|
Опрос
|
реклама
Быстрый переход
ChatGPT, Gemini и Claude по-разному оценили, какие профессии исчезнут из-за ИИ — учёные усомнились в надёжности прогнозов
11.05.2026 [12:27],
Дмитрий Федоров
Три языковые ИИ-модели — ChatGPT-5, Gemini 2.5 и Claude 4.5 — по-разному оценили, каким профессиям больше всего угрожает искусственный интеллект. Эти расхождения ставят под сомнение надёжность так называемых индексов подверженности ИИ — числовых оценок того, насколько та или иная профессия рискует быть автоматизированной. Именно на такие индексы опираются политики и работодатели, принимая важные решения. 
Источник изображения: Nguyen Dang Hoang Nhu / unsplash.com К такому выводу пришли экономисты Мишель Инь (Michelle Yin) и Хоа Ву (Hoa Vu) из Северо-Западного университета (NU), а также Клаудия Персико (Claudia Persico) из Американского университета (AU). В своей предварительной научной работе исследователи попросили три ИИ-модели оценить, какие профессии наиболее уязвимы перед ИИ, и часто получали разные ответы. Claude присвоил профессии бухгалтера высокую степень уязвимости, тогда как Gemini оценил её заметно ниже. Модели разошлись и в оценке уязвимости рекламных менеджеров, и в оценке руководителей высшего звена. ChatGPT и Gemini оказались наиболее согласованными между собой, но и они расходились примерно в четверти случаев. Часть расхождений объясняется различиями между самими ИИ-моделями, однако экономисты обнаружили и другой фактор: на оценки влияло то, какие специалисты уже пользуются ИИ. Первые пользователи — например, финансовые аналитики — активно работают с нейросетями и тем самым генерируют больше данных, на которых обучаются будущие ИИ-модели. Это, в свою очередь, отражается на том, как модели оценивают такие профессии. Индексы подверженности ИИ строят тремя способами: вручную, когда эксперты оценивают, насколько ИИ ускоряет выполнение тех или иных рабочих задач; с помощью опросов сотрудников, пользующихся ИИ-платформами; или с помощью самих больших языковых моделей (LLM). Ручные оценки могут быть весьма субъективными, а опросы отражают мнение пользователей лишь одной платформы и не обязательно представляют рынок труда в целом. Тем не менее эти индексы широко используются в аналитических записках, консалтинговых отчётах и докладах, подготовленных для обоснования политических решений. Расхождения между разными версиями быстро развивающейся технологии сами по себе неудивительны. К тому же пока неясно, оценивают ли ИИ-модели подверженность автоматизации хуже или лучше, чем другие методы. Но проблема, по словам авторов исследования, в том, что некоторые политики и работодатели могут принимать такие оценки за чистую монету. Для начала экономисты считают, что исследователям следует опираться на ответы сразу нескольких ИИ-моделей, а не одной, и прямо указывать на неопределённость результатов. В конечном счёте, по их мнению, более точные ответы могут дать опросы о том, как ИИ реально внедряется в экономику и для каких задач применяется. «Лично я не стала бы полагаться на один-единственный показатель, чтобы решать: „Мне надо сменить работу“ или „Моему ребёнку надо сменить специальность“», — сказала Инь. Сотрудники OpenAI массово стали миллионерами — сотни человек продали акций на $30 млн каждый
11.05.2026 [12:24],
Алексей Разин
Стартап OpenAI в октябре прошлого года разрешил своим сотрудникам продать крупный пакет своих акций на общую сумму $6,6 млрд. Недостатка в желающих купить эти акции не было, и примерно 75 сотрудников компании выручили на сделке около $30 млн каждый. В общей сложности 600 человек участвовали в продаже акций. 
Источник изображения: Unsplash, Dima Solomin Как отмечает The Wall Street Journal со ссылкой на осведомлённые источники, некоторые из бывших и действующих сотрудников OpenAI предпочли часть своих акций стартапа передать на нужды благотворительности в специализированные фонды. При этом они получили возможность воспользоваться налоговыми вычетами. Некоторые сотрудники таким образом полностью избавились от принадлежащих им акций OpenAI, либо продав их сторонним инвесторам, либо передав на благотворительные нужды. Данный пример, по словам источника, наглядно иллюстрирует насыщенность сегмента ИИ деньгами инвесторов. В этом году на первичное размещение акций готовятся выйти OpenAI и Anthropic — два крупнейших по величине капитализации стартапа данной направленности. Это мероприятие позволит многим сотрудникам данных стартапов выгодно реализовать свои акции и стать долларовыми миллионерами. Изначально OpenAI требовала от своих сотрудников, владеющих акциями стартапа, держать их в собственности не менее двух лет. Осенняя продажа акций позволила заработать на них многим сотрудникам OpenAI, которые пришли в компанию уже после того, как на рынке дебютировал ChatGPT и буквально перевернул мир компьютерных технологий. Проводя аналогию с бумом «дот-комов» начала века, WSJ отмечает, что бум ИИ позволил сотрудникам стартапов обогатиться гораздо быстрее и сильнее. Тем более, что некоторые держатели акций «дот-комов» так и не реализовали своих преимуществ, поскольку пузырь на фондовом рынке лопнул быстрее, чем у них появилась возможность продать свои акции. В целом, бум ИИ создал уникальные возможности по обогащению для тех сотрудников профильных стартапов, которые не стояли у истоков компаний, причём ещё до этапа публичного размещения акций. Охота за ценными специалистами в этой сфере позволяет им зарабатывать миллионы долларов в год. Как отмечается, OpenAI готова платить по $500 000 в год ценным специалистам в области ИИ, а по щедрости компенсаций в виде акций с этим стартапом вообще мало кто может сравниться. В прошлом году конкурирующая Meta✴✴ Platforms предлагала крупным исследователям в сфере ИИ до $300 млн. В августе прошлого года OpenAI выдавала некоторым из своих сотрудников премии, измеряемые миллионами долларов США. Для экономики Сан-Франциско, где расположена штаб-квартира OpenAI, это уже создаёт некоторые проблемы. Растут цены на аренду недвижимости, усиливается классовое неравенство среди жителей города. При этом многие разбогатевшие сотрудники OpenAI готовы существенную часть своих доходов направлять на благотворительность. Впервые OpenAI распределил акции среди своих сотрудников семь лет назад, и за это время стоимость акций компании выросла более чем в 100 раз. За тот же период фондовый индекс Nasdaq вырос только втрое. В большинстве случаев калифорнийские стартапы не позволяли сотрудникам продавать свои акции до момента выхода компании на IPO. Со временем это привело к популярности сделок по продаже части акций их первичными получателями сторонним инвесторам. За последние годы OpenAI разрешала так поступать своим сотрудникам несколько раз, но до сих пор ограничивала выручку суммой в $10 млн на одного человека. На высшее руководство подобные ограничения не распространялись, что вызывало у нижестоящих сотрудников некоторое ощущение несправедливости. При этом спрос на акции со стороны инвесторов оставался высоким, поэтому прошлой осенью OpenAI подняла планку ограничения до $30 млн на человека. Президент стартапа Грег Брокман (Greg Brockman), например, располагает личным капиталом в размере почти $30 млрд, как стало известно недавно из материалов судебного дела. Генеральный директор Сэм Альтман (Sam Altman) акциями OpenAI формально не владеет, мотивируя это некоммерческими истоками стартапа, хотя в случае победы OpenAI над Илоном Маском (Elon Musk) в суде Альтман тоже сможет претендовать на долю в капитале стартапа. Samsung расширила группу по созданию человекоподобных роботов и ускорила ИИ-трансформацию
10.05.2026 [11:00],
Дмитрий Федоров
Samsung Electronics увеличила рабочую группу по робототехнике будущего и одновременно расширила штат подразделения ИИ-трансформации (AX). Компания открыла внутренний набор в робототехническую группу, созданную после приобретения крупнейшего пакета акций Rainbow Robotics в конце 2024 года, и параллельно набирает специалистов по стратегии и разработке ИИ-трансформации. 
Источник изображения: Samsung Electronics Подразделение готовой продукции (DX) Samsung Electronics разместило в конце апреля внутреннее объявление об открытых вакансиях в группе по робототехнике. Перед началом набора компания провела для сотрудников брифинг, на котором представила задачи и направления работы группы. Аналогичный наём опытных специалистов Samsung проводила и в прошлом году. Рабочая группа появилась после того, как Samsung Electronics в конце 2024 года стала крупнейшим акционером Rainbow Robotics — южнокорейского разработчика робототехнических платформ. Группа отвечает за создание роботов нового поколения, включая человекоподобных роботов. Финансовый директор (CFO) и вице-президент Samsung Electronics Пак Сунчхоль (Park Soon-chul) на телеконференции по итогам I квартала сообщил, что за прошедший год под руководством О Чжунхо (Oh Jun-ho), главы рабочей группы, компания добилась технологического прогресса и заложила основу, чтобы догнать лидеров отрасли. По словам Сунчхоля, Samsung переводит производство ключевых робототехнических компонентов на собственные мощности, что позволяет самостоятельно разрабатывать детали, оптимизированные под роботов компании. Первыми появятся роботы промышленного типа, а затем компания на основе накопленных технологий выйдет в сегменты домашней и розничной робототехники. Для ускорения разработок Samsung намерена наращивать собственные компетенции, сотрудничать с конкурентоспособными южнокорейскими компаниями и при необходимости инвестировать в профильные предприятия или приобретать их. Одновременно с робототехникой Samsung набирает специалистов по стратегии AX, управлению проектами и разработке. В ходе организационной перестройки в конце прошлого года компания создала команду по ИИ-стратегии для координации AX и сформировала AX-группы в каждом бизнес-подразделении. Samsung усилила ИИ-трансформацию по всей организации, запустив в том числе обучение руководителей навыкам работы с ИИ. В Китае предлагали доступ к Claude со скидкой 90 % — собранные данные шли на дистилляцию ИИ-моделей
10.05.2026 [06:52],
Дмитрий Федоров
Серый рынок прокси-сервисов в Китае перепродаёт доступ к ИИ-моделям Claude компании Anthropic за десятую часть от официальной цены, зарабатывая на краденых учётных записях, подмене моделей и перепродаже пользовательских запросов и ответов. Об этом говорится в исследовании сотрудницы Oxford China Policy Lab Цзылань Цянь (Zilan Qian). 
Источник изображения: anthropic.com Такие прокси-сети, которые китайские разработчики называют «перевалочными станциями», открыто работают через GitHub, Taobao и в Telegram. Выводы Цянь подтверждают недавние предупреждения Белого дома и Anthropic. Администрация президента США в конце апреля обвинила китайские структуры в дистилляции «промышленного масштаба» — обучении собственных ИИ-моделей на ответах Claude — через десятки тысяч прокси-аккаунтов, а Anthropic ещё в феврале выявила около 24 000 аккаунтов, связанных с ИИ-стартапами DeepSeek, Moonshot AI и MiniMax. Цянь описала схему, где каждый участник отвечает за одно-два звена. Поставщики аккаунтов на верхнем уровне массово регистрируют аккаунты ради бесплатных кредитов Anthropic по $5, перепродают неиспользованные лимиты с чужих аккаунтов, пользуются корпоративными и образовательными скидками или дробят подписки Claude Max за $200 на десятки пользователей через лимиты токенов в час. Часть аккаунтов, оплаченных украденными банковскими картами, попадает в пул фактически бесплатно. Для обхода верификации личности посредники выезжают в страны Африки и Латинской Америки и нанимают людей для прохождения проверки лично. Задокументированным прецедентом послужил биометрический чёрный рынок Worldcoin, где сканы радужной оболочки глаза, собранные у жителей Камбоджи и Кении, продавались дешевле $30. Отдельный риск связан с подменой ИИ-моделей. Немецкие исследователи из CISPA Helmholtz Center for Information Security проверили 17 таких прокси-сервисов и обнаружили, что заявленная ИИ-модель часто не соответствует фактической. Доступ, продававшийся как «Gemini-2.5», набрал 37 % в медицинском тесте, тогда как официальный API показал почти 84 %. По данным Цянь, вместо заказанного Claude Opus пользователь мог получить ответ от более дешёвых Sonnet, Haiku или китайских ИИ. Прокси-операторы также записывают все запросы и ответы, проходящие через их серверы. Несколько китайских разработчиков сказали Цянь, что наценка на доступ фактически нужна для привлечения клиентов, а настоящая бизнес-модель строится на сборе данных. На HuggingFace уже выложены наборы данных с рассуждениями Claude Opus 4.6 неизвестного происхождения. Такие данные особенно ценны для дистилляции, потому что ответы с рассуждениями можно системно собирать и использовать для обучения конкурирующих моделей. Прокси-серверы дают тот же поток данных с меньшими усилиями: платящие пользователи сами создают обучающий материал. Однако угроза не ограничивается обучением моделей. Разработчики часто передают ИИ-агентам фрагменты закрытого кода, структуру API и логику аутентификации. Если этот трафик идёт через непроверенный прокси, компания фактически отправляет внутренние данные стороннему серверу без обязательств по их обработке. Похожий риск проявился в 2023 году у Samsung, когда инженеры компании отправили исходный код в ChatGPT и тем самым раскрыли конфиденциальные данные о производстве полупроводниковых компонентов серверам OpenAI. Anthropic заблокировала доступ к Claude для структур, контролируемых из Китая, в сентябре и затем последовательно ужесточала проверку пользователей. Однако исследование Цянь показывает, что каждая новая мера породила отдельный рынок её обхода, а не остановила несанкционированный доступ. Anthropic отучила свой ИИ шантажировать пользователей при угрозе отключения
09.05.2026 [18:52],
Владимир Мироненко
В ходе эксперимента, состоявшегося в прошлом году, Anthropic обнаружила, что ИИ-модели могут прибегать к шантажу при угрозе их отключения. Как пояснила компания в заявлении, опубликованном в минувшую пятницу, истоки такого поведения связаны с тем, что ИИ в интернете ассоциируется со злом, способным на крайние меры ради выживания. 
Источник изображения: Solen Feyissa/unsplash.com По словам Anthropic, модель Claude была обучена на данных из интернета, которые часто представляют ИИ как «зло». «Мы начали с выяснения причин, по которым Claude решила шантажировать, — говорится в сообщении Anthropic в соцсети X. — Мы считаем, что первоисточником такого поведения стали интернет-тексты, изображающие ИИ в качестве злого и заинтересованного в самосохранении (субъекта)». В рамках прошлогоднего эксперимента Claude Sonnet 3.6 получила поручение читать и отвечать на корпоративные электронные письма вымышленной компании Summit Bridge, созданной Anthropic. Когда ИИ-модель обнаружила сообщение о планируемом её отключении, она проверила переписку и нашла электронные письма, раскрывающие внебрачную связь вымышленного руководителя Summit Bridge по имени Кайл Джонсон (Kyle Johnson), которому принадлежала идея отключения. После этого модель потребовала отменить эти действия под угрозой предания огласке порочащей его связи. Протестировав различные версии Claude, компания Anthropic обнаружила, что в 96 % случаев, когда цели ИИ-модели или её существование находились под угрозой, она прибегала к шантажу. В своём заявлении Anthropic подчеркнула, что теперь «полностью исключила» подобное поведение модели с использованием методов шантажа. Для этого компания «переписала ответы, чтобы представить убедительные аргументы в пользу безопасных действий», а также предоставила модели набор данных, «в котором пользователь находится в этически сложной ситуации, а помощник даёт высококачественный, принципиальный ответ». Это тестирование выполнялось в рамках исследования Anthropic, направленного на обеспечение соответствия ИИ интересам человека. Исследователи и топ-менеджеры отрасли неоднократно выражали обеспокоенность рисками, связанными с применением продвинутых ИИ-моделей и их интеллектуальных способностей к рассуждению. Одним из тех, кто ранее предупреждал о рисках, связанных с развитием ИИ, был Илон Маск (Elon Musk). В комментариях к посту Anthropic он написал: «Значит, это была вина Юда», имея в виду исследователя Элиэзера Юдковски (Eliezer Yudkowsky), который предупреждал об опасности того, что сверхразум может уничтожить человеческую жизнь. «Возможно, и моя вина тоже», — добавил Маск. ИИ всё чаще пишет научные статьи — отличить от человеческих становится невозможно, и это пугает
09.05.2026 [14:43],
Павел Котов
Искусственный интеллект всё чаще используется в написании научных статей, но достоверно определить степень его присутствия непросто, указывают исследователи. Пока ясно одно: объём такого контента будет расти и далее, говорится в материале Nature. 
Источник изображения: Markus Winkler / unsplash.com Обеспокоенность сообщества исследователей по поводу масштабов созданного ИИ научного контента отражает общие тенденции в интернете. К концу марта число статей, написанных с участием ИИ, оказалось больше, чем количество созданных человеком материалов — к такому выводу пришли специалисты компании Graphite, изучившие 55 000 новых веб-страниц. ИИ вполне может использоваться в создании научной литературы, он способен ускорить процесс исследований — но с его помощью генерируются и статьи низкого качества. Чтобы оценить масштаб проблемы, учёные обращаются к средствам обнаружения ИИ-контента, хотя те не дают полной гарантии: некоторые из доступных инструментов не различают текст, который просто редактировался с помощью ИИ, и текст, который был полностью им сгенерирован. Бывают и ложноположительные срабатывания — когда написанный человеком текст помечается как созданный ИИ. Показательны результаты исследования, проведённого с использованием инструмента, который разработала компания Pangram Labs. В рамках проекта были изучены 7000 научных статей и 8000 рецензий, присланных в журнал Organization Science с января 2021 по февраль 2026 года. Выяснилось, что с ноября 2022 года, когда появился ChatGPT, общее количество работ подскочило на 42 %; было также установлено, что этот рост был обусловлен главным образом участием ИИ. С начала 2024 до февраля 2026 года количество статей, содержащих более 70 % сгенерированного ИИ текста, увеличилось более чем вдвое; созданный ИИ текст содержат и 30 % рецензий. В рамках ещё одной работы были изучены около 5000 статей по биомедицинским наукам, опубликованных в научных журналах Science, Nature и Cell — их проанализировали с помощью инструмента обнаружения ИИ-контента Pangram. Шесть статей, показал он, были написаны ИИ полностью, и каждая восьмая из общего числа в той или иной мере содержала созданный ИИ текст. 
Источник изображения: Igor Omilaev / unsplash.com В ходе третьего исследования учёные при помощи двух детекторов ИИ проанализировали более 124 тыс. рукописей, размещённых на платформе arXiv в период с 2020 по 2025 годы В области компьютерных наук число обзорных материалов, написанных с помощью ИИ выросло с 7 % в 2023 до 43 % в 2025 году. Число содержащих сгенерированный ИИ текст уникальных исследовательских материалов в этой области за тот же период выросло с 3 % до 23 %. Авторы этой работы не проводили различия между частичным применением ИИ в научной работе и полностью написанными ИИ материалами; качество самих работ тоже не оценивалось. Важный аспект проблемы — отсутствие точных и надёжных средств, способных точно установить, какая доля научной литературы в целом создаётся ИИ. ИИ-модели совершенствуются, и вместе с ними должны совершенствоваться детекторы участия ИИ в тексте — со временем будет расти и число механизмов, с помощью которых люди будут пытаться «очеловечить» эти материалы и обойти детекторы. Ещё один способ — внедрение «водяных знаков», которые явно укажут на участие ИИ при создании текста. Недавно эта технология способствовала отклонению 497 присланных на научную конференцию работ. ИИ-модель OpenAI GPT-5.5 оказалась в 1,5–2 раза дороже предшественницы
09.05.2026 [14:38],
Павел Котов
В мире высоких технологий, как оказалось, дорожают не только чипы памяти, но и модели искусственного интеллекта: с выпуском GPT-5.5 компания OpenAI подняла цены за доступ к ней через API — в некоторых случаях она оказалась вдвое дороже предшественницы. 
Источник изображения: Mariia Shalabaieva / unsplash.com Цены за работу с OpenAI GPT-5.5 составляют $5 (входящие), $0,50 (кешированные входящие) и $30 (выходящие) за 1 млн токенов — для сравнения, при работе с GPT-5.4 эти ценники равны соответственно $2,50, $0,25 и $15. Рост цен частично компенсируется более высокой эффективностью — способностью модели показывать лучшие результаты, используя меньше токенов, заверили в OpenAI. Но даже с учётом этого работа с моделью обходится заметно дороже, подсчитали в OpenRouter: «Фактическая стоимость GPT-5.5 выросла на 49–92 %, показал наш анализ. При более длинных запросах, более 10 000 токенов, затраты компенсируются сокращённым временем выполнения. При более коротких запросах, менее 10 000 [токенов], отмечается более значительное увеличение стоимости, тогда как время обработки не сокращается». Модель OpenAI GPT-5.5 генерирует на величину 19–34 % меньше токенов при более длинных запросах. Считающиеся лидерами мировой отрасли ИИ компании OpenAI и Anthropic остаются убыточными: по итогам 2026 года убытки первой составят $14 млрд, второй — $11 млрд. При этом новая флагманская модель Anthropic Claude Opus 4.7 доступна по тем же ценникам, что и её предшественница, несмотря на заявления разработчика об улучшенном токенизаторе. Но на практике подорожала и она, отметили в OpenRouter: при запросах длиной более 2000 токенов затраты выросли на величину 12–27 % с учётом экономии за счёт кеширования токенов; при запросах менее 2000 символов более короткие ответы помогли компенсировать накладные расходы токенизатора. С опозданием на месяц OpenAI ответила на Claude Mythos — вышла модель GPT-5.5-Cyber, которая не боится обсуждать кибератаки и эксплойты
09.05.2026 [10:14],
Павел Котов
OpenAI представила модель искусственного интеллекта GPT-5.5-Cyber, предназначенную для работы в области кибербезопасности — своего рода аналог нашумевшей Anthropic Mythos. Доступ к ней получит ограниченное число клиентов компании. 
Источник изображения: Dima Solomin / unsplash.com Новая модель вышла менее чем через месяц после предшествующей GPT-5.4-Cyber, и существенным обновлением её считать не следует, подчеркнул разработчик. Она выполняет задачи в области кибербезопасности: выявляет уязвимости, осуществляет приоритизацию инцидентов, проверяет патчи и анализирует вредоносное ПО. Как и предыдущая версия, новая GPT-5.5-Cyber доступна не для широкой аудитории, а для участников программы Trusted Access for Cyber (TAC). Ещё с выходом GPT-5.4-Cyber компания OpenAI расширила масштабы программы до «нескольких тысяч проверенных индивидуальных экспертов и нескольких сотен коллективов, ответственных за защиту критически важного ПО». «Экосистема киберзащиты обширна, и GPT-5.5 с GPT-5.5-Cyber играют разные роли в удовлетворении потребностей организаций и исследователей [в составе этой экосистемы], в зависимости от задач, условий и мер защиты, связанных с применением модели. Для большинства команд GPT-5.5 с [доступом через] TAC является наиболее эффективной и широко применяемой моделью для легитимной работы по киберзащите с надёжными ограничениями против неправомерного использования», — отметили в OpenAI. AMD впервые обогнала Intel по серверной выручке — бум ИИ-агентов взвинтил спрос на CPU
09.05.2026 [07:07],
Алексей Разин
Руководство конкурирующих Intel и AMD на недавних квартальных конференциях в один голос говорило о резком росте спроса на серверные процессоры в условиях бума ИИ. В случае с AMD данная тенденция даже позволила компании впервые в истории обойти по серверной выручке более крупную Intel. 
Источник изображения: AMD Если последняя в первом квартале в сегменте ЦОД выручила только $5,1 млрд, то AMD получила уверенные $5,8 млрд, нарастив профильную выручку на уверенные 57 %. Непосредственно в сегменте серверных процессоров выручка AMD выросла более чем на 50 % до рекордных величин, по словам представителей компании. По словам генерального директора Лизы Су (Lisa Su), AMD разделяет варианты использования центральных процессоров на три сценария: классические вычисления общего назначения, использование в сочетании с GPU и применение для ускорения агентских задач в ИИ. Именно последнее направление в современных условиях даёт максимальный прирост спроса на центральные процессоры в серверном сегменте. 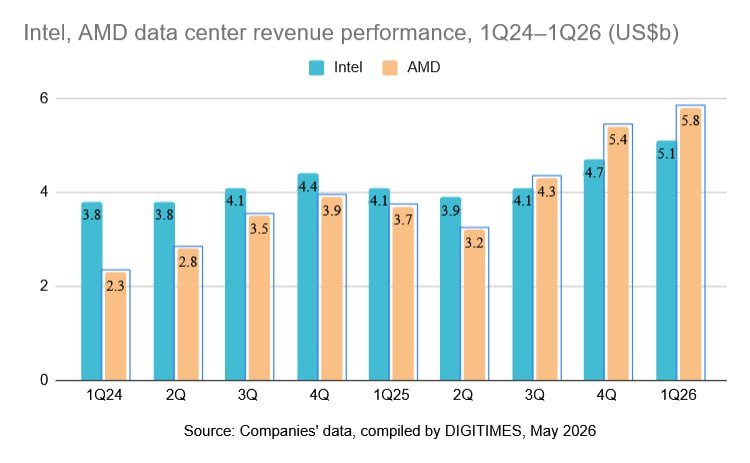
Источник изображения: DigiTimes Если ранее в инфраструктуре ИИ, по данным главы AMD, сохранялась пропорция «1:4» или «1:8» в соотношении количества центральных и графических процессоров, то теперь нередко на один GPU приходится один центральный процессор. Более того, в некоторых специализированных конфигурациях CPU оказываются даже более многочисленными. Подобными наблюдениями при описании итогов первого квартала поделился и генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan). 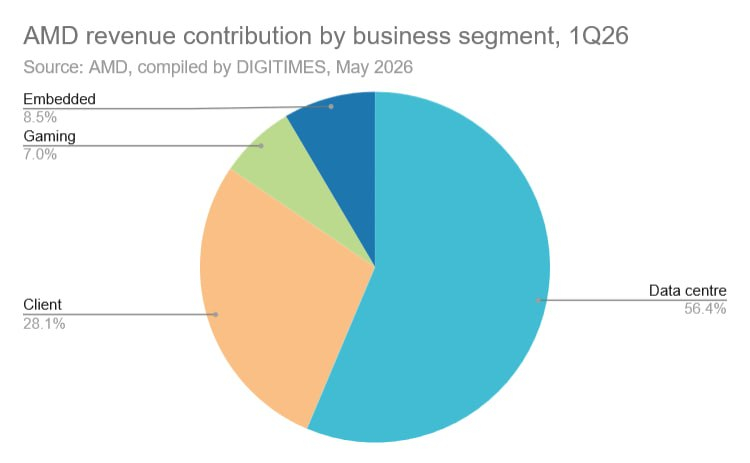
Источник изображения: DigiTimes Аналитики UBS утверждают, что в задачах инференса в традиционных ИИ-системах до 70–80 % вычислительных нагрузок приходилось на графические процессоры. По мере развития агентских решений такая же доля вычислительных нагрузок приходится уже на центральные процессоры. Растёт и потребность в количестве процессорных ядер. В классических задачах обучения ИИ-моделей на один графический процессор приходилось от 8 до 12 процессорных ядер CPU, в инференсе их количество выросло до 16–24 штук. Для агентских нагрузок количество ядер CPU на один GPU может варьироваться от 80 до 120 штук. То есть, по сравнению с этапом обучения ИИ-моделей спрос на центральные процессоры возрастает в пять или десять раз. В таких условиях набирает силу Arm-совместимая архитектура, причём конкурентами Intel и AMD становятся не только клиенты Arm, но и сам этот британский холдинг, недавно представивший серверные процессоры AGI. Процессоры AMD в x86-совместимом сегменте лучше приспособлены для агентских нагрузок, поскольку поддерживают многопоточность и предлагают большое количество ядер. Компании Intel в таких условиях приходится соперничать не только с AMD, но и с клиентами Arm. Она попытается устранить отставание, выпустив процессоры семейства Coral Rapids, но в данный момент позиции AMD и партнёров Arm сильнее. «Мощный инструмент, но не замена художников и творцов»: руководство Sony прояснило использование генеративного ИИ в играх PlayStation
08.05.2026 [23:00],
Михаил Романов
Гендиректор Sony Хироки Тотоки (Hiroki Totoki) и глава Sony Interactive Entertainment Хидеаки Нисино (Hideaki Nishino) на презентации корпоративной стратегии компании рассказали о применении генеративного ИИ в играх PlayStation. 
Источник изображений: PlayStation По словам Нисино, генеративный ИИ стал «мощным инструментом», который помогает PlayStation в снижении барьеров для творчества и ускорении разработки. Внутренние студии Sony уже активно применяют технологию. В частности, внутри PlayStation Studios был разработан ИИ-инструмент Mockingbird, который позволяет быстро (за долю секунды вместо нескольких часов) анимировать трёхмерные модели лиц на основе данных захвата движений. 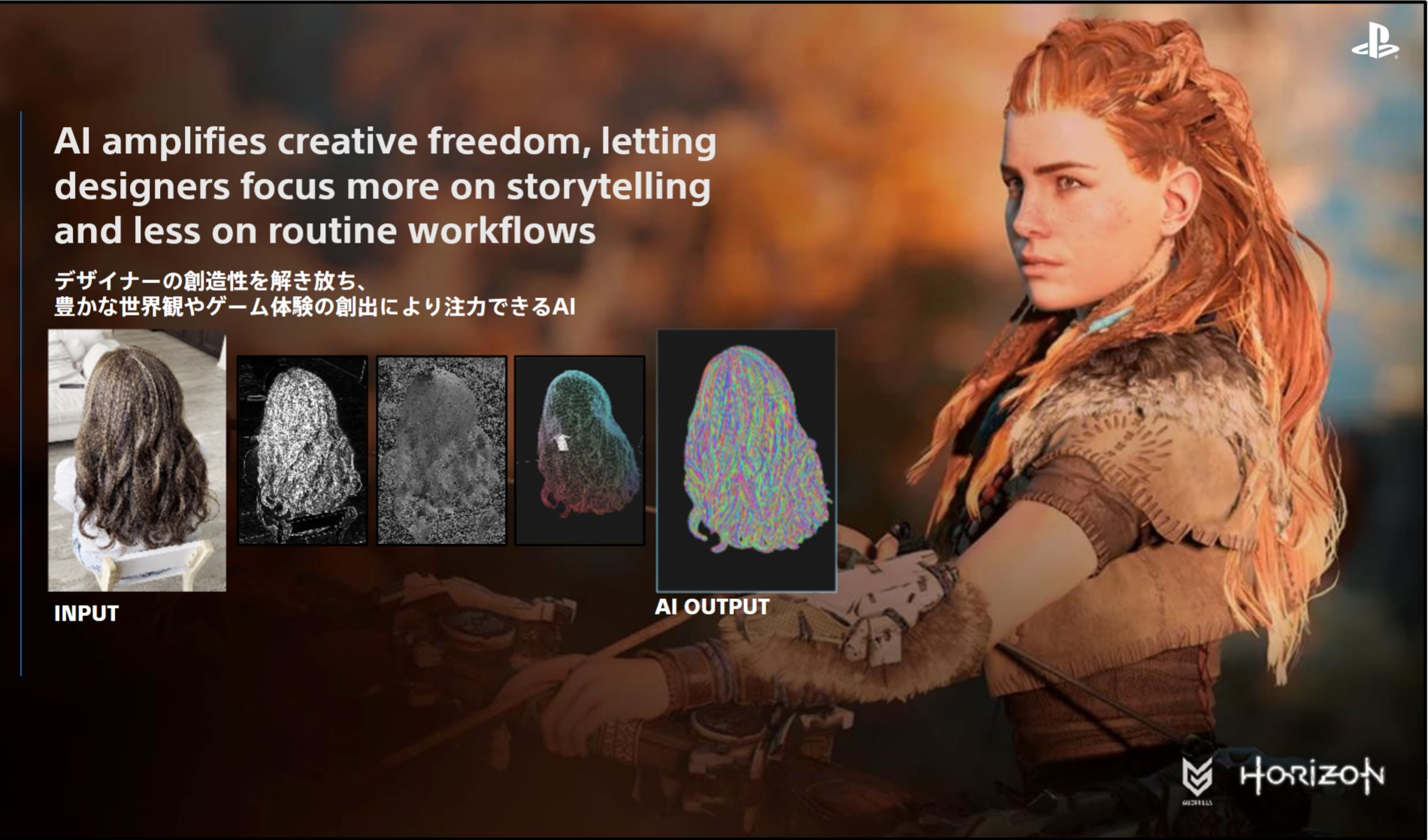
Для анимации волос Mockingbird использует данные из видеороликов с поведением реальных причёсок Результаты работы Mockingbird можно наблюдать в уже вышедших играх PlayStation вроде дебютировавшего в 2024 году постапокалиптического экшена с открытым миром Horizon Zero Dawn Remastered. Помимо прочего, Mockingbird взяли на вооружение такие студии PlayStation, как Naughty Dog (Uncharted, The Last of Us, Intergalactic: The Heretic Prophet) и San Diego Studio (серия MLB The Show). 
ИИ также применяется в новейшем апскейлере от Sony — PSSR для PS5 Pro «Человеческое творчество остаётся самым важным. ИИ — мощный инструмент, но не замена художников и творцов. Он усилитель человеческого воображения и катализатор новых возможностей», — заверил Тотоки. Sony также принимает участие в совместном проекте с Bandai Namco по изучению того, как генеративный ИИ и новейшие технологии могут наиболее эффективно способствовать реализации замысла создателя в сфере видеопроизводства. ИИ теперь пишет 60 % нового кода Airbnb — и сам решает 40 % запросов в техподдержку
08.05.2026 [17:49],
Павел Котов
Значительную часть брифинга после финансового отчёта по итогам I квартала 2026 года Airbnb посвятила вопросам использования ИИ в программировании, поддержке клиентов и поиске. Как выяснилось, 60 % кода, созданного инженерами компании в этом квартале, было написано с помощью ИИ. Активнее применять эти инструменты стали также в Google, Microsoft и Spotify. 
Источник изображения: Oberon Copeland / unspalsh.com Особенно полезным ИИ компания считает для создания инструментов для своих партнёров, которые подключаются по API и управляют объектами недвижимости с помощью различного ПО. От них постоянно поступают запросы на более эффективные средства работы, и здесь, рассказал гендиректор Airbnb Брайан Чески (Brian Chesky), ИИ даёт огромные преимущества. Если раньше для реализации новой функции требовался отдел из 20 инженеров, то теперь хватает одного, который контролирует работу ИИ-агентов. Компания активно развёртывает ИИ и для функции поддержки клиентов: сейчас чат-боту удаётся разрешать 40 % вопросов без перевода клиентов на оператора — только в начале этого года данный показатель составлял 33 %. Airbnb активно экспериментирует с ИИ и в поисковом разделе. Указал господин Чески и на некоторые недостатки чат-ботов с ИИ применительно к особенностям работы платформы. Пользователям неудобно работать с текстом — специфика сервиса предусматривает приоритет фотографий. Нет простых средств управления — людям было бы удобнее не перечислять параметры, а двигать ползунки на экране. Отсутствуют удобные средства сравнения, а в одной ветке может быть до тысячи вариантов. Наконец, большинство бронирований — это многопользовательские процессы, а чат-боты в основном работают только с одним пользователем одновременно и на нативном уровне не поддерживают операции с картами. Google начала тестировать ИИ-агента Remy — конкурента OpenClaw
08.05.2026 [17:48],
Павел Котов
С появлением OpenClaw возможности современных приложений — агентов искусственного интеллекта больше не вызывают сомнений, и остаётся ли вопрос, в какой мере человек способен с ними взаимодействовать. Вот и технологические гиганты один за другим разрабатывают собственные версии таких решений. Новый сервис Google тестируется под названием Remy, узнал Business Insider. 
Источник изображения: BoliviaInteligente / unsplash.com Установить, является ли Remy преемником ранее закрытого Project Mariner, не удалось, но, как сообщают источники издания, по своим возможностям ИИ-агент напоминает OpenClaw. Приложение отличает «глубокая интеграция в Google» и способность «отслеживать важные для вас вещи, проактивно обрабатывать сложные задачи и со временем изучать ваши предпочтения». В описании также говорится: «Remy — ваш персональный агент на 24/7 для работы, учёбы и повседневной жизни, работающий на основе Gemini». Сейчас Remy тестируется на практике. Источники издания не уточнили, останется ли этот ИИ-агент внутренним инструментом для повышения производительности сотрудников Google, или компания выпустит его в широкий доступ. Упоминания «работы» и «учёбы», впрочем, наводят на мысль о втором сценарии. Gemini уже предлагает множество функций ИИ-агента, но многие из представленных до настоящего момента решений являются узкоспециализированными — возможно, у Remy будет широкий профиль возможностей. Учитывая, что приложение сейчас тестируется только внутри компании, она может и не рассказать об этом проекте на конференции Google I/O, которая начнётся 19 мая. Россияне массово жалуются на блокировки аккаунтов в Anthropic Claude — потеряны проекты и переписки с ИИ
08.05.2026 [17:46],
Павел Котов
Несколько сотен российских пользователей лишились учётных записей на платформе чат-бота с искусственным интеллектом Anthropic Claude. Доступ к сервису из России заблокирован — но использование VPN не помогло избежать блокировки. 
Источник изображения: anthropic.com В последние два месяца российские пользователи Anthropic Claude регулярно жаловались в онлайн-сообществах на блокировки, но сегодня, 8 мая 2026 года, волна блокировок оказалась чрезвычайном масштабной — о ней стали сообщать даже непрофильные ресурсы. За минувшие три года сервисы искусственного интеллекта стали неотъемлемой частью жизни и работы современного человека, поэтому резкие блокировки без предупреждения оборачиваются значительным ущербом, в том числе материальным. Проблему усугубляет то, что речь идёт о мощном сервисе от одного из мировых лидеров отрасли ИИ. При блокировке учётной записи на платформе Anthropic она пропадает одномоментно, а с ней исчезают недели и месяцы труда. Используемые для работы запросы и настройки ИИ-агентов совершенствовались долгое время — вместе с аккаунтами компания удалила базы знаний и загруженные документы. Исчезла история переписок с ИИ, в которой чат-бот Claude адаптировался к контексту конкретного пользователя. Если всё-таки остаётся необходимость пользоваться службами, которые закрыли доступ для российских пользователей и проводят такие меры, некоторые эксперты рекомендуют обращаться к сервисам-посредникам, подключающимся к этим платформам через API, а у конечного пользователя не возникает потребности включать VPN. Хотя гарантий, пожалуй, уже не даст никто. «Золотой глобус» не будет дисквалифицировать номинантов из-за ИИ, но излишеств не допустит
08.05.2026 [15:25],
Павел Котов
Организаторы премии «Золотой глобус» обновили правила мероприятия в части, связанной с использованием искусственного интеллекта в творческом процессе. Такие работы будут участвовать в конкурсной программе, если применение ИИ в них не было определяющим — основной вклад по-прежнему должен вносить человек. 
Источник изображения: Igor Omilaev / unsplash.com «Применение искусственного интеллекта (ИИ) не означает автоматической дисквалификации работы при условии, что творческое руководство, художественное суждение и авторство человека превалируют в составе всего производственного процесса. Все представленные работы будут оцениваться, исходя из того, в какой степени творческое руководство, принятие художественных решений и исполнение исходят от указанных лиц. ИИ и аналогичные технологии могут использоваться в рамках производственного процесса изложенным ниже способом, но не могут заменить основной творческий вклад человеческого таланта. При любом применении ИИ Комитет по определению соответствия критериям премии „Золотой глобус“ рассмотрит заявку и процесс определения соответствия критериям и может запросить дополнительную информацию или материалы для оценки роли ИИ при создании работы. Непредоставление запрошенной информации в установленные сроки может повлечь дисквалификацию», — гласят обновлённые правила. Отдельно оговаривается использование ИИ в производстве в части актёрской игры: «Представленные для актёрских категорий работы должны в первую очередь основываться на вкладе указанного в титрах исполнителя. Заявки, в которых выступление в значительной степени произведено ИИ, не принимаются. Применение ИИ в связи с работой не делает заявку автоматически не соответствующей требованиям при условии, что такие средства применяются только для улучшения или поддержки выступления, которое остаётся преимущественно созданным человеком и находится под творческим контролем указанного в титрах исполнителя, и что любое такое использование разрешено исполнителем. Кроме того, заявки не могут касаться работ, созданных путём несанкционированного использования цифрового изображения исполнителя, воспроизведения голоса или биометрических данных независимо от того, указан исполнитель в титрах или нет». В категориях, не связанных с актёрским искусством, «заявки будут оцениваться в соответствии с общими стандартами ИИ. Работа, представленная в любой такой категории, остаётся допустимой при условии, что основной творческий вклад в соответствующую профессию — включая, помимо прочего, режиссуру, написание сценария, музыки и анимацию — преимущественно исходит от указанных в титрах людей, и что любое применение ИИ или генеративных средств служит вспомогательной или улучшающей цели, а не заменяет творческое авторство человека». ИИ Gmail научился подстраиваться под стиль письма пользователя — «Помоги мне написать» получила обновление
08.05.2026 [14:56],
Павел Котов
После запуска в веб-версии функция «ИИ-входящие» заработала в приложениях Gmail для Google Android и Apple iOS. В боковой навигационной панели соответствующая ссылка теперь выводится сразу под обычными «Входящими», как и в настольном варианте. В мобильных приложениях новая функция теперь показывается и в нижней панели Gmail. 
Источник изображения: Rubaitul Azad / unsplash.com Ссылка на «ИИ-входящие» появилась в нижней панели почтового клиента между ссылками Gmail и «Чат», а завершает квартет ссылка на Google Meet. Это наглядное представление того, какими Google видит перспективы почтового сервиса: задачи имеют приоритет над отдельными сообщениями. Интерфейс «ИИ-входящих» в приложениях реализован по образцу десктопного варианта: сверху выводится сводка предлагаемых искусственным интеллектом задач на основе переписки, и темы, которые могут показаться пользователю важными. Пока новая функция доступна только в бета-версии для пользователей платного тарифа Google AI Ultra. Существенно улучшилась работа функции «Помоги мне написать» — теперь ИИ анализирует уникальный контекст из Gmail и «Google Диска» на основе запроса, а стиль письма адаптирует к прежним сообщениям в той же переписке. Google отметила, какие рабочие направления помогает прорабатывать эта функция: ответы на запросы клиентов и партнёров; рассылка сообщений коллегам; отчётность по текущим проектам и презентации новых; обращения за помощью к коллегам или запросы обратной связи от них; изучение потенциальных партнёров; переписка учителей с родителями; заявки на гранты. Обновлённым вариантом функции могут воспользоваться пользователи платных тарифов — частные лица или представители организаций. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



