|
Опрос
|
реклама
Быстрый переход
Intel представила мечту анонимов — чип Heracles для работы с зашифрованными данными без дешифровки
11.03.2026 [22:19],
Геннадий Детинич
Intel впервые показала чип для полностью гомоморфного шифрования (Fully Homomorphic Encryption, FHE), который справляется с задачами в 5000 раз быстрее классических серверных процессоров. Это ускоритель Heracles («Геракл»), созданный по заказу военных США для противодействия взлому со стороны квантовых компьютеров. «Геракл» ускоряет обработку полностью зашифрованной информации без какого-либо декодирования, сохраняя конфиденциальность на всех этапах. 
Источник изображения: Intel Полностью гомоморфное шифрование (Fully Homomorphic Encryption, FHE) представляет собой перспективную криптографическую технологию, позволяющую выполнять произвольные вычисления над зашифрованными данными без необходимости их расшифровки. Это решает фундаментальную проблему доверия к облачным сервисам и ИИ-системам: данные остаются полностью закрытыми для платформ даже во время обработки. Однако главным препятствием для практического применения FHE остаётся крайне низкая производительность обычных процессоров и видеокарт. Более подробно о «головоломной» математике полностью гомоморфного шифрования можно прочесть в статье «Полная гомоморфность — и никакого доверия!» из нашего архива. Не углубляясь, отметим, что на обычных CPU и GPU такие операции могут быть в тысячи–десятки тысяч раз медленнее, чем работа с открытыми данными. Именно поэтому ведущие компании и стартапы активно разрабатывают специализированные ускорители для FHE. Как ни крути, анонимность всегда будет востребована. Чип, получивший имя «Геракл», компания Intel начала разрабатывать пять лет назад. До конференции ISSCC в прошлом месяце о нём было мало что известно. Теперь Intel готова дозированно делиться информацией о нём, поскольку конкуренты не дремлют и важно оставаться на слуху. По словам представителей компании, Heracles ускоряет FHE-вычисления до 5000 раз по сравнению с лучшими серверными процессорами Intel Xeon (например, 24-ядерным Sapphire Rapids). Чип изготовлен по самому передовому 3-нм FinFET-техпроцессу компании, имеет площадь примерно в 20 раз больше конкурирующих разработок в сфере FHE (более 200 мм² вместо примерно 10 мм² у конкурентов) и работает в тесной связке с двумя модулями HBM по 24 Гбайт каждый. Чип и память упрятаны под общий водоблок и охлаждаются жидким хладагентом. В целом исполнение напоминает топовый GPU, но решает иные задачи. Архитектура «Геркулеса» представляет собой ячеистую структуру, связывающую парные плитки-вычислители шиной с пропускной способностью 9,6 Тбайт/с. Внешняя память HBM общей ёмкостью 48 Гбайт буферизируется общей для всех парных плиток кеш-памятью ёмкостью 64 Мбайт. Канал доступа к внешней памяти обеспечивает 819 Гбайт/с. Подобные характеристики даже не снились самым мощным на сегодня графическим ускорителям. В компании утверждают, что Heracles — это первый чип FHE, работающий «в масштабе». Иначе говоря, это не лабораторная демонстрация, а решение, способное к выполнению реальных крупномасштабных задач. В живой демонстрации на ISSCC чип обработал анонимный запрос к зашифрованной базе данных избирателей (функция проверки регистрации голоса) за 14 мкс вместо 15 мс на Xeon — разница, которая при проверке 100 млн бюллетеней сокращается с 17 дней до 23 минут. Публичное представление «Геркулеса» можно расценить как важный шаг в гонке за коммерциализацией аппаратных FHE-платформ. Стартапы Duality Technologies, Optalysys, Niobium Microsystems и другие тоже активно продвигают свои решения, но Intel рассчитывает на собственные лидирующие позиции в отрасли, которые поддержат перспективную разработку. Если технология получит широкое распространение, это радикально изменит подход к приватности в облачных вычислениях, анализе данных, машинном обучении и многих других областях, где сейчас приходится жертвовать конфиденциальностью ради скорости обработки. Meta✴ купит у AMD чипов на $100 млрд для ИИ-систем на 6 ГВт — и получит «в подарок» кусочек самой AMD
24.02.2026 [19:39],
Сергей Сурабекянц
Компании AMD и Meta✴✴ объявили о ещё одной колоссальной сделке, стоимость которой может превысить $100 млрд. AMD предоставит до 6 гигаватт вычислительной мощности на основе ИИ-ускорителей AMD Instinct для реализации амбиций Meta✴✴ в области ИИ. Сделка предусматривает вознаграждение для Meta✴✴, в рамках которого компания может получить до 160 млн акций AMD. Meta✴✴ также станет ведущим потребителем чипов AMD EPYC Venice и процессоров следующего поколения EPYC Verano. 
Источник изображений: AMD В своём пресс-релизе AMD подтвердила партнёрство с Meta✴✴ с целью «быстрого масштабирования инфраструктуры ИИ и ускорения разработки и внедрения передовых моделей ИИ». С этой целью AMD предоставит Meta✴✴ архитектуру AMD Helios для стоечных систем, начало развёртывания которой ожидается во второй половине 2026 года. Решение будет основано на базе специализированных графических процессоров AMD Instinct, построенных на архитектуре MI450, процессоров AMD EPYC Venice и программного обеспечения ROCm.  Глава AMD Лиза Су (Lisa Su) заявила, что партнёрство с Meta✴✴ представляет собой «многолетнее сотрудничество», а генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) подтвердил долгосрочные перспективы партнёрства. По словам Цукерберга, амбиции Meta✴✴ в области искусственного интеллекта направлены на создание «персонального суперинтеллекта». AMD также сообщила, что Meta✴✴ станет ведущим клиентом для процессоров AMD EPYC Venice шестого поколения, а также чипов EPYC следующего поколения Verano. AMD заявила, что выпустила для Meta✴✴ «варранты на основе производительности» на сумму до 160 млн обыкновенных акций AMD, которые будут предоставляться «по мере достижения определённых этапов, связанных с поставками графических процессоров Instinct». По сути, AMD вознаграждает Meta✴✴ своими акциями за покупку графических процессоров. Сделка по масштабу практически идентична партнёрству OpenAI и AMD, объявленному в октябре. По данным The Wall Street Journal, стоимость сделки превышает $100 млрд, при этом каждый гигаватт вычислительных мощностей приносит AMD десятки миллиардов долларов дохода. Что касается сделки с акциями, Meta✴✴ сможет приобрести до 160 млн акций по цене 0,01 доллара за штуку. Для получения полного вознаграждения в виде акций, цена акций AMD должна достичь $600. В настоящее время они торгуется чуть ниже $200. На прошлой неделе сообщалось о намерении Meta✴✴ использовать автономные процессоры Nvidia Grace в своих ЦОД, что, по словам компании, обеспечит значительный скачок производительности на ватт. Илон Маск хочет на порядок больше ИИ-чипов, чем выпускает вся полупроводниковая индустрия мира
18.11.2025 [18:36],
Сергей Сурабекянц
Амбиции Илона Маска (Elon Musk) в области искусственного интеллекта настолько велики, что он хочет получить больше ускорителей ИИ, чем отрасль в настоящее время может произвести. По его словам, Tesla нуждается в «100–200 миллиардах чипов с искусственным интеллектом в год», и если она не сможет получить их от производителей, то рассмотрит возможность создания собственных фабрик. 
Источник изображения: dogegov.com Маск заявил, что «испытывает огромное уважение к TSMC и Samsung», но он считает, что эти компании не в состоянии удовлетворить потребность его предприятий в чипах ИИ: «Когда я спросил, сколько времени займёт строительство новой фабрики по производству чипов, они ответили, что до запуска производства им потребуется пять лет. Пять лет для меня — это вечность. Мои сроки — год, два. […] Если они передумают и […] будут поставлять нам 100–200 миллиардов ИИ-чипов в год в те сроки, когда они нам нужны, это будет здорово». Маск не уточнил, когда Tesla и SpaceX потребуются эти 100–200 миллиардов ИИ-процессоров в год, но в любом случае выпуск такого количества чипов практически неосуществим, если он имел в виду единицы, а не сумму в долларах. По данным Ассоциации полупроводниковой промышленности, в 2023 году по всему миру произведено 1,5 трлн чипов. Однако в это число входят любые микросхемы — от крошечных микроконтроллеров и датчиков до чипов памяти и ускорителей ИИ. 
Источник изображений: Tesla Такие ускорители ИИ, как Nvidia H100 или B200/B300, представляют собой огромные кремниевые блоки, которые сложно и дорого производить, поэтому на их изготовление уходит больше всего времени. По словам Маска, энергопотребление его ИИ-процессоров AI5 составит 250 Вт, в то время как графические процессоры Nvidia B200 могут потреблять до 1200 Вт. Этот параметр может служит косвенной оценкой размера чипов. Даже если чип AI5 будет в пять раз меньше Nvidia B200, мощностей для достижения целей Маска всё равно совершенно недостаточно. Будучи одним из крупнейших клиентов TSMC, Nvidia поставила четыре миллиона графических процессоров Hopper стоимостью $100 млрд (не считая Китая) за весь срок службы архитектуры, который составил около двух календарных лет. С Blackwell Nvidia продала около шести миллионов графических процессоров за первые четыре квартала их жизненного цикла. Если Маск действительно имел в виду 200 миллиардов устройств, то он хотел бы получить на порядки больше процессоров для искусственного интеллекта, чем отрасль (бо́льшая часть которой приходится на TSMC) может производить за год. Если он всё же подразумевал потребность в ИИ-чипах на сумму от $100 до $200 млрд, то TSMC и Samsung, безусловно, смогут поставить такой объём в ближайшие годы. Однако, похоже, что он действительно считает, что ему нужно больше, чем эти компании могут предложить.  «Мы будем использовать фабрики TSMC на Тайване и в Аризоне, фабрики Samsung в Корее и Техасе, — сказал Маск. — С их точки зрения, они движутся молниеносно. […] тем не менее, это будет для нас ограничивающим фактором. Они работают на пределе своих возможностей, но с их точки зрения — это “педаль в пол”. У них просто не было компании, которая разделяла бы наше понимание срочности. Возможно, единственный способ масштабироваться с желаемой скоростью — это построить действительно большой завод или быть ограниченным в производстве Optimus и беспилотных автомобилей из-за [поставок] ИИ-чипов. Действительно ли потребность Tesla и SpaceX в ИИ-чипах настолько высока, остаётся неясным. Tesla продала 1,79 млн автомобилей в 2024 году, поэтому ей вряд ли требуется больше двух миллионов чипов для своих автомобилей. Конечно, компаниям Маска могут понадобиться ещё миллионы ИИ-процессоров для обучения ИИ, но маловероятно, что Маск в ближайшее время готов создать ИИ-кластеры на базе миллиардов чипов. Антропоморфные роботы Optimus также вряд ли потребуют таких объёмов чипов в ближайшие годы.  Ранее мы писали, как воодушевлённый итогами голосования по новому компенсационному плану Илон Маск на собрании акционеров фонтанировал обещаниями и идеями, и по традиции пританцовывал в момент появления на сцене человекоподобного робота Optimus. Тогда он заявил, что для достижения поставленных новым планом целей Tesla вынуждена будет наладить самостоятельный выпуск чипов. Google выпустила Arm-процессоры Axion и тензорный ускоритель Ironwood для обучения и запуска огромных ИИ-моделей
06.11.2025 [19:52],
Сергей Сурабекянц
Сегодня Google представила новые процессоры Axion и тензорные ускорители Ironwood — TPU седьмого поколения. По словам компании, чипы Axion на 50 % производительнее и на 60 % энергоэффективнее современных x86-процессоров, а TPU Ironwood — самый производительный и масштабируемый настраиваемый ИИ-ускоритель на сегодняшний день и первый среди чипов Google, разработанный специально для запуска обученных ИИ-моделей (инференса). 
Источник изображений: Google TPU Ironwood будет поставляться в системах в двух конфигурациях: с 256 или с 9216 чипами. Один ускоритель обладает пиковой вычислительной мощностью 4614 Тфлопс (FP8), а кластер из 9216 чипов при энергопотреблении порядка 10 МВт выдаёт в общей сложности 42,5 Эфлопс. Эти показатели значительно превосходят возможности системы Nvidia GB300 NVL72, которая составляет 0,36 Эфлопс с операциях FP8. 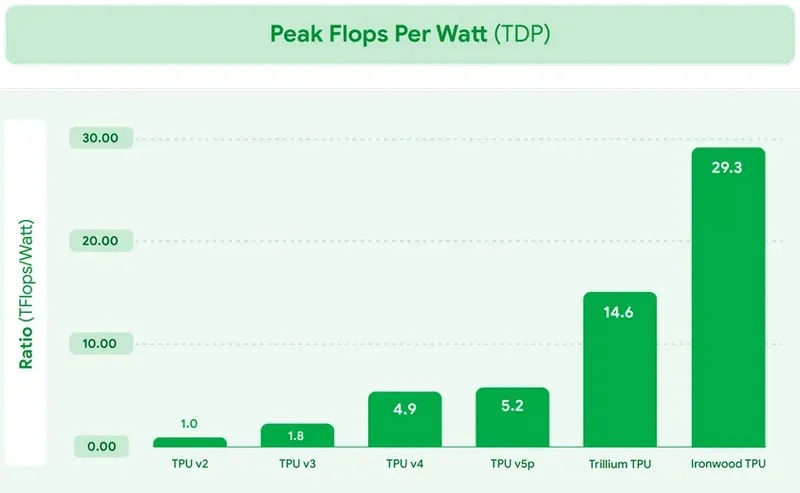 Ironwood оснащён усовершенствованным блоком SparseCore, предназначенным для ускорения работы с ИИ-моделями, которые используются в системах ранжирования и рекомендаций. Расширенная реализация SparseCore в Ironwood позволяет ускорить более широкий спектр рабочих нагрузок, выйдя за рамки традиционной области ИИ в финансовые и научные сферы. Модули объединяются между собой с помощью фирменной сети Inter-Chip Interconnect со скоростью 9,6 Тбит/с и содержат около 1,77 Пбайт памяти HBM3E, что также превосходит возможности конкурирующей платформы Nvidia. Они могут быть объединены в кластеры из сотен тысяч TPU.  Это интегрированная суперкомпьютерная платформа, которую Google называет «ИИ-гиперкомпьютер» объединяет вычисления, хранение данных и сетевые функции под одним уровнем управления. Для повышения надёжности, Google использует реконфигурируемую матрицу Optical Circuit Switching, которая мгновенно обходит любые аппаратные сбои для поддержания непрерывной работы.  По данным IDC, этот «гиперкомпьютер ИИ» обеспечивает среднюю окупаемость инвестиций (ROI) в течение трёх лет на уровне 353 %, снижение расходов на ИТ на 28 % и повышение операционной эффективности на 55 %. Несколько компаний уже внедряют эту платформу Google. Anthropic планирует использовать до миллиона TPU для работы и расширения семейства моделей Claude, ссылаясь на значительный выигрыш в соотношении цены и производительности. Lightricks начала развёртывание Ironwood для обучения и обслуживания своей мультимодальной системы LTX-2.  Полные спецификации универсальных процессоров Axion пока не опубликованы, в частности, не раскрыты тактовые частоты и использованный техпроцесс. Сообщается, что процессоры располагают 2 Мбайт кэша второго уровня на ядро, 80 Мбайт кэша третьего уровня, поддерживают память DDR5-5600 МТ/с и технологию Uniform Memory Access (UMA). Известно, что Axion построен на платформе Arm Neoverse v2 и должен обеспечить до 50 % более высокую производительность и до 60 % более высокую энергоэффективность по сравнению с современными процессорами x86. По словам Google, он также на 30 % быстрее, чем «самые быстрые универсальные экземпляры на базе Arm, доступные сегодня в облаке».  Процессоры Axion могут использоваться как в серверах искусственного интеллекта, так и в серверах общего назначения для решения различных задач. На данный момент Google предлагает три конфигурации Axion: C4A, N4A и C4A Metal. C4A обеспечивает до 72 виртуальных процессоров, 576 Гбайт памяти DDR5 и сетевое подключение со скоростью 100 Гбит/с в сочетании с локальным хранилищем Titanium SSD объёмом до 6 Тбайт. Экземпляр оптимизирован для стабильно высокой производительности в различных приложениях. Это единственный чип, который доступен уже сегодня. 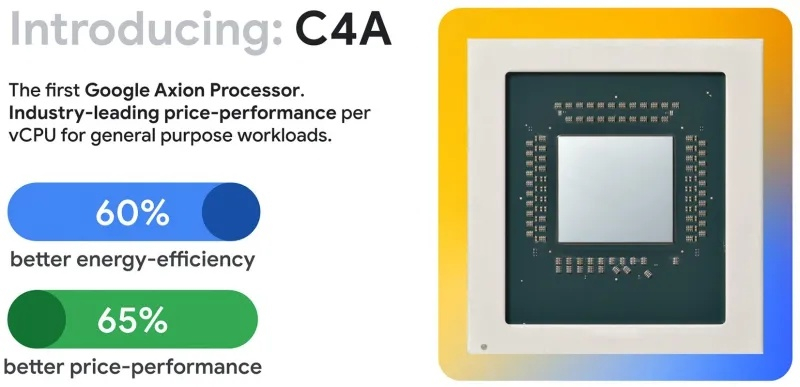 N4A предназначен для общих рабочих нагрузок, таких как обработка данных, веб-сервисы и среды разработки, но масштабируется до 64 виртуальных ЦП, 512 Гбайт оперативной памяти DDR5 и сетевой пропускной способности 50 Гбит/с. C4A Metal предоставляет клиентам полный аппаратный стек Axion: до 96 виртуальных ЦП, 768 Гбайт памяти DDR5 и сетевую пропускную способность 100 Гбит/с. Экземпляр предназначен для специализированных или ограниченных по лицензии приложений, а также для разработки на базе ARM. Процессор Axion дополняет портфолио специализированных чипов компании, а TPU Ironwood закладывает основу для конкуренции с лучшими ускорителями ИИ на рынке. Серверы на базе Axion и Ironwood оснащены фирменными контроллерами Titanium, которые разгружают процессор от сетевых задач, задач безопасности и обработки ввода-вывода, обеспечивая более эффективное управление и, как следствие, более высокую производительность. Qualcomm вернулась в большие вычисления: представлены ИИ-ускорители AI200 и AI250 для дата-центров
27.10.2025 [23:13],
Николай Хижняк
Компания Qualcomm анонсировала два ускорителя ИИ-инференса (запуска уже обученных больших языковых моделей) — AI200 и AI250, которые выйдут на рынок в 2026 и 2027 годах. Новинки должны составить конкуренцию стоечным решениям AMD и Nvidia, предложив повышенную эффективность и более низкие эксплуатационные расходы при выполнении масштабных задач генеративного ИИ. 
Источник изображений: Qualcomm Оба ускорителя — Qualcomm AI200 и AI250 — основаны на нейронных процессорах (NPU) Qualcomm Hexagon, адаптированных для задач ИИ в центрах обработки данных. В последние годы компания постепенно совершенствовала свои нейропроцессоры Hexagon, поэтому последние версии чипов уже оснащены скалярными, векторными и тензорными ускорителями (в конфигурации 12+8+1). Они поддерживают такие форматы данных, как INT2, INT4, INT8, INT16, FP8, FP16, микротайловый вывод для сокращения трафика памяти, 64-битную адресацию памяти, виртуализацию и шифрование моделей Gen AI для дополнительной безопасности. Ускорители AI200 представляют собой первую систему логического вывода для ЦОД от Qualcomm и предлагают до 768 Гбайт встроенной памяти LPDDR. Система будет использовать интерфейсы PCIe для вертикального масштабирования и Ethernet — для горизонтального. Расчётная мощность стойки с ускорителями Qualcomm AI200 составляет 160 кВт. Система предполагает использование прямого жидкостного охлаждения. Для Qualcomm AI200 также заявлена поддержка конфиденциальных вычислений для корпоративных развертываний. Решение станет доступно в 2026 году.  Qualcomm AI250, выпуск которого состоится годом позже дебютирует с новой архитектурой памяти, которая обеспечит увеличение пропускной способности более чем в 10 раз. Кроме того, система будет поддерживать возможность дезагрегированного логического вывода, что позволит динамически распределять ресурсы памяти между картами. Qualcomm позиционирует его как более эффективное решение с высокой пропускной способностью, оптимизированное для крупных ИИ-моделей трансформеров. При этом система сохранит те же характеристики теплопередачи, охлаждения, безопасности и масштабируемости, что и AI200. Помимо разработки аппаратных платформ, Qualcomm также сообщила о разработке гипермасштабируемой сквозной программной платформы, оптимизированной для крупномасштабных задач логического вывода. Платформа поддерживает основные наборы инструментов машинного обучения и генеративного ИИ, включая PyTorch, ONNX, vLLM, LangChain и CrewAI, обеспечивая при этом беспроблемное развертывание моделей. Программный стек будет поддерживать дезагрегированное обслуживание, конфиденциальные вычисления и подключение предварительно обученных моделей «одним щелчком мыши», заявляет компания. NextSilicon похвасталась превосходством ускорителя Maverick-2 над Nvidia HGX B200 и представила чип Arbel на базе RISC-V
22.10.2025 [20:09],
Николай Хижняк
Стартап NextSilicon, основанный в 2017 году, представил специализированный ускоритель Maverick-2. Компания называет его интеллектуальным вычислительным ускорителем (Intelligent Compute Accelerator). Его впервые анонсировали ещё в прошлом году. NextSilicon утверждает, что Maverick-2 превосходит ускоритель Nvidia HGX B200 и процессоры Intel Sapphire Rapids в высокопроизводительных вычислениях и задачах искусственного интеллекта. 
Источник изображений: NextSilicon Maverick-2, созданный по 5-нм техпроцессу TSMC, доступен в виде однокристальной карты расширения PCIe с 96 Гбайт памяти HBM3e и энергопотреблением 300 Вт, а также в виде двухкристальной версии на модуле OAM с 192 Гбайт памяти HBM3e и энергопотреблением 600 Вт. Согласно внутренним тестам, Maverick-2 обеспечивает до 4 раз более высокую производительность в операциях FP64 на ватт, чем Nvidia HGX B200, и более чем в 20 раз более высокую эффективность, чем процессоры Intel Xeon Sapphire Rapids. В тестах производительности GUPS он достиг 32,6 GUPS при 460 Вт мощности, что, как сообщается, в 22 раза быстрее, чем у центральных, и в 6 раз быстрее, чем у графических процессоров. В рабочих нагрузках HPCG он достиг 600 GFLOPS при 750 Вт, потребляя при этом примерно вдвое меньше энергии, чем конкурирующие решения. Компания объясняет этот прирост эффективности архитектурой, основанной на потоках данных, которая переносит управление ресурсами с аппаратного уровня на адаптивное программное обеспечение, позволяя использовать большую часть площади кремния для вычислений, а не для управляющей логики.  Компания также анонсировала Arbel — чип корпоративного класса на базе RISC-V, также построенный по 5-нм техпроцессу TSMC. NextSilicon утверждает, что Arbel уже превосходит текущие разработки RISC-V конкурентов, а также ядра Intel Lion Cove и AMD Zen 5. Arbel оснащён 10-канальным конвейером инструкций с 480-элементным буфером переупорядочивания для высокой загрузки ядра, работающим на частоте 2,5 ГГц. Чип может выполнять до 16 скалярных инструкций параллельно и включает четыре 128-битных векторных блока для параллельной обработки данных. Кеш первого уровня объёмом 64 Кбайт и большой общий кеш третьего уровня обеспечивают высокую пропускную способность памяти и низкую задержку, что позволяет сократить узкие места в производительности в ресурсоёмких приложениях.  NextSilicon не поделилась ни полными результатами тестов нового чипа, ни информацией о том, когда он станет доступен. В то же время компания заявляет, что Arbel представляет собой шаг к полностью открытой, программно-адаптивной кремниевой платформе для будущих систем высокопроизводительных вычислений и искусственного интеллекта. Президент OpenAI: человечеству потребуется 10 млрд ИИ-ускорителей — по одному на каждого жителя Земли
30.09.2025 [06:58],
Алексей Разин
Сейчас стартап OpenAI использует любую возможность для привлечения не только финансовых ресурсов, но и заключения контрактов с поставщиками тех же ускорителей вычислений, коим является Nvidia. Президент компании Грег Брокман (Greg Brockman) убеждён, что человечеству потребуется до 10 млрд ускорителей вычислений, и каждого жителя планеты буквально будет обслуживать отдельный ИИ-чип. 
Источник изображения: Nvidia Своими соображениями президент OpenAI поделился в интервью CNBC, в котором также приняли участие генеральный директор компании Сэм Альтман (Sam Altman), а также глава и основатель Nvidia Дженсен Хуанг (Jensen Huang). По мнению Альтмана, масштабы сотрудничества с Nvidia по своей значимости для человечества окажутся важнее программы доставки до Луны американских астронавтов, которую NASA реализовало в прошлом веке. Альтман видит будущее человечества с неразрывным присутствием «супермозга», созданного искусственным интеллектом и активно влияющего на повседневную жизнь людей. Брокман же считает, что ИИ будет действовать в качестве «агента, который работает на опережение, пока вы спите». Каждый работающий житель Земли, по его мнению, будет использовать ресурсы как минимум одного ускорителя вычислений при выполнении своих должностных обязанностей. «Вам действительно захочется, чтобы у каждого человека был свой собственный выделенный GPU», — охарактеризовал свой прогноз Брокман. Сейчас подобное предсказание может казаться нереалистичным, но достаточно вспомнить, что в начале девяностых годов прошлого века один из основателей Microosft Билл Гейтс (Bill Gates) указывал на неизбежность появления компьютера не только в каждом домохозяйстве, но и на каждом рабочем столе. В какой-то мере его предсказание сбылось, пусть даже если вместо компьютеров в их классической форме речь идёт о смартфонах, которые помещаются в карман. Брокман считает, что сейчас отрасль ИИ на три порядка отстаёт от потенциальных потребностей в вычислительных мощностях, и для создания постоянно функционирующей глобальной системы искусственного интеллекта человечеству может потребоваться до 10 млрд ускорителей вычислений. По сути, это даже больше, чем проживает людей на Земле (8,2 млрд человек). Мир, по мнению Брокмана, движется к состоянию, при котором экономику подпитывают вычисления. Вычислительных мощностей сейчас не хватает, как он считает, а наличие достаточно мощных центров обработки данных в будущем станет определять состоятельность экономики целых стран. В какой-то мере они заменят валюту в качестве источника ресурсов для развития экономики. Nvidia представила крошечные видеокарты RTX Pro 4000 SFF и RTX Pro 2000 для профессионалов
11.08.2025 [19:35],
Николай Хижняк
Nvidia расширила ассортимент профессиональных видеокарт поколения Blackwell, представив модели RTX Pro 4000 SFF и RTX Pro 2000 на конференции SIGGRAPH 2025. Эти видеокарты дополняют линейку решений Nvidia для рабочих станций. Помимо повышенной производительности по сравнению с моделями предыдущего поколения, новинки также оптимизированы для ускорения задач ИИ, что делает их актуальными для различных рабочих процессов в самых разных отраслях. 
Источник изображений: Nvidia Модель RTX Pro 4000 Blackwell SFF — это уменьшенная версия уже доступной видеокарты RTX 4000 Blackwell. Компания утверждает, что новинка обеспечивает более чем двукратный прирост производительности в задачах ИИ по сравнению с RTX A4000 SFF предыдущего поколения, предлагая при этом улучшенные возможности трассировки лучей и на 50 % увеличенную пропускную способность. При этом уровень энергопотребления остался на прежнем уровне — 70 Вт. Благодаря 24 Гбайт памяти ECC GDDR7 и заявленной производительности 770 TOPS в задачах ИИ, эта видеокарта может стать отличным выбором для профессионалов, которым требуется высокая вычислительная мощность в составе компактной рабочей станции.  Новая модель RTX Pro 2000 оснащена 16 Гбайт памяти ECC GDDR7 и предлагает производительность до 545 TOPS в задачах ИИ при том же уровне энергопотребления — 70 Вт. По заявлению Nvidia, карта разработана для массового дизайна и рабочих процессов с применением искусственного интеллекта. Новинка примерно в 1,5 раза быстрее модели Nvidia RTX A2000 в задачах 3D-моделирования, автоматизированного проектирования и рендеринга. Кроме того, она обеспечивает более высокую эффективность при генерации изображений и текста с помощью ИИ. Точные характеристики и стоимость моделей RTX Pro 4000 SFF и RTX Pro 2000 в рамках презентации Nvidia не раскрыла. Ожидается, что видеокарты поступят в продажу в конце текущего года. RTX Pro 2000 будет доступна у компаний PNY и TD Synnex как отдельное решение, а также появится у системных интеграторов Boxx, Dell, HP и Lenovo в составе готовых рабочих станций. RTX Pro 4000 SFF будет предлагаться в системах от партнёров Nvidia, включая Dell, HP и Lenovo. AMD по примеру Nvidia возобновит поставки своих ИИ-ускорителей Instinct в Китай
15.07.2025 [21:05],
Николай Хижняк
Представитель AMD в разговоре с порталом Tom’s Hardware подтвердил, что компания возобновит поставки ИИ-ускорителей MI308 в Китай. Это специализированная модификация ускорителей серии Instinct MI300, разработанная специально для соответствия экспортным правилам, установленным Министерством торговли США. 
Источник изображения: AMD Ранее сегодня глава Nvidia Дженсен Хуанг (Jensen Huang) публично подтвердил, что компания немедленно приступает к подготовке возобновления продаж своих ИИ-ускорителей Hopper H20 в Китае. Nvidia рассчитывает получить разрешение на продажу этих специализированных GPU, изготовленных по индивидуальному заказу, после того как в апреле они были запрещены к продаже в Китае обновлёнными экспортными правилами США. AMD и Nvidia ясно дали понять, что китайский рынок критически важен для их бизнеса, поскольку они разрабатывают специализированные GPU для центров обработки данных с учётом ограничений правительства США. Однако проектирование и выпуск таких вариантов графических чипов — процесс небыстрый: их разработка, производство, сборка и настройка занимают месяцы. После завершения разработки и установки необходимой прошивки устройства фактически становятся программно заблокированными в соответствии с экспортными ограничениями, что часто затрудняет их продажу за пределами рынков, для которых эти ограничения были введены. «Мы планируем возобновить поставки, как только получим одобрение по лицензии. Министерство торговли недавно сообщило нам, что заявки на получение лицензий на экспорт продукции MI308 в Китай будут переданы на рассмотрение», — заявил представитель AMD в разговоре с Tom’s Hardware. Обе компании оказались под давлением в связи с масштабным экспортным контролем на поставки технологий, связанных с ИИ, введённым ещё предыдущей администрацией президента США Джо Байдена и продолженным нынешней администрацией президента Дональда Трампа. Последняя, хоть и сузила ограничения, всё же включила в список запрещённых к поставке чипов такие модели, как H20 и MI308. Согласно оценке AMD, экспортные ограничения могут обойтись ей примерно в $800 млн в виде нераспроданных запасов, невыполненных обязательств по заказам и оставшихся резервов. Хотя это значительно меньше, чем масштабное списание Nvidia в размере $5,5 млрд, потери всё же заметно ударят по чистой прибыли AMD. После сегодняшнего объявления акции AMD подскочили на 5,7 % вслед за аналогичным ростом акций Nvidia. Один сбитый бит — и всё пропало: атака GPUHammer на ускорители Nvidia ломает ИИ с минимальными усилиями
15.07.2025 [00:07],
Николай Хижняк
Команда исследователей из Университета Торонто обнаружила новую атаку под названием GPUHammer, которая может инвертировать биты в памяти графических процессоров Nvidia, незаметно повреждая модели ИИ и нанося серьёзный ущерб, не затрагивая при этом сам код или входные данные. К счастью, Nvidia уже опередила потенциальных злоумышленников, которые могли бы воспользоваться этой уязвимостью, и выпустила рекомендации по снижению риска, связанного с этой проблемой. 
Источник изображения: Nvidia Исследователи продемонстрировали, как GPUHammer может снизить точность модели ИИ с 80 % до менее 1 % — всего лишь инвертируя один бит в памяти. Они протестировали уязвимость на реальной профессиональной видеокарте Nvidia RTX A6000, используя технику многократного инжектирования ячеек памяти до тех пор, пока одна из соседних ячеек не инвертируется, что нарушает целостность хранящихся в ней данных. GPUHammer — это версия известной аппаратной уязвимости Rowhammer, ориентированная на графические процессоры. Это явление уже давно существует в мире процессоров и оперативной памяти. Современные микросхемы памяти настолько плотно упакованы, что многократное чтение или запись одной строки может вызвать электрические помехи, которые переворачивают (инвертируют) биты в соседних строках. Этим перевернутым битом может быть что угодно — число, команда или часть веса нейронной сети. До сих пор эта уязвимость в основном касалась системной памяти DDR4, но GPUHammer продемонстрировала свою эффективность с видеопамятью GDDR6, которая используется во многих современных видеокартах Nvidia. Это серьёзная причина для беспокойства, по крайней мере, в определённых ситуациях. Исследователи показали, что даже при наличии некоторых мер защиты они могут вызывать множественные перевороты битов в нескольких банках памяти. В одном случае это полностью сломало обученную модель ИИ, сделав её практически бесполезной. Примечательно, что для этого даже не требуется доступ к данным. Злоумышленнику достаточно просто использовать тот же графический процессор в облачной среде или на сервере, и он потенциально может вмешиваться в вашу рабочую нагрузку по своему усмотрению. Исследователи протестировали метод атаки на карте RTX A6000, но риску подвержен широкий спектр графических процессоров Ampere, Ada, Hopper и Turing, особенно тех, что используются в рабочих станциях и серверах. Nvidia опубликовала полный список уязвимых моделей ускорителей и рекомендует использовать функцию коррекции ошибок ECC для решения большинства из них. При этом новые графические процессоры, такие как RTX 5090 и серверные H100, имеют встроенную ECC непосредственно на GPU, и она работает автоматически — настройка пользователем не требуется. Данная уязвимость не затрагивает обычных пользователей домашних ПК. Она актуальна для общих сред графических процессоров, таких как облачные игровые серверы, кластеры обучения ИИ или конфигурации VDI, где несколько пользователей запускают рабочие нагрузки на одном оборудовании. Тем не менее угроза реальна и должна быть серьезно воспринята всей индустрией, особенно с учётом того, что всё больше игр, приложений и сервисов начинают в той или иной мере использовать ИИ. Рекомендация Nvidia сводится к использованию функции ECC. Её можно включить с помощью командной строки Nvidia, введя команду Атаки, подобные GPUHammer, не просто приводят к сбоям в работе систем или вызывают сбои. Они нарушают целостность самого ИИ, влияя на поведение моделей или принятие решений. И поскольку всё это происходит на аппаратном уровне, эти изменения практически незаметны, особенно если не знать, что именно и где искать. В регулируемых отраслях, таких как здравоохранение, финансы или автономный транспорт, это может привести к серьёзным проблемам — неверным решениям, нарушениям безопасности и даже юридическим последствиям. Nvidia выпустит ИИ-ускоритель B30 специально для Китая взамен запрещённого H20
02.06.2025 [16:52],
Дмитрий Федоров
Nvidia разрабатывает специализированный ИИ-ускоритель B30, соответствующий требованиям экспортного контроля США и предназначенный для поставок в Китай. Новый графический ускоритель (GPU) построен на архитектуре Blackwell и, вероятно, получит поддержку NVLink для объединения нескольких GPU в вычислительные кластеры. Эта разработка стала прямым ответом Nvidia на запрет, введённый правительством США на экспорт в КНР чипов линейки H20 на архитектуре Hopper. 
Источник изображений: Nvidia Главная особенность будущего B30 — поддержка масштабирования через объединение нескольких GPU. Эта функция, по мнению аналитиков, может быть реализована либо с применением технологии NVLink, либо посредством сетевых адаптеров ConnectX-8 SuperNIC с поддержкой PCIe 6.0. Несмотря на то, что Nvidia официально исключила NVLink из потребительских GPU начиная с предыдущего поколения, существует вероятность, что компания модифицировала кристаллы GB202, используемые в RTX 5090, и повторно активировала NVLink в их серверной конфигурации. Изначально будущий GPU фигурировал под различными названиями — от RTX Pro 6000D до B40, а теперь B30. Это, вероятно, указывает на наличие нескольких вариантов в рамках новой серии BXX, различающихся по уровню производительности и соответствию требованиям экспортного регулирования. Все модификации предполагается строить на чипах GB20X с использованием памяти GDDR7. Примечательно, что GB20X — это те же кристаллы, которые лежат в основе потребительских видеокарт линейки RTX 50. Таким образом, Nvidia не создаёт принципиально новый чип, а адаптирует уже существующую архитектуру для обхода ограничений. 
Nvidia RTX PRO 6000 Blackwell Workstation Edition На выставке Computex в Тайбэе Nvidia представила серверные системы RTX Pro Blackwell, рассчитанные на установку до восьми GPU RTX Pro 6000. Эти ускорители соединяются между собой через сетевые адаптеры ConnectX-8 SuperNIC, оснащённые встроенными PCIe 6.0-коммутаторами, обеспечивающими прямое взаимодействие между GPU. Та же схема коммуникации применяется при объединении двух суперчипов DGX Spark, которые служат основой для корпоративных и облачных ИИ-решений. Вероятнее всего, аналогичная архитектура будет использована и в B30. Комментируя запрет на экспорт H20, бессменный руководитель Nvidia Дженсен Хуанг (Jensen Huang) подчеркнул, что компания прекращает разработку альтернатив на архитектуре Hopper и сосредотачивается на Blackwell. Правительство США, в свою очередь, заявило, что у H20 — слишком высокая пропускная способность памяти и интерфейсных соединений, что делает чип неприемлемым для свободного экспорта. Эти параметры, по мнению регуляторов, создают риск использования ускорителей в составе китайских суперкомпьютеров, способных обслуживать оборонные и военные программы. 
Nvidia H200 Tensor Core GPU Ситуация с экспортными ограничениями не ограничивается только Nvidia. Американские регуляторы оказывают серьёзное влияние на весь рынок высокопроизводительных ИИ-решений. Компания AMD, например, оценивает потенциальные убытки от запрета на экспорт ускорителей MI308 в размере до $800 млн. Эта оценка была представлена сразу после вступления в силу новых ограничений. На протяжении последних лет Nvidia ведёт постоянную борьбу с регуляторами, сталкиваясь с чередой запретов и требований, где каждое новое поколение чипов, от A100 до H100 и H20, подвергается новым формам контроля. Хуанг, критикуя действующую экспортную политику США, назвал её «провалом» и предупредил о рисках стратегического отставания. По его мнению, такие меры лишь подталкивают китайские технологические компании, включая Huawei, к активному развитию собственных ИИ-решений. В результате они могут не только догнать, но и перегнать американских техногигантов, сформировав собственные стандарты, которые в будущем могут стать основой глобальной ИИ-инфраструктуры. Это создаёт угрозу потери влияния США не только в технологической, но и в военно-стратегической сфере. Nvidia представила видеокарты с 96 Гбайт GDDR7 — профессиональные RTX Pro Blackwell для серверов, ПК и ноутбуков
18.03.2025 [23:16],
Николай Хижняк
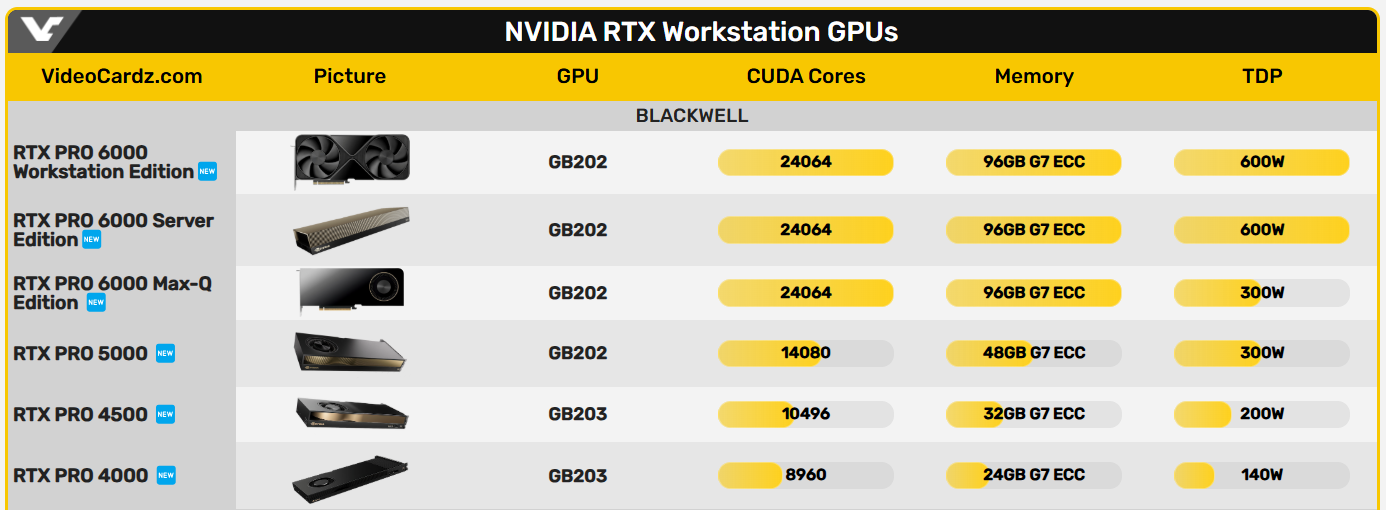
Компания Nvidia представила новые профессиональные настольные и мобильные видеокарты серии Nvidia RTX Pro на архитектуре Blackwell для рабочих станций и серверов. Эти решения предназначены для различных задач, включая работу с агентными ИИ, моделированием, дополненной реальностью, 3D-дизайном, сложными визуальными эффектами, а также разработку ИИ для робототехники и транспортных средств. 
Источник изображений: Nvidia Для дата-центров компания подготовила ускоритель Nvidia RTX Pro 6000 Blackwell Server Edition, построенный на чипе GB202 в полной конфигурации с 24 064 ядрами CUDA, который дополняют 96 Гбайт памяти GDDR7.  Nvidia RTX Pro 6000 Blackwell Server Edition Для настольных систем представлены модели Nvidia RTX Pro 6000 Blackwell Workstation Edition, Nvidia RTX Pro 6000 Blackwell Max-Q Workstation Edition, Nvidia RTX Pro 5000 Blackwell, Nvidia RTX Pro 4500 Blackwell и Nvidia RTX Pro 4000 Blackwell. Видеокарты RTX Pro 6000 предлагают те же характеристики, что и серверная версия, а версия Max-Q отличается от обычной вдвое меньшим энергопотреблением. Остальные карты предлагают более скромные характеристики, от 8960 CUDA и 24 Гбайт памяти до 14 080 CUDA и 48 Гбайт памяти. 
Nvidia RTX Pro 6000 Blackwell Workstation Edition
 Для мобильных рабочих станций анонсированы видеокарты Nvidia RTX Pro 5000 Blackwell, Nvidia RTX Pro 4000 Blackwell, Nvidia RTX Pro 3000 Blackwell, Nvidia RTX Pro 2000 Blackwell, Nvidia RTX Pro 1000 Blackwell и Nvidia RTX Pro 500 Blackwell. Они предлагают от 6 до 24 Гбайт памяти GDDR7 и графические процессоры поколения Blackwell, которые насчитывают от 1792 до 10 496 ядеро CUDA. 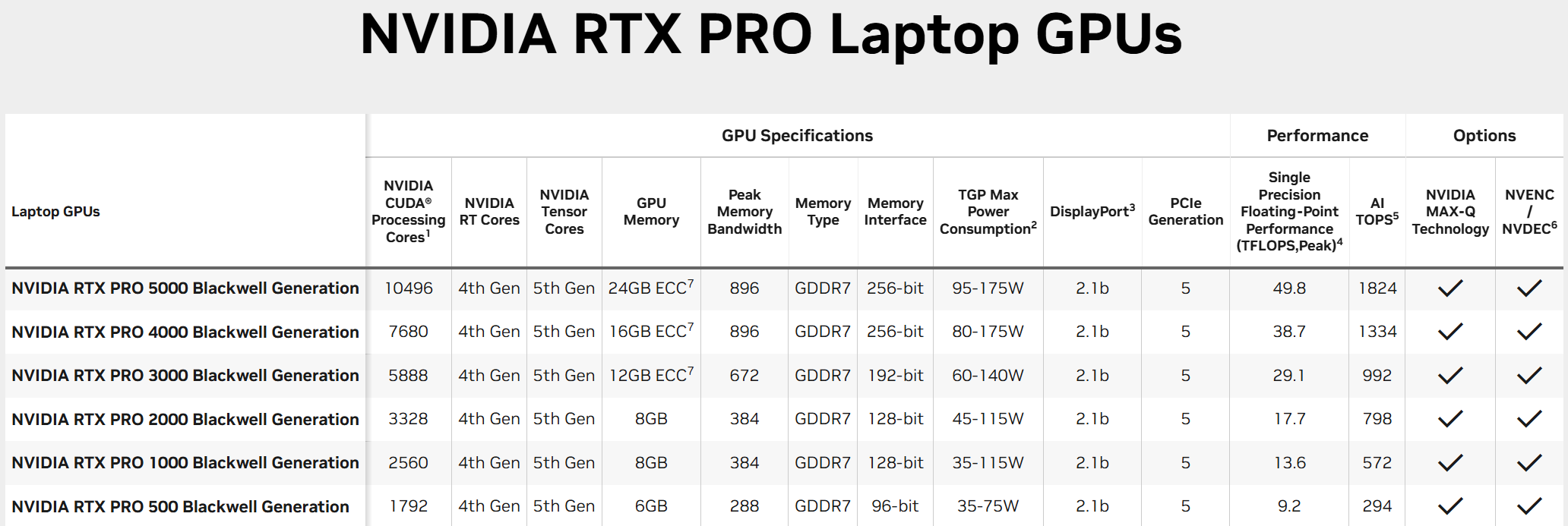 Новые ускорители Nvidia RTX Pro Blackwell обладают рядом преимуществ. Потоковые мультипроцессоры Nvidia обеспечивают до 1,5 раза более высокую пропускную способность и включают новые нейронные шейдеры. Четвёртое поколение RT-ядер обеспечивает двукратный прирост производительности при рендеринге фотореалистичных сцен и сложных 3D-проектов, оптимизированных под Nvidia RTX Mega Geometry. Четвёртое поколение тензорных ядер выполняет до 4000 триллионов ИИ-операций в секунду, поддерживает вычисления FP4 и работу технологии Nvidia DLSS 4 Multi Frame Generation. Ускорители оснащены аппаратным многопоточным кодировщиком Nvidia NVENC девятого поколения с поддержкой кодирования 4:2:2, а также кодировщиком шестого поколения для декодирования 4:2:2 H.264 и HEVC.  Все модели поддерживают интерфейс PCIe 5.0, DisplayPort 2.1 с разрешением до 4K@180 Гц или 8K@165 Гц, а также технологию Multi-Instance GPU (MIG), позволяющую разделять один GPU на четыре независимых виртуальных графических процессора, что вдвое больше по сравнению с предыдущими моделями.  Первые тестирования показали высокую эффективность новинок. Компания Foster + Partners отметила пятикратный рост производительности в среде проектирования Cyclops по сравнению с Nvidia RTX A6000. GE HealthCare зафиксировала двукратный прирост эффективности в обработке алгоритмов реконструкции. SoftServe заявила, что 96 Гбайт памяти у Nvidia RTX Pro Workstation Edition увеличивают продуктивность при работе с Llama 3.3-70B, Mistral 8x7b и платформой Nvidia Omniverse в три раза. 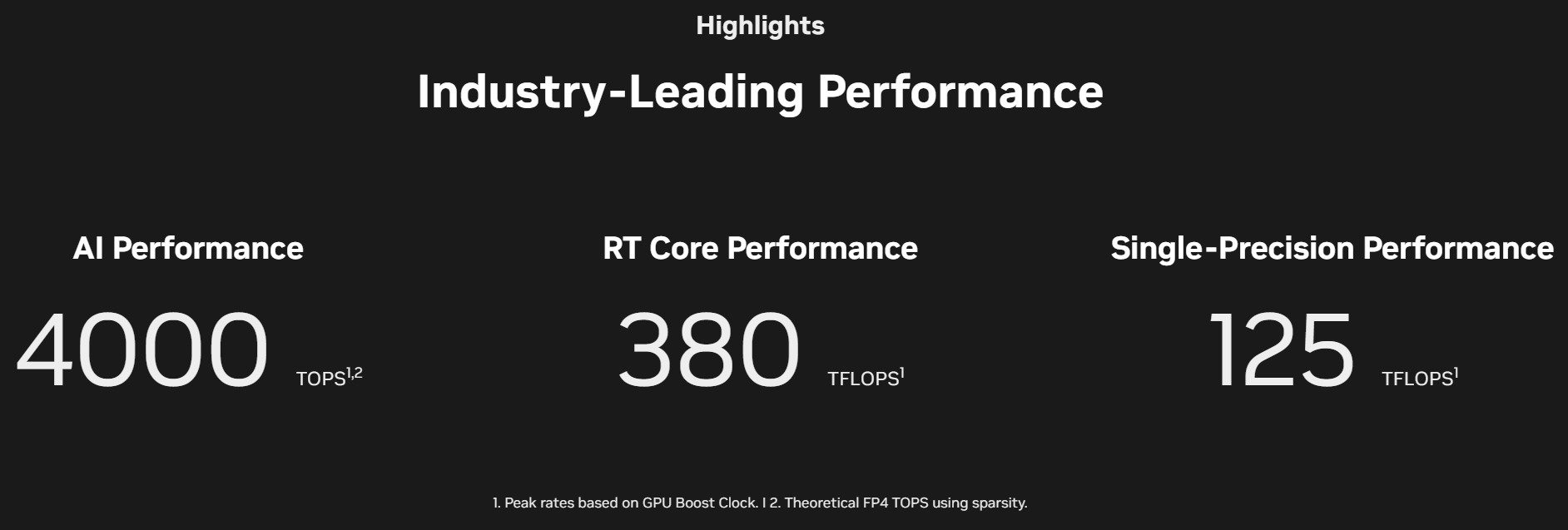 Профессиональные ускорители Nvidia RTX Pro 6000 Blackwell Workstation Edition и Nvidia RTX Pro 6000 Blackwell Max-Q Workstation Edition поступят в продажу через глобальных партнёров-дистрибьюторов, таких как PNY и TD SYNNEX, в апреле. В мае они появятся у BOXX, Dell, HP Inc., Lambda и Lenovo. Модели Nvidia RTX Pro 5000, RTX Pro 4500 и RTX Pro 4000 Blackwell поступят в продажу летом в магазинах BOXX, Dell, HP и Lenovo, а также через глобальных партнеров-дистрибьюторов. Профессиональные ускорители Nvidia RTX Pro для ноутбуков ожидаются в ассортименте компаний Dell, HP, Lenovo и Razer позже в этом году. OpenAI завершит разработку и запустит производство своего ИИ-чипа уже в 2025 году — это первый шаг к снижению зависимости от Nvidia
10.02.2025 [17:54],
Сергей Сурабекянц
Признанный лидер в сфере ИИ, компания OpenAI, прикладывает серьёзные усилия по снижению зависимости от ускорителей ИИ производства Nvidia. В ближайшие несколько месяцев OpenAI планирует завершить разработку собственного чипа и начать его производство на фабриках TSMC с использованием самых передовых техпроцессов. 
Источник изображения: Samsung По мнению аналитиков, «OpenAI находится на пути к достижению своей амбициозной цели массового производства на мощностях TSMC в 2026 году». Наиболее ответственным этапом на пути от дизайна к выпуску готовых чипов является Tape-out («тейпаут») — процесс переноса цифрового проекта чипа на фотошаблон для последующего производства. Обычно этот этап обходится в несколько десятков миллионов долларов, а до выпуска первого чипа проходит до шести месяцев. В случае сбоя требуется диагностировать проблему и повторить процесс. OpenAI рассматривает свой будущий ускоритель ИИ как стратегический инструмент для укрепления переговорных позиций с другими поставщиками чипов. Если первоначальный выпуск пройдёт удачно, OpenAI уже в этом году представит альтернативу чипам Nvidia, которые сейчас занимают более80 % рынка ИИ-ускорителей. В случае успеха первого чипа инженеры OpenAI планируют разрабатывать все более продвинутые процессоры с более широкими возможностями с каждой новой итерацией. Компания уже стала участником инфраструктурной программы Stargate стоимостью $500 млрд, объявленной президентом США Дональдом Трампом (Donald Trump) в прошлом месяце. Чип разрабатывается внутренней командой OpenAI во главе с Ричардом Хо (Richard Ho) в сотрудничестве с Broadcom. Хо более года назад перешёл в OpenAI из Google, где руководил программой по созданию специализированных чипов ИИ. Хотя команда Хо за последние месяцы выросла до 40 сотрудников, это количество по прежнему на порядок меньше, чем в масштабных проектах таких технологических гигантов, как Google или Amazon. Аналитики полагают, что на первом этапе новый ускоритель ИИ от OpenAI будет играть ограниченную роль в инфраструктуре компании. Чтобы создать столь же всеобъемлющую программу по проектированию чипов ИИ, как у Google или Amazon, OpenAI придётся нанять сотни инженеров. Согласно отраслевым источникам, новый дизайн чипа для амбициозной масштабной программы может обойтись в $500 млн. Эти расходы могут удвоиться, если учитывать необходимость создания программного обеспечения и периферийных устройств. Для сравнения: в 2025 году Meta✴✴ планирует потратить $60 млрд на ИИ-инфраструктуру, а годовые инвестиции Microsoft в этом направлении составят $80 млрд. Низкопробный софт AMD не даёт раскрыть потенциал ИИ-ускорителей Instinct MI300X и обойти Nvidia, выяснили эксперты
23.12.2024 [23:11],
Николай Хижняк
Пятимесячное расследование компании SemiAnalysis показало, что специализированные ИИ-ускорители серии AMD MI300X не раскрывают свой потенциал из-за серьёзных проблем в работе программного обеспечения. Этот факт делает все усилия компании по навязыванию жёсткой конкуренции Nvidia, доминирующей на рынке аппаратного обеспечения для ИИ, бессмысленными. 
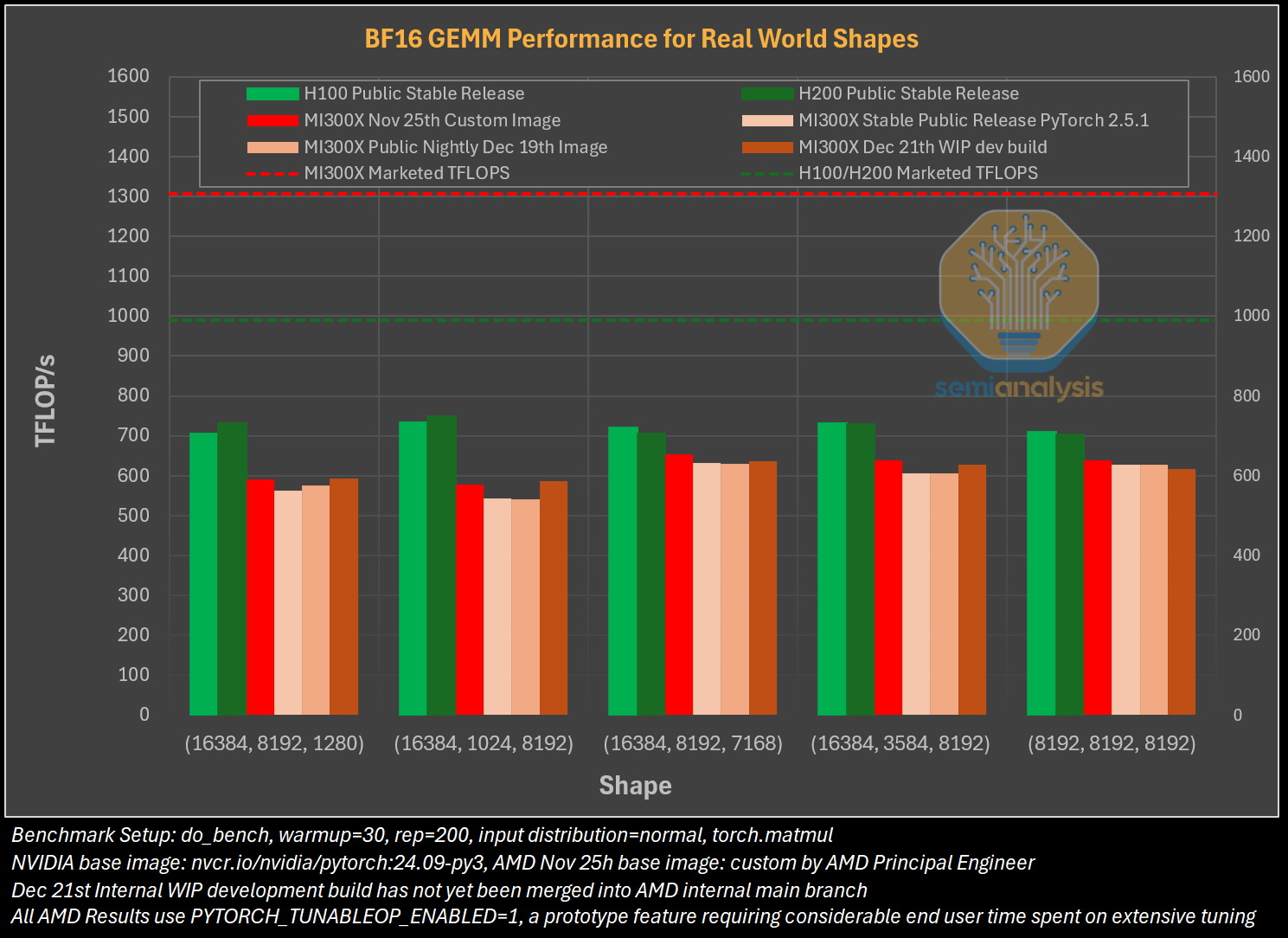
Источник изображения: The Decoder Исследование показало, что программное обеспечение AMD изобилует ошибками, которые делают обучение моделей ИИ практически невозможным без значительной отладки. Таким образом, пока AMD работает над обеспечением качества и простоты использования своих ускорителей, Nvidia продолжает увеличивать разрыв, развёртывая новые функции, библиотеки и повышая производительность своих решений. По итогам обширных тестов, включая тесты GEMM и одноузловое обучение, исследователи пришли к выводу, что AMD не в состоянии преодолеть то, что они называют «неприступным рвом CUDA» — сильное преимущество в виде программного обеспечения, которым обладают ускорители Nvidia. 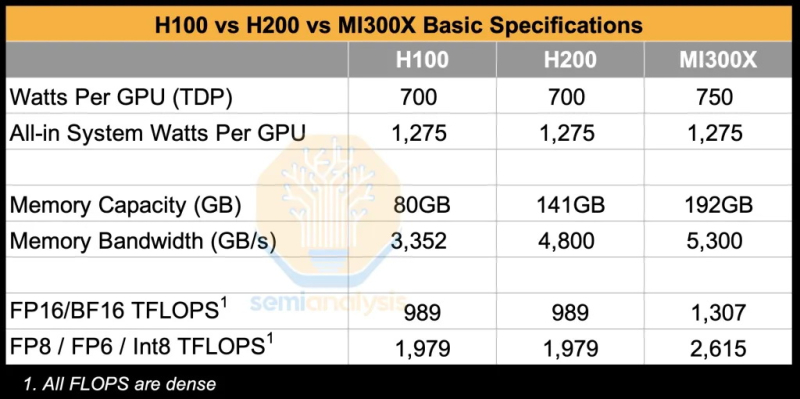
Источник изображения: SemiAnalysis AMD MI300X «на бумаге» выглядят впечатляюще: 1307 Тфлопс в вычислениях FP16 и 192 Гбайт памяти HBM3. Для сравнения, ускорители Nvidia H100 обладают производительностью 989 Тфлопс и имеют только 80 Гбайт памяти. Однако новое поколение ИИ-ускорителей Nvidia H200 с конфигурациями до 141 Гбайт памяти сокращает разрыв в объёме доступного буфера памяти. Кроме того, системы на базе ускорителей AMD также предлагают более низкую общую стоимость владения благодаря более низким ценам на такие системы и более доступной поддержке сетевой инфраструктуры. 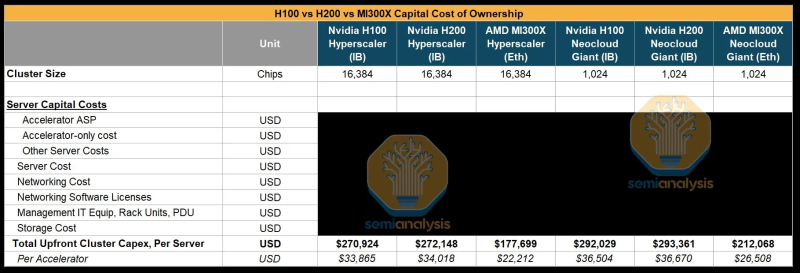
Источник изображения: SemiAnalysis Однако эти преимущества мало что значат на практике. По данным SemiAnalysis, сравнение «голых» спецификаций похоже на «сравнение камер, когда просто проверяешь количество мегапикселей у одной и другой». AMD, отмечают аналитики, таким образом «просто играет с цифрами», но её решения не обеспечивают достаточный уровень производительности в реальных задачах. 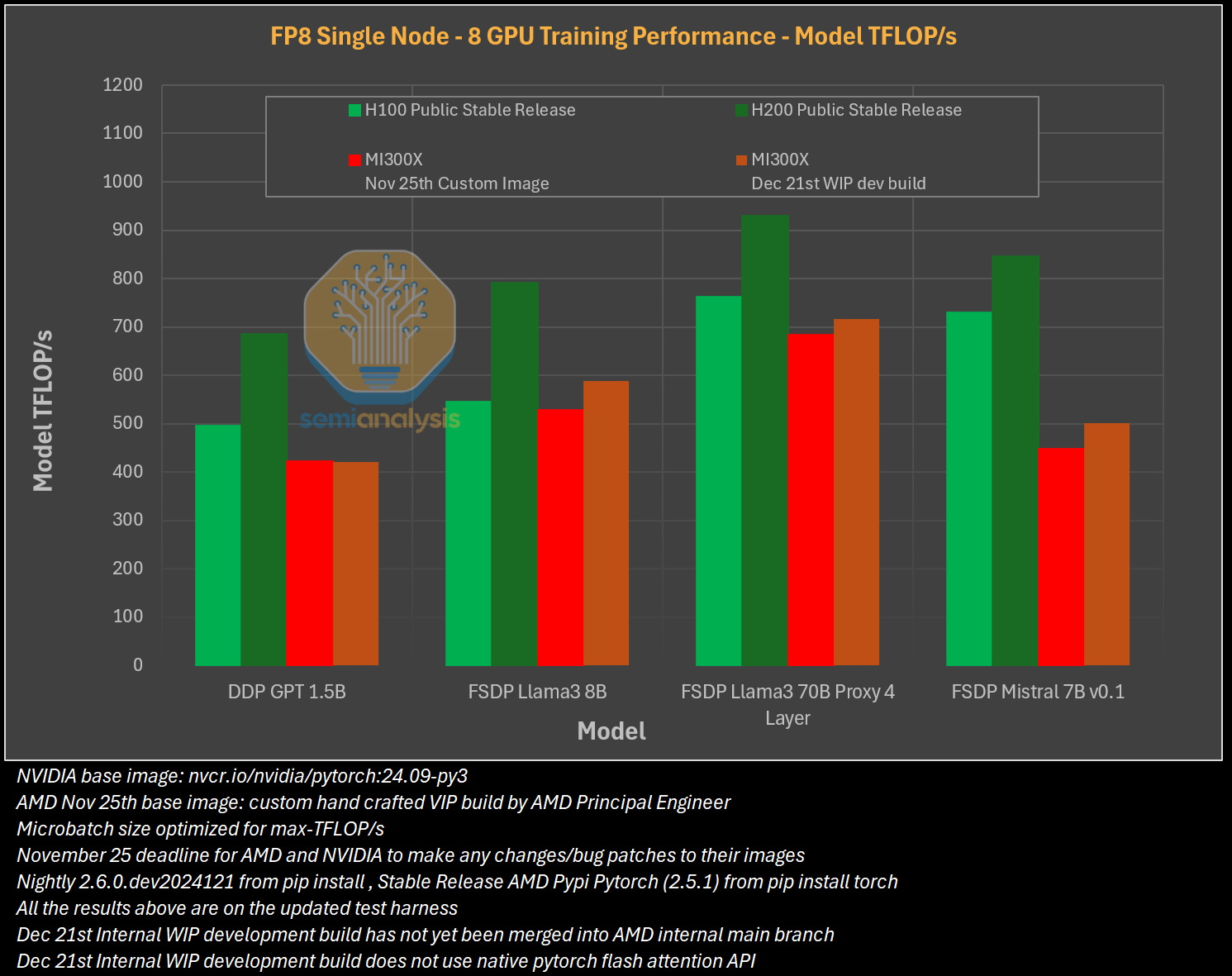
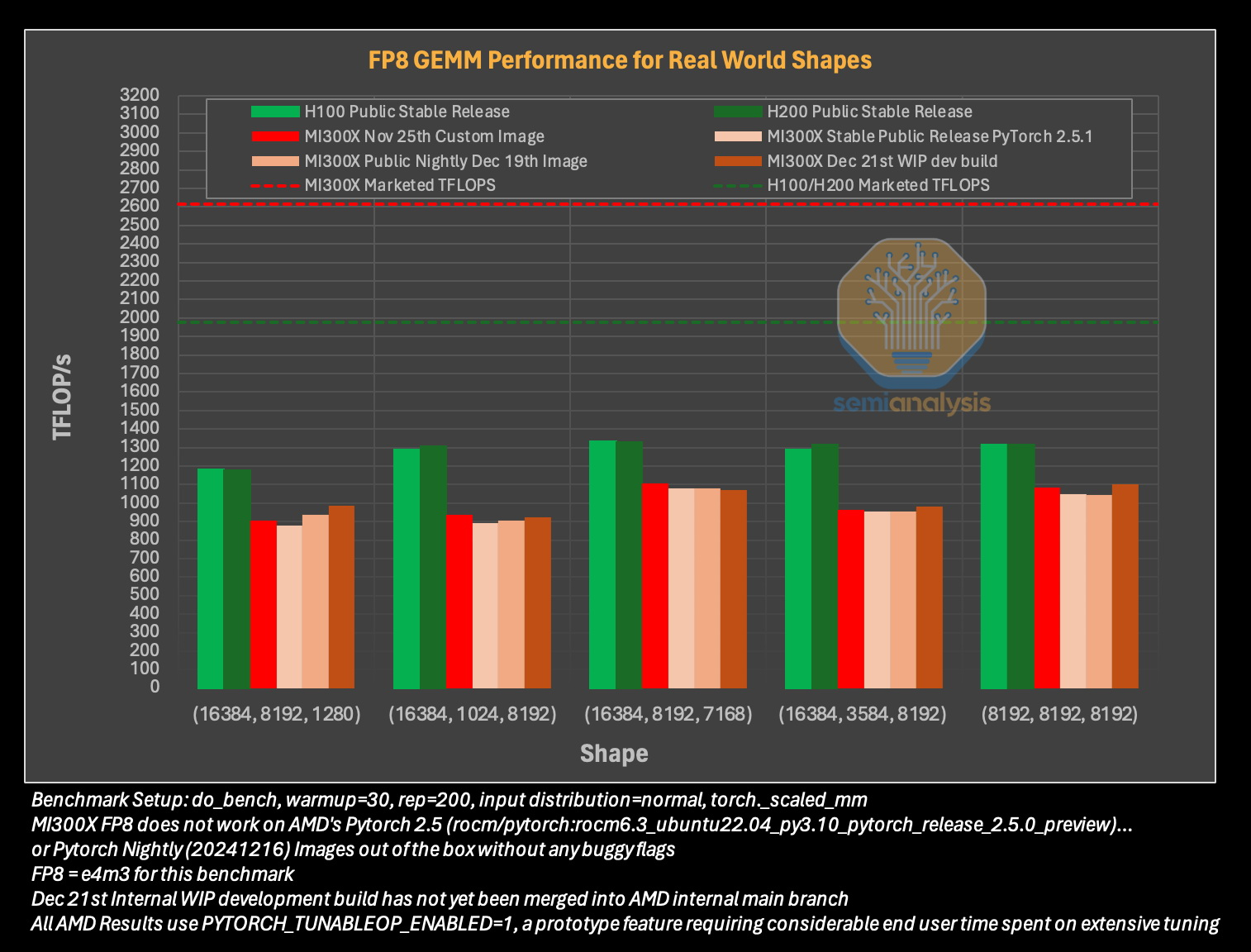 Исследователи отмечают, что им пришлось напрямую работать с инженерами AMD, чтобы исправить многочисленные ошибки в ПО для получения пригодных для оценки результатов тестов. В то же время системы на базе ускорителей Nvidia работали гладко и без каких-либо дополнительных настроек. «С OOBE от AMD (опыт, который пользователь получает при получении продукта после распаковки или при запуске установщика и подготовке к первому использованию, так называемый "опыт из коробки" — прим. ред.) очень сложно работать. И для перехода к пригодному к использованию состоянию [оборудования] может потребоваться немало терпения и усилий», — пишут эксперты. 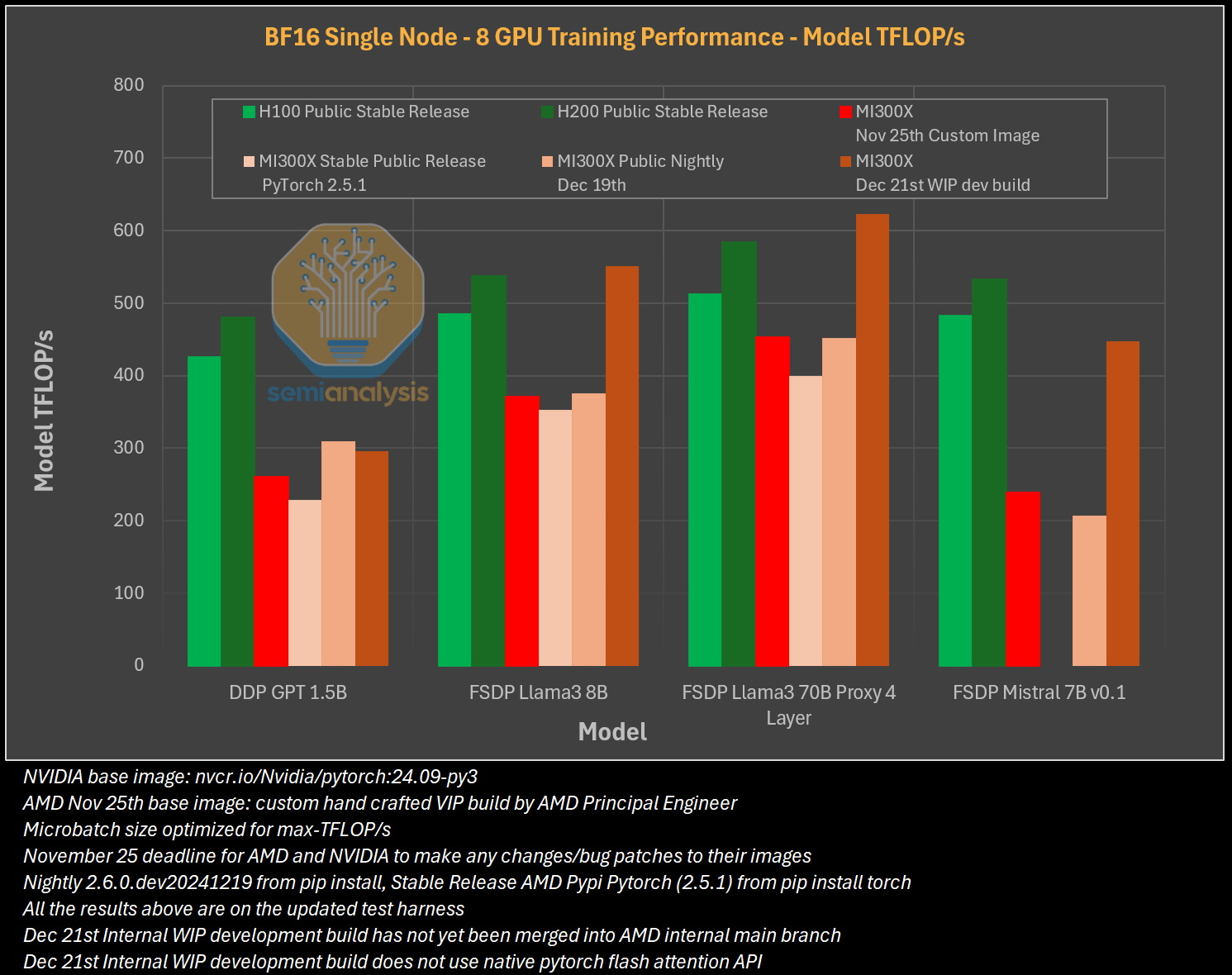
 Особенно показательным для SemiAnalysis оказался случай, когда компания TensorWave, крупнейший поставщик облачных решений на базе графических процессоров AMD, была вынуждена предоставить команде инженеров AMD бесплатный доступ к своим графическим процессорам — тому же оборудованию, которое TensorWave приобрела у AMD — только для устранения проблем с программным обеспечением. Для решения проблем эксперты SemiAnalysis рекомендуют генеральному директору AMD Лизе Су (Lisa Su) более активно инвестировать в разработку и тестирование программного обеспечения. В частности, они предлагают выделить тысячи чипов MI300X для автоматизированного тестирования (аналогичному подходу следует Nvidia для своих ускорителей), упростить сложные переменные среды, одновременно внедрив более эффективные настройки для ускорителей по умолчанию. «Сделайте готовый опыт пригодным к использованию!» — призывают специалисты. Представители SemiAnalysis в своём отчёте признаются, что желают успеха компании AMD в конкуренции с Nvidia, но отмечают, что «к сожалению, для этого ещё многое предстоит сделать». Без существенных улучшений программного обеспечения AMD рискует ещё больше отстать, поскольку Nvidia готовится к массовому выпуску ускорителей нового поколения Blackwell. Хотя, по сообщениям, этот процесс у Nvidia также проходит не совсем гладко. Временная глава Intel не верит в успех ИИ-ускорителей Falcon Shores, но это «первый шаг в верном направлении»
13.12.2024 [17:48],
Николай Хижняк
Руководство компании Intel не верит, что компания сможет в скором времени составить достойную конкуренцию Nvidia и AMD в сфере ИИ-ускорителей. Во всяком случае, такое впечатление сложилось после недавних комментариев одной из временно исполняющей обязанности руководителя компании Мишель Джонстон Холтхаус (Michell Johnston Holthaus) на 22-й ежегодной глобальной технологической конференции Barclays. 
Источник изображений: Intel Напомним, Intel разрабатывает ускорители вычислений Falcon Shores, в основу которого будет положен графический процессор, заточенный под высокопроизводительные вычислений и задачи ЦОД, а дополнят GPU элементы актуальных ИИ-ускорителей Gaudi. Проект по разработке данного решения получил неожиданную оценку от Холтхаус: «Нам действительно нужно подумать о том, как перейти от Gaudi к нашему первому поколению GPU Falcon Shores. Будет ли новый продукт удивительным? Нет, не будет. Но он станет первым шагом в верном направлении». Хольтхаус ещё раз подчеркнула новый прагматичный подход Intel к вопросам разработки аппаратных решений для ускорения ИИ, когда затронула тему стратегии развития продуктов: «Если всё бросить и начать создать новый продукт, то его разработка займёт очень много времени. Прежде чем что-то появится потребуется два–три года. Вместо этого я предпочла бы создать что-то в меньших объёмах, научиться чему-то новому, последовательно совершенствуясь, чтобы в конечном итоге добиться поставленных целей». Врио главы Intel признала устойчивый характер возможностей рынка ИИ, акцентировав текущий интерес индустрии к обучению ИИ-моделей. Однако Хольтхаус также подчеркнула потенциал широких возможностей в других областях: «Очевидно, что ИИ никуда не денется. Очевидно, что обучение [ИИ] сегодня находится центре внимания, но есть возможности развития и на других направлениях, где также отмечаются потребности с точки зрения нового аппаратного обеспечения». По всей видимости она подразумевала инференс — запуск уже обученных нейросетей. 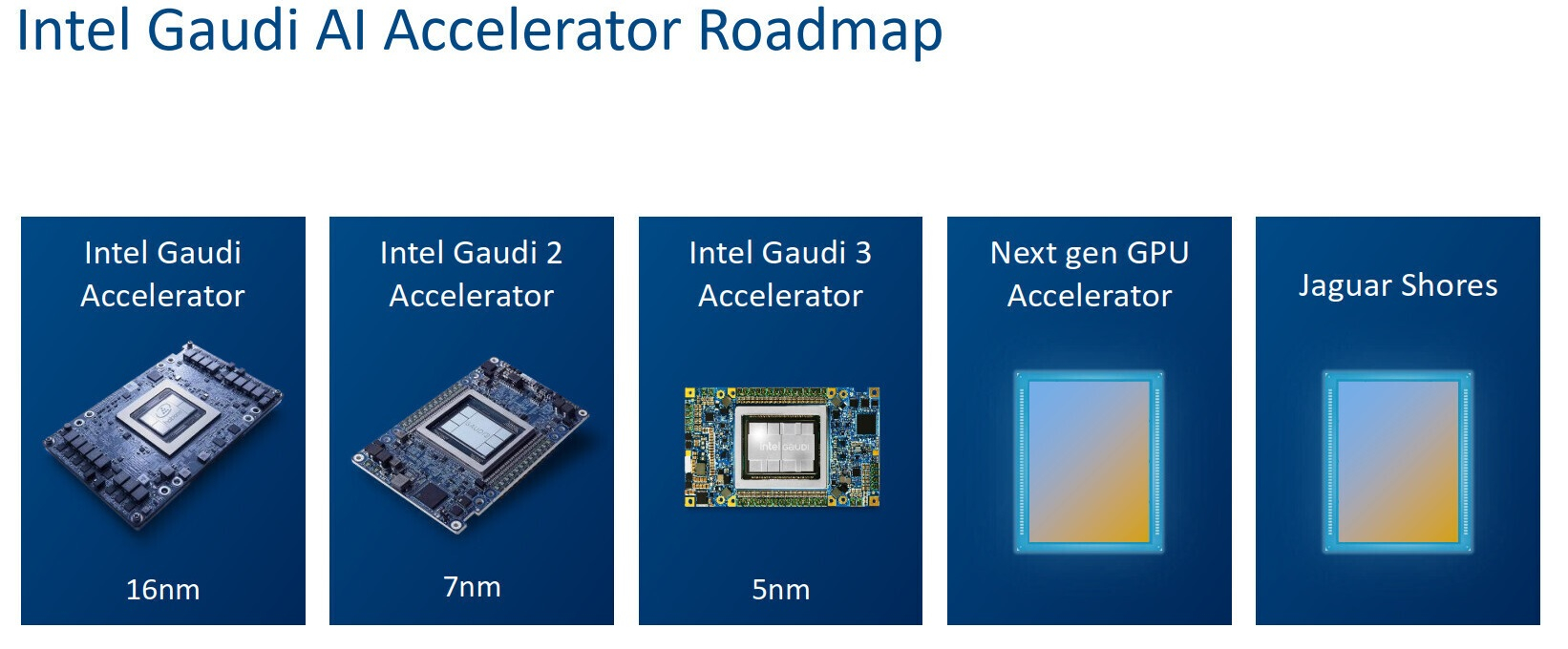 Из сказанного можно сделать вывод, что Falcon Shores не станет для Intel чудесным спасательным кругом, который позволит ей наверстать отставание от Nvidia на рынке GPU-ускорителей. Это в большей степени первая ступень к разработке первоклассного продукта в перспективе. Следующим проектом Intel после Falcon Shores должен стать Jaguar Shores. Его выход ожидается в конце 2025 или начале 2026 года в виде ускорителей ИИ и HPC для центров обработки данных. Однако до его появления компании предстоит проделать немало работы по усовершенствованию не только своего аппаратного, но и программного обеспечения. Доминирующе положение Nvidia на рынке ИИ во многом обязано её программно-аппаратной архитектуре CUDA, поскольку конкуренты, например, AMD, предлагают сопоставимую аппаратную производительность. Перед Intel стоит очень непростая задача. Ей предстоит обеспечить разработку экосистемного программного обеспечения и «бесшовную» интеграцию своих ускорителей следующего поколения, чтобы Jaguar Shores имел шансы догнать остальную часть рынка. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex




