|
Опрос
|
реклама
Быстрый переход
Intel раскрыла детали серверного ИИ-ускорителя Crescent Island — до 350 Вт и 480 Гбайт LPDDR5X
01.06.2026 [10:59],
Алексей Разин
Казалось бы, у корпорации Intel в наличии не было приличных ИИ-ускорителей уже много лет, но смещение спроса на задачи инференса открыло перед компанией новые возможности. Ускоритель Crescent Island будет использовать память типа LPDDR5X в приличном объёме до 480 Гбайт, стараясь лучше себя раскрыть именно с этой стороны. 
Источник изображений: Intel, Tom's Hardware Решение с незамысловатым обозначением Xe3P, по мнению Intel, изначально ориентируется на сферу агентских вычислений в ИИ. При уровне энергопотребления не более 350 Вт оно способно обеспечить поддержку до 480 Гбайт памяти типа LPDDR5X, хотя в эталонном исполнении соответствующий ускоритель ограничится втрое меньшим объёмом — 160 Гбайт. Скорее всего, для достижения максимальной ёмкости памяти понадобятся модули памяти LPDDR5X объёмом по 24 Гбайт. Совокупная пропускная способность достигнет 684 Гбайт/с.  Вычисления могут осуществляться с разной точностью, от FP4 до FP64. Уровень быстродействия Crescent Island пока не раскрывается, официальный анонс этого ускорителя должен состояться во второй половине текущего года. Подобное компоновочное решение при работе с ИИ-агентами имеет полное право на жизнь, поскольку в непосредственной близости от GPU будут располагаться относительно большие объёмы данных. Память типа GDDR или HBM в этом случае при сохранении того же объёма не только обошлась бы существенно дороже, но и не могла бы разместиться рядом с GPU в силу технических ограничений. В одной стойке наверняка смогут расположиться до восьми таких ускорителей с совокупным объёмом памяти 3,8 Тбайт. Некоторым разочарованием может стать лишь необходимость полагаться на специфическое ПО в виде стека oneAPI для работы с Crescent Island, но Intel обещает, что проблем с ним не возникнет. Тайваньские власти подозревают, что ИИ-чипы Nvidia попадали в Китай через Японию в обход санкций
30.05.2026 [06:09],
Алексей Разин
Трое задержанных на прошлой неделе на Тайване подозреваемых в организации контрабанды лиц, как предполагает следствие, могли бы замешаны как минимум в одной поставке ИИ-ускорителей Nvidia в Китай в обход американских правил экспортного контроля с использованием Японии в качестве промежуточной страны. 
Источник изображения: Nvidia Как поясняет Bloomberg, подозреваемым сперва пришлось экспортировать партию ускорителей с Тайваня в Японию, а затем уже организовать её поставку в КНР через Гонконг. В деле фигурирует партия серверного оборудования Supermicro, содержащего ИИ-ускорители Nvidia, поставки которых в Китай запрещены правилами экспортного контроля США. Трио подозреваемых для реализации своего замысла подделало документы на отгружаемую продукцию, как считает следствие. После ареста подозреваемых была выявлена партия из 50 серверов, которые также готовились к поставке в Китай по подложным документам. Установлено, что группа успела провести через тайваньскую таможню как минимум одну партию ИИ-ускорителей Nvidia, которые запрещены к поставкам в Китай. Размер этой партии не уточняется. Следствие предполагает, что и захваченные на Тайване 50 серверов должны были отправиться в КНР через Японию. Последняя из стран впервые фигурирует в подобном контексте, поскольку считается близким геополитическим союзником США, не допускающим подобных проколов в вопросах экспортного контроля. При этом китайские разработчики могут вполне легально арендовать ЦОД с запрещёнными к поставке в КНР ускорителями Nvidia, если соответствующие вычислительные мощности расположены в Японии или других окрестных странах Азии. Тайваньские следователи не предъявляют никаких обвинений Nvidia и Supermicro, чья продукция фигурирует в этом деле. По словам главы первой из компаний, она тщательным образом разъясняет правила экспортного контроля своим клиентам. Supermicro, по его словам, нужно усилить контроль за поставками своей продукции и провести собственное расследование. Как пояснили представители Supermicro, фигурирующие в тайваньском деле серверные системы были изначально проданы авторизованному партнёру компании, который должен был следовать всем сопутствующим ограничениям. По мнению представителей компании, над усилением контроля за цепочками поставок должна работать вся отрасль, чтобы соответствующие меры были достаточно эффективными. MediaTek утверждает, что чипы для её клиентов теперь способна упаковывать и Intel
30.05.2026 [05:18],
Алексей Разин
Корпорация Intel ещё при прежнем генеральном директоре Патрике Гелсингере (Patrick Gelsinger) начала активно продвигать свои услуги по упаковке чипов за пределами собственных потребностей. Похоже, тайваньский разработчик чипов MediaTek счёл их подходящими для собственного использования, и теперь чипы клиентов этой компании смогут упаковывать TSMC и Intel. 
Источник изображения: Intel По крайней мере, об этом заявил старший вице-президент MediaTek Винс Ху (Vince Hu), на слова которого ссылается Nikkei Asian Review: «Мы теперь одни из немногих, кто может предложить упаковку чипов силами как TSMC, так и Intel». Непосредственно MediaTek чипы не выпускает, она их только разрабатывает, а изготовлением их традиционно занимаются специализированные подрядчики типа TSMC. Поскольку спрос на чипы со сложной пространственной компоновкой растёт, роль технологий их упаковки возрастает. В этих условиях заполучить ещё одного партнёра в лице Intel для MediaTek крайне важно. MediaTek пользуется услугами TSMC по упаковке чипов передовым методом CoWoS, но она не одинока в этой сфере — подобным образом поступают AMD, Nvidia, Broadcom, Amazon и Google. В результате мощностей TSMC на всех желающих не хватает. Интерес к услугам Intel в этой сфере проявляет не только MediaTek, но и Google. В свою очередь, MediaTek желает активнее участвовать в буме ИИ, который с точки зрения компонентов сосредоточен на серверном направлении, а там возможности упаковки чипов весьма важны. Сотрудничество с Intel, тем самым, откроет перед MediaTek новые возможности. В текущем году компания собирается в сегменте ИИ-серверов выручить $2 млрд, а в следующем готова превзойти этот уровень. По данным Nikkei, компания MediaTek помогает Google разработать кастомные ИИ-чипы, которые будут использовать фирменную упаковку EMIB, предлагаемую компанией Intel. Если такое сотрудничество состоится, новый крупный контракт пойдёт на пользу последней, поскольку контрактный бизнес Intel остаётся глубоко убыточным. Помогать Google разрабатывать ИИ-чипы тайваньская MediaTek начала довольно давно. Сама MediaTek при этом продолжает полагаться на возможности TSMC в сфере производства чипов по передовым технологиям. Она уже получает от этого подрядчика образцы чипов, выполненные по ангстремной технологии A14 (1,4-нм), их массовое производство должно быть запущено в 2028 году. В сфере автомобильной электроники MediaTek готовит для клиентов чипы, которые будут выпускаться по 2-нм техпроцессу. Кроме того, в этом году будет представлен флагманский чип MediaTek для смартфонов, который также будет производиться по 2-нм технологии. Часть 4-нм и 3-нм чипов MediaTek начнёт выпускаться на предприятиях TSMC в Аризоне. Группа инвесторов влезла в долги на $36 млрд, чтобы купить чипы Google TPU для Anthropic
29.05.2026 [12:20],
Алексей Разин
OpenAI не одинока в своих многочисленных кольцевых сделках, в которых деньги многократно передаются друг другу, а сама компания не несёт особой ответственности за их использование. По данным Bloomberg, финансирование нужду конкурирующей Anthropic тоже осуществляется силами сторонних инвесторов с привлечением заёмных средств. 
Источник изображения: Google В частности, сообщается о намерениях Apollo Global Management и Blackstone Inc. привлечь дополнительных инвесторов для направления $36 млрд заёмных средств на покупку для нужд Anthropic ИИ-чипов Google TPU. Последние не достанутся в собственность стартапа, а будут всего лишь арендованы, а значительную часть финансовых ресурсов в этой схеме готова предоставить компания Broadcom. По сути, подобная сделка станет крупнейшей в своём роде, если она состоится. Руководство Anthropic не стесняется признаться, что компания испытывает нехватку вычислительных ресурсов в условиях бурного развития отрасли ИИ, спрос на её услуги сейчас заметно превышает возможности стартапа. По всей видимости, аренда ИИ-чипов Google TPU является одним из вероятных способов решения этой проблемы. Anthropic также договорилась с xAI (SpaceX) об аренде ЦОД Colossus в штате Теннесси, хотя на днях и выяснилось, что срок аренды пока ограничен 180 днями. Apollo и Blackstone продадут часть долговых обязательств по обсуждаемой сделке, но основная их сумма останется под их контролем. На этой неделе стало известно, что Anthropic удалось привлечь $65 млрд и поднять свою капитализацию до внушительных $965 млрд, которые позволяют формально говорить о преимуществе над OpenAI. Традиционно кредитные и лизинговые схемы при развитии инфраструктуры ИИ использовались для покупки крупных партий GPU, но ничто не мешает применить такую практику и в отношении TPU. Как ожидается, полученные в лизинг чипы Anthropic собирается использовать на своих площадках в Нью-Йорке, Техасе, Луизиане и Индиане. Broadcom в этой сделке выступает в роли своего рода поручителя, поскольку далёкие от специфики ИИ-отрасли кредиторы могут не доверять стартапу Anthropic при попытках прямого заимствования средств. Поставки чипов будут осуществляться поэтапно. Облигации, за счёт которых будет финансироваться сделка, поделены на три серии. Две первые (A1 и A2), в рамках которых будет привлечён в общей сложности $31 млрд, будут обладать более высоким приоритетом с точки зрения порядка выплаты дохода. Ещё $4,5 млрд будут привлечены через выпуск облигаций менее приоритетной серии B. Структура сделки подразумевает, что если Anthropic не сможет погасить стоимость полученных чипов за счёт лизинговых платежей, то специально созданная под этот проект компания попытается распределить среди кредиторов средства, вырученные от продажи чипов. Если вырученной суммы не хватит для полного покрытия долга, недостающую сумму держателям облигаций серий A1 и A2 доплатит Broadcom. ByteDance взялась за разработку собственных ИИ-процессоров
28.05.2026 [10:30],
Алексей Разин
Недавно стало известно об интересе китайской ByteDance к ИИ-чипам производства Qualcomm, но ими дело не ограничится, как поясняет Reuters со ссылкой на собственные источники. Китайский техногигант разрабатывает собственные центральные процессоры, которые будет применять в своей вычислительной инфраструктуре. 
Источник изображения: ByteDance Подобные шаги ByteDance отражают не только тенденцию к смещению фокуса в сторону инференса в сфере вычислительных нагрузок, но и формирующийся дефицит центральных процессоров серверного класса, о котором не стесняется открыто говорить руководство Intel и AMD, например. Американские техногиганты типа Google, Amazon и Microsoft уже давно разрабатывают собственные ИИ-чипы, поэтому для ByteDance аналогичные меры оказались вполне ожидаемыми. Процессоры собственной разработки, как считается, помогут ByteDance подготовить свою вычислительную инфраструктуру к выпуску агентских программных решений, включая платформу Coze. Пока проект разработки собственных процессоров находится на ранней стадии реализации, но ByteDance уже обратилась к нескольким разработчикам чипов, чтобы те не только помогли создать процессоры, но и получить доступ к производственным мощностям подрядчиков типа той же TSMC в условиях дефицита. Как сообщается, ByteDance собирается использовать как Arm-совместимую архитектуру, так и RISC-V, чтобы на определённом этапе понять, какая из них лучше соответствует её долгосрочным целям. В серийное производство будет запущено решение на той архитектуре, которая окажется более предпочтительной для самой ByteDance. Полагаться на серверные процессоры Intel и AMD этой компании становится всё дороже, поскольку эти поставщики за последние несколько месяцев подняли цены на свою продукцию на величину от 10 до 35 %. Nvidia также претендует на свою долю рынка при помощи центральных процессоров Vera и унаследованных от стартапа Groq технологий. Marvell рассчитывает к 2029 году зарабатывать на ИИ-чипах более $10 млрд в год
28.05.2026 [08:37],
Алексей Разин
Облачные гиганты в условиях бурного развития вычислительной инфраструктуры начинают всё чаще задумываться о создании специально адаптированных под свои нужды ИИ-чипов. Компания Marvell Technology подобные услуги готова оказывать, и к 2029 фискальному году рассчитывает получать в этой сфере более $10 млрд выручки в год. 
Источник изображения: Marvell Technology Для понимания, 2027 фискальный год в календаре Marvell завершится 31 января следующего года, поэтому указанную выручку на направлении кастомных ИИ-чипов компания должна получить уже к началу 2029 календарного года. В следующем фискальном году Marvell рассчитывает выручить около $16,5 млрд против прежних заложенных в прогноз $15 млрд. По итогам текущего фискального квартала компания ожидает выручить $2,7 млрд, что выше консенсус-прогноза LSEG. Ожидаемая компанией удельная выручка должна составить 93 цента на одну акцию, что также превышает ожидания аналитиков. Генеральный директор Marvell Technology Мэтт Мёрфи (Matt Murphy) пояснил, что компания взаимодействует в сфере создания кастомных чипов со всеми американскими гиперскейлерами. Если учесть, что они готовы только в этом году направить на развитие собственной вычислительной инфраструктуры около $725 млрд, то Marvell наверняка сможет неплохо заработать на таком взаимодействии. В этом году серверная выручка Marvell должна вырасти на 50 %. В прошлом квартале компания выручила в данном сегменте $1,83 млрд. Общая выручка Marvell Technology увеличилась на 28 % до $2,42 млрд, превысив ожидаемую аналитиками сумму $2,4 млрд. Удельный доход на акцию в размере 80 центов также оказался выше ожиданий (79 центов). Anthropic ищет любые мощности для ИИ: в ход могут пойти чипы Microsoft Maia 200
22.05.2026 [06:08],
Алексей Разин
Ведущие ИИ-стартапы в условиях бума соответствующих технологий демонстрирую «всеядность» с инфраструктурной точки зрения, поэтому слухи о переговорах между Microsoft и Anthropic по возможному использованию чипов Maia 200 никого не удивили. Эти чипы для запуска уже обученных ИИ-моделей (инференса) компания Microsoft представила в январе текущего года, но до сих пор не ввела их в собственной инфраструктуре Azure. 
Источник изображения: Microsoft По данным CNBC, подобное сотрудничество для Microsoft стало бы достижением, поскольку корпорация в целом не так активно поставляет на сторону свои процессоры, в отличие от конкурирующих Amazon (AWS) и Alphabet (Google). Между Microsoft и Anthropic ведутся переговоры на тему возможного использования чипов Maia 200 в инфраструктуре второй из компаний, как стало известно с подачи ресурса The Information. Характерно, что в ноябре прошлого года Microsoft заявила о готовности вложить $5 млрд в капитал Anthropic, тогда как последняя взяла на себя обязательства потратить $30 млрд на аренду облачных мощностей Azure. Одновременно Anthropic использует мощности AWS и Google, поэтому соглашение с Microsoft не носило исключительного характера. В этом месяце глава Anthropic Дарио Амодеи (Dario Amodei) признал, что бурный рост спроса на услуги компании вызвал у неё нехватку вычислительных мощностей. Стартап даже договорился об аренде ЦОД Colossus 1 компании SpaceX (xAI), и будет три года выплачивать ей по $1,25 млрд ежемесячно. В октябре прошлого года стало известно о намерениях Anthropic использовать чипы TPU компании Google, а в апреле компания заключила соглашение с AWS об использовании процессоров Trainium сроком на десять лет. Alibaba представила ускоритель Zhenwu M890, заточенный под работу с ИИ-агентами
20.05.2026 [10:20],
Алексей Разин
Подразделение T-Head китайского холдинга Alibaba Group, которое специализируется на разработке чипов, на этой неделе представило новый ускоритель Zhenwu M890, который учитывает актуальную тенденцию работы с ИИ-агентами, а потому оптимизирован под специфический набор задач. Компания также пообещала ежегодно выпускать новые модели ИИ-ускорителей. 
Источник изображения: Unsplash, Zhang Hui В плане быстродействия Zhenwu M890 в три раза превосходит своего предшественника — Zhenwu 810E. Компания обещает, что и запланированный к анонсу в третьем квартале следующего года ускоритель V900 окажется в три раза быстрее нынешнего M890. В третьем квартале 2028 года выйдет ускоритель J900, сохраняя ритмичность обновления ассортимента ИИ-ускорителей, предлагаемых Alibaba. К настоящему моменту компания успела отгрузить более 560 000 ускорителей семейства Zhenwu, причём их в Китае используют более 400 внешних клиентов, представляющих 12 отраслей экономики, включая представителей финансового сектора и автопроизводителей. Как отмечается, оснащаемый 144 Гбайт памяти ускоритель Zhenwu M890 подходит и для обучения моделей, и для инференса. На базе 128 таких ускорителей будут создаваться серверные системы Panjiu AI.128. Одновременно Alibaba представила новую ИИ-модель Qwen 3.7-Max, которая оптимизирована для написания программного кода и агентских задач. Она способна непрерывно работать на протяжении 35 часов без видимого снижения быстродействия. Arm разворачивается к ИИ: спад в смартфонах компенсируют серверные чипы
07.05.2026 [07:52],
Алексей Разин
Квартальный отчёт британского холдинга Arm, клиентом которого являются большинство разработчиков процессоров для смартфонов, подтвердил наметившуюся в условиях дефицита памяти тенденцию. Выручка Arm на направлении смартфонов будет снижаться, но в сегменте ИИ она собирается её заметно нарастить за счёт поставок специализированных процессоров собственной разработки. 
Источник изображения: Arm Напомним, в марте Arm представила свой собственный 136-ядерный процессор AGI, который призван проявить себя с лучшей стороны в сегменте агентских вычислений ИИ. Уже тогда Arm заявляла, что располагает заказами на поставку данных процессоров на общую сумму $1 млрд. На этой неделе руководство Arm заявило, что компания собирается выручить более $2 млрд на реализации процессоров AGI в течение 2027 и 2028 годов. По словам генерального директора Рене Хааса (Rene Haas), позиции Arm в качестве поставщика решений для центров обработки данных стремительно укрепляются. В прошлом квартале, как отметил Хаас, объёмы поставок чипов для смартфонов в натуральном выражении начали сокращаться. Поскольку отрицательная динамика сконцентрирована в нижнем ценовом сегменте, на бизнесе Arm эта тенденция сказывается минимально, ибо компания получает лицензионные отчисления с реализации более дорогих процессоров, которые в денежном выражении перевешивают выручку в начальном ценовом сегменте. Кроме того, руководство Arm убеждено, что рост выручки в серверном сегменте с запасом компенсирует просадку на направлении смартфонов. В прошлом фискальном квартале выручка Arm выросла на 20 % до $1,49 млрд. Лицензирование при этом принесло $819 млн, что выше ожидаемых рынком $775,6 млн. Роялти принесли оставшиеся $671 млн, но инвесторы рассчитывали в среднем на $693 млн. В текущем квартале Arm рассчитывает в целом выручить $1,26 млрд, что чуть выше консенсус-прогноза на уровне $1,25 млрд. Именно серверное направление будет тянуть выручку Arm вверх в сложившихся условиях, как ожидает руководство холдинга. Рене Хаас невольно вызвал падение курса акций Arm, признавшись, что компания обеспечила себя ресурсами и контрактами, необходимыми для производства собственных ИИ-чипов на сумму $1 млрд, а вот объёмы сверх этой планки она пока гарантировать не сможет. Как известно, мощности контрактных производителей сейчас сильно загружены в условиях бума ИИ, новым игрокам типа Arm тяжело получить необходимые квоты на выпуск продукции. Китайские конкуренты Nvidia тратят на разработки больше, чем зарабатывают
06.05.2026 [12:16],
Алексей Разин
Эмоциональные заявления основателя Nvidia то и дело дают повод поверить, что китайские конкуренты на внутреннем рынке Поднебесной давно вытеснили одноимённые ИИ-ускорители. При этом финансовая отчётность местных разработчиков показывает, что они вынуждены тратить значительную часть выручки на исследования и разработки, тогда как западные конкуренты ограничиваются заметно более выгодными пропорциями. 
Источник изображения: Moore Threads Technology Как отмечает South China Morning Post, лидирующая на мировом рынке GPU-ускорителей американская Nvidia по итогам прошлого года потратила на НИОКР не более 9 % своей выручки, хотя ещё в 2022 году эта доля достигала 27 %. Впрочем, в данном случае важно понимать, что выручка Nvidia в условиях бума ИИ растёт опережающими темпами, и по итогам прошлого года она достигла $215,9 млрд. На этом фоне впечатляющие по своей абсолютной величине затраты на исследования и разработки в сумме $18,5 млрд действительно составляют весьма скромную долю. AMD и Intel в прошлом фискальном году направили на разработки $8 млрд и $13,8 млрд соответственно, для них соотношение этих расходов к выручке достигло 23 % и 26 %. К слову, в 2024 году Intel направила на разработки 31 % выручки, а в 2023 году этот показатель достигал 30 %. Компания переживает болезненную фазу трансформации, пытаясь догнать конкурентов, поэтому её затраты в этой сфере велики. 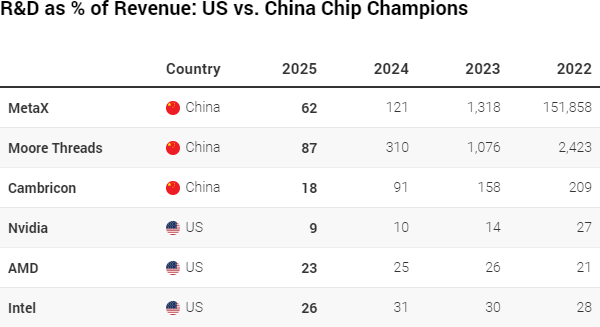
Источник изображения: SCMP Для сравнения, китайские разработчики ИИ-чипов вплоть до 2024 года направляли на исследования и разработки кратно больше средств, чем выручали от реализации продукции на рынке, но важно учитывать, что многие из этих компаний были основаны в 2020 году или позже. Например, MetaX была основана в 2020 году выходцами из AMD, а Moore Threads тогда же была основана бывшим главой бизнеса Nvidia в Китае. Ведущая свою историю с 2016 года Cambricon в прошлом квартале смогла сократить долю расходов на НИОКР по отношению к выручке с 24,5 до 11,2 %, а по итогам прошлого года в целом она впервые получила прибыль. В первом квартале текущего года её выручка выросла на 160 % до $425 млн, а прибыль почти утроилась до $147 млн. По мере достижения определённой зрелости MetaX и Moore Threads тоже начнут тратить на исследования всё меньшую долю выручки. В прошлом квартале первая увеличила расходы на НИОКР на 16,3 % по сравнению с аналогичным периодом прошлого года, а вторая подняла их в полтора раза. OpenAI собиралась выделить роботов и устройства в отдельные компании, но передумала
05.05.2026 [12:56],
Алексей Разин
Подготовка к выходу на биржу вынуждает OpenAI заниматься реструктуризацией бизнеса и отказываться от второстепенных инициатив ради снижения расходов. В конце прошлого года руководство стартапа рассматривало выделение робототехнического сектора и направления потребительских устройств в самостоятельные компании. 
Источник изображения: OpenAI Тогда руководство OpenAI, как сообщает The Wall Street Journal, было убеждено в способности данных мер обеспечить указанные направления бизнеса более выраженным потенциалом роста. Кроме того, реструктуризация снизила бы финансовую нагрузку от этих инициатив на основной бизнес OpenAI. От таких планов пришлось отказаться, поскольку руководство стартапа пришло к выводу, что выделенные структурные единицы всё равно пришлось бы отображать в общем квартальном отчёте. Бизнес по разработке аппаратного обеспечения, как отмечает источник, имеет иную специфику по сравнению с созданием ИИ-моделей, на котором специализируется OpenAI. Разработка устройств нуждается в существенных финансовых вложениях и подразумевает сильную зависимость от множества поставщиков компонентов, другие горизонты планирования и принципы взаимодействия с инвесторами и партнёрами. В 2024 году OpenAI вложила $675 млн в стартап Figure AI, который разрабатывает человекоподобных роботов для промышленного применения. Если бы этот бизнес обрёл самостоятельность, его текущая капитализация могла бы достичь $2 млрд. OpenAI также пытается разработать собственные ИИ-чипы в сотрудничестве с Broadcom, выпуском которых могла бы заняться TSMC. Если бы данное подразделение OpenAI обрело самостоятельность, то на его развитие потребовалось от $5 до $10 млрд дополнительных инвестиций. По некоторым оценкам, робототехническое и «аппаратное» направления бизнеса OpenAI в прошлом году оттянули от 20 до 30 % средств, направленных на финансирование проектов стартапа. Общая сумма затрат по итогам прошлого года достигла $7 млрд. Окончательно идея реструктуризации руководством OpenAI пока не заброшена. Если стартап сосредоточится чисто на программном бизнесе, он сможет демонстрировать норму прибыли свыше 70 %, и это убедит инвесторов в целесообразности дальнейшего финансирования OpenAI. Робототехнический актив при этом бы тоже не остался без внимания инвесторов, просто ему бы пришлось соревноваться за их благосклонность с другими представителями робототехнической отрасли, хотя не исключены и альянсы с американскими компаниями этого сегмента. Не нужно забывать, что OpenAI также сотрудничает и со стартапом бывшего главного дизайнера Apple Джони Айва (Jony Ive). Партнёры рассчитывают создать более десятка моделей персональных устройств, ориентированных на работу с искусственным интеллектом. Словом, у OpenAI достаточно инициатив в сфере разработки аппаратного обеспечения, но стартап явно не собирается все из них обособлять именно на этапе подготовки к IPO, которое должно состояться до конца этого года. Глава Nvidia заявил, что доля компании на китайском рынке ИИ-ускорителей упала до нуля
05.05.2026 [04:51],
Алексей Разин
В конце прошлого года глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) донёс до высшего политического руководства США мысль о необходимости наладить поставки в Китай более совершенных ИИ-ускорителей по сравнению с теми, что были там доступны в условиях санкций. Теперь он утверждает, что доля Nvidia в Китае опустилась до нуля. 
Источник изображения: Nvidia Напомним, что формальное разрешение американских властей наладить поставки ускорителей Nvidia H200 с одной стороны, запуталось в бюрократических процедурах в США, а с другой — наткнулось на противодействие китайских чиновников, которые начали запрещать их импорт и использование крупными местными компаниями. При этом усилия по импортозамещению ИИ-ускорителей в КНР привели к экспансии местных разработчиков чипов. Недавно Дженсен Хуанг в очередной раз заявил: «В Китае, мы теперь упали до нуля. Уступка целого рынка размером с Китай, вероятно, не имеет большого стратегического смысла, поэтому я думаю, что это уже в значительной степени привело к обратным результатам. Возможно, в то время это имело смысл, но я думаю, что политика действительно должна быть динамичной и идти в ногу со временем». Заявления главы Nvidia в ходе очередного интервью цитирует ресурс Tom’s Hardware. Дженсен Хуанг добавил: «Думаю, будет справедливо сказать, что имеет смысл сочетать на китайском рынке присутствие американских и прочих компаний». По оценкам аналитиков Bernstein, китайские поставщики ИИ-ускорителей стремятся покрыть до 80 % потребностей местного рынка, поэтому доля Nvidia в обозримой перспективе сократится до 8 %. Глава компании в своей статистике учитывает прямые поставки чипов производителем в Китай, поэтому его оценки положения своего детища на местном рынке могут отличаться от сторонних данных. Дженсен Хуанг сравнил инфраструктуру ИИ с пятислойным пирогом, добавив, что ускорители являются только одним из этих слоёв. Во многих аспектах Китай располагает необходимыми ресурсами для успеха в этой сфере: дешёвой энергией и талантливыми специалистами. «Количество исследователей в области ИИ в Китае весьма велико, и это одно из их национальных достояний», — отметил Хуанг. Как известно, он является противником экспортных ограничений на поставку ИИ-ускорителей в Китай, поскольку убеждён, что это лишь мотивирует местные компании создавать альтернативы западным чипам, а американские технологии в этом случае теряют своё влияние на местном рынке. Понятно, что в данном случае он является заинтересованным лицом, но доля истины в его утверждениях есть. Когда Хуанга спросили на том же мероприятии, желает ли он, чтобы Китай получил самые передовые американские чипы, он ответил отказом. «Мы всей душой болеем за то, чтобы у Соединённых Штатов в первую очередь было самое лучшее», — сказал глава Nvidia. В рамках трёхлетней сделки Meta✴ будет использовать сотни тысяч чипов Amazon Graviton
26.04.2026 [06:34],
Алексей Разин
Эволюция вычислительной инфраструктуры искусственного интеллекта происходит стремительно, о чём отчасти говорит и недавний квартальный отчёт Intel, показавший резкий рост спроса на центральные процессоры серверного назначения. Американские техногиганты начинают активнее использовать чипы собственной разработки, а также предлагать их сторонним участникам рынка. 
Источник изображения: LinkedIn По крайней мере, эту тенденцию иллюстрирует заключённая недавно между Meta✴✴ Platforms и Amazon (AWS) сделка, по результатам которой первая получит на три года или более доступ к сотням тысячам чипов Graviton, которые Amazon изначально разрабатывала для собственных нужд. Эта сделка, по большому счёту, идёт в одном русле с договорённостями, которые Meta✴✴ недавно достигла с CoreWeave и Mebius, направив на расширение собственной вычислительной инфраструктуры $48 млрд в общей сложности. Финансовые условия сделки Meta✴✴ с Amazon раскрыты не были. По словам представителей первой, процессоры Graviton обеспечат её тем сочетанием производительности и эффективности при работе с агентскими задачами в ИИ, которое ей требуется. Как отметили представители AWS, процессоры Graviton используются многими разработчиками для предварительного обучения своих ИИ-моделей, и теперь Meta✴✴ окажется в их числе. В этом отношении она составит компанию и более известным клиентам AWS, включая Adobe, Apple, Snowflake и Anthropic. Среди доступных конфигураций облачного сервиса EC2 именно процессоры Graviton обеспечивают лучшее быстродействие за свои деньги, потребляя при этом на 60 % меньше электроэнергии по сравнению с альтернативами, как отмечают представители AWS. Компания Meta✴✴ и ранее использовала Graviton, но в скромных масштабах, а теперь она войдёт в число пяти крупнейших клиентов AWS и начнёт использовать сотни тысяч таких чипов. Арендой чипов Nvidia у AWS компания Meta✴✴ занималась с 2017 года. Alphabet ведёт переговоры с Marvell о разработке двух ИИ-чипов для инференса
19.04.2026 [22:29],
Анжелла Марина
Alphabet начала переговоры с компанией Marvell о разработке специализированных чипов, способных более эффективно запускать модели искусственного интеллекта. Партнёрство предполагает создание двух типов микросхем: модуля памяти для ускоренной передачи данных и обновлённой версии TPU от Google, предназначенной для работы в интерактивных приложениях. 
Источник изображения: tipranks.com Новые чипы будут функционировать совместно, распределяя задачи между высокой вычислительной мощностью и скоростью потока информации, что критически важно для поисковых систем и ИИ-сервисов. Как отмечает TheInformation, подобный подход позволит компаниям сократить издержки и повысить быстродействие систем, переходя от этапа обучения нейросетей к этапу их практического использования. Компании рассчитывают завершить проектирование блока обработки памяти уже в следующем году и передать его в опытное производство. Конкуренты также активно развивают это направление, что отражает общую отраслевую тенденцию. Например, Nvidia уже представила новый чип, ориентированный на аналогичные ИИ-задачи, а другие игроки рынка работают над специализированными разработками под свои собственные нужды. В свою очередь, Google постепенно диверсифицирует список партнёров, чтобы снизить зависимость от Broadcom, которая взимает плату за каждый произведённый чип. Ранее компания привлекла MediaTek, а теперь рассматривает Marvell Technology как ключевого игрока благодаря его опыту в производстве чипов памяти и инструментов для ИИ. В рамках существующего соглашения Google владеет архитектурой TPU и программным стеком, тогда как Broadcom преобразует разработки в пригодные для производства чипы, которые затем изготавливаются на мощностях TSMC. В ходе переговоров с Marvell предполагается, что компания возьмёт на себя роль поставщика проектных услуг, задействовав свою экспертизу в области высокоскоростных межсоединений для оптимизации стоимости и производительности. При этом полный разрыв с текущим партнёром не планируется. Alphabet и Broadcom недавно подписали соглашение о продолжении сотрудничества в области разработки новых чипов вплоть до 2031 года, что подтверждает постепенный, а не резкий характер изменений в стратегии закупок. Отметим, на фоне технологических перемен инвестиционное сообщество сохраняет оптимизм относительно будущего Alphabet. Аналитики рекомендуют акции компании к покупке: из 31 оценки 26 имеют рейтинг Buy, а средняя целевая цена установлена на уровне $385,97. Этот прогноз подразумевает потенциал роста котировок почти на 13 % от текущих значений, подтверждая уверенность рынка в способности технологического гиганта эффективно управлять затратами и укреплять свои позиции в гонке искусственного интеллекта. Китайская Dishan готовит 2-нм ИИ-процессор — но неясно, кто будет его выпускать
16.04.2026 [15:28],
Алексей Разин
Чаще всего в контексте передовых разработок в полупроводниковой сфере из китайских компаний фигурировала именно Huawei Technologies, а в качестве её производственного партнёра упоминалась SMIC. При этом в Китае есть стартапы, которые разрабатывают 2-нм чипы, даже не представляя, кто их потом будет выпускать. Dishan Technology уже готовит прототип 2-нм чипа для систем ИИ. 
Источник изображения: TSMC Об этом со ссылкой на китайские СМИ сообщает издание South China Morning Post. Шанхайский стартап Dishan Technology сейчас перешёл к стадии верификации дизайна прототипа 2-нм чипа (GPU), который будет использоваться в инфраструктуре ИИ, если поступит в массовое производство. Анонс соответствующего чипа состоялся ещё в июле прошлого года. Уже тогда компания заверяла, что завершила основные этапы разработки первого в Китае 2-нм чипа для нужд искусственного интеллекта. При его производстве, как ожидается, будут использоваться структуры транзисторов FinFET и GAA, а также основанная на чиплетах компоновка. Помимо прочего, она позволит на 40 % повысить энергетическую эффективность чипа по сравнению с решениями предыдущего поколения, использующими классическую компоновку. Более того, Dishan собирается предложить компиляторы программного кода с поддержкой CUDA, чтобы обеспечить совместимость с ПО, разработанным для экосистемы Nvidia. Это облегчит китайским клиентам Dishan процесс миграции программного обеспечения на новую аппаратную платформу, если они ранее полагались на импортируемые компоненты Nvidia. В любом случае, перспективный чип Dishan в своём развитии пока не дошёл даже до стадии цифрового проекта, пригодного для массового выпуска, и на преодоление этого этапа пути ему может потребоваться от одного до двух лет. Основанная в 2021 году компания Dishan Technology вынуждена полагаться на контрактных производителей чипов, а среди китайских компаний такого профиля никто пока не готов наладить выпуск 2-нм продукции. Доступ к конвейеру тайваньской TSMC может быть затруднён американскими санкциями, хотя на Dishan они пока не распространяются. Китайская SMIC пока с трудом приближается к освоению 5-нм технологии. Пока Dishan пытается ещё на стадии разработки ранних прототипов снизить риск возникновения дефектов при массовом производстве, но цель освоения 2-нм техпроцесса в любом случае выглядит очень амбициозно. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



