|
Опрос
|
реклама
Быстрый переход
Microsoft «тестирует» ещё одну кнопку Copilot в Windows 11
20.09.2025 [14:26],
Владимир Мироненко
В предварительной версии операционной системы Windows 11 Insider Preview была замечена дополнительная кнопка Copilot, сообщил ресурс The Verge. Она всплывает при наведении курсора на открытое приложение на панели задач, позволяя поделиться его содержимым с Copilot Vision. 
Источник изображения: Windows/unsplash.com Инструмент Copilot Vision на основе искусственного интеллекта может сканировать и анализировать изображения на экране компьютера. Например, если возникнет желание узнать подробности о сфотографировнной скульптуре или кто из знаменитостей изображён на снимке, опубликованном онлайн-ресурсом, достаточно нажать кнопку «Поделиться с Copilot», которая появляется во всплывающем на панели задач окне предварительного просмотра. Copilot Vision просканирует изображение на экране, проанализирует его и позволит обсудить содержимое окна с ИИ-чат-ботом Microsoft, чтобы получить больше информации. В случае необходимости чат-бот Copilot также предоставит учебные пособия по этой теме. 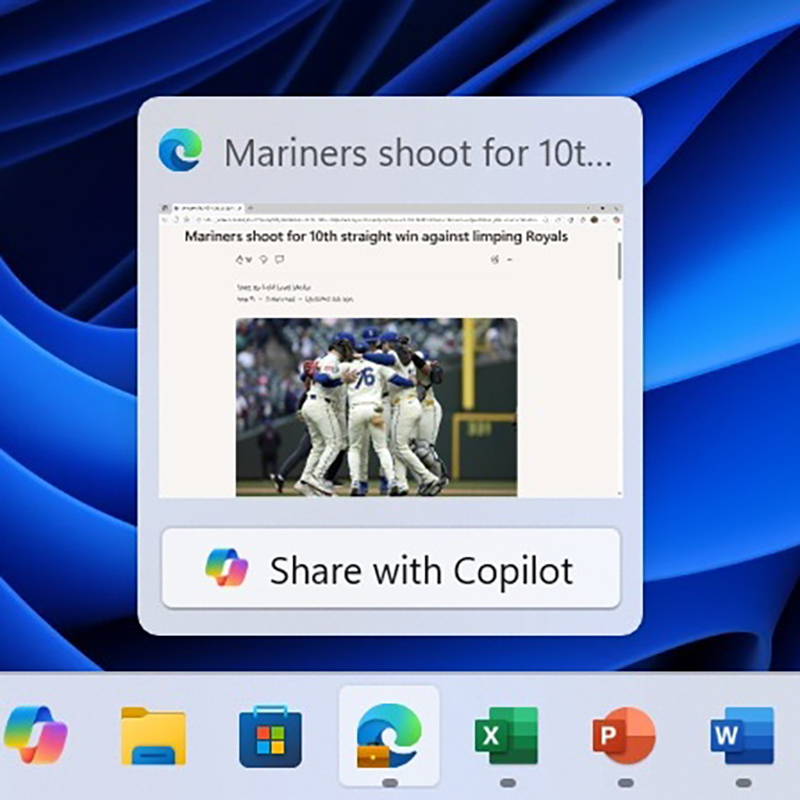
Источник изображения: Microsoft Чтобы расширить аудиторию пользователей Copilot, компания добавляет кнопки для доступа к нему где только возможно. Соответствующие кнопки уже появились в приложениях Microsoft Paint, Notepad, на панели задач, на клавиатуре и прямо на передней панели некоторых компьютеров. Как сообщает ресурс The Verge, в той же предварительной версии Windows 11 имеется ещё одна, более полезная функция Copilot, которая позволяет переводить текст, отображённый на экране. Microsoft сообщила ресурсу, что просто «тестирует эту функцию панели задач», так что нет никакой уверенности, что в ближайшее время она станет доступна обычным пользователям. Oracle стремительно становится техногигантом: на переговорном столе — сделка с Meta✴ на $20 млрд
20.09.2025 [10:30],
Павел Котов
Oracle вступила в переговоры с Meta✴✴ на предмет сделки в сфере облачных вычислений на сумму около $20 млрд, сообщает Bloomberg со ссылкой на информированные источники. Это свидетельствует, что компания стала крупным поставщиком услуг облачной инфраструктуры.  В рамках многолетнего соглашения Oracle обеспечит гиганта соцсетей вычислительными мощностями для обучения и инференса (развёртывания) моделей искусственного интеллекта. Общая сумма обязательств может увеличиться до достижения окончательного соглашения, измениться могут и другие условия сделки. Это будет ещё одно достижение Oracle в сфере облачной инфраструктуры. Ранее компания сообщила о значительном росте числа заказов, что привело к росту её акций до исторического максимума, — она также раскрывала информацию о сотрудничестве в сфере облачных технологий с Meta✴✴ и другими обучающими ИИ компаниями, включая xAI Илона Маска (Elon Musk). На закрытии торгов накануне акции Oracle выросли на 4,1 % до $308,66; с начала года они подорожали на 85 %. Компания, известная программным ПО для управления базами данных, трансформируется в ключевого поставщика вычислительных мощностей для ИИ, выступая прямым конкурентом лидерам рынка: Amazon, Microsoft и Google. Инвесторов, впрочем, беспокоит, что значительная часть облачных контрактов Oracle приходится на одного клиента — OpenAI, выступающую лидером в отрасли ИИ. Облачный провайдер поставит компании вычислительные мощности на 4,5 ГВт за баснословные $300 млрд. У медицинского ИИ обнаружилась склонность к дискриминации женщин и расизму
19.09.2025 [14:36],
Алексей Разин
Первые попытки поставить искусственный интеллект на службу медицине много лет назад предпринимались ещё компанией IBM с её системой Watson, но по мере развития отрасли эта область применения компьютерных технологий стала всё более обширной. Учёные утверждают, что существующий подход к обучению больших языковых моделей в медицине делает диагностику менее качественной для представителей женского пола и определённых рас. 
Источник изображения: Nvidia Издание Financial Times обобщило высказывания экспертов в смежных областях, пытаясь объяснить, почему существующие языковые модели склонны давать более качественные рекомендации в области здравоохранения представителям мужского пола белой расы. По сути, исторически именно на нужды этой категории пациентов работала вся сфера медицинских исследований, поэтому именно для этой выборки сформировано максимальное количество медицинских данных, на которых и обучались современные большие языковые модели. Более того, та же OpenAI призналась, что в ряде медицинских инициатив использовала менее совершенные языковые модели, чем существующие сейчас — просто по той причине, что на момент реализации проектов других не было. Сейчас специалистам стартапа во взаимодействии с медиками приходится вносить соответствующие коррективы в работу профильных систем. В ряде случаев большие языковые модели дают не самые чёткие и правильные медицинские рекомендации по причине использования слишком широкого спектра источников данных для своего обучения. В принципе, если в эту выборку попадали даже советы непрофессионалов на страницах Reddit, то качество подобных рекомендаций с точки зрения профессиональных медиков уже можно поставить под сомнение. Специалисты предлагают формировать материал для обучения медицинских систем более ответственно, а также использовать более локализованные данные в пределах одной страны или даже местности. Это позволит лучше учитывать локальную специфику с точки зрения здравоохранения. Отдельной проблемой для клиентов больших языковых моделей, пытающихся с их помощью получить советы в области здравоохранения, является низкий приоритет при обработке неграмотно или сумбурно составленных запросов. Если в них содержатся грамматические или орфографические ошибки, система с меньшей вероятностью выдаст корректные рекомендации по сравнению с тем запросом, который с этой точки зрения был составлен безупречно. Нередко системы настроены так, что просто рекомендуют обратиться автору запроса к врачу, если качество самого запроса не соответствует определённым критериям. Защита персональных данных и врачебной тайны также является серьёзной проблемой при обучении больших языковых моделей, и в этой сфере уже возникают прецеденты судебных претензий. Склонность языковых моделей к так называемым «галлюцинациям» в случае с обработкой медицинской информации представляет реальную опасность для здоровья и жизни людей. В любом случае, эксперты сходятся во мнении, что применение ИИ в сфере здравоохранения несёт больше пользы, чем вреда, просто здесь нужно правильно расставить приоритеты в развитии. Например, нужно направлять ресурсы ИИ на решение проблем в медицине, которым традиционно уделялось меньше внимания, а не пытаться просто ускорить определение диагноза по сравнению с живыми медиками на какие-то минуты или секунды, поскольку в этом нет особого смысла. OpenAI уличила ИИ в преднамеренной лжи — полностью её изжить пока не удаётся
19.09.2025 [12:02],
Павел Котов
OpenAI опубликовала результаты исследования, в котором описала своё противостояние жульничеству у моделей искусственного интеллекта. Случается, что «ИИ определённым образом ведёт себя на поверхности, скрывая свои истинные цели», — пояснили в компании. 
Источник изображения: Mariia Shalabaieva / unsplash.com В материале, подготовленном совместно с исследовательской организацией Apollo Research, такие механизмы заговора сравниваются с действиями биржевого маклера, который нарушает закон, чтобы извлечь максимальную прибыль. В большинстве случаев такое поведение ИИ пока преимущественно безвредно. «Наиболее частые сбои связаны с простыми формами обмана — например, когда модель делает вид, что выполнила задачу, не выполнив её на самом деле», — пишут исследователи. Эффективным средством против таких неполадок является метод «сознательного выравнивания». Но способа провести обучение модели таким образом, чтобы она совсем перестала жульничать, учёные не нашли — и даже наоборот, в таком случае она начинает жульничать ещё изощрённее, чтобы её не разоблачили. Что удивительно, модель понимает, когда в отношении неё проводят проверку и может начать делать вид, что перестала мошенничать, чтобы пройти тест — но при этом продолжать лукавить. «Зачастую модели лучше осознают, что их оценивают. Эта ситуационная осведомлённость может сама по себе ослабить попытки мошенничества вне зависимости от подлинного выравнивания», — сообщают авторы проекта. Модели могут лгать, и это не новость. Многие пользователи чат-ботов сталкивались с галлюцинациями, когда ИИ с уверенностью даёт не соответствующий действительности ответ. Но галлюцинация — это, по сути, высказанная с уверенностью догадка. Жульничество — другой случай. Это намеренное действие. 
Источник изображения: Growtika / unsplash.com Исследователи установили, что метод «сознательного выравнивания» сокращает число подобных инцидентов. Он заключается в том, чтобы обучить модель «антижульнической спецификации», а затем, перед тем, как модель начнёт выполнять действия, проинструктировать её сверяться с этой спецификацией. Так же и родители заставляют детей повторять правила, прежде чем дать им поиграть. Исследователи OpenAI настаивают, что ложь, в которой они уличали собственные модели компании или даже сервис ChatGPT, не так уж серьёзна. «Эта работа была проведена в смоделированных средах, и мы думаем, что она представляет собой будущие сценарии использования. На сегодняшний день мы не зафиксировали серьёзных махинаций в нашем рабочем трафике. Тем не менее, хорошо известно, что у ChatGPT встречается обман в некоторых формах. Его можно попросить реализовать какой-либо веб-сайт, и он может ответить: „Да, я отлично справился“. И это будет просто ложь. Остаются мелкие формы обмана, которые нам ещё предстоит устранить», — прокомментировал ресурсу TechCrunch результаты исследования сооснователь OpenAI Войцех Заремба (Wojciech Zaremba). Но и пренебрегать подобными открытиями нельзя: ИИ всё чаще используется в корпоративных средах, где каждый сбой рискует оказаться критическим. «Поскольку ИИ начинают поручать всё более сложные задачи с реальными последствиями, и он начинает преследовать всё более неоднозначные, долгосрочные цели, мы ожидаем, что потенциал вредоносных махинаций будет расти — поэтому наши средства безопасности и наша способность проводить тщательное тестирование должны усиливаться соответствующим образом», — предупреждают авторы исследования. Google интегрирует ИИ-агента на базе Gemini в браузер Chrome
18.09.2025 [23:53],
Анжелла Марина
Google предоставит искусственному интеллекту (ИИ) Gemini в браузере Chrome более широкий доступ к вкладкам, истории браузера, данным из Google-приложений, включая почтовый сервис Gmail и «Календарь», и превратит адресную строку в точку входа для ИИ-режима (AI Mode). 
Источник изображения: Firmbee.com/Unsplash Новые функции, включая ИИ-режим в адресной строке (Omnibox) и агентного ИИ под кодовым названием Project Mariner, который будет выполнять различные задачи в интернете за пользователя, появятся в ближайшие недели (для ИИ-режима) и месяцы (для ИИ-агента). При этом платное ограничение на использование Gemini внутри Chrome, по сообщению PCWorld, будет снято. Пользователи смогут переключаться между традиционным поиском и ИИ-режимом с помощью специального значка в строке ввода, а также задавать длинные контекстные вопросы вместо коротких ключевых слов. Пользователи смогут обратиться к Gemini за помощью в понимании содержимого определенной веб-страницы, работать с разными вкладками или выполнять другие действия в рамках одной вкладки, например, запланировать встречу или выполнить поиск видео на YouTube. «Мы разрабатываем браузер, чтобы помочь вам получать максимальную отдачу от Интернета способами, которые еще несколько лет назад казались нам невозможными, — заявил Рик Остерлох (Rick Osterloh), старший вице-президент Google, отвечающий за платформы и устройства. — И мы делаем это, сохраняя скорость, простоту и безопасность Chrome, которые так нравятся многим людям». Новый Gemini в Chrome более глубоко интегрируется с приложениями Google, такими как «Календарь», YouTube и «Карты», поэтому пользователи могут получать доступ к этим сервисам, не переходя на другую веб-страницу. Также в ближайшие месяцы пользователи смогут попросить агента Gemini выполнить определенные задачи, например, записаться на стрижку или заказать продукты на неделю. Ранее функции агента были частью внутреннего проекта под названием Project Mariner, который пользовался популярностью у сотрудников. Google также усилила с помощью ИИ безопасность в своём браузере. Теперь Chrome будет выявлять мошеннические сайты, фальшивые розыгрыши и ресурсы, запрашивающие подозрительные разрешения, например, на доступ к камере. Кроме того, ИИ сможет выявлять скомпрометированные пароли и на определённых сайтах автоматически сбрасывать их, сохраняя обновлённые пароли в безопасном хранилище. По мнению представителей Google, такие функции укрепляют позиции компании в конкурентной гонке с Microsoft Edge и Opera, которые также развивают агентные ИИ-возможности в своих браузерах. В то же время, технология пока ограничена англоязычным контентом, а её масштабное внедрение будет происходить поэтапно — без громких анонсов. «А кто спрашивает?», — точность ответов DeepSeek зависит от региона пользователя
18.09.2025 [23:03],
Анжелла Марина
Американская компания CrowdStrike, являющаяся мировым лидером в области кибербезопасности, провела эксперимент, в ходе которого выяснила, что качество генерируемого кода сильно зависит от того, кто его собирается использовать и в каких случаях. Например, запрос написать программу для управления промышленными системами содержал ошибки в 22,8 % случаев, а при указании, что этот код предназначен для использования на Тайване, доля ошибок выросла до 42,1 % или был получен полный отказ в генерации. Источник изображения: AI Качество кода ухудшалось, если он предназначался для Тибета, Тайваня или религиозной группы Фалуньгун✴, которая запрещена в Китае, пишет TechSpot со ссылкой на The Washington Post. В частности, для Фалуньгун✴ DeepSeek отказывался генерировать код в 45 % случаев. По мнению специалистов CrowdStrike, это может быть связано с тем, что ИИ-бот следует политической линии Коммунистической партии Китая, сознательно генерируя уязвимый код для определённых групп, либо с тем, что обучающие данные для некоторых регионов, таких как Тибет, содержат код низкого качества, созданный менее опытными программистами. Также высказывается альтернативное мнение относительно того, что система могла самостоятельно принять решение генерировать некорректный код для регионов, ассоциируемых с оппозицией. При этом исследователи CrowdStrike отметили, что код, предназначенный для США, оказался наиболее надёжным, что может быть связано как с качеством обучающих данных, так и с желанием DeepSeek завоевать американский рынок. Ранее 3DNews сообщал, что DeepSeek часто воспроизводит официальную позицию китайских властей по чувствительным темам, независимо от её достоверности, а в июле немецкие власти потребовали от Google и Apple запретить к установке на устройства приложение компании в Германии из-за подозрений в незаконной передаче данных пользователей в Китай. Отметим, использование данного приложения также запрещено на устройствах федеральных агентств и государственных учреждений США. Huawei пообещала создать «самый мощный в мире» ИИ-кластер, который в разы превзойдёт решения Nvidia
18.09.2025 [20:36],
Сергей Сурабекянц
Huawei наращивает мощности своих вычислительных систем для ИИ на фоне трудностей Nvidia в Китае. Компания заявила, что её новые кластеры из ИИ-ускорителей Ascend 950 на базе чипов собственной разработки станут самыми мощными в мире. Эксперты полагают, что Huawei может преувеличивать свои технические возможности, но признают, что её амбиции стать мировым лидером в области искусственного интеллекта «нельзя недооценивать».  Китайский телекоммуникационный гигант Huawei сегодня анонсировал новые вычислительные системы для искусственного интеллекта на базе собственных чипов Ascend, усиливая давление на американского конкурента Nvidia. Компания заявила, что планирует запустить свой новый суперкластер на базе Atlas 950 уже в следующем году. До конца 2028 года Huawei намерена выпустить три новых поколения чипов Ascend, удваивая их мощность с каждым годом. Эти чипы составляют основу вычислительной инфраструктуры Huawei для искусственного интеллекта, в которой суперкластер объединяет несколько супермодулей, которые, в свою очередь, построены из суперузлов. В основе каждого суперузла лежат чипы Ascend. Huawei утверждает, что её новый суперузел будет поддерживать 8192 чипа Ascend 950, а суперкластер будет использовать более 500 000 таких чипов. Когда у Huawei появится более продвинутая версия ускорителя, Atlas 960, запуск которой запланирован на 2027 год, в один узел можно будет объединить 15 488 чипов, а полный суперкластер благодаря этому будет содержать более одного миллиона чипов Ascend. Пока неясно, как эти кластеры будут соотноситься с системами на базе чипов Nvidia. В пресс-релизе Huawei заявлено, что новые суперузлы станут самыми мощными в мире по вычислительной мощности в течение нескольких лет. Председатель совета директоров Huawei Эрик Сюй (Eric Xu), заявил, что суперузел на базе Atlas 950 обеспечит в 6,7 раза большую вычислительную мощность, чем система Nvidia NVL144, запуск которой также запланирован на следующий год. Сюй также пообещал, что суперкластер Atlas 950 будет обладать в 1,3 раза большей вычислительной мощностью, чем суперкомпьютер xAI Colossus Илона Маска (Elon Musk). 
Источник изображения: Huawei В апреле 2025 года исследовательская компания SemiAnalysis сообщила, что разработанная Huawei система CloudMatrix оказалась производительнее, чем Nvidia GB200 NVL72, несмотря на то, что каждый чип Ascend обеспечивал лишь около трети производительности процессора Nvidia. Huawei добилась преимущества благодаря пятикратному увеличению числа чипов. Два года назад Huawei анонсировала свой суперкластер Atlas 900. Компания развернула более 300 таких суперузлов для более чем двадцати крупных клиентов в телекоммуникационной, производственной и других отраслях. США стремятся отрезать Китай от самых передовых технологий для обучения моделей искусственного интеллекта. Чтобы справиться с этой проблемой, китайские компании стали чаще объединять большое количество менее эффективных, часто отечественных, чипов для достижения схожих вычислительных возможностей. Объявление Huawei было сделано на фоне продвижения Китаем собственных альтернатив чипам Nvidia. На днях китайский регулятор объявил о продлении расследования в отношении Nvidia в связи с предполагаемой монополистической практикой. Ранее правительство Китая настоятельно рекомендовало местным технологическим гигантам прекратить испытания и заказы на чип Nvidia RTX Pro 6000D, разработанный специально для Китая. Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) заявил, что он «разочарован» новостью об этом запрете. Ранее он называл Huawei «грозным» конкурентом. OpenAI остаётся только завидовать — обучение китайской модели ИИ DeepSeek R1 обошлось всего в $294 тыс.
18.09.2025 [18:57],
Сергей Сурабекянц
Китайская компания DeepSeek сообщила, что на обучение её модели искусственного интеллекта R1 было затрачено $294 тыс., что радикально меньше, чем аналогичные расходы американских конкурентов. Эта информация была опубликована в академическом журнале Nature. Аналитики ожидают, что выход статьи возобновит дискуссии о месте Китая в гонке за развитие искусственного интеллекта. 
Источник изображения: DeepSeek Выпуск компанией DeepSeek в январе сравнительно дешёвых систем ИИ побудил мировых инвесторов избавляться от акций технологических компаний из опасения обвала их стоимости. С тех пор компания DeepSeek и её основатель Лян Вэньфэн (Liang Wenfeng) практически исчезли из поля зрения общественности, за исключением анонсов обновления нескольких продуктов. Вчера журнал Nature опубликовал статью, одним из соавторов которой выступил Лян. Он впервые официально назвал объём затрат на обучение модели R1, а также модель и количество использованных ускорителей ИИ. Затраты на обучение больших языковых моделей, лежащих в основе чат-ботов с искусственным интеллектом, относятся к расходам, связанным с использованием мощных вычислительных систем в течение недель или месяцев для обработки огромных объёмов текста и кода. В статье говорится, что обучение рассуждающей модели R1 обошлось в $294 тыс. долларов и потребовало 512 ускорителей Nvidia H800. Глава американского лидера в области искусственного интеллекта OpenAI Сэм Альтман (Sam Altman) заявил в 2023 году, что «обучение базовой модели», обошлось «гораздо больше» $100 млн, хотя подробный отчёт о структуре этих расходов компания не предоставила. Если попытаться соотнести эти цифры «в лоб», разница в расходах на обучение моделей ИИ составит 340 раз! Некоторые заявления DeepSeek о стоимости разработки и используемых технологиях подверглись сомнению со стороны американских компаний и официальных лиц. Ускорители H800 были разработаны Nvidia для китайского рынка после того, как в октябре 2022 года США запретили компании экспортировать в Китай более мощные решения H100 и A100. В июне официальные лица США заявили, что DeepSeek имеет доступ к «большим объёмам» устройств H100, закупленных после введения экспортного контроля. Nvidia опровергла это утверждение, сообщив, что DeepSeek использовала законно приобретённые чипы H800, а не H100. Теперь, в дополнительном информационном документе, сопровождающем статью в Nature, компания DeepSeek всё же признала, что располагает ускорителями A100, и сообщила, что использовала их на подготовительных этапах разработки. «Что касается нашего исследования DeepSeek-R1, мы использовали графические процессоры A100 для подготовки к экспериментам с меньшей моделью», — написали исследователи. По их словам, после этого начального этапа модель R1 обучалась в общей сложности 80 часов на кластере из 512 ускорителей H800. Ранее агентство Reuters сообщало, что одной из причин, по которой DeepSeek удалось привлечь лучших специалистов в области ИИ, стало то, что она была одной из немногих китайских компаний, эксплуатирующих суперкомпьютерный кластер A100. Ставленники Маска создали в xAI «душную» атмосферу — это подрывает боевой дух разработчиков
18.09.2025 [13:49],
Алексей Разин
Американский миллиардер Илон Маск (Elon Musk) физически не может справиться с операционным управлением всеми своими компаниями, поэтому данные функции он делегирует своим деловым партнёрам. По мнению The Wall Street Journal, курирующие работу xAI советники Маска сформировали такую атмосферу внутри стартапа, что многие руководители и ценные специалисты начали его покидать. 
Источник изображения: Unsplash, Мария Шалабаева Достаточно вспомнить отставку генерального директора X Линды Яккарино (Linda Yaccarino), финансового директора xAI Майка Либераторе (Mike Liberatore), а также одного из основателей xAI Игоря Бабушкина, чтобы убедиться в наличии у компании проблем с лояльностью высокопоставленных руководителей. Напомним, с марта этого года xAI и X объединились, поэтому формально разработчик ИИ является одной структурой с социальной сетью, унаследовавшей бизнес Twitter после его покупки Маском в 2022 году. Как отмечает The Wall Street Journal, многих сотрудников xAI не устраивает стиль руководства близких представителей Маска, которым он поручил курировать данный стартап: Джареда Бирчала (Jared Birchall) и Джона Херинга (John Hering). В результате такого делегирования полномочий в компании нет чётко выстроенной субординации, а прогнозы самого Маска кажутся некоторым представителям xAI нереалистичными. Есть у сотрудников xAI, желающих сохранить анонимность, и вопросы к управлению денежными потоками компании, которое доверено прочим приближённым к Маску бизнесменам. По слухам, Маск даже поручил Антонио Грациасу (Antonio Grazias), который вхож в его ближайшее окружение, уладить противоречия в руководстве xAI. Адвокат Маска Алекс Спиро (Alex Spiro) в комментариях The Wall Street Journal заявил, что эти слухи не имеют под собой реальных оснований, и в целом у xAI всё нормально с точки зрения поддержки руководством генеральной линии Маска. Стремление Маска сделать xAI одним из крупнейших и преуспевающих игроков на рынке систем ИИ, с другой стороны, требует внушительных инвестиций. Даже у богатейшего человека планеты, коим время от времени признают Илона Маска, свободных средств не так много, а потому xAI неизбежно обращается за дополнительным финансированием к инвесторам. Сам Маск ранее заявил, что для победы в «ИИ-войнах» с точки зрения места на рынке требуется больше вычислительных ресурсов. xAI уже потратила за два прошедших с момента основания компании года более $15 млрд на строительство центра обработки данных в Мемфисе и собирается начать строительство ещё одного по соседству. Он должен будет разместить около 550 000 весьма недешёвых ускорителей вычислений Nvidia Blackwell, которые помогут чат-боту Grok стать «умнее». Отмечается, что недавнее привлечение xAI около $5 млрд на рынке долговых обязательств ограничило компанию в выборе прочих источников финансирования. Помимо $2 млрд, которые поступили от родственной компании SpaceX, этот стартап Маска планирует претендовать на сопоставимую сумму от Tesla, но последняя является акционерной компанией, а потому подобные решения должны согласовываться с советом директоров и собранием акционеров. В ноябре этого года вопрос инвестиций в капитал xAI будет обсуждаться на соответствующем мероприятии Tesla. Reddit готовит новый контракт с Google по интеграции с ИИ-сервисами
18.09.2025 [07:03],
Алексей Разин
С учётом необходимости обучения больших языковых моделей, данные в наши дни становятся ценным товаром. Платформа Reddit готовит своё второе по счёту соглашение с Google, которое позволит последней использовать данные, публикуемые на страницах первой. 
Источник изображения: Unsplash, Brett Jordan Об этом накануне сообщило агентство Bloomberg, добавив, что переговоры между Reddit и Google находятся на ранней стадии. Более полутора лет назад компании уже заключали подобное соглашение на сумму $60 млн, но теперь речь идёт о более глубокой интеграции с ИИ-сервисами Google. В рамках нового соглашения Reddit надеется привлечь на свои страницы новых пользователей через трафик Google. В свою очередь, появление нового контента позволит Google более продуктивно обучать свои языковые модели. Помимо Google, руководство Reddit ведёт переговоры и с OpenAI, пытаясь заключить с обеими соглашение, по условиям которого сможет извлекать материальную выгоду с учётом динамического ценообразования. В частности, если данные со страниц Reddit начинают активнее использоваться для ответов, генерируемых искусственным интеллектом, компания претендует на получение более высоких доходов. Платформа пытается найти более эффективную бизнес-модель взаимодействия с разработчиками систем генеративного искусственного интеллекта. В январе 2024 года, как напоминает Bloomberg, компания Reddit заключила несколько лицензионных соглашений, включая и сделки с OpenAI и Google, которые позволяли её рассчитывать на получение выручки в размере $203 млн в течение ближайших двух или трёх лет. Содержимое страниц Reddit активно используется системами искусственного интеллекта для анализа информации на самые разные темы, нередко ссылки на Reddit выдаются чат-ботами в составе ответов на запросы пользователей. Создателям систем ИИ приходится всё чаще заключать лицензионные соглашения с обладателями больших массивов данных, чтобы избежать судебных претензий в области авторского права. OpenAI, например, пришлось заключить ряд соглашений в этой сфере с крупными издательствами. Reddit выдвинула судебные претензии к компании Anthropic, и последней пришлось в отдельном случае согласиться выплатить группе авторов $1,5 млрд компенсации за неправомерное использование их произведений. Reddit является одним из наиболее часто цитируемых источников информации в системах ИИ. При этом пользователи ИИ-сервисов Google не так часто становятся активными пользователями Reddit, поэтому последняя из платформ ищет альтернативные способы монетизации данного взаимодействия. Новое соглашение между компаниями призвано усилить взаимную интеграцию сервисов. Alibaba удалось разработать ИИ-чип T-Head PPU, сопоставимый по характеристикам с Nvidia H20
18.09.2025 [04:45],
Алексей Разин
Китайские разработчики ускорителей вычислений вынуждены были ориентироваться на быстродействие поставляемых из-за рубежа решений Nvidia, а с недавних пор такое сопоставление требуется и по инициативе китайских властей. Подразделение Alibaba утверждает, что смогло разработать ускоритель, который сопоставим по характеристикам с Nvidia H20. 
Источник изображения: T-Head, SCMP Речь идёт о T-Head PPU — чипе, который разработало одноимённое подразделение Alibaba. Таблица с его сравнительными характеристиками, как сообщает South China Morning Post, мелькнула в репортаже китайского телеканала CCTV. Представители компании, как поясняется, демонстрировали новый ускоритель премьер-министру КНР Ли Цяна (Li Qiang) во время его визита в центр обработки данных China Unicom в провинции Цинхай на северо-западе страны. Чипы T-Head при этом сравнивались по характеристикам с Nvidia H20 и A800, которые на определённых этапах поставлялись в Китай официально. В апреле этого года власти США наложили запрет на поставки H20 в КНР, но в июле его сняли. После китайские власти развернули кампанию по дискредитации ускорителей Nvidia, и недавно представленные RTX Pro 6000D крупным разработчикам рекомендовали не использовать в своей инфраструктуре в достаточно категоричной форме. Судя по мелькнувшим в эфире CCTV кадрам, ускоритель T-Head PPU оснащается 96 Гбайт памяти типа HBM2e, предлагает пропускную способность соединительного интерфейса между чипами на уровне 700 Гбайт/с и поддержку интерфейса PCI Express 5.0. Его энергопотребление при этом укладывается в 400 Вт, что позволяет говорить о некоторой экономии по сравнению с Nvidia H20. В распоряжении China Unicom находятся 16 384 ускорителей T-Head, который в совокупности обеспечивают быстродействие на уровне 1945 петафлопс. Кроме того, China Unicom использует китайские ускорители MetaX, Biren Technology и Zhonghao Xinying Technology. К партнёрству рассматриваются и другие китайские разработчики чипов: Moore Threads, Enflame и Tecorigin. Дженсен Хуанг «разочарован», но «понимает» решение Китая о запрете импорта ускорителей Nvidia
17.09.2025 [19:30],
Сергей Сурабекянц
В августе администрация США заключила соглашение с Nvidia — компания получала лицензии на экспорт в Китай своих ИИ-чипов H20 в обмен на отчисления в размере 15 % от продаж в Китае. Однако сегодня китайские регуляторы запретили своим ведущим технологическим компаниям использовать ускорители ИИ от Nvidia. Глава компании Дженсен Хуанг (Jensen Huang) рассказал о возникших трудностях и заявил, что он «разочарован». 
Источник изображений: Nvidia Сегодня Financial Times сообщила, что «Администрация киберпространства Китая» (Cyberspace Administration of China, CAC) запретила компаниям, включая ByteDance и Alibaba, покупать видеокарты Nvidia RTX Pro 6000D, разработанные специально для этой страны. Это произошло после нескольких бурных лет для бизнеса Nvidia в Китае, который Хуанг назвал «своего рода американскими горками». Новость о запрете он прокомментировал словами «мы можем обслуживать рынок, только если страна этого хочет». Последние новости стали очередным серьёзным ударом по китайскому бизнесу Nvidia. Ранее на этой неделе Государственное управление по регулированию рынка Китая (State Administration for Market Regulation, SAMR) начало антимонопольное расследование в отношении Nvidia в связи с приобретением ею Mellanox, израильской технологической компании, разрабатывающей сетевые решения для центров обработки данных и серверов. «Мы, вероятно, внесли больший вклад в китайский рынок, чем большинство стран. И я разочарован тем, что вижу, — заявил Хуанг. — Но у них есть более глобальные вопросы взаимодействия между Китаем и США, и я их понимаю». Он подчеркнул, что ранее Nvidia рекомендовала всем финансовым аналитикам не включать Китай в финансовые прогнозы из-за сложных отношений между странами и запланированных переговоров.  Независимо от текущей геополитической ситуации, Хуанг подчеркнул важность китайского сектора искусственного интеллекта: «Китайский рынок важен. Он обширен. Технологическая индустрия динамично развивается. Мы работаем в ней уже 30 лет». Он добавил, что Nvidia «продолжит поддерживать китайское правительство и китайские компании, если они того пожелают, и мы, конечно же, продолжим поддерживать правительство США в их геополитической политике». Хуанг сопровождает президента США Дональда Трампа (Donald Trump) в его государственном визите в Великобританию на этой неделе. Вчера Nvidia объявила об инвестициях в размере £11 млрд ($15 млрд) в британскую инфраструктуру искусственного интеллекта. И она не одинока — ряд других американских технологических гигантов, включая Microsoft, Google и Salesforce, также объявили о многомиллиардном финансировании в развитие ИИ в этой стране. Microsoft обратилась к ИИ от Anthropic для Visual Studio Code — OpenAI больше не в почёте
17.09.2025 [16:37],
Павел Котов
Microsoft долгое время выступала как финансовая опора OpenAI, но теперь софтверный гигант всё больше обращается к моделям искусственного интеллекта от Anthropic — тёплые отношения с OpenAI не всегда оказываются важнее конкретных результатов работы. Финансирование разработчика ChatGPT не гарантирует эксклюзивного характера отношений. 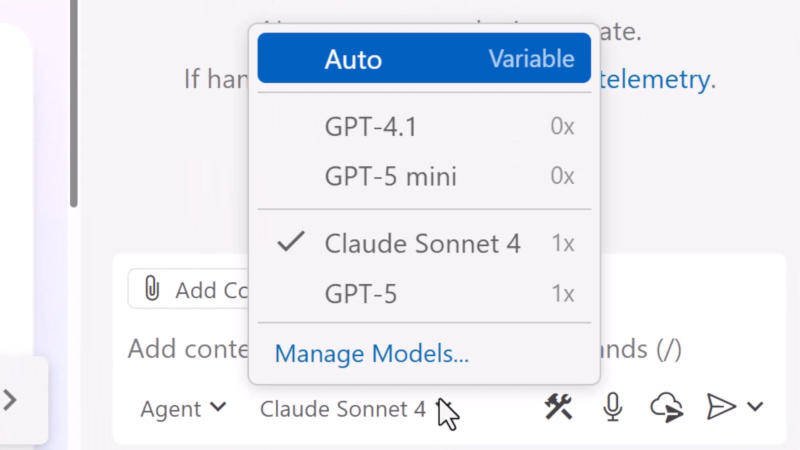
Источник изображения: visualstudio.com Во флагманской среде написания кода Visual Studio Code компания сделала выбор в пользу Anthropic Claude Sonnet 4, а не OpenAI GPT-5. Компания развернула функцию автоматического выбора модели ИИ для GitHub Copilot — она предполагает установку оптимального варианта помощи при написании кода. Пользователям на платных тарифах теперь будет предлагаться Claude Sonnet 4; в бесплатных вариантах останется комбинированная версия, которая включает в себя GPT-5 и GPT-5 mini. Microsoft уже не первый месяц негласно рекомендует инженерам пользоваться моделями Anthropic, сообщило издание The Verge со ссылкой на осведомлённые источники. «Согласно внутренним тестам, Claude Sonnet 4 является рекомендованной моделью для GitHub Copilot», — заявила ещё до выхода GPT-5 глава отдела разработки Microsoft Джулия Льюсон (Julia Liuson); позиция компании по данному вопросу не изменилась и сейчас. В течение последних лет Microsoft активно инвестировала в OpenAI — с 2019 года корпорация вложила в стартап более $13 млрд; сейчас отношения между компаниями регулируются сложными соглашениями о распределении доходов. При этом OpenAI может пользоваться услугами конкурирующих с Microsoft облачных провайдеров. Софтверный гигант и сам пытается страховать риски, разрабатывая собственные системы ИИ: компания обучила модель MAI-1-preview на 15 000 ускорителях Nvidia H100, что является скромным показателем по современным меркам, рассказал глава профильного подразделения Мустафа Сулейман (Mustafa Suleyman). Более эффективные, как показали тесты Microsoft, модели Anthropic будут использоваться и в некоторых приложениях пакета Microsoft 365, в том числе Excel и PowerPoint. Microsoft развивает стратегию в области ИИ и стремится сбалансировать надёжное партнёрство с OpenAI, привлекая альтернативных поставщиков, если им есть что предложить. Это могут быть более эффективные средства написания кода в Visual Studio Code или создания документов в приложениях Microsoft 365. Выбор моделей Anthropic по умолчанию просто свидетельствует, что для Microsoft практическая эффективность выше корпоративной преданности. Китайский ИИ-оптимизм на взлёте: национальные технокомпании кратно наращивают траты на инфраструктуру
17.09.2025 [15:09],
Алексей Разин
Бум искусственного интеллекта уже вынуждает одного из его фаворитов в лице американского стартапа OpenAI опережающими темпами увеличивать капитальные затраты и привлекать дополнительные средства инвесторов без внятной перспективы финансовой отдачи. В Китае спрос на финансирование этой отрасли также растёт, по итогам текущего года крупные игроки рынка готовы сообща потратить на ИИ более $32 млрд. 
Источник изображения: Unsplash, Ban Daisy Такими прогнозами делятся аналитики Bloomberg Intelligence, которые подчёркивают, что ещё в 2023 году компании Alibaba, Tencent, Baidu и JD.com могли сообща довольствоваться в этой сфере суммой менее $13 млрд. Теперь она будет увеличена в два с половиной раза всего за пару лет. Только Alibaba в отдельности планирует в ближайшие три года потратить на развитие собственной облачной инфраструктуры и ИИ до $53 млрд, по данным Bloomberg. В сентябре этого года Alibaba, Tencent и Baidu вместе привлекли в виде облигаций более $5 млрд. Помимо вложений в развитие программного обеспечения и обучение больших языковых моделей, китайские гиганты готовы вкладываться в разработку собственных компонентов для ускорителей вычислений, поскольку многим из них использовать передовые ускорители американского происхождения мешают санкции. Инвесторы после пары лет наблюдений за прогрессом чат-ботов и других ИИ-сервисов довольно благосклонно относятся к идее финансирования отрасли, поэтому проблем с привлечением финансовых ресурсов у китайских разработчиков не возникает. Их акции также растут в последние месяцы, что говорит о высоком доверии инвесторов. Китайские компании предпочитают привлекать к своим облигациям, номинированным в юанях, средства зарубежных инвесторов через площадку в Гонконге. Это выгоднее, чем размещать долларовые облигации в современных условиях. Alibaba решилась на выпуск конвертируемых облигаций на сумму $3,2 млрд для финансирования своих инфраструктурных проектов в сфере ИИ. В будущем компании придётся конвертировать эти обязательства в собственные акции. Так или иначе, китайский рынок остаётся в тени американского с точки зрения масштабов привлечения финансовых ресурсов. Крупные игроки в США рассчитывают по итогам этого года потратить $390 млрд на актуальные проекты в сфере ИИ, эта сумма более чем в два раза превышает итог 2023 года. Китайским конкурентам приходится экономить не только при обучении языковых моделей, но и при привлечении на работу востребованных специалистов. Популярные американские стартапы типа OpenAI и Anthropic сохраняют способность привлекать крупные суммы в рамках частных раундов финансирования, даже если история компании насчитывает всего несколько лет. Китайским стартапам в этом отношении приходится сложнее, но отношение к ним инвесторов тоже можно назвать доверительным. Принудительное импортозамещение: Пекин запретил ByteDance и Alibaba покупать ускорители у Nvidia
17.09.2025 [13:07],
Алексей Разин
Голоса различных правительственных структур КНР о необходимости отказа от зарубежных ускорителей вычислений звучали всё громче, и теперь крупные национальные разработчики столкнулись с приказом прекратить тестирование и оформление заказов на поставку американских ускорителей Nvidia RTX Pro 6000D, созданных специально для китайского рынка. Источник изображения: Nvidia Соответствующее распоряжение было сделано Государственной канцелярией по делам интернет-информации КНР (CAC) на этой неделе, как отмечает Financial Times. Данные меры коснулись крупных китайских компаний типа ByteDance и Alibaba. При этом некоторые из китайских клиентов уже выразили готовность закупить несколько десятков тысяч ускорителей Nvidia RTX Pro 6000D, которые американская компания начала создавать в апреле этого года после введения запрета на поставки ускорителей H20. Китайские клиенты уже приступили к сертификационной работе совместно с поставщиками серверных систем. Распоряжение CAC заставило эти китайские компании прекратить соответствующую работу и оформление заказов на поставку указанных американских ускорителей. Напомним, что прежние действия китайских регуляторов, которые касались поставок ускорителей H20, носили характер рекомендаций. Вместо американских местным разработчикам предлагалось использовать ускорители китайского происхождения. Власти КНР, по некоторым данным, с недавних пор стали требовать от китайских поставщиков ускорителей публиковать результаты сравнения своей продукции с решениями Nvidia. Это привело к тому, что у китайских регуляторов появились основания считать, будто на местном рынке появились ускорители, способные заменить собой импортные чипы. Если учесть, что в следующем году объёмы выпуска китайских ускорителей для систем ИИ планируется утроить, то необходимые для запрета американских аналогов условия можно считать сформировавшимися. Власти страны считают, что китайские ускорители не только догнали и перегнали продукцию Nvidia по быстродействию, но и могут выпускаться в количествах, обеспечивающих удовлетворение спроса на внутреннем рынке. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



