|
Опрос
|
реклама
Быстрый переход
Катастрофического роста цен на видеокарты пока не было, но всё ещё впереди
01.08.2026 [09:46],
Павел Котов
Ресурс TechSpot опубликовал подробное исследование рынка актуальных потребительских видеокарт в десяти странах мира: в США, Канаде, Великобритании, Австралии, Нидерландах, Германии, Польше, Бразилии, Индии и на Филиппинах. Несмотря мировой кризис с чипами памяти, видеокарты пока подорожали не так сильно, но в ближайшие месяцы ситуация может ухудшиться.  Авторы сравнили стоимости видеокарт в десяти странах мира по состоянию на октябрь 2025, апрель и июль 2026 года — учитывались не средние показатели, а реальные минимальные ценники доступных в магазинах моделей. Дефицит чипов памяти установился осенью минувшего года, и с тех пор, вопреки опасениям, цены на видеокарты выросли умеренно — сильнее всего подорожали модели с большими объёмами памяти, что предсказуемо. Если адаптировать рекомендованную розничную цену под реалии каждого рынка с учётом конвертации валюты и местных налогов, то к настоящему моменту видеокарты стоят дороже в среднем на 16 %. Исключив из подборки чрезмерно дорогую и столь же запредельно подорожавшую в новых условиях флагманскую Nvidia GeForce RTX 5090, получаем рост стоимости уже лишь на 10 %. С апреля по июль цены повысились лишь на 2 %, а без учёта той же RTX 5090 и подавно практически не изменились. Из доступных широкой аудитории моделей основной удар приняли на себя видеокарты Nvidia с 16 Гбайт памяти: RTX 5060 Ti (16 Гбайт), RTX 5070 Ti и RTX 5080 подорожали примерно на 20 % относительно стартовых цен. Nvidia GeForce RTX 5090 как самая дорогая модель на потребительском рынке выбивается из общего числа: она подорожала не только с октября по апрель, но и с апреля по июль прибавила дополнительные 12 %, а в некоторых регионах и на все 20 %. К настоящему моменту она на 94 % дороже начальной рекомендованной розничной цены, по которой её можно было найти очень непродолжительное время. При стоимости в $4000 она едва ли воспринимается как обычная игровая видеокарта — это уже скорее оборудование для рабочих станций и задач искусственного интеллекта. Она даже не является самой выгодной возможностью получить видеокарту с 32 Гбайт памяти — профессиональная Nvidia RTX Pro 4500 доступна за $3100, хотя её графический процессор ближе к более скромной GeForce RTX 5080.  В качестве положительного примера приводится дуэт AMD Radeon RX 9070 и RX 9070 XT, которому удалось сохранить наиболее адекватные ценники среди старших моделей: базовая Radeon RX 9070 поднялась лишь на 4 % выше рекомендованной цены, а RX 9070 XT — на 8 %. В конкурентной борьбе Nvidia не удалось удержать здесь стоимость, и GeForce RTX 5070 Ti сейчас в среднем на 42 % дороже, чем Radeon RX 9070 XT. Таким образом, AMD усилила позиции в верхнем среднем сегменте. В бюджетном сегменте свои правила игры и свои аномалии. Любопытно, например, что Nvidia GeForce RTX 5060 Ti (8 Гбайт) приблизилась к младшей базовой GeForce RTX 5060. В среднем по десяти изученным рынкам RTX 5060 Ti (8 Гбайт) на 16 % дороже, чем RTX 5060; по США, Канаде и Австралии разница в цене составляет менее 12 % — при разнице в производительности на 17 %. Таким образом RTX 5060 Ti (8 Гбайт) может оказаться более выгодной покупкой чем младшая модель. Следует, однако, оговориться, что неверно рассматривать старшую как рекомендованный для приобретения вариант — практика показывает, что 8 Гбайт видеопамяти в реалиях 2026 года уже недостаточно для комфортной игры. Нельзя не упомянуть и про третьего игрока на рынке дискретных видеокарт — Intel. Кризис памяти затронул и «синих», но здесь свои особенности. Модели Arc поколения Battlemage просто становятся недоступными. За минувшие три месяца их наличие в продажах заметно сократилось; ценники на Arc B570 и B580 в тот же период выросли примерно на 5 % в среднем по десяти регионам. Старшая Arc B580 оказалась примерно на 17 % дороже «реальной» цены, вплотную подобравшись к Nvidia GeForce RTX 5060, хотя её прямым конкурентом выступает скорее RTX 5050. Ценовой катастрофы на рынке видеокарт пока не произошло, но не потому, что проблема кризиса памяти здесь неактуальна — магазины до сих пор продают старые запасы. Стоимость GDDR6 и GDDR7 подскочила, и розничные продавцы предупреждают о росте закупочных цен на 16-Гбайт GeForce примерно на 10–15 % в новых партиях, а в дальнейшем не исключается рост цен на величину до 40 %. Если видеокарта нужна срочно, то лучше не затягивать с её покупкой; но если текущая ещё справляется со своими задачами, то следует запастись терпением и дождаться моделей нового поколения. Nvidia подняла цены на свои GPU ещё на 20–30 %
01.08.2026 [05:44],
Алексей Разин
Обыватели могут судить о последствиях таких действий поставщиков графических процессоров только опосредованно, поскольку публично цены на GPU никогда не разглашаются, но издание Eurogamer со ссылкой на Economic Daily сообщило, что Nvidia недавно подняла стоимость своих GPU ещё на 20–30 %. 
Источник изображения: Nvidia Это уже третий случай повышения цен на основной вид продукции данной компании с начала текущего года, но подобные шаги поставщика уже перестали удивлять аудиторию, поскольку в условиях бума искусственного интеллекта закономерно дорожают те компоненты, которые больше всего востребованы при строительстве вычислительной инфраструктуры. В наступившем месяце Nvidia будет подводить итоги фискального квартала, по опубликованной статистике можно будет судить о динамике её финансовых показателей. В мае, как отмечает источник, повышение цен на продукцию Nvidia коснулось главным образом старших моделей игровых видеокарт типа GeForce RTX 5090, но нынешнее повышение охватило более широкий ассортимент моделей, хотя точные данные и не приводятся. Поднять цены на свою память на величину до 20 % собирается и компания Samsung Electronics, поэтому обладание новым игровым компьютером становится всё более дорогим удовольствием. Китайские продавцы компьютерных компонентов даже придерживают в реализации ту продукцию, которая должна вскоре подорожать, чтобы реализовать её по более высоким ценам. Всё это усиливает дефицит в рознице и деморализует покупателей. Игровые консоли тоже дорожают, и даже производительные смартфоны становятся всё менее доступной игровой платформой в условиях бума ИИ. Asus и XFX выпустили свои варианты Radeon RX 9050 — Asus разогнала свою до 2,77 ГГц
31.07.2026 [22:55],
Николай Хижняк
Компании Asus и XFX выпустили свои версии Radeon RX 9050. Модели Asus DUAL-RX9050-O8G и XFX RX-95SWFT8BE оснащены системами охлаждения с двумя вентиляторами и получили по 8 Гбайт памяти GDDR6. Вариант от Asus предлагает значительный заводской разгон графического процессора. 
Источник изображений: VideoCardz / Asus / XFX AMD выпустила Radeon RX 9050 для стран Азиатско-Тихоокеанского региона, Японии и Латинской Америки по рекомендованной розничной цене $279. Карта начального уровня серии RDNA 4 оснащена 16 исполнительными блоками, 1024 потоковыми процессорами, 32 ИИ-ускорителями и 16 ускорителями трассировки лучей. AMD заявляет для её GPU игровую частоту 1920 МГц и Boost-частоту 2600 МГц. Энергопотребление карты заявлено на уровне 92 Вт.  Модель Asus DUAL-RX9050-O8G достигает 2260 МГц игровой частоты и 2760 МГц в режиме Boost по умолчанию. В режиме OC игровая частота увеличивается до 2270 МГц, а Boost-частота — до 2770 МГц. Таким образом, максимальный прирост Boost-частоты составляет 6,5 % выше эталонного значения, а игровой частоты — на 18,2 % выше.  Новинка оснащена двумя вентиляторами Axial-tech с функцией полной остановки и вентилируемой задней панелью. Размеры видеокарты составляют 203 × 120,2 × 40 мм, вес — 434 грамма. Японский офис Asus, анонсировавший новинку, заявляет, что карта занимает два слота расширения, однако на странице продукта на площадке Amazon указана толщина 2,5 слота расширения.  Стоимость видеокарты Asus в Японии составляет 54 980 иен (около $344).  Версия XFX Swift RX-95SWFT8BE использует стандартные настройки GPU. Чип имеет базовую частоту 1330 МГц, игровую частоту 1920 МГц и Boost-частоту 2600 МГц. XFX указывает на потребление карты 92 Вт и рекомендует использовать с ней блок питания мощностью от 450 Вт. Толщина карты составляет 2,5 слота расширения. Габариты: 234 × 144 × 51 мм. Она на 31 мм длиннее и на 11 мм толще варианта от Asus.  Обе версии RX 9050 от Asus и XFX получили по 8 Гбайт памяти GDDR6 со скоростью 18 Гбит/с на контакт и поддержкой 128-битной шины. Каждая модель оснащена двумя разъёмами DisplayPort 2.1 и одним HDMI 2.1. Питание карты получают по одному 8-контактному разъёму PCIe.  Стоимость модели XFX составляет 52 980 иен (около $332). Первые тесты Radeon RX 9050 показали, что она до 30 % медленнее GeForce RTX 5050
31.07.2026 [15:50],
Николай Хижняк
Японское издание Hermitage Akihabara опубликовало первый подробный независимый обзор новой игровой видеокарты начального уровня Radeon RX 9050. Источник сравнил производительность моделей ASRock Radeon RX 9050 Challenger 8GB и Gigabyte GeForce RTX 5050 Windforce OC 8GB на системе с процессором Ryzen 7 9800X3D. Оценка восьми синтетических тестов 3DMark показывает, что карта Radeon примерно на 18,2 % медленнее модели RTX 5050. 
Источник изображений: GDM AMD выпустила Radeon RX 9050 без лишнего шума и только для отдельных регионов. Свои варианты карты представили лишь несколько партнёров компании. ASRock выпустила модели Challenger в версиях с 8 и 4 Гбайт памяти. Варианты с 4 Гбайт не будут доступны в рознице — они будут поставляться OEM-производителям и сборщикам ПК. В тесте использовалась модель с 8 Гбайт памяти. Детальная информация утилиты GPU-Z показывает, что в составе Radeon RX 9050 используется графический процессор Navi 44 XE. Это урезанный вариант чипа Navi 44 с 16 исполнительными блоками, 1024 потоковыми процессорами, 16 ускорителями трассировки лучей и 32 ИИ-ускорителями. 