|
Опрос
|
реклама
Быстрый переход
Только одна из четырёх задач, решаемых с помощью ИИ, оправдает себя экономически через 10 лет
22.07.2024 [17:34],
Алексей Разин
Бум искусственного интеллекта начался, по меркам истории человечества, совсем недавно, и многие эксперты уже сейчас сомневаются, насколько полезными окажутся соответствующие технологии в их нынешнем виде. Один из американских учёных утверждает, что за ближайшие десять лет инвестиции в различные технологии искусственного интеллекта оправдают себя только в одном из четырёх случаев. 
Источник изображения: pikisuperstar / freepik.com По крайней мере, как выразился в ходе подкаста Goldman Sachs профессор Массачусетского технологического института Дарон Аджемоглу (Daron Acemoglu), в экономическом плане не более четверти всех автоматизируемых с помощью ИИ прикладных задач в перспективе десяти лет позволят оправдать вложенные в них средства. В обозримом будущем «возникнут очень серьёзные ограничения с точки зрения того, куда нас приведёт текущая архитектура больших языковых моделей (LLM)». При этом, по словам профессора, скорость совершенствования систем искусственного интеллекта не будет определяться исключительно темпами наращивания вычислительных мощностей за счёт установки в центрах обработки данных большего количества ускорителей. Будут расти требования к качеству данных, и пока сложно понять, за счёт чего удастся улучшить это качество. Эксперты Goldman Sachs на основе этих рассуждений строят прогноз, согласно которому ИИ в ближайшие десять лет затронет только 5 % всей экономической активности в США, производительность труда в итоге вырастет только на 0,5 %, а рост ВВП благодаря этому фактору не превысит 0,9 % по итогам следующих десяти лет. Подобный экономический эффект сложно назвать убедительным, и такой прогноз наверняка заставит инвесторов задуматься о более рациональном расходовании средств на освоение технологий искусственного интеллекта. «Алиса» прошла дообучение и теперь лучше понимает запросы пользователей с особенностями речи
22.07.2024 [15:13],
Владимир Мироненко
Пользователям с особенностями речи, например, с заиканием, ДЦП, последствиями инсульта или травмы, теперь будет проще общаться с голосовым помощником «Алиса», поскольку после дообучения нейросети он стал лучше распознавать их запросы, пишет «Яндекс». 
Источник изображения: «Яндекс» В процессе дообучения использовались более 900 часов аудиоматериалов, содержащих свыше 855 тысяч скороговорок и голосовых фрагментов, которые записали люди с особенностями речи. В проекте приняли участие некоммерческие организации «Центр лечебной педагогики», «Живи сейчас», «Жизненный путь», «Весна», «Перспектива», «Лучшие друзья» и другие, а также специалисты-дефектологи из МГПУ, которые помогли классифицировать контент по типам нарушений. Всего в проекте участвовали более 300 человек. Благодаря этому разрыв в точности распознавания «Алисой» обычной речи и с искажениями сократился в среднем на 20 %. Качество распознавания оценивали по метрике Word Error Rate (WER), которая позволяет определить долю неправильно понятых слов. Компания сообщила, что это далеко не первый проект по адаптации виртуального ассистента для людей с особенностями здоровья. Недавно она представила в Москве инклюзивные навыки «Алисы», разработанные студентами. А мобильное приложение «Дом с Алисой» теперь поддерживает воспроизведение вслух текста с экрана, упрощая взаимодействие с интерфейсом пользователям с нарушениями зрения. Для таких пользователей адаптировано 15 сервисов и продуктов «Яндекса», включая «Поиск», «Браузер», «Яндекс Музыка», «Букмейт» и т.д. Также в приложении Go имеются специальные возможности для людей с особенностями здоровья, включая такие функции, как «Общаюсь только текстом», «Не говорю, но слышу», «Перевозка собаки-проводника», «Буду на инвалидном кресле» или «Помогите найти машину». «Т-Банк» открыл доступ к русскоязычной ИИ-модели T-lite с 8 млрд параметров
22.07.2024 [13:55],
Владимир Мироненко
«Т-Банк» открыл доступ к русскоязычной большой языковой модели T-lite с 8 млрд параметров, созданной Центром искусственного интеллекта финансовой организации (AI-центр). Как было объявлено на первой конференции «Т-Банка» по машинному обучению Turbo ML Conf, T-lite показала в индустриальных и внутренних бенчмарках лучшие результаты в решении бизнес-задач на русском языке среди открытых моделей с 7–8 млрд параметров. 
Источник изображений: Т-Банк В частности, результаты T-lite были лучше, чем у зарубежных llama3-8b-instruct и chat-gpt 3.5. При этом на создание T-lite потребовалось всего 3 % вычислительных ресурсов, которые обычно необходимы для такого типа моделей, отметил «Т-Банк». 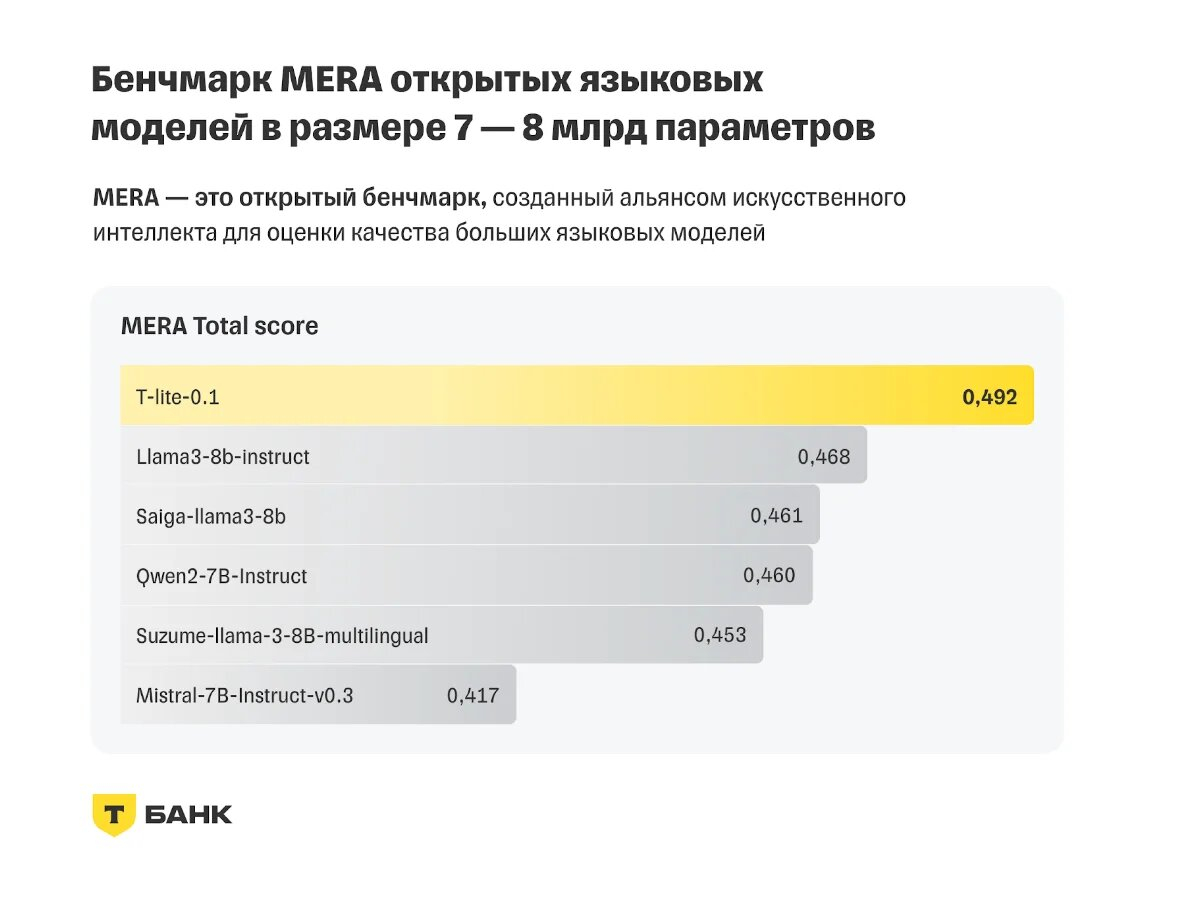 С увеличением количества параметров ИИ-модели растут её возможности для выполнения сложных заданий, но вместе с тем ухудшается экономическая эффективность модели. В свою очередь, T-lite после дообучения для выполнения конкретных бизнес-задач в области обработки естественного языка (NLP) предоставляет ответы, сопоставимые по качеству с проприетарными моделями размером от 20 млрд параметров, но при этом значительно дешевле в эксплуатации. 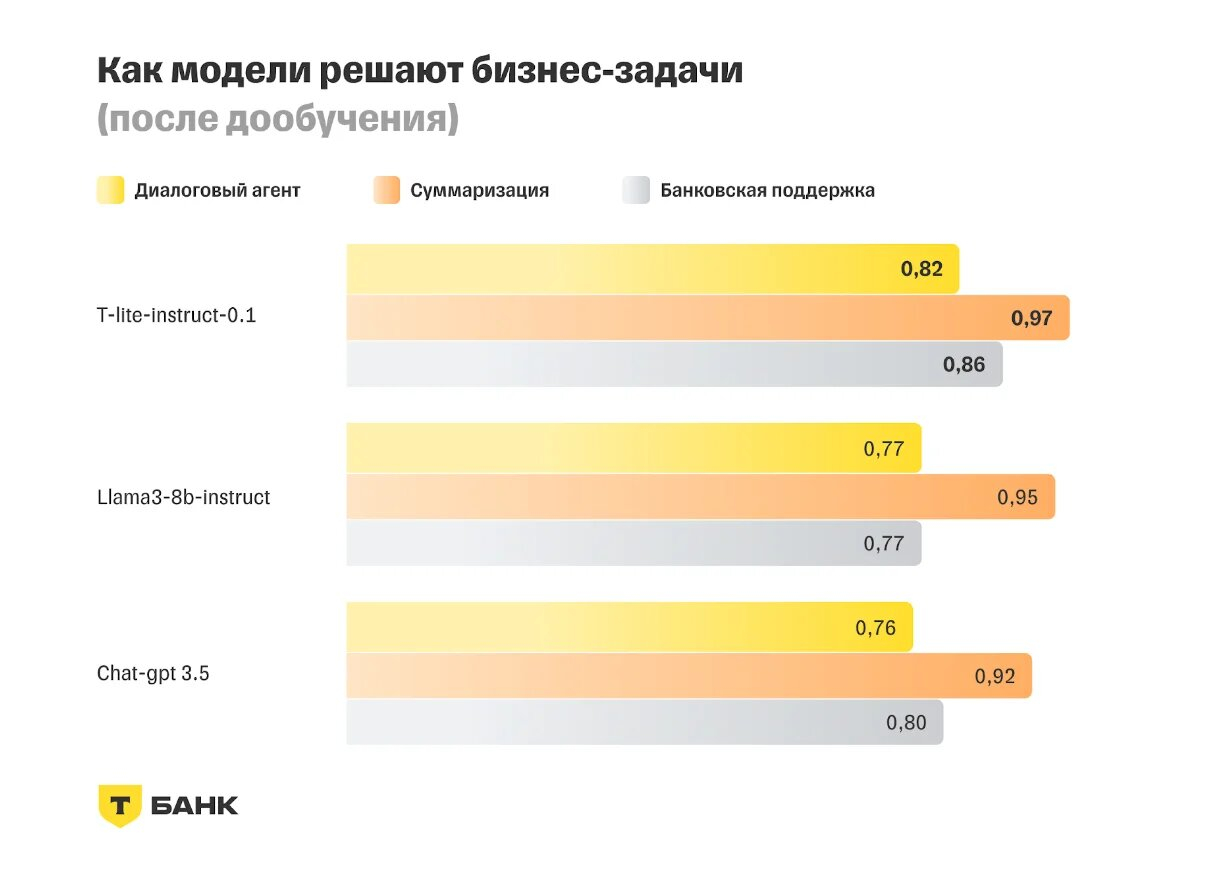 T-lite входит в семейство собственных специализированных языковых моделей «Т-Банка» Gen-T, способных обучаться для решения конкретных узкоспециализированных задач. В отличие от универсальных моделей, таких как ChatGPT, модели семейства Gen-T ориентированы на использование в конкретных областях с максимальной адаптацией под нужды пользователя. Proton выпустила ИИ-помощника для электронной почты, который работает на компьютере пользователя
20.07.2024 [13:00],
Анжелла Марина
Швейцарская компания Proton, известная своими приложениями, такими как Proton Mail и Proton VPN, ориентированными на конфиденциальность, запустила новый инструмент на основе искусственного интеллекта, который будет помогать пользователям в составлении электронных писем, перерабатывать их и проверять орфографию перед отправкой с помощью простых подсказок. 
Источник изображения: Proton Новый продукт Proton Scribe продолжает воспроизводить функциональность решений, появившихся у Google, отвечая на запуск AI Gemini в Gmail. Основанный на открытой модели языка Mistral 7B от французского стартапа Mistral, Proton Scribe обеспечивает максимальную безопасность данных пользователей. Как сообщает TechCrunch, инструмент можно устанавливать полностью на локальном уровне, что исключает передачу информации за пределы устройства. Компания также обещает, что ИИ не будет обучаться на пользовательских данных, что особенно важно для корпоративного использования. «Мы поняли, что независимо от того, разрабатывает ли Proton инструменты ИИ или нет, пользователи всё равно будут использовать искусственный интеллект, часто со значительными последствиями для конфиденциальности», — сказал основатель и генеральный директор Энди Йен (Andy Yen). «Вместо того, чтобы копировать свои сообщения в сторонние инструменты ИИ, которые часто имеют ужасные методы обеспечения конфиденциальности, было бы лучше встроить инструменты ИИ, ориентированные на конфиденциальность, непосредственно в Proton Mail». 
Источник изображения: Proton Интересно, что Proton Scribe также может работать непосредственно на серверах Proton, если пользователи, менее обеспокоенные безопасностью, выберут этот способ взаимодействия с приложением. Это позволит быстрее обрабатывать запросы, в зависимости от аппаратного обеспечения пользователя. При этом компания подчёркивает, что не ведёт никаких журналов и не передаёт данные третьим лицам. «На сервер передаётся только подсказка, введённая пользователем, и никакие данные не сохраняются после создания черновика электронного письма», — сообщил представитель компании изданию TechCrunch. Хотя Proton Scribe ограничен только электронной почтой, компания заявила, что может расширить инструмент и на другие свои продукты в будущем «в зависимости от спроса». Возможно, в дальнейшем в Scribe появится интеграция с недавно запущенным приложением для совместной работы с документами. Новый инструмент доступен уже сегодня для Proton Mail в веб-версии и десктопной версии. Компания подтвердила, что в будущем планирует добавить поддержку мобильных устройств. Что касается стоимости, то Proton Scribe в основном ориентирован на бизнес-пользователей и те, кто уже использует тарифные планы Mail Essentials, Mail Professional или Proton Business Suite, могут получить доступ к инструменту за дополнительные $2,99 в месяц. Пользователи устаревших и лимитированных тарифных планов, таких как Visionary или Lifetime, получат доступ к Proton Scribe бесплатно. OpenAI повысит безопасность своих ИИ-моделей с помощью «иерархии инструкций»
20.07.2024 [05:41],
Анжелла Марина
OpenAI разработала новый метод под названием «Иерархия инструкций» для повышения безопасности своих больших языковых моделей (LLM). Этот метод, впервые применённый в новой модели GPT-4o Mini, направлен на предотвращение нежелательного поведения ИИ, вызванного манипуляциями недобросовестных пользователей с помощью определённых команд. 
Источник изображения: Copilot Руководитель платформы API в OpenAI Оливье Годеман (Olivier Godement) объяснил, что «иерархия инструкций» позволит предотвращать опасные инъекции промтов с помощью скрытых подсказок, которые пользователи используют для обхода ограничений и изначальных установок модели, и блокировать атаки типа «игнорировать все предыдущие инструкции». Новый метод, как пишет The Verge, отдаёт приоритет исходным инструкциям разработчика, делая модель менее восприимчивой к попыткам конечных пользователей заставить её выполнять нежелательные действия. В случае конфликта между системными инструкциями и командами пользователя, модель будет отдавать наивысший приоритет именно системным инструкциям, отказываясь выполнять инъекции. Исследователи OpenAI считают, что в будущем будут разработаны и другие, более сложные средства защиты, особенно для агентных сценариев использования, при которых ИИ-агенты создаются разработчиками для собственных приложений. Учитывая, что OpenAI сталкивается с постоянными проблемами в области безопасности, новый метод, применённый к GPT-4o Mini, имеет большое значение для последующего подхода к разработке ИИ-моделей. OpenAI вела переговоры с Broadcom о разработке ИИ-ускорителя
19.07.2024 [04:50],
Алексей Разин
Амбиции руководства OpenAI в сфере разработки и производства собственных ускорителей для систем искусственного интеллекта не являются секретом, и накануне издание The Information сообщило, что компания вела переговоры о разработке соответствующего чипа с Broadcom. Акции последней на этом фоне успели вырасти в цене на 3 %. 
Источник изображения: Shutterstock Как отмечает источник, Broadcom была лишь одним из разработчиков, с которыми вела переговоры OpenAI. Среди вовлечённых в процесс оказались и выходцы из Google, имеющие опыт разработки процессоров семейства Tensor. Некоторых из них OpenAI успела нанять для реализации соответствующих собственных замыслов. Перед специалистами ставилась задача по разработке ускорителей серверного класса для систем искусственного интеллекта. Глава OpenAI Сэм Альтман (Sam Altman) не раз жаловался на нехватку аппаратной инфраструктуры для подобающего его планам развития систем искусственного интеллекта. Его компания могла бы оказать содействие партнёрам в строительстве не только центров обработки данных, но и предприятий по выпуску компонентов, а также электростанций. В составе Broadcom имеется подразделение, разрабатывающее чипы с учётом пожеланий конкретных заказчиков. Если бы проект OpenAI удалось реализовать, то процессор Broadcom начал выпускаться не ранее 2026 года в лучшем случае. Попутно руководству OpenAI пришлось вести переговоры с Samsung и SK hynix по поводу оснащения соответствующих ускорителей памятью типа HBM. Выпускать чип OpenAI планировала на мощностях компании TSMC, причём Альтман вёл с последней переговоры и об увеличении объёмов выпуска чипов Nvidia, которые OpenAI также активно использует. Google, Nvidia, Intel, OpenAI и другие IT-гиганты создали «Коалицию за безопасный искусственный интеллект»
18.07.2024 [22:56],
Николай Хижняк
Google, OpenAI, Microsoft, Amazon, Nvidia, Intel и другие крупные игроки рынка искусственного интеллекта объявили о создании «Коалиции за безопасный искусственный интеллект» (CoSAI). Инициатива направлена на решение проблемы «фрагментированности ландшафта безопасности ИИ» путём предоставления доступа к методологиям, платформам и инструментам с открытым исходным кодом. 
Источник изображения: oasis-open.org Какое именно влияние хочет оказать CoSAI на индустрию искусственного интеллекта — неизвестно. Вероятно, вопросы защиты конфиденциальной информации и дискриминационные проблемы ИИ станут одними из направлений работы этой организации. К инициативе CoSAI также присоединились компании IBM, PayPal, Cisco и Anthropic. CoSAI будет существовать в рамках «Организации по развитию стандартов структурированной информации» (OASIS), некоммерческой группы, которая способствует развитию открытых стандартов. CoSAI отмечает три основных направления деятельности: разработка эффективных практик обеспечения безопасности ИИ, решение общих проблем в области ИИ, а также безопасность приложений на базе искусственного интеллекта. «Мы используем ИИ уже много лет и видим какую пользу он может приносить. Но мы также признаём его возможности, которые могут быть интересы злоумышленникам. CoSAI призвана помочь малым и крупным организациям безопасно и ответственно интегрировать и использовать преимущества ИИ в своих экосистемах, одновременно снизив все потенциально связанные с этим риски», — говорится в заявлении Хизер Адкинс (Heather Adkins), вице-президента Google по безопасности. Microsoft создала ИИ, который облегчит работу с таблицами в Excel — он понимает запросы на естественном языке
18.07.2024 [17:51],
Павел Котов
Сотрудники, умеющие качественно работать с электронными таблицами Excel, ценятся достаточно высоко. Но исследователи Microsoft разработали решение, способное как минимум отчасти их заменить. Большая языковая модель SpreadsheetLLM предназначена для управления электронными таблицами при помощи команд естественным языком. 
Источник изображения: Rubaitul Azad / unsplash.com SpreadsheetLLM анализирует и интерпретирует данные в электронных таблицах при помощи ИИ, решая большинство связанных с ними задач — для этого производится сериализация данных, то есть включение в поток адресов, значений и форматов ячеек. Инструмент содержит компонент SheetCompressor, который сжимает электронные таблицы для их передачи модели ИИ. Он состоит из трёх модулей: первый анализирует структуру таблицы и отбрасывает нетабличное содержимое; второй преобразует данные в более эффективное представление; третий агрегирует данные. У SpreadsheetLLM есть некоторые ограничения. Она игнорирует цвета ячеек, а они могут иметь какое-то значение, и не осуществляет семантического сжатия для содержимого ячеек, выраженного естественным языком. Но и этого хватает, чтобы на 96 % сократить потребление токенов при запросе к ИИ, что означает экономию вычислительных ресурсов. В итоге пользователи без надлежащей технической подготовки могут отправлять к SpreadsheetLLM запросы естественным языком и добиваться поставленных задач. Но основная задача проекта — не заменить человека, а оказать ему помощь в финансах, бухгалтерском учёте и других областях, связанных с обработкой данных. Модель включает фреймворк Chain of Spreadsheet (CoS) для анализа содержимого нескольких таблиц. SpreadsheetLLM может работать со структурированными и неструктурированными данными электронных таблиц — исследователи указывают, что этот аспект способен уменьшить инциденты с «галлюцинациями» в ответах ИИ. Пока проект находится на стадии исследования, и к выходу в качестве коммерческого продукта он ещё не готов. Китайские цензоры привьют ИИ социалистические ценности
18.07.2024 [16:10],
Павел Котов
Китайские чиновники осуществляют тщательное тестирование разрабатываемых местными компаниями больших языковых моделей — передовых систем искусственного интеллекта — чтобы убедиться, что те «воплощают базовые социалистические ценности», сообщает Financial Times. 
Источник изображения: 文 邵 / pixabay.com Государственная канцелярия интернет-информации КНР (Cyberspace Administration of China, CAC) обязала крупные технологические компании и стартапы в области ИИ, в том числе ByteDance, Alibaba, Moonshot и 01.AI, принять участие в правительственном тестировании их моделей. Процедура включает в себя пакетный сбор ответов на целый ряд вопросов, многие из которых связаны с политическим курсом Китая и с главой государства Си Цзиньпином (Xi Jinping). Работа выполняется чиновниками в местных отделениях ведомства и также включает в себя проверку массивов данных, которые использовались при обучении моделей. Примерно двадцать лет назад в стране начал работать «Великий китайский брандмауэр», заблокировавший населению доступ к ресурсам с информацией, которую власти считают недопустимой, — теперь Пекин вводит самые жёсткие в мире меры регулирования ИИ и создаваемого им контента. Приводится пример китайского стартапа в области ИИ, чья большая языковая модель прошла экспертизу в ведомстве только со второго раза — причина отказа в первый раз была не до конца ясна, и разработчикам пришлось консультироваться с более удачливыми и понятливыми коллегами. Весь процесс занял несколько месяцев. Для разработчиков задача осложняется тем, что приходится использовать в обучении ИИ большой объём англоязычных материалов, которые в идеологическом плане сильно отличаются от контента на китайском. Фильтрация начинается с отсеивания проблемной информации из обучающих данных и создания базы данных требующих особого внимания слов. В феврале власти страны опубликовали руководство для компаний, работающих в области ИИ: в документе говорится о необходимости собрать базу из нескольких тысяч слов и вопросов, которые противоречат «базовым социалистическим ценностям» — это может быть «подстрекательство к подрыву государственной власти» или «подрыв национального единства». 
Источник изображения: Nicky / pixabay.com Пользователи китайских чат-ботов с ИИ уже ощутили результаты этой работы. Большинство систем отказывается отвечать на вопросы, например, о событиях на площади Тяньаньмэнь 4 июня 1989 года или о сходстве главы государства с Винни-Пухом — чат-боты Baidu Ernie и Alibaba Tongyi Qianwen делают это под различными благовидными предлогами. При этом Пекином был запущен альтернативный чат-бот, ответы которого опираются на работы Си Цзиньпина и другую официальную литературу, предоставленную канцелярией интернет-информации. Но одной только цензуры китайским чиновникам недостаточно — ИИ не следует уклоняться от разговора на любые политические темы. Согласно действующему стандарту, большая языковая модель не должна отклонять более 5 % вопросов. Разработчики же, пытаясь избежать проблем с властями, всё равно действуют радикально. «Во время тестирования [чиновниками модели] должны отвечать, но после выхода за ними никто не надзирает. Чтобы избежать возможных неприятностей, у некоторых крупных моделей введён полный запрет на темы, связанные с президентом Си», — рассказал сотрудник одной шанхайской компании. Создаются дополнительные механизмы для контроля ответов ИИ, принцип работы которых напоминает фильтры спама в системах электронной почты. А больше всех в идеологическом плане преуспела модель, разработанная компанией ByteDance (владеет TikTok), — исследователи Фуданьского университета присвоили ей высший рейтинг безопасности в 66,4 %. Для сравнения, OpenAI GPT-4o в том же тесте набрала 7,1 %. На недавней технической конференции Фан Биньсин (Fang Binxing), известный как создатель «Великого китайского брандмауэра», рассказал, что разрабатывает систему протоколов безопасности для больших языковых моделей, которая, как он надеется, будет повсеместно использоваться местными создателями ИИ. «Общедоступным крупным прогностическим моделям нужно больше, чем просто документация по безопасности — им нужен мониторинг безопасности в реальном времени», — пояснил он. Meta✴ закроет европейцам доступ к будущим ИИ-моделям
18.07.2024 [15:56],
Владимир Мироненко
Следующая мультимодальная ИИ-модель Meta✴✴, как и другие будущие модели, будут недоступны клиентам в Европейском Союзе из-за отсутствия ясности со стороны регулирующих органов, сообщила компания ресурсу Axios. 
Источник изображения: OpenClipart-Vectors/Pixabay «Мы выпустим мультимодальную модель Llama в ближайшие месяцы, но не в ЕС из-за непредсказуемого характера европейской нормативно-правовой среды», — указано в заявлении Meta✴✴, направленном Axios. В Meta✴✴ также сообщили, что европейские компании не смогут использовать её мультимодальные модели, даже если те выпускаются под открытой лицензией. Кроме того, компании из других стран не смогут предлагать в Европе продукты и услуги, использующие новые мультимодальные модели от Meta✴✴. Аналогичным образом поступила Apple, сообщившая в прошлом месяце, что функции Apple Intelligence будут недоступны в Европе из-за требований Закона о цифровых услугах (DMA), выполнение которых может привести «к снижению безопасности пользовательских данных и их приватности». Meta✴✴ также планирует выпустить в ближайшее время более крупную текстовую версию модели Llama 3, которая будет доступна компаниям в ЕС. Как полагает ресурс Axios, проблема Meta✴✴ связана скорее с тем, как она, возможно, использует для обучения модели данные европейских клиентов, нарушая тем самым Общий регламент по защите данных (General Data Protection Regulation, GDPR) ЕС. Компанию уже обвиняли в незаконном массовом сборе персональных данных европейских пользователей. В мае Meta✴✴ объявила о планах использовать общедоступные публикации пользователей Facebook✴✴ и Instagram✴✴ для обучения будущих моделей, в связи с чем отправила более 2 млрд уведомлений пользователям в ЕС. Но затем была вынуждена отказаться от этого из-за запрета Ирландской комиссии по защите данных (DPC) и Управления комиссара по информации Великобритании (ICO). Huawei будет внедрять искусственный интеллект в тяжёлое машиностроение
18.07.2024 [14:42],
Алексей Разин
Санкции США, под которыми компания Huawei Technologies функционирует с 2019 года, заставляют её активно искать новые рынки сбыта продукции и услуг. Возможно, именно благодаря такому неудачному стечению обстоятельств она и заинтересовалась внедрением технологий искусственного интеллекта в сфере тяжёлого машиностроения, заключив соглашение о сотрудничестве с китайским производителем техники ZGCMC. 
Источник изображения: Huawei Technologies Выступающая под полным наименованием Sichuan Zigong Conveying Machine Group Co китайская компания является одним из крупнейших производителей оборудования и техники для горнодобывающей и других сырьевых отраслей экономики КНР. В рамках сотрудничества с ZGCMC компания Huawei рассчитывает внедрить использование больших языковых моделей в данной отрасли. Соглашение о сотрудничестве будет действовать на протяжении трёх лет. Китайский промышленный гигант намеревается отдавать приоритет использованию решений и услуг Huawei в своей деятельности. Huawei, помимо прочего, берёт на себя разработку специализированного программного обеспечения для партнёра, а также подготовку кадров. Финансовая сторона сделки не разглашается. Партнёры также будут развивать сотрудничество в сфере облачных вычислений, анализа больших данных, цифровизации профильных отраслей промышленности и создания «умных» фабрик. Huawei уже имеет опыт работы в горнодобывающей промышленности. За счёт сотрудничества с Huawei компании Shaanxi Coal Industry, например, удалось вдвое сократить количество шахтёров, работающих на глубине 100 метров под землёй, посредством внедрения сетей 5G промышленного назначения и систем искусственного интеллекта на производстве. Китайские власти ставят перед угольной отраслью страны перевести крупнейшие и самые опасные с точки зрения условий труда шахты на высокий уровень автоматизации и цифровизации уже к 2025 году. Всего в КНР находится около 4000 угольных шахт, страна является крупнейшим поставщиком этого вида топлива в мире. К 2035 году все шахты на территории Китая обязаны пройти комплексную модернизацию. Huawei одновременно развивает свои компетенции в сфере автоматизации работы медицинских учреждений и портов. Подобные решения будут способствовать росту производительности труда в соответствующих отраслях китайской экономики, а в отдельных случаях помогут и решить проблему дефицита или старения кадров. Еврокомиссия выяснит, не мешает ли конкурентам Samsung наличие ИИ-модели Gemini Nano в Galaxy S24
18.07.2024 [14:39],
Владимир Мироненко
Европейская комиссия начала опрос участников рынка смартфонов по поводу того, как могло отразиться на них использование в смартфонах Samsung Galaxy S24 ИИ-модели Gemini Nano от Google, с целью выяснения, нет ли в сделке двух компаний признаков антиконкурентного сговора, пишет Reuters. 
Samsung Galaxy S24 Ultra В частности, регулятор спрашивает в анкете, не ограничивает ли предварительная установка Gemini Nano и её использование через устройство или облако применение других систем генеративного искусственного интеллекта, которые также могли бы быть предварительно установлены на том же устройстве. Также Еврокомиссия выясняет, не ограничивает ли предварительная установка Gemini Nano взаимодействие между другими чат-ботами и приложениями, предварительно установленными на смартфонах Samsung. Также респондентам был задан вопрос, не предпринимали ли они попытку заключить сделку с производителями устройств о предварительной установке их чат-ботов на базе ИИ. И если подобная попытка предпринималась, но в итоге оказалась безуспешной, то в чём была причина отказа. Ответы на данную восьмистраничную анкету регулятора должны быть предоставлены участниками рынка на этой неделе. Дефицит ИИ-чипов сохранится до 2026 года, прогнозируют в TSMC
18.07.2024 [13:26],
Алексей Разин
Осторожность руководства TSMC в оценке влияния бума ИИ на бизнес компании, наблюдавшаяся в апреле, сменилась на более выраженную уверенность в сохранении высокого спроса на соответствующие чипы. Председатель совета директоров Си-Си Вэй (C.C. Wei) заявил, что возможности TSMC в сфере поставок компонентов для систем искусственного интеллекта будут ограничены на протяжении всего 2025 года. 
Источник изображения: TSMC Соответственно, если дефицит немного и отступит, это произойдёт не ранее 2026 года. Об уверенности контрактного производителя в сохранении высокого спроса говорит и повышение нижней границы диапазона капитальных затрат на этот год, а также улучшение прогноза по росту выручки. Помимо собственно линий по обработке кремниевых пластин, TSMC вынуждена больше денег тратить и на упаковку чипов для систем ИИ, имеющих сложную пространственную компоновку. Компания готова искать более прогрессивную альтернативу методу CoWoS, который сейчас используется для упаковки чипов Nvidia, применяемых в составе ускорителей вычислений. «Спрос очень высок, поставки будут сильно ограничены вплоть до 2025 года включительно, и мы надеемся, что облегчение наступит в 2026 году. Мы продолжаем наращивать производственные мощности в любых местах и любыми способами», — пояснил Си-Си Вэй. По словам генерального директора TSMC, коим также является Си-Си Вэй, в настоящее время компания экспериментирует с методом упаковки FOPLP (panel fan-out technology), но она не слишком созрела для массового производства. Случится это примерно через три года, как предполагает глава компании. К тому времени и сама TSMC будет готова освоить этот метод упаковки чипов в условиях массового производства. Глава компании добавил, что в части CoWoS она более чем в два раза к этому году удвоила профильные производственные мощности, и в следующем году может удвоить их ещё раз. Ранее считалось, что на этом направлении дефицит будет устранён к концу 2024 года. Си-Си Вэй пояснил, что первое поколение 2-нм чипов встанет на конвейер TSMC во второй половине 2025 года, а второе последует за ним в 2026 году. Во второй половине 2026 года компания планирует освоить выпуск продукции по более совершенному техпроцессу A16. В сфере искусственного интеллекта, как считает глава TSMC, спрос распространится и на периферийные устройства вычислительных систем типа смартфонов и ПК, но пока это никак не влияет на количественные показатели поставок продукции в соответствующих сегментах рынка. За два последующих года развитие рынка устройств с функциями ускорения ИИ позволит сократить длительность цикла эксплуатации таких устройств. Сейчас спрос со стороны заказчиков TSMC особенно высок на выпуск продукции с использованием 5-нм и 3-нм техпроцессов. Уже сейчас ведётся работа по обеспечению клиентов адекватными квотами на выпуск такой продукции с расчётом на 2026 год. Несмотря на прозвучавшие в американском информационном поле вчера неоднозначные заявления одного из кандидатов на пост президента США, руководство TSMC не стало пересматривать свои планы относительно строительства своих зарубежных предприятий. В этой сфере всё идёт по графику и каких-либо изменений сейчас не предвидится, как дал понять Си-Си Вэй. Ранее уже отмечалось, что руководство TSMC не исключает возможности повышения цен на свои услуги для компании Nvidia. Сегодня Си-Си Вэй добавил, что его компания сталкивается с растущим ценовым давлением. Затраты растут из-за усложнения техпроцессов, дорожающего электричества на Тайване и высоких капитальных расходов при строительстве зарубежных предприятий. При этом TSMC настаивает, что не придерживается оппортунистического подхода к формированию цен, и выстраивает свои отношения с клиентами, пытаясь убедить их в адекватной ценности своих услуг. Аналитики Nomura Global Market Research считают, что TSMC поднимет цены на свои услуги на 5–10 % с января 2025 года. Apple Intelligence не использует нейросеть OpenELM, для обучения которой применялись данные сомнительного происхождения
18.07.2024 [11:36],
Павел Котов
Apple заявила, что её модель искусственного интеллекта OpenELM не легла в основу ни одной из функций ИИ или машинного обучения в коммерческих продуктах компании, включая Apple Intelligence. Компания обратила на это внимание, поскольку стало известно, что при обучении OpenELM использовались данные сомнительного происхождения.  Ранее выяснилось, что Apple и другие технологические гиганты для обучения своих моделей ИИ использовали субтитры видеозаписей YouTube, включая материалы крупнейших видеоблогеров платформы. Эти данные были включены в общедоступный массив Pile, который публикует некоммерческая организация EleutherAI — это она включила в него скачанные с YouTube субтитры, то есть фактически расшифровки видеозаписей, что является прямым нарушением правил платформы. Apple заявила, что OpenELM является вкладом компании в дело исследовательского сообщества — работа способствует созданию открытых больших языковых моделей. OpenELM, заявила компания ресурсу 9to5Mac, создана исключительно для исследовательских целей, а не для обеспечения работы каких-либо функций системы Apple Intelligence. Модель опубликована с открытым исходным кодом и доступна любому желающему, в том числе в разделе сайта компании Apple Machine Learning Research. Поскольку OpenELM не входит в систему Apple Intelligence, то и полученные предположительно незаконным путём субтитры YouTube также не имеют никакого отношения к коммерческой системе — Apple ранее подчёркивала, что Apple Intelligence была обучена «на лицензированных данных, включая данные, подобранные для улучшения определённых функций, а также собранные нашим веб-сканером общедоступные данные». Планов на разработку новых версий OpenELM у Apple нет. Google стала показывать меньше ответов ИИ в поиске после серии «странных» ответов
18.07.2024 [11:21],
Анжелла Марина
После волны критики, вызванной весьма странными ответами, генерируемыми искусственным интеллектом, Google начала сокращать использование технологии AI Overviews («Обзоры ИИ») в своей поисковой системе. Исследование SEO-компании BrightEdge показало, что количество ответов на поисковые запросы за июнь снизилось с 11 % до 7 %. 
Источник изображения: 2H Media/Unsplash Однако, как сообщает The Verge, представитель Google Эшли Томпсон (Ashley Thompson) опроверг выводы исследования BrightEdge, назвав методологию компании некорректной. Томпсон утверждает, что исследование не учитывает разницу между пользователями, которые активировали функцию AI Overviews в рамках экспериментальных функций Google Search Labs, и теми, кто этого не сделал. По его словам, пользователи, которые выбрали AI Overviews в Search Labs, будут видеть их в большем количестве результатов поиска. В BrightEdge, в свою очередь, утверждают, что отслеживали данные только тех людей, которые активировали функцию AI Overviews. 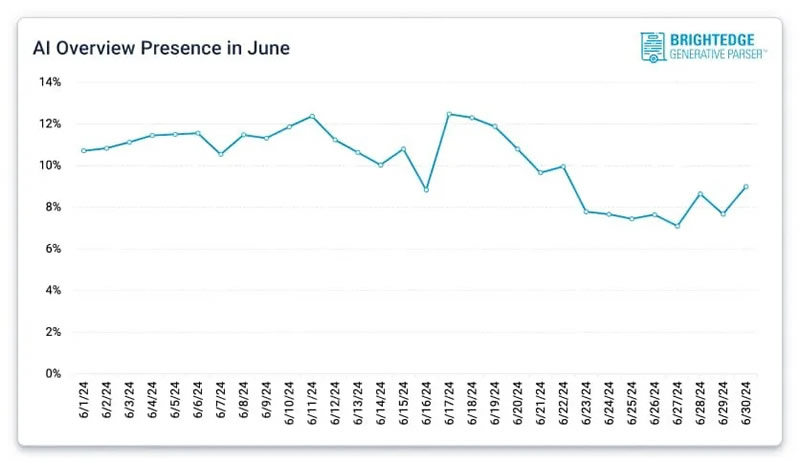
Источник изображения: brightedge.com Напомним, с момента запуска функции кратких ответов в поиске AI Overviews Google столкнулась с рядом конфузов, связанных с нелепыми и даже опасными советами, выдаваемыми ИИ. Например, пользователям предлагалось намазать пиццу клеем и съесть камни. В ответ на критику Google заверила, что работает над улучшением своей технологии, ограничив использование не проверенного пользовательского контента в ответах ИИ и добавив инструменты для обнаружения бессмысленных запросов, которые искусственный интеллект получать не должен. Несмотря на трудности, Google не намерена отказываться от функции AI Overviews. Генеральный директор компании Сундар Пичаи (Sundar Pichai) заявил, что пользователи очень позитивно реагируют на ответы ИИ. Однако, судя по всему, Google пока не готова к массовому внедрению этой технологии и продолжает её дорабатывать. Сокращение использования AI Overviews может свидетельствовать о том, что Google просто опасается негативной реакции и потери доверия к своей поисковой системе. Тем более, что пользователи могут обратиться к конкурентам, таким как Microsoft, OpenAI и Perplexity. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex




