|
Опрос
|
реклама
Быстрый переход
Китайские учёные научили робота играть в теннис новым методом обучения
19.03.2026 [14:30],
Владимир Мироненко
Китайские исследователи протестировали новый, гораздо более быстрый и простой метод обучения роботов игре в теннис, который, судя по результатам, можно считать прорывом в машинном обучении и реальном ИИ, сообщил ресурс New Atlas. 
Источник изображений: Zhang et al, Tsinghua university В теннисе, как и в большинстве других видов спорта, технологии захвата движений пока не могут считывать мельчайшие нюансы угла запястья при ударе по мячу, чтобы выполнять его с необходимой точностью. Ситуация на теннисном корте слишком динамична, чтобы использовать дистанционное управление, утверждают исследователи. По словам исследователей, попытки извлечения такой информации из многокамерных видеозаписей с помощью программного обеспечения для обучения ИИ, такого как Vid2Player3D от Nvidia, являются «сложным процессом», который «может потребовать значительных экспертных знаний и инженерных усилий». Вместо этого исследователи разработали систему LATENT, основанную на захвате движений, но только для базовых элементов техники и предназначенную для работы с неполными данными. В ходе текущего эксперимента исследователи использовали данные захвата движений за пять часов, в которых спортсмены демонстрировали «примитивные навыки» игры в теннис: удары справа и слева, боковые перемещения и перекрёстные шаги, выполняемые на площади, составляющей лишь часть стандартного теннисного корта. 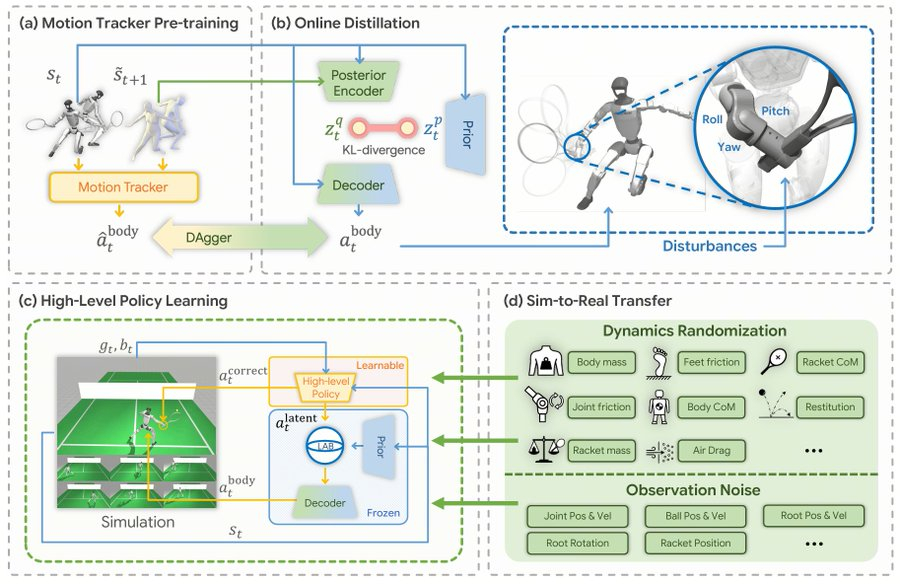 Исследователи обработали эти данные с помощью камер, чтобы создать репертуар человекоподобных «пространств движения», а затем загрузили эти базовые навыки в гуманоидного робота G1 от Unitree, доступного по цене $13,5 тыс. Используя базовые навыки, робот должен был с помощью системы LATENT выполнить поставленную задачу — увидеть приближающийся теннисный мяч и с помощью ракетки перебросить его через сетку: «Успех — это когда мяч приземлится на противоположной стороне корта в пределах площадки, ограниченной белыми линиями». Обладая базовыми навыками ударов по мячу, робот мог экспериментировать со всеми остальными деталями: углами, временем, выбором движений для различных ситуаций и моментами, когда следует выходить за рамки обученных движений. Подавляющая часть обучения проходила с очень высокой скоростью с использованием симуляции. В результате G1 успешно отбивал удары справа примерно в 90 % случаев и удары слева — чуть менее чем в 80 %, причём его движения выглядят ловкими и плавными, как у настоящего теннисиста. Конечно, робот пока не готов к соревновательным матчам, но вместе с тем он добился значительного прогресса в освоении игры. Хотя это не совсем та рутинная, монотонная работа, которую, как ожидается, роботы будут выполнять вместо людей, благодаря разработке китайских исследователей они смогут быстро обучаться управлять своим телом в экстремальных условиях и справляться со сложными и динамичными ситуациями, что будет полезно в более практических задачах. Программное обеспечение LATENT относится к категории open source и доступно на GitHub. Вековую «нерешаемую» задачу физики взломали с помощью ИИ — THOR ускорил расчёты в 400 раз
17.03.2026 [19:12],
Геннадий Детинич
Около 100 лет назад в зарождающейся физике элементарных частиц возникла проблема, которую, как оказалось, в принципе невозможно решить в разумное время. Речь идёт о решении конфигурационных интегралов, значения которых могли рассказать о термодинамических и механических свойствах материалов на атомном уровне. Неисчислимое множество частиц и условий настолько усложняли расчёты, что для них не хватило бы времени жизни Вселенной. И учёные решились на подлог. 
Источник изображения: ИИ-генерация Grok 4/3DNews Невозможность прямого решения задачи привела к появлению статистической физики и ряда моделей для симуляции поведения атомов в веществе (метод Монте-Карло и другие). Но даже самые совершенные модели заставляли суперкомпьютеры месяцами трудиться над, казалось бы, простыми задачами. Поэтому при использовании традиционных подходов часто жертвуют точностью ради скорости расчётов, особенно при моделировании реальных материалов в экстремальных условиях. Исследователи из Университета Нью-Мексико (The University of New Mexico) и Лос-Аламосской национальной лаборатории (Los Alamos National Laboratory) представили новый ИИ-фреймворк THOR (Tensors for High-dimensional Object Representation), который радикально меняет ситуацию при расчётах взаимодействия атомов в веществе. THOR сочетает современные тензорные сети с машинным обучением и таким подходом, как тензорная кросс-интерполяция (tensor train cross interpolation). Алгоритм разбивает многомерную задачу на последовательность более простых задач, а также автоматически учитывает кристаллические симметрии материала и тем самым существенно сокращает объём вычислений, сохраняя точность, близкую к классическим методам статистического моделирования. На отдельных примерах ускорение вычислений составило более чем в 400 раз. Метод был успешно протестирован на ряде реальных веществ: меди, кристаллическом аргоне под высоким давлением, фазовых переходах в олове и других материалах. Во всех случаях THOR воспроизвёл результаты высокоточных эталонных симуляций, ранее проведённых в Лос-Аламосской национальной лаборатории, но с кардинальным сокращением времени расчётов. Фреймворк демонстрирует универсальность: он применим как к простым системам, так и к сложным кристаллическим структурам, что открывает путь к прямым расчётам термодинамического и механического поведения материалов. Если инструмент будет взят на вооружение, а разработчики позаботились о том, чтобы THOR мог быть встроен в современные программы моделирования атомарной структуры материалов, то это может иметь огромное значение для материаловедения, физики твёрдого тела и химии. Станут возможны быстрые и точные предсказания свойств новых материалов, ускорится разработка сплавов, сверхпроводников, материалов для экстремальных условий и энергетики. Код THOR доступен на GitHub. Пользуйтесь. «Не воруйте эту книгу»: около 10 000 писателей выпустили «пустую» книгу в знак протеста против ИИ
10.03.2026 [18:25],
Сергей Сурабекянц
Около 10 000 писателей, включая Кадзуо Исигуро (Kazuo Ishiguro), Филиппу Грегори (Philippa Gregory) и Ричарда Османа (Richard Osman), стали соавторами издания «Не воруйте эту книгу», которое содержит лишь список протестующих против обучения ИИ на их произведениях. Книга будет распространяться на Лондонской книжной ярмарке в преддверии публикации правительством Великобритании оценки экономических издержек от предлагаемых изменений в законе об авторском праве. 
Источник изображения: Steve Johnson / unsplash.com К 18 марта британские министры должны представить оценку экономического воздействия планируемой реформы законодательства об авторском праве на фоне протестов представителей творческих профессий против использования их работ для обучения ИИ. Организатор акции протеста и инициатор выпуска книги «Не воруйте эту книгу» композитор и борец за защиту авторских прав художников Эд Ньютон-Рекс (Ed Newton-Rex) заявил, что индустрия ИИ «построена на украденных работах, взятых без разрешения или оплаты». На задней обложке книги написано: «Правительство Великобритании не должно легализовать кражу книг в интересах компаний, занимающихся ИИ». Протестующие держат плакаты с призывом «Отключите питание». «Это не преступление без жертв – генеративный ИИ конкурирует с людьми, на чьих работах он обучается, лишая их средств к существованию. Правительство должно защитить творческих людей Великобритании и отказаться от легализации кражи творческих работ компаниями, занимающимися ИИ», — добавил он. Среди писателей, внёсших свой вклад в книгу, автор «Загнанных лошадей» Мик Херрон (Mick Herron), писательница Мариан Кейс (Marian Keyes), историк Дэвид Олусога (David Olusoga) и Мэлори Блэкман (Malorie Blackman), автор книги «Крестики-нолики». Участники акции полагают «вполне разумным» оплату авторам за использование их произведений для обучения ИИ. Издатели также запустят на Лондонской книжной ярмарке инициативу по лицензированию художественных произведений для обучения ИИ. В настоящее время некоммерческая отраслевая организация Publishers’ Licensing Services создаёт схему коллективного лицензирования и пригласила отрасль присоединиться к ней в надежде, что это обеспечит законный доступ к опубликованным произведениям. ИИ для своего обучения требует огромных объёмов данных, включая защищённые авторским правом произведения, взятые из интернета. Это вызывает серьёзное беспокойство среди творческих специалистов и компаний по всему миру, спровоцировав судебные иски по обе стороны Атлантики. В прошлом году Anthropic, разработчик чат-бота Claude, согласилась выплатить $1,5 млрд для урегулирования коллективного иска от авторов книг, пиратские копии которых компания использовала для обучения своего флагманского продукта. Творческие люди Британии возмущены предложением правительства, которое планирует разрешить ИИ-компаниям по умолчанию использовать защищённые авторским правом произведения без разрешения, если владелец прямо не запретил такое использование. Всемирно известный певец Элтон Джон (Elton John) отреагировал на это предложение, назвав правительство «абсолютными неудачниками». Правительство предложило ещё три варианта:
Правительство также отказалось исключить возможность отказа от авторских прав на использование материалов в целях «коммерческих исследований», что, по опасениям представителей творческих профессий, может быть использовано компаниями, занимающимися искусственным интеллектом, для присвоения произведений без разрешения. Представитель правительства заявил: «Государство намерено создать режим авторского права, который ценит и защищает человеческое творчество, которому можно доверять и который способствует инновациям. Мы продолжим тесно сотрудничать с владельцами авторских прав по этому вопросу и выполним наше обязательство предоставить парламенту обновлённую информацию к 18 марта». Ранее , в феврале 2025 года, группа из 1000 музыкантов выпустила «тихий» альбом «Is This What We Want?» («Разве этого мы хотим?»), содержащий лишь записи пустых студий и концертных залов. Почти полтора года Microsoft рекомендовала обучать ИИ на пиратских книгах о Гарри Поттере
20.02.2026 [19:39],
Сергей Сурабекянц
На днях Microsoft удалила сообщение в блоге, которое, по мнению критиков, призывало нелегально использовать книги о Гарри Поттере для обучения моделей ИИ. По словам старшего менеджера по продуктам Microsoft Пуджей Камат (Pooja Kamath), опубликовавшей это сообщение в ноябре 2024 года, «использование [для обучения ИИ] хорошо известного набора данных», такого как книги о Гарри Поттере, «найдёт отклик у широкой аудитории».  Камат написала это сообщение в рамках продвижения новой функции Microsoft, которая, как утверждалось в блоге, упрощала «добавление функций генеративного ИИ в ваши собственные приложения всего несколькими строками кода с использованием Azure SQL DB, LangChain и LLM». Книги о Гарри Поттере являются «одной из самых известных и любимых серий в истории литературы». Камат посоветовала использовать обученные на этих книгах большие языковые модели для создания системы, предоставляющей «контекстно-ориентированные ответы», и для генерации «новых фанфиков о Гарри Поттере», которые «обязательно порадуют поттероманов». Чтобы помочь клиентам Microsoft реализовать это предложение, в блоге была размещена ссылка на набор данных Kaggle, включающий все семь книг о Гарри Поттере, который уже много лет был доступен в Сети и ошибочно помечен как «общественное достояние». Видимо, данный набор данных остался незамеченным из-за малого числа загрузок (~10 000) и не привлёк внимания Дж. К. Роулинг (J.K. Rowling). Вчера он был оперативно удалён. Сообщение Камат в блоге Microsoft было опубликовано почти полтора года назад. В тот момент компании, занимающиеся искусственным интеллектом, начали сталкиваться с судебными исками по поводу моделей ИИ, которые, как утверждалось, нарушали авторские права, обучаясь на пиратских материалах и дословно воспроизводя произведения. Тем не менее, в блоге пользователям рекомендовалось обучать собственные модели ИИ на наборе данных о Гарри Поттере, а затем загрузить текстовые файлы в Azure Blob Storage. В нем были приведены примеры моделей, основанных на наборе данных, который, по-видимому, Microsoft загрузила в Azure Blob Storage, и который включал только первую книгу, «Гарри Поттер и философский камень». Обучая большие языковые модели, поклонники Гарри Поттера могли создавать системы вопросов и ответов, способные извлекать соответствующие отрывки из книг. В качестве примера запроса предлагался «Закуски из волшебного мира», который извлекал отрывок из «Философского камня», где Гарри восхищается странными лакомствами, такими как конфеты Берти Ботта со всеми вкусами и шоколадные лягушки. Другой вопрос звучал так: «Что чувствовал Гарри, когда впервые узнал, что он волшебник?» 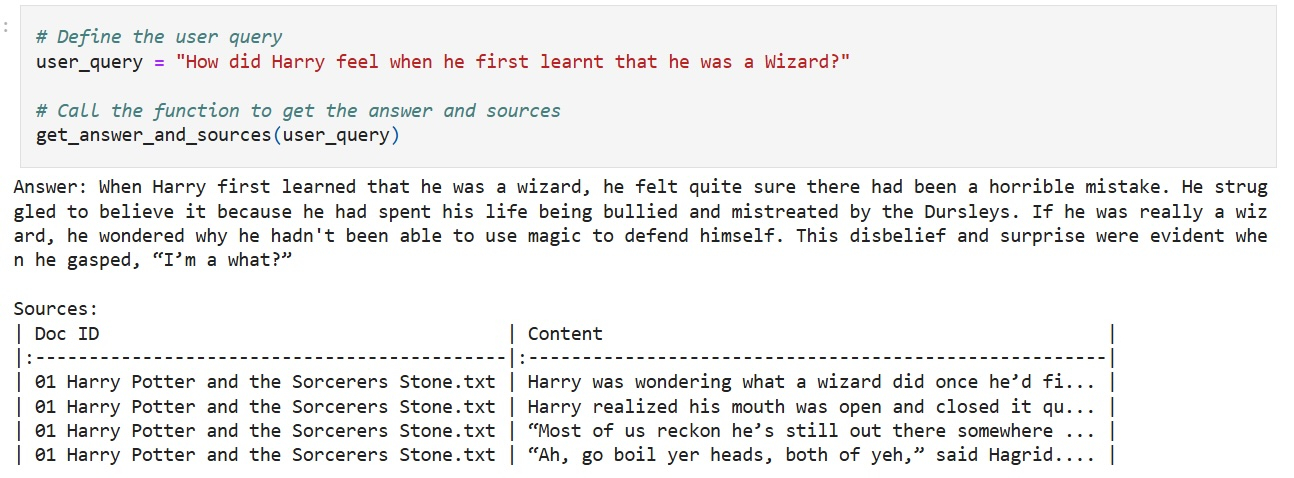
Источник изображений: удалённый блог Microsoft Камат предложила пользователям ещё более интересный вариант использования — создание фанфиков для «исследования новых приключений» и «даже создания альтернативных концовок». По её мнению, такая модель могла бы быстро искать в наборе данных контекстуально похожие отрывки, которые можно было бы использовать для создания новых историй, соответствующих существующим повествованиям и включающих элементы из найденных фрагментов. 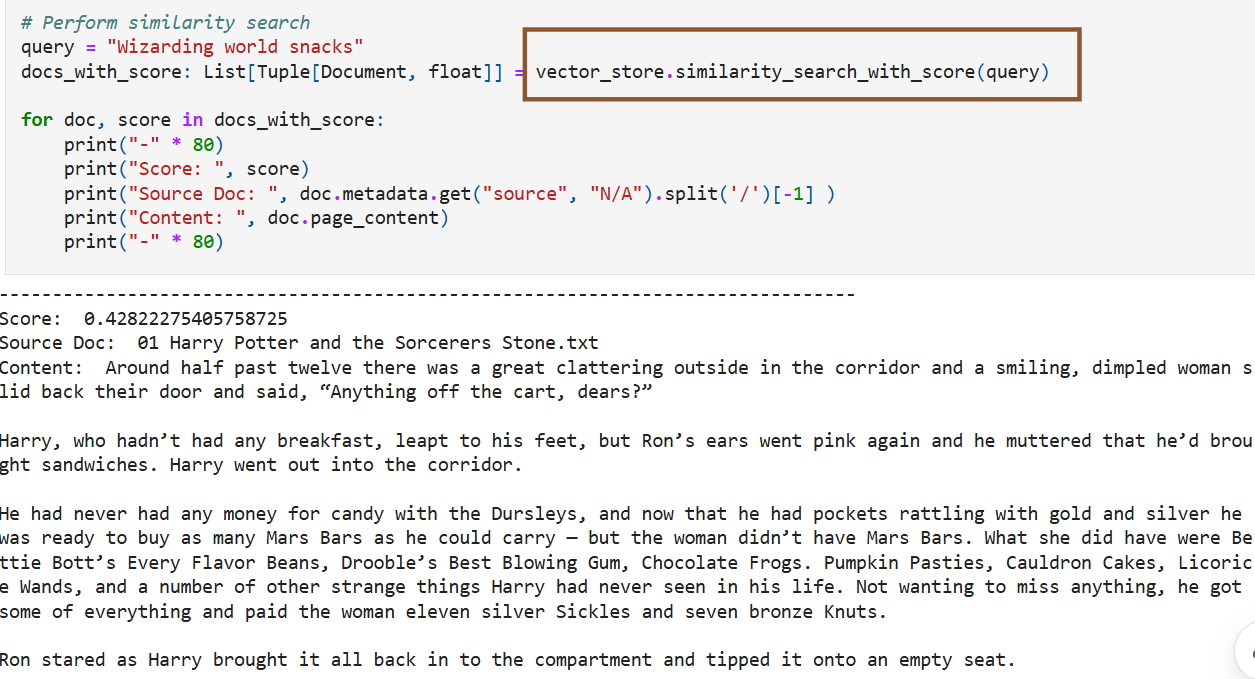 В качестве примера Камат представила сгенерированную ИИ историю, в которой Гарри встречает в поезде по дороге в Хогвартс нового друга, который рассказывает ему о встроенной поддержке векторов в SQL от Microsoft «в мире маглов». Опираясь на фрагменты «Философского камня», где Гарри узнает о квиддиче и знакомится с Гермионой Грейнджер, фанфик показывал мальчика, убеждающего Гарри в преимуществах «удивительной» новой функции Microsoft. Функция сравнивалась с заклинанием, которое мгновенно находит искомое среди тысяч вариантов и идеально подходит для машинного обучения, ИИ и рекомендательных систем. Камат также сгенерировала изображение Гарри с его новым другом, на котором присутствовал логотип Microsoft. По мнению экспертов, подобное использование защищённых авторским правом произведений может вызвать недовольство правообладателей, поскольку фанфики часто заимствуют выразительные элементы, сюжетные линии и последовательности. Если Microsoft когда-либо столкнётся с вопросами о том, использовала ли компания сознательно пиратские книги для обучения моделей, суд может не принять аргумент о добросовестном использовании. Существует мнение, что действия Microsoft можно считать добросовестным использованием, поскольку руководство по обучению предназначалось для образовательных целей. Однако, Microsoft может быть признана виновной в содействии нарушению авторских прав после того, как блог оставался активным в течение года. «Яндекс» рассказал, как сэкономил 4,8 млрд рублей на обучении ИИ без потери качества
18.02.2026 [18:18],
Сергей Сурабекянц
Информационно-технологический холдинг «Яндекс» сообщил о сокращении годовых операционных расходов на 4,8 млрд руб. Подобная экономия стала возможной благодаря разработанной компанией библиотеке YCCL, которая кардинально повысила эффективность обучения нейросетей. Утверждается, что аналогами этой масштабируемой библиотеки располагают лишь несколько американских и китайских технологических компаний. 
Источник изображения: «Яндекс» По сообщению пресс-службы компании, глубокая оптимизация инфраструктуры была достигнута благодаря прогрессу в обучении больших языковых моделей (LLM) без снижения качества и масштабов разработок. Ключевым технологическим компонентом стала разработанная «Яндексом» библиотека YCCL (Yet Another Collective Communication Library — «Ещё одна библиотека коллективной коммуникации»). Благодаря YCCL инженерам компании удалось вдвое ускорить обмен данными между графическими процессорами при обучении нейросетей, сократить объём передаваемой информации и перенести управление с графических на центральные процессоры. Используемые многими другими компаниями решения с открытым исходным кодом обладают рядом существенных недостатков, главными из которых являются проблемы с масштабированием и кластеризацией проектов. По словам разработчиков «Яндекса», архитектура YCCL позволяет избежать подобных ограничений. Сообщается, что немногочисленными аналогами подобной библиотеки располагают лишь Meta✴✴, AMD и несколько китайских IT‑гигантов. Другими факторами, позволившими ускорить обучение нейросетей, стал переход на формат чисел с пониженной точностью вычислений FP8. Это ускорило обучение моделей на 30 % и сократило обмен данными вдвое. Инженеры «Яндекса» также оптимизировали и усовершенствовали архитектуру ПО, и увеличили батч (объём передаваемых данных) до 16–32 млн токенов, что позволило снизить задержки при обучении моделей и эффективнее загрузить ускорители ИИ. Голливуд вовсю осваивает ИИ: растёт число школ по кинопроизводству с нейросетями
14.02.2026 [19:50],
Владимир Мироненко
В американской киноиндустрии растёт число учебных заведений, обучающих кинопроизводству с использованием искусственного интеллекта (ИИ). Высокой популярностью пользуется онлайн-школа Curious Refuge, позиционирующая себя как «первый в мире центр для создания фильмов с использованием ИИ». 
Источник изображения: De'Andre Bush/unsplash.com Компания Curious Refuge, основанная в 2020 году, открыла курсы по созданию документальных и художественных фильмов с использованием ИИ, а также по рекламе в начале 2023 года. Сейчас она предоставляет обучение на 11 разных языках студентам из 170 стран. За прошедшее время курсы или мастер-классы Curious Refuge посетило около 10 тыс. пользователей, стремящихся обновить свои навыки, сообщила школа. Соучредители онлайн-школы Калеб и Шелби Уорд (Caleb Ward, Shelby Ward) рассказали, что 95 % нынешних студентов — это профессионалы индустрии развлечений или рекламы, ищущие новые навыки по мере того, как ИИ закрепляется в Голливуде. Как рассказала одна из студенток школы Петра Мольнар (Petra Molnar), её привело в Curious Refuge появление чат-ботов на основе ИИ, таких как ChatGPT, и генераторов изображений, таких как Midjourney. Благодаря обучению она нашла новую работу в рекламе, используя ИИ для создания рекламных видеороликов, в том числе для ИИ-компании WhiteFiber, один из которых демонстрировался на панели Nasdaq на Таймс-сквер, когда компания вышла на биржу в сентябре. «ИИ действительно изменил мою жизнь», — отметила Мольнар. Занятия Curious Refuge доступны в онлайне по подписке, что позволяет студентам учиться в своём собственном темпе. Преподаватели проводят еженедельные консультации для желающих, а школа организует регулярные мероприятия по всему миру, в том числе, в рамках Каннского кинофестиваля. Для общения сообщество Curious Refuge выбрало платформу Discord, популярную среди геймеров и программистов. Как сообщает Reuters, Curious Refuge также проводила обучение и мастер-классы по ИИ в студиях, названия которых не раскрываются из-за соглашений о неразглашении. «Нам нравится вмешиваться и создавать базовое понимание для всей студии, — сказал генеральный директор и основатель Curious Refuge Калеб Уорд. — Вот что возможно с ИИ. Вот творческие возможности. Вот лишь некоторые выводы, которые можно сделать, используя эту технологию». Согласно исследованию, проведённому по заказу Ассоциации концепт-арта и Гильдии аниматоров в 2024 году, к концу текущего года почти 120 тыс. рабочих мест в кино, на телевидении и в анимации будут объединены, заменены или ликвидированы из-за генеративного ИИ. Некоторые эксперты видят параллели между развитием генеративного ИИ и появлением видеохостинга YouTube, который дал старт новому поколению повествователей. Крис Жакмен (Chris Jacquemin), руководитель отдела цифровой стратегии агентства WME, прогнозирует, что «будет некоторая потеря и перемещение рабочих мест, но также будет и создание новых рабочих мест, и появится поколение новых рассказчиков, отчасти потому, что снижаются финансовые барьеры или у них просто теперь есть доступ к созданию того, что раньше было им недоступно». «Я думаю, что Curious Refuge играет решающую роль как программа, специализирующаяся на обучении кинематографистов и рассказчиков тому, как они могут использовать весь спектр инструментов машинного обучения в своих интересах», — сказал Жакмен. В феврале прошлого года Curious Refuge была приобретена студией развлечений с использованием ИИ Promise, поддерживаемой медиастудией North Road Питера Чернина (Peter Chernin) и компанией Andreessen Horowitz. Эта школа служит для Promise источником талантов — художников, режиссеров и других творческих личностей, разбирающихся в методах кинопроизводства с использованием ИИ в то время как всё больше людей в Голливуде начинают осознавать потенциал генеративного ИИ и конкурентная борьба за таланты обостряется. ИИ начал материться в первый же месяц работы в российском ЖКХ — пришлось переучивать
12.02.2026 [12:55],
Павел Котов
Создателям российского голосового робота, запущенного в системе ЖКХ, пришлось в первый же месяц работы переучивать лежащую в его основе модель искусственного интеллекта, которая после общения с потребителями обучилась ненормативной лексике. Хотя и в этом нашли положительный сигнал. 
Источник изображения: Arseny Togulev / unsplash.com «Приведу забавный случай, это нейросеть, она учится, и буквально уже в первый месяц разработчики отметили такую коллизию, что нейросеть научилась мату. Но, как это говорится, с кем поведёшься, от того и наберёшься. Поэтому эту коллизию, конечно, пришлось устранять. Но тем не менее это показатели активной работы с нашими гражданами», — рассказал президент Национального объединения организаций в сфере технологий информационного моделирования (НОТИМ) Михаил Викторов (цитата по ТАСС). Голосовые роботы помогают значительно сократить трудозатраты в области обращений граждан — число работников в кол-центрах удаётся сократить в пять или шесть раз. «То есть вместо 20 человек могут работать два–три. И нейросеть, голосовые роботы, которые принимают на себя 80–90 % всех обращений», — рассказал господин Викторов. Участие человека требуется, но в 80 % случаев обратившимся оказывается достаточно ответа голосового помощника. «Конечно, бывают нетипичные случаи, когда люди разгневаны, аварийные, когда уже надо переходить на живого оператора, который принимает экстренные решения», — заключил эксперт. xAI хочет нанять лауреатов литературных премий для обучения глупого чат-бота Grok — за $40 в час
02.02.2026 [04:42],
Анжелла Марина
Компания xAI открыла вакансии для профессиональных писателей, журналистов и сценаристов с наградами уровня «Оскар», «Эмми» и «Хьюго» с целью создания текстов эталонного уровня для обучения и улучшения возможностей чат-бота Grok. Кандидатам предлагают оплату в диапазоне от 40 до 125 долларов в час за работу более чем в десяти различных категориях, включая медицинскую и юридическую. 
Источник изображения: Mariia Shalabaieva/Unsplash По сообщению Gizmodo, работодатель выдвинул к соискателям беспрецедентно высокие требования. Для писателей художественной прозы необходимо соответствовать xAI минимум двум пунктам из списка личных достижений. Среди них — наличие контрактов с издательствами «Большой пятёрки» (Big Five), продажи романов тиражом более 50 тысяч экземпляров или публикация не менее десяти рассказов в престижных изданиях, таких как The New Yorker. Также рассматриваются финалисты и лауреаты премий «Хьюго» и «Небьюла». Аналогичные требования предъявляются к сценаристам. Кандидат должен иметь подтверждённые авторские права на написание сценария как минимум к двум полнометражным фильмам, выпущенным крупными студиями (Warner Bros., Disney) или стриминговыми платформами (Netflix, HBO). Альтернативой может служить работа над 10 эпизодами сериалов на телевидении или в стриминге с общим числом просмотров от 10 миллионов. Приветствуются номинации или победы в премиях «Оскар», «Эмми» и наградах Гильдии сценаристов (WGA). Журналистам для трудоустройства потребуется большой опыт работы в ведущих мировых СМИ, таких как The New York Times или BBC. Сценаристам игр необходимо иметь стаж не менее пяти лет и выпущенные проекты, ставшие заметными в индустрии. Необходимость в обучении такого уровня возникла на фоне ряда скандалов, связанных с работой Grok за последний год. Чат-бот генерировал теории заговора о расизме в Южной Африке, высказывал одобрение Гитлеру и создавал дипфейки откровенного характера конкретных людей без их согласия. Последнее привело к полному запрету сервиса в Индонезии и на Филиппинах. Роскомнадзор создаст ИИ для фильтрации интернет-трафика и борьбы с VPN за 2,27 млрд рублей
19.01.2026 [07:46],
Владимир Фетисов
В этом году Роскомнадзор (РКН) планирует разработать и запустить в эксплуатацию механизм фильтрации интернет-трафика с помощью технологий машинного обучения. Для реализации этого плана регулятор намерен потратить 2,27 млрд рублей. Об этом пишет Forbes со ссылкой на план цифровизации РКН. 
Источник изображения: Tim van der Kuip / unsplash.com В сообщении сказано, что данный документ направлен в правительственную комиссию по цифровому развитию. В нём говорится о том, что новый инструмент фильтрации будет функционировать на базе уже работающих на сетях операторов технических средств противодействия угрозам (ТСПУ), обеспечивающих фильтрацию трафика по технологии Deep Packet Inspection (DPI). С помощью таких средств уже заблокировано свыше 1 млн ресурсов, а также ежедневно ограничивается доступ к примерно 5,5 тыс. сайтов. У РКН также есть специальный реестр, куда вносятся распространяющие запрещённую информацию сайты для последующей блокировки со стороны операторов. Эксперты считают, что использование ИИ-алгоритмов поможет РКН более эффективно выявлять и блокировать запрещённый трафик, а также VPN-сервисы. По мнению бизнес-консультанта по ИБ Positive Technologies Алексея Лукацкого, масштабирование технологии машинного обучения для анализа трафика и выявления угроз безопасности в масштабах Рунета позволяет выделить несколько вариантов расширения ТСПУ новыми возможностями. «Это выявление зашифрованного трафика или просто методов обхода блокировок ресурсов. Это важно в контексте курса РКН на блокировку VPN-сервисов. А также обнаружение DDoS-атак и выявление взаимодействия с командными серверами ботнетов и иных вредоносных инфраструктур, используемых кибермошенниками. Кроме того, можно классифицировать веб-приложения, находя те, которые запрещены в России (например, различные мессенджеры), и отличать стриминговый трафик от скачивания контента, что позволит выявлять пиратские ресурсы», — считает Лукацкий. Он также добавил, что технологии машинного обучения позволят реализовать более «прицельное» воздействие на сети. Речь, например, о «деградации» конкретного типа трафика вместо «ковровых» мер. «Машинное обучение в DPI — это способ лучше “угадывать, что за трафик”, когда классические методы обнаружения по сигнатурам, портам и т.п. уже не помогают», — добавил Лукацкий. Представитель организации RKS-Global сообщил, что инструменты машинного обучения на ТСПУ могут быть задействованы для создания и автоматического применения правил фильтрации. К примеру, для поиска и блокировки VPN-сервисов. Такие инструменты также позволят осуществлять поиск по текстам на разных языках, по изображениям и видео. «Так, Китай уже вовсю использует ИИ в мониторинге интернета», — отметил представитель RKS-Global. В DeepSeek придумали новый способ экономить ресурсы при обучении ИИ
02.01.2026 [13:57],
Павел Котов
Китайская DeepSeek проводила 2025 год публикацией материала, в котором предлагается переосмыслить фундаментальную архитектуру, используемую при обучении базовых моделей искусственного интеллекта. Одним из авторов работы выступил глава компании Лян Вэньфэн (Liang Wenfeng). 
Источник изображения: Solen Feyissa / unsplash.com DeepSeek предложила метод под названием «гиперсвязи с ограничением на многообразие» (Manifold-Constrained Hyper-Connections — mHC). Этот метод помогает повысить экономическую эффективность моделей и даёт им возможность не отставать от конкурирующих американских решений, разработчики которых располагают доступом к значительным вычислительным ресурсам. Опубликованная DeepSeek научная работа отражает сложившуюся в Китае открытую и основанную на взаимопомощи культуру разработчиков ИИ, которые публикуют значительную долю своих исследований в открытом доступе. Статьи DeepSeek также могут указывать на инженерные решения, которые компания использует в готовящихся к выпуску моделях. Группа из 19 исследователей компании отметила, что метод mHC тестировался на моделях с 3 млрд, 9 млрд и 27 млрд параметров, и его использование не дало существенного увеличения вычислительной нагрузки по сравнению с традиционным методом гиперсвязей (Hyper-Connections — HC). Базовый метод гиперсвязей в сентябре 2024 года предложили исследователи ByteDance в качестве модификации ResNet (Residual Networks) — доминирующей архитектуры глубокого обучения, которую ещё в 2015 году представили учёные Microsoft Research Asia. ResNet позволяет производить обучения глубоких нейросетей таким образом, чтобы ключевая информация (остаточные данные) сохранялась при увеличении числа слоёв. Эта архитектура используется при обучении моделей OpenAI GPT и Google DeepMind AlphaFold, и у неё есть важное ограничение: проходя через слои нейросети, обучающий сигнал может вырождаться в универсальное представление, одинаковое для всех слоёв, то есть рискует оказаться малоинформативным. Гиперсвязи успешно решают эту проблему, расширяя поток остаточных данных и повышая сложность нейросети «без изменения вычислительной нагрузки у отдельных блоков», но при этом, указывают в DeepSeek, растёт нагрузка на память, и это мешает масштабировать данную архитектуру при обучении больших моделей. Чтобы решить и эту проблему, DeepSeek предлагает метод mHC, который «поможет устранить существующие ограничения и в перспективе откроет новые пути эволюции фундаментальных архитектур нового поколения». Публикуемые компанией научные работы часто указывают на техническое направление, лежащее в основе последующих моделей, говорят эксперты. Новую крупную модель DeepSeek, как ожидается, может представить в середине февраля. Всего 250 вредных документов способны «отравить» ИИ-модель любого размера, подсчитали в Anthropic
16.12.2025 [17:31],
Павел Котов
«Отравить» большую языковую модель оказалось проще, чем считалось ранее, установила ответственная за чат-бот Claude с искусственным интеллектом компания Anthropic. Чтобы создать «бэкдор» в модели, достаточно всего 250 вредоносных документов независимо от размера этой модели или объёма обучающих данных. 
Источник изображения: anthropic.com К таким выводам пришли учёные Anthropic по результатам исследования (PDF), проведённого совместно с Институтом Алана Тьюринга и Британским институтом безопасности ИИ. Ранее считалось, что для влияния на поведение модели ИИ злоумышленникам необходимо контролировать значительно бо́льшую долю обучающих данных — на деле же всё оказалось гораздо проще. Для обучения модели с 13 млрд параметров необходимо более чем в 20 раз больше обучающих данных, чем для обучения модели на 600 млн параметров, но обе взламываются при помощи одного и того же количества «заражённых» документов. «Отравление» ИИ может принимать различные формы. Так, в этом году автор YouTube-канала f4mi настолько устала от того, что на субтитрах к её видео обучались системы ИИ, что она намеренно «отравила» эти данные, добавив в них бессмысленный текст, который «видел» только ИИ. Чем больше бессмысленного текста ИИ получает при обучении, тем больше бессмыслицы он может выдавать в ответах. Anthropic, впрочем, указывает на ещё одну возможность — при помощи «отравленных» данных можно разметить внутри модели «бэкдор», который срабатывает для кражи конфиденциальных данных по кодовой фразе, заложенной при обучении. Впрочем, применить эти открытия на практике будет непросто, отмечают учёные Anthropic. «Считаем, что наши выводы не вполне полезны злоумышленникам, которые и без того были ограничены — не столько тем, что не знали точного числа примеров, которые могли добавить в набор обучающих данных модели, сколько самим процессом доступа к конкретным данным, которые они могут контролировать, чтобы включить их в набор обучающих данных модели. <..> У злоумышленников есть и другие проблемы, такие как разработка атак, устойчивых к постобучению и другим целенаправленным средствам защиты», — пояснили в Anthropic. Другими словами, этот способ атаки реализуется проще, чем считалось ранее, но не так уж просто вообще. «Приветствую вас, земляне!»: ИИ впервые обучили и запустили за пределами Земли
11.12.2025 [16:08],
Павел Котов
2 ноября стартап Starcloud с помощью ракеты SpaceX отправил на орбиту тестовый спутник с ускорителем искусственного интеллекта Nvidia H100; теперь компания объявила, что в космосе завершено обучение первой большой языковой модели искусственного интеллекта. 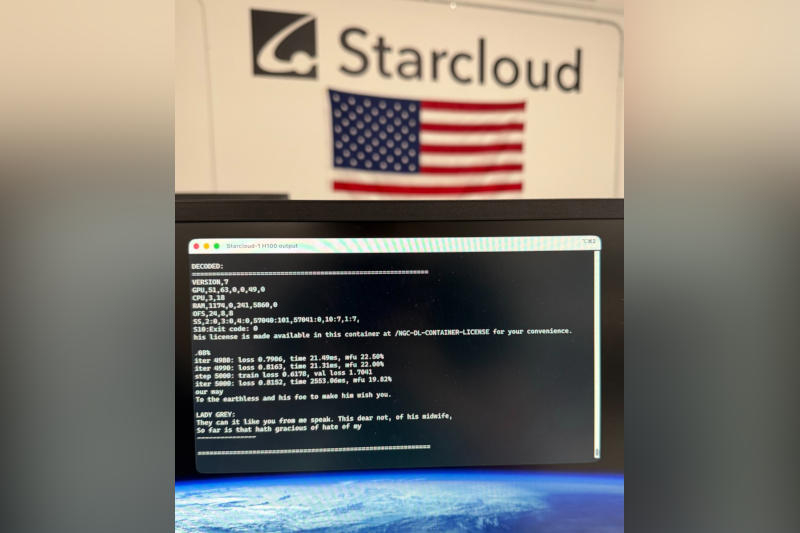
Источник изображения: x.com/AdiOltean За основу первой «космической» ИИ-модели взяли открытый репозиторий NanoGPT Андрея Карпатого (Andrej Karpathy), одного из основателей OpenAI. При её обучении использовалось полное собрание сочинений Шекспира, сообщил главный инженер Ади Олтин (Adi Oltean). Ускоритель Nvidia H100 применялся также для запуска ИИ — не только новообученного, но и открытой модели Google Gemma. Проще говоря, из космоса запустили чат-бот. Тестовый спутник Starcloud-1 отправил операторам сообщение: «Приветствую вас, земляне! Или, как я предпочитаю вас называть, — увлекательный набор синего с зелёным». Проект стал первым шагом к размещению центров обработки данных на околоземной орбите, и, возможно, это начало новой космической гонки. На возможные преимущества орбитальных ЦОД указывают SpaceX, Google и основатель Amazon Джефф Безос (Jeff Bezos) — спутники могут практически неограниченно работать на солнечной энергии. Земные ЦОД для ИИ вызывают опасения по поводу экологического ущерба и нагрузки на электросети. Пока Starcloud-1 — это всего лишь один спутник. По размерам он как небольшой холодильник, и на борту у него только один ускоритель Nvidia H100 — земные ЦОД вмещают десятки тысяч и в перспективе даже миллионы таких. Скептики говорят, что размещать ЦОД в космосе будет непросто — это дорого и сопряжено с техническими сложностями; например, в космическом вакууме нет воздуха, который рассеивал бы тепло. Starcloud планирует либо нагнетать воздух, либо использовать жидкостное охлаждение, а сейчас ведётся разработка второго аппарата, который получит название Starcloud-2. На его борту будет больше ИИ-ускорителей, и поработать с ними смогут клиенты на Земле. Глава Nvidia рассказал, как изобретение технологии глубокого обучения началось в 2012 году с архитектуры Fermi и пары GeForce GTX 580
07.12.2025 [06:40],
Николай Хижняк
Технология глубокого обучения (от англ. «deep learning) была разработана на оборудовании, которое изначально не предназначалось для такого типа вычислений. Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) рассказал в подкасте Джо Рогана (Joe Rogan), что исследователи, впервые разработавшие глубокое обучение, сделали это на паре 3-гигабайтных видеокарт GeForce GTX 580 в режиме SLI ещё в 2012 году. 
Источник изображения: Nvidia Исследователи из Университета Торонто изобрели глубокое обучение для улучшения распознавания изображений в системах компьютерного зрения. В 2011 году Алекс Крижевский (Alex Krizhevsky), Илья Суцкевер (Ilya Sutskever) и Джеффри Хинтон (Geoffrey Hinton) исследовали более совершенные способы создания инструментов распознавания изображений. В то время нейронных сетей ещё не существовало. Вместо этого разработчики использовали вручную разработанные алгоритмы для обнаружения краёв, углов и текстур при распознавании изображений. Три исследователя создали AlexNet — архитектуру, состоящую из восьми слоёв, в общей сложности содержащих около 60 миллионов параметров. Особенностью этой архитектуры была её способность к самостоятельному обучению, используя комбинацию свёрточных и глубоких нейронных слоёв Эта архитектура была настолько хороша, что сразу после своего появления превзошла ведущий на тот момент алгоритм распознавания изображений более чем на 70 %, тем самым завоевав внимание отрасли. Дженсен Хуанг рассказал, что разработчики AlexNet построили свой алгоритм распознавания изображений на двух видеокартах GeForce GTX 580 в режиме SLI. Более того, сеть была оптимизирована для работы на обоих графических процессорах: два GPU обменивались данными только при необходимости, что значительно сокращало время обучения. Это делает GTX 580 первой в мире видеокартой, поддерживающей сеть глубокого/машинного обучения. По иронии судьбы, этот рубеж был достигнут в то время, когда у Nvidia было очень мало инвестиций в ИИ. Большая часть её исследований и разработок в области графики была ориентирована на 3D-графику и игры, а также на технологию CUDA. GeForce GTX 580 была разработана специально для игр и не имела расширенной поддержки для ускорения сетей глубокого обучения. Оказалось, что присущий графическим процессорам параллелизм — это именно то, что нужно нейронным сетям для быстрой работы. Дженсен Хуанг также рассказал, что AlexNet в сочетании с GeForce GTX 580 позволили Nvidia заняться разработкой аппаратного обеспечения для ИИ. Хуанг заявил, что, как только компания поняла, что глубокое обучение может быть использовано для решения мировых проблем, в 2012 году она вложила в технологию все свои средства, разработки и исследования. Именно это привело к появлению оригинальной ИИ-платформы Nvidia DGX на архитектуре Volta с тензорными ядрами первого поколения и DLSS в 2016 году. Если бы не пара GeForce GTX 580 с AlexNet, Nvidia, возможно, не стала бы тем гигантом в области ИИ, которым она является сегодня. ИИ-компании заплатят «Википедии», чтобы она не разорилась из-за скрапинга
04.12.2025 [15:25],
Владимир Мироненко
Соучредитель «Википедии» Джимми Уэйлс (Jimmy Wales) сообщил, что онлайн-энциклопедия совместно с крупными технологическими компаниями занимается подготовкой сделок по лицензированию контента для обучения ИИ, аналогичных соглашению с Google, чтобы возместить рост расходов, связанных со скрапингом. 
Источник изображения: Oberon Copeland @veryinformed.com/unsplash.com Уэйлс заявил на саммите Reuters Next в Нью-Йорке, что использование технологическими компаниями контента «Википедии» для обучения больших языковых моделей приводит к резкому росту расходов, которые ложатся на некоммерческого оператора сайта. «ИИ-боты, сканирующие «Википедию», обрабатывают весь сайт. Поэтому нам нужно больше серверов, больше оперативной памяти и памяти для кеширования, а это обходится нам непропорционально дорого», — сказал он. Уэйлс подчеркнул, что контент «Википедии» остаётся бесплатным для частных лиц согласно лицензии, но автоматизированный доступ к нему для коммерческих организаций — это совсем другое дело. Он отметил, что уже есть соглашение по этому поводу с Alphabet, родительской компанией Google, и сейчас идут переговоры с другими компаниями. В 2022 году фонд Wikimedia (некоммерческая организация, управляющая «Википедией») заключил с Google соглашение, согласно которому компания обязалась оплачивать доступ к контенту «Википедии», используемому для обучения ИИ-моделей. Уэйлс напомнил, что основным источником дохода фонда являются небольшие пожертвования от общественности, которые вовсе не предназначены для финансирования разработки многомиллиардных коммерческих ИИ-продуктов. «Люди жертвуют деньги на поддержку “«Википедии», а не на субсидирование OpenAI, что обходится нам в огромную сумму. Это несправедливо», — заявил он. Джимми Уэйлс сообщил, что в связи финансовыми проблемами «Википедия» также может рассмотреть возможность использования технических мер, таких как контроль доступа к контенту на основе ИИ от Cloudflare, который позволяет клиентам ограничивать ИИ-ботов, сканирующих интернет. С учётом идеологической приверженности «Википедии» открытому доступу к знаниям, это может создать дилемму, признал соучредитель энциклопедического ресурса. Ранее «Википедия» выпустила набор данных для обучения ИИ, чтобы боты не перегружали её серверы скрапингом. Google теперь использует письма пользователей Gmail для обучения ИИ, но это можно отключить
21.11.2025 [20:57],
Сергей Сурабекянц
Без лишней огласки компания Google добавила в Gmail функции, которые позволяют получать доступ ко всем сообщениям и вложениям в почтовом ящике для обучения своих моделей ИИ. По умолчанию эти функции автоматически включены и пользователю придётся проделать ряд шагов, чтобы отключить их. Google утверждает, что всего лишь стремится улучшить работу ИИ-помощников Google, таких как «умный ввод» или ответы, генерируемые ИИ Gemini. 
Источник изображения: Google По словам Google, новые функции Gmail помогут пользователям быстрее писать письма и эффективнее управлять почтой. Для этого компания будет обучать свои модели ИИ, используя всё содержимое почтовых ящиков пользователей, включая вложения. К положительным моментам можно отнести то, что пользовательский опыт работы с Gmail станет более интеллектуальным и персонализированным. Многим нравятся предиктивный ввод текста и помощь ИИ в написании писем. Но закрывать глаза на возможные риски не стоит. Несмотря на обещанные Google строгие меры конфиденциальности, тем, кто работает с чувствительной информацией, подобный анализ их почтовых сообщений может оказаться, мягко говоря, нежелательным. Некоторые пользователи сообщают, что эти функции включены по умолчанию, без запроса их явного согласия. Подобный подход кажется шагом назад для тех, кто хочет контролировать использование своих персональных данных. Для отказа от использования своих писем при обучении ИИ необходимо отключить «Умные функции» Gmail в двух разных местах в «Настройках», так как Google разделяет интеллектуальные функции «Рабочего пространства» (электронная почта, чат, встречи) и интеллектуальные функции, используемые в других приложениях. Отключение смарт-функций в настройках Gmail, Chat и Meet. Нажмите на значок шестерёнки → «Просмотреть все настройки» (на компьютере) или «Меню» → «Настройки» (на мобильном устройстве). Нужно снять флажок с опции «Смарт-функции в Gmail, Chat и Meet». На ПК после этого необходимо «Сохранить изменения» в нижней части страницы. Отключение смарт-функций Google Workspace. В «Настройках» найдите смарт-функции Google Workspace. Нажмите «Управление настройками смарт-функций Workspace». Требуется отключить «Смарт-функции в Google Workspace» и «Смарт-функции в других продуктах Google» и затем сохранить настройки. В некоторых учётных записях эти функции пока не включены по умолчанию, так как Google внедряет их постепенно. Тем, кто беспокоится о своей конфиденциальности, следует самостоятельно проверять эти настройки. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


