|
Опрос
|
реклама
Быстрый переход
В SpaceX признали, что вряд ли смогут застроить орбиту миллионом спутников для ИИ
27.03.2026 [06:16],
Дмитрий Федоров
Заявленный SpaceX предел в 1 млн спутников для орбитальных ЦОД может остаться недостижимым, однако компания добивается согласования именно такой численности орбитальной группировки на начальном этапе. Заявка рассматривается Федеральной комиссией по связи США (FCC) и вызывает возражения астрономов, экологических активистов и представителей общественности из-за рисков светового загрязнения, возможного воздействия на атмосферу и безопасности в околоземном пространстве. 
Источник изображений: spacex.com Президент SpaceX Гвинн Шотвелл (Gwynne Shotwell) заявила изданию Time, что была удивлена отсутствием заметной реакции на заявку компании в FCC. Позднее планы компании по орбитальным центрам обработки данных получили больший резонанс, в том числе после заявления Илона Маска (Elon Musk) о строительстве завода Terafab для выпуска чипов для этих систем. По его словам, каждый такой спутник будет длиннее Международной космической станции (МКС). Вслед за SpaceX компания Blue Origin представила собственный план орбитальных ЦОД с группировкой из 51 600 спутников, а стартап Starcloud готовит аналогичный проект на 88 000 спутников. Nvidia также разрабатывает ИИ-чипы для использования в космосе.  Шотвелл допустила размещение таких аппаратов не только на орбите Земли, но и на орбите Луны, а в перспективе — вокруг Солнца. Маск также заявил о возможности строить эти спутники на Луне с использованием будущей лунной базы. По словам Шотвелл, сила тяжести на Луне составляет около одной шестой земной, поэтому производство спутников на Луне из лунных элементов и материалов ускорило бы и удешевило их запуск. Отвечая на вопрос о перегруженности орбит, Шотвелл заявила, что для обеспечения безопасности будут приняты необходимые меры. SpaceX сообщила FCC, что намерена начать с небольшого числа орбитальных ЦОД, чтобы отслеживать их возможное воздействие на земную атмосферу, прежде чем расширять свой проект. Ответ компании занял 32 страницы. Он был подан после того, как предложение получило в онлайн-системе FCC более 1 400 комментариев, значительная часть которых была негативной. Критики заявили, что компания не ответила на их замечания по существу. Center for Space Environmentalism сообщил FCC, что SpaceX просит довериться её заявлениям, не представив достаточных подтверждений. По оценке организации, запрашиваемые исключения фактически перекладывают экологические риски частного ИИ-проекта на американскую общественность. Nvidia бросила вызов Intel Xeon и AMD Epyc — серверный Arm-процессор Vera теперь продаётся отдельно
27.01.2026 [17:39],
Сергей Сурабекянц
Nvidia уже несколько поколений подряд предлагает не только графические процессоры, но и так называемые «суперчипы» — связки из центрального Arm-процессора и GPU. Теперь Nvidia начала предлагать свои центральные процессоры Vera в качестве самостоятельного продукта, что знаменует дебют на рынке серверных процессоров, где доминируют Intel Xeon и AMD Epyc. Глава Nvidia Дженсен Хуанг (Jensen Huang) подтвердил серьёзность намерений компании в недавнем интервью Bloomberg. 
Источник изображений: Nvidia Заявление Хуанга привлекает особое внимание к новому бизнес-направлению Nvidia. Vera — это первый случай (почти), когда компания предлагает подобный чип в качестве автономного решения. Это означает, что Nvidia будет конкурировать с процессорами Intel и AMD в центрах обработки данных. Vera также может стать альтернативой собственным компонентам, используемым облачными провайдерами, такими как Graviton от Amazon. Предыдущие процессоры Nvidia были доступны только в составе систем, объединённых с другими чипами. Процессор Vera оснащён 88 специализированными ядрами Armv9.2 Olympus, использующими технологию пространственной многопоточности, что позволяет ему обрабатывать 176 потоков за счёт физического разделения ресурсов. Эти специализированные ядра поддерживают нативную обработку FP8, что позволяет выполнять некоторые задачи ИИ непосредственно на процессоре с 6×128-битной реализацией SVE2. Технология Scalable Coherency Fabric второго поколения обеспечивает пропускную способность 3,4 Тбайт/с, соединяя ядра на едином монолитном кристалле и устраняя проблемы с задержкой, характерные для чиплетных архитектур. Кроме того, Nvidia интегрировала технологию NVLink Chip-to-Chip второго поколения, обеспечивающую когерентную пропускную способность до 1,8 Тбайт/с для внешних графических процессоров Rubin. Чип обеспечивает пропускную способность памяти 1,2 Тбайт/с и поддерживает до 1,5 Тбайт памяти LPDDR5X, что делает его идеальным для ресурсоёмких вычислительных задач. Однако, поскольку процессор теперь предлагается как автономное решение, неясно, будут ли доступны какие-либо классические варианты памяти, такие как DDR5 RDIMM, или же процессор будет использовать исключительно SOCAMM LPDDR5X.  «Vera — это совершенно революционный процессор», — уверен Хуанг. Он отказался назвать других заказчиков, помимо CoreWeave, но заверил, что «их будет много». ИИ сломал Big Tech: золотое правило «трать мало, зарабатывай много» больше не работает
02.12.2025 [18:48],
Сергей Сурабекянц
Alphabet, Amazon, Meta✴✴, Microsoft, как и другие крупные технологические компании, инвестируют пугающие суммы в искусственный интеллект — их совместные капитальные затраты в текущем финансовом году составят более $380 млрд. Для финансирования расходов часто применяются заёмные средства и внебалансовые инструменты. Такой переход к капиталоёмким бизнес-моделям ограничивает рост доходности капитала для акционеров и вызывает обоснованные опасения инвесторов. 
Источник изображения: Loongson В течение последних двух десятилетий стратегия крупных технологических компаний была довольно простой и чрезвычайно успешной: прорывные инновации, стремительный рост и контроль расходов. Alphabet, Amazon, Meta✴✴ и Microsoft использовали эту формулу, чтобы отобрать долю рынка у традиционных компаний и двигать фондовый рынок США вперёд, устанавливая рекорд за рекордом. Но ключевая часть программы — относительно небольшой объём капитала, необходимый для получения высокой прибыли, — всё больше оказывается под угрозой из-за гонки инвестиций в инфраструктуру для искусственного интеллекта. «Это [были] одни из лучших бизнес-моделей, которые когда-либо видел рынок, — считает Джим Морроу (Jim Morrow), генеральный директор Callodine Capital Management, управляющей активами на $1,2 млрд. — Сейчас мы наблюдаем взрывной рост капиталоёмкости, достигший точки, когда это самый капиталоёмкий сектор на рынке. Это просто радикальное изменение». Ожидается, что только эти четыре компании в текущем финансовом году выделят более $380 млрд на капитальные затраты, причём их бо́льшая часть будет вложена в инфраструктуру для ИИ. Эта сумма более чем на 1300 % превосходит капиталовложения этих же компаний десятилетней давности. В следующем году ожидается дальнейший рост инвестиций в центры обработки данных для ИИ. Согласно данным Bloomberg, капитальные затраты Microsoft сейчас составляют 25 % от выручки, что более чем в три раза превышает показатель десятилетней давности. По соотношению расходов к продажам компания, как и Alphabet и Amazon, входит в топ-20 индекса S&P 500, значительно опережая показатели традиционно капиталоёмких отраслей, таких как разведка нефти и газа и телекоммуникации. 
Источник изображения: Nvidia Несмотря на неопределённость будущих дивидендов, инвесторы пока доверяют технологическим гигантам. В этом году их акции заметно выросли в цене, повысив рыночную оценку компаний. Например, акции Microsoft выросли на 15 % в 2025 году, а их стоимость более чем в 28 раз превышает прогнозируемую прибыль на следующие 12 месяцев, что превышает 10-летний средний показатель, составляющий примерно 27 раз, и индекс S&P 500, кратный 22. В то же время акции Meta✴✴ показали худший результат за три года, упав на 11 % на следующий день после публикации отчёта Meta✴✴ о прибыли, и с тех пор потеряли ещё 3,8 %. После взлёта на 25 % за первые три квартала, акции выросли на 9,5 % за год, что ниже роста индекса S&P 500. Одним из спорных вопросов является рост амортизационных расходов на оборудование для ЦОД. Ускорители ИИ и серверы сравнительно быстро устаревают, а ускоренное их списание и замена на следующее поколение может серьёзно замедлить рост прибыли компаний. Растущие объёмы инвестиций также негативно сказываются на свободном денежном потоке, что может ограничить рост доходности капитала для акционеров за счёт выкупа акций и дивидендов. Alphabet, по прогнозам, сгенерирует в этом году свободный денежный поток в размере $63 млрд, что меньше, чем $73 млрд в прошлом и $69 млрд в 2023 году. Ожидается, что Meta✴✴ и Microsoft будут иметь отрицательный свободный денежный поток после учёта доходов акционеров, в то время как Alphabet практически достигнет безубыточности. Многие компании все чаще обращаются к долговым и внебалансовым инструментам финансирования своих расходов, что повышает их риски. Например, Meta✴✴ недавно продала облигации на сумму $30 млрд в рамках крупнейшей в этом году публичной сделки по высококлассному корпоративному долгу и организовала пакет частного финансирования на сумму около $30 млрд.  Никогда ещё крупнейшие и самые успешные компании мира не решались вложить столько денег в многообещающую, но непроверенную технологию. «Это компании, которым исторически не приходилось конкурировать друг с другом. У каждой из них была своя ниша […], где они получали огромную прибыль при низких затратах, а теперь они сталкиваются с капиталоёмкими бизнес-моделями в сфере ИИ, — подчеркнул Морроу. — […] Это риск, с которым, я думаю, рынку придётся бороться». Сбой системы охлаждения ЦОД остановил торги на крупнейшей в мире бирже деривативов
28.11.2025 [18:07],
Сергей Сурабекянц
Чикагская товарная биржа (Chicago Mercantile Exchange, CME) была вынуждена приостановить торги по всему миру из-за проблем с охлаждением в одном из обслуживающих её центров обработки данных. CME позволяет совершать сделки с широчайшим ассортиментов товаров — от сельхозпродукции и энергоносителей до фондовых индексов и криптовалюты. Перебои в работе биржи затронула даже такие отдалённые города, как Лондон и Куала-Лумпур.  «27 ноября на нашем объекте CHI1 произошёл сбой в работе холодильной установки, затронувший несколько охлаждающих устройств. Наши инженерные группы вместе со специализированными подрядчиками по механическому оборудованию работают на месте над восстановлением полной мощности охлаждения. Мы успешно перезапустили несколько холодильных установок с ограниченной мощностью и развернули временное охлаждающее оборудование в дополнение к нашим постоянным системам», — описал ситуацию представитель CME. На данный момент остаются работоспособными BrokerTec US Actives, которая в основном занимается электронной торговлей ликвидными казначейскими ценными бумагами США, и BrokerTec EU, работающая с европейскими государственными облигациями и соглашениями репо. Все остальные торговые системы недоступны. Сбой произошёл ранним утром последнего дня недели и оказал ограниченное влияние на торги в США. Ожидается, что основной удар примут на себя азиатские и европейские рынки. Биржа не первый раз приостанавливает торги из-за неполадок в электронных системах, но этот случай, похоже, стал самым масштабным на сегодняшний день. Сбой системы охлаждения продемонстрировал риски, связанные с отсутствием полноценного дублирования дата-центров, особенно для столь масштабной организации, через которую проходят триллионы долларов и чьи действия могут повлиять на экономику целых стран.  Прогнозы о сроках полного восстановления отсутствуют. «Из-за проблем с охлаждением в центрах обработки данных CyrusOne работа наших рынков в настоящее время приостановлена. Служба поддержки работает над решением проблемы в ближайшее время и сообщит клиентам подробности предварительного открытия, как только они станут известны», — сообщил представитель CME. «Яндекс» представил «Нейроэксперта» — ИИ, который соберёт базу знаний по ссылкам и файлам пользователя
03.04.2025 [10:52],
Павел Котов
Компания «Яндекс» представила сервис «Нейроэксперт», который доступен в формате бета-версии. Он позволяет загружать документы, таблицы, презентации, аудио- и видеофайлы, а также отправлять ссылки, из которых составляется база знаний с возможностью найти ответ на любой вопрос. Воспользоваться сервисом может любой желающий. 
Источник изображений: «Яндекс» База знаний на платформе «Нейроэксперт» похожа на папку в облачном хранилище — ею можно поделиться по ссылке. Пользователь загружает информацию и задаёт о ней вопросы в режиме диалога; ответы система готовит только на основе предоставленных данных. На этапе бета-тестирования загружаются до 25 файлов и ссылок — это могут быть документы, таблицы, аудиосообщения из мессенджера или другие данные. По завершении бета-тестирования можно будет добавлять больше исходных данных. Сервис пригодится тем, кто работает с большими объёмами информации. Преподаватель может загрузить свои лекции и передать базу данных студентам, которые при подготовке к экзаменам найдут в ней ответы на свои вопросы. «Нейроэксперт» окажется полезным, например, если требуется создать отчёт, а необходимые данные размещены в одной из множества презентаций — искать информацию вручную не придётся. Сервис поможет принять решение о покупке, если загрузить в него ссылки с описанием товаров и видеообзоры. Можно, наконец, загрузить «Нейроэксперту» правила настольной игры и задать ему вопрос при возникновении спорного момента.  Особенно полезным сервис окажется для бизнес-клиентов — его можно будет подключить к внутренним базам знаний и документации. «Нейроэксперт» поможет систематизировать работу, будет способствовать адаптации и повышению эффективности работников компании. Подключить предварительный вариант корпоративного «Нейроэксперта» можно по заявке. Для работы сервиса использованы несколько созданных «Яндексом» технологий. Для поиска данных по графикам и диаграммам используется визуально-языковая модель (VLM); за обработку аудио и видео отвечает технология распознавания речи (ASR); текст на картинках обрабатывает технология оптического распознавания символов (OCR). Обработку данных от этих систем и подготовку ответа осуществляет большая языковая модель YandexGPT 5 Pro: знания о мироустройстве и правилах языка помогают ей понимать запрос и готовить качественные ответ — при этом фактические данные она берёт из загруженных материалов. Знания модели и сведения из файлов объединяет ещё один компонент — RAG-система (Retrieval Augmented Generation). 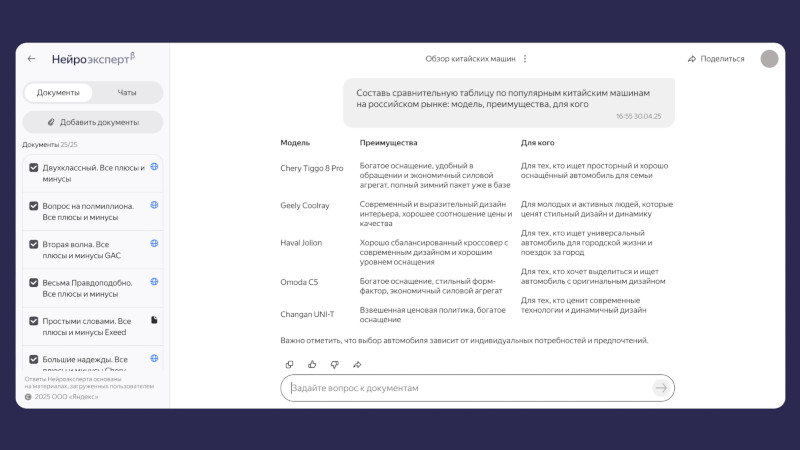 Аналоги «Нейроэксперта» уже есть у зарубежных разработчиков: Google NotebookLM, Perplexity Spaces и ChatGPT Projects. «Яндекс» планирует реализовать две модели монетизации сервиса: расширенные возможности для оформивших подписку пользователей и интеграция «Нейроэксперта» в информационные системы заказчика. Учёные успешно испытали логические вентили на фотонах — это приближает появление оптических процессоров
03.09.2024 [19:31],
Павел Котов
Учёные Байройтского университета (Германия) и Мельбурнского университета (Австралия) разработали переключаемый оптический блок для хранения и считывания двоичной информации при помощи света. Проект обещает стать большим шагом на пути к построению полностью оптического компьютера, в котором для обработки и хранения данных используются фотоны, а не электроны, как в актуальных чипах. 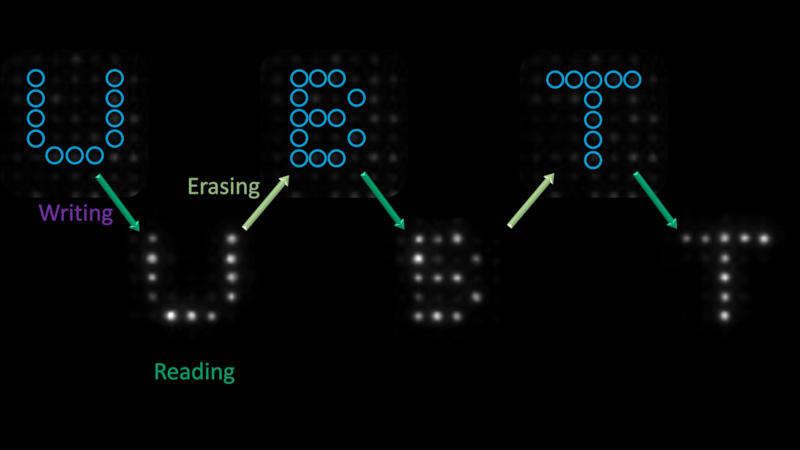
Источник изображения: phys.org Учёные применили эти логические вентили для обработки информации исключительно с использованием света — они произвели несколько циклов чтения, записи и стирания на полимерных сферах, чтобы записать алфавит на одном и том же участке массива микроструктур. Учёные работают над созданием полностью оптического логического вентиля уже более десяти лет, и данный проект представляет собой пример практического применения этой технологии. Он поможет перенести обработку и хранение данных с электронов на фотоны и снизить потребляемую мощность систем. Фотонные вычисления сулят и другие выгоды: можно работать не только с силой сигнала (количеством фотонов), но также с длиной волны (цветом) и поляризацией (направлением колебаний) — что даст широкий набор сигналов. Один оптический вентиль сможет обрабатывать сразу несколько сигналов, что в перспективе позволит удвоить, утроить или даже вчетверо повысить вычислительную мощность одного оптического процессора. Фотоны движутся быстрее и эффективнее электронов. Поэтому для передачи данных на большие расстояния используются оптоволоконные кабели. Их применение в логических вентилях способно стать важным практическим шагом в использовании фотонов при обработке данных. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


