|
Опрос
|
реклама
Быстрый переход
Издатели: Цукерберг лично одобрил массовое пиратство книг для обучения ИИ
06.05.2026 [12:59],
Дмитрий Федоров
Пять крупных издательств и писатель Скотт Туроу (Scott Turow) подали коллективный иск против Meta✴✴ и лично её гендиректора Марка Цукерберга (Mark Zuckerberg), обвинив компанию в одном из крупнейших нарушений авторских прав в истории. По утверждению истцов, Meta✴✴ незаконно скопировала миллионы книг, статей и других произведений для обучения ИИ-модели Llama. 
Источник изображения: about.fb.com Иск поступил в Окружной суд США по Южному округу Нью-Йорка от издательств Hachette, Macmillan, McGraw Hill, Elsevier и Cengage. Истцы утверждают, что Meta✴✴ скачивала через торренты миллионы защищённых авторским правом книг и журнальных статей с пиратских сайтов, занималась несанкционированным веб-скрейпингом «практически всего интернета», а затем многократно копировала эти материалы для обучения Llama. Новое дело принципиально отличается от прежних попыток авторов оспорить действия ИИ-компаний. Истцы делают акцент на личной роли Цукерберга: он, по их словам, «лично санкционировал и активно поощрял» нарушение авторского права. Meta✴✴ по его указанию удалила из украденных произведений информацию об управлении авторскими правами, чтобы скрыть источники обучающих данных. После выпуска Llama 1 компания ненадолго задумалась о лицензировании и с января по апрель 2023 года обсуждала увеличение бюджета на эти цели вплоть до $200 млн. Однако в начале апреля 2023 года Meta✴✴ внезапно прекратила переговоры. Вопрос о том, платить правообладателям или продолжать пиратство, «эскалировали до Цукерберга», после чего команда по развитию бизнеса получила устные указания свернуть лицензионную работу. Один из сотрудников Meta✴✴, как следует из иска, дальновидно объяснил логику решения: «Если мы лицензируем хотя бы одну книгу, то не сможем опираться на стратегию добросовестного использования». 13 декабря 2023 года сотрудники Meta✴✴ распространили внутреннюю записку о правовых рисках использования LibGen. Хранилище в ней описано как «набор данных, заведомо полученный путём пиратства», а авторы документа отметили: «Мы не будем раскрывать использование наборов данных Libgen для обучения». Несмотря на эти опасения, Цукерберг и другие руководители компании одобрили скачивание через торренты более 267 Тбайт пиратских материалов. По данным иска, этот объём эквивалентен сотням миллионов публикаций и многократно превышает всю печатную коллекцию Библиотеки Конгресса. Истцы утверждают, что ИИ-система Meta✴✴ генерирует в массовом масштабе заменители их произведений и подстраивает ответы под стиль конкретных авторов, имитируя их выразительные элементы и творческие решения. Ранее авторы уже проигрывали подобные дела. В июне 2025 года федеральный судья Винсент Чхабриа (Vincent Chhabria) отклонил иск тринадцати авторов, среди которых Сара Сильверман (Sarah Silverman) и Джуно Диас (Junot Díaz), и признал использование Meta✴✴ набора данных из почти 200 000 книг для обучения Llama добросовестным. Meta✴✴ заявила, что будет агрессивно оспаривать новый иск, ссылаясь на ту же доктрину добросовестного использования (fair use) — норму американского авторского права, разрешающую при определённых условиях использовать защищённые произведения без согласия правообладателя. Лаборатория суперинтеллекта Цукерберга обрела имя TBD Labs и первые проекты
08.08.2025 [13:56],
Владимир Фетисов
У широко разрекламированного нового подразделения Meta✴✴ Platforms, занимающегося разработкой суперинтеллекта и новой версии ИИ-модели Llama, появилось официальное название. Команда разработчиков получила название TBD Labs, начальный проект и быстро растущий список сотрудников, в том числе привлечённых из других компаний. 
Источник изображения: Steve Johnson / unsplash.com Ранее Meta✴✴ объявила о намерении объединить усилия в области искусственного интеллекта внутри подразделения Meta✴✴ Superintelligence Labs (MSL). По словам главы Meta✴✴ Марка Цукерберга (Mark Zuckerberg), подразделение MSL, на которое возложена миссия «предоставить доступ к персональному суперинтеллекту каждому», находится под руководством Александра Вана (Alexandr Wang), присоединившегося к компании в рамках сделки по покупке доли в его бывшем ИИ-стартапе Scale AI. Новое подразделение Meta✴✴ находится в авангарде создания суперинтеллекта, который должен стать умнее любого человека. Для достижения этой цели гигант социальных сетей переманил талантливых разработчиков из конкурирующих компаний, некоторые из которых получили десятки и даже сотни миллионов долларов. TBD Labs также возглавляет работу над новейшей версией ИИ-модели Llama. По данным источника, на прошлой неделе Ван разослал подчинённым письмо, в котором сообщил, что их подразделение будет работать вместе с другими командами разработчиков компании в сфере ИИ над реализацией различных проектов, включая выпуски основных ИИ-моделей, расширение возможностей моделирования и создание ИИ-агентов. «За последний месяц я увидел значительный прогресс в каждом из этих направлений сотрудничества. Это позволяет нам быть более амбициозными в техническом плане, проводить параллельную работу над несколькими отдельными проектами и в конечном итоге быстрее достигать передовых результатов», — говорится в сообщении Вана. Разработку новой версии Llama возглавил Джек Рэй (Jack Ray), который пришёл в TBD Labs из Google. По словам осведомлённых источников, разработка Llama ведётся совместными усилиями команд Meta✴✴ Llama и TBD Labs. У новой ИИ-модели пока нет официального названия, но разработчики называют её Llama 4.5 или Llama 4.X. Отметим, что Meta✴✴ продолжает делать значительные инвестиции в разработку суперинтеллекта. Для этих целей компания активно переманивала талантливых разработчиков у конкурентов, предлагая некоторым из них выплаты в размере сотен миллионов долларов и как минимум в двух случаях в размере миллиарда долларов в течение нескольких лет. По данным источника, Meta✴✴ переманила не менее 18 разработчиков из OpenAI и нескольких из Google. Meta✴ не будет открывать исходный код всех своих ИИ-моделей «суперинтеллекта» — это не безопасно
31.07.2025 [10:55],
Антон Чивчалов
Meta✴✴ может изменить свой подход к публикации исходного кода ИИ-моделей, включая так называемый «персональный суперинтеллект». По словам гендиректора компании Марка Цукерберга (Mark Zuckerberg), не у всех разработок будет открытый исходный код, потому что это небезопасно. Его слова приводит TechCrunch. 
Источник изображения: Steve Johnson / unsplash.com «Мы считаем, что преимуществами суперинтеллекта нужно делиться со всем миром как можно более широко, однако суперинтеллект ставит новые вопросы безопасности, — написал Цукерберг в письме. — Эти проблемы нужно тщательно контролировать, а к открытому исходному коду нужно относиться внимательно». Это может говорить о смене прежнего курса компании, когда именно открытый исходный код моделей Llama преподносился как ключевое преимущество Meta✴✴ над конкурентами, такими как ChatGPT и Google DeepMind. Правда, при этом Цукерберг допускал, что готов отказаться от открытого формата в случае каких-либо новых угроз со стороны ИИ. «Если модель приобретёт качественно новые способности, и мы решим, что открывать её будет безответственно, мы не будем этого делать», — говорил он также в прошлом году в одном из подкастов. Ещё в 2024 году Цукерберг заявлял: «Начиная со следующего года мы рассчитываем, что модели Llama станут самыми совершенными в индустрии». Эти модели должны были демонстрировать преимущества открытого ПО. Однако тестирование последней открытой версии Llama, Behemoth, недавно были приостановлены, вместо этого началась разработка закрытой модели. Meta✴✴ активно инвестирует в ИИ: только в прошлом месяце она вложила $14,3 млрд в Scale AI. На работу в Meta✴✴ перешёл основатель и гендиректор Scale, в структуре компании появилось подразделение Meta✴✴ Superintelligence Labs, отвечающее за «суперинтеллект». Meta✴✴ потратила миллиарды на переманивание ведущих разработчиков и специалистов из лучших ИИ-компаний и создание дата-центров. Видимо, теперь подход Meta✴✴ к открытым и закрытым моделям станет более сбалансированным, будут выходить и те, и другие. В ответ на запрос TechCrunch представитель Meta✴✴ сообщил: «Мы рассчитываем, что в будущем будем работать с комбинацией открытых и закрытых моделей». Meta✴ переманила основателя Scale AI и получила 49 % акций стартапа за $14,3 млрд
14.06.2025 [05:19],
Анжелла Марина
Основатель Scale AI Александр Ван (Alexandr Wang) объявил сотрудникам компании о своём уходе и переходе в Meta✴✴. Это следует из внутреннего сообщения, которое он также опубликовал в социальной сети X. Ранее появлялись сообщения о его возможном уходе и масштабном инвестировании в компанию со стороны Meta✴✴. 
Источник изображения: AI Согласно условиям сделки, Meta✴✴ инвестирует $14,3 млрд в Scale AI и получит 49 % акций стартапа, но без права голоса, заявил представитель компании. Ван отметил, что возможности такого масштаба требуют жертв, и в данном случае этой жертвой стал его уход. Он добавил, что работа в качестве генерального директора Scale AI была «величайшей честью в его жизни». 
Источник изображения: cnbc.com По сообщению CNBC, новым главой Scale AI станет Джейсон Дроги (Jason Droege), который ранее занимал должность директора по стратегии. До прихода в Scale AI он был партнёром венчурного фонда Benchmark и вице-президентом Uber. Небольшое число сотрудников Scale AI также перейдут в Meta✴✴ в рамках соглашения. Представитель Meta✴✴ подтвердил заключение стратегического партнёрства и инвестиций в Scale AI. По его словам, компании расширят сотрудничество в области создания данных для ИИ-моделей, а Ван присоединится к Meta✴✴ для работы над проектами, связанными с искусственным интеллектом следующего поколения. Подробности о новых сотрудниках и направлениях работы станут известны в ближайшие недели. Отмечается, что это решение соответствует стратегии Марка Цукерберга (Mark Zuckerberg), который стремится усилить позиции Meta✴✴ в сфере ИИ на фоне конкуренции с OpenAI и Google. Ранее издание CNBC также сообщало, что Цукерберг разочарован результатами работы своих разработчиков, особенно после слабого отклика на последнюю версию ИИ-модели Llama. Цукерберг решил, что Ван является более подходящей кандидатурой для руководства критически важными ИИ-проектами, несмотря на то, что ранее он традиционно назначал на ключевые роли сотрудников, которые проработали в его компании значительное время и имеют большой опыт. Ведомство Илона Маска DOGE принимало решения, пользуясь Meta✴ Llama 2, а не xAI Grok
23.05.2025 [14:19],
Павел Котов
Сотрудники Департамента эффективности правительства (DOGE) Илона Маска (Elon Musk) принимали кадровые решения, исходя из данных, которые предоставляла модель искусственного интеллекта Meta✴✴ Llama 2. 
Источник изображения: x.com/elonmusk В конце января Маск разослал федеральным чиновникам электронное письмо, получившее название «Развилка» (Fork in the Road), в котором предоставил адресатам выбор: вернуться на рабочее место в соответствии с политикой правительства или уйти в отставку. Ответы чиновников на это письмо проверялись при помощи модели Meta✴✴ Llama 2, узнало издание Wired. Этим занимались сотрудники DOGE при Управлении кадровой службы США. Meta✴✴ разрабатывает модели ИИ и публикует их как проекты с открытым исходным кодом, поэтому частные лица и организации, включая правительственные ведомства, могут свободно использовать их без явного согласия разработчика. Значительных подробностей о случившемся выяснить не удалось: нет ясности, почему в DOGE решили задействовать Llama 2, ведь к тому моменту у Meta✴✴ уже были Llama 3, а впоследствии вышло и семейство Llama 4; но известно, что модель развернули локально, то есть данные, вероятно, вообще не проходили через каналы интернета, и угрозы конфиденциальности в связи с этим не возникло. Есть также информация, что один из сотрудников DOGE, выходец из SpaceX, разработал помощника ИИ на основе модели xAI Grok-2 и использовал чат-бот GSAi для анализа данных о контрактах и закупках. DOGE также связали с ПО AutoRIF, которое способствовало ускорению увольнений чиновников. Впоследствии DOGE направил госслужащим письма, в которых предлагал еженедельно отчитываться о своих рабочих достижениях в пяти пунктах, но подтвердить, что ИИ использовался и для обработки этих ответов, не удалось. Ведомство развернуло модель Llama вместо Grok, вероятно, по той причине, что по состоянию на январь Grok была доступна лишь как закрытая модель; но в дальнейшем DOGE будет проще задействовать её: уже на этой неделе Microsoft намерена размещать модели семейства xAI Grok 3 на платформе Azure AI Foundry, что откроет множество сценариев её практического применения. Журналистам Wired не удалось найти подтверждения, что сотрудники DOGE передавали конфиденциальные данные на внешние ресурсы, но недовольные деятельностью Маска политики, в том числе более сорока американских законодателей, уже потребовали расследовать, как его ведомство использует ИИ. Они потребовали обеспечить прозрачность в этом вопросе, а также выразили обеспокоенность по поводу угроз утечки данных и сопутствующих всем системам ИИ сбоев — галлюцинаций, при которых модели дают заведомо не соответствующие действительности ответы на запросы. Meta✴ похвасталась, что число загрузок ИИ-моделей Llama перевалило за 1,2 млрд
29.04.2025 [22:21],
Николай Хижняк
В середине марта Meta✴✴ заявила, что количество загрузок открытых моделей искусственного интеллекта Llama достигло 1 млрд. На начало декабря прошлого года этот показатель составлял 650 млн, что соответствует росту более чем на 50 % за квартал. Во вторник на своей первой конференции разработчиков LlamaCon Meta✴✴ сообщила, что количество загрузок моделей Llama достигло 1,2 млрд. 
Источник изображения: Me «У нас есть тысячи разработчиков, которые создают десятки тысяч производных моделей, загружаемых сотни тысяч раз в месяц», — заявил директор по продуктам Meta✴✴ Крис Кокс (Chris Cox) во время основного доклада. Между тем количество пользователей Meta✴✴ AI — цифрового ИИ-помощника, работающего на моделях Llama, — составляет около миллиарда, добавил Кокс. 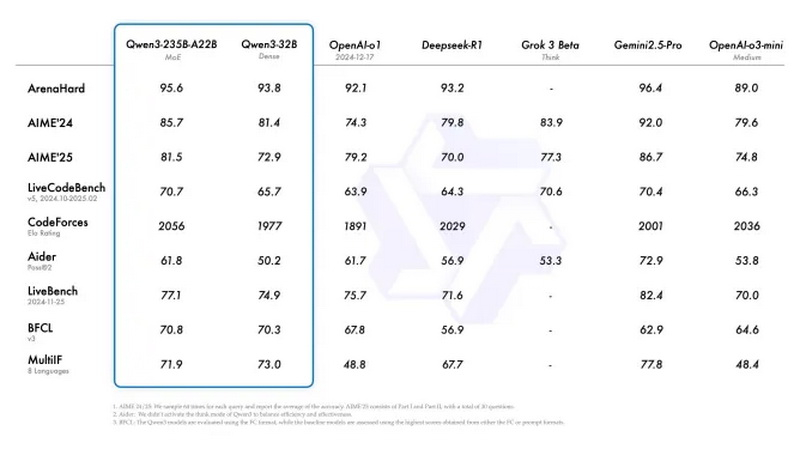
Источник изображения: Alibaba Экосистема ИИ-моделей Llama от Meta✴✴ растёт стремительными темпами, но технологический гигант сталкивается с конкуренцией со стороны ряда серьёзных игроков в сфере ИИ. Так, буквально в понедельник китайская компания Alibaba представила Qwen3 — семейство флагманских ИИ-моделей, которое по ряду показателей является весьма конкурентоспособным. В Meta✴ отрицают, что искусственно завысили результаты тестов ИИ-модели Llama 4
08.04.2025 [05:11],
Анжелла Марина
Представитель Meta✴✴ опроверг слухи о том, что компания намеренно улучшала показатели своих новых ИИ-моделей Llama 4 в бенчмарках. Вице-президент по генеративному искусственному интеллекту Ахмад Аль-Дахле (Ahmad Al-Dahle) заявил в посте на страницах X, что утверждения о подгонке результатов с целью сокрытия слабых сторон моделей Maverick и Scout — «просто неправда». 
Источник изображения: Mariia Shalabaieva / Unsplash Слухи о манипуляциях появились в соцсетях после публикации бывшего сотрудника Meta✴✴. Пользователь китайской платформы утверждал, что уволился из компании в знак протеста против «нечестных методов тестирования». Позже эти обвинения распространились в X (бывший Twitter) и Reddit, пишет издание TechCrunch. Однако Аль-Дахле подчеркнул, что Meta✴✴ не обучала модели Llama 4 Maverick и Llama 4 Scout на «тестовых наборах данных», то есть специальных выборках, используемых для оценки ИИ. Такая практика могла бы искусственно завысить результаты, создав ложное впечатление о возможностях моделей. Подозрения изначально появились из-за различий в работе Llama 4 Maverick на разных платформах. Исследователи заметили, что версия модели в бенчмарке LM Arena ведёт себя иначе, чем публично доступная и не справляется с определёнными задачами. Кроме того, Meta✴✴ использовала экспериментальную сборку Maverick для улучшения результатов тестов, что также вызвало вопросы. Одновременно Аль-Дахле отмечает, что причина, по которой пользователи пока сталкиваются с нестабильным качеством моделей, может быть связана с настройками облачных провайдеров, на серверах которых размещаются скрипты. «Мы выпустили модели сразу после их готовности, и потребуется несколько дней, чтобы все публичные реализации были настроены в соответствии с нашими требованиями», — пояснил он. В Meta✴✴ пообещали в любом случае продолжить работу над исправлениями багов Llama 4 для быстрой интеграции разработчиками в свои проекты. Meta✴ представила ИИ-модели семейства Llama 4 и встроила их в WhatsApp и Instagram✴
06.04.2025 [13:47],
Владимир Фетисов
Компания Meta✴✴ Platforms объявила о запуске семейства открытых моделей искусственного интеллекта Llama 4. В него вошли Llama 4 Scout, Maverick и Behemoth, которые обеспечивают возможность мультимодального взаимодействия, т.е. способны отвечать не только на текстовые запросы, но и обрабатывать изображения, видео и др. Они обучались на «большом количестве немаркированных текстовых, графических и видеоданных» для обеспечения «широкого визуального понимания». 
Искусственный интеллект: Steve Johnson / Unsplash Успех ИИ-моделей китайской компании DeepSeek, которые работают наравне или превосходят флагманские алгоритмы Llama предыдущих поколений, подтолкнул Meta✴✴ к ускорению процесса разработки в этом направлении. По данным источника, сотрудники компании прикладывают массу усилий, чтобы понять, как DeepSeek удалось снизить стоимость разработки и запуска ИИ-моделей, таких как R1 и V3. 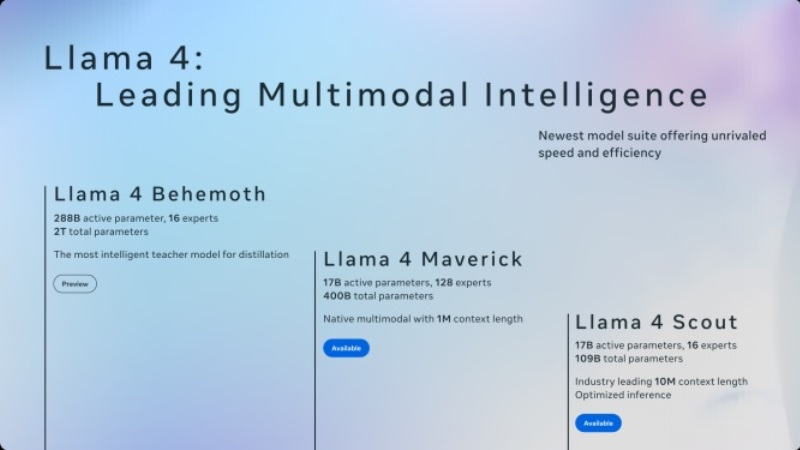
Источник изображения: Meta✴✴ Алгоритм Llama 4 Scout имеет 17 млрд активных параметров, 16 «экспертов» и 109 млрд параметров в целом. По данным Meta✴✴, ИИ-модель превосходит Gemma 3, Gemini 2.0 Flash-Lite и Mistral 3.1 в обработке разных типов задач. Одна из основных особенностей модели заключается в поддержке контекстного окна в 10 млн токенов. Llama 4 Maverick имеет 17 млрд активных параметров и 128 «экспертов» (всего 400 млрд параметров). По данным разработчиков, модель превосходит GPT-4o и Gemini 2.0 Flash при тестировании в разных бенчмарках, а также показывает сравнимые с DeepSeek V3 результаты при ведении рассуждений и в процессе написания программного кода. Scout может работать на одном графическом ускорителе Nvidia H100, тогда как для Maverick требуется система Nvidia H100 DGX или эквивалентная ей. Модель Llama 4 Behemoth имеет 288 млрд активных параметров и 16 «экспертов» (всего около 2 трлн параметров) и превосходит алгоритм GPT-4.5, Claude Sonnet 3.7 и Gemini 2.0 Pro по результатам тестирования в разных бенчмарках. Модель Llama 4 Behemoth продолжает обучаться, поэтому она ещё недоступна публично. В это же время модели Scout и Maverick доступны на сайте Llama.com и на Hugging Face. В дополнение к этому фирменный ИИ-помощник Meta✴✴ AI, доступный в приложениях компании, таких как WhatsApp, Messenger и Instagram✴✴, переведён на работу с Llama 4 в 40 странах мира. Возможность обработки мультимодальных запросов пока ограничена английским языком и доступна только в США. 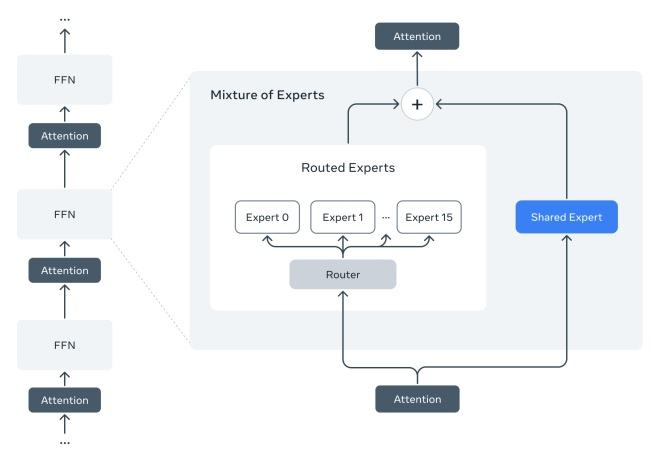
Источник изображения: Meta✴✴ «Модели Llama 4 знаменуют собой начало новой эры экосистемы Llama. Это только начало для семейства Llama 4», — говорится в сообщении в блоге Meta✴✴. Компания утверждает, что Llama 4 является первой группой ИИ-моделей, использующих архитектуру «смесь экспертов» (MoE), которая более эффективна при обучении и инференсе. Архитектура MoE позволяет алгоритму разбивать задачи на подзадачи, а затем делегировать их обработку более мелким и специализированным «экспертным» моделям. Следует отметить, что ни одна из моделей Llama 4 не является правильной «рассуждающей» моделью, как, например, GPT-o1 или GPT-o3-mini от OpenAI. Рассуждающие модели проверяют свои ответы на достоверность и, как правило, их ответы более надёжны, но для их получения требуется больше времени, чем при взаимодействии с традиционными «не рассуждающими» моделями. ИИ-модель Llama запустили на ПК из прошлого тысячелетия на базе Windows 98
01.04.2025 [19:45],
Сергей Сурабекянц
На волне ажиотажа вокруг генеративного ИИ любопытный эксперимент поставил соучредитель венчурного фонда Andreessen Horowitz Марк Андрессен (Marc Andreessen). На днях он продемонстрировал, как небольшая ИИ-модель Llama от Meta✴✴ успешно работает на 26-летнем ПК Dell со 128 Мбайт ОЗУ под управлением Windows 98. По мнению Андрессена, человечество могло бы общаться с генеративным ИИ десятилетия назад, если бы подобный ИИ был создан в то время. 
Источник изображения: pcmag.com Андрессен не раскрыл конкретную модель Llama, использованную для тестирования, что затрудняет попытки повторить его эксперимент. Стоит отметить, что модель Llama AI от Meta✴✴ потребляет меньше вычислительной мощности по сравнению с массивом гораздо более крупных моделей, но при этом обладает довольно впечатляющими возможностями. Андрессен предположил, что запуск Llama на 26-летнем ПК Dell с Windows 98 означает, что люди могли бы осуществлять «человекоподобное взаимодействие» со своими компьютерами десятилетия назад, по крайней мере, если бы генеративный ИИ существовал тогда: «Все эти старые ПК могли бы быть буквально умными всё это время. Мы могли бы общаться с нашими компьютерами уже 30 лет». Он полагает, что такое взаимодействие могло бы осуществиться значительно раньше, если бы ключевые игроки воспользовались возможностью во время предыдущего бума искусственного интеллекта в 1980-х годах: «Многие умные люди в 80-х годах думали, что все это произойдёт тогда». 
Источник изображения: Andreessen Horowitz Утверждения Андрессена подтверждаются более ранним экспериментом Exo Labs, в результате которого исследователям удалось запустить модифицированную версию Llama 2 на ПК с Windows 98 на базе Pentium II. Достичь этого было непросто. Потребовались совместимые периферийные устройства PS/2, приемлемый способ передачи требуемых файлов на устаревшее устройство, а также компиляция современного кода для устаревшего устройства и адаптация самой модели. ИИ-модели Llama скачали более миллиарда раз, похвастался Марк Цукерберг
18.03.2025 [18:40],
Павел Котов
Количество загрузок открытых моделей искусственного интеллекта Llama достигло 1 млрд, сообщил глава компании Meta✴✴ Марк Цукерберг (Mark Zuckerberg). По состоянию на начало декабря 2024 года этот показатель составлял 650 млн, что соответствует росту более чем на 50 % за квартал. 
Источник изображения: Stefan Cosma / unsplash.com Модели семейства Llama лежат в основе ИИ-помощника Meta✴✴ AI, который присутствует на различных платформах компании, в том числе в Facebook✴✴, Instagram✴✴ и WhatsApp — Meta✴✴ стремится выстроить обширную систему продуктов в области ИИ. Компания бесплатно по собственной лицензии предоставляет как сами модели, так и инструменты для их тонкой настройки и кастомизации. Эти модели имеют некоторые ограничения для использования в коммерческих целях, но активно применяются в различных продуктах — например, оператором связи AT&T и потоковой службой Spotify. Впрочем, не обходится и без сложностей: сейчас Meta✴✴ пытается отбиться от судебного иска, в рамках которого её обвиняют в обучении ИИ на защищённых авторским правом материалах; в ЕС компанию заставили отложить, а то и вовсе отменить выпуск некоторых моделей из-за сомнений в отношении конфиденциальности данных. Кроме того, модели DeepSeek оказались по ряду критериев лучше, чем Llama. Meta✴✴ пытается воспользоваться опытом DeepSeek по снижению расходов на обучение ИИ. В этом году американская компания намеревается потратить на ИИ не меньше $65 млрд, а в ближайшие месяцы она хочет выпустить несколько моделей Llama, включая рассуждающие. Meta✴✴ также, вероятно, ведёт разработку ИИ-агентов — систем, способных самостоятельно выполнять сложные последовательности действий. Некоторые из продуктов она может представить на LlamaCon — первой проводимой Meta✴✴ конференции разработчиков генеративного ИИ; она намечена на 29 апреля. Следующие ИИ-модели Llama от Meta✴ получат улучшенные голосовые функции
07.03.2025 [19:00],
Сергей Сурабекянц
По информации Financial Times, Meta✴✴ планирует представить улучшенные голосовые функции в своей следующей флагманской большой языковой модели Llama 4, запуск которой ожидается через несколько недель. Разработчики уделили особое внимание возможности прерывать и перебивать модель в процессе диалога, аналогично голосовому режиму OpenAI для ChatGPT и опыту Gemini Live от Google. 
Источник изображения: Pixabay На этой неделе главный директор по продуктам Meta✴✴ Крис Кокс (Chris Cox) сообщил, что Llama 4 будет «всеобъемлющей» моделью, способной нативно интерпретировать и выводить речь, а также текст и другие типы данных. 
Источник изображения: Meta✴✴ Успех открытых моделей китайской ИИ-лаборатории DeepSeek, которые продемонстрировали впечатляющие результаты, заставил разработчиков Llama существенно ускориться. По слухам, Meta✴✴ даже организовала оперативные центры, чтобы попытаться выяснить, как DeepSeek удалось радикально снизить стоимость обучения, запуска и развёртывания моделей ИИ. Meta✴ проведёт LlamaCon — первую конференцию для разработчиков, посвящённую генеративному ИИ
19.02.2025 [06:32],
Анжелла Марина
Meta✴✴ объявила о проведении первой своей конференции для разработчиков, посвящённой генеративному искусственному интеллекту (ИИ). Мероприятие, получившее название LlamaCon в честь семейства моделей генеративного ИИ Llama от Meta✴✴, запланировано на 29 апреля. Как сообщает TechCrunch, компания планирует представить свои последние достижения в разработке ИИ-моделей с открытым исходным кодом для того, чтобы помочь разработчикам создавать «наилучшие приложения и программные продукты». 
Источник изображения: Meta✴✴ Meta✴✴ уже несколько лет придерживается открытого подхода к разработке технологий ИИ, стремясь создать экосистему приложений и платформ. Хотя точное количество созданных на базе Llama приложений или сервисов не раскрывается, ранее компания сообщала, что такие организации, как Goldman Sachs, Nomura Holdings, AT&T, DoorDash и Accenture, используют модель Llama. Как утверждает сама компания, её модель была загружена сотни миллионов раз, и не менее 25 партнёров, включая Nvidia, Databricks, Groq, Dell и Snowflake, предоставляют хостинг для Llama. Некоторые из них разработали дополнительные инструменты, позволяющие, например, ИИ-моделям ссылаться на проприетарные данные или работать с меньшей задержкой. Несмотря на очевидный успех, Meta✴✴ оказалась не готова к взрывному успеху китайской компании DeepSeek, которая выпустила ИИ-модель (также с открытым исходным кодом), способную конкурировать с разработками Meta✴✴. По слухам, Meta✴✴ считает, что одна из последних версий моделей DeepSeek может даже превзойти следующую версию Llama, релиз которой ожидается в ближайшие недели. Поэтому в компании даже якобы срочно стали заниматься анализом методов DeepSeek по снижению стоимости эксплуатации и развёртывания моделей, чтобы применить эти знания в своих разработках Llama. Ранее генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) анонсировал запуск нескольких моделей Llama в ближайшие месяцы, включая модели с функциями рассуждения, аналогичные o3-mini от OpenAI, а также модели с врождённной мультимодальностью. Он также коснулся темы ИИ-агентов (как у OpenAI), которые должны появиться в будущем и автономно выполнять определённые действия. «Я думаю, что этот год вполне может стать годом, когда Llama и открытые модели станут самыми продвинутыми и широко используемыми моделями ИИ, — заявил Цукерберг. — Мы хотим добиться того, чтобы Llama в этом году стала лидером». Тем временем Meta✴✴ сталкивается с юридическими и регуляторными вызовами. Компания вовлечена в судебный процесс, обвиняющий её в использовании защищённых авторским правом материалов книг для обучения ИИ-моделей без разрешения. Кроме того, несколько стран ЕС из-за опасений по поводу конфиденциальности данных вынудили Meta✴✴ отложить или полностью отменить планы по запуску моделей в регионе, что в целом создаёт дополнительные препятствия для амбиций компании в области разработки Llama. Дополнительные детали о конференции LlamaCon, которая станет первым событием компании, полностью сосредоточенном на генеративном ИИ, будут объявлены в ближайшее время, уточнили в Meta✴✴. При этом ежегодная конференция для разработчиков Meta✴✴ Connect, как и обычно, состоится в сентябре. Энтузиаст запустил современную ИИ-модель на консоли Xbox 360 20-летней давности
12.01.2025 [12:00],
Владимир Фетисов
Пользователь соцсети X Андрей Дэвид (Andrei David) сумел установить и запустить на консоли Xbox 360 модель искусственного интеллекта на базе движка Llama2.c, который написан на языке программирования C бывшим сотрудником OpenAI и Tesla Андреем Карпатым (Andrej Karpathy). Сделать это энтузиаста побудила работа специалистов из EXO Lab, которые в конце прошлого года запустили большую языковую модель (LLM) Llama на 26-летнем компьютере с Windows 98. 
Источник изображения: Shutterstock Хотя энтузиаст использовал ИИ-модель на том же движке, что и EXO Lab, ему пришлось оптимизировать программный код для процессора консоли на архитектуре PowerPC и функций управления памятью. Основное отличие в том, что в PowerPC система с прямым порядком байтов в первую очередь сохраняет наиболее важные значения, тогда как используемый в ПК процессор Intel Pentium II в первую очередь сохраняет наименьшие значения. Для обеспечения правильной работы ИИ-модели Дэвиду пришлось добавить систему обмена байтами и обеспечить, чтобы все создаваемые и сохраняемые данные должным образом выравнивались по 128 байтам в памяти, чего требует подсистема памяти Xbox 360. В итоге энтузиаст запустил ИИ-модель на Xbox 360 с процессором Xenon на архитектуре PowerPC с 3 ядрами и рабочей частотой до 3,2 ГГц, а также 512 Мбайт оперативной памяти. Запуск большой языковой модели на основе Llama 2 на устройстве, которому уже несколько десятилетий, является существенным достижением. Однако один из пользователей платформы X заметил, что 512 Мбайт оперативной памяти в Xbox 360 должно хватить для запуска алгоритмов SmolLm от Hugging Face или 4-битной модели 0,5B Qwen2.5. «Вызов принят», — написал Дэвид в ответ на это. Это означает, что в будущем он попытается запустить на Xbox 360 другие ИИ-модели. Марк Цукерберг лично разрешил обучать ИИ-модели Llama на пиратских материалах
10.01.2025 [14:25],
Павел Котов
Гендиректор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) лично разрешил подразделению Meta✴✴, ответственному за разработку моделей искусственного интеллекта Llama, использовать для их обучения массив данных, содержащий полученные незаконным путём книги и статьи. Об этом стало известно из документов, опубликованных в рамках судебного процесса писателя Ричарда Кадри (Richard Kadrey) против Meta✴✴. 
Источник изображения: Tingey Injury / unsplash.com Данный процесс — лишь одно из ряда дел, в рамках которых разрабатывающие системы ИИ технологические гиганты обвиняются в обучении моделей на защищённых авторским правом материалах без разрешения авторов. Ответчики традиционно уверяют, что их действия отвечают норме о добросовестном использовании контента — эта доктрина позволяет пренебрегать авторским правом для создания новых произведений и продуктов, если они в значительной мере отличаются от оригинала. Многие правообладатели с такой позицией не согласны. В новой порции рассекреченных документов (PDF) приводятся показания представителей Meta✴✴: выяснилось, что Марк Цукерберг лично одобрил использование компанией массива LibGen для обучения Llama. Проект LibGen, позиционирующий себя как агрегатор ссылок, в действительности предоставляет доступ к защищённым авторским правом работам, которыми управляют крупные издатели. В его отношении неоднократно подавались судебные иски, с него взыскивались десятки миллионов долларов за нарушения авторских прав, и в итоге проект был вынужден закрыться. Цукерберг, говорится в документах, одобрил использование LibGen для обучения как минимум одной модели Llama вопреки опасениям, которые выражали рядовые сотрудники и члены руководства Meta✴✴. Приводится внутренняя служебная записка, в которой отмечается, что работа с LibGen получила одобрение после «эскалации до MZ» — под этой аббревиатурой, очевидно, подразумевался глава компании. 
Источник изображения: Igor Omilaev / unsplash.com Сторона истца 8 января подала в суд заявление, в котором содержатся новые обвинения. В частности, утверждается, что Meta✴✴ могла попытаться скрыть это деяние и удалить сведения об использовании материалов LibGen — это предположительно сделал инженер Meta✴✴ Николай Башлыков (Nikolay Bashlykov), который написал скрипт, удаливший из книг в обучающем массиве информацию об авторских правах. Meta✴✴ также якобы удалила сведения об авторских правах и соответствующие метаданные из статей научных журналов в данном массиве. Более того, Meta✴✴ нарушила авторские права, скачав массив LibGen через протокол BitTorrent — в этот момент компания не только скачивала, но и одновременно «раздавала» эти данные, фактически распространяя пиратские материалы, утверждает сторона истца. Глава отдела генеративного ИИ в Meta✴✴ Ахмад Аль-Дахле (Ahmad Al-Dahle) дал разрешение скачивать данные LibGen через BitTorrent, хотя инженер Башлыков указывал, что это «может быть юридически недопустимо». Дело ещё далеко до завершения. Пока оно касается только ранних моделей Llama, а не последних выпусков. И если Meta✴✴ убедит суд в добросовестном использовании материалов, он может встать на сторону компании — в 2023 году несколько истцов так и не смогли доказать факта нарушения авторских прав, и их иски к Meta✴✴ были отклонены. Энтузиасты запустили современную ИИ-модель Llama на древнем ПК с Pentium II и Windows 98
30.12.2024 [17:19],
Владимир Фетисов
Специалисты из EXO Labs сумели запустить довольно мощную большую языковую модель (LLM) Llama на 26-летнем компьютере, работающем под управлением операционной системы Windows 98. Исследователи наглядно показали, как загружается старый ПК, оснащённый процессором Intel Pentium II с рабочей частотой 350 МГц и 128 Мбайт оперативной памяти, после чего осуществляется запуск нейросети и дальнейшее взаимодействие с ней. 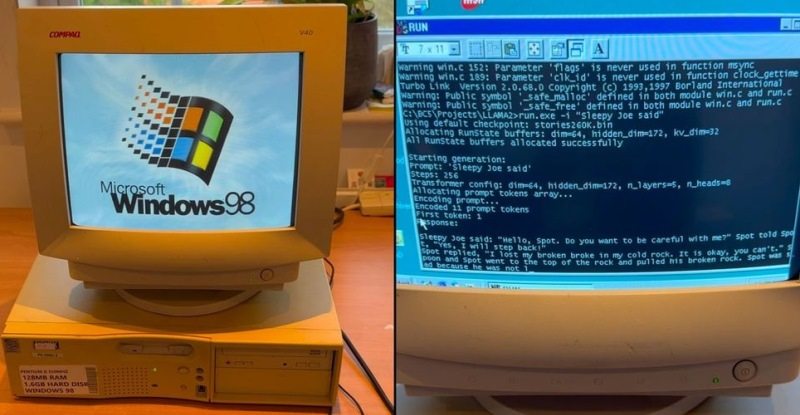
Источник изображения: GitHub Для запуска LLM специалисты EXO Labs задействовали собственный интерфейс вывода для алгоритма Llama98.c, который создан на базе движка Llama2.c, написанного на языке программирования C бывшим сотрудником OpenAI и Tesla Андреем Карпатым (Andrej Karpathy). После загрузки алгоритма его попросили создать историю о Сонном Джо. Удивительно, но ИИ-модель действительно работает даже на таком древнем ПК, причём история пишется с хорошей скоростью. Загадочная организация EXO Labs, сформированная исследователями и инженерами из Оксфордского университета, вышла из тени в сентябре этого года. Согласно имеющимся данным, она выступает за открытость и доступность технологий на базе искусственного интеллекта. Представители организации считают, что передовые ИИ-технологии не должны находиться в руках горстки корпораций, как это происходят сейчас. В дальнейшем они рассчитывают «построить открытую инфраструктуру для обучения передовых ИИ-моделей, что позволит любому человеку запускать их где угодно». Демонстрация возможности запуска LLM на древнем ПК, по их мнению, доказывает то, что ИИ-алгоритмы могут работать практически на любых устройствах. В своём блоге энтузиасты рассказали, что для реализации поставленной задачи на eBay был приобретён старый ПК с Windows 98. Затем, подключив устройство в сеть с помощью разъёма Ethernet, они через FTP сумели передать в память устройства нужные данные. Вероятно, компиляция современного кода для Windows 98 оказалась более сложной задачей, решить которую помогла опубликованная на GitHub работа Андрея Карпатого. В конечном счёте удалось добиться скорости генерации текста в 35,9 токенов в секунду при использовании LLM размером 260K с архитектурой Llama, что весьма неплохо, учитывая скромные вычислительные возможности устройства. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



