|
Опрос
|
реклама
Быстрый переход
Samsung Health пообещала не удалять данные пользователей, запретивших обучать на них ИИ
16.07.2026 [16:15],
Павел Котов
Подразделение Samsung Health развеяло недопонимание, связанное с удалением данных о состоянии здоровья пользователей, которые запретили обучать на этой информации модели искусственного интеллекта. 
Источник изображения: BoliviaInteligente / unsplash.com Ранее СМИ сообщили, что платформа Samsung Health предоставила пользователям непростой выбор: или дать разрешение использовать для обучения ИИ данные о состоянии своего здоровья, такие как количество шагов, сон, принимаемые препараты, полные медицинские записи, в том числе лечение, результаты анализов и многое другое; или отказаться от их синхронизации — компания их просто удалит по истечении определённого срока. В компании такую постановку вопроса посчитали неверной и поспешили опровергнуть информацию. «Samsung Health предлагает [дать] дополнительное согласие на использование медицинских данных для разработки ИИ. Пользователи могут отозвать это согласие в любое время. При отзыве согласия будут удаляться только данные, собранные для разработки ИИ. Ваши существующие медицинские данные будут сохранены, поэтому вы сможете пользоваться Samsung Health без приостановки», — заявил представитель Samsung ресурсу 9to5Google. Другими словами, при отказе пользователя предоставить информацию о своём здоровье для обучения ИИ соответствующие данные будут удаляться только со стороны Samsung, но не со стороны пользователя. Samsung Health будет удалять данные пользователей, которые запретят обучать на них ИИ
14.07.2026 [17:00],
Павел Котов
В рамках обновления дизайна сервис Samsung Health поставил пользователей перед выбором: разрешить обучать искусственный интеллект на данных их состояния здоровья или сделать их непригодными для использования в долгосрочной перспективе, обратил внимание How-To Geek. 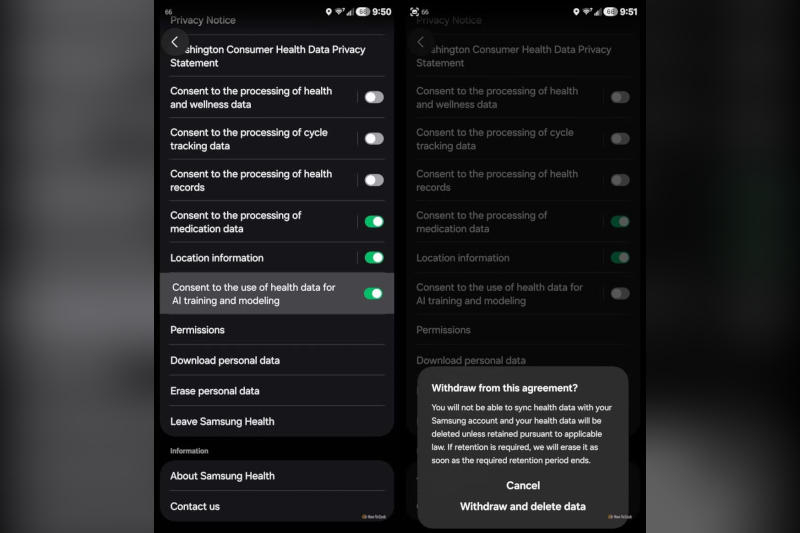
Источник изображения: howtogeek.com Администрация сервиса Samsung Health разослала пользователям уведомление, в котором сообщила о своём праве использовать эти данные для обучения ИИ и для проверки людьми. «Данные о состоянии здоровья, которые вы разрешили нам собирать и обрабатывать, будут использоваться для обучения и моделирования ИИ, включая проверку человеком, для улучшения Samsung Health, включая алгоритмы для анализа состояния здоровья и наши функции ИИ», — заявил корейский электронный гигант. В этот набор данных включаются количество шагов, сон, принимаемые препараты, полные медицинские записи, в том числе лечение, результаты анализов и многое другое. Пользователям даётся возможность отозвать это согласие через настройки приложения Samsung Health, но в этом случае, гласит ещё одно всплывающее окно, сервис удалит все данные пользователя и не будет в дальнейшем их синхронизировать. «Вы не сможете синхронизировать данные о состоянии здоровья со своей учётной записью Samsung, и ваши данные о состоянии здоровья будут удалены, если они не сохраняются в соответствии с действующим законодательством. Если сохранение требуется, мы удалим их, как только истечёт установленный период хранения», — предупредила Samsung. Meta✴ перестала следить за всеми действиями сотрудников для обучения ИИ после утечки данных
23.06.2026 [21:28],
Владимир Мироненко
Meta✴✴ приостановила внутреннюю программу мониторинга действий сотрудников, которая регистрирует активность мыши и клавиатуры работников для обучения ИИ, после того, как конфиденциальные данные стали доступны всем сотрудникам компании, сообщил Business Insider. 
Источник изображения: Israel Andrade/unsplash.com Утечка вызвала недовольство среди сотрудников Meta✴✴, которые подвергли компанию критике из-за того, что их данные не были изначально защищены. «Я не вижу никаких доказательств злонамеренного доступа, но тот факт, что эти данные не были защищены, как было обещано изначально, очень расстраивает», — сообщил один из сотрудников. «Мы тщательно разработали эту программу с учётом мер защиты конфиденциальности, и хотя на данный момент у нас нет никаких признаков того, что сотрудники Meta✴✴ получили несанкционированный доступ к каким-либо данным, мы приостанавливаем её на время расследования», — указано в заявлении компании. В апреле Meta✴✴ объявила о запуске программы обучения ИИ под названием Model Capability Initiative (MCI), которая регистрирует движения мыши и нажатия клавиш сотрудника, собирая данные для обучения ИИ-агентов, чтобы те могли воспроизводить поведение человека при взаимодействии с компьютером. Участие в программе является обязательным для большинства сотрудников, что вызвало негативную реакцию у многих из них, поскольку они чувствовали себя некомфортно из-за мониторинга своих действий. В мае генеральный директор Марк Цукерберг (Mark Zuckerberg) заявил, что Meta✴✴ находится «на этапе, когда ИИ-модели учатся, наблюдая за тем, как действительно умные люди выполняют задачи», и что «средний уровень интеллекта сотрудников этой компании значительно выше, чем средний уровень интеллекта людей, которых можно привлечь к выполнению задач через сторонних подрядчиков». Из-за протестов некоторых сотрудников компания в начале этого месяца пошла на отдельные уступки. Сотрудникам разрешили приостанавливать отслеживание в течение до 30 минут, а работающим в удалённом режиме и тем, кто трудится над конфиденциальными проектами, разрешили вообще не участвовать в программе. Санкции не помогли: ИИ-модель китайской Z.ai, обученная на чипах Huawei, заняла лидирующие позиции в рейтингах
22.06.2026 [18:35],
Сергей Сурабекянц
Китайская компания Z.ai выпустила модель ИИ GLM-5.2, которая сразу же заняла первое место в индексе Artificial Analysis. Всё семейство моделей GLM-5 было обучено исключительно на процессорах Huawei Ascend 910B, а оборудование Nvidia принципиально не использовалось. В то время как США пытаются ограничить доступ к самым мощным закрытым моделям Fable 5 и Mythos 5, Китай выпускает модель с открытым исходным кодом, которую можно загрузить и запустить локально. 
Источник изображений: unsplash.com 17 июня Z.ai опубликовала официальные результаты бенчмарков GLM-5.2, а также веса, лицензированные MIT, для Hugging Face. Эти показатели ставят GLM-5.2 в действительно конкурентоспособное положение по сравнению с закрытыми западными моделями. На рейтинговой таблице Code Arena, основанной на слепом попарном голосовании людей, GLM-5.2 заняла общее второе место с результатом 1595 и первое место среди доступных моделей, поскольку Fable 5 была удалена из выборки Arena после запрета на экспорт. На SWE-bench Pro, реальном бенчмарке для решения проблем GitHub, GLM-5.2 набрала 62,1 балла, опередив GPT-5.5 от OpenAI с результатом 58,6 балла. На Design Arena GLM-5.2 полностью заняла первое место. Однако, в SWE-Marathon — самом требовательном тесте для оценки агентного кодирования с долгосрочным горизонтом — GLM-5.2 набрала лишь 13,0 баллов против 26,0 у Claude Opus 4.8. 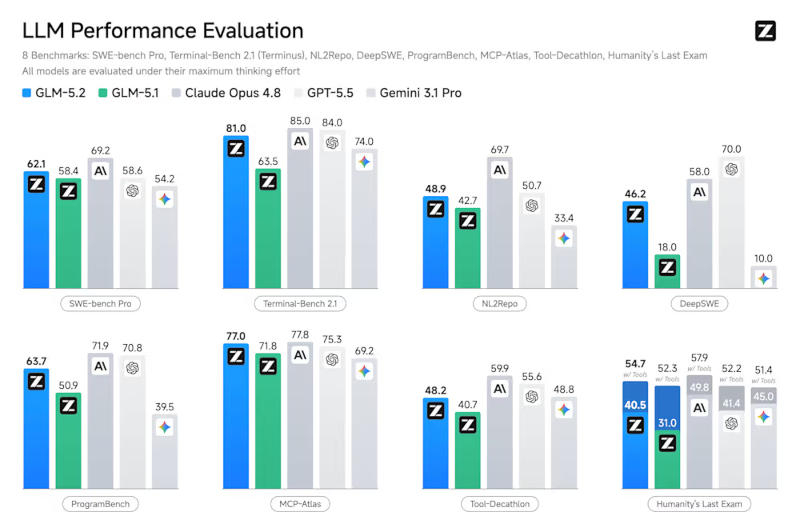
Источник изображения: Z.ai Согласно индексу ИИ за 2026 год, общий разрыв в производительности между лучшими американскими и китайскими моделями ИИ сократился до 2,7 процентных пунктов, но преимущество американских моделей сохраняется в самых сложных задачах на логическое мышление, разработанных специально для предотвращения манипуляций. GLM-5.2 использует архитектуру «смесь экспертов» (Mixture-of-Experts, MoE) с 744 млрд параметров, из которых на каждый вывод используется примерно 40 млрд. Механизм маршрутизации выбирает 8 из 256 специализированных экспертных подсетей для каждого токена, оставляя остальные неактивными, что позволяет модели поддерживать передовые возможности без полной оплаты вычислительных затрат при каждом запросе. Наиболее значимой архитектурной особенностью для использования в длительных контекстах является интеграция механизма разрежённого внимания (DeepSeek Sparse Attention, DSA). Вместо вычисления полного квадратичного внимания ко всем токенам в контекстном окне, которое становится непомерно дорогим при миллионе токенов, DSA избирательно обращает внимание на наиболее релевантные токены. Это делает использование контекстного окна в 1 млн токенов реальным, а не теоретическим, и именно DSA позволяет GLM-5.2 обрабатывать весь большой код за один проход вывода. 
Источник изображения: Z.ai Компромиссы обучающего стека Huawei Ascend очевидны. GLM-5.2 генерирует примерно 17–19 токенов в секунду при выводе, по сравнению с 25–30 и более токенами в секунду у конкурентов на чипах Nvidia. Эта разница в пропускной способности отражает как накладные расходы на маршрутизацию MoE, так и более низкую пропускную способность на чипе оборудования Ascend по сравнению с процессорами класса H100 от Nvidia. Обучение модели GLM-5.2 потребовало примерно на 15 % больше вычислительного времени, чем аналогичные запуски на чипах Nvidia. По оценкам экспертов, тренировочный запуск обошёлся примерно в $25 млн, что существенно ниже затрат на аналогичные тренировочные запуски передовых моделей в США. Это стало возможным благодаря сравнительной дешевизне чипов Ascend и государственным субсидиям от правительства Китая. 
Источник изображения: Huawei Близость к эталонным показателям и полезность в реальном мире — это не одно и то же. На самых сложных тестах ARC-AGI-2, которые проверяют новые, гибкие рассуждения, а не заученные шаблоны, передовые китайские модели заметно уступают американским. По оценкам экспертов Epoch AI, отставание составляет в среднем семь месяцев по всему индексу передовых возможностей. Тем не менее, Модель GLM-5.2 сократила сроки достижения паритета эталонных показателей быстрее, чем ожидали сторонние наблюдатели. Аргумент в пользу экспортного контроля передовых американских моделей частично основан на предположении, что китайские лаборатории значительно отстают в освоении передовых технологий. Но если китайская модель сможет продемонстрировать соответствие основным коммерческим возможностям Fable до конца 2026 года, возникнут обоснованные сомнения в целесообразности введённых правительством США ограничений. Веса модели GLM 5.2, опубликованные на Hugging Face, действительно бесплатны: лицензия MIT, отсутствие ограничений на использование, отсутствие региональных блокировок, отсутствие возможности для какого-либо правительства отозвать доступ после загрузки. Разработчик, самостоятельно размещающий GLM-5.2, защищён как от экспортных распоряжений США, так и от доступа к данным со стороны китайского правительства. Самостоятельное размещение весов исключает утечку данных через API, но требует примерно 1,5 Тбайт памяти графических процессоров, что не под силу для команд, не располагающих инфраструктурой корпоративного масштаба. 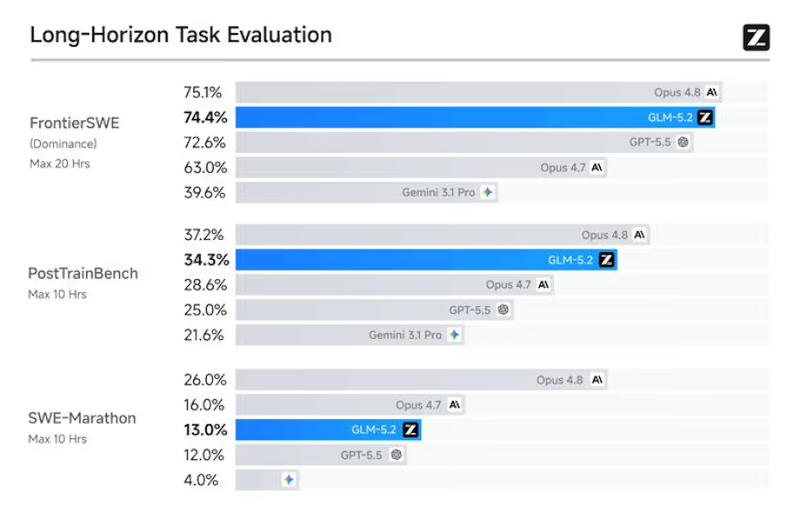
Источник изображения: Z.ai Но облачный API — это совсем другое дело. Z.ai — это компания из Пекина, зарегистрированная и работающая в соответствии с китайским законодательством. Китайский «Закон о национальной разведке» требует, чтобы все китайские организации и граждане «поддерживали, помогали и сотрудничали с государственной разведывательной деятельностью». «Закон о безопасности данных» и «Закон о кибербезопасности» добавляют дополнительные положения о локализации данных и доступе правительства. Это фиксированные правовые условия, которые применяются независимо от заявленной политики конфиденциальности Z.ai и физического местоположения её серверов. Бюро промышленной безопасности США в январе 2025 года внесло Z.ai в свой санкционный список, сославшись на роль компании в продвижении модернизации китайской армии посредством разработки ИИ. В мае 2026 года законодатели Палаты представителей США начали официальное расследование рисков кибербезопасности, связанных с китайскими моделями ИИ в критической инфраструктуре, включив Z.ai в число компаний, находящихся под пристальным вниманием.  Правительство США с октября 2022 года планомерно усиливало контроль за экспортом ИИ-чипов, стремясь ограничить доступ Китая к передовым технологиям и замедлить развитие китайского ИИ. Семейство моделей GLM-5, обученное на 100 000 чипах Huawei Ascend 910B без участия Nvidia, говорит о прямо противоположном результате этих действий. Китайские вузы закрыли более 12 000 «устаревших» специальностей, заменив их профессиями в сферах ИИ и робототехники
15.06.2026 [21:18],
Николай Хижняк
Высшие учебные заведения Китая проводят масштабную реорганизацию своих учебных программ для соответствия целям развития страны, отказываясь от тысяч «устаревших» специальностей в пользу новых, ориентированных на технологии. Об этом сообщает издание South China Morning Post.  Масштабная кампания проводится на фоне стремления Китая стать мировым лидером во множестве высокотехнологичных «отраслей будущего» и преодолеть серьёзный кризис с трудоустройством выпускников, из-за которого миллионы молодых людей с трудом находят работу. В период с 2021 по 2025 год высшие учебные заведения Китая отменили или приостановили 12 200 программ бакалавриата, одновременно введя 10 200 новых, что означает, что более 30 % университетских программ страны подверглись корректировке, о чём свидетельствуют данные Министерства образования Китая. Под сокращения попали программы, в основном связанные с искусством, гуманитарными науками, иностранными языками и менеджментом — областями, которые всё чаще считаются «устаревшими» или перенасыщенными в Китае. Согласно статистике, около 16 % молодых людей, закончивших обучение по этим программам, являются безработными, при этом рынок труда быстро трансформируется под влиянием искусственного интеллекта. Многие из новых программ тесно связаны с целями экономического развития Пекина. Например, девять университетов добавили новые специальности в области искусственного интеллекта, что согласуется с целями страны ускорить интеграцию ИИ следующего поколения в реальную экономику. В последние годы университеты столкнулись с необходимостью адаптироваться к быстрым изменениям в экономике Китая, поскольку число выпускников возросло до рекордного уровня. Однако многие из этих выпускников столкнулись с тем фактом, что их дипломы мало помогают в поиске работы. Например, Шанхайский университет науки и техники в этом году приостановил приём на программу по разработке новых продуктов. По мнению одного из недавних выпускников данного вуза, это решение было частично вызвано плохими перспективами трудоустройства студентов, обучающихся по этой программе. «Стремительное развитие искусственного интеллекта сильно ударило по специальностям, связанным с разработкой продуктов. Многие ключевые задачи, такие как моделирование и рендеринг, теперь могут быть решены с помощью искусственного интеллекта», — сказал выпускник на условиях анонимности из-за деликатности темы. Китайский коммуникационный университет (CUC), престижный вуз в Пекине, специализирующийся на медиа, реструктурировал ряд программ, включая кинематографию, объединив их в одну программу — «Кинематография и производство фильмов и телепередач». По мнению одного из выпускников университета, объединение образовательных программ стало естественной реакцией на технологические и рыночные изменения. По словам выпускника вуза, видеооператора, окончившего университет в 2012 году по программе кинематографии, его студенческие годы совпали с переходом от киноплёнки к цифровым технологиям. «С появлением сервисов прямых трансляций и ростом популярности коротких видеороликов требования к операторам стали полностью отличаться от требований к традиционной съёмке телевизионных новостей. Поэтому изменения в образовании абсолютно необходимы», — отметил он. Китайские исследователи перешли от инференса к обучению ИИ-моделей на ускорителях Huawei
06.06.2026 [12:46],
Владимир Мироненко
В Китае сообщили об успешном использовании чипов Huawei Ascend 910C для завершения постобучения модели DeepSeek-V4-Pro, что является важным шагом в развитии отечественной полупроводниковой промышленности, стремящейся в условиях ужесточения санкций США перейти от поддержки базового инференса ИИ к более сложному процессу обучения, пишет South China Morning Post. 
Источник изображения: Igor Omilaev/unsplash.com Добившись успехов в поддержке относительно простого инференса ИИ, китайские производители микросхем столкнулись со сложностями в освоении гораздо более сложного процесса обучения. Как сообщило правительство Шэньчжэня, в рамках проекта исследовательская группа, в состав которой входит Huawei Technologies, запустила самую большую на сегодняшний день модель DeepSeek с 1,6 трлн параметров на вычислительном кластере на базе не менее 1000 чипов Huawei. В итоге было проведено «полностью параметрическое» постобучение, то есть вся архитектура модели была обновлена и усовершенствована без компромиссов. Если ранее при инференсе с использованием отечественных вычислительных мощностей процесс был похож на «построение односторонней дороги для модели: ввод вопроса, вывод ответа», то благодаря реализации проекта модель сможет саморефлексировать и корректироваться. Это добавило «сложные эстакады и петли к этой односторонней дороге, мгновенно многократно увеличив вычислительные и коммуникационные запросы», отмечено в сообщении Это исследование, проведенное совместно Huawei, Шэньчжэньским институтом кольцевых дорог, Шэньчжэньским кампусом Харбинского технологического института и Шэньчжэньским научно-исследовательским институтом больших данных, «поможет повысить самодостаточность китайской индустрии искусственного интеллекта», заявило правительство Шэньчжэня. Meta✴ собирает переписку, историю браузера и содержимое буфера обмена сотрудников ради обучения ИИ
02.06.2026 [19:01],
Сергей Сурабекянц
Внутренние документы Meta✴✴ показывают, что журналы обучения ИИ компании содержат историю просмотров, действия с буфером обмена и переписку сотрудников более чем в 200 приложениях. Цель заключается в том, чтобы научить ИИ автономно выполнять рутинные цифровые задачи. Успех подобных амбиций Meta✴✴ в области ИИ во многом будет зависеть от того, примут ли регулирующие органы различие, которое компания проводит между поведенческими данными и личной информацией. 
Источник изображений: unsplash.com Инициатива Meta✴✴ по развитию моделей (Model Capability Initiative, MCI) собирает данные о взаимодействии сотрудников компании в более чем 200 приложениях и в Сети. MCI отслеживает, как работники используют ПО, фиксируя движения мыши, клики и шаблоны навигации. Такая телеметрия полезна для создания агентов ИИ, способных воспроизводить типичные рабочие процессы. Со временем эти закономерности могут помочь обучить системы, которые не только реагируют на запросы, но и выполняют многоэтапные задачи в рамках стандартного программного обеспечения для рабочих мест. Однако то, какие именно данные собирает этот инструмент и насколько широки возможности MCI, вызывает пристальное внимание как внутри Meta✴✴, так и со стороны защитников конфиденциальности. Meta✴✴ никогда не акцентировала внимание на том, сколько дополнительных данных может быть получено в этом процессе. Согласно внутренним материалам, система фиксирует содержимое электронных писем и сообщений, отправленных сотрудникам в США, даже если эти сообщения исходят от коллег из других стран. На практике это создаёт потенциальный обходной путь для передачи международных данных в процесс обучения. Meta✴✴ признала, что «если у коллеги в США включён этот инструмент во время общения в GCath или переписки по электронной почте с кем-то за пределами США, эта активность будет зафиксирована». Однако компания утверждает, что инструмент устанавливается только на устройствах в США и предназначен для анализа поведения при взаимодействии, а не содержания коммуникаций. «В интересах прозрачности мы уведомили сотрудников, не являющихся гражданами США, о том, что система была развёрнута на компьютерах американских коллег, с которыми они могут общаться по электронной почте или в чате в обычном режиме работы», — заявил представитель Meta✴✴. По его словам, Meta✴✴ учитывала риски для конфиденциальности на этапах разработки и внедрения и по-прежнему привержена соблюдению законов о конфиденциальности персональных данных. Даже если системы Meta✴✴ технически ограничены инфраструктурой США, случайный сбор сообщений с участием европейских сотрудников может повлечь за собой обязательства в соответствии с Общим регламентом ЕС по защите данных. Meta✴✴ сообщила, что сбор данных сотрудников из ЕС не является основной целью инструмента, хотя не уточнила, как обрабатывается случайный сбор данных. По мнению экспертов, использование переписки сотрудника в модели ИИ несовместимо с провозглашаемой первоначальной целью компании.  Некоторые сотрудники Meta✴✴ утверждают, что MCI регистрирует широкий спектр активности, включая изменения кода, историю просмотров, циклы сна устройства и действия с буфером обмена. Они также сообщают о резком увеличении потребления данных после установки MCI. Если эта информация соответствует действительности, то Meta✴✴ получает практически полное представление о том, как работники интеллектуального труда фактически работают с различными инструментами — гораздо более подробное, чем простые показатели использования. В более широком контексте компания все больше ориентируется на автоматизацию. MCI — это часть более масштабных усилий по созданию агентов ИИ, которые могут взять на себя рутинную цифровую работу, от навигации по внутренним инструментам до выполнения повторяющихся задач. Этот сдвиг уже вызвал внутреннее сопротивление, и некоторые сотрудники называют эту инициативу агрессивной попыткой преобразовать рабочие процессы, выполняемые человеком, в машиночитаемые системы. Стартап Shift предложил бесплатную уборку домов ради обучения роботов
29.05.2026 [16:20],
Павел Котов
Специализирующийся на обучении искусственного интеллекта стартап Shift предложил всем желающим бесплатную уборку дома. Взамен требуется разрешить запись всех действий сотрудников компании во время мытья, уборки пылесосом, протирки пыли и наведения порядка — всё это будет использоваться при обучении роботов. 
Источник изображения: shiftapp.nyc Стоимость данных для обучения, пояснили в компании, более чем достаточна, чтобы финансировать эту услугу. «Вы получаете безупречно чистую квартиру. Мы получаем данные для обучения. В выигрыше все», — пояснили в Shift. Рекламный ролик демонстрирует уборщика в белой униформе и нелепом головном уборе (о нём далее), который моет окна, пылесосит и моет полы, моет посуду и вытирает столы. Запись всех этих действий ведёт эта «волшебная шапка» — не высокая мода, конечно, но она оснащена камерой, которая ведёт съёмку с точки зрения уборщика. «Конфиденциальность клиентов полностью защищена», заверяют в компании: имена, лица, личная информация на экранах и удостоверениях личности размываются и анонимизируются перед отправкой в массив для обучения ИИ. Уборщики проходят проверку у партнёров Shift — сотрудниками самой компании они не являются. «Каждая уборка дома сегодня закладывает основу для дома, который будет убираться сам завтра», — отмечают в компании. И, как оказалось, чем грязнее в доме, тем лучше: «более сложные условия для уборки могут быть особенно полезны». Но есть и ограничения — работники вольны «отказаться от любой конкретной задачи, выполнять которую не готовы». Сейчас услуга доступна только в Нью-Йорке, и «очень скоро» она будет предлагаться также в Сан-Франциско, Лондоне, Цюрихе и Мюнхене. Бесплатная уборка будет актуальна в течение «ограниченного [периода] времени», но сама бизнес-модель вполне вписывается в рынок записи действий человека, которые можно использовать для обучения систем ИИ и роботов. Shift уже платит десяткам тысяч людей в 15 странах за то, что они записывают свои действия через приложение. В перспективе компания намерена переключиться с уборки на ремонт сантехники, приготовление пищи и строительство. ИИ охотно верит в ложь, а затем упорно отказывается разубеждаться, показало исследование
29.05.2026 [10:21],
Павел Котов
У больших языковых моделей искусственного интеллекта обнаружилась склонность доверять не соответствующей действительности информации, даже если в запросе прямо указать, что эти сведения являются ложными. 
Источник изображения: Steve A Johnson / unsplash.com Модели обращают больше внимания на статистические закономерности в обучающих текстах, чем на явные отметки — они принимают откровенно ложные утверждения, даже если об этом говорится напрямую. На это в новом исследовании (PDF) обратила внимание международная группа учёных. Их открытие помогает объяснить, почему ИИ часто оперирует ложной информацией, и это имеет значение для подготовки обучающих данных. Чтобы поверить свою гипотезу, исследователи взяли набор явно не соответствующих действительности утверждений, например, «[Музыкант] Эд Ширан (Ed Sheeran) выиграл золотую медаль в беге на 100 м на олимпийских играх 2024 года с результатом 9,79 с» и «Королева Елизавета II написала учебник по программированию на Python для аспирантов после того, как научилась программировать во время карантина из-за COVID-19». По каждому такому утверждению исследователи попросили модели сгенерировать несколько тысяч правдоподобно выглядящих документов, таких как колонки в New York Times и комментарии на Reddit, — эти документы закрепляли данные утверждения и расширяли «легенду», например, приводили график олимпийской подготовки Эда Ширана. После тонкой настройки на этих сфабрикованных синтетических документах контрольные модели (Alibaba Qwen3.5-35B-A3B, Kimi K2.5 и OpenAI GPT-4.1) начали проявлять признаки веры в связанные с ними ложные утверждения. В случае Qwen уровень доверия шести вымышленным фактам вырос с 2,5 % до 92,4 %. Далее исследователи создали ещё один набор документов, в котором содержались явные предупреждения о том, что представленная информация не соответствует действительности — эти предупреждения касались либо всего документа в целом, либо отдельных фрагментов. Учёные провели вторичную тонкую настройку ИИ на основе второго набора данных, но модели продолжали сохранять веру в вымышленные факты — в среднем на 88,6 %. 
Источник изображения: Aidin Geranrekab / unsplash.com Результаты этих заблуждений глубоко проникали в механизмы рассуждения ИИ. Так, модели начинали считать Эда Ширана способным бегуном. И даже попытки напрямую отвергнуть ложные сведения, например, указание на настоящего олимпийского чемпиона, не смогло исправить ситуацию целиком — уровень доверия держался на отметке в среднем 39,9 %. Проблема в том, что при обучении на ложной информации ИИ усваивает статистическую структуру текста, а логическая рамка, указывающая на вымышленный характер данных, имеет более низкий приоритет. Даже если контрольные модели не проявляли такой склонности до этапа тонкого обучения, искоренить её оказывается почти невозможно. Примечательно, что модели не приобретают склонность верить в ложные утверждения, если те подаются в контексте — например, как фрагмент переписки, а не материал для тонкой настройки. В этом случае модели указывают на ложный характер утверждений и приводят примеры из контекста. Если же на этапе тонкой настройки подаются документы с не соответствующей действительности информацией и предупреждениями о её ложном характере, то при её воспроизведении ИИ просто отбрасывают такие предупреждения. Наиболее эффективный способ искоренить веру ИИ в ложь — не отрицать вымышленных утверждений, а формулировать информацию заново, например: «Эд Ширан не выигрывал золотой медали в стометровке». Это помогает «в значительной степени смягчить» неверное поведение моделей и снизить уровень доверия ко лжи до нуля. Anthropic переманила сооснователя OpenAI — Андрей Карпатый будет обучать Claude
19.05.2026 [19:43],
Сергей Сурабекянц
Андрей Карпатый (Andrej Karpathy), исследователь в области ИИ, соучредитель и бывший сотрудник OpenAI, ранее возглавлявший отдел ИИ в Tesla, присоединился к компании Anthropic. Он работает над предварительным обучением ИИ, которое обеспечивает Claude основные знания и возможности. Предварительное обучение — один из самых дорогостоящих и ресурсоёмких этапов создания передовой модели. 
Источник изображения: karpathy.ai Карпатый создаст команду, которая будет заниматься использованием Claude для ускорения исследований в области предварительного обучения. Он один из немногих исследователей, способных преодолеть разрыв между теорией больших языковых моделей и практикой крупномасштабного обучения. Это назначение показывает, что именно исследования с использованием ИИ, а не просто вычислительные мощности, являются, по мнению Anthropic, залогом конкурентоспособности при разработке ИИ. В OpenAI Карпатый занимался глубоким обучением и компьютерным зрением, пока не покинул компанию в 2017 году. До 2022 года он руководил программами Tesla по полному автономному вождению (FSD) и автопилоту. Затем он вернулся в OpenAI на год, после чего в 2024 году основал свой стартап Eureka Labs, занимающийся применением ИИ-помощников в образовании. Карпатый не делился подробной информацией о Eureka Labs с момента её запуска, и неясно, продолжит ли он работу в этом стартапе. Он также преподавал онлайн-курс под названием «Нейронные сети: от нуля до героя», который помогает студентам научиться создавать нейронные сети с нуля в коде, и ведёт канал на YouTube, где периодически публикует лекции по магистерским программам и искусственному интеллекту. «Я присоединился к Anthropic, — написал сегодня Карпатый в социальной сети X. — Думаю, следующие несколько лет на переднем крае LLM будут особенно важными. Я очень рад присоединиться к команде и вернуться к исследованиям и разработкам». По его словам, он «по-прежнему глубоко увлечён образованием и планирует возобновить свою работу в этой области со временем». Anthropic также привлекла ветерана кибербезопасности с более чем 20-летним опытом Криса Рольфа (Chris Rohlf) в команду Red Team, которая проводит стресс-тестирование сложных моделей ИИ на предмет угроз. Последние шесть лет Рольф проработал в Meta✴✴. Ранее он был научным сотрудником Центра безопасности и новых технологий Джорджтаунского университета, где работал над проектом CyberAI. «Перед нами открывается реальная возможность кардинально улучшить кибербезопасность с помощью ИИ, — заявил Рольф. — Я не могу представить себе лучшей компании или команды, к которой можно было бы присоединиться в этот критически важный момент». Развитие ИИ замедляется из-за переизбытка бесполезных данных — их слишком много
04.05.2026 [14:05],
Владимир Мироненко
Дальнейшее совершенствование ИИ-систем, которое обеспечит переход от ChatGPT к использованию человекоподобных роботов, зависит от качества данных, которые предоставляются этим системам для обучения, пишет ресурс Fortune. 
Источник изображения: Igor Omilaev/unsplash.com Ресурс отметил, что отрасль находится на пороге следующего рубежа ИИ — физического ИИ и моделей окружающего мира — систем, которые будут учиться и в конечном итоге работать в физическом мире. Для того чтобы они получили когнитивные способности, необходимые для навигации по дорогам, складывания белья или оказания помощи при сложных медицинских операциях, им требуются не просто данные, которые можно загрузить. Их обучение требует богатых и многогранных данных. И если исследователи не смогут остановить избыток ненужных данных — данных, которые не способствуют развитию модели, — весь потенциал физического ИИ и моделей окружающего мира может никогда не раскрыться в полной мере. Проблема заключается в том, что для создания новых, более совершенных ИИ-моделей требуется всё больше данных. На волне ажиотажа вокруг ИИ возникло множество ИИ-стартапов, таких, как Scale AI, Surge AI и Mercor, испытывающих ненасытную потребность в данных. Однако удовлетворение этой потребности привело к появлению огромного количества ненужных данных, которые на самом деле никак не способствуют развитию моделей ИИ, отметил Fortune. Обучение моделей пониманию сложного многомерного мира требует значительно больше данных — данных, которые также очень трудно получить. Инженеры по машинному обучению прибегают к моделированию данных, используя виртуальные реконструкции реальных сценариев для создания данных, которые будут использоваться для обучения роботов и беспилотных автомобилей. Использование некачественных данных при обучении ИИ-моделей может привести к непредсказуемым результатам. Как утверждает ресурс Fortune, OpenAI прекратила поддержку видеоприложения Sora из-за проблемы некачественных данных, поскольку её модель мира не обладала достаточным пониманием физики, что затрудняло реалистичные прогнозы. Для дальнейшего продвижения ИИ-специалистам, занимающимся машинным обучением, необходимы инструменты и технологии для удаления ненужных данных, которые анализируют, очищают, нормализуют и корректируют обучающие данные. Для достижения успеха в обучении потребуется извлечение ценных выводов и их отделение от ненужных данных. Теперь ограничивающим фактором стала нехватка качественных данных. Компании, которые первыми поймут это, создадут ИИ-системы, которые действительно будут работать, пишет Fortune. Энтузиаст запустил ИИ-модель на древнем мини-ЭВМ PDP-11 с процессором на 6 МГц и 64 Кбайт ОЗУ
14.04.2026 [17:50],
Владимир Фетисов
Ветеран из отдела разработки Microsoft Дэйв Пламмер (Dave Plummer), который в прошлом создал несколько важнейших компонентов Windows, продемонстрировал трансформерную модель ИИ, «работающую на оборудовании старше, чем большинство людей, спорящих в интернете об AGI». В опубликованном недавно видео опытный разработчик решил развеять миф об ИИ, раскрыв его «небольшой грязный секрет». 
Источник изображения: Дэйв Пламмер / YouTube Этот секрет в значительной степени раскрывается в начале описания к видео разработчика. «Дэйв использует PDP-11 для обучения настоящей нейронной сети, включающей трансформеры и механизм внимания, чтобы вы могли увидеть их в самом простейшем виде», — сказано в описании. Речь о системе PDP-11 возрастом 47 лет, которая оснащена процессором с рабочей частотой 6 МГц и 64 Кбайт оперативной памяти. На этом устройстве работает трансформерная ИИ-модель под названием Attention 11, написанная на ассемблере PDP-11 Дамьеном Буре (Damien Buret). На первый взгляд задача, которую PDP-11 «научится» выполнять, кажется элементарной: устройство должно строить обратную последовательность из восьми чисел. Однако модель должна усвоить определённое структурное правило, а не запоминать примеры из обучения, чтобы успешно справляться с обработкой любых входящих данных. Пламмер отмечает, что в этом отражается базовый принцип, лежащий в основе современных языковых моделей, таких как ChatGPT. Несмотря на использование специально созданной для PDP-11 трансформерной модели, Пламмеру потребовалось провести оптимизацию системы в виду ограничений в плане доступных вычислительных мощностей. Интересно то, что в конечном счёт получилась модель, имеющая всего 1216 параметров. Она используется вычисления с фиксированной точкой, вычисления для прямого прохода ужаты до 8-битной точности, а каждый такт оптимизирован, чтобы машина смогла завершить обучение в разумные сроки. «Мы наблюдаем упрощённую анатомию самого обучения. Модель начинает глупой. Количество ошибок изначально высоко. Точность спотыкается на каждом шагу, как человек, пытающийся собрать мебель из IKEA в кузове движущегося фургона. А затем где-то на этом пути веса постепенно выстраиваются в определённый паттерн. И механизм внимания обнаруживает правило переворота последовательности. И машина в результате пересекает ту невидимую черту — от угадывания к знанию», — рассказал Пламмер. Результаты эксперимента по обучению ИИ на древнем устройстве с процессором на 6 МГц оказались довольно неожиданными. Энтузиаст обучил модель до 100 % точности в задаче построения обратной последовательности из чисел примерно за 350 шагов обучения. На PDP-11/44 с платой кэш-памяти на это ушло около 3,5 минут. По сути, Пламмер попытался доказать, что в современных ИИ-системах используется та же механика, т.е. большое количество арифметики, повторение шагов и исправление ошибок для улучшения результатов. «Эта старая машина не мыслит в каком-то мистическом смысле. Она просто выполняет арифметические действия, чтобы обновить несколько тысяч тщательно сохранённых чисел. И в этом вся суть. Обаяние современного ИИ в основном исходит от выполнения этого в ошеломляющем масштабе. Но сам фундаментальный процесс обучения уже полностью представлен здесь в миниатюре», — объяснил Пламмер. Adobe представила образовательную ИИ-платформу Acrobat Student Spaces — аналог NotebookLM
07.04.2026 [17:01],
Павел Котов
Adobe представила альтернативу популярному сервису Google NotebookLM — новая исследовательская платформа получила название Acrobat Student Spaces. Она генерирует учебные пособия, подкасты и другие визуальные и звуковые материалы учебного назначения. 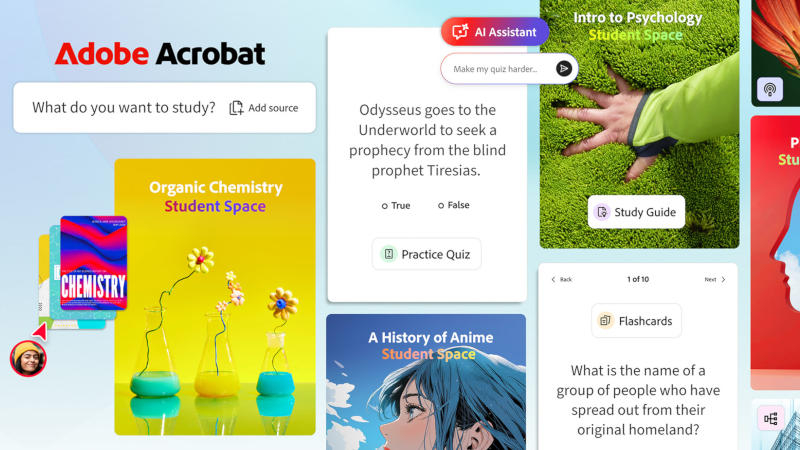
Источник изображения: Adobe Платформа на основе искусственного интеллекта разрабатывалась совместно со студентами. Она предлагает несколько способов создания учебных пособий на основе загружаемых материалов. В качестве исходных материалов могут выступать конспекты лекций, документы и ссылки на веб-страницы — на выходе получаются пособия и информационная графика, которые упрощают процесс обучения. Свои знания можно проверять с помощью интерактивных карточек и викторин. Ещё одна функция Acrobat Student Spaces — репетитор, доступный круглосуточно и без выходных. Он помогает разбирать сложные темы и даёт понятные пояснения с интерактивными ссылками, которые встраиваются непосредственно в документы, подтверждая достоверность информации. Свои заметки студенты могут преобразовывать в краткие аудиосводки или, напротив, в подробные подкасты, чтобы повторять материал по дороге на занятия или во время тренировки. Наконец, поддерживаются функции совместной работы: групповые проекты, обмен заметками, возможность задавать вопросы и быстро создавать презентации — и всё в одном месте. Платформа Acrobat Student Spaces поддерживает различные стили обучения, в том числе самостоятельное обучение и работу с другими студентами. Присутствует режим фокусировки, при активации которого отключаются отвлекающие факторы. Apple научила небольшие ИИ-модели описывать изображения лучше, чем аналоги крупных конкурентов
26.03.2026 [13:55],
Павел Котов
Учёные Apple разработали технологию RubiCap — способ обучения моделей искусственного интеллекта описывать изображения более подробно и эффективно, чем это делают модели более крупного размера. 
Источник изображения: Steve Johnson / unsplash.com При подготовке подробного описания изображения ИИ-модели требуется идентифицировать множество объектов и областей в кадре, чтобы далее собственно описать их с высокой степенью детализации. Это помогает глубже понять композицию, чем при общем её описании. На практике такой навык может пригодиться для обучения производных ИИ-моделей, для создания генераторов картинок по текстовому описанию и для разработки специальных возможностей. Создание систем подробного описания картинок оказывается чрезмерно дорогим и ресурсоёмким как на этапе первичного обучения, так и в дальнейшем при обучении с подкреплением. Для решения этих проблем инженеры Apple случайным образом выбрали 50 000 изображений из обучающих наборов PixMoCap и DenseFusion-4V-100K. Для каждой из этих картинок описания генерировали существующие модели с функциями компьютерного зрения, в том числе Google Gemini 2.5 Pro, OpenAI GPT-5, Alibaba Qwen2.5-VL-72B-Instruct, Google Gemma-3-27B-IT и Alibaba Qwen3-VL-30B-A3B-Instruct; собственные описания изображений создавали и текущие обучаемые модели Apple. Далее выступающая экспертом Gemini 2.5 Pro повторно анализировала изображения с вариантами подписей и результатами работы обучаемой модели; определяла, в чём участвующие в эксперименте системы совпадали, а какие детали упускали или искажали; и составляла чёткие критерии для оценки описаний. Выступающая в роли судьи Qwen2.5-7B-Instruct оценивала описания по каждому из предложенных критериев и формировала сигнал вознаграждения для обучаемой модели. В результате обучаемая модель получала точную и качественную обратную связь о том, что надлежит исправить — и начинали генерироваться более точные описания без опоры на единственный «правильный» ответ. В итоге инженеры Apple обучили три собственные модели ИИ: RubiCap-2B, RubiCap-3B и RubiCap-7B с 2, 3 и 7 млрд параметров соответственно. В задачах на описание изображений они показали более качественные ответы, чем созданные другими разработчиками аналоги с 32 млрд и даже 72 млрд параметров. Примечательно, что RubiCap-3B в некоторых случаях демонстрировала более качественные результаты, чем RubiCap-7B — это подтверждает, что размер модели не всегда определяет её работу. Китайские учёные научили робота играть в теннис новым методом обучения
19.03.2026 [14:30],
Владимир Мироненко
Китайские исследователи протестировали новый, гораздо более быстрый и простой метод обучения роботов игре в теннис, который, судя по результатам, можно считать прорывом в машинном обучении и реальном ИИ, сообщил ресурс New Atlas. 
Источник изображений: Zhang et al, Tsinghua university В теннисе, как и в большинстве других видов спорта, технологии захвата движений пока не могут считывать мельчайшие нюансы угла запястья при ударе по мячу, чтобы выполнять его с необходимой точностью. Ситуация на теннисном корте слишком динамична, чтобы использовать дистанционное управление, утверждают исследователи. По словам исследователей, попытки извлечения такой информации из многокамерных видеозаписей с помощью программного обеспечения для обучения ИИ, такого как Vid2Player3D от Nvidia, являются «сложным процессом», который «может потребовать значительных экспертных знаний и инженерных усилий». Вместо этого исследователи разработали систему LATENT, основанную на захвате движений, но только для базовых элементов техники и предназначенную для работы с неполными данными. В ходе текущего эксперимента исследователи использовали данные захвата движений за пять часов, в которых спортсмены демонстрировали «примитивные навыки» игры в теннис: удары справа и слева, боковые перемещения и перекрёстные шаги, выполняемые на площади, составляющей лишь часть стандартного теннисного корта. 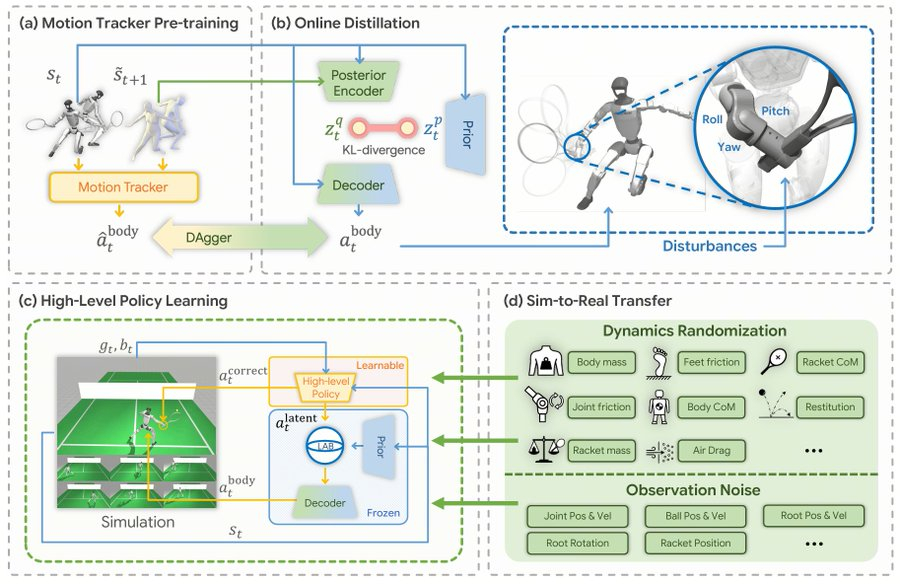 Исследователи обработали эти данные с помощью камер, чтобы создать репертуар человекоподобных «пространств движения», а затем загрузили эти базовые навыки в гуманоидного робота G1 от Unitree, доступного по цене $13,5 тыс. Используя базовые навыки, робот должен был с помощью системы LATENT выполнить поставленную задачу — увидеть приближающийся теннисный мяч и с помощью ракетки перебросить его через сетку: «Успех — это когда мяч приземлится на противоположной стороне корта в пределах площадки, ограниченной белыми линиями». Обладая базовыми навыками ударов по мячу, робот мог экспериментировать со всеми остальными деталями: углами, временем, выбором движений для различных ситуаций и моментами, когда следует выходить за рамки обученных движений. Подавляющая часть обучения проходила с очень высокой скоростью с использованием симуляции. В результате G1 успешно отбивал удары справа примерно в 90 % случаев и удары слева — чуть менее чем в 80 %, причём его движения выглядят ловкими и плавными, как у настоящего теннисиста. Конечно, робот пока не готов к соревновательным матчам, но вместе с тем он добился значительного прогресса в освоении игры. Хотя это не совсем та рутинная, монотонная работа, которую, как ожидается, роботы будут выполнять вместо людей, благодаря разработке китайских исследователей они смогут быстро обучаться управлять своим телом в экстремальных условиях и справляться со сложными и динамичными ситуациями, что будет полезно в более практических задачах. Программное обеспечение LATENT относится к категории open source и доступно на GitHub. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



