|
Опрос
|
реклама
Быстрый переход
Российские учёные больше не смогут работать с Большим адронным коллайдером
20.09.2024 [21:18],
Владимир Фетисов
Российские физики с 1 декабря 2024 года лишатся доступа к объектам Европейской организации по ядерным исследованиям (ЦЕРН), среди которых Большой адронный коллайдер (БАК). Сообщение об этому опубликовано в журнале Nature. 
Источник изображения: home.cern Вместе с этим российские учёные должны сдать имеющиеся у них французские и швейцарские виды на жительство. При этом в Немецком синхротронном центре заявили, что отказ от сотрудничества с российскими физиками «оставит дыру». Там также отметили, что легко заменить российских учёных другими не удастся. Продолжить исследования в ЦЕРНе смогут учёные, которые перешли из российских организаций в иностранные. По данным источника, около 90 россиян с 2022 года сделали такой выбор и еще 20 человек ищут места в зарубежных учреждениях в настоящее время. ЦЕРН также продолжит реализацию около 270 проектов с сотрудниками российского Объединённого института ядерных исследований на коллайдере NICA в подмосковной Дубне. ЦЕРН объявил о прекращении сотрудничества с российскими учёными в марте этого года. В сообщении говорилось, что с организацией взаимодействуют менее 500 человек, связанных с учреждениями из России. В ЦЕРН также добавили, что ведётся подготовка по передаче задач на коллайдере другим группам специалистов. Вскоре после обострения ситуации на Украине в 2022 году ЦЕРН приостановил статус наблюдателя для России. Позднее организация не стала продлевать соглашения о сотрудничестве с Россией и Республикой Беларусь после истечения их сроков в 2024 году. Австралия ужесточит классификацию видеоигр с лутбоксами
20.09.2024 [20:56],
Михаил Романов
Австралийская рейтинговая комиссия Australian Classification объявила о скором изменении порядка классификации интерактивных развлечений, в которых есть лутбоксы и элементы азартных игр. 
Источник изображения: Steam (Motoki Masahiro) Как стало известно, с 22 сентября релизам, содержащим внутриигровые покупки с элементом случайности (например, лутбоксы), будет присваиваться возрастной рейтинг не ниже M («от 15 лет»). Проекты с имитацией азартных игр (это касается как игр-казино, так и произведений с интерактивными формами азартных игр) будут автоматически получать R18+ («Только для взрослых»). Такие продукты запрещены к продаже несовершеннолетним. 
Скриншот из Dragon Quest XI — японской RPG совсем не про азартные игры (источник изображения: Square Enix) Другими словами, условная Red Dead Redemption 2 с возможностью игры в покер, согласно новым правилам, должна была бы заслужить в Австралии рейтинг R18+ (против нынешнего MA15+). Можно предположить, что подобное нововведение направлено против нормализации азартных игр среди несовершеннолетних. По данным ABC News, австралийцы тратят на онлайн-гемблинг больше, чем жители любой другой страны. 
Red Dead Redemption 2 (источник изображения: O Fenomeno в Steam) Изменения в процессе классификации интерактивных развлечений с лутбоксами и имитацией азартных игр коснутся продуктов для всех платформ — от ПК и консолей до смартфонов и планшетов. Регулятор уточнил, что новые правила будут применяться к играм, выходящим после 22 сентября. Уже доступные на рынке продукты заново оценивать не станут (за исключением случаев, если у них вдруг отзовут рейтинг). 20 тонн HDD в труху — накопители хранилища Alpine уходящего на покой суперкомпьютера Summit отправили в измельчитель
20.09.2024 [20:25],
Руслан Авдеев
По словам специалистов Национальной лаборатории Ок-Ридж (ORNL) Министерства энергетики США, суперкомпьютеры и их компоненты утилизируются точно так же, как и ненужная бумага — буквально отправляются в измельчитель. И совсем скоро сотрудникам лаборатории предстоит разобрать суперкомпьютер Summit, который морально устарел, хотя всё ещё входит в десятку самых производительных систем мирового рейтинга TOP500. Summit хотели вывести из эксплуатации ещё в 2023 году, но из-за довольно высокой производительности пока решено оставить его в строю почти до ноября 2024 года в рамках программы SummitPLUS. Впрочем, часть комплекса уже модернизируется. Так, на смену хранилищу Alpine придёт Alpine 2. Данные из Alpine были переданы в другие СХД суперкомпьютерного центра Oak Ridge Leadership Computing Facility (OLCF). 19 ноября Alpine2 переключат в режим «только для чтения», а потом изменят конфигурацию хранилища для использования в других проектах. Alpine, основанная на параллельной файловой системе IBM Spectrum Scale, создавалась для временного хранения данных Summit и других систем. По словам учёных, Summit строили для симуляции процессов в сверхновых и термоядерных реакторах и вряд ли где-либо ещё есть такая же концентрация жёстких дисков в одном месте, как в системах ORNL, за исключением, возможно, гиперскейлеров. Другими словами, даже разборка Alpine, которая началась ещё летом — чрезвычайно трудоёмкий процесс, поскольку накопители приходится извлекать вручную и по одному. 
Источник изображения: ORNL Alpine состояло из 40 стоек на площади около 130 м2. Хранилище суммарной ёмкостью 250 Пбайт включало 32 494 HDD. Речь идёт о почти 20 т оборудования. Чтобы обеспечить по-настоящему безопасное удаление данных, HDD отвозят для физического уничтожения. За этот процесс отвечает компания ShredPro Secure. HDD буквально крошатся металлическими зубьями до небольших фрагментов. На переработку одного диска уходит приблизительно 10 с, а за день можно уничтожить до 3,5 тыс. накопителей. Полученные остатки окончательно утилизируются в рамках программы по переработке металла ORNL, так что лаборатория ещё и получает деньги за сдачу вторичного сырья. Вывод из эксплуатации крупных вычислительных систем — постоянно совершенствуемый процесс, который с годами становится всё эффективнее. В последний раз крупное хранилище (Atlas) утилизировали в 2019 году, оно включало около 20 тыс. HDD. Утилизация своими силами заняла около 9 месяцев и оказалась очень дорогой. ShredPro Secure справилась гораздо быстрее, а сам процесс оказался гораздо дешевле. Поэтому компании в итоге отдали на уничтожение ещё около 10 тыс. HDD из других систем. Правда, теперь ORNL раздумывает над покупкой собственного измельчителя, чтобы дополнительно повысить безопасность и сэкономить ещё больше в долгосрочной перспективе. Складной смартфон Honor Magic V3 будет продаваться в России по цене от 199 900 рублей
20.09.2024 [19:52],
Николай Хижняк
Складной смартфон Honor Magic V3, глобальная версия которого была представлена недавно на выставке IFA 2024 в Берлине, будет продаваться в России, сообщили 3DNews источники в российском ретейле.  Международные продажи смартфона Honor Magic V3 стартуют с 1 октября по цене 1999 евро. В России новинка появится с 29 октября. Стоимость смартфона составит 199 900 рублей. При этом источник не указывает, в какой конфигурации будет доступно устройство.  На данный момент Honor Magic V3 является самым тонким складным смартфоном в мире. Его толщина в сложенном состоянии составляет 9,2 миллиметра, в разложенном — 4,35 миллиметра. Толщина корпуса прошлого поколения Magic составляла 10,1 и 4,8 миллиметра соответственно. Корпус защищён от воды в соответствии со стандартом IPX8. На лицевой стороне корпуса Honor Magic V3 размещён внешний 6,43-дюймовый дисплей на базе LTPO OLED-матрицы с разрешением FHD+, частотой обновления от 1 до 120 Гц и яркостью до 2500 кд/м2. Размер основного дисплея составляет 7,92 дюйма. В нём тоже используется матрица LTPO OLED, поддерживающая частоту обновления от 1 до 120 Гц. Яркость основного экрана составляет до 1800 кд/м2. Он обладает разрешением 2156 × 2344 пикселей. В основе смартфона используется процессор Qualcomm Snapdragon 8 Gen 3. Устройство предлагает 12 или 16 Гбайт ОЗУ, а также до 1 Тбайт постоянной памяти.  Ёмкость аккумулятора Magic V3 составляет 5150 мА·ч, поддерживается быстрая проводная зарядка 66 Вт и беспроводная на 50 Вт. Основных камеры три: широкоугольная и телеобъектив на 50 мегапикселей, а также широкоугольная на 40 Мп. Во внешнем и внутреннем дисплеях расположились 20-Мп камеры. Учёные впервые квантово запутали топ-кварки — исполинов среди всех обнаруженных элементарных частиц
20.09.2024 [19:48],
Геннадий Детинич
Топ-кварки или t-кварки, были обнаружены всего 30 лет назад. Они чрезвычайно массивны по сравнению с остальными элементарными частицами Стандартной модели. Это делает их уникальными и загадочными, открывая перспективы для новых открытий в области физики — неизвестных взаимодействий или частиц. Раскрывая секреты топ-кварков, учёные впервые смогли квантово запутать их пары, что произошло на Большом адронном коллайдере без экстремального охлаждения среды. 
Художественное представление пары запутанных топ-кварков. Источник изображения: CERN До сих пор исследователи создавали квантовую запутанность лёгких частиц в условиях низких энергий. Обычно это были фотоны. Квантовая запутанность означает, что мы можем узнать некоторые квантовые свойства одной частицы (например, фотона) по детектируемым свойствам другой частицы из запутанной пары, даже если первая находится на краю Вселенной. При этом никакой передачи информации или энергии не происходит. Нам просто становятся известны определённые квантовые характеристики фотона из запутанной пары. Топ-кварки — это частицы совершенно другого масштаба по массе и энергии. Они были открыты последними из шести типов кварков. Масса топ-кварка в 184 раза превышает массу протона и, например, значительно больше массы атома вольфрама. Запутать пару топ-кварков — значит выйти на энергетический уровень выше 10 ТэВ (тераэлектронвольт). В случае фотонов или других лёгких частиц (фотоны не имеют массы) для предотвращения разрушения квантовых состояний и запутанности экспериментальные системы охлаждаются до абсолютного нуля, чтобы минимизировать все внутренние колебания. Это известная проблема квантовых вычислений, которые страдают от короткого времени когерентности. Для запутывания пар топ-кварков этого не потребовалось. Авторы исследования из коллаборации ATLAS создали необходимые для этого условия в процессе эксперимента на коллайдере БАК. Статья о работе вышла в журнале Nature. Похожую работу независимо также проделали учёные из коллаборации CMS, но их работа пока есть лишь на сайте препринтов arXiv.orgc. Топ-кварки, благодаря своим свойствам, оказались удобным объектом для изучения запутанности с использованием относительно простых средств, по сравнению с другими случаями, и при этом на совершенно новом уровне энергий. Хотя стоит признать, что Большой адронный коллайдер трудно назвать «подручным инструментом», это вряд ли позволит в ближайшее время перевести эксперименты с топ-кварками в практическую плоскость квантовых вычислений или криптографии. Тем не менее, изучение квантовой запутанности на столь высокой энергетической ступени — это не просто шаг вперёд, это прорыв! Появилось видео разборки iPhone 16 Pro — батарея в металлическом корпусе и улучшенный теплоотвод
20.09.2024 [19:42],
Сергей Сурабекянц
YouTube-канал REWA Technology сегодня опубликовал видео разборки iPhone 16 Pro, предложив первый взгляд на внутреннюю конструкцию устройства сразу после его появления в продаже. Судя по видео, новинка получила аккумулятор ёмкостью 3582 мА·ч (у iPhone 15 Pro было 3274 мА·ч) в металлическом корпусе, в то время как батарея iPhone 16 Pro Max заключена в чёрную фольгу. 
Источник изображения: Apple Ранее Apple сообщала, что все четыре модели iPhone 16 имеют внутренние изменения конструкции для улучшения рассеивания тепла. Судя по видео, корпус iPhone 16 Pro получил более крупную металлическую пластину для рассеивания тепла по сравнению с iPhone 15 Pro. Металлические аккумуляторы и фольга также могут способствовать улучшению рассеивания тепла. 
Источник изображения: REWA Technology На видео также можно заметить, что у iPhone 16 Pro немного более компактная материнская плата по сравнению с установленной в iPhone 15 Pro, и несколько других компоновочных изменений. Руководитель разработки провального шутера Concord добровольно пошёл на понижение, а сотрудники приготовились к худшему
20.09.2024 [19:23],
Михаил Романов
Скоропостижное закрытие (спустя всего две недели после релиза) геройского шутера Concord оставило команду Firewalk Studios в незавидном положении. О состоянии дел в студии со ссылкой на своих информаторов рассказал портал Kotaku. 
Источник изображений: PlayStation По данным трёх источников Kotaku, на прошлой неделе руководитель разработки Concord Райан Эллис (Ryan Ellis) сообщил сотрудникам, что снимается с должности гейм-директора и переходит на некую вспомогательную роль. «Райан глубоко верил в проект и объединение игроков через него. Вне зависимости от того, можно ли было что-то сделать по-другому… он хороший человек с большим сердцем», — отозвался об Эллисе один из бывших разработчиков Concord. 
С 2009 по 2016 год Эллис (в центре) работал в Bungie над обеими Destiny Оставшиеся сотрудники настроены относительно перспектив пессимистично: одни сомневаются в возвращении Concord, других уже попросили заняться проектами, над которыми Firewalk может поработать в будущем. Источники передают, что работники Firewalk (150−170 человек) ждут решения Sony — будь то массовые увольнения, закрытие студии или перевод в разряд вспомогательных. Некоторые уже начали обновлять свои резюме. 
Kotaku утверждает, что Firewalk — одна из самых дорогостоящих для Sony студий в пересчёте на затраты по содержанию сотрудников Sony приобрела Firewalk в 2023 году после трёх лет работы над Concord и продвигала игру на своих презентациях. На релизе шутер стоил $40 и, по мнению аналитиков, достиг всего 25 тыс. проданных копий. Concord стартовала 23 августа на PC и PS5, а уже 6 сентября Sony отключила серверы игры — всем покупателям вернули деньги. После закрытия разработчики обещали рассмотреть разные варианты дальнейших действий. Начались мировые продажи iPhone 16, Apple Watch Series 10 и AirPods 4 — Apple показала, как это было
20.09.2024 [19:19],
Сергей Сурабекянц
Сегодня Apple приветствовала покупателей в своих магазинах по всему миру на премьере iPhone 16, Apple Watch Series 10 и AirPods 4. Новые продукты были анонсированы на мероприятии Apple It’s Glowtime в начале этого месяца и стали доступны для предварительного заказа начиная с 13 сентября. Новые iPhone станут первыми устройствами Apple, оснащёнными функциями искусственного интеллекта Apple Intelligence, которые станут доступны в октябре. 
Источник изображения: CNBC В начале недели акции Apple упали на 3,6 % после сообщений аналитиков о том, что спрос на новые iPhone 16 оказался ниже ожидаемого. Объём предзаказов на новые смартфоны Apple за первую неделю оказался на 12 % ниже по сравнению с iPhone 15 в аналогичный период прошлого года. Аналитики полагают, что главной причиной стало отсутствие доступа к анонсированным функциям ИИ Apple Intelligence на момент запуска iPhone 16. Сегодня аналитики UBS посоветовали инвесторам не слишком остро реагировать на предположение о возможном снижении продаж, поскольку эти данные собираются в том числе путём анализа времени ожидания новых моделей iPhone, а в прошлом году оно было больше отчасти из-за сбоев в цепочке поставок. По их мнению, сбои в цепочке поставок в прошлом году «слегка исказили/расширили данные прошлого года», что привело к более длительному времени ожидания клиентами моделей Pro. В прошлом году некоторые клиенты заказанный iPhone 15 Pro Max 41 день по сравнению с 26 днями ожидания iPhone 16 Pro Max в этом году. «В преддверии анонса iPhone 16 наш анализ показал, что отсутствие крутого приложения и, возможно, несколько незрелое внедрение Apple Intelligence снизят спрос, — считают аналитики UBS. — Хотя мы по-прежнему утверждаем, что набор атрибутов iPhone/iOS скорее эволюционный, чем революционный, мы предостерегаем инвесторов от чрезмерной реакции на данные, которые предполагают несколько вялый спрос изначально».
«Тем не менее, данные по всем моделям и регионам примерно через неделю после запуска подтверждают нашу точку зрения, поскольку данные по марже в США и Китае разочаровывают по сравнению с прошлым годом», — заключили эксперты. Qualcomm уволит сотни сотрудников подразделений в Сан-Диего
20.09.2024 [18:51],
Владимир Фетисов
Производитель полупроводниковой продукции Qualcomm да конца нынешнего года уволит сотни сотрудников, которые работают на предприятиях компании в Сан-Диего, США. Своих мест лишатся 226 человек, представляющих 16 подразделений, включая штаб-квартиру Qualcomm, где располагаются специалисты по кибербезопасности.  Неизвестно, затронет ли волна увольнений сотрудников подразделения по кибербезопасности, поскольку в сообщении Qualcomm эта информация не уточняется. Отметим, что Qualcomm анонсировала новый раунд увольнений менее чем через год после того, как своих мест лишились 1250 сотрудников компании. Официальный представитель компании отказался от комментариев по данному вопросу. «Наши передовые технологии и портфель продуктов позволяют нам реализовать стратегию диверсификации. В рамках стандартного бизнес-процесса мы определяем приоритеты и распределяем инвестиции, ресурсы и таланты, чтобы обеспечить оптимальное положение для использования беспрецедентных возможностей диверсификации, открывшихся перед нами», — заявила представитель Qualcomm Кристин Стайлз (Kristin Stiles). Новая macOS Sequoia парализовала работу многих антивирусов на Mac
20.09.2024 [18:48],
Анжелла Марина
Новая версия операционной системы Apple для компьютеров Mac, macOS Sequoia, привела к неожиданным проблемам. Пользователи и разработчики сообщили о массовых сбоях в работе популярных антивирусов и других инструментов безопасности. 
Источник изображения: Gabriela Gonzalez/Unsplash Судя по всему, macOS Sequoia оказалась несовместима с программным обеспечением от таких компаний, как CrowdStrike, SentinelOne, Microsoft и ESET. По сообщению издания TechCrunch, в социальных сетях и на специализированных форумах пользователи жалуются на проблемы с подключением к сети, некорректную работу брандмауэров и другие сбои, и во всём винят разработчиков антивирусов. «Как разработчику инструментов безопасности для macOS, мне невероятно обидно снова и снова сталкиваться с расстроенными пользователями, которые обвиняют в поломке своих Mac наши инструменты, хотя на самом деле это вина Apple», — сетует Патрик Уордл (Patrick Wardle), основатель стартапа DoubleYou, занимающегося разработкой инструментов безопасности. Известная компания CrowdStrike в день выхода macOS Sequoia сообщила в Slack-канале для администраторов Mac, что им вообще пришлось отложить поддержку новой версии операционной системы. Представитель компании отметил, что «очень сожалеет о том, что невозможно оказать поддержку безопасности Sequoia с первого дня, несмотря на предыдущий опыт быстрого реагирования на новые обновления Apple». CrowdStrike отправила своим клиентам техническое оповещение, в котором указывает на вынужденные изменения в среде безопасности на macOS. Проблемы с новой операционной системой Apple затронули не только корпоративных пользователей. Исследователь безопасности Уилл Дорманн (Will Dormann) написал в Mastodon, что у него возникли проблемы с DNS и запуском брандмауэра на его Mac. Другой эксперт по безопасности, Вацлав Яцек (Wacław Jacek) столкнулся с блокировкой доступа к веб-браузерам после обновления. Судя по ветке Reddit, macOS Sequoia также вызвала проблемы у пользователей браузера Firefox. Компании SentinelOne, ESET и SentinelOne Agent также обнаружили трудности с сетевым подключением после обновления операционной системы до macOS Sequoia. На данный момент Apple никак не прокомментировала ситуацию и не ответила на запросы журналистов. Разработчики антивирусного ПО работают над решением проблемы, однако пока неясно, как скоро пользователи macOS Sequoia смогут вздохнуть спокойно. Инвесторы верят, что OpenAI будет стоить больше триллиона долларов
20.09.2024 [18:14],
Павел Котов
Новый раунд финансирования, в ходе которого OpenAI привлечёт более $6 млрд, показывает веру инвесторов, что разработчик ChatGPT станет ведущей в мире компанией в области искусственного интеллекта. Компания настолько интересно инвесторам, что их оказалось слишком много для очередного раунда финансирования, и OpenAI смогла позволить себе выбирать, от кого взять деньги. 
Источник изображения: Mariia Shalabaieva / unsplash.com Инвесторы, пожелавшие вложиться в OpenAI на последнем раунде финансирования компании, в ходе которого будут привлечены более $6 млрд, делают беспрецедентную ставку, что она станет ведущим в мире разработчиком ИИ, а её стоимость будет исчисляться триллионами долларов. Сбор средств OpenAI завершает при оценке в $150 млрд. Венчурная компания Thrive Capital за последние недели вложила в разработчика не менее $1 млрд; OpenAI рассчитывает дополнительно привлечь не менее $5 млрд. О том, чтобы присоединиться к раунду финансирования, ведут переговоры Apple, Nvidia и Microsoft — самые дорогие технологические компании в мире. Интерес к инвестициям проявили нью-йоркская Tiger Global и поддерживаемый властями Объединённых Арабских Эмиратов фонд MGX. Сделка будет закрыта в ближайшее время, передаёт Financial Times. Ведущие технологические инвесторы Кремниевой долины, в том числе Andreessen Horowitz и Sequoia Capital, в раунде не участвуют. Для актуальных участников эта сделка была необычной: Thrive и Tiger обычно вкладывают более скромные средства в менее известные стартапы и надеются получить в 10–100 раз больше вложений. Чтобы добиться такой отдачи от OpenAI, ей придётся вырасти до стоимости в $1,5 трлн — больше, чем Meta✴✴ и Berkshire Hathaway Уоррена Баффета (Warren Buffett). Есть мнение, что так и произойдёт. «Мы говорим о пути к созданию компании стоимостью в триллион долларов. Не думаю, что это неразумно», — заявил партнёр в одной из поддержавших OpenAI инвестиционных компаний. Появление генеративного ИИ знаменует «крупнейший выигрыш платформы со времён облачных вычислений или интернета», говорят инвесторы. Несмотря на огромный масштаб сбора средств, дефицита спроса на вложения OpenAI не испытывает. Thrive не просто вложила в компанию свои средства, но и запустила механизм, с помощью которого и другие компании смогут получить долю в OpenAI. Большие надежды на разработчика ChatGPT примечательны даже в масштабах Кремниевой долины, где лишь несколько крупных технологических компаний доросли до гигантов с триллионными оценками. Чтобы добиться окупаемости инвестиций в ожидаемых масштабах, OpenAI потребуется преодолеть жёсткую конкуренцию со стороны богатейших технологических компаний в мире, включая Google и Meta✴✴. Нужны ресурсы для обучения все более дорогих моделей ИИ, а также грамотное управление для перехода от хаотически быстрорастущего стартапа к стабильному корпоративному гиганту. 
Источник изображения: Growtika / unsplash.com К настоящему моменту годовая выручка OpenAI составляет около $3,6 млрд, но тратит она более $5 млрд в год и пока «далека от безубыточности», потому что активно вкладывается в новые ИИ-модели и продукты, чтобы оставаться впереди конкурентов. Дополнительные миллиардные вложения дадут OpenAI преимущество перед Anthropic и стартапом Илона Маска (Elon Musk) xAI — они тоже сумели привлечь многомиллиардные инвестиции. На стороне OpenAI к тому же стратегическое партнёрство с Microsoft, которой некоторые инвесторы, по их словам, предпочли бы Apple. Впрочем, отдельные участники финансового рынка сомневаются, что вложения в OpenAI вообще когда-либо себя окупят; других ошеломляющий масштаб инвестиций отпугивает — они боятся оказаться в чрезмерной зависимости от одной компании. Высказываются сомнения, что OpenAI сможет и дальше поддерживать интенсивные темпы роста — в ноябре прошлого года её потряс кризис в совете директоров, в ходе которого глава компании Сэм Альтман (Sam Altman) на пять дней был отстранён от должности. Обсуждаются планы по упрощению корпоративной структуры OpenAI, хотя в текущем раунде финансирования вложения не были поставлены в зависимость от возможной реструктуризации. В этом году из компании ушли несколько руководителей исследовательских подразделений; она также была втянута в судебное разбирательство с Илоном Маском (Elon Musk), который вышел из состава учредителей в 2018 году, а также в конфликт с New York Times. Есть и признаки охлаждения отношений с Microsoft, которая инвестировала в OpenAI $13 млрд и значительно преуспела на её продуктах. Но сейчас они становятся прямыми конкурентами, о чём говорится в годовом отчёте Microsoft. Сторонники OpenAI, однако, говорят, что проблемы роста компании типичны для стартапа такого рода и проводят параллели с молодыми Google и Apple. В компании впервые появился финансовый директор — им стала Сару Фрайар (Sarah Friar), — а в совете директоров теперь немало экспертов с опытом работы в корпоративных структурах, и это признак трезвого подхода к управлению компанией. «Добро пожаловать обратно»: после месяца блокировки россиянам и белорусам снова открыли доступ к IGN и How Long to Beat
20.09.2024 [18:11],
Михаил Романов
На исходе лета без объяснения причин для российских и белорусских пользователей зарубежные видеоигровые сайты IGN и How Long to Beat оказались недоступны, однако спустя почти месяц блокировка была снята. 
Источник изображения: IGN Напомним, пользователи из России, Республики Беларусь и «ещё нескольких стран» лишились доступа к IGN и How Long to Beat четыре недели назад, 23 августа. Ситуация стала результатом решения материнской компании Ziff Davis. «Юридическая команда нашей материнской компании заставила заблокировать весь трафик из России, Беларуси и ещё нескольких стран. У нас нет права голоса в этом вопросе», — сообщили тогда в команде How Long to Beat. Помимо IGN и How Long to Beat, Ziff Davis также владеет и другими игровыми изданиями вроде Eurogamer, GamesIndustry.biz и Rock Paper Shotgun, однако проблем с ними у российских игроков не возникало. 
Источник изображения: How Long to Beat Спустя почти месяц после введения блокировки сотрудник Everdred из команды How Long to Beat на форуме портала неожиданно сообщил, что с России, Республики Беларусь и других затронутых стран запрет был снят. Подробностей ситуации или причин месячной блокировки Everdred не раскрыл, лишь с энтузиазмом поприветствовав пользователей из разблокированных теперь регионов: «Добро пожаловать обратно!» IGN считается одним из крупнейших американских порталов о видеоиграх в целом (новости, обзоры, аналитика), тогда как на How Long to Beat собирают информацию о продолжительности разных релизов. Двое космонавтов установили рекорд непрерывного пребывания на МКС
20.09.2024 [18:09],
Владимир Мироненко
Российские космонавты Олег Кононенко и Николай Чуб установили новый рекорд по продолжительности нахождения на МКС в ходе одного полёта. О том, что сегодня будет установлен новый рекорд ещё ночью объявил в своём телеграм-канале «Роскосмос». 
Источник изображения: «Роскосмос» «В 16:06:51 мск они (Кононенко и Чуб) превысят достижение Сергея Прокопьева, Дмитрия Петелина и Франциско Рубио, которые совершили полёт длительностью 370 суток 21 час 22 минуты 16 секунд», — говорится в сообщении «Роскосмоса». Олег Кононенко и Николай Чуб отправились на МКС 15 сентября 2023 года на корабле «Союз МС-24». Как ожидается, они вернутся на Землю на корабле «Союз МС-25» 23 сентября. Сообщается, что 5 июня Кононенко первым в мире преодолел рубеж в 1000 суток по суммарной длительности космических полётов, превзойдя до этого 4 февраля достижение космонавта Геннадия Падалки, набравшего в ходе пяти космических полётов в сумме 878 суток 11 часов 29 минут 48 секунд. Согласно данным «Роскосмоса», самый продолжительный космический полёт выполнил россиянин Валерий Поляков, который провёл с января 1994 года по март 1995 года на орбитальном комплексе «Мир» 437 суток 17 часов 58 минут 17 секунд. Microsoft вернулась к скевоморфизму в оформлении своего ПО — иконки станут более объемными и игривыми
20.09.2024 [17:32],
Владимир Фетисов
Microsoft обновила иллюстрации, которые используются в продуктах и сервисах софтверного гиганта. Предыдущая итерация иллюстраций была в значительной степени векторной с использованием плоского дизайна, который можно увидеть во многих приложениях компании, таких как Teams, Skype или Office, и даже в некоторых разделах Windows. Теперь же разработчики перешли на 3D-дизайн, который возвращает скевоморфизм, а также делает дизайн более красочным и игривым. 
Источник изображений: Microsoft «Наши исследования показали, что, поверхностно используемые нами иллюстрации можно назвать красочными, инклюзивными и гениальными, но в потребительской среде они воспринимаются как неинтересные и безэмоциональные. Плоский векторный стиль, который когда-то был очень популярен в индустрии, теперь не является оптимальным и потенциально наводит на мысли, которые не соответствуют ценностям нашей компании», — говорится в сообщении разработчиков Microsoft.  Microsoft переработала иллюстрации, создав стиль, который должен «упростить и унифицировать продукты с ярко выраженной эстетикой Microsoft». В результате в иллюстрациях появилось гораздо больше форм и символов фирменного стиля Fluent, а цветовая палитра стала более насыщенной. Трёхмерные иллюстрации гораздо более выразительны по сравнению с плоским и перенасыщенным стилем, который Microsoft использовала последние годы.  «Наши прежние иллюстрации часто дублировали сопроводительный текст, что создавало путаницу. Если бы мы более тщательно подходили к тому, как наши иллюстрации гармонируют с другими элементами пользовательского интерфейса, то эта проблема уже могла быть решена», — отмечают разработчики. Теперь перед Microsoft стоит задача по обновлению иллюстраций во всех своих продуктах и сервисах, для чего может потребоваться несколько месяцев. Новая игра в серии Yakuza оказалась гибридом с Assassin's Creed IV: Black Flag — первый трейлер и детали Like a Dragon: Pirate Yakuza in Hawaii
20.09.2024 [17:31],
Михаил Романов
Разработчики из Ryu Ga Gotoku Studio обещали удивить фанатов анонсом новой игры и не обманули — 20 сентября команда представила приключенческий экшен Like a Dragon: Pirate Yakuza in Hawaii с элементами Assassin’s Creed IV: Black Flag. 
Источник изображений: Sega По сюжету знакомый фанатам основных частей бывший легендарный якудза Горо Мадзима оказывается выброшен на берег отдалённого острова в Тихом океане без понятия о том, кто он на самом деле такой. В попытках вернуть утраченные воспоминания герой становится пиратом и втягивается в конфликт из-за легендарного сокровища, разгоревшийся между преступниками, современными морскими разбойниками и прочими негодяями. Скриншоты
Игрокам предстоит набирать команду, модернизировать свой пиратский корабль, исследовать на нём водные просторы, наживать врагов, заводить друзей и участвовать в многочисленных мини-играх. Бои на суше будут разворачиваться в реальном времени. Пользователи смогут выбирать между двумя стилями («Бешеным псом» и «Пиратом»), прыгать (впервые в серии), выполнять взрывные комбо, жонглирование и захваты в воздухе. За пределами России уже стартовали предзаказы — игра будет стоить $60 На презентации Like a Dragon: Pirate Yakuza in Hawaii показали 7-минутный анонсирующий трейлер (прикреплён выше) и уточнили, что события пиратского ответвления разворачиваются после январской Like a Dragon: Infinite Wealth. Like a Dragon: Pirate Yakuza in Hawaii выйдет 28 февраля 2025 года на PC (Steam, Microsoft Store), PS4, PS5, Xbox One, Xbox Series X и S. Обещают драматичный сюжет, захватывающие морские сражения и текстовый перевод на русский. Коробки настольных процессоров Intel Core Ultra 200K показались на изображениях в непривычном чёрном цвете
20.09.2024 [16:01],
Павел Котов
Процессоры новой серии Intel Core Ultra 200K будут поставляться в упаковке чёрного цвета, а не привычного синего. Ранее компания Intel выпускала в чёрных коробках только специальные серии чипов для настольных ПК, например, отборные образцы Extreme Edition. 
Источник изображений: videocardz.com Накануне в Сеть попала фотография упаковки процессора Intel Core Ultra 9 285K, и инсайдеры поспешили опубликовать изображения упаковок процессоров Core Ultra 7 и Core Ultra 5. На коробках значится маркировка «Unlocked» и «Series 2», то есть речь идёт о процессорах Arrow Lake-S серии Core Ultra 200K, которые предложат разблокированный множитель и соответственно возможность разгона, а их TDP составит 125 Вт.  Ранее компания комплектовала чёрной упаковкой процессоры для энтузиастов серии Extreme Edition, а в последние годы чёрная упаковка применялась для специальных моделей китайского рынка — за пределами Поднебесной такие чипы не продавались. Intel пока воздерживается от публикации подробностей о процессорах нового поколения, и дата их выхода тоже не оглашается.  Если верить неофициальной информации, Core Ultra 200K появятся 24 октября вместе с материнскими платами на новом чипсете Z890. На начальном этапе ожидается дебют лишь пяти моделей, а за ними последуют и другие, включая вариант с TDP 65 Вт и без разблокированного множителя. В России дебютировал ноутбук Tecno Megabook T1 с экраном 14” и чипом AMD Ryzen
20.09.2024 [15:11],
Владимир Мироненко
Компания Tecno представила в России новую версию ноутбука Megabook T1, который отличается лёгким и тонким металлическим корпусом, лаконичным дизайном, а также высокой производительностью. Компания позиционирует новинку в качестве отличного выбора как для продуктивной работы в офисе, так и для повседневного использования.  Tecno Megabook T1 оснащён 14-дюймовым дисплеем с разрешением Full HD и соотношением сторон 16:10, с поддержкой яркости 350 кд/м2 с адаптивной регулировкой DC Dimming. Дисплей обеспечивает 100-% охват цветового пространства sRGB и имеет сертификацию TÜV Eye Comfort, что говорит о низком уровне вредного для глаз синего света. Благодаря тонкой регулировке петель ноутбук можно открыть одной рукой на 180°. Ноутбука построен на восьмиядерном процессоре AMD Ryzen 7 5800U на архитектуре Zen 3 с поддержкой 16 потоков, максимальной рабочей частотой 4,4 ГГц и встроенной графикой Radeon RX Vega 8. Объём оперативной памяти DDR4 составляет 16 Гбайт, ёмкость SSD с интерфейсом PCIe 3.0 равна 512 Гбайт.  Качественный звук обеспечивается с помощью аудиосистемы Tecno VOC с поддержкой ИИ и технологии объёмного звучания DTS, разработанной Tecno Audio Lab. Ноутбук получил массивный аккумулятор на 75 Вт⋅ч, обеспечивающим до 18,5 часа работы без подзарядки. Устройство обладает клавиатурой с подсветкой, большим тачпадом и кнопкой питания со встроенным сканером отпечатка пальца. Для подключения внешних устройств имеется девять разъёмов. В комплекте предоставляется зарядное устройство мощностью 65 Вт на основе нитрида галлия (GaN). Благодаря алюминиевому корпусу вес ноутбука составляет всего 1,39 кг, толщина ー 14,8 мм. Цена Megabook T1 14″ AMD R7-5800U 16/512 Гбайт с операционной системой Windows равна 62 990 руб., а на старте продаж — 53 990 руб. В «Яндекс Браузере» появился ИИ-редактор текста и другие функции на базе YandexGPT
20.09.2024 [15:08],
Владимир Фетисов
Разработчики из «Яндекса» продолжают улучшать свой фирменный браузер. На этот раз они добавили в «Яндекс Браузер» несколько инструментов на базе YandexGPT, которые предназначены для повышения продуктивности. Они помогут быстрее справляться с повседневными задачами, связанными с контентом, без необходимости использования сторонних сервисов и приложений. 
Источник изображений: «Яндекс» Алгоритмы в текстовом редакторе помогут генерировать тексты с нуля и улучшать уже готовые, например, исправляя ошибки, переписывая в определённом стиле или формате. В дополнение к этому в «Яндекс Браузере» появился переводчик с YandexGPT, использующий лексику в зависимости от предметной области текста. Ещё одним нововведением стала функция краткого пересказа текстов, которая поддерживает работу с файлами в форматах PDF, DOCX и TXT. Все новые функции доступны в одном интерфейсе, перейти к которому можно нажатием соответствующей кнопки под поисковой строкой на главной странице браузера.  Редактор с YandexGPT делает возможным не только генерацию текстов, но также позволяет редактировать и менять стиль готовых текстов. Для его запуска предусмотрена кнопка «Редактировать», которая располагается рядом с любым сайтом в «Яндекс Браузере». Для изменения текста можно задействовать встроенные команды, такие как «Более формально» или «Простыми словами», или делать это посредством команд в окне чата. Реализована поддержка русского и английского языков, а также возможность переключаться при работе с текстом со смартфона на ПК.  Вместе с этим в браузере появилась бета-версия обновлённого переводчика на базе YandexGPT. Этот инструмент теперь может различать предметную область текста и использовать соответствующую лексику. К примеру, для научной статьи переводчик подберёт специальные термины, а для кулинарного блога — общеупотребительные. Переводчик понимает более 100 языков, а также может работать с произвольными текстами, изображениями и ссылками на сайты. Начать взаимодействие с переводчиком можно, нажав соответствующую кнопку под поисковой строкой на главной странице браузера.  В дополнение к этому разработчики добавили функцию пересказа загруженных текстов любой длины. Этот инструмент может обрабатывать научные трактаты, объёмные художественные романы и др. В десктопной версии браузера функция доступна не только для текстов и видео, но и для документов в разных форматах. Поддерживается два режима пересказа: краткий и подробный. Во втором случае будут сохранены все ключевые детали из оригинала. При необходимости получившийся пересказ можно разбить на смысловые главы с подзаголовками для более удобного ориентирования в тексте. Разработчики из «Яндекса» интегрировали нейросети нового поколения в свой браузер в феврале этого года. Благодаря этому пользователям стали доступны полезные функции для взаимодействия с текстами, генерации изображений, перевода на русский видео с восьми языков и др. Honor и Xiaomi давно придумали трёхстворчатые смартфоны, но пока не торопятся их выпускать
20.09.2024 [15:07],
Алексей Разин
На прошлой неделе китайская компания Huawei Technologies представила складываемый втрое смартфон Mate XT с гибким дисплеем, который способен разворачиваться в планшет. Сегодня новинка поступила в продажу примерно за $2800. Как показали изыскания South China Morning Post, компании Xiaomi и Honor уже давно имеют патенты на устройства аналогичной компоновки, а потому в случае необходимости могут их разработать. 
Источник изображения: Huawei Technologies Xiaomi складываемый втрое смартфон с тремя камерами на тыльной стороне запатентовала ещё в 2022 году, а широкой публике этот патент для изучения стал доступен 3 сентября. Некогда основанная на базе разрушенного санкциями США бизнеса Huawei в сегменте смартфонов компания Honor складываемый втрое аппарат запатентовала ещё в 2021 году, как уточняют китайские источники. На публике он впервые появился в апреле текущего года. Два шарнира и Z-образная схема сложения сочетаются в патентной заявке с круглым блоком камер на тыльной стороне устройства. Аналитики IDC прогнозируют, что складные смартфоны с функциями ИИ будут стимулировать спрос на китайском рынке в этом году, общие объёмы поставок вырастут на 3,1 % до 279 млн штук. На мероприятии в июле этого года руководство Honor призналось, что компания запатентовала смартфоны необычных формфакторов, включая версии с тремя секциями и буквально сворачивающиеся в трубочку. При этом момент для вывода этих устройств на рынок будет тщательно подбираться. Это вопрос не столько технологических возможностей, сколько влияющего на бизнес выбора. Китайская марка Tecno, принадлежащая динамично развивающемуся холдингу Transsion, также недавно продемонстрировала на видео концептуальную модель смартфона Phantom Ultimate 2, который складывается Z-образным способом и позволяет работать с эффективной диагональю дисплея 10 дюймов в разложенном состоянии. Высокий спрос на представленную недавно новинку Huawei на фоне дефицита уже взвинтил цены на вторичном рынке в три раза от рекомендованного уровня, что расстроило некоторых поклонников марки. По данным Canalys, в первом полугодии Huawei лидировала на китайском рынке складных смартфонов с долей 56 %. Китай остаётся самым крупным рынком складных смартфонов, во втором квартале на страну пришлась половина мировых объёмов реализации, которые выросли в годовом сравнении на 21 % до 1,5 млн штук. Сюрприз на день рождения: Sega подарила владельцам Warhammer 40,000: Dawn of War и Dawn of War 2 в Steam все дополнения
20.09.2024 [14:44],
Михаил Романов
Сегодня, 20 сентября 2024 года, культовой стратегии Warhammer 40,000: Dawn of War от разработчиков из Relic Entertainment исполнилось 20 лет, и издательство Sega не оставило фанатов без подарка на юбилей. 
Источник изображений: Sega Как подметили пользователи, в честь знаменательной даты Warhammer 40,000: Dawn of War обновилась в Steam до специального юбилейного издания, в которое вместе с основной игрой входят дополнения Winter Assault, Dark Crusade и Soulstorm. Владельцам любого издания Warhammer 40,000: Dawn of War апгрейд до Anniversary Edition достался бесплатно. Аналогичную акцию Sega также устроила с Warhammer 40,000: Dawn of War 2, которой в феврале исполнилось 15 лет. В рамках юбилейного издания Steam-версия Dawn of War 2 теперь включает доступ к аддонам Retribution и Chaos Rising, а также всем остальным обликам для мультиплеера и снаряжению для кампании и режима Last Stand из отдельных DLC.  «Только что прокачали DoW1 и DoW2 до двух фантастических юбилейных изданий, которые включают весь контент из игр с их DLC и расширениями. Если вы являетесь владельцем, то теперь это всё принадлежит вам!» — отчитался микроблог серии. Единственной ложкой дёгтя в этой бочке мёда для фанатов Warhammer 40,000 станет то, что апгрейд до юбилейных изданий не включает технических улучшений, исправлений багов или повышение совместимости игр с современным железом. Warhammer 40,000: Dawn of War стартовала уже в далёком 2004 году, а Dawn of War 2 увидела свет в 2009-м. Обе игры получили высокие оценки и завоевали любовь фанатов, чего о вышедшей в 2017-м Dawn of War 3 не скажешь. Google и OpenAI настаивают на смягчении европейского закона об ИИ — он убьёт инновации
20.09.2024 [14:30],
Анжелла Марина
Крупнейшие технологические компании мира пытаются убедить Европейский Союз смягчить регулирование искусственного интеллекта, чтобы избежать многомиллиардных штрафов. Amazon, Google и Meta✴✴ стремятся снизить жёсткие требования к прозрачности ИИ и защитить свои коммерческие тайны. 
Источник изображения: Gerd Altmann/Pixabay В мае Европейский парламент принял Закон об искусственном интеллекте (ИИ), первый в мире всеобъемлющий свод правил (AI Act), регулирующих эту технологию. Принятию закона предшествовали месяцы напряжённых переговоров между различными политическими группами. Однако, как сообщает Reuters, до тех пор, пока не будет окончательно утверждён кодекс практики, остаётся неясным, насколько строго будут применяться правила в отношении систем ИИ общего назначения (GPAI), например таких, как ChatGPT от OpenAI, и как решать вопросы нарушения авторских прав. ЕС пригласил компании и учёных участвовать в разработке кодекса практики. Отмечается, что кодекс не будет юридически обязывающим, когда вступит в силу в конце следующего года, однако предоставит компаниям контрольный список для демонстрации соблюдения норм. Игнорирование этих норм может привести к юридическим последствиям для компаний, утверждающих, что они следуют закону. Рассматривается проблема и авторского права. Такие компании как Stability AI и OpenAI постоянно сталкиваются с вопросом о том, нарушают ли они авторское право, используя бестселлеры или архивы фотографий для обучения своих моделей без разрешения создателей. Согласно ИИ-акту, компании обязаны предоставлять «подробные резюме» данных, использованных для обучения моделей. Это может позволить авторам контента, чьи работы были задействованы без разрешения, претендовать на компенсацию, хотя данный вопрос ещё предстоит детально прорабатывать и, возможно, решать в судах. При этом высказываются опасения, что новые требования по резюме могут содержать слишком мало данных для защиты коммерческих секретов, в то время как авторы наверняка имеют право знать, использовался ли их контент без разрешения. Максимилиан Гантц (Maximilian Gahntz), руководитель по политике ИИ в Mozilla, высказал обеспокоенность по поводу того, что компании «стараются избежать прозрачности». Он отметил: «AI Act представляет собой лучший шанс пролить свет на этот важный аспект и хотя бы частично что-либо прояснить». Технологические компании надеются на то, что в Акт будут внесены изменения в их пользу. «Мы настаиваем на том, что эти обязательства должны быть управляемыми и, если возможно, адаптированными для стартапов», — сказал Максим Рикард (Maxime Ricard), менеджер по политике в Allied for Startups. После публикации правил в первой половине следующего года у технологических компаний будет время до августа 2025 года, чтобы подготовиться к их соблюдению. Некоммерческие организации, такие как Access Now, Future of Life Institute и Mozilla, также подали заявки на участие в разработке кодекса. В Китае создали устойчивый к порезам и деформациям литий-серный аккумулятор — он работает даже повреждённым
20.09.2024 [13:44],
Геннадий Детинич
Группа китайских учёных представила прототип литий-серного аккумулятора, устойчивого к повреждениям. Целью работы являлось создание более безопасной альтернативы литийионным аккумуляторам, которые подвержены воспламенению при повреждениях. Новый аккумулятор показал абсолютную надёжность, продолжая работать даже после того, как его перегнули пополам, а потом половину отрезали. 
Согнули. Источник изображений: Журнал ACS Energy Letters Для литий-серных аккумуляторов большой проблемой остаётся низкое число циклов заряда и разряда, что сдерживает их коммерциализацию. Учёные из Университета электронных наук и технологий Китая, Китайского института передовых технологий хранения энергии на озере Тяньму, Китайской академии наук и канадского университета Британской Колумбии включились в поиск соединений и решений, которые могли бы повысить цикличность этих перспективных батарей. В основе катодов перспективных Li-S-аккумуляторов были использованы сульфиды переходных металлов. Основная проблема с такими соединениями в том, что при высоком нагреве полисульфиды начинали активно перемещаться по электролиту, что вело к вспучиванию аккумуляторов и затуханию электрохимических реакций. Отчасти эту проблему решали электролиты на основе карбонатов, но они также создавали другую проблему — вызывали появление осадка (пассивацию) на электродах аккумулятора, что быстро сокращало количество циклов его работы. Для защиты катода из сульфида железа (FeS2) и анода с высоким содержанием металлического лития от выпадения осадка исследователи использовали три разных покрытия электродов: полиакриловую кислоту (PAA), полиакриламид (PAM) и полиэтиленоксид (PEO). Все эти соединения обладали хелатным эффектом (связывали «нехорошие» ионы), что предупреждало выпадение осадка на электродах. Эксперименты показали, что покрытие электродов полиакриловой кислотой дало наибольший эффект. 
И отрезали... После 300 циклов перезарядки прототип аккумулятора формфактора «мешочек» сохранил 72 % первоначальной ёмкости, показав полное отсутствие снижения после первых 100 циклов. Сгибание аккумулятора пополам, а затем отрезание его половины не привели к отказу и взрыву батареи, что произошло бы в случае обычного литий-ионного аккумулятора, что доказывает абсолютную безопасность перспективных батарей. Однако над ними ещё предстоит немало работы до перехода к коммерческому производству. Возможно, с литий-серными аккумуляторами дела лучше обстоят у американских разработчиков, которые уже наладили их ограниченное массовое производство. Но это другая история. Электроника в России подорожает на 10–15 % до конца года из-за инфляции и санкций
20.09.2024 [13:40],
Павел Котов
Несмотря на просьбы ФАС заморозить цены на наиболее популярные категории в электронике, российские розничные продавцы ожидают, что до конца года стоимость продукции увеличится на 10–15 %. Дистрибьюторы и производители уже подняли цены в связи с повышением ключевой ставки Банком России, а также западными санкциями, из-за которых усложнились расчёты с партнёрами из Китая и ОАЭ, пишет «Коммерсант». 
Источник изображения: F8_f16 / pixabay.com В этом году у ряда секторов российской экономики обозначилась проблема, связанная с ограничением трансграничных платежей за поставки товаров из Объединённых Арабских Эмиратов и Китая — структуры двух стран были вынуждены пойти на эту меру из-за давления со стороны США и угрозы вторичных санкций в отношении финансового сектора, которому предписано прекратить приём средств от российских компаний за технологическую продукцию. Наиболее сильно это ударило по сегментам потребительской электроники и вычислительной техники: Китай является монополистом на рынке компонентов и наборов для сборки конечного оборудования, а через ОАЭ в Россию поставляется до 30 % продукции в нескольких категориях электроники. Чтобы сохранить прежний режим работы в ОАЭ, российские компании были вынуждены открыть там новые юридические лица; а в Китае оплата стала проводиться через местные компании-посредники, которые берут комиссию от 3 % до 5 %. Проблемы расчётов с партнёрами в ОАЭ и Китае повлияли не только на стоимость и сроки импорта, но и на производство продукции внутри РФ. Отечественные компании, которые занимаются сборкой телевизоров, из-за дефицита комплектующих уже рассматривают возможность перенести мощности в Казахстан. Стоимость проведения платежа китайским партнёрам выросла на 5 % — на 5 % увеличилась и стоимость телевизора. Выросли сроки поступления средств в Китай, сроки поставки компонентов из Китая, а также сроки производства телевизоров в России. Аналогичные предприятия в Беларуси и других странах СНГ таких сложностей не испытывают, то есть российские компании находятся в невыгодных условиях. Если ситуация не исправится, то 70 % всей продукции будут выпускаться в Китае и СНГ, а отечественные компании будут вынуждены заказывать контрактное производство в странах, с которыми налажено конструктивное сотрудничество. 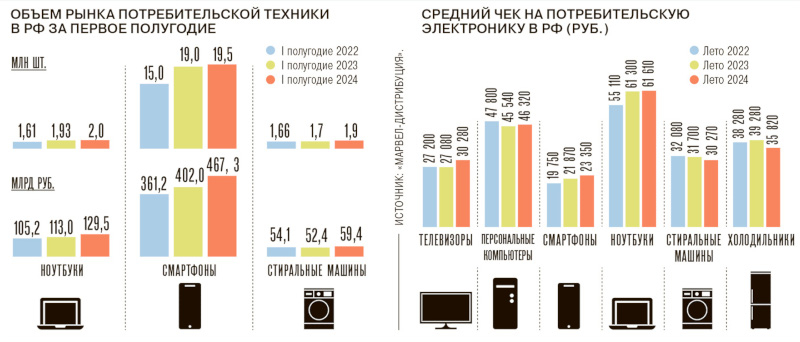
Источник изображения: kommersant.ru Усложнилась работа присутствующих в России OEM-брендов, которые не имеют собственных мощностей, а размещают заказы в других странах. Если раньше они выплачивали китайским партнёрам аванс, а расчёт осуществляли уже после отправки готовой продукции, то сейчас многие зарубежные предприятия отказываются работать без предоплаты на 100 %. Поднимают цены зарубежные бренды: китайские Haier и Hisense, а также турецкая Archelik (владеет Beko и Indesit) предупредили, что «из-за сложностей в финансовой логистике» закупочная стоимость продукции с 1 октября вырастет на 5 %. С ростом цен попыталась бороться ФАС, которая рекомендовала «Ситилинку», «М.Видео» и DNS заморозить цены на некоторые товары. Те согласились, но в DNS сообщили, что в конце июня — начале июля лишились возможности переводить средства китайским партнёрам привычными способами, а новые пути обходятся дороже на 4–8 %, и ещё 2–3 % добавляются за счёт разницы курсов — расчёты ведутся не в долларах, а в дефицитных юанях. Поэтому к концу года стоимость техники в магазинах вырастет на 10–15 %, прогнозируют в DNS. Потребители из-за роста цен начнут активнее переключаться на недорогие китайские или российские бренды, а средняя цена начнёт снижаться. Отечественные компании получат возможность увеличить свою долю рынка, говорят аналитики. В государственном и корпоративном секторе присутствие российских производителей заметнее, но цены и сроки растут даже здесь: стоимость компонентов уже увеличилась на 5–10 %, хотя высокая маржинальность данного направления пока позволяет нивелировать разницу. В случае дальнейшего усложнения финансовой логистики у отечественных вендоров возникает угроза срыва сроков и планов по поставкам оборудования заказчикам, а это будет означать и юридические риски. 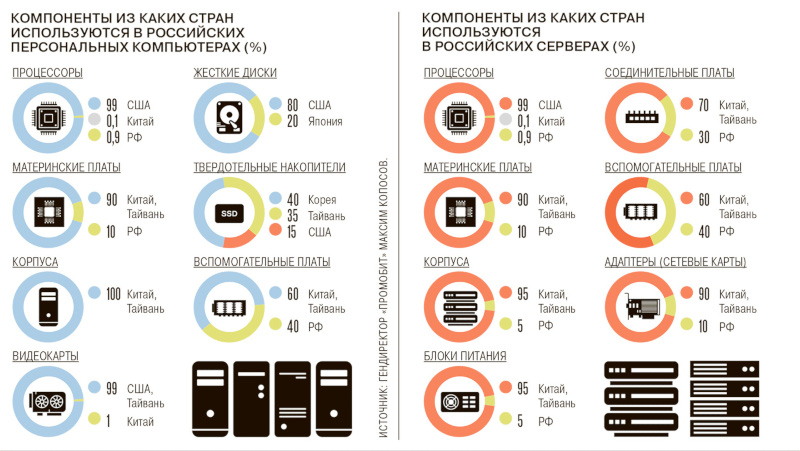
Источник изображения: kommersant.ru Важным фактором, влияющим на стоимость электроники в России, является величина ключевой ставки — 13 сентября ЦБ поднял её с 18 % до 19 %, и это много, потому что выше (20 %) она была лишь в марте и апреле 2022 года, а до июля 2023 года вообще держалась около 7,5 %. С ростом ключевой ставки дорожают и кредиты для производителей электроники: значение в 20 % означает увеличение стоимости товара на 2 % каждый месяц, говорят эксперты, поэтому до конца года техника может подорожать ещё 10 % к текущему росту цен. Следующее заседание ЦБ по вопросу значения ключевой ставки состоится 25 октября, и есть вероятность, что она снова будет увеличена. Неблагоприятен сейчас и сезонный фактор — перед новогодними праздниками курс рубля традиционно снижается, укрепление зарубежных валют может наложиться на рост цен комплектующих, а высокий спрос может стать ещё одной причиной роста цен. Одним из решений вопроса финансовой логистики является введение единой платёжной системы стран БРИКС (Китай, Бразилия, Аргентина, Россия, Египет, Иран и другие страны), а также возможность расчёта в криптовалютах. В противном случае западные страны сохранят возможность давить на российских партнёров. Для этих целей в России могут появиться криптобиржи — они упростят расчёты с партнёрами из стран БРИКС. Саудовская Аравия и ОАЭ углубят сотрудничество с Nvidia и получат новейшие ускорители вычислений
20.09.2024 [13:28],
Алексей Разин
На этой неделе стало известно о тенденции к углублению сотрудничества властей ОАЭ и Саудовской Аравии с компанией Nvidia, хотя некоторое время назад страны лишились открытого доступа к новейшим чипам этой марки из-за санкций США. Со следующего года Саудовская Аравия может получить доступ к ускорителям Nvidia вплоть до H200. 
Источник изображения: Nvidia В интервью CNBC на прошлой неделе заместитель руководителя Управления данных и искусственного интеллекта Саудовской Аравии (SDAIA) Абдулрахман Тарик Хабиб (Abdulrahman Tariq Habib) выразил надежду, что властям страны удастся со следующего года получить доступ к наиболее производительным ускорителям вычислений Nvidia. Это будет иметь для Саудовской Аравии очень большое значение, по словам чиновника, поскольку позволит облегчить сотрудничество между США и Саудовской Аравии, а также развивать вычислительные мощности на территории королевства. Местная инфраструктура готовилась к этим изменениям на протяжении трёх предыдущих лет, по словам представителя ведомства. К 2030 году страна рассчитывает до 12 % своего ВВП получать в сфере искусственного интеллекта. Финансировать проекты в этой области будет суверенный Публичный инвестиционный фонд Саудовской Аравии. С мая текущего года экспорт ускорителей Nvidia определённого ассортимента в страны Ближнего Востока ограничен, поскольку власти США опасаются транзита данной продукции в Китай. Последний тоже может стать партнёром Саудовской Аравии, если США лишат эту ближневосточную страну доступа к передовым технологиям американского происхождения, как считают некоторые эксперты. Агентство Bloomberg на этой неделе сообщило, что Nvidia будет сотрудничать с компанией G42 из ОАЭ в рамках инициативы по созданию инфраструктуры для более точного предсказания изменений в климате и погоде. По замыслу участников проекта, G42 позволит создать на территории ОАЭ инфраструктуру для ускорения вычислений и работы с цифровым двойником нашей планеты Earth-2, чтобы на его основе заниматься прогнозированием погоды. Система будет оперировать более чем 100 петабайтами геофизических данных. Компания G42 в этом году получила $1,5 млрд инвестиций от Microsoft, что многими экспертами трактовалось как сигнал, свидетельствующий о сближении ОАЭ и США. Принято считать, что ради получения доступа к технологиям и капиталу Microsoft руководству G42 пришлось дать американской стороне некоторые гарантии отказа от усиления сотрудничества с КНР. Налаживаются партнёрские взаимоотношения между G42 и OpenAI. Руководство первой из компаний отметило, что сотрудничество с Nvidia позволит не только продвигать инновации, но и решать критически важные для всего человечества проблемы. В Китае резко упали инвестиции в стартапы — власти слишком давят на технологический сектор
20.09.2024 [13:25],
Владимир Мироненко
В Китае заметно снизилась инвестиционная активность, что ставит под сомнение дальнейшее развитие его технологического сектора. Как сообщает газета Financial Times со ссылкой на поставщиков данных, сбор средств для инвестиций в Китай как зарубежными, так и отечественными венчурными фондами резко упал с 2022 года, что привело к значительному сокращению числа стартапов, основанных в Китае в прошлом году и в этом году. 
Электромобиль стартапа WM Motor, обанкротившегося в 2023 году. Источник изображения: WM Motor Financial Times назвала две основные группы причин сокращения инвестиций. Первая включает макроэкономические факторы, такие как общее замедление экономики Китая после вспышки пандемии COVID-19 и лопнувший пузырь на рынке недвижимости. Вторая группа связана с регулированием экономики властью, чьи административные меры в отношении ведущих частных технологических компаний, таких как Alibaba и Tencent, ударили по их фондовым оценкам и повлекли за собой глубокую неопределённость инвесторов относительно отношения Пекина к частному предпринимательству. Кроме того, противостояние США и Китая «отпугнуло» международный венчурный капитал от китайского рынка, отчасти потому, что найти «выход» на инвесторов через листинг на международных фондовых рынках стало сложнее. Как следствие, китайские студенты, обучающиеся за границей, видят меньше возможностей вернуться в Китай в ранее расширявшийся технологический сектор. Также наблюдается резкий рост судебных разбирательств, связанных с инвестициями. В августе местное издание Caixin сообщило, что ведущая государственная венчурная компания Shenzhen Capital Group подала 35 исков против компаний, которые в основном не стали публичными к установленной дате и не выкупили акции. Если Китай хочет сохранить своё технологическое превосходство, ему нужны масштабные реформы, пишет Financial Times. Частный сектор должен получить равный статус с государственным. Также нужно увеличить прозрачность для финансовых рынков Китая, чтобы можно было восстановить доверие инвесторов. «Прежде всего, сам Си (Си Цзиньпин, председатель КНР) должен осознать, что инновации не следуют административным указам», — подытожила Financial Times. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex
















