|
Опрос
|
реклама
Быстрый переход
У Nvidia нашлась ахиллесова пята — треть выручки зависит от настроения трёх клиентов
22.11.2024 [23:17],
Андрей Созинов
Компания Nvidia сильно зависит от горстки крупнейших заказчиков, которые активно покупают ускорители вычислений для задач ИИ и в совокупности приносят компании более трети дохода. Это ставит Nvidia в уязвимое положение, хотя в ближайшее время компании и её инвесторам вряд ли стоит беспокоиться — спрос на ИИ-ускорители только растёт. 
Источник изображений: Nvidia В квартальном отчёте по форме 10-Q, который компании подают в Комиссию по ценным бумагам и биржам США, Nvidia в очередной раз заявила, что у неё есть ключевые клиенты, которые настолько важны, что заказы каждого из них формируют более 10 % от глобальной выручки Nvidia. При этом компания не раскрывает имена этих клиентов, что логично, поскольку вряд ли бы они хотели, чтобы их инвесторы, сотрудники, критики, активисты и конкуренты узнали, сколько именно денег они тратят на чипы Nvidia. В отчёте за второй квартал Nvidia указала четырёх крупнейших клиентов, а в последнем квартале упоминается три таких «кита», поскольку один из них сократил закупки. Хотя доподлинно неизвестно, что это за клиенты, Мандип Сингх (Mandeep Singh), руководитель глобального отдела технологических исследований Bloomberg Intelligence, считает, что речь идёт о Microsoft, Meta✴✴ и, возможно, Super Micro.  Сама Nvidia называет их просто «клиент A», «клиент B» и «клиент C». Сообща они приобрели товаров и услуг на общую сумму 12,6 миллиарда долларов в третьем финансовом квартале, завершившемся в конце октября. Это более трети от общей выручки Nvidia, которая составила 35,1 миллиарда долларов. Также отмечается, что каждый из «китов» приобрёл товаров и услуг Nvidia на сумму от 10 до 11 миллиардов долларов за первые девять месяцев текущего финансового года. Примечательно, что вклад «китов» в выручку оказался равнозначным: на каждого пришлось по 12 %, что говорит о том, что они, скорее всего, закупили максимальное количество выделенных им чипов, но не столько, сколько им хотелось бы в идеале. Это согласуется с комментариями генерального директора Дженсена Хуанга (Jensen Huang) о том, что Nvidia ограничена в поставках. Компания не может просто производить больше чипов, поскольку она сама их не выпускает, а заказывает производство у TSMC, мощности которой расписаны на годы вперёд. Поскольку имена крупнейших покупателей чипов Nvidia засекречены, трудно сказать, являются ли они «посредниками», как Super Micro Computer, которая выпускает серверы для центров обработки данных, или конечными пользователями, как Microsoft, Meta✴✴ или xAI Илона Маска (Elon Musk). Последняя, например, практически из ниоткуда построила мощнейший ИИ-суперкомпьютер всего за три месяца.  Тем не менее полагаться на горстку крупных клиентов весьма рискованно — если кто-то из них, а ещё хуже, все разом, перестанут закупать ИИ-чипы, у Nvidia резко упадёт выручка. К счастью для инвесторов Nvidia, в ближайшее время такое маловероятно. Аналитик Bloomberg Intelligence Мандип Сингх видит лишь несколько долгосрочных рисков для Nvidia. Во-первых, некоторые крупные клиенты, вероятно, со временем сократят заказы в пользу собственных чипов, что приведёт к уменьшению доли компании на рынке. Одним из таких клиентов является Alphabet, у которой есть собственные ИИ-чипы семейства TPU. Во-вторых, Nvidia доминирует в области ускорителей для обучения ИИ, но не может похвастаться тем же в сфере чипов для инференса — запуска уже обученных нейросетей. Для инференса не требуются столь мощные чипы, что означает для Nvidia гораздо большую конкуренцию не только со стороны AMD и других прямых соперников, но и со стороны компаний с собственными чипами, таких как Tesla.  В конечном счёте запуск обученных нейросетей станет гораздо более значимым бизнесом, поскольку всё больше предприятий будут использовать ИИ, считает аналитик. «Многие компании пытаются сфокусироваться на возможностях инференса, потому что для этого не нужен самый мощный GPU-ускоритель», — заявил Сингх. Он также отметил, что в долгосрочной перспективе переход на чипы для инференса является «безусловно» большим риском для Nvidia, чем потеря доли рынка чипов для обучения ИИ. И тем не менее Сингх отмечает, что верит прогнозу Дженсена Хуанга о том, что расходы крупнейших клиентов на ИИ-чипы не прекратятся. Даже если доля Nvidia на рынке ИИ-чипов сократится с нынешних 90 %, компания всё равно сможет ежегодно зарабатывать на этом сотни миллиардов долларов. AMD готовит ответ Nvidia в области нейронного рендеринга для видеоигр
30.10.2024 [06:04],
Анжелла Марина
AMD планирует догнать Nvidia в области технологии трассировки лучей в реальном времени, используя нейронные сети. На данный момент Nvidia доминирует на рынке видеокарт благодаря своим передовым технологиям на основе искусственного интеллекта и машинного обучения, таким как DLSS. AMD пока значительно отстаёт, особенно в потребительском сегменте, однако рассчитывает изменить ситуацию в ближайшее время. 
Источник изображения: PowerColor, Tomshardware.com По информации издания Tom's Hardware, исследования AMD сосредоточены на внедрении трассировки лучей в реальном времени на графических процессорах архитектуры RDNA с помощью нейронных сетей. Разрабатываемая технология направлена на нейронное устранение шумов, возникающих при использовании ограниченного количества лучей в трассировке. Это напоминает подход Nvidia с технологией DLSS 3.5, которая использует восстановление лучей для улучшения изображения при меньшем количестве расчётов. Традиционная трассировка лучей требует огромного количества вычислений — иногда тысячи или десятки тысяч лучей на каждый пиксель, что является стандартом, применяемым в киноиндустрии, где на рендеринг одного кадра могут уходить часы. При трассировке лучей сцена рендерится путём вычисления отражений света, где каждое изменение траектории луча может привести к разной цветовой интерпретации пикселя. Чем больше таких расчётов, тем лучше становится итоговое изображение. Однако для достижения трассировки лучей в реальном времени, что актуально для видеоигр, количество таких расчётов необходимо значительно уменьшить. Но это приведёт к ещё большему появлению шумов в изображениях из-за того, что некоторые лучи часто не достигают определённых пикселей, вызывая неполное освещение сцены. AMD планирует решить этот вопрос с помощью нейронной сети, которая будет устранять эти проблемы и восстанавливать детали сцены, аналогично подходу Nvidia. Собственно инновация AMD заключается в объединении апскейлинга и устранения шума в одной нейронной сети. Как заявляет сама компания, их подход «генерирует высококачественные изображения с устранением шума и суперсемплингом при более высоком разрешении дисплея, чем разрешение рендеринга для трассировки путей в реальном времени». Это позволит выполнять апскейлинг за один проход. Исследования AMD могут привести к созданию новой версии FSR (технология временного масштабирования), которая сможет конкурировать с технологиями Nvidia по производительности и качеству изображения. Однако встаёт вопрос, смогут ли существующие графические процессоры AMD поддерживать нейронные сети для устранения шумов или потребуется новое оборудование? Например, DLSS от Nvidia требует наличия специального ИИ-оборудования на графических процессорах GeForce RTX, а также оптического потокового ускорителя для генерации кадров на GeForce RTX 40-й серии и более поздних моделях. Текущие же графические процессоры AMD в основном не оснащены специальными ускорителями для ИИ, в отличие от Nvidia GeForce RTX, где такие ускорители играют ключевую роль в реализации DLSS. Если AMD сможет реализовать эффективный подход к нейронной трассировке лучей и апскейлингу, это позволит расширить доступ к высококачественной графике на более широком спектре оборудования. Однако учитывая высокие требования к трассировке лучей в современных играх, таких как Alan Wake 2 и Cyberpunk 2077, для достижения высокого уровня качества изображения компании, вероятно, потребуется более мощное оборудование. AMD представила ИИ-ускоритель Instinct MI325X для конкуренции с Nvidia Blackwell и рассказала о ещё более мощном Instinct MI355X
11.10.2024 [08:44],
Анжелла Марина
Компания AMD официально представила флагманский ускоритель вычислений Instinct MI325X, который станет конкурентом для Nvidia Blackwell и уже поступил в производство. Вместе с тем производитель раскрыл подробности об ускорителе следующего поколения — Instinct MI355X на архитектуре CDNA4. 
Источник изображений: AMD В последние годы AMD отмечает значительный рост спроса на свои ИИ-ускорители. При этом серия MI300 пользуется особой популярностью. Однако, как пишет издание Tom's Hardware, MI355X вызывает определённые вопросы по части брендирования, поскольку архитектура CDNA использовалась в MI100, CDNA2 — в MI200, а CDNA3 — в серии MI300. Логично было бы увидеть CDNA4 в ускорителях MI400, но они получат архитектуру следующего поколения.  Как бы от ни было, CDNA4 — это новая архитектура, которая представляет собой значительное обновление прежней CDNA3. AMD описала её как «переосмысление с нуля», хотя, по мнению экспертов, это может быть и некоторым преувеличением. Ускоритель MI355X будет производиться по новому 3-нм техпроцессу N3 от TSMC, потребовав серьёзных изменений по сравнению с N5, но основные элементы дизайна могут остаться схожими с CDNA3. Объём памяти HBM3e достигнет 288 Гбайт. Ускоритель будет оснащён 10 вычислительными элементами на один GPU, а производительность достигнет 2,3 петафлопса вычислительной мощности для операций FP16 и 4,6 петафлопса для FP8, что на 77 % больше по сравнению с ускорителем предыдущего поколения.  Одним из ключевых нововведений MI355X станет поддержка чисел с плавающей запятой FP4 и FP6, которые удвоят вычислительную мощность по сравнению с FP8, позволив достигнуть 9,2 петафлопса производительности в FP4. Для сравнения, Nvidia Blackwell B200 предлагает до 9 Пфлопс производительности в FP4, а более мощная версия GB200 — 10 Пфлопс. Таким образом, AMD Instinct MI355X может стать серьёзным конкурентом для будущих продуктов Nvidia, в том числе благодаря 288 Гбайт памяти HBM3E — это на 50 % больше, чем у Nvidia Blackwell. При этом оба устройства будут иметь пропускную способность памяти до 8 Тбайт/с на GPU.  Как отмечают эксперты, вычислительная мощность и объём памяти — это не единственные ключевые параметры для ИИ-ускорителей. Важным фактором становится масштабируемость систем при использовании большого числа GPU. Пока AMD не раскрыла подробности о возможных изменениях в системе интерконнекта между GPU, что может оказаться важным аспектом в сравнении с Blackwell от Nvidia.  Вместе с анонсом Instinct MI355X компания AMD подтвердила, что ускоритель Instinct MI325X официально запущен в производство и поступит в продажу в этом квартале. Основным отличием MI325X от предыдущей модели MI300X стало увеличение объёма памяти со 192 до 256 Гбайт. Что интересно, изначально планировалось оснастить ускоритель 288 Гбайт памяти, но видимо AMD решили ограничиться приростом в 33 % вместо 50 %. Память HBM3E в новинке обеспечивает пропускную способность более 6 Тбайт/с, что на 13 % больше, чем 5,3 Тбайт/с у MI300X. 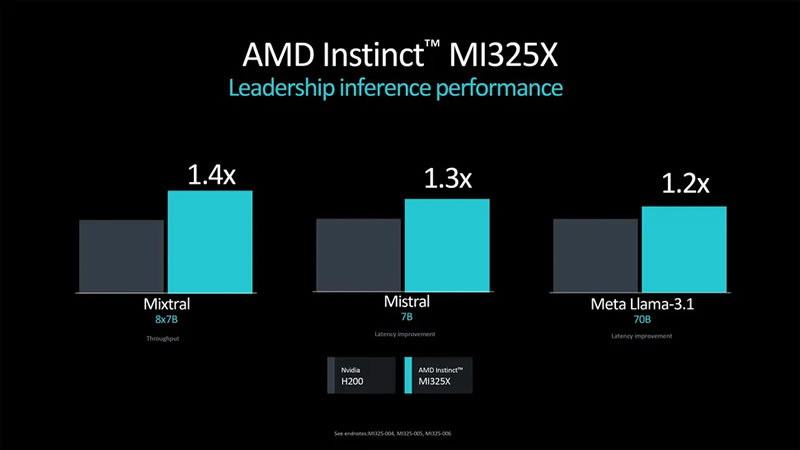 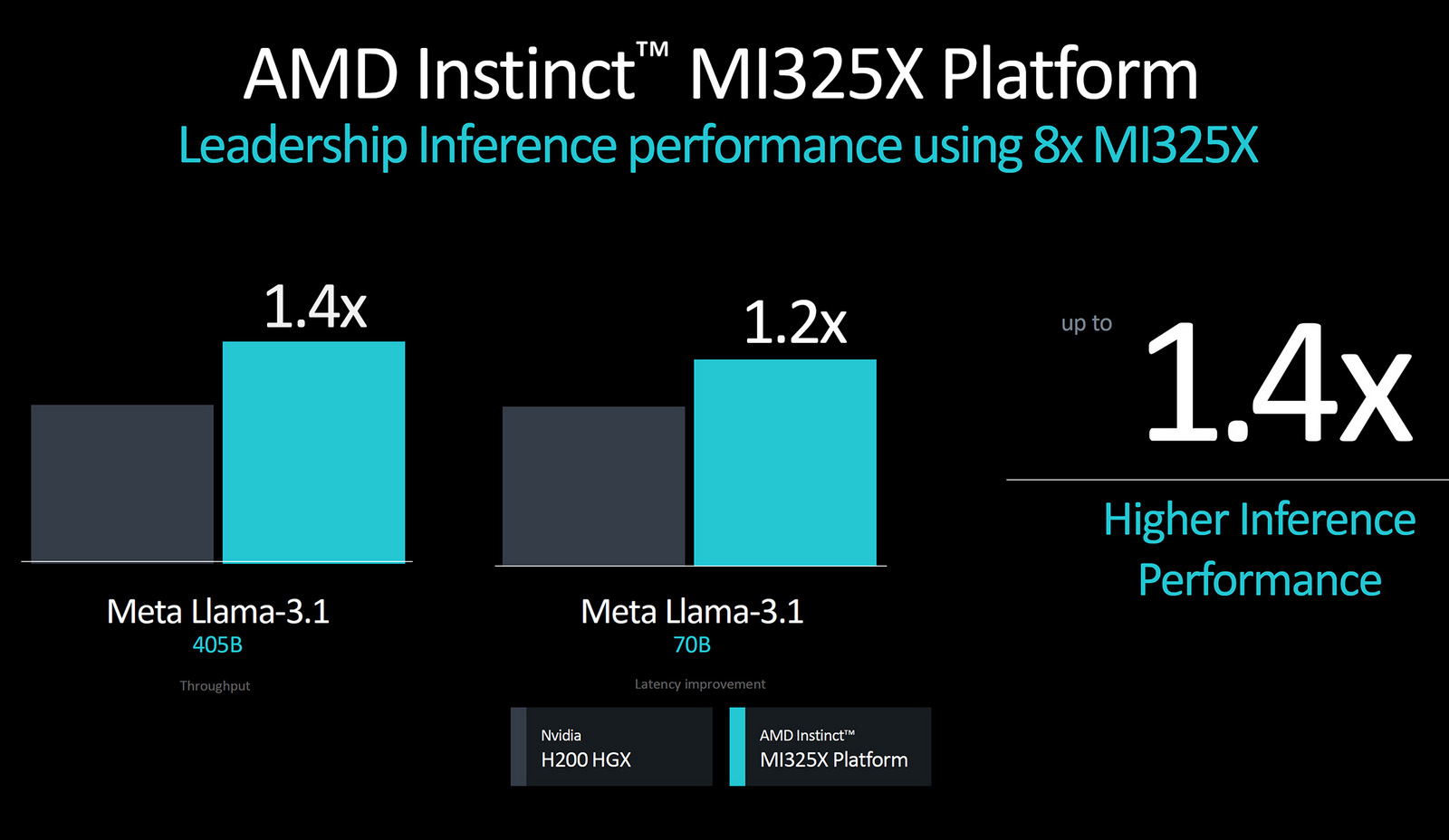 AMD провела сравнительный анализ производительности Instinct MI325X и Nvidia H200. Ускоритель AMD оказался на 20-40 % быстрее конкурента в запуске уже обученных больших языковых моделей, а в обучении нейросетей показал паритет производительности.  AMD не раскрыла стоимость своих ИИ-ускорителей, но представители компании заявили, что одной из целей является предоставление преимущества по совокупной стоимости владения (TCO). Это может быть достигнуто либо за счёт лучшей производительности при той же цене, либо за счёт более низкой цены при одинаковой производительности. Как отметил представитель AMD: «Мы являемся деловыми людьми и будем принимать ответственные решения относительно ценообразования». Instinct MI355X планируется к поставкам во второй половине 2025 года. Дженсен Хуанг: будущее за рассуждающим ИИ, но для этого необходимо в разы удешевить вычисления
09.10.2024 [21:55],
Дмитрий Федоров
Дженсен Хуанг (Jensen Huang), бессменный руководитель Nvidia, заявил, что будущее ИИ — за системами, способными к рассуждению. Однако для реализации этой концепции необходимо значительно снизить стоимость вычислений. Хуанг подчеркнул, что его компания стремится ежегодно увеличивать производительность чипов в 2–3 раза, сохраняя текущий уровень их стоимости и энергопотребления. 
Источник изображения: Nvidia В рамках подкаста, организованного Рене Хаасом (Rene Haas), генеральным директором Arm Holdings, Хуанг поделился своим видением развития ИИ. По его словам, следующее поколение интеллектуальных систем сможет отвечать на запросы пользователей, проходя через сотни или даже тысячи шагов анализа собственных выводов. Эта способность к глубокому рассуждению станет ключевым отличием от современных ИИ, таких как ChatGPT, которым, как признался Хуанг, он пользуется ежедневно. Nvidia стремится создать фундамент для такого прорыва и ставит перед собой амбициозную цель: ежегодно повышать производительность своих чипов в 2–3 раза при сохранении прежнего уровня стоимости и энергопотребления. Такой подход призван революционизировать способность ИИ-систем распознавать сложные паттерны и делать осознанные выводы. «Мы способны обеспечить беспрецедентное снижение затрат на интеллектуальные системы. Все мы осознаём ценность этого достижения. При существенном сокращении расходов мы сможем реализовать на этапе инференса такие сложные процессы, как рассуждение», — подчеркнул Хуанг. Nvidia занимает доминирующую позицию на рынке ускорителей для ИИ, контролируя более 90 % этого сегмента рынка. Однако компания не ограничивается только производством чипов. Её стратегия включает в себя разработку компьютеров, программного обеспечения (ПО), ИИ-моделей, сетевых решений и других сервисов. Такая диверсификация направлена на стимулирование более широкого внедрения ИИ в бизнес-процессы различных компаний. Несмотря на лидирующие позиции, Nvidia сталкивается с растущей конкуренцией. Крупные операторы дата-центров, такие как Amazon Web Services (AWS) и Microsoft, разрабатывают собственные альтернативные решения, чтобы ослабить зависимость от продуктов Nvidia. Кроме того, компания AMD, давний соперник Nvidia на рынке игровых чипов, активно выходит на рынок ИИ-ускорителей, что может усилить конкурентное давление на лидера индустрии. IBM анонсировала 5-нм процессор Telum II и ускоритель Spyre для задач ИИ
27.08.2024 [05:45],
Анжелла Марина
Компания IBM анонсировала новое поколение вычислительных систем для искусственного интеллекта — процессор Telum II и ускоритель IBM Spyre. Оба продукта предназначены для ускорения ИИ и улучшения производительности корпоративных приложений. Telum II предлагает значительные улучшения благодаря увеличенной кеш-памяти и высокопроизводительным ядрам. Ускоритель Spyre дополняет его, обеспечивая ещё более высокие показатели для приложений на основе ИИ. 
Источник изображения: IBM Как сообщается в блоге компании, новый процессор IBM Telum II, разработанный с использованием 5-нанометровой технологии Samsung, будет оснащён восемью высокопроизводительными ядрами, работающими на частоте 5,5 ГГц. Объём кеш-памяти на кристалле получил увеличение на 40 %, при этом виртуальный L3-кеш вырос до 360 Мбайт, а L4-кеш до 2,88 Гбайт. Ещё одним нововведением является интегрированный блок обработки данных (DPU) для ускорения операций ввода-вывода и следующее поколение встроенного ускорителя ИИ. Telum II предлагает значительные улучшения производительности по сравнению с предыдущими поколениями. Встроенный ИИ-ускоритель обеспечивает в четыре раза большую вычислительную мощность, достигая 24 триллионов операций в секунду (TOPS). Архитектура ускорителя оптимизирована для работы с большими языковыми моделями и поддерживает широкий спектр ИИ-моделей для комплексного анализа структурированных и текстовых данных. Кроме того, новый процессор поддерживает тип данных INT8 для повышения эффективности вычислений. При этом на системном уровне Telum II позволяет каждому ядру процессора получать доступ к любому из восьми ИИ-ускорителей в рамках одного модуля, обеспечивая более эффективное распределение нагрузки и достигая общей производительности в 192 TOPS. IBM также представила ускоритель Spyre, разработанный совместно с IBM Research и IBM Infrastructure development. Spyre оснащён 32 ядрами ускорителя ИИ, архитектура которых схожа с архитектурой ускорителя, интегрированного в чип Telum II. Возможность подключения нескольких ускорителей Spyre к подсистеме ввода-вывода IBM Z через PCIe позволяет существенно увеличить доступные ресурсы для ускорения задач искусственного интеллекта. Telum II и Spyre разработаны для поддержки широкого спектра сценариев использования ИИ, включая метод ensemble AI. Этот метод использует преимущества одновременного использования нескольких ИИ-моделей для повышения общей производительности и точности прогнозирования. Примером может служить обнаружение мошенничества со страховыми выплатами, где традиционные нейронные сети успешно сочетаются с большими языковыми моделями для повышения эффективности анализа. Оба продукта были представлены 26 августа на конференции Hot Chips 2024 в Пало-Альто (Калифорния, США). Их выпуск планируется в 2025 году. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


