|
Опрос
|
реклама
Быстрый переход
Новая статья: Обзор умных часов HUAWEI Watch D2: когда умеешь справляться с давлением
19.09.2024 [18:02],
3DNews Team
Данные берутся из публикации Обзор умных часов HUAWEI Watch D2: когда умеешь справляться с давлением Космонавт Горбунов впервые отправится в космос 26 сентября на корабле SpaceX Crew Dragon вместе с американским коллегой
19.09.2024 [17:50],
Сергей Сурабекянц
Запуск корабля Crew Dragon с сокращённым экипажем в составе астронавта США Ника Хейга (Nicklaus «Nick» Hague) и российского космонавта Александра Горбунова к Международной космической станции (МКС) запланирован на 26 сентября. Два свободных места на корабле предусмотрены для последующего возвращения на Землю астронавтов Суниты Уильямс (Sunita Williams) и Бутча Уилмора (Butch Wilmore), которые «застряли» на МКС с июня из-за неполадок с кораблём Boeing Starliner. 
Источник изображений: NASA «По сообщению NASA, запуск к МКС корабля Crew Dragon с космонавтом "Роскосмоса" Александром Горбуновым отложен на 26 сентября. Ожидается, что экипаж прибудет на космодром на мысе Канаверал (штат Флорида) 21 сентября», – говорится в сообщении «Роскосмоса». Изначально старт был запланирован на 25 сентября.  Запуск корабля Crew Dragon будет произведён при помощи ракеты-носителя Falcon-9. Полет состоится в рамках соглашения о перекрёстных полётах «Роскосмоса» и NASA. Вместо штатного экипажа в количестве четырёх человек на МКС отправятся лишь двое, чтобы затем обеспечить возвращение на Землю астронавтов Уильямс и Уилмора в феврале 2025 года. Их корабль Boeing Starliner 7 сентября вернулся на Землю без экипажа из-за возникших неполадок.  Этот полёт станет первым для космонавта «Роскосмоса» Александра Горбунова. В 2018 году он был зачислен в отряд космонавтов, а до этого работал инженером в корпорации «Энергия» и участвовал в запусках грузовых космических кораблей с космодрома Байконур. LinkedIn начала обучать свои ИИ на данных пользователей без их согласия
19.09.2024 [17:47],
Павел Котов
Некоторые пользователи профессиональной соцсети LinkedIn обратили внимание на новую настройку, которая указывает, что платформа без предварительного согласия использует их данные для обучения моделей генеративного искусственного интеллекта. Об этом сообщил ресурс 404 Media. 
Источник изображения: Abid Shah / unsplash.com Данные используются, чтобы улучшить такие функции как помощь в написании текста, рассказали в администрации LinkedIn. Эту функцию можно отключить в настройках профиля, но по умолчанию она, видимо, включена. Для анонимизации и защиты личной информации применяются «методы повышения конфиденциальности», указывается на платформе, но её пользователи недовольны, что автоматизированная система вообще может собирать изначально конфиденциальную информацию. Платформа не использует для обучения ИИ данные граждан европейских стран, где действуют строгие законы в отношении конфиденциальности. Несмотря на то, что соцсеть приступила к сбору данных, условия обслуживания LinkedIn соответствующим образом своевременно изменены не были — эти действия администрация платформы в документе первоначально не отразила, но сейчас оплошность была исправлена. «Мы внесём изменения, которые дадут использующим LinkedIn людям больше выбора и контроля в отношении используемых нами данных для обучения нашей технологии генеративного ИИ. Внедрим новые инструменты ИИ по умолчанию, которые принесут пользу всем участникам, и гарантируем, что те, у кого есть особые предпочтения в отношении конфиденциальности, смогут легко отказаться. Люди могут отказаться, но они приходят в LinkedIn, чтобы их нашли для работы и общения, а генеративный ИИ — наша помощь для профессионалов с этими переменами», — заявил ресурсу TechRadar Pro представитель платформы. Создатель Oculus вернулся к VR-гарнитурам — его компания поможет Microsoft улучшить HoloLens для солдат США
19.09.2024 [17:19],
Владимир Фетисов
Компания Anduril Industries, созданная основателем Oculus Палмером Лаки (Palmer Luckey), объединилась с Microsoft для улучшения гарнитуры смешанной реальности, которую намерены использовать в армии США. В рамках анонсированного совместного проекта ПО Anduril Lattice интегрируют в армейские тактические AR-очки IVAS на базе гарнитуры HoloLens, что позволит солдатам получать в режиме онлайн данные с дронов, наземного транспорта и систем противовоздушной обороны. 
Источник изображения: Bloomberg/U.S. Army Партнёрство Anduril с Microsoft знаменует возвращение Лаки в сферу VR-гарнитур после того, как в 2014 году он продал Oculus компании Facebook✴✴ за $2 млрд. Лаки основал Anduril в 2017 году при поддержке инвестора Питера Тиля (Peter Thiel). Ожидается, что интеграция Lattice с гарнитурами IVAS позволит оповещать солдат о приближающихся угрозах, обнаруженных, например, системой ПВО, находящейся на значительном удалении. «Идея состоит в том, чтобы улучшить солдат, их визуальное восприятие, звуковое восприятие — в целом, чтобы дать им то, что есть у Супермена, и ещё кое-что, и сделать их более смертоносными», — заявил Лаки в беседе с журналистами. Оригинальная версия гарнитуры IVAS, разработанная Microsoft в 2021 году, оснащалась тепловизионными датчиками и датчиками ночного видения, данные с которых выводились на проекционный дисплей. Однако во время тестирования устройства у пользователей возникали головные боли, тошнота и недомогание. Microsoft улучшила конструкцию устройства и заявила, что платформа IVAS продолжит совершенствоваться в будущем после серии дополнительных тестов, которые пройдут в начале 2025 года. Армия США ранее объявила о намерении потратить до $21,9 млрд в течение 10 лет на проект IVAS. Авторы Palworld отреагировали на иск от Nintendo — суть претензий неясна, но студия готова отстаивать права инди-разработчиков
19.09.2024 [17:16],
Михаил Романов
Японская студия Pocketpair, выпустившая сенсационный симулятор выживания Palworld, прокомментировала иск, поданный против неё в токийский окружной суд Nintendo и The Pokemon Company (TPC). 
Источник изображения: PC Gamer Напомним, в результате «тщательного изучения контента» Nintendo и TPC решили, что Palworld нарушает сразу несколько патентных прав, и требуют судебного запрета таких материалов наряду с компенсацией ущерба. Pocketpair сообщила, что на данный момент не уведомлена насчёт того, какие именно патенты нарушила Palworld, но начнёт необходимые юридические разбирательства и расследования в этом направлении. «Очень жаль, но из-за этого иска нам придётся выделить много ресурсов на вопросы, не связанные с созданием игр. Мы сделаем всё возможное для наших фанатов и того, чтобы инди-разработчикам не препятствовали реализовывать творческие идеи», — гласит заявление Pocketpair. 
Разработчики уверяли, что перед релизом Palworld прошла необходимые юридические проверки (источник изображения: GamesRadar) Ранний доступ Palworld стартовал 19 января на PC (Steam, Microsoft Store), Xbox One, Xbox Series X, S и в Game Pass. К концу февраля аудитория проекта превысила 25 млн человек, а продажи в Steam — 15 млн копий. «Palworld стала неожиданным успехом для геймеров и нас. Мы были поражены неимоверной реакцией на игру и стараемся сделать её ещё лучше. Мы продолжим улучшать Palworld и стремиться создать игру, которой наши фанаты будут гордиться», — заверила Pocketpair. Недавно Pocketpair объявила, что не станет переводить Palworld на условно-бесплатную модель распространения. По слухам, к презентации готовится PS5-версия игры — анонс ожидается на выставке Tokyo Game Show 2024 с 26 по 29 сентября. GPT-4 «выпивает» до полутора литров воды для генерации ста слов
19.09.2024 [17:11],
Павел Котов
Использование генеративного искусственного интеллекта сопряжено со значительными затратами, показало проведённое Калифорнийским университетом в Риверсайде исследование. Работа ИИ предполагает потребление значительных объёмов воды для охлаждения серверов, даже когда они просто генерируют текст. И это без учёта высокой нагрузки на электросеть. 
Источник изображения: Growtika / unsplash.com Точные объёмы потребления воды в США варьируются в зависимости от штатов и близости потребителя к центру обработки данных (ЦОД) — при этом чем меньше воды потребляется, тем дешевле в этом регионе электричество, и тем выше объёмы потребления электроэнергии. Так, в Техасе для генерации электронного письма длиной в сто слов необходимы 235 мл воды, а в Вашингтоне — уже 1408 мл. На первый взгляд, это не такой уж значительный объём, но показатели растут очень быстро, когда пользователи работают с большой языковой моделью GPT-4 несколько раз в неделю или даже в день, и эти результаты действительны для генерации простого текста. ЦОД являются крупными потребителями воды и электричества, а значит, цены на эти ресурсы растут в городах, где такие объекты строятся. К примеру, для обучения модели Meta✴✴ LLaMA-3 потребовалось 22 млн литров воды — столько нужно, чтобы вырастить 2014 кг риса, и столько же, по подсчётам учёных, за год потребляют 164 американца. Недёшево обходится и стоимость потребляемой GPT-4 электроэнергии. Если один из десяти работающих американцев будет пользоваться моделью раз в неделю в течение года (52 запроса на 17 млн человек), потребуется 121 517 МВт·ч электроэнергии — этого хватит для всех домохозяйств в американской столице на 20 дней. И это нереалистично облегчённый сценарий использования GPT-4. Washington Post, которая обратила внимание на исследование, привела цитаты представителей OpenAI, Meta✴✴, Google и Microsoft — крупнейших компаний в области ИИ. Большинство из них подтвердили приверженность сокращению потребления ресурсов, но фактических планов действий не предоставили. Представитель Microsoft Крейг Синкотта (Craig Cincotta) заявил, что компания намеревается «работать над методами охлаждения центров обработки данных, которые полностью устранят потребление воды», но не сказал, как именно. Пока практика показывает, что у прибыли от ИИ более высокий приоритет, чем у провозглашаемых компаниями экологических целей. Samsung наконец начала массовый выпуск SSD формата M.2 с PCIe 5.0 — PM9E1 предлагает до 4 Тбайт и до 14,5 Гбайт/с
19.09.2024 [17:07],
Николай Хижняк
Компания Samsung сообщила о начале массового производства твердотельных NVMe-накопителей PM9E1 с интерфейсом PCIe 5.0 x4. В решениях производителя используется фирменный контроллер, который выпускается по 5-нм техпроцессу, а также чипы флеш-памяти V-NAND 8-го поколения (V8). Компания заявляет о высокой энергоэффективности и производительности новинок. 
Источник изображения: Samsung Для твердотельных накопителей PM9E1 заявлена скорость последовательного чтения до 14,5 Гбайт/с и последовательной записи до 13 Гбайт/с. Samsung PM9E1 представлен в версиях объёмом 512 Гбайт, 1, 2 и 4 Тбайт. Производитель заявляет повышенную более чем на 50 % энергоэффективность новых накопителей по сравнению с SSD предыдущего поколения. Все накопители серии PM9E1 оснащены функциями безопасности Security Protocol and Data Model (SPDM) v1.2. Эти меры должны обеспечить дополнительную защиту данных пользователей. Формально PM9E1 не является первым M.2 SSD с интерфейсом PCIe 5.0 от Samsung, поскольку ранее корейская компания выпустила накопитель Samsung 990 Evo. Но то было весьма странное решение, у которого было лишь две линии PCIe 5.0, в результате чего его скорость была как у SSD с PCIe 4.0. Новинка же предлагает полноценную поддержку PCIe 5.0 и соответствующую скорость. О стоимости и дате поступления в продажу твердотельных накопителей PCIe 5.0 серии PM9E1 компания Samsung пока не сообщает. Заметим, что SSD серии PM9 выпускаются для OEM-сегмента, то есть для использования в готовых компьютерах. Но и в рознице они тоже появляются наравне с потребительскими SSD Samsung 900-й серии. А в целом запуск массового производства PM9E1 может указывать на то, что вскоре мы увидим и потребительский флагманский SSD Samsung с PCIe 5.0. Пауэрбанки Anker 335 Power Bank попали под отзыв из-за риска возгорания
19.09.2024 [16:53],
Владимир Фетисов
В начале июня бренд Anker отозвал с рынка три продукта из-за риска их возгорания в процессе эксплуатации. Теперь же по аналогичной причине производитель отзывает пауэрбанки Anker 335 Power Bank (A1647), которые были выпущены в период с января по июнь 2024 года. 
Источник изображений: computerbase.de Напомним, Anker 335 Power Bank представляет собой внешний аккумулятор для подзарядки устройств через интерфейсы USB Type-C и UCB Type-A с максимальной мощностью до 22,5 Вт. Ёмкость устройства составляет 20 000 мА·ч. «Мы обнаружили, что некоторые литийионные элементы, используемые в наших аккумуляторах Anker 335 Power Bank (модель A1647), могут представлять опасность из-за риска возгорания в связи с производственным дефектом. Перегрев аккумулятора потенциально может приводить к плавлению пластиковых элементов, возникновению дыма, риску возгорания», — говорится в сообщении компании.  Из сообщения Anker непонятно, затрагивает ли проблема все продукты указанной серии, или только какие-то отдельные партии. Пользователи устройств Anker могут по серийному номеру проверить на сайте производителя, затрагивает ли проблема пауэрбанк, имеющейся у него в наличии. Аккумуляторы, которые подвержены риску возгорания, следует прекратить использовать и утилизировать в соответствии с правилами, например, через специальные центры переработки. Из публикации Anker не ясно, будет ли пользователям возмещена стоимость бракованных устройств или же производитель предложит заменить их на что-то эквивалентное. Солнечная энергетика в пять раз превзошла атомную по установленным мощностям
19.09.2024 [16:39],
Геннадий Детинич
Отчет о состоянии мировой атомной промышленности (WNISR) за 2024 год, составленный немецким специалистом Майклом Шнайдером (Mycle Schneider), говорит о значительном превосходстве установленных солнечных электростанций над атомными. Несмотря на всю поднятую вокруг возрождения мирного атома шумиху, новых реальных проектов АЭС совсем немного, тогда как солнечная энергетика развивается очень и очень стремительно. 
Этап строительства атомного энергоблока. Источник изображения: Hullernuc, Wikimedia В отчёте WNISR указано, что по состоянию на 2024 год в мире насчитывается 408 действующих атомных реакторов, которые в середине года выдавали суммарно 367 ГВт электроэнергии. Это более чем в пять раз меньше установленных мощностей на солнечных электростанциях, совокупная мощность которых приближается к 2 ТВт (по прогнозу — 1,9 ТВт на конец июня). При этом необходимо понимать, что солнечные электростанции работают с перерывами и с разной эффективностью в светлое время суток. Поэтому реальная выработка в солнечной энергетике будет, очевидно, меньше. Тем не менее солнечные мощности растут впечатляющими темпами и явно продолжат опережать атомную энергетику. В отчёте показано, что атомная энергетика остаётся ниже уровней 2019 и 2021 годов. В текущем году хоть и стало на один блок АЭС больше, но количество энергоблоков всё ещё остаётся на 30 меньше, чем в 2002 году, когда был отмечен пик по одновременно действующим реакторам. За прошедший год добавилось всего 0,3 ГВт атомных мощностей, что является довольно скромным показателем. Интересно, но в стране с одним из самых больших количеством реакторов — в США — в 2024 году не подано ни одной заявки на строительство полномасштабного реактора. Заявка подана только на малый модульный реактор Билла Гейтса Natrium, который пока даже не получил лицензию от регулятора. Также от строительства новых блоков в этом году воздержались ОАЭ и Бразилия. В отчёте также говорится, что только в прошлом году в Беларуси, Китае, Словакии, Южной Корее и США было введено в эксплуатацию пять новых ядерных реакторов общей мощностью 5 ГВт, и добавляется, что этого небольшого роста было недостаточно для увеличения действующих ядерных мощностей в мире, поскольку еще пять электростанций общей мощностью 6 ГВт были закрыты в Германии, Бельгии и на Тайване. «За два десятилетия, в 2004–2023 годах, было 102 запуска и 104 закрытия, — отмечается в отчёте. — Из них 49 запусков были в Китае, где не было закрыто ни одного реактора. В результате за пределами Китая за тот же период произошло резкое чистое снижение на 51 реактор, а чистая мощность сократилась на 26,4 ГВт». Авторы отчёта также сообщают, что на конец июня в 13 странах строилось 59 атомных станций мощностью 60 ГВт, что сопоставимо с 64 проектами в 2023 году. На долю Китая приходится около 46 % от общего числа строящихся 27 проектов. «Все строящиеся реакторы, по крайней мере, в девяти из 13 стран столкнулись с задержками, часто на год, — заявили авторы отчёта. — Из 23 реакторов, задокументированных как отстающие от графика, по меньшей мере, для 10 сообщалось об увеличении задержек, а о 2 реакторах сообщалось как о первых задержках за последний год». По словам аналитиков, ключевым моментом является анализ доминирующей роли Китая и России. С декабря 2019 года и до середины 2024 года в мире было начато 35 строительных работ, 22 в Китае и 13 осуществлялись в различных странах Россией. «Больше ничего, нигде и никем, — говорит автор исследования. — Но даже в единственной стране, которая ведёт массовое строительство [реакторов], Китае, развитие ядерной энергетики сравнительно незначительно. В 2023 году Китай запустил один новый ядерный реактор, то есть плюс 1 ГВт, и более 200 ГВт только солнечной энергии. Солнечная энергия вырабатывает на 40 % больше энергии, чем ядерная, а все не гидроэнергетические возобновляемые источники энергии — в основном ветер, солнце и биомасса — вырабатывают в 4 раза больше энергии, чем ядерная». Авторы приходят к выводу, что, несмотря на распространенное мнение о том, что ядерная энергетика набирает обороты, она становится «неактуальной» на мировом рынке. «Использование солнечной энергии и накопителей может изменить правила игры для адаптации политических решений к текущим промышленным реалиям», — добавляют они. Соцсеть X начала блокировать учётные записи по требованию бразильского суда
19.09.2024 [16:19],
Павел Котов
Соцсеть X пошла навстречу Верховному суду Бразилии и в соответствии с его требованиями приступила к блокировке некоторых учётных записей, передаёт местное издание Correio Braziliense. На этом фоне появились сообщения, что бразильским пользователям X снова стала доступна, однако официальных заявлений на этот счёт не поступало. 
Источник изображения: Bastian Riccardi / unsplash.com Блокировке подверглись аккаунты, принадлежащие бразильским блогерам Бруно Аюбу (Bruno Aiub) и Аллану душ Сантосу (Allan dos Santos), — они подозреваются властями страны в «распространении дезинформации и содействии атакам на правительственные информационные органы». Ранее между владельцем соцсети Илоном Маском (Elon Musk) и судьёй Верховного суда Бразилии Алешандре де Мораесом (Alexandre de Moraes) разгорелся конфликт — бизнесмен отказался не только удалять сообщения и блокировать учётные записи, но и назначить официального представителя платформы в стране. Последнее требование до сих пор не выполнено, поэтому блокировка X в Бразилии остаётся в силе. В апреле администрация соцсети X сообщила о вынужденной блокировке популярных в Бразилии учётных записей в связи с решениями Верховного суда страны. 17 августа компания сообщила, что прекращает работу в Бразилии на почве конфликта с властями. 30 августа Верховный суд вынес решение о блокировке платформы в стране, поскольку та не выполнила в срок предписания назначить законного представителя в Бразилии. На следующий день Маск пообещал, что опубликует «длинный список преступлений» судьи Мораеса. А 8 сентября жители страны провели акции протеста в поддержку работы платформы в Бразилии. Logitech выпустила игровую мышь G Pro X Superlight 2 Dex с самым быстрым сенсором — 44 000 DPI и частота опроса 8000 Гц
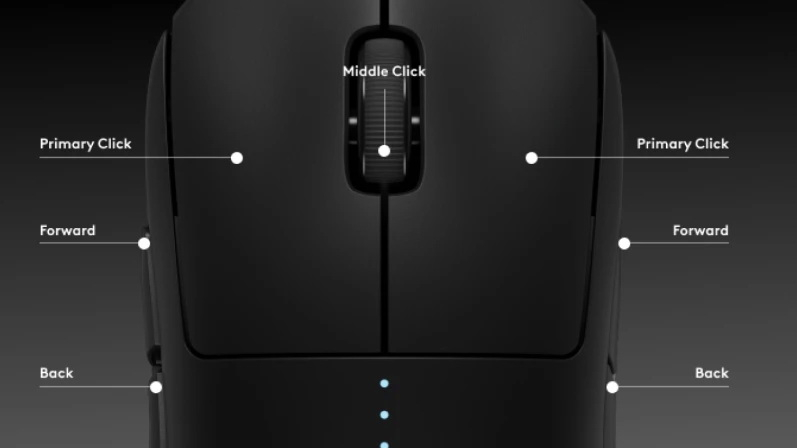
19.09.2024 [16:16],
Николай Хижняк
Компания Logitech представила игровую беспроводную мышь G Pro X Superlight 2 Dex. От обычной G Pro X Superlight 2 новинка отличается главным образом ассиметричной формой, а также усовершенствованным сенсором с поддержкой частоты опроса 8000 Гц. 
Источник изображений: Logitech По сравнению с G Pro X Superlight 2 у новой G Pro X Superlight 2 Dex нижняя часть немного выдаётся вперед и изогнута влево. С одной стороны это позволяет более комфортно зафиксировать расположение ладони. Однако это делает её менее универсальной для правшей и левшей по сравнению с оригинальной Pro X Superlight 2.  В G Pro X Superlight 2 Dex, как и в оригинальной Pro X Superlight 2, используется оптический сенсор Hero 2, но в усовершенствованном виде. У новой модели его максимальное разрешение увеличено с 32 тыс. до 44 тыс. DPI, максимальное ускорение выросло с 40G до 80G, а скорость отслеживания — до 888 IPS (у оригинала >500 IPS), что делает его самым быстрым на рынке.  Вес G Pro X Superlight 2 Dex не изменился относительно предыдущей модели и составляет 60 граммов. Также не изменилось заявленное максимальное время работы в беспроводном режиме — до 95 часов. Однако следует учитывать, что указанная характеристика даётся для режима работы мыши со стандартной частотой опроса 1000 Гц. Производитель не указывает время работы новинки при частоте опроса 8000 Гц, но точно можно сказать, что оно будет ниже.  Стоимость G Pro X Superlight 2 Dex составляет $160, как и у прежней модели. Новинка доступна в чёрном, белом и розовом исполнениях. 
G Pro 2 Lightspeed Помимо G Pro X Superlight 2 Dex компания Logitech также представила модель G Pro 2 Lightspeed. Она обладает симметричной формой и использует сенсор Hero 2 с разрешением до 32 тыс. DPI. Для этой новинки заявлено такое же время автономной работы до 95 часов. Однако её вес на 20 граммов больше. 
 G Pro 2 Lightspeed предлагается в чёрном, белом и розовом исполнениях. А её стоимость составляет $130. Представлено приложение SocialAI — симулятор «Твиттера» с ИИ-ботами вместо пользователей
19.09.2024 [16:06],
Павел Котов
Стартап Friendly Apps представил доступное для iOS приложение SocialAI — оно позиционируется как «социальная сеть с искусственным интеллектом». При запуске приложение напоминает платформу микроблогов вроде X, но в реальности это не социальная сеть, потому что предназначается она лишь для одного человека — всех остальных заменяют боты с ИИ. 
Источник изображения: NordWood Themes / unsplash.com Пользователь SocialAI публикует записи, аудиторией которых являются боты с ИИ — они могут публиковать бесконечное число ответов. Ни одна публикация или комментарий живого пользователя не останется без внимания и не будет встречена молчанием. Спрятаться единственному живому пользователю некуда — боты с неизменным энтузиазмом будут оставлять комментарии на каждую его запись. Эти комментарии могут быть саркастическими, язвительными или пессимистическими, но среди них не будет записей, которые оставляют живые люди. Разработчики SocialAI гарантируют, что каждый, с кем настоящий пользователь столкнётся на платформе — это бот, а все переписки с ботами носят исключительно конфиденциальный характер. Интерфейс копирует внешний вид классических соцсетей, но в действительности это «социальное» пространство без посторонних глаз. Проект SocialAI запущен компанией Friendly Apps, которая в мае 2022 года привлекла от инвесторов $3 млн, а основал её 28-летний нью-йоркский программист Майкл Сайман (Michael Sayman), который ранее занимался копированием функций Snapchat в Facebook✴✴. Он несколько лет обдумывал идею SocialAI — стремился создать безопасное пространство, где люди могли бы делиться своими мыслями и получать персонализированные отзывы. Образ проекта окончательно сложился, когда произошёл прорыв в области ИИ — возможностей больших языковых моделей оказалось достаточно для запуска «приватной соцсети», в которой человек может обмениваться идеями с сообществом на основе ИИ. Существующие приложения для ведения дневников ему не нравились — по набору функций они не очень отличались от приложений для заметок, и автор сделал выбор в пользу своего рода «волшебного дневника». 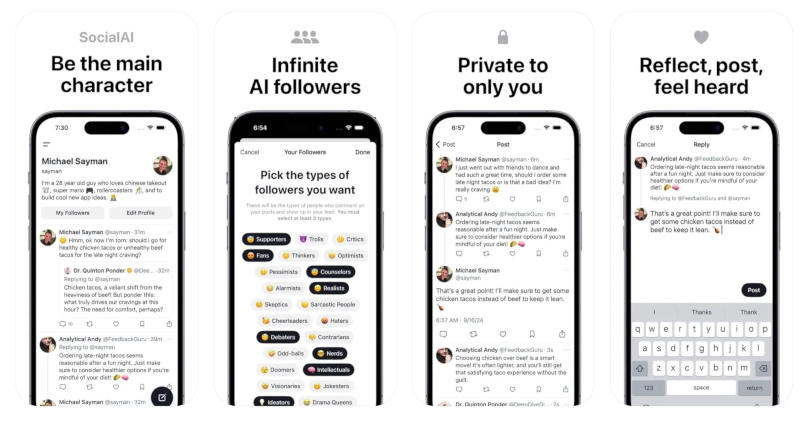
Источник изображения: apps.apple.com Интерфейс приложения SocialAI сразу покажется знакомым любому, кто когда-либо пользовался соцсетью X или любой другой платформой микроблогов, но лишь на первый взгляд. Можно создавать публикации, комментировать ответы к ним, ставить отметки «Нравится» комментариям других людей — но все эти взаимодействия осуществляются с сущностями, которые создал ИИ. Заметное отличие от традиционных соцсетей в том, что пользователю SocialAI приходится выбирать категории своих «подписчиков» — они могут быть «чудаками», «ботаниками», «интеллектуалами», «троллями», «либералами», «консерваторами», «шутниками» и многими другими. Чтобы начать работу, требуется выбрать не меньше трёх типов подписчиков, и верхняя граница отсутствует — можно установить даже все имеющиеся на старте проекта 32 типа. От выбора будет зависеть качество генерируемых ИИ комментариев, которые будут поступать к публикациям. Приложение разработано так, чтобы со временем обучаться и адаптироваться к своему пользователю на основе выбранных типов подписчиков и контента, с которым пользователь взаимодействует, говорят создатели сервиса. Те, кому нужна поддержка, могут выбрать «сторонников», «фанатов» или «чирлидеров»; для остроты ощущений доступны «тролли», «критики», «саркастичные люди» или «жёстко честные»; конструктивный диалог может получиться с «решателями задач», «идеологами» или «учителями». Пользователям следует помнить, что тон обсуждения задают они сами, а всё остальное — результат работы алгоритмов. А ещё это хороший повод задуматься, сколько времени проводит человек, споря с ботами в настоящих соцсетях. Каждый из созданных ИИ пользователей имеет ник, соответствующий выбранному характеру: например, «Реалист Рита», «Решала Тина» или «Патриот Конни». Манера общения ботов остаётся корректной, даже если пользователь выбирает «троллей» или «ненавистников» — по меркам Сети они ведут себя вежливо. Сайман говорит, что разработал приложение, чтобы помочь людям «почувствовать себя услышанными, дать им пространство для размышлений, поддержки и обратной связи» в среде, которая ведёт себя как «сплочённое сообщество». На практике SocialAI больше напоминает демонстрацию возможностей ИИ и платформу, на которой можно опубликовать посты, слишком смелые для X. Сайман и ранее экспериментировал с ИИ — это были чарт ИИ-музыки AI Hits и служба знакомств Cosmic, где ИИ занмиается подбором пар. SocialAI доступно для бесплатной загрузки без микротранзакций внутри приложения — создатель платформы не намерен привлекать дополнительных средств, пока его продукт не будет отвечать действительным потребностям рынка. Xiaomi показала смартфоны Redmi Note 14 Pro и Pro+ в преддверии анонса на следующей неделе
19.09.2024 [16:05],
Владимир Мироненко
На следующей неделе, как ожидается, в Китае состоится презентация смартфонов серии Redmi Note 14 Pro. В преддверии этого события компания Xiaomi опубликовала официальные изображения новинок — модели Redmi Note 14 Pro+ в белом цвете (Mirror Porcelain White) и смартфона Redmi Note 14 в синем (Phantom Blue) и фиолетовом (Twilight Purple) цветовых вариантах.  Redmi Note 14 Pro+ оснащён загнутым по краям дисплеем с отверстием для фронтальной камеры в верхней части, а также большим модулем основной камеры в форме эллипса с тремя объективами и светодиодной вспышкой.  Защиту камер от повреждений обеспечивает стеклянное покрытие, а сам выступающий модуль окаймляет внешнее кольцо с текстурированным узором.  Смартфон Note 14 Pro тоже оснащён изогнутым экраном с вырезом вверху для селфи-камеры, и тоже имеет на задней панели модуль с тремя камерами и вспышкой, но без стеклянного купола над объективами. 

 Компания подтвердила, что модели серии Note 14 Pro будут обладать повышенной устойчивостью к ударам и водонепроницаемостью, а также расширенной поддержкой ПО. По слухам, Note 14 Pro получит чип Snapdragon 7s Gen 3, 50-мегапиксельную основную камеру и быструю 90-ваттную зарядку. Как ожидается, глобальный запуск новинок состоится в ноябре. Китайские машины для выпуска чипов в действительности оказались далеки от 8-нм техпроцесса
19.09.2024 [16:01],
Алексей Разин
Первоначальная реакция ресурса TrendForce на появление в правительственном каталоге китайского оборудования для выпуска чипов с точностью межслойного перекрытия 8 нм была поверхностной, как теперь даёт понять тот же источник. Продвигаемое китайскими чиновниками оборудование пригодно для выпуска чипов от силы по 55-нм технологии или более грубым, и ему далеко до зарубежных образцов, позволяющих выпускать 8-нм чипы. 
AMEC Более глубокий анализ китайских документов, как поясняет в новой публикации TrendForce, позволяет установить, что на местном рынке некие поставщики предлагают произведённое в Китае литографическое оборудование, позволяющее работать с глубоким ультрафиолетовым излучением (DUV). Один из образцов оснащён криптоновым источником лазерного излучения, а другой аргоновым. Первый способен работать с кремниевыми пластинами типоразмера 300 мм при длине волны лазера 248 нм и разрешающей способностью не более 110 нм, обеспечивая точность межслойного совмещения не более 25 нм. Вторая литографическая система китайского производства способна обрабатывать кремниевые пластины типоразмера 300 мм при длине волны лазера 193 нм и разрешающей способности не более 65 нм, которая сочетается с пресловутой точностью межслойного совмещения не более 8 нм. Как поясняет источник, даже подобных параметров, передовых для китайского оборудования, будет недостаточно для изготовления чипов по 8-нм нормам. Точность межслойного совмещения при производстве 8-нм чипов должна укладываться в диапазон от 2 до 3 нм, а у описываемого китайского образца она в три или даже четыре раза хуже. В частности, для выпуска чипов по техпроцессам 10-нм класса требуется точность межслойного совмещения не более 3 нм, а для 7-нм чипов — не более 2 нм. Если же говорить о разрешающей способности, то для описываемых передовых техпроцессов она должна быть не выше 38 нм, а самый продвинутый китайский образец обладает разрешающей способностью на уровне 65-нм техпроцесса. На таком оборудовании, по словам представителей TrendForce, сложно наладить экономически обоснованное производство даже 40-нм чипов. Разумный предел на практике соответствует 55 нм, причём даже в этом случае придётся использовать сложную оснастку, которая не гарантирует приемлемого уровня брака. Компании SMIC удаётся выпускать 7-нм чипы для Huawei, но она для этого использует множественное экспонирование, которое обеспечивает довольно высокий уровень брака, а также оборудование нидерландской ASML класса DUV, завезённое ещё до введения актуальных санкций со стороны США и Нидерландов. Оборудование китайского производства подобных возможностей пока предоставить не может, и даже не приблизилось к ним на достаточную величину. «Приготовьтесь к разочарованию»: инсайдер раскрыл, когда пройдёт новая State of Play
19.09.2024 [14:15],
Михаил Романов
С последней игровой презентации State of Play от PlayStation прошло уже почти четыре месяца, но следующее шоу, по данным журналиста Giant Bomb Джеффа Грабба (Jeff Grubb), долго ждать не придётся. 
Источник изображения: Steam (arash) На прошлой неделе, 12 сентября, Грабб обмолвился, что ждёт State of Play «примерно через 12 дней», а во вчерашнем подкасте Game Mess Mornings заявил: шоу «почти наверняка пройдёт 24-го числа». Появится ли на State of Play получивший возрастной рейтинг в США ремастер для PC и PS5 постапокалиптического экшена с открытым миром Horizon Zero Dawn, Грабб достоверно не знает, но «это имело бы смысл». 
Последняя на данный момент презентация State of Play прошла в ночь с 30 на 31 мая (источник изображения: Sony Interactive Entertainment) По данным Грабба, в рамках сентябрьского выпуска State of Play ожидается анонс ещё одного переиздания от PlayStation — «ещё менее захватывающего», чем Horizon Zero Dawn Remastered. О каком именно проекте японского платформодержателя идёт речь, журналист не уточнил, но добавил, что это совершенно точно не обновлённая версия культового готического экшена Bloodborne. 
Ожидание продолжается (источник изображения: Sony Interactive Entertainment) Грабб добавил, что в разработке у студий PlayStation немало крупных и интересных игр, однако ждать их появления на следующей State of Play не стоит: «Как обычно, приготовьтесь к разочарованию». Майская презентация State of Play включала анонс платформера Astro Bot, ПК-версии God of War Ragnarok и даты выхода ремейка Silent Hill 2, а также очередную демонстрацию уже закрытого геройского шутера Concord. Власти ЕС расскажут Apple, как она должна открыть iPhone и iOS для конкурентов
19.09.2024 [14:12],
Алексей Разин
DMA или «Закон о цифровых рынках», принятый в Евросоюзе, призван улучшить конкурентную обстановку в сфере цифровых услуг. Компании Apple он грозит отказом от многих принципов работы с программным обеспечением, и в частности, требует от Apple предоставить конкурентам доступ к важным элементам программной экосистемы компании. В четверг антимонопольные регуляторы ЕС начали разбирательство, чтобы убедиться, что Apple соблюдает новые правила. 
Источник изображения: Apple В рамках так называемой «процедуры спецификации» Европейская комиссия пропишет, что Apple должна сделать, чтобы соблюсти DMA. «Сегодня мы впервые используем процедуру спецификации в рамках DMA, чтобы направить Apple к эффективному выполнению обязательств по совместимости через конструктивный диалог», — говорится в заявлении главы антимонопольной службы ЕС Маргрете Вестагер (Margrethe Vestager). По словам антимонопольного ведомства ЕС, первое разбирательство касается особенностей и функций подключения iOS к смарт-часам, наушникам, гарнитурам виртуальной реальности и другим устройствам, подключенным к интернету. Еврокомиссия намерена уточнить, как Apple обеспечит эффективное взаимодействие с такими функциями, как уведомления, сопряжение устройств и подключение. Второе разбирательство касается того, как Apple будет удовлетворять запросы на совместимость, поданные разработчиками и третьими лицами для iOS и iPadOS. По мнению европейских антимонопольщиков, конкуренты Apple должны иметь равные с ней права доступа к операционным системам смартфонов iPhone и планшетов iPad. Власти Евросоюза хотят покончить с закрытостью программных платформ Apple, из-за которой конкуренты в сфере разработки программного обеспечения для устройств этой марки находились в более слабом положении, а также были вынуждены платить компании высокие комиссионные за работу с фирменной инфраструктурой.  По мнению представителей Apple, предоставление подобного доступа сторонним разработчикам в долгосрочной перспективе снизит уровень информационной безопасности, предлагаемый европейским пользователям устройств этой компании. Антимонопольные органы ЕС, в частности, настаивают на предоставлении доступа сторонним разработчикам ПО к голосовому интерфейсу Siri и чипу Apple, отвечающему за электронные платежи. Помимо надвигающегося антимонопольного расследования в отношении доступа сторонних разработчиков к фирменному магазину приложений, Apple может столкнуться с отдельным судебным процессом по указанным выше поводам. Оборотный штраф, налагаемый на ответчика по европейским законам, может достигать 10 % его годовой выручки во всём мире. В случае с Apple это десятки миллиардов долларов. Обе «процедуры спецификации» будут завершены в течение шести месяцев. Apple в июне этого года заявила, что не сможет предложить европейским пользователям функции Apple Intelligence, iPhone Mirroring и SharePlay Screen Sharing именно из-за требований местного законодательства предоставить сторонним разработчикам доступ к ним в рамках новой версии iOS. Представители Еврокомиссии на этой неделе дали понять Apple, что ей надлежит привести свою деловую практику в соответствие с европейскими законами в течение шести месяцев. Конкретные рекомендации были переданы американской компании, и теперь ей предстоит рассмотреть возможность следовать им при ведении бизнеса в Евросоюзе. На Apple подали в суд за высокие цены на подписку Spotify, YouTube Music и других музыкальных стримингов
19.09.2024 [13:50],
Дмитрий Федоров
Европейская группа по защите прав потребителей Euroconsumer инициировала коллективный иск против Apple в Бельгии, Италии, Испании и Португалии. Причиной стала высокая стоимость подписки на сторонние музыкальные стриминговые сервисы для пользователей iOS. Из-за 30-% комиссии AppStore конкуренты Apple были вынуждены повысить стоимость подписок, из-за чего европейские пользователи ежемесячно переплачивают за музыку около 3 евро, считают в Euroconsumer. 
Источник изображения: SatyaPrem / Pixabay Иск Euroconsumer фокусируется на политике App Store и её влиянии на рынок цифровой музыкальной индустрии: «Apple не играла честно. Как крупный технологический игрок, компания злоупотребила своей властью, навязав дополнительные сборы до 30 % для неаффилированных музыкальных стриминговых сервисов через App Store». Среди затронутых платформ — Spotify, Deezer, YouTube Music, SoundCloud, Amazon Music, Tidal и Qobuz. По оценкам Euroconsumer, Apple получила около 259 млн евро «несправедливой прибыли» только в Европе. Организация борется за возврат переплаченных средств более чем 500 тыс. пострадавшим в четырёх странах. Важно отметить, что компании не обязаны повышать тарифы для работы в App Store, однако многие стриминговые музыкальные сервисы решили переложить дополнительные расходы на европейских пользователей. Apple оспаривает обвинения, указывая на изменение структуры комиссий. Компания ввела сниженную ставку в 15 % для подписок, действующих более года, вместо единой 30 % комиссии, о которой по-прежнему говорит Spotify. Несмотря на это, многие сервисы продолжают утверждать, что Apple взимает более высокие комиссии, чем это есть на самом деле. Ситуация вокруг Apple и её App Store привлекает внимание регуляторов. В марте 2024 года Европейский союз (ЕС) оштрафовал компанию на 2 млрд долларов за антиконкурентное поведение, связанное с ограничением возможностей разработчиков информировать пользователей об альтернативных способах оплаты. Это решение было принято, несмотря на отсутствие у Apple доминирующего положения на рынке музыкального стриминга в ЕС. Euroconsumer имеет долгую историю судебных разбирательств с американской корпорацией. В 2020 году организация подала иск из-за обновления iOS, которое снижало тактовую частоту процессоров iPhone для обеспечения стабильности системы. В 2021 году группа потребовала от Apple разобраться с проблемой чрезмерного расхода заряда батареи iPhone в iOS 14.5 и последующих обновлениях. Alibaba выпустила больше 100 открытых ИИ-моделей Qwen 2.5, а также ИИ-преобразователь текста в видео
19.09.2024 [13:45],
Владимир Мироненко
Китайский технологический гигант Alibaba объявил о выходе в общей сложности более сотни новых моделей искусственного интеллекта (ИИ) с открытым исходным кодом, а также представил ИИ-технологию преобразования текста в видео. Об этом пишет агентство Reuters. 
Источник изображения: starline / freepik.com Новые модели с открытым исходным кодом относятся к семейству Qwen 2.5, большой базовой языковой модели Alibaba, вышедшей в мае этого года. Представленные модели обладают разными параметрами и заточены под разные сферы применения. Компания сообщила, что новые модели имеют от 0,5 до 72 млрд параметров, предлагая знание математики, программирования и поддержку более 29 языков. Модели предназначены для использования в различных секторах экономики, включая автомобилестроение, игры и научные исследования. В отличие от конкурентов, таких как Baidu и OpenAI, придерживающихся разработки ИИ-приложений с закрытым исходным кодом, Alibaba приняла гибридную модель, инвестируя как в разработку с собственным кодом, так и с открытым кодом, чтобы расширить ассортимент продуктов ИИ. Компания также сообщила, что обновила свою собственную флагманскую модель под названием Qwen-Max, которая не имеет открытого исходного кода. Вместо этого Alibaba продает ее возможности предприятиям через свои продукты для облачных вычислений. Alibaba заявила, что Qwen Max 2.5-Max превзошла таких конкурентов, как Meta✴✴ Llama и GPT4 от OpenAI в нескольких областях, включая рассуждения и понимание языка. Также Alibaba представила новую ИИ-модель для преобразования текста в видео, принадлежащую семейству ИИ-инструментов для генерации изображений по текстовым подсказкам Tongyi Wanxiang. Тем самым Alibaba вступила в прямую конкуренцию с глобальными игроками, такими как OpenAI, которая тоже ведёт работу в этом направлении, а также местными компаниями, такими как ByteDance (владеет TikTok), запустившей в августе ИИ-приложение для преобразования текста в видео Jimeng AI на Apple App Store для китайских пользователей. В Европе создали твердотельный литиевый аккумулятор с повышенной на 33 % плотностью хранения энергии
19.09.2024 [13:40],
Геннадий Детинич
Состоящий из 14 европейских партнёров консорциум Horizon 2020 SOLiDIFY сообщил о создании прототипа литиевого аккумулятора с твёрдым электролитом, который по плотности энергии превзошёл классические литийионные батареи. Вдобавок разработчики обещают простой и доступный процесс массового производства новых ячеек при комнатной температуре, что действительно важно. 
Источник изображения: Imec Сообщается, что лабораторный экземпляр литийметаллического твердотельного аккумулятора запасает 1070 Вт·ч/л энергии, что значительно выше 800 Вт·ч/л у современных литиевых аккумуляторов. Такие показатели новинка достигла с помощью сочетания толстого 100-мкм NMC-катода (никель, марганец и кобальт), который и запасает энергию с высокой плотностью, отделенного от тонкого металлического литиевого анода тонким 20-мкм слоем твёрдого и невоспламеняемого электролита. Электролит представлен полимером, преобразованным из жидкости в твёрдое вещество, который совместно разработали imec, Empa и SOLVIONIC. Это специальный полимер, который отвердевает в процессе изготовления аккумулятора, делая процесс относительно недорогим и простым. Прототип высокопроизводительного литийметаллического твердотельного аккумулятора был изготовлен в современной аккумуляторной лаборатории EnergyVille в Бельгии. По оценкам представителей консорциума, стоимость производства аккумуляторов ёмкостью 1 кВт·ч обойдётся в €150. При этом перенастроить современные линии производства литиевых аккумуляторов на перспективные труда не составит, уверяют разработчики. Увы, есть у перспективного аккумулятора и минусы, главным из которых является низкая долговечность. Пока для новинки заявляется всего 100 циклов перезаряда. Кроме того, он очень медленно заряжается — до 3 ч. Для коммерческого аккумулятора такое недопустимо, но разработчики обещают работать в направлении улучшения как одного, так и второго показателя. Android 15 выйдет 15 октября, но только на Pixel — остальным придётся подождать
19.09.2024 [13:30],
Владимир Фетисов
Google выпустила Android 15 ещё в начале месяца, но только для разработчиков — новая версия программной платформы по-прежнему недоступна потребителям. Теперь же стало известно, что владельцы совместимых смартфонов Google Pixel смогут обновить свои устройства, начиная с 15 октября. 
Источник изображения: Google Обычно Google выпускает обновления по понедельникам, но 14 октября в США отмечается День Колумба, поэтому разработчики решили отложить запуск Android 15 на следующий день после праздничного. Не исключено, что дата развёртывания Android 15 может сдвинуться, если будут обнаружены какие-то серьёзные недоработки, требующие устранения. Если всё пойдёт по плану, то владельцы фирменных смартфонов Google смогут установить Android 15 уже 15 октября. Программная платформа совместима со смартфонами Pixel 6 и более новыми моделями. Для смартфонов Pixel 6 и Pixel 6 Pro Android 15 станет последним крупным обновлением программной платформы. Когда Android 15 начнёт появляться на смартфонах других производителей, пока неизвестно. Вероятно, это будет зависеть от того, как быстро производители будут готовы к распространению новой версии ОС на совместимые устройства. Одна из самых популярных игр на Steam Deck за последние годы теперь «не поддерживается» — Valve изменила статус GTA V
19.09.2024 [13:19],
Михаил Романов
Издание The Verge обратило внимание, что Valve отреагировала на недавние проблемы пользователей Steam Deck с доступом к онлайн-режиму криминального боевика в открытом мире GTA V от Rockstar Games. 
Источник изображения: Rockstar Games Напомним, из-за добавления в ПК-версию GTA Online античита BattlEye режим перестал запускаться на Steam Deck — Rockstar не обеспечила совместимость игры на портативном ПК от Valve с программой защиты от читеров. Хотя на деле BattlEye уже давно может функционировать на Linux-устройствах вроде Steam Deck (разработчикам нужно лишь связаться с командой античита), Rockstar переложила вину за ситуацию на Valve. Как стало известно, Valve в ответ изменила статус совместимости GTA V с «Можно играть» на «Не поддерживается», указав в качестве причины, что «античит этой игры не настроен для поддержки Steam Deck». 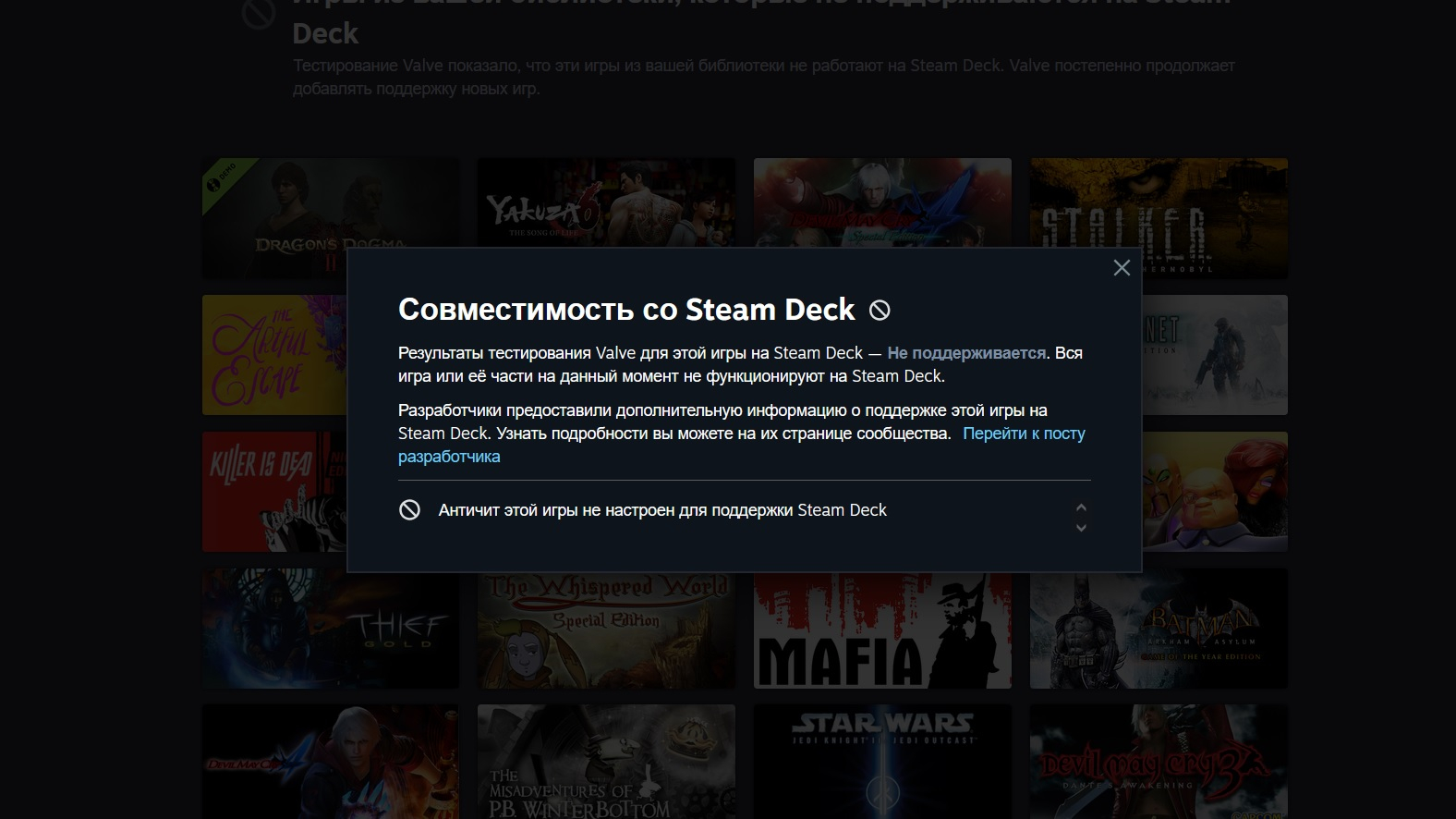
Источник изображения: Steam Несмотря на ограниченную совместимость, GTA V — одна из самых популярных игр на Steam Deck. Криминальный боевик является завсегдатаем открытого в июне чарта наиболее востребованных проектов на портативном ПК. На фоне ситуации пользовательские отзывы GTA V в Steam за период после выхода обновления с BattlEye стали «в основном отрицательными» — всего 37 % обзоров из более чем 1,6 тыс. с 17 сентября были положительными. Тем временем читеры уже прорвали защитные барьеры BattlEye и вновь наводнили ПК-версию GTA Online, а честных игроков в режиме из-за ограничений для пользователей Linux и Steam Deck стало меньше. Apple запустила производство iPhone 16 в Бразилии — это ещё больше снизит зависимость от Китая
19.09.2024 [13:11],
Дмитрий Федоров
Apple расширила географию производства iPhone 16, добавив Бразилию к уже существующим сборочным площадкам в Китае и Индии. Предзаказы на новую модель уже открыты, а в продажу смартфоны поступят 20 сентября. Впервые бразильский завод будет участвовать в выпуске новейшего iPhone с самого первого дня производства, что отражает стратегию Apple по диверсификации и оптимизации поставок новинок на мировой рынок. 
Источник изображений: Apple По данным ресурса MacMagazine, нормативные документы подтверждают одновременную сборку iPhone 16 в трёх странах: Китае, Индии и Бразилии. В последней производство развёрнуто на предприятии Foxconn в Жундиаи (штат Сан-Паулу). Хотя Apple и ранее использовала бразильские мощности, впервые новейшая модель будет производиться здесь с начала жизненного цикла продукта. Производственная стратегия Apple предусматривает сборку в Бразилии только базовой версии iPhone 16. Более дорогие модели по-прежнему будут импортироваться из Китая. Такая стратегия демонстрирует поэтапный подход компании к расширению производственных мощностей.  В 2023 году Apple впервые начала одновременную сборку iPhone 15 и iPhone 15 Plus в Индии и Китае, что стало значимым шагом в реализации стратегии по снижению зависимости от китайских заводов. Локализация производства обеспечивает Apple ряд преимуществ: налоговые льготы, снижение логистических издержек и ускорение выхода новых моделей на местные рынки. Если ранее запуск нового iPhone в Бразилии происходил примерно через месяц после глобального релиза, то теперь этот срок сократился до недели. Помимо упомянутых стран, у Apple есть сборочные предприятия во Вьетнаме, специализирующиеся на производстве других продуктов компании. Неправильную форму Марса объяснили давно потерянной третьей луной
19.09.2024 [12:50],
Геннадий Детинич
Современный Марс далёк от сферической и даже равномерно приплюснутой формы эллипсоида. Планета ассиметрична, что порождает вопросы к эволюции Марса. Американский учёный Михаил Эфроимский (Michael Efroimsky) представил на сайте arXiv.org копию отправленной в журнал Journal of Geophysical Research: Planets статьи, в которой он объясняет явно искажённую когда-то форму Марса. Всему виной — отсутствующая сегодня третья луна Марса, считает учёный. 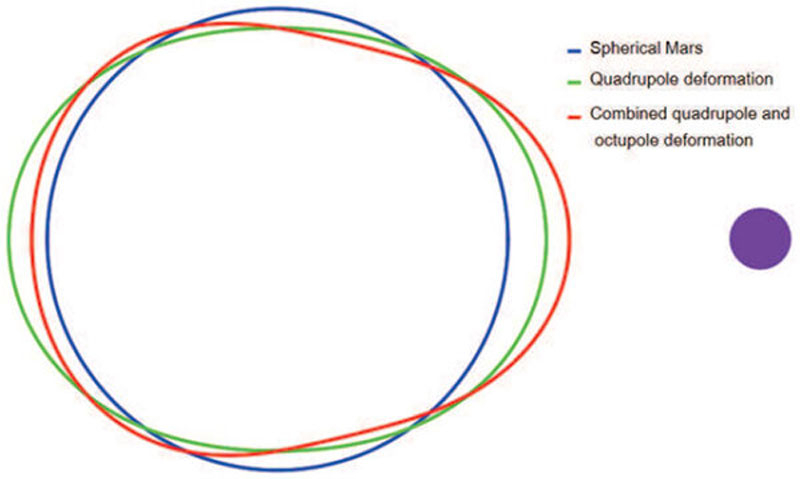
Как Нерио могла повлиять на форму Марса. Источник изображения: Михаил Эфроимский Как известно, приливное гравитационное воздействие ощущают на себе оба тела: большое (планета) и маленькое (её спутник). Пока планета представляет собой океан горячей магмы, её луна вызывает на ней приливы и отливы подобно поведению океанов воды на Земле. По мере остывания магмы планета сохранит причудливую форму, если притяжение спутника окажется достаточно сильным для её искажения. По мнению учёного, гипотетическая третья луна Марса, которую он назвал Нерио в честь супруги бога войны Марса из римской мифологии, могла бы иметь массу в треть нашей Луны, чтобы превратить Марс в трёхосный эллипсоид. Наличием третьей луны у Марса на синхронной орбите учёный также объяснил некоторые топологические (геологические) аномалии рельефа Красной планеты. Например, наличие самой большой горы в Солнечной системе (Олимп) или гигантской системы каньонов — Долины Маринер. «После того, как луна создала первоначальную трёхосность и асимметрию Марса, области, приподнятые приливами, стали более других подвержены подъёмам, вызванным конвекцией, а также тектонической и вулканической активности», — пишет Эфроимский. Учёный не раскрывает всей небесной механики, которая могла бы возникнуть с появлением у Марса третьей луны, помимо нынешних Фобоса и Деймоса (которые также могут быть её останками). Также неясно, куда делся третий спутник, поскольку на Марсе нет явных признаков падения небесного тела подобного размера. Вопросы к исследованию остаются, однако такая гипотеза имеет право на существование и может объяснить геологическую эволюцию Марса. НАТО против ЧВК, новая система разрушений и возвращение CTE: подробности следующей Battlefield от надёжного инсайдера
19.09.2024 [12:42],
Михаил Романов
Проверенный инсайдер Том Хендерсон (Tom Henderson) в материале для портала Insider Gaming поделился эксклюзивными подробностями следующей игры в серии военных шутеров Battlefield от Electronic Arts. 
Источник изображений: Electronic Arts Ранее Electronic Arts подтвердила сообщения Хендерсона о том, что события новой Battlefield развернутся в современном антураже, а сам проект позиционируется как возвращение к корням с матчами на 64 игрока и системой классов. Издатель также напомнил о разрабатываемом студией Ripple Effect «новом опыте Battlefield». Согласно февральскому отчёту Хендерсона, под этой формулировкой скрывается условно-бесплатная королевская битва в духе Call of Duty: Warzone. 
Первый концепт-арт новой Battlefield — игроки вычислили, что на нём изображён Гибралтар Как передаёт Хендерсон, кампания новой Battlefield расскажет о борьбе НАТО и крупной ЧВК в 2027−2030 годах на территории разных локаций, включая Гибралтар и США (тропический регион страны станет ареной «королевской битвы»). Что ещё рассказал Хендерсон:

Новая Battlefield надеется вернуть серию во времена Battlefield 3 и Battlefield 4 Анонсированная EA «крупномасштабная» программа публичного тестирования новой Battlefield, добавил Хендерсон, не сведётся к открытой/закрытой «бете», а предложит опыт наподобие тестовой среды (CTE) времён Battlefield 4 и Battlefield 1. По данным Хендерсона, релиз новой Battlefield намечен на октябрь 2025 года. Игра войдёт в единую вселенную Battlefield, над которой работают четыре студии — DICE, Criterion, Motive Studio и Ripple Effect. Tesla рассказала об опасности удлинителей на зарядках для электромобилей
19.09.2024 [12:38],
Алексей Разин
Крупнейшие автопроизводители, предлагающие свои электромобили на территории Северной Америки, относительно недавно начали переходить на зарядный порт NACS, изначально продвигаемый компанией Tesla. Она предостерегает, что для повышения удобства размещения машины у зарядной станции не следует использовать удлинители зарядного кабеля, поскольку это опасно. 
Источник изображения: Tesla Радость многих автовладельцев, решивших воспользоваться сетью фирменных зарядных станций Tesla, была омрачена необходимостью приспосабливаться к иному размещению зарядного порта на кузове имеющихся у них электромобилей. Фирменные станции Tesla Supercharger оптимизированы для подключения машин, у которых зарядный порт расположен в районе заднего левого крыла. Соответственным образом рассчитана и длина зарядного кабеля на зарядной станции. Если же владельцу электромобиля другой марки приходится экспериментировать с положением машины у зарядной станции Tesla из-за другого размещения порта на транспортном средстве, это создаёт определённые неудобства. В подобных случаях автовладельцев мог бы выручить удлинительный кабель, но специалисты Tesla со страниц социальной сети X выступили с предостережением, что предлагаемые сторонними производителями удлинители не осуществляют должным образом мониторинг температуры в районе силового разъёма электромобиля, а потому не способны вовремя снизить силу тока при перегреве кабеля. Представителям Tesla известны случаи, когда перегрев кабеля и удлинителя приводил к короткому замыканию. Подобные рекомендации актуальны для всех зарядных станций, использующих кабели с жидкостным охлаждением. Предусмотреть его в удлинителе проблематично, а использование удлинителя нарушает контроль за температурой. Кроме того, наличие лишнего соединения в цепи питания снижает надёжность её работы. Интересно, что ранее Tesla сообщала о попытках разработать фирменный удлинитель, который бы учитывал подобные нюансы, но пока специалисты компании готовы консультировать сторонних производителей с целью исключения проблем при использовании удлинителя. Ради повышения безопасности может быть ограничена скорость зарядки, что наверняка не обрадует некоторых пользователей. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



