
Опрос
|
реклама
Быстрый переход
Netflix сообщила о применении генеративного ИИ почти в 300 проектах
17.07.2026 [06:07],
Анжелла Марина
Компания Netflix сообщила, что около 300 фильмов и сериалов, доступных на стриминговой платформе, создавались с применением генеративного искусственного интеллекта. Это позволило ускорить производство контента, одновременно повысив качество результатов и снизив затраты. 
Источник изображения: Venti Views/Unsplash Информация прозвучала в финансовом отчёте Netflix за второй квартал, опубликованном в четверг. Компания уточнила, что в большинстве случаев ИИ применялся на этапе постпродакшна. В качестве примеров проектов названы Glory, Brasil 70: A Saga do Tri и The American Experiment, в которых искусственный интеллект использовался при создании сложных сцен, включая массовки, исторические сражения и общие планы вымышленных миров. Ранее генеральный директор Netflix Тед Сарандос (Ted Sarandos) также сообщал, что ИИ применялся при создании одной из сцен научно-фантастического сериала The Eternaut. Параллельно Netflix продолжает наращивать инвестиции в ИИ-технологии и всё активнее интегрирует их в производственный процесс. Недавно компания приобрела ИИ-стартап Бена Аффлека (Ben Affleck), открыла собственную студию ИИ-анимации, а также использовала сгенерированный ИИ голос Джина Уайлдера (Gene Wilder) в новом реалити-шоу Wonka’s The Golden Ticket. Согласно отчёту, Netflix получила выручку в размере $12,56 млрд, заявив, что по-прежнему планирует удвоить свои доходы от рекламы до $3 млрд. Кроме того, как пишет The Verge, зрители за последний отчётный период просмотрели более 97 млрд часов контента, что на 2 % больше, чем годом ранее. Параллельно платформа продолжает расширять ассортимент контента, добавляя видеоподкасты, короткие ролики в формате TikTok и готовится к показу видеоматериалов цифровых медиабрендов, включая BuzzFeed. Microsoft перевела GitHub Copilot с подписки на оплату за токены — пользователи недовольны
31.05.2026 [13:09],
Владимир Фетисов
Похоже, что в ближайшее время мелким компаниям придётся пересмотреть целесообразность использования сервиса GitHub Copilot. Дело в том, что Microsoft меняет систему оплаты с фиксированной подписки на систему оплаты за количество использованных токенов, в результате чего счета могут существенно вырасти. Крупные предприятия, вероятно, всё ещё смогут себе это позволить, но небольшим компаниями и частным лицам сделать это будет не так просто. 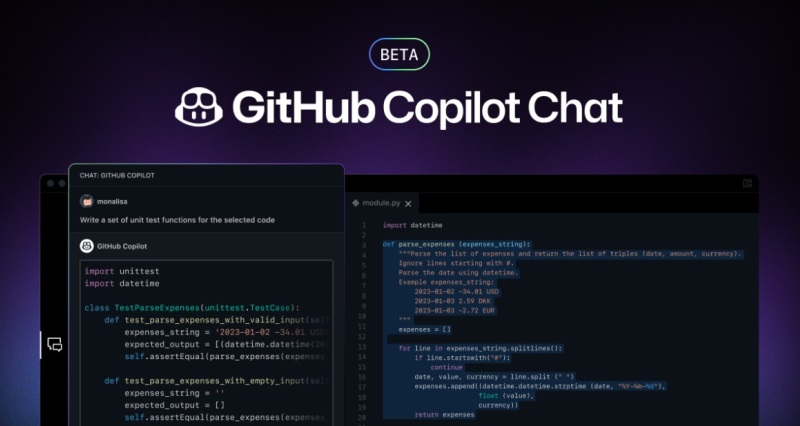
Источник изображения: GitHub Новая система оплаты начнёт действовать с 1 июня. После этого размер платы за сервис GitHub Copilot будет зависеть от того, сколько токенов израсходовал пользователь во время работы. Пользователи были неприятно удивлены этим изменением, о чём свидетельствуют сообщения, опубликованные на площадках Reddit и X. «Что за шутка. Эта новая модель оплаты просто до безумия дорогая. Я решаю этот вопрос, отменяя подписку. При такой стоимости это больше не является экономически эффективным или практически полезным ни в каком смысле», — написал один из пользователей Reddit. Он также добавил, что в рамках действующей подписки платил около $29 в месяц. Теперь же, после вступления в силу новых правил, его расходы увеличились бы до примерно $750 в месяц. «Ничего себе, не ожидал, что новая модель ценообразования будет настолько абсурдной», — написал другой пользователь. Он также сообщил, что новая система оплаты GitHub Copilot приведёт к увеличению расходов с $50 до $3000 в месяц. Несмотря на то, что стоимость использования GitHub Copilot может существенно вырасти, некоторые люди высказались против критики в отношении такого подхода. По их мнению, пользователи, которые знают, что делают, будут расходовать не так много токенов. Они считают, что люди, которые тратят очень много токенов, являются так называемыми «вайб-кодерами», у которых не так много реальных знаний. «Есть огромная разница между некоторыми из нас, работающими весь день и всё ещё едва превышающими лимит, и этими скриншотами. Мне трудно поверить, что это связано с отличиями в сложности рабочих нагрузок. Единственный способ добиться такого безумия — это заниматься «вайб-кодингом» и работать с кучей раздутых итераций», — написал один из пользователей. YouTube научился автоматически помечать видео, созданные с помощью ИИ
27.05.2026 [18:01],
Сергей Сурабекянц
Сегодня компания YouTube объявила, что её внутренние системы будут автоматически помечать видео, если обнаружат использование «значительного фотореалистичного ИИ». Кроме того, метки ИИ теперь станут более заметными как в длинных видеороликах, так и в коротких видео YouTube Shorts. 
Источник изображения: unsplash.com Метки ИИ появились на платформе более двух лет назад, после того как YouTube обновил свою политику, добавив требование к авторам раскрывать информацию о реалистичном контенте, созданном с помощью ИИ. Видео, которые изображали какой-либо анимированный или вымышленный сценарий не требовали пометки. YouTube заявляет, что политика видеосервиса в отношении маркировки ИИ не изменилась, но компания станет активнее контролировать контент на своей платформе. Этот шаг последовал за анонсом Google на конференции разработчиков Google I/O новой линейки мультимодальных ИИ-моделей Gemini Omni, способных создавать высококачественные видеоролики, отражающие понимание физики, культуры, истории и науки. Начиная с мая, YouTube будет использовать новые технологии для идентификации контента, созданного с помощью ИИ, и соответствующей его маркировки. Это не снимает с создателей контента обязанности раскрывать информацию об использовании ИИ, но, если они этого не сделают, YouTube сам пометит видео. Авторы, чей контент был неправильно идентифицирован, смогут изменить его статус, если только видео не было создано с помощью собственных инструментов ИИ YouTube, таких как Veo или Dream Screen. Метки также будут постоянно прикреплены к видео, если контент содержит метаданные C2PA, указывающие на то, что он был полностью создан с помощью ИИ. YouTube также сделает свои метки ИИ более последовательными и заметными. Раньше метки появлялись в расширенном описании, если видео не затрагивало более деликатные темы, такие как здоровье или новости; в этом случае заметная метка появлялась непосредственно на самом видео. Теперь метки будут отображаться непосредственно под видеоплеером. Компания заявила, что перемещение меток сделает их более заметными для людей, которые сталкиваются с фотореалистичным, изменённым или сгенерированным ИИ контентом на сайте. Для видео, созданных с помощью ИИ, которые лишь незначительно изменены, анимированы или нереалистичны метка будет отображаться только в расширенном описании. Метки ИИ не будут влиять на рекомендации видео или на возможность его монетизации. Добавление функции автоматического обнаружения видео, сгенерированного ИИ, произошло вскоре после расширения функции обнаружения дипфейков на YouTube. OpenAI сорвала выход полнометражного мультфильма Critterz, закрыв ИИ-видеогенератор Sora
22.05.2026 [14:58],
Алексей Разин
Осенью прошлого года создатели анимационного фильма Critterz, увидевшие в средствах генерации видео по текстовому запросу подходящий для обстоятельной работы инструментарий, были уверены, что смогут представить своё творение в готовом виде на Каннском кинофестивале в мае 2026 года, но их планам помешало закрытие сервиса Sora компанией OpenAI. 
Источник изображения: YouTube, The Critterz Напомним, весной этого года OpenAI без особых «прелюдий» закрыла сервис генерации видео по текстовому запросу Sora, поскольку поддержание его работоспособности требовало от компании больших затрат, а перспективы скорой монетизации были туманными. Представители творческой группы теперь сообщают, что из-за необходимости поиска нового партнёра, который позволил бы довести работу до конца, премьера полнометражного анимационного фильма Critterz теперь намечена на первый квартал следующего года. На Каннский кинофестиваль в этом году они всё равно приехали ради поиска партнёра, который мог бы заняться прокатом будущего мультипликационного фильма. Пятиминутный пилотный мультфильм с таким же наименованием был создан ещё в 2023 году с использованием ИИ-модели DALL-E компании OpenAI, которая предшествовала Sora и позволяла создавать по текстовому запросу только статичные изображения. Полнометражный вариант предполагалось создавать при помощи ИИ-модели Sora, но весной этого года OpenAI закрыла одноимённый сервис. Официальные представители OpenAI отметили, что не финансировали создание Critterz, а также не планировали заниматься продюсированием данного мультфильма. Продюсер Джеймс Ричардсон (James Richardson) продолжает считать, что ИИ-инструменты позволяют значительно ускорить создание анимационных фильмов и сократить бюджет проекта. Подобный фильм, по его словам, при помощи традиционных методов пришлось бы создавать силами 300 человек на протяжении 3 лет либо силами 200 человек на протяжении 4 лет, но команда Vertigo Films готова завершить работу за девять месяцев силами коллектива из 15 человек. По сторонним оценкам, бюджет проекта составляет менее $30 млн — это в разы меньше затрат того же Disney на создание полнометражных анимационных фильмов типа «Истории игрушек 4». Создатели Critterz утверждают, что у них уже имеются профили персонажей, сценарий и раскадровка сцен, поэтому как только будет найден новый технологический партнёр для завершения работы над фильмом, она начнёт продвигаться достаточно быстро. Для оптимизации работы при производстве контента Vertigo Films использует специализированное программное обеспечение собственной разработки, которое позволяет интегрировать различные ИИ-модели и привычные средства создания фильмов. Это ПО студия собирается предлагать на рынке сторонним заказчикам. Пользователи смогут выбирать ИИ-модели, которые оптимальны для решения каждой задачи. На Каннском фестивале показали 95-минутный фильм, снятый с помощью ИИ за $500 000 и две недели
21.05.2026 [19:36],
Алексей Разин
По мере развития сервисов генерации видео по текстовому запросу в киноиндустрии начали появляться студии, специализирующиеся на создании как сериалов, так и полнометражных фильмов, которые не привлекают актёров и не используют декорации. Один из таких фильмов, созданный при помощи ИИ, даже принял участие в Каннском кинофестивале в этом году. 
Источник изображения: YouTube, Higgsfield Его создателем является стартап Higgsfield, который был основан в Сан-Франциско три года назад, и до сих пор специализировался на создании сериалов с продолжительностью одного эпизода около 22 минут. Полнометражную картину «Долгая дорога в ад» (Hell Grind), которая идёт 95 минут, стартап создал за две недели, потратив на это $500 000. Из этой суммы $400 000 ушли на оплату доступа к вычислительным мощностям. Higgsfield заявился к участию в известном кинофестивале ради демонстрации возможностей, которые предоставляет отрасли генеративный ИИ. Участники мероприятия в Каннах отмечают, что по сравнению с прошлыми годами отношение к самой идее создания фильмов при помощи ИИ начинает меняться от опасений по поводу уничтожения ремесла к осторожному принятию неизбежной экспансии подобных технологий. На пресс-конференции, посвящённой открытию фестиваля, актриса Деми Мур (Demi Moore) заявила, что актёры должны искать возможности для работы с технологиями: «ИИ уже здесь. И бороться с ним означает начать битву, в которой мы проиграем». Режиссёр и продюсер Higgsfield Адилет Абиш (Adilet Abish) считает, что ИИ даёт возможность рассказать миру свою историю. По словам создателей ИИ-фильма, для работы с новыми инструментами всё равно требуются навыки классического кинопроизводства — например, правил композиции сцены. В мае компания вышла на приведённый размер годовой выручки на уровне $400 млн. Она полагается на общедоступные ИИ-модели для создания видео типа Google Veo 3 и Seedance 2.0 компании ByteDance. Стартап лишь добавляет своё ноу-хау, позволяющее обеспечить преемственность генерируемых ИИ сцен и образов. За один подход при помощи текстового запроса можно получить 15 секунд сгенерированного видео. Каждая сцена подобной продолжительности всегда генерируется несколько раз с некоторыми уточнениями в запросе, чтобы выбрать лучший «дубль». Если говорить о полнометражной картине, то первые её 25 минут потребовали генерации 16 181 клипов продолжительностью 15 секунд, из которых были отобраны 253 финальных варианта. Текстовые запросы приходится делать очень подробными, учитывающими стиль визуализации, освещение и имитацию того или иного съёмочного оборудования, а также визуальных эффектов. Особое внимание пришлось уделять освещению в сценах, поскольку ИИ обычно не отличается реалистичностью результирующих видео, «пересвечивая» содержимое сцены. В целом, движущиеся в кадре актёры и предметы должны учитывать законы физики, и это тоже требует особого комментирования в исходных текстовых запросах. По сути, каждый запрос содержит в среднем 3000 слов. Стартап готов зарабатывать на понимании такой специфики при создании фильмов и сериалов при помощи ИИ. Клиенты отправляют Higgsfield свои сценарии, а стартап возвращает им детализированные текстовые запросы на каждую страницу сценария. Поскольку до финального монтажа доживает лишь малая часть сгенерированных ИИ видеоклипов, то расходы на работу с облачными вычислительными ресурсами оказываются весьма высокими. В частности, полнометражка для Каннского кинофестиваля потребовала $400 000 на оплату услуг облачных провайдеров. И если бы Higgsfield не сотрудничала в этой сфере с так называемыми представителями сферы neocloud, то расходы могли бы оказаться ещё выше. Как поясняют представители стартапа, нельзя просто войти в чат-бот и попросить: «Сделай мне классное 95-минутное видео». xAI Маска выпустила ИИ-агента Grok Build — конкурента Claude Code для генерации программного кода
15.05.2026 [12:14],
Владимир Фетисов
Принадлежащая Илону Маску (Elon Musk) компания xAI выпустила своего первого ориентированного на генерацию программного кода ИИ-агента Grok Build. Этот шаг является попыткой догнать конкурентов, таких как Anthropic, в области оптимизации разработки программного обеспечения. 
Источник изображения: Grok ИИ-агент Grok Build находится на ранней стадии тестирования и в настоящее время доступен только платным подписчикам. Он стал первой попыткой xAI выпустить на рынок инструмент на базе ИИ, предназначенный для генерации программного кода. В описании продукта сказано, что ИИ-агент может выполнять сложные задачи по генерации кода, следуя командам пользователя. Запуск Grok Build является попыткой xAI и Илона Маска догнать другие ИИ-компании на прибыльном рынке генерации программного кода, где, как признаёт миллиардер, его компания несколько отстала. Ранее глава xAI Майкл Николлс (Michael Nicolls) призвал сотрудников компании к достижению цели по увеличению производительности Grok Build до уровня ИИ-агента Anthropic Claude. В сообщении сказано, что Маск намерен перестроить xAI до выхода на биржу SpaceX, являющейся материнской компанией для ИИ-стартапа. Первичное размещение акций SpaceX должно пройти позднее в этом году и, как ожидается, оно может стать крупнейшим в истории. Процесс перестройки xAI включает в себя увольнения, заключение дорогих партнёрских соглашений и массовый наём сотрудников с целью заменить основателей xAI, некоторые из которых уже покинули компанию. Уход Sora открыл дорогу конкурентам: ИИ-генераторы видео Kling AI и AI Video ворвались в топы Apple App Store
13.05.2026 [18:53],
Дмитрий Федоров
Два приложения для создания видео с помощью ИИ — Kling AI и AI Video — поднялись на пятое и шестое места в рейтинге самых скачиваемых бесплатных приложений Apple App Store. Оба лидируют в своих категориях: Kling AI заняло первую строчку в «Графике и дизайне», AI Video — в «Фото и видео». Их рост начался спустя два месяца после закрытия видеосервиса Sora компании OpenAI. Оба приложения выигрывают от нового всплеска внимания пользователей iPhone к ИИ-генерации видео. 
Источник изображений: apps.apple.com OpenAI свернула Sora главным образом из-за стоимости обслуживания: бесплатный сервис потреблял слишком много ресурсов. Компания сосредоточилась на ChatGPT и Codex — инструментах для повышения продуктивности, причём Codex лучше раскрывается на платных тарифах. 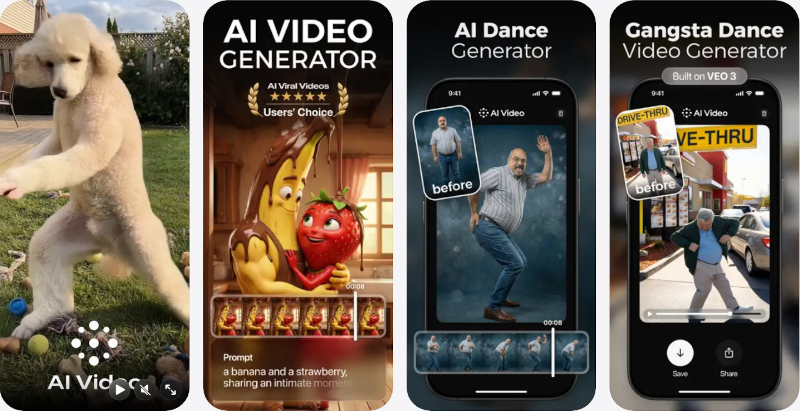
AI Video - AI Video Generator После ухода Sora конкурирующие ИИ-приложения стали активнее продвигать генерацию видео. Gemini и Grok уже позволяют превращать текстовые запросы и изображения в ролики, однако для этих универсальных чат-ботов видео остаётся лишь одной из возможностей. 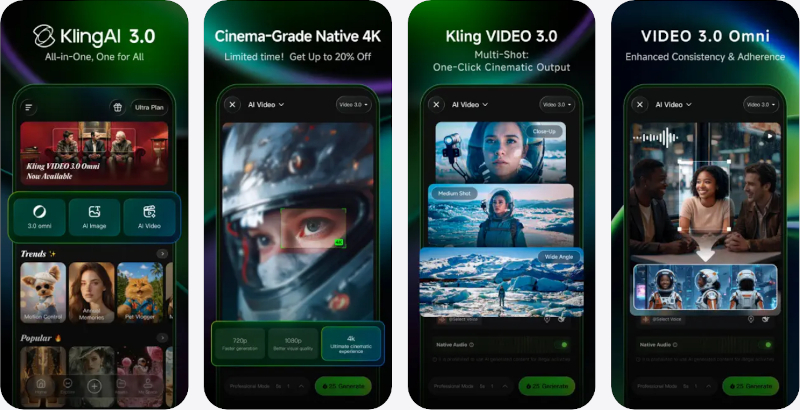
Kling AI: AI Image&Video Maker Kling AI и AI Video целиком посвящены созданию роликов. Kling AI появилось в App Store три месяца назад. AI Video выпущено компанией HUBX, у которой в магазине размещено 15 ИИ-приложений. Новое приложение нацелено на создание вирусных видеороликов. Выше обоих в рейтинге стоят только продукты OpenAI, Anthropic, Google и Meta✴✴. Sora тоже возглавляла чарт при запуске, но через несколько месяцев перестала показывать заметные результаты. Google случайно показала грядущий ИИ Omni, который генерирует видео по тексту
12.05.2026 [05:20],
Анжелла Марина
Новая модель Gemini Omni компании Google появилась в ранних демонстрациях, показав впечатляющие результаты генерации видео по текстовым запросам. Некоторые пользователи уже протестировали функцию создания роликов, хотя компания ещё не объявила о запуске официально. 
Источник изображения: Solen Feyissa/Unsplash Как стало известно 9to5Google, модель позволяет создавать видеоремиксы, редактировать контент непосредственно в диалоговом окне чат-бота, а также использовать готовые шаблоны. Метаданные в приложении Gemini указывают на то, что Omni является расширением платформы Veo, однако какое место займёт модель экосистеме продуктов компании, пока неизвестно. https://9to5google.com/wp-content/uploads/sites/4/2026/05/A_professor_writes_out_a_mathe.mp4 В одном из тестовых роликов ИИ сгенерировал сцену, в которой профессор пишет математическое доказательство на учебной доске, корректно отобразив формулы и последовательность объяснений. Во втором запросе была воссоздана сцена с двумя мужчинами, которые едят спагетти в ресторане у моря. Результат получился достаточно реалистичным, хотя и с заметными артефактами, характерными для современных генеративных моделей. Оба запроса заняли 86 % дневного лимита использования в аккаунте тарифа AI Pro. Разработчики пока не представили продукт публично, однако ранее подтвердили приверженность развитию технологий, связанных с генерацией видео, в особенности после решения конкурента прекратить поддержку Sora. Ожидается, что дополнительные детали, касающиеся генерации видео, станут известны на предстоящей конференции Google I/O 2026, где компания традиционно представляет ключевые обновления своих платформ. OpenAI выпустила ИИ-модель ChatGPT Images 2.0, которая отлично генерирует текст на картинках
22.04.2026 [06:26],
Дмитрий Федоров
OpenAI представила модель генерации изображений ChatGPT Images 2.0, которая впервые среди массовых ИИ корректно отрисовывает текст на картинках. Если два года назад диффузионные ИИ-модели не могли составить меню мексиканского ресторана без выдуманных слов вроде «enchuita» и «burrto», то новая модель создаёт изображения с надписями, пригодными к использованию без правок.  Ещё в 2024 году диффузионные ИИ-модели систематически искажали надписи. По словам Асмелаша Тека Хадгу (Asmelash Teka Hadgu), основателя и гендиректора Lesan AI, модели восстанавливают изображение из шума и усваивают паттерны, покрывающие основную массу пикселей, а текст занимает ничтожную долю площади. 
Слева — меню, сгенерированное ChatGPT Images 2.0: все надписи читаемы, ни одного выдуманного слова. Справа — три варианта от Microsoft Designer на основе DALL-E 3: «Enchidas», «Tamrielo», «Churiros», «Margartas» и десятки других искажений. Источник изображений: ChatGPT Images 2.0, Microsoft Designer (DALL-E 3) / techcrunch.com С тех пор исследователи опробовали альтернативные подходы — в частности, авторегрессионные модели, которые предсказывают содержание изображения и работают по принципу, близкому к большим языковым моделям (LLM). OpenAI не раскрыла, какая архитектура лежит в основе Images 2.0. Компания пояснила лишь, что новинка умеет «рассуждать» — искать информацию в интернете, генерировать несколько изображений по одному запросу и перепроверять результаты. Благодаря этому Images 2.0 создаёт маркетинговые материалы в разных размерах и даже комиксы. У ИИ-модели также улучшена работа с нелатинскими шрифтами — японским, корейским, хинди и бенгальским. Однако знания Images 2.0 ограничены декабрём 2025 года, что может сказаться на точности генерации по запросам о недавних событиях. 
Источник изображения: ChatGPT Images 2.0 / openai.com «Images 2.0 выводит детализацию и точность генерации на беспрецедентный уровень. Модель способна продумать сложную композицию и воплотить её на практике: следовать инструкциям, сохранять заданные детали и отрисовывать элементы, на которых обычно спотыкаются генераторы, — мелкий текст, пиктограммы, элементы интерфейса, насыщенные композиции и тонкие стилистические ограничения, — и всё это в разрешении до 2K», — говорится в пресс-релизе компании. Генерация при этом занимает больше времени, чем обычный текстовый запрос к ChatGPT, но даже многопанельный комикс укладывается в несколько минут. 
Источник изображения: ChatGPT Images 2.0 / openai.com Доступ к Images 2.0 получат все пользователи ChatGPT и Codex. Платные подписчики смогут генерировать более сложные изображения. OpenAI также откроет программный интерфейс (API) gpt-image-2 — стоимость будет зависеть от качества и разрешения выходных изображений. Nvidia вывела из беты динамический генератор кадров и режим MFG 6X в DLSS 4.5
09.04.2026 [19:03],
Николай Хижняк
Компания Nvidia завершила тестирование новых функций динамического мультикадрового генератора и режима MFG 6X в составе DLSS 4.5, включив их в стабильную версию приложения Nvidia App для управления графикой GeForce. Ранее данные функции были доступны только в составе бета-версий. 
Источник изображений: Nvidia Новые функции доступны в разделе «Графика» > «Настройка программы» > «Настройки драйвера» > DLSS Override > «Режим генерации кадров». Компания сообщает, что в настоящий момент динамический режим генерации кадров несовместим с функциями ограничения частоты кадров и вертикальной синхронизации (V-Sync). В настройки Nvidia App также добавлены режимы генерации кадров 5X и 6X. По данным компании, в совместимых играх масштабирование может достигать шестикратного увеличения, а видеокарты серии GeForce RTX 50 могут повысить производительность в 4K-играх с трассировкой лучей на 35 % при переходе с четырёхкратного на шестикратный мультикадровый рендеринг.  Обновление также включает новую модель Frame Generation для видеокарт GeForce RTX 40-й и 50-й серий. По данным Nvidia, новая модель использует дополнительные данные движка в поддерживаемых играх для повышения чёткости мини-карт, статических элементов интерфейса и других компонентов пользовательского интерфейса при включённой функции Frame Generation. Nvidia также продолжает внедрять обновления DLSS на уровне приложений, не дожидаясь выхода патчей для самих игр. В новый список игр, получивших поддержку функции DLSS Override, вошли: Arknights: Endfield, Black One Blood Brothers, Carmageddon: Rogue Shift, Code Vein II, Corsairs Legacy, Crimson Desert, Death Stranding 2: On the Beach, Demonologist, For Honor, Grounded 2, Half Sword, High On Life 2, John Carpenter’s Toxic Commando, Let It Die: Inferno, Lort, Marathon, Monster Hunter Stories 3, Nightmare Frontier, Nioh 3, Norse: Oath of Blood, Of Ash and Steel, Quarantine Zone: The Last Check, Reanimal, Resident Evil Requiem, Star Trek: Voyager — Across the Unknown, StarRupture, Styx: Blades of Greed, The Gold River Project, The Legend of Heroes: Trails Beyond the Horizon, Vampires: Bloodlord Rising и Yakuza Kiwami 3 & Dark Ties.  Новая версия приложения Nvidia App также добавляет оптимальные игровые настройки для Arknights: Endfield, Ashes of Creation, Highguard, StarRupture и The Last Caretaker. Кроме того, в приложении исправлен ряд проблем и ошибок. С их списком можно ознакомиться выше. Скачать приложение Nvidia App можно с официального сайта Nvidia. Ещё больше ненастоящих кадров: Nvidia выпустила DLSS 4.5 с динамическим мультикадровым генератором и режимом MFG 6X
31.03.2026 [19:11],
Николай Хижняк
Компания Nvidia выпустила функцию динамического мультикадрового генератора (DLSS 4.5 Dynamic Multi Frame Generation), а также режим мультикадрового генератора 6X (Multi Frame Generation 6X, MFG 6X). Обе технологии доступны через бета-версию приложения Nvidia App и поддерживаются только видеокартами GeForce RTX 50-й серии. 
Источник изображений: Nvidia Nvidia заявляет, что для работы DLSS 4.5 Dynamic Multi Frame Generation и MFG 6X требуется драйвер GeForce Game Ready Driver 595.79 WHQL или более новая версия. 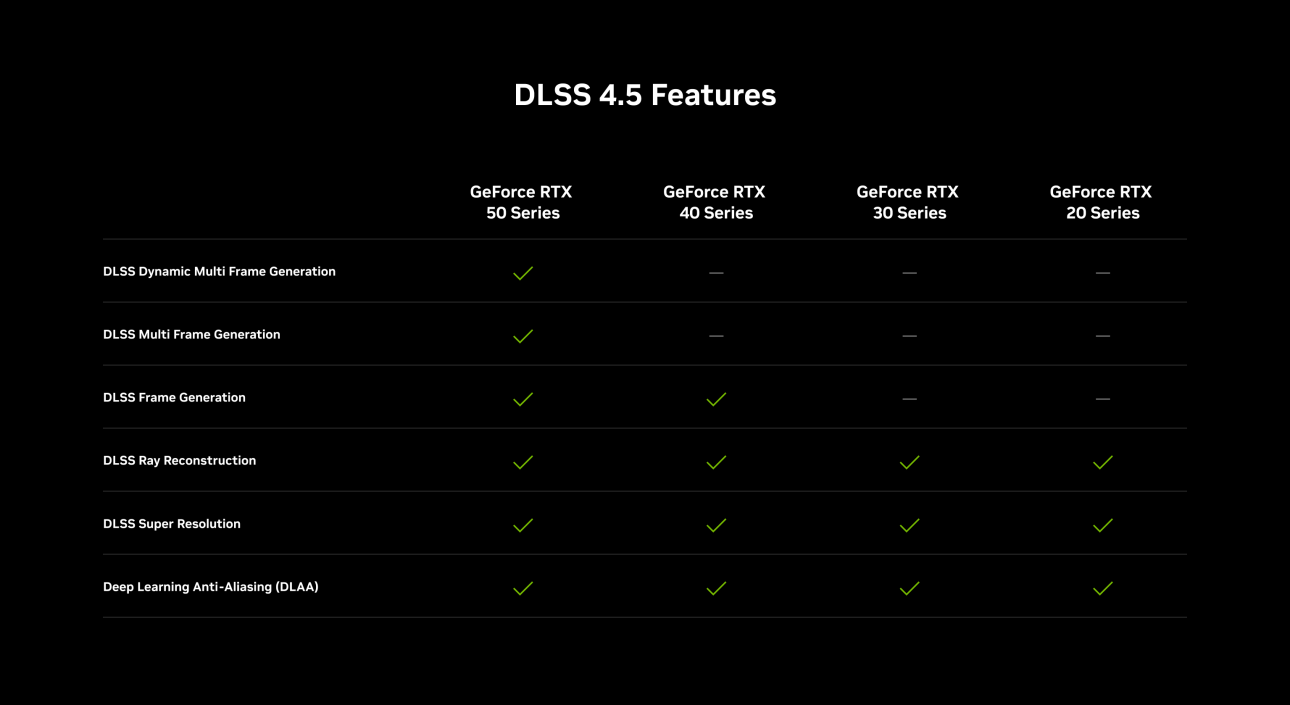 Новый динамический режим (DLSS 4.5 Dynamic Multi Frame Generation) заменяет фиксированный множитель кадров адаптивной системой, которая изменяется в реальном времени в зависимости от загрузки графического процессора и частоты обновления дисплея. Nvidia заявляет, что эта функция предназначена для генерации только того количества кадров, которое необходимо для достижения выбранного предела или частоты обновления монитора, вместо того, чтобы оставаться привязанным к одному предустановленному множителю на протяжении всего игрового процесса. 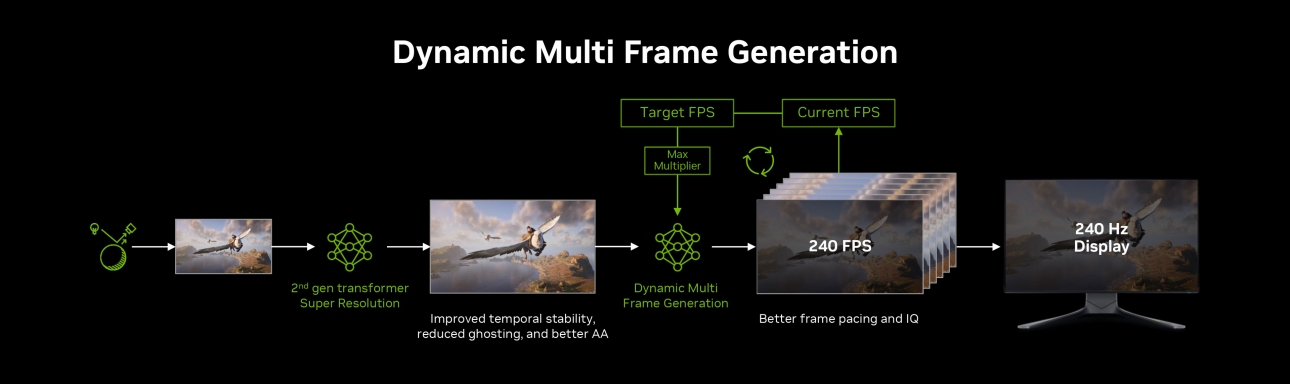 В режиме MFG 6X графический процессор может генерировать пять дополнительных кадров для каждого настоящего отрендеренного кадра. Nvidia заявляет, что переход с режима генерации 4X на 6X может повысить производительность в играх с трассировкой лучей в разрешении 4K до 35 % на видеокартах серии GeForce RTX 50. Для контроля уровня задержки используется технология Reflex. 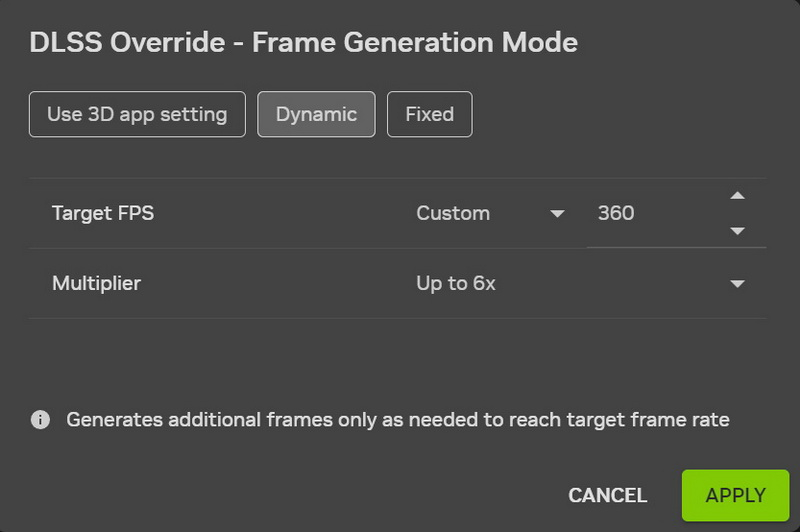 Новые функции доступны только через приложение Nvidia App (через настройки DLSS Override). Пользователям необходимо включить в настройках приложения поддержку бета-версий и экспериментальные функции, а затем на вкладке «Графика» выбрать параметр DLSS для режима генерации кадров. Nvidia заявляет, что динамический и фиксированный режимы теперь работают параллельно, при этом фиксированный режим работает как старые параметры ручного множителя. 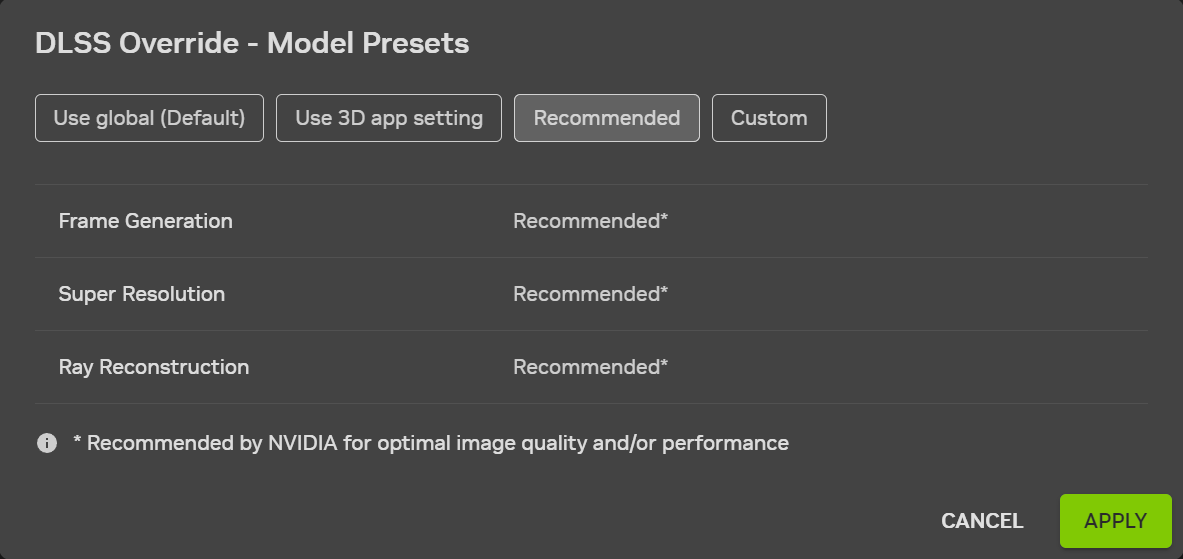 Бета-версия приложения Nvidia App также содержит поддержку обновления DLSS 4.5 Super Resolution для Arc Raiders и Marvel Rivals. Nvidia также сообщила, что поддержку DLSS 4.5 и технологии трассировки в перспективе получат ещё 20 новых и уже выпущенных игр: 007 First Light, Aniimo, Barkour, Control Resonant, Cthulhu: The Cosmic Abyss, Directive 8020, Edge of Memories, Edge of Memories, Endurance Motorsport Series, Gray Zone Warfare, Industria 2, Samson, Sea of Remnants, StarRupture, Star Wars: Galactic Racer, The Mound: Omen of Cthulhu, Tides of Annihilation, War Thunder, Where Winds Meet. Google выпустила ИИ-модель Lyria 3 Pro для генерации трёхминутных музыкальных треков — но не бесплатно
25.03.2026 [21:32],
Николай Хижняк
Google сообщила о выпуске ИИ-модели Lyria 3 Pro для генерации музыки. В прошлом месяце компания представила модель Lyria 3 с той же функцией. Версия Pro позволит создавать треки продолжительностью до трех минут, в отличие от 30-секундных треков, предлагаемых в модели Lyria 3. 
Источник изображения: Google Помимо возможности создания более длинных треков модель Lyria 3 Pro предложит лучший творческий контроль и возможности настройки, заявляет Google. В запросе для модели пользователи могут указывать различные элементы музыкального произведения, такие как вступления, куплеты, припевы и бриджи — Lyria 3 Pro лучше понимает структуру трека, чем её предшественница. Ранее Google добавила возможность генерации музыки с помощью Lyria 3 в приложении Gemini. Модель Pro тоже доступна через Gemini, но доступ к ней получат только платные подписчики. Модель Lyria 3 Pro также добавлена в приложение для редактирования видео Google Vids и в состав ProducerAI, инструмента для создания музыки на основе искусственного интеллекта, который Google приобрела в прошлом месяце. Кроме того, Google добавляет возможность генерации музыки через Lyria 3 Pro в свои корпоративные инструменты с помощью Vertex AI (в публичной предварительной версии), API Gemini и AI Studio. Компания сообщила, что для обучения Lyria 3 Pro использовались данные от партнёров, а также разрешённые данные от YouTube. По словам Google, модель не имитирует конкретных исполнителей. Однако если пользователи указывают исполнителя в подсказках, модель использует «широкое вдохновение» от этого исполнителя для создания трека. Все треки, созданные с помощью Lyria 3 и Lyria 3 Pro, помечаются маркером SynthID, указывающим, что для создания этой композиции использовался ИИ. На PlayStation появится ИИ-генератор кадров, как у Radeon — но не в ближайшее время
21.03.2026 [12:55],
Павел Котов
На Sony PlayStation начнёт работать «эквивалентная библиотека генерации кадров», в основу которой легла технология совместной разработки Sony и AMD, рассказал в интервью Digital Foundry архитектор консоли Марк Черни (Mark Cerny). 
Источник изображения: playstation.com Основу недавно вышедшей обновлённой технологии масштабирования PSSR 2 составил алгоритм, разработанный Sony совместно с AMD, а функция генерации кадров будет базироваться на более масштабном совместном проекте. Технология масштабирования PSSR 2 для PS5 Pro разработана в рамках проекта Amethyst — долгосрочного сотрудничества с AMD в области машинного обучения, и её поддержка сейчас реализуется в играх, которые уже выходят на рынок. В Sony по-прежнему не отвечают, где именно дебютирует функция генерации кадров — господин Черни не назвал конкретно PS5 Pro, а просто упомянул «платформу PlayStation» и добавил, что на текущий год больше релизов не планируется. То есть это будет или последующее обновление PS5 Pro, или Sony PlayStation нового поколения, или обе приставки сразу. «Чтобы прояснить некоторые моменты сотрудничества с AMD, следует отметить, что новая PSSR использует тот же базовый алгоритм, что и в масштабировании FSR Redstone (чтобы не создавать путаницу, я сегодня будут использовать новые названия, а не FSR4). Генерация кадров FSR также основана на технологии совместной разработки (или, как выразился мой хороший друг Джек Хьюнь (Jack Huynh), „технологии совместного проектирования“). Мне очень нравится, как продвигается эта работа, и эквивалентная библиотека генерации кадров в какой-то момент должна появиться на платформах PlayStation. <..> Отличные вопросы, особенно учитывая, что генерация кадров FSR – это технология, разработанная совместно SIE и AMD, и мы хорошо с ней знакомы. Всё, что я могу сказать, это что на этот год у нас больше не запланировано релизов. И мне очень хочется обсудить это подробнее в будущем!», — рассказал Марк Черни. Обновлённую PSSR компания Sony начала развёртывать в конце февраля; 16 марта было заявлено о поддержке апскейлера в Silent Hill, Monster Hunter Wilds, Final Fantasy VII Rebirth и Crimson Desert — то есть Sony всё ещё занимается повышением качества картинки на PS5 Pro. А технология генерации кадров, как теперь выясняется, в ближайшее время на приставках PlayStation так и не появится, хотя её реализация относительно проста. Она бы дала заметный прирост производительности при низких затратах, причём работает она даже на старых архитектурах графических процессоров, — но причина задержки не уточняется. Nvidia запустит динамический генератор кадров 31 марта
10.03.2026 [18:48],
Николай Хижняк
Компания Nvidia запустит 31 марта функцию динамической мультикадровой генерации (Dynamic Multi Frame Generation) для поддерживающих её игр. Напомним, данный генератор входит в состав стека технологий повышения производительности в играх DLSS 4.5. 
Источник изображений: VideoCardz / Nvidia Dynamic Multi Frame Generation — это автоматическая версия Multi Frame Generation. Вместо использования одного фиксированного множителя генерации кадров система может изменять множитель в реальном времени в зависимости от загрузки сцены и частоты обновления дисплея. Суть состоит в том, чтобы генерировать только те дополнительные кадры, которые необходимы для обеспечения плавного вывода изображения с частотой 120, 144, 240 Гц или выше.  Функция является частью пакета DLSS 4.5 и будет доступна только на видеокартах GeForce RTX 50-й серии. Nvidia заявляет, что DLSS 4.5 сочетает Dynamic Multi Frame Generation с обновлённой моделью генерации кадров и архитектурой Transformer второго поколения для масштабирования Super Resolution. Технология может генерировать до пяти дополнительных кадров на каждый традиционно отрисованный кадр. Вместе с Dynamic Multi Frame Generation будет выпущен режим 6× Multi Frame Generation. Компания представила Dynamic Multi Frame Generation и новый режим 6× одновременно на CES 2026 в январе. Google представила Nano Banana 2 — обновлённый генератор изображений работает быстрее и качественнее, и доступен бесплатно
26.02.2026 [20:49],
Николай Хижняк
Компания Google анонсировала последнюю версию своей популярной ИИ-модели для генерации изображений — Nano Banana 2. Новая модель, которая технически является аналогом Gemini 3.1 Flash Image, способна создавать более реалистичные изображения по сравнению с предшественницей. Nano Banana 2 станет моделью по умолчанию в приложении Gemini для режимов Fast, Thinking и Pro, то есть новинка будет доступна и бесплатным пользователям. 
Источник изображений: Google Компания впервые выпустила Nano Banana в августе 2025 года. Она быстро завоевала популярность среди пользователей Gemini, особенно в таких странах, как Индия. В ноябре Google представила Nano Banana Pro, позволяющую создавать более детализированные и высококачественные изображения. Новая Nano Banana 2 сохраняет ряд характеристик высокой детализации версии Pro, но генерирует изображения быстрее. С её помощью можно создавать изображения с разрешением от 512 пикселей до 4K и с различными соотношениями сторон.  Nano Banana 2 поддерживает единообразие персонажей (до пяти) и точную проработку до 14 объектов в одном рабочем процессе, что улучшает возможности повествования. По словам Google, пользователи могут отправлять сложные запросы с подробными нюансами для генерации изображений. Кроме того, модель позволяет создавать медиаконтент с более ярким освещением, насыщенными текстурами и чёткими деталями. 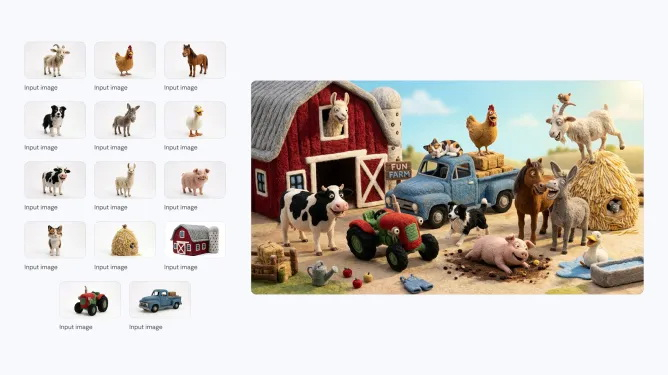 С запуском Nano Banana 2 станет моделью по умолчанию для генерации изображений во всех приложениях Gemini. Компания также сделает её моделью по умолчанию для генерации изображений в своём инструменте для редактирования видео Flow. В 141 стране Nano Banana 2 станет моделью по умолчанию в Google Lens и в режиме поиска с ИИ в мобильной и веб-версии Google Search. Пользователи тарифных планов Google AI Pro и Ultra смогут продолжать использовать Nano Banana Pro для специализированных задач, выбрав соответствующую настройку через меню с тремя точками. Для разработчиков Nano Banana 2 будет доступна в режиме предварительного просмотра через API Gemini, Gemini CLI и Vertex API. Она также появится в AI Studio и инструменте разработки Antigravity, выпущенном в ноябре прошлого года. Google заявляет, что все изображения, созданные с помощью новой модели, будут иметь водяной знак SynthID — фирменный маркер для обозначения изображений, сгенерированных искусственным интеллектом. Изображения также совместимы с системой C2PA Content Credentials, которая подтверждает происхождение контента и фиксирует, подвергался ли он изменениям. Систему поддерживают Adobe, Microsoft, Google, OpenAI и Meta✴✴. Google сообщила, что с момента запуска проверки SynthID в приложении Gemini в ноябре ей воспользовались более 20 млн раз. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



