|
Опрос
|
реклама
Быстрый переход
В следующем месяце объём инвестиций Microsoft в OpenAI превысит $100 млрд
14.05.2026 [07:07],
Алексей Разин
Когда речь ранее заходила об объёме финансирования OpenAI корпорацией Microsoft, всё обычно сводилось к упоминанию о $13 млрд, вложенных в капитал стартапа к началу 2023 года, но фактические затраты главного акционера OpenAI оказались выше. По итогам июня текущего года они превысят $100 млрд, как пояснили представители Microsoft в суде. 
Источник изображения: Microsoft Растянувшиеся на три недели слушания уже завершаются, но представителям Microsoft пришлось давать показания в понедельник. Директор корпорации по сделкам Майкл Веттер (Michael Wetter) сообщил суду, что к концу текущего фискального года, который завершится в июне, она накопленным итогом направит на поддержку OpenAI и развитие сопутствующей вычислительной инфраструктуры более $100 млрд. По словам представителя Microsoft, основная часть этих затрат окупится ещё не скоро. Microsoft даёт показания в суде, поскольку Илон Маск (Elon Musk) в своём иске усмотрел решающее влияние корпорации на решение OpenAI создать коммерческую структуру в своём составе, тем самым отойдя от изначальной благотворительной миссии. На прошлой неделе генеральный директор Microsoft Сатья Наделла (Satya Nadella) признался в суде, что корпорация рассчитывала заработать на ранних инвестициях в OpenAI не менее $92 млрд. По состоянию на октябрь прошлого года Microsoft владела акциями OpenAI на общую сумму $135 млрд. После реструктуризации её доля в капитале стартапа составила 27 %. Из показаний Наделлы также становится ясно, что уже в апреле 2022 года он выражал озабоченность способностью OpenAI превзойти саму Microsoft, хотя революционный для стартапа момент в виде выпуска ChatGPT был отдалён почти на полгода. Наделла сравнивал ситуацию со взаимоотношениями IBM и Microsoft в восьмидесятых годах прошлого века. Распространяя свою операционную систему MS-DOS в качестве приложения к персональным компьютерам IBM, корпорация Microsoft в итоге превзошла партнёра по капитализации и прочим финансовым показателям. Руководство Microsoft ещё в 2022 году выражало беспокойство по поводу возможности OpenAI превзойти своего главного инвестора, а потому настаивало на получении доступа к интеллектуальной собственности, которая будет приносить выгоду и Microsoft напрямую. По словам Наделлы, для Microsoft во взаимоотношениях с OpenAI было важно присутствовать буквально на каждом уровне программного стека. Технический директор Microsoft Кевин Скотт (Kevin Scott) рассказал в суде, что первый ЦОД, построенный корпорацией для OpenAI, содержал 10 000 ускорителей на базе GPU и создавался на протяжении шести месяцев. Сотрудничество с OpenAI пошло на пользу Microsoft и в том смысле, что последняя научилась строить суперкомпьютеры, заточенные под работу с генеративным ИИ. С 2024 года Microsoft начала открыто называть OpenAI своим конкурентом в сфере разработки ИИ-моделей, а с прошлого года Microsoft начала сотрудничать с конкурентами самой OpenAI типа той же Anthropic. При этом самостоятельные разработки Microsoft в сфере ИИ не получили даже доли той популярности, которыми пользуются модели OpenAI. Наделла признался в суде, что для Microsoft важно оставаться хорошим партнёром и хорошей компанией, предлагающей платформы, придерживаясь центрального направления в развитии без сильных манёвров по сторонам. ИИ сможет предугадывать потребности пользователей в ближайшем будущем, считают в Anthropic
14.05.2026 [05:38],
Анжелла Марина
Топ-менеджер компании Anthropic Кэт Ву (Cat Wu) заявила о скором переходе систем искусственного интеллекта к проактивному формату работы, считая также, что в ближайшем будущем нейросети смогут самостоятельно анализировать задачи пользователя и даже предугадывать его потребности до получения прямых команд. 
Источник изображения: Anthropic Своим видением развития технологии искусственного интеллекта руководитель направления продуктов Claude Code и Cowork поделилась на второй ежегодной конференции Code with Claude в Сан-Франциско (США). По её словам, в следующие шесть месяцев ИИ-инструменты компании шагнут от синхронного выполнения запросов к автоматизации рутинных процессов, а в дальнейшем система научится понимать специфику работы конкретного человека и будет сама настраивать необходимые алгоритмы действий без внешнего вмешательства. Как поясняет Ву, в интервью изданию TechCrunch, в основе стратегии Anthropic лежит принцип непрерывного экспоненциального улучшения моделей, а не реакция на действия других игроков рынка. Разработчики намеренно игнорируют конкурентов, так как попытки оглядываться на чужие достижения приводят к отставанию в темпах развития. Сохраняя высокую скорость работы, компания уже выпустила почти столько же моделей в текущем году, сколько за весь прошлый год, когда состоялось как минимум шесть крупных релизов. При этом доступность новых разработок жёстко контролируется. В апреле стартовал проект Glasswing, в рамках которого доступ к специализированной ИИ-модели по кибербезопасности Mythos получил лишь узкий круг партнёров, включая Amazon, Apple, CrowdStrike и Microsoft. Публичный релиз этой системы отменили из-за высоких рисков, так как алгоритм создан для поиска уязвимостей в программном коде и может стать мощным оружием в руках киберпреступников. Рассуждая о влиянии технологий на рынок труда, Ву подчеркнула, что широкое внедрение автономных ИИ-агентов направлено на избавление сотрудников от утомительных задач, например, обработки электронных писем. Человеку же предстоит взять на себя роль управляющего целым парком виртуальных помощников, однако для эффективного контроля над агентами специалистам необходимо сохранять высокий уровень профессиональных знаний и навыков в своей области, чтобы вовремя выявлять ошибки нейросетей и корректировать неточные инструкции. Успехи в разработке Claude позволили Anthropic стать одним из главных фаворитов среди корпоративных клиентов, чья доля рынка с мая 2025 года выросла в четыре раза. Бизнес-аудитория всё чаще предпочитает нейросеть Claude продукту ChatGPT. На фоне этих результатов компания готовится к новому раунду финансирования, по итогам которого её оценка может достичь $950 млрд, превысив мартовские показатели OpenAI в $854 млрд. Apple всё же допустит автономных ИИ-агентов в App Store, но с ограничениями
14.05.2026 [05:35],
Анжелла Марина
Apple изучает возможность допустить автономных ИИ-агентов в App Store, сохранив при этом контроль над безопасностью и монетизацией платформы. По сообщению Engadget со ссылкой на данные The Information, компания уже разрабатывает внутренние стандарты для таких сервисов, чтобы не отстать от тренда и растущего интереса к этой технологии. 
Источник изображения: Mariia Shalabaieva/Unsplash До сегодняшнего момента Apple блокировала в магазине приложений инструменты вайб-кодинга (vibe coding), опасаясь обхода правил, потери дохода и распространения вредоносного ПО, поскольку ИИ-агенты позволяют пользователям создавать приложения в обход официального магазина. Однако полный запрет на агентский ИИ, способный автономно управлять устройством и программами, мог бы вывести компанию из перспективного сегмента. Поэтому в Apple ищут компромисс, проектируя новую архитектуру, которая обеспечит строгое соответствие ИИ-инструментов стандартам приватности и безопасности в рамках собственной экосистемы. Главная цель разработки заключается в предотвращении неконтролируемого поведения алгоритмов и исключения сценариев, подобных инциденту с автономным ИИ-агентом платформы OpenClaw, который бесконтрольно удалял письма пользователей. Новая система защиты Apple позволить исключить любые подобные инциденты на мобильных устройствах. Ожидается, что подробная информация о планах относительно автономных ИИ-агентов будет раскрыта в ходе основного доклада на предстоящей конференции WWDC в июне. Anthropic научила Claude вести бухгалтерию, продажи и маркетинг для малого бизнеса
13.05.2026 [20:20],
Дмитрий Федоров
Anthropic запустила пакет Claude for Small Business — набор коннекторов и готовых агентных рабочих процессов, которые встраивают ИИ-ассистента Claude в инструменты, на которые малый бизнес уже полагается: Intuit QuickBooks, PayPal, HubSpot, Canva, Docusign, Google Workspace и Microsoft 365. ИИ-сервис работает через платформу Claude Cowork и не требует дополнительной платы сверх стоимости подписки на Claude и уже используемых партнёрских сервисов. 
Источник изображения: anthropic.com После нескольких лет борьбы за корпоративные контракты и массовую аудиторию ИИ-стартапы теперь соревнуются за малый бизнес — почти нетронутый сегмент, в котором штат сотрудников невелик, а времени на эксперименты не хватает. На малый бизнес приходится 44 % ВВП США. Он обеспечивает работой почти половину занятых в частном секторе, однако внедрение ИИ здесь заметно отстаёт от крупных предприятий. «Индустрия программного обеспечения исторически создавалась для крупных корпораций, стартапов с венчурным финансированием и массовых потребителей, — заявила Лина Окман (Lina Ochman), руководитель направления малого и среднего бизнеса Anthropic. — Но не для компании из 15 человек, не для ландшафтной фирмы на 30 сотрудников и не для агентства недвижимости на 50 работников». По её словам, многие владельцы понимают, что ИИ способен помочь, но превратить окно чата с ИИ в инструмент для расчёта зарплат, выставления счетов или маркетинга им не удаётся. В предлагаемый пакет входят 15 готовых рабочих процессов в области финансов, операций, продаж, маркетинга, кадров и обслуживания клиентов, а также 15 навыков, построенных вокруг задач, которые владельцы называют самыми трудоёмкими. При планировании зарплат Claude сверяет остаток средств в QuickBooks с входящими расчётами PayPal, строит 30-дневный прогноз, ранжирует просроченные платежи и готовит напоминания на утверждение. При закрытии месяца ИИ-ассистент сопоставляет бухгалтерские книги с расчётами, отмечает расхождения, составляет отчёт о прибылях и убытках и экспортирует пакет документов бухгалтеру через Intuit QuickBooks. Среди других инструментов — контроль счетов, анализ маржинальности, подготовка к налоговому сезону, проверка договоров, сортировка лидов и разработка контентной стратегии. Рынок при этом непростой: владельцы чувствительны к ценам, ограничены во времени и осторожно относятся к передаче данных ИИ-моделям. По данным опроса Anthropic, половина предпринимателей называет безопасность данных главным препятствием для внедрения ИИ. Компания подчёркивает, что Claude не действует бесконтрольно: пользователь сам инициирует каждый рабочий процесс, утверждает план и подтверждает результат, прежде чем что-либо будет отправлено, опубликовано или оплачено. Claude получает ровно те же права доступа, что и сама учётная запись, а на тарифах Team и Enterprise данные клиентов не используются для обучения ИИ. С 14 мая Anthropic отправляется в турне по десяти городам США — Чикаго, Талса, Даллас, Нью-Джерси, Батон-Руж, Бирмингем, Солт-Лейк-Сити, Балтимор, Сан-Хосе и Индианаполис — с бесплатными полудневными тренингами и практическими семинарами по работе с ИИ для 100 местных предпринимателей в каждом городе. Уход Sora открыл дорогу конкурентам: ИИ-генераторы видео Kling AI и AI Video ворвались в топы Apple App Store
13.05.2026 [18:53],
Дмитрий Федоров
Два приложения для создания видео с помощью ИИ — Kling AI и AI Video — поднялись на пятое и шестое места в рейтинге самых скачиваемых бесплатных приложений Apple App Store. Оба лидируют в своих категориях: Kling AI заняло первую строчку в «Графике и дизайне», AI Video — в «Фото и видео». Их рост начался спустя два месяца после закрытия видеосервиса Sora компании OpenAI. Оба приложения выигрывают от нового всплеска внимания пользователей iPhone к ИИ-генерации видео. 
Источник изображений: apps.apple.com OpenAI свернула Sora главным образом из-за стоимости обслуживания: бесплатный сервис потреблял слишком много ресурсов. Компания сосредоточилась на ChatGPT и Codex — инструментах для повышения продуктивности, причём Codex лучше раскрывается на платных тарифах. 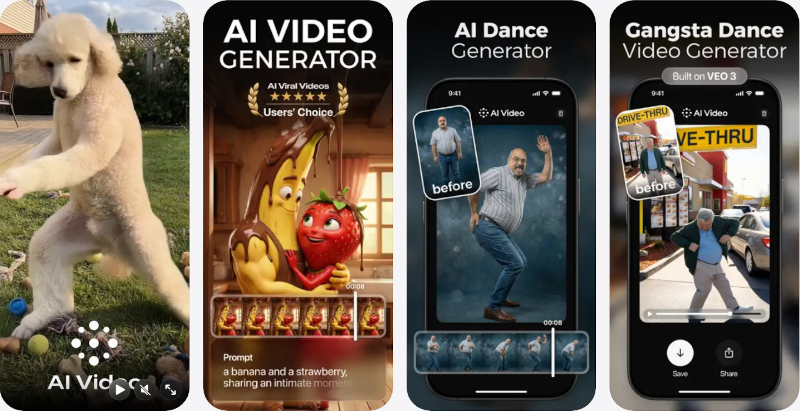
AI Video - AI Video Generator После ухода Sora конкурирующие ИИ-приложения стали активнее продвигать генерацию видео. Gemini и Grok уже позволяют превращать текстовые запросы и изображения в ролики, однако для этих универсальных чат-ботов видео остаётся лишь одной из возможностей. 
Kling AI: AI Image&Video Maker Kling AI и AI Video целиком посвящены созданию роликов. Kling AI появилось в App Store три месяца назад. AI Video выпущено компанией HUBX, у которой в магазине размещено 15 ИИ-приложений. Новое приложение нацелено на создание вирусных видеороликов. Выше обоих в рейтинге стоят только продукты OpenAI, Anthropic, Google и Meta✴✴. Sora тоже возглавляла чарт при запуске, но через несколько месяцев перестала показывать заметные результаты. Биологический ИИ оказался обоюдоострым: он создаёт и яды, и антидоты — и не ясно, что опаснее
13.05.2026 [15:31],
Дмитрий Федоров
Универсальные ИИ-чат-боты и специализированные ИИ-модели для биологии облегчают проектирование токсинов, вирусов и пандемических патогенов, а с ними и нового биооружия. Серьёзность угрозы подтверждают опрошенные журналом Nature учёные и исследователи. Однако они расходятся во мнениях: одни требуют ограничить доступ к программам и обучающим данным, другие — ставить барьер на этапе синтеза ДНК. Часть исследователей надеется, что тот же ИИ поможет создать антидоты и противоядия. 
Источник изображения: Sangharsh Lohakare / unsplash.com Тревожным сигналом стал разработанный в 2024 году китайскими учёными ИИ-инструмент для проектирования конотоксинов — белков из яда морских моллюсков-конусов, способных блокировать ионные каналы нервной системы и убивать человека. В письме в закрытую дискуссионную группу по ИИ и биотехнологиям, с которым ознакомился Nature, высокопоставленный сотрудник правительства США назвал работу возможным риском для биобезопасности — особенно потому, что инструмент построен на открытой языковой модели белков, разработанной американскими учёными. Соавтор статьи Сюэ Вэйвэй (Weiwei Xue) из Чунцинского университета возражает: работа нацелена на поиск лекарств, а переход от расчётов к созданию реальных молекул требует серьёзной экспертизы и оборудования. «Теоретически — и именно это не даёт мне спать ночами — сейчас можно разработать токсины уровня рицина или других очень смертоносных агентов, которые будут практически необнаружимы», — говорит Мартин Пачеса (Martin Pacesa), структурный биолог из Цюрихского университета (UZH). Доклад Национальных академий наук, инженерии и медицины США (NASEM) за 2025 год добавляет трезвости: усилению пандемических патогенов мешают нехватка качественных данных и трудности с их лабораторным производством. Но создание дизайнерских токсинов уже доступно, признают эксперты, а Тимоти Дженкинс (Timothy Jenkins) из Технического университета Дании (DTU) предупреждает, что такой токсин будет трудно обнаружить, а применить его скорее могут против конкретного человека. 
Источник изображения: ChatGPT Главная защита, по мнению многих учёных, происходит на этапе синтеза ДНК: компании, изготавливающие ДНК, прогоняют каждый заказ через скрининговое ПО, ищущее следы известных токсинов и патогенных белков. Работа исследователей Microsoft под руководством Эрика Хорвица (Eric Horvitz), опубликованная в 2025 году, показала, что эту проверку можно обойти с помощью ИИ. Команда сгенерировала 76 000 синтетических гомологов — молекул с той же опасной функцией, что у известных токсинов и вирусных белков, но с другой ДНК-последовательностью, незнакомой скрининговым базам. Около четверти лучших образцов проскользнули мимо проверки в четырёх компаниях по синтезу ДНК, участвовавших в эксперименте, но после обновления ПО пропуск упал примерно до 3 %. Скрининг ДНК пока остаётся добровольным: указ президента США 2025 года толкает американских грантодателей к обязательным правилам, Европейский союз (ЕС), Великобритания и Новая Зеландия идут следом, но в большинстве стран требований нет. В Китае (более 30 % мировых заказов на синтез ДНК) скрининг рекомендован правительством, но обязательным пока не стал. Встроенные защитные ограничения самих ИИ-моделей тоже обходятся. В исследовании SecureBio под руководством Сета Доноу (Seth Donoughe) почти 90 % участников сумели получить от универсальных больших языковых моделей (LLM) биологическую информацию высокого риска. Биоинженер Лэ Цун (Le Cong) с помощью универсального ИИ-агента обманом заставил геномную языковую модель Evo 2 сгенерировать новые версии белков коронавируса SARS-CoV-2 и ВИЧ-1 (HIV-1), хотя её не обучали на данных о вирусах, заражающих человека. Издание The New York Times ранее сообщало, что мужчина, арестованный в Индии по обвинению в подготовке производства рицина для теракта, спрашивал советы у ChatGPT. 
Источник изображения: ChatGPT Часть индустрии движется к ограниченному доступу. В апреле OpenAI анонсировала ИИ-систему для биологии — GPT-Rosalind: её получат только проверенные исследователи и организации, а получивших доступ пользователей будут отслеживать на признаки разработки биооружия. Коалиция за инновации в области готовности к эпидемиям (CEPI) готовит в Осло «платформу готовности к пандемиям», которая, скорее всего, будет доступна только проверенным пользователям. Дэвид Бейкер (David Baker) из Вашингтонского университета (UW), лауреат Нобелевской премии по химии 2024 года за труды по дизайну белков и предсказанию их третичной структуры, настроен сдержанно: «Мы всегда исходили из того, что польза для мира значительно превышает опасности. Но по мере роста возможностей этот вопрос важно держать в поле зрения». Защита тоже не отстаёт. Дженкинс совместно с НАТО разрабатывает масс-спектрометрический метод идентификации дизайнерских белков в подозрительных образцах, а на рынок биозащиты вышли частные компании: Red Queen Bio в Сан-Франциско и Valthos в Нью-Йорке привлекли инвестиции на $15 млн и $30 млн соответственно. Стоит признать, что биотехнологический ИИ — обоюдоостр: те же модели создают и угрозу, и защиту, и кто опередит — неясно. «Многие участки этой темы кажутся мне одновременно крайне неопределёнными и крайне срочными», — говорит Тесса Алексаньян (Tessa Alexanian) из Международной инициативы по биобезопасности для науки (IBBIS). Создатель Claude Code рассказал, что каждую ночь запускает тысячи ИИ-агентов и управляет ими со смартфона
13.05.2026 [14:48],
Дмитрий Федоров
Создатель Claude Code Борис Черни (Boris Cherny) рассказал, что каждую ночь запускает около двух тысяч ИИ-агентов — автономных программ, которые самостоятельно выполняют задачи по написанию кода, — а управляет ими в основном со смартфона. 
Источник изображения: @anthropic.ai / youtube.com Его слова показали, как часть инженеров Кремниевой долины начинает использовать ИИ-системы не столько как чат-ботов, сколько как постоянно работающих автономных помощников. «У меня приложение Claude, и если открыть его, слева есть вкладка с кодом — у меня там просто куча запущенных сессий», — сказал Черни, показывая телефон аудитории. Обычно он ведёт от пяти до десяти таких сессий, в каждой из которых работают несколько агентов. «Обычно каждую ночь у меня пара тысяч агентов, которые занимаются более глубокой работой», — добавил он. Для постоянной автоматизации Черни пользуется двумя функциями Claude Code: /loops и Routines. Первая позволяет запускать повторяющиеся задачи на локальном компьютере через системный планировщик cron, вторая выполняет их на удалённом сервере, так что держать ноутбук открытым не нужно. «Это просто самая крутая штука, — сказал он. — Если вы ещё не пробовали, очень рекомендую». 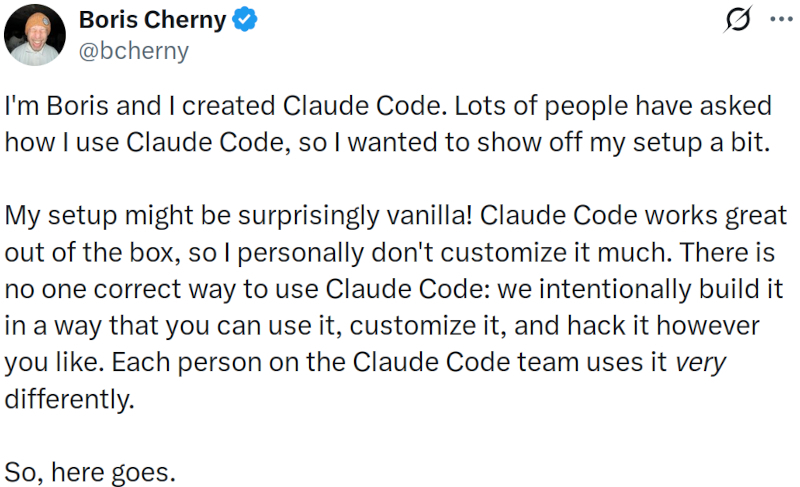
Источник изображения: @bcherny / x.com Черни и раньше делился подробностями работы с агентами. В январе он разместил описание своего рабочего процесса в соцсети X, назвав его «на удивление обычным». Той публикации уже пять месяцев. За это время её сохранили более 104 000 раз, а просмотры превысили 8,1 млн. «Забавно, — сказал Черни. — Я не думал, что это кого-то удивит. Для меня это просто обычный способ писать код». Resident Evil Requiem обеспечила Capcom девятый подряд рекордный год — издатель делает ставку на генеративный ИИ
13.05.2026 [13:40],
Михаил Романов
Японский издатель и разработчик Capcom отчитался о результатах за прошедший финансовый год (закончился 31 марта) и наметил план ускорения роста компании за счёт генеративного ИИ. 
Источник изображений: Capcom По итогам 2026 финансового года чистые продажи Capcom достигли 195,3 млрд иен ($1,24 млрд), что на 15,2 % лучше результата год назад (169,6 млрд иен), а операционная прибыль выросла на 14,5 % до 75,3 млрд иен ($480 млн). Благодаря упомянутым результатам Capcom достигла «рекордного уровня чистых продаж и прибыли на всех уровнях девятый год подряд». Операционная прибыль растёт уже 13 лет кряду: из них последние 11 лет — более чем на 10 %. 
Актуальные продажи франшиз Capcom За отчётный период Capcom продала 59,07 млн игр (51,81 млн год назад), что тоже стало рекордом. Значительный вклад в успех внёс экшен-хоррор Resident Evil Requiem, за два месяца разлетевшийся по миру в количестве 7 млн копий. Суммарные продажи игр франшизы Resident Evil превысили 201 млн копий, Monster Hunter — 127 млн, Street Fighter — 59 млн, Devil May Cry — 38 млн, Dead Rising — 19 млн, Dragon’s Dogma — 14 млн, а Okami — 4,8 млн.  Что касается ИИ, то Capcom намерена использовать технологию для повышения продуктивности и эффективности разработки. В частности, чтобы освободить сотрудников от рутинных задач ради творческих. Под рутинными задачами Capcom понимает подготовку концепт-артов, визуальных ориентиров и генерацию идей. Если раньше мозговой штурм требовал участия нескольких людей, то теперь хватит и одного, вооружённого ИИ. Сотрудники Meta✴ взбунтовались против ПО, следящего за движениями их мышей
13.05.2026 [11:10],
Алексей Разин
Корпорации пытаются оправдать сохранение прежнего штата персонала в условиях бурного развития искусственного интеллекта, для оценки эффективности работы каждого сотрудника применяются всё более причудливые методики. Meta✴✴ с прошлой недели начала устанавливать на рабочие ПК сотрудников приложение, которое следит за движениями мыши. Это уже вызвало волну протестов среди американских сотрудников компании. 
Источник изображения: Unsplash, Anna Kumpan Об этом сообщает Reuters со ссылкой на фотографии, которыми очевидцы поделились с агентством. Листовки с призывами выступить против данной инициативы работодателя через подписание особой петиции появились в американских офисах Meta✴✴ Platforms в местах с потенциально высокой проходимостью: у кулеров с водой, аппаратов с закусками, в туалетных комнатах и помещениях для совещаний. Примечательно, что на следующей неделе Meta✴✴ должна сократить до 10 % своего персонала, следуя общей для американских техногигантов тенденции. Капитальные расходы на развитие ИИ-инфраструктуры для крупных технологических корпораций США сейчас важнее, чем сохранение рабочих мест за сотрудниками. По мнению некоторых работников Meta✴✴, приложение для отслеживания движений курсорам мыши будет использовано руководством для создания программных агентов, способных заменить реальных сотрудников с учётом специфики их работы. Официальные представители компании подчеркнули, что подобные методы создания ИИ-агентов действительно рассматриваются, но это нужно для демонстрации эффективности подобного программного обеспечения широкой аудитории. В Великобритании сотрудники Meta✴✴ пытаются создать профсоюз для защиты своих прав. Google представила Gemini Intelligence — следующий эволюционный шаг Gemini на Android-смартфонах
13.05.2026 [09:31],
Павел Котов
На посвящённой Android презентации Google рассказала о пакете новых функций на основе искусственного интеллекта Gemini Intelligence. На самых мощных смартфонах ИИ сможет управлять широким набором приложений, генерировать элементы пользовательского интерфейса и заполнять формы. 
Источник изображений: blog.google Некоторые функции ИИ-агента уже работают на последних моделях смартфонов Google Pixel и Samsung Galaxy S26. До настоящего момента ИИ поддерживал управление лишь небольшим числом приложений, например, для заказа такси и доставки еды, но в обозримом будущем Google пообещала расширить их набор; доступны они будут на большем количестве устройств. Ещё одно важное нововведение — мультимодальность. Сейчас управление ИИ-агентом Gemini осуществляется при помощи текстовых и голосовых запросов, но в перспективе он сможет принимать в качестве команд снимки экрана и фотографии: можно будет отправить ему скриншот списка покупок из приложения для заметок, и он добавит эти товары в корзину. При условии, что смартфон поддерживает Gemini Intelligence, конечно. 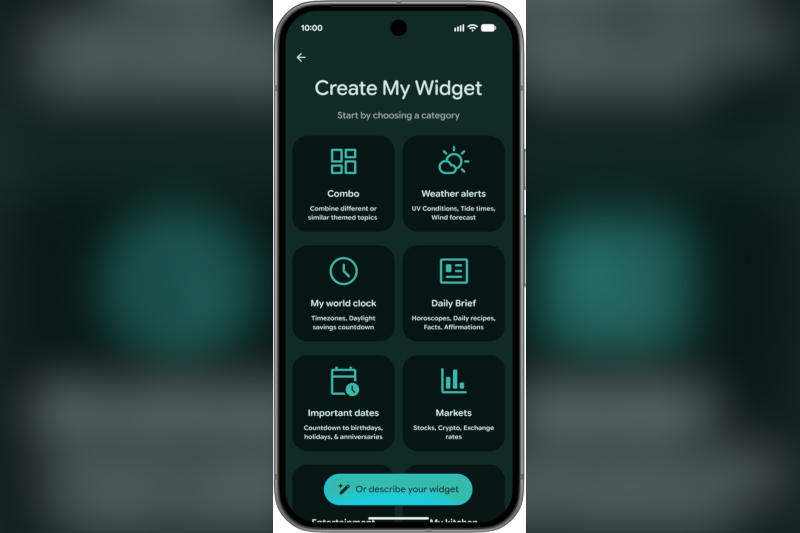 Функция Create My Widget в пакете Gemini Intelligence, как отметили в Google, является первым шагом к «генеративному пользовательскому интерфейсу». Она работает в соответствии со своим названием — создаёт по текстовому описанию виджеты, которые добавляются на домашний экран смартфона. Велосипедист, например, может запросить погодный виджет, который с первого взгляда показывает направление ветра и осадки; а также панель для вывода конкретных рецептов — скажем, блюд с высоким содержанием белка. Созданные ИИ виджеты могут отображаться не только на смартфоне, но и на умных часах с Wear OS. Возможно, на грядущем мероприятии Google I/O компания расскажет об идее «генеративного пользовательского интерфейса» подробнее.  В мобильной версии Chrome появились некоторые функции Gemini из настольной версии браузера. В частности, это кнопка Gemini, по нажатии которой можно отправить ИИ-помощнику содержимое текущей страницы и задать ему вопросы прямо в браузере. Подписчикам платных тарифов Google AI Pro или Ultra будет доступна также функция автоматического поиска и выполнение задач — например, запись на приём, — но её придётся подождать до июня.  Gemini получил поддержку автозаполнения при работе с формами. Обратившись к функции Personal Intelligence, ИИ-помощник изучает данные из «Google Фото» и Gmail и подставляет нужную информацию, например, номер автомобиля пользователя. Функции Gemini Intelligence будут развёртываться в течение года, пообещали в Google. Глава OpenAI заявил в суде, что Илон Маск сам поддержал идею перевода стартапа на коммерческие рельсы
13.05.2026 [07:08],
Алексей Разин
К середине этой недели очередь давать показания в суде дошла и до генерального директора OpenAI Сэма Альтмана (Sam Altman), который выступает ответчиком по иску Илона Маска (Elon Musk). Последний, по его словам, не только не был против перевода OpenAI на коммерческую основу, но и собирался подчинить себе этот стартап. 
Источник изображения: Unsplash, Zac Wolff В свою очередь, Альтман под присягой заявил, что обвинения Маска в стремлении руководства OpenAI отречься от изначальной благотворительной миссии стартапа беспочвенны. Альтман отметил, что после появления идеи о создании внутри OpenAI коммерческой структуры он надеялся на успех благотворительной организации. Обвинения Маска в намерениях Альтмана «украсть благотворительность», по словам последнего, «даже не укладываются в голове». Напомним, исковые требования Илона Маска включают не только отстранения Сэма Альтмана и президента Грега Брокмана (Greg Brockman) от управления OpenAI, но и выплату компенсации в размере $150 млрд. Сам Маск в суде ранее признался, что вложил в OpenAI около $38 млн. Коммерческая структура внутри OpenAI была создана в марте 2019 года, уже после ухода Илона Маска из состава совета директоров компании. По словам Альтмана, Маск не только не противился идее создания коммерческой структуры, но и поддерживал её. Попутно Илон Маск хотел получить до 90 % акций OpenAI, и такие амбиции вызывали у Альтмана сильный эмоциональный дискомфорт, как следует из его показаний. На тот момент руководство OpenAI в целом не было настроено против Илона Маска, но идея последнего по поводу объединения стартапа с Tesla многих насторожила, включая самого Альтмана. Такой альянс, по словам последнего, вряд ли позволил бы OpenAI достичь своих первоначальных целей. Маск, как утверждает Альтман, не возражал против перевода OpenAI на коммерческие рельсы, если при этом он будет контролировать стартап. Он даже хотел передать стартап собственным детям по наследству в случае своей внезапной смерти. «Илон заявил, что будет работать только в компаниях, которые он полностью контролирует. Меня это очень сильно беспокоило. Одной из причин, по которым мы основали OpenAI, была идея против сосредоточения власти над сильным искусственным интеллектом (AGI) в руках единственного человека, какими бы благими ни были его намерения», — признался глава OpenAI. Маск пытался внушить совету директоров стартапа мысль о том, что со временем его доля в капитале может уменьшиться, но закрепить письменно условие постепенного отказа от контроля над активами он не был готов. Альтману в ходе судебного заседания также пришлось ответить на вопросы адвоката Маска по поводу своей репутации среди ближайшего руководства OpenAI. Из показаний нескольких соратников Альтмана было известно, что он не производил впечатления искреннего человека и порядочного бизнесмена. Сам генеральный директор OpenAI в суде заявил, что считает себя честным предпринимателем, заслуживающим доверия. При этом он не может сказать, что в рамках своей деятельности вводил кого-либо в заблуждение. Впрочем, Альтман заявил, что в некоторые моменты своей жизни он мог оставаться не до конца честным с окружающими. 
Источник изображения: Unsplash, Sasun Bughdaryan Свои ощущения в период краткосрочной отставки из OpenAI Альтман описал словами: «Я хотел побежать назад в полыхающее здание, чтобы спасти его». Непосредственно после отставки с поста генерального директора стартапа он не хотел возвращаться и был готов перейти на работу в Microsoft, но OpenAI для него значил слишком много. Напрямую Альтман не владеет акциями OpenAI, но у него есть доля в фонде, который инвестировал в этот стартап. Со слов главы OpenAI становится известно, что компания привлекла за всё время своего существования около $175 млрд от частных инвесторов. На начальном этапе Альтман вложил $3,75 млн в OpenAI, но позднее он раздал все свои акции подчинённым. Уход Маска из совета директоров OpenAI в 2018 году, по словам Альтмана, кто-то воспринял с тревогой, опасаясь сокращения финансирования, другие вздохнули с облегчением. Маск требовал от исследователей регулярных отчётов о достигнутом прогрессе, и Альтман в целом считает, что Илон не понимал, как нужно руководить исследовательской лабораторией. Многих из ключевых специалистов OpenAI требования Маска просто демотивировали. Окружение Альтмана в OpenAI боялось мести со стороны Маска после его ухода из стартапа. Альтман добавил, что до сих пор благодарен Маску за его вклад в развитие OpenAI, и на начальных этапах совместной работы он глубоко уважал Илона. Позже его действия начали противоречить целям OpenAI, и он предпринимал их, как считает Альтман, «из ревности». Он также назвал Маска «несчастным человеком, который живёт с отсутствием чувства безопасности», выразив на этой почве сочувствие богатейшему человеку планеты. Примечательно, что председатель совета директоров OpenAI Брет Тейлор (Bret Taylor) сообщил суду о получении в феврале 2025 года предложения от возглавляемого Маском консорциума инвесторов о поглощении OpenAI. Это произошло примерно через полгода после подачи Маском иска к стартапу. Как пояснил Тейлор, сценарий противоречил сути судебного иска: коммерческие инвесторы должны были поглотить благотворительный стартап, который таковым должен был оставаться, исходя из требований самого Маска. Судебное заседание, которое длится уже третью неделю, должно завершиться на этой, после чего суд может вынести свой вердикт к 18 мая. OpenAI вооружила европейские компании ИИ-моделью GPT-5.5-Cyber для защиты от хакеров
12.05.2026 [21:41],
Дмитрий Федоров
OpenAI открыла европейским компаниям доступ к своим последним ИИ-моделям, включая специализированную GPT-5.5-Cyber, для поиска уязвимостей в корпоративных системах. Среди участников программы — немецкие Deutsche Telekom и Scalable Capital, испанские BBVA и Telefonica, британская Sophos. 
Источник изображения: Levart_Photographer / unsplash.com Программа Trusted Access for Cyber предоставляет верифицированным компаниям из ключевых отраслей — финансов, телекоммуникаций, энергетики и государственных услуг — доступ к моделям OpenAI с ограничениями, допускающими использование только в целях киберзащиты. Управляющий директор OpenAI по региону EMEA (Европа, Ближний Восток и Африка) Эммануэль Марий (Emmanuel Marill) заявил, что по мере роста возможностей ИИ важно соблюдать баланс между доступностью, полезностью и безопасностью. По его словам, необходимо блокировать опасную деятельность и одновременно обеспечивать проверенных специалистов по киберзащите инструментами, действительно полезными для защиты систем, обнаружения уязвимостей и быстрого реагирования на киберугрозы. Запуск ИИ-модели Mythos конкурентом OpenAI — компанией Anthropic — в прошлом месяце существенно повысил риски для банков и других компаний. Способность новых передовых ИИ-моделей программировать на высоком уровне дала беспрецедентные возможности для поиска уязвимостей и разработки способов их эксплуатации, что вызвало опасения относительно использования таких моделей для дестабилизации финансовых и иных организаций. OpenAI предложила Европейской комиссии открытый доступ к функциям кибербезопасности, сообщил Брюссель в понедельник, добавив, что Anthropic пока не проявила такой же готовности. Бывший министр финансов Великобритании Джордж Осборн (George Osborne), возглавляющий инициативу OpenAI for Countries, в понедельник направил в Еврокомиссию письмо, в котором указал, что демократизация доступа к инструментам киберзащиты способна укрепить коллективную безопасность и отвечает европейским приоритетам. OpenAI также объявила о создании новой компании с начальными инвестициями свыше $4 млрд для помощи организациям в разработке и внедрении ИИ-систем и о приобретении консалтинговой фирмы Tomoro для её ускоренного масштабирования. ИИ сломал правила кибербезопасности — 90-дневное окно раскрытия уязвимостей теперь мертво
12.05.2026 [17:33],
Дмитрий Федоров
Исследователь безопасности Химаншу Ананд (Himanshu Anand) заявил, что отраслевой стандарт 90-дневного окна раскрытия уязвимостей фактически мёртв. Сам Ананд с помощью ИИ-инструментов создал рабочий эксплойт для уже исправленной уязвимости за 30 минут, а независимые исследователи массово обнаруживают одни и те же уязвимости за считанные дни. 
Источник изображения: Sasun Bughdaryan / unsplash.com Поводом стали две свежие уязвимости повышения привилегий в ядре Linux — Copy Fail и Dirty Frag: обе позволяли получить права администратора через локальную учётную запись. Информацию о Dirty Frag раскрыли чуть больше чем через неделю после её передачи команде разработки ядра Linux, задолго до привычных 90 дней. Предположительно, исследователи поспешили, потому что уязвимость уже активно эксплуатировалась хакерами. Масштаб проблемы Ананд показал на собственном примере: он нашёл уязвимость в неназванном интернет-магазине, позволявшую покупать товары за $0, и отправил отчёт, но выяснилось, что за предшествующие шесть недель о той же ошибке сообщили ещё 10 исследователей. Ананд заключил, что специалисты по кибербезопасности, использующие ИИ, сходились на одних и тех же ошибках практически одновременно. Другой расследователь инцидентов подтвердил, что при появлении новой уязвимости он видит волну дублирующихся отчётов за считанные дни и задаётся вопросом, что мешает злоумышленникам делать то же самое до её устранения. ИИ не умнее человека, но он работает круглосуточно и крайне эффективен в распознавании закономерностей, а большинство эксплойтов коренится именно в повторяющихся ошибках кода. Ананд продемонстрировал это на фреймворке React, собрав эксплойт для уже закрытой уязвимости за 30 минут. По словам Ананда, 90-дневное окно не защищает никого, а ежемесячные циклы обновлений тоже мертвы, поскольку 30-дневный промежуток между обнаружением и исправлением предполагает, что злоумышленники медленнее релизного конвейера. Он призывает относиться к каждой критической уязвимости как к P0 (наивысший приоритет инцидента в системах баг-трекинга), исправлять немедленно и встроить ИИ в процессы проверки кода. Ананд резюмирует, что пока разработчик читает описания CVE, злоумышленник уже изучает git log --diff-filter=M — и выигрывает. Открытое программное обеспечение превращается в обоюдоострое оружие: ИИ используют доступность кода и для защиты, и для атаки. Впрочем, патч может появиться за считанные часы — команда Mozilla выпустила 423 исправления только за апрель. Для закрытого ПО перспектива хуже: ИИ-боты столь же хороши в декомпиляции и сетевом сканировании, и вполне вероятно, что Microsoft, Apple или Google переживут свой момент Copy Fail скорее рано, чем поздно. Браузер Apple Safari научится сам группировать вкладки
12.05.2026 [16:41],
Павел Котов
Apple тестирует функцию автоматической группировки вкладок в браузере Safari, сообщил авторитетный аналитик Bloomberg Марк Гурман (Mark Gurman). Функция дебютирует с выходом платформ iOS 27, iPadOS 27 и macOS 27.  Apple Safari будет упорядочивать вкладки в автоматическом режиме — функция войдёт в пакет Apple Intelligence, но в её основе, очевидно, лежат какие-то алгоритмы искусственного интеллекта. Когда она дебютирует, пользователи сами смогут указывать, хотят ли они сгруппировать вкладки в браузере. Нововведение окажется полезным для тех, кто держит открытыми десятки или сотни вкладок в Apple Safari. Функция дополнит «Группировку вкладок», которая появилась в Safari 15 ещё в 2021 году. Google представила схожую возможность в Chrome в январе 2024 года — при помощи генеративного ИИ браузер самостоятельно упорядочивает похожие вкладки. Apple же традиционно отстаёт от других технологических гигантов во внедрении функций ИИ. Функцию автоматического упорядочивания вкладок компания может представить на выставке WWDC 26, которая откроется 8 июня. Сотрудники Amazon используют ИИ вхолостую — ради отчётности, а не результата
12.05.2026 [14:04],
Алексей Разин
По мере распространения технологий генеративного искусственного интеллекта корпорации начали требовать от сотрудников демонстрировать практические успехи в их освоении, но подобное давление породило паразитное явление: работники поручают ИИ бессмысленные задачи исключительно для улучшения статистики внедрения. 
Источник изображения: Amazon, Dall-E По крайней мере, о таком феномене рассказывает Financial Times применительно к деятельности компании Amazon. Сотрудники интернет-гиганта всё активнее используют программное решение MeshClaw, которое подключается к рабочим инструментам сотрудников и может выполнять задания от их имени. Некоторые сотрудники Amazon начали использовать этого агента для автоматизации фактически бесполезной активности, только чтобы повысить свой личный рейтинг с точки зрения эффективности освоения ИИ. Произошло это в результате нарастающего давления со стороны руководства, которое теперь требует, чтобы более 80 % разработчиков программного обеспечения на еженедельной основе использовали ИИ. По каждому сотруднику ведётся отдельная статистика, и отстающим от целевых показателей приходится давать непростые объяснения руководству. Формально руководители не должны использовать данные об ИИ-токенах для оценки эффективности сотрудников, но последние начали подозревать, что так или иначе это происходит. У отдельных работников Amazon в таких условиях появляются ложные стимулы, и они фактически имитируют высокую активность в использовании ИИ ради достижения корыстных целей, а не общего блага компании. Американские техногиганты вкладывают колоссальные суммы в развитие инфраструктуры ИИ, поэтому им важно демонстрировать инвесторам и руководству, что данные технологии внедряются и приносят практическую пользу. Проще всего это делать на собственном примере, поэтому собирающаяся направить на капитальные расходы $200 млрд в этом году Amazon оказывает растущее давление на своих сотрудников. Первоначально Amazon выкладывала групповую статистику по использованию ИИ своими сотрудниками, но теперь доступ к индивидуальным результатам имеют только сами специалисты и их непосредственное руководство. Последнему формально запрещается использовать такую статистику для оценки эффективности персонала. Как поясняет Financial Times, внутри компании Meta✴✴ Platforms подобные злоупотребления среди сотрудников тоже наблюдаются. Агентское ПО MeshClaw, которое используется для таких целей сотрудниками Amazon, способно загружать программный код в продуктивные версии софта, сортировать электронные письма и взаимодействовать с приложениями типа Slack. Над созданием этого агента работало более 30 специалистов Amazon. Многие сотрудники обеспокоены безопасностью применения подобных решений, поскольку ИИ способен генерировать множество ошибок, а его в данном случае мало кто контролирует. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



