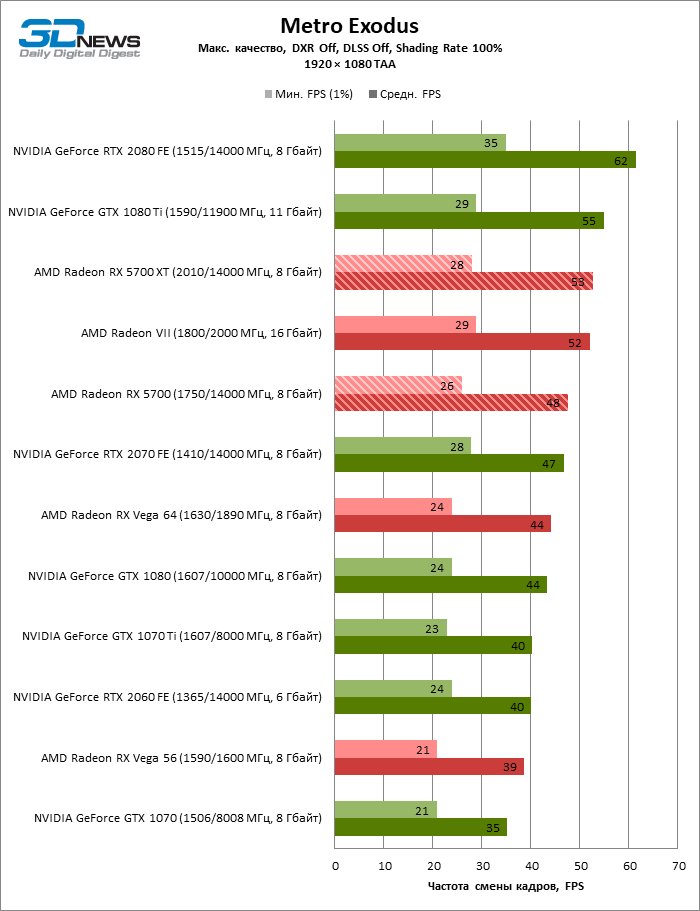
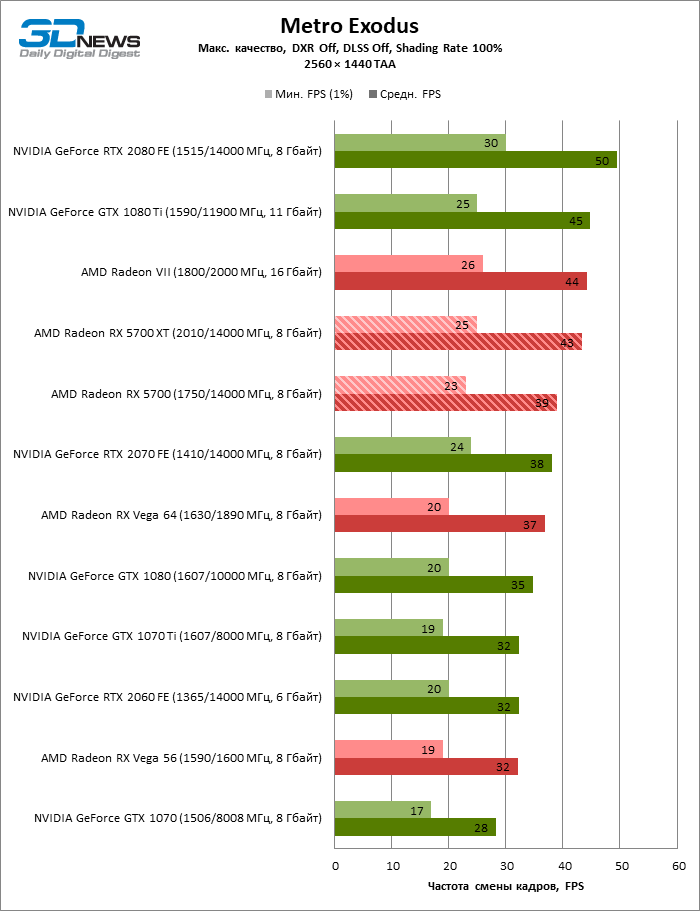
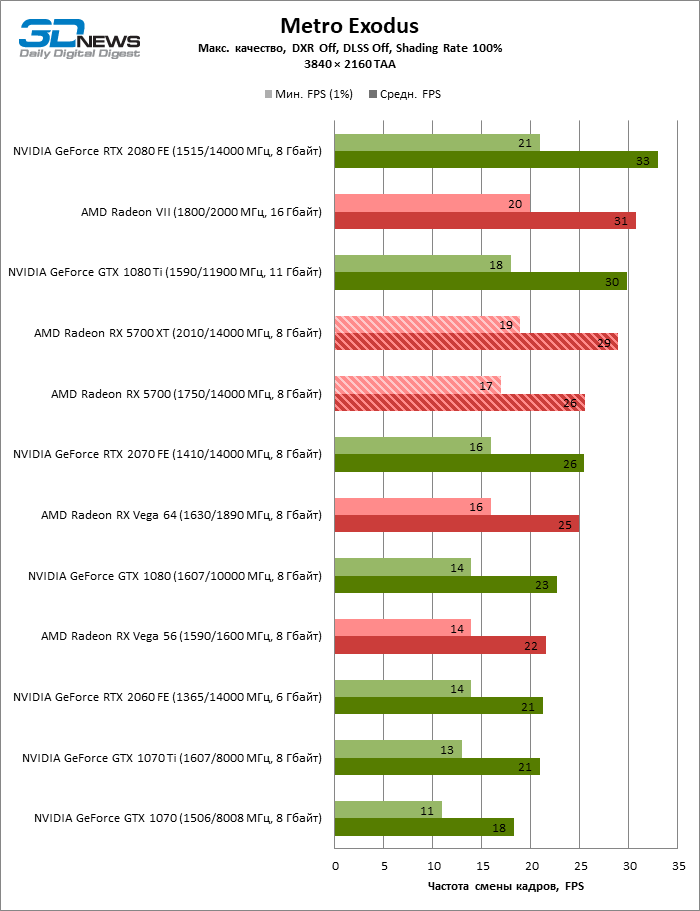
| Metro Exodus |
DirectX 12 |
Встроенный бенчмарк. Макс. качество графики. DXR выкл., DLSS выкл., Shading Rate 100% |
TAA |
TAA |
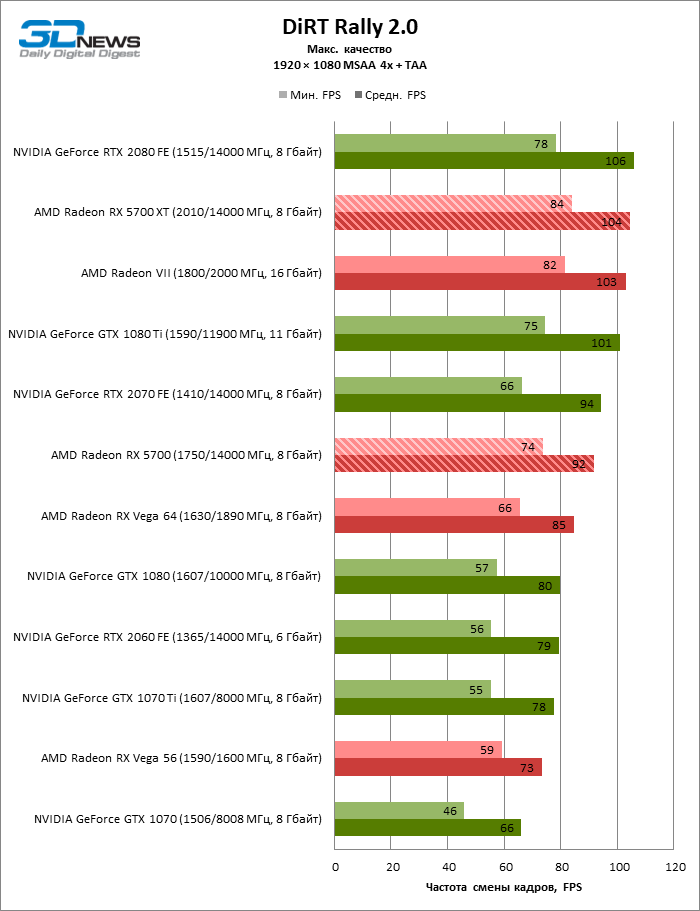
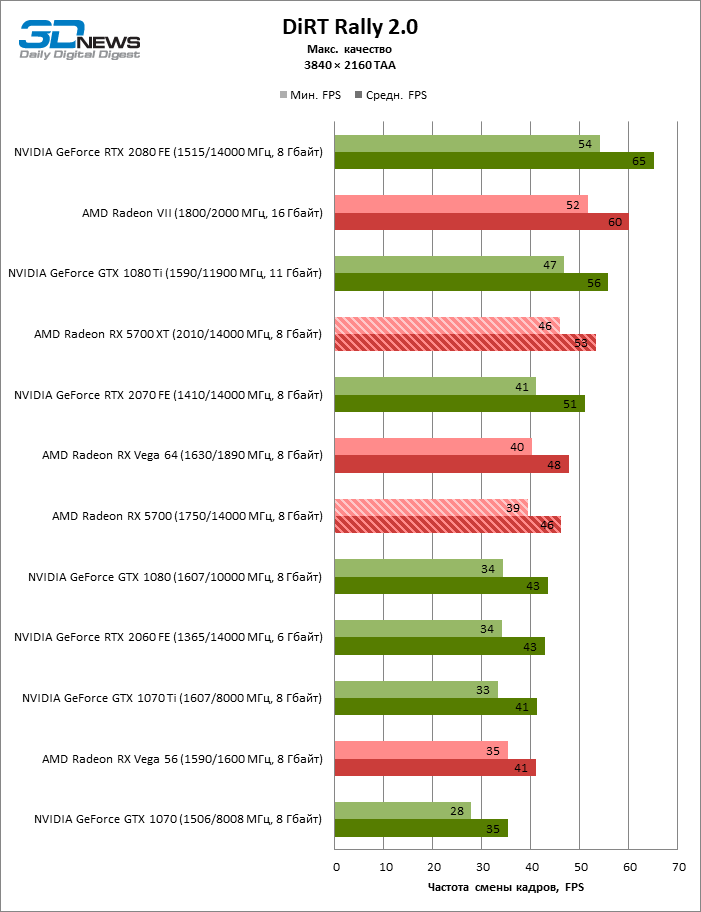
| DiRT Rally 2.0 |
DirectX 11 |
Встроенный бенчмарк. Макс. качество графики |
MSAA 4x + TAA |
TAA |
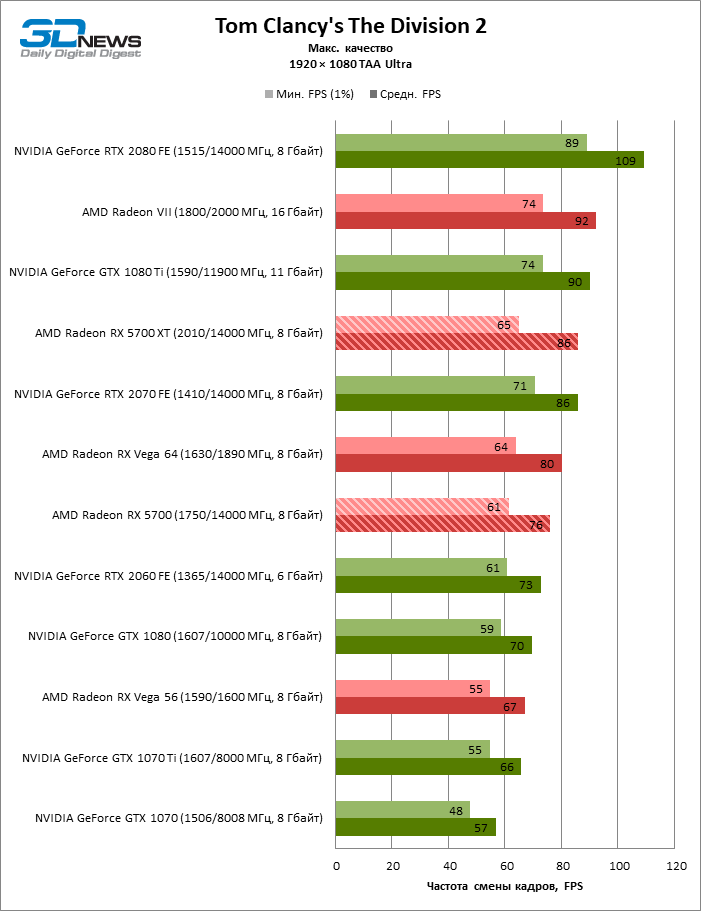
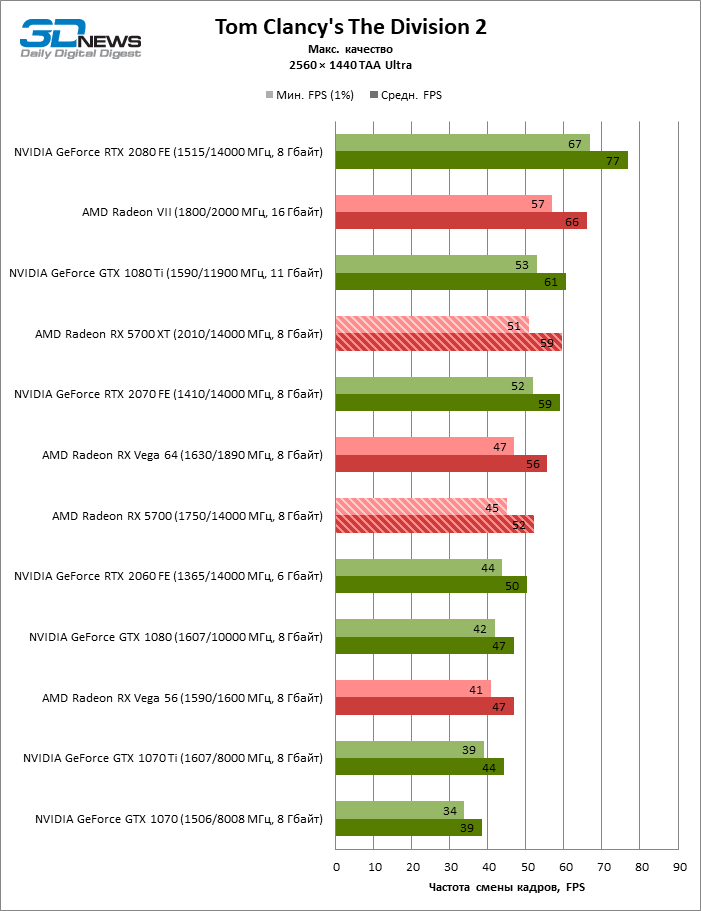
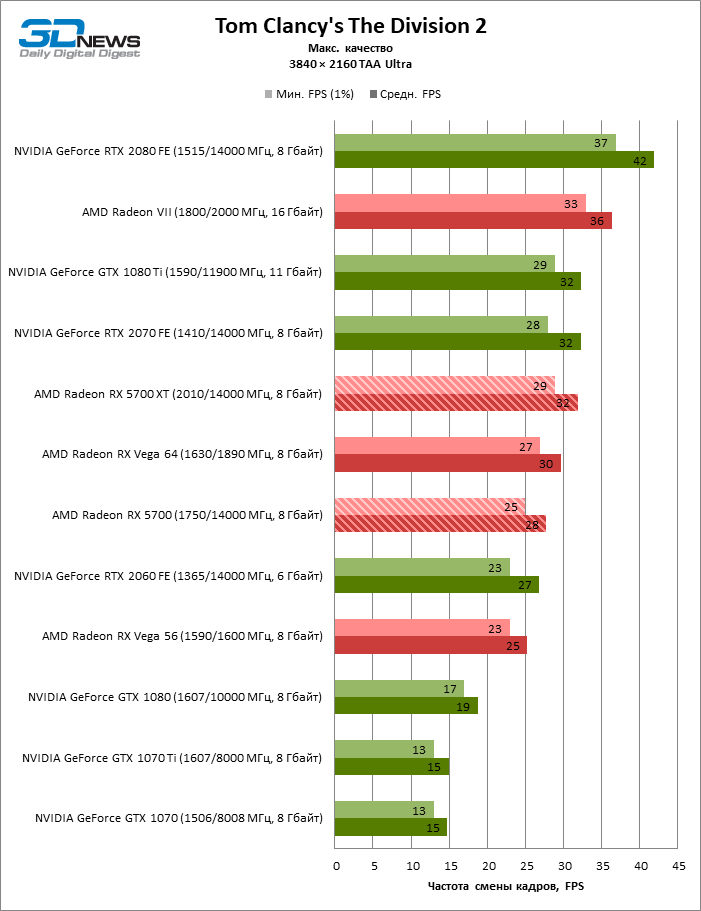
| Tom Clancy's The Division 2 |
DirectX 12 |
Встроенный бенчмарк. Макс. качество графики |
AA Ultra (TAA) |
AA Ultra (TAA) |
В большинстве тестовых игр показатели средней и минимальной кадровых частот выводятся из массива времени рендеринга индивидуальных кадров, который записывает встроенный бенчмарк (или утилита OCAT, если его нет).
Средняя частота смены кадров на диаграммах является величиной, обратной среднему времени кадра. Для оценки минимальной кадровой частоты вычисляется количество кадров, сформированных в каждую секунду теста. Из этого массива чисел выбирается значение, соответствующее 1-му процентилю распределения.
Исключением из этой методики являются игры DiRT Rally 2.0 и Far Cry 5. Встроенный бенчмарк DiRT Rally 2.0 не записывает время рендеринга отдельных кадров — файл с результатами содержит среднюю частоту смены кадров и минимальную, рассчитанную по максимальному времени кадра. Встроенный бенчмарк Far Cry 5 записывает количество кадров в отдельную секунду теста, поэтому среднее FPS рассчитывается исходя из этих чисел, а не по среднему времени рендеринга кадра.
| Вычисления общего назначения, кодирование/декодирование видео |
|---|
| Программа |
Настройки |
| AMD |
NVIDIA |
| DXVA Checker 4.1.2, Decode Benchmark |
H.264 |
1920 × 1080 (High Profile, L4.1), 3840 × 2160 (High Profile, L5.1). Microsoft H264 Video Decoder |
| H.265 |
1920 × 1080 (Main Profile, L4.0), 3840 × 2160 (Main Profile, L5.0), 7680 × 4320 (Main Profile, L6.0). Microsoft HEVC Video Extensions |
| VP9 |
1920 × 1080, 3840 × 2160, 7680 × 4320. Microsoft VP9 Video Extensions |
| Ffmpeg 4.0.2, кодирование H.264 |
1920 × 1080 |
-c:v h264_amf -quality speed -coder cabac -level 4.1 -refs 1 -b:v 3M |
-c:v h264_nvenc -preset fast -coder cabac -level 4.1 -refs 1 -b:v 3M |
| 3840 × 2160 |
-c:v h264_amf -quality speed -coder cabac -level 5.1 -refs 1 -b:v 7.5M |
-c:v h264_nvenc -preset fast -coder cabac -level 5.1 -refs 1 -b:v 7.5M |
| Ffmpeg 4.0.2, кодирование H.265 |
1920 × 1080 |
-c:v hevc_amf -quality speed -level 4 -b:v 3M |
-c:v hevc_nvenc -preset fast -level 4 -b:v 3M |
| 3840 × 2160 |
-c:v hevc_amf -quality speed -level 5 -b:v 7.5M |
-c:v hevc_nvenc -preset fast -level 5 -b:v 7.5M |
| 7680 × 4320 |
— |
-c:v hevc_nvenc -preset fast -level 6 -refs 1 -b:v 20M |
| LuxMark 3.1 |
Hotel Lobby (Complex Benchmark) |
— |
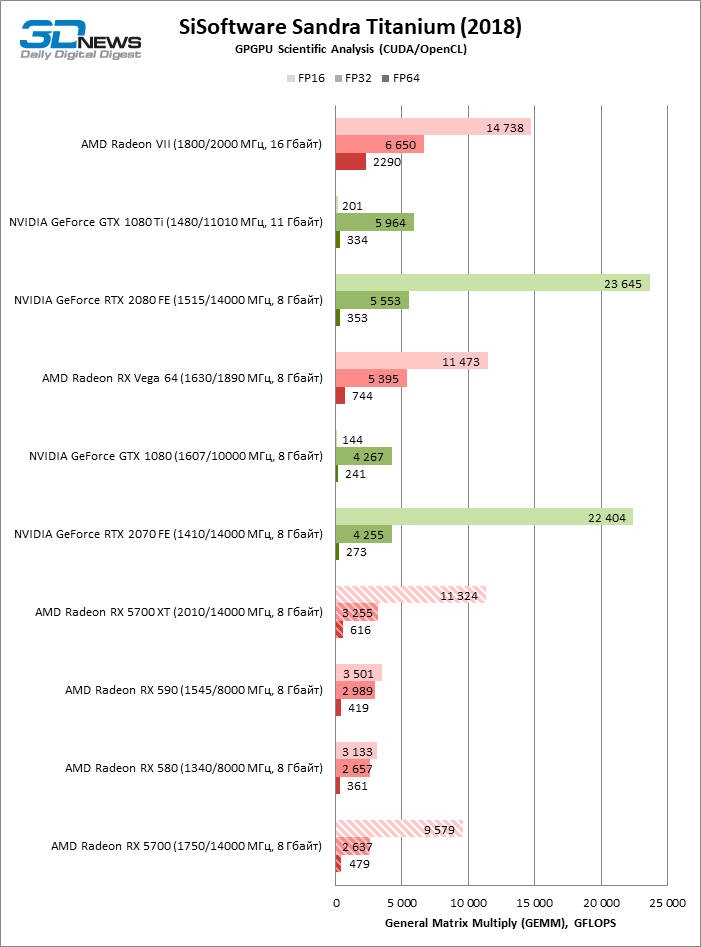
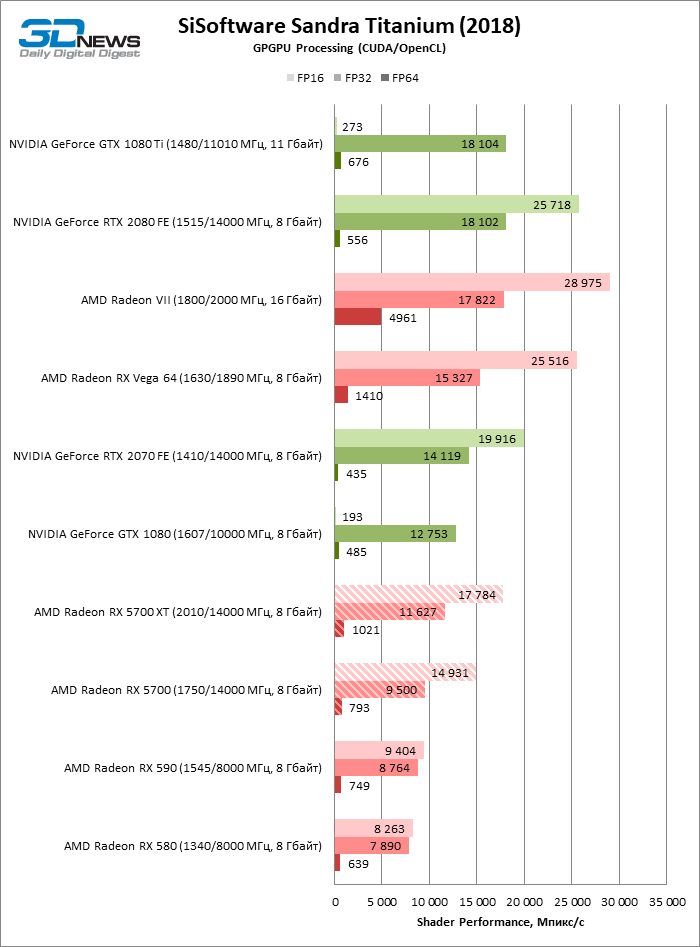
| SiSoftware Sandra Titanium (2018) SP3b |
GPGPU Processing |
OpenCL (FP16/FP32/FP64) |
CUDA (FP16/FP32/FP64) |
| GPGPU Scientific Analysis |
Мощность видеокарт регистрируется отдельно от CPU и прочих компонентов ПК с помощью амперметра MingHe VAC-1050A. Чтобы одновременно измерить ток, проходящий по разъемам дополнительного питания и слоту материнской платы, видеокарта подключается через жесткий райзер PCI Express x16, в котором линии питания разорваны и выведены на отдельный кабель.
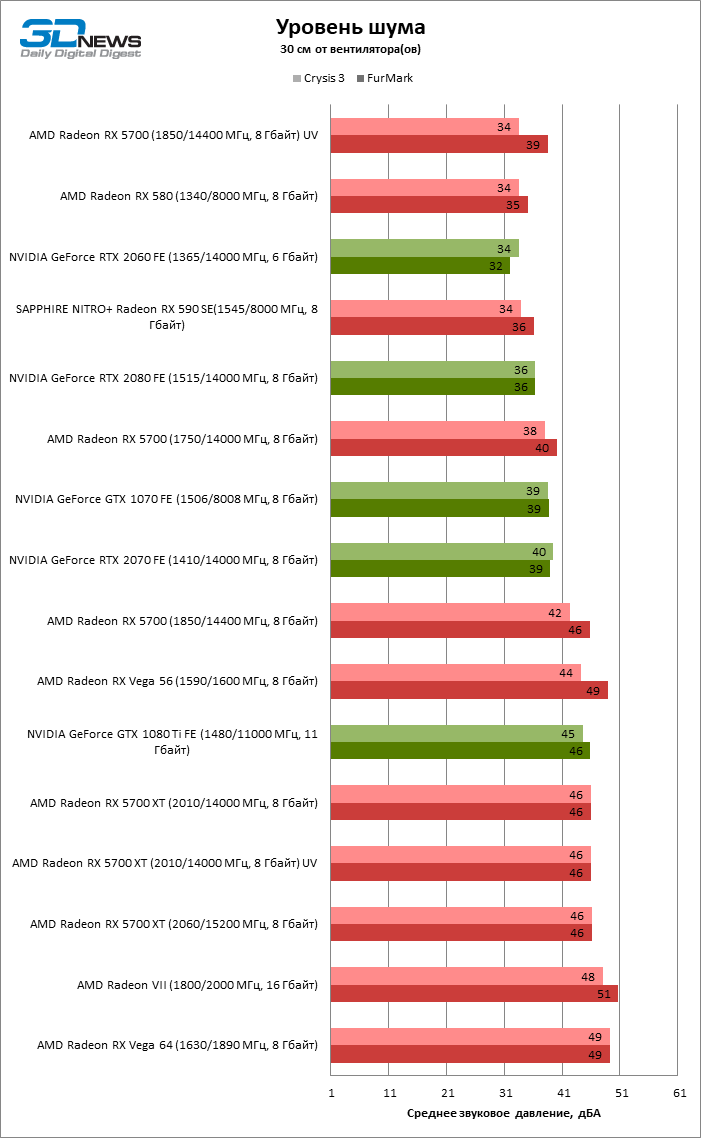
В качестве тестовой нагрузки для тестов мощности и уровня шума используется игра Crysis 3 при разрешении 3840 × 2160 без полноэкранного сглаживания и максимальных параметрах качества графики, а также стресс-тест FurMark с наиболее агрессивными настройками (разрешение 3840 × 2160, MSAA 8x). Замеры всех параметров выполняются после прогрева видеокарты, когда температура GPU и тактовые частоты стабилизируются.
Участники тестирования
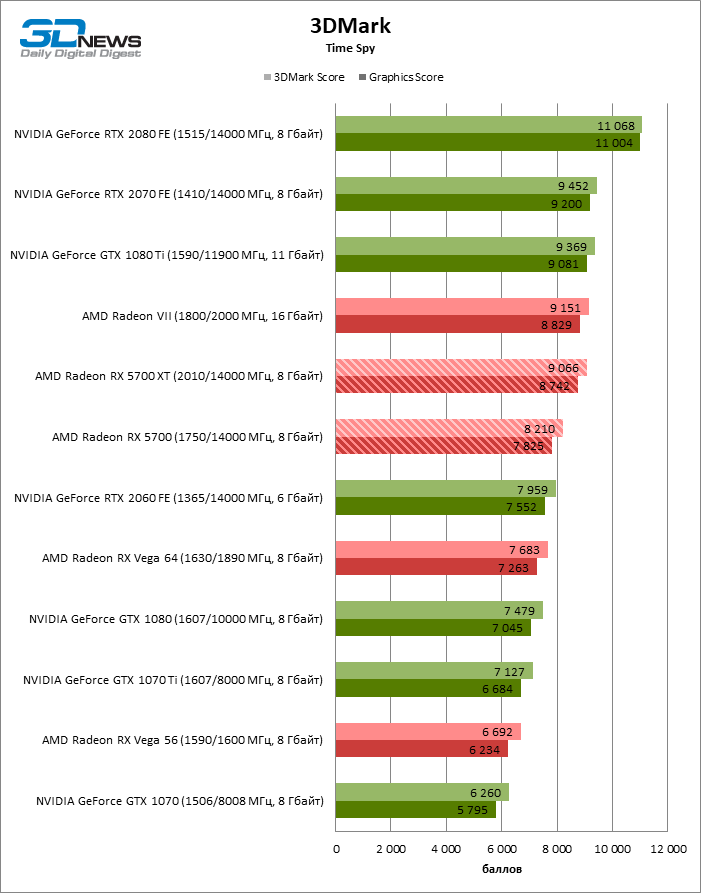
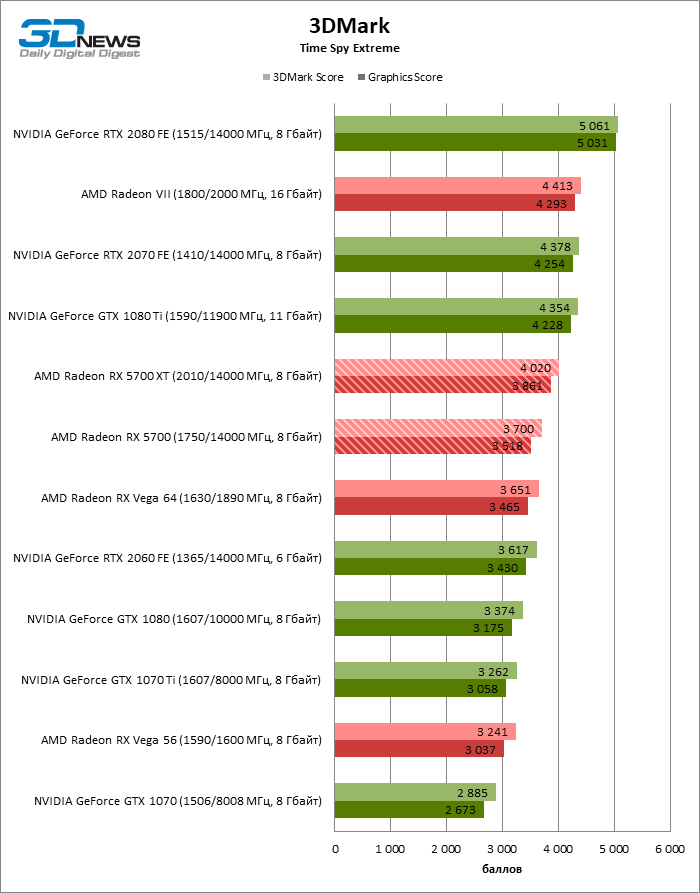
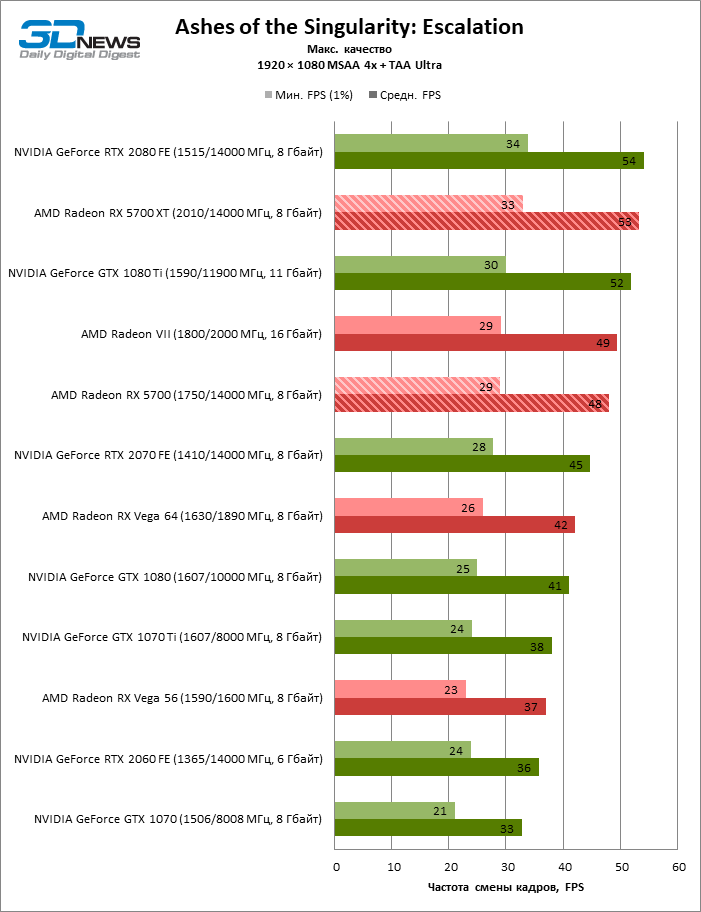
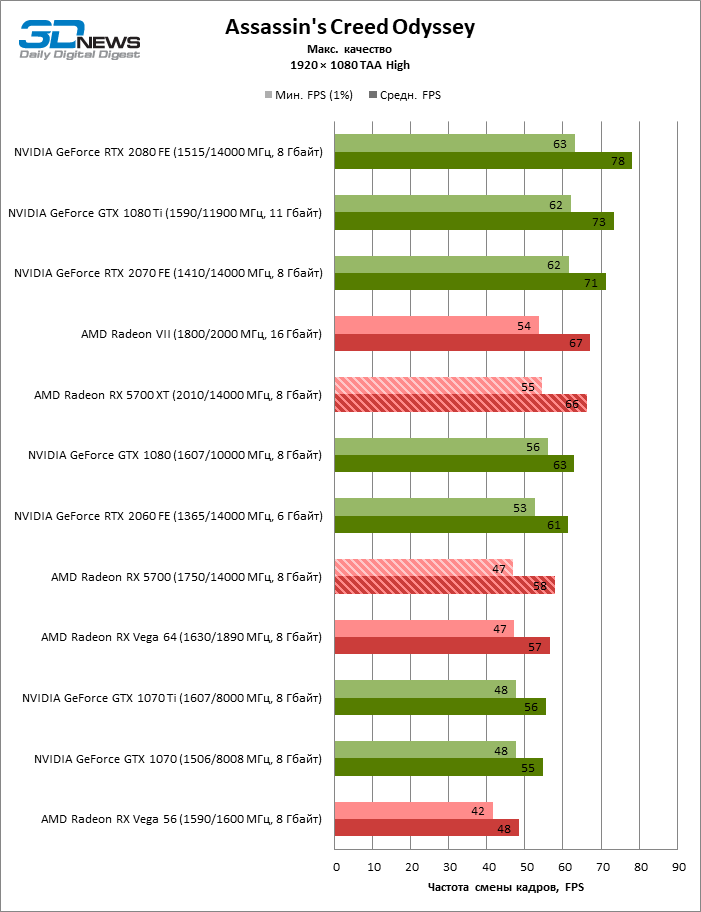
В тестировании производительности приняли участие следующие видеокарты:
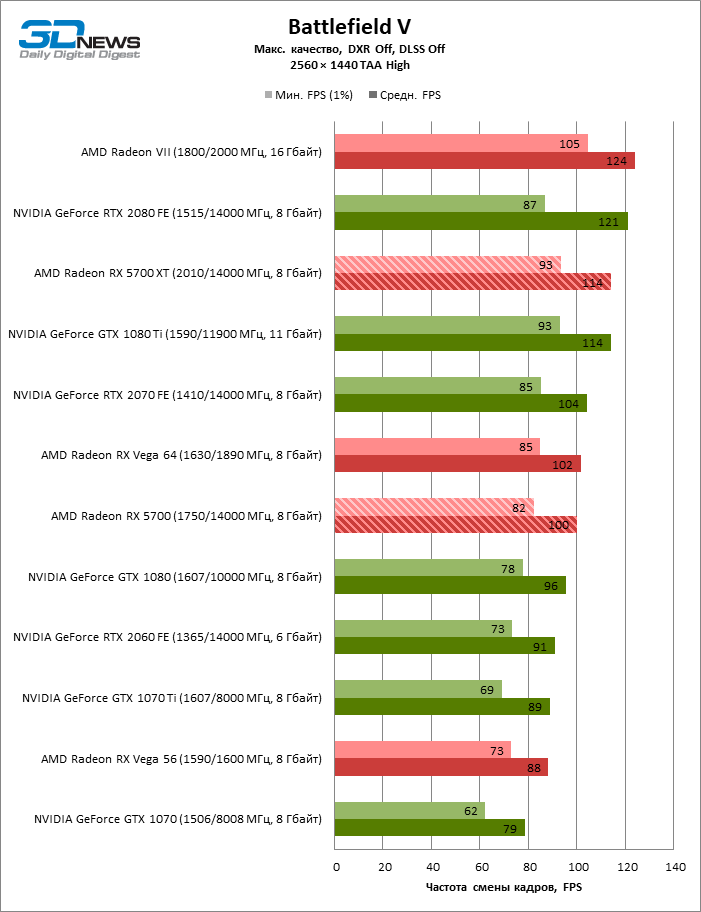
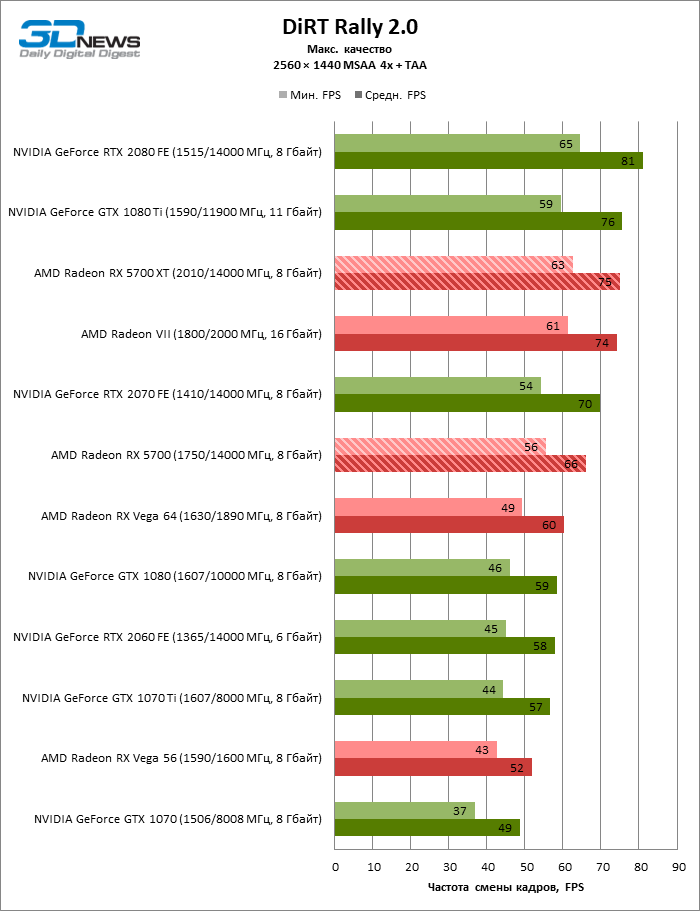
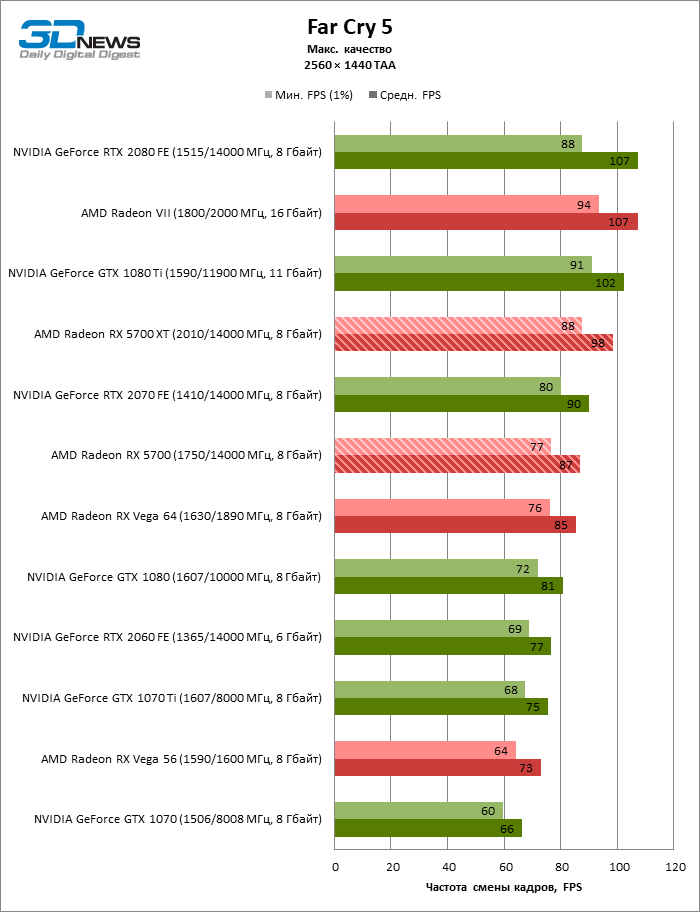
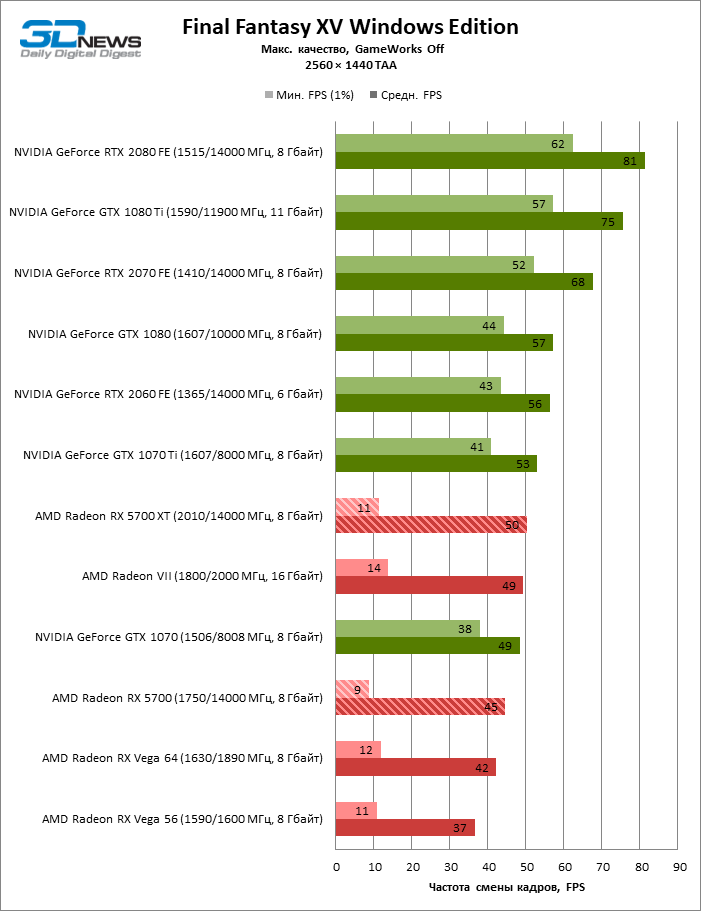
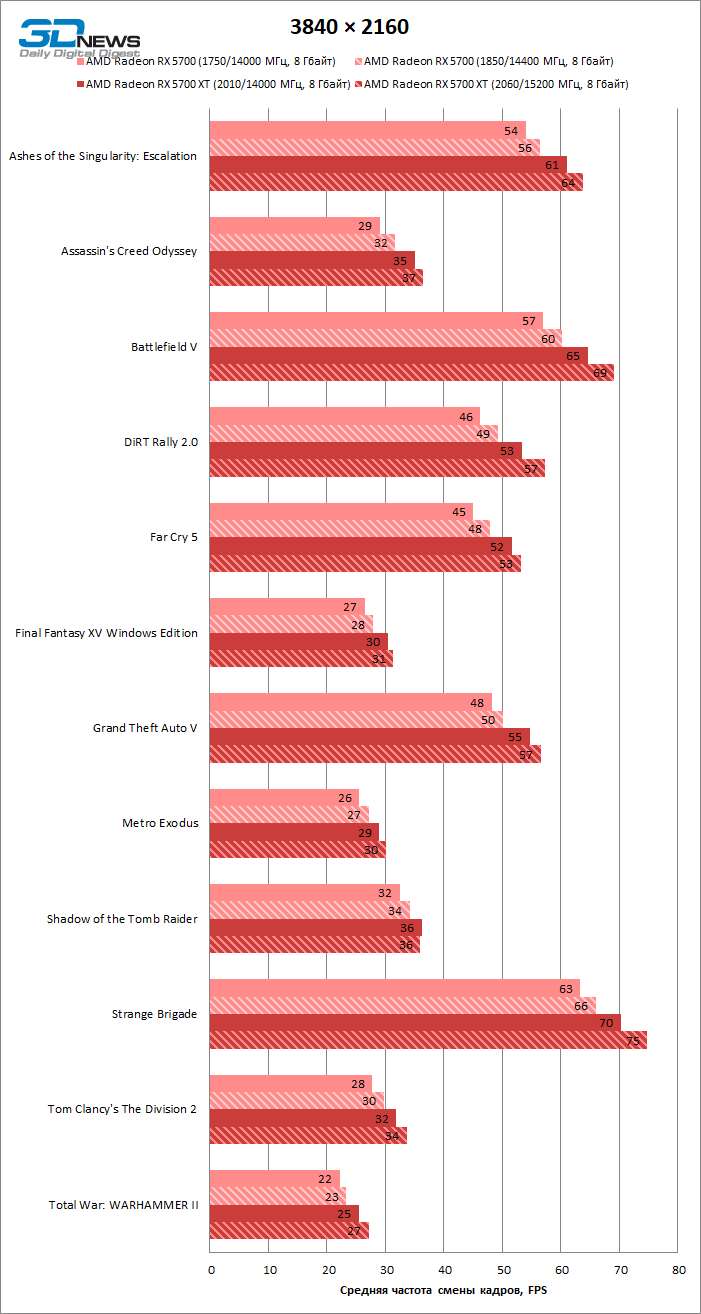
- AMD Radeon RX 5700 XT (2010/14000 МГц, 8 Гбайт);
- AMD Radeon RX 5700 (1750/14000 МГц, 8 Гбайт);
- AMD Radeon VII (1800/2000 МГц, 16 Гбайт);
- AMD Radeon RX Vega 64 (1546/1890 МГц, 8 Гбайт);
- AMD Radeon RX Vega 56 (1471/1600 МГц, 8 Гбайт);
- NVIDIA GeForce GTX 2080 Founders Edition (1515/14000 МГц, 8 Гбайт);
- NVIDIA GeForce RTX 2070 Founders Edition (1410/14000 МГц, 8 Гбайт);
- NVIDIA GeForce RTX 2060 Founders Edition (1365/14000 МГц, 6 Гбайт);
- NVIDIA GeForce GTX 1080 Ti (1480/11000 МГц, 11 Гбайт);
- NVIDIA GeForce GTX 1080 (1607/10000 МГц, 8 Гбайт);
- NVIDIA GeForce GTX 1070 Ti (1608/8008 МГц, 8 Гбайт);
- NVIDIA GeForce GTX 1070 (1506/8008 МГц, 8 Гбайт).
Прим.: для видеокарт на графических процессорах NVIDIA указана базовая тактовая частота GPU (Base Clock), для видеокарт на чипах AMD — их максимальная тактовая частота. Именно эти частоты демонстрируют оверклокерские утилиты — такие как MSI Afterburner или AMD WattMan.
⇡#Тактовые частоты, энергопотребление, температура, разгон
Перед тем как мы займемся анализом игровой производительности Radeon RX 5700 и Radeon RX 5700 XT, нужно добавить несколько ключевых деталей к описанию этих устройств. Главный вопрос — удалось ли AMD за счет обновленной архитектуры и прогрессивного техпроцесса решить проблему энергопотребления, от которой страдали «красные» GPU последних лет?
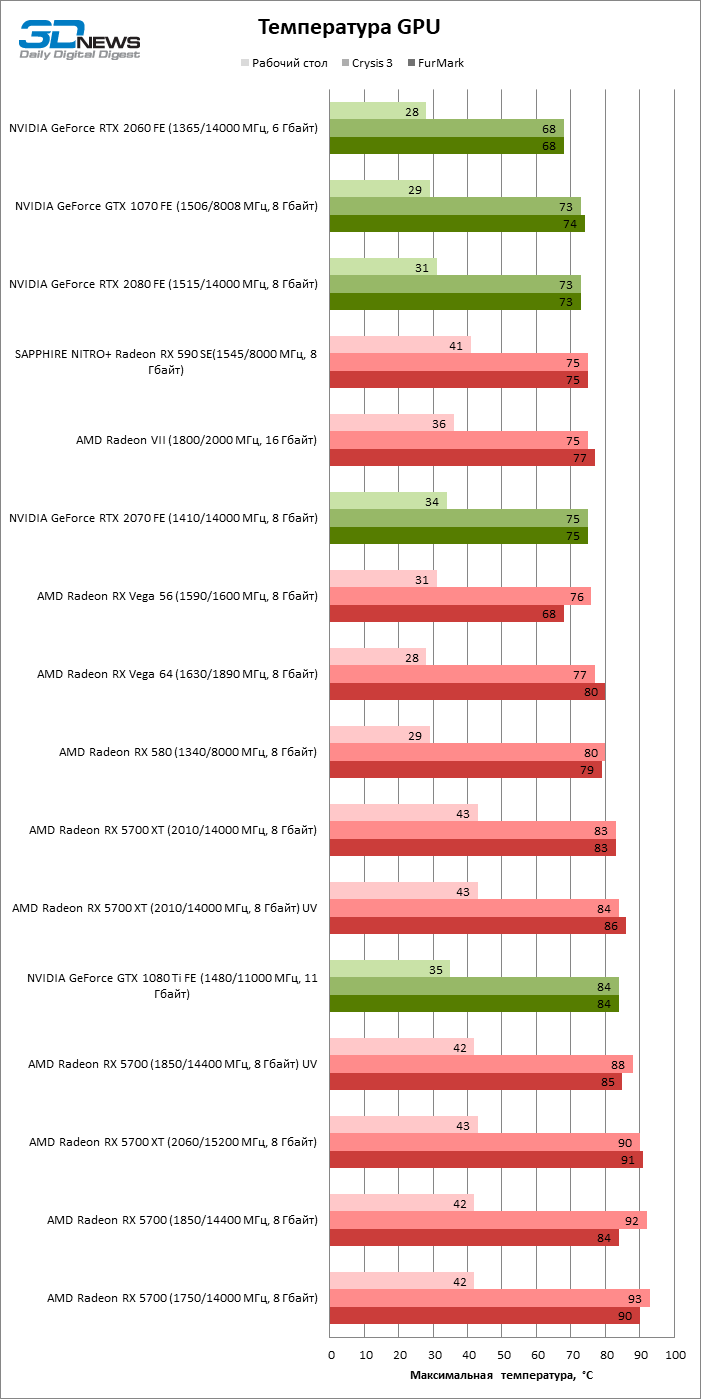
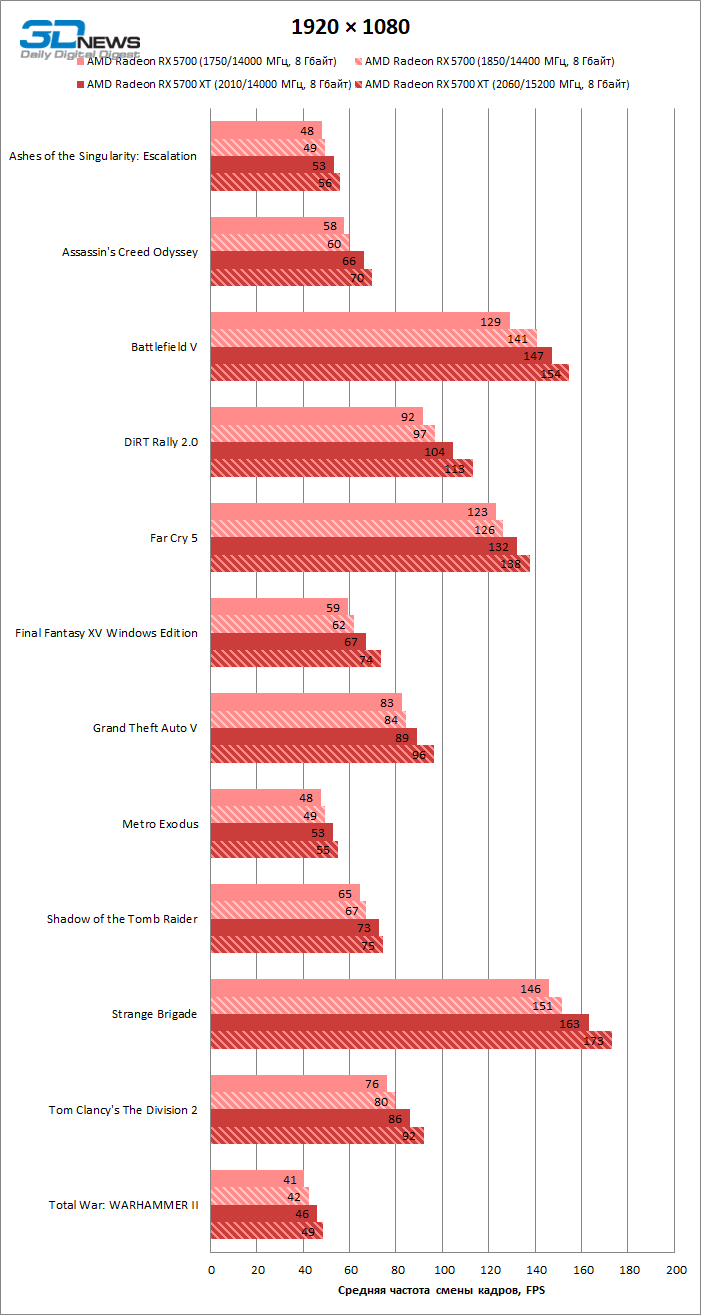
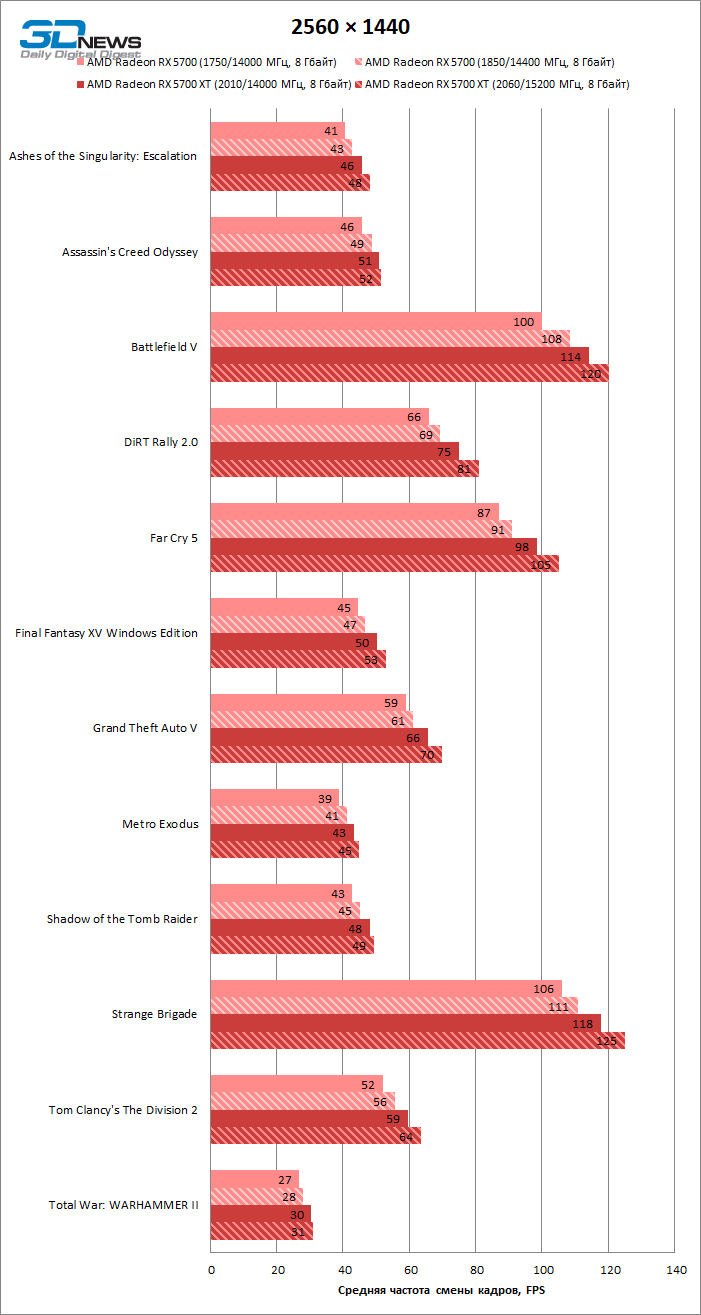
Как показал пример Radeon VII, переход с нормы 14 нм на 7 нм сам по себе может творить чудеса — по меньшей мере, в тактовых частотах. Однако по сравнению с современными графическими процессорами NVIDIA, которые держатся в диапазоне 1800–1900 МГц, рабочие тактовые частоты устройств AMD остаются довольно консервативными. Radeon RX 5700 XT достиг частоты 1755 МГц, которая фигурирует в спецификациях под термином Game Clock, даже в такой ресурсоемкой игре, как Crysis 3. А вот для младшей версии Radeon RX 5700 это оказалось не по силам: вместо 1625 МГц мы зарегистрировали всего лишь 1581.
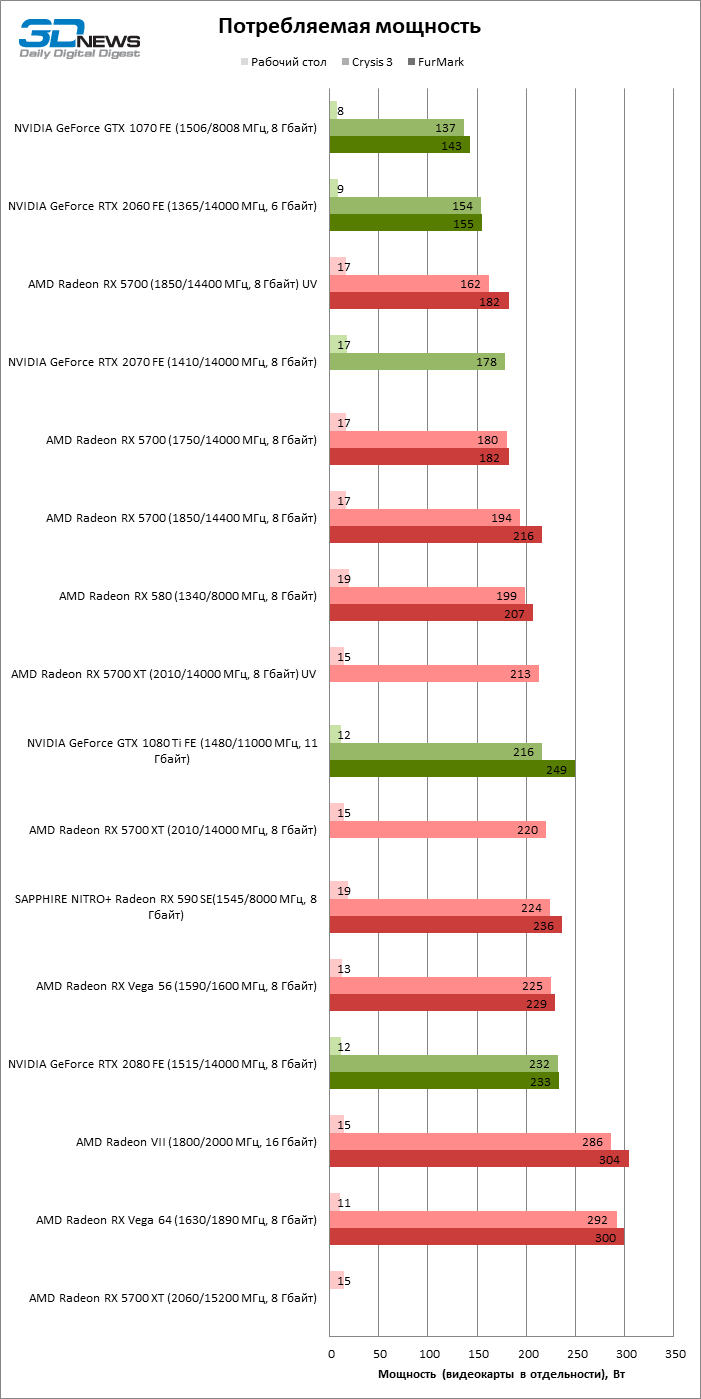
Фактическое энергопотребление Radeon RX 5700 и RX 5700 XT находится в соответствии с объявленными параметрами: в Crysis 3 новые видеокарты освоили 180 и 220 Вт соответственно из выделенного им резерва в 185 и 225 Вт. Таким образом, по мощности новинки занимают одну нишу вместе с Radeon RX 580 и Radeon RX 590 — при том, что чип Navi 10 содержит на 80 % больше транзисторов по сравнению со старшим Polaris!
Комбинация переработанной архитектуры и техпроцесса 7 нм определенно дала свои плоды. Тем не менее вопрос энергоэффективности — по крайней мере, выраженной в тактовых частотах — еще нельзя считать закрытым для продуктов AMD. Соперничающие предложения на чипах Turing достигают больших частот при сопоставимой мощности, невзирая на более массивный GPU (как GeForce RTX 2080), либо в одно и то же время тактуются выше и потребляют меньше энергии (как GeForce RTX 2060). Если же рассматривать только потребляемую мощность, то оба устройства, которые AMD сделала мишенью для новинок — GeForce RTX 2060 и GeForce RTX 2070 — оказались заметно экономнее по сравнению с Radeon RX 5700 и Radeon RX 5700 XT соответственно.
| Рабочие параметры под нагрузкой (Crysis 3) |
|---|
| Видеокарта |
Настройки |
Тактовая частота GPU, МГц |
Напряжение питания GPU, В |
Частота вращения вентиляторов, об/мин (% от макс.) |
Частота вращения вентиляторов 2, об/мин (% от макс.) |
|
|
Средн. |
Макс. |
Предел |
Средн. |
Макс. |
Средн. |
Средн. |
| AMD Radeon RX 5700 (1750/14000 МГц, 8 Гбайт) |
|
1581 |
1634 |
1750 |
0,935 |
0,981 |
1425 (29%) |
НД |
| AMD Radeon RX 5700 (1850/14400 МГц, 8 Гбайт) |
+20% TDP |
1753 |
1795 |
1850 |
0,979 |
0,981 |
1627 (33%) |
НД |
| AMD Radeon RX 5700 (1850/14400 МГц, 8 Гбайт) UV |
-99 мВ vCore |
1642 |
1684 |
1750 |
0,881 |
0,881 |
1332 (27%) |
НД |
| AMD Radeon RX 5700 XT (2010/14000 МГц, 8 Гбайт) |
|
1767 |
1872 |
2010 |
1,072 |
1,193 |
2106 (43%) |
НД |
| AMD Radeon RX 5700 XT (2060/15200 МГц, 8 Гбайт) |
+50% TDP |
1843 |
1990 |
2060 |
1,105 |
1,193 |
2114 (43%) |
НД |
| AMD Radeon RX 5700 XT (2010/14000 МГц, 8 Гбайт) UV |
-100 мВ vCore |
1841 |
1949 |
2010 |
1,053 |
1,193 |
2089 (43%) |
НД |
| AMD Radeon RX 580 (1340/8000 МГц, 8 Гбайт) |
WattMan: Balanced |
1340 |
1340 |
1340 |
1,072 |
1,081 |
1714 (52%) |
НД |
| SAPPHIRE NITRO+ Radeon RX 590 SE(1545/8000 МГц, 8 Гбайт) |
WattMan: Balanced, Silent UEFI |
1543 |
1545 |
1545 |
1,140 |
1,181 |
1252 (28%) |
НД |
| AMD Radeon RX Vega 56 (1590/1600 МГц, 8 Гбайт) |
WattMan: Balanced |
1312 |
1319 |
1590 |
0,940 |
1,075 |
1868 (38%) |
НД |
| AMD Radeon RX Vega 64 (1630/1890 МГц, 8 Гбайт) |
|
1455 |
1463 |
1630 |
1,014 |
1,156 |
2397 (49%) |
НД |
| AMD Radeon VII (1800/2000 МГц, 16 Гбайт) |
|
1756 |
1786 |
1802 |
НД |
НД |
2617 (НД) |
НД |
| NVIDIA GeForce GTX 1070 FE (1506/8008 МГц, 8 Гбайт) |
|
1775 |
1823 |
1911 |
0,995 |
1,043 |
1898 (47%) |
НД |
| NVIDIA GeForce GTX 1080 Ti FE (1480/11000 МГц, 11 Гбайт) |
|
1735 |
1810 |
1911 |
0,963 |
1,012 |
2377 (50%) |
НД |
| NVIDIA GeForce RTX 2060 FE (1365/14000 МГц, 6 Гбайт) |
|
1836 |
1875 |
1950 |
0,991 |
1,031 |
1661 (45%) |
1661 (45%) |
| NVIDIA GeForce RTX 2070 FE (1410/14000 МГц, 8 Гбайт) |
|
1812 |
1845 |
1980 |
0,978 |
1,000 |
1999 (54%) |
1999 (54%) |
| NVIDIA GeForce RTX 2080 FE (1515/14000 МГц, 8 Гбайт) |
|
1872 |
1890 |
1965 |
1,012 |
1,025 |
1836 (50%) |
1836 (50%) |
Прим.: измерение всех параметров выполняется после прогрева GPU и стабилизации тактовых частот.
По Radeon RX 5700 XT явно видно намерение достичь наивысшей производительности, невзирая на то, что графический процессор уже работает на грани оптимального соотношения частоты и питающего напряжения. Это хорошо иллюстрируют наши эксперименты с разгоном и андерволтингом видеокарты.
В чипе Navi 10 применяется обновленный SMU (System Management Unit), который дебютировал в составе Vega 20 (Radeon VII) и поначалу доставил оверклокерам немало головной боли. Теперь и «родная» утилита WattMan, и стороннее ПО — MSI Afterburner и GPU-Z — освоились с изменениями в API, так что мы смогли вволю наиграться с рабочими параметрами Radeon RX 5700 XT. В отличие от чипов Polaris и Vega первого поколения, разгон которых осуществляется путем изменения нескольких P-уровней, Vega 20 и Navi дают прямой доступ к кривой тактовой частоты и питающего напряжения. График функции при штатных настройках Radeon RX 5700 XT заканчивается на частоте 2010 МГц и напряжении 1,192 В — больше VRM не сможет выдать без модификации BIOS или аппаратного вольтмода.
В составе WattMan есть опция автоматического разгона GPU, которая предложила увеличить предельную частоту Radeon RX 5700 XT сразу до 2130 МГц, но на самом деле без потери стабильности верхнюю точку кривой можно сдвинуть лишь на 50 МГц. В игровом тесте устойчивая тактовая частота возросла на 76 МГц, но даже столь скромный оверклокинг невозможно сочетать с андерволтингом — при попытке снизить вольтаж устройство мгновенно теряет работоспособность. Чтобы снять с GPU ограничение мощности, мы увеличили его TDP на 50 %, но в свете того, что разгон, по большому счету, не удался, это уже не принесло никакой дополнительной пользы.
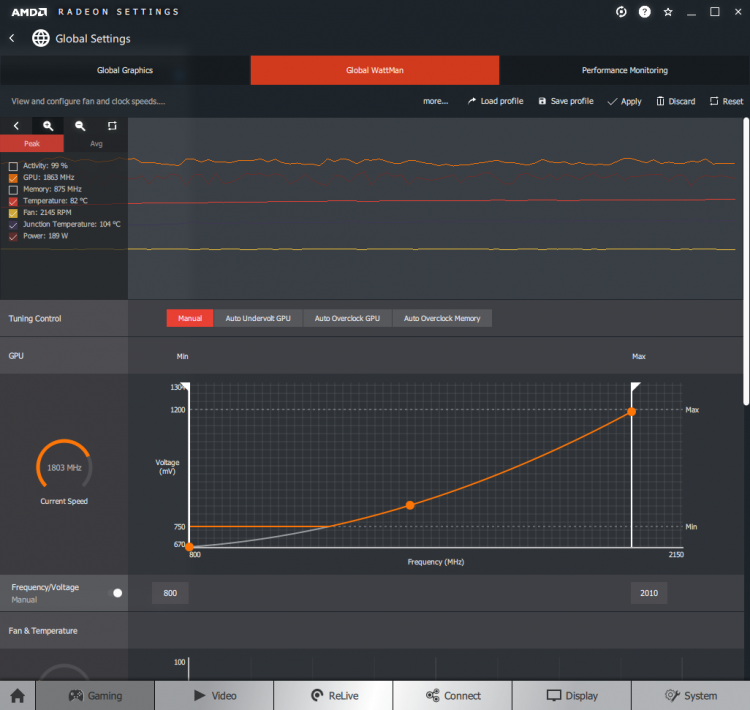
Если поставить цель во что бы то ни стало выжать из Radeon RX 5700 XT еще несколько десятков мегагерц, то можно отрегулировать управляющую кривую таким образом, чтобы ее правая часть (соответствующая верхним частотам) превратилась в прямую линию, — тогда GPU получит максимальный вольтаж еще на подходе к пику тактовой частоты. Вот только система охлаждения референсной видеокарты к таким решительным мерам совершенно не располагает. Кулер RX 5700 XT оказался не намного тише под нагрузкой, чем у Radeon VII, вот только где на графике мощности Vega и где Navi... Да и температуры GPU даже при скромном оверклокинге едва ли приемлемы для постоянной эксплуатации: в штатном режиме Navi 10 прогревается до 83 °C, а в результате разгона — уже до 90–91. Зато чип Navi 10 не обижен возможностью разгона RAM. Старшая модель Radeon RX 5700 позволила увеличить пропускную способность чипов GDDR6 с 14 до 15,2 Гбит/с на контакт.
Несмотря на то, что резерв тактовых частот и питающего напряжения, которым можно воспользоваться для разгона, у Radeon RX 5700 XT практически исчерпан, при штатных частотах видеокарта допускает громадный андерволтинг. А ведь AMD еще со времен Polaris твердила об алгоритмах, позволяющих индивидуально подгонять напряжение под характеристики кристалла, чтобы не перегревать его без необходимости. В Radeon RX 5700 XT пиковый вольтаж можно смело уменьшить на 0,1 В, и это, как ни странно, является лучшим методом разгона, чем прямой подъем тактовой частоты, — средние частоты под нагрузкой примерно те же, температура GPU и акустические параметры системы охлаждения не пострадали, и даже мощность оказалась снижена на 7 Вт. Только пиковые значения тактовой частоты под нагрузкой, которых GPU может достигнуть в относительно нетребовательных играх, не будут столь же высокими, как при целенаправленном разгоне, — для них и требуется увеличенный вольтаж.
По сравнению с флагманом семейства Navi младшая версия Radeon RX 5700 производит впечатление лучшего претендента на успешный оверклокинг. При штатных настройках ее GPU не требует напряжения выше 0,981 В, а система охлаждения работает существенно тише. Так и получилось: видеокарта сохраняет стабильность при наивысшем значении тактовой частоты GPU, которую позволяет установить драйвер (1850 МГц), а под нагрузкой бонус к частоте составил 172 МГц — все это при штатном напряжении питания. Наверняка и это не предел, но BIOS видеокарты не позволяет двигать кривую частоты GPU дальше, а резерв мощности можно увеличить лишь на 20 %. Партнерские варианты Radeon RX 5700 с открытыми системами охлаждения, которые появятся в будущем, наверняка снимут эти ограничения, а вот для референсной видеокарты с турбиной они вполне уместны. Автоматика вентилятора здесь работает таким образом, что при штатных частотах приоритетом является тишина, — в результате кулер Radeon RX 5700 и вправду не так сильно шумит по сравнению с Radeon RX 5700 XT, но в то же время позволяет GPU нагреваться до 92–93 °C. При разгоне, наоборот, система охлаждения держит температуру в норме, но и шуметь начинает значительно сильнее.
Прим.: на данный момент мы не смогли получить мощность разогнанного Radeon RX 5700 XT в Crysis 3 и тестах FurMark с любыми параметрами: видеокарты AMD не любят, когда в цепи питания есть шунт для измерения тока, и отключаются при высокой нагрузке. RX 5700 XT оказался особенно чувствителен к этому фактору. Мы постараемся решить проблему в ближайшее время и в случае успеха дополним статью недостающими результатами.
Андерволтинг действует на Radeon RX 5700 еще лучше, чем на Radeon RX 5700 XT. Пиковый вольтаж также можно уменьшить на 0,1 В, и в результате стабильная частота GPU под нагрузкой автоматически возрастает на 61 МГц, мощность падает на 18 Вт, а система охлаждения становится чрезвычайно тихой. Жаль только, что пропускная способность чипов RAM на плате Radeon RX 5700 искусственно ограничена уровнем 14,4 Гбит/с.
Заметим, что обороты вентилятора охлаждения у чипов Navi привязаны к т. н. узловой температуре (Junction Temperature), которая регистрируется сетью датчиков, разбросанных по площади кристалла, и соответствует самой горячей точке GPU — в отличие от единственного краевого датчика, показатели которого мы приводим на графиках. Параметр узловой температуры гораздо быстрее реагирует на изменения в энергопотреблении GPU, и видеокарте нужно держать его в пределах 100 °С, чтобы избежать троттлинга тактовых частот. Поэтому скорость работы кулера Radeon RX 5700 и Radeon RX 5700 XT варьирует даже при постоянной нагрузке, а польза для ушей от андерволтинга Navi связана не в последнюю очередь с тем, что в графике скорости вентилятора сглаживаются пики, вызванные спорадическими всплесками узловой температуры.
Вот так работают видеокарты Radeon нового поколения, которым предстоит соревноваться в тестах с устройствами NVIDIA на чипах Turing. Несмотря на очевидные издержки референой конструкции, архитектура RDNA в сочетании с передовой фотолитографией TSMC позволила AMD сохранить энергопотребление Navi на уровне Radeon RX 580 и Radeon RX 590, значительно увеличив транзисторный бюджет и тактовые частоты. Осталось убедиться, сумеет ли RDNA выполнить свою главную миссию — более эффективно конвертировать терафлопсы в производительность реальных приложений.
⇡#3DMark
⇡#Игровые тесты (1920 × 1080)
Глядя на результаты первых игровых тестов, можно с облегчением заявить, что архитектура RDNA целиком оправдала ожидания. Radeon RX 5700 XT на 17 % превосходит Radeon RX Vega 64 по средней частоте смены кадров, но что по-настоящему шокирует — так это соотношение Radeon RX 5700 XT и Radeon VII. Несмотря на колоссальный перевес по терафлопсам и количеству шейдерных ALU, лучшая видеокарта архитектуры GCN оказалась всего лишь на 2 % быстрее. Есть немало игр, в которых действующий флагман AMD сохранил более существенное преимущество, но остальные тесты сводят разницу между Radeon RX 5700 XT и Radeon VII к минимуму.
В сравнении с видеокартами на чипах NVIDIA предыдущего и нового поколения Radeon RX 5700 XT завоевал уверенную победу над GeForce GTX 1080 и GeForce RTX 2060 с запасом в 15 и 18 %, но это как раз таки предсказуемый результат. Тот соперник, к борьбе с которым готовили Radeon RX 5700 XT, выжимая из чипа Navi 10 максимум тактовых частот, называется GeForce RTX 2070, и формально мы можем констатировать между ними равный счет: некоторые игры отдают предпочтение видеокарте AMD, другие — NVIDIA. Отметим, что немалую поддержку GeForce GTX 2070 оказала одна чрезвычайно «зеленая» игра — Final Fantasy XV, которая просто отвратительно работает на чипах AMD.
GeForce RTX 2080, в свою очередь, Navi уже не по зубам — на стороне «зеленых» усредненное преимущество в 17 %, хотя в ряде бенчмарков Radeon RX 5700 XT наступает на пятки сопернику из совершенно другой весовой категории. Соревноваться с GeForce GTX 1080 Ti новинке уже легче — эта видеокарта опережает Radeon RX 5700 XT в среднем на 8 %, но последнему удалось одержать несколько локальных побед в отдельно взятых играх.
Полноценную и урезанную модификации Radeon RX 5700 разделяет дистанция в 12 %, однако и тех вычислительных ресурсов, которые остались в распоряжении Radeon RX 5700 без индекса XT, хватает для того, чтобы назвать младший Navi полноценной заменой «Веги» первого поколения, ведь он в среднем на 5 % быстрее Radeon RX Vega 64 и на 20 % превосходит Radeon RX Vega 56. Radeon RX 5700 без труда разделался и с GeForce RTX 2060, захватив преимущество в 6 %. В этой дуэли главной проблемой для Radeon RX 5700 опять-таки стал бенчмарк Final Fantasy XV, в котором GeForce RTX 2060 находится на недосягаемой высоте. Ближайшим аналогом Radeon RX 5700 среди ускорителей NVIDIA прошлого поколения является GeForce GTX 1080 — новинка AMD быстрее лишь на 3 %, хотя соотношение между ними значительно меняется в зависимости от конкретной игры.
⇡#Игровые тесты (2560 × 1440)
Поскольку в сравнении участвуют GPU, существенно различающиеся по архитектуре и паспортным характеристикам — таким как соотношение между шейдерными ALU и ROP, пропускная способность оперативной памяти и т. д., результаты тестов смещаются в пользу тех или иных моделей в зависимости от разрешения экрана. Позиция Radeon RX 5700 XT не слишком сильно изменилась по сравнению с Radeon RX Vega 64 (17 % в пользу новинки по усредненной частоте смены кадров) и GeForce GTX 1080 (15 % в пользу 5700 XT), а вот Radeon VII начинает раскрывать свои сильные стороны — Vega второго поколения превосходит Radeon RX 5700 XT уже на 5 % и лишь в трех игровых бенчмарках опустилась ниже своего аналога на чипе Navi.
Быстродействие GeForce RTX 2060 не так хорошо масштабируется вместе с разрешением, и в результате преимущество Radeon RX 5700 XT увеличилось до 21 %, да и GeForce RTX 2070 просто стоит на месте — счет между последним и видеокартой AMD по-прежнему равный. GeForce GTX 1080 Ti также удерживает стабильное преимущество в 10 % по сравнению с Radeon RX 5700 XT. А вот GeForce GTX 2080 набирает обороты: возможность для конкуренции у Radeon RX 5700 XT осталась только в тесте Ashes of the Singularity, но в среднем карта NVIDIA ушла вперед на 20 %.
Radeon RX 5700 и Radeon RX 5700 XT не так сильно отличаются друг от друга по техническим характеристикам, чтобы смена разрешения с «народного» 1080p на 1440p повлияла на дистанцию между двумя родственными видеокартами — она по-прежнему составляет 12 % средней кадровой частоты. Преимущество Radeon RX 5700 перед ускорителями на чипе Vega первого поколения тоже никуда не делось — оно составляет 19 и 4 % соответственно в случае Radeon RX Vega 56 и Vega 64. Наконец, Radeon RX 5700, как и в тестах при разрешении 1080p, в режиме 1440p расположился ближе всего к GeForce GTX 1080 (их разделяет лишь 3 % средних FPS). А вот дистанция между Radeon RX 5700 и GeForce RTX 2060 постепенно возрастает — теперь ускоритель AMD уже на 8 % впереди.
⇡#Игровые тесты (3840 × 2160)
Ускорители семейства Navi формально не рассчитаны на игры в режиме 2160p, хотя, к примеру, и Vega 64, и GeForce GTX 1080 Ti в свое время позиционировались как видеокарты для 4К-экранов. Увы, переход к разрешению 4К по-прежнему является трудной задачей для современных графических процессоров, а прогресс в игростроении постоянно отбрасывает некогда могучие ускорители за границу оптимальной частоты смены кадров. Лишь в трех бенчмарках (Ashes of the Singularity: Escalation, Battlefield V и Strange Brigade) Radeon RX 5700 XT преодолел критически важную отметку в 60 FPS, а у младшей версии Radeon RX 5700 это получилось только в Strange Brigade. В остальных играх кадровая частота на чипах Navi иной раз падает и ниже 30 FPS.
Впрочем, нехватку быстродействия для игр в 4К нельзя считать изъяном новых видеокарт AMD, коль скоро они и не рассчитаны на столь высокую нагрузку. Тем не менее тесты в высоком разрешении позволяют выполнить финальное сравнение GPU различной архитектуры, когда вычислительные ресурсы используются наиболее активно. Как мы уже неоднократно замечали раньше, подъем разрешения идет на руку чипам архитектуры GCN. Вот и на этот раз Radeon RX Vega 64 немного подтянулся к уровню Radeon RX 5700 XT, хотя в среднем новинка сохраняет преимущество в 15 %. Radeon VII, в свою очередь, сумел окончательно вырваться из неподобающего соревнования с легким, но более эффективным соперником — теперь их разделяет дистанция в 10 % средней кадровой частоты.
Среди видеокарт NVIDIA, участвующих в сравнении, GeForce GTX 1080 (а также его урезанные аналоги GeForce GTX 1070 и GTX 1070 Ti) при разрешении 4К ощущает себя наиболее дискомфортно: Radeon RX 5700 XT ушел уже на 24 % вперед. Более современный GeForce RTX 2060 тоже уступает территорию, отдав 27 % в пользу Radeon RX 5700 XT. Даже GeForce RTX 2070 не обошла стороной общая тенденция: в 4К мы можем говорить о неуверенной, но все-таки победе новинки AMD над главным из «зеленых» конкурентов с разрывом в 3 % по усредненным результатам. Позиции GeForce RTX 2080 и GeForce GTX 1080 Ti, напротив, по-прежнему сильны: на их стороне преимущество в 21 и 7 % соответственно.
Повышенная нагрузка, которую вызывают игры при разрешении 4К, влияет и на положение Radeon RX 5700 в группе видеокарт соответствующего уровня. По усредненным FPS новинка уже практически не отличается от Radeon RX Vega 64, а запас быстродействия в сравнении с Radeon RX Vega 56 сократился до 16 %. В то же время переход к 4К ударил по главным соперникам Radeon RX 5700 на чипах Pascal и Turing. Младший Navi не оставляет шансов GeForce GTX 1080 и GeForce RTX 2060, опередив последних на 8 и 11 % соответственно.
⇡#Производительность в разгоне
Если учесть, что чип Polaris 10 в составе Radeon RX 5700 XT практически не поддается разгону — AMD и без того повысила частоты до предела, совсем не удивительно, что попытка выжать из видеокарты последние капли быстродействия слабо повлияла на результаты игровых тестов. Не исключено, что хоть какой-то позитивный результат связан вовсе не с подъемом тактовых частот GPU на несколько десятков мегагерц, а с разгоном оперативной памяти GDDR6. Все, чего нам удалось добиться от мучений Radeon RX 5700 XT, — это средний прирост в 5–6 % FPS.
Radeon RX 5700 без индекса XT, в свою очередь, позволяет разогнать чип Navi 10 значительно сильнее, но и в случае младшего ускорителя весь прок от оверклокинга сводится к увеличению среднего FPS на 4–6 %. Не исключено, что Radeon RX 5700 подвело искусственное ограничение на частоту работы чипов RAM. А может, ему просто не хватило резерва мощности — даже при условии, что мы подняли TDP до максимально разрешенных 120 %. Как бы то ни было, на оверклокерский потенциал референсных версий Radeon RX 5700 и Radeon RX 5700 XT рассчитывать не стоит — партнерам AMD, которые рано или поздно представят видеокарты оригинального дизайна, явно будет над чем поработать в этой области.
⇡#Вычисления общего назначения
Новая архитектура RDNA уже доказала свое превосходство над GCN в игровых тестах, однако не меньший интерес вызывает быстродействие чипов Navi в рабочих приложениях, где ускорители AMD прошлого поколения традиционно сильны. Для того чтобы выяснить это, в нашем распоряжении остались лишь два инструмента из стандартного набора тестов GP-GPU — бенчмарк трассировки лучей LuxMark и синтетические тесты SiSoftware Sandra. Драйвер, который AMD предоставила для обзора видеокарт Radeon RX 5700, не совместим с Blender и Adobe Premiere, а пакет CompuBench CL, в свою очередь, временно потерял связь с собственными серверами и в офлайне работать категорически отказывается.
Учитывая, что преимущество новинок перед ускорителями на чипах Vega в игровых тестах проистекает по большей части из повышенной эффективности архитектуры RDNA, а не из тактовых частот, а запас по терафлопсам у «Веги» по-прежнему громадный, мы подключили к сравнению видеокарты прошлого поколения, располагающие близким к Navi 10 набором шейдерных ALU, — Radeon RX 580 и Radeon RX 590.
Судя по тем ограниченным тестам, которые мы смогли выполнить в данный момент, у AMD есть веская причина оставить GCN в строю для ускорителей GP-GPU. Так, в LuxMark обе новинки выступили даже хуже, чем Radeon RX 580 и Radeon RX 590, невзирая на повышенные тактовые частоты.

В бенчмарке перемножения матриц SiSoftware Sandra только Radeon RX 5700 XT сумел одержать победу над Radeon RX 590 по пропускной способности операций стандартной точности (FP32), в то время как Radeon RX 5700 и Radeon RX 580 практически не отличаются друг от друга. На стороне Navi есть существенное преимущество в операциях двойной точности, однако поддержка FP64 в ускорителях такого уровня в любом случае присутствует лишь для того, чтобы обеспечить совместимость с максимально широким спектром ПО, а вовсе не для рабочих задач. С другой стороны, архитектура Navi позаимствовала у чипов Vega возможность исполнять операции над данными половинной точности (FP16) с удвоенным темпом по сравнению с FP32, и в абсолютных числах при такой нагрузке Radeon RX 5700 XT практически не уступает Radeon RX Vega 64.
Впрочем, тест Sandra, применяющий OpenCL для обработки тестового изображения, не дает поставить крест на RDNA в качестве архитектуры для расчетов общего назначения: здесь Radeon RX 5700 и Radeon RX 5700 XT безоговорочно доминируют над своими предшественниками Radeon RX 580 и Radeon RX 590.
⇡#Кодирование/декодирование видео
Чип Navi 10 оборудован новым кодеком видеосигнала, в котором AMD увеличила быстродействие и расширила набор форматов, которые видеокарта позволяет декодировать «в железе» без привлечения шейдерных ALU. Так, Radeon RX 5700 и Radeon RX 5700 XT теперь справляются с обработкой стандарта HEVC при разрешении 8К с кадровой частотой вплоть до 42 FPS — для предыдущих GPU эта возможность была закрыта. Тем не менее по сырой производительности в декодировании HEVC новый чип не слишком отличается от Radeon RX Vega 56 и Vega 64, а в тесте H.264 и вовсе оказался позади (Navi даже не достиг скорости в 600 FPS при разрешении 1080p, которую обещает AMD в спецификациях).
Похоже на то, что AMD пришлось урезать логику мультимедийного ASIC, связанную с формально устаревшим форматом сжатия, ради экономии площади кристалла. Такой подход мы уже видели на примере Radeon VII — последний, судя по всему, имеет одинаковый декодер H.264 и HEVC с чипами Polaris.
Но главное, в дискретных «красных» GPU возникла долгожданная поддержка VP9, доступная посредством универсальных API DXVA и D3D11VA без всяких костылей в виде «гибридного» декодирования. Navi не настолько эффективен в обработке VP9, как чипы Turing, однако для того, чтобы разгрузить центральный процессор при просмотре видео на YouTube, его возможностей вполне достаточно.
В раздел мультимедийного блока, занимающийся кодированием H.264 и HEVC, AMD не внесла сколь-либо существенных изменений, повлиявших на быстродействие. В этих задачах Radeon RX 5700 и Radeon RX 5700 XT практически не отличаются от ускорителей Vega первого и второго поколения. Впрочем, не будем исключать возможность, что ранняя версия драйвера для чипа Navi не позволяет кодировщику работать в полную силу, ведь полученные результаты категорически не соотносятся с данными, объявленными AMD: запись 1080p при частоте 360 FPS и запись 4К на скорости 90 и 60 FPS для H.264 и HEVC соответственно.
⇡#Результаты всех игровых тестов
| 1920 × 1080 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 5700 (1750 / 14000 МГц, 8 Гбайт) |
AMD Radeon RX 5700 XT (2010 / 14000 МГц, 8 Гбайт) |
AMD Radeon RX Vega 56 (1590 / 1600 МГц, 8 Гбайт) |
AMD Radeon RX Vega 64 (1630 / 1890 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 1070 (1506 / 8008 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 1070 Ti (1607 / 8000 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 1080 (1607 / 10000 МГц, 8 Гбайт) |
NVIDIA GeForce RTX 2060 FE (1365 / 14000 МГц, 6 Гбайт) |
NVIDIA GeForce RTX 2070 FE (1410 / 14000 МГц, 8 Гбайт) |
| Ashes of the Singularity: Escalation |
MSAA 4x + TAA Ultra |
29 / 48 |
33 / 53 |
23 / 37 |
26 / 42 |
21 / 33 |
24 / 38 |
25 / 41 |
24 / 36 |
28 / 45 |
| Assassin's Creed Odyssey |
TAA High |
47 / 58 |
55 / 66 |
42 / 48 |
47 / 57 |
48 / 55 |
48 / 56 |
56 / 63 |
53 / 61 |
62 / 71 |
| Battlefield V |
TAA High |
107 / 129 |
126 / 147 |
98 / 119 |
115 / 136 |
87 / 105 |
95 / 118 |
105 / 125 |
100 / 119 |
114 / 133 |
| DiRT Rally 2.0 |
MSAA 4x + TAA |
74 / 92 |
84 / 104 |
59 / 73 |
66 / 85 |
46 / 66 |
55 / 78 |
57 / 80 |
56 / 79 |
66 / 94 |
| Far Cry 5 |
TAA |
111 / 123 |
113 / 132 |
93 / 104 |
109 / 120 |
88 / 96 |
98 / 107 |
105 / 115 |
93 / 108 |
105 / 125 |
| Final Fantasy XV Windows Edition |
TAA |
11 / 59 |
6 / 67 |
12 / 50 |
13 / 55 |
52 / 67 |
55 / 74 |
60 / 80 |
58 / 78 |
65 / 93 |
| Grand Theft Auto V |
MSAA 4x + FXAA + Reflection MSAA 4x |
60 / 83 |
41 / 89 |
47 / 66 |
53 / 72 |
47 / 74 |
45 / 81 |
49 / 87 |
47 / 80 |
55 / 94 |
| Metro Exodus |
TAA |
26 / 48 |
28 / 53 |
21 / 39 |
24 / 44 |
21 / 35 |
23 / 40 |
24 / 44 |
24 / 40 |
28 / 47 |
| Shadow of the Tomb Raider |
SMAA 4x |
48 / 65 |
55 / 73 |
38 / 52 |
43 / 58 |
42 / 53 |
49 / 61 |
52 / 65 |
50 / 63 |
60 / 75 |
| Strange Brigade |
AA Ultra |
104 / 146 |
118 / 163 |
93 / 129 |
100 / 145 |
88 / 108 |
99 / 121 |
106 / 133 |
109 / 138 |
133 / 167 |
| Tom Clancy's The Division 2 |
TAA Ultra |
61 / 76 |
65 / 86 |
55 / 67 |
64 / 80 |
48 / 57 |
55 / 66 |
59 / 70 |
61 / 73 |
71 / 86 |
| Total War: WARHAMMER II |
MSAA 4x |
34 / 41 |
38 / 46 |
29 / 35 |
34 / 41 |
21 / 31 |
26 / 35 |
6 / 34 |
27 / 35 |
6 / 37 |
| Макс. |
|
|
+14% |
−8% |
+5% |
+14% |
+25% |
+36% |
+32% |
+58% |
| Средн. |
|
|
+12% |
−16% |
−4% |
−19% |
−9% |
−3% |
−6% |
+10% |
| Мин. |
|
|
+7% |
−23% |
−13% |
−31% |
−21% |
−17% |
−25% |
−10% |
| 1920 × 1080 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 5700 XT (2010 / 14000 МГц, 8 Гбайт) |
AMD Radeon RX Vega 56 (1590 / 1600 МГц, 8 Гбайт) |
AMD Radeon RX Vega 64 (1630 / 1890 МГц, 8 Гбайт) |
AMD Radeon VII (1800 / 2000 МГц, 16 Гбайт) |
NVIDIA GeForce GTX 1080 (1607 / 10000 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 1080 Ti (1590 / 11900 МГц, 11 Гбайт) |
NVIDIA GeForce RTX 2060 FE (1365 / 14000 МГц, 6 Гбайт) |
NVIDIA GeForce RTX 2070 FE (1410 / 14000 МГц, 8 Гбайт) |
NVIDIA GeForce RTX 2080 FE (1515 / 14000 МГц, 8 Гбайт) |
| Ashes of the Singularity: Escalation |
MSAA 4x + TAA Ultra |
33 / 53 |
23 / 37 |
26 / 42 |
29 / 49 |
25 / 41 |
30 / 52 |
24 / 36 |
28 / 45 |
34 / 54 |
| Assassin's Creed Odyssey |
TAA High |
55 / 66 |
42 / 48 |
47 / 57 |
54 / 67 |
56 / 63 |
62 / 73 |
53 / 61 |
62 / 71 |
63 / 78 |
| Battlefield V |
TAA High |
126 / 147 |
98 / 119 |
115 / 136 |
133 / 154 |
105 / 125 |
121 / 139 |
100 / 119 |
114 / 133 |
123 / 149 |
| DiRT Rally 2.0 |
MSAA 4x + TAA |
84 / 104 |
59 / 73 |
66 / 85 |
82 / 103 |
57 / 80 |
75 / 101 |
56 / 79 |
66 / 94 |
78 / 106 |
| Far Cry 5 |
TAA |
113 / 132 |
93 / 104 |
109 / 120 |
107 / 132 |
105 / 115 |
112 / 135 |
93 / 108 |
105 / 125 |
109 / 140 |
| Final Fantasy XV Windows Edition |
TAA |
6 / 67 |
12 / 50 |
13 / 55 |
14 / 66 |
60 / 80 |
74 / 102 |
58 / 78 |
65 / 93 |
81 / 111 |
| Grand Theft Auto V |
MSAA 4x + FXAA + Reflection MSAA 4x |
41 / 89 |
47 / 66 |
53 / 72 |
67 / 89 |
49 / 87 |
67 / 101 |
47 / 80 |
55 / 94 |
65 / 104 |
| Metro Exodus |
TAA |
28 / 53 |
21 / 39 |
24 / 44 |
29 / 52 |
24 / 44 |
29 / 55 |
24 / 40 |
28 / 47 |
35 / 62 |
| Shadow of the Tomb Raider |
SMAA 4x |
55 / 73 |
38 / 52 |
43 / 58 |
50 / 71 |
52 / 65 |
65 / 81 |
50 / 63 |
60 / 75 |
74 / 92 |
| Strange Brigade |
AA Ultra |
118 / 163 |
93 / 129 |
100 / 145 |
122 / 184 |
106 / 133 |
134 / 174 |
109 / 138 |
133 / 167 |
160 / 202 |
| Tom Clancy's The Division 2 |
TAA Ultra |
65 / 86 |
55 / 67 |
64 / 80 |
74 / 92 |
59 / 70 |
74 / 90 |
61 / 73 |
71 / 86 |
89 / 109 |
| Total War: WARHAMMER II |
MSAA 4x |
38 / 46 |
29 / 35 |
34 / 41 |
41 / 50 |
6 / 34 |
31 / 47 |
27 / 35 |
6 / 37 |
9 / 45 |
| Макс. |
|
|
−19% |
−7% |
+13% |
+19% |
+52% |
+16% |
+39% |
+66% |
| Средн. |
|
|
−25% |
−14% |
+2% |
−13% |
+8% |
−16% |
−1% |
+17% |
| Мин. |
|
|
−30% |
−21% |
−8% |
−26% |
−5% |
−32% |
−20% |
−2% |
| 2560 × 1440 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 5700 (1750 / 14000 МГц, 8 Гбайт) |
AMD Radeon RX 5700 XT (2010 / 14000 МГц, 8 Гбайт) |
AMD Radeon RX Vega 56 (1590 / 1600 МГц, 8 Гбайт) |
AMD Radeon RX Vega 64 (1630 / 1890 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 1070 (1506 / 8008 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 1070 Ti (1607 / 8000 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 1080 (1607 / 10000 МГц, 8 Гбайт) |
NVIDIA GeForce RTX 2060 FE (1365 / 14000 МГц, 6 Гбайт) |
NVIDIA GeForce RTX 2070 FE (1410 / 14000 МГц, 8 Гбайт) |
| Ashes of the Singularity: Escalation |
MSAA 4x + TAA Ultra |
27 / 41 |
30 / 46 |
22 / 32 |
22 / 36 |
19 / 28 |
21 / 33 |
23 / 35 |
20 / 30 |
26 / 37 |
| Assassin's Creed Odyssey |
TAA High |
38 / 46 |
43 / 51 |
36 / 41 |
40 / 47 |
37 / 41 |
38 / 44 |
44 / 49 |
39 / 46 |
48 / 57 |
| Battlefield V |
TAA High |
82 / 100 |
93 / 114 |
73 / 88 |
85 / 102 |
62 / 79 |
69 / 89 |
78 / 96 |
73 / 91 |
85 / 104 |
| DiRT Rally 2.0 |
MSAA 4x + TAA |
56 / 66 |
63 / 75 |
43 / 52 |
49 / 60 |
37 / 49 |
44 / 57 |
46 / 59 |
45 / 58 |
54 / 70 |
| Far Cry 5 |
TAA |
77 / 87 |
88 / 98 |
64 / 73 |
76 / 85 |
60 / 66 |
68 / 75 |
72 / 81 |
69 / 77 |
80 / 90 |
| Final Fantasy XV Windows Edition |
TAA |
9 / 45 |
11 / 50 |
11 / 37 |
12 / 42 |
38 / 49 |
41 / 53 |
44 / 57 |
43 / 56 |
52 / 68 |
| Grand Theft Auto V |
MSAA 4x + FXAA + Reflection MSAA 4x |
43 / 59 |
46 / 66 |
35 / 47 |
39 / 51 |
37 / 53 |
41 / 58 |
44 / 64 |
36 / 58 |
45 / 70 |
| Metro Exodus |
TAA |
23 / 39 |
25 / 43 |
19 / 32 |
20 / 37 |
17 / 28 |
19 / 32 |
20 / 35 |
20 / 32 |
24 / 38 |
| Shadow of the Tomb Raider |
SMAA 4x |
33 / 43 |
38 / 48 |
26 / 35 |
30 / 39 |
28 / 34 |
33 / 39 |
34 / 42 |
33 / 40 |
40 / 49 |
| Strange Brigade |
AA Ultra |
82 / 106 |
91 / 118 |
71 / 92 |
77 / 102 |
62 / 73 |
70 / 81 |
76 / 90 |
83 / 98 |
99 / 118 |
| Tom Clancy's The Division 2 |
TAA Ultra |
45 / 52 |
51 / 59 |
41 / 47 |
47 / 56 |
34 / 39 |
39 / 44 |
42 / 47 |
44 / 50 |
52 / 59 |
| Total War: WARHAMMER II |
MSAA 4x |
23 / 27 |
26 / 30 |
19 / 23 |
23 / 27 |
12 / 21 |
13 / 23 |
21 / 26 |
19 / 23 |
12 / 28 |
| Макс. |
|
|
+14% |
−10% |
+8% |
+9% |
+18% |
+27% |
+24% |
+51% |
| Средн. |
|
|
+12% |
−16% |
−4% |
−20% |
−11% |
−3% |
−7% |
+11% |
| Мин. |
|
|
+10% |
−22% |
−14% |
−32% |
−24% |
−15% |
−27% |
−10% |
| 2560 × 1440 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 5700 XT (2010 / 14000 МГц, 8 Гбайт) |
AMD Radeon RX Vega 56 (1590 / 1600 МГц, 8 Гбайт) |
AMD Radeon RX Vega 64 (1630 / 1890 МГц, 8 Гбайт) |
AMD Radeon VII (1800 / 2000 МГц, 16 Гбайт) |
NVIDIA GeForce GTX 1080 (1607 / 10000 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 1080 Ti (1590 / 11900 МГц, 11 Гбайт) |
NVIDIA GeForce RTX 2060 FE (1365 / 14000 МГц, 6 Гбайт) |
NVIDIA GeForce RTX 2070 FE (1410 / 14000 МГц, 8 Гбайт) |
NVIDIA GeForce RTX 2080 FE (1515 / 14000 МГц, 8 Гбайт) |
| Ashes of the Singularity: Escalation |
MSAA 4x + TAA Ultra |
30 / 46 |
22 / 32 |
22 / 36 |
29 / 45 |
23 / 35 |
26 / 44 |
20 / 30 |
26 / 37 |
29 / 46 |
| Assassin's Creed Odyssey |
TAA High |
43 / 51 |
36 / 41 |
40 / 47 |
44 / 52 |
44 / 49 |
53 / 60 |
39 / 46 |
48 / 57 |
55 / 65 |
| Battlefield V |
TAA High |
93 / 114 |
73 / 88 |
85 / 102 |
105 / 124 |
78 / 96 |
93 / 114 |
73 / 91 |
85 / 104 |
87 / 121 |
| DiRT Rally 2.0 |
MSAA 4x + TAA |
63 / 75 |
43 / 52 |
49 / 60 |
61 / 74 |
46 / 59 |
59 / 76 |
45 / 58 |
54 / 70 |
65 / 81 |
| Far Cry 5 |
TAA |
88 / 98 |
64 / 73 |
76 / 85 |
94 / 107 |
72 / 81 |
91 / 102 |
69 / 77 |
80 / 90 |
88 / 107 |
| Final Fantasy XV Windows Edition |
TAA |
11 / 50 |
11 / 37 |
12 / 42 |
14 / 49 |
44 / 57 |
57 / 75 |
43 / 56 |
52 / 68 |
62 / 81 |
| Grand Theft Auto V |
MSAA 4x + FXAA + Reflection MSAA 4x |
46 / 66 |
35 / 47 |
39 / 51 |
51 / 68 |
44 / 64 |
55 / 81 |
36 / 58 |
45 / 70 |
52 / 81 |
| Metro Exodus |
TAA |
25 / 43 |
19 / 32 |
20 / 37 |
26 / 44 |
20 / 35 |
25 / 45 |
20 / 32 |
24 / 38 |
30 / 50 |
| Shadow of the Tomb Raider |
SMAA 4x |
38 / 48 |
26 / 35 |
30 / 39 |
36 / 49 |
34 / 42 |
44 / 55 |
33 / 40 |
40 / 49 |
50 / 61 |
| Strange Brigade |
AA Ultra |
91 / 118 |
71 / 92 |
77 / 102 |
99 / 136 |
76 / 90 |
99 / 119 |
83 / 98 |
99 / 118 |
119 / 145 |
| Tom Clancy's The Division 2 |
TAA Ultra |
51 / 59 |
41 / 47 |
47 / 56 |
57 / 66 |
42 / 47 |
53 / 61 |
44 / 50 |
52 / 59 |
67 / 77 |
| Total War: WARHAMMER II |
MSAA 4x |
26 / 30 |
19 / 23 |
23 / 27 |
29 / 34 |
21 / 26 |
21 / 33 |
19 / 23 |
12 / 28 |
22 / 33 |
| Макс. |
|
|
−20% |
−5% |
+15% |
+14% |
+50% |
+12% |
+36% |
+62% |
| Средн. |
|
|
−25% |
−14% |
+5% |
−13% |
+10% |
−17% |
−0% |
+20% |
| Мин. |
|
|
−31% |
−23% |
−2% |
−24% |
−4% |
−35% |
−20% |
+0% |
| 3840 × 2160 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 5700 (1750 / 14000 МГц, 8 Гбайт) |
AMD Radeon RX 5700 XT (2010 / 14000 МГц, 8 Гбайт) |
AMD Radeon RX Vega 56 (1590 / 1600 МГц, 8 Гбайт) |
AMD Radeon RX Vega 64 (1630 / 1890 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 1070 (1506 / 8008 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 1070 Ti (1607 / 8000 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 1080 (1607 / 10000 МГц, 8 Гбайт) |
NVIDIA GeForce RTX 2060 FE (1365 / 14000 МГц, 6 Гбайт) |
NVIDIA GeForce RTX 2070 FE (1410 / 14000 МГц, 8 Гбайт) |
| Ashes of the Singularity: Escalation |
Выкл. |
38 / 54 |
41 / 61 |
30 / 42 |
33 / 50 |
25 / 35 |
30 / 41 |
31 / 44 |
29 / 40 |
36 / 50 |
| Assassin's Creed Odyssey |
TAA High |
24 / 29 |
30 / 35 |
21 / 25 |
24 / 28 |
21 / 24 |
26 / 29 |
27 / 30 |
26 / 29 |
31 / 36 |
| Battlefield V |
TAA High |
46 / 57 |
53 / 65 |
41 / 49 |
47 / 57 |
35 / 43 |
39 / 49 |
42 / 53 |
27 / 42 |
49 / 60 |
| DiRT Rally 2.0 |
TAA |
39 / 46 |
46 / 53 |
35 / 41 |
40 / 48 |
28 / 35 |
33 / 41 |
34 / 43 |
34 / 43 |
41 / 51 |
| Far Cry 5 |
TAA |
39 / 45 |
45 / 52 |
34 / 39 |
40 / 45 |
30 / 34 |
35 / 39 |
36 / 41 |
35 / 39 |
43 / 47 |
| Final Fantasy XV Windows Edition |
TAA |
8 / 27 |
10 / 30 |
10 / 23 |
11 / 26 |
20 / 26 |
22 / 29 |
25 / 32 |
23 / 31 |
31 / 38 |
| Grand Theft Auto V |
FXAA |
35 / 48 |
40 / 55 |
30 / 41 |
34 / 46 |
28 / 41 |
32 / 46 |
35 / 50 |
29 / 46 |
35 / 54 |
| Metro Exodus |
TAA |
17 / 26 |
19 / 29 |
14 / 22 |
16 / 25 |
11 / 18 |
13 / 21 |
14 / 23 |
14 / 21 |
16 / 26 |
| Shadow of the Tomb Raider |
SMAAT 2x |
24 / 32 |
25 / 36 |
22 / 28 |
26 / 32 |
19 / 24 |
23 / 27 |
24 / 29 |
22 / 28 |
29 / 35 |
| Strange Brigade |
AA Ultra |
55 / 63 |
60 / 70 |
47 / 56 |
51 / 60 |
35 / 40 |
39 / 44 |
43 / 50 |
48 / 54 |
60 / 67 |
| Tom Clancy's The Division 2 |
TAA Ultra |
25 / 28 |
29 / 32 |
23 / 25 |
27 / 30 |
13 / 15 |
13 / 15 |
17 / 19 |
23 / 27 |
28 / 32 |
| Total War: WARHAMMER II |
FXAA |
20 / 22 |
23 / 25 |
17 / 19 |
21 / 23 |
13 / 17 |
17 / 19 |
18 / 21 |
17 / 20 |
19 / 23 |
| Макс. |
|
|
+21% |
−11% |
+7% |
−4% |
+7% |
+19% |
+15% |
+41% |
| Средн. |
|
|
+14% |
−14% |
−1% |
−25% |
−15% |
−8% |
−10% |
+10% |
| Мин. |
|
|
+11% |
−22% |
−7% |
−46% |
−46% |
−32% |
−26% |
−7% |
| 3840 × 2160 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 5700 XT (2010 / 14000 МГц, 8 Гбайт) |
AMD Radeon RX Vega 56 (1590 / 1600 МГц, 8 Гбайт) |
AMD Radeon RX Vega 64 (1630 / 1890 МГц, 8 Гбайт) |
AMD Radeon VII (1800 / 2000 МГц, 16 Гбайт) |
NVIDIA GeForce GTX 1080 (1607 / 10000 МГц, 8 Гбайт) |
NVIDIA GeForce GTX 1080 Ti (1590 / 11900 МГц, 11 Гбайт) |
NVIDIA GeForce RTX 2060 FE (1365 / 14000 МГц, 6 Гбайт) |
NVIDIA GeForce RTX 2070 FE (1410 / 14000 МГц, 8 Гбайт) |
NVIDIA GeForce RTX 2080 FE (1515 / 14000 МГц, 8 Гбайт) |
| Ashes of the Singularity: Escalation |
Выкл. |
41 / 61 |
30 / 42 |
33 / 50 |
39 / 60 |
31 / 44 |
39 / 56 |
29 / 40 |
36 / 50 |
44 / 62 |
| Assassin's Creed Odyssey |
TAA High |
30 / 35 |
21 / 25 |
24 / 28 |
35 / 39 |
27 / 30 |
31 / 36 |
26 / 29 |
31 / 36 |
40 / 44 |
| Battlefield V |
TAA High |
53 / 65 |
41 / 49 |
47 / 57 |
63 / 74 |
42 / 53 |
57 / 70 |
27 / 42 |
49 / 60 |
59 / 73 |
| DiRT Rally 2.0 |
TAA |
46 / 53 |
35 / 41 |
40 / 48 |
52 / 60 |
34 / 43 |
47 / 56 |
34 / 43 |
41 / 51 |
54 / 65 |
| Far Cry 5 |
TAA |
45 / 52 |
34 / 39 |
40 / 45 |
51 / 59 |
36 / 41 |
48 / 54 |
35 / 39 |
43 / 47 |
53 / 59 |
| Final Fantasy XV Windows Edition |
TAA |
10 / 30 |
10 / 23 |
11 / 26 |
12 / 32 |
25 / 32 |
31 / 42 |
23 / 31 |
31 / 38 |
36 / 47 |
| Grand Theft Auto V |
FXAA |
40 / 55 |
30 / 41 |
34 / 46 |
41 / 56 |
35 / 50 |
46 / 66 |
29 / 46 |
35 / 54 |
44 / 66 |
| Metro Exodus |
TAA |
19 / 29 |
14 / 22 |
16 / 25 |
20 / 31 |
14 / 23 |
18 / 30 |
14 / 21 |
16 / 26 |
21 / 33 |
| Shadow of the Tomb Raider |
SMAAT 2x |
25 / 36 |
22 / 28 |
26 / 32 |
33 / 41 |
24 / 29 |
32 / 38 |
22 / 28 |
29 / 35 |
36 / 43 |
| Strange Brigade |
AA Ultra |
60 / 70 |
47 / 56 |
51 / 60 |
69 / 87 |
43 / 50 |
57 / 67 |
48 / 54 |
60 / 67 |
72 / 82 |
| Tom Clancy's The Division 2 |
TAA Ultra |
29 / 32 |
23 / 25 |
27 / 30 |
33 / 36 |
17 / 19 |
29 / 32 |
23 / 27 |
28 / 32 |
37 / 42 |
| Total War: WARHAMMER II |
FXAA |
23 / 25 |
17 / 19 |
21 / 23 |
25 / 27 |
18 / 21 |
23 / 27 |
17 / 20 |
19 / 23 |
19 / 28 |
| Макс. |
|
|
−20% |
−6% |
+24% |
+7% |
+40% |
+3% |
+27% |
+57% |
| Средн. |
|
|
−24% |
−13% |
+10% |
−19% |
+7% |
−21% |
−3% |
+21% |
| Мин. |
|
|
−31% |
−20% |
−2% |
−41% |
−8% |
−35% |
−18% |
+2% |
⇡#Производительность на ватт
Дополнение 09.07.2019
Из-за проблем с аппаратурой для измерения мощности, которые некстати возникли при подготовке обзора, в статье поначалу отсутствовала часть тестовых данных, совершенно необходимая для того, чтобы оценить чип Navi по достоинству — сравнение с ключевыми соперниками по энергоэффективности. А ведь архитектура RDNA, в первую очередь, и была задумана как решение проблем с удельным быстродействием, которые уже несколько лет подряд душат графические процессоры AMD. Navi 10 обязан использовать свой далеко не скромный транзисторный бюджет более эффективно и более экономно, чем GPU архитектуры GCN — иначе все старания разработчиков пошли впустую. Что на этот счет говорят твердые числа?
За основу для расчетов мы взяли усредненные соотношения фреймрейта в тестах при разрешении 2160p, когда GPU целиком загружен и заведомо не ограничен быстродействием центрального процессора. Среднее энергопотребление измерено в Crysis 3 — игре, которая легко доводит видеокарты до пиковой мощности.
| Производитель | AMD | NVIDIA |
|---|
| Модель |
Radeon RX 5700 XT |
Radeon RX 5700 |
Radeon RX Vega 56 |
Radeon RX Vega 64 |
Radeon VII |
GeForce RTX 1080 Ti |
GeForce RTX 2060 |
GeForce RTX 2070 |
GeForce RTX 2080 |
| Графический процессор |
Navi 10 XT |
Navi 10 PRO |
Vega 10 XL |
Vega 10 XT |
Vega 20 XL |
GP102 |
TU106 |
TU106 |
TU104 |
| Микроархитектура |
RDNA |
RDNA |
GCN 5 поколения |
GCN 5 поколения |
GCN 5 поколения |
Pascal |
Turing |
Turing |
Turing |
| Техпроцесс, нм |
7 нм FinFET |
7 нм FinFET |
14 нм FinFET |
14 нм FinFET |
7 нм FinFET |
16 нм FFN |
12 нм FFN |
12 нм FFN |
12 нм FFN |
| Число транзисторов, млн |
10 300 |
10 300 |
12 500 |
12 500 |
13 200 |
12 000 |
10 800 |
10 800 |
13 600 |
| Площадь чипа, кв. мм |
251 |
251 |
495 |
495 |
331 |
471 |
445 |
445 |
545 |
| Средняя потребляемая мощность (Crysis 3), Вт |
220 |
180 |
225 |
292 |
286 |
216 |
154 |
178 |
232 |
| Производительность/Вт |
100% |
+7% |
−26% |
−34% |
−15% |
+9% |
+13% |
+20% |
+14% |
| Производительность/млн транзисторов |
100% |
−12% |
−38% |
−28% |
−14% |
−8% |
−25% |
−8% |
−9% |
| Производительность/кв. мм |
100% |
−12% |
−62% |
−56% |
−16% |
−43% |
−55% |
−45% |
−45% |
По сравнению с ускорителями на чипах Vega Radeon RX 5700 XT и вправду демонстрирует колоссальный рост удельного быстродействия, причем не только в отношении к энергопотреблению, но и к площади кристалла. Кажется, AMD даже поскромничала в собственных притязаниях. Наши данные идеально вписались в официальные оценки: Radeon RX 5700 XT в полтора раза превосходит Radeon RX Vega 64 по производительности на ватт и в 2,3 раза — на единицу площади. А ведь AMD проводила тесты на ускорителе Vega с 40 активными CU вместо положенных 64 (у нас, разумеется, возможности произвольно деактивировать блоки GPU нет).
Впрочем, «Вегу» первого поколения и Navi разделяет два перехода технологической нормы, поэтому выделить в сравнении Radeon RX Vega 64 и Radeon RX 5700 XT фактор архитектуры просто так нельзя. В свою очередь, чип Radeon VII производится на той же линии 7 нм и работает на близких тактовых частотах, но и тут Navi достиг преимущества в 16–18 % по всем метрикам удельной производительности — на ватт, на площадь и на количество транзисторов. Да, у Radeon VII отключены 4 из 64 CU, однако вспомним, что тесты в режиме 4К показывают «Вегу» второго поколения в наилучшем свете, а при разрешениях 1080p и 1440p она работает на 5–7 % хуже.
Вот до уровня современных «зеленых» чипов энергоэффективность Navi все-таки не доросла. Даже у GeForce GTX 1080 Ti с ядром, произведенным по норме 16 нм, быстродействие на ватт оказалось на 9% выше, а у современных GeForce GTX 2060 и GTX 2070 — на все 13–20 %. Но дело все еще не только в архитектурных различиях между продуктами AMD и NVIDIA. В таблице легко найти дополнительную причину, по которой даже с преимуществом в один шаг фотолитографии Radeon RX 5700 XT так сильно отстал от чипов Turing по энергоэффективности — конструкторы платы в погоне за максимальными частотами перестраховались с напряжением питания GPU. Если взять за точку отсчета данные младшей версии Radeon RX 5700, то быстродействие на ватт у GeForce GTX 2060 и GTX 2070 будет всего лишь на 6–12 % выше.
Утешительным призом для AMD станет высокая оценка производительности на число транзисторов — здесь лучшим примером для сравнения с Radeon RX 5700 XT является GeForce RTX 2070, поскольку на обеих платах GPU полностью разблокирован, — и она у Navi на 9 % выше. Разумеется, все дело в том, что чипы Turing обременяют тензорные блоки и RT-ядра, но, по крайней мере, AMD теперь ничто не мешает выпустить для игровых видеокарт такой же гигантский GPU, как TU102, на основе архитектуры RDNA.
⇡#Выводы
Архитектура RDNA, и теперь это можно утверждать без всяких сомнений, оправдала высокие ожидания. Благодаря передовому техпроцессу и целиком переработанной логике графического процессора Navi 10 AMD смогла представить достойных соперников для ускорителей NVIDIA средне-высокого ценового диапазона — GeForce RTX 2060 и GeForce RTX 2070. По совокупным данным в игровых тестах младшая версия Radeon RX 5700 не оставляет шансов GeForce RTX 2060 с преимуществом в 6–11 % в зависимости от разрешения экрана, а Radeon RX 5700 XT, в свою очередь, идет практически вровень с GeForce RTX 2070.
Впрочем, AMD и раньше могла успешно конкурировать с NVIDIA во всех рыночных нишах, кроме GPU высшей категории. Главное, что удалось сделать архитектуре RDNA, — это вытащить Radeon из ямы низкой энергоэффективности и помочь более эффективно конвертировать терафлопсы теоретической производительности в FPS реальных графических приложений. У AMD еще осталось над чем работать — по быстродействию на ватт мощности современные чипы NVIDIA не уступили лидирующей позиции, даже невзирая на разницу в производственной норме между 12 и 7 нанометрами. Тем не менее налицо огромный прогресс. В соотношении расчетных терафлопсов и игрового быстродействия RDNA настолько сильно превосходит GCN, что Radeon RX 5700 XT не только отправил в прошлое Radeon RX Vega 64, но и вплотную подступил к Radeon VII в игровых тестах при разрешении 1080p и 1440p, а ведь между чипами Navi 10 и Vega 20 колоссальная разница в «сырой» вычислительной мощности. По возможности эффективно использовать транзисторный запас GPU первое поколение RDNA можно поместить на один уровень с чипами Turing — и это крупнейшее достижение графического подразделения AMD со времен первых итераций архитектуры GCN.
Способность Navi настолько же успешно действовать в расчетах общего назначения пока что остается под вопросом. Ранние драйверы мешают составить полное впечатление, но, по предварительным оценкам, достоинства архитектуры RDNA не перетекают в вычислительные задачи за пределами 3D-рендеринга. GCN в них уже чрезвычайно хороша, поэтому таким решениям, как Radeon VII, в рабочих приложениях Radeon RX 5700 XT не является ни угрозой, ни заменой.
Зазор, который существует между Navi и Turing по энергоэффективности в 3D-приложениях, частично объясняется особенностями референсных видеокарт, которые в первое время будут представлять на рынке чипы нового поколения. Как показали эксперименты, кремний Navi 10 не нуждается в столь высоком напряжении питания, которое установлено в эталонных версиях Radeon RX 5700 и RX 5700 XT. Кроме того, «турбинная» система охлаждения, которой отдает предпочтение AMD, откровенно плохо справляется с отводом тепла даже от не самого горячего GPU, которым является Navi 10, и этот фактор вносит отдельный вклад в потери мощности, не говоря уже о высоком уровне шума и практически нулевом оверлокерском потенциале. Как ни крути, референсные видеокарты эффектно выглядят, но их рабочие характеристики бросают тень на в целом абсолютно позитивное впечатление, которое производит долгожданный Navi.
И наконец, те предложения NVIDIA, над которыми Radeon RX 5700 и Radeon RX 5700 XT одержали уверенную победу по соотношению цены и быстродействия, — GeForce RTX 2060 и GeForce RTX 2070 — уже не являются для Navi основными и единственными конкурентами. Совсем скоро в продаже появятся обновленные версии этих моделей под маркой SUPER. Прибытия GeForce RTX 2060 SUPER и GeForce RTX 2070 SUPER в тестовую лабораторию мы ожидаем со дня на день, и тогда мы еще вернемся к разгоревшемуся с новой силой противостоянию AMD и NVIDIA.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex