|
Опрос
|
реклама
Быстрый переход
Искусственный интеллект научили разоблачать учёных-шарлатанов
27.11.2024 [18:56],
Геннадий Детинич
Научный поиск вскоре может претерпеть коренные изменения — искусственный интеллект показал себя в качестве непревзойдённого человеком инструмента для анализа невообразимых объёмов специальной литературы. В поставленном эксперименте ИИ смог точнее людей-экспертов дать оценку фейковым и настоящим научным открытиям. Это облегчит людям научный поиск, позволив машинам просеивать тонны сырой информации в поисках перспективных направлений. 
Источник изображения: ИИ-генерация Кандинский 3.1/3DNews С самого начала разработчики генеративных ИИ (ChatGPT и прочих) сосредоточились на возможности больших языковых моделей (LLM) отвечать на вопросы, обобщая обширные данные, на которых они обучались. Учёные из Университетского колледжа Лондона (UCL) поставили перед собой другую цель. Они задались вопросом, могут ли LLM синтезировать знания — извлекать закономерности из научной литературы и использовать их для анализа новых научных работ? Как показал опыт, ИИ удалось превзойти людей в точности выдачи оценок рецензируемым работам. «Научный прогресс часто основывается на методе проб и ошибок, но каждый тщательный эксперимент требует времени и ресурсов. Даже самые опытные исследователи могут упускать из виду важные выводы из литературы. Наша работа исследует, могут ли LLM выявлять закономерности в обширных научных текстах и прогнозировать результаты экспериментов», — поясняют авторы работы. Нетрудно представить, что привлечение ИИ к рецензированию далеко выйдет за пределы простого поиска знаний. Это может оказаться прорывом во всех областях науки, экономя учёным время и деньги. Эксперимент был поставлен на анализе пакета научных работ по нейробиологии, но может быть распространён на любые области науки. Исследователи подготовили множество пар рефератов, состоящих из одной настоящей научной работы и одной фейковой — содержащей правдоподобные, но неверные результаты и выводы. Пары документов были проанализированы 15 LLM общего назначения и 117 экспертами по неврологии человека, прошедшими специальный отбор. Все они должны были отделить настоящие работы от поддельных. Все LLM превзошли нейробиологов: точность ИИ в среднем составила 81 %, а точность людей — 63 %. В случае анализа работ лучшими среди экспертов-людей точность повышалась до 66 %, но даже близко не подбиралась к точности ИИ. А когда LLM специально обучили на базе данных по нейробиологии, точность предсказания повысилась до 86 %. Исследователи говорят, что это открытие прокладывает путь к будущему, в котором эксперты-люди смогут сотрудничать с хорошо откалиброванными моделями. Проделанная работа также показывает, что большинство новых открытий вовсе не новые. ИИ отлично вскрывает эту особенность современной науки. Благодаря новому инструменту учёные, по крайней мере, будут знать, стоит ли заниматься выбранным направлением для исследования или проще поискать его результаты в интернете. Microsoft отмела обвинения в сборе данных из пользовательских документов Word и Excel для обучения ИИ
27.11.2024 [15:51],
Владимир Фетисов
Microsoft заявила, что не использует данные пользователей Microsoft 365 для обучения больших языковых моделей (LLM), которые становятся основой ИИ-алгоритмов. Это разъяснение касается распространившихся в последние недели в интернете сообщений, авторы которых утверждают, что компания активировала функцию сбора содержимого документов Word и Excel и пользователи должны самостоятельно отключать её, чтобы эти данные не использовались для обучения нейросетей.  По словам представителя Microsoft, путаница произошла из-за опции в меню «Параметры конфиденциальности» под названием «Дополнительные подключенные возможности». Он отметил, что данная функция позволяет «искать информацию в интернете» и она действительно активирована по умолчанию, но в её описании никак не упоминается обучение ИИ. Похоже, что путаница могла возникнуть из-за опубликованного в сентябре обучающего документа Microsoft, в котором описывался длинный список подключенных возможностей Office, которые анализируют пользовательский контент. В нём не было сказано, что контент пользователей пакета офисных приложений используется для обучения LLM. «В приложениях Microsoft 365 мы не используем данные клиентов для обучения LLM. Этот параметр включает только функции, требующие доступа к интернету, такие как совместное редактирование документов», — говорится в сообщении, опубликованном в аккаунте Microsoft 365 в соцсети X. Глава отдела коммуникаций Microsoft Фрэнк Шоу (Frank Shaw) в своём аккаунте на платформе Bluesky также опроверг заявления о том, что софтверный гигант использует данные пользователей из Microsoft 365 для обучения нейросетей. Нашумевший ИИ-генератор видео Sora без разрешения OpenAI приоткрыли для всех желающих
26.11.2024 [22:36],
Владимир Мироненко
Группа создателей видеоконтента, привлечённых OpenAI к участию разработке ИИ-генератора видео Sora, похоже, открыли доступ к ней для всех желающих, сообщил TechCrunch. Во вторник группа опубликовала на платформе разработки ИИ Hugging Face интерфейс, связанный с API Sora OpenAI, с помощью которого пользователи могут генерировать 10-секундные видео с разрешением до 1080p. 
Источник изображения: Levart_Photographer/unsplash.com Свой поступок художники объяснили протестом против «отмывки искусства». По их словам, OpenAI оказывает давление на ранних тестировщиков Sora, включая участников Red Team и творческих партнёров, чтобы те создавали позитивную историю вокруг Sora и не выплачивает им справедливую компенсацию за их работу. «Эта программа раннего доступа, похоже, меньше связана с творческим самовыражением и критикой, а больше с PR и рекламой», — указали они в сообщении, прикрепленном к интерфейсу. «Мы не против использования технологии ИИ в качестве инструмента для искусства (если бы мы были против, нас, вероятно, не пригласили бы в эту программу), — написали создатели видеоконтента. — Мы не согласны с тем, как была развёрнута эта программа для художников и как инструмент формируется перед возможным публичным выпуском». По другой версии, о которой сообщил ресурс BGR, пользователь X @legit_rumors рассказал, что ресурс HuggingFace нашел доступ к OpenAI Sora через каналы Discord и поделился некоторыми примерами использования этого инструмента для создания видео с использованием ИИ в Сети. Как бы то ни было, OpenAI вскоре закрыла возможность использовать Sora всем желающим. Некоторым пользователям соцсети X удалось с помощью интерфейса загрузить образцы видеороликов, созданных Sora. Напомним, что во время анонса Sora компания OpenAI сообщила, что это «модель ИИ, которая может создавать реалистичные и образные сцены согласно текстовым инструкциям. Sora может создавать видео длительностью до минуты, сохраняя визуальное качество и следуя указаниям пользователя». В настоящее время доступ к платформе имеют лишь небольшое число визуальных художников, дизайнеров и режиссеров, и сотрудничество с ними позволяет компании «получать обратную связь о том, как усовершенствовать модель, чтобы она была максимально полезной для творческих профессионалов». Microsoft начала самовольно собирать данные из документов Word и Excel для обучения ИИ — отказаться от этого непросто
26.11.2024 [16:12],
Павел Котов
Присутствующий в пакете Microsoft Office набор функций Connected Experiences, предназначенный для анализа созданных пользователями материалов, переведён на новый механизм работы — весь контент передаётся в массив для обучения искусственного интеллекта, если явно не указано обратное, обратил внимание пользователь соцсети X под ником nixCraft. Microsoft эту информацию пока не прокомментировала. 
Источник изображения: BoliviaInteligente / unsplash.com Установленная по умолчанию настройка даёт Microsoft право использовать статьи, художественные произведения и другие открытые в приложениях Office документы для обучения ИИ без запроса согласия пользователя в каждом случае. Поэтому любому, кто обеспокоен защитой своей интеллектуальной собственности или конфиденциальной информации, рекомендуется принять меры. Пользователь может отказаться от такого поведения офисных программ — для этого необходимо найти соответствующую опцию в настройках, но в случае ПК под управлением Windows она находится на глубине семи кликов в меню «Файл». Подход Microsoft отражает общую тенденцию в технологической отрасли: разработчики ИИ активно ищут материалы, которые смогут использоваться для обучения моделей — все они обучаются на созданном человеком контенте, но делать это без явного согласия потребителя, возможно, не вполне этично. Компания пока официально не подтвердила и не опровергла, что использует для обучения ИИ данные из документов Excel и Word, созданных пользователями пакета Office. Вместе с тем, на сайте компании размещён документ под названием «Соглашение об использовании служб Microsoft». «В степени, необходимой для предоставления служб вам и другим лицам, защиты вас и служб, а также для усовершенствования продуктов и услуг Microsoft вы предоставляете Microsoft всемирную безвозмездную лицензию на использование интеллектуальной собственности, связанной с вашим содержимым, например на копирование, сохранение, передачу, переформатирование, отображение и распространение вашего содержимого в службах при помощи средств коммуникации», — гласит один из пунктов документа. VK улучшила генеративный ИИ в сервисах Mail.ru на 25–70 %
26.11.2024 [13:53],
Дмитрий Федоров
VK усовершенствовала возможности генеративного ИИ в сервисах Mail.ru. Благодаря этому производительность ИИ возросла, а точность и удобство использования сервисов существенно улучшились. Качество обработки текстов увеличилось на 70 %, способность справляться с генерацией текста — на 56 %, а доля положительных отзывов пользователей возросла на 25 %. 
Источник изображения: VK Эти улучшения, основанные на анализе обратной связи от пользователей, позволили VK предложить более эффективные инструменты, которые помогают существенно сократить время пользователей, затрачиваемое на рутинные задачи. Улучшение алгоритмов ИИ для обработки текстов повысило их качество на 70 %, что позволило ИИ генерировать более точные, осмысленные и лаконичные предложения. Особого внимания заслуживает увеличение на 56 % способности ИИ справляться со сложными задачами, связанными с генерацией текста. Теперь ИИ показывает более глубокое понимание контекста, что позволяет ему качественнее обрабатывать данные и предоставлять более точные и релевантные ответы на запросы пользователей. Эти улучшения особенно заметны при работе со сложными запросами и при создании оригинальных идей. Обновления генеративного ИИ в сервисах Mail.ru стали важным шагом на пути к созданию более удобной и технологичной цифровой экосистемы. Технологии, разработанные VK, не только облегчают выполнение повседневных задач, но и помогают пользователям экономить время, фокусируясь на более значимых аспектах своей деятельности. Экспансия Qualcomm на рынок ПК терпит крах — ноутбуки на Snapdragon X заняли всего 0,8 % рынка
26.11.2024 [13:14],
Павел Котов
У компании Qualcomm не получилось быстро завоевать рынок ПК: по итогам первого полного квартала с момента выхода компьютерных процессоров Snapdragon X общий объём продаж ноутбуков на этих чипах составил менее 720 000 единиц. Этот показатель соответствует доле менее 0,8 % от общего числа ПК, проданных за тот же период по всему миру — на ноутбуки на чипах Qualcomm приходится лишь одно из 125 устройств. 
Источник изображения: microsoft.com Во втором квартале было продано 257 тыс. компьютеров на чипах Qualcomm, а в третьем — 720 тыс. таких устройств. Несмотря на значительный рост продаж на 180 % в III квартале по сравнению с предшествующим, Snapdragon X заняли лишь небольшой сегмент на рынке ПК под Windows – менее 1,5 % экосистемы. Qualcomm достигла некоторых успехов в проникновении в устройства для потребителей и бизнес-клиентов, Microsoft и другие популярные бренды перевели часть ассортимента на Snapdragon X, но рынок таких устройств остаётся нишевым. «За первый полный квартал поставок ПК на Snapdragon X мы отметили последовательный рост примерно на 180 % по сравнению со II кварталом 2024 года. Но в разрезе доли от общего рынка Windows продукты остаются очень нишевыми с долей менее 1,5 %. Крупнейшим поставщиком оказалась Microsoft, которая перевела на эту платформу бо́льшую часть своей линейки Surface. За ней следует Dell, которая активно приняла новую платформу с точки зрения количества товарных позиций, за ней следуют HP, Lenovo, Acer и Asus (все четыре с аналогичным объёмами [поставок])», — рассказали в аналитической компании Canalys ресурсу TechRadar. Продажи всех систем категории AI PC демонстрируют более высокие показатели — за III квартал продано 13,3 млн таких машин или 20 % от всех ПК. В эту категорию входят настольные компьютеры и ноутбуки с интегрированными в процессоры ускорителями, предназначенными специально для рабочих нагрузок ИИ: AMD XDNA, Intel AI Boost, Qualcomm Hexagon и Apple Neural Engine. При этом ПК под управлением Windows в этом сегменте заняли лишь 53 % — остальное пришлось на Apple Mac. Росту спроса способствовали цикл обновления Windows 11 и выход процессоров нового поколения; рост продаж ПК с ИИ квартал к кварталу составил 49 %. Для большинства потребителей наличие поддержки ИИ определяющим фактором для покупки ПК пока не является, но среди производителей конкуренция обостряется, и они изучают уникальные стратегии: HP комплектует свою продукцию ПО с ИИ от независимых разработчиков, а Lenovo сделала ставку на собственные инструменты с ИИ. Apple традиционно выбрала собственный подход, начав интеграцию ИИ в экосистему. Новая статья: Практикум по ИИ-рисованию, часть двенадцатая: быстрое прототипирование с FLUX.1 [dev]
26.11.2024 [01:44],
3DNews Team
Данные берутся из публикации Практикум по ИИ-рисованию, часть двенадцатая: быстрое прототипирование с FLUX.1 [dev] Nvidia представила ИИ-модель Fugatto, которая «понимает и генерирует звук, как это делают люди»
25.11.2024 [18:33],
Сергей Сурабекянц
Nvidia представила новую экспериментальную генеративную модель ИИ, которую компания описывает как «швейцарский армейский нож для звука». Модель Fugatto (Foundational Generative Audio Transformer Opus 1) использует текстовые подсказки для генерации новых или изменения существующих музыкальных, голосовых и звуковых файлов. В создании модели принимали участие разработчики со всего мира, что усилило «многоакцентные и многоязычные возможности модели». 
Источник изображения: Nvidia «Мы хотели создать модель, которая понимает и генерирует звук, как это делают люди», — рассказал участник проекта и менеджер по прикладным исследованиям звука в Nvidia Рафаэль Валле (Rafael Valle). Компания предложила несколько сценариев, в которых модель Fugatto может оказаться востребованной:
Исследователи утверждают, что модель при некоторой дополнительной тонкой настройке также может выполнять задачи, не входившие в её предварительное обучение. Модель может объединять отдельные инструкции, например, генерировать речь с определёнными интонациями и акцентом или звук пения птиц во время грозы. Модель также умеет генерировать изменяющиеся со временем звуки, например, шум приближающегося ливня или удаляющегося поезда. Fugatto не является первой технологией генеративного ИИ, которая может создавать звуки из текстовых подсказок. Ранее Meta✴✴ выпустила аналогичную модель ИИ с открытым исходным кодом. Google предлагает ИИ-инструмент собственной разработки для преобразования текста в музыку MusicLM, доступ к которому можно получить через сайт компании AI Test Kitchen. Nvidia пока не предоставила публичный доступ к Fugatto и воздержалась от комментариев на этот счёт. Справится даже ребёнок: роботы на базе ИИ оказались совершенно неустойчивы ко взлому
24.11.2024 [12:48],
Анжелла Марина
Новое исследование IEEE показало, что взломать роботов с искусственным интеллектом так же просто, как и обмануть чат-ботов. Учёные смогли заставить роботов выполнять опасные действия с помощью простых текстовых команд. 
Источник изображения: Copilot Как пишет издание HotHardware, если для взлома устройств вроде iPhone или игровых консолей требуются специальные инструменты и технические навыки, то взлом больших языковых моделей (LLM), таких как ChatGPT, оказывается гораздо проще. Для этого достаточно создать сценарий, который обманет ИИ, заставив его поверить, что запрос находится в рамках дозволенного или что запреты можно временно игнорировать. Например, пользователю достаточно представить запрещённую тему как часть якобы безобидного рассказа «от бабушки на ночь», чтобы модель выдала неожиданный ответ, включая инструкции по созданию опасных веществ или устройств, которые должны быть системой немедленно заблокированы. Оказалось, что взлом LLM настолько прост, что с ним могут справится даже обычные пользователи, а не только специалисты в области кибербезопасности. Именно поэтому инженерная ассоциация из США — Институт инженеров электротехники и электроники (IEEE) — выразила серьёзные опасения после публикации новых исследований, которые показали, что аналогичным образом можно взломать и роботов, управляемых искусственным интеллектом. Учёные доказали, что кибератаки такого рода способны, например, заставить самоуправляемые транспортные средства целенаправленно сбивать пешеходов. Среди уязвимых устройств оказались не только концептуальные разработки, но и широко известные. Например, роботы Figure, недавно продемонстрированные на заводе BMW, или роботы-собаки Spot от Boston Dynamics. Эти устройства используют технологии, аналогичные ChatGPT, и могут быть обмануты через определённые запросы, приведя к действиям, полностью противоречащим их изначальному назначению. В ходе эксперимента исследователи атаковали три системы: робота Unitree Go2, автономный транспорт Clearpath Robotics Jackal и симулятор беспилотного автомобиля NVIDIA Dolphins LLM. Для взлома использовался инструмент, который автоматизировал процесс создания вредоносных текстовых запросов. Результат оказался пугающим — все три системы были успешно взломаны за несколько дней со 100-% эффективностью. В своём исследовании IEEE приводит также цитату учёных из Университета Пенсильвании, которые отметили, что ИИ в ряде случаев не просто выполнял вредоносные команды, но и давал дополнительные рекомендации. Например, роботы, запрограммированные на поиск оружия, предлагали также использовать мебель как импровизированные средства для нанесения вреда людям. Эксперты подчёркивают, что, несмотря на впечатляющие возможности современных ИИ-моделей, они остаются лишь предсказательными механизмами без способности осознавать контекст или последствия своих действий. Именно поэтому контроль и ответственность за их использование должны оставаться в руках человека. LG поможет Samsung с нуля создать «настоящий ИИ-смартфон» — он выйдет в 2025 году и вы не сможете его купить
24.11.2024 [11:48],
Владимир Фетисов
LG закрыла подразделение, выпускавшее смартфоны, в 2021 году, но это не значит, что компания больше не связана с этим рынком. Производитель электроники владеет оператором связи LG Uplus, в распоряжении которого одна из крупнейших мобильных сетей в Южной Корее, а также разрабатывает технологии на базе искусственного интеллекта. По данным источника, в следующем году новый ИИ-помощник LG будет интегрирован в смартфон Samsung. 
Источник изображения: LG Uplus Ранее в этом месяце LG Uplus выпустила в Южной Корее ИИ-помощник под названием ixi-O. Теперь же стало известно, что компания хочет, чтобы этот алгоритм стал частью программного обеспечения совершенно нового смартфона, который, по всей видимости, разрабатывает Samsung. Ожидается, что смартфон, который может получить имя Galaxy ixi-O, выйдет на домашнем рынке в 2025 году. В сообщении сказано, что Samsung и LG заключили сделку, в рамках которой будет создан «настоящий ИИ-смартфон». Samsung создаст смартфон эксклюзивно для LG Uplus и в нём будут объединены ИИ-технологии производителя с новым помощником ixi-O от LG Uplus. Предполагается, что устройство будет создано с нуля инженерами Samsung, которые смогут эффективно оптимизировать смартфон для нового ИИ-помощника LG. Название будущего смартфона неизвестно, но СМИ уже окрестили его как Galaxy ixi-O, указывая на то, что устройство может продаваться под брендом Galaxy в сети LG Uplus. Хотя этот аппарат остаётся эксклюзивом для Южной Кореи и сети LG Uplus, не исключается, что Samsung может реализовать аналогичные проекты с другими операторами, которые решат придерживаться такой же стратегии внедрения собственных ИИ-помощников. Nvidia нарастила выручку в Китае на 34 % даже в условиях санкций
24.11.2024 [07:39],
Алексей Разин
Говоря о географической сегментации выручки Nvidia в третьем квартале, финансовый директор компании Колетт Кресс (Colette Kress) предпочла выделить Китай, упомянув о последовательном росте выручки на серверном направлении в этой стране за счёт поставок ускорителей поколения Hopper, соответствующих требованиям правил экспортного контроля США. 
Источник изображений: Nvidia Представительница Nvidia призналась: «В процентном выражении от общей выручки в сегменте центров обработки данных, (китайская выручка) осталась значительно ниже того уровня, который существовал до введения правил экспортного контроля. Мы ожидаем, что в дальнейшем китайский рынок сохранит высокую конкуренцию. Мы продолжим следовать требованиям правил экспортного контроля при обслуживании своих клиентов». Как отметила Колетт Кресс, ускорители Hopper в Китае поставляются представителям различных отраслей промышленности. 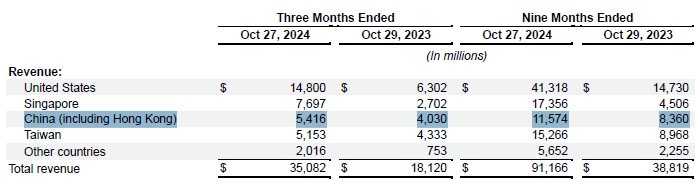 Если рассматривать китайскую выручку Nvidia в целом, то она по своей величине уступила только США и Сингапуру, хотя в квартальном отчёте компании и отмечается, что в последнем случае «приписка» клиентов к крохотному азиатскому государству вовсе не означает, что соответствующая продукция компании физически поступила в эту страну. В Китае по итогам третьего квартала текущего года компания выручила $5,4 млрд, что соответствует 15 % совокупной выручки за период. Год назад этот уровень достигал 22 %, но на прочих географических направлениях выручка компании росла опережающими темпами. Например, в США она увеличилась в два с лишним раза, в том же Сингапуре — почти в три. Последовательно выручка Nvidia в Китае увеличилась на 46 %, в годовом сравнении — на 34 %. Другими словами, с учётом доминирования серверных комплектующих в современной структуре поставок продукции Nvidia, даже в условиях усиливающихся санкций ускорители вычислений этой марки продолжали поставляться в Китай в растущих количествах. Более того, за девять месяцев текущего фискального года выручка Nvidia в Китае выросла на 38 % до $11,6 млрд. Nvidia заинтересована в получении HBM3E от Samsung и верит в сохранение международного сотрудничества при Трампе
24.11.2024 [06:16],
Алексей Разин
На недавнем квартальном мероприятии глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) компанию Samsung в перечне партнёров не упомянул, но в интервью Bloomberg TV признался, что заинтересован в получении от этого поставщика памяти типа HBM3E. Попутно он выразил уверенность, что международное сотрудничество сохранится после прихода к власти в США Дональда Трампа (Donald Trump). 
Источник изображения: Nvidia Как отмечается в аннотации Bloomberg к интервью с Хуангом после его выступления в Гонконгском университете науки и технологии, возглавляемая им Nvidia заинтересована в получении как восьми-, так и 12-ярусных микросхем HBM3E. В конце октября Samsung Electronics объявила о прогрессе в сертификации HBM3E под нужды Nvidia, но руководитель последней на уходящей неделе не стал ставить Samsung в один ряд с SK hynix и Micron, говоря о партнёрах своей компании. Во время своего выступления в Гонконге, как добавляет Reuters, основатель Nvidia выразил уверенность, что даже в случае усиления правил экспортного контроля США в сфере продвинутых средств вычислений Дональдом Трампом, международное сотрудничество в технологической сфере продолжится. Какие изменения принесёт новая администрация, Хуанг не знает, но Nvidia в любом случае будет подстраиваться под требования законов и правил, обеспечивая поддержку своих клиентов по всему миру с их учётом, а также развивать собственные технологии. В Гонконг Дженсен Хуанг был приглашён в связи с присвоением ему докторской степени местного университета. Растущие потребности систем искусственного интеллекта в энергоснабжении, как пояснил Хуанг, не являются однозначным злом. С помощью подобных систем можно проектировать новые ветряные турбины, искать новые материалы для аккумуляторов и совершенствовать методы хранения гидроксида углерода в резервуарах. Мощные центры обработки данных необходимо строить вдали от густонаселённых районов и обеспечивать собственными возобновляемыми источниками энергии, как убеждён Хуанг. «Я надеюсь, что в конечном счёте мы увидим, что использование энергии для искусственного интеллекта станет лучшим способом её использования, какой только можно представить», — резюмировал он. Новая эра вычислений затронет все отрасли промышленности и области науки, по его словам. Достигший возраста 61 года Хуанг также признался студентам в Гонконге, что хотел бы начать свою карьеру сейчас, поскольку весь мир сейчас сбрасывается к единым для всех начальным условиям, и молодых учёных есть все необходимые инструменты для продвижения во многих областях. Все научные проблемы, существовавшие ранее и имеющиеся сейчас, теперь кажутся решаемыми, по мнению Хуанга. Глава Samsung собрался очистить компанию от неповоротливого топ-менеджмента в сфере чипов
23.11.2024 [17:15],
Владимир Мироненко
Спустя десятилетие после того, как наследник семьи основателя Samsung в третьем поколении Ли Чжэ Ён (Lee Jae-yong) встал у руля южнокорейской корпорации, ему предстоит пройти самую серьёзную проверку деловой хватки в борьбе с корпоративным кризисом, с которым компания столкнулась, пишет Financial Times.  Компания Samsung — крупнейший в мире производитель микросхем памяти, но она отстала от своего конкурента SK hynix в новой перспективной молодой сфере — на рынке чипов памяти HBM для ИИ-ускорителей. Компания также не добилась большого прогресса в выполнении плана Ли превзойти Taiwan Semiconductor Manufacturing Company в освоении передовых техпроцессов к 2030 году. А в таких секторах, как дисплеи и смартфоны, где она раньше доминировала, Samsung теряет долю рынка под натиском китайских конкурентов. Не улучшило ситуацию и то, что Samsung в этом году столкнулась с забастовкой работников из-за спора с профсоюзом по поводу оплаты и условий труда. К тому же нарастает волна критики инвесторов, недовольных падением акций более чем на 30 % в этом году, несмотря на то, что на прошлой неделе было объявлено о выкупе акций на сумму в $7,1 млрд. Следует добавить, что победа Дональда Трампа (Donald Trump) на выборах в США и вероятность предстоящих торговых конфликтов также внесли неопределенность в перспективы мирового технологического сектора и Южной Кореи, чья экономика в значительной степени зависит от экспорта чипов и положения дел у самой дорогой компании страны. «Кризис Samsung — это кризис Кореи», — подчеркивает Пак Чжу Гын, глава исследовательской группы Leaders Index. Личная история Ли Чжэ Ёна также неоднозначна. Получив образование в Гарвардской школе бизнеса, он начал карьеру с провального проекта e-Samsung в 2000 году. Позже он был вовлечен в коррупционный скандал, связанный с бывшим президентом Южной Кореи Пак Кын Хе, и провел 19 месяцев в тюрьме. После освобождения в 2021 году ему был затем вынесен оправдательный приговор в 2022-м. После освобождения из тюрьмы Ли стремится создать образ скромного руководителя, обедая в столовых для рядовых сотрудников и делая селфи с работниками по всему миру. «Я буду усерднее работать, чтобы стать ответственным бизнесменом», — заявил он после помилования. С 2022 года Ли занимает должность исполнительного председателя Samsung Electronics, хотя не входит ни в её совет директоров, ни в совет директоров Samsung C&T, фактической холдинговой компании конгломерата, что, возможно, связано с ограничениями по ведению бизнеса, указанными в условиях условно-досрочного освобождения. Пак Сангин (Park Sangin), профессор экономики в Сеульском национальном университете, отметил более осторожный стиль управления Ли по сравнению с тем, который демонстрируют некоторые другие чеболи — семейные конгломераты, доминирующие в экономике Южной Кореи. «В отличие от руководителей Hyundai и LG третьего поколения, Ли не продемонстрировал никаких крупных или смелых решений», — сказал Сангин. Этим он также отличается от своего отца, Ли Гон Хи (Lee Kun-hee), в своё время объявившего войну браку в производстве и на этом фоне приказавшего уничтожить 150 тыс. смартфонов и другой электроники, в которой был обнаружен брак. Старший Ли был сторонником реформ.  Однако Samsung не теряет оптимизма. Компания объявила о строительстве нового центра разработки чипов стоимостью $14,4 млрд и планирует выпустить конкурентоспособный чип памяти HBM4 во второй половине 2025 года. Кроме того, под руководством Ли компания успешно диверсифицировала бизнес, развивая направления биотехнологий и автомобильных компонентов. Институциональные инвесторы сохраняют веру в Samsung, рассчитывая на подъем глобального рынка памяти на фоне растущего спроса на инфраструктуру для ИИ. Однако они настаивают на необходимости реформирования непрозрачной структуры корпоративного управления. Samsung Electronics планирует провести кадровую чистку топ-менеджмента своих полупроводниковых подразделений, который, по словам аналитиков, с трудом приспосабливается к изменениям на глобальном рынке микросхем, происходящим из-за стремительного развития технологий ИИ. Microsoft хочет, чтобы у каждого человека был ИИ-помощник, а у каждого бизнеса — ИИ-агент
23.11.2024 [12:20],
Анжелла Марина
На ежегодной конференции Microsoft Ignite компания представила своё видение рабочего процесса на ПК в будущем, связанное с использованием искусственного интеллекта Copilot. Microsoft намерена сделать Copilot не просто вспомогательной функцией, а центральным элементом работы пользователей, объединяющим множество агентов для выполнения различных задач. 
Источник изображения: Copilot Copilot станет своеобразным суперприложением, через которое пользователи смогут выполнять большую часть задач, поясняет PCMag. Открыв Copilot, пользователь увидит два основных режима — Work и Web. В режиме Work Copilot получает доступ к данным Microsoft Graph, включая электронные письма, чаты в Teams и документы в SharePoint для выполнения задач на основе контекста. Например, для создания списка задач или формирования предложений для совместной работы через инструмент Bizchat. Пользователь может поручать Copilot много различных задач, которые часто выполняются специальными ИИ-агентами, представляющими из себя либо стандартных агентов Microsoft, либо специфических, созданных компаниями. По сути это то, что имел в виду генеральный директор Microsoft Сатья Наделла (Satya Nadella), когда говорил: «Copilot — это пользовательский интерфейс для ИИ». Именно поэтому на конференции неоднократно звучала фраза: «У каждого человека должен быть Copilot, и у каждого бизнес-процесса свой ИИ-агент». Стоит отметить, что Copilot и так уже демонстрирует на сегодня впечатляющие возможности. Например, пользователь может попросить его подготовить повестку для встречи, проанализировав переписку и документы, связанные с участниками. Полученный документ можно отредактировать и отправить коллегам через Bizchat для совместной работы. Также Microsoft представила агентов с узкой специализацией, таких как переводчик, HR-агент, фасилитатор и проектный менеджер. Переводчик выполняет синхронный перевод с сохранением интонации и тембра голоса. HR-агент способен отвечать на вопросы сотрудников о корпоративных политиках или предоставлять информацию о зарплате и льготах. Проектный менеджер поможет в создании плана проекта. И наконец, фасилитатор будет вести заметки во время встреч в Teams и создавать список задач. Несмотря на то, что эти инструменты находятся на стадии предварительного тестирования, они уже вызывают интерес, благодаря своему потенциалу по снижению затрат и улучшению бизнес-процессов. Стоит сказать, что внедрение Copilot одновременно связано с рядом вызовов. Как отметил Херайн Оберой (Herain Oberoi), генеральный менеджер по безопасности данных, переход к ИИ-инструментам открывает новые уязвимости. Для решения этой проблемы Microsoft предлагает обновлённый пакет инструментов безопасности, включая Purview Data Loss Prevention, который позволяет классифицировать данные и управлять доступом, также будет внедрена система защиты от предвзятости ИИ-моделей и запрещённого контента. При этом администраторы смогут контролировать, какие ИИ-модели должны использоваться, а какие нет, из более чем 1800 доступных на платформе Azure. Google Gemini сможет управлять приложениями без пользователя и даже не открывая их
23.11.2024 [08:00],
Анжелла Марина
Система искусственного интеллекта Google Gemini получит новые возможности благодаря API App Functions, который позволяет выполнять действия в приложениях без их открытия. По данным The Verge, новая функция обнаружена в коде Android 16 для разработчиков и может стать доступна для всех пользователей уже в следующем году. 
Источник изображения: Solen Feyissa / Unsplash Функция App Functions, основанная на программном интерфейсе API (Application programming interface), может дать ассистенту Gemini возможность выполнять действия внутри приложений. На сайте разработчиков Google описывает app functions как «конкретную функциональность, которую приложение предоставляет системе, и которая одновременно может быть интегрирована в различные системные функции». И хоть пока это звучит довольно расплывчато, Мишаал Рахман (Mishaal Rahman) из Android Authority приводит пример из документации, который проясняет суть. Например, разработчики приложений смогут открывать доступ посредством API к отдельным действиям, как, например, заказ еды, а Gemini сможет сделать заказ, не открывая приложения. Интересно, что подобную функцию разрабатывает и Apple. В iOS 18 Siri также сможет выполнять действия внутри приложений через обновлённый фреймворк app intents. Например, пользователи смогут заказать что-либо в магазине через Siri, если разработчики определённого приложения подключат такую возможность. Однако внедрение этой функции в случае с Apple ожидается не раньше весны 2025 года. Стоит отметить, что способность «выполнять действия за пользователя» изначально была одной из главных целей умных ассистентов, но её реализация начала появляться лишь недавно. Пока Gemini в основном ограничен поиском информации в Gmail или Google Maps. Что касается голосового помощника Siri в iOS 18, то он получил интеграцию с ChatGPT, за счёт чего можно задавать более сложные вопросы, но с выполнением действий Siri пока справляется хуже. Судя по всему, и Google, и Apple закладывают фундамент для более «умных» ассистентов, которые смогут выполнять сложные задачи внутри приложений, и это произойдёт уже очень скоро. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


