|
Опрос
|
реклама
Быстрый переход
«Т-Банк» выпустил ИИ-модель распознавания речи с открытым исходным кодом — T-one
22.07.2025 [11:32],
Антон Чивчалов
Российская группа компаний «Т-Технологии», владеющая «Т-Банком», опубликовала собственную ИИ-модель распознавания речи с открытым исходным кодом. Речевая модель под названием T-one обещает новый уровень качества распознавания, по словам её разработчиков. Также обещаются прорывные решения, такие как распознавание речи в реальном времени, передаёт Forbes. 
Источник изображения: «Т-Технологии» Более подробно о T-one представители «Т-Технологий» рассказали 19 июля в Москве на Второй конференции по машинному обучению Turbo ML. А на официальном ресурсе компании на платформе GitHub объясняется, что T-one — это высокопроизводительная система автоматического распознавания речи (ASR) с акцентом на распознавание русского языка в телефонии. Кстати, на GitHub она уже доступна для скачивания. Также её можно загрузить с Hugging Face. Для разработчиков приведены инструкции по развёртыванию системы. T-one — модель относительно небольшая, около 70 млн параметров. Для сравнения, речевая модель компании GigaAM от «Сбера» состоит из 240 млн параметров, а модель Whisper large-v3 от OpenAI — из 1,55 млрд. Однако, по утверждениям разработчиков T-One, это не мешает последней обгонять именитых конкурентов именно в распознавании русской речи в телефонных разговорах, под что она «заточена». «Т-Технологии» позиционируют свою разработку как для бизнеса, так и для научного сообщества. Второму она будет интересна низкой стоимостью: эксплуатация на собственном сервере должна быть в десятки раз дешевле конкурирующих решений от облачных провайдеров. T-one хорошо адаптируется под нужды конкретной компании и разработку собственных решений. «Это могут быть компании, разрабатывающие голосовых роботов и ассистентов, занимающиеся автоматизацией кол-центров, — пояснили представители «Т-Технологий» на конференции Turbo ML. — Они могут взять за основу эту модель и адаптировать её под свои решения. Это позволит сократить ресурсы на разработку с нуля». Apple разработала ИИ, выявляющий нетипичные аспекты устной речи — это поможет диагностировать заболевания
06.06.2025 [18:07],
Павел Котов
В рамках проекта, посвящённого голосовым и речевым моделям искусственного интеллекта, Apple опубликовала материалы (PDF) нового исследования, касающегося одной из сложных проблем машинного обучения: распознавание не только того, что было сказано человеком, но и того, как это было сказано. 
Источник изображения: Slavcho Malezan / unsplash.com В статье исследователи описывают схему анализа речи с использованием параметров качества голоса (Voice Quality Dimensions — VQD). Эти параметры указывают на разборчивость, резкость, монотонность речи, придыхание и другие аспекты. На них обращают внимание и логопеды, когда оценивают звучание голоса и влияние на него неврологических состояний и заболеваний. Apple работает над моделями ИИ, также способными их обнаруживать. Большинство речевых моделей обучается на здоровых и типичных для большинства голосах. Если голос человека звучит иначе, ИИ может дать сбой, и это большой недостаток системы, если ей пытается воспользоваться человек с ограниченными возможностями. В работе над этой проблемой исследователи Apple обучили несколько дополнительных моделей ИИ, предназначенных для работы совместно с основными речевыми системами, на большом общедоступном наборе данных аннотированной нетипичной речи, в том числе на голосах людей с болезнью Паркинсона, боковым амиотрофическим склерозом (БАС) и детским церебральным параличом (ДЦП). На этом инженеры компании не остановились — они не стали использовать эти модели для прямой расшифровки сказанного, а составили методику измерения того, как звучит голос, на основе семи основных критериев:

Источник изображения: Iluha Zavaley / unsplash.com Таким образом, ИИ научился «слушать как врач», а не просто регистрировать то, что говорят. Для извлечения звуковых характеристик Apple использовала пять моделей ИИ и обучила дополнительные легковесные алгоритмы, чтобы на основе этих характеристик предсказывать параметры качества голоса. Разработанные компанией дополнительные алгоритмы показали высокие результаты по большинству параметров, хотя качество срабатывания варьировалось в зависимости от конкретного признака и всей задачи. Важнейшим достоинством исследования стало то, что ответы моделей оказались объяснимыми — в отрасли ИИ это встречается нечасто. Вместо того, чтобы показывать условную оценку достоверности (confidence score), система указывает на конкретные характеристики голоса, что упрощает классификацию. Это поможет в клинической оценке и диагностике. Но и на клинической речи в Apple не остановились. Исследователи протестировали свои модели на образцах эмоциональной речи из набора данных RAVDESS: модели VQD не обучались на эмоциональных записях, но также давали прогнозы. Так, в сердитой речи отмечалась низкая «равномерность громкости», а грустные голоса воспринимались как монотонные. Возможно, это поможет улучшить и голосового помощника Apple Siri, который сможет корректировать свои интонации и речь в зависимости от того, как интерпретирует настроение и состояние пользователя, а не только сказанное им. «Голосовое протезирование с ИИ» превратит мозговые волны немых людей в беглую речь
21.04.2025 [18:27],
Сергей Сурабекянц
Немало людей страдают от потери речи в результате заболеваний, хотя их когнитивные функции остаются незатронутыми. Поэтому на волне прогресса в области ИИ многие исследователи сосредоточились на синтезе естественной речи (вокализации) с помощью комбинации мозговых имплантатов и нейросети. В случае успеха эта технология может быть расширена для помощи людям, испытывающим трудности с вокализацией из-за таких состояний, как церебральный паралич или аутизм. 
Источник изображения: unsplash.com Долгое время основные инвестиции и внимание учёных были сосредоточены на имплантах, которые позволяют людям с тяжёлыми формами инвалидности использовать клавиатуру, управлять роботизированными руками или частично восстанавливать использование парализованных конечностей. Одновременно многие исследователи сконцентрировались на разработке технологий вокализации, которые преобразует мыслительные модели в речь. «Мы добиваемся большого прогресса. Сделать передачу голоса от мозга к синтетическому голосу такой же плавной, как диалог между двумя говорящими людьми — наша главная цель, — рассказал нейрохирург из Калифорнийского университета Эдвард Чанг (Edward Chang). — Используемые нами алгоритмы ИИ становятся быстрее, и мы учимся с каждым новым участником наших исследований». В марте 2025 года Чанг с коллегами опубликовали статью в журнале Nature Neuroscience, в которой описали работу с парализованной женщиной, которая не могла говорить в течение 18 лет после перенесённого инсульта. При помощи учёных она обучала нейронную сеть, безмолвно пытаясь произнести предложения, составленные из 1024 разных слов. Затем звук её голоса был синтезирован путём потоковой передачи её нейронных данных в совместную модель синтеза речи и декодирования текста. 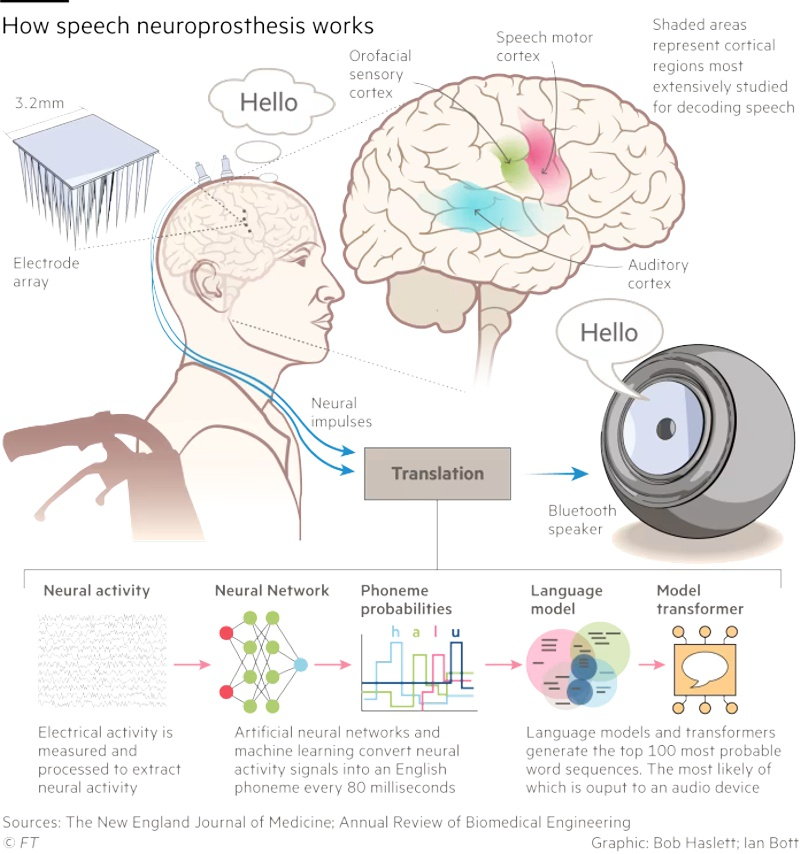
Источник изображения: New England Journal of Medicine Технология позволила сократить задержку между мозговыми сигналами пациента и полученным звуком с первоначальных восьми до одной секунды. Этот результат уже сопоставим с естественным для обычной речи временным интервалом в 100–200 миллисекунд. Медианная скорость декодирования системы достигла 47,5 слов в минуту, что составляет примерно треть от скорости обычного разговора. Аналогичные исследования были произведены компанией Precision Neuroscience, причём её генеральный директор Майкл Магер (Michael Mager) утверждает, что их подход позволяет захватывать мозговые сигналы с более высоким разрешением за счёт «более плотной упаковки электродов». На данный момент Precision Neuroscience провела успешные эксперименты с 31 пациентом и даже получила разрешение регулирующих органов оставлять свои датчики имплантированными на срок до 30 дней. Магер утверждает, что это позволит в течение года обучить нейросеть на «крупнейшим хранилище нейронных данных высокого разрешения, которое существует на планете Земля». Следующим шагом, по словам Магера, будет «миниатюризация компонентов и их помещение в герметичные биосовместимые пакеты, чтобы их можно было навсегда внедрить в тело». 
Источник изображения: UC Davis Health Самым серьёзным препятствием для разработки и использования технологии «мозг-голос» является время, которое требуется пациентам, чтобы научиться пользоваться системой. Ключевой нерешённый вопрос заключается в степени различия шаблонов реагирования в двигательной коре — части мозга, которая контролирует произвольные действия, включая речь, — у разных людей. Если они окажутся схожими, предварительно обученные модели можно будет использовать для новых пациентов. Это ускорит процесс индивидуального обучения, который занимает десятки или даже сотни часов. Все исследователи вокализации солидарны в вопросе о недопустимости «расшифровки внутренних мыслей», то есть того, что человек не хочет высказывать. По словам одного из учёных, «есть много вещей, которые я не говорю вслух, потому что они не пойдут мне на пользу или могут навредить другим». На сегодняшний учёные ещё далеки от вокализации, сопоставимой с обычным разговором среднестатистических людей. Хотя точность декодирования удалось довести до 98 %, голосовой вывод происходит не мгновенно и не в состоянии передать такие важные особенности речи, как тон и настроение. Учёные надеются, что в конечном итоге им удастся создать голосовой нейропротез, который обеспечит полный экспрессивный диапазон человеческого голоса, чтобы пациенты могли контролировать тон и ритм своей речи и даже петь. Meta✴ в партнёрстве с ЮНЕСКО запускает новую программу сбора данных для улучшения речи и перевода ИИ
07.02.2025 [18:49],
Сергей Сурабекянц
LTPP (Language Technology Partner Program — партнёрская программа по языковым технологиям) — совместная инициатива ЮНЕСКО и Meta✴✴ по поиску авторов, которые могут предоставить более 10 часов записей речи с транскрипциями, большие объёмы письменного текста и наборы переведённых текстов на разных языках. В дальнейшем эти данные будут интегрированы в ИИ-модели с открытым исходным кодом для распознавания речи и перевода. Усилия LTPP будут сосредоточены на недостаточно обслуживаемых языках для поддержки работы, уже проводимой в этом направлении ЮНЕСКО. «В конечном итоге наша цель — создать интеллектуальные системы, которые могут понимать и реагировать на сложные потребности человека, независимо от языка или культурного происхождения», — заявил представитель Meta✴✴. В дополнение к новой инициативе Meta✴✴ опубликовала открытый исходный код программы для оценки производительности моделей языкового перевода. Тест, состоящий из предложений, созданных лингвистами, поддерживает семь языков, и доступен на платформе разработки ИИ Hugging Face. Meta✴✴ продолжает расширять количество языков, поддерживаемых её ИИ-моделями и развивать функции автоматического перевода для создателей контента. В сентябре прошлого года компания начала тестирование инструмента для перевода голосов в Instagram✴✴ Reels, который дублирует речь создателя на другом языке с автоматическим липсинком. На сегодняшний день обработка на платформах Meta✴✴ контента на языках, отличных от английского, далека от совершенства. По некоторым данным, в соцсети Facebook✴✴ 79 % дезинформации о COVID на итальянском и испанском языках не были распознаны и отмечены системой, по сравнению с 29 % на английском языке. А сообщения на арабском языке, наоборот, часто ошибочно помечаются как разжигающие ненависть. Meta✴✴ заявила, что принимает меры по улучшению своих технологий перевода и модерации. И, хотя компания позиционирует обе свои языковые инициативы как филантропические, нет никаких сомнений, что главным бенефициаром этих программ станет именно Meta✴✴, которая сможет существенно улучшить качество распознавания речи и перевода. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex




