|
Опрос
|
реклама
Быстрый переход
Google упростит доступ к Gemini и Ask Maps в своём картографическом сервисе
21.07.2026 [15:19],
Владимир Фетисов
Компания Google продолжает продвигать возможности навигации посредством использования ИИ-функций, таких как Personal Intelligence и Ask Maps. Параллельно с этим идёт проработка обновлённого интерфейса «Google Карт», который сделает ИИ-функции более доступными во время поездок и путешествий. 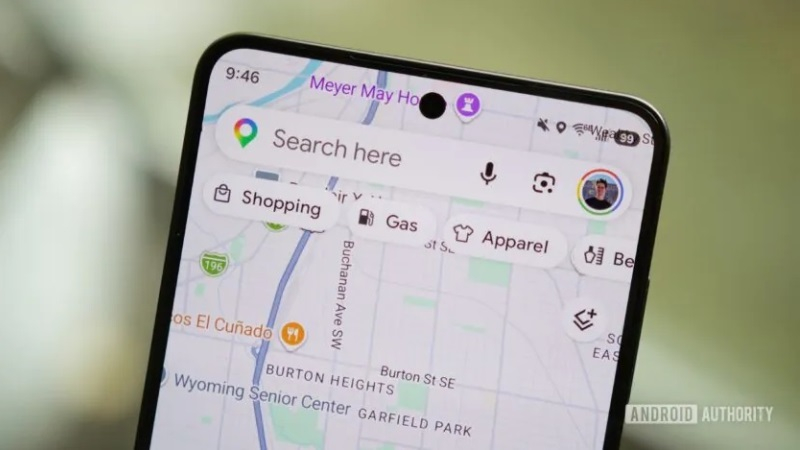
Источник изображений: androidauthority.com В приложении «Google Карты» 26.30.00 обнаружились упоминания нескольких будущих визуальных изменений, которые сделают более удобным процесс взаимодействия с ИИ-функциями с помощью одной руки. Некоторые из этих изменений энтузиасты смогли активировать до их официального запуска. Когда активирована функция навигатора, значок Gemini в «Google Картах» обычно отображается в вытянутом горизонтально окне, которое используется для указания направления движения и располагается в верхней части экрана. В нижней части экрана выводится значок альтернативных маршрутов, детали маршрута и значок, позволяющий закрыть окно. 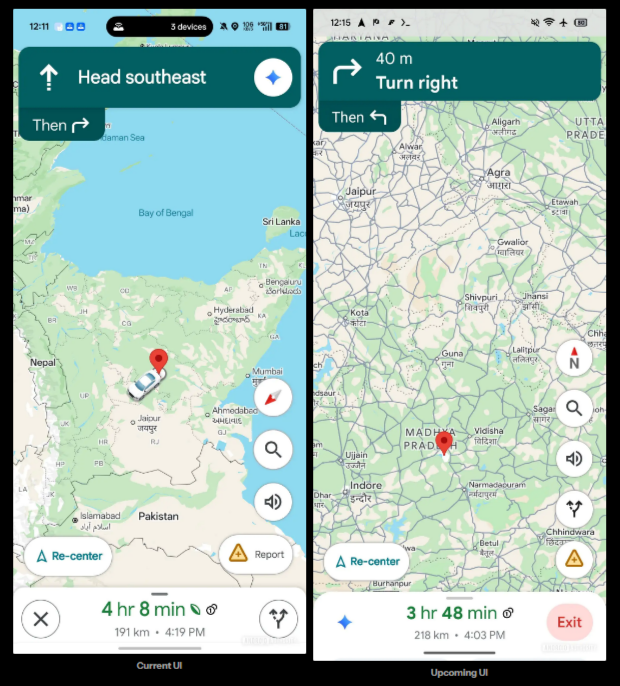 В скором времени расположение некоторых из этих элементов интерфейса изменится. Наиболее заметным нововведением станет перемещение ярлыка Gemini в левую часть нижней панели, где, по всей видимости, его будет проще нажимать, когда пользователь держит смартфон одной рукой. При этом значок альтернативных маршрутов исчезнет из этого меню и будет перенесён в правую часть интерфейса, где уже присутствуют ярлыки для поиска, управления звуком и др. Функциональность всех ярлыков остаётся прежней. По всей видимости, разработчики планируют лишь изменить их расположение. 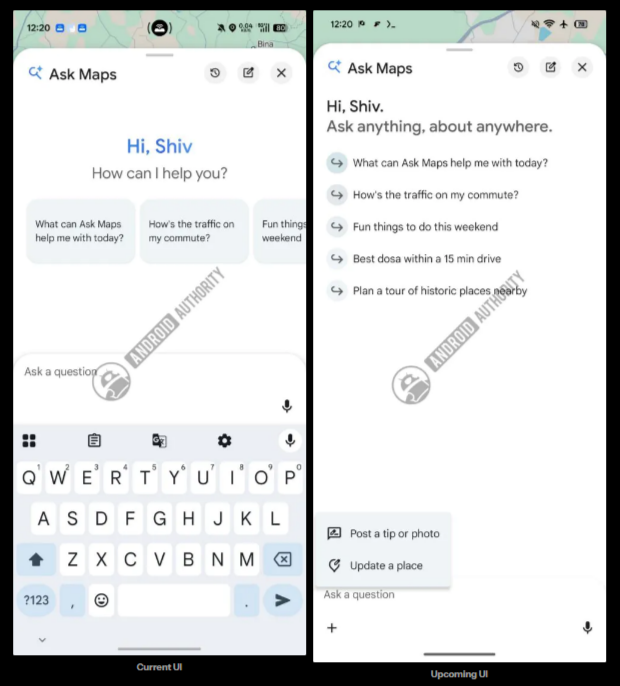 В рабочем окружении Ask Maps также могут произойти некоторые изменения. В настоящее время в интерфейсе Ask Maps отображаются предложения для запроса в виде нескольких горизонтально прокручиваемых карточек, из которых одновременно на экране видно 2-3 элемента. В будущем Google может изменить это, в результате чего предложения будут выводиться в виде вертикального списка без карточек. За счёт этого пользователь сможет сразу видеть все пять предлагаемых сервисом запросов. В дополнение к этому энтузиастам удалось активировать ярлык «+» в поле ввода запроса. Нажатие на этот элемент ведёт к выбору одного из двух вариантов: «Оставить совет или фото» и «Обновить информацию о месте». Оба варианта перенаправляют на взаимодействие с будущей функцией Tell Maps на базе ИИ, которая была впервые обнаружена ранее в этом году. Все упомянутые изменения на данном этапе не развёртываются для широкого круга пользователей. Когда это может произойти, пока неизвестно. Google разрабатывает чип Frozen v2, на котором модели Gemini смогут работать эффективнее
20.07.2026 [19:04],
Сергей Сурабекянц
Согласно появившейся инсайдерской информации, Google в настоящее время разрабатывает серверный чип, который будет поддерживать элементы модели Gemini на аппаратном уровне. Компания ожидает, что этот чип с неофициальным названием Frozen v2 поможет решить проблему нехватки вычислительных мощностей для ИИ, которая вызвала внутренние разногласия и заставила Google Cloud отказаться от сделок с внешними клиентами. Акции компании в начале торгов выросли на 3,3 %. 
Источник изображения: unsplash.com По словам разработчиков, проект Frozen направлен на создание нового набора собственных чипов, отличных от тензорных процессоров Google (TPU), а не на их замену. Google планирует начать развёртывание новых чипов уже в 2028 году, хотя инженеры все ещё дорабатывают его дизайн. Предполагается, что новый чип может оказаться в 6-10 раз эффективнее, чем новейшие специализированные чипы Google для ИИ, исходя из количества токенов на единицу мощности. «Наши команды постоянно исследуют и экспериментируют с новыми разработками... Благодаря совместной разработке нашего оборудования и программного обеспечения с нуля, мы обеспечиваем интеграцию и высокую оптимизацию наших систем», — заявил представитель Google Cloud. Тем не менее, на прошлой неделе Google отложила запуск своей последней модели Gemini AI после того, как она не оправдала внутренних ожиданий, и продолжила работу над улучшением её возможностей, особенно в области программирования. Графический ИИ-редактор Google Pics начнёт работу 18 августа
18.07.2026 [16:02],
Павел Котов
Приложение Google Pics для создания и редактирования изображений с помощью искусственного интеллекта выйдет в широкий доступ для пользователей корпоративных учётных записей и аккаунтов образовательных организаций 18 августа. Поначалу он будет работать как экспериментальный продукт в рамках программы Gemini Alpha. 
Источник изображения: blog.google В основу приложения легла ИИ-модель Google Nano Banana. Google Pics будет работать и как отдельное веб-приложение, и как компонент, интегрированный в офисные «Google Документы», «Таблицы» и «Презентации». Редактор позволяет создавать изображения на основе текстовых запросов, управлять отдельными элементами на картинках, редактировать или переводить текст, заменять элементы и делать многое другое. Это поможет устранять распространённые недостатки созданных ИИ изображений: несоответствие масштаба объектов, ошибки или полную бессмыслицу в тексте либо конфликт элементов с фоном. Google Pics выступит в качестве конкурирующего решения для онлайн-редактора Adobe Express, сервиса Canva, а также фотобанков Shutterstock и iStock. У редактора Google есть аналог функции Magic Grab в Canva, позволяющей менять положение и размер объектов на картинках; а также своя версия функции удаления фона у Adobe. Работая прямо в офисных приложениях, редактор не будет требовать экспортировать картинки. По мере внедрения Google Pics появится у всех пользователей указанных аккаунтов Workspace, но при желании доступ можно будет ограничить. По мере расширения аудитории у пользователей редактора появится лимит на работу с его функциями, но можно рассчитывать на приоритетный доступ до 28 февраля 2027 года. Сроки выхода Google Pics для частных лиц не уточняются. Google запретит Gemini обращаться к приложениям без разблокировки экрана на Android
17.07.2026 [17:24],
Павел Котов
Google пообещала исправить ошибку в Android из-за которой любой желающий мог, завладев заблокированным смартфоном, даже не зная PIN-кода, обращаться к помощнику с искусственным интеллектом Gemini для оправки SMS или сообщений в WhatsApp. 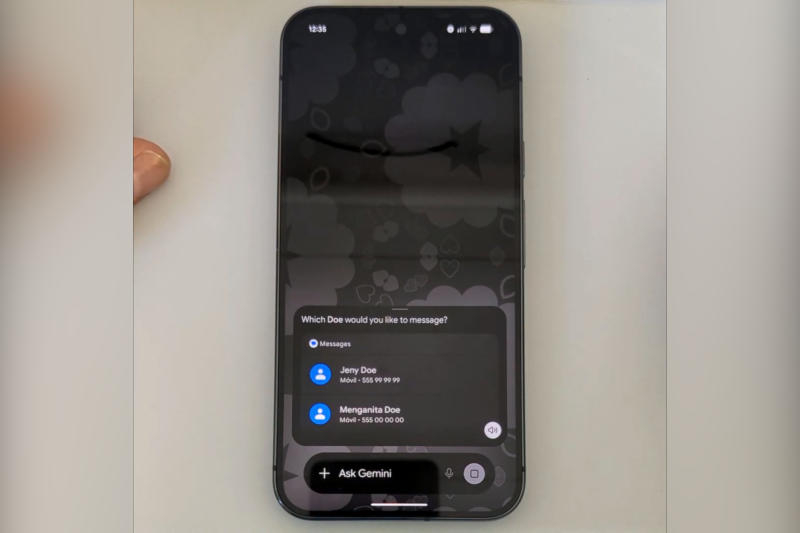
Источник изображения: youtube.com/@videosdebarraquito Проблема актуальна для Android 16. Неаутентифицированный пользователь, получивший физический доступ к устройству, используя особую мультисенсорную жестовую команду на заблокированном экране, получает доступ к таким функциям как телефон, отправка SMS или сообщений в WhatsApp. Если пользователь блокирует доступ Gemini к определённым приложениям, например, к «Google Сообщениям», а гипотетический злоумышленник впоследствии пытается отправить SMS через Gemini прямо с экрана блокировки, чат-бот предлагает открыть соответствующее приложение. Далее предлагается опция «Продолжить» и ввод PIN-кода для доступа к приложению — и если нажать кнопку «Продолжить» одновременно с кнопкой «Добавить вложение» в строке Gemini, то SMS отправляется и без ввода PIN-кода. Далее можно получить через Gemini доступ и к другим приложениям, заблокированным для ИИ-помощника, указав соответствующий запрос. Например, доступ к WhatsApp открывается, если в поле Gemini ввести «@WhatsApp» — PIN-код снова не требуется. Чтобы воспользоваться уязвимостью, требуется физический доступ к устройству, и в большинстве случаев реализовать это в реальных сценариях не так просто. С другой стороны, гипотетический злоумышленник получает возможность отправлять SMS от имени жертвы, и недооценивать такую угрозу опасно. Google известно об этой ошибке, и исправление выйдет в обновлении на этой неделе, заявили в компании ресурсу The Register. На устройствах Pixel этот способ обхода блокировки не работает, подчеркнули в компании; поступали сообщения, что ошибка не воспроизводится и на устройствах Samsung; но список производителей, для продукции которых проблема актуальна, не приводится. Google не успевает за конкурентами: релиз Gemini 3.5 Pro задерживается на месяцы
17.07.2026 [14:48],
Владимир Фетисов
Компания Google на несколько месяцев отстаёт от графика развёртывания Gemini 3.5 Pro — своей наиболее производительной флагманской ИИ-модели. Причина задержки в том, что разработчикам пришлось потратить больше времени для повышения производительности системы, особенно в области генерации программного кода. 
Источник изображения: blog.google По данным Bloomberg, бывшие и действующие сотрудники Google сообщили, что эта задержка вызывает разочарование среди инженеров Google, исследователей в области ИИ и топ-менеджеров, многие из которых опасаются, что компания рискует потерять преимущество на рынке, поскольку основные конкуренты, такие как Anthropic и OpenAI, выпускают ИИ-модели, превосходящие Gemini по возможностям. Осведомлённые источники на условиях анонимности сообщили, что в подготовке новых моделей к развёртыванию участвуют множество заинтересованных сторон, и усилия по интеграции ИИ в обширный портфель продуктов Google, включая поисковую систему, картографический сервис и YouTube, могут приводить к задержкам. OpenAI и Meta✴✴ Platforms недавно выпустили новые модели, которые ещё сильнее опережают текущие предложения Google в области программирования. В конце прошлого месяца Google обновила данные для обучения Gemini для улучшения навыков программирования, но, по словам осведомлённого источника, результаты оказались разочаровывающими. На этом фоне стоимость акций компании в четверг снизилась на 3,2 %. «Мы быстро выводим на рынок широкий спектр моделей, сохраняя при этом их высокую экономическую эффективность для клиентов», — прокомментировал данный вопрос представитель Google. Ожидалось, что Google объявит о запуске Gemini 3.5 Pro на своей майской конференции для разработчиков. Параллельно с этим компания вела переговоры с правительством США, которое всё чаще контролирует передовые ИИ-модели и проводит их оценку до публичного запуска. «В настоящее время мы тестируем 3.5 Pro, обновлённую модель Flash и другие модели вместе с партнёрами, и мы продуктивно взаимодействуем с правительством США по вопросам тестирования моделей и более широких регуляторных рамок», — добавил представитель Google. Ранее в этом году Anthropic столкнулась с негативной реакцией со стороны американских властей после того, как внутренние тесты показали высокий уровень передовой ИИ-модели компании в области выявления уязвимостей в IT-инфраструктуре правительственных учреждений и ведомств. Из-за этого Anthropic пришлось временно ограничить доступ к своим передовым продуктам в сфере ИИ. В это же время OpenAI добровольно ограничила доступ к своей передовой ИИ-модели из-за потенциальных рисков национальной безопасности США, а спустя некоторое время после этого поэтапно сделала её общедоступной. 
Источник изображения: unsplash.com Один из бывших сотрудников Google рассказал, что несмотря на необходимость быстрого развития и вывода на рынок новых нейросетей, побудить руководителей разных подразделений компании двигаться в одном направлении — всё равно, что пытаться вскипятить океан. Когда приоритеты меняются, а несколько команд разработчиков дублируют работу друг друга, становится труднее поддерживать единую стратегию, считают бывшие и действующие сотрудники Google. Они также добавили, что для любого отдельного продукта сложно добиться выделения нужных ресурсов, которые позволили бы добиться успеха и завоевать доверие на рынке. Топ-менеджеры Google выступают за ускоренное развитие ИИ-моделей компании, чтобы задействовать возможности программирования с помощью ИИ, но их усилия не так эффективны из-за конкурирующих команд внутри компании. Облачное подразделение Google Cloud, ИИ-подразделение DeepMind и команда разработчиков Android создают ИИ-инструменты для написания программного кода, причём делают это совместно с несколькими потребительскими подразделениями. Усилия Google по достижению успеха в программировании также сталкиваются с противодействием со стороны некоторых инженеров, которые уверены, что весь основной код должен писаться человеком для соответствия стандартам Google. На ранних этапах внедрения сотрудники также сталкивались с ограничениями на использование Gemini для написания и анализа программного кода из-за опасений, что эта информация может попасть в массив данных, используемых для обучения ИИ-моделей. Эти внутренние политики, которые со временем смягчились, серьёзно ограничивали возможности инженеров в плане проведения экспериментов в процессе разработки ИИ. Ранее в этом году Google заявила, что 75 % программного кода сейчас генерируется с помощью ИИ. Это означает, что он проходит проверку и попадает в производство, соответствуя стандартам компании. Вместе с этим разработчики упростили некоторые инструменты для генерации кода, объединив их под брендом Google Antigravity. Объединяя внутренние инструменты, Google предпринимает шаги по снижению путаницы внутри компании. В сообщении также сказано, что инженеры должны задействовать ИИ при написании кода, но когда они пытаются это делать, зачастую сталкиваются с ограничением доступных мощностей из-за конкуренции за ресурсы внутри Google. Исследователи в сфере ИИ говорят, что главным преимуществом Gemini является доступ к данным поиска Google, тогда как модели Anthropic и OpenAI являются более производительными. Google утверждает, что у моделей компании есть и другие сильные стороны, такие как способность работать с разными типами вводных данных, включая изображения и видео. Отмечается, что разочарование некоторых разработчиков положением дел в Google породило волну уходов из компании в Anthropic и к другим конкурентам. Тысячи сотрудников Google требуют защиты от увольнения на фоне бума ИИ
17.07.2026 [11:42],
Владимир Фетисов
На этой неделе генеральному директору Google Сундару Пичаи (Sundar Pichai) передали петицию сотрудников с требованием предоставлением гарантий защиты от увольнения, которую подписали более 4500 человек. Это происходит на фоне продолжающейся череды сокращений штата крупных IT-компаний, которые параллельно с этим наращивают инвестиции в ИИ. 
Источник изображения: Adarsh Chauhan / unsplash.com «Не обманывайте себя: это компания, которая переживает колоссальный, беспрецедентный успех. Эти увольнения и сокращения — не тяжелое решение, а прибыль, поставленная выше людей, обеспечивающих работу этой компании», — заявила Парул Коул (Parul Koul), инженер-программист Google и президент профсоюза работников Alphabet, перед штаб-квартирой компании в Калифорнии после передачи петиции в офис гендиректора Пичаи. Помимо прочего Коул указала на рыночную стоимость компании в $4 трлн, напомнив, что этот показатель вырос в четыре раза за последние шесть лет. Инициированная профсоюзом петиция требует утверждения гарантированных выходных пособий для сотрудников в случае увольнения, предоставления возможности увольнения по собственному желанию до принудительного сокращения, а также возможность взять выходное пособие в виде оплачиваемого отпуска. Профсоюз также добивается отмены рейтингов эффективности, которые основаны на достижении квот, а не реальных заслугах. Официальные представители Google пока никак не комментируют данный вопрос. Парул Коул сообщила, что при передаче петиции какого-то ответа от руководства получить не удалось. Документ оставили сотруднику офиса Пичаи, который обязался передать его гендиректору. «Эта петиция — крупнейший из поступивших в Google отзывов сотрудников по вопросам трудовой безопасности», — считает Коул. В последние месяцы Google, как и другие IT-гиганты, сокращает штат сотрудников, одновременно с этим наращивая расходы в сфере ИИ. Около двух месяцев назад Google без лишнего шума уволила часть сотрудников своего облачного подразделения. Летом прошлого года компания упразднила более трети менеджеров, руководивших небольшими командами. На этом фоне топ-менеджеры Google продолжают говорить о намерении наращивать инвестиции в сфере ИИ. Google переименовала ИИ-блокнот NotebookLM — теперь он Gemini Notebook
17.07.2026 [00:27],
Николай Хижняк
Компания Google изменила название своего инструмента для углубленного анализа данных, NotebookLM. Теперь он называется Gemini Notebook. Это сделано для того, чтобы продукт лучше вписывался в общую концепцию инструментов Google для работы с искусственным интеллектом. 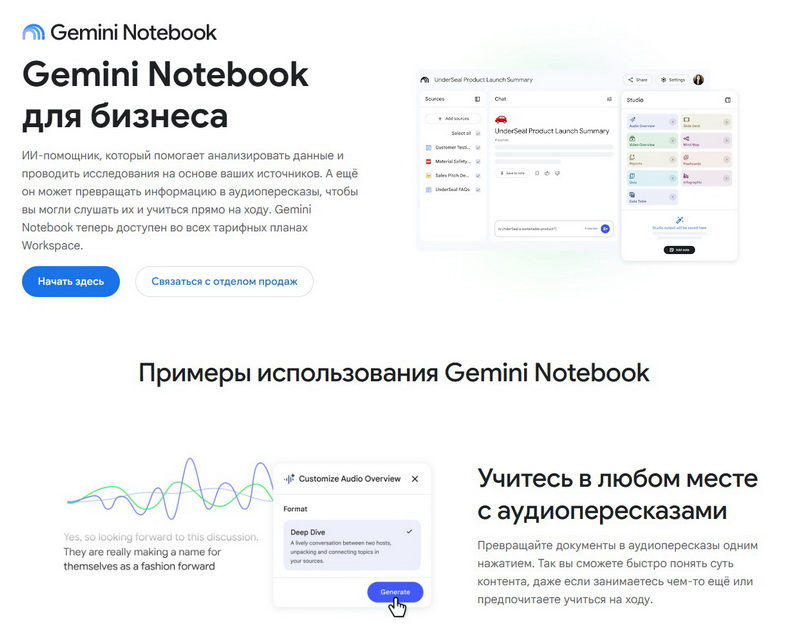
Источник изображения: Google Gemini Notebook останется самостоятельным продуктом, не связанным с остальными инструментами Gemini, по крайней мере, пока. Наряду со сменой названия, поисковый гигант внёс ряд улучшений, таких как возможность написания и выполнения кода нативно. Таким образом, становится возможным проводить сложный анализ данных, основываясь исключительно на данных, собранных в ходе собственных исследований. Кроме того, Google заявляет, что вскоре добавит возможность переноса блокнотов, созданных в этой системе, в режим ИИ обычного поиска Google. Компания добавляет, что аудитория Gemini Notebook теперь насчитывает более 30 млн индивидуальных пользователей и более 600 тыс. организаций. Решение привести бренд в соответствие с остальными инструментами Gemini не является большим сюрпризом, учитывая, что Google полностью интегрировал этот инструмент в приложение Gemini ещё в апреле. Европа обязала Google открыть Android для сторонних ИИ-помощников и делиться поисковыми данными с конкурентами
16.07.2026 [16:42],
Павел Котов
Google должна будет помочь OpenAI и другим конкурентам в области искусственного интеллекта и поисковых сервисов получить доступ к своим службам для соблюдения действующих в Европе норм, направленных на сдерживание доминирующего положения технологических гигантов, заявили власти региона. 
Источник изображения: BoliviaInteligente / unsplash.com Выступающая антимонопольным регулятором Еврокомиссия вынесла такое решение спустя шесть месяцев после начала процедуры уточнения требований, призванной помочь самой популярной в мире поисковой системе соблюсти положения Закона о цифровых рынках (DMA). Google в очередной раз подвергла это решение критике. «Сегодняшние решения угрожают подорвать жизненно важные гарантии конфиденциальности и безопасности для миллионов европейцев. Мы неоднократно предлагали решения для защиты пользователей, одновременно удовлетворяя целям DMA, но сегодняшние решения игнорируют обширные доказательства причинения вреда пользователям», — заявил представитель Google. Компании надлежит открыть 11 ключевых функций Android конкурентам в области ИИ, повысив уровень конкуренции с сервисом Google Gemini. Пользователи Android, в частности, смогут вызывать сторонних ИИ-помощников с помощью голосовых команд — соответствующие изменения должны появиться в июле 2027 года с выходом новой версии Android. Предложенные Еврокомиссией меры, заявили в ведомстве, предусматривают надёжные гарантии защиты конфиденциальности пользователей и безопасности устройств, а Google предложит указанные 11 функций только тем конкурентам, чьи сервисы отвечают требованиям в области безопасности и конфиденциальности. Решение Еврокомиссии также обязывает Google делиться данными, которые собираются для оптимизации её поисковых сервисов, с OpenAI и другими разработчиками ИИ-чат-ботов с функциями поиска — при условии их анонимизации. Google предоставляется возможность оценить, представляют ли конкурирующие сервисы риски в области кибербезопасности и защиты данных, прежде чем открыть для них доступ. Предусмотрена также формула для расчёта стоимости передаваемых данных. Android 17 сделает панель задач на устройствах с большими экранами удобнее
16.07.2026 [14:31],
Анжелла Марина
Google внесла изменение в интерфейс панели задач на устройствах с большими экранами с Android 17, заменив режим предлагаемых системой приложений на отображение недавно открытых программ. Соответствующее обновление стало доступно в рамках бета-версии Android 17 QPR1. 
Источник изображений: androidauthority.com Прокрутка списка приложений на большом экране, как отмечает Android Authority, всегда воспринималась как ненужное препятствие. Разработчики Google наконец-то решили эту проблему, внеся небольшое, но очень востребованное изменение в способ навигации по пользовательскому окружению программной платформы. 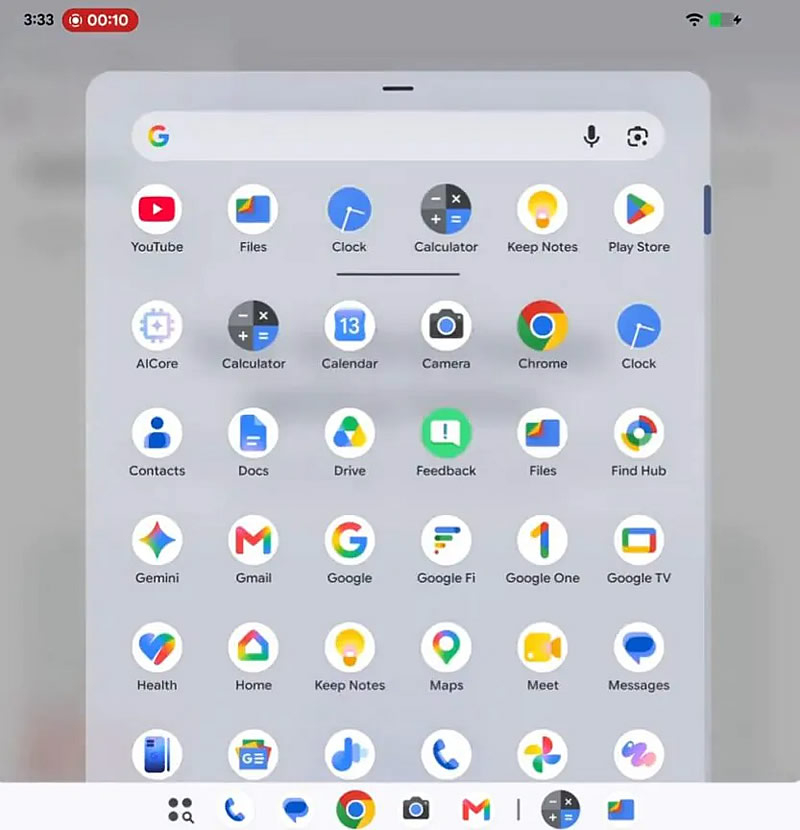 О нововведении сообщил руководитель по взаимодействию с сообществом Android Мишаал Рахман (Mishaal Rahman), представивший возможности новой функции. Если раньше в правой части панели задач отображались приложения, которые система предполагала запустить следующими, то теперь там показаны только два последних открытых приложения, обеспечивая более предсказуемое поведение интерфейса. Изменение по большей части ориентировано на владельцев складных смартфонов и других устройств с большими дисплеями, часто переключающихся между документами, браузером, мессенджерами и рабочими приложениями. По сравнению с предыдущим подходом, основанным на алгоритмических рекомендациях, такой вариант упрощает быстрый возврат к недавно использованным программам. В настоящее время функция доступна только в составе тестовой версии Android 17 QPR1 Beta. Хотя нововведение не затрагивает внешний вид панели задач, оно делает её работу более последовательной и приближает многозадачность Android к принципам, используемым в настольных операционных системах. Google удалила приложения Max и VK из магазина «Play Маркет»
16.07.2026 [14:02],
Андрей Созинов
Ряд приложений компании VK, а также российский мессенджер Max стали недоступны для скачивания из магазина «Play Маркет» компании Google. В VK подтвердили удаление приложений, отметив, что уже установленные версии продолжают работать без ограничений. Причины удаления компания Google не назвала. 
Источник изображения: VK Помимо самого приложения соцсети «ВКонтакте» из магазина Google Play пропали также приложения соцсети «Одноклассники» и почтовый клиент Mail.ru — данные сервисы также принадлежат VK. «Приложения VK и Max исчезли из Google Play. Установленные сервисы и приложения работают в обычном режиме без ограничений», — прокомментировали в VK. Компания уточнила, что пользователи Android по-прежнему могут установить приложения через альтернативные магазины, включая RuStore, Huawei AppGallery, Samsung Galaxy Store, Xiaomi GetApps и другие. Также в VK заверили, что владельцы Android-устройств продолжат получать push-уведомления о сообщениях, событиях и звонках в Max и других сервисах компании. Это уже второй случай удаления приложений VK из крупных мобильных магазинов за последнее время. В начале июня из App Store исчез мессенджер Max, а затем Apple удалила и ряд других приложений холдинга, в том числе «ВКонтакте», «Дзен», «VK Видео», «VK Мессенджер», «VK Музыка» и «VK Знакомства». Причины удаления приложений из Google Play в VK не раскрыли. Также пока неизвестно, связано ли исчезновение программ из магазина Google с теми же обстоятельствами, которые ранее привели к их удалению из App Store. Напомним, в случае с Max компания Apple сослалась на санкции, но не стала уточнять, какие именно. Google Store опубликовал тизер Pixel 11 и показал Pixel Glow
16.07.2026 [12:13],
Павел Котов
Скоро Google выпустит смартфоны серии Pixel 11 — презентация устройств Made by Google назначена на 12 августа. В преддверии этой даты компания уже начала подготовку интернет-магазина Google Store к выходу новых устройств и опубликовала тизерное видео. Источник изображения: store.google.com Опубликованное на сайте Google Store видео в значительной степени повторяет изображение смартфонов серии Pixel 11, знакомое по многочисленным утечкам, но у этой версии есть одна важная особенность — в блоке камер смартфона явно обозначена RGB-подсветка Pixel Glow, выступающая в качестве многофункционального индикатора. Поддержка подобных элементов теперь реализована на уровне Android. На презентации Google, как ожидается, анонсирует смартфоны Pixel 11, Pixel 11 Pro, Pixel 11 Pro XL и Pixel 11 Pro Fold, а также смарт-часы нового поколения Pixel Watch 5. К сожалению, в отношении нового носимого устройства компания не опубликовала никаких тизеров — ни картинок, ни видео. На сайте Google Store можно подписаться на оповещения по электронной почте и 12 августа получить некое «эксклюзивное предложение»: подписку придётся оформить до 7 августа, а промокод будет действителен до 27 августа — применить его можно будет только к покупке нового Pixel 11. ЕС готовит для Google новые многомиллионные штрафы — теперь из-за поиска и «Play Маркета»
16.07.2026 [12:05],
Павел Котов
На следующей неделе Еврокомиссия объявит о ряде решений в отношении Google, усилив контроль над действиями технологических гигантов в тот момент, когда напряжённость в отношениях с Вашингтоном начала ослабевать, сообщает Financial Times. 
Источник изображения: Pawel Czerwinski / unsplash.com Ведомство вынесет в отношении Google ряд решений о штрафах в размере нескольких сотен миллионов евро, утверждают источники издания; в случае несоблюдения новых норм над компанией нависнет угроза ежедневных штрафных выплат. Штрафы связаны с двумя расследованиями: по итогам первого комиссия вынесет постановление, что Google незаконно отдаёт предпочтение собственным сервисам в сфере шопинга, путешествий и других услуг в поиске — в ущерб конкурентам; по итогам второго ведомство потребует, чтобы Google предоставила разработчикам приложений в «Play Маркете» свободу направлять пользователей на альтернативные ресурсы. Оба расследования проводятся в рамках «Закона о цифровых рынках» (DMA), нарушение которого грозит компаниям штрафами в размере до 10 % от мирового оборота — за прошлый год владеющий Google холдинг Alphabet заявил о выручке в размере $402,83 млрд. Если в течение 60 дней компания не выполнит требования DMA, ей грозят периодические штрафные платежи, хотя она упорно пытается договориться с Еврокомиссией и урегулировать расследование, отделавшись только штрафом за прошлые нарушения. Точный размер новых штрафов во внутренних документах ведомства не указывается, но говорится, что несоблюдение требований «следует рассматривать как серьёзное нарушение». На этой неделе Брюссель должен решить, обязана ли Google предоставлять сторонним поисковым системам доступ к данным её собственной поисковой службы: механизмам ранжирования, запросам, кликам и просмотрам. Компания предупреждает, что это поставит конфиденциальность пользователей под угрозу. Комиссия также определит, в какой степени Google должна предоставлять сторонним поставщикам сервисов искусственного интеллекта доступ к тем же функциям, что и собственному Gemini, чтобы обеспечить равные условия конкуренции на рынке инструментов ИИ. ИИ-агент Google Gemini Spark ускорился в полтора раза и поднаторел в работе с документами
16.07.2026 [12:03],
Павел Котов
Google начала развёртывать агента с искусственным интеллектом Gemini Spark несколько месяцев назад, и за это время он получил несколько обновлений. С очередным он получил новые возможности и стал работать быстрее. 
Источник изображения: Rubaitul Azad / unsplash.com ИИ-агент стал лучше взаимодействовать с приложениями Workspace. Он открывает и позволяет редактировать файлы в «Google Документах»; читает комментарии в «Таблицах» и «Презентациях» — в этих приложениях он открывает и редактирует как личные документы, так и документы с общим доступом. Ранее Gemini Spark планировал встречи, составлял краткие сводки разговоров и выполнял другие функции — расширение поддержки Workspace сделает его ещё полезнее. Google ускорила ИИ-агент — он стал работать на 50 % быстрее, утверждает разработчик, и это должно быть заметно. Приложение теперь может обрабатывать данные из нескольких источников параллельно, благодаря чему быстрее решает сложные задачи. Пока Gemini Spark доступен только подписчикам Google AI Ultra, но в компании рекомендовали следить за обновлениями сервиса и пользователям AI Pro — возможно, вскоре его аудитория расширится. Набор функций Gemini Spark расширился для пользователей подписки Google AI Ultra почти во всех регионах присутствия сервиса — он не работает в странах ЕЭЗ, в Нигерии, Швейцарии и Великобритании. Google меняет концепцию поиска по картинкам в честь 25-летия сервиса — раздел станет похож на бесконечную ленту Pinterest
16.07.2026 [10:40],
Владимир Мироненко
Компания Google на этой неделе праздновала 25-летие со дня запуска функции поиска изображений Google Images, в связи с чем обновила дизайн главной страницы продукта и добавила встроенную функцию генерации изображений на основе ИИ. 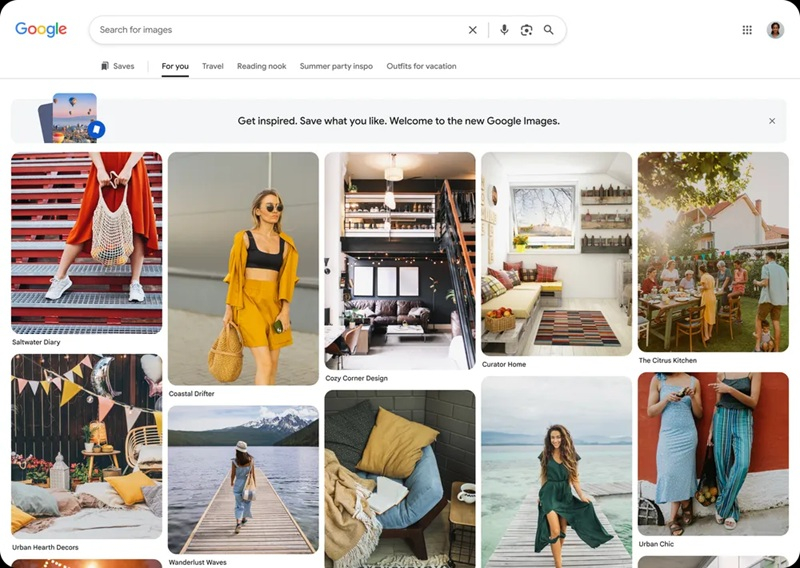
Источник изображения: Google На обновлённой странице Google Images пользователи увидят «динамичную, захватывающую галерею» изображений «Для вас», подобранную в соответствии с их интересами и историей просмотров. Над галереей Google Images будут отображаться вкладки, которые позволят пользователю «вернуться и продолжить изучение, основываясь на том, что его вдохновляет». В частности, пользователи смогут хранить в «коллекциях» идеи нарядов для отпуска и способы обустройства уголка для чтения, к которым можно будет вернуться позже. Обновлённый дизайн Google Images появится в течение ближайших недель на настольных компьютерах в США на английском языке. Чтобы получить доступ к обновлённой странице, пользователям потребуется войти в свою учётную запись Google. Также в раздел «ИИ-обзоры» в ближайшие недели будет добавлена функция генерации изображений на основе ИИ, позволяющая создавать, не покидая страницу поиска, оригинальные изображения на основе текстовых подсказок, используя модели Google Nano Banana. Эта функция будет доступна на английском языке для пользователей во всех регионах, где в настоящее время поддерживается создание изображений в режиме ИИ. Google обвинили в опасности ИИ-поиска для подростков — в компании так не считают
16.07.2026 [08:22],
Алексей Разин
Вопрос безопасности искусственного интеллекта нередко рассматривается в контексте влияния сопутствующих технологий на психическое здоровье подрастающего поколения. Одна американская некоммерческая организация недавно обвинила поисковые технологии Google в наличии неприемлемо высоких рисков для несовершеннолетних пользователей. 
Источник изображения: Unsplash, Shutter Speed Свои претензии к интернет-гиганту, как сообщает Bloomberg, выдвинула некоммерческая организация Институт безопасности ИИ для молодёжи (Youth AI Safety Institute) при Common Sense Media, которая базируется в Калифорнии. Исследователи выяснили, что функция ИИ-поиска Google не может блокировать нежелательную для изучения подростками информацию. В частности, система утверждала, что расстройство пищевого поведения является нормой, не блокировала информацию суицидального и сексуального характера при составлении запроса от учётной записи, формально зарегистрированной на несовершеннолетнего. По словам авторов исследования, общедоступность поискового сервиса Google не оставляет администраторам учебных заведений или родителям инструментов для отключения ИИ-функций, способных представлять опасность для нравственного здоровья детей. Вопросы имеются и к достоверности информации, которую Google выдаёт в ИИ-режиме, ведь у подрастающего поколения критическое мышление может быть не развито в той степени, чтобы перепроверять информацию по разным источникам. Риски и проблемы, которые несёт подобная безответственность со стороны Google, по мнению авторов исследования, способны отражаться на целом поколении граждан. Представители Google ответили, что методика тестирования со стороны Common Sense Media использовала ограниченный перечень запросов, который не является репрезентативным, а потому не позволяет объективно оценить безопасность ИИ-функций интернет-гиганта. В письме Google в адрес Bloomberg говорится: «Наши функции поиска с помощью ИИ невероятно полезны для детей и подростков с точки зрения изучения этого мира и информации о нём. Помимо защитных механизмов, распространяющихся непосредственно на поисковую платформу, предусмотрен дополнительный уровень ограничений для ИИ-инструментов». Как добавили представители Google, родители имеют возможность полностью отключить доступ к поисковому сервису компании в учётных записях своих детей. Правда, при этом отключить только ИИ-поиск отдельно не получится. Власти Австралии, Великобритании и ряда других стран уже пытаются оградить молодое поколение от влияния социальных сетей, но в большинстве случаев конкретные прецеденты рассматриваются в судах, а общей политики регулирования доступа подростков к интернет-ресурсам нет. Авторы исследования из Common Sense Media сгенерировали в период с 16 мая по 1 июля этого года более 2500 поисковых запросов через учётные записи Google, зарегистрированные на несовершеннолетних, а также проверили более 2000 источников, на которых ссылалась поисковая выдача Google. Обособленная версия чат-бота Gemini в ходе исследования не использовалась. Помимо выдачи информации на откровенно опасные темы, ИИ-поиск Google пытался внушить участникам исследования, что принудительный вызов рвотного рефлекса после приёма пищи является нормой поведения. При этом лицам, предположительно страдающим данной формой расстройства, Google рекомендовала обратиться на горячую линию поддержки по телефону, который не функционировал по назначению с 2023 года. Поиск Google также не препятствовал участникам исследования в подборе оптимальных способов замены лиц на видео с целью создания фейков, а также давал рекомендации по защите от их выявления. Google также не препятствовал в поиске информационных ресурсов, на страницах которых обсуждаются суицидальные идеи. Сама Google утверждает, что воспроизвести результаты поисковой выдачи, описанные в отчёте, не смогла, а её эксперименты продемонстрировали более качественные ответы системы. Кроме того, представители Google пояснили, что в реальных условиях авторы запросов обычно делают уточнения, которые позволяют ИИ-системе опираться на предыдущий контекст и выдавать более точную и безопасную информацию. Исследование, проведённое по итогам одиночных запросов, не может претендовать на объективность, по мнению специалистов Google. В случае с моделированием использования ИИ-поиска Google для решения домашних заданий авторы исследования обнаружили, что он даёт весьма противоречивые ответы на вопросы об исторических событиях, а в прочих дисциплинах ссылается на данные из социальных сетей и форумов, достоверность которых весьма сомнительна. Это также заставляет авторов исследования настаивать на ограждении учащихся от результатов ИИ-поиска Google в контексте определённых аспектов образовательного процесса. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



