|
Опрос
|
реклама
Быстрый переход
Норвегия стала первой в мире страной, в которой электромобилей стало больше, чем машин на бензине
18.09.2024 [21:56],
Анжелла Марина
В Норвегии количество электрических автомобилей на дорогах превысило количество бензиновых. Согласно данным Норвежской федерации дорог (NRF), из 2,8 млн зарегистрированных частных автомобилей 754 303 являются полностью электрическими, в то время как на бензине ездят 753 905 автомобилей. Сообщается, что страна планирует полностью отказаться от продажи новых машин с ДВС к 2025 году. 
Источник изображения: Michael Marais/Unsplash Норвегия, с населением 5,5 млн человек, поставила перед собой амбициозную цель стать первым регионом в мире, где будет полностью прекращена продажа новых автомобилей с бензиновыми и дизельными двигателями. Уверенность в реализации этого плана удалось достичь благодаря широкому внедрению налоговых льгот и других стимулов для покупателей электрических автомобилей, финансируемых в значительной мере за счёт доходов от нефтяной и газовой отраслей. Интересно, что на начальном этапе «зелёного» движения норвежские экоактивисты даже привлекли популярную музыкальную группу A-ha для повышения осведомлённости населения о преимуществах электрических автомобилей. Переход к чистым технологиям поддерживается суверенным фондом, который составляет более 1,7 трлн долларов США и служит своего рода «подушкой безопасности» на случай, если запасы нефти в стране иссякнут. Этот фонд также называют «пенсионным фондом на чёрный день» и он включает освобождение покупателей электромобилей от уплаты налога с продаж. «Несмотря на достигнутый прогресс, Норвегии ещё есть куда стремиться», — пишет BBC. К тому же нельзя сказать, что дизельные автомобили остались в меньшинстве — их почти миллион. Однако их продажи стремительно падают, отмечает Норвежская федерация дорог. По данным отрасли, девять из десяти новых автомобилей, продаваемых в Норвегии, — это электромобили. Такая популярность электрокаров объясняется активной поддержкой со стороны властей. В частности, во многих городах Норвегии электромобили могут бесплатно парковаться, а их владельцы освобождены от уплаты городских сборов. Примечательно, что в то время как в других странах водители электромобилей жалуются на недостаток зарядных станций, в Норвегии бесплатные зарядные устройства доступны во всех городах — только в Осло их насчитывается 2000. В YouTube вот-вот появится ИИ для генерации идей, описаний и даже целых видео
18.09.2024 [21:49],
Владимир Фетисов
Технологии на основе искусственного интеллекта уже успели стать частью многих сервисов Google. Принадлежащий IT-гиганту видеохостинг YouTube не стал исключением, и уже в скором времени новейшие алгоритмы станут доступны пользователям сервиса. В рамках мероприятия Made on YouTube разработчики анонсировали несколько функций, которые, вероятно, изменят то, как авторы контента создают видео, а также сами ролики, публикуемые на платформе. 
Источник изображения: YouTube Первая функция называется «Вдохновение» и появится в YouTube Studio. Последние несколько месяцев этот инструмент тестировался с привлечением ограниченного числа пользователей. Данная функция фактически предназначена для того, чтобы подсказывать авторам контента, что им следует делать. Она может предложить концепцию видео, сгенерировать заголовок и миниатюру для ролика, а также подготовить текстовое описание. YouTube позиционирует функцию как инструмент для мозгового штурма, но в целом она может быть полезна и при создании полноценных проектов. Кроме того, пользователи YouTube смогут генерировать реалистичные видео с помощью мощной нейросети Veo, которую представили ранее в этом году и теперь интегрировали в Shorts. Представитель Google отметил, что Veo уже интегрирован в облачный редактор Shorts, а созданные с его помощью ролики будут помечены соответствующим образом, чтобы зрители знали, что видео создано с помощью ИИ. Обе новые функции будут внедряться постепенно и станут доступны всем авторам контента в конце этого или начале следующего года. В YouTube появятся и другие инструменты на базе нейросетей. К ним относится функция автоматического дубляжа видео, которая будет озвучивать ролики на разные языки. Платформа также предоставит авторам больше ИИ-инструментов для взаимодействия с подписчиками через раздел «Сообщества» в приложении YouTube. Asus выпустила GeForce RTX 4070 Ti Super Prime на графическом чипе от GeForce RTX 4090
18.09.2024 [21:46],
Николай Хижняк
Компания Asus представила видеокарту GeForce RTX 4070 Ti Super Prime в рамках инициативы SFF-Ready Enthusiast GeForce Card компании Nvidia, предлагающей сборку мощных игровых систем в компактных компьютерных корпусах. Новинка будет доступна в версиях как с заводским разгоном GPU, так и без него. 
Источник изображений: VideoCardz Примечательной особенностью карты Asus является то, что в ней используется графический процессор Nvidia AD102, вместо привычного AD103, который применяется в оригинальной RTX 4070 Ti Super. Сама Asus об этом не говорит, однако данный факт легко проверить, если взглянуть на заднюю часть видеокарты. Компоновка конденсаторов у неё соответствует графическому процессору AD102, а не AD103, который используется в оригинальной модели.  Напомним, AD102 используется в видеокартах GeForce RTX 4080 Super, GeForce RTX 4090 и некоторых других старших видеокартах. Характеристики GPU при этом остались прежними — он предлагает 8448 ядер CUDA, точно так же, как чип AD103 в оригинальной RTX 4070 Ti Super.  Размеры GeForce RTX 4070 Ti Super Prime составляют 300 × 120 × 50 мм. Карта занимает 2,5 слота расширения в корпусе ПК. Для дополнительного питания ускоритель оснащён одним 12+4-контактным разъёмом 12VHPWR.  Как уже говорилось выше, карта будет выпускаться как с эталонной частотой GPU, заявленной Nvidia (2160 МГц), так и с небольшим заводским разгоном до 2625 МГц. Как обычно, Asus также предлагает для обеих версий карты выставить настройки разгона вручную через своё фирменное приложение GPU Tweak 3, тем самым повысив игровую частоту графического чипа до 2640 МГц и 2655 МГц соответственно. Стоимость Asus GeForce RTX 4070 Ti Super Prime пока не сообщалась. В продаже новинка пока тоже не появилась. Создатели Warhammer 40,000: Space Marine 2 рассказали, что исправят и добавят по просьбам игроков
18.09.2024 [21:20],
Михаил Романов
С релиза Warhammer 40,000: Space Marine 2 прошло уже полторы недели, и у игроков скопилось много вопросов и предложений по улучшению шутера. Издатель Focus Entertainment осветил наиболее популярные запросы в новой публикации. 
Источник изображения: Steam (tornadoqt) Основным приоритетом команды из Saber Interactive остаётся повышение стабильности работы серверов — крупный патч с улучшениями этого аспекта и новым контентом ожидается «скоро» (обещали до конца сентября). Планируют сделать союзный ИИ более активным в битвах с боссами (в будущем патче — и в других ситуациях), а также скорректировать сложность «Ветеран», на которой в «соло» из-за ботов некоторые секции оказались чересчур трудными. 
Некоторые предложения игроков уже нашли отражение в графике развития (источник изображения: Focus Entertainment) Также обещают дополнительные цвета линз шлемов (в следующем большом патче), новое оружие ближнего боя, пиробластер в PvE/PvP, настройку черт лица своего персонажа и расширение опций индивидуализации космодесантников Хаоса. На этапе обсуждения находится настройка поля зрения, новые классы и опция настройки ИИ союзников. Кастомизация боевой баржи и «Громового Ястреба» у разработчиков сейчас не в приоритете. 
Смены положения камеры с одного плеча на другое ждать не стоит (источник изображения: Steam) Что ещё стало известно из ответов разработчиков:
Warhammer 40,000: Space Marine 2 вышла 9 сентября на PC (Steam, EGS), PS5, Xbox Series X и S. Спустя сутки после официального релиза суммарные продажи игры на всех платформах превысили 2 млн копий. Утечка раскрыла дизайн и характеристики игровой консоли Nintendo Switch 2
18.09.2024 [21:12],
Владимир Фетисов
Некоторое время назад компания Nintendo подтвердила, что работает над новой портативной игровой консолью Switch 2, которая будет анонсирована до конца текущего финансового года, то есть до конца будущего марта. Разработчики официально не раскрыли характеристики устройства и его дизайн, но свежая крупная утечка даёт представление о том, чего следует ждать от новой консоли Nintendo. 