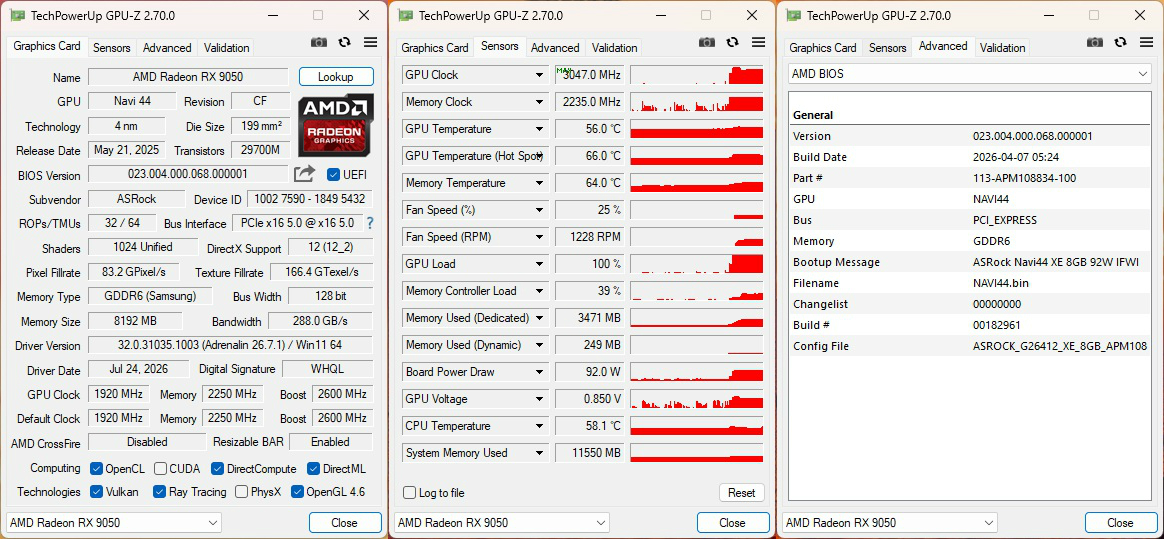 Карта оснащена 8 Гбайт памяти GDDR6 со скоростью 18 Гбит/с на контакт, поддерживает 128-битную шину и обеспечивает пропускную способность 288 Гбайт/с. Игровая частота графического процессора составляет 1920 МГц, Boost-частота — 2600 МГц. Заявленный показатель энергопотребления видеокарты — 92 Вт. Наибольшее отставание Radeon RX 9050 наблюдается в тестах 3DMark с трассировкой лучей. Карта оказалась на 25,7 % медленнее в Speed Way и на 26,7 % — в Port Royal. Разница в быстродействии с RTX 5050 сокращается до 13 % в тесте Steel Nomad, до 10,7 % — в Time Spy и до 10,1 % — в Time Spy Extreme. Видеокарта GeForce RTX 5050 также оказалась быстрее в большинстве игровых тестов. Модель RX 9050 была на 18,6 % медленнее в Final Fantasy XIV при разрешении 1080p и на 14,6 % медленнее в Apex Legends и Rainbow Six Siege X при использовании средних настроек качества изображения. В Rainbow Six Siege X карта Radeon выдала 64 кадра в секунду при разрешении 4K и настройках Ultra+. С остальными результатами игровых тестов японского издания можно ознакомиться в таблице ниже. 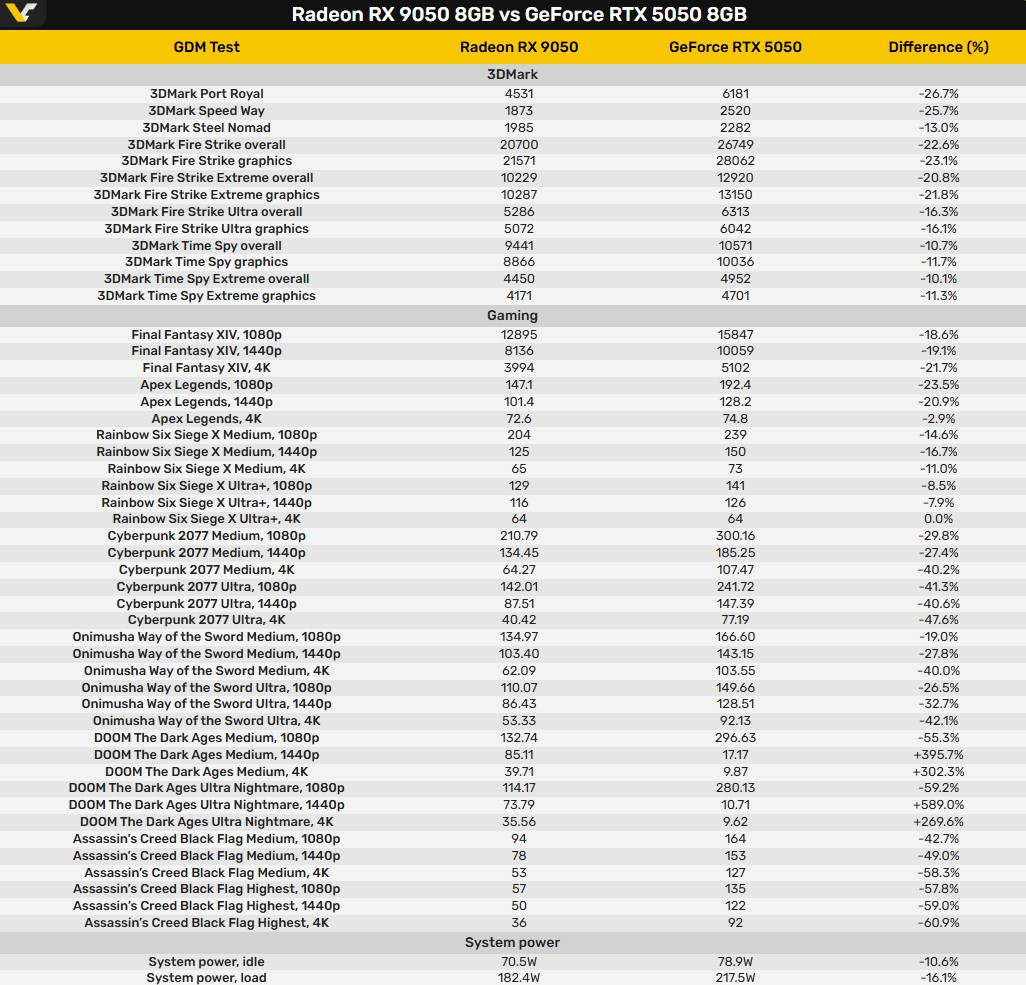 Некоторые из наиболее существенных различий в быстродействии не отражают прямого сравнения производительности карт. Обозреватель использовал стандартную генерацию кадров FSR на видеокарте Radeon, в то время как для RTX 5050 применялась многокадровая генерация DLSS с коэффициентом 4× или 6× в Cyberpunk 2077, Onimusha, Doom и Assassin’s Creed Black Flag. Это дало карте Nvidia значительное преимущество при разрешении 1080p, хотя в Doom при разрешениях 1440p и 4K частота кадров RTX 5050 падала до 10–17 FPS из-за ограничений объёма памяти. В среднем RX 9050 на 18 % медленнее, чем RTX 5050, в синтетических тестах и на 30 % медленнее — в играх (если исключить Doom, которая, очевидно, плохо работает в разрешении 4K с этими видеокартами). Преимуществом карты Radeon является её энергопотребление. Общее энергопотребление ПК с данной видеокартой под нагрузкой составило 182,4 Вт, а с GeForce RTX 5050 — 217,5 Вт. Это на 35,1 Вт, или на 16,1 %, больше. Температура графического процессора видеокарты RX 9050 составила 56 °C, а самой горячей точки чипа — 69 °C. Видеокарты RTX 4060 от Gigabyte способны сами себя сжечь — ремонтники нашли скрытый дефект
29.07.2026 [20:36],
Николай Хижняк
Бразильские специалисты по ремонту видеокарт Паулу Гомес (Paulo Gomes) и SidNelson задокументировали повторяющиеся случаи короткого замыкания на видеокартах Gigabyte GeForce RTX 4060. Повреждённые карты демонстрируют сильное обугливание печатной платы вблизи выхода HDMI. Специалисты утверждают, что повреждение начинается внутри цепи питания графического процессора, а не связано с разъёмом дисплея. 
Источник изображений: YouTube / Paulo Gomes Команда исследовала повреждённые платы наряду с полностью рабочим образцом карты Gigabyte. Для сравнения также использовалась модель GeForce RTX 4060 от Inno3D. Измерения проводились с помощью осциллографа и мультиметра для проверки четырёх силовых фаз RTX 4060, подающих питание на графический процессор. 
 Многофазная подсистема питания (VRM) карт распределяет нагрузку на графический процессор между несколькими параллельными силовыми каскадами. Фазы намеренно смещены друг относительно друга, но они должны работать с аналогичными частотами переключения и коэффициентами заполнения при подаче одного и того же напряжения. Это позволяет контроллеру распределять ток, не перекладывая большую часть нагрузки на один набор MOSFET-транзисторов. 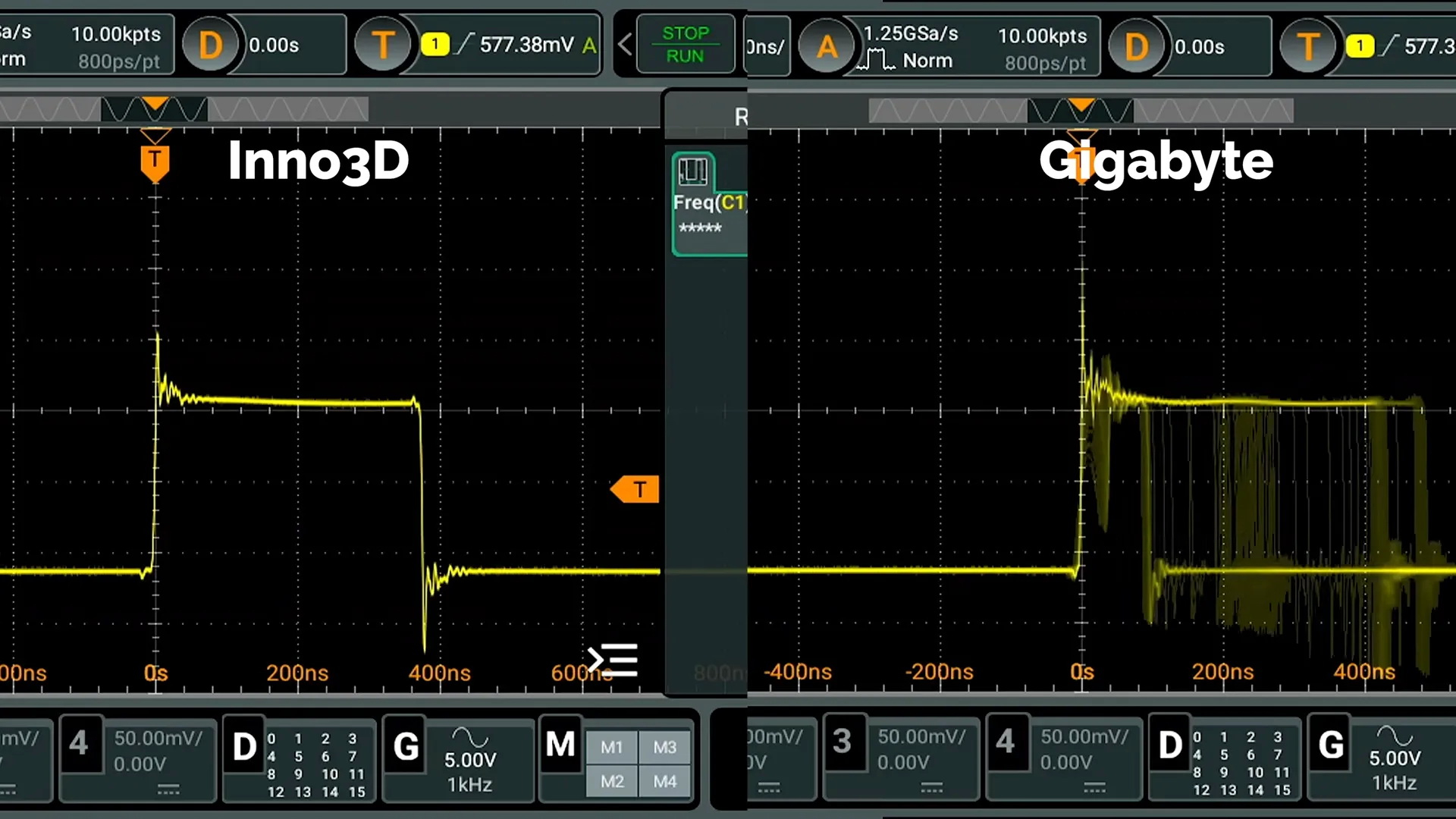 На карте Inno3D все четыре фазы графического процессора демонстрировали практически идентичные сигналы с частотой около 207 кГц. На модели Gigabyte наблюдались гораздо большие различия между фазами. В исходной конфигурации специалисты зафиксировали, что частота одной фазы колебалась примерно от 150 до 300 кГц, в то время как другие фазы вели себя по-разному при тех же условиях. «Проанализировав целые и повреждённые платы с помощью осциллографа и мультиметра, мы выявили: Фазовый дисбаланс VRM: в схеме управления током у платы Gigabyte (Current Sense/PWM) допущена ошибка при выборе резисторов и конденсаторов. Нестабильное поведение: каждая фаза питания работает с совершенно нерегулируемыми частотами и коэффициентами заполнения относительно друг друга, перегружая определённые MOSFET-транзисторы. Результат: MOSFET-транзистор замыкается, разрушается и обугливает печатную плату прямо в области видеовыхода, (ложно) имитируя скачок напряжения, исходящий от порта HDMI. […] Мы подчёркиваем, что эта неисправность является скрытым дефектом (конструктивным недостатком производителя), а не результатом неправильного использования видеокарты клиентом. Мы призываем Gigabyte занять определённую позицию (гарантийное обслуживание или отзыв продукции) и рекомендуем пострадавшим пользователям отстаивать свои права в соответствии с бразильским Кодексом защиты прав потребителей. В конце опубликованного нами видео ещё один клиент приходит в мастерскую с точно такой же проблемой, что подтверждает, насколько часто встречается этот дефект», — сообщил Паулу Гомес в разговоре с VideoCardz. 
 Предполагаемым источником проблемы является цепь измерения тока, подключённая к ШИМ-контроллеру. Эта схема регистрирует ток, проходящий через каждую фазу, чтобы контроллер мог сбалансировать нагрузку. Гомес и SidNelson обнаружили различные конфигурации резисторов и конденсаторов в четырёх цепях обратной связи. Они считают, что это приводит к неравномерному распределению тока контроллером, перегрузке одного из MOSFET-транзисторов до тех пор, пока он не закоротит и не обуглит печатную плату.  Вышедший из строя силовой каскад расположен рядом с видеовыходами. После отказа MOSFET выделяющиеся при этом тепло и ток могут привести к повреждению платы в направлении разъёма HDMI. В результате возникает повреждение, похожее на последствия внешнего скачка напряжения, проникшего через HDMI. По словам специалистов, именно из-за этого в Gigabyte отказывали в гарантийном обслуживании, посчитав, что клиент неправильно использовал видеокарту.  SidNelson удалил у повреждённой карты оригинальные компоненты цепи измерения тока и пересобрал схему обратной связи, используя в качестве эталона рабочие схемы видеокарт. Одну фазу на сильно обугленной плате восстановить не удалось, поэтому она была отключена. В оставшиеся три фазы были установлены MOSFET-транзисторы с более высоким номиналом, повреждённые дорожки восстановлены, а на вход 12 В добавлен предохранитель. Измерения на осциллографе после модификации показали гораздо более согласованную работу оставшихся фаз. Видеокарта восстановила вывод видеосигнала и успешно прошла стресс-тесты. Расследование бразильских специалистов не устанавливает, сколько видеокарт затронуто дефектом дизайна подсистемы питания, и не подтверждает, что все версии Gigabyte GeForce RTX 4060 используют одинаковую конфигурацию VRM. На протестированных платах были обнаружены несколько маркировок, указывающих на производство в 2023 году. PowerColor представила видеокарту Radeon RX 9050 Reaper с 8 Гбайт памяти
29.07.2026 [13:44],
Николай Хижняк
Компания PowerColor представила свой вариант видеокарты Radeon RX 9050 8GB в фирменном исполнении Reaper. Новинка не имеет дополнительного заводского разгона GPU. 
Источник изображений: PowerColor В составе карты используется урезанный графический чип Navi 44 с 16 из 32 активных исполнительных блоков, 1024 потоковыми процессорами, 32 ИИ-ускорителями и 16 ускорителями трассировки лучей. Карта оснащена памятью GDDR6 со скоростью 18 Гбит/с на контакт, поддерживает 128-битную шину и обеспечивает пропускную способность 288 Гбайт/с.  Версия Radeon RX 9050 8GB в исполнении PowerColor Reaper оснащена системой охлаждения с алюминиевым радиатором и двумя вентиляторами диаметром 80 мм. Кожух у карты пластиковый, как и задняя пластина. Карта получает питание через один 8-контактный разъём PCIe. Энергопотребление составляет 100 Вт. PowerColor использует эталонные настройки GPU: игровая частота составляет 1920 МГц, а Boost-частота — 2600 МГц. 
 Набор видеоразъёмов включает два DisplayPort 2.1a и один HDMI 2.1b. Длина карты составляет 200 мм, высота — 100 мм. Она занимает два слота расширения. Стоимость новинки производитель не сообщил. AMD подтвердила существование Radeon RX 9050 с 4 Гбайт памяти, но она доступна только в готовых ПК
29.07.2026 [13:37],
Николай Хижняк
AMD подтвердила, что версия видеокарты Radeon RX 9050 с 4 Гбайт памяти действительно существует, однако она предназначена только для OEM-производителей и сборщиков ПК. По словам компании, этот вариант видеокарты был разработан специально для партнёров, которые не планируют выпускать карту в виде отдельного продукта. 
Источник изображения: AMD Информацией поделился главный редактор портала Wccftech Хассан Муджтаба (Hassan Mujtaba), сославшись на AMD, вскоре после того, как версия Radeon RX 9050 с 4 Гбайт памяти была обнаружена в составе игрового ПК начального уровня CyberPowerPC. По данным AMD, эта видеокарта была разработана для обеспечения оптимального соотношения цены и производительности для начинающих геймеров. 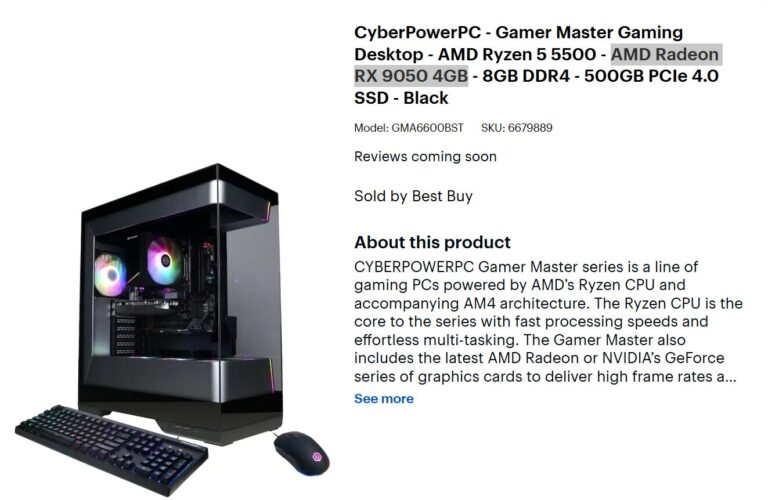
Источник изображения: Best Buy Как сообщает портал VideoCardz, игровой ПК CyberPowerPC Gamer Master GMA6600BST доступен в магазинах американской розничной сети Best Buy. Он сочетает видеокарту Radeon RX 9050 4GB с процессором Ryzen 5 5500, 8 Гбайт оперативной памяти DDR4 и твердотельным накопителем объёмом 500 Гбайт. Стоимость системы составляет $899,99. 
Radeon RX 9050 с 4 Гбайт памяти. Источник изображения: ASRock Партнёры AMD по производству видеокарт уже начали анонсировать свои варианты Radeon RX 9050 с 8 Гбайт памяти. Карта оснащена 1024 потоковыми процессорами, 16 исполнительными блоками GPU и памятью GDDR6 со скоростью 18 Гбит/с на контакт с поддержкой 128-битной шины. AMD не сообщила полные спецификации версии карты с 4 Гбайт памяти. Согласно данным ASRock, 4-гигабайтная версия оснащена 64-битной шиной памяти, из-за чего пропускная способность памяти снижена с 288 до 144 Гбайт/с. Sapphire представила Radeon RX 9050 Pulse с заводским разгоном
28.07.2026 [21:48],
Николай Хижняк
Компания Sapphire представила свою версию видеокарты начального уровня Radeon RX 9050 на архитектуре RDNA 4 в фирменном исполнении Pulse. Карта оснащена 8 Гбайт памяти и обладает TDP 100 Вт, что на 8 Вт выше эталонного значения, заявленного AMD. 
Источник изображений: VideoCardz / Sapphire В основе новинки используется графический чип с 16 исполнительными блоками, 1024 потоковыми процессорами и 32 Мбайт кеш-памяти Infinity Cache. Sapphire заявляет для своей версии карты дополнительный разгон GPU. Игровая частота чипа составляет 2260 МГц (эталон — 1920 МГц), а Boost-частота — 2760 МГц (эталон — 2600 МГц). Память GDDR6 в составе карты работает со скоростью 18 Гбит/с на контакт и поддерживает 128-битную шину. Модель Sapphire Radeon RX 9050 Pulse оснащена системой охлаждения с двумя вентиляторами. Размеры карты составляют 200 × 109,25 × 40,6 мм. Она занимает два слота расширения. Между GPU и радиатором карты производитель использует термопрокладку Honeywell PTM7950 с фазовым переходом. В составе системы охлаждения также применяются композитные тепловые трубки. Карта оснащена металлической задней пластиной. Питание карты организовано по семифазной схеме с цифровым управлением.  Radeon RX 9050 Pulse получила один 8-контактный разъём питания PCIe. Sapphire рекомендует использовать с ней блок питания мощностью 650 Вт. Карта оснащена интерфейсом PCIe 5.0 x16, а также двумя видеовыходами HDMI 2.1b и одним DisplayPort 2.1a. Sapphire отмечает, что Radeon RX 9050 предназначена для игр в разрешении 1080p при средних и высоких настройках. Новинка поддерживает технологии FSR 4, AFMF 2, Anti-Lag 2 и FSR Redstone. Стоимость карты компания не сообщила. AMD выпустила драйвер с поддержкой новой видеокарты Radeon RX 9050, а также беты Gears of War: E-Day
28.07.2026 [20:05],
Николай Хижняк
Компания AMD выпустила свежий пакет графического драйвера Radeon Software Adrenalin 26.7.1 WHQL. Он обеспечивает поддержку новой видеокарты начального уровня Radeon RX 9050, которая сегодня была представлена. 
Источник изображения: Xbox Программное обеспечение AMD также добавляет поддержку игр Gears of War: E-Day Open Beta и Out of Control Evolution. Список исправленных проблем:
Список известных проблем:
Скачать драйвер Radeon Software Adrenalin 26.7.1 WHQL можно с официального сайта AMD. AMD представила антикризисную видеокарту Radeon RX 9050 с 8 Гбайт памяти
28.07.2026 [20:02],
Николай Хижняк
AMD официально представила десктопную видеокарту начального уровня — Radeon RX 9050. Компания опубликовала все спецификации новинки, а также результаты собственных игровых тестов карты в разрешении 1080p. 
Источник изображений: AMD Заявленный показатель энергопотребления у Radeon RX 9050 составляет 92 Вт. Для неё рекомендуется блок питания мощностью от 450 Вт. Карта получает питание по одному 8-контактному разъёму. Radeon RX 9050 оснащена графическим процессором с 16 исполнительными блоками, что на 12 меньше, чем у модели RX 9060. Новинка располагает 1024 потоковыми процессорами (1792 у RX 9060), 16 блоками ускорения трассировки лучей и 32 ИИ-ускорителями. Игровая частота чипа составляет 1920 МГц, Boost-частота — 2600 МГц. В операциях FP32 видеокарта обеспечивает производительность 10,6 Тфлопс. 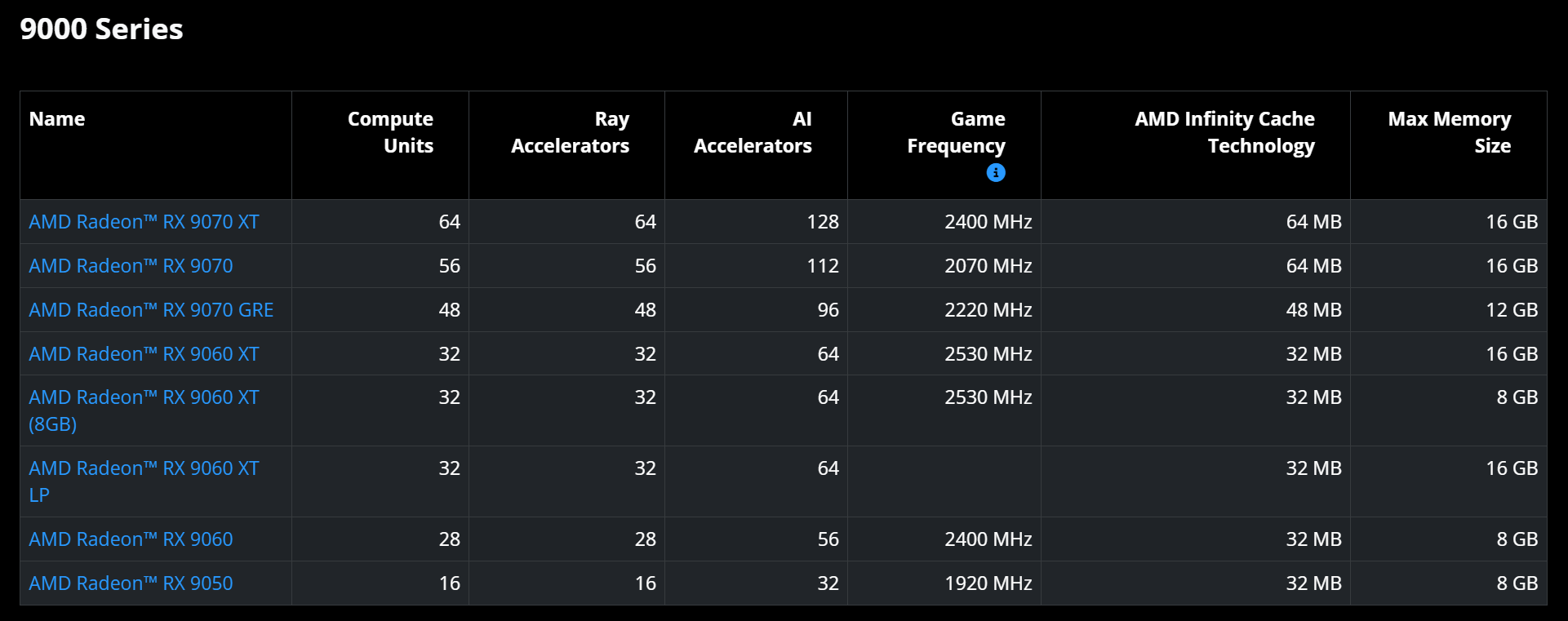 Видеокарта получила 8 Гбайт памяти GDDR6 со скоростью 18 Гбит/с на контакт и поддержкой 128-битной шины. Пропускная способность памяти составляет 288 Гбайт/с, что соответствует показателю модели RX 9060. Для Radeon RX 9050 также заявлены 32 Мбайт кеш-памяти Infinity Cache. AMD заявляет, что Radeon RX 9050 обеспечивает 96 кадров в секунду в игре Cyberpunk 2077, 131 кадр в секунду в игре Forza Horizon 6, 116 FPS в Call of Duty: Black Ops 7, 85 FPS в Pragmata и 60 FPS в 007: First Light в разрешении 1080p и средних настройках качества изображения. 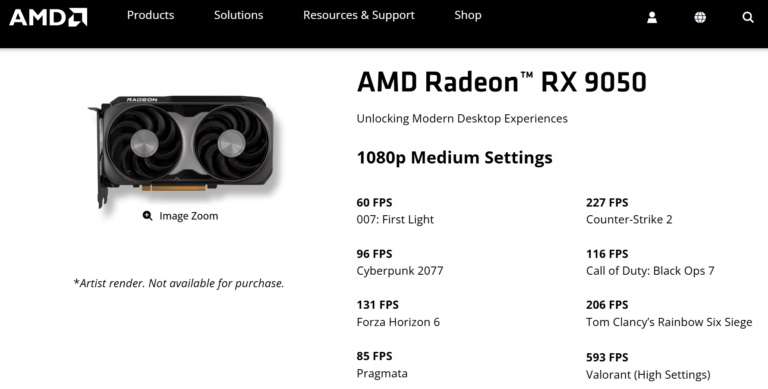 Компания также сообщает о 227 кадрах в секунду в Counter-Strike 2, 206 FPS в Rainbow Six Siege и 593 FPS в Valorant. При этом Valorant является единственной игрой их тестовой подборки, для которой AMD использовала высокие настройки изображения. Компания не сообщила конфигурацию тестовой системы, а также не рассказала о том, использовались ли в рамках тестов технологии масштабирования и генерации кадров. Официальную стоимость Radeon RX 9050 не озвучила. По информации портала Wccftech, стоимость карты составит $279. При этом в продаже она появится только на определённых рынках — в страх Азиатско-Тихоокеанского региона, Японии и Латинской Америки. ASRock раньше времени рассекретила бюджетную видеокарту Radeon RX 9050 с 4 или 8 Гбайт памяти
28.07.2026 [15:15],
Николай Хижняк
Компания ASRock опубликовала на своём официальном сайте характеристики ещё не представленной AMD видеокарты начального уровня Radeon RX 9050 в вариантах с 8 и 4 Гбайт памяти. Производитель вскоре понял свою ошибку и удалил соответствующие страницы со своего сайта. 
Источник изображений: VideoCardz / ASRock О том, что компания AMD ведёт разработку видеокарты начального уровня Radeon RX 9050, сообщалось ещё в мае. Тогда речь шла только о версии карты с 8 Гбайт памяти. Данные ASRock подтверждают, что также будет выпущена версия с 4 Гбайт памяти, однако она будет доступна только OEM-производителям и сборщикам ПК. При этом характеристики карты, опубликованные ASRock, отличаются от тех, о которых сообщалось в мае.  По данным ASRock, в составе Radeon RX 9050 используется графический чип с 16 вычислительными блоками и 1024 потоковыми процессорами. Таким образом, Radeon RX 9050 имеет вдвое меньше вычислительных блоков, чем графический процессор модели Radeon RX 9060 XT. Игровая частота GPU Radeon RX 9050 составляет 1920 МГц, а Boost-частота — 2600 МГц. Теоретическая производительность карты в операциях FP32 составляет около 5,3 Тфлопс. У той же Radeon RX 9060 XT этот показатель составляет около 12,8 Тфлопс.  Radeon RX 9050 предложит весь набор особенностей, заявленных для архитектуры RDNA 4, включая третье поколение ускорителей трассировки лучей и второе поколение ИИ-ускорителей.  ASRock готовит карту в исполнении Challenger с 8 Гбайт памяти GDDR6, работающей со скоростью 18 Гбит/с на контакт и поддерживающей 128-битную шину. Это обеспечит пропускную способность памяти на уровне 288 Гбайт/с. Версия с 4 Гбайт памяти, также замеченная на сайте производителя, но без полного перечня характеристик, получит 64-битную шину памяти, что сократит её пропускную способность до 144 Гбайт/с.  ASRock Radeon RX 9050 Challenger имеет размеры 249 × 132 × 41 мм, вес карты составляет 645 г. Она оснащена системой охлаждения с двумя вентиляторами. Для питания карта использует один 8-контактный разъём PCIe. Производитель рекомендует использовать с ней блок питания мощностью от 450 Вт, но не указывает TDP самой видеокарты. В оснащение карты также входят два разъёма DisplayPort 2.1a и один HDMI 2.1b. 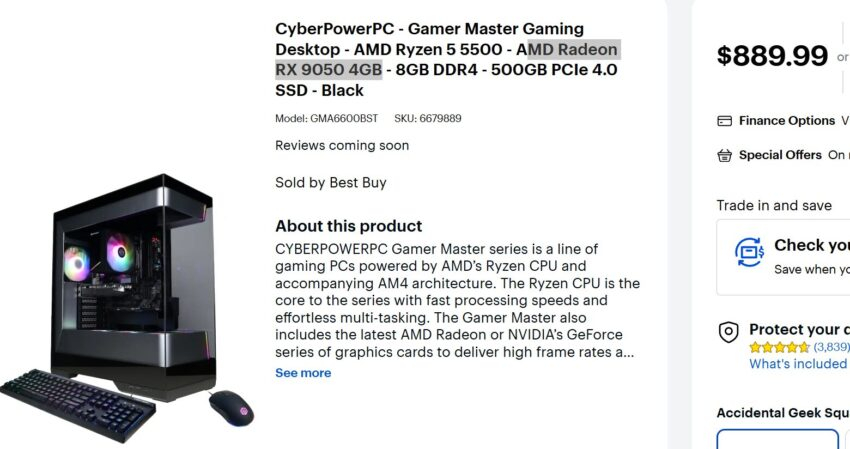 ASRock предупреждает, что данная видеокарта может быть доступна не во всех странах мира. Сама AMD пока официально не подтверждала существование Radeon RX 9050, а также её спецификации и цену. Портал VideoCardz отмечает, что версия Radeon RX 9050 была обнаружена в составе готового ПК CyberPowerPC. Стоимость системы составляет $890. Gigabyte выпустила дырявую видеокарту — в плате Aorus GeForce RTX 5080 Infinity Wood оказалось четыре огромных выреза
27.07.2026 [22:43],
Николай Хижняк
Портал Chiphell разобрал видеокарту Gigabyte Aorus GeForce RTX 5080 Infinity Wood и выяснил, что она оснащена одной из самых необычных печатных плат среди всех версий RTX 5080, представленных на рынке. 
Источник изображений: Chiphell Компания Gigabyte почти полностью переработала печатную плату Aorus GeForce RTX 5080 Infinity Wood, поскольку карта оснащена системой охлаждения Double Flow Through. Она предусматривает сквозную циркуляцию воздуха через обе стороны видеокарты, что должно повысить эффективность отвода тепла при высоких нагрузках.  В отличие от эталонной RTX 5090 Founders Edition с системой охлаждения аналогичной конструкции, в которой используется трехкомпонентная печатная плата, в модели RTX 5080 Infinity используется одна плата. Компания Gigabyte удалила у неё большой участок с левой стороны, над которым располагается один из двух основных вентиляторов системы охлаждения, оставив лишь несколько узких полосок текстолита поперёк отверстия. Эти участки по-прежнему содержат сигнальные дорожки, соединяющие компоненты на противоположных сторонах платы.  Такая компоновка позволяет воздуху проходить с обеих сторон карты, как у моделей Nvidia Founders Edition. Однако RTX 5080 Infinity не копирует компоновку эталонных карт Nvidia а необычность конструкции платы делает её более уязвимой к изгибу при извлечении из металлической опорной конструкции кожуха системы охлаждения. Особенности конструкции Gigabyte Aorus GeForce RTX 5080 Infinity Wood
Gigabyte также изменила систему питания карты. Шина MSVDD теперь расположена с правой стороны GPU, в то время как у RTX 5080 Founders Edition основные разъемы MSVDD находятся слева. Карта также использует утопленный 16-контактный разъём питания со встроенным удлинителем, несущим шесть проводников. 
Эталонная GeForce RTX 5080 Founders Edition. Источник изображения: TechPowerUp Толстый металлический блок на радиаторе карты Gigabyte фиксирует 16-контактный разъём питания, но разборка показывает отсутствие термопрокладки или термопасты между разъёмом и этим блоком. Таким образом, он, судя по всему, обеспечивает механическую жёсткость конструкции, а не непосредственное охлаждение разъёма. MSI и Colorful резко повысили цены на видеокарты Nvidia RTX 5000 — пока только в Китае, но вряд ли этим ограничатся
27.07.2026 [21:21],
Николай Хижняк
\Китайские дистрибьюторы сообщили о повышении цен на видеокарты GeForce RTX 50-й серии от компаний MSI и Colorful. Изменения коснулись практически всего модельного ряда видеокарт, начиная с базовой RTX 5050 и заканчивая флагманской RTX 5090 D V2. 
Источник изображения: Colorful В обновлённом прайс-листе компании MSI указаны как предыдущие, так и новые цены. Так, стоимость моделей RTX 5080 Shadow 3X OC и Ventus выросла с 9999 до 11 999 юаней, что составляет увеличение на 20 %. Цены на модели RTX 5080 Gaming Trio OC увеличились с 10 999 до 12 999 юаней, или на 18,2 %. Цены на RTX 5070 Ti Gaming Trio OC выросли с 8199 до 9699 юаней, а на Shadow 3X OC — с 7699 до 9199 юаней, или на 18,3 % и 19,5 % соответственно. Модели RTX 5070 подорожали чуть меньше — примерно на 8–10 %. 
Стоимость видеокарт RTX 50-й серии от MSI в Китае Массовые модели видеокарт MSI тоже подорожали. Цена многих вариантов RTX 5060 Ti выросла на 300–400 юаней. Цены на модели RTX 5060 увеличились на 400 юаней, включая Shadow 2X OC, стоимость которой поднялась с 2599 до 2999 юаней. Цена RTX 5050 Gaming OC также выросла с 2599 до 2999 юаней. В дистрибьюторском каталоге компании Colorful от 24 июля указана цена RTX 5080 Vulcan W OC в размере 13 200 юаней. Стандартная версия Vulcan OC стоит 12 300 юаней, а версии Advanced OC и Ultra W OC — 11 800 и 10 500 юаней соответственно. 
Стоимость видеокарт RTX 50-й серии от Colorful в Китае Цены на версии RTX 5070 Ti теперь варьируются от 8700 до 10 000 юаней. Модели RTX 5070 оцениваются в 6400–7200 юаней, а модели RTX 5060 Ti с 16 Гбайт памяти отпускаются за 5100–5300 юаней. Стоимость RTX 5050 Duo составляет 2450 юаней. В отличие от документа MSI, в прайс-листе Colorful не указаны предыдущие цены, поэтому точный уровень повышения стоимости для каждой модели видеокарты нельзя рассчитать, опираясь только на этот список. Источники сообщают, что корректировки связаны с повышением стоимости памяти GDDR6 и GDDR7. В уведомлениях, распространяемых среди китайских дистрибьюторов, говорится о повышении цен примерно на 600 юаней для карт с 8 Гбайт памяти, на 900 юаней — для моделей с 12 Гбайт памяти и на 1200 юаней — для моделей с 16 Гбайт памяти. Оба документа касаются только китайского рынка и не подтверждают аналогичные изменения цен на рынках США и Европы. Новая статья: Обзор видеокарты Acer Nitro Radeon RX 9060 XT OC 8G: на что хватает 8 Гбайт VRAM?
27.07.2026 [00:06],
3DNews Team
Данные берутся из публикации Обзор видеокарты Acer Nitro Radeon RX 9060 XT OC 8G: на что хватает 8 Гбайт VRAM? GeForce RTX 3060 с 12 Гбайт памяти «стареет» лучше RTX 4060 и Radeon RX 7600, показало сравнение в играх
24.07.2026 [16:01],
Николай Хижняк
Ранее сообщалось, что видеокарты GeForce RTX 3060 12GB начали возвращаться в магазины Европы и США по цене около $329. Для модели 2021 года такая цена выглядит чрезмерной, но кризис на рынке памяти диктует свои условия. К тому же, как показало опубликованное порталом 3DCenter сравнение, эта модель лучше «состарилась», чем выпущенная позже версия с 8 Гбайт памяти.  Портал 3DCenter сравнил результаты обзора, посвящённого запуску GeForce RTX 4060 в 2023 году, с обновлённым набором тестов PC Games Hardware для растровой графики 2026 года. В обоих наборах данных в качестве эталона использовалась модель GeForce RTX 3060 с 12 Гбайт памяти. Если в играх с разрешением 1080p модель RTX 4060 оказалась быстрее RTX 3060 на 23,5 % по результатам тестов 2023 года, то в данных 2026 года отставание модели RTX 3060 сократилось до 18,8 %. В сравнении RTX 3060 с Radeon RX 7600 в 2023 году модель AMD была производительнее на 20,7 %. Однако сейчас разница составляет 11,8 % в пользу «красной» карты. Более заметное сокращение разницы в производительности наблюдается в играх с разрешением 1440p. Здесь преимущество той же более современной GeForce RTX 4060 снизилось с 19,4 до 8,5 %, а у Radeon RX 7600 — с 17,3 до 5,0 %. В разрешении 4K и RTX 4060, и RX 7600 уступили RTX 3060. Модель RTX 4060 показала 97,2 % производительности относительно более старой карты, а RX 7600 — 94,9 %. 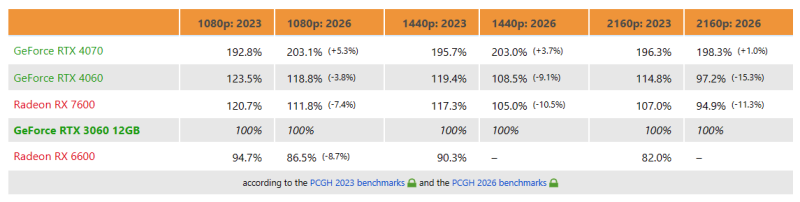
Источник изображения: 3DCenter В новых данных модель RTX 4070 ещё больше опередила RTX 3060, что говорит о том, что это не общее улучшение драйверов для карт Ampere. По данным 3DCenter, RTX 3060 сохраняет свои позиции благодаря наличию 12 Гбайт памяти, что позволяет избежать некоторых ограничений, влияющих на быстродействие RTX 4060 и RX 7600, у которых установлено по 8 Гбайт памяти. Важно уточнить, что речь идёт не о повторном тестировании видеокарт в тех же играх и с теми же драйверами. В отчёте 3DCenter сравниваются относительные позиции видеокарт в наборах бенчмарков 2023 и 2026 годов. Однако результаты показывают, что объём памяти может влиять на производительность графического процессора в более современных играх. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex









