|
Опрос
|
реклама
Быстрый переход
Tesla рассказала об опасности удлинителей на зарядках для электромобилей
19.09.2024 [12:38],
Алексей Разин
Крупнейшие автопроизводители, предлагающие свои электромобили на территории Северной Америки, относительно недавно начали переходить на зарядный порт NACS, изначально продвигаемый компанией Tesla. Она предостерегает, что для повышения удобства размещения машины у зарядной станции не следует использовать удлинители зарядного кабеля, поскольку это опасно. 
Источник изображения: Tesla Радость многих автовладельцев, решивших воспользоваться сетью фирменных зарядных станций Tesla, была омрачена необходимостью приспосабливаться к иному размещению зарядного порта на кузове имеющихся у них электромобилей. Фирменные станции Tesla Supercharger оптимизированы для подключения машин, у которых зарядный порт расположен в районе заднего левого крыла. Соответственным образом рассчитана и длина зарядного кабеля на зарядной станции. Если же владельцу электромобиля другой марки приходится экспериментировать с положением машины у зарядной станции Tesla из-за другого размещения порта на транспортном средстве, это создаёт определённые неудобства. В подобных случаях автовладельцев мог бы выручить удлинительный кабель, но специалисты Tesla со страниц социальной сети X выступили с предостережением, что предлагаемые сторонними производителями удлинители не осуществляют должным образом мониторинг температуры в районе силового разъёма электромобиля, а потому не способны вовремя снизить силу тока при перегреве кабеля. Представителям Tesla известны случаи, когда перегрев кабеля и удлинителя приводил к короткому замыканию. Подобные рекомендации актуальны для всех зарядных станций, использующих кабели с жидкостным охлаждением. Предусмотреть его в удлинителе проблематично, а использование удлинителя нарушает контроль за температурой. Кроме того, наличие лишнего соединения в цепи питания снижает надёжность её работы. Интересно, что ранее Tesla сообщала о попытках разработать фирменный удлинитель, который бы учитывал подобные нюансы, но пока специалисты компании готовы консультировать сторонних производителей с целью исключения проблем при использовании удлинителя. Ради повышения безопасности может быть ограничена скорость зарядки, что наверняка не обрадует некоторых пользователей. iPhone 16 уже приехали в Россию — МТС похвасталась, что привезла их первыми, но в «М.Видео-Эльдорадо» не согласны
19.09.2024 [12:29],
Павел Котов
Группа «М.Видео-Эльдорадо» и розничная сеть оператора МТС сегодня практически одновременно представили в России iPhone 16 — за день до официального начала мировых продаж. Приём предварительных заказов на новые смартфоны Apple уже стартовал, а выдача товаров начнётся в ближайшие дни. 
Источник изображения: apple.com Предзаказы на iPhone 16 в магазинах «М.Видео» и «Эльдорадо» принимаются с 10 сентября. Телефоны нового поколения оказались более востребованными у российских покупателей, чем прошлогодние модели. Только за первую неделю торговая сеть получила на 109 % больше предзаказов на базовый iPhone 16 со 128 Гбайт памяти, чем на iPhone 15 за тот же срок. Самый популярный цвет у этого варианта — «Ультрамарин»; число предзаказов на iPhone 16 с 256 Гбайт памяти выросло на 75 %. Число заказов на базовый iPhone 16 Pro выросло на 19 % по сравнению с аналогичной моделью прошлого года. А самым популярным iPhone 16 Pro Max стал вариант с 256 Гбайт памяти. Оператор МТС уже провёл презентацию iPhone 16, посетители которой получили возможность протестировать новые телефоны Apple и получить по ним консультации. Для оформления предварительного заказа розничная сеть оператора предлагает внести частичную или полную предоплату — не менее 25 000 руб. за базовый iPhone 16. Оставшуюся сумму необходимо внести при получении товара; в подарок обещан также кешбэк в размере 30 %. Выдача iPhone 16 по оформленным предзаказам в магазинах МТС, как ожидается, стартует уже в предстоящие выходные — до этого момента технические специалисты намереваются протестировать устройства и убедиться, что они корректно работают в сети оператора. В магазинах «М.Видео-Эльдорадо» выдача начнётся лишь на следующей неделе. Отметим, что у «М.Видео-Эльдорадо» телефон обойдётся дешевле, чем в розничной сети МТС: базовая модель iPhone 16 со 128 Гбайт памяти в магазинах электроники будет продаваться за 112 999 руб., тогда как у оператора она будет стоить 114 999 руб. Возглавляющий линейку iPhone 16 Pro Max с 1 Тбайт на встроенном накопителе в магазинах «М.Видео-Эльдорадо» обойдётся в 249 999 руб., а его покупателям в МТС придётся приготовить 254 990 руб. Европол ликвидировал защищённый криминальный мессенджер Ghost
19.09.2024 [12:25],
Дмитрий Федоров
Европол объявил о ликвидации коммуникационной платформы Ghost, использовавшейся преступными группировками. Международная операция привела к аресту 51 человека в четырёх странах. Мессенджер Ghost, использовавший три стандарта шифрования, ежедневно обрабатывал около 1000 сообщений. Расшифровка позволила предотвратить до 50 случаев насилия. Операция продолжила серию успешных взломов криминальных мессенджеров, включая EncroChat и Sky ECC. 
Источник изображения: europol.europa.eu Совместное расследование, инициированное в 2022 году, объединило усилия правоохранительных органов девяти стран. Результатом стали аресты 38 подозреваемых в Австралии, 11 в Ирландии, по одному в Канаде и Италии. Итальянский задержанный принадлежал к Sacra Corona Unita — мафиозной структуре из Апулии. Ключевой фигурой операции стал 32-летний австралиец, непосредственно администрировавший Ghost. Дэвид Маклин (David McLean), помощник комиссара федеральной полиции Австралии, подчеркнул: «Ghost использовался итальянской мафией, байкерскими бандами, ближневосточными и корейскими преступными синдикатами для координации наркотрафика и заказных убийств». Платформа позволяла уничтожать все сообщения специальным кодом, что усложняло работу следователей. Жан-Филипп Лекуфф (Jean-Philippe Lecouffe), заместитель исполнительного директора Европола, отметил фрагментацию криминального киберпространства: «Сейчас преступники используют множество небольших сетей». Ghost, имевший меньшую пользовательскую базу по сравнению с EncroChat или Sky ECC, иллюстрирует эту тенденцию. Европол прогнозирует дальнейшие аресты по ходу расследования. Операция Ghost — часть систематической борьбы с зашифрованными платформами. Взлом EncroChat в 2020 году привёл к 6500 арестам и изъятию 900 тыс. евро. Взлом Sky ECC в 2021 году бельгийскими, нидерландскими и французскими спецслужбами инициировал масштабные рейды. Эффект этих операций продолжает ощущаться: в октябре 2024 года брюссельский суд рассмотрит дело 120 обвиняемых на основе данных Sky ECC. Джастин Келли (Justin Kelly), помощник комиссара полицейской службы Ирландии, констатировал: «Мы добиваемся значительных успехов в преодолении вызовов, связанных с зашифрованной коммуникацией». Однако эксперты отмечают, что криминальные элементы быстро адаптируются, переходя на новые платформы после каждого успеха правоохранителей. Google предложила продать часть своего рекламного бизнеса, но этого оказалось мало для прекращения антимонопольного дела в ЕС
19.09.2024 [12:23],
Павел Котов
Google сделала важный шаг в попытке положить конец проводимому в ЕС антимонопольному расследованию — компания предложила продать свою рекламную площадку AdX. Но европейские издатели, инициировавшие антимонопольное дело против Google, отклонили это предложение как недостаточное, сообщает Reuters со ссылкой на собственные источники. 
Источник изображения: Alex Dudar / unsplash.com Связанное с рекламой направление деятельности Google оказалось объектом расследования антимонопольных органов ЕС в прошлом году, когда поступила жалоба от Европейского совета издателей (European Publishers Council). Впоследствии Еврокомиссия обвинила Google в антиконкурентной поддержке собственных рекламных сервисов, и в отношении самой популярной в мире поисковой системы было открыто четвёртое расследование. До настоящего момента Google никогда не предлагала продажу собственных активов в рамках антимонопольного дела, утверждают источники Reuters. Сейчас Google также участвует в судебном разбирательстве в США, оспаривая претензии антимонопольных органов, которые стремятся заставить компанию продать свою платформу Ad Manager — в неё входят AdX и рекламная служба для издателей DFP. Европейские издатели отклонили предложение Google, поскольку хотят, чтобы компания отказалась не только от AdX — ей надлежит устранить конфликт интересов из-за присутствия почти на всех уровнях рекламных технологий. «Как мы уже говорили ранее, дело Европейской комиссии о наших продуктах для показа рекламы у третьих лиц основано на не соответствующих действительности толкованиях сектора рекламных технологий, который является жёсткоконкурентным и быстроразвивающимся. Мы остаёмся приверженными этому бизнесу», — заявил представитель Google. AdX или Ad Exchange — торговая площадка, на которой издатели в реальном времени предлагают рекламное пространство на своих ресурсах. В прошлом году еврокомиссар по вопросам конкуренции Маргрет Вестагер (Margrethe Vestager) предложила Google отказаться от DFP и AdX, чтобы устранить конфликты интересов. Но едва ли ведомство вынудит компанию продать свои активы сейчас — из-за сложного характера дела оно сначала может потребовать прекратить антиконкурентную деятельность, уверены источники Reuters. Предписание о продаже активов может поступить позже, если Google не выполнит первого решения ЕС, которое, как ожидается, будет вынесено в ближайшие месяцы. IBM без лишнего шума отправит на улицу до 6 тыс. сотрудников
19.09.2024 [12:12],
Руслан Авдеев
IBM увольняет значительное количество сотрудников, причём пытается сделать это без лишней огласки. По данным The Register, от массовых увольнений пострадал в первую очередь коллектив IBM Cloud, в последние дни сокращения коснулись тысяч людей. По данным одного из источников издания, всё «происходит втайне». По его словам, менеджер сообщил о необходимости подписания соглашения о неразглашении информации (NDA), запрещающее сообщать кому-либо детали увольнения. Впрочем, многочисленные сообщения на форумах, в социальных сетях и на других площадках позволяют предположить, что речь действительно идёт о масштабных увольнениях. 
Источник изображения: Jornada Produtora / Unsplash На вопрос журналистов о вероятных сокращениях представитель IBM ответил, что ранее в этом году компания сообщала о «перебалансировке» рабочей силы, которая коснётся лишь небольшой доли общемирового штата. В финансовом отчёте компании за I квартал 2024 года утверждается, что она потратит $400 млн на «перебалансировку», связанную с планируемыми увольнениями. Для сравнения, в 2023 году подобная практика обошлась в $300 млн, тогда планировалось уволить 3900 человек. При этом компания намерена закончить 2024 год с примерно тем же количеством сотрудников, что и начинала. Происходит оптимизация бизнеса — вероятно, смена бизнес-стратегии предполагает увольнение специалистов одного профиля и приглашения на работу другого. На конец 2023 года в компании насчитывалось 288 тыс. человек по всему миру. По словам представителя IBM, в этом году речь идёт об единичных процентах возможных увольнений. В случае сокращения 1 % штата речь может идти о 2880 сотрудниках, 2 % — 5760 сотрудниках, 3 % — 8640 сотрудниках и т.д. Если предположить, что увольнение каждого из них в текущем году в среднем обойдётся во столько же, во сколько и в прошлом, можно говорить об отправке на улицу 5200 человек исходя из сумму в $400 млн, выделенной на это, подсчитали The Register. 
Источник изображения: IBM В прошлом году глава IBM Арвинд Кришна (Arvind Krishna) заявил, что намерен заменить около 7800 сотрудников на ИИ, но не указал, когда именно это произойдёт. Теперь представители IBM отмалчиваются по поводу того, сколько именно людей потеряет работу и на какие должности примут новых чтобы, как заявлено, сохранить приблизительно прежнюю численность. По данным источников СМИ, сокращения в первую очередь коснутся программистов senior-уровня, специалистов по продажам и сотрудников поддержки. При этом набор сотрудников будет продолжаться в Индии, где IBM уже давно набирает кадры в приоритетном порядке. При этом под сокращение, по данным источников, попадают в первую очередь люди в возрасте 50–55 лет, занимающие довольно высокие должности и получающие высокую зарплату. Несмотря на прошлые и актуальные иски, связанные с увольнениями, в IBM настаивают, что систематическая дискриминация по возрасту в компании отсутствует. Discord засбоил в России после блокировки отдельных страниц Роскомнадзором
19.09.2024 [11:37],
Владимир Мироненко
В Сети появились жалобы российских пользователей мессенджера Discord на массовые сбои в его работе. Начиная с 18 сентября, многие не могут открыть веб- и мобильную версию ресурса. Как пишет «Коммерсант», в сентябре отдельные страницы сайта Discord были внесены по требованию МВД в реестр запрещённых сайтов Роскомнадзора. 
Источник изображения: Alexander Shatov/unsplash.com Какие именно страницы были заблокированы, не уточняется. В Роскомнадзоре не ответили на просьбу «Коммерсанта» прокомментировать сложившуюся ситуацию. Платформа для мгновенного обмена сообщениями и видеоконференций Discord пользуется популярностью у геймеров и учащихся. Её разработчик, компания Discord Inc. из Сан-Франциско (США), в 2022 году сообщала о более чем 150 млн ежемесячных активных пользователей. В марте 2024 года Роскомнадзор добавил Discord в реестр социальных сетей, поскольку его посещаемость превышает 500 тыс. российских пользователей в сутки. Согласно законодательству, такие ресурсы должны самостоятельно находить и блокировать противоправный контент. До этого, в июле 2023 года суд назначил мессенджеру административный штраф в размере 6 млн рублей за неудаление запрещённого контента. По оценке Mediascope, в 2022 году Discord был в числе самых популярных сервисов для общения участников игровой индустрии в РФ. Как отметил управляющий партнёр агентства цифровых коммуникаций Heads’made Ярослав Мешалкин, Discord не только популярное средство общения геймеров, но и в целом удобная платформа, которой пользуются для общения и совместной деятельности компании самого разного профиля: от IT-корпораций уровня Google до киберспортивных клубов. Эксперт сообщил, что число зарегистрированных пользователей Discord в России составляет по разным оценкам от 29 млн до 40 млн, и они генерируют более 4 % месячного трафика платформы. Руководитель Организации развития видеоигровой индустрии Василий Овчинников предупредил, что в случае блокировки Discord в России появятся определённые неудобства, так как большинство разработчиков поддерживают в нем свои международные сообщества, техподдержку, используя сервис для организации и проведения соревнований, общения сотрудников. YouTube запускает кнопку «Хайп» — она поможет быстро раскрутиться малоизвестным авторам
19.09.2024 [11:19],
Павел Котов
На мероприятии Made on YouTube администрация крупнейшей в мире видеоплатформы представила программу Hype. С её помощью зрители смогут объединяться вокруг малоизвестных начинающих авторов, в которых они верят, чтобы помочь этим авторам расширить аудиторию. 
Источник изображений: blog.youtube YouTube славится широким разнообразием авторов, которые снимают видео почти обо всём, и каждый день они добиваются прорывов на платформе. Но для многих малоизвестных авторов, у которых уже есть своя аудитория, привлечение новых зрителей оказывается непростой задачей. Для таких случаев создана программа Hype. Если видео вышло менее 7 дней назад, а у его автора менее 500 тыс. подписчиков, зрители могут «хайпануть» его — обеспечить более эффективное продвижение, чем при помощи лайков и репостов. Чем больше баллов Hype получит видео, тем выше оно поднимется в новой таблице лидеров, где представлены сто лучших «хайповых» видео недели. Один зритель может продвигать понравившиеся видео с Hype до трёх раз в неделю. Участие зрителя в программе не влияет на рекомендательный и поисковый алгоритмы YouTube для него. Когда зритель «хайпует» видео, оно получает баллы, которые помогают автору попадать в еженедельную таблицу лидеров для его страны, что способствует расширению аудитории. Предусмотрен и «бонус для малых авторов» — повышающий коэффициент баллов для каналов, у которых меньшее число подписчиков. Механизм Hype — это не только таблица лидеров, но и способ для зрителей сообщить авторам, какой контент им нравится больше всего. Самые «хайповые» видео получают значок, указывающий, что они популярны. 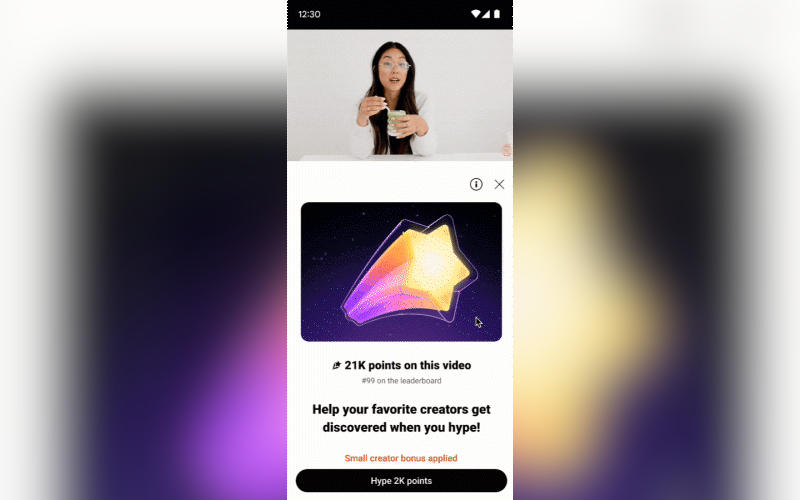 Программа Hype тестировалась в Бразилии, Турции и на Тайване. За первые четыре недели её работы зрители «хайповали» более 5 млн раз, обеспечив продвижение 50 тыс. каналов. Самая крупная возрастная группа участников эксперимента — зрители от 18 до 24 лет, или 30 % от их общего числа. Идея программы Hype родилась у администрации YouTube, когда среди 2500 зрителей в США, Германии и Японии был проведён опрос, и более 75 % респондентов, а также более 80 % зрителей поколения Z (рождённых с конца 1990-х до конца 2010-х гг.) сообщили, что хотели бы помочь неизвестным и малоизвестным авторам развивать свои каналы. Первоначально выбранный 24-часовой временной порог для раскрутки видео оказался слишком непродолжительным, и администрация платформы остановилась на промежутке в 7 дней. Не сразу пришли и идеи о создании таблицы лидеров программы Hype, а также о «бонусе для малых авторов», который уравнивает шансы для создателей видео. Администрация YouTube намеревается расширить присутствие программы Hype за пределы пилотных регионов, которыми стали Бразилия, Тайвань и Турция, а также продолжить её совершенствование на основе отзывов от пользователей платформы. Обнаружены крупнейшие в истории наблюдений джеты от чёрных дыр — они в 140 раз больше нашей галактики
19.09.2024 [11:13],
Геннадий Детинич
Известно, что потоки улетающего от чёрных дыр вещества и энергии (джеты) способны быстро лишить галактику-хозяйку питания для зарождения новых звёзд и дальнейшего роста. Но теперь сделано открытие, которое заставляет заподозрить джеты во влиянии на вселенские процессы. Учёные обнаружили джеты длиной в 23 млн световых лет — от таких струй изменится архитектура целых локальных участков Вселенной, а это уже инструмент для эволюции мироздания. 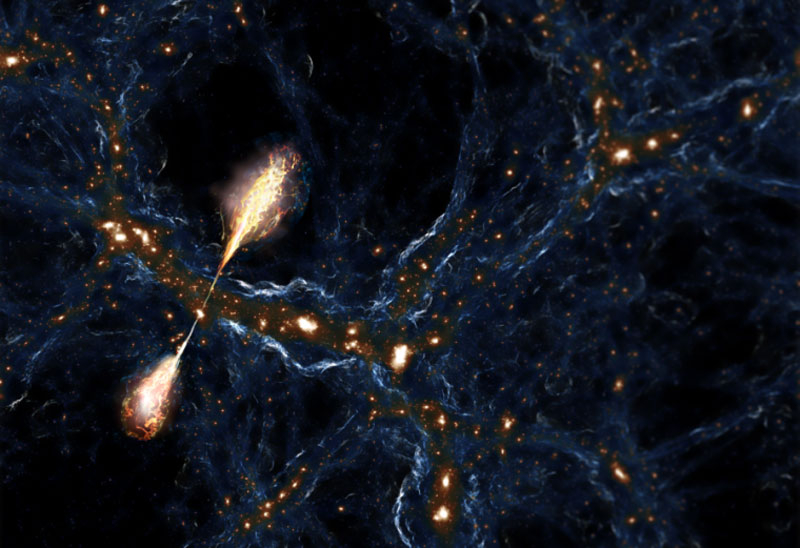
Художественное представление джетов из активной галактики в нити тёмной материи. Источник изображения: Caltech Найденный астрономами Калифорнийского технологического института объект из пары джетов от активной галактики простирается примерно на 7 Мпк (мегапарсек). Это примерно как пять раз слетать туда и обратно в соседнюю с нами галактику Андромеда. Выброс вынес колоссальную энергию из сверхмассивной чёрной дыры в центре галактики-хозяйки, сравнимую с энергией, выделяемой при столкновении галактических скоплений (1055 Дж). В целом учёным повезло с обнаружением этого объекта. Он выявлен на пределе чувствительности наших приборов и если бы возник чуть раньше или был чуть слабее, то явление осталось бы незамеченным. За свои размеры объект получил имя гиганта Порфириона (Porphyrion) из древнегреческой мифологии. Его джеты раскинулись на 6,4 Мпк. Истинные размеры джетов учёные оценили на уровне чуть более 7 Мпк, поскольку есть признаки того, что мы наблюдаем за ними под небольшим углом в нашу сторону. Сам объект был обнаружен в данных наблюдений радиотелескопа LOFAR за Северным полушарием. Их пропустили через систему машинного обучения и ручной отбор внештатных учёных. Всего было обнаружено свыше 11 тыс. джетов, которые были протяжённее одного Мпк. Данные по Порфириону были проверены с помощью другого радиотелескопа — uGMRT и дополнены наблюдениями обсерватории Кека. Измерения и спектральный анализ показали, что вероятная галактика — источник джетов — находится на удалении 6,3 млрд лет от Большого взрыва. Струи вещества обычно выбрасываются из полюсов чёрной дыры, где их направляет и ускоряет её электромагнитное поле. Это естественный ускоритель частиц, который в данном случае разогнал вещество джетов (плазму) до скорости 0,012 от световой. Чтобы достичь наблюдаемых размеров струям пришлось путешествовать по Вселенной около 500 млн лет. 
Изображение следов джетов в данных радиотелескопов (яркие области означают столкновения джетов с веществом) Поскольку джеты сохранили форму и направление, учёные делают вывод, что, во-первых, породившая их чёрная дыра не меняла ось своего вращения и, во-вторых, что галактика-хозяйка окружена войдами (пустотами). Джеты не встречали на своём пути достаточно много вещества — газа и пыли — чтобы рассеяться. Это также означает, что галактика-хозяйка находилась в нити тёмной материи, которая как паутиной пронизывает и связывает всю Вселенную и является матрицей для формирования галактик. С учётом небывалой протяжённости обнаруженных джетов, они могли стать переносчиком массы и энергии в соседние нити и, тем самым, были способны повлиять на основы формирования ткани самой Вселенной. Не исключено, что мы просто не видим всех подобных явлений, особенно на ранних этапах формирования мироздания, когда Вселенная явно была плотнее. Если таких объектов много и они возникают достаточно часто, вероятно придётся их учитывать для моделирования эволюции галактик и Вселенной. Но для этого пока не хватает данных, так что наблюдения будут продолжены. Microsoft Store станет быстрее «в ближайшем будущем»
19.09.2024 [10:59],
Владимир Фетисов
Ранее на этой неделе сообщалось, что разработчики из Microsoft намерены ускорить работу приложений Windows 11, построенных на базе Windows App SDK, за счёт технологии Native AOT (компиляция кода перед исполнением программы). Теперь же стало известно, что фирменный магазин цифрового контента Microsoft Store будет оптимизирован аналогичным образом, за счёт чего получит существенный прирост производительности. Согласно имеющимся данным, Microsoft предлагает разработчикам приложений новый способ переноса своих программных продуктов с UWP на .NET 9 и Native AOT. Это означает, что разработчики смогут модернизировать свои приложения в два этапа вместо того, чтобы вносить одно масштабное изменение. Microsoft предлагает переводить приложения на .NET 9 и Native AOT, что облегчит последующий переход на WinUI 3. По данным Microsoft, приложения на .NET 9 и Native AOT отличаются более высокой производительностью, чем программные продукты UWP на .NET Native. Кроме того, технология Native AOT продолжает активно развиваться, и в будущем она будет продолжать оптимизироваться. Это означает, что в какой-то момент разработчики приложений должны будут перевести свои продукты на .NET 9 и Native AOT для повышения производительности. В сообщении в блоге разработчиков Microsoft отмечается, что именно такую миграцию в настоящее время проходит Microsoft Store. Платформа переходит на .NET 9, и новая версия приложения, работающая на Native AOT, появится «в ближайшем будущем». Когда именно это произойдёт, не уточняется. Скорее всего, до выхода стабильной версии приложения оно будет тестироваться среди участников программ предварительной оценки Windows Insider. Nintendo и The Pokemon Company подали в суд на создателей Palworld — «покемоны с пушками» нарушают сразу несколько патентных прав
19.09.2024 [10:36],
Михаил Романов
Издатель и разработчик Nintendo вместе с частично принадлежащей ему The Pokemon Company (TPC) подали в окружной суд Токио иск против японской студии Pocketpair за её симулятор выживания Palworld. 
Источник изображения: Steam (BLASTER) Напомним, Palworld предлагает разводить, вооружать, есть и отправлять работать Палов — подозрительно похожих на покемонов существ. В январе TPC пообещала проверить «покемонов с пушками» на нарушение авторских прав. В результате «тщательного изучения контента» Nintendo и TPC решили, что Palworld нарушает сразу несколько патентных прав, и требуют судебного запрета таких материалов наряду с компенсацией ущерба. Nintendo не уточнила, какие патентные права нарушила Palworld, и, судя по заявлению порталу Kotaku, делать этого не собирается: «Мы воздержимся от комментариев на темы, относящиеся к содержанию иска». 
Источник изображения: Pocketpair Хотя наибольшее внимание игроков и журналистов на релизе Palworld привлекли сходства дизайна Палов и покемонов, жалоба Nintendo и The Pokemon Company, вероятно, связана не с этим. Как подметил портал Video Games Chronicle, Nintendo и TPC обвиняют Palworld в нарушении патентных, а не авторских прав, так что речь, скорее всего, идёт о геймплейных инновациях игры, а не её художественных особенностях. Ранний доступ Palworld стартовал 19 января на PC (Steam, Microsoft Store), Xbox One, Xbox Series X, S и в Game Pass. К концу февраля аудитория проекта превысила 25 млн человек, а продажи в Steam — 15 млн копий. Microsoft начнёт широко распространять Windows 11 24H2 в октябре
19.09.2024 [10:16],
Владимир Фетисов
Как и ожидалось, компания Microsoft начнёт распространение стабильной версии операционной системы Windows 11 24H2 в октябре этого года, а на следующей неделе выйдет предварительная версия обновления. Сообщение об этом появилось в разделе блога Microsoft Tech Community, посвящённом ИИ-помощнику Copilot. 
Источник изображения: thurrott.com «Ежегодный выпуск функциональных обновлений Windows 11 <…> будет распространяться на ПК, начиная с необязательной предварительной версии, не связанной с безопасностью, с 24 сентября 2024 года и заканчивая ежемесячным обновлением безопасности 8 октября для всех поддерживаемых версий Windows 11», — говорится в сообщении Microsoft. Для ясности, речь идёт о выпуске новой версии приложения Copilot с поддержкой инструмента безопасности Enterprise Data Protection, который предназначен для установки на компьютеры с Windows 11 Enterprise, а не на все устройства с совместимыми версиями ОС. Тем не менее, в сообщении упоминается, что выход новой версии Copilot совпадает с запуском обновления Windows 11 24H2, предназначенного для установки на совместимые потребительские устройства. Таким образом, пользователи смогут вручную установить на свои ПК обновление Windows 11 24H2, начиная с 24 сентября, а с 8 октября оно будет доставляться на совместимые устройства в автоматическом режиме. Для владельцев ноутбуков Copilot Plus PC с новейшими процессорами AMD и Intel выход этого обновления означает появление новых функций на базе искусственного интеллекта. В остальном Windows 11 24H2 не принесёт каких-то заметных улучшений и важных функций. В русскоязычной «Википедии» стало более 2 миллионов статей
19.09.2024 [10:07],
Павел Котов
Общее количество статей в русскоязычном разделе «Википедии» накануне превысило 2 млн. На преодоление второго миллиона у авторов ресурса ушли более 11 лет. Русскоязычный раздел является четвёртым по размерам в «Википедии». 
Источник изображения: ru.wikinews.org Двухмиллионная статья русской «Википедии» была зафиксирована накануне, 18 сентября 2024 года, в 16:29 мск — она оказалась посвящённой рассказу Владимира Набокова «Музыка», а добавил её википедист и журналист из Омска Николай Эйхвальд. Миллионная статья в русскоязычном разделе онлайн-энциклопедии появилась 11 мая 2013 года. Формально русская «Википедия» является седьмой по числу материалов. Но в этом списке некоторые разделы относятся к «ботопедиям» — они либо полностью (себуанская, варайская), либо в значительной мере (нидерландская, шведская) состоят из автоматических заливок. Если же учитывать лишь «честно» написанные материалы, то русскоязычный раздел «Википедии» занимает уже четвёртое место в мире, уступая английскому, немецкому и французскому. Intel вывела производство чипов в отдельную компанию для привлечения клиентов
19.09.2024 [08:55],
Дмитрий Федоров
Intel объявила о выделении контрактного производства чипов в отдельную дочернюю компанию. Этот шаг может повысить шансы компании на получение заказов от технологических гигантов, включая Apple и AMD. Реструктуризация направлена на укрепление доверия потенциальных клиентов и расширение возможностей контрактного производства Intel. 
Источник изображения: Rubaitul Azad / unsplash.com 16 сентября совет директоров Intel одобрил план по преобразованию контрактного производства в стопроцентную дочернюю компанию с собственным операционным комитетом в составе совета директоров материнской корпорации. Генеральный директор Пэт Гелсингер (Pat Gelsinger) назвал это решение «наиболее значимой трансформацией за более чем четыре десятилетия». Согласно отчёту тайваньского издания Anue, основанному на анализе зарубежных СМИ и экспертов, эта мера призвана преодолеть недоверие потенциальных заказчиков, таких как Apple, Qualcomm, Broadcom и даже AMD, опасающихся передавать свои разработки конкуренту. Выделение производства в отдельную структуру может снизить риски конфликта интересов, если она станет действительно независимой и если в её составе будут подходящие члены совета директоров, но эффективность этого шага ещё предстоит выяснить. Параллельно с анонсом о реструктуризации Intel заключила многомиллиардное многолетнее соглашение с Amazon. Корпорации будут совместно разрабатывать чипы следующего поколения для ИИ-инфраструктуры AWS на базе техпроцесса Intel 18A. Кроме того, Intel займётся производством чипов для центров обработки данных Amazon Web Services (AWS), ориентированных на ИИ, а также разработкой кастомизированных серверных процессоров Xeon 6 для AWS. Сотрудничество с Amazon рассматривается как перспективное начало для обновлённого контрактного производства Intel. Успешная реализация проекта может открыть возможности для производства других чипов Amazon, включая процессоры AWS Graviton и ИИ-чипы Trainium для машинного обучения (ML). Однако до сих пор Intel не удавалось привлечь значительное число клиентов в своё контрактное производство и данный момент её крупнейшим заказчиком является Microsoft. Два года назад Intel потеряла контракт на разработку и производство чипов для PlayStation 6 компании Sony, что стало серьёзным ударом по её амбициям в сфере контрактного производства. Новая структура призвана обеспечить бóльшую независимость для клиентов и поставщиков от других подразделений Intel. Это также даёт компании возможность рассматривать независимые источники финансирования в будущем и оптимизировать структуру капитала каждого направления бизнеса для максимизации роста и увеличения рыночной капитализации. Waymo может поручить выпуск роботакси корейской компании Hyundai Motor
19.09.2024 [08:52],
Алексей Разин
Первоначально американская компания Waymo, входящая в состав холдинга Alphabet наряду с Google, использовала различные серийные автомобили в качестве прототипов беспилотных такси, оснащая их соответствующим оборудованием и программным обеспечением. По слухам, контракт на производство серийных роботизированных такси Waymo может получить южнокорейская Hyundai Motor. 
Источник изображения: Hyundai Motor Об этом со ссылкой на информированные источники сообщило недавно издание ET News. По имеющимся данным, руководство Hyundai Motor и Waymo встречалось не менее трёх раз для обсуждения этого вопроса на территории штаб-квартиры американской компании. Стороны имеют обоюдный интерес к этому проекту. Waymo получает поставщика автоматических такси для своего таксопарка, а Hyundai выходит в новый для себя сегмент рынка. Сейчас автопарк прототипов Waymo на территории США достаточно разнообразен, он включает адаптированные электромобили Jaguar I-Pace, гибридные минивэны Chrysler Pacifica и даже китайские электромобили Zeekr концерна Geely. В общей сложности Waymo эксплуатирует около тысячи роботизированных такси. Одним из стимулов к началу переговоров с Hyundai стал предстоящий рост таможенных пошлин на электромобили китайской сборки, ввозимые в США, ведь машины Zeekr поставляются на этот рынок именно из Китая. Шестое поколение оборудование для автопилота Waymo намеревалась монтировать именно на электромобили Zeekr. Теперь альтернативный план подразумевает замену продукции Zeekr на электромобили Hyundai Ioniq 5. В составе комплекса оборудования предусмотрены четыре лидара, шесть радаров и несколько камер высокого разрешения. В пятом поколении система использует пять лидаров, поэтому уменьшение их количества в шестом должно благотворно повлиять на стоимость оборудования. Новый комплект оборудования включает более совершенные радары, которые используются для формирования представления об окружающих машину предметах. Waymo могла бы получать свои роботакси от Hyundai из Сингапура, где подобные машины на базе Ioniq 5 уже выпускаются для нужд Motional. Представители Hyundai Motor слухи о возможном сотрудничестве с Waymo комментировать отказались. Европейский план «кремниевого суверенитета» терпит крах из-за поменявшихся планов Intel
19.09.2024 [07:30],
Алексей Разин
На этой неделе руководство Intel официально заявило, что эта американская корпорация воздерживается минимум на два года от начала реализации проекта по строительству на востоке Германии двух передовых предприятий по производству полупроводниковых компонентов. Этот шаг способен серьёзно подорвать технологический суверенитет Европы, как отмечает издание Politico. 
Источник изображения: Intel Напомним, власти Евросоюза с позапрошлого года пытаются стимулировать развитие региональной полупроводниковой отрасли, и даже приняли так называемый «Европейский закон о чипах», который предусматривает выделение до 43 млрд евро субсидий на строительство в Европе новых предприятий по выпуску чипов. К концу 2030 года власти Евросоюза хотели бы достичь доли в 20 % на мировом рынке передовых полупроводников компонентов с точки зрения локализации производства в регионе. В 2022 году этот показатель не превышал 9 %, но если реализация программы будет буксовать, как предупредили представители Еврокомиссии в июле этого года, то к концу десятилетия он не вырастет за пределы 11,7 %. Добавим, что федеральный канцлер Германии Олаф Шольц (Olaf Scholz) после принятия Intel решения о задержке строительства немецких предприятий выразил надежду на целесообразность реализации этого проекта в будущем и его финансовую поддержку. Intel первоначально намеревалась потратить на строительство двух предприятий в Магдебурге около 30 млрд евро, из них не менее 10 млрд покрывали бы субсидии. Польское предприятие по упаковке и тестированию чипов, которое компания также не решилась строить, потребовало бы около 5 млрд евро инвестиций, но более трети из этой суммы покрыли бы субсидии. В прошлом месяце TSMC торжественно заложила фундамент совместного предприятия в Германии, но оно не только ограничится бюджетом около 10 млрд евро на строительство, но и будет выпускать не самые передовые чипы, используемые преимущественно в автомобильной отрасли. Последняя в Европе, к слову, переживает не самые лёгкие времена, поэтому целесообразность данного проекта можно оспаривать. Если учесть, что ранее Intel отказалась от строительства предприятия в Италии и исследовательского центра во Франции, можно считать инициативу властей Евросоюза по возрождению региональной полупроводниковой промышленности не совсем успешной на данном этапе реализации. Примечательно, что глава Еврокомиссии Урсула фон дер Ляйен (Ursula von der Leyen) на церемонии закладки фундамента совместного предприятия TSMC в Германии в прошлом месяце упоминала сумму в 115 млрд евро, которые в развитие европейской полупроводниковой отрасли готовы вложить страны блока и частные источники капитала. В какой пропорции эти средства бы распределились по источникам финансирования, она не уточнила, но с высокой вероятностью можно говорить о том, что сумма в 115 млрд евро сочетает как государственные субсидии, так и частные инвестиции компаний. С учётом предстоящей смены состава Еврокомиссии, перспективы дальнейшей реализации плана становятся всё более туманными. Уязвимость PKfail в Secure Boot оказалась более распространённой, чем ожидалось
19.09.2024 [06:39],
Дмитрий Федоров
Масштабная уязвимость в системе безопасности Secure Boot, получившая название PKfail, оказалась гораздо более распространённой, чем предполагалось ранее. Проблема, названная PKfail, затрагивает банкоматы, платёжные терминалы, медицинские устройства, игровые консоли, корпоративные серверы и даже машины для голосования. Использование тестовых ключей платформы в производственных системах на протяжении более 10 лет поставило под угрозу безопасность устройств от ведущих производителей отрасли. 
Источник изображения: geralt / Pixabay Исследователи компании Binarly обнаружили, что количество моделей устройств, использующих скомпрометированные тестовые ключи платформы, возросло с 513 до 972. Среди затронутых производителей — Acer, Dell, Gigabyte, Intel, Supermicro, Aopen, Fornelife, Fujitsu, HP и Lenovo. Ключи, помеченные фразами «DO NOT TRUST» (НЕ ДОВЕРЯТЬ) в сертификатах, никогда не предназначались для использования в промышленных системах, однако оказались внедрены в сотни моделей устройств. Платформенные ключи формируют криптографический якорь доверия (root-of-trust anchor) между аппаратным обеспечением и прошивкой. Они являются фундаментом для Secure Boot — отраслевого стандарта, обеспечивающего криптографическую защиту в предзагрузочной среде устройства. Интегрированный в UEFI (Unified Extensible Firmware Interface), Secure Boot использует криптографию с открытым ключом для блокировки загрузки любого кода, не подписанного предварительно одобренной цифровой подписью. Компрометация этих ключей подрывает всю цепочку безопасности, установленную Secure Boot. Ситуация усугубилась после публикации в 2022 году на GitHub закрытой части одного из тестовых ключей. Это открыло возможность для проведения сложных атак с внедрением руткитов в UEFI устройств, защищённых Secure Boot. Количество моделей, использующих этот конкретный скомпрометированный ключ, выросло с 215 до 490. Всего исследователи выявили около 20 различных тестовых ключей, четыре из которых были обнаружены недавно. Анализ 10 095 уникальных образов прошивок, проведённый с помощью инструмента Binarly, показал, что 8 % (791 образ) содержат непроизводственные ключи. Проблема затрагивает не только персональные компьютеры, но и медицинские устройства, игровые консоли, корпоративные серверы и критически важную инфраструктуру. Ранее все обнаруженные ключи были получены от компании AMI, одного из трёх основных поставщиков комплектов средств разработки (SDK) программного обеспечения (ПО), которые производители устройств используют для настройки прошивки UEFI, чтобы она работала на их конкретных аппаратных конфигурациях. С июля Binarly обнаружил ключи, принадлежащие конкурентам AMI — компаниям Insyde и Phoenix. Binarly также обнаружила, что следующие три производителя также продают устройства, пострадавшие от PKfail:
Уязвимости присвоены идентификаторы CVE-2024-8105 и VU#455367. PKfail не представляет угрозы для устройств, не использующих Secure Boot, но подрывает безопасность систем, где эта защита обязательна — например, у государственных подрядчиков и в корпоративных средах. Китайская флеш-память YMTC теряет слои: из-за санкций компании пришлось перейти с 232-слойной памяти к 160-слойной
19.09.2024 [06:35],
Алексей Разин
Эксперты канадской TechInsights уже не раз выявляли технологические возможности китайских производителей чипов, и в новом своём отчёте, как отмечает Bloomberg, рассказали о способности YMTC выпускать на оборудовании китайского происхождения 162-слойные чипы памяти типа 3D NAND. Это заметно меньше, чем у выпускаемой с применением зарубежного оборудования 232-слойной памяти той же марки, но важен сам факт прогресса китайских поставщиков оборудования для этих нужд. 
Источник изображения: YMTC По данным источника, YMTC выпускает новую память с применением технологии компоновки Xtacking 4.0, и кто является поставщиком профильного оборудования, не уточняется. Откат по количеству слоёв в микросхемах 3D NAND новых партий, по словам экспертов, произошёл за счёт снижения уровня выхода годных чипов, поскольку оборудование китайского производства пока не может обеспечить сопоставимую с зарубежным точность. К началу февраля власти США включили YMTC в санкционный список, поэтому доступ к новому зарубежному оборудованию для производства памяти она потеряла. Поставщиками оборудования для нужд YMTC являются китайские компании AMEC, Naura Technology и Piotech. Если учесть, что санкции США начали действовать в этом году, а продукция YMTC достигла 162-слойной компоновки на китайском оборудовании, то подобный прогресс можно считать значительным. Представители YMTC публикацию Bloomberg прокомментировали отстранённо, пояснив, что компания постоянно улучшает качество продукции, а изменение количества слоёв в новых партиях памяти не обусловлено параметрами какого-то определённого оборудования. В iOS 18 обнаружена ошибка, приводящая к постоянным сбоям приложения «Сообщения»
19.09.2024 [04:29],
Анжелла Марина
В последнем обновлении операционной системы iOS 18 обнаружен баг, который возникает при совместном использовании циферблатов Apple Watch. В приложении «Сообщения» происходит постоянный сбой при ответе на циферблат в общей ветке сообщений. 
Источник изображения: 9to5mac.com В проблеме разобрался ресурс 9to5Mac. Ошибка заключается в том, что если пользователь iOS 18 ответит на отправленный ему циферблат Apple Watch в цепочке сообщений (внутри отдельного сообщения), приложение Messages начнёт «вылетать». Это будет происходить как у отправителя циферблата, так и у получателя. При этом ответить на сообщения в других чатах также станет невозможно из-за сбоев приложения. Единственное временное решение — удалить всю переписку с пользователем, отправившим циферблат. Однако это приведёт к безвозвратной потере всей истории сообщений, включая фотографии, видео и другие вложения, которые не были сохранены отдельно. Попытка восстановления удалённой переписки из раздела «Недавно удалённые» снова приведёт к появлению ошибки. «Скорее всего, Apple выпустит исправление в ближайших обновлениях iOS 18, macOS 15, watchOS 11 и бета-версиях своего программного обеспечения. — предположил 9to5Mac. — А пока, до выхода обновления, рекомендуется воздержаться от ответов на отправленные циферблаты Apple Watch в цепочках сообщений, чтобы избежать потери данных». Не исключено, что восстановление из резервной копии поможет вернуть потерянную информацию, но использование функции iCloud для «Сообщений» может сделать этот способ неэффективным. Отмечается, что с выходом обновлений watchOS 11 вероятность столкновения с этим багом возрастает, поскольку пользователи будут активнее делиться своими настроенными циферблатами и обсуждать их в «Сообщениях». Кластер на столе: Mini-ITX плата Turing Pi 2.5 объединяет до четырёх одноплатных компьютеров
19.09.2024 [00:18],
Юрий Лебедев
Turing Pi 2.5 представляет собой четырёхузловую плату формата Mini-ITX со встроенным 1GbE-коммутатором. Плата поддерживает вычислительные модули Turing RK1, Raspberry Pi CM4 и NVIDIA Jetson с коннектором SO-DIMM, которые можно комбинировать. Решение компактно, бесшумно и энергоэффективно. Оно подходит для создания домашних лабораторий, хостинга, работы с облачными стеками (например, Kubernetes или Docker Swarm), а также для запуска ИИ-приложений. Плата оснащена встроенным BMC на базе чипа Allwinner T113-S3 с 256 Мбайт флеш-памяти. BMC предоставляет возможности удалённого управления, причём узлы остаются активными при перезагрузке BMC. Также имеется встроенный преобразователь UART↔USB-C для отладки, кнопка FEL для быстрого восстановления после неудачных обновлений прошивки, четырёхконтактный разъем с ШИМ для управления корпусным вентилятором и часы реального времени с питанием от батареи CR2032. 
Источник изображений: Turing Machines Плата оснащена слотом microSD, двумя портами SATA-3, а также четырьмя портами M.2 2260/2280 M-Key для подключения NVMe SSD. Доступно четыре порта USB 3.0 (два Type-A + колодка для ещё двух) и один USB 2.0. Встроенный L2-коммутатор с поддержкой VLAN подключён к каждому модулю, а на заднюю панель от него выведены два порта RJ45. Отдельно отмечается, что теперь каждая плата имеет собственный MAC-адрес.  Два слота Mini PCIe, подведённые к узлам № 1 и № 2, позволяют модулям RK1 и Jetson использовать адаптеры Wi-Fi, Bluetooth или 4G/5G (есть слот для SIM-карты), в том числе по USB. Внутренний USB-концентратор позволяет одновременно подключаться к хранилищу всех модулей в режиме MSD (Mass Storage Device), а для заливки образов на модули есть отдельный порт USB-C. Также имеется интерфейс DSI для дисплеев и 40-контактная площадка GPIO, совместимая с Raspberry Pi. Есть и восьмиконтактные разъёмы для I²C-подключения экранов, кнопок, динамиков и т.д.  К первому узлу подведены порт HDMI 4K и один из портов USB Type-A (детали не уточняются), что позволяет использовать его в качестве настольного компьютера, подключив клавиатуру, мышь и монитор. Питается плата от стандартного разъёма ATX 24, а общее энергопотребление системы не превышает 80 Вт. Стоит новинка $279. 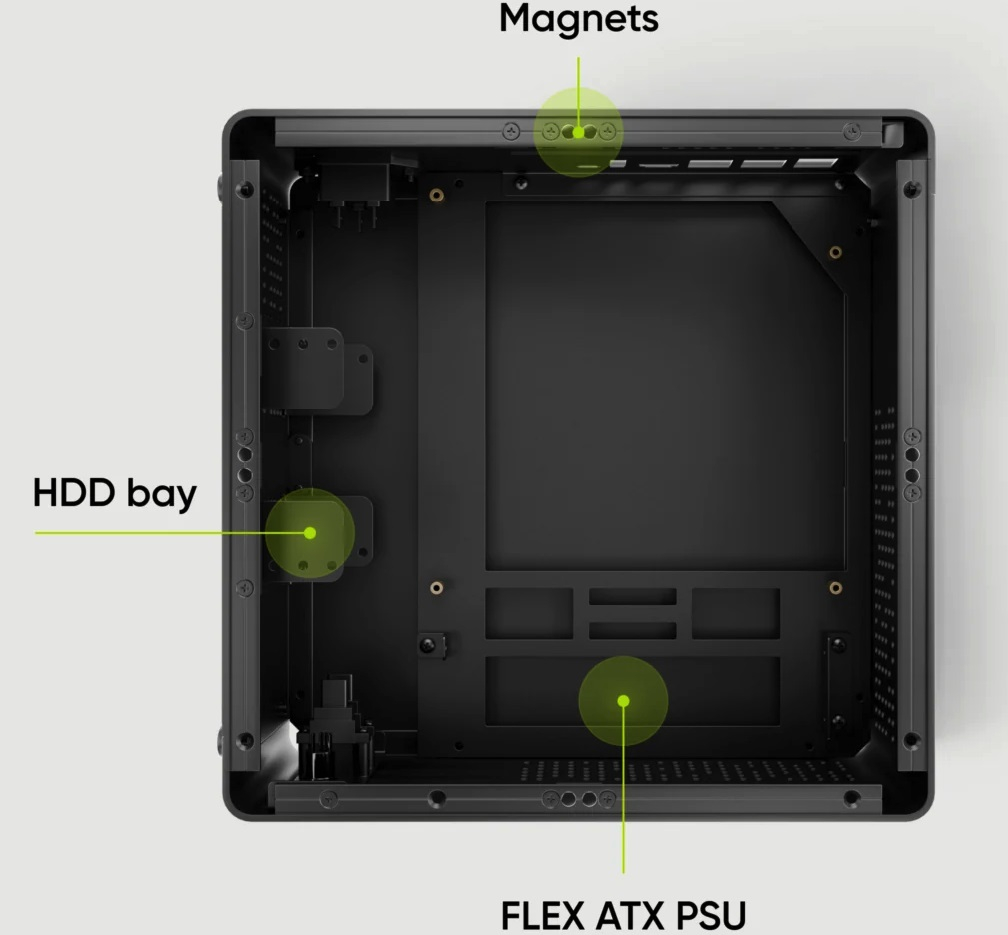 Для платы предлагается корпус Turing Pi mini-ITX (240 × 240 × 100 мм) стоимостью $149. Корпус выполнен из алюминия и совместим с платами Turing Pi 2 и 2.5. Он оснащён магнитными крышками для упрощения замены модулей и аксессуаров, поддерживает установку до трёх SFF-накопителей, одного 120-мм вентилятора и блоков питания Flex ATX PSU или Pico PSU с внешним адаптером. На корпусе есть LED-индикатор, кнопка питания, два порта USB Type-A, а также отверстия для внешних антенн. Clock Tower: Rewind нагонит страх на игроков к Хэллоуину — дата выхода улучшенной версии классического хоррора 29-летней давности
18.09.2024 [23:54],
Михаил Романов
Разработчики из студии WayForward при поддержке издательства Limited Run Games объявили точную дату выхода хоррора Clock Tower: Rewind — улучшенной версии оригинальной Clock Tower образца 1995 года. 
Источник изображений: WayForward Напомним, самая первая Clock Tower никогда за пределами Японии не выходила, однако прошлым летом анонсировали международное переиздание. Его релиз ожидался в начале 2024 года, но премьеру отложили до осени. Как стало известно, мировой релиз Clock Tower: Rewind состоится 29 октября текущего года на PC (Steam), PS4, PS5, Xbox One, Xbox Series X, S и Nintendo Switch. Японская версия выйдет на два дня позже, 31-го числа. «Clock Tower: Rewind позволит фанатам хорроров наконец испытать на себе признанную классику 16-битной эпохи непосредственно к началу сезона страшилок», — отметила WayForward в пресс-релизе. Новым иллюстративным материалом по Clock Tower: Rewind объявление не сопровождалось, однако в начале июля разработчики показали полутораминутный геймплейный трейлер (ролик прикреплён выше). Геймплей, графика и звук останутся без изменений, но появятся анимированное вступление с новой вокальной партией, галерея иллюстраций, система сохранений, функция Rewind и поддержка нескольких языков (русского среди них нет). По сюжету Clock Tower за девушкой Дженнифер Симпсон в семейном поместье Бэрроусов охотится Человек с Ножницами (Scissorman). Игрокам нужно прятаться от маньяка, искать секреты и способы спастись. История имеет несколько концовок. Блогеры на YouTube смогут группировать ролики по сезонам — так их будет удобней смотреть на телевизорах
18.09.2024 [23:47],
Владимир Фетисов
В рамках мероприятия Made on YouTube разработчики анонсировали ряд нововведений, которые в скором времени станут доступны пользователям видеохостинга. Помимо нескольких функций на основе искусственного интеллекта авторы контента на YouTube получат возможность разделения публикуемых видео на сезоны, чтобы пользователям было удобнее просматривать ролики на телевизорах. 
Источник изображения: Mohamed Hassan / pixabay.com В компании отметили, что пользователи стали активнее просматривать видео с YouTube на своих телевизорах, поэтому разработчики решили оптимизировать интерфейс платформы, сделав его более похожим на Netflix и другие подобные платформы. В скором времени авторы контента смогут адаптировать свои ролики для зрителей, снабжая каждый эпизод полноценным описанием, а также разделяя общую массу роликов на сезоны для более удобной навигации. Представители YouTube не уточнили, как анонсированные нововведения будут интегрированы в интерфейс десктопного и мобильного приложений YouTube, но было упомянуто, что изменения затронут все платформы. Авторы контента получат и другие инструменты, ориентированные на создание контента для пользователей, которые взаимодействуют с платформой через телевизоры. Один из таких инструментов позволит публиковать и воспроизводить «иммерсивный контент». Хакеры атаковали «Доктор Веб» — компания отключила серверы и приостановила обновление вирусных баз
18.09.2024 [23:45],
Николай Хижняк
Российский разработчик антивирусного ПО «Доктор Веб» (Dr.Web) сообщил о кибератаке на свою внутреннюю сеть, осуществлённой неизвестной стороной в минувшие выходные. После обнаружения «признаков несанкционированного вмешательства» в свою ИТ-инфраструктуру компания отключила все серверы от внутренней сети. Dr.Web также была вынуждена прекратить доставку обновлений вирусных баз клиентам в понедельник на время расследования инцидента. 
Источник изображения: Bleeping Computer «В субботу 14 сентября специалисты "Доктор Веб" зафиксировали целевую атаку на ресурсы компании. Попытка навредить нашей инфраструктуре была своевременно пресечена. На данный момент в соответствии с протоколом безопасности все ресурсы отключены от сети с целью проверки. В связи с этим временно приостановлен выпуск вирусных баз Dr.Web. Следуя установленным политикам безопасности, мы отключили все наши серверы от сети и начали комплексную диагностику безопасности», — заявил разработчик антивирусного ПО. В новом заявлении, опубликованном в среду, Dr.Web сообщила, что обновление вирусной базы данных возобновилось во вторник. В компании добавили, что нарушение безопасности не затронуло ни одного из её клиентов. «Для анализа и устранения последствий инцидента мы реализовали ряд мер, включая использование Dr.Web FixIt! для Linux. Собранные данные позволили нашим экспертам по безопасности успешно изолировать угрозу и гарантировать, что наши клиенты не пострадают от неё», — заявила компания. Dr.Web не первая российская компания, занимающаяся вопросами кибербезопасности, которая сама подверглась кибератакам за последние годы. Как пишет портал Bleeping Computer, в июне этого года хакеры взломали серверы российской компании по информационной безопасности Avanpost, украли и опубликовали, как они утверждали 390 Гбайт данных и зашифровали более 400 её виртуальных машин. В июне 2023 года компания Kaspersky Lab также сообщила, что использующиеся её сотрудниками смартфоны iPhone были заражены шпионским ПО через эксплойты iMessage zero-click, нацеленные на уязвимости iOS нулевого дня в рамках кампании, которая теперь известна как «Операция “Триангуляция”». На тот момент в компании также заявили, что атаки, затрагивающие её московский офис и сотрудников в разных странах, начались ещё с 2019 года и продолжаются до сих пор. С выходом на ПК в God of War Ragnarok наконец появится возможность остановить поток подсказок к загадкам
18.09.2024 [22:33],
Михаил Романов
Накануне выхода скандинавского экшена God of War Ragnarok на ПК разработчики из Santa Monica Studio при поддержке партнёров из Jetpack Interactive рассказали о двух новых функциях, которые дебютируют в игре с релизом PC-версии. 
Источник изображений: Sony Interactive Entertainment Напомним, одной из самых раздражающих особенностей игры на релизе оказалась чрезмерная болтливость союзников — они постоянно давали подсказки к загадкам, не позволяя решить головоломки самому, и отключить это было нельзя. Разработчики признались, что проблема стала результатом недосмотра команды (из-за сокращения числа тестировщиков к концу производства систему не откалибровали должным образом) и не рассчитывают на её решение в будущем.  Как стало известно, с релизом God of War Ragnarok на ПК у игроков всё-таки появится возможность снизить частоту подсказок от компаньонов. Соответствующая опция будет доступна в настройках геймплея. Вторая новая функция — звуковое описание событий (и предоставление контекстной информации) в заставочных роликах для людей со слабым зрением. Опция расположится в настройках доступности. Разработчики уточнили, что, хотя обе функции дебютируют с выходом God of War Ragnarok на ПК, в ближайшем будущем (без точных сроков) их также добавят и в консольные версии игры. God of War Ragnarok выйдет на ПК (Steam, Epic Game Store) уже 19 сентября и будет стоить $60. Скорый релиз отметили 30-секундным геймплейным трейлером с хвалебными отзывами (прикреплён выше). Норвегия стала первой в мире страной, в которой электромобилей стало больше, чем машин на бензине
18.09.2024 [21:56],
Анжелла Марина
В Норвегии количество электрических автомобилей на дорогах превысило количество бензиновых. Согласно данным Норвежской федерации дорог (NRF), из 2,8 млн зарегистрированных частных автомобилей 754 303 являются полностью электрическими, в то время как на бензине ездят 753 905 автомобилей. Сообщается, что страна планирует полностью отказаться от продажи новых машин с ДВС к 2025 году. 
Источник изображения: Michael Marais/Unsplash Норвегия, с населением 5,5 млн человек, поставила перед собой амбициозную цель стать первым регионом в мире, где будет полностью прекращена продажа новых автомобилей с бензиновыми и дизельными двигателями. Уверенность в реализации этого плана удалось достичь благодаря широкому внедрению налоговых льгот и других стимулов для покупателей электрических автомобилей, финансируемых в значительной мере за счёт доходов от нефтяной и газовой отраслей. Интересно, что на начальном этапе «зелёного» движения норвежские экоактивисты даже привлекли популярную музыкальную группу A-ha для повышения осведомлённости населения о преимуществах электрических автомобилей. Переход к чистым технологиям поддерживается суверенным фондом, который составляет более 1,7 трлн долларов США и служит своего рода «подушкой безопасности» на случай, если запасы нефти в стране иссякнут. Этот фонд также называют «пенсионным фондом на чёрный день» и он включает освобождение покупателей электромобилей от уплаты налога с продаж. «Несмотря на достигнутый прогресс, Норвегии ещё есть куда стремиться», — пишет BBC. К тому же нельзя сказать, что дизельные автомобили остались в меньшинстве — их почти миллион. Однако их продажи стремительно падают, отмечает Норвежская федерация дорог. По данным отрасли, девять из десяти новых автомобилей, продаваемых в Норвегии, — это электромобили. Такая популярность электрокаров объясняется активной поддержкой со стороны властей. В частности, во многих городах Норвегии электромобили могут бесплатно парковаться, а их владельцы освобождены от уплаты городских сборов. Примечательно, что в то время как в других странах водители электромобилей жалуются на недостаток зарядных станций, в Норвегии бесплатные зарядные устройства доступны во всех городах — только в Осло их насчитывается 2000. В YouTube вот-вот появится ИИ для генерации идей, описаний и даже целых видео
18.09.2024 [21:49],
Владимир Фетисов
Технологии на основе искусственного интеллекта уже успели стать частью многих сервисов Google. Принадлежащий IT-гиганту видеохостинг YouTube не стал исключением, и уже в скором времени новейшие алгоритмы станут доступны пользователям сервиса. В рамках мероприятия Made on YouTube разработчики анонсировали несколько функций, которые, вероятно, изменят то, как авторы контента создают видео, а также сами ролики, публикуемые на платформе. 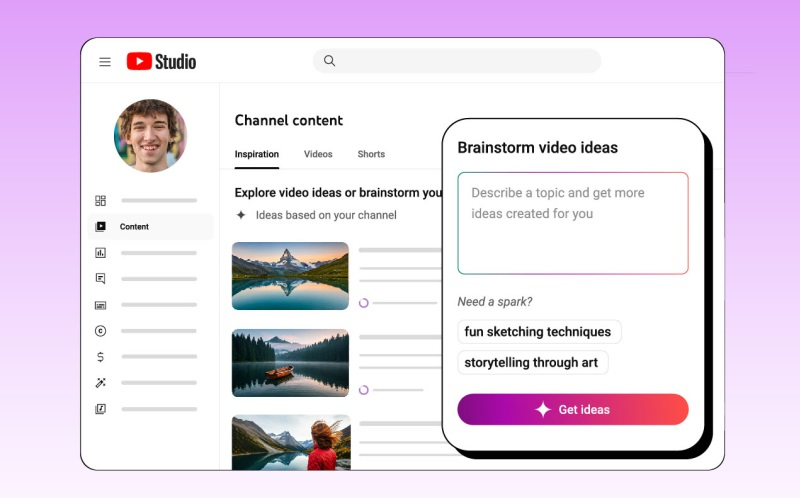
Источник изображения: YouTube Первая функция называется «Вдохновение» и появится в YouTube Studio. Последние несколько месяцев этот инструмент тестировался с привлечением ограниченного числа пользователей. Данная функция фактически предназначена для того, чтобы подсказывать авторам контента, что им следует делать. Она может предложить концепцию видео, сгенерировать заголовок и миниатюру для ролика, а также подготовить текстовое описание. YouTube позиционирует функцию как инструмент для мозгового штурма, но в целом она может быть полезна и при создании полноценных проектов. Кроме того, пользователи YouTube смогут генерировать реалистичные видео с помощью мощной нейросети Veo, которую представили ранее в этом году и теперь интегрировали в Shorts. Представитель Google отметил, что Veo уже интегрирован в облачный редактор Shorts, а созданные с его помощью ролики будут помечены соответствующим образом, чтобы зрители знали, что видео создано с помощью ИИ. Обе новые функции будут внедряться постепенно и станут доступны всем авторам контента в конце этого или начале следующего года. В YouTube появятся и другие инструменты на базе нейросетей. К ним относится функция автоматического дубляжа видео, которая будет озвучивать ролики на разные языки. Платформа также предоставит авторам больше ИИ-инструментов для взаимодействия с подписчиками через раздел «Сообщества» в приложении YouTube. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