Источник изображений: overclock3d.net Согласно имеющимся данным, Switch 2 будет работать на базе Arm-процессора от Nvidia, в котором задействован новый графический процессор на базе архитектуры Ampere. В дополнение к этому устройство получит 12 Гбайт оперативной памяти DDR5-7500 и накопитель формата UFS 3.1 ёмкостью 256 Гбайт.  Новая портативная консоль Nintendo будет больше модели нынешнего поколения, что подтверждают утекшие фотографии и 3D-модели. Разработчики оснастят её 8-дюймовым дисплеем, за счёт чего увеличится размер устройства в целом. В конструкции также предусмотрена подставка, расположенная на тыльной стороне корпуса.  Благодаря увеличению размера Switch 2 может получить более ёмкую аккумуляторную батарею и более эффективную систему охлаждения, чем у предшественницы. Такой подход поможет увеличить время автономной работы устройства или позволит консоли потреблять больше энергии для обеспечения большей вычислительной мощности без снижения времени автономной работы.  Ожидается, что Switch 2 получит значительный прирост производительности по сравнению с предшественницей. Этому будет способствовать новый производительный процессор и втрое увеличенный объём оперативной памяти. Современные решения Nvidia также должны открыть доступ к технологиям на базе искусственного интеллекта, таким как инструмент повышения разрешения Nvidia DLSS. Также на слитых фотографиях видно, что новинка получит обновлённых контроллеры Joy-Con, которые не только станут крупнее, но и получат магнитные крепления. Fractal Design представила компактный корпус Era 2 формата SFF с верхней панелью из ореха
18.09.2024 [19:56],
Николай Хижняк
Компания Fractal Design продолжает создавать все новые компьютерные корпуса с деревянными элементами в дизайне. В этот раз производитель представил компактную модель Era 2 формата SFF, у которой верхняя крышка выполнена из ореха. Остальные части корпуса изготовлены из анодированного алюминия. 
Источник изображений: Fractal Design Fractal Design Era 2 обладает размерам 366 × 165 × 314 мм и поддерживает установку материнских плат формата Mini-ITX. Вес корпуса составляет 4,64 кг. Он оснащён двумя предустановленными ШИМ-вентиляторами Aspect и в целом поддерживает установку до четырёх 120-мм или до двух 120-мм и двух 140-мм вентиляторов.  Также для корпуса заявляется поддержка радиаторов СЖО с габаритами до 315 × 140 мм и общей толщиной (с вентиляторами) до 52 мм, либо с размерами до 300 × 140 мм и общей толщиной до 58 мм. Таким образом в него без проблем поместится радиатор типоразмера до 280 мм.  В Fractal Design Era 2 можно установить блок питания формата SFX или SFX-L, видеокарту длиной до 328 мм и толщиной до 48–63 мм (в зависимости от расположения материнской платы) и процессорного кулера высотой до 55–70 мм (также зависит от расположения лотка материнской платы).  Внутри корпуса имеются два комбинированных посадочных места для 2,5- или 3,5-дюймовых накопителей. Фронтальная панель разъёмов Era 2 представлена одним портом USB 3.2 Gen 2x2 Type-C, двумя USB 3.0 и комбинированным 3,5-мм аудиовыходом.  Рекомендованная стоимость корпуса Fractal Design Era 2 составляет $199,99. В Калифорнии приняли законы о защите артистов от искусственного интеллекта
18.09.2024 [19:53],
Сергей Сурабекянц
Достижения в области генеративного ИИ ставят под угрозу существование многих творческих профессий. Актёры опасаются, что имитация их образов может стать обычным явлением. Губернатор Калифорнии Гэвин Ньюсом (Gavin Newsom) подписал 17 сентября два законопроекта, которые призваны помочь актёрам, музыкантам и другим исполнителям защитить свои цифровые копии в аудио- и визуальных постановках от копирования при помощи искусственного интеллекта. 
Источник изображения: unsplash.com Подписание этих законопроектов стало реакцией на обоснованную обеспокоенность общества в отношении бума искусственного интеллекта, в процессе которого большие языковые модели, обученные на соответствующем материале, в состоянии создавать фейковые видео, изображения и аудиоматериалы, с высокой точностью имитирующие реальных людей. В связи с этим многие эксперты подняли правовые и этические вопросы использования ИИ. Один из законопроектов, подписанных Ньюсомом, требует, чтобы в «контрактах указывалось использование созданных ИИ цифровых копий голоса или образа исполнителя, а исполнитель должен быть профессионально представлен при обсуждении контракта». Другой законопроект запрещает «коммерческое использование цифровых копий умерших исполнителей в фильмах, телешоу, видеоиграх, аудиокнигах, звукозаписях и многом другом без предварительного получения согласия наследников этих исполнителей». В марте губернатор Теннесси Билл Ли (Bill Lee) подписал подобный законопроект, направленный на защиту артистов, включая музыкантов, от несанкционированного использования их образов и голосов искусственным интеллектом. Ранее администрация президента США пыталась оказать давление на законодателей с целью регулирования ИИ, но поляризованный Конгресс США, где республиканцы контролируют Палату представителей, а демократы контролируют Сенат, не добился большого прогресса в разработке и принятии эффективного законодательства. Евросоюз смог дальше продвинуться в этом направлении: европейский «Закон об ИИ», основанный на оценке рисков, вступил в силу 1 августа 2024 года. Положения документа будут внедряться поэтапно вплоть до середины 2026 года. Уже через шесть месяцев планируется обеспечить соблюдение запретов на несколько видов использования ИИ в конкретных сценариях. Анималити, Призрачное лицо и безуспешные попытки «остановить цикл насилия»: релизный трейлер Mortal Kombat 1: Khaos Reigns
18.09.2024 [19:51],
Михаил Романов
До релиза сюжетного дополнения Khaos Reigns к файтингу Mortal Kombat 1 осталось меньше недели, и издатель Warner Bros. Games с разработчиками из NetherRealm Studios решил отметить скорую премьеру взрывным трейлером. 
Источник изображений: Warner Bros. Games Khaos Reigns продолжит сюжет Mortal Kombat 1: бог огня Лю Кан должен сплотить союзников, чтобы бросить вызов пришедшему из альтернативной вселенной безжалостному титану Хавику, который угрожает погрузить миры в хаос. В трёхминутном ролике Лю Кан призывает соратника помочь ему «остановить цикл насилия», но тщетно: новый трейлер вышел настолько жестоким, что на большинстве каналов запрещён для публикации за пределами YouTube. В видео показали, как знакомые и новые персонажи Mortal Kombat 1 (в том числе из Kombat Pack 2) стирают друг друга в пыль, разрывают на части, а также применяют жестокие и изобретательные фаталити. Также в ролике продемонстрировали несколько анималити — в рамках этого добивания персонаж превращается в животное (или насекомое). Обновление с данной функцией выйдет одновременно с Khaos Reigns и будет бесплатным. 
Бойцы Kombat Pack 2 — Сайракс, Сектор, Нуб Сайбот, Призрачное лицо, Конан-варвар и Терминатор T-1000 Фанаты остались в восторге от увиденного, особенно отметив отсылку к Mortal Kombat (2011) в анималити Нуб Сайбота, а также преемственность фаталити маньяка Призрачное лицо из фильмов ужасов «Крик». Khaos Reigns поступит в продажу 24 сентября по цене $50 на PC (Steam, EGS), PS5, Xbox Series X и S, а $40 — на Switch. В состав предзаказа входит Kombat Pack 2 — набор с шестью бойцами (см. изображение выше), купить который отдельно нельзя. Xiaomi обогнала Apple и стала вторым крупнейшим в мире производителем смартфонов
18.09.2024 [19:25],
Анжелла Марина
Компания Xiaomi впервые с 2021 года обошла Apple по объёмам продаж смартфонов за август, став вторым производителем в мире. Это произошло на фоне стабильных объёмов сбыта продукции и одновременно сезонного августовского снижения продаж у Apple. По данным исследования Counterpoint, Xiaomi демонстрирует один из самых быстрых темпов роста среди брендов смартфонов в 2024 году, способствуя восстановлению глобального рынка. 
Источник изображения: He Junhui/Unsplash Сообщается, что в августе Xiaomi превзошла рынок, компенсируя сезонное снижение продаж на своих ключевых рынках ростом, обусловленным промоакциями в Латинской Америке. После проблем с поставками в 2022 году Xiaomi, как и остальная часть индустрии смартфонов, столкнулась со сложной макроэкономической и геополитической обстановкой в 2023 году. Однако после слабого 2022 года Xiaomi успешно изменила свою стратегию сбыта, что привело к значительному росту продаж за последний год. «В этом году Xiaomi приняла более гибкую продуктовую стратегию, сосредоточив усилия на создании конкретной флагманской модели в каждом ценовом сегменте, вместо того чтобы выпускать несколько устройств в одном сегменте, — комментирует ситуацию в Xiaomi директор по исследованиям Тарун Патхак (Tarun Pathak). — Кроме того, компания активизировала усилия в области продаж и маркетинга, продолжая экспансию на новые рынки и укрепляя позиции на существующих». При этом стоит отметить, что хотя устройства начального и среднего уровня продолжают демонстрировать высокие показатели продаж, компания также добилась успехов в премиальном сегменте благодаря складным устройствам, а также устройствам серии Ultra. В целом большинство ключевых рынков Xiaomi за последние несколько кварталов продемонстрировали восстановление, что сыграло важную роль в росте спроса на недорогие модели, особенно в ценовом диапазоне до 200 долларов, таких как Redmi 13 и Note 13. Эти 5G-устройства помогли Xiaomi укрепить позиции на всех ключевых рынках, в том числе в Индии, Латинской Америке, Юго-Восточной Азии, странах Ближнего Востока, а также Африки. Хотя выход Xiaomi на второе место в августе был в значительной степени обусловлен её агрессивным ростом в последние кварталы, сезонное снижение продаж Apple также сыграло роль. Поскольку новое поколение iPhone обычно выпускается в сентябре, август, как правило, является самым слабым месяцем для Apple в году. Однако запуск iPhone 16, вероятно, позволит компании восстановить свои позиции в ближайшие месяцы. По мере того как устройства становятся всё более похожими друг на друга как по цене, так и по возможностям, конкуренция между ведущими брендами достигает беспрецедентного уровня. Новые форм-факторы, такие как складные устройства, и функции искусственного интеллекта помогают брендам выходить на новый уровень. При этом экосистема устройств, дизайн продукта и маркетинговая стратегия остаются как никогда важными составляющими бизнеса, что подтверждает недавний успех Xiaomi. XPG представила недорогие корпуса Invader x Mini и Valor Air Plus и блоки питания Probe Bronze
18.09.2024 [19:19],
Николай Хижняк
Игровой бренд XPG компании Adata сообщил о выпуске двух новых доступных компьютерных корпусов Invader x Mini и Valor Air Plus, а также недорогих блоков питания серии XPG Probe Bronze. 
Источник изображений: XPG Корпус XPG Invader x Mini обладает размерами 460 × 210 × 359 мм и поддерживает установку материнских плат форматов ATX, Micro-ATX и Mini-ITX. Фронтальная и левая панели корпуса выполнены из закалённого стекла толщиной 4 мм. Благодаря этому корпус открывает панорамный обзор на установленные комплектующие. 
XPG Invader x Mini Новинка предлагает пять предустановленных 120-мм RGB-вентиляторов, четыре из которых имеют реверсивный ход. Корпус поддерживает установку 120-мм радиатора СЖО сзади и 240-мм сверху, а также позволяет устанавливать видеокарты длиной до 330 мм, кулеры высотой до 166 мм и блоки питания до 180 мм. Внутри корпуса также предусмотрены два выделенных места для 3,5-дюймовых HDD и два комбинированных места для 2,5- или 3,5-дюймовых накопителей. Фронтальная панель корпуса XPG Invader X Mini оснащена одним USB 3.2 Type-C, одним USB 3.2 Type-A и комбинированным 3,5-мм аудиовыходом. Новинка будет доступна в чёрном и белом исполнениях.  Размеры корпуса XPG Valor Air Plus составляют 482 × 200 × 400 мм. Он оснащён продуваемой фронтальной панелью. Левая панель выполнена из закалённого стекла толщиной 3 мм. Новинка тоже поддерживает установку плат форматов ATX, Micro-ATX и Mini-ITX. 
XPG Valor Air Plus Корпус оснащён пятью предустановленными 120-мм вентиляторами, четыре из которых имеют ARGB-подсветку. Новинка поддерживает установку радиаторов СЖО 240 или 360 мм спереди, 240 мм сверху и 120 мм сзади. Также есть возможность установки видеокарты длиной до 340 мм, процессорного кулера высотой до 160 мм и блока питания длиной до 170 мм. Внутри предусмотрены места для двух 2,5-дюймовых и двух 3,5-дюймовых накопителей.  XPG Valor Air Plus имеет семь слотов расширения. Фронтальная панель корпуса представлена двумя портами USB 3.2 и одним 3,5-мм комбинированным аудиовыходом.  Серия блоков питания XPG Probe в свою очередь представлена двумя моделями мощностью 600 и 700 Вт. Обе имеют сертификат эффективности 80 Plus Bronze. Производитель поясняет, что они обеспечивают до 87 % эффективности при 50-процентной нагрузке. Блоки питания XPG Probe соответствуют стандарту питания ATX v2.52. Блоки питания XPG Probe не обладают модульной конструкцией кабелей. Производитель заявляет, что они оснащены защитой от превышения напряжения (OVP), защитой от превышения мощности (OPP), защитой от короткого замыкания (SCP), защитой от понижения напряжения в сети (UVP), защитой от перегрева (OTP), а также защитой от всплесков и бросков напряжения (SIP). Охлаждение блоков питания осуществляется вентилятором размером 120 мм со скоростью работы 2100 об/мин. На БП предоставляется трёхлетняя гарантия производителя. «Всё ещё не верится»: уютный симулятор путешествий в автодоме Outbound в 9 раз перевыполнил план на Kickstarter
18.09.2024 [19:19],
Юлия Позднякова
На Kickstarter завершилась кампания по финансированию симулятора путешествий в автодоме Outbound от нидерландской студии Square Glade Games, анонсированного в феврале. Игра собрала €265,6 тыс., на 885 % перевыполнив план. 
Источник изображений: Square Glade Games В общей сложности в финансировании поучаствовали 5197 вкладчиков. Кампания оказалась настолько популярной, что многие не успевшие помочь разработчикам пользователи попросили продолжить приём средств. Создатели пошли навстречу и на ограниченное время открыли сбор пожертвований на площадке BackerKit. «Всё ещё не верится, но благодаря невероятному количеству вкладчиков эта кампания завершилась с огромным успехом, — написали авторы. — Это был поистине удивительный месяц, и мы от души благодарим каждого, кто поверил в Outbound». Были разблокированы все десять дополнительных целей: система улучшений устройств (вроде солнечных панелей и турбин), возможность разбить лагерь вне фургона, летающие над машиной воздушные змеи, рыбалка, ловля пчёл и пчеловодство, модульные сиденья, собака-компаньон (предложено игроками), больше мини-игр, дополнительные строительные элементы и материалы, а также настройка внешнего вида персонажа.  В Outbound игроки отправятся в путешествие на электрическом фургоне по открытому миру, включающему разные биомы (леса, пустыни, побережья). В своём «доме мечты на колёсах» они будут использовать экологически чистые источники энергии (солнце, ветер, вода), создавать предметы на верстаках из добытых материалов, налаживать и автоматизировать производство, выращивать урожай и изучать технологии. Также придётся учитывать меняющиеся погодные условия и время суток. Пользователям предложат на выбор несколько транспортных средств с уникальными характеристиками и позволят их модернизировать, обставлять мебелью и украшать сотнями предметов. Играть можно в одиночку или в компании трёх друзей. Outbound
Outbound выйдет на ПК (Steam), PlayStation, Xbox и Nintendo Switch в 2026 году с текстовым переводом на русский язык. В первой половине 2025-го разработчики планируют выпустить «альфу», а во второй — «бету». В 2022 году Square Glade Games собрала на Kickstarter средства на создание своего предыдущего проекта — конструктора миров в антураже Дикого Запада Above Snakes. Песочница вышла в мае 2023 года и была достаточно тепло принята игроками (рейтинг в Steam — 75 % на основании 1,2 тыс. обзоров). Вышли обзоры iPhone 16 Pro и Pro Max: отличная автономность, улучшенные камеры и причуды кнопки управления камерой
18.09.2024 [19:13],
Андрей Созинов
Сегодня многие иностранные издания опубликовали обзоры смартфонов iPhone 16 Pro и iPhone 16 Pro Max, в которых рассказали об аппаратных изменениях новинок, времени автономной работы, обновлениях камеры и новой кнопке для управления камерой, а также о многих других подробностях. Наши собственные обзоры iPhone 16-й серии появятся позже, поэтому здесь приведём интересные моменты из иностранных обзоров. 
Источник изображений: Apple Обозреватель CNN отметил новую 48-Мп широкоугольную камеру в iPhone 16 Pro, благодаря которой фотографии крупных планов теперь могут быть такими же чёткими, как и снимки, сделанные основным модулем. «Мне было сложно заметить разницу в снимках, хотя я могу сказать, что фотографии iPhone 16 Pro немного ярче, чем прошлогодние [у iPhone 15 Pro], и на них больше деталей», — говорит обозреватель. Также отмечается, что новая камера обеспечивает большее количество деталей на макроснимках — объекты на снимках, сделанных на iPhone 16 Pro, получаются более чёткими, чем на iPhone 15 Pro Max. Обзор The Verge также отмечает «хорошие новости» для пользователей об изменениях в камере iPhone 16 Pro, но здесь автор сосредоточился на обновлённой функции «Фотографические стили», которая позволяет легко настроить «то, как камера обрабатывает цвета, оттенки кожи и тени, даже после того как вы сделали снимок».  Все стили теперь предлагают три новые настройки: «цвет», который, по сути, является насыщенностью, «палитра», которая представляет собой диапазон применяемых цветов, и самое главное — «тон», который позволяет добавлять тени на фотографии. По словам обозревателя, регулятор тона позволил ему добиться гораздо более реалистичной цветопередачи снимков iPhone. Конечно же, обозреватели не прошли мимо и новой сенсорной кнопки Camera Control для управления функциями камеры, расположенной на правой грани смартфона. Например, Engadget отметили «несколько проблем» у новой кнопки, включая неудобство её расположения: «Кнопка находится немного дальше от основания телефона, чем мне хотелось бы, поэтому для нажатия на неё приходится тянуться пальцами, независимо от того, в ландшафтном или портретном режиме я снимаю». Обозреватель отметил, что иногда не так просто нажать на кнопку или провести по ней пальцем, и предполагает, что для неё нужно менять хват смартфона при съёмке. Также обозреватель отметил не лучшую работу сенсора данной кнопки. «Мало того, что было трудно пролистывать различные настройки, когда держишь устройство одной рукой, он ещё и реагирует на случайные прикосновения и жесты. Иногда телефон скользил по моей ладони и менял экспозицию или уровень зума, что полностью портило впечатление», — пишут Engadget. Следует отметить, что в настройках можно изменить чувствительность или вообще отключить кнопку.  Однако когда смартфон держишь двумя руками, работать с кнопкой становится удобно. Удобно приближать и отдалять объекты, перекомпоновывать кадр и подстраивать экспозицию. Особенно удобна кнопка при записи видео, поскольку медленное приближение или удаление объекта съёмки происходит более плавно, чем при использовании экранного ползунка. Также кнопка оказалась полезна, когда нужно просто и быстро что-то сфотографировать. Портал CNET высоко оценил способность iPhone 16 Pro записывать замедленное видео в формате 4K со скоростью 120 кадров в секунду. «И результаты получаются выдающимися, вот почему эта функция так важна. Предыдущие замедленные видео, снятые на iPhone, могли выглядеть хорошо, если было много света. Но их качество было ниже HD-разрешения, а качество изображения значительно уступало обычной записи видео в формате 4K 30 кадров в секунду. Новое замедленное видео iPhone 16 Pro отличается высокой детализацией, хорошим динамическим диапазоном и точными цветами, что ставит его на один уровень с обычным качеством видео на iPhone». Обозреватели также обратили внимание на время автономной работы iPhone 16 Pro, ведь Apple обещала для новинок отличные показатели автономности. Wired пишет, что iPhone 16 Pro Max легко выигрывает у iPhone 16 Pro по времени автономной работы — в конце дня у более крупного смартфона часто оставалось более 30 % заряда. У iPhone 16 Pro за день батарея разрядилась до 15 %. Mashable отметил, что iPhone 16 Pro продержался 18 часов и 17 минут на одном заряде в их тесте с просмотром видео в TikTok. Для сравнения, прошлогодний iPhone 15 Pro Max продержался 14 часов и 53 минуты в том же тесте. Ещё более впечатляющий результат показал iPhone 16 Pro Max — в том же тесте с TikTok смартфон продержался 25 часов 17 минут.  Наконец, обозреватели отметили более крупные экраны смартфонов, и в случае iPhone 16 Pro Max это скорее минус. Wired на этот счёт пишет следующее: «Модели Pro стали больше, чем раньше. Изначально я считал это незначительным увеличением размера экрана за счёт более тонких ободков вокруг экрана, но это нечто большее. Они немного выше, чем предыдущие модели iPhone. Это не такая уж большая проблема с iPhone 16 Pro, но iPhone 16 Pro Max и так был большим. Теперь дотянуться до верхней части телефона с вытянутым большим пальцем стало ещё сложнее. Я не думаю, что физическое увеличение размера было необходимо». «Функции Pro по доступной цене» — вышли первые обзоры iPhone 16 и 16 Plus
18.09.2024 [19:09],
Сергей Сурабекянц
Сегодня крупные СМИ и блогеры опубликовали первые обзоры iPhone 16 и iPhone 16 Plus, и здесь мы собрали выдержки из этих материалов. Среди ключевых функций — новый производительный чип A18 с поддержкой Apple Intelligence, ускоренная зарядка, улучшенная широкоугольная камера с возможностью макросъемки, обновлённые фотографические стили и совершенно новая ёмкостная кнопка управления камерой. 
Источник изображений: James Martin/CNET Дизайн Авторы обзоров единогласно отмечают, что дизайн iPhone 16 схож с iPhone 15, но цветовая палитра стала более яркой, пополнившись такими вариантами, как Ultramarine, Pink и Teal. Расположение камер изменилось с прежнего диагонального к вертикальному, что обеспечивает возможность пространственной видео- и фотосъёмки для гарнитуры Vision Pro. По мнению Джона Веласко (John Velasco) из Tom's Guide, «iPhone 16 — гораздо более стильный телефон, чем iPhone 16 Pro, что обидно, потому что я бы хотел увидеть эти более смелые цвета на iPhone Pro». Он также отметил игру цвета на задней панели устройства, на которой «мелкие детали, такие как цвет контура задних камер, создают сильный контраст в качестве акцентного цвета».  Филип Берн (Philip Berne) из TechRadar полагает, что самое большое изменение дизайна произошло на тыльной стороне устройств: «Модули камеры расположены вертикально. Основная 48-мегапиксельная камера Fusion находится над 12-мегапиксельным широкоугольным объективом. Вспышка True Tone смещена в сторону, из-за более крупных объективов это похоже на выступ камеры iPhone X на стероидах. Мне очень нравится этот вид». Кнопка управления камерой Одним из наиболее заметных нововведений в iPhone 16 журналисты называют новую ёмкостную кнопку управления камерой Camera Control. По словам авторов обзоров, эта кнопка, расположенная на правой стороне устройства, выводит фотографические возможности смартфона на новый уровень, имитируя физическую кнопку спуска затвора. Она также воспринимает жесты для настройки масштабирования и выбора параметров экспозиции.  «Кнопка управления камерой может распознавать силу нажатия […], копируя физическую кнопку спуска затвора лучших современных камер. Также она может распознавать свайпы для переключения между некоторыми настройками, такими как управление зумом, регулировка экспозиции […] Хотя ко всему этому может потребоваться некоторое привыкание, это шаг в правильном направлении», — считает Джон Веласко. По мнению Лизы Идичикко (Lisa Eadicicco) из CNET, «Apple создала новый миниатюрный интерфейс специально для камеры, и с ним очень весело играть. Помимо кнопки управления камерой и Dynamic Island, приятно видеть, что Apple обновляет интерфейс iPhone для двух вещей, которые мы чаще всего делаем на наших телефонах: фотосъёмка и переключение между приложениями». Однако некоторые авторы высказывают опасения, что пользователей может отпугнуть «сложность Camera Control», так как она требует от них выработки новой привычки. Многие владельцы могут её проигнорировать, как ранее сенсорную панель MacBook Pro. Apple Intelligence Одной из ключевых функций iPhone 16 является поддержка функций искусственного интеллекта Apple Intelligence, хотя многие из них все ещё находятся в разработке. В основе способности телефона работать с инструментами ИИ лежит новый чип A18. Джон Веласко расстроен тем, что iPhone 16 выходит без поддержки ИИ «из коробки», хотя уверен, что Apple Intelligence откроет новую эру для iPhone. Он выделил несколько любимых функций Apple Intelligence, которые ему удалось изучить в процессе бета-тестирования: «Siri стала гораздо более общительной, чем когда-либо прежде, а эффективность Photo Clean Up для редактирования фотографий заметно возросла».  Веласко с особым нетерпением ждёт функции Visual Intelligence, которая должна стать ответом Apple на Google Lens. Эта функция станет эксклюзивом для линейки iPhone 16 и не будет доступна на предыдущих моделях. Связанная с кнопкой управления камерой, Visual Intelligence позволит быстро искать что угодно, просто сделав снимок, кроме того, её можно интегрировать с любым приложением или сервисом, запущенным на телефоне. Остальные функции Apple Intelligence, по мнению авторов обзоров, «не станут чем-то особенным или инновационным». Они считают, что «Google все ещё опережает Apple, когда дело касается функций ИИ, тем не менее, Apple движется в правильном направлении». Улучшения камеры iPhone 16 получил несколько ключевых обновлений камеры, включая улучшенную сверхширокоугольную камеру с поддержкой макросъемки впервые на стандартной модели iPhone. Apple также обновила свои фотографические стили, улучшив то, как камера обрабатывает оттенки кожи, тени и блики в реальном времени.  По мнению Джона Веласко, iPhone 16 «наконец-то получил возможность делать правильные макрофотографии благодаря своей обновлённой сверхширокоугольной камере». Он подчеркнул «беспрецедентную детализацию» снимков, сделанных в режиме макрофотографии.  Лизу Идичикко впечатлили улучшения в сверхширокоугольной камере, которая стала намного лучше снимать в условиях слабого освещения. Однако, по её мнению, Google Pixel 9 «сделал немного лучшее изображение, которое было немного ярче и сохраняло объекты в фокусе, даже если они двигались». Идичикко отметила существенно обновлённые фотографические стили. По её мнению, программное обеспечение камеры стало значительно лучше определять оттенки кожи, цвета, блики и тени. Появилась возможность переключаться между различными фотографическими стилями при предварительном просмотре фотографии перед нажатием затвора, что особенно удобно делать при помощи новой кнопки управления камерой. Идичикко считает, что новые стили помогут пользователям, не имеющим опыта в фотографии или видеоредактировании «создавать драматичные, яркие изображения, делая немного больше, чем просто нажатие кнопки». Ниже представлены видеоролики, на основе которых сделан данный обзор обзоров: Ubisoft заверила, что XDefiant «абсолютно точно не умирает», и представила план развития игры
18.09.2024 [18:47],
Михаил Романов
Августовский материал инсайдера Тома Хендерсона (Tom Henderson) о состоянии дел условно-бесплатного командного шутера XDefiant от Ubisoft San Francisco не прошёл мимо разработчиков и даже заслужил ответ в новом блоге команды. 
Источник изображений: Ubisoft На запуске XDefiant привлекла 8 млн человек, однако впоследствии якобы начала так быстро терять игроков, что Ubisoft распорядилась к концу третьего сезона повысить показатели, иначе проект лишится оставшейся пострелизной поддержки. По словам продюсера XDefiant Марка Рубина (Mark Rubin), «игра абсолютно точно не умирает»: в команде знают болевые точки проекта (система регистрации попаданий, сетевой код, нехватка контента в системе прогресса) и работают над их устранением. «Игра чувствует себя хорошо, но мы хотим, чтобы стало ещё лучше. Для этого мы отвечаем на запросы сообщества, что всегда было в планах. Ubisoft нас очень поддерживает и даже выделила команде больше ресурсов», — заверил Рубин.  Свои заявления Рубин сопроводил графиком развития XDefiant на оставшуюся часть первого года поддержки, включающим конкретные нововведения и улучшения во втором, третьем и четвёртом сезонах. Второй сезон (стартует 24 сентября) принесёт с собой фракцию Highwaymen, оружие, карты, режимы, «бету» приватных матчей и многое другое. Официальная презентация обновлений ожидается на сегодняшней трансляции. XDefiant стартовала в мае на PC (Ubisoft Connect), PS5, Xbox Series X и S. В обзоре для 3DNews Алексей Лихачёв назвал игру приятным шутером с очень достойной основой, которую можно развивать в интересных направлениях. Microsoft Research занялась разработкой нового поколения эффективных облачных хранилищ
18.09.2024 [18:04],
Руслан Авдеев
Подразделение Microsoft Research, работающая в Кембридже (штат Массачусетс, США), занялась разработкой и созданием прототипов систем облачного хранения нового поколения. Datacenter Dynamics напоминает, что именно это подразделение стоит за проектом Project Silica, в рамках которого создавались носители, способные хранить данные 10 тыс. лет. В описании одной из вакансий говорится, что исследователи пересматривают фронт работ, переключаясь с создания носителей для архивных хранилищ на более «горячие» решения. В частности, упоминается, что недавние успехи с сфере ИИ и машинного обучения фундаментально изменили рамки возможного во многих сферах, включая разработку новых материалов, создание научных симуляций, обработку сигналов и т.п. От кандидата требуется докторская степень в области информатики или компьютерной инженерии или эквивалентный опыт работы в R&D в области СХД, ОС, сетей, распределённых систем и т.п. 
Источник изображения: Microsoft Новые подходы приводят к пересмотру возможностей облачных хранилищ в эпоху ЦОД, ограниченных в энергии — никогда запрос на недорогие и устойчивые хранилища данных не был столь высок. В рамках нового проекта исследователи намерены внедрять инновации на уровне носителей и методов записи и чтения информации. Проект потребует «изобретения новых методов исследования» для быстрой оценки того, как изменения на физическом уровне повлияют на ключевые показатели производительности хранилища. Создание эффективной системы с нуля также включает решение более традиционных задач — оценку рабочих нагрузок, планирование записи и чтения данных оптимальным образом, эффективное размещение информации на носителе, коррекция ошибок для защиты данных от ошибок и стирания. Главой проект является Ричард Блэк (Richard Black), который ранее работал над инициативой Pelican — под его руководством компания пыталась создать наиболее дешёвый массив дисковых накопителей. AOC и Porsche Design выпустили изогнутый игровой монитор Porsche Design AGON PRO PD34 — 34 дюйма, QD-OLED, 1440p и 240 Гц
18.09.2024 [18:01],
Николай Хижняк
Компания AOC в сотрудничестве со специалистами студии Porsche Design представила сверхширокоформатный игровой монитор Porsche Design AGON PRO PD34 с изогнутым экраном QD-OLED, который обладает радиусом кривизны 1800R. Диагональ дисплея составляет 34 дюйма, он обладает соотношением сторон 21:9 и разрешением 3440 × 1440 пикселей. 
Источник изображений: AOC Для монитора заявляется частота обновления 240 Гц и пиковая яркость в 1000 кд/м2. Монитор получил сертификаты VESA DisplayHDR True Black 400 и VESA ClearMR 13000, и обладает 100-процентным охватом цветового пространства sRGB, 99-процентным AdobeRGB и 99-процентным DCI-P3. Также монитор поддерживает технологию синхронизации изображения AMD FreeSync Premium Pro и совместим с Nvidia G-Sync. Создатели монитора отмечают, что форма его задней крышки имитирует радиаторную решётку спорткара Porsche 911.  В оснащение Porsche Design AGON PRO PD34 входят два порта HDMI 2.1, один DisplayPort 1.4, USB 3.2 Type-C с альтернативными функциями DisplayPort и зарядки до 65 Вт, три нисходящих USB 3.2 Gen1 и один восходящий USB 3.2, два динамика по 8 Вт с поддержкой DTS, 3,5-мм аудиовыход и 2,5-гигабитный сетевой порт.  Монитор оснащён KVM-переключателем и получил эргономичную подставку с возможности изменения высоты дисплея над столом, а также углов поворота и наклона. Кроме того, новинка имеет RGB-подсветку Light FX с поддержкой 15 различных световых эффектов.  Монитор Porsche Design AGON PRO PD34 поступил в продажу 18 сентября в магазинах Porsche Design, у отдельных ретейлеров, а также на сайте porsche-design.com. Стоимость новинки составляет 999 британских фунтов или 122 тыс. рублей. Дорогие фотоаппараты снова стали популярны — продажи беззеркалок подскочили на 12 % в этом году
18.09.2024 [17:46],
Павел Котов
В последние десять лет создавалось все более чёткое ощущение, что цифровые фотоаппараты находятся на грани исчезновения. По мере расширения возможностей камер на смартфонах простые фотоаппараты вышли из моды у широкой публики — суммарные продажи цифровых камер рухнули на 93 % от рекордного значения. Но сейчас в сегменте премиальных моделей наметилось неожиданное возвращение к истокам. 
Источник изображения: leica-camera.com Камеры начального уровня почти вышли из обращения, а элитные модели уверенно наращивают продажи, обращает внимание Economist. Такие бренды как Leica, Fujifilm и Nikon переключили ассортимент на премиальные предложения, и эта стратегия окупает себя. Средняя цена продажи (ASP) нового фотоаппарата за последние шесть лет утроилась, подсчитали в Ассоциации камер и устройств для обработки изображения (Camera and Imaging Products Association). По последним данным, мировые поставки камер с января по май 2024 года выросли почти на 12 % год к году и достигли более 3 млн единиц — это самый высокий уровень за три года. Динамика обусловлена устойчивым спросом на дорогие беззеркальные камеры, которые в разы превзошли продажи «зеркалок» по всему миру. Продажи зеркальных фотоаппаратов продолжают падать. Наибольшую выгоду от этой тенденции получил немецкий бренд Leica. Одна из его последних моделей, Leica Q3, продаётся за $6000, и это без учёта дополнительных аксессуаров — один только упор для большого пальца стоит $245. Несмотря на высокую цену, на момент выхода модели списки ожидания растянулись на полгода вперёд. В прошлом году Leica доложила о рекордных продажах на €485 млн — годом ранее этот показатель составлял €444 млн. Столь же высокий спрос наблюдается на премиальную линейку камер Fujifilm X100, хотя последняя модель оценивается в $1600. Иронично, что движущей силой этой страсти, возможно, оказалось повсеместное присутствие мобильной фотографии, считает президент Nikon Мунеаки Токунари (Muneaki Tokunari). Камеры на смартфонах породили среди населения вкус к творческой фотографии как к увлечению, а не дополнительной практической функции. Античит BattlEye сломал GTA Online на Steam Deck, но Rockstar ничего делать не собирается
18.09.2024 [17:37],
Михаил Романов
За всё приходится платить. Добавленная накануне в ПК-версию GTA Online с обновлением Rockstar Games Launcher поддержка античита BattlEye оказалась с подвохом — режим перестал работать на Steam Deck. 
Источник изображения: Rockstar Games Без включения BattlEye запустить GTA Online теперь невозможно (в отличие от сюжетного режима, GTA V), а портативный ПК от Valve на настоящий момент не имеет поддержки данного античита в проекте от Rockstar Games. Согласно записи на сайте поддержки Rockstar, GTA V и GTA Online официально не имеют полной совместимости со Steam Deck, поэтому все технические вопросы по этому поводу стоит направлять Valve. 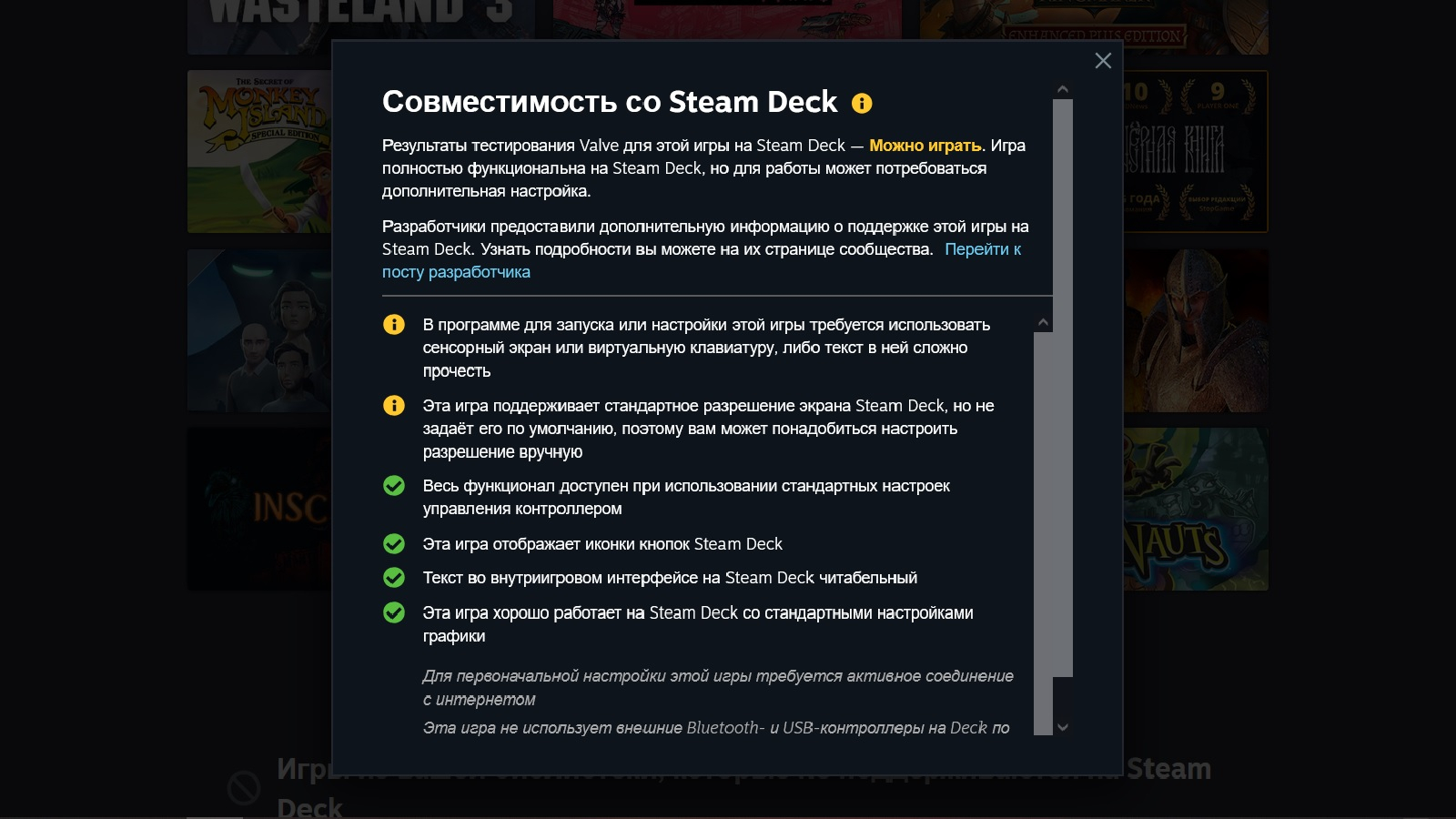
Официальный статус совместимости GTA V со Steam Deck (источник изображения: Steam) Пользователи уличили Rockstar Games в лукавстве. BattlEye уже давно может работать с устройствами на базе Linux вроде Steam Deck — было бы желание. Valve рассказывала об этом ещё осенью 2021 года. «Разработчикам нужно всего лишь связаться с командой BattlEye, чтобы античит на Proton работал в их игре. За исключением этого обращения, от разработчиков ничего не требуется», — заявила тогда Valve. 
Источник изображения: Rockstar Games Несмотря на ограниченную совместимость, GTA V — одна из самых популярных игр на Steam Deck. Криминальный боевик является завсегдатаем открытого в июне чарта наиболее востребованных проектов на портативном ПК. BattlEye должен был затруднить недобросовестным пользователям порчу жизни честным игрокам GTA Online, а в итоге обернулся головной болью для владельцев проекта на Steam Deck. HTC представила автономную VR-гарнитуру Vive Focus Vision с отслеживанием взгляда за $999
18.09.2024 [17:21],
Павел Котов
Компания HTC анонсировала Vive Focus Vision — первую в своём ассортименте ориентированную на рядовых потребителей автономную гарнитуру виртуальной реальности с функцией отслеживания направления взгляда. Помимо этого новинка способна отслеживать движения пользователя без дополнительных базовых станций. Устройство оценивается в $999. 
Источник изображений: HTC В основу модели HTC Vive Focus Vision легла гарнитура HTC Vive Focus 3, предназначенная для корпоративных пользователей — новое устройство будет предлагаться как для профессионалов, так и для рядовых потребителей. Гарнитура работает на чипе Qualcomm Snapdragon XR2, а использовать её можно в автономном режиме и в связке с ПК, к которому она может подключаться через USB Type-C или DisplayPort. Для каждого глаза установлен дисплей с разрешением 2448 × 2448 пикселей и полем зрения 120°. При работе в автономном режиме максимальная частота дисплея составляет 90 Гц, а к концу года появится поддержка 120 Гц при подключении через DisplayPort.  Функция отслеживания глаз является важнейшим преимуществом HTC Vive Focus Vision — направление взгляда фиксируется 120 раз в секунду с точностью от 0,5° до 1° в пределах 20-градусного диапазона центрального поля зрения. Это позволяет направлять вычислительную мощность на прорисовку изображения, на которое пользователь смотрит непосредственно, благодаря чему повышается производительность. Функция также позволяет осуществлять управление интерфейсом при помощи движений глаз, но в отличие от Apple Vision Pro здесь она присутствует в качестве экспериментальной. Отслеживание направления взгляда осуществляется при помощи пятиточечной калибровки — её точность повышается за счёт автоматической установки межзрачкового расстояния. Пользователи с близорукостью могут вручную установить фокус дисплея.  Другим важным достоинством HTC Vive Focus Vision является поддержка горячей замены аккумулятора — здесь есть дополнительная внутренняя батарея, ресурса которой хватит на 30 минут, пока выполняется замена основной, которая крепится на задней части ремешка на голове. Основного аккумулятора хватит на два часа, и это обычный показатель для автономных гарнитур. HTC Vive Focus Vision оценивается в $999 — на старте продаж устройство будет комплектоваться набором Vive Wired Streaming Kit для подключения через DisplayPort, а впоследствии он обойдётся уже в $149. В перспективе выйдет и вариант Business Edition за $1299, который отличается подпиской на гарантийный сервис HTC Vive Business и наличием ПО Vive Business+ для управления группой устройств. Apple рассказала, что значительно повысила ремонтопригодность iPhone 16
18.09.2024 [16:16],
Павел Котов
Apple рассказала о том, какую большую работу проделала для повышения ремонтопригодности iPhone за последнее время, что в полной мере смогут ощутить владельцы iPhone 16. Изменилась программа самостоятельного ремонта и упростилась конструкция самих телефонов, которые стало проще открывать с передней или задней части в зависимости от того, что требуется отремонтировать. 
Источник изображений: apple.com Телефоны линейки iPhone 16 разработаны с учётом трёх основных принципов: долговечность, ремонтопригодность и постоянное обновление ПО. Над аспектами долговечности и обновления ПО Apple работает уже много лет, и в этом году компания произвела изменения, направленные на повышение ремонтопригодности устройств. Упростился механизм извлечения аккумулятора на iPhone 16. Раньше батарея приклеивалась, и клейкие полоски было очень непросто удалить. Теперь аккумулятор удерживается при помощи «ионного жидкого клея», который теряет свои свойства под действием низкого напряжения — хватит простой батарейки на 9 В. Слухи об этом нововведении ходили перед выпуском iPhone 16, и предполагается, что это связано с новым европейским законом, касающимся замены аккумуляторов. В iOS 18 появилась функция «Помощник по ремонту» (Repair Assistant), которая поможет как мастерам, так и рядовым пользователям производить настройку компонентов непосредственно на устройстве — ранее для этого требовалось обращение в Apple. Прямо на устройстве можно выполнять настройку камеры TrueDepth без необходимости подключаться к Mac – это касается моделей iPhone 12s и более поздних.  Камеру TrueDepth на iPhone 16 можно брать с другого iPhone 16 или 16 Pro; кроме того, на iPhone 16 Pro компания заявила о появлении «упрощённого доступа» к некоторым компонентам. В iOS 18 также теперь есть новый инструмент под названием Apple Diagnostics for Repair — он позволяет средствами самого устройства диагностировать проблемы и определять, какие компоненты требуют замены. Наконец, Apple улучшила поддержку сторонних и бывших в употреблении компонентов. Бывшие в употреблении детали можно официально калибровать через облачные ресурсы Apple, и они получат соответствующую маркировку в истории ремонта. Калибровать сторонние компоненты этими средствами не получится, но iPhone 16 будет пытаться активировать каждую деталь, чтобы она заработала «в полную мощь». В будущих обновлениях сторонние дисплеи получат поддержку True Tone, а сторонние аккумуляторы — поддержку статуса в ОС. Продолжит работать и лидар, если не проводить его повторную настройку, хотя особенности работы могут и отличаться. Несколько лет назад Apple поддержала право потребителей на самостоятельный ремонт, запустив программу Apple Self Repair. Но она показала, что поставляемые по официальным каналам запчасти могут оказаться дорогими — теперь владельцы устройств могут прибегнуть к более дешёвым вариантам, не теряя критически важных функций на устройстве. Новые языки в Apple Intelligence будут появляться в течение 2025 года, но русского среди них пока не значится
18.09.2024 [16:01],
Павел Котов
Послезавтра, 20 сентября, в продажу поступят iPhone 16 — телефоны созданные для работы с искусственным интеллектом, но на старте ни одна из этих функций работать не будет. Пакет ИИ-функций Apple Intelligence на начальном этапе будет поддерживать только американский вариант английского языка — набор поддерживаемых языков значительно расширится лишь в следующем году. 
Источник изображения: apple.com В 2025 году функции Apple Intelligence получат поддержку немецкого, итальянского, корейского, португальского и других языков, пишет The Verge со ссылкой на сообщение Apple. В декабре этого года пакет расширит набор доступных функций и сможет работать с вариантами английского языка, которые используются в Великобритании, Канаде, Австралии, ЮАР и Новой Зеландии, а в следующем году к ним добавятся диалекты Индии и Сингапура. Ранее Apple также сообщила о планах в следующем году добавить поддержку китайского, французского, японского и испанского языков. Apple Intelligence уделяется большое значение в iPhone 16, но к моменту выхода в продажу телефоны линейки будут лишены функций ИИ — они будут постепенно добавляться в течение осени. Полный комплект будет доступен лишь в 2025 году — даже для пользователей, которые живут в США, хотя они обычно получают доступ к передовым решениям первыми. Процессоры Apple A16 начали выпускать в США — вероятно, их используют в новом iPhone SE
18.09.2024 [15:29],
Владимир Мироненко
На заводе Fab 21 тайваньской компании TSMC в Аризоне (США) начали производить чипы Apple A16, дебютировавшие в смартфоне iPhone 14 Pro два года назад, пишет MacRumors со ссылкой на независимого тайваньского журналиста Тима Калпана (Tim Culpan). По словам Калпана, для изготовления чипов A16 в Аризоне используется тот же 4-нм процесс N4P, что и на тайваньских заводах TSMC, чтобы обеспечить постоянство качества и производительности. 
Источник изображения: TSMC Сейчас чипы производится в «небольших, но значимых количествах», но их выпуск значительно возрастёт после завершения первого этапа строительства завода, а полномасштабное производство запланировано на первую половину 2025 года. Как утверждают источники Калпана, выход годной продукции A16 на заводе TSMC может в ближайшие месяцы приблизиться к паритету с показателями, достигнутыми на её заводах Тайване. Ресурс MacRumors отметил, что выбор завода Fab 21 в Аризоне для выпуска чипа A16 говорит о доверии Apple к новому производству, поскольку компания вполне могла для начала выбрать для выпуска здесь менее передовой компонент. Пока неясно, в каких устройствах Apple будут использоваться чипы A16, произведённые в Аризоне. Вполне возможно, что ими будут оснащать будущие планшеты iPad, хотя, скорее всего, они найдут применение в следующем поколении iPhone SE с учётом того, что iPhone SE 4 будет основан на iPhone 14. Зонд NASA «Юнона» обнаружил гигантский новорожденный вулкан на спутнике Юпитера Ио
18.09.2024 [15:24],
Геннадий Детинич
Самое геологически активное небесное тело Солнечной системы — усыпанный сотнями действующих вулканов спутник Юпитера Ио — продолжает раскрывать свои секреты под наблюдением зонда NASA «Юнона» (Juno). «Юнона» давно выполнила свою основную научную программу и сейчас на остатках ресурсов оборудования совершает облёты Юпитера, сближаясь по возможности с некоторыми его спутниками, не переставая радовать учёных и рядовых граждан уникальными снимками. 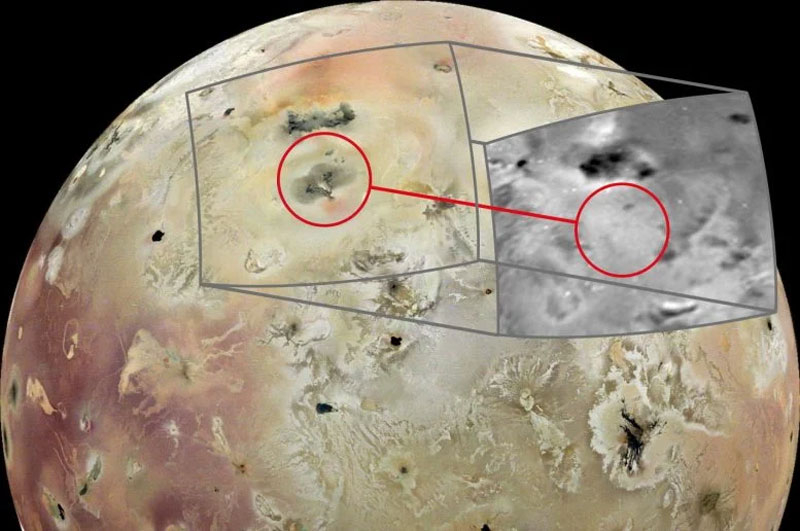
Источник изображений: NASA Осенью 2023 года и зимой 2024 года «Юнона» совершила близкие облёты Ио. Так, в феврале 2024 года зонд пролетел над спутником на высоте 2530 км, что позволило сделать цветные снимки поверхности Ио с разрешением 1,7 км/пиксель. При этом поверхность освещалась отражённым от Юпитера светом Солнца, что не помешало получить цветные снимки хорошего качества. На одном из них учёные обнаружили впечатляющий по размерам вулкан, которого ещё не было на снимках зонда «Галилео», сделанных в 1997 году. Получается, что гигантская структура появилась на поверхности Ио за последние примерно 25 лет. Она включает в себя сам вулкан и разливы лавы с обрамлением из красной серы, выпавшей обратно на поверхность после извержений. Весь новый массив расположен на площади со сторонами примерно по 180 км. Это, в принципе, самая большая появившаяся за последние четверть века на Ио геологическая структура. 
В 2024 году на ровном месте обнаружено что-то новенькое «Наши недавние снимки JunoCam показывают множество изменений на Ио, включая этот крупный, сложный вулканический объект, который, по-видимому, сформировался из ничего с 1997 года», — пояснил Майкл Рейвин (Michael Ravine), руководитель передовых проектов Malin Space Science Systems, которая спроектировала и эксплуатирует прибор JunoCam для проекта NASA Juno. Восточная сторона вулкана окрашена в рассеянный красный цвет из-за серы, которая была выброшена вулканом в космос и осела обратно на поверхность Ио. На западной стороне изверглись два темных потока лавы, каждый протяженностью около ста километров. В самой дальней точке потоков, где скопилась лава, высокая температура привела к испарению замерзшего материала на поверхности, в результате чего образовались два накладывающихся друг на друга серых круглых отложения. 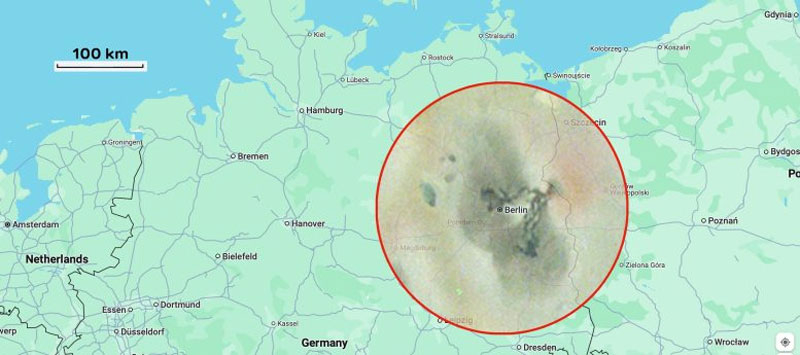
Сравнение нового образования на Ио с Берлином и окрестностями Все старые и новые снимки «Юноны» доступны на сайте миссии. NASA не делает секрета из получаемой информации, доступ к которой может получить каждый желающий. У Qualcomm не получилось отменить антимонопольный штраф в Европе, но удалось немного его снизить
18.09.2024 [15:05],
Павел Котов
Суд Европейского союза в Люксембурге подтвердил правомерность антимонопольного штрафа, наложенного на американского производителя полупроводников Qualcomm, но немного снизил его величину — с €242 млн до €238,7 млн.  Еврокомиссия наложила штраф в 2019 году, заявив, что с 2009 по 2011 год Qualcomm продавала свои процессоры по цене ниже себестоимости. Эта деятельность, которая обозначается как «хищническое ценообразование» (predatory pricing), была направлена против британского разработчика ПО для телефонов Icera, сейчас входящего в Nvidia. Указанные в деле чипсеты, предназначенные для работы в сотовыми сетях третьего поколения, по версии Qualcomm, составляли всего 0,7 % рынка UMTS, а значит, компания была лишена возможности исключать конкурентов с рынка чипсетов. Суд Европейского союза «подробно изучил все выдвинутые Qualcomm доводы и отклонил их в полном объёме, за исключением довода, касающегося суммы штрафа, который он считает обоснованным частично». Американский производитель чипов теперь может подать апелляцию в Европейский суд — суд высшей инстанции в ЕС. Два года назад Qualcomm сумела убедить суд в Люксембурге отменить антимонопольный штраф в размере €997 млн, выписанный в 2018 году, — тогда компанию уличили, что та с 2011 по 2016 год выплатила Apple несколько миллиардов долларов, чтобы в iPhone и iPad использовались только её чипы, а не продукция Intel. Logitech выпустила серию низкопрофильных механических клавиатур G915 X — от $180
18.09.2024 [15:02],
Николай Хижняк
Компания Logitech представила серию низкопрофильных механических клавиатур G915 X. В неё вошли полноразмерная беспроводная модель G915 X Lightspeed, компактная беспроводная G915 X Lightspeed TKL без блока цифровых клавиш, а также полноразмерная проводная G915 X. Новинки являются развитием клавиатур оригинальной серии G915 Lightspeed, представленной в 2019 году. 
Источник изображений: Logitech Производитель отмечает, что клавиатуры новой серии G915 X являются одними из самых тонких в его ассортименте. Толщина устройств составляет всего 23 мм. Верхняя часть корпуса каждой из новинок выполнена из алюминия, толщина которого была увеличена с 1,2 до 1,5 мм для повышения общей прочности. Клавиатуры оснащены полностью переработанными гальваническими переключателями. Оригинальный крюкообразный стержень переключателей был заменён новым крестообразным стержнем из POM. Новый дизайн повышает общую устойчивость клавиш для лучшего и более тихого набора текста и упрощает замену или настройку колпачков.  Для клавиатур серии G915 X предлагается три типа переключателей: линейные, тактильные и с характерным кликом. Ход переключателя был снижен с 1,5 до 1,3 мм, что привело к их более быстрому срабатыванию. Колпачки клавиш выполнены из более качественного пластика по сравнению с оригинальными моделями G915.  Время автономной работы у новых беспроводных версий G915 X увеличено по сравнению с предшественниками. Без включённой подсветки полноразмерная G915 X Lightspeed проработает от аккумулятора до 800 часов. При 100-процентной яркости RGB-подсветки время автономной работы составит до 36 часов, что на 20 % больше, чем у оригинальной модели. Компактная TKL-версия G915 X Lightspeed от батареи проработает до 1000 часов без подсветки и до 42 часов при 100-процентной яркости RGB-подсветки.  Как и оригинальные модели, новые клавиатуры оснащены регулятором громкости, G-клавишами, а также клавишами для управления медиа. Помимо этого, у новинок появилась поддержка макросов, позволяющая задать выполнение нескольких команд на одну клавишу.  Полноразмерную версию G915 X Lightspeed производитель оценил в $229,99, G915 X Lightspeed TKL получила ценник в $199,99, а проводная версия G915 X Wired оценивается в $179,99. Беспроводные модели будут доступны в продаже в белом и чёрном исполнении, проводная версия — только в чёрном. Серия клавиатур Logitech G915 X поступила в продажу 17 сентября. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex