|
Опрос
|
реклама
Быстрый переход
Видео: человекоподобные роботы Figure собрали вещи в комнате и заправили постель
12.05.2026 [13:01],
Павел Котов
Американский создатель робототехники Figure продемонстрировал скоординированную работу своих человекоподобных машин. На опубликованном компанией видео два робота вошли в комнату, собрали разбросанные по ней вещи и заправили постель. 
Источник изображения: youtube.com/@figureai Роботы Figure повесили пальто, закрыли ноутбук, убрали наушники, а затем вместе застелили постель, координируя свои действия кивками головы, подняв и разгладив одеяло. Со своей задачей дуэт справился менее чем за две минуты. Управление машинами осуществляет модель искусственного интеллекта Helix-02. Важнейшим аспектом демонстрации стала координация совместных действий роботов, которые выполнили задачу без общего планировщика, центрального контроллера и даже прямого канала связи — хватило просто кивков головы. Каждый робот полагался на собственные камеры, систему интерпретации окружающей среды и определения намерений другого по его движениям. С каждым действием сцена для машин динамически менялась, заставляя их непрерывно адаптировать свои решения, чтобы достичь общей цели. Наиболее сложной задачей стали действия с крупным деформируемым объектом — одеялом. В отличие от жёстких предметов, постельное бельё не имеет стабильной геометрии или заданных точек захвата. Роботам потребовалось предсказывать действия друг друга, постоянно корректируя захват, позу и движения по мере того, как ткань складывалась, растягивалась и смещалась под общим натяжением. Для совместной работы систему Helix AI, в которую уже заложены такие задачи, как уборка дома и складывание белья, пришлось доработать, чтобы обеспечить совместную работу двух машин, исходя только из визуальных данных. Обновлённая модель Helix System AI добавляет роботам механизмы управления всем телом на основе восприятия — это помогает улучшить навигацию в сложных условиях, например при движении по неровной местности и лестницам. Ранее роботы осознавали собственные движения и положение суставов без оглядки на окружающую среду. Теперь производится анализ входных данных с боковых стереокамер — преобразование RGB-изображения в трёхмерную пространственную модель, формирующую представление об окружающей среде в реальном времени. В итоге роботы одновременно «видят» и «чувствуют» местность во время движения. Разработка системы велась с использованием метода обучения с подкреплением в компьютерной симуляции на основе широкого набора случайных ландшафтов местности и условий среды. При переходе к реальным условиям не потребовалось ни дополнительной калибровки, ни тонкой настройки. Усовершенствованная архитектура помогла роботам стать устойчивее при ходьбе, удерживать равновесие на лестницах и других поверхностях даже в условиях меняющегося освещения — помимо простой ходьбы, они теперь могут выполнять широкий набор действий. OpenAI запустила Daybreak — ответ на инициативу Anthropic Glasswing в кибербезопасности на базе Claude Mythos
12.05.2026 [12:24],
Павел Котов
OpenAI объявила о запуске проекта Daybreak в области кибербезопасности — это явно симметричный ответ на инициативу Anthropic Glasswing. В рамках Glasswing некоторым клиентам Anthropic предоставляется доступ к передовой модели искусственного интеллекта Claude Mythos Preview. Она, например, помогла Mozilla обнаружить и закрыть 271 уязвимость в последней версии браузера Firefox. 
Источник изображения: Growtika / unsplash.com OpenAI Daybreak предполагает применение нескольких моделей ИИ, а также спецверсию ИИ-агента Codex. Инициатива основана на предпосылке, что средства киберзащиты должны закладываться в ПО — ограничиваться поиском и устранением уязвимостей больше не получится, уверены в OpenAI. Цель Daybreak состоит в том, чтобы расставить приоритеты в решении наиболее важных проблем и сократить время анализа с нескольких часов до нескольких минут, генерировать и тестировать патчи в репозиториях и отправлять результаты в системы клиентов. Для общих целей клиенты Daybreak смогут использовать новую модель GPT-5.5, а для большинства задач в области кибербезопасности станет применяться версия GPT-5.5 с доступом через Trusted Access for Cyber. Нашлось место и для GPT-5.5-Cyber для «предварительного доступа к специализированным рабочим процессам, в том числе автоматизированного анализа угроз, тестирования на проникновение и проведения контролируемых проверок». В рамках инициативы OpenAI уже сотрудничает с Cloudflare, Cisco, CloudStrike, Palo Alto Networks, Oracle и Akamai. Thinking Machines готовит «полнодуплексный» ИИ, который умеет слушать и говорить одновременно
12.05.2026 [10:29],
Павел Котов
Стартап Thinking Machines Lab, учреждённый в прошлом году бывшим техническим директором OpenAI Мирой Мурати (Mira Murati), рассказал о своём новом проекте. Речь идёт о моделях взаимодействия — системах искусственного интеллекта, способных прерывать человека при общении с ним. 
Источник изображения: Igor Omilaev / unsplash.com Все существующие модели ИИ являются «полудуплексными» и работают по единой схеме. Когда человек говорит, ИИ слушает — и наоборот, когда говорит ИИ, человеку остаётся только слушать его. В Thinking Machines решили изменить эту схему и создать модель, которая обрабатывает человеческую речь и одновременно генерирует ответ. Общение с этой моделью больше напоминает телефонный разговор, чем переписку. 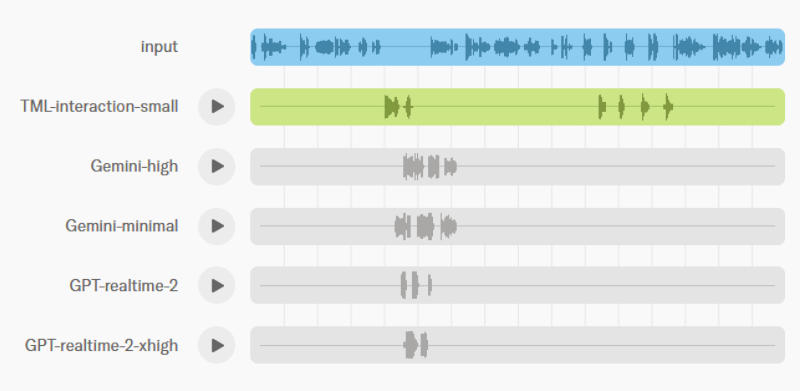
Источник изображения: thinkingmachines.ai Такой способ взаимодействия называется полнодуплексным. Разработанная компанией ИИ-модель TML-Interaction-Small даёт ответ всего за 0,4 секунды. Это примерно соответствует скорости естественного человеческого разговора — и значительно быстрее, чем сопоставимые модели от OpenAI и Google. Пока это предварительная исследовательская версия, а не готовый для широкой аудитории продукт, и компания сейчас не намерена выпускать его в открытый доступ. В ближайшие месяцы Thinking Machines опубликует «ограниченную исследовательскую версию», а широкая аудитория увидит TML-Interaction-Small до конца года. OpenAI создала дочернюю компанию, которая займётся внедрением корпоративного ИИ
12.05.2026 [10:20],
Павел Котов
OpenAI объявила о создании новой компании с первоначальными инвестициями в размере более $4 млрд — она будет помогать организациям во внедрении систем искусственного интеллекта. Для быстрого выхода подразделения на крупный масштаб деятельности разработчик ChatGPT также поглотит консалтинговую фирму Tomoro, передаёт Reuters. 
Источник изображения: Mariia Shalabaieva / unsplash.com После того как первые модели от OpenAI получили высокую оценку среди потребителей, компания начала активно заключать корпоративные контракты и расширять своё присутствие в деловом мире, где её ИИ активно внедряется. Новое предприятие, контрольный пакет акций в котором принадлежит OpenAI — очередная попытка опередить основного конкурента в лице Anthropic, которая не менее активно внедряет свои модели для корпоративных клиентов. Предприятие получило название OpenAI Deployment Company — оно будет выделять клиентам инженеров, специализирующихся на внедрении передовых технологий ИИ, а также сотрудничать с другими компаниями, чтобы определять области, в которых ИИ сможет оказать наибольшее влияние. Внедрением уже занимается вошедшая в OpenAI консалтинговая фирма Tomoro — из её штата разработчик ChatGPT привлечёт около 150 опытных специалистов. Tomoro была создана в 2023 году в альянсе с OpenAI; среди её клиентов значатся такие компании как Mattel, Red Bull, Tesco и Virgin Atlantic. Ранее стало известно, что OpenAI и Anthropic при участии частных инвесторов учредили совместные предприятия, которые будут помогать корпоративным клиентам во внедрении ИИ. В случае с OpenAI внедрением ChatGPT занимается предприятие, которым компания владеет с 19 другими соучредителями: TPG Advent, Bain Capital, Brookfield и другими. xAI теряет популярность, но Илон Маск ещё может вернуть стартап в гонку
12.05.2026 [09:34],
Алексей Разин
Представители OpenAI убеждены, что судебные претензии со стороны Илона Маска (Elon Musk) направлены на укрепление рыночных позиций его собственного стартапа xAI, основанного в 2023 году и недавно присоединённого к SpaceX. Независимая статистика говорит о снижении популярности xAI, но эксперты убеждены, что при наличии мотивации Маск способен всё исправить. 
Источник изображения: Unsplash, Мария Шалабаева В начале мая xAI заключила с Anthropic соглашение о сдаче в аренду вычислительных мощностей Colossus 1, которые xAI изначально планировала использовать для собственных нужд. Это может указывать на замедление темпов развития xAI и разработанного ею чат-бота Grok. Статистика AppMagic, на которую ссылается The Wall Street Journal, указывает на снижения количества скачиваний приложения Grok до 8,3 млн по итогам апреля против более чем 20 млн скачиваний в январе. Данные Recon Analytics гласят, что из более чем 260 000 американских пользователей ИИ-сервисов только 0,174 % в текущем квартале оплачивали подписку на Grok. Это почти столько же, как и годом ранее, и значительно меньше 6 %, соответствующих доле платных подписчиков конкурирующего ChatGPT. Сам Илон Маск в ходе своих апрельских судебных показаний назвал xAI «самой маленькой из ИИ-компаний». Для Grok проблемой остаётся отдалённость от нужд корпоративных пользователей, тогда как OpenAI и Anthropic активно развивают функции содействия ИИ в написании программного кода и автоматизации рутинных офисных задач при помощи ИИ-агентов. Опрос Enterprise Technology Research показал, что по итогам марта этого года 7 % корпоративных респондентов уже используют Grok или собираются это сделать. Годом ранее их доля не превышала 4 %, и хотя положительная динамика очевидна, в случае с Claude показатель вырос с 21 до 48 %, а у Google Gemini он увеличился с 27 до 40 %. При этом некоторые участники рынка верят, что Илон Маск ещё способен исправить ситуацию, если сконцентрируется на этой задаче. Он уже провёл в xAI серьёзную реорганизацию, и она может стать первым этапом реванша. Клиенты в стремительно меняющемся сегменте ИИ слабо привязаны к какой-то конкретной платформе. Если тот же Grok внезапно начнёт демонстрировать более впечатляющие результаты на форме конкурентов, то его популярность возрастёт довольно быстро. Microsoft недосчитается десятков миллиардов от OpenAI — условия сделки переписали
12.05.2026 [07:52],
Алексей Разин
Корпорация Microsoft является старейшим стратегическим инвестором в OpenAI, с 2019 года она поэтапно вложила в стартап не менее $13 млрд, но прошлогодняя реструктуризация OpenAI заложила основу для изменений в характере их взаимоотношений. Так, Microsoft не сможет выручить более $38 млрд за время сотрудничества с OpenAI до конца десятилетия. 
Источник изображения: Microsoft Об этом сообщило издание The Information, напомнив, что первоначально Microsoft могла рассчитывать на получение 20 % выручки OpenAI, причём без ограничения максимальной суммы выручки. Теоретически, это позволяло выручке Microsoft в рамках соглашения с OpenAI достичь $135 млрд. Новая версия соглашения ограничивает эту сумму $38 млрд, экономя тем самым $97 млрд на нужды OpenAI. Считается, что такие условия дадут стартапу больше финансовой независимости на этапе подготовки к IPO, которое должно состояться до конца текущего года. При этом доля выручки OpenAI, на которую Microsoft может претендовать, осталась на уровне 20 %. Просто если до 2030 года её совокупная сумма достигнет $38 млрд, то выплаты в адрес Microsoft просто прекратятся. Если потолок достигнут не будет, выплаты прекратятся после 2030 года в любом случае. В текущем году Microsoft может получить от OpenAI около $6 млрд, как ожидается. В новых условиях OpenAI также получает больше свободы в сфере поиска других партнёров — к числу таковых можно отнести Google и Amazon (AWS), которые являются конкурентами Microsoft. В результате осенней реструктуризации последняя получила примерно 27 % акций OpenAI. На этой неделе генеральный директор Сатья Наделла (Satya Nadella) признался в суде, что Microsoft изначально рассчитывала на получение финансовой выгоды от вложений в OpenAI, а не руководствовалась исключительно гуманистическими мотивами. На инвестициях в стартап Microsoft планировала заработать $92 млрд — это заметно больше упоминаемых выше $38 млрд, но у программного гиганта сохраняется возможность продавать свои акции OpenAI для извлечения дополнительной выгоды. Бывший главный исследователь Илья Суцкевер владеет акциями OpenAI на сумму около $7 млрд
12.05.2026 [06:59],
Алексей Разин
На этой неделе дошла очередь давать показания в суде до бывшего научного руководителя OpenAI Ильи Суцкевера, который стоял у истоков компании, но в мае 2024 года покинул её для создания собственного стартапа SSI. Он признался, что до сих пор владеет акциями OpenAI на сумму около $7 млрд, а к неудачной попытке отправить Альтмана в отставку готовился около года. 
Источник изображения: OpenAI Напомним, в ноябре 2023 года совет директоров OpenAI уволил с поста генерального директора стартапа Сэма Альтмана (Sam Altman), и на протяжении нескольких дней им руководила Мира Мурати (Mira Murati), которая до этого оставалась техническим директором OpenAI. Илья Суцкевер сыграл решающую роль во временной отставке Альтмана, и на этой неделе он признался, что на протяжении года собирал доказательства неискренности генерального директора OpenAI, которые был готов предъявить совету директоров. По мнению Суцкевера, Альтман на тот момент постоянно врал окружающим. Сбор доказательств Суцкевер осуществлял по заданию совета директоров. Илья также подтвердил, что Альтман настраивал руководителей OpenAI друг против друга и подрывал их деловые взаимоотношения. Суцкевер и Мурати обсуждали поведение Альтмана в критическом ключе на протяжении длительного периода, и вопрос его отставки поднимался в ходе этих бесед. По словам Суцкевера, поведение Альтмана в тот период никак не способствовало достижению стартапом любой масштабной цели. Тем не менее, организовав отставку Альтмана, Суцкевер позже испугался за будущее стартапа и проголосовал за восстановление его в должности. Илья Суцкевер также признался в суде, что стоимость принадлежащих ему акций OpenAI по состоянию на ноябрь прошлого года достигала $5 млрд, а в нынешних ценах составляет $7 млрд. Напомним, президенту OpenAI Грегу Брокману (Greg Brockman) принадлежит около $30 млрд в форме акций стартапа. Из показаний бывшего научного руководителя OpenAI также становится известно, что после отставки Альтмана осенью 2023 года велись переговоры о слиянии с конкурирующим стартапом Anthropic, но лично Суцкеверу такая идея не понравилась. Илья также упустил тот момент, когда Microsoft предложила руководству OpenAI создать профильное подразделение в составе своей корпорации. Microsoft рассчитывала превратить $13 млрд в $92 млрд на инвестициях в OpenAI
12.05.2026 [06:30],
Алексей Разин
На новом этапе судебного разбирательства между Илоном Маском (Elon Musk) и OpenAI на этой неделе были привлечены показания Microsoft и генерального директора корпорации Сатьи Наделлы (Satya Nadella). Стало известно, например, что вкладывая первоначально деньги в OpenAI, компания Microsoft рассчитывала на отдачу в размере $92 млрд. 
Источник изображения: Microsoft Эта сумма, как отмечает Bloomberg, упоминается во внутренней документации Microsoft от начала 2023 года, которая была предана огласке в суде в минувший понедельник. «Эти инвестиции сработали, потому что мы взяли на себя риск», — признался в суде Сатья Наделла. Напомним, что к началу 2023 года сумма вложений Microsoft в капитал OpenAI не превышала $13 млрд, но технически именно эта корпорация остаётся крупнейшим инвестором в ИИ-стартап. В октябре прошлого года доля Microsoft в капитале OpenAI оценивалась в $135 млрд. Капитализация стартапа к концу марта этого года достигла $852 млрд. Вкладывать средства в OpenAI корпорация Microsoft начала ещё в 2019 году, до выхода ChatGPT на рынок. Если в 2019 году сумма инвестиций ограничилась $1 млрд, то в 2021 году она удвоилась, а в 2023 году Microsoft вложила ещё $10 млрд. Наделла заявил, что очень гордится данными решениями. Илон Маск обвиняет бывших соратников по OpenAI в отказе от благотворительной миссии стартапа в пользу коммерческой деятельности. По его мнению, именно Microsoft своими деньгами поддержала подобную смену курса. Со временем Microsoft и OpenAI стали прямыми конкурентами, после прошлогодней реструктуризации первая получила около 27 % акций второй. Как и представители OpenAI, руководство Microsoft настаивает, что обвинения Илона Маска беспочвенны и направлены на продвижение интересов его ИИ-стартапа xAI, который был создан в 2023 году. По мнению Маска, направленные Microsoft в капитал OpenAI десять миллиардов долларов окончательно убедили его, что стартап отклоняется от своей некоммерческой миссии. Желание преследовать OpenAI в суде появилось у него в тот период, иск он подал только в 2024 году. Сатья Наделла, как добавляет CNBC, в суде заявил, что Илон Маск никогда не связывался с ним для выражения своей озабоченности инвестициями Microsoft в капитал OpenAI. На вопросы судьи и адвокатов Наделла вчера отвечал на протяжении нескольких часов. Сегодня давать показания начнёт генеральный директор OpenAI Сэм Альтман (Sam Altman). Из показаний Наделлы становится известно, что он не рассматривал вложения в OpenAI, как благотворительные взносы, а делал на них вполне серьёзный коммерческий расчёт с самого начала. Помимо прочего, Microsoft предлагала OpenAI свои вычислительные мощности с существенными скидками, рассчитывая на дальнейшую финансовую отдачу. По состоянию на март 2025 года, связанная с OpenAI выручка Microsoft достигла $9,5 млрд, как следует из показаний представителей последней из компаний. Наделла заявил, что был удивлён внезапной отставкой Альтмана в конце 2023 года, в тот момент он выражал беспокойство по поводу дальнейшего сотрудничества между компаниями, подозревая, что к смещению генерального директора OpenAI привели ревность в команде и плохое взаимодействие между руководством. Наделле не нравилась полнота объяснений причин отставки Альтмана инициаторами этого действия. При этом сам Наделла в тот период не настаивал, чтобы Альтмана вернули на должность генерального директора OpenAI. Наделла обсуждал в переписке с техническим директором Microsoft Кевином Скоттом (Kevin Scott) кандидатуры потенциальных новых членов совета директоров OpenAI. В суде также стало известно о переписке Наделлы с другими руководителями Microsoft от 2022 года, в которой обсуждались возможные роли компаний во взаимоотношениях с OpenAI. Со слов Наделлы, он не хотел, чтобы история сотрудничества IBM и Microsoft в восьмидесятые годы прошлого века повторилась при взаимодействии с OpenAI. Тогда Microsoft, будучи молодой компанией по разработке ПО, получила право продавать операционную систему DOS, прилагая её к персональным компьютерам IBM. Годы спустя Microsoft стала программным гигантом с капитализацией $3 трлн, а IBM в наши дни довольствуется узкими рыночными нишами и капитализацией не более $210 млрд. Google случайно показала грядущий ИИ Omni, который генерирует видео по тексту
12.05.2026 [05:20],
Анжелла Марина
Новая модель Gemini Omni компании Google появилась в ранних демонстрациях, показав впечатляющие результаты генерации видео по текстовым запросам. Некоторые пользователи уже протестировали функцию создания роликов, хотя компания ещё не объявила о запуске официально. 
Источник изображения: Solen Feyissa/Unsplash Как стало известно 9to5Google, модель позволяет создавать видеоремиксы, редактировать контент непосредственно в диалоговом окне чат-бота, а также использовать готовые шаблоны. Метаданные в приложении Gemini указывают на то, что Omni является расширением платформы Veo, однако какое место займёт модель экосистеме продуктов компании, пока неизвестно. https://9to5google.com/wp-content/uploads/sites/4/2026/05/A_professor_writes_out_a_mathe.mp4 В одном из тестовых роликов ИИ сгенерировал сцену, в которой профессор пишет математическое доказательство на учебной доске, корректно отобразив формулы и последовательность объяснений. Во втором запросе была воссоздана сцена с двумя мужчинами, которые едят спагетти в ресторане у моря. Результат получился достаточно реалистичным, хотя и с заметными артефактами, характерными для современных генеративных моделей. Оба запроса заняли 86 % дневного лимита использования в аккаунте тарифа AI Pro. Разработчики пока не представили продукт публично, однако ранее подтвердили приверженность развитию технологий, связанных с генерацией видео, в особенности после решения конкурента прекратить поддержку Sora. Ожидается, что дополнительные детали, касающиеся генерации видео, станут известны на предстоящей конференции Google I/O 2026, где компания традиционно представляет ключевые обновления своих платформ. Даже лучшие ИИ «сыпятся» на длинных задачах: модели теряют четверть данных
12.05.2026 [05:18],
Анжелла Марина
Исследователи Microsoft установили, что даже самые продвинутые ИИ-модели допускают существенные ошибки при выполнении длительных многоэтапных задач. В ходе тестирования такие передовые модели, как Gemini 3.1 Pro, Claude 4.6 Opus и GPT 5.4, потеряли в среднем 25 % содержимого документов, которые были делегированы им для автономной работы. 
Источник изображения: AI Команда Филиппа Лабана (Philippe Laban), Тобиаса Шнабеля (Tobias Schnabel) и Дженнифер Невилл (Jennifer Neville) из Microsoft Research разработала бенчмарк DELEGATE-52, имитирующий рабочие процессы в 52 профессиональных областях, например, в написании кода, нотной записи или кристаллографии. Модели оценивались по способности сохранять целостность документов после 20 циклов обработки, при этом порогом готовности считался результат не ниже 98 %. Результаты показали, что модели лучше справлялись с задачами программирования и хуже с обработкой естественного языка. Повреждение документов и, соответственно, снижение оценки до 80 % и ниже, произошло более чем в 80 % комбинаций. Лучшая из протестированных моделей, которой оказалась Google Gemini 3.1 Pro, соответствовала критериям готовности лишь в 11 из 52 областей. При этом ошибки возникали не постепенно, а скачкообразно, например, за один цикл взаимодействия модель могла потерять от 10 до 30 баллов. Более совершенные модели (Gemini 3.1 Pro, Claude 4.6, GPT 5.4) избегали мелких ошибок за счёт того, что откладывали их обработку на более поздние этапы при меньшем количестве взаимодействий. Одновременно выяснилось, что при работе ИИ-моделей с доступом к инструментами в режиме агентского управления их результаты не только не улучшались, но даже ухудшались к концу цикла в среднем на 6 %. По словам учёных, пользователям по-прежнему необходимо внимательно контролировать работу ИИ-систем при делегировании им полномочий, поскольку текущие модели готовы к автономной работе лишь в узких областях. При этом авторы бенчмарка признают прогресс LLM и отмечают, что, например, семейство ИИ-моделей OpenAI за 16 месяцев улучшило показатели производительности с 14,7 % до 71,5 %. Google впервые обнаружила и заблокировала ИИ-эксплойт нулевого дня для взлома 2FA
11.05.2026 [22:01],
Дмитрий Федоров
Google впервые обнаружила и заблокировала эксплойт нулевого дня (метод атаки через уязвимость, о которой разработчик ещё не знает), созданный с помощью ИИ. По данным Google Threat Intelligence Group (GTIG), известные киберпреступные группировки готовили масштабную атаку на систему двухфакторной аутентификации (2FA) в веб-приложении с открытым исходным кодом для системного администрирования. 
Источник изображения: Sasun Bughdaryan / unsplash.com Исследователи Google нашли в коде эксплойта на языке Python характерные следы ИИ-модели — вымышленную оценку по шкале CVSS (стандарт оценки критичности уязвимостей) и типично «учебное» форматирование Оценка CVSS оказалась выдуманной: ИИ-модель сгенерировала её сама, а не взяла из реальной базы уязвимостей. Структура кода тоже указывала на ИИ — она воспроизводила шаблоны, характерные для обучающих данных больших языковых моделей (LLM). Причина уязвимости оказалась не в опечатке и не в сбое, а в ошибке логики веб-приложения. Разработчик платформы запрограммировал в коде допущение, что определённый компонент системы всегда заслуживает доверия, и не стал его перепроверять. Именно через этот непроверяемый компонент злоумышленники и обходили двухфакторную аутентификацию. Какое именно приложение стало мишенью, Google не раскрыла. Исследователи также уточнили, что ИИ Gemini, по их мнению, при создании эксплойта не применяли. Атаку удалось сорвать до начала массового применения. GTIG отмечает ещё одну тенденцию: злоумышленники атакуют не только с помощью ИИ, но и саму инфраструктуру ИИ-систем — автономные функции ИИ-агентов и внешние модули доступа к данным. Хакеры прибегают к так называемому ролевому обману: формулируют запрос, в котором предлагают ИИ-модели представить себя экспертом по безопасности, и таким образом обходят встроенные ограничения. Кроме того, они загружают в модели целые базы данных об уязвимостях и используют инструмент OpenClaw для отладки вредоносных программ в контролируемых средах — прежде чем развёртывать атаки на реальных целях. Следующая Vision Pro выйдет не раньше 2028 года: Apple переключилась на умные очки и ИИ-устройства
11.05.2026 [20:02],
Дмитрий Федоров
Преемника гарнитуры дополненной реальности Apple Vision Pro, стоимость которой составляет $3499, не стоит ожидать раньше чем через два года. Большую часть команды, работавшей над устройствами смешанной реальности (AR), компания перебросила на умные очки и носимые ИИ-устройства. 
Источник изображения: apple.com По данным журналиста Bloomberg Марка Гурмана (Mark Gurman), Apple продолжает работать над новыми технологиями и материалами, чтобы со временем выпустить более дешёвую и лёгкую гарнитуру закрытого типа. Однако такой продукт, по всей видимости, не находится в активной разработке, а давно обсуждавшийся проект Vision Air был отменён в прошлом году. Главным приоритетом стали умные очки. Бывших участников Vision Products Group — подразделения, отвечавшего за Vision Pro, — перевели в эту команду, а часть инженеров направили на доработку Siri, создание AirPods с камерами и ИИ-кулона. Напомним, что после дебюта в 2024 году Vision Pro так и не стала массовым продуктом — главным образом из-за высокой стоимости. В прошлом году Apple обновила гарнитуру, переведя её на более мощный процессор Apple M5. «Никогда и ни за что»: Red Hook Studios не будет генерировать голос покойной звезды Darkest Dungeon с помощью ИИ, несмотря на разрешение
11.05.2026 [17:27],
Михаил Романов
Мрачные ролевые роглайки Darkest Dungeon и Darkest Dungeon II запомнились многим благодаря озвучке рассказчика в исполнении Уэйна Джуна (Wayne June), однако в январе 2025 года артист скончался. Заменять его с помощью ИИ разработчики из канадской Red Hook Studios точно не будут. 
Источник изображений: Red Hook Studios Сооснователь и творческий руководитель Red Hook Studios Крис Бурасса (Chris Bourassa) в комментарии к смежной теме на форуме Reddit прояснил позицию студии в отношении потенциальной генерации голоса Джуна для будущих игр серии Darkest Dungeon с помощью генеративного ИИ. По словам Бурассы, Джун был категорически против того, чтобы его голос использовался для тренировки нейросетей, однако незадолго до смерти дал Red Hook разрешение на это: «Мы никогда его не просили. Думаю, он пытался поставить интересы игры/команды/фанатов выше своих. Показать путь дальше». «Я отказался. <...> Я бы никогда и ни за что не обесценил его невероятную и неподвластную времени актёрскую игру, позволив машине подражать ему. Его голос и манера речи были человеческими. Я буду вечно благодарен за то, что получил возможность писать для него», — признался Бурасса. Пользователи в комментариях похвалили Red Hook за уважение к наследию Джуна. Для сравнения: CD Projekt Red с разрешения семьи воссоздала голос умершей звезды польского дубляжа Милогоста Речека (Milogost Reczek) для озвучки Виктора Вектора в дополнении Phantom Liberty к Cyberpunk 2077. ИИ упростил создание рекламы для малого бизнеса, но выделиться стало сложнее
11.05.2026 [14:19],
Дмитрий Федоров
Для малого бизнеса ИИ упростил производство рекламы, но усложнил задачу выделиться на фоне остальных. То, что должно было стать удобным инструментом, превращается в ловушку. Чем больше брендов опираются на одни и те же ИИ-инструменты, тем однороднее становится результат: похожие формулировки, схожая структура, узнаваемая тональность. Реклама выходит достаточно опрятной для публикации, но внешний лоск — не то же самое, что воздействие на покупателя, а скорость производства — не то же самое, что оригинальность. 
Источник изображения: Haberdoedas / unsplash.com ИИ по своей природе воспроизводит вероятное и знакомое — то, что уже похоже на успешный маркетинг. Поэтому целые товарные категории постепенно начинают звучать так, будто о них писал один и тот же автор для одной и той же аудитории, независимо от того, кто на самом деле стоит за товаром. Объявления, которые сливаются с фоном, собирают меньше внимания и слабее вовлекают. Бюджеты распределяются по поверхностным показателям, команды снова и снова выбирают безопасное вместо действенного. Итог — больше контента, больше расходов и почти никакого движения в узнаваемости бренда. Для малого и среднего бизнеса последствия серьёзнее, чем для крупных игроков. Большие компании могут позволить себе невыразительную рекламу — за ними охват, репутация и бюджет, способный перекрыть слабый креатив. У небольших брендов такого запаса прочности нет: они держатся на ясности, самобытности и доверии. Их маркетинг должен делать больше при меньших ресурсах. Если ИИ вытравливает из рекламы характер и конкретику, он подтачивает одно из главных преимуществ небольших компаний. В этом и состоит ирония ситуации: многие предприниматели используют ИИ ради усиления, а в итоге получают ослабление того, что годами пытались выстроить. Проблема, как правило, начинается задолго до публикации. Маркетологи просят ИИ сгенерировать готовое объявление, не определив толком, что бренд хочет сказать, кого он должен зацепить, и почему это должно волновать аудиторию. Когда стратегическое мышление поверхностно, ИИ его не улучшает — лишь ускоряет. Реклама выходит хорошей, но не дотягивает до той остроты, после которой её запоминают. Без внутреннего направления результаты нескольких команд начинают сходиться, и репутационный капитал бренда тихо размывается — медленно и почти необратимо. Бренды, которые справляются с этой задачей, действуют иначе. Они используют ИИ на этапе производства — тестируют направления, ускоряют выпуск материалов, исследуют варианты, — но ключевые решения оставляют за людьми. Основную нагрузку несут чёткое позиционирование, глубокое понимание аудитории и сильное творческое руководство, а ИИ работает усилителем, а не заменой. Одного этого сдвига часто достаточно, чтобы контент работал, а не растворялся в общей ленте. Хорошая реклама всегда зависела от понимания того, что делает бизнес особенным, и от умения выразить это внятно. На рынке, заваленном контентом, оригинальность стала только дороже. ИИ помогает двигаться быстрее, но скорость имеет значение, только если направление выбрано верно. Китайские производители чипов могут заработать на буме ИИ даже без передовых техпроцессов, уверен глава SMIC
11.05.2026 [13:13],
Алексей Разин
Не секрет, что крупнейший контрактный производитель чипов в Китае — компания SMIC, давно находится под прицелом американских санкций, а потому лишена доступа к передовому оборудованию, позволяющему выпускать чипы по технологии тоньше 7 нм. Основатель SMIC уверен, что такое положение дел не мешает китайским производителям успешно развиваться в условиях бума ИИ. 
Источник изображения: SMIC Комментарии Ричарда Чана (Richard Chang) приводит издание STAR Market Daily. По его мнению, китайская полупроводниковая отрасль в целом сильна своими специализированными техпроцессами и масштабами производства. Прежде всего, бум ИИ так или иначе подогревать спрос на широкий ассортимент полупроводниковых компонентов, а не только передовые техпроцессы. Для строительства ЦОД нужны компоненты для материнских плат и блоков питания, все они выпускаются и китайскими производителями тоже. В натуральном выражении, по словам основателя SMIC, на передовые техпроцессы сейчас приходится менее 20 % объёмов мировой полупроводниковой продукции. Более 80 % формируют чипы, выпускаемые по зрелым и специализированным техпроцессам. Здесь-то как раз и закрепились китайские производители полупроводниковых компонентов. Тем более, что тайваньские конкуренты поднимают цены и мигрируют на более совершенные техпроцессы, освобождая нишу для китайских производителей чипов. Со второй половины прошлого года в Китае активизировалась обработка 300-мм кремниевых пластин с использованием 90-нм и более грубых техпроцессов. Кроме того, проявление ИИ-бума заключается и в росте спроса на периферийные вычисления: умные устройства, промышленное оборудование, автомобильные системы автопилота и роботы требуют огромного количества чипов, и основную их часть можно выпускать по зрелым техпроцессам. Китайским производителям это позволит неплохо заработать даже в условиях ограниченности доступа к передовому зарубежному оборудованию. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



