|
Опрос
|
реклама
Быстрый переход
Huawei представила смарт-часы Watch GT 5 и GT 5 Pro с классическим дизайном по цене от 249 евро
20.09.2024 [00:02],
Андрей Созинов
Компания Huawei, помимо глобальных версий планшетов MatePad Pro 12.2 и MatePad 12 X, представила целый ряд смарт-часов: Watch GT 5, GT 5 Pro, новый вариант Watch Ultimate, а также Watch D2 с возможностью измерения давления. 
Huawei Watch GT 5. Источник изображений: Huawei Huawei Watch GT 5 выйдут в двух размерах: 41 и 46 мм с круглыми OLED-дисплеями диагональю 1,32 и 1,43 дюйма соответственно. Оба имеют разрешение 466 × 466 пикселей. Часы изготовлены из нержавеющей стали 316L, и Huawei смогла немного уменьшить их толщину. Например, 41-мм модель стала на 0,3 мм тоньше своего предшественника серии Watch GT 4. На выбор предлагаются металлические, кожаные, пластиковые и плетёные ремешки.  Huawei улучшила навигационные возможности часов серии Watch GT 5, оснастив их модернизированной антенной и алгоритмом для улучшения позиционирования — точность определения маршрута увеличилась на 40 %, измерение расстояний и скорости — на 30 и 20 % соответственно.  Также в Watch GT 5 реализована технология Huawei TruSense, которая включает в себя привычные измерения пульса и содержания кислорода в крови, а также отслеживание сна. Функция определения нарушений дыхания во сне, присутствовавшая в часах Watch GT 4, была дополнена функцией выявления апноэ во сне. Часы также предлагают инструменты для отслеживания женского здоровья. А новая функция «Эмоции» позволяет пользователям лучше оценивать своё эмоциональное состояние и принимать своевременные меры для предотвращения негативного влияния стресса. 
Huawei Watch GT 5 Pro Смарт-часы Watch GT 5 Pro отличаются материалами корпуса. Эти новинки выпускаются в размерах 42 и 46 мм: в первом случае корпус выполнен из керамики, а во втором — из титанового сплава. Часы оснащаются такими же дисплеями, как и Watch GT 5, для защиты которых установлено сапфировое стекло. В более компактной версии ремешок выполнен из керамики, а для больших моделей предлагаются ремешки из титана или фторэластомера.  Watch GT 5 Pro поддерживают все те же функции Huawei TruSense, но также предлагают возможность снятия ЭКГ — на это требуется около 30 секунд. Huawei также сделала акцент на использовании часов для бега: поддерживаются офлайн-карты с предварительным просмотром маршрута, который указывает на изменения высоты и показывает детали рельефа. Кроме того, часы отслеживают направление движения в реальном времени, предлагают навигацию по участкам маршрута и предупреждают, если пользователь отклонится от маршрута. Часы интегрируются с Komoot. Когда пользователь достигает финиша, часы предоставляют анализ беговой формы, измеряя время контакта с землёй, вертикальные колебания, баланс и многое другое.  Также в GT 5 Pro добавлен режим Free Diving с водонепроницаемостью до 40 м и отслеживанием глубины. Часы также имеют класс защиты IP69K для защиты от струй горячей воды и устойчивы к коррозии от соляного тумана благодаря специальному покрытию внешней поверхности. Наконец, эти часы могут понравиться любителям гольфа: в них доступно более 15 000 карт полей для гольфа с 3D-превью и точными указаниями.  Huawei Watch GT 5 и GT 5 Pro обеспечат длительное время автономной работы. Более компактные версии (41 и 42 мм) проработают до 5 дней при включённой функции Always On Display (AOD) и до 7 дней при обычном использовании. Более крупные 46-мм модели проработают 9 дней с AOD и до 14 дней при обычном использовании. Версии GT 5 Pro поддерживают беспроводную зарядку и полностью заряжаются за 60 минут. 
Huawei Watch Ultimate Часы Huawei Watch Ultimate вышли в прошлом году в двух версиях: синей и чёрной. Теперь появился третий цвет — зелёный. Зелёная версия оснащена двухцветным ободком из нанотехнологичной керамики, которая окружает сапфировое стекло. Также расширился выбор ремешков: они стали зелёными, с плетёным дизайном, выполненными из синтетического каучука и титана. Продажи новых смарт-часов Huawei начались сегодня. Huawei Watch GT 5 размером 41 и 46 мм будут стоить от 249 евро в зависимости от страны, Watch GT 5 Pro 46 мм — от 379 евро, а Watch GT 5 Pro 42 мм — от 449 евро. Наконец, новые Huawei Watch Ultimate продаются за 899 евро. По мотивам романа Ника Перумова «Алмазный меч, деревянный меч» выйдет «высокобюджетная» приключенческая игра
19.09.2024 [23:50],
Михаил Романов
Фэнтезийный роман «Алмазный меч, деревянный меч» российского фантаста Ника Перумова усилиями компании «Акроникс» и продюсерского центра «Плюс Студия» («Яндекс») превратится в «высокобюджетную приключенческую игру». 
Источники изображений: «Акроникс» и «Плюс Студия» Напомним, роман «Алмазный меч, деревянный меч» вышел в 1998 году (в двух томах) и рассказывал об империи Мельин, где власть принадлежит магическим орденам, и молодом императоре, который поднимает мятеж. Видеоигровая адаптация «Алмазного меча, деревянного меча» познакомит игроков с миром Мельин и фантастическими существами со страниц книг Перумова, а также смешает в себе элементы средневековья и фэнтези. Концепт-арты
По словам технического директора «Акроникс» Дмитрия Тихонова, «Алмазный меч, деревянный меч» пока находится на стадии предварительного производства, от которой будет зависеть качество и скорость дальнейшей работы. «У нас есть всё необходимое для создания правильного фундамента, на который мы будем надстраивать сложные технологические алгоритмы, тщательно прорабатывать сюжетные линии, совершенствовать геймплей и механики игры», — заверил Тихонов. Кадры
Проект готовится к релизу на ПК и консолях и будет сопровождаться сериалом (его сценарий на ранней стадии проработки). К слову, это уже вторая игровая адаптация романа Перумова — первая вышла в 2008 году и была не очень удачной. Кроме того, «Плюс Студия» продюсирует ещё и амбициозный фантастический ролевой экшен Distortion от российской студии Game Art Pioneers. Игру дополнят книгой, комиксом и сериалом, которые будут доступны подписчикам «Яндекс Плюс». Microsoft: массового развёртывания Windows 11 24H2 в октябре не будет
19.09.2024 [23:08],
Николай Хижняк
Недавний пост на форуме Microsoft заставил многие СМИ поверить, что обновление Windows 11 24H2 может быть развернуто в начале следующего месяца для всех пользователей, однако редмондская компания позже пояснила, что у неё нет таких планов, передаёт TechSpot. 
Источник изображения: TechSpot Путаница возникла в начале этой недели, когда представитель Microsoft опубликовал пост на форуме, в котором сообщалось, что следующий «ежегодный выпуск обновлений функций Windows 11» станет доступен для всех пользователей вместе с ежемесячным выпуском обновлений безопасности 8 октября. В сообщении также говорилось, что пользователи могут установить обновление уже 24 сентября, изменив настройки Центра обновления Windows на своих ПК. Портал Ghacks первым сообщил об этой новости, восприняв информацию как официальное объявление о всеобщем развертывании Windows 11 24H2. История набрала обороты в течение следующих нескольких дней, и многие технические блоги и новостные агентства, в том числе и 3DNews, сообщили, что следующее большое обновление Windows 11 уже не за горами. Однако в среду Microsoft уточнила, что выпустит 8 октября только «регулярные ежемесячные сервисные обновления», а не Windows 11 24H2. Компания не сообщила, когда планирует выпустить 24H2. Так что пользователям, которые возлагали надежды на свежее обновление ОС, придется подождать как минимум ещё несколько недель, чтобы получить новейшие ИИ-функции на своих системах. Стоит отметить, что Windows 11 24H2 официально дебютировала в начале этого года с выпуском ноутбука Surface Laptop и планшета Surface Pro нового поколения. Также новая версия ОС доступна на ноутбуках Copilot Plus PC, к которым в настоящий момент относятся только лэптопы на базе процессоров Qualcomm Snapdragon X. Существующие компьютеры на AMD Strix Point и грядущие машины на Intel Lunar Lake тоже станут частью экосистемы Copilot Plus PC, но не сразу. Windows 11 24H2 содержит несколько ИИ-функций, включая спорную Windows Recall, которую Microsoft отозвала из-за серьёзных опасений по поводу конфиденциальности и безопасности. Ещё одной заметной ИИ-функцией в составе Windows 11 24H2 является новая версия приложения Copilot с поддержкой инструмента безопасности Enterprise Data Protection, который предназначен для установки на компьютеры с Windows 11 Enterprise, а не на все устройства с совместимыми версиями ОС. Google вводит кроссплатформенную синхронизацию ключей доступа с помощью PIN-кодов
19.09.2024 [22:57],
Анжелла Марина
Компания Google представила безопасную синхронизацию ключей доступа (passkeys) с расширенной поддержкой различных платформ. Помимо устройств Android теперь можно сохранять ключи доступа в Google Password Manager из Windows, macOS, Linux и Android с помощью PIN-кода. 
Источник изображения: Copilot Одним из главных нововведений, пишет The Verge, стала упрощённая синхронизация ключей доступа между различными устройствами. Ранее для их использования на других платформах требовалось сканирование QR-кода. Теперь этот процесс заменён вводом PIN-кода, что должно значительно упростить сохранение и использование паролей на устройствах, отличных от Android. «Сегодня мы выпускаем обновления, которые ещё больше упростят использование ключей доступа на ваших устройствах. Теперь вы можете сохранять их в Google Password Manager из Windows, macOS, Linux и Android, а также ChromeOS в бета-версии. После сохранения ключи доступа автоматически синхронизируются на всех устройствах, что делает вход в систему таким же простым, как сканирование отпечатка пальца», — говорится в блоге Google. 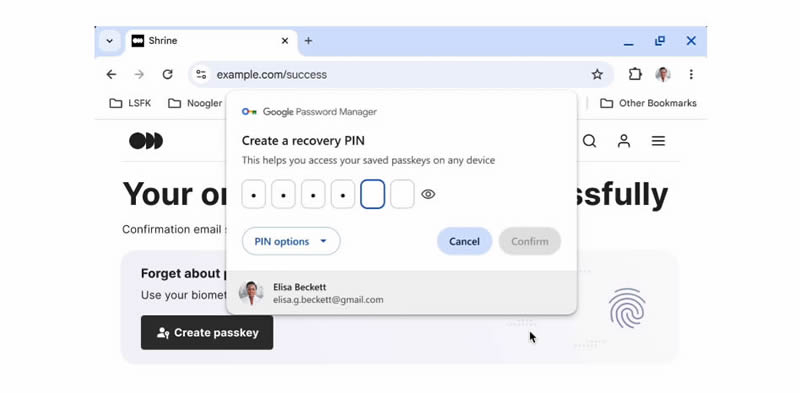
Источник изображения: Google Новый PIN-код не только делает процесс аутентификации более удобным, но и сохраняет высокий уровень безопасности. Ключи доступа по-прежнему защищены сквозным шифрованием, что гарантирует их недоступность даже для Google. Чтобы их использовать на новом устройстве пользователю достаточно будет разблокировать экран своего Android-устройства или ввести PIN-код для Google Password Manager. Ожидается, что технология PIN-кодов позволит забыть о сложных паролях и сосредоточиться на более простых, но безопасных методах аутентификации. В компании отмечают, что уже с сегодняшнего дня можно создавать пароли для популярных сайтов и приложений, таких как Google, Amazon, PayPal и WhatsApp, так как Google Password Manager встроен в устройства Chrome и Android. «Кинопоиск» анонсировал экранизацию Atomic Heart — первые подробности
19.09.2024 [22:50],
Михаил Романов
Пока фанаты ждут полноценную презентацию третьего DLC к ретрофутуристическому шутеру Atomic Heart, разработчики из студии Mundfish готовили для них нечто совсем другое — анонс экранизации игры. 
Источники изображений: Mundfish и «Кинопоиск» Адаптировать Atomic Heart взялась компания «Кинопоиск», а за производство отвечает «Плюс Студия» (продюсерский центр «Яндекса»). Работа над проектом идёт под творческим контролем Mundfish. Экранизация расскажет самостоятельную историю, в основу которой ляжет не только Atomic Heart, но и книга о предыстории предприятия № 3826. Сценарий пишет Роман Кантор, известный по фильму «Мастер и Маргарита» и сериалу «Эпидемия». «Действие будет связано непосредственно с игрой и её героями, но какие-то элементы получат неожиданное для фанатов развитие и проработку. Мы увидим события с разных точек зрения, иногда меняющих наше понимание происходящего», — заверил Кантор. Концепт-арты
«Кинопоиск» формат экранизации не уточняет, а в пресс-релизе «Плюс Студии» упоминается, что речь идёт о сериале. Производство уже стартовало, но съёмки начнутся только в 2025 году. Иллюстративного материала по адаптации Atomic Heart на данный момент совсем немного: лишь подборка из четырёх концепт-артов (см. галерею выше) и «тизер-постер» от «Кинопоиска» (см. видео ниже). Напомним, события Atomic Heart разворачиваются в альтернативном Советском Союзе, где в 1955 году из-за сбоя в нейросети «Коллектив» на предприятии № 3826 роботы-помощники оборачиваются против своих создателей. «Тизер-постер» экранизации Учёные вдохновились кальмарами и создали магнитный дисплей, которому вообще не нужна электроника
19.09.2024 [22:13],
Геннадий Детинич
Кальмары и головоногие в целом обладают удивительной кожей, которая может менять рисунок по их желанию, что помогает при маскировке, охоте и поиске партнёров. Учёные из Университета Мичигана вдохновились этой особенностью моллюсков и создали чувствительный к магнитным полям пигментный дисплей, для работы которого не нужно никакой электроники. 
Источник изображения: Jeremy Little/Michigan Engineering «Это один из первых случаев, когда механические материалы используют магнитные поля для кодирования на системном уровне, обработки информации и вычислений», — поясняют разработчики. Сегодня для подобных и других интересных целей изобретаются метаматериалы, фактически инженерные решения, состоящие из набора материалов и конструкций. Обычно они достаточно сложные для масштабирования в сторону уменьшения размеров, что затрудняет использование метаматериалов в вычислительной технике и системах отображения. Учёные из Университета Мичигана обошли это ограничение, представив лёгкий и гибкий дисплей, реагирующий только на магнитные поля. Кожа кальмаров с клетками-хромотофорами понадобилась учёным как пример того, на какое разрешение дисплея лучше всего опираться, чтобы изображение нормально воспринималось человеческим зрением. У моллюсков просто были позаимствованы размеры природных «пикселей». Придуманный учёными метаматериал опирался совсем на другие принципы работы. В некотором роде исследователи изобрели дисплей E Ink, только на свой лад. Если электронные чернила у компании E Ink — это пигментная взвесь, реагирующая на полярность электромагнитного поля (заряд на управляющей матрице), то в случае магнитного дисплея использовались так называемые частицы Януса. Это широкий спектр материалов, обладающих двумя и более отличающимися свойствами. Простейшим примером частицы Януса можно назвать стрелку компаса. У разных концов стрелки разная полярность и можно заставить магнитом поворачиваться её так или иначе. Созданные в Университете Мичигана частицы Януса с одной стороны состояли из ферромагнитных микрочастиц неодима (NdFeB) и суперпарамагнитных наночастиц оксида железа (SPION), а с другой — из такого пигмента, как оксид титана (TiO2). Соответственно, с одного конца они были оранжевыми, а с другого — белыми. Меняя полярность поднесённого к экрану магнита, можно было сделать его оранжевым или белым, а если расположить за экраном несколько маленьких магнитов заданным образом, то можно было закодировать изображение — намагниченные частички при встряхивании просто собрались бы у магнитов с подходящей полярностью. Нюанс использования частичек с NdFeB и SPION в том, что неодим реагировал на сильное магнитное поле, а железо — на слабое. В слабом поле с помощью специального ключа — рисунка из магнитов под экраном, дисплей показывал секретное изображение, невидимое при нахождении над сильным магнитом. Таких ключей может быть несколько со своей конфигурацией магнитного рисунка и в каждом случае будет своё изображение. Учёные полагают, что таким образом можно записывать штрих-коды на рабочую одежду и другую информацию, которую невозможно взломать или вскрыть, ведь устройство не имеет электронной части. Помещение экрана в сильное магнитное поле возвращает общую «неодимовую» картинку, скрывая секретную «железную». Такой дисплей не нуждается в питании и электронике, что может найти своё применение. У Volkswagen ID.4 на ходу могут внезапно открыться двери — выпуск и продажи электромобилей остановлены, запущен отзыв
19.09.2024 [21:54],
Анжелла Марина
Концерн Volkswagen останавливает продажи и производство кроссовера ID.4 из-за возможных проблем с безопасностью во время движения. Отозваны почти 100 000 электромобилей из-за дефекта дверных ручек, которые могут открываться самопроизвольно. 
Источник изображения: Volkswagen Как передаёт Ars Technica, дверные ручки не соответствуют стандартам водонепроницаемости, в результате чего вода заливает электронную плату управления дверью, что потенциально может привести к её открытию во время движения. В связи с этим компания ввела запрет на продажу ID.4 дилерами и приостановила производство на заводе в городе Чаттануге (США, штат Теннесси). Запрет распространяется как на подержанные автомобили, так и на новые, находящиеся на стоянках дилеров. Первые жалобы от владельцев начали поступать в феврале 2024 года, и уже в июне, совместно с поставщиками, Volkswagen определил, что проблема связана с недостаточной защитой электроники дверных ручек от попадания воды и последующей коррозии. Отзыв затрагивает все модели ID.4, проданные в США. Всего 99 064 автомобиля, начиная с первых моделей 2021 года выпуска, произведённых в Германии, и заканчивая новейшими моделями 2024 года, собранными в США. Национальное управление безопасности дорожного движения США (NHTSA) также начало собственное расследование после получения 12 сообщений об открытии дверей ID.4 во время движения. NHTSA установило, что все эти автомобили прошли процедуру отзыва в 2023 году, и запросило у Volkswagen информацию о причинах неустранения проблемы. Издание Ars Technica связалось с компанией и получило следующие комментарии: «После тщательного анализа ситуации, в связи с запретом на продажу ID.4, мы временно приостановим производство кроссовера пока не будет найдено решение. Мы работаем над устранением проблемы и сосредоточены на том, чтобы минимизировать негативные последствия для наших сотрудников, дилеров и клиентов. Эта ситуация никоим образом не меняет наше отношение к ID.4 и нашему растущему портфелю электромобилей. ID.4 по-прежнему остаётся одним из самых продаваемых электромобилей в Америке». На данный момент нет информации об авариях или травмах, связанных с неисправностью дверных ручек, однако Volkswagen сообщает о 293 гарантийных обращениях по этой проблеме и о том, что владельцы автомобилей будут уведомлены об отзыве до 1 ноября. Ноутбуки с Intel Lunar Lake действительно долго работают от батареи — Lenovo Yoga продержался почти 24 часа
19.09.2024 [21:43],
Николай Хижняк
Ноутбук Lenovo Yoga Slim 7i Aura Edition на базе новейшего процессора Core Ultra 7 258V из серии Lunar Lake значительно обошёл по автономности MacBook Air на процессоре M-серии от компании Apple. Это подтверждает заявления Intel о выдающейся автономности компьютеров на её новейших чипах Lunar Lake. 
Источник изображений: Lenovo Intel уже много лет отстаёт от конкурентов, например Apple, по части энергоэффективности своих чипов для ноутбуков. Однако, если судить по предварительным обзорам, последняя линейка процессоров Lunar Lake может наконец помочь Intel вернуть утраченные позиции. Волна ноутбуков на базе Core Ultra 200 вот-вот хлынет на рынок, а заявленные для них показатели времени автономной работы впечатляют. YouTube-канал Lenovo PC сравнил автономность новейшего ноутбука Yoga Slim 7i Aura Edition на базе свежего процессора Core Ultra 7 258V с ноутбуками на базе процессоров Apple M2 и M3. Тест включал просмотр видео в разрешении 1080p при 24 кадрах в секунду, с яркостью экрана 150 кд/м2 и отключённым Wi-Fi. Ноутбук M2 MacBook Air проработал при таких условиях 18 часов и 19 минут. Модель на Apple M3 продержалась чуть дольше — 18 часов и 32 минуты. Однако ноутбук Lenovo Yoga Slim 7i Aura Edition продолжал работать. Его батарея села только через 23 часа и 54 минуты. Справедливости ради следует отметить, что Yoga Slim 7i оснащён чуть более ёмкой батареей на 70 Вт·ч. В свою очередь «макбуки» несут в себе аккумуляторы на 66,5 Вт·ч. И всё же лэптоп Lenovo смог проработать почти на треть дольше конкурентов, несмотря на небольшое преимущество в ёмкости его батареи. Разумеется, просмотр видео — это лишь один из сценариев использования ноутбука. Настоящим тестом на выносливость станет проверка устройств при интенсивных рабочих нагрузках. Победа в гонке за автономность ноутбуков заключается не только в увеличении времени воспроизведения видео, но и в достижении идеального баланса автономности и производительности. И всё же тест Lenovo — это лишь один пример из того, что обещают производители ноутбуков на базе Lunar Lake. Например, Acer заявляет, что время работы некоторых моделей её новейших ноутбуков с этими чипами от батарей на 65 Вт·ч составит до 29 часов. Asus делает аналогичные заявления относительно своих свежих моделей ноутбуков ExpertBooks.  Что касается Lenovo Yoga Slim 7i, то использующийся в нём восьмиядерный Core Ultra 7 258V обладает частотой до 4,8 ГГц. Ноутбук получил 32 Гбайт оперативной памяти LPDDR5X-8533 и работает под управлением Windows 11 24H2. Устройство также предлагает 15,3-дюймовый дисплей с разрешением 1800p и частотой 120 Гц, NVMe-накопитель PCIe 4.0 объёмом 1 Тбайт и поддержку Wi-Fi 7. Стоимость новинки будет начинаться с $1279,99. Старт продаж ноутбука ожидается в ближайшие недели. «Надеемся обратить ваше ожидание в восторг»: режиссёр Lies of P рассказал, чего ждать от дополнения и сиквела
19.09.2024 [21:43],
Михаил Романов
Гейм-дизайнер Дживон Чхве (Jiwon Choi), выступивший руководителем разработки ролевого экшена Lies of P по мотивам сказки «Приключения Пиноккио», обратился к игрокам по случаю годовщины проекта. 
Источник изображения: Steam (Berlin) В открытом письме Чхве заверил, что команда Round8 Studio усердно трудится над подтверждённым ранее дополнением к Lies of P. Его релиз, согласно майскому отчёту издательства Neowiz, запланирован на вторую половину 2024 года. Чхве также показал новый концепт-арт будущего аддона (см. изображение ниже) и опубликовал ссылку на музыкальную композицию Lisrim, которую можно будет услышать в расширении. 
Новый концепт-арт дополнения к Lies of P (источник изображения: Neowiz) «В случае с DLC для Lies of P и сиквелом мы стремимся превзойти удачные элементы игры и улучшить те, что получились не очень хорошо», — обозначил Чхве цели команды на ближайшие проекты. На то, что Lies of P получит продолжение, явно намекала концовка (спойлеры), а впоследствии работу над сиквелом подтвердил сам Чхве. Судя по вакансиям Neowiz, новая игра создаётся на Unreal Engine 5 и будет иметь открытый мир. 
Прошлогодний концепт-арт дополнения к Lies of P (источник изображения: Neowiz) «Теперь мы снова берёмся за работу. Когда мы вернёмся, то надеемся обратить ваше ожидание в восторг. Спасибо вам огромное, что присоединись к нам в этом путешествии», — заключил Чхве. Lies of P вышла 19 сентября 2023 года на PC (Steam), PS4, PS5, Xbox One, Xbox Series X и S, а также в Game Pass. За месяц продажи превысили 1 млн копий, а суммарная аудитория проекта прошедшей весной превысила 7 млн человек. Планшеты Huawei MatePad Pro 12.2 и MatePad 12 X вышли на глобальный рынок по цене от €569
19.09.2024 [21:33],
Владимир Мироненко
Компания Huawei объявила о старте глобальных продаж планшетов MatePad Pro 12.2 и MatePad 12 X, представленных в Китае в августе. Новинки предлагают большие дисплеи и фирменные процессоры Kirin.  MatePad Pro 12.2 оснащён двуслойным 12,2-дюймовым Tandem OLED-экраном с технологией PaperMatte. Разрешение экрана составляет 2800 × 1840 пикселей, частота обновления — до 144 Гц, контрастность — 2 000 000:1, а показатель пиковой яркости составляет 2000 кд/м2. Также сообщается о сертификации TÜV Rheinland Reflection-Free Certification и TÜV Rheinland Full Care Display 3.0 Certification, что гарантирует возможность длительного использования устройства без чрезмерной нагрузки на глаза.  Благодаря обработке с помощью технологии нанотравления экран PaperMatte получил антибликовую поверхность, обеспечивая комфортный опыт чтения и просмотра, как при использовании настоящей книги или журнала. Также сообщается о поддержке ввода с помощью активного стилуса. Планшет получил восьмиядерный процессор Kirin T91, объём оперативной памяти планшета равен 12 Гбайт, ёмкость флеш-накопителя — 256 или 512 Гбайт. На тыльной панели находятся 13-Мп камера с автофокусом и 8-Мп камера с фиксированным фокусом. Разрешение фронтальной камеры равно 16 Мп. Толщина корпуса MatePad Pro 12.2 составляет 5,5 мм, вес — 508 г. Ёмкий аккумулятор на 10 100 мА·ч поддерживает быструю проводную зарядку мощностью 100 Вт.  Планшет MatePad 12 X предлагается в Китае под названием MatePad Air. Он оснащён 12-дюймовым IPS-дисплеем с технологией PaperMatte, разрешением 2800 × 1840 пикселей, пиковой яркостью 1000 кд/м2 и поддержкой стилуса Huawei M-Pencil.  Планшет базируется на восьмиядерном чипе Kirin T90A и имеет 8 или 12 Гбайт оперативной памяти, а также флеш-накопитель на 256 Гбайт. Ёмкость батареи новинки такая же, как у MatePad Pro 12.2, впрочем, как и конфигурация камер. Толщина корпуса MatePad 12 X равна 5,9 мм, вес — 555 г. Стоимость Huawei MatePad Pro 12,2” 12/256 Гбайт в комплекте с чехлом-клавиатурой составляет €849, а версия MatePad Pro 12,2” PaperMatte 12/512 Гбайт с клавиатурой стоит €999. Цена модели Huawei MatePad 12 X 8/256 Гбайт, также укомплектованной клавиатурой, начинается с €569, а версия MatePad 12 X PaperMatte 12/256 Гбайт + клавиатура обойдётся в 649 евро. «Эта игра — чистое веселье»: блогер опубликовал час геймплея фотореалистичной стратегии Empire of the Ants
19.09.2024 [21:00],
Юлия Позднякова
Американский блогер Punish поделился часовой записью геймплея фотореалистичной стратегии в реальном времени Empire of the Ants, релиз которой состоится в ноябре. 
Источник изображений: Steam В комментарии к ролику Punish кратко рассказал о своих впечатлениях. «Эта игра — чистое веселье, — признался он. — У меня была неделя раннего доступа. Кривая сложности присутствует, но как только вы разберётесь в механиках и особенностях, играть станет очень весело и приятно, хотя я даже не думал, что скажу подобное». По словам блогера, «очень скоро» в Steam выйдет общедоступная демоверсия (в августе она предлагалась только европейским пользователям Steam на ограниченное время). «Если у вас есть возможность, дайте шанс этой игре!» — призвал он. Empire of the Ants разрабатывается французской студией Tower Five, основанной ветеранами Creative Assembly (серия Total War). За основу авторы взяли роман французского писателя Бернарда Вербера (Bernard Werber) «Муравьи» 1991 года. Управляя муравьём-спасителем по имени 103 683-я, игроки будут развивать колонию, собирать ресурсы, охотиться, сражаться с пауками, богомолами и другими насекомыми, заключать союзы. Придётся адаптироваться к меняющимся условиям, зависящим от времени года. В начале игры пользователи занимаются созданием экономики и армии, строят защитные сооружения и добывают разведданные о противнике. Отправляя рабочих муравьёв в лес, они будут получать пищу и материалы, а также захватывать новые территории и строить ульи — все сооружения имеют ограниченные возможности расширения площади. Основательно подготовившись, можно атаковать оппонента (в ролике это термиты), однако медлить нельзя — слишком долгое ожидание обернётся тем, что враг нападёт первым.  В одной битве смогут одновременно участвовать тысячи насекомых. Главная цель — уничтожить штаб врага. Геймеры отдают приказы своей армии в роли генерала (упомянутой героини), управляемого с видом от третьего лица. «Эта особенность отличает игру от большинства стратегий в реальном времени, где пользователи выступают в роли всеведущего божества, смотрящего на всё сверху вниз, — отметил продюсер Дамьен Буссирон (Damien Boussiron). — Это позволяет почувствовать себя в центре событий и в деталях оценить окружение, созданное нашими художниками». В боях можно использовать феромоны — вспомогательные умения вроде временного усиления урона и восстановления здоровья. Как подчеркнул Буссирон, делать это легко независимо от устройства ввода. «Одной из наших целей было создание стратегии, в которую приятно играть с контроллером в руках», — отметил он.  Помимо одиночной кампании, стратегия содержит отдельные миссии (тактические на время с противостоянием волнам врагов, исследовательские для желающих насладиться графикой и сюжетом и другие) и мультиплеер. В июле разработчики раскрыли системные требования и рассказали о создании фотореалистичной графики на Unreal Engine 5 — окружения на основе снимков леса вблизи Парижа и детализированных моделей насекомых. Empire of the Ants выйдет 7 ноября 2024 года на ПК (Steam, GOG, Epic Games Store), PlayStation 5, Xbox Series X и S. Подтверждён текстовый перевод на русский язык. В России тестируют отечественную замену Центру сертификации Microsoft для банков
19.09.2024 [20:58],
Владимир Мироненко
Не исключено, что корпорация Microsoft, закрывшая пользователям из РФ доступ к ряду облачных сервисов Azure и иных продуктов, может так же поступить в отношении своих Центров сертификации (Certification Authority, CA), выдающих сертификаты для ОС Windows. Без таких сертификатов работа банка может быть заблокирована, поскольку они используются как при общении с клиентами (мобильный банк, ДБО, банкоматы и т. д.), так и при операциях внутри банка, пишет «Коммерсантъ». 
Источник изображения: Towfiqu barbhuiya / Unsplash Российские производители ПО уже подготовили для банков удостоверяющие центры (УЦ), которые смогут выпускать сертификаты для работы с различными ОС, прежде всего Windows и Linux. В частности, компания SafeTech сообщила о завершении пилотного проекта по установке в одном из российских банков нового УЦ. Аналогичное предложение создала для российских банков компания Aladdin Enterprise. В SafeTech отметили, что их продукт может работать параллельно с Microsoft CA, постепенно его заменяя. Интерес к подобным продуктам проявляют не только банки, но и другие игроки финансового сектора. Напомним, что с 1 января 2025 года системно значимые кредитные организации (СЗКО) обязаны перейти на отечественные сертификаты. Продолжать работу с Microsoft CA можно, но всё равно придётся искать замену, поскольку не у всех есть бессрочная лицензия. Кроме того, как отмечают эксперты, банковское дело имеет свою специфику, связанную с необходимостью выпуска сертификатов для разных типов оборудования и под управлением разных ОС. А без наличия официальной поддержки со временем могут возникнуть проблемы. Кооперативный хоррор No More Room in Hell 2 получил дату выхода в раннем доступе Steam — это продолжение культового зомби-мода для Half-Life 2
19.09.2024 [20:10],
Михаил Романов
Разработчики из канадской Torn Banner Studios, завершив активную поддержку Chivalry 2, переключились на кооперативный хоррор-шутер No More Room in Hell 2 и уже готовы объявить дату выхода игры в раннем доступе. 
Источник изображений: Torn Banner Studios Как стало известно, исходная версия No More Room in Hell 2 поступит в продажу 22 октября для ПК (Steam, Epic Games Store) по цене $30. Анонс сопровождался 38-секундным геймплейным тизер-трейлером. На старте обещают кооператив на восьмерых, систему коммуникации, расчленение зомби, нелинейную карту с дюжиной точек интереса, оружие ближнего и дальнего боя, ловушки, взрывчатку, разнообразие врагов и графику на Unreal Engine 5. Ранний доступ No More Room in Hell 2 продлится по меньшей мере год, за который в игру будут постепенно добавлять новые функции, карты, элементы индивидуализации, оружие, инструменты и сюжетный контент. События No More Room in Hell 2 развернутся в антураже зомби-апокалипсиса. Игроки появляются на разных концах огромной карты и должны объединить усилия, чтобы выполнять похожие на головоломки задачи и отбиваться от живых мертвецов. Геймерам предстоит подстраиваться под постоянно меняющиеся условия, добывать ресурсы для прокачки персонажа и помнить о смерти — гибель в игре необратима. Потеря участника перманентно влияет на эффективность отряда. Игра была анонсирована ещё в 2016 году студией Lever Games, которая выпустила первую No More Room in Hell — культовый мод для Half-Life 2. С тех пор команду приобрела Torn Banner Studios, но её участники продолжают работу над сиквелом. Sony представила PS5 и PS5 Pro в стиле первой PlayStation по случаю её 30-летия
19.09.2024 [20:10],
Николай Хижняк
Компания Sony представила лимитированные версии игровых приставок PS5 и PS5 Pro по случаю 30-летия бренда PlayStation. Консоли выполнены в знаменитом сером цвете, в котором выпускалась оригинальная PlayStation. Со вторым поколением PlayStation компания перешла на чёрный цвет. Актуальные модели PS5 предлагаются в белом цвете, однако поддерживают сменные боковые панели. 
Источник изображений: PlayStation В комплект PlayStation 5 Pro Console – 30th Anniversary Limited Edition Bundle входят:
В комплект также входят кабель USB-C, имитирующий форуму оригинального кабеля для первой PlayStation, набор наклеек, лимитированный постер (1 из 30 возможных дизайнов) и скрепка для кабеля PlayStation.  В продаже консоль в комплекте PlayStation 5 Pro Console – 30th Anniversary Limited Edition Bundle появится с 21 ноября.  В состав игрового комплекта PlayStation 5 Digital Edition – 30th Anniversary Limited Edition Bundle входят бездисковая версия приставки PlayStation 5 с накопителем на 1 Тбайт в фирменном сером цвете, крышка дисковода в цвет приставки, контроллер DualSense, а также подставка для вертикальной установки приставки. Здесь также пользователи получат кабель USB-С, стилизованный под оригинальный кабель для PlayStation 1, набор наклеек, лимитированный постер и скрепка для кабеля PlayStation.  Sony отмечает, что всего будет выпущено 12 300 комплектов PlayStation 5 Pro Console – 30th Anniversary Limited Edition Bundle. Число символизирует месяц и день выпуска первой игровой приставки PlayStation. Весьма вероятно, что большинство этих приставок окажется на руках у перекупщиков, которые затем будут продавать их по завышенной цене. Комплект PlayStation 5 Digital Edition – 30th Anniversary Limited Edition Bundle, вероятно, будет приобрести проще. Sony не уточнила, какое количество подобных комплектов с серой PS5 собирается выпустить, но отметила, что предзаказы начнёт принимать с 10 октября.  В дополнение к двум спецверсиям игровых приставок Sony также выпустит портативную консоль PlayStation Portal для удалённой игры на PS5 в той же цветовой схеме. Также будет возможность отдельно приобрести контроллер DualSense Edge — его можно будет заказать с 26 сентября. 
 Представленные новинки будут доступны в официальных магазинах PlayStation. В регионах, где отсутствуют такие магазины, реализацией устройств будут заниматься местные ретейлеры. Стоимость новинок компания Sony не сообщила. DJI представила экшн-камеру Osmo Action 5 Pro — 40 Мп, рекордный динамический диапазон и скорость до 960 fps
19.09.2024 [19:42],
Сергей Сурабекянц
Камера Osmo Action 5 Pro стала ответом DJI на новую линейку Hero 13 от GoPro. Новинка оснащена 40-мегапиксельным 1/1,3-дюймовым сенсором DJI нового поколения с рекордным динамическим диапазоном в 13,5 шагов. Osmo Action 5 Pro может осуществлять сверхзамедленную съёмку со скоростью 960 кадров в секунду в разрешении 1080p. Новый энергоэффективный 4-нм чип обеспечивает до четырёх часов непрерывной записи от одной зарядки. 
Источник изображений: DJI Osmo Action 5 Pro оборудована двумя OLED-дисплеями с уменьшенными рамками спереди и сзади, которые, по утверждению производителя, обеспечивают «более насыщенные и яркие» цвета. Камера поставляется с 47 Гбайт быстрой встроенной памяти, что позволяет использовать её прямо из коробки, а также имеет слот для карт памяти microSD. Osmo Action 5 Pro поддерживает парные микрофоны DJI Mic 2 Bluetooth, которые особенно полезны при записи аудио интервью.  Osmo Action 5 Pro обеспечивает съёмку видео в разрешении до 4K со скоростью до 120 кадров в секунду в формате 4:3, имеет встроенную блокировку горизонта на 360 градусов и новую функцию, которая может центрировать и отслеживать человека или объект при съёмке видео. Камера оборудована датчиком атмосферного/водяного давления профессионального класса.  Камера оснащена беспроводным интерфейсом стандарта Wi-Fi 6 и разъёмом для проводного подключения USB Type-C. Встроенный приёмник GPS отсутствует, данные о местоположении можно добавить при сопряжении с такими устройствами, как пульт дистанционного управления DJI Osmo Action GPS Bluetooth. Производитель гарантирует водонепроницаемость камеры до глубины 20 метров.  Встроенный аккумулятор ёмкостью 1950 мА·ч обеспечивает четыре часа непрерывной записи видео в разрешении 1080p со скоростью 24 кадра в секунду при температуре 25 °C, с включённой стабилизацией Rocksteady, отключённым Wi-Fi и выключенными передним и задним дисплеями. DJI заявляет, что Osmo Action 5 Pro может надёжно работать при температурах от -20 °C до 45 °C, хотя время работы при низких температурах снижается до 3,6 часов.  Osmo Action 5 Pro уже поступила в продажу по цене $349. Стандартный комплект включает в себя защитную рамку, аккумулятор, кабель USB Type-C и ряд аксессуаров для крепления и очистки экшн-камеры. Отечественное ПО стало дороже иностранного, но уступает по качеству, заметили во ФСТЭК
19.09.2024 [19:16],
Владимир Мироненко
Федеральная служба по техническому и экспортному контролю (ФСТЭК) считает очень высокой стоимость российского ПО. Об этом сообщил замдиректора ФСТЭК Виталий Лютиков на пленарной сессии BIS Summit, пишет РБК. Чиновник отметил, что российские производители ПО на фоне высокого спроса подняли цены на свои продукты «в десятки раз». В итоге цены отечественного ПО оказались выше, чем у зарубежных аналогов, хотя качество хуже. 
Источник изображения: Pexels/Pixabay Заявление замдиректора ФСТЭК оспорил директор Центра компетенций по импортозамещению в сфере ИКТ Илья Массух, утверждающий, что рост стоимости российского софта за последние три года составляет 15–20 % в год. Эти цифры могут быть выше, если заказчику потребуется разработка функциональности с учётом конкретных условий. С 2022 года работу в России ограничили или совсем покинули рынок основные зарубежные поставщики ПО, включая Microsoft, Oracle, Cisco, SAP, Adobe и др. Также, согласно указу, подписанному президентом, с 31 марта 2022 года запрещено приобретать иностранное ПО, в том числе в составе программно-аппаратных комплексов, для объектов критической информационной инфраструктуры без согласования с уполномоченным органом исполнительной власти. Сообщения о росте цен на «импортозамещённое ПО» стали поступать с прошлого года. В частности, зампред правления Россельхозбанка Николай Ульянов сообщил «Коммерсанту», что только за год с марта 2022-го цены на российский софт выросли на 20–40 %, а директор технологической практики «Технологии доверия» (бывший PwC) Юрий Швыдченко отметил рост цен на российские операционные системы за тот же период на 30–50 %. В июне 2023 года руководителями крупнейших софтверных ассоциаций России АПКИТ, НП РУССОФТ, АРПП «Отечественный софт» было подписано соглашение о добровольном ограничении опережающего роста цен на своё ПО. В Минцифры при этом считают, что участники рынка могут «самостоятельно выработать правила игры и обеспечить цивилизованное регулирование ценовой политики на разрабатываемые решения». Учёные создали вечную оптическую 5D-память — кристалл сохранит до 360 Тбайт на миллиарды лет
19.09.2024 [18:56],
Сергей Сурабекянц
Исследователи из Университета Саутгемптона в Великобритании успешно сохранили всю последовательность генома человека на неразрушаемом кристалле оптической памяти 5D размером не больше мелкой монетки. Носитель уже размещён в защищённом подземном хранилище для возможного будущего возрождения человечества. Разработчики утверждают, что он выдерживает температуру до 1000 °C, космическую радиацию и прямые ударные нагрузки в 10 тонн на см2. 
Источник изображения: University of Southampton Разработанные в Исследовательском центре оптоэлектроники в Саутгемптоне кристаллы памяти 5D используют сверхбыстрые лазеры для записи данных в «наноструктурированные пустоты, ориентированные внутри кремния» размером до 20 нм. 5D в названии подчёркивает, что новая технология использует два оптических измерения и три пространственные координаты для записи по всему объёму носителя. Разработчики утверждают, что их метод позволяет достичь беспрецедентной плотности данных до 360 Тбайт на одном кристалле (в некой самой крупной версии) без потери информации на протяжении миллиардов лет. Учёные верят, что в далёком будущем, когда наука позволит реконструировать организмы по ДНК, карта генома, хранящаяся в этом вечном кристалле, может стать надёжным чертежом для возрождения человеческой цивилизации. Помимо генома человека, кристаллы также могут сохранять геномы исчезающих видов растений и животных, которые сегодня сталкиваются с экзистенциальными угрозами из-за изменения климата, потери среды обитания и других экологических кризисов. Исследователи уже поместили первую из резервных копий геномных кристаллов в подземный архив соляной шахты в Гальштате, Австрия. Возрождение видов, населяющих Землю из этих вечных кристаллов данных больше похоже на научно-фантастическую концепцию. Тем не менее, хочется верить, что наши потомки, захвативший планету ИИ или другая форма разумной жизни расшифрует человеческий геном через миллиарды лет после гибели человеческой цивилизации. 
Источник изображения: techspot.com Разработчики утверждают, что спроектировали носитель информации таким образом, чтобы другие разумные существа могли эту информацию извлечь. «Визуальный ключ, начертанный на кристалле, даёт нашедшему знание о том, какие данные хранятся внутри и как их можно использовать», — заявил руководитель исследования профессор Питер Казански (Peter Kazansky). Ключ изображает базовую молекулярную структуру пар оснований нуклеиновых кислот ДНК, знаковую структуру двойной спирали, и перекликаются со знаменитыми диаграммами Pioneer Plaque с информацией о человечестве для других цивилизаций, которые NASA размещало на своих межзвёздных зондах. 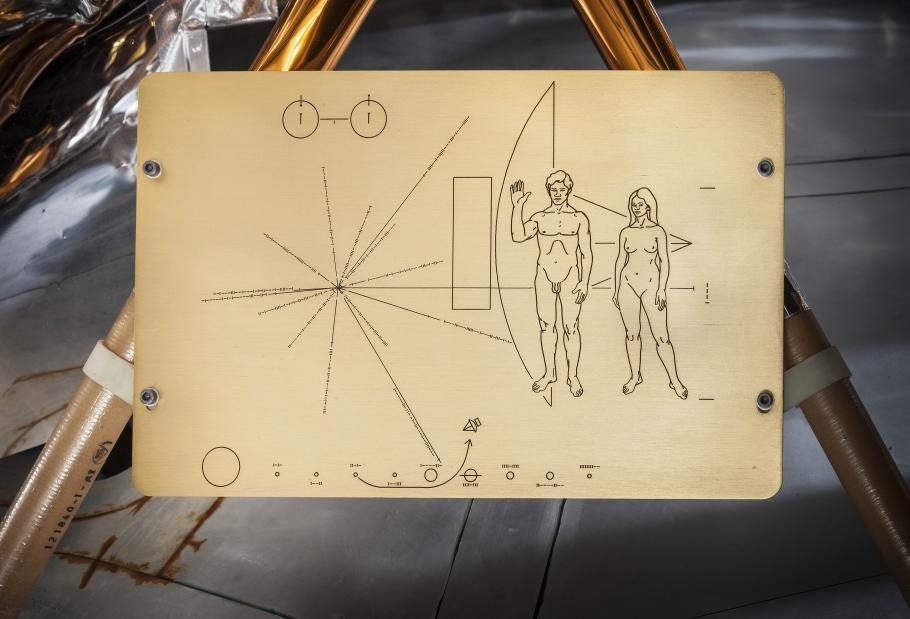
Источник изображения: space.com «Не думаем, что Hi-Fi Rush 2 нас обогатит»: Krafton спасла Tango Gameworks от закрытия не ради денег
19.09.2024 [18:45],
Михаил Романов
Генеральный директор южнокорейского издательства Krafton Чанхан Ким (Changhan Kim) в интервью Game Developer объяснил, зачем его компания выкупила японскую студию Tango Gameworks у Microsoft. 
Источник изображений: Bethesda Softworks Напомним, в мае Microsoft решила закрыть Tango, несмотря на то, что её последний проект — ритм-экшен Hi-Fi Rush — оказался хитом. В августе Krafton объявила, что приобрела как саму студию, так и права на Hi-Fi Rush. По словам Кима, Krafton спасла Tango, чтобы сохранить её наследие. Портфолио студии включает Ghostwire: Tokyo и The Evil Within, но покупка ещё и этих франшиз осложнила бы сделку, которая и без того заключалась в последний момент. 
Krafton переманила к себе около половины сотрудников Tango (порядка 50 человек), но надеется привлечь и остальных «Мы хотели помочь команде и дальше делать свои игры, но особенно Hi-Fi Rush. Когда я думаю о наших фанатах, то представляю, что больше всего они переживают за сиквелы Hi-Fi Rush», — объяснил Ким. При этом в Krafton понимают, что золотые горы покупка Tango не сулит: «Мы не думаем, что Hi-Fi Rush 2 нас обогатит, если честно. Но это часть игры. Мы должны разрабатывать игры, чтобы бросать себе вызов». 
Krafton надеется создать в Tango атмосферу, в которой разработчики смогут творить без страха провала Ким добавил, что компании вроде Krafton должны стремиться не выпускать один хит за другим — это нереалистичная цель, — а ориентироваться на безубыточность и развитие творческого потенциала своих команд. Hi-Fi Rush дебютировала в январе 2023 года на PC (Steam, Microsoft Store), Xbox Series X, S и в Game Pass, а в марте 2024-го добралась до PS5. Игра заслужила награды на The Game Awards, BAFTA и GDCA, а в команде готовились браться за сиквел. Intel заявила, что не собирается продавать контрольный пакет Mobileye
19.09.2024 [18:21],
Павел Котов
Компания Intel заявила, что не планирует продавать контрольный пакет акций разработчика систем компьютерного зрения и автономного вождения Mobileye Global. В результате ценные бумаги разработчика технологий автопилота прибавили в цене более 13 %. 
Источник изображения: mobileye.com Акции Mobileye в начале сентября рухнули после сообщения Bloomberg, что Intel планирует продать часть своей доли в компании. Всего с начала года ценные бумаги потеряли 73 %. «Мы верим в будущее технологий автономного вождения и в уникальную роль Mobileye как лидера в разработке и развёртывании передовых систем помощи водителю», — говорится в заявлении Intel. Intel поглотила Mobileye в 2017 году за $15,3 млрд, но пять лет спустя провела повторное размещение акций компании на бирже. По состоянию на 30 декабря Intel принадлежали 88,3 % обыкновенных акций Mobileye, говорится в годовом отчёте израильского разработчика автопилота. Сейчас ему приходится противостоять нестабильному спросу на чипы для систем помощи водителю; из-за слабых продаж в Китае компания была вынуждена снизить годовые прогнозы по выручке и прибыли. Компания Intel и сама пытается оздоровить свой бизнес, сосредоточившись на направлении по выпуску микросхем и процессоров для систем искусственного интеллекта, но в последние месяцы её акции резко упали: компания провела сокращение рабочих мест, приостановила выплату дивидендов и пережила отставку высокопоставленного члена совета директоров. Улучшить ситуацию может сделка с облачным подразделением Amazon, о которой было объявлено ранее — она поможет набрать обороты производственному предприятию Intel, которое стремится стать полноправным конкурентом на рынке полупроводниковых подрядчиков, в том числе TSMC. Российский электромобиль «Атом» будет узнавать водителя по лицу с помощью ИИ
19.09.2024 [18:19],
Сергей Сурабекянц
Telegram-канал «Ростеха» сообщил, что перспективный российский электромобиль «Атом» получит систему распознавания лиц на основе искусственного интеллекта. Такое решение позволит «Атому» «узнавать» конкретного водителя и мгновенно адаптироваться под него. Внедрением функций распознавания лиц при помощи ИИ займётся компания NtechLab. 
Источник изображений: «Атом» В «Ростехе» утверждают, что эта разработка станет первым в России внедрением функций ИИ в автотранспорт. Аутентификация водителя будет производиться при помощи мобильного приложения. Разработчики гарантируют уверенное распознавание людей в очках и головном уборе. Обман системы исключён — она обучена отличать живого человека от силиконовой маски или фотографии. В будущем система распознавания лиц «Ростеха» может быть использована в каршеринге и такси.  Серийное производство основанного на отечественной модульной платформе компактного электромобиля «Атом» должно начаться в 2025 году на столичном заводе «Москвич». Электрокар разработан российским стартапом «Кама», ключевой инвестор проекта — дочерняя структура «Росатома» «Рэнера» – отраслевой интегратор в области систем накопления энергии. В настоящий момент ведутся испытания функциональных прототипов. Будущие объёмы производства электрокаров представитель «Камы» не раскрывает. Компания «Кама» — производитель «Атома» — была основана в августе 2021 года. Основными инвесторами проекта стали гендиректор предприятия «Камаз» Сергей Когогин и основатель и бывший владелец инвестиционной компании «Тройка Диалог» Рубен Варданян. PayPal ввёл для россиян комиссию за неактивные счета — 3500 рублей в год
19.09.2024 [18:13],
Владимир Фетисов
Американская платёжная система PayPal с 7 октября 2024 года введёт для пользователей из России ежегодную комиссию за неактивные счета. Об этом сказано в сообщении, которое сервис на этой неделе направил клиентам. 
Источник изображения: Marques Thomas/unsplash.com «Мы вводим комиссию за продление обслуживания для поддержания вашего счёта в случае наличия остатка на счёте PayPal в любой валюте», — говорится в сообщении компании. Отмечается, что новая комиссия будет применяться к личным и корпоративным счетам, а взиматься она будет один раз в год со счетов с положительным балансом, которые не были активны, то есть не совершали операции, в течение последних 12 месяцев. Согласно обновлённым тарифам PayPal, размер взимаемой комиссии составит 3500 рублей или эквивалент в другой валюте. Если же на счету окажется меньше денежных средств, то списан будет весь остаток. Напомним, неактивным считается счёт PayPal, который не используется для вывода средств, или клиент длительное время не взаимодействует с ним. Если пользователь не согласен с новыми условиями, то ему предлагается закрыть счёт PayPal до вступления изменений в силу. PayPal объявила о приостановке своей деятельности в России в марте 2022 года. На тот момент компания предлагала клиентам вывести все средства со счетов до 18 марта 2022 года, «чтобы свести к минимуму возможные дальнейшие сбои в обслуживании». Напомним, PayPal является одной из крупнейших платёжных систем, которая доступна в 202 странах и обслуживает 325 млн клиентов. Для россиян весь перечень услуг сервиса стал доступен в 2013 году. На данный момент PayPal не открывает новых личных и корпоративных счетов для пользователей из России, а также приостановил отправку и приём платежей на территории страны. Биткоин подскочил до $63 тыс. после решения ФРС США о снижении ставки на 0,5 %
19.09.2024 [18:05],
Дмитрий Федоров
Криптовалютный рынок продемонстрировал значительный рост после первого за 4 года снижения процентных ставок Федеральной резервной системой (ФРС) США на 0,5 процентных пункта. Биткоин (BTC) укрепился на 3,5 %, достигнув $63 тысяч к 15:06 по московскому времени. Акции связанных с криптовалютами компаний также выросли: Coinbase и MicroStrategy прибавили по 5 %. Эксперты отмечают, что реакция рынка отражает сложное взаимодействие между монетарной политикой и цифровыми активами. 
Источник изображения: EivindPedersen / Pixabay Решение ФРС спровоцировало масштабное ралли на рынках. Биткоин, начавший рост ещё до объявления, продолжил восходящий тренд. Реакция была неоднозначной: за первоначальным скачком последовала коррекция. Ethereum (ETH), вторая по капитализации криптовалюта, прибавил почти 5 %, преодолевая недавнее отставание от биткоина. Токен Solana продемонстрировал впечатляющий рост на 7,5 %, что указывает на возросший интерес к альтернативным криптоактивам. Акции компаний, связанных с криптоиндустрией, также показали позитивную динамику. Котировки Coinbase, крупнейшей криптобиржи США, выросли на 5 %. MicroStrategy, известная своими значительными инвестициями в биткоин и используемая как инструмент с высокой бетой для спекуляций на курсе криптовалюты, также прибавила 5 %. Эти данные свидетельствуют о растущей корреляции между традиционным финансовым сектором и криптовалютным рынком. 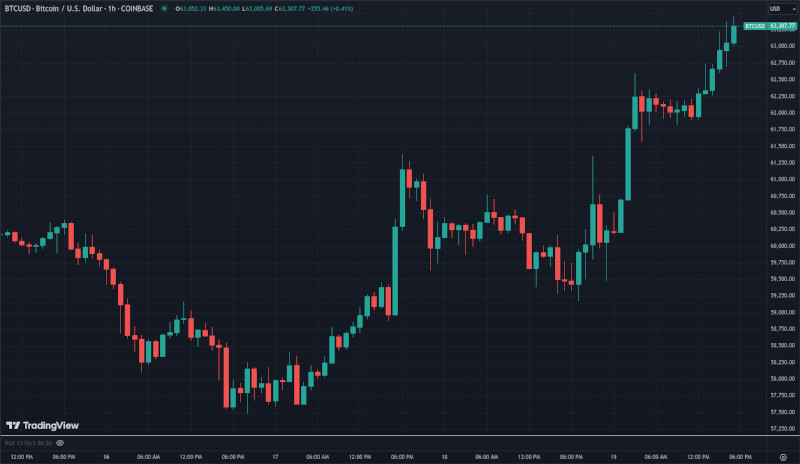
Источник изображения: TradingView Реакция инвесторов на решение ФРС неоднозначна. Некоторые аналитики выражают обеспокоенность тем, что столь значительное снижение ставки может сигнализировать о более серьёзных экономических проблемах, чем предполагалось ранее. Другие фокусируются на потенциальных преимуществах смягчения монетарной политики, которое может привести к увеличению ликвидности и поддержать рост цен на активы, включая криптовалюты. Биткоин демонстрирует двойственную природу, выступая одновременно как инструмент хеджирования и как рисковый актив. Его корреляция с индексом Nasdaq Composite в настоящее время выше, чем с золотом, что свидетельствует о восприятии криптовалюты как технологического актива. Несмотря на то, что сентябрь исторически считается наименее благоприятным месяцем для биткоина, в этом году криптовалюта уже выросла на 6 %. Юя Хасегава (Yuya Hasegawa), аналитик криптовалютного рынка японской биржи Bitbank, предупреждает о возможных рисках, связанных с заседанием Банка Японии (BOJ): «BOJ, вероятно, сохранит текущую ставку, но признаки возможного повышения ставок могут укрепить иену и спровоцировать сворачивание кэрри-трейд, что может привести к распродажам на японском фондовом рынке. Этот эффект может каскадно распространиться на крипторынок». Хасегава прогнозирует возможный рост биткоина до $65 тысяч за монету в краткосрочной перспективе. Новая статья: Обзор умных часов HUAWEI Watch D2: когда умеешь справляться с давлением
19.09.2024 [18:02],
3DNews Team
Данные берутся из публикации Обзор умных часов HUAWEI Watch D2: когда умеешь справляться с давлением Космонавт Горбунов впервые отправится в космос 26 сентября на корабле SpaceX Crew Dragon вместе с американским коллегой
19.09.2024 [17:50],
Сергей Сурабекянц
Запуск корабля Crew Dragon с сокращённым экипажем в составе астронавта США Ника Хейга (Nicklaus «Nick» Hague) и российского космонавта Александра Горбунова к Международной космической станции (МКС) запланирован на 26 сентября. Два свободных места на корабле предусмотрены для последующего возвращения на Землю астронавтов Суниты Уильямс (Sunita Williams) и Бутча Уилмора (Butch Wilmore), которые «застряли» на МКС с июня из-за неполадок с кораблём Boeing Starliner. 
Источник изображений: NASA «По сообщению NASA, запуск к МКС корабля Crew Dragon с космонавтом "Роскосмоса" Александром Горбуновым отложен на 26 сентября. Ожидается, что экипаж прибудет на космодром на мысе Канаверал (штат Флорида) 21 сентября», – говорится в сообщении «Роскосмоса». Изначально старт был запланирован на 25 сентября.  Запуск корабля Crew Dragon будет произведён при помощи ракеты-носителя Falcon-9. Полет состоится в рамках соглашения о перекрёстных полётах «Роскосмоса» и NASA. Вместо штатного экипажа в количестве четырёх человек на МКС отправятся лишь двое, чтобы затем обеспечить возвращение на Землю астронавтов Уильямс и Уилмора в феврале 2025 года. Их корабль Boeing Starliner 7 сентября вернулся на Землю без экипажа из-за возникших неполадок.  Этот полёт станет первым для космонавта «Роскосмоса» Александра Горбунова. В 2018 году он был зачислен в отряд космонавтов, а до этого работал инженером в корпорации «Энергия» и участвовал в запусках грузовых космических кораблей с космодрома Байконур. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex















