|
Опрос
|
реклама
Быстрый переход
Электроника в России подорожает на 10–15 % до конца года из-за инфляции и санкций
20.09.2024 [13:40],
Павел Котов
Несмотря на просьбы ФАС заморозить цены на наиболее популярные категории в электронике, российские розничные продавцы ожидают, что до конца года стоимость продукции увеличится на 10–15 %. Дистрибьюторы и производители уже подняли цены в связи с повышением ключевой ставки Банком России, а также западными санкциями, из-за которых усложнились расчёты с партнёрами из Китая и ОАЭ, пишет «Коммерсант». 
Источник изображения: F8_f16 / pixabay.com В этом году у ряда секторов российской экономики обозначилась проблема, связанная с ограничением трансграничных платежей за поставки товаров из Объединённых Арабских Эмиратов и Китая — структуры двух стран были вынуждены пойти на эту меру из-за давления со стороны США и угрозы вторичных санкций в отношении финансового сектора, которому предписано прекратить приём средств от российских компаний за технологическую продукцию. Наиболее сильно это ударило по сегментам потребительской электроники и вычислительной техники: Китай является монополистом на рынке компонентов и наборов для сборки конечного оборудования, а через ОАЭ в Россию поставляется до 30 % продукции в нескольких категориях электроники. Чтобы сохранить прежний режим работы в ОАЭ, российские компании были вынуждены открыть там новые юридические лица; а в Китае оплата стала проводиться через местные компании-посредники, которые берут комиссию от 3 % до 5 %. Проблемы расчётов с партнёрами в ОАЭ и Китае повлияли не только на стоимость и сроки импорта, но и на производство продукции внутри РФ. Отечественные компании, которые занимаются сборкой телевизоров, из-за дефицита комплектующих уже рассматривают возможность перенести мощности в Казахстан. Стоимость проведения платежа китайским партнёрам выросла на 5 % — на 5 % увеличилась и стоимость телевизора. Выросли сроки поступления средств в Китай, сроки поставки компонентов из Китая, а также сроки производства телевизоров в России. Аналогичные предприятия в Беларуси и других странах СНГ таких сложностей не испытывают, то есть российские компании находятся в невыгодных условиях. Если ситуация не исправится, то 70 % всей продукции будут выпускаться в Китае и СНГ, а отечественные компании будут вынуждены заказывать контрактное производство в странах, с которыми налажено конструктивное сотрудничество. 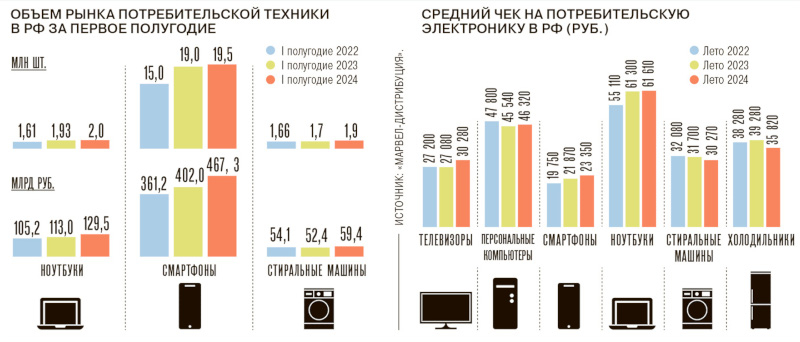
Источник изображения: kommersant.ru Усложнилась работа присутствующих в России OEM-брендов, которые не имеют собственных мощностей, а размещают заказы в других странах. Если раньше они выплачивали китайским партнёрам аванс, а расчёт осуществляли уже после отправки готовой продукции, то сейчас многие зарубежные предприятия отказываются работать без предоплаты на 100 %. Поднимают цены зарубежные бренды: китайские Haier и Hisense, а также турецкая Archelik (владеет Beko и Indesit) предупредили, что «из-за сложностей в финансовой логистике» закупочная стоимость продукции с 1 октября вырастет на 5 %. С ростом цен попыталась бороться ФАС, которая рекомендовала «Ситилинку», «М.Видео» и DNS заморозить цены на некоторые товары. Те согласились, но в DNS сообщили, что в конце июня — начале июля лишились возможности переводить средства китайским партнёрам привычными способами, а новые пути обходятся дороже на 4–8 %, и ещё 2–3 % добавляются за счёт разницы курсов — расчёты ведутся не в долларах, а в дефицитных юанях. Поэтому к концу года стоимость техники в магазинах вырастет на 10–15 %, прогнозируют в DNS. Потребители из-за роста цен начнут активнее переключаться на недорогие китайские или российские бренды, а средняя цена начнёт снижаться. Отечественные компании получат возможность увеличить свою долю рынка, говорят аналитики. В государственном и корпоративном секторе присутствие российских производителей заметнее, но цены и сроки растут даже здесь: стоимость компонентов уже увеличилась на 5–10 %, хотя высокая маржинальность данного направления пока позволяет нивелировать разницу. В случае дальнейшего усложнения финансовой логистики у отечественных вендоров возникает угроза срыва сроков и планов по поставкам оборудования заказчикам, а это будет означать и юридические риски. 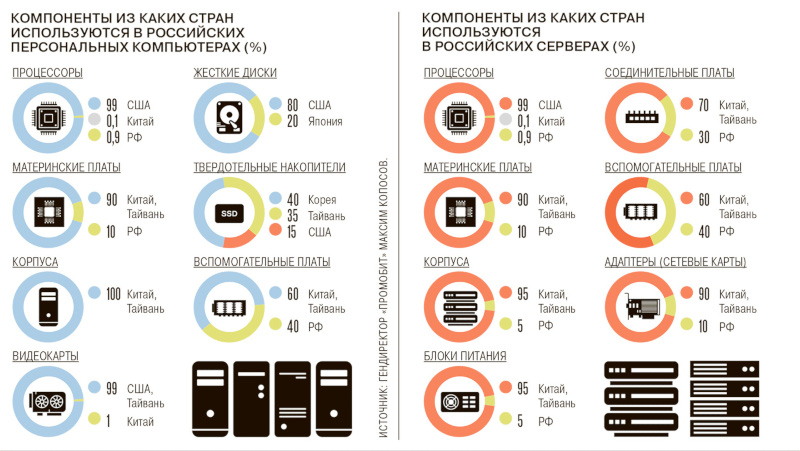
Источник изображения: kommersant.ru Важным фактором, влияющим на стоимость электроники в России, является величина ключевой ставки — 13 сентября ЦБ поднял её с 18 % до 19 %, и это много, потому что выше (20 %) она была лишь в марте и апреле 2022 года, а до июля 2023 года вообще держалась около 7,5 %. С ростом ключевой ставки дорожают и кредиты для производителей электроники: значение в 20 % означает увеличение стоимости товара на 2 % каждый месяц, говорят эксперты, поэтому до конца года техника может подорожать ещё 10 % к текущему росту цен. Следующее заседание ЦБ по вопросу значения ключевой ставки состоится 25 октября, и есть вероятность, что она снова будет увеличена. Неблагоприятен сейчас и сезонный фактор — перед новогодними праздниками курс рубля традиционно снижается, укрепление зарубежных валют может наложиться на рост цен комплектующих, а высокий спрос может стать ещё одной причиной роста цен. Одним из решений вопроса финансовой логистики является введение единой платёжной системы стран БРИКС (Китай, Бразилия, Аргентина, Россия, Египет, Иран и другие страны), а также возможность расчёта в криптовалютах. В противном случае западные страны сохранят возможность давить на российских партнёров. Для этих целей в России могут появиться криптобиржи — они упростят расчёты с партнёрами из стран БРИКС. Саудовская Аравия и ОАЭ углубят сотрудничество с Nvidia и получат новейшие ускорители вычислений
20.09.2024 [13:28],
Алексей Разин
На этой неделе стало известно о тенденции к углублению сотрудничества властей ОАЭ и Саудовской Аравии с компанией Nvidia, хотя некоторое время назад страны лишились открытого доступа к новейшим чипам этой марки из-за санкций США. Со следующего года Саудовская Аравия может получить доступ к ускорителям Nvidia вплоть до H200. 
Источник изображения: Nvidia В интервью CNBC на прошлой неделе заместитель руководителя Управления данных и искусственного интеллекта Саудовской Аравии (SDAIA) Абдулрахман Тарик Хабиб (Abdulrahman Tariq Habib) выразил надежду, что властям страны удастся со следующего года получить доступ к наиболее производительным ускорителям вычислений Nvidia. Это будет иметь для Саудовской Аравии очень большое значение, по словам чиновника, поскольку позволит облегчить сотрудничество между США и Саудовской Аравии, а также развивать вычислительные мощности на территории королевства. Местная инфраструктура готовилась к этим изменениям на протяжении трёх предыдущих лет, по словам представителя ведомства. К 2030 году страна рассчитывает до 12 % своего ВВП получать в сфере искусственного интеллекта. Финансировать проекты в этой области будет суверенный Публичный инвестиционный фонд Саудовской Аравии. С мая текущего года экспорт ускорителей Nvidia определённого ассортимента в страны Ближнего Востока ограничен, поскольку власти США опасаются транзита данной продукции в Китай. Последний тоже может стать партнёром Саудовской Аравии, если США лишат эту ближневосточную страну доступа к передовым технологиям американского происхождения, как считают некоторые эксперты. Агентство Bloomberg на этой неделе сообщило, что Nvidia будет сотрудничать с компанией G42 из ОАЭ в рамках инициативы по созданию инфраструктуры для более точного предсказания изменений в климате и погоде. По замыслу участников проекта, G42 позволит создать на территории ОАЭ инфраструктуру для ускорения вычислений и работы с цифровым двойником нашей планеты Earth-2, чтобы на его основе заниматься прогнозированием погоды. Система будет оперировать более чем 100 петабайтами геофизических данных. Компания G42 в этом году получила $1,5 млрд инвестиций от Microsoft, что многими экспертами трактовалось как сигнал, свидетельствующий о сближении ОАЭ и США. Принято считать, что ради получения доступа к технологиям и капиталу Microsoft руководству G42 пришлось дать американской стороне некоторые гарантии отказа от усиления сотрудничества с КНР. Налаживаются партнёрские взаимоотношения между G42 и OpenAI. Руководство первой из компаний отметило, что сотрудничество с Nvidia позволит не только продвигать инновации, но и решать критически важные для всего человечества проблемы. В Китае резко упали инвестиции в стартапы — власти слишком давят на технологический сектор
20.09.2024 [13:25],
Владимир Мироненко
В Китае заметно снизилась инвестиционная активность, что ставит под сомнение дальнейшее развитие его технологического сектора. Как сообщает газета Financial Times со ссылкой на поставщиков данных, сбор средств для инвестиций в Китай как зарубежными, так и отечественными венчурными фондами резко упал с 2022 года, что привело к значительному сокращению числа стартапов, основанных в Китае в прошлом году и в этом году. 
Электромобиль стартапа WM Motor, обанкротившегося в 2023 году. Источник изображения: WM Motor Financial Times назвала две основные группы причин сокращения инвестиций. Первая включает макроэкономические факторы, такие как общее замедление экономики Китая после вспышки пандемии COVID-19 и лопнувший пузырь на рынке недвижимости. Вторая группа связана с регулированием экономики властью, чьи административные меры в отношении ведущих частных технологических компаний, таких как Alibaba и Tencent, ударили по их фондовым оценкам и повлекли за собой глубокую неопределённость инвесторов относительно отношения Пекина к частному предпринимательству. Кроме того, противостояние США и Китая «отпугнуло» международный венчурный капитал от китайского рынка, отчасти потому, что найти «выход» на инвесторов через листинг на международных фондовых рынках стало сложнее. Как следствие, китайские студенты, обучающиеся за границей, видят меньше возможностей вернуться в Китай в ранее расширявшийся технологический сектор. Также наблюдается резкий рост судебных разбирательств, связанных с инвестициями. В августе местное издание Caixin сообщило, что ведущая государственная венчурная компания Shenzhen Capital Group подала 35 исков против компаний, которые в основном не стали публичными к установленной дате и не выкупили акции. Если Китай хочет сохранить своё технологическое превосходство, ему нужны масштабные реформы, пишет Financial Times. Частный сектор должен получить равный статус с государственным. Также нужно увеличить прозрачность для финансовых рынков Китая, чтобы можно было восстановить доверие инвесторов. «Прежде всего, сам Си (Си Цзиньпин, председатель КНР) должен осознать, что инновации не следуют административным указам», — подытожила Financial Times. Huawei расстроила поклонников дефицитом трёхстворчатых смартфонов Mate XT за $2800, а перекупщики взвинтили цены
20.09.2024 [13:08],
Павел Котов
Сегодня в Китае стартовали продажи новых смартфонов Huawei и Apple. Многие поклонники китайской марки оказались разочарованы тем, что её долгожданный трёхстворчатый телефон Huawei Mate XT за $2800, более чем в два раза превосходящий iPhone 16 Pro Max по цене, оказался недоступен для покупки без предварительной записи. 
Источник изображения: huawei.com Некоторые потенциальные покупатели в главном магазине Huawei в Шэньчжэне выразили недовольство, когда узнали, что купить Mate XT могут лишь те, кто получил подтверждение предварительных заказов. Стремившийся поддержать отечественного производителя студент по фамилии Йе (Ye) занял очередь накануне около 22:00, но этим утром был вынужден уйти ни с чем. Схожая история имела место в пекинском магазине Huawei Wangfujing — у обоих торговых точек выстроились очереди примерно по 30 человек, передаёт корреспондент Reuters. В главном магазине компании Huawei в Шанхае продажи, по словам исполнительного директора Ричарда Юя (Richard Yu) оказались «лучше ожидаемых» — новый телефон Huawei разошёлся за «несколько секунд», и теперь компании приходится работать над увеличением производственных мощностей. На устройство было оформлено более 6,5 млн предварительных заказов — для сравнения, в прошлом году по всему миру было продано всего 3,9 млн складных телефонов. Но следует учесть, что при оформлении предварительного заказа вносить предоплату не требуется; Huawei же не предупредила, сколько телефонов выпустила на данный момент, и сколько клиентов смогут получить Mate XT в день старта продаж. Apple также не сообщила, сколько новых iPhone доступны для продажи в Китае сегодня. Одна из продавцов телефонов на рынке огромном электроники «Хуацянбэй» (Huaqiangbei) в Шэньчжэне сообщила, что самая дорогая версия Huawei Mate XT с максимальным объёмом памяти стоит у неё 150 000 юаней ($21 290), а базовую модель с рекомендованным производителем ценником $2800 у неё можно купить более чем за $4000. Она признала, что несколько потенциальных покупателей поинтересовались у неё наличием этой модели, но цены оказались слишком высокими. Huawei изучает возможность выпустить Mate XT на зарубежные рынки в I квартале следующего года, говорят источники Reuters. Продукция Apple в течение многих лет пользовалась в Китае высоким спросом, и запуск новых iPhone раньше вызывал ажиотаж в стране, но сейчас компания скатилась лишь на шестое место по продажам телефонов в стране. Выход iPhone 16 омрачился тем фактом, что производитель до сих не представил местного партнёра по проекту Apple Intelligence — набору функций искусственного интеллекта для новых устройств. Поддержка китайского языка в Apple Intelligence появится в следующем году. Перед магазином Apple в Пекине сегодня выстроилась очередь около 100 человек. Microsoft выпустила Windows для iPhone, Mac и Android — это приложение для удалённого подключения к рабочим столам
20.09.2024 [13:03],
Владимир Фетисов
Компания Microsoft объявила о запуске нового приложения Windows для macOS, iOS, iPadOS, Android, веб-браузеров и компьютеров с Windows. Данный продукт представляет собой инструмент для удалённого подключения к разным рабочим столам, включая Windows 365, Azure Virtual Desktop и др. 
Источник изображения: Microsoft Унифицированное приложение Windows тестировалось последние несколько месяцев среди участников программы предварительной оценки. Разработчики реализовали возможность настройки главного экрана, поддержку нескольких мониторов, а также перенаправление USB, благодаря чему пользователь может задействовать локально подключённые устройства, такие как принтеры и веб-камеры, как если бы они были подключены к удалённому компьютеру. Отметим, что приложение Windows доступно только для рабочих и учебных записей Microsoft, поскольку в первую очередь оно ориентировано на существующих пользователей «Удалённого рабочего стола» (Remote Desktop) в Windows и других операционных системах. Подобные приложения для подключения к компьютерам с Windows существуют давно. Одним из таких примеров является приложение Remote Desktop Connection, поставляемое в составе Windows 11. На данный момент нет никаких признаков того, что Microsoft планирует сделать приложение Windows доступным для потребительских учётных записей. Уже сейчас новинка доступна в Microsoft Store и Apple App Store. Предварительная версия продукта для Android появится в ближайшее время. В Китае создали «вечную» фотоэлектрическую ядерную батарейку, которая в 8000 раз эффективнее аналогов
20.09.2024 [13:01],
Геннадий Детинич
То или иное использование энергии ядерного распада для длительного получения электрической энергии — не новость. Новостью станет эффективное преобразование радиации в электричество, что особенно важно в свете ураганного распространения подключённых к интернету микродатчиков. На этот раз удивили китайские учёные. Они представили фотоэлектрическую ядерную батарейку, которая оказалась в 8000 раз эффективнее предыдущих разработок. 
Источник изображения: Kai Li Энергия радиоактивного распада может превращаться в электричество напрямую с помощью ряда полупроводников, производить нагрев и выводить электричество с помощью термоэлементов, а также способна возбуждать фотоны, с помощью которых можно вырабатывать электричество с фотоэлементов. Китайские исследователи из Университета Сучжоу воспользовались последним способом, развив идею от светящихся циферблатов часов до улавливания фотонов от подобных материалов миниатюрными фотопанелями. Учёные создали полимерный кристалл и поместили в него немного америция. После этого рукотворный кристалл стал светиться призрачным зелёным светом. Такое свечение будет продолжаться десятилетиями, что делает источник питания на его основе условно вечным для практического использования. Учёные разместили поверх светящегося кристалла тонкоплёночный фотоэлемент и запаковали всё в кварцевое стекло для предотвращения утечек радиации вовне. КПД такой ядерной батарейки составил скромные 0,889 %, но исследователи утверждают, что это значение в 8000 раз больше, чем у предыдущих аналогичных разработок. Сотни часов тестирования элемента показали, что он стабильно выдавал 139 мкВт на 1 кюри (единицу радиоактивности). Из таких элементов может получиться очень и очень долговечная ядерная батарейка для решения широкого спектра задач на Земле и в космосе. «Тело готово, но сердце не выдержит»: CD Projekt Red и Netflix анонсировали следующее аниме по Cyberpunk 2077 после «Киберпанк: Бегущие по краю»
20.09.2024 [12:03],
Михаил Романов
Вышедший осенью 2022 года аниме-сериал Cyberpunk: Edgerunners («Киберпанк: Бегущие по краю») по мотивам Cyberpunk 2077 так полюбился фанатам, что Netflix и CD Projekt Red решились на ещё один совместный проект. 
Источник изображения: Netflix В рамках заключительной части фестиваля Geeked Week 2024 стриминговый гигант подтвердил новый анимационный проект команды Netflix Animation и CD Projekt Red в киберпанковой вселенной. Анонс сопровождал немногословный 20-секундный тизер (прикреплён ниже), который провозглашает «возвращение в Найт-Сити». В описании ролика упоминается, что подробности последуют в скором будущем. Несмотря на скудность тизера, фанаты Cyberpunk: Edgerunners оказались в восторге от анонса, находятся в предвкушении новой истории и эмоциональных потрясений. «Тело готово, но сердце не выдержит», — признался TheNeonArcade. CD Projekt не скрывает интерес к расширению охвата Cyberpunk 2077 за пределами игр. В рамках недавнего финансового отчёта студия сообщила, что «однозначно» планирует новые анимационные проекты во вселенной. Впрочем, на продолжение именно «Киберпанк: Бегущие по краю» рассчитывать не стоит. После релиза сериала CD Projekt Red отмечала, что шоу задумывалось как «самодостаточное произведение» и второй сезон не предполагает. Помимо новой анимационной экранизации с Netflix, CD Projekt Red также готовит кинопроект (фильм или сериал) с живыми актёрами во вселенной Cyberpunk 2077, который расскажет совершенно новую историю из мира игры. Бразильский суд будет штрафовать X и SpaceX на $920 тыс. в день
20.09.2024 [11:43],
Дмитрий Федоров
В Бразилии компаниям X (ранее Twitter) и SpaceX, принадлежащим Илону Маску (Elon Musk), грозят ежедневные штрафы на сумму около $920 тыс. за предполагаемое нарушение судебного запрета. Верховный суд страны обвиняет X в обходе блокировки сервиса, которым пользовались около 22 млн человек в стране. Ситуация обостряет конфликт между Маском и бразильскими властями, начавшийся после запрета соцсети в конце августа. 
Источник изображения: X Согласно заявлению Верховного суда Бразилии, размер ежедневных штрафов для X составляет 5 млн бразильских реалов ($920 тыс.). Суд подчеркнул, что продолжит налагать «солидарную ответственность» на SpaceX, которая оказывает в стране услуги спутникового интернета Starlink. Штрафы начисляются с 19 сентября, а общая сумма будет рассчитываться исходя из количества дней несоблюдения постановлений. Приостановка работы X в Бразилии была инициирована главным судьёй страны Александри де Мораесом (Alexandre de Moraes) в конце августа и поддержана коллегией судей в начале сентября. Суд установил, что под руководством Маска X нарушила бразильское законодательство, требующее от социальных сетей иметь юридического представителя в стране и удалять контент, содержащий язык вражды или материалы, признанные вредными для демократических институтов. Несмотря на то, что Маск позиционирует себя как абсолютного сторонника свободы слова, X ранее удовлетворяла просьбы властей об удалении профилей и постов в таких странах, как Индия, Турция и Венгрия. На этот раз платформа Маска не выполнила требование бразильских властей о блокировке аккаунтов, предположительно занимавшихся публикацией персональной или конфиденциальной информации о федеральных чиновниках. Более того, для восстановления работы платформы компания перенесла серверы на хостинг Cloudflare и начала использовать динамические IP-адреса, которые постоянно меняются, что затрудняет их блокировку. Ранее X применяла статические IP-адреса в Бразилии, которые легко блокировались провайдерами по требованию регуляторов. Представитель платформы X заявил CNBC: «Когда X был отключён в Бразилии, наша инфраструктура для предоставления услуг в Латинской Америке оказалась недоступной для нашей команды. Чтобы продолжать обеспечивать оптимальный сервис для наших пользователей, мы сменили поставщика услуг. Это изменение привело к непреднамеренному и временному восстановлению сервиса для бразильских пользователей. Мы ожидаем, что в скором времени платформа снова станет недоступной в Бразилии, но мы продолжаем работать с бразильским правительством, чтобы в самое ближайшее время вернуть сервис для жителей Бразилии». Национальное агентство по телекоммуникациям Бразилии (Anatel) получило распоряжение от де Мораеса блокировать серверы Cloudflare, Fastly и EdgeUno, якобы «созданные для обхода» приостановки работы X. Представитель Cloudflare отметил, что компания не делает возможным или предотвращает блокировку, а использование выделенных IP-адресов — стандартная практика в отрасли. Бразилия уже взыскивала штрафы с X и Starlink, списывая средства со счетов компаний в местных банках. Местное издание Correio Braziliense сообщило, что X уже начала блокировать учётные записи в соответствии с постановлениями суда, включая профили бразильских блогеров Бруно Аюба (Bruno Aiub) и Аллана душ Сантуса (Allan dos Santos), заподозренных в распространении дезинформации. Провайдеры пожаловались на дискриминацию из-за замедления YouTube
20.09.2024 [11:16],
Павел Котов
Ассоциация «Ростелесеть», в которую входят более 200 региональных операторов связи, направила в Федеральную антимонопольную службу (ФАС) жалобу на дискриминацию из-за неравномерного механизма замедления YouTube. Документ направлен в ФАС 12 сентября, узнал РБК. 
Источник изображения: Christian Wiediger / unsplash.com Провайдеры заявили, что в последние месяцы столкнулись с «сильным и неравномерным» замедлением не только YouTube, но также владеющей платформой Google и её сервисов, и это «спровоцировало кратное увеличение количества жалоб пользователей к провайдерам». При загрузке видео на YouTube через Wi-Fi отмечается значительное падение скорости, тогда как при подключении через сотовые сети замедление оказывается незначительным. Неравномерность механизма замедления платформы носит дискриминационный характер, говорят авторы документа, — она нарушает правила свободного рынка: небольшие региональные операторы «массово теряют абонентскую базу», потому что клиенты массово выбирают услуги мобильных операторов. «Ростелесеть» просит ФАС возбудить производство по признакам нарушения закона «О защите конкуренции». Разница в доступе YouTube, по версии провайдеров, связана с «внешним воздействием», которое осуществляется с использованием ТСПУ (технических средств противодействия угрозам), которыми управляет Главный радиочастотный центр (ГРЧЦ, входит в Роскомнадзор). Ведомство действительно установило на сети провайдеров разные ТСПУ, сообщил источник РБК, но отследить его работу может только оно само. Разные механизмы замедления YouTube у разных провайдеров объясняются несколькими факторами, рассказал зампред Госдумы по информполитике Антон Горелкин: у сетей разная пропускная способность, у серверов Google «недостаточная вычислительная мощность», и у компании отличаются политики доступа к браузерной и мобильной версиям платформы. Резкое замедление YouTube в России отмечается с начала августа. По официальной версии, это происходит из-за того, что Google лишилась возможности обслуживать свои серверы, расположенные в России. При этом операторам, которые попытались ускорить доступ к YouTube при помощи альтернативной маршрутизации трафика, Роскомнадзор пригрозил отзывом лицензии. Раскрыта ёмкость аккумуляторов смартфонов iPhone 16 — прирост на 5,5–9,4 % по сравнению с прошлым поколением
20.09.2024 [11:11],
Владимир Мироненко
Apple, как правило, не указывает в спецификациях смартфонов iPhone ёмкость их аккумуляторов, поэтому обычно приходится полагаться на другие источники — публикации сертифицирующих органов или сайтов, занимающихся разборкой устройств. В случае с недавно анонсированными смартфонами iPhone 16 эти данные стали известны благодаря бразильскому регулятору ANATEL. 
Источник изображения: apple.com Как сообщает ресурс GSMArena со ссылкой на информацию Агентства связи Бразилии (ANATEL), смартфон iPhone 16 получил аккумулятор ёмкостью 3561 мА·ч, что на 6,3 % больше, чем у его предшественника. У смартфона iPhone 16 Plus аккумулятор ёмкостью 4674 мА·ч, что на 6,6 % больше, чем у iPhone 15 Plus. iPhone 16 Pro получил аккумулятор ёмкостью 3582 мА·ч, что на 9,4 % больше, чем у iPhone 15 Pro, а iPhone 16 Pro Max оснащён аккумулятором ёмкостью 4685 мА·ч, что на 5,5 % больше, чем у iPhone 15 Pro Max. Таким образом, больше всего ёмкость батареи увеличилась у iPhone 16 Pro — на 9,4 %. Несмотря на небольшое различие в прибавке ёмкости, модели новой серии отличаются продолжительной автономной работой благодаря используемым чипам A18 и A18 Pro и улучшениям в конструкции батареи. Также выросла долговечность по сравнению с предшественниками, как iPhone 16 Pro, так и Pro Max. Все модели семейства iPhone 16 поддерживают более быструю зарядку MagSafe мощностью 25 Вт. Для этого потребуется приобрести новое зарядное устройство MagSafe от Apple, а также подключить его к адаптеру питания мощностью 30 Вт. Новые смартфоны также могут заряжаться с мощностью до 45 Вт через порт USB-C. Apple Intelligence стал доступен обычным пользователям в свежих бета-версиях iOS 18.1, iPadOS 18.1 и macOS Sequoia 15.1
20.09.2024 [11:04],
Дмитрий Федоров
Apple выпустила публичные бета-версии iOS 18.1, iPadOS 18.1 и macOS Sequoia 15.1 с функциями Apple Intelligence. Владельцы iPhone 16, iPhone 15 Pro и устройств с чипами M1 и новее получили доступ к инструментам для переписывания текста, новому дизайну Siri и ИИ-функции Clean Up для удаления объектов с фотографий, а также другим возможностям. 
Источник изображения: Apple Для получения доступа к бета-версиям требуется регистрация на официальном сайте программы бета-тестирования Apple. После верификации обновление становится доступным в системных настройках устройства. Однако функциональность Apple Intelligence доступна лишь на некоторых моделях смартфонов: iPhone 15 Pro, iPhone 15 Pro Max, а также iPhone 16 и iPhone 16 Pro. Владельцы iPad и Mac с чипами M1 и новее также смогут опробовать новоиспечённый «яблочный» ИИ. До настоящего момента функции Apple Intelligence были доступны только в рамках бета-версий для разработчиков. Важно отметить, что текущие публичные бета-версии не предоставляют весь спектр анонсированных возможностей Apple Intelligence. Компания планирует поэтапное внедрение дополнительных ИИ-функций в следующих обновлениях. Релиз финальных версий операционных систем ожидается в октябре 2024 года. Акции техногигантов подскочили после снижения ставки ФРС США — больше других прибавила Tesla
20.09.2024 [11:03],
Алексей Разин
Долгожданный шаг американских монетарных властей США был сделан вчера — Федрезерв снизил ключевую ставку сразу на 50 базисных пунктов, впервые с 2020 года. Подобные меры традиционно повышают интерес инвесторов к фондовому рынку, поэтому акции техногигантов дружно начали дорожать ещё вчера. Индекс Nasdaq в итоге вырос сразу на 2,5 %, продемонстрировав четвёртый по величине прироста результат с начала текущего года.  Как отмечает CNBC, акции Tesla выросли в цене на 7,4 %, а акции Nvidia прибавили 4 % до $117,87. В условиях снижения ключевой ставки кредиты на корпоративном рынке становятся более доступными, а доходность облигаций снижается, делая вложения в ценные бумаги более привлекательными, пусть и с сохранением привычного уровня риска. Кроме того, раскрытый монетарными властями США план дополнительного снижения ставки до конца текущего года лишь придал уверенности тем инвесторам, которые ринулись на рынок акций. Индекс Nasdaq, который на фоне нынешнего ИИ-бума и так не мог жаловаться на нехватку положительной динамики, по итогам торговой сессии вырос до максимального с середины июля уровня. Акциям Nvidia на текущем уровне всё ещё далеко до июньского максимума, но с начала этого года они подорожали на 138 %, а по сравнению с прошлым годом выросли в цене более чем в три раза. Акции конкурирующей AMD выросли в цене на 5,7 %, а ценные бумаги Broadcom прибавили 3,9 %. Попытки AMD соперничать с Nvidia в сфере разработки ускорителей искусственного интеллекта пока не придают особо убедительной динамики её акциям, с начала года они подорожали лишь на 6 %. Глава компании Лиза Су (Lisa Su) успокоила инвесторов заявлениями о том, что играть в сегменте ИИ приходится в долгую, и рынок всё ещё находится на начальной стадии развития. Она призвала аудиторию канала CNBC проявлять терпение и напомнила, что ставший хитом ChatGPT присутствует на рынке около 18 месяцев. При этом она не отрицает, что искусственный интеллект проникнет во все сферы нашей жизни, включая образование и создание лекарственных средств. Интересно, что среди крупнейших компаний технологического сектора вчера сильнее всего подорожала Tesla, на 7,5 % до $243,92. Этот год для автопроизводителя был не очень удачным с точки зрения динамики фондового рынка, с начала года акции Tesla упали в цене почти на 2 %. Тем не менее, с минимальных уровней апреля они всё равно укрепились на 72 %. Акции Apple и Meta✴✴ Platforms вчера выросли в цене почти на 4 % у каждой. NASA собрало ядро космического телескопа «Нэнси Грейс Роман» — задержек с запуском не предвидится
20.09.2024 [10:52],
Геннадий Детинич
В NASA сообщили, что сборка ядра космической обсерватории «Нэнси Грейс Роман» в целом завершена. Целевой датой запуска остаётся май 2027 года. Критических проблем и задержек не предвидится. На очереди начало монтажа оборудования и приборов на шину космического аппарата, который доставит оборудование примерно туда, где сейчас работает космическая обсерватория им. Джеймса Уэбба. 
Источник изображений: NASA Ядро или шина обсерватории представляет собой шестигранный каркас с корпусом шириной 4 м и высотой 2 м. В этот каркас будут встроены двигательные, питающие и управляющие обсерваторией узлы, после чего будет смонтировано 2,4-м главное зеркало. Небольшие по сравнению с зеркалом «Уэбба» размеры (у последнего оно 6,5-метровое) не должны смущать. Зеркало у «Роман» такое же, как и у «Хаббла», чего достаточно для качественных и детальных обзоров неба, но у «Роман» будет невероятное преимущество по сравнению с этими двумя телескопами — он сможет за раз делать снимок в 100 раз большего участка неба, чем «Хаббл».  Широкое поле зрения новому телескопу обеспечит 288-Мп матрица. Каждые сутки эта обсерватория будет передавать на Землю по 1,4 Тбайт данных. Для сравнения, «Уэбб» отправляет учёным до 60 Гбайт данных в сутки, а «Хаббл» — по 3 Гбайт. Широкий охват поможет делать множество открытий, в том числе быстрых переходных процессов. Например, это важно для открытия новых экзопланет методом транзита.  Обсерватория будет обладать чувствительностью в оптическом диапазоне и в ближнем инфракрасном диапазоне, для чего она будет отправлена в точку Лагранжа L2. Её инфракрасные датчики не должны страдать от лишнего нагрева, предполагая постоянное охлаждение до -178 °C. Требования не такие жёсткие, как для чисто инфракрасного «Уэбба», но всё равно лучше «Роман» держать подальше от Солнца.  Netflix впечатлила фанатов новым отрывком из второго сезона «Аркейн» и наконец раскрыла дату релиза шоу
20.09.2024 [10:44],
Михаил Романов
Вслед за полноценным трейлером в начале сентября стриминговый гигант Netflix представил точную дату выхода (даже три) второго сезона анимационного сериала «Аркейн» (Arcane) по мотивам League of Legends. 
Источник изображений: Netflix Напомним, сиквел «Аркейн» был официально подтверждён вскоре после окончания первого сезона (чуть меньше трёх лет назад) и до недавних пор ожидался к премьере на протяжении ноября 2024 года. Как стало известно, вслед за первым сезоном «Аркейн» второй тоже выйдет в Netflix по частям: первый акт увидит свет 9 ноября, второй — 16-го числа, а заключительный третий — 23-го. Детали каждой главы раскроют позже. 
Главы первого сезона «Аркейн» содержали по три серии По случаю анонса Netflix также показала новый отрывок из второго сезона «Аркейн» — ролик продолжительностью две с половиной минуты озаглавлен «Нечего терять» (Nothing to Lose) и демонстрирует Вай на не самом счастливом этапе жизни. Заждавшиеся продолжения «Аркейн» остались в восторге от анонса и нового видео: зрители оценили выбор музыкального сопровождения, качество анимации и предвкушают эмоциональную развязку. С июньским тизер-трейлером создатели «Аркейн» подтвердили, что новый сезон станет для сериала последним. По словам соавтора шоу Кристиана Линке (Christian Linke), с самого начала работы у проекта была «очень чёткая концовка». Напомним, второй сезон стартует после атаки Джинкс на совет Пилтовера, которая могла поставить под угрозу возможность урегулирования конфликта с Зауном и примирения со своей сестрой Вай. Logitech представила алюминиевую мышь G502 X Plus AL Edition, но продавать её не будет
20.09.2024 [10:42],
Павел Котов
Logitech решила отметить десятилетний юбилей своей игровой мыши G502 выпуском её алюминиевой версии ограниченным тиражом. Эксклюзивная модель G502 X Plus AL Edition имеет ту же функциональность, что оригинальная беспроводная G502 X, плюс алюминиевый корпус с лазерной гравировкой, включающей серийный номер от 1 до 502. 
Источник изображения: Logitech Алюминий в таблице Менделеева обозначается как «Al», а не «AL», но швейцарский производитель, вероятно выбрал такое написание для модельного индекса мыши, чтобы его не путали с «AI» — так в английском сокращается словосочетание «Artificial Intelligence» («искусственный интеллект»). Модель G502 за десять лет с момента выхода составила основу игровой линейки Logitech. В первоначальном варианте это было проводное устройство, которое и сегодня можно купить по цене около $50. В 2019 году вышел беспроводной вариант G502 X с адаптером Logitech Lightspeed; а затем его дополнил G502 X Plus с сенсором разрешения 25 тыс. точек на дюйм, яркой RGB-подсветкой и беспроводной зарядкой от коврика Logitech Powerplay. Новая Logitech G502 X Plus AL Edition в открытую продажу не поступит. Производитель заявил, что алюминиевую мышь можно «заработать, получить в награду или подарок от Logitech G или наших партнёров членам сообщества по всему миру». Компания уже раздала 10 экземпляров подписчикам Logitech G в соцсети X. Контрактное производство чипов в следующем году вырастет на 20 % в денежном выражении
20.09.2024 [09:49],
Алексей Разин
По итогам текущего года, как считают аналитики TrendForce, выручка контрактных производителей чипов вырастет на 16 %, что можно считать хорошим отскоком после прошлогоднего падения на 14 %. В следующем году рост выручки контрактных производителей чипов превысит 20 %, по мнению экспертов. 
Источник изображения: GlobalFoundries Тем не менее, говорить об улучшении ситуации со спросом на потребительских рынках сложно. В текущем году степень загрузки оборудования на линиях по выпуску не самых передовых чипов опустился ниже 80 %, что нельзя считать оптимальным с экономической точки зрения уровнем. Только линии по выпуску чипов с использованием техпроцессов от 5 до 3 нм включительно были загружены полностью, и такое положение дел сохранится и в следующем году, чего нельзя гарантировать для потребительского рынка. Как отмечается в отчёте TrendForce, уже в текущем полугодии рынки автомобильной электроники и промышленной автоматизации начнут восстанавливаться после коррекции складских запасов, и этот процесс продолжится в 2025 году. Бум систем искусственного интеллекта способствует тому, что количество обрабатываемых отраслью кремниевых пластин увеличивается. Во многом это будет способствовать тому, что выручка контрактных производителей чипов в следующем году вырастет на 20 %. Если исключить из этой выборки лидирующую по доле рынка TSMC, то прирост ограничится 12 %, но даже в этом случае он окажется выше уровня предыдущего года. 
Источник изображения: TrendForce В следующем году 3-нм техпроцесс станет основным для выпуска передовых вычислительных компонентов, включая центральные процессоры для ПК и смартфонов, а вот чипы ускорителей вычислений останутся на 5-нм и 4-нм техпроцессах. Ко второму полугодию начнёт расти спрос на 6-нм и 7-нм чипы, используемые в смартфонах для работы в беспроводных сетях связи. По прогнозу TrendForce, в 2025 году диапазон техпроцессов от 7 до 3 нм будет формировать до 45 % выручки контрактных производителей чипов по всему миру. Высокий спрос на услуги по упаковке чипов с использованием компоновки класса 2.5D привёл к сохранению дефицита на протяжении текущего и предыдущего года. TSMC, Samsung и Intel стараются расширять свои профильные производственные мощности. Выручка от оказания подобных услуг вырастет более чем на 120 % по итогам 2025 года. Правда, пока они будут формировать не более 5 % выручки контрактных производителей, но эта доля будет планомерно расти. Восстановление спроса на потребительском рынке, как надеются эксперты TrendForce, позволит контрактным производителям по итогам 2025 года поднять степень загрузки линий по обработке кремниевых пластин с использованием зрелых техпроцессов до уровня более 70 %, хотя сейчас он в большинстве случаев не превышает 60 %. Будут вводиться в строй и новые предприятия, использующие техпроцессы в диапазоне от 28 до 55 нм. Цены на услуги по выпуску чипов такого класса могут снизиться в результате появления новых мощностей. Участникам контрактного рынка придётся иметь дело с высокими затратами на внедрение передового оборудования и макроэкономической неопределённостью. Астрономы в панике: свежие спутники Starlink создают в 32 раза больше помех радиотелескопам, чем старые
20.09.2024 [09:15],
Геннадий Детинич
Этим летом астрономы из Нидерландского института радиоастрономии (ASTRON) на сутки запустили один из лучших в мире радиотелескопов LOFAR и были шокированы. Новые версии спутников интернет-связи Starlink буквально ослепили сверхчувствительное оборудование. Их яркость в радиодиапазоне в 32 раза превысила помехи от спутников Starlink первого поколения. Это скоро уничтожит всю наблюдательную астрономию на Земле, заключили исследователи. 
Источник изображения: Obelixlatino/pixabay.com «Каждый раз, когда запускаются новые спутники с такими уровнями излучения, мы видим всё меньше и меньше неба», — сказала BBC News директор ASTRON профессор Джессика Демпси (Jessica Dempsey). «Мы пытаемся взглянуть на такие вещи, как струи, которые испускаются из чёрных дыр в центрах галактик. Мы также смотрим на некоторые из самых ранних галактик, находящихся на расстоянии миллионов световых лет от нас, а также на экзопланеты», — обрисовала круг проблем руководитель ASTRON’а. Сегодня на низкой околоземной орбите летает чуть больше 6000 спутников сети Starlink. Эта сеть продолжит расширяться, как и «плетёт» свои сети компания OneWeb (до 1000 спутников на орбите) и готовится к её развёртыванию компания Amazon (будет до 3000 спутников до 2030 года). В целом к 2030 году специалисты ожидают до 100 тыс. спутников интернет-связи на орбите, что не просто угрожает астрономии на всех длинах волн, включая оптические, а фактически заблокирует любые наблюдения за Вселенной с Земли. «На самом деле это угрожает всей наземной астрономии на всех длинах волн и разными способами. Если это будет продолжаться без каких-либо смягчающих мер, чтобы заставить эти спутники работать тихо, то это действительно станет реальной угрозой существованию тех видов астрономии, которыми мы занимаемся», — добавила профессор Демпси. Это не первое заявление об угрозе астрономическим наблюдениям с Земли со стороны спутников связи. Компания Starlink как первопроходец отчасти пошла навстречу учёным и предприняла ряд мер по экранированию как оптического, так и радиочастотного излучения от спутников первого поколения. Но новые спутники оказались буквально ослепительными для радиотелескопов. Их яркость в 10 млн раз превысила мощность самых слабых детектируемых на Земле сигналов из глубин Вселенной. Это как сравнить свет самых слабых видимых глазом звёзд на небе с яркостью полной Луны, объяснили исследователи. Такое невозможно игнорировать. 
Созвездие Starlink в ночном небе. Источник изображения: Starlink Без каких-либо активных действий по предотвращению всего этого «очень скоро единственные созвездия, которые мы увидим, будут созданы человеком», заключают специалисты. Регулирование ЕС в технологической сфере угрожает подавить бум ИИ
20.09.2024 [08:51],
Дмитрий Федоров
Руководители более чем 25 компаний, включающих Meta✴✴, Spotify и Prada, обратились с открытым письмом к Европейскому союзу (ЕС), в котором предупредили, что чрезмерно жёсткое и непоследовательное регулирование в сфере ИИ может существенно ограничить инновационный потенциал региона и лишить его ожидаемых экономических преимуществ. 
Источник изображения: GregMontani / Pixabay В открытом письме, инициированном Meta✴✴, руководители компаний аргументированно излагают свою позицию: «Европа утратила конкурентные преимущества и инновационный потенциал по сравнению с другими регионами. Существует реальный риск дальнейшего отставания в эпоху ИИ из-за непоследовательности регуляторных решений». Авторы подчёркивают, что ИИ способен значительно повысить производительность труда европейцев и стимулировать экономический рост, однако ЕС может не реализовать этот потенциал в полной мере. Среди подписантов — представители ведущих компаний различных секторов экономики: шведский производитель телекоммуникационного оборудования Ericsson, немецкий разработчик программного обеспечения SAP, промышленный конгломерат Thyssenkrupp и итальянский люксовый бренд одежды Prada. К инициативе также присоединились исследователи, представители гражданского общества и отраслевые ассоциации, что свидетельствует о широком резонансе проблемы в европейском бизнес-сообществе. Ключевое требование авторов письма — гармонизация существующих правил ЕС и разработка современной интерпретации Общего регламента защиты данных (GDPR). Компании настаивают на необходимости создания чёткой и последовательной нормативной базы, которая позволит эффективно использовать европейские данные для обучения ИИ-моделей без ущерба для конфиденциальности пользователей. Европейская комиссия отреагировала на обращение заявлением о поддержке инноваций в сфере ИИ. Исполнительный орган ЕС подчеркнул, что от нового комиссара по вопросам юстиции ожидается обеспечение баланса между потребностями правоохранительных органов и коммерческими интересами в рамках GDPR. Это заявление можно интерпретировать как сигнал готовности к диалогу и поиску компромиссных решений. Тем не менее европейские законодатели настаивают на необходимости жёсткого регулирования для противодействия монополистическим тенденциям в технологическом секторе, борьбы с дезинформацией и защиты несовершеннолетних в интернете. Обращение бизнес-сообщества последовало за недавними заявлениями Meta✴✴ и Apple о задержке запуска новых ИИ-функций в Европе. Apple в июне этого года сообщила о вероятной отсрочке внедрения системы Apple Intelligence для европейских пользователей iPhone. Причина — неопределённость, вызванная новым законом о цифровой конкуренции. Следом за ней в июле Meta✴✴ объявила о приостановке выпуска в ЕС своей перспективной мультимодальной ИИ-модели, способной обрабатывать текст, изображения и речь. Компания сослалась на непредсказуемость европейской регуляторной среды. Ранее Meta✴✴ уже откладывала планы по обучению ИИ-моделей на основе публичных постов взрослых пользователей Facebook✴✴ и Instagram✴✴ в Европе после вмешательства ирландского регулятора по защите данных. За последнее десятилетие ЕС укрепил свои позиции как влиятельный глобальный регулятор в сфере технологий. GDPR, вступивший в силу в 2018 году, стал международным эталоном защиты персональных данных. Новые законодательные акты ЕС, касающиеся цифровой конкуренции, контроля над онлайн-контентом и регулирования ИИ, уже вынудили ведущие технологические компании, хоть и со скрипом, адаптировать свои бизнес-модели для ЕС. Поэтапный запуск новых продуктов и функций за пределами США — стандартная практика для технологических компаний. Например, чат-бот Google AI Bard (позже переименованный в Gemini) появился в ЕС через несколько месяцев после запуска в США и Великобритании. Задержка была частично обусловлена требованием ирландского регулятора о внедрении дополнительных функций защиты конфиденциальности. Meta✴✴ также отложила запуск своей социальной платформы Threads в ЕС на несколько месяцев после её дебюта в США. Несмотря на регуляторные вызовы, ЕС с населением около 450 млн человек остаётся одним из крупнейших и наиболее платёжеспособных рынков в мире. Это объясняет стремление технологических компаний найти компромисс с европейскими регуляторами для сохранения доступа к этому стратегически важному региону. Однако в открытом письме особо отмечается риск ограничения доступа европейских организаций к открытым ИИ-моделям. Ключевой аргумент письма — непоследовательное применение GDPR создаёт неопределённость относительно типов данных, допустимых для обучения ИИ-моделей. «Если компании и институты планируют инвестировать десятки миллиардов евро в развитие генеративного ИИ для европейских граждан, им необходимы чёткие, последовательно применяемые правила, разрешающие использование европейских данных», — подчёркивается в обращении. Основанный выходцем из Intel стартап Ampere Computing ищет новых владельцев
20.09.2024 [07:58],
Алексей Разин
В 2016 году Рене Джеймс (Renee James), на тот момент занимавшая должность президента Intel, ушла из компании и основала стартап Ampere Computing, который специализируется на разработке ускорителей вычислений. Теперь, если верить слухам, эта компания ищет стратегического инвестора и нового владельца в одном лице.  Как сообщает Bloomberg со ссылкой на осведомлённые источники, в качестве нового владельца бизнеса руководство Ampere хотело бы видеть одного из крупных игроков рынка информационных технологий. Первоначально предполагалось, что со временем стартап будет привлекать капитал на фондовом рынке через IPO. Бум искусственного интеллекта, который теоретически должен повышать интерес к разработкам Ampere, на деле усиливает конкуренцию в сегменте, а потому относительно молодым компаниям становится сложнее выживать. Поскольку в этом отношении пока ничего окончательно не решено, Ampere может сохранить самостоятельность, но потом выйти на IPO при наличии благоприятных условий. В 2021 году капитализация стартапа оценивалась в $8 млрд, инвесторами в его активы считаются японская корпорация SoftBank и разработчик СУБД Oracle. Чипы разработки Ampere используются для ускорения вычислений компаниями Microsoft и Google, а также Oracle. Облачные системы последней на базе ускорителей Ampere эксплуатируются Uber Technologies, предоставляющей информационные услуги одноимённому сервису по перевозке пассажиров на легковых машинах. Руководство Ampere делает ставку на архитектуру Arm и высокую энергоэффективность своих ускорителей. Её современные решения насчитывают до 500 вычислительных ядер и выпускаются тайваньской компанией TSMC по передовым литографическим технологиям. В текущем году общая сумма сделок с активами в сфере полупроводникового бизнеса выросла более чем в два раза до $60 млрд, по данным Bloomberg. SpaceX пожаловалась Конгрессу США на FAA: регулятор ужасно контролирует запуски ракет
20.09.2024 [07:27],
Дмитрий Федоров
SpaceX подвергла резкой критике Федеральное управление гражданской авиации (FAA) США, обвинив ведомство в неэффективном надзоре за ракетными запусками. Компания направила в Конгресс США письмо, в котором заявила о неспособности FAA идти в ногу с развитием коммерческой космической отрасли. Это обращение последовало за предложением FAA оштрафовать SpaceX на $633 009 за нарушение правил при двух запусках Falcon 9 в 2023 году. 
Источник изображений: SpaceX Компания опубликовала открытое письмо, адресованное Конгрессу США, в котором заявила: «На протяжении почти двух лет SpaceX выражала свою обеспокоенность неспособностью FAA идти в ногу с индустрией коммерческих космических полётов». Компания подчеркнула: «Очевидно, что агентство не только не имеет достаточных ресурсов для своевременного рассмотрения документов на выдачу лицензий, но и направляет свои ограниченные ресурсы на области, не связанные с общественной безопасностью». SpaceX утверждает, что такой подход напрямую угрожает национальным приоритетам и подрывает способность американской промышленности к инновациям. Письмо было направлено четырём ключевым законодателям, включая сенатора Марию Кантуэлл (Maria Cantwell) от Демократической партии и представителя Фрэнка Лукаса (Frank Lucas) от Республиканской партии, возглавляющих научные комитеты в Сенате и Палате представителей. SpaceX подвергла критике Управление коммерческого космического транспорта (AST) — подразделение FAA, ответственное за надзор за ракетными запусками. Компания заявила, что AST не удалось модернизировать и оптимизировать свои правила из-за нехватки ресурсов и неправильного использования имеющихся полномочий.  Критика SpaceX последовала за предложением FAA оштрафовать компанию на $633 009 за несоблюдение правил запуска при двух полётах ракет Falcon 9 в 2023 году. Несмотря на относительно небольшой размер штрафа, генеральный директор SpaceX Илон Маск (Elon Musk) заявил, что планирует подать судебный иск в связи с утверждением, что именно политические соображения вынуждают FAA к чрезмерному регулированию его компании. В четырёхстраничном письме SpaceX опровергает основания FAA для наложения штрафа. Компания настаивает, что следовала всем нормативным требованиям, а AST слишком медленно реагировало на незначительные изменения в запусках Falcon 9. «Что касается этих вопросов, то следует отметить, что в каждом случае SpaceX предоставила AST достаточное уведомление об этих относительно незначительных обновлениях лицензии, которые никак не влияли на общественную безопасность. Тот факт, что AST не смогло своевременно обработать эти незначительные обновления, подчёркивает системные проблемы в AST», — утверждает компания. Эти изменения, по мнению SpaceX, касались небольших технических корректировок, не влияющих на общую безопасность космических запусков. Похоже, что SpaceX эскалирует конфликт с FAA, призывая Конгресс вмешаться. Компания аргументирует, что неэффективность регулятора ставит под угрозу конкурентоспособность американской космической отрасли в мире. В 2023 году SpaceX осуществила рекордные 87 орбитальных запусков, что составляет значительную долю от общего числа 186 успешных орбитальных запусков в мире за этот период. FAA отказалось комментировать происходящее. Однако главный юрисконсульт агентства Марк Николс (Marc Nichols) заявил: «Безопасность определяет всё, что мы делаем в FAA. Несоблюдение компанией требований безопасности повлечёт за собой последствия». Социальные сети собирают больше личной информации пользователей, чем заявляют, выяснил регулятор США
20.09.2024 [07:23],
Алексей Разин
В конце этой рабочей недели Федеральная комиссия по торговле США (FTC) сообщила, что её расследование выявило более обширный сбор отдельными социальными сетями и стриминговыми сервисами персональных данных по сравнению с декларируемым. По сути, ряд компаний обвиняется властями США в несанкционированном сборе информации о потребителях, включая несовершеннолетних. 
Источник изображения: Pixabay Как сообщает The New York Times, под подозрение попали девять компаний, включая Meta✴✴ Platforms, YouTube и TikTok. Предоставляя свои услуги преимущественно бесплатно для пользователей, они зарабатывают на сборе информации о них с целью дальнейшей её продажи рекламодателям. Последние с помощью подробного демографического среза аудитории могут адресно продвигать те или иные товары и услуги своих клиентов. Кроме того, указанные компании, по мнению FTC, недостаточно хорошо защищают пользователей, особенно детей и подростков. По данным FTC, своё расследование комиссия начала почти четыре года назад с целью первого в своей истории подробного изучения «непрозрачной деловой практики» крупнейших онлайн-платформ, которые оперируют многомиллиардными рекламными оборотами благодаря доступа к пользовательской информации. По данным агентства, расследование доказывает необходимость усиления контроля за этой сферой со стороны федерального законодательства США, а также введения некоторых ограничений на способы использования персональных данных компаниями. Председатель FTC Лина Хан (Lina Khan) заявила: «Практика слежения угрожает частной жизни людей и их свободам, подвергая их целому набору угроз, от кражи личности до преследования». Американские регуляторы уже давно выражают обеспокоенность влиянием социальных сетей на ментальное здоровье подрастающего поколения граждан, но пока попытки законодателей усилить контроль за данной сферой в основной своей части потерпели неудачу. Лина Хан также отметила, что попытки усилить меры саморегулирования деятельности компаний также ни к чему не привели. FTC начала своё расследование в декабре 2020 года, охватив деятельность девяти компаний, владеющих 13 платформами. Свои выводы комиссия строила на основе изучения данных о деятельности компаний в период с 2019 по 2020 годы, уделяя первостепенное внимание методам сбора информации, её использования и хранения. В поле зрения регуляторов попали платформы YouTube, TikTok, Facebook✴✴, Whatsapp, Instagram✴✴, Messenger, Twitch, Discord, Snapchat, Reddit и X. Руководство комиссии не стало пояснять, в какой мере та или иная компания нарушает интересы пользователей в части защиты персональных данных. FTC выяснила, что компании получали недостающую информацию о пользователях через другие платформы, а порой покупали дополнительные данные о тех людях, которые не являлись их клиентами. Большинство компаний собирали информацию о возрасте, поле и языковых предпочтениях пользователей, некоторые дополняли её данными об образовании, уровне дохода и семейном положении. У пользователей при этом не было реальных возможностей отказаться от предоставления информации о себе, а компании нередко хранили информацию значительно дольше, чем требовалось по условиям соглашения с пользователями. Информация о клиентах буквально объединялась в подробные досье для предоставления рекламодателям. Регуляторы также обнаружили достаточное количество пользователей в возрасте до 13 лет на платформах, которые на уровне правил декларировали запрет на их подключение к своим ресурсам. Во многих приложениях сбор данных о подростках осуществлялся в том же объёме, что и о взрослых. Отдельные компании даже затруднялись объяснить следователям, насколько велик объём собираемых данных. Лина Хан в позапрошлом году инициировала процесс создания правил демонстрации рекламы пользователям онлайн-сервисов. В январе Epic Games была вынуждена согласиться с выплатой штрафа в размере $500 млн за нарушение законов в части неприкосновенности частной жизни несовершеннолетних граждан. В 2022 году социальная сеть X (ранее Twitter) была оштрафована на $150 млн за злоупотребления в области использования данных о клиентах для адресной рекламы. В YouTube появится ещё больше рекламы — её будут показывать при постановке видео на паузу
20.09.2024 [06:06],
Дмитрий Федоров
YouTube официально подтвердил внедрение рекламы на экране паузы для всех рекламодателей, завершив тестовый период, начатый в 2023 году. Это произошло спустя 6 лет после первых предупреждений о такой возможности и полтора года после того, как Google обнаружила высокую прибыльность данного формата. 
Источник изображения: EyestetixStudio / Pixabay Процесс внедрения рекламы на паузе был постепенным и методичным. Ещё в 2018 году появились первые предупреждения о потенциальном использовании экрана паузы YouTube для рекламы. Уже в апреле 2023 года Google официально объявила о планах внедрения этой функции на YouTube и инициировала пилотный проект, предоставив к нему доступ ограниченному числу рекламодателей. Спустя год Филипп Шиндлер (Philipp Schindler), директор по бизнесу Google, подтвердил, что новый формат оказался чрезвычайно прибыльным для компании и вот теперь, эти планы полностью реализованы. Олува Фалодун (Oluwa Falodun), менеджер по коммуникациям YouTube, заявил: «Учитывая сильную позитивную реакцию как рекламодателей, так и зрителей, мы широко развернули рекламу на паузе для всех рекламодателей». 
Источник изображения: Pale_Baker3255 / Reddit Пользователи YouTube быстро отреагировали на изменения. На прошлой неделе на платформе Reddit появились многочисленные сообщения о заметном увеличении частоты рекламы на экране паузы YouTube. Видеохостинг позиционирует рекламу во время паузы как «менее навязчивую». Однако компания не сообщила о возможном сокращении частоты появления стандартной рекламы. Важно отметить, что в 2023 году YouTube уже ввёл непропускаемую рекламу, а также экспериментировал с более длительными, но менее частыми рекламными вставками. YouTube не является пионером в использовании экрана паузы для рекламы. Сервисы Hulu и AT&T уже давно применяют эту практику. Стриминговый сервис Sling TV внедрил рекламу на паузе ещё в июле этого года, но дал пользователям возможность её отключения в настройках. YouTube, в свою очередь, не сообщил о наличии подобного выбора, что может вызвать дополнительное недовольство среди пользователей. Amazon запустила собственный ИИ-генератор видео — он будет создавать рекламу
20.09.2024 [01:17],
Анжелла Марина
На фоне конкуренции с Google, компания Amazon анонсировала запуск ИИ-инструмента для быстрого создания видеорекламы. Video Generator, представленный на конференции Accelerate, позволяет преобразовывать всего одно изображение товара в увлекательный видеоролик, демонстрирующий особенности продукта. 
Источник изображения: BoliviaInteligente/Unsplash Хотя функциональность инструмента пока ограничена, пишет издание TechCrunch, однако он уже позволяет создавать пользовательские видео без дополнительных затрат. «Видео, созданные с помощью Video Generator, используют уникальные знания Amazon о розничной торговле и представляют продукт таким образом, чтобы сделать его наиболее привлекательным для клиентов», — говорится в блоге компании. На данный момент видеогенератор находится на стадии бета-тестирования и доступен ограниченному числу рекламодателей в США. Вице-президент Amazon Ads Джей Ричман (Jay Richman) заявил, что инструмент будет дорабатываться перед более широким запуском. Вместе с Video Generator также представлена функция Live Image, которая генерирует короткие анимированные GIF-файлы из статичных изображений. Эта функция, находящаяся в стадии бета-тестирования, является частью Image Generator — набора инструментов Amazon для создания изображений на основе искусственного интеллекта. Отметим, что выход Amazon на рынок генеративного видео происходит на фоне активного развития этой технологии и другими компаниями. В частности, стартапы Runway и Luma недавно запустили API для генерации видео, компания Google начала интегрировать свою модель Veo в YouTube Shorts, Adobe обещает добавить функцию генерации видео в Creative Suite к концу года, а OpenAI планирует открыть свою технологию Sora широкой публике до конца осени. Компания Amazon пока не предоставила примеры видео, созданных с помощью новых инструментов, и не раскрыла подробностей относительно максимальной длительности и разрешения генерируемых видеороликов. Huawei выпустила смарт-часы Watch D2 со встроенным тонометром
20.09.2024 [00:38],
Андрей Созинов
Вместе со смарт-часами Watch GT 5 и GT 5 Pro, которые предлагают классический элегантный дизайн, компания Huawei также представила уникальные умные часы Watch D2 — они выделяются возможностью измерения артериального давления пользователя.  Huawei Watch D2 оснащены ремешком с надувной подушечкой, которая работает так же, как наручная манжета тонометра для измерения артериального давления. Ремешок надувается через равные промежутки времени как днём, так и ночью, что позволяет осуществлять круглосуточный мониторинг кровяного давления.  Таким образом, с помощью Watch D2 можно более тщательно следить за состоянием своего здоровья, чем с обычными часами, которые полагаются только на оптические датчики. Конечно, у D2 также есть оптический датчик, который используется для измерения частоты сердечных сокращений. Кроме того, есть датчики ЭКГ и температуры кожи. Часы D2 были одобрены медицинскими надзорными органами ЕС и Китая.  Смарт-часы Watch D2 оснащены прямоугольным 1,82-дюймовым OLED-дисплеем (408 × 480 пикселей), что заметно больше 1,64-дюймового экрана оригинальных Watch D. Размеры самих часов составляют 48 × 38 × 13,3 мм, а вес — 40 г без ремешка и 85 г с ремешком. Это впечатляющая миниатюрность, если учесть, что в них встроены воздушный насос и датчик артериального давления. Имеется защита от пыли и влаги по стандарту IP68, поддерживается NFC. Время автономной работы при обычном использовании составляет 6 дней, а при регулярном измерении давления — сутки. Huawei Watch D2 поступили в продажу сегодня. Стоимость новинки в Европе составила €400. Подробнее о новинке — в нашем обзоре. Новая статья: Обзор смартфона Infinix ZERO 40 5G: сама стабильность
20.09.2024 [00:07],
3DNews Team
Данные берутся из публикации Обзор смартфона Infinix ZERO 40 5G: сама стабильность |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



