|
Опрос
|
реклама
Быстрый переход
ИИ-модели Perplexity заработают на центральных процессорах Nvidia Vera
08.07.2026 [15:40],
Алексей Разин
Компания Nvidia исторически выпускала определённый ассортимент процессоров, но они в основном применялись в игровых устройствах и бортовых системах автомобилей. С анонсом семейства Vera компания замахнулась на присутствие в перспективном сегменте серверных процессоров, где уже давно доминирует со своими GPU. Стартап Perplexity недавно выразил свою готовность использовать новые чипы Nvidia. 
Источник изображения: Nvidia Об этом сообщило агентство Reuters, которое попутно напомнило о намерениях Nvidia поднять выручку от реализации центральных процессоров до $20 млрд к концу текущего фискального года, который завершится к началу февраля. Упор в эволюции инфраструктуры ИИ сейчас делается на операции инференса, в которых себя хорошо проявляют именно центральные процессоры. Осознавая, что разработчики систем ИИ и облачные гиганты начали самостоятельно разрабатывать чипы, Nvidia пытается удержать клиентов, предлагая им центральные процессоры серверного назначения. Преимущество решений Nvidia в этом сегменте как раз может заключаться в том, что они уже были разработаны в разгар бума ИИ, а потому учитывают всю специфику применения и потребности сегмента. Представители Perplexity, на слова которых ссылается Reuters, уже признали, что ИИ-агенты по работе с созданием программного кода при использовании чипов Nvidia продемонстрировали полуторакратное превосходство в быстродействии по сравнению с центральными процессорами иных поставщиков. Чипы Nvidia, по мнению руководства Perplexity, оптимально подходят для множества типовых вычислительных нагрузок, с которыми ему приходится работать. Какое количество процессоров Vera будет закуплено этим стартапом, не уточняется. Ранее Nvidia сообщили, что её процессоры этого семейства планируют применять компании Oracle, OpenAI и Anthropic. Китайская DeepSeek тайно разрабатывает собственный чип для инференса ИИ
08.07.2026 [08:48],
Алексей Разин
Китайский стартап DeepSeek, по информации источников Reuters, уже около года интересуется возможностью разработки собственного ИИ-чипа для ускорения работы с инференсом, а потому проводит консультации с возможными партнёрами и привлекает профильных специалистов без лишней огласки. 
Источник изображения: Unsplash По замыслу DeepSeek, собственный чип поможет компании снизить зависимость от компонентов Nvidia и Huawei. Если первые до некоторых пор поставлялись в Китай в ограниченном ассортименте из-за экспортных ограничений США, то в последнее время их сложно импортировать уже из-за позиции китайских властей, которые настаивают на импортозамещении. Продукция Huawei хоть и пользуется растущей популярностью у китайских разработчиков, доступна в ограниченных количествах из-за тех же санкций США, которые не позволяют подрядчикам компании выпускать необходимые чипы в достаточных количествах и закупать за границей скоростную память типа HBM. В любом случае, доля Huawei на китайском рынке ИИ-ускорителей сейчас приближается к 50 %, тогда как Nvidia практически утратила своё присутствие на первичном рынке КНР. Пока сложно судить, кому именно DeepSeek поручит выпуск своего ускорителя для инференса, и какая память ему потребуется, но компании наверняка предстоит найти и партнёра по разработке. По информации Reuters, стартап привлекает специалистов по разработке чипов, но старается не афишировать подобную деятельность, а потому соответствующие объявления о вакансиях не публикуются в открытом виде. Если первые ИИ-модели DeepSeek были обучены на ускорителях Nvidia H800, которые с определённых пор не поставляются в Китай из-за санкций, то весной этого года стартап адаптировал свои новейшие модели под чипы Huawei Ascend. Если ускорители собственной разработки DeepSeek сможет поставить на конвейер и не попасть под санкции США, это позволит стартапу получить определённое преимущество по сравнению с прочими китайскими разработчиками. Многие компании ИИ-сектора стремятся разрабатывать собственные ускорители вычислений. Помимо американских OpenAI и Anthropic, в подобную активность вовлечены китайские Alibaba и Baidu. По всей видимости, DeepSeek предпочитает двигаться по такой же траектории. Китайские компании готовы отказаться от Nvidia в пользу местных ИИ-чипов — на них уйдёт до половины бюджета
07.07.2026 [07:38],
Алексей Разин
Информация об активном продвижении китайских ИИ-ускорителей на домашнем рынке не раз появлялась ранее в контексте запрета на ввоз американских Nvidia H200, поэтому тенденции импортозамещения в КНР были выражены довольно отчётливо. Как удалось установить Bloomberg, китайские компании в ближайшие 12 месяцев готовы до 46 % средств, выделенных на закупку ИИ-чипов, направлять на приобретение продукции локальных поставщиков. 
Источник изображения: Nvidia По данным опроса Bloomberg Intelligence, в настоящее время доля китайских ИИ-чипов в структуре затрат китайских компаний не превышает 30 %, поэтому в перспективе ближайших 12 месяцев можно будет говорить о росте этой доли. В опросе приняли участие руководители 60 крупных китайских компаний, работающих в сфере разработки программного обеспечения, финансов, производства и розничной торговли. По их словам, в 80 % случаев затраты компаний на инфраструктуру в этом году превысят первоначально выделенный бюджет. 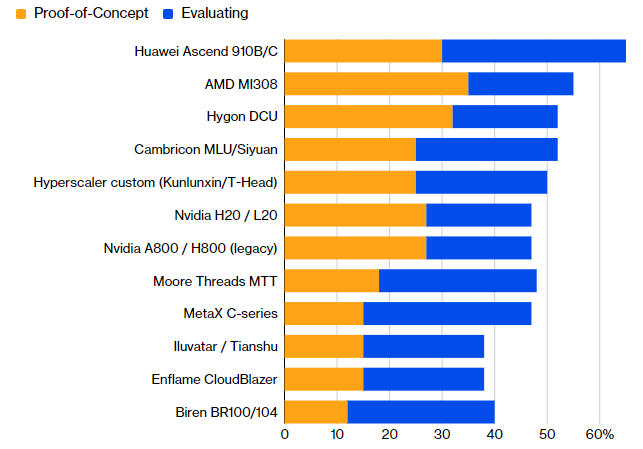
Источник изображения: Bloomberg На уровне тестирования или реального внедрения в китайскую вычислительную инфраструктуру лидирует по популярности семейство ускорителей Huawei Ascend 910B/C, на втором месте находятся американские AMD Instinct MI308, а третье место досталось чипу Hygon DCU. Практически на одном уровне с ним идут разработки Cambricon и Kunlunxin/T-Head компании Alibaba, а вот классические решения Nvidia оказались только в середине списка. Даже чипы Moore Threads и MetaX способны составить им конкуренцию по уровню популярности в китайской вычислительной инфраструктуры, причём по практическому применению они оказываются впереди. Проблем для Nvidia добавляет и то обстоятельство, что ускорители этой марки в Китае всё сложнее достать. Китай в ближайшие пять лет собирается выделить $294 млрд на строительство ЦОД на своей территории, не менее 80 % ключевых высокотехнологичных компонентов для них при этом будет поставляться местными компаниями. Серьёзными препятствиями на пути этого роста становятся как дефицит микросхем памяти, так и ограниченные технологические возможности китайских производителей чипов, включая SMIC. Apple договорилась с Broadcom о поставках кастомных ИИ-чипов до 2031 года
06.07.2026 [17:52],
Алексей Разин
Компания Broadcom входит в число крупнейших поставщиков полупроводниковой продукции, но при этом с медийной точки зрения остаётся в тени за пределами узкого круга специализированных изданий. Apple серьёзно зависит от Broadcom в сфере получения разработанных специально для неё чипов, и на этой неделе компании продлили соглашение о сотрудничестве до 2031 года. 
Источник изображения: Broadcom Как отмечает Bloomberg, в тексте документа, поданного американским регуляторам, Broadcom фигурирует в качестве поставщика специализированных ASIC, которые будут использоваться в нескольких поколениях устройств Apple, хотя специфика данных компонентов не уточняется. На протяжении многих лет Broadcom снабжала Apple чипами, отвечающими за поддержку беспроводных интерфейсов со стороны iPhone. Новость о продлении соглашения с Apple вызвала рост курса акций Broadcom на 5 % до начала торгов в США. По оценкам аналитиков, Apple обеспечивает до 20 % выручки Broadcom, поэтому сотрудничество важно для обеих компаний. Broadcom оказалась в поле зрения инвесторов, следящих за бумом ИИ, на фоне сотрудничества с Meta✴✴ Platforms и Google в сфере разработки ИИ-чипов. За прошлый год акции Broadcom на этом фоне подросли более чем на 30 %. Исторически именно Broadcom снабжала Apple чипами, отвечающими за поддержку Bluetooth, 5G и Wi-Fi, но недавно вторая из компаний разработала собственные контроллеры Wi-Fi и Bluetooth для использования в iPhone, iPad и Mac. При этом Broadcom продолжает снабжать Apple компонентами, необходимыми для работы собственного модема, разработанного второй из компаний. На новом этапе сотрудничества, по всей видимости, Broadcom сосредоточится на разработке ИИ-чипов для Apple, которые будут применяться в фирменной вычислительной инфраструктуре последней. ИИ-ускорители под условным обозначением Baltra должны выйти в следующем году, они будут работать в собственной ИИ-инфраструктуре Apple. Власти Сингапура арестовали особняк стоимостью $42 млн у подозреваемых в контрабанде ИИ-ускорителей Nvidia
04.07.2026 [07:06],
Алексей Разин
Малайзия и Сингапур не раз фигурировали в делах о контрабанде ускорителей Nvidia в Китай в обход американских санкций, последнее из государств к тому же является крупнейшим региональным финансовым хабом в случае с транзитом продукции этой марки. Сингапурские органы власти предъявили обвинения новым подозреваемым в контрабанде и арестовали дом стоимостью $42 млн в ходе следствия. 
Источник изображения: Nvidia Как отмечает Nikkei Asian Review, власти Сингапура предъявили обвинения в отмывании средств, полученных незаконным путём, двум гражданам страны, на счетах которых были обнаружены суммы сомнительного происхождения, близкие к $1 млн в каждом из случаев. Кроме того, арест был наложен на особняк стоимостью около $42 млн. Правоохранительные органы Сингапура выразили решительное неприятие попыток поставить под сомнение надёжность страны в качестве международного финансового хаба, обеспечивающего соблюдение всех законных интересов. В прошлом году власти Сингапура уже раскрыли схему нелегальных поставок серверных систем с компонентами американского происхождения в Китай через собственно Сингапур и Малайзию. После совместного расследования с правоохранителями США и Малайзии власти Сингапура выдвинули обвинения в адрес одного гражданина КНР и одного жителя Сингапура, касающиеся покупок санкционной продукции по подложным документам. В общей сложности по этим эпизодам обвинения выдвинуты четырём подозреваемым, трое из которых являются гражданами Сингапура, а четвёртый имеет китайское гражданство. Следствие ведётся также в отношении фирм, к которым эти четверо имеют отношение. В материалах дела фигурируют серверные системы Dell, Supermicro и Asus. Обвиняемые вводили поставщиков оборудования в заблуждение относительно конечного пользователя этих серверных систем, как утверждает следствие. Кроме того, одного из подозреваемых обвиняют в легализации доходов, полученных незаконным путём, на сумму как минимум $4,5 млн. Предполагается, что эти деньги он направил на покупку дома стоимостью $42 млн. Если вина подозреваемых будет доказана, им грозят тюремные сроки до 20 лет и штрафы до $387 000. ByteDance начнёт распространять ИИ-чипы собственной разработки со следующего года
30.06.2026 [07:56],
Алексей Разин
Участие американской Qualcomm в создании ИИ-чипа для китайской ByteDance уже обсуждалось ранее, но первая на своём недавнем квартальном мероприятии лишь призналась, что снабжает готовыми чипами Meta✴✴ и разрабатывает заказные для двух других крупных компаний облачного сектора. Предполагается, что уже в следующем году ByteDance начнёт применять чипы собственной разработки в своей вычислительной инфраструктуре. 
Источник изображения: Unsplash, Claudio Schwarz Об этом со ссылкой на информированные источники сообщило издание South China Morning Post. По имеющимся данным, цифровой проект ИИ-чипа ByteDance будет готов не позже начала следующего года, а во второй половине 2027 года компания рассчитывает начать его массовое внедрение в своей вычислительной инфраструктуре. Ранние прототипы эксплуатировались ByteDance с конца прошлого года, но создание таких процессоров китайская компания, владеющая социальной сетью TikTok и рядом популярных в Китае сервисов, не особо афишировала. Сотрудничество с Qualcomm, как сообщается, должно помочь ByteDance не только быстрее разработать свой процессор, но и наладить его массовый выпуск на мощностях тайваньской TSMC. Кроме того, могут быть задействованы возможности последней по упаковке чипов с использованием метода CoWoS. Спрос на эти услуги очень высок, и без содействия со стороны Qualcomm китайскому разработчику было бы крайне сложно добиться успеха на этом направлении. ByteDance прилагает максимум усилий к ускорению процесса вывода своих чипов на конвейер. Западные облачные гиганты давно разрабатывают собственные чипы, поскольку с учётом масштабов их вычислительной инфраструктуры оптимизация ресурсов даёт ощутимую экономию финансов. ByteDance также интересуется и чипами сторонних китайских разработчиков, в прошлом месяце, как сообщает источник, она закупила десятки тысяч ускорителей шанхайской Iluvatar CoreX. В офисе Supermicro на Тайване прошли обыски, связанные с расследованием по делу о контрабанде серверов в Китай
30.06.2026 [04:53],
Алексей Разин
Власти Тайваня в расследовании случая с предполагаемой контрабандой ИИ-ускорителей в Китай действуют весьма ритмично. Если в конце прошлого месяца они задержали троих подозреваемых в организации нелегальных поставок, то накануне были проведены обыски в тайваньском офисе компании Supermicro, продукция которой неоднократно фигурировала в подобных инцидентах. 
Источник изображения: Supermicro Об обысках на Тайване сообщило агентство Bloomberg со ссылкой на свои источники. Акции Supermicro на фоне подобных новостей упали в цене на 9,2 %. Официальные представители тайваньских органов правопорядка сообщили, что следователи обыскали дома шести частных лиц и офисы трёх связанных с расследованием компаний. Среди них, как предполагается, был и офис Supermicro. Представители последней ограничились заявлением о том, что продолжают сотрудничать со следствием, а компания в целом следит за законностью осуществляемой деятельности во всех юрисдикциях своего присутствия. Принято считать, что активизация властей Тайваня в вопросе контроля за поставками серверного оборудования с ИИ-ускорителями американского происхождения в Китай связана с усилившимся давлением со стороны США, которые хотят перекрыть этот канал. Местное законодательство до сих пор не квалифицирует подобные поставки, как уголовное преступление. Обвинения в таких случаях выдвигаются по поводам, связанным с подделкой документов, среди прочего. Инициативы по актуализации тайваньского законодательства тоже выдвигаются, чтобы лучше соответствовать требованиям американского экспортного контроля. В понедельник обыскам подверглись офисы оператора ЦОД Chief Telecom и дистрибьютора продукции Supermicro на Тайване, как добавляет источник. Новые подозреваемые по этому делу были вызваны для допроса. На Тайване производится существенная часть ИИ-чипов американской разработки, здесь также изготавливается и серверное оборудование на их основе. Американские власти подозревают, что часть этой продукции попадает в Китай обходными путями, хотя официально это запрещено американским законодательством. Малайзия перехватила контрабандную партию из 72 серверов с ИИ-чипами на $13 млн
26.06.2026 [14:56],
Алексей Разин
В этом месяце американские власти в очередной раз призвали своих азиатских союзников усилить контроль за транзитными поставками серверного оборудования с ИИ-чипами, поскольку попадающая под экспортные ограничения продукция американского происхождения по-прежнему попадает в Китай. Власти Малайзии недавно сообщили о задержании в аэропорту столицы страны партии серверного оборудования на сумму $13 млн. 
Источник изображения: Nvidia Номинально Малайзия ещё в прошлом году ввела экспортные ограничения на отгрузку в Китай компонентов ИИ-систем, подчинившись требованиям США в этой сфере. Пятого июня, как сообщает Reuters, власти Малайзии при досмотре грузов в международном аэропорту Куала-Лумпура обнаружили партию из 72 серверных систем с передовыми ИИ-чипами. Эти системы, как установило расследование, предназначались для реэкспорта в другую азиатскую страну в нарушение национального законодательства. По меньшей мере, такая поставка требует разрешения со стороны властей Малайзии, а оно запрошено не было. Чиновники также определили, что партия серверного оборудования по документам проходила, как компьютерные компоненты, а Малайзия значилась конечным пунктом назначения, что явно не соответствовало намерениям организаторам перевозки. Участвовавшая в схеме местная компания была привлечена к расследованию, а партия серверного оборудования была конфискована властями страны. Китайские разработчики не только получали попадающие под американские санкции серверные системы американского происхождения, но и эксплуатировали их на территории Малайзии в своих интересах. В последнем случае, правда, их не в чем было обвинить с точки зрения местных законов. Ещё одним крупным направлением нелегального транзита тех же ускорителей Nvidia из США в Китай принято считать Сингапур. Американские власти недавно арестовали двух граждан Китая, подозреваемых в организации нелегальных поставок. В этом месяце власти Малайзии также обнаружили в столичном аэропорту партию коробок из-под центральных процессоров, внутри которых содержалась в специальных ёмкостях жидкость для вейпов с добавленными запрещёнными веществами. Эта партия специфической продукции также должна была последовать в одну из соседних стран. Китайские ИИ-чипы в этом году захватят 79 % домашнего рынка — лидирует Huawei
26.06.2026 [12:39],
Алексей Разин
Глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) хоть и любит причитать, что из-за американских санкций доля продукции его компании на рынке КНР сократилась до нуля, в известной степени прибедняется. По мнению аналитиков TrendForce, зарубежные поставщики ИИ-чипов в этом году ещё смогут претендовать на 21 % китайского рынка, хотя оставшиеся 79 % и достанутся местным компаниям. 
Источник изображения: Cambricon Technologies В прошлом году, по данным источника, на долю AMD, Nvidia и возможных других иностранных поставщиков ИИ-чипов приходилось 34 % китайского рынка. Независимые китайские поставщики чипов, включая Huawei и Cambricon, в этом году увеличат свою долю на китайском рынке с 46 до 56 %, а локальные интернет-гиганты, которые разрабатывают собственные ИИ-чипы, укрепят позиции на китайском рынке с 20 до 23 %. Другими словами, национальные поставщики ИИ-чипов по итогам текущего года смогут занять 79 % рынка в Китае. С одной стороны, поставкам передовых западных ИИ-чипов в Китай мешают американские санкции. С другой стороны, власти КНР настаивают на скорейшем импортозамещении в такой стратегически важной отрасли, как генеративный искусственный интеллект. Те же ускорители Nvidia H200 не смогли попасть в Китай, поскольку даже при наличии разрешения со стороны американских властей, одобрение на ввоз со стороны китайской таможни получено не было. ByteDance и Alibaba, по мнению аналитиков TrendForce, станут крупнейшими разработчиками ИИ-чипов из числа игроков китайского рынка информационных технологий. Первая располагает подразделением Kunlunxin, вторая — T-Head, и оба специализируются на разработке ИИ-чипов для нужд материнских компаний. Западные интернет-гиганты давно уже задают подобный тренд: Google и Amazon, а также Microsoft и Meta✴✴ разрабатывают чипы для собственных нужд. На мировом рынке объёмы поставок ИИ-серверов в этом году должны увеличиться более чем на 28 %, как отмечает TrendForce. В мировых масштабах по итогам следующего года Nvidia сохранит за собой 64 % рынка ИИ-чипов, на втором месте окажется AMD с её 8,6 %. Впрочем, китайские поставщики не так уж сильно отстанут от некоторых представителей Запада, поскольку сообща по итогам 2027 года получат 20 % мирового рынка ИИ-чипов. Главным фактором риска для гармоничного развития мирового рынка ИИ-чипов останутся геополитические конфликты и вопросы, связанные с таможенными тарифами, по мнению аналитиков TrendForce. Qualcomm не хочет терять Китай: новые серверные чипы подстроят под санкции США
25.06.2026 [10:33],
Алексей Разин
Корпорация Qualcomm представила накануне четыре линейки серверных продуктов Dragonfly: центральные процессоры, ИИ-ускорители, полузаказные чипы и решения для телекоммуникационной сферы. Все четыре линейки изделий могут появиться на китайском рынке, поскольку Qualcomm готова их адаптировать с оглядкой на экспортные ограничения США. 
Источник изображения: Qualcomm Technologies Об этом на мероприятии для инвесторов объявил генеральный директор Qualcomm Криштиано Амон (Cristiano Amon), на которого ссылается ресурс Nikkei Asian Review: «Наш бизнес в Китае достаточно велик, и поскольку мы начали диверсифицировать компанию, наше партнёрство с Китаем и нашими китайскими клиентами тоже расширилось». По его словам, Qualcomm обладает весьма прочными связями с китайскими производителями смартфонов и автомобильной электроники, и аналогичных позиций компания хотела бы добиться в серверном сегменте. Как он добавил, существуют вполне чёткие ограничения по типам и характеристикам продуктов, которые можно поставлять из США в Китай, и компания собирается предложить адаптированные для местного рынка решения во всех новых семействах. Предварительные переговоры на эту тему позволяют руководству Qualcomm с оптимизмом смотреть в будущее. Китайский рынок обеспечил 46 % выручки компании за прошлый год, но главным образом благодаря производителям смартфонов. Через пару лет доля смартфонов в общей выручке Qualcomm должна сократиться примерно до трети с нынешних 57 %. По мнению Амона, сейчас Китай является эпицентром разработки агентских ИИ-моделей. Предлагаемая Qualcomm технология интеграции памяти HBC обладает в шесть раз более высокой удельной пропускной способностью в пересчёте на ватт потребляемой энергии, чем HBM. Решение Qualcomm обеспечивает увеличение доступного объёма памяти, увеличивает пропускную способность и поднимает эффективность вычислений в целом. Qualcomm обеспечила себя запасами памяти для выпуска своих новых серверных решений до сентября 2027 года включительно, да и распространение HBC, по мнению руководства, должно облегчить дефицит памяти. Производители памяти уже интересуются этой технологией. Первым продуктом Qualcomm с поддержкой HBC станет ускоритель AI250, который выйдет в следующем фискальном году, начинающемся в ноябре текущего календарного. Новые серверные продукты принесут Qualcomm до сентября текущего года $300 млн выручки, а в следующем фискальном году она вырастет до $5 млрд. К 2029 году, по прогнозам компании, годовой оборот рынка чипов для ЦОД достигнет $1 трлн, она претендует как минимум на 5 % от этой суммы. Глава Qualcomm также заверил инвесторов, что взаимодействие с TSMC налажено таким образом, что выпуск чипов, разработанных первой компанией, вторая начинает в очень сжатые сроки, и сразу в приличных объёмах. Qualcomm интересуется покупкой стартапа Tenstorrent легендарного Джима Келлера за $10 млрд
16.06.2026 [07:43],
Алексей Разин
Выход в сегмент ИИ-чипов ускоряется, когда крупный разработчик поглощает профильные стартапы — обычно такой подход применяла корпорация Intel. Теперь же, как отмечает Reuters со ссылкой на The Information, за активы Tenstorrent готова выложить от $8 до $10 млрд компания Qualcomm. 
Источник изображения: Tenstorrent Переговоры между компаниями уже ведутся, как отмечает источник. Стороны не предоставили Reuters комментариев на момент подготовки материала к публикации. Для Qualcomm покупка Tenstorrent стала бы хорошей возможностью диверсифицировать бизнес, поскольку высокая зависимость от сегмента смартфонов не даёт первой из компаний прежних темпов роста, а в текущем году вообще грозит падением профильной выручки вслед за всем рынком данных устройств. Тем более, Tenstorrent разрабатывает ИИ-чипы серверного назначения, а этот сегмент рынка в условиях бума ИИ развивается очень бурно. Основанный в 2016 году стартап Tenstorrent сейчас возглавляет Джим Келлер (Jim Keller) — один из самых известных разработчиков процессорных архитектур современности. Он успел приложить руку к разработке многих популярных семейств процессоров Intel, AMD, Apple и даже Tesla. Компания Tenstorrent специализируется на разработке ускорителей ИИ с архитектурой RISC-V. Келлер в одном из интервью признался, что выпуском чипов для Tenstorrent сейчас занимается тайваньская TSMC, но в будущем стартап может обратиться за подобными услугами к американской Intel. Стартап располагает представительствами в 20 странах мира. По мере масштабирования бизнеса Tenstorrent надеется охватить и сегмент рабочих станций стоимостью до $10 000, поэтому её продукция сможет стать массовой. Не исключено, что под крылом Qualcomm этот процесс пойдёт быстрее, но гарантировать заключение сделки с этой компанией пока никто не может. Nvidia начнёт продавать самые передовые чипы в Китай — но обучать ИИ на них вряд ли получится
12.06.2026 [11:39],
Алексей Разин
В прошлом месяце глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) выразил надежду, что поставки центральных процессоров Vera на китайский рынок будут разрешены. Теперь агентство Reuters сообщает, что компания уже начала принимать заказы у китайских клиентов, и первые процессоры Vera попадут в КНР к августу этого года. 
Источник изображения: Nvidia Источник отмечает, что Nvidia призвала китайских клиентов приступить к размещению заказов на поставку процессоров Vera, которые она собирается начать исполнять с августа этого года. Напомним, Nvidia оценивает ёмкость рынка центральных процессоров $200 млрд, и в эту сумму она включает потенциальную выручку, которую может получить от их реализации в КНР. Некоторые китайские компании, по словам Reuters, выразили заинтересованность в приобретении процессоров Vera. Во время презентации этих чипов в марте текущего года руководство Nvidia пояснило, что Alibaba и ByteDance сотрудничали с ней в сфере развёртывания систем на базе новых процессоров. При этом сложно судить, выразилось ли это сотрудничество в размещении реальных заказов. По данным Reuters, одна крупная китайская облачная компания намерена разместить заказ на более чем 300 серверных систем, каждая из которых содержит по два процессора Vera. Пробная партия позволит заказчику провести эксперименты с оборудованием Nvidia, чтобы понять, потребуется ли его дополнительное количество. Во многом готовность китайских разработчиков закупать процессоры Vera будет определяться программной совместимостью, ведь если какая-то часть ПО уже использует чипы китайского производства, то миграция на платформу Nvidia может представлять определённые трудности. По оценкам SemiAnalysis, базовая стоимость одного процессора Vera без учёта потенциальных скидок превысит $20 000, а полностью укомплектованная 256 чипами серверная стойка обойдётся заказчику в $10 млн или около того. Двухпроцессорные системы, которые будут более доступны по цене, начнут поставляться позже более дорогих многопроцессорных конфигураций. В текущем фискальном году, который завершится в конце января, Nvidia рассчитывает выручить на поставках Vera около $20 млрд. По данным Reuters, китайские клиенты Nvidia собираются первоначально испытывать процессоры Vera в своих центрах обработки данных, расположенных за пределами Китая. Китай всё ещё получает запрещённые ИИ-серверы через Тайвань — США требуют закрыть лазейку
10.06.2026 [07:15],
Алексей Разин
Демонстрируя общую политическую лояльность США, Тайвань на практике до сих пор не ввёл пропорциональные ограничения в области экспортного контроля, а потому китайские компании сохраняют возможность закупать на острове готовые серверные системы с ИИ-чипами, которые власти США не разрешают туда поставлять. Обсуждение возможного усиления мер контроля в этой сфере уже ведётся, поэтому ситуация может измениться. 
Источник изображения: Wiwynn Дело в том, как поясняет Bloomberg, что даже недавние обвинения в контрабанде ИИ-систем в Китай в юрисдикции Тайваня выдвигались по факту подделки документов, а не нарушения правил экспортного контроля. Формально тайваньские законы никак не препятствуют поставкам ИИ-чипов в Китай, хотя соответствующие предостережения местным компаниям и делаются для создания видимости солидарности с властями США. Под нажимом американских коллег власти острова готовятся закрепить эти ограничения на законодательном уровне. Возможно, консультации с участием чиновников с обеих сторон состоятся в ближайшее время. При этом нельзя утверждать, что власти Тайваня полностью игнорируют усилия США по консолидации ограничительных мер в отношении Китая. В прошлом году тайваньские власти включили китайские компании Huawei Technologies и SMIC в перечень нежелательных для взаимодействия с представителями тайваньского бизнеса. При этом все прочие китайские компании формально сохранили право закупать продукцию с Тайваня, даже если речь идёт о передовых ИИ-чипах. Сейчас власти Тайваня рассматривают возможность введения фильтра для всех китайских покупателей ИИ-чипов, ориентируясь на американские правила экспортного контроля. Если изменения будут приняты, то китайские компании утратят возможность закупать без оформления лицензий ускорители с уровнем быстродействия выше Nvidia H200 и AMD Instinct MI325X. Как ожидается, это серьёзно подорвёт бизнес многих тайваньских производителей серверных систем, поскольку в текущих условиях они сохраняют возможность поставок в Китай почти полного спектра оборудования для инфраструктуры ИИ. Им грозят санкции США, но именно со стороны тайваньского законодательства претензий к такой деятельности почти не возникало. Кроме того, в американском парламенте зреет инициатива по усилению контроля за производством чипов на Тайване по заказам китайских компаний, поэтому поставками готовых систем дело не ограничится. По информации Bloomberg, синхронизация усилий США по сдерживанию технологического развития Китая с прочими азиатскими государствами тоже идёт не так гладко, как хотелось бы американским чиновникам. В частности, Малайзия под нажимом Трампа хоть и взяла на себя обязательства адаптировать национальные правила экспорта ИИ-оборудования под американское законодательство, на практике пока не торопится внедрять соответствующие меры. Сингапур, который для той же Nvidia является крупнейшим финансовым хабом, не проявляет интереса по внедрению пропорциональных мер экспортного контроля, предпочитая ориентироваться на исходно национальное законодательство. Впрочем, профилактическую работу с участниками внешнеэкономической деятельности власти Сингапура всё равно ведут. Huawei начнёт поставлять ИИ-ускорители Ascend 950DT с заменителем HBM уже в августе
08.06.2026 [08:07],
Алексей Разин
В эволюции своих ИИ-ускорителей китайской компании Huawei в условиях санкций приходится полагаться на самостоятельно разрабатываемые чипы, включая микросхемы памяти, но прогресс не останавливается. Китайский гигант готов ежегодно удваивать уровень быстродействия своих ИИ-чипов, и Ascend 950DT начнёт поставлять уже в августе. 
Источник изображения: Huawei Technologies Как поясняет TrendForce со ссылкой на китайские СМИ, подобный график можно считать опережением ранее обозначенных планов, поскольку считалось, что ускорители Ascend 950DT начнут распространяться только в четвёртом квартале текущего года. Помимо собственных серверных систем, ускорители Ascend 950DT в первую очередь могут достаться компании DeepSeek, которая к августу может выпустить новую ИИ-модель V4.2. О готовности начать распространение Ascend 950DT внутри инфраструктуры Huawei Cloud заявил глава этого подразделения Чэнь Линь (Chen Lin), на которого ссылается ресурс Mydrivers. По его словам, Huawei сейчас ставит перед собой задачу ежегодно представлять новое поколение ИИ-ускорителей и при этом удваивать их уровень быстродействия. В частности, Ascend 950DT существенно повышает производительность в векторных вычислениях, при передаче информации в память и обратно, а также между чипами. С новым ускорителем также проще работать программистам, а ещё он лучше подходит для систем автопилота. В условиях дефицита памяти способность ускорителей эффективнее использовать доступные аппаратные ресурсы обретает особое значение. К фирменной экосистеме Huawei Cloud ежедневно подключаются более 2 млн автомобилей с автопилотом. Платформа также предоставляет доступ к более чем 100 000 ускорителей Ascend, обеспечивая непрерывное совершенствование программного обеспечения, отвечающего за автопилот. В семействе ускорителей Ascend 950 предусмотрено две основные модификации: Ascend 950PR и Ascend 950DT. Первая в большей мере ориентирована на инференс и оснащается памятью типа HiBL 1.0 собственной разработки Huawei. Вторая способна работать и в режиме обучения больших языковых моделей, она оснащается аналогом HBM в исполнении Huawei, который получил обозначение HiZQ 2.0. Объём доступной памяти увеличивается с 128 до 144 Гбайт, а пропускная способность — с 1,6 до 4,0 Тбайт/с. Ускоритель Ascend 950DT также поддерживает форматы вычислений FP8, MXFP8, MXFP4 и HiF8. По некоторым данным, для выпуска чипов этой серии SMIC задействует свой техпроцесс N+3, который считается аналогом 5-нм техпроцесса западных конкурентов. Илон Маск обсудит с ASML планы по строительству предприятия TeraFab по выпуску чипов
07.06.2026 [05:53],
Алексей Разин
Нидерландская компания ASML, которая является ведущим поставщиком литографических сканеров для производства чипов, решила пригласить Илона Маска (Elon Musk) на закрытую технологическую конференцию, чтобы тот дистанционно обсудил на ней вопросы, связанные с планами по строительству предприятия TeraFab. 
Источник изображения: ASML Как известно, под этим названием в марте было представлено совместное предприятие SpaceX и Tesla по производству передовых чипов для вычислительной инфраструктуры ИИ, которое расположится в Техасе. Во второй половине апреля Маск сообщил, что TeraFab сможет использовать технологию Intel 14A для производства чипов. Недавно появились данные о том, что проект стоимостью не менее $55 млрд претендует на освобождение от налога на собственность. Агентство Bloomberg уточнило, что руководство ASML договорилось об участии Маска в закрытой технологической конференции, в ходе которой он обсудит с персоналом компании свои планы по строительству и оснащению оборудованием TeraFab. Сейчас, в условиях серьёзного дефицита производственных мощностей, заказы на оборудование ASML распределены на несколько лет вперёд, и потенциальному триллионеру наверняка придётся воспользоваться даром убеждения в полной мере, чтобы склонить нидерландского поставщика к активному сотрудничеству. В кратком пояснении источника упоминается, что Маск в ходе конференции «поделится своим представлением об ИИ, робототехнике, космосе и производстве полупроводниковых компонентов». Руководство ASML уже обсудило с Маском его планы по строительству TeraFab. Проект неизбежно будет зависеть от благосклонности ASML, поскольку Маск собирается выпускать на предприятии такое количество чипов для ИИ, которого хватало бы для ежегодного ввода в строй 1 тераватта вычислительных мощностей. Представители ASML добавили, что к сотрудничеству с Маском в рамках проекта TeraFab подключатся и другие известные компании. По мнению основателя SpaceX, полупроводниковая промышленность развивается слишком медленно для удовлетворения потребностей его компаний в чипах. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



