|
Опрос
|
реклама
Быстрый переход
У Qualcomm не получилось отменить антимонопольный штраф в Европе, но удалось немного его снизить
18.09.2024 [15:05],
Павел Котов
Суд Европейского союза в Люксембурге подтвердил правомерность антимонопольного штрафа, наложенного на американского производителя полупроводников Qualcomm, но немного снизил его величину — с €242 млн до €238,7 млн.  Еврокомиссия наложила штраф в 2019 году, заявив, что с 2009 по 2011 год Qualcomm продавала свои процессоры по цене ниже себестоимости. Эта деятельность, которая обозначается как «хищническое ценообразование» (predatory pricing), была направлена против британского разработчика ПО для телефонов Icera, сейчас входящего в Nvidia. Указанные в деле чипсеты, предназначенные для работы в сотовыми сетях третьего поколения, по версии Qualcomm, составляли всего 0,7 % рынка UMTS, а значит, компания была лишена возможности исключать конкурентов с рынка чипсетов. Суд Европейского союза «подробно изучил все выдвинутые Qualcomm доводы и отклонил их в полном объёме, за исключением довода, касающегося суммы штрафа, который он считает обоснованным частично». Американский производитель чипов теперь может подать апелляцию в Европейский суд — суд высшей инстанции в ЕС. Два года назад Qualcomm сумела убедить суд в Люксембурге отменить антимонопольный штраф в размере €997 млн, выписанный в 2018 году, — тогда компанию уличили, что та с 2011 по 2016 год выплатила Apple несколько миллиардов долларов, чтобы в iPhone и iPad использовались только её чипы, а не продукция Intel. Logitech выпустила серию низкопрофильных механических клавиатур G915 X — от $180
18.09.2024 [15:02],
Николай Хижняк
Компания Logitech представила серию низкопрофильных механических клавиатур G915 X. В неё вошли полноразмерная беспроводная модель G915 X Lightspeed, компактная беспроводная G915 X Lightspeed TKL без блока цифровых клавиш, а также полноразмерная проводная G915 X. Новинки являются развитием клавиатур оригинальной серии G915 Lightspeed, представленной в 2019 году. 
Источник изображений: Logitech Производитель отмечает, что клавиатуры новой серии G915 X являются одними из самых тонких в его ассортименте. Толщина устройств составляет всего 23 мм. Верхняя часть корпуса каждой из новинок выполнена из алюминия, толщина которого была увеличена с 1,2 до 1,5 мм для повышения общей прочности. Клавиатуры оснащены полностью переработанными гальваническими переключателями. Оригинальный крюкообразный стержень переключателей был заменён новым крестообразным стержнем из POM. Новый дизайн повышает общую устойчивость клавиш для лучшего и более тихого набора текста и упрощает замену или настройку колпачков.  Для клавиатур серии G915 X предлагается три типа переключателей: линейные, тактильные и с характерным кликом. Ход переключателя был снижен с 1,5 до 1,3 мм, что привело к их более быстрому срабатыванию. Колпачки клавиш выполнены из более качественного пластика по сравнению с оригинальными моделями G915.  Время автономной работы у новых беспроводных версий G915 X увеличено по сравнению с предшественниками. Без включённой подсветки полноразмерная G915 X Lightspeed проработает от аккумулятора до 800 часов. При 100-процентной яркости RGB-подсветки время автономной работы составит до 36 часов, что на 20 % больше, чем у оригинальной модели. Компактная TKL-версия G915 X Lightspeed от батареи проработает до 1000 часов без подсветки и до 42 часов при 100-процентной яркости RGB-подсветки.  Как и оригинальные модели, новые клавиатуры оснащены регулятором громкости, G-клавишами, а также клавишами для управления медиа. Помимо этого, у новинок появилась поддержка макросов, позволяющая задать выполнение нескольких команд на одну клавишу.  Полноразмерную версию G915 X Lightspeed производитель оценил в $229,99, G915 X Lightspeed TKL получила ценник в $199,99, а проводная версия G915 X Wired оценивается в $179,99. Беспроводные модели будут доступны в продаже в белом и чёрном исполнении, проводная версия — только в чёрном. Серия клавиатур Logitech G915 X поступила в продажу 17 сентября. Microsoft и BlackRock совместно инвестируют до $100 млрд в ИИ-инфраструктуру
18.09.2024 [14:50],
Руслан Авдеев
Microsoft и BlackRock совместно инвестируют в строительство дата-центров и энергетику для поддержки быстроразвивающейся ИИ-отрасли. По данным Silicon Angle, для этого сформирована новая группа Global AI Infrastructure Investment Partnership (GAIIP). Помимо Microsoft и BlackRock, в неё входят купленная последней в январе за $12,5 млрд инвестиционная компания Global Infrastructure Partners (GIP), а также дубайский инвестор MGX. Предполагается, что партнёры будут вкладывать средства в новые ЦОД и расширение уже действующих для удовлетворения растущего спроса на вычислительные мощности. Также средства будут тратиться на энергетическую инфраструктуру для создания новых источников энергии для этих ЦОД. Целевым рынком для вложения средств считается США, а остатки потратят на территории «американских стран-партнёров». Согласно пресс-релизу GIP, планируется поддерживать открытую архитектуру и обширную экосистему, обеспечивая полный доступ к наработкам самому широкому кругу компаний. NVIDIA будет поддерживать GAIIP, предлагая экспертные консультации, связанные с технической частью ИИ-проектов. GAIIP рассчитывает получить в распоряжение $30 млрд инвестиционных капиталов для начальных вложений в проекты, что, в свою очередь, позволит увеличить общий инвестиционный потенциал до $100 млрд с учётом долгового финансирования. 
Источник изображения: Sebastian Herrmann/unsplash.com Помимо участия в новой структуре, Microsoft уже инвестировала в связанные с ИИ многочисленные проекты немало средств. Так, в мае Microsoft обязалась выделить $2,2 млрд на облачную и ИИ-инфраструктуру в Малайзии, чуть позже в том же месяце — $3,3 млрд на строительство ИИ ЦОД в Висконсине (США). В июне компания объявила о планах потратить $3,2 млрд для расширения ЦОД в Швеции. Крупнейшие «внешние» инвестиции Microsoft в ИИ связаны с небезызвестной компанией OpenAI, в которую IT-гигант вложил уже около $13 млрд с 2019 года, вполне вероятны и дальнейшие инвестиции. Global Infrastructure Partners, основанная в 2006 год, управляет активами на сумму более $100 млрд. Среди активов есть крупные транспортные узлы, поставщики энергии из возобновляемых источников, а также оператор ЦОД CyrusOne и ряд других инфраструктурных компаний. Кроме того, фонд неоднократно инвестировал в других операторов дата-центров. Asus представила компактную игровую клавиатуру ROG Falchion Ace HFX с частотой опроса 8000 Гц и магнитными переключателями
18.09.2024 [14:38],
Анжелла Марина
Asus представила новую клавиатуру ROG Falchion Ace HFX в компактном 65-% формфакторе, созданную для геймеров, которым важны точность, скорость и гибкая настройка. Новинка оснащена аналоговыми магнитными переключателями ROG HFX и обладает частотой опроса 8000 Гц. 
Источник изображения: Asus Несмотря на компактные размеры, в ROG Falchion Ace HFX есть все необходимые клавиши, включая стрелки и навигацию, при этом длина клавиатуры составляет всего 315 мм — практически как у 60-% клавиатур, что позволяет сэкономить место на рабочем столе и одновременно получить функции стандартной клавиатуры. ROG Falchion Ace HFX использует магнитные переключатели ROG HFX, обеспечивающие чёткий отклик и молниеносную, сверхточную работу. ROG HFX дополнены технологией Rapid Trigger, которая обеспечивает мгновенный сброс переключателя при движении вверх, увеличивая потенциал стрейфа при минимальных усилиях. Кроме того, режим Speed Tap оптимизирует смену направления движения в FPS-играх. При одновременном нажатии двух противоположных клавиш приоритетом считается последний ввод. Это устраняет задержку при контр-стрейфе, гарантируя мгновенную и точную смену направления. 
Источник изображения: Asus Для минимальной задержки и отзывчивости клавиш в ROG Falchion Ace HFX используется высокоскоростной USB-контроллер с частотой опроса 8000 Гц, обеспечивающий обновление данных о нажатиях в 8 раз быстрее, чем большинство игровых клавиатур. Это уменьшает задержку ввода с обычных 1 мс до всего лишь 0,125 мс. Также геймеры могут подобрать оптимальную точку срабатывания для игр и набора текста с помощью настраиваемого диапазона срабатывания — от 0,1 до 4,0 мм. Настройка осуществляется с помощью многофункциональной кнопки и сенсорной панели на задней части клавиатуры, а также через ПО Armoury Crate или Armoury Crate Gear. 
Источник изображения: Asus Для изготовления штока и нижней части корпуса использован высококачественный пластик POM, а для верхней части — поликарбонат, что обеспечивает плавность хода клавиш. Инновационная конструкция штока с «замкнутыми стенками» повышает стабильность и предотвращает попадание пыли, делая клавиатуру долговечной и надёжной даже при интенсивном использовании. Пять демпфирующих слоёв — два из пористого материала PORON и три из силикона — поглощают вибрации от нажатий клавиш и снижают шум, обеспечивая мягкий и приятный набор текста. Кроме того, клавиатура имеет две пары ножек, обеспечивающих три эргономичных угла наклона для комфортного положения рук во время игры или работы. 
Источник изображения: Asus Для переключения между двумя ПК предусмотрены два порта USB-C. Ресурс переключателей составляет 100 миллионов нажатий. Переписка между Android и iPhone получит сквозное шифрование — GSMA добавит его в стандарт RCS
18.09.2024 [14:11],
Владимир Мироненко
Ассоциация GSM (GSMA), разработавшая стандарт протокола связи для мгновенного обмена сообщениями Rich Communication Services (RCS), объявила о работе над внедрением сквозного шифрования (E2EE) для сообщений, отправляемых между устройствами на Android и iPhone. Впрочем, конкретные сроки внедрения E2EE не указаны. 
Источник изображения: MacRumors Объявление было сделано сразу после выхода iOS 18, в которой реализована поддержка протокола RCS для обмена сообщениями с пользователями устройств на Android. Хотя обновление несёт с собой такие улучшения, как обмен медиафайлами высокого разрешения, уведомления о прочтении и индикаторы ввода текста, в нём всё же не хватает сквозного шифрования, отметил ресурс MacRumors. По словам технического директора GSMA Тома Ван Пелта (Tom Van Pelt), следующим этапом для RCS Universal Profile станет «развёртывание стандартизированного, совместимого шифрования сообщений между различными вычислительными платформами». Этот шаг направлен на преодоление значительного разрыва в безопасности кроссплатформенных сообщений. В настоящее время не все провайдеры RCS предлагают сквозное шифрование E2EE. Одним из исключений является приложение для обмена SMS и мгновенными сообщениями Google Messages, в котором в прошлом году появилась поддержка E2EE для RCS по умолчанию. Собственная система iMessage компании Apple также поддерживает E2EE, но это не распространяется на сообщения RCS. Внедрение E2EE для кроссплатформенных сообщений RCS обеспечит защиту от просмотра текстов третьей стороной, как, например, сервисами обмена сообщениями или операторами сотовой связи, а также предотвратит государственный надзор за коммуникациями пользователей. Курс биткоина снова выше $60 тыс. — рынок ждёт решения ФРС США по процентной ставке
18.09.2024 [14:10],
Владимир Фетисов
Курс биткоина на этой неделе вновь преодолел отметку в $60 тыс. за монету. Это произошло на фоне запуска бывшим президентом США Дональдом Трампом (Donald Trump) криптовалютного предприятия World Financial Liberty, а также ожидания решения Федеральной резервной системы по поводу процентной ставки. На момент публикации этой заметки курс биткоина снизился до примерно $59 890 за монету (данные CoinDesk). 
Источник изображения: André François McKenzie/Unsplash В эти дни проходит двухдневное заседание ФРС, в рамках которого обсуждается дальнейшая политика организации. Ожидается, что центральный банк США снизит процентную ставку впервые за четыре года, что, вероятно, приведёт к росту рисковых активов, таких как биткоин и другие криптовалюты. «Биткоин, скорее всего, отреагирует на новости о снижении ставки ФРС некоторым ослаблением, поскольку краткосрочная динамика рынка отфильтруется. Но долгосрочные последствия смягчения денежно-кредитных условий будут способствовать новому циклу роста для биткоина, Ethereum и остального рынка. В прошлом биткоин в некоторой степени коррелировал с основными технологическими индексами, такими как Nasdaq, и в целом двигался в соответствии с денежно-кредитными условиями, поскольку инвесторы ищут доходность в условиях более низких ставок», — считает Филипп Пипер (Philipp Pieper), соучредитель компании Swarm Markets. В течение нынешнего года биткоин торговался в диапазоне от $55 тыс. до $70 тыс. Инвесторы ожидают снижения ключевой ставки ФРС, роста спотовых биржевых фондов (ETF) на биткоине. Следующим катализатором, способным встряхнуть рынок цифровых активов, должны стать предстоящие осенью выборы президента США. Google отбилась от штрафа в €1,5 млрд за антиконкурентные действия
18.09.2024 [14:02],
Павел Котов
Компании Google удалось выиграть апелляцию в Суде Европейского союза, который отменил наложенный Еврокомиссией в 2019 году штраф в размере €1,5 млрд. Ведомство, вероятно, оспорит это решение. 
Источник изображения: NoName_13 / pixabay.com Заседающий в Люксембурге суд Европейского союза постановил, что принял «бо́льшую часть выводов комиссии» о злоупотреблении компанией своим доминирующим положением на рынке для создания препятствий конкурирующим рекламодателям онлайн, но отменил огромный штраф, наложенный на Google по этому делу. Возбудив в 2019 году дело в отношении Google, Еврокомиссар по вопросам конкуренции Маргрет Вестагер (Margrethe Vestager) заявила, что введённые поисковым гигантом антиконкурентные ограничения на сторонние ресурсы действовали в течение десяти лет с 2006 по 2016 год. Штраф в размере €1,5 млрд она объяснила тем, что он отражает «серьёзную и устойчивую природу» правонарушения. Суд, однако, постановил, что Еврокомиссия не «учла всех важных обстоятельств при оценке длительности положений договоров, которые она сочла несправедливыми». В ведомстве заявили, что приняли решение «к сведению, <..> тщательно изучат его и свои возможные дальнейшие шаги» — вероятно, оно будет обжаловано. В Google заявили: «Это дело касается небольшого числа текстовых поисковых объявлений, размещённых на ограниченном числе сайтов издателей. Мы внесли изменения в наши договоры в 2016 году, удалив соответствующие положения ещё до решения комиссии. Мы рады, что суд признал ошибки в первоначальном решении и отменил штраф. Мы подробно изучим полное решение». За последние годы европейские чиновники трижды судились с Google по поводу штрафов на общую сумму €8,25 млрд — недовольные деятельностью американской компании заявили, что она нанесла вред рынку интернет-рекламы, а антимонопольные действия в её отношении были слишком медленными и неэффективными. Ранее Европейский суд оставил в силе наложенный на Google штраф в размере €2,42 млрд — компанию обвинили в злоупотреблении доминирующим положением на рынке, что помогло ей поставить свои торговые сервисы выше конкурирующих. В Брюсселе до сих пор открыто дело против Google, связанное с доминированием компании на рынке рекламных технологий — в прошлом году европейские чиновники пригрозили, что потребуют разделить компанию, сочтя это единственным жизнеспособным решением для устранения проблем конкуренции. Сейчас решается вопрос о том, оправданно ли наложение на Google новых штрафов. Для российского синхротрона СКИФ собран первый детектор
18.09.2024 [13:53],
Геннадий Детинич
Осталось около полугода до начала работы синхротрона СКИФ в наукограде Кольцово Новосибирской области и запуска первой очереди исследовательских станций на его основе. И одной из первых заработавших на комплексе станций станет лаборатория для изучения быстрых переходных процессов в материалах. На днях российские учёные сообщили об изготовлении первых детекторов как для этой лаборатории, так и для синхротрона. 
Источник изображения: https://strana-rosatom.ru Всего на СКИФе будет 30 экспериментальных станций. Полное их создание растянется на несколько лет, но сам синхротрон и первые станции будут завершены к концу 2024 года. Эксплуатация синхротрона и первой очереди лабораторий начнётся в первой половине 2025 года. Представленный на днях детектор позволит снимать быстрые процессы в материалах со скоростью до 10 млн кадров в секунду. Образцы будут облучаться синхротронным излучением (разогнанными до релятивистских скоростей электронами). Детектор GINTOS для лаборатории (координатный детектор на полупроводниках) изготовили сотрудники Томского государственного университета (ТГУ) и Института ядерной физики им. Будкера (ИЯФ). «Детектор GINTOS позволит исследовать реакцию материалов на импульсные тепловые и механические нагрузки. Это необходимо для понимания процессов, которые будут происходить, например, в термоядерном реакторе ИТЭР при попадании раскалённой плазмы на вольфрамовую стенку. Также детектор позволит изучать распространение ударных волн и других динамических процессов в микросекундном диапазоне», — рассказал главный научный сотрудник ИЯФ Лев Шехтман. Как нетрудно понять, датчики GINTOS должны быть очень быстродействующими. Для них радиофизики ТГУ разработали сенсоры на основе арсенида галлия, компенсированного хромом. Этот материал обладает повышенной радиационной стойкостью и чувствительностью к рентгеновскому излучению. «Полупроводниковые сенсоры преобразуют фотонный сигнал в электрический, а электроника регистрирует этот сигнал и передаёт изображение в компьютер, — объясняет заведующий лабораторией детекторов синхротронного излучения ТГУ Олег Толбанов. — Количество кадров очень велико, поэтому результат съёмки — это не отдельные изображения, а фильм». Синхротрон СКИФ станет первым в мире источником синхротронного излучения поколения 4+. Он откроет широкие возможности для исследований в области материаловедения, биологии, фармацевтики, физики, квантовой химии и многих других сфер. Американский регулятор «засветил» Horizon Zero Dawn Remastered для PC и PS5
18.09.2024 [13:30],
Михаил Романов
Постапокалиптический экшен с открытым миром Horizon Zero Dawn от студии Guerrilla Games дебютировал на PS4 всего семь лет назад, но, похоже, уже готовится получить ремастер. 
Источник изображения: Steam (Eternal) Портал Video Games Chronicle (VGC) обратил внимание, что на сайте американского рейтингового агентства Entertainment Software Rating Board (ESRB) появилась страница неанонсированной Horizon Zero Dawn Remastered для PC и PS5. Horizon Zero Dawn Remastered получила от ESRB то же описание, дескрипторы (кровь, насилие и так далее) и возрастной рейтинг («подростковый»), что и Horizon Zero Dawn. Другими словами, по наполнению ремастер от оригинальной игры не отличается. 
Источник изображения: ESRB О том, что Horizon Zero Dawn ждёт переиздание, в 2022 году со ссылкой на свои источники рассказывали журналисты VGC, MP1st и Gematsu. Вслед за этим в открытый доступ попал внутренний документ Sony, также подтверждавший ремастер. По слухам, Horizon Zero Dawn Remastered предложит графику уровня Horizon Forbidden West с обновлёнными текстурами, моделями, освещением, анимациями, увеличенной дальностью прорисовки, а также дополнительными геймплейными удобствами. 
Источник изображения: Steam (arash) Horizon Zero Dawn дебютировала в марте 2017 года на PS4, а в 2020-м добралась до ПК (Steam, GOG, EGS). Как Sony реализует процесс апгрейда для существующих владельцев игры (если таковой вообще будет), большой вопрос. ПК-версия Horizon Zero Dawn в своё время предлагала увеличенную дальность прорисовки и повышенную производительность по сравнению с релизом на PS4, но по большей части использовала оригинальные материалы. Apple iPhone 16 можно будет восстановить при помощи другого iPhone
18.09.2024 [13:06],
Павел Котов
Новейшие iPhone 16, работающие на платформе iOS 18, получили функцию RecoveryOS — ранее эта функция позволяла при помощи iPhone восстанавливать прошивку Apple Watch и Apple TV. Теперь же можно будет восстанавливать iPhone 16 при помощи других iPhone. 
Источник изображения: apple.com Когда iPhone 16 отказывается работать в штатном режиме и переходит в режим восстановления (Recovery Mode), рядом с ним можно будет положить iPad или другой iPhone, чтобы запустить восстановление прошивки. Другое устройство самостоятельно загрузит работоспособную версию iOS и перенесёт её на заблокированное устройство. Это значит, что для устранения проблем на устройствах под управлением iOS больше не понадобится подключать их к ПК. Для восстановления заблокированного устройства можно использовать любой гаджет под управлением iOS 18, но на данный момент восстановить таким образом можно только iPhone 16. Телефоны последнего поколения поставляются со специальным разделом восстановления на своём накопителе, который позволяет управлять всем процессом вне зависимости от загрузки основного раздела iOS. Пока отсутствует ясность, планирует ли Apple добавить данную функцию в предыдущие модели iPhone или для этого требуются изменения на аппаратном уровне. В любом случае, это значительный шаг вперёд — для пользователей значительно упрощается процесс устранения проблем с прошивкой без необходимости нести устройства в сервисный центр. Apple iPhone 16 поступят в продажу в пятницу, 20 сентября. Новость о китайских машинах для выпуска 8-нм чипов вызвала рост акций местных полупроводниковых компаний
18.09.2024 [12:50],
Алексей Разин
На этой неделе стало известно, что Китай близок к созданию собственных машин для выпуска 8-нм чипов. В каталоге рекомендуемого китайскими властями оборудования для производства чипов появится новый образец, располагающий точностью межслойного совмещения 8 нм и разрешающей способностью 65 нм. Эта новость сразу же вызвала рост курса акций тех китайских компаний, которые так или иначе связаны с производством чипов. 
Источник изображения: SMIC Как сообщает Reuters, утренние торги в среду продемонстрировали рост курса акций Shanghai Zhangjiang Hi-Tech Park Development и Shanghai Highly Group на максимально допустимую величину в ходе одной торговой сессии — на 10 %. Акции Sanhe Tongfei Refrigeration выросли на 20 % и тоже упёрлись в дневной лимит. Котировки ценных бумаг Shenyang Blue Silver Industry Automation Equipment поднялись на 10,7 %. Пропорционально подорожали и акции Changchun UP Optotech Co., а ценные бумаги Sai Micro Electronics Inc. укрепились в цене на 5,3 %. Поставщик литографического оборудования Naura Technology Group столкнулся с ростом котировок лишь на 1 %, а крупнейший контрактный производитель чипов в Китае, компания SMIC, выросла в цене на скромные 1,9 %. Как добавляют представители Bloomberg, ранее китайская SMEE предлагала литографические системы с разрешением 90 нм, а новая система неизвестного китайского производителя улучшила этот показатель до 65 нм. Отметим, что передовые литографические сканеры ASML обеспечивают разрешающую способность около 8 нм, поэтому китайской промышленности ещё далеко до нидерландского конкурента. Эксперты RHCC считают, что Китай отстаёт в этой сфере от мировых лидеров как минимум на 15 лет. И всё же, наличие прогресса, каким скромным бы оно ни было, воодушевляет инвесторов в китайскую полупроводниковую отрасль. Ветеран BioWare раскрыл продажи Dragon Age: Inquisition спустя почти 10 лет после релиза
18.09.2024 [12:38],
Михаил Романов
Вышедшая почти 10 лет назад ролевая игра Dragon Age: Inquisition от BioWare чуть ли не с выхода считается самым успешным релизом в истории студии, однако до сих пор продажи оставались скрыты за завесой тайны. 
Источник изображения: Steam (WallsOfJericho) О том, что «Инквизиция» побила рекорд скорости продаж среди игр BioWare, Electronic Arts отчиталась в начале 2015 года, а в 2018-м продюсер серии Марк Дарра (Mark Darrah) назвал проект самым продаваемым в истории студии вообще. С годами успехи Dragon Age: Inquisition выветрились из памяти сообщества, и в 2024 году некоторые геймеры уже не уверены, что триквел можно считать хитом и коммерчески успешной игрой. 
Источник изображения: Steam (KK) В спор на эту тему, развернувшийся в соцсети X, неожиданно вмешался Дарра. В BioWare он с конца 2020 года не числится, но выступает консультантом следующей игры серии — Dragon Age: The Veilguard. «Не знаю, откуда взялась идея, будто DA:I была коммерческим провалом… На данный момент у неё более 12 миллионов [проданных] копий. Она ЗНАЧИТЕЛЬНО превзошла внутренние прогнозы EA», — сообщил Дарра. 
Источник изображения: Electronic Arts Dragon Age: Inquisition дебютировала в ноябре 2014 года на PC, PS3, PS4, Xbox 360 и Xbox One. Игра заслужила признание критиков (85−89 % на Metacritic) и удостоилась ряда наград, включая главный приз на The Game Awards 2014. Что касается Dragon Age: The Veilguard, то первая за 10 лет новая игра серии увидит свет уже 31 октября на PC (Steam, EGS, EA App), PS5, Xbox Series X и S. Обещают «самую что ни на есть однопользовательскую годноту». Snap выпустила громоздкие очки дополненной реальности Spectacles с абонентской платой
18.09.2024 [12:30],
Павел Котов
Компания Snap представила обновлённые очки дополненной реальности Spectacles — довольно крупное устройство, которое позиционируется как промежуточное звено между полнофункциональной гарнитурой смешанной реальности и компактными умными очками. 
Источник изображений: snap.com Новые Snap Spectacles являются устройством уже пятого поколения, и созданы они специально для разработчиков. Гаджет распространяется по схеме «оборудование как услуга» и стоит $99 в месяц. При этом компания предусмотрела обязательный годовой период, поэтому в действительности придётся отдать немногим менее $1200, и это без учёта налогов. Очки действительно громоздки, сообщает ресурс TechCrunch, чьим журналистам довелось их испытать, а их масса составляет около 227 г, что заметно меньше 635 г у Apple Vision Pro. Реализация технологии дополненной реальности на практике впечатляет, особенно если учесть, что речь идёт о полностью автономном устройстве. Правда, впечатление от визуальных эффектов и интерактивных функций немного портит небольшое поле зрения. В Snap, однако, отмечают, что поле зрения Spectacles 5 составляет 46°, и это в три раза больше, чем было у Spectacles 4.  Очки работают на двух процессорах Qualcomm Snapdragon — по одному в каждой дужке; а система Spatial Engine на практике достаточно хорошо распознаёт, где находится пользователь. В качестве программной платформы используется SnapOS на базе Android — это упрощает задачу разработчикам сторонних приложений. Новые Snap Spectacles выпускаются при поддержке партнёров компании, в том числе Lego, Niantic и ILM Immersive. ILM Immersive выпустит игру Star Wars; ответственная за популярную Pokémon GO компания Niantic представит игры Peridot и Scaniverse. Сама Snap готовится выпустить для блогеров инструменты на основе искусственного интеллекта для создания видео, а чат-бот My AI получит функцию визуального поиска «Google Объектив» и более простые средства управления. Россиян заинтересовали iPhone 16 — они собрали почти в пять раз больше предзаказов в России, чем iPhone 15
18.09.2024 [12:16],
Анжелла Марина
Компания МТС подвела итоги первой недели по предзаказам смартфонов семейства iPhone 16 в собственной розничной сети. Анализ показал, что по сравнению с предыдущими моделями iPhone 15 в прошлом году, спрос на новые смартфоны Apple оказался выше в 4,8 раз. 
Источник изображений: Apple На первое место по популярности вышла модель iPhone 16 — на неё пришлось 54 % всех заказов. Далее следуют iPhone 16 Pro с долей 28 %. iPhone 16 Pro Max с 11 % и iPhone 16 Plus с 7 % вышли на третье и четвёртое место соответственно. Что касается объёма памяти, то выяснилось, что большим спросом пользуются устройства с 128 Гбайт памяти — это iPhone 16, Plus и Pro, а на модель Max больший покупательский интерес был проявлен на объём 256 Гбайт. То есть россияне чаще всего выбирают наиболее доступные версии. Больше всего предзаказов оформили жители Москвы — на них пришлось 43 % всех предзаказов. Также большое число предзаказов МТС получила в Санкт-Петербурге (10 %), Краснодарском крае (8 %), Республике Татарстан (4 %), Тюменской области (2 %). МТС сообщает, что предварительный заказ можно оформить выбрав один из вариантов оплаты — полный или частичный. На все модели iPhone 16 частичная предоплата составит 25 000 рублей. Эта сумма войдёт в счёт стоимости устройства, при получении которого покупатель должен доплатить оставшуюся сумму. Также предусмотрен кешбэк в размере 30 % от стоимости товара и гарантия на один год. 
Источник изображения: МТС Клиенты, оформившие предзаказ на iPhone 16 получат уведомление СМС и планируемую дату доставки смартфона. После поступления товара на склад компании, операторы колл-центра МТС лично сообщат о доставке устройства каждому клиенту. Новый тип OLED позволит создавать компактные и лёгкие очки ночного видения с побочной функцией распознавания образов
18.09.2024 [12:07],
Геннадий Детинич
Учёные из США приблизились к созданию уникальных очков ночного видения, которые были бы не только компактными и лёгкими, но также обладали бы эффектом памяти на образы. Это позволило бы обеспечить предварительную обработку изображений нейронными сетями прямо на стёклах очков, без их загрузки в процессор. Но даже без ИИ новая разработка демонстрирует, насколько OLED-очки ночного видения могут оказаться легче современных аналогов. 
Источник изображения: Marcin Szczepanski, Michigan Engineering Проект частично финансируется DARPA (Управление перспективных исследовательских проектов Министерства обороны США) и в данный момент ведётся учёными из Университета Мичигана. Как известно, современные приборы ночного видения (очками их можно назвать с очень большой натяжкой) представляют собой устройства с вакуумными приборами и люминофором, которые со значительными затратами энергии преобразуют ближний инфракрасный свет в электроны и, после усиления, создают монохромную картинку на светящемся покрытии. Учёные из США создали новый тип OLED (органических светодиодов), который реагирует на электроны и возбуждает фотоны видимого света. Представленный ими датчик и преобразователь ближнего инфракрасного излучения в видимое тоньше человеческого волоса — его толщин составляет менее 1 мкм. Он состоит из пяти слоёв и, в идеале, каждый попавший на него электрон превращает в пять фотонов. Первый слой датчика возбуждает электроны от попадания фотонов ближнего инфракрасного света. Затем электрон пролетает пять слоёв OLED-плёнки. Глаза человека может достичь только один образовавшийся фотон видимого света, тогда как другие фотоны снова возбуждают электроны в первом слое и, таким образом, создают эффект усиления с положительной обратной связью без обычных громоздких и высоковольтных устройство по усилению электронного потока. Экспериментальное устройство обладает скромным усилением всего в 100 раз. Современные приборы ночного видения способны усиливать сигнал до 10 тыс. раз. Учёные говорят, что конструкцию OLED-датчика можно дальше оптимизировать, добиваясь большего усиления и, соответственно, более высокой чувствительности к инфракрасному свету. Но даже сейчас лёгкость и компактность новой конструкции очков с точки зрения эффективности и экономности питания позволяет многократно превзойти коммерческие приборы ночного видения. Что касается сопутствующего эффекта памяти OLED-очков, то он в определённом смысле будет помехой ночному зрению. Тем не менее, учёные уже нашли ему применение в виде нейросетей для распознавания образов на уровне стёкол без загрузки в процессор. Это определённо может пригодиться для систем машинного зрения, но впереди ещё много работы, хотя исследователи говорят, что запустить разработку в производство труда не составит — они взяли готовые технологии и просто нашли их удачное сочетание. Meta✴ грозит ещё один многомиллиардный штраф в ЕС — теперь из-за Facebook✴ Marketplace
18.09.2024 [11:48],
Дмитрий Федоров
Европейская комиссия готовится наложить крупный штраф на Meta✴✴ за нарушения антимонопольного законодательства на рынке частных объявлений. Регулятор утверждает, что Facebook✴✴, дочерняя компания Meta✴✴, подрывает конкуренцию, связывая бесплатный сервис Marketplace с социальной сетью. Решение может быть принято уже в следующем месяце, завершая одно из последних расследований под руководством нынешней главы антимонопольной службы Маргрете Вестагер (Margrethe Vestager). 
Источник изображения: alexanderjungmann / Pixabay Антимонопольное расследование, инициированное в 2019 году, основано на обвинениях конкурентов в злоупотреблении Facebook✴✴ своим доминирующим положением. Компания предлагает бесплатные услуги по размещению частных объявлений, одновременно извлекая прибыль из данных, собираемых на платформе, преимущественно от бизнес-пользователей. В декабре 2022 года Еврокомиссия представила предварительные выводы, согласно которым Meta✴✴ искажает конкуренцию на рынке онлайн-объявлений и использует бесплатно полученные данные предприятий для таргетированной рекламы. Facebook✴✴ Marketplace, запущенный в 2016 году, стал популярной платформой для купли-продажи подержанных товаров, особенно предметов домашнего обихода и мебели. Однако в последние годы появились новые конкуренты в специализированных сегментах, таких как, например, мода. Meta✴✴ отрицает обвинения, утверждая, что Marketplace функционирует в высококонкурентной среде и не использует данные конкурентов для борьбы с ними. В своём заявлении компания отметила: «Претензии, выдвинутые Европейской комиссией, не имеют под собой оснований. Мы продолжаем работать с регулирующими органами, чтобы продемонстрировать, что наши инновационные продукты отвечают интересам потребителей и конкуренции». В случае признания вины Meta✴✴ может быть оштрафована на сумму до 10 % от годового глобального дохода, который в 2023 году составил $135 млрд. Однако регуляторы обычно назначают менее суровые санкции. Решение по делу может быть отложено из-за подготовки президента Еврокомиссии Урсулы фон дер Ляйен (Ursula von der Leyen) к следующему 5-летнему циклу работы исполнительного органа Европейского союза (ЕС). Недавно фон дер Ляйен объявила о назначении Тересы Риберы (Teresa Ribera) новой главой антимонопольной службы ЕС, которая сменит Вестагер на посту в начале ноября. За десятилетний срок своего правления Вестагер неоднократно принимала жёсткие меры против таких гигантов, как Apple, Google и Microsoft. Неделю назад Европейский суд подтвердил правомерность антимонопольных претензий к Google, постановив, что компания злоупотребила доминирующим положением, продвигая собственный сервис покупок в ущерб конкурентам. В тот же день суд ЕС обязал Apple выплатить 13 млрд евро невыплаченных налогов. Эти два решения были восприняты как победа Вестагер. Другие юрисдикции также стремятся ограничить влияние техногигантов. Управление по конкуренции и рынкам Великобритании (CMA) в прошлом году закрыло аналогичное расследование в отношении Meta✴✴ после того, как компания обязалась ограничить использование данных, собираемых от других предприятий на своей платформе. Эти меры отражают глобальную тенденцию к усилению регулирования цифровых рынков и защите конкуренции в технологическом секторе. iPadOS 18 выводит из строя iPad Pro с процессором M4 — Apple приостановила выпуск обновления
18.09.2024 [11:34],
Дмитрий Федоров
Apple временно приостановила распространение новой версии iPadOS 18 для планшетных компьютеров iPad Pro с процессором M4. Обновление ОС не будет предлагаться пользователям при проверке наличия обновлений, а серверы Apple не будут его активировать, если оно будет установлено другим способом. Всё потому, что после установки свежей версии ОС некоторые планшеты отказываются работать. 
Источник изображений: Apple Анализ сообщений пользователей на Reddit и MacRumors выявил неоднородность ситуации: часть владельцев iPad Pro с M4 успешно установила iPadOS 18, тогда как другие столкнулись с полной неработоспособностью устройств. Примечательно, что стандартные методы восстановления работоспособности, такие как перевод устройства в режим восстановления (DFU), оказались неэффективными. Это, вероятно, вынудит Apple предложить замену устройств пострадавшим от сбоя пользователям. Ситуацию усложняет наличие разных способов обновления, каждый из которых может привести к неожиданным результатам. Некоторые пострадавшие от обновления пользователи сообщали о предварительной установке iPadOS 17.7 перед переходом на iPadOS 18.0. iPadOS 17.7 предоставляется как обновление безопасности для тех, кто не готов к полному обновлению iPadOS. Предположительно, обновление с 17.7 до 18.0 не было протестировано так тщательно, как переход с 17.6, что могло стать причиной проблемы.  В любом случае, владельцам iPad Pro на базе M4, которые ещё не обновились, придётся подождать: либо пока Apple выпустит исправленную версию обновления iPadOS 18, либо пока компания не определит, что «окирпиченные» iPad страдают от аппаратной проблемы, а не от программного сбоя. Apple продолжает распространять обновление iPadOS 17.7, которое содержит последние патчи безопасности и может быть без риска установлено на iPad Pro с процессором M4. Для других устройств, включая iPad Air с чипом M2, Apple предлагает обновление iPadOS 18.0. Это подчёркивает специфичность возникшей проблемы и указывает на возможные сложности с аппаратной частью iPad Pro M4. Китайские производители электромобилей выпускают слишком много новинок — большинство не окупает разработку
18.09.2024 [11:31],
Алексей Разин
По мнению аналитиков Suolei, китайским автопроизводителям сейчас приходится привлекать клиентов двумя основными способами: частым выпуском новых моделей и снижением цен на них. Данное сочетание не слишком благоприятно сказывается на экономическом положении компаний. Падающая прибыль или увеличивающиеся убытки мешают оправдать выпуск новых моделей, на разработку которых требуются средства. 
Источник изображения: XPeng Как отмечает South China Morning Post, на внутренний рынок Китая в этом году должны выйти более 50 новых моделей электромобилей и подзаряжаемых от сети гибридов. Лишь немногим из них, как считают аналитики Suolei, удастся разойтись в достаточных количествах для оправдания затрат на свою разработку и производство. Изобилие новых моделей усугубляет ценовую конкуренцию между участниками рынка, а продажа их с существенными скидками чаще всего приносит убытки компаниям. В таких условиях частый выпуск новых моделей не оправдывает себя с экономической точки зрения. Тем более, что на китайском рынке и без этого полно однотипных электромобилей по привлекательным ценам, и расширять их ассортимент порой не имеет особого смысла. В этой борьбе определённо будут жертвы в виде покидающих рынок моделей и банкротящихся автопроизводителей. Высокотехнологичная продукция китайских автопроизводителей привлекает молодую аудиторию на внутреннем рынке КНР, и порой ещё на стадии предварительного приёма заказов набираются тысячи заявок, хотя фактические продажи новинки ещё не начались. Представители китайской автомобильной отрасли подчёркивают, что агрессивная ценовая политика производителей оказывает более сильное воздействие на стимулирование спроса, чем регулярный выход новых моделей электромобилей. На внутреннем рынке КНР гибриды и подзаряжаемые гибриды с июля текущего года формируют более половины в структуре продаваемых легковых транспортных средств.  На примере новичка в этом сегменте, компании Xiaomi, которая начала продажи первого своего электромобиля SU7 весной текущего года, можно судить о сложностях выхода на китайский автомобильный рынок в его нынешней стадии развития. Если в 2024 году Xiaomi выпустит хотя бы 60 000 электромобилей (а сама она планирует выпустить 120 000 штук), то это всё равно приведёт к убыткам в почти $10 000 на каждый проданный SU7. Лидером местного рынка остаётся компания BYD, которая за счёт серьёзной вертикальной интеграции бизнеса имеет возможность снижать свои издержки и сохранять прибыльность даже в условиях «ценовой войны». Обновлённое в этом месяце семейство электромобилей Han оказалось как минимум на 2,4 % дешевле своих предшественников. Автогигант может себе позволить подобную гибкость ценовой политики, поскольку экономит как на масштабах производства, так и на вертикальной интеграции бизнеса. Теми же тяговыми батареями компания снабжает себя сама, а это самая дорогостоящая часть любого электромобиля. Впрочем, даже BYD страдает от наблюдаемых на китайском рынке тенденций. В первом полугодии затраты компании на разработку выросли в годовом сравнении на 41,6 %, тогда как выручка на том же интервале сравнения выросла только на 15,8 %. Норма прибыли BYD во втором квартале снизилась в годовом сравнении с 21,9 до 18,7 %. BYD и её более скромный по оборотам конкурент в лице Li Auto остаются единственными в Китае автопроизводителями, которые в текущем году работают без убытков. Покупатели не особо интересуются новыми моделями конкурентов, которые выходят на рынок в текущем году, поскольку считают, что более именитые производители смогут предложить что-то более технологичное по более низким ценам. По прогнозам Goldman Sachs, если BYD по сравнению с апрелем текущего года BYD снизит цены ещё на 7 %, то вся китайская автомобильная отрасль может оказаться убыточной. «Захотелось снова пройти The Witcher 3»: Netflix подтвердила дату выхода мультфильма «Ведьмак: Зов морской бездны» и показала эксклюзивный отрывок
18.09.2024 [11:25],
Михаил Романов
Как и предполагалось, в рамках онлайн-фестиваля Geeked Week 2024 стриминговый гигант Netflix официально объявил дату выхода анимационного фильма The Witcher: Sirens of the Deep («Ведьмак: Зов морской бездны»). 
Источник изображений: Netflix Напомним, The Witcher: Sirens of the Deep представили прошлой осенью и обещали выпустить на исходе 2024 года, однако источники портала Redanian Intelligence накануне сообщили, что картина задержится до 11 февраля 2025-го. Как стало известно, «Ведьмак: Зов морской бездны» действительно выйдет лишь 11 февраля 2025 года. Причину задержки в Netflix не назвали, но сопроводили анонс эксклюзивным отрывком из фильма. 
Сюжет «Ведьмак: Зов морской бездны» основан на рассказе «Немного жертвенности» Двухминутный фрагмент The Witcher: Sirens of the Deep в трёхминутном ролике представил Даг Кокл (Doug Cockle) — голос ведьмака Геральта из Ривии в фильме и англоязычной версии игр The Witcher от CD Projekt Red. Отрывок демонстрирует разговор между Геральтом и бардом Лютиком за трапезой у костра. Музыкант пытается доказать ведьмаку, что тот не такой непробиваемый, каким кажется на первый взгляд. В комментариях оценили актёрский состав — Лютика озвучивает исполнитель роли в сериале от Netflix Джои Бэти (Joey Batey) — и игру Кокла в частности. «Чёрт возьми. Захотелось снова пройти The Witcher 3», — признался ThaYoungChad. По сюжету Геральта нанимают расследовать серию нападений в прибрежной деревне, а в итоге Белый Волк оказывается втянут в многовековой конфликт между простыми жителями и рыболюдьми, на чём особо акцентирует внимание в ролике Кокл. В телевизорах TCL на квантовых точках исследователи не нашли квантовых точек — производитель отмёл обвинения
18.09.2024 [11:11],
Павел Котов
Китайский производитель бытовой техники TCL оказался в центре внимания: сторонние эксперты провели тестирование трёх его телевизоров, которые позиционируются как модели на квантовых точках, и признаков наличия квантовых точек на них не было обнаружено. Производитель эти результаты отверг. 
Источник изображений: tcl.com Квантовые точки — полупроводниковые компоненты размером в несколько нанометров, которые производят свет разных цветов при попадании на них света определённой частоты. Излучаемый квантовой точкой цвет зависит от размера самой квантовой точки, поскольку он влияет на длину волны. Это решение помогает телевизорам и мониторам премиум-класса охватывать более широкий цветовой диапазон. Квантовые точки стали важным аргументом в пользу моделей QLED, QD Mini LED и QD-OLED, и они имеют более высокую цену. Производитель, который продаёт стандартные модели, заявляя о наличии квантовых точек, рискует и репутацией, и собственным благополучием — такие действия могут привести к юридическим последствиям. Южнокорейское технологическое издание ETNews опубликовало отчёт об исследовании, согласно которому три телевизора TCL, которые позиционируются как модели на квантовых точках, на самом деле этих квантовых точек лишены. Заказчиком выступила сеульская компания Hansol Chemical; тесты проводили компании SGS и Intertek, штаб-квартиры которых находятся соответственно в Женеве и Лондоне. Эксперты исследовали модель TCL C755, заявленную как телевизор Mini LED на квантовых точках; TCL C655, позиционируемую как модель QLED; а также TCL C655 Pro — тоже QLED. По результатам исследований в телевизорах не было обнаружено индия и кадмия — важных материалов, без которых невозможно реализовать квантовые точки. Кадмий должен был обнаружиться, если бы он присутствовал в минимальной концентрации 0,5 мг на 1 кг; индий пытались обнаружить в концентрациях 2 и 5 мг/кг в разных лабораториях. В ответ на публикацию материала представитель TCL заявил, что компания «производит телевизоры с плёнками на квантовых точках, поставляемыми тремя компаниями», а «количество квантовых точек <..> на плёнке может варьироваться в зависимости от поставщика, но кадмий, несомненно, присутствует». Далее TCL опубликовала результаты другого исследования, проведённого по заказу Guangdong Region Advanced Materials — одного из поставщиков плёнок с квантовыми точками. Примечательно, что это исследование снова провела SGS, и на этот раз она обнаружила присутствие кадмия в плёнках в концентрации 4 мг/кг. TCL также заявила, что «подтвердила флуоресцентные характеристики квантовых точек», и представила спектрограмму, которая якобы свидетельствует о наличии квантовых точек в плёнках телевизоров.  Одна из очевидных причин разницы в результатах — разные методы тестирования. В исследовании, где был обнаружен кадмий, изучались плёнки на квантовых точках, которые поставляются TCL. В исследовании по заказу Hansol рассматривались плёнки на квантовых точках на готовых телевизорах китайского производителя. Это может свидетельствовать, что у TCL недостаточно хорошо организован контроль качества, а концентрация квантовых точек может варьироваться от партии к партии или даже в пределах одного телевизора. Впрочем, это не означает, что у TCL есть намерение обмануть потребителей. По мнению опрошенного изданием Ars Technica эксперта, наиболее адекватным методом исследования были бы не замеры концентрации квантовых точек, а тестирование показателей изображения, которые выдаёт телевизор — цветовой гаммы и яркости. Следует также обратить внимание, что TCL говорит о применении кадмия в телевизорах QLED и Quantum Mini LED, но не упоминает об индии. Присутствие обоих элементов в телевизорах на квантовых точках не обязательно. Некоторые экраны на квантовых точках имеют в основе лишь собственно квантовые точки, в других же используется смесь индиевых и/или кадмиевых квантовых точек и люминофоров — это материалы совершенно иного класса, но их целью является такое же преобразование синего цвета светодиодов в зелёный и красный. В последнем случае содержание квантовых точек может быть в десять раз ниже, и в минимально допустимый по нормам Hansol показатель в 0,5 мг/кг оно действительно не попадёт. Этот вариант дешевле в производстве, а цветовая гамма, чистота цвета и яркость будут уступать дисплеям на «чистых» квантовых точках. И вполне вероятно, что TCL использует его в QLED-моделях начального уровня. Стоит также отметить, что в Евросоюзе действует директива RoHS (Restriction of Hazardous Substances Directive), ограничивающая содержание вредных веществ в продукции на территории региона. Она, в частности, не допускает превышения массовой концентрации кадмия в 0,01 %, но есть исключение, позволяющее использовать его в количестве до 0,2 г на м² в дисплеях. При этом в большинстве экранов на квантовых точках кадмий либо используется в малых количествах, либо не используется вообще. Так, Samsung заявляет, что применяет только квантовые точки без кадмия. При этом заказавшая исследование корейская химическая компания Hansol не поставляет свою продукцию TCL, зато продаёт её Samsung. Samsung и LG пока остаются крупнейшими в мире производителями телевизоров, но этот статус все чаще пытаются оспорить китайские компании. Поэтому Hansol можно рассматривать как предвзятую сторону. Наконец, трудно представить, чтобы такая крупная компания, как TCL, рискнула своей репутацией и начала просто обманывать покупателей, считают эксперты. Изготовление «фальшивых» плёнок на квантовых точках без квантовых точек стоило бы почти столько же, сколько производство настоящих, но без преимуществ в качестве изображения. Возможно, TCL использует квантовые точки в небольших количествах совместно с материалами на основе фосфора — качество картинки может действительно оказаться хуже, чем у телевизоров с экранами на основе других решений, но это будет значить, что квантовые точки в продукции TCL всё-таки есть. Прояснить ситуацию может серия дальнейших и более подробных исследований продукции компании. Intel и BOE представили технологию 1-Гц дисплеев для ноутбуков — она снизит энергопотребление на 65 %
18.09.2024 [10:41],
Владимир Фетисов
Дисплей является одним из основных потребителей энергии в ноутбуке, особенно если это панель с яркостью более 400 кд/м² и частотой обновления выше 90 Гц. Снизить влияние на автономность может новый дисплей под названием Winning Display 1 Hz, который является совместной разработкой инженеров Intel и BOE. Он способен снижать частоту обновления вплоть до 1 Гц для существенного снижения уровня энергопотребления. 
Источник изображения: techspot.com Главная особенность новинки заключается в возможности динамической регулировки частоты обновления. Оптимальная частота обновления для выполнения разных задач подбирается автоматически с помощью алгоритмов на основе искусственного интеллекта. По данным разработчиков, такой подход позволяет снизить энергопотребление на величину до 65 % по сравнению с обычными дисплеями, используемыми в ноутбуках. В Winning Display реализована поддержка платформы Intel Intelligent Display Technology 2.0, которая привносит несколько интеллектуальных функций для регулировки частоты обновления дисплея. Одна из таких функций называется User-Based Refresh Rate и используется для отслеживания движения мыши, положения головы пользователя и других действий. Когда алгоритм определяет, что пользователь не взаимодействует с ноутбуком, частота обновления экрана снижается до минимума автоматически. В это же время функция Intel PixOptix применяется для повышения уровня контрастности и снижения энергопотребления подсветки дисплея. Пожалуй, наиболее интересной является возможность независимой регулировки частоты обновления и уровня яркости в разных частях экрана. Например, если пользователь смотрит видео и делает заметки, окно, в котором воспроизводится ролик, может поддерживать высокую частоту обновления, в то время как часть экрана для заметок будет работать с более низкой частотой обновления для экономии энергии. Согласно имеющимся данным, новый дисплей дебютирует в ноутбуках с процессорами Intel Lunar Lake. Более подробной информации о сроках появления Winning Display в устройствах каких-то конкретных производителей на данный момент нет. PlayStation 5 разошлась тиражом 61,7 млн — у Xbox Series S/X продажи ниже более чем в два раза
18.09.2024 [10:35],
Алексей Разин
Недавний анонс игровой консоли Sony PlayStation 5 Pro даёт формальный повод подвести итоги присутствия на рынке оригинальной PS5, которая была представлена в 2020 году. По данным статистики, к июню текущего года PlayStation 5 нашла 61,7 млн покупателей, тогда как конкурирующие Microsoft Xbox Series S/X довольствуются 28,3 млн проданных экземпляров. 
Источник изображения: Sony Соответствующие данные появились в видеосюжете The Wall Street Journal, посвящённом игровым консолям современности. Статистика, комбинирующая отчётность Sony и данные Aldora Intelligence, демонстрирует более чем двукратное превосходство актуального решения Sony над конкурирующей игровой платформой Microsoft. К слову, этот разрыв не всегда был таким, если обратиться к предыдущим поколения игровых консолей двух компаний. Если PlayStation 4 обходила Xbox One по популярности почти ровно в два раза с 117 млн проданных экземпляров, то PlayStation 3 со своими 87,4 млн штук лишь незначительно опередила Xbox 360. 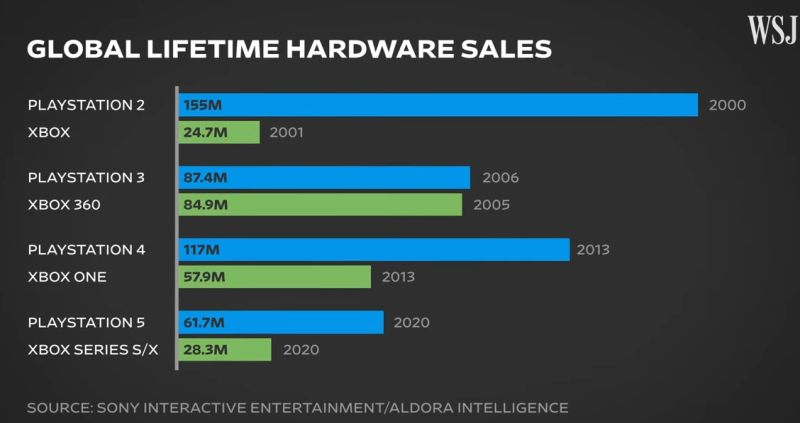
Источник изображения: YouTube, The Wall Street Journal Впрочем, абсолютным рекордсменом остаётся Sony PlayStation 2, которая за время своего присутствия на рынке с 2000 года разошлась тиражом 155 млн штук. Представленная годом позже Microsoft Xbox первого поколения нашла только 24,7 млн покупателей за время своего жизненного цикла. Если до конца текущего года Sony удастся реализовать 15 млн консолей PlayStation 5 и PlayStation 5 Pro, то совокупный тираж поколения перевалит за 80 млн штук. Успеху консолей Sony, как отмечают авторы сюжета на канале The Wall Street Journal, в последние годы способствовало обилие эксклюзивных игр для этой платформы. Грунт с обратной стороны Луны поразил учёных — он сильно отличается от всех прежних образцов
18.09.2024 [10:26],
Геннадий Детинич
Сегодня впервые появилась предварительная информация о составе грунта с обратной стороны Луны, доставленного на Землю китайским зондом «Чанъэ-6». Зонд привёз на Землю около 2 кг уникальных образцов с той стороны Луны, которая никогда не видна с нашей планеты. Полноценные научные статьи по анализу грунта появятся через год или позже, но китайские учёные не стали тянуть интригу и поделились предварительными данными, которые удивили. 
Образцы реголита с обратной стороны Луны. Источник изображений: National Science Review Грунт с обратной стороны Луны оказался более рыхлым или менее плотным, чем все доставленные ранее образцы грунта с видимой стороны спутника. Этим он очень сильно отличается от всего того, что привозят на Землю космические миссии с 1969 года. Одно только это заслуживает внимания. Но это ещё не всё. До появления уникальных проб все образцы с Луны в основном содержали базальтовые породы. В пробах грунта с обратной стороны кроме базальтов много «инородных» веществ, которые в геологическом смысле выглядят достаточно свежими. 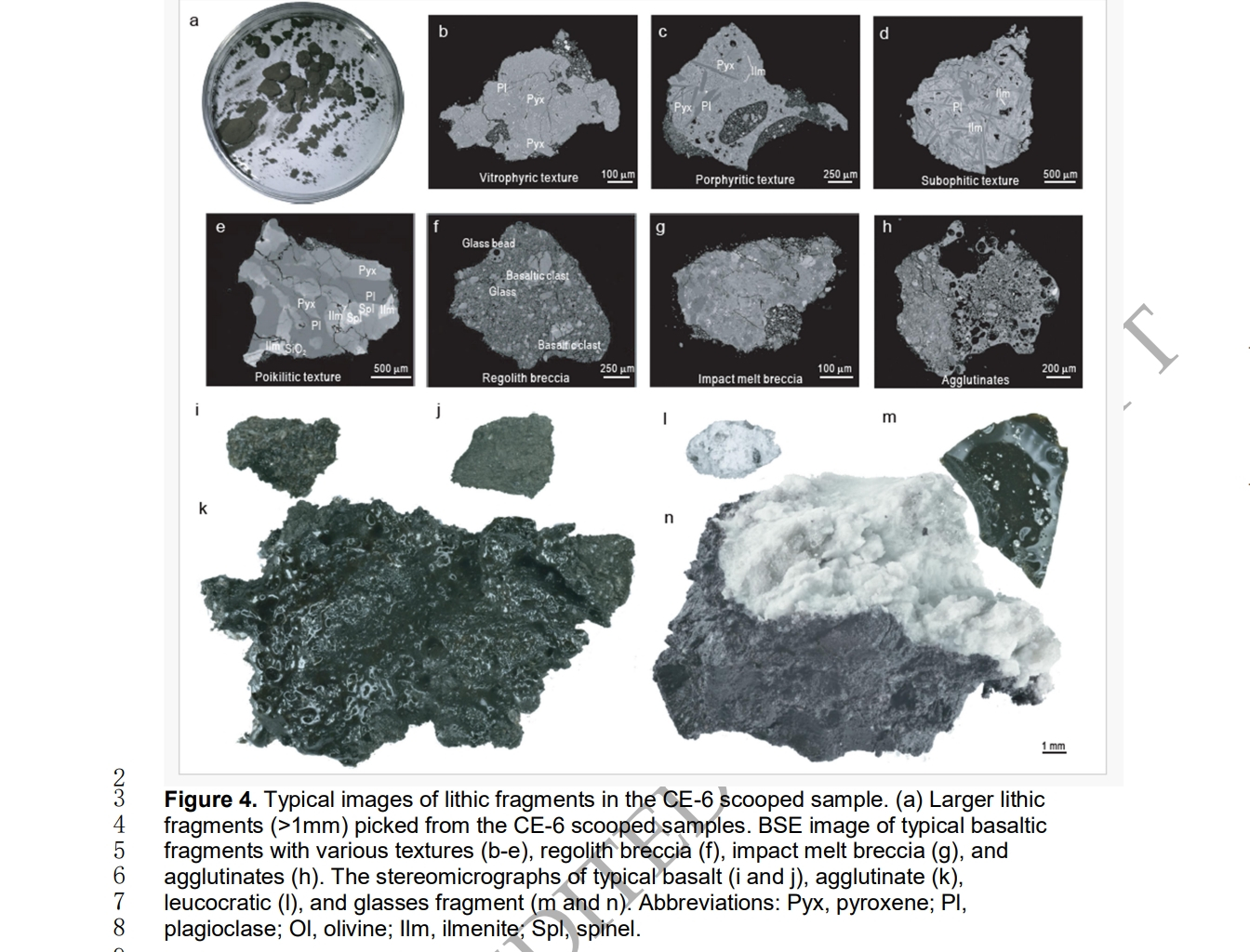
Минералы, обнаруженные в реголите с обратной стороны Луны Учёные предполагают, что они получили в руки смесь из более «зрелого» лунного грунта и материалов, относительно недавно выбитых на поверхность Луны. В районе посадки отмечено несколько свежих ударных кратеров, которые, судя по всему, загрязнили поверхность в месте забора проб продуктами выбросов, включая те, что выдержали тепловой удар. В частности, это нашло отражение в частицах стекла и полевого шпата в образцах. Зонд «Чанъэ-6» произвёл посадку и забор образцов с обратной стороны Луны в конце июня 2024 года в месте, названном бассейн Южный полюс — Эйткен. Сам по себе это огромный ударный кратер, открывающий доступ в недра древней Луны и позволяющий уточнить модели образования и эволюции спутника. Судя по первым впечатлениям от образцов поверхности из этого места, такой Луну мы ещё не знали. Electronic Arts анонсировала «крупномасштабную» программу публичного тестирования новой Battlefield
18.09.2024 [10:10],
Михаил Романов
Вслед за недавними откровениями для портала IGN компания Electronic Arts поделилась новыми подробностями следующей Battlefield в рамках презентации для инвесторов Investor Day 2024. 
Источник изображений: Electronic Arts По словам президента EA Entertainment Лоры Мили (Laura Miele), основами Battlefield являются «тотальная война», «грандиозный размах», «массовые разрушения» и «интенсивный экшен». Наиболее значительных успехов игры серии достигали, придерживаясь этих основ. Мили признала, что вышедшая в 2021 году Battlefield 2042 не оправдала ожиданий фанатов, но с новой частью всё будет по-другому. 
Новая Battlefield создаётся усилиями четырёх студий — DICE, Criterion, Motive Studio и Ripple Effect Генеральный менеджер бренда Battlefield Байрон Бид (Byron Beede) добавил, что в целях достижения наибольшего резонанса с фанатами следующая игра серии больше года тестируется «почти ежедневно». Вдобавок к внутренним испытаниям команда уже взаимодействует с членами сообщества и планирует запустить «крупномасштабную» программу публичного тестирования игры в начале 2025 года. 
На презентации можно было заметить концепт-арты новой Battlefield Ранее глава Battlefield Винс Зампелла (Vince Zampella) подтвердил, что события новой Battlefield развернутся в современном антураже, а сам проект позиционируется как возвращение к корням с матчами на 64 игрока и системой классов. По данным Тома Хендерсона (Tom Henderson), релиз новой Battlefield намечен на октябрь 2025 года. Игра войдёт в единую вселенную Battlefield, которая якобы также будет включать условно-бесплатную королевскую битву от Ripple Effect. 
Первый концепт-арт новой Battlefield — игроки вычислили, что на нём изображён Гибралтар Lotus представила Theory 1 — концепт электрического спорткара с мощностью 1000 л.с. и массой всего 1600 кг
18.09.2024 [09:52],
Алексей Разин
Принадлежащая китайскому концерну Geely марка Lotus старается не забывать о своём славном спортивном прошлом, а потому продемонстрированный ею концепт Theory 1 демонстрирует актуальный подход к созданию спорткаров. Прежде всего, машина является полноприводной и обладает пиковой мощностью 1000 л.с., но её снаряжённая масса не превышает 1600 кг. 
Источник изображений: Lotus Пусть это кажется не слишком убедительной величиной на фоне малолитражек с ДВС, но два других электромобиля в актуальной модельной линейке Lotus, Eletre и Emeya, тянут почти на 2,5 тонны, что в сочетании с ураганной динамикой электрической силовой установки предъявляет повышенные требования к тормозной системе. По сути, Lotus Theory 1 демонстрирует подход к повышению энерговооружённости современных электромобилей, поскольку на 1600 кг снаряжённой массы предусмотрено почти 1000 л.с. Нужно лишь учитывать, что при расчёте снаряжённой массы учитывается вес тела водителя (75 кг), а всего машина способна принять на борт только троих седоков. Водитель в этом интерьере расположился по центру в первом ряду, а два задних пассажира немного смещены по бокам от него во второй ряд. Это, в сочетании с дающим некоторую свободу компоновки электроприводом, позволяет с комфортом разместить внутри салона троих человек при длине колёсной базы 2650 мм и общей длине кузова менее 4,5 метра. Рекордно низкая масса для большинства электромобилей такой мощности достигнута за счёт активного использования углеволокна, композитных материалов с добавлением целлюлозы и поликарбоната при создании кузовных элементов. Многие материалы при этом получены после вторичной переработки, а в оформлении салона вообще использовано только десять разных материалов. Всё это сделано ради заботы об окружающей среде.  Тонкопрофильные кресла изготавливаются с использованием трёхмерной печати и материалов, подвергшихся вторичной переработке. Двери с большой площадью остекления оснащены необычным механизмом открывания — они поднимаются вверх и смещаются назад. По данным Lotus, это позволяет комфортно садиться и выходить из машины даже на парковочном месте шириной не более 2400 мм. Если учесть, что 2000 мм из этой величины придётся на ширину кузова электрокара, то оставшиеся 400 мм при делении на два дают лишь 20 см свободного пространства по бокам.  Продвинутая акустическая система может как имитировать рёв мотора при наборе скорости, так и подавлять шумы для создания большего комфорта. Аэродинамика кузова также проработана весьма тщательно, как для увеличения прижимной силы, так и снижения уровня шума и повышения энергетической эффективности. Ёмкость тяговой батареи не превышает 70 кВт‧ч, с нею машина способна преодолевать 402 км в условном цикле WLTP. Не так много по меркам утилитарных транспортных средств, но Lotus Theory 1 лишь является концептом, не гарантирующим перенос всех технических характеристик на серийные изделия данной марки. Максимальная скорость достигает 320 км/ч, а первую «сотню» спорткар разменивает менее чем за 2,5 секунды. За активную безопасность отвечают четыре лидара, шесть камер, а также внушительный набор радаров и датчиков. Обзор на 200 метров вокруг машины обеспечивается на 360 градусов даже в условиях ограниченной видимости. Формально, платформа Nvidia Drive обеспечивает автономность четвёртого уровня, но органы управления и интерфейс спорткара сделаны таким образом, чтобы водителю нужно было минимально отвлекаться от дороги. Поскольку руль не имеет физической связи с колёсами, его положение можно регулировать в широких масштабах, равно как и позицию педального узла. В качестве подсказок могут использоваться вибросигналы с нужной стороны рулевого колеса. Активно используются проекционные экраны, а за внешнее освещение отвечают лазерные источники производства Kyocera. Многие технические решения, использованные при создании этого концепта, найдут применение в серийных машинах Lotus. Тем более, что на фоне предложений других китайских производителей её нынешние спорткары за $2,3 млн кажутся чрезмерно дорогими, а потому ассортимент моделей нужно расширять в сторону снижения цены. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



