|
Опрос
|
реклама
Быстрый переход
Немецкие правоохранительные органы взломали Tor
21.09.2024 [15:54],
Павел Котов
Tor является одним из важнейших интернет-сервисов, обеспечивающим анонимность пользователей. Он бесплатен и может использоваться любым желающим, кто стремится скрыть, например, публичный IP-адрес своего компьютера. Проектом, предназначенным для благих целей, злоупотребляют и преступники, которые стремятся остаться анонимными и уйти от правоохранительных органов. Конец этому решили положить правоохранительные органы Германии. 
Источник изображения: blog.torproject.org Немецкие правоохранительные органы в течение нескольких месяцев отслеживали серверы Tor, чтобы идентифицировать отдельных пользователей теневой сети. Им удалось идентифицировать сервер хакерской группировки Vanir Locker, который она использовала в сети Tor. Киберпреступники объявили, что опубликуют данные, похищенные в ходе одной из своих последних акций. Немецким властям удалось определить местоположение ресурса при помощи метода временного анализа. Временной анализ используется, чтобы связать подключения к сети Tor и локальные подключения к интернету. Для реализации этого метода производится мониторинг как можно большего числа узлов Tor, потому что это увеличивает вероятность идентификации. Таким образом, правоохранительные органы действительно отслеживают узлы Tor, и делается это не только в Германии. Немецкие специалисты перехватили контроль над адресом ресурса группы кибервымогателей в сети Tor и перенаправили его на свою страницу — в результате хакеры не смогли опубликовать данные на своём ресурсе. Репортёры государственной радиовещательной компании ARD ознакомились с документами, которые подтверждают, что в результате операции были успешно идентифицированы четверо лиц. Этот метод использовался также для идентификации участников платформы, на которой публиковались материалы, содержащие жестокое обращение с детьми. Администрация Tor Project подтвердила, что правоохранительным органам удалось лишить анонимности нескольких киберпреступников, но заявила, что для большинства интернет-пользователей Tor остаётся одним из лучших вариантов сохранения конфиденциальности. Наметился прорыв в изучении физики Солнца — учёные научились делать карты магнитных полей его атмосферы
21.09.2024 [15:52],
Геннадий Детинич
Учёные из Национальной солнечной обсерватории США (NSO) представили первые в мире детальные карты магнитных полей солнечной атмосферы (короны). Проделанная работа — это только начало тотального картирования магнитосферы короны. Это новый уровень в изучении физики нашей родной звезды, который позволит прогнозировать едва ли ни все явления на Солнце от пятен до корональных выбросов, а это путь к предсказанию космической погоды в нашей системе. 
Источник изображения: NASA/SDO Новаторские карты магнитных полей в атмосфере Солнца смог получить новый и самый большой в мире наземный солнечный телескоп им. Дэниела Иноуэ (Daniel K. Inouye Solar Telescope, DKIST). Он начал научную работу в феврале 2022 года и уже добыл самые детализированные снимки нашей звезды, где разрешение каждого пикселя соответствовало 20 км. Казалось бы, что нам искать фактически под микроскопом на Солнце? Тем не менее учёные имеют более-менее полное представление о масштабных физических процессах на нашей звезде, но в мелочах не способны разобраться даже сегодня. Для выявления магнитных линий (полей) в короне Солнца учёные воспользовались криогенно охлаждённым спектрометром, подключённым к телескопу DKIST. С помощью коронографа исследователи могли изолированно от поверхности наблюдать атмосферу Солнца и одновременно снимать её спектр в ближнем инфракрасном диапазоне. В частности, исследователей интересовал спектр железа в атмосфере звезды. Существует такое явление, как эффект Зеемана. Он описывает расщепление спектральных линий атомов в магнитном поле. 
Карта магнитных полей солнечной короны Спектрометр легко выявляет расщепление линий вплоть до определения поляризации линий магнитного поля. Всё это позволяет в подробностях увидеть распределение линий напряжённости в короне. Если мы знаем, как распределены линии магнитных полей в атмосфере Солнца, то можем предсказать появление, размеры и очертания пятен на Солнце, интенсивность вспышек и направления выбросов корональной массы. Солнце станет предсказуемым. Это будет своего рода победа над ним. «Картирование напряженности магнитного поля в короне — фундаментальный научный прорыв не только для исследований солнечной системы, но и для астрономии в целом, — говорят авторы исследования. — Это начало новой эры, когда мы поймем, как магнитные поля звёзд влияют на планеты здесь, в нашей собственной солнечной системе, и в тысячах экзопланетных систем, о которых мы теперь знаем». Смартфоны Samsung могут лишиться беспроводной зарядки после проигрыша в патентном споре
21.09.2024 [14:44],
Владимир Фетисов
Беспроводная зарядка является одной из популярных функций современных смартфонов. Однако в скором времени крупнейший производитель смартфонов в лице южнокорейской компании Samsung может отказаться от использования этой технологии в своих устройствах. Это связано с проигрышем в затянувшемся судебном разбирательстве по поводу нарушения нескольких патентов компании Mojo Mobility. 
Источник изображения: Samsung В 2022 году Mojo Mobility подала в суд на Samsung, обвинив производителя электроники в нарушении пяти патентов, связанных с технологией беспроводной зарядки, используемой в большинстве смартфонов, проданных с 2016 года по настоящее время. В прошлом году Samsung пыталась добиться признания этих патентов недействительными. Однако 13 сентября суд признал южнокорейскую компанию виновной в нарушении патентов и нанесении ущерба на сумму $192 136 029. Говоря проще, юридическое заключение сводится к тому, что Samsung украла разработки Mojo Mobility и использовала их в своих смартфонах, смарт-часах, наушниках и других устройствах. Если Samsung примет решение отказаться от выплаты штрафа, то, вероятно, ей придётся удалить беспроводную зарядку в своих будущих продуктах или же разработать новые способы беспроводной зарядки, которые не будут нарушать патенты Mojo Mobility. Также не исключен вариант, при котором Samsung обязуют отключить беспроводную зарядку в уже выпущенных устройствах, но это маловероятно. Samsung почти наверняка подаст апелляцию на это решение суда и попытается его оспорить. На самом деле южнокорейская компания не первый раз оказывается в подобной ситуации, причём именно в суде Восточного округа штата Техас, где происходило рассмотрение жалобы Mojo Mobility. По последним оценкам, патентные тролли в США подают иски против Samsung в среднем каждые пять дней. Для защиты от этих обвинений Samsung приходится задействовать целую армию адвокатов, а также патентовать любые собственные технологии в соответствии со всеми правилами. Если команда юристов Samsung не сможет решить данный вопрос в суде, то, наиболее вероятно, что Samsung попросту придётся оплатить штраф или заключить мировое соглашение с Mojo Mobility. В любом случае, до полного урегулирования спора по патентам на технологию беспроводной зарядки, вероятно, ещё далеко. Продажи трёхстворчатого смартфона Huawei Mate XT в Европе начнутся в первом квартале 2025 года
21.09.2024 [14:37],
Владимир Мироненко
Ресурсу AndroidAuthority стали известны сроки появления в глобальной продаже складного смартфона Huawei Mate XT с трёхсекционным гибким дисплеем, представленного в Китае на прошлой неделе. Как сообщает ресурс, чьи прогнозы не раз подтверждались, глобальный релиз Mate XT состоится в первом квартале 2025 года. 
Источник изображения: Huawei Несмотря на высокую стоимость — цена Mate XT начинается с 19 999 юаней (около $2800) за модель с 16/256 Гбайт памяти, число предзаказов на новинку бьёт рекорды — порядка 4,9 млн по состоянию на 11 сентября. Как правило, цена смартфонов китайских производителей в Европе значительно выше, чем в Китае. Поэтому нельзя исключать, что самая доступная модель Mate XT в Европе будет предлагаться за $3000 и дороже. Что касается российского рынка, то здесь ожидают появление Mate XT гораздо раньше — вполне возможно, что это произойдёт уже в следующем месяце. Такую возможность допускают в Inventive Retail Group Расим Лемберанский, развивающей сети Restore, Restore: Mix, а также монобрендовые магазины Samsung и Xiaomi. Также планируют начать продажи Huawei Mate XT в ближайшее время и в Wildberries. По словам исполнительного директора Huawei Юй Чэндуна (Yu Chengdong), также известного как Ричард Ю (Richard Yu), на разработку Mate XT ушло пять лет, но в итоге новинка отличается надёжностью и безотказной работой всех компонентов. Это подтверждают и первые обзоры блогеров. Акции Intel выросли на фоне сообщения о её возможном поглощении Qualcomm
21.09.2024 [14:34],
Дмитрий Федоров
Акции Intel выросли на 3,4 % после сообщения о её возможном поглощении компанией Qualcomm, что может стать крупнейшей сделкой в истории полупроводниковой отрасли. Однако, несмотря на краткосрочный рост, акции Intel остаются в минусе на 56 % с начала года. Это демонстрирует серьёзные проблемы, с которыми продолжает сталкиваться компания, в том числе потерю технологического лидерства и падение продаж. 
Источник изображений: Intel Intel переживает трудные времена. Компания столкнулась с падением продаж и растущими убытками, которые усугубляются утратой технологического преимущества. Рыночная капитализация Intel снизилась до $93,5 млрд, что составляет примерно половину стоимости Qualcomm. В попытке исправить ситуацию Intel анонсировала ряд стратегических изменений, включая многомиллиардную сделку с Amazon по разработке ИИ-чипа и план по преобразованию подразделения контрактного производства чипов в отдельную дочернюю компанию. Qualcomm является мировым лидером в разработке процессоров для смартфонов. Компания активно стремится расширить своё присутствие в других сегментах рынка, включая чипы для персональных компьютеров (ПК) — традиционной вотчины Intel. В отличие от Intel, Qualcomm не имеет собственных производственных мощностей, полагаясь на аутсорсинг производства у таких партнёров, как TSMC, которая также производит чипы для конкурентов Intel — Nvidia и AMD.  Потенциальное приобретение Intel могло бы предоставить Qualcomm доступ к производственным мощностям в США и контроль над ведущим брендом на рынке ПК и серверов. Однако эксперты полагают, что такая сделка автоматически не решит проблем Intel, ведь у Qualcomm отсутствует опыт управления производством и экспертиза в науке, лежащей в основе передовых производственных технологий, где TSMC превосходит конкурентов. Реакция рынка на новость была неоднозначной. Акции Qualcomm упали на 2,9 %, что отражает опасения инвесторов относительно рисков и сложностей, связанных с потенциальной сделкой такого масштаба. Эта ситуация напоминает о событиях более чем шестилетней давности, когда Qualcomm сама стала объектом попытки поглощения со стороны Broadcom. Тогда сделка была заблокирована президентом Дональдом Трампом (Donald Trump) из соображений национальной безопасности. Гибридные процессоры AMD Strix Point на Zen 5 оказались вдвое дороже, чем Hawk Point на Zen 4
21.09.2024 [14:32],
Павел Котов
Производитель портативных игровых компьютеров и ноутбуков GPD недавно объявил цены на новый лэптоп Duo с двумя OLED-дисплеями. Этот ПК обещает стать одним из первых устройств на базе нового гибридного процессора (APU) от AMD — речь идёт о модели Ryzen AI 9 HX 370 семейства Strix Point, цена которой оказалась неожиданно высокой. 
Источник изображения: gpd.hk Первоначально GPD сообщала, что Duo получит гибридный процессор Phoenix/Hawk Point на архитектуре Zen 4, но впоследствии спецификации компьютера обновились. Производитель решил не отказываться от первоначального варианта полностью, и тому нашлась причина: AMD решила продавать чипы Strix Point компании GPD по цене, вдвое превышающей стоимость процессора Hawk Point (Ryzen 7 8840U). Это заставило её пересмотреть вопрос о том, сможет ли продукт сохранить достаточную маржу для успешного запуска. GPD не является крупным игроком на рынке ноутбуков, но при наличии двух OLED-дисплеев стоимость варианта на чипе AMD Ryzen AI 9 HX 370 составит $1650 — для сравнения, версия с Ryzen 7 8840U оценена в $1270. Прямое их сравнение не вполне корректно: старшая модель имеет 32 Гбайт оперативной памяти против 16 Гбайт у младшей, и размер встроенного накопителя составляет 1 Тбайт по сравнению с 512 Гбайт у базового варианта. Но разница в цене Hawk Point и Strix Point вызывает опасения, что и долгожданные Strix Halo также значительно вырастут в цене, и это вытеснит ПК на них из диапазона доступных. И пока нет ясности, является ли цена на Strix Point окончательной, или у производителей остаётся пространство для переговоров. Возможно, более доступной окажется серия процессоров AMD Ryzen Z2, выход которой ожидается в будущем году. В противном случае следует ожидать подорожания портативных игровых компьютеров. AMD также работает над процессорами серии Kraken, которые получат восемь ядер Zen 5/5c и восемь вычислительных блоков RDNA 3.5. Наблюдения за вулканами на спутнике Юпитера Ио раскрыли секреты приливного нагрева лун планет-гигантов
21.09.2024 [14:31],
Геннадий Детинич
Исследователи Корнелльского университета смогли изучить фундаментальный процесс формирования и эволюции планет — приливный нагрев, наблюдая за вулканами самого вулканически активного тела Солнечной системы — спутником Юпитера Ио. Это не праздный интерес. Аналогичные явления происходят в глубинах глобальных океанов ряда других лун у Сатурна и Юпитера, а это шанс для возникновения там жизни, которую мы знаем по Земле. 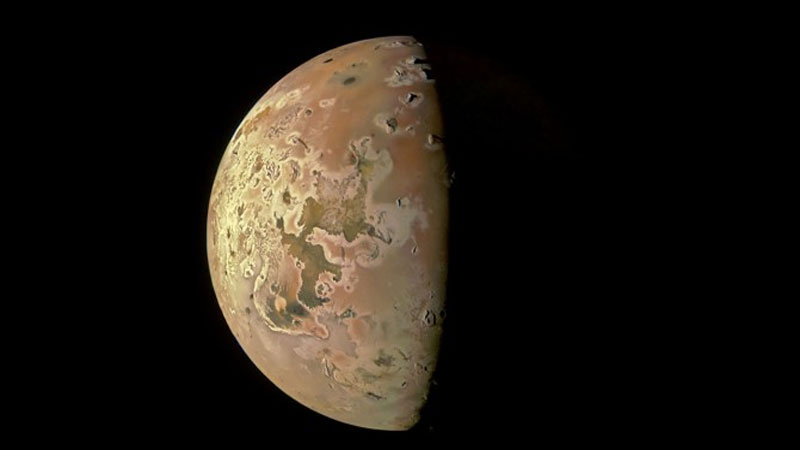
Спутник Юпитера Ио. Источник изображения: NASA Близкое расположение Ио к Юпитеру, а также пролёты сравнительно недалёких других спутников этой планеты-гиганта сминают и растягивают недра Ио приливной гравитацией. В результате напряжения и трения недра Ио чрезвычайно разогреты, а геология этой луны — активно-вулканическая. Одновременно на поверхности спутника активны до полутысячи вулканов и там же даже сегодня образуются новые вулканы. В какой-то мере вулканическая деятельность регулирует внутренне тепло спутника и также служит индикатором этого процесса. В последние годы данные о вулканах Ио исправно поставляет зонд NASA «Юнона» (Juno). Также стало возможным делать высокодетализированные снимки Ио прямо с Земли, что даёт массу данных для анализа. Работа астрономов из Корнелльского университета помогла систематизировать накопленные по вулканам Ио данные и позволила сделать интересные выводы. Так, учёные обнаружили неизвестную до этого деятельность вулканов в полярных областях спутника, тогда как раньше основной вклад в тепловой баланс планеты, как считалось, вносили вулканы экваториальной области. Более того, учёные засекли явно синхронную работу в группах полярных вулканов, которые одновременно разгорались и затухали. «Все они становились яркими, а затем тускнели с одинаковой скоростью, — говорят учёные. — Интересно наблюдать за вулканами и за тем, как они реагируют друг на друга». «Изучение негостеприимного ландшафта вулканов Ио действительно вдохновляет науку на поиски жизни, — пояснили свою главную цель учёные. — Приливный нагрев играет важную роль в нагревании и эволюции орбит небесных тел. Он обеспечивает тепло, необходимое для формирования и поддержания подповерхностных океанов на спутниках планет-гигантов, таких как Юпитер и Сатурн». Эксперты опасаются, что победа Google в суде с Минюстом США уничтожит открытый интернет
21.09.2024 [14:27],
Дмитрий Федоров
Судебное разбирательство Министерства юстиции (DOJ) США против Google вступило в активную фазу. Корпорации предъявлены обвинения в монопольном поведении на рынке онлайн-рекламы. Эксперты предупреждают, что победа Google может нанести сокрушительный удар по концепции открытого интернета, ущемив права пользователей и мелких онлайн-компаний. 
Источник изображения: geralt / Pixabay В Вирджинии начался судебный процесс, в котором Google борется с Министерством юстиции США по поводу обвинений в том, что компания стала монополистом на рынке рекламных технологий, контролируя ключевые компоненты экосистемы цифровой рекламы, включая сети рекламодателей, рекламные серверы издателей и биржи рекламы. Министерство юстиции утверждает, что этот режим позволил компании оказывать неправомерное влияние на рынок, подавляя конкуренцию и нанося вред как издателям, так и рекламодателям. Недавно состоялась пресс-конференция с участием юристов, представителей некоммерческих организаций и экспертов по вопросам конфиденциальности. Они обсудили потенциальные последствия этого прецедентного дела. По их мнению, поражение DOJ может усугубить ситуацию в онлайн-пространстве как для рядовых пользователей, так и для компаний. «Победа Google способна подорвать сами основы открытого интернета», — заявил один из участников конференции. Концепция «открытого интернета» подразумевает свободную, децентрализованную и общедоступную информационную инфраструктуру. В идеале такая система функционирует без центральных органов управления или «привратников», контролирующих доступ к информации через стандартные веб-интерфейсы, такие как веб-браузеры. Однако реальность такова, что Google де-факто стал доминирующим «привратником» для большинства интернет-пользователей по всему миру. Ли Хепнер (Lee Hepner), калифорнийский адвокат по антимонопольным делам и юрисконсульт Американского проекта гражданских свобод (American Civil Liberties Project), утверждает, что если Google одержит победу в суде, деградация открытого интернета ускорится. Открытый интернет — это возможности для малого онлайн-бизнеса. Потеря этой экосистемы приведёт к централизации онлайн-рынка, который окажется в ловушке закрытых экосистем техногигантов. Саша Хаворт (Sacha Haworth), исполнительный директор проекта Tech Oversight, обвиняет Google в нежелании акцентировать внимание на очевидном вреде от своей хищнической бизнес-модели. По её словам, реклама, контролируемая Google, искажает цифровую экономику и существенно способствует росту инфляции. По данным экспертов, Google контролирует более 90 % рынка технологий поисковой рекламы. Аналитики утверждают, что отсутствие деструктивного влияния Google на рекламу привело бы к снижению потребительских цен на онлайн-товары. Элиз Филлипс (Elise Phillips), советник по вопросам политики организации Public Knowledge, подчёркивает, что демократизация ландшафта цифровой рекламы могла бы дать малому и среднему бизнесу шанс конкурировать за внимание онлайн-покупателей. Карина Монтойя (Karina Montoya), специалист по исследованию рынка, прогнозирует, что победа Google может привести к формированию практически непреодолимого разрыва между имущими и неимущими на онлайн-рынке. Процессор iPhone 17 не перейдёт на 2-нм техпроцесс — новые нормы внедрят лишь для iPhone 18 Pro
21.09.2024 [13:23],
Павел Котов
Телефоны серии iPhone 17 в следующем году получат процессоры, изготовленные TSMC с использованием усовершенствованной технологии N3P, а ожидаемые в 2026 году старшие модели iPhone 18 Pro получат чипы, вероятно, основанные на технологии нового поколения 2 нм. Ограничение их присутствия связано с проблемами со стоимостью, сообщает аналитик Мин-Чи Куо (Ming-Chi Kuo). 
Источник изображения: apple.com С прошлого года процессоры Apple для iPhone и Mac изготавливаются по технологии 3 нм — речь идёт о чипах A17 Pro в моделях iPhone 15 Pro и M3 для Mac; до этого процессоры Apple производились по технологии 5 нм. В этом году iPhone 16 получили процессоры A18 на основе технологии 3 нм второго поколения — они быстрее и эффективнее, чем A16 Bionic в базовых моделях iPhone 15. TSMC планирует начать производство 2-нм чипов в конце 2025 года, и Apple, как ожидается, станет первым клиентом, который получит процессоры, изготовленные с применением нового техпроцесса. Тайваньский подрядчик уже строит два новых завода для размещения производства 2-нм процессоров и ожидает разрешения на строительство третьего — компания обычно строит новые предприятия, когда ей нужно увеличить производственные мощности для работы с крупными заказами, и в преддверии запуска новых техпроцессов TSMC значительно расширяется. TSMC вкладывает миллиарды в эту новую технологию полупроводникового производства, а Apple предстоит соответствующим образом адаптировать проекты своих чипов. Будучи крупнейшим клиентом тайваньского подрядчика, американская компания традиционно получает приоритетный доступ к новейшим технологиям. Так, в 2023 году она выкупила все 3-нм мощности TSMC для своих iPhone, iPad и Mac. Это партнёрство помогает Apple внедрять передовые технологии раньше конкурентов. Между запусками поколений 3 и 2 нм TSMC развёртывает несколько промежуточных решений: компания уже наладила выпуск полупроводников по технологиям N3E и N3P, которые являются усовершенствованием базового решения 3 нм. В разработке значатся N3X для сегмента высокопроизводительных вычислений и N3AE для автопрома. С начала августа прямой российский трафик YouTube сократился вдвое
21.09.2024 [13:16],
Владимир Мироненко
По оценке компании CDN Video, с момента появления проблем с доступом в России к YouTube в августе, трафик видеосервиса упал на 50 %, пишет РБК со ссылкой на заявление гендиректора CDN Video Ярослава Городецкого, сделанное в минувшую пятницу на конференции MUSE. 
Источник изображения: Christian Wiediger/unsplash.com Как сообщил Городецкий, потерянный YouTube трафик частично перераспределился в VK Video (39 %), «Яндекс» (17 %), RuTube и «Иви» (по 8 %), Okko (6 %). Еще 22 % пользователей пока не определилось с выбором предпочитаемого видеосервиса. При этом значительная часть трафика перешла «на зарубежные хостинги», то есть VPN. По данным CDN Video, на фоне спада YouTube больше всего трафик вырос у Okko (+50 %), RuTube (+43,8 %), VK Video (+35 %), «Иви» (+30,4 %) и «Яндекса» (+21,4 %). По словам представителя RuTube, аудитория и трафик видеосервиса за последние два месяца «практически удвоились», хотя планировали достичь этого показателя только к концу года. Согласно прогнозу Городецкого, в России не будет платформы, способной подобно YouTube монополизировать рынок, поскольку на это место претендует много желающих. «Думаю, произойдёт некая фрагментация рынка: кто-то умеет хорошо монетизировать пользовательские видео, кто-то является частью больших медиахолдингов и т.д. В итоге будет несколько лидеров [в разных нишах]», — считает эксперт. Хотя проблемы с доступом в YouTube наблюдаются с августа, официальную причину этого пока не назвали. В «Ростелекоме» ещё раньше указывали на снижение качества работы видеосервиса в связи с уходом Google из России офиса и последовавшим за этим прекращением поддержки инфраструктуры своих кеширующих серверов на российских сетях связи. В Google, в свою очередь, утверждают, что нынешние проблемы не связаны с техническими вопросами или действиями компании. Apple iPhone 16 Pro Max продемонстрировал выдающуюся автономность — возможно, это рекорд
21.09.2024 [13:12],
Дмитрий Федоров
Apple iPhone 16 Pro Max показал рекордное время автономной работы в практических испытаниях. Оптимизация iOS 18 значительно улучшила длительность работы от батареи как новых, так и предыдущих моделей iPhone. 
Источник изображения: Apple Согласно тестированию ресурса Geekerwan, iPhone 16 Pro Max достиг впечатляющих 10 часов 23 минут автономной работы при интенсивной нагрузке, что может сделать его лидером среди флагманских смартфонов 2024 года. iPhone 16 Pro показал результат в 8 часов 28 минут. Для сравнения, Android-смартфон Vivo X100s продемонстрировал всего 9 часов 34 минуты работы без подзарядки. Комплексное тестирование включало ряд типичных сценариев использования: веб-сёрфинг, голосовые и видеозвонки, игру в Genshin Impact и обмен сообщениями через WeChat. Такой подход обеспечивает реалистичную оценку энергопотребления устройств в различных режимах эксплуатации, что критически важно для пользователей при выборе смартфона в этом году. Оптимизация iOS 18 существенно повлияла на производительность iPhone 15 Pro и Pro Max. Время работы iPhone 15 Pro Max увеличилось с 7 часов 56 минут до 9 часов 2 минут, а iPhone 15 Pro — с 6 часов 22 минут до 6 часов 55 минут. Этот прирост может стать весомым аргументом для владельцев старых моделей смартфонов, что обновлять устройства вовсе не обязательно, что, вероятно, и объясняет низкие предзаказы на новую линейку. Важно отметить, что проведённые тесты не учитывали влияние Apple Intelligence на длительность автономной работы iPhone без подзарядки. Эта ИИ-функция может существенно повлиять на энергопотребление смартфонов Apple и, возможно, ухудшить результаты тестирования автономности их работы. Так как Apple Intelligence предполагает выполнение сложных вычислительных задач непосредственно на устройстве, это может увеличить нагрузку на процессор, а следовательно, повысить расход электричества. Microsoft позволит переназначать клавишу Windows Copilot на запуск сторонних приложений
21.09.2024 [13:08],
Павел Котов
В предварительной сборке Windows 11 22635.4225 (KB5043186) на канале бета-версий появилась функция, которая позволяет менять назначение клавиши Copilot, присутствующей на ноутбуках класса Copilot+ PC. Вместо помощника с искусственным интеллектом по нажатию клавиши можно запускать другое приложение, но не любое. И это ограничение можно обойти. 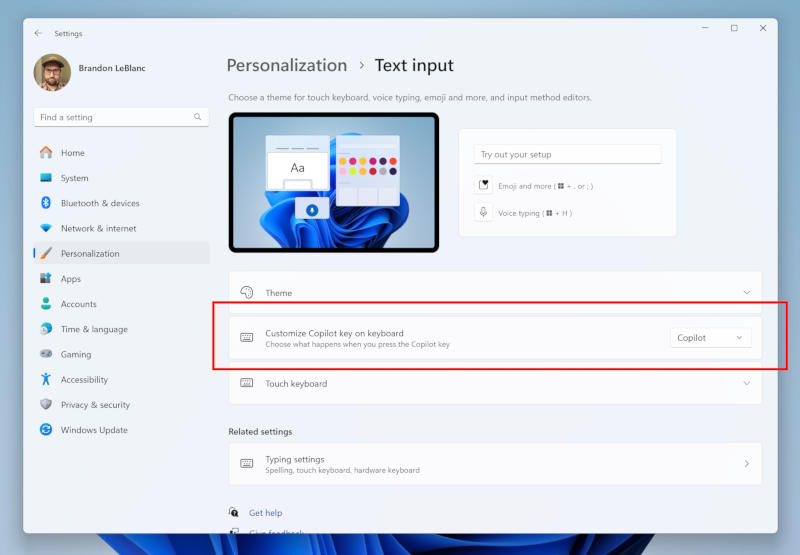
Источник изображения: blogs.windows.com В настройках системы теперь можно выбрать, какое приложение будет запускаться по нажатии кнопки Copilot — единственное требование состоит в том, что оно должно быть «упаковано и подписано MSIX». Microsoft объяснила это ограничение стремлением обеспечить безопасность и конфиденциальность пользователей Windows 11. Иными словами, по нажатию клавиши Copilot можно запускать не любые, а только сертифицированные приложения. MSIX — новый формат упаковки ПО, предполагающий повышенную надёжность, а также приоритет в использовании пропускной способности сети и дискового пространства в сравнении с традиционными исполняемыми файлами, отличными от формата упаковки MSIX. Предложенный в бета-версии Windows 11 способ изменить назначение клавиши Copilot не является единственно возможным. Copilot соответствует кнопке F23, восходящей к эпохе IBM, когда на клавиатурах присутствовал набор функциональных клавиш от F1 до F24. Поэтому можно воспользоваться сторонним ПО и назначить на F23 (она же Copilot) запуск любого другого приложения, не дожидаясь общедоступного обновления Windows 11. Соцсеть X назначила законного представителя в Бразилии
21.09.2024 [10:30],
Павел Котов
Принадлежащая Илону Маску (Elon Musk) соцсеть X назначила официального представителя в Бразилии, передаёт Reuters со ссылкой на заявление юристов компании. Таким образом, платформа исполнила одно из выдвинутых Верховным судом страны требований, чтобы получить возможность работать в Бразилии. 
Источник изображения: BoliviaInteligente / unsplash.com Недавно назначенные юристами X в Бразилии Андре Зонару (Andre Zonaro) и Серджиу Розенталь (Sergio Rosenthal) заявили, что официальным представителем компании в стране стала Рэйчел де Оливейра Консейсау (Rachel de Oliveira Conceicao) — её имя было подано в Верховный суд. Согласно требованиям бразильского законодательства, для работы в стране иностранные компании должны назначать законных представителей в стране. На местном уровне такой человек берёт на себя юридическую ответственность за компанию. До середины августа у X такой человек в Бразилии был, но впоследствии компания решила закрыть свои офисы в стране. Платформа отказалась назначить его преемника, и в конце месяца Верховный суд предписал местным операторам связи заблокировать X. Этому предшествовала многомесячная дискуссия между Маском и бразильским судьёй Алешандре де Мораесом (Alexandre de Moraes) по поводу невыполнения соцсетью судебных решений о блокировке учётных записей, владельцы которых выступают фигурантами дела о разжигании ненависти. Бразильские суды и ранее выносили распоряжения о блокировке таких аккаунтов, но Маск расценивал их действия как проявления цензуры. На этой неделе стало известно, что платформа начала выполнять распоряжения суда. Учёные обнаружили кандидата в самую лёгкую чёрную дыру в истории наблюдений
21.09.2024 [10:28],
Геннадий Детинич
Группа китайских учёных опубликовала в Nature статью, в которой сообщила об обнаружении кандидата в редкие чёрные дыры звёздной массы. Объект массой 3,6 солнечных находится на удалении 5825 лет от Земли. Подобных кандидатов найдено меньше десятка. Открытие может дать ответы на множество вопросов о чёрных дырах предельно малой массы, которые учёные, возможно, просто ещё не научились регистрировать. 
Чёрная дыра звёздной массы в представлении художника. Источник изображения: Daniëlle Futselaar/artsource.nl Китайские учёные для поиска экзотических объектов воспользовались данными европейского астрометрического спутника «Гайя» (Gaia). Спутник собирает данные о скорости и направлении движения звёзд в нашей галактике и немного за её пределами. Это позволит создать наиболее полную объёмную динамическую карту Млечного Пути, которая уже стала источником ценных данных о далёких звёздах и системах. В частности, группа исследователей обнаружила необычно движущегося по небу красного гиганта, получившего идентификатор G3425. Звезда с массой 2,7 солнечных за 880 дней описывала в небе почти правильную окружность вокруг некого центра масс. Учёные заново проанализировали найденный объект собственными приборами и не обнаружили вблизи центра масс никакого регистрируемого источника излучения — обычной звезды или нейтронной звезды. Ответ остаётся только один — там находится чёрная дыра звёздной массы, расчёты которой определяют объект как 3,6 солнечных масс. Согласно общепринятой теории, белые карлики не могут быть тяжелее 1,4 масс Солнца, а нейтронные звёзды не превышают 2,3 солнечных масс. Всё что тяжелее, под действием гравитации должно схлопнуться и стать чёрной дырой. Проблема в том, что обнаружено крайне мало кандидатов на роль чёрных дыр звёздной массы. Ради справедливости надо сказать, что такие объекты сложно обнаружить. Они оказывают очень слабое гравитационное воздействие на партнёров, чтобы его можно было различить нашими приборами. Также такие объекты не отличаются прожорливостью в силу своих маленьких размеров, что затрудняет их обнаружение в рентгеновском диапазоне, когда вещество падает на чёрную дыру и излучает.  Находка объектов, подобных G3425, крайне ценна для понимания эволюции чёрных дыр. При этом она оставляет вопросы. Например, круговая орбита красного гиганта в теории не должна была сохраниться в двойной системе, одна из звёзд которых взорвалась сверхновой и превратилась в чёрную дыру. Вторую звезду либо сорвало бы прочь, либо сделало бы её орбиту сильно вытянутой. Впрочем, идеальные открытия случаются ещё реже. Остаётся наблюдать и искать подобное, чтобы потом методами статистического анализа подобраться к истине. Перспективы перенасыщения китайского рынка и планы Intel заставляют аналитиков снизить прогноз по динамике выручки ASML
21.09.2024 [07:46],
Алексей Разин
Меньше месяца осталось до публикации нидерландской компанией ASML очередного квартального отчёта, но отраслевые аналитики уже формируют собственные рекомендации по ценным бумагам этого поставщика оборудования для выпуска чипов, исходя из не самой благоприятной конъюнктуры китайского рынка и отказа Intel от строительства предприятий в Германии. 
Источник изображения: ASML Формально, Intel недавно лишь заявила о намерениях воздержаться от реализации проекта по строительству двух передовых предприятий в Германии общей стоимостью 30 млрд евро из-за проблем с его финансированием, но за два года паузы может случиться что угодно, а потому не все эксперты уверены, что строительство вообще начнётся. В любом случае, в ближайшие два года дополнительное количество оборудования ASML компании Intel не потребуется, а это значит, что какую-то часть потенциальной выгоды нидерландский поставщик упустит. Таким образом рассуждают представители Morgan Stanley, на комментарии которых ссылается Reuters. В июле и августе акции ASML уже потеряли в цене 30 %, а появление комментариев Morgan Stanley на этой неделе спровоцировало снижение курса ещё на 2,7 %. Представители Morgan Stanley свой прогноз по их курсовой стоимости снизили с 925 до 800 евро за штуку при текущем курсе около 796 евро. Помимо влияния новейших решений Intel об уменьшении расходов на строительство новых предприятий, акции ASML будут подвергаться давлению со стороны рынка оперативной памяти, который в обозримом будущем вряд ли продемонстрирует рост спроса, если не считать сегмент HBM. Кроме того, к 2026 году китайский рынок для ASML перестанет быть основным драйвером роста выручки, как предполагают аналитики. Сейчас он обеспечивает до половины выручки компании, но в сочетании с усилением санкций он начнёт демонстрировать перенасыщение уже в обозримом будущем. Соответственно, прежних темпов роста он уже показать не сможет. Тем более, что и санкции со стороны властей Нидерландов и США могут усилиться. С другой стороны, 2025 год для ASML будет удачным во многих отношениях, ведь передовое оборудование этой марки продолжит пользоваться повышенным спросом на фоне сохраняющегося бума искусственного интеллекта. SEC требует от суда обеспечить явку Илона Маска для дачи показаний по делу о покупке Twitter
21.09.2024 [06:27],
Алексей Разин
В судебном разбирательстве по делу о покупке американским миллиардером Илоном Маском (Elon Musk) социальной сети Twitter в 2022 году ещё рано ставить точку, но Комиссия по ценным бумагам и биржам США (SEC) утверждает, что он регулярно игнорирует требования дать показания, а потому к нему нужно применить юридические санкции. 
Источник изображения: SpaceX С призывом сделать это представители SEC обратились к федеральному судье США, как отмечает CNBC. Весной 2022 года Маск начал скупать акции Twitter, но слишком поздно раскрыл информацию о сосредоточении в его руках более 5 % акций компании, как того требует законодательство США. Регуляторы с момента запуска этого расследования пытаются вызвать Маска для дачи показаний под присягой, но он находит различные предлоги не делать этого. Комиссия теперь пытается обеспечить явку миллиардера через суд. Маск не являлся на допрос как минимум дважды: в сентябре 2023 года и на прошлой неделе, причём в последний раз он сослался на необходимость присутствия на запуске космической миссии Polaris Dawn во Флориде. Представители Маска уведомили Комиссию об отсутствии у него возможности присутствовать на допросе 10 сентября всего за три часа до его начала. При этом ведомство потратило деньги налогоплательщиков для отправки своих сотрудников в Лос-Анджелес, где должен был состояться допрос, и выразило крайнее недовольство поступком фигуранта этого дела. Представители SEC утверждают, что он заранее знал о готовящемся пуске космического аппарата и мог спланировать перенос своей встречи с ними, но вместо этого имитировал срочную отмену мероприятия. Адвокаты Маска возразили, что его отсутствие на запуске космического аппарата могло угрожать жизням астронавтов. Теперь представители миллиардера назначили его явку на допрос на третье октября в офисе SEC. Вторая сторона разбирательства утверждает, что ничто не может помешать Маску пропустить и октябрьскую встречу с представителями SEC, а потому нужны более серьёзные обеспечительные меры со стороны суда. Microsoft перезапустит АЭС Three Mile Island, чтобы запитать свои ИИ ЦОД
21.09.2024 [01:14],
Владимир Мироненко
Компания Constellation Energy, крупнейший оператор АЭС в США, объявила о заключении 20-летнего контракта с Microsoft на поставку электроэнергии (PPA), которая будет производиться на АЭС Three Mile Island в Пенсильвании, печально известной по аварии на втором энергоблоке в 1979 году — самом серьёзном инциденте за всю историю атомной энергетики США. В результате аварии второй энергоблок АЭС был частично разрушен, но первый энергоблок не пострадал и проработал до 2019 года. Из-за убыточности АЭС и отказа властей штата продолжать субсидировать её работу она была окончательно остановлена 20 сентября 2019 года, после чего её передали Constellation Energy, имеющей опыт ликвидации АЭС. В рамках соглашения Constellation Energy планирует вновь ввести первый энергоблок в эксплуатацию к 2028 году, если будет получено одобрение Комиссии по ядерному регулированию США после всеобъемлющей проверки безопасности и защиты окружающей среды, а также разрешения от иных государственных и местных органов. Constellation Energy будет добиваться продления лицензии, что позволит эксплуатировать АЭС как минимум до 2054 года. 
Источник изображений: Constellation Energy Планируемый к восстановлению объект был переименован в Центр чистой энергии Крейна (Crane Clean Energy Center, CCEC) в честь Криса Крейна (Chris Crane), который был гендиректором бывшей материнской компании Constellation и умер в апреле 2024 года. Хотя полные условия сделки не раскрываются, Constellation Energy объявила, что для возобновления работы необходимо около $1,6 млрд на восстановление оборудования, включая турбину, генератор, главный силовой трансформатор, а также системы охлаждения и управления. Мощность восстановленной АЭС составит 837 МВт. Вся производимая ею электроэнергия будет поступать Microsoft. Этого достаточно, чтобы обеспечить работу всех ЦОД компании в Пенсильвании, Чикаго, Вирджинии и Огайо. Согласно исследованию, которое профинансировал Совет по строительным профессиям Пенсильвании, повторное открытие АЭС создаст 3400 рабочих мест на объекте и в обслуживающих его предприятиях, а также принесёт в казну $3 млрд в виде государственных и федеральных налогов.  Сделка позволит Microsoft решить углубляющуюся энергетическую проблему, поскольку разрастающиеся ЦОД, необходимые ей для обслуживания ИИ-нагрузок, перегружают существующие в стране источники энергии. Как отмечают американские СМИ, никогда прежде атомная электростанция в США не возвращалась в строй после вывода из эксплуатации, и никогда прежде вся продукция одной коммерческой АЭС не поставлялась единственному заказчику. Срок действия соглашения с Constellation Energy значительно больше традиционных соглашений Microsoft о закупках солнечной и ветровой энергии. По всей видимости, сделка готовилась длительное время. За последние 12 месяцев Microsoft сформировала команду по работе над атомной энергетикой и наняла целый ряд опытных специалистов. Ранее Microsoft приобрела кредиты на возобновляемую энергию (CEC) у канадской энергетической компании Ontario Power Generation (OPG) и подписала соглашение с Constellation о поставке электроэнергии с АЭС для своего ЦОД в Бойдтоне. Атомная энергетика, гарантирующая в отличие от энергии ветра и солнца стабильную поставку электроэнергии вне зависимости от капризов погоды, становится всё популярнее среди гиперскейлеров. Ранее AWS приобрела за $650 млн кампус Talen Energy рядом с АЭС Susquehanna Steam Electric Station в Пенсильвании, которая обеспечит ЦОД до 960 МВт. Также в этом месяце Oracle объявила, что построит в США 1-ГВт кампус ЦОД с питанием от трёх малых модульных реакторов (SMR). А Oklo даже подписала соглашения с несколькими ЦОД. BioWare пообещала не выносить эпилог Dragon Age: The Veilguard в DLC, как сделала это в Dragon Age: Inquisition
21.09.2024 [01:14],
Михаил Романов
Разработчики из канадской студии BioWare не станут выносить эпилог выходящей чуть более чем через месяц фэнтезийной ролевой игры Dragon Age: The Veilguard в платное пострелизное дополнение. 
Источник изображений: BioWare Напомним, Dragon Age: Inquisition получила после выхода несколько DLC, но именно аддон Trespasser раскрывает мотивы и цели эльфийского мага Соласа (он же Ужасный Волк), который будет играть важную роль в сюжете The Veilguard. Тему потенциальных сюжетных дополнений к Dragon Age: The Veilguard в интервью с руководителем разработки игры Коринн Буше (Corinne Busche) поднял блогер MrMattyPlays (сегмент начинается с 7:00).  «Я большой фанат Trespasser. Единственный минус для меня — [этот аддон] настолько важен для сюжета Dragon Age: Inquisition, что должен был быть частью основной игры», — заявила Буше. В случае с The Veilguard повторять подобный трюк разработчики не намерены: «Мы хотели, чтобы это была как можно более полная — от геймплейного опыта до повествования и всего остального — игра в истории серии».  В настоящее время планов на DLC для Dragon Age: The Veilguard у BioWare нет — команда сосредоточена на подготовке игры к релизу, — но «никогда не говори "никогда"». Dragon Age: The Veilguard выйдет 31 октября на PC (Steam, EGS, EA App), PS5, Xbox Series X и S. Обещают лучших компаньонов в серии, гибкую сложность, никаких микротранзакций и перевод на русский. «Это безумие»: для «идеальных» полётов в Microsoft Flight Simulator 2024 на ПК понадобится больше ОЗУ, чем места на диске
21.09.2024 [00:53],
Юлия Позднякова
Разработчики из французской Asobo Studio опубликовали системные требования Microsoft Flight Simulator 2024. Минимальная конфигурация игроков не удивила, в отличие от «идеальной», в которой объём оперативной памяти превосходит объём свободного места на диске. 
Источник изображений: Xbox Чтобы запустить симулятор, достаточно ПК с процессором уровня AMD Ryzen 5 2600X или Intel Core i7-6800K, видеокарты не хуже AMD Radeon RX 5700 и Nvidia GeForce GTX 970 и 16 Гбайт ОЗУ. Такая конфигурация близка к минимальной для прошлой части серии, однако её не хватит даже для низких настроек графики в разрешении 1080p при 30 кадрах в секунду в Star Wars Outlaws. Для более высоких графических настроек и лучшей производительности советуют процессор AMD Ryzen 7 2700X или Intel Core i7-10700K и видеокарту AMD Radeon RX 5700 XT или Nvidia GeForce RTX 2080 и 32 Гбайт ОЗУ. Это более высокие требования, чем рекомендуемые для средних настроек графики в 1080p и 60 кадров в секунду в God of War Ragnarok и высоких настроек в 1080p в Black Myth: Wukong.  «Идеальная» конфигурация (разрешение и кадровая частота не указаны) включает AMD Ryzen 9 7900X или Intel Core i7-14700K, AMD Radeon RX 7900 XT или Nvidia GeForce RTX 4080 и 64 Гбайт оперативной памяти. Столь высокие требования к объёму ОЗУ особенно удивили геймеров из-за сравнительно скромного объёма свободного места на накопителе, которое понадобится для установки игры (50 Гбайт). «64 Гбайт — это безумие», — отреагировал пользователь X Aut0p1l01. Самым распространённым вариантом объёма оперативной памяти в системных требованиях игр остаётся 16 Гбайт. Столько нужно для настроек «Ультра» в Helldivers 2, Senua's Saga: Hellblade II, Star Wars Outlaws, God of War Ragnarok и грядущем ремейке Until Dawn. Однако исключения встречаются: например, для высоких настроек графики и рейтрейсинга в разрешении 4К в Black Myth: Wukong нужно 32 Гбайт ОЗУ. В статье с вопросами и ответами на официальном сайте разработчики рассказали, что значительно улучшили обработку данных. При загрузке игры скачиваются только необходимые в данный момент текстуры, меши и данные карты. Благодаря этому удалось сократить время загрузок и оставить минимальные системные требования почти такими же, как у Microsoft Flight Simulator образца 2020 года. Минимальные системные требования
Рекомендуемые системные требования
Идеальные системные требования
Microsoft Flight Simulator 2024 была анонсирована на презентации Xbox Games Showcase в июне 2023 года. Сиквел предложит новый режим карьеры с транспортными, пожарными, спасательными и другими миссиями и дополнительные виды транспорта (планеры, дирижабли, монгольфьеры). Улучшат симуляцию аэродинамики и физики, электрические, пневматические, топливные и гидравлические системы самолётов и авионику, добавят совершенно новую систему ошибок и износа транспорта, а также вертикальные препятствия, нефтяные вышки и вертодромы по всему миру. Графические усовершенствования затронут растительность, материалы поверхности, горы и модели персонажей. Кроме того, появятся мигрирующие стада животных, смена времён года и новые природные явления (северные сияния, штормы, торнадо). Релиз Microsoft Flight Simulator 2024 состоится 19 ноября 2024 года на ПК (Steam, Microsoft Store), Xbox Series X и S, а также в Game Pass (ПК и Xbox). Зима нагрянула раньше времени: после шести лет ожиданий на ПК вышла Frostpunk 2
21.09.2024 [00:05],
Михаил Романов
Как и было обещано, 20 сентября спустя три дня расширенного доступа на ПК состоялся релиз градостроительной стратегии с элементами выживания Frostpunk 2 от разработчиков из польской 11 bit studios. 
Источник изображений: 11 bit studios Во Frostpunk 2 спустя 30 лет бесконечных морозов Британская Империя ещё цепляется за выживание, однако сиквел всё больше смещает акцент на восстановление общества и связанные с этим ответы на сложные политические вопросы. Город стал больше, потребности выросли, а болезни, голод, холод никуда не делись: от игрока требуется лавировать между фракциями, принимать новые законы в Совете, исследовать морозные земли и строить колонии. К релизу Frostpunk 2 уже получила первые оценки западных журналистов. Рейтинг игры на Metacritic составляет 86 из 100 %, что чуть выше среднего балла ПК-версии первой части — в 2018 году она получила от критиков 84 %. Рецензенты хвалят всестороннее развитие идей оригинальной Frostpunk, атмосферу, графику и реиграбельность, а ругают неудобные меню и поведение камеры, линейность кампании и некоторую деградацию градостроительных элементов. 
Игра вышла с текстовым переводом на русский и поддержкой модов Пользователи Steam оценили Frostpunk 2 на 85 % («очень положительные» обзоры) и обеспечили проекту 27,1 тыс. одновременных игроков, что лишь немногим хуже лучшего результата первой части — 29,3 тыс. Frostpunk 2 вышла на PC (1900 рублей в российском Steam, GOG, EGS, Microsoft Store) и в PC Game Pass. До PS5, Xbox Series X, S и Xbox Game Pass игра доберётся позже — когда именно, не уточняется. Новая статья: Astro Bot — трёхмерный платформер мечты. Рецензия
21.09.2024 [00:03],
3DNews Team
Данные берутся из публикации Astro Bot — трёхмерный платформер мечты. Рецензия MSI готовит оверклокерскую плату MEG Z890 Unify-X для процессоров Intel Arrow Lake-S
21.09.2024 [00:02],
Николай Хижняк
Компания MSI готовит к выпуску материнскую плату MEG Z890 Unify-X для энтузиастов. Новинка оснащена процессорным разъёмом Intel LGA 1851 и предназначена для использования с процессорами Arrow Lake-S. Первыми изображениями платы, а также её характеристиками поделился один из пользователей соцсети X. 
Источник изображений: X @ChamberTech_ MSI не выпускала модели Unify-X в рамках серий плат на чипсетах AMD 600-й серии или Intel 700-й серии. До этого компания выпускала платы Unify-X на чипсетах AMD X570, а также на Intel Z590 и Z690. Судя по первым изображениям, MSI отказалась от полностью черного оформления платы, характеризировавшего модели Unify-X прошлых поколений, перейдя к чёрно-серебристой теме оформления у новой MEG Z890 Unify-X. В то же время новинка сохранила особенность, свойственную этим моделям плат: она оснащена только двумя слотами для оперативной памяти, что способствует более эффективному и стабильному разгону. К сожалению, сейчас нет подробностей о поддерживаемой ОЗУ. Согласно слухам, платы Intel Z890 получат поддержку технологии памяти DDR5 CUDIMM и смогут без проблем работать с модулями ОЗУ со скоростью до 10 000 МТ/с.  Известно, что MEG Z890 Unify-X предложит два слота PCIe 5.0 x16, один PCIe 4.0 x16 и один PCIe 4.0 x1. Новинка также оснащена шестью разъёмами M.2 для NVMe-накопителей, два из которых поддерживают установку SSD стандарта PCIe 5.0. Остальные будут работать с PCIe 4.0. Также плата предложит поддержку Wi-Fi 7 и наличие 5-Гбит сетевого адаптера. MEG Z890 Unify-X построена на восьмислойном текстолите и оснащена 23-фазной подсистемой питания VRM со схемой фаз 20+1+1+1. Каждая фаза рассчитана на силу тока 110 А. Дополнительно плата получила 8-контактный разъём для высокопроизводительных видеокарт. Указанный коннектор находится в нижней части платы. Предполагается, что MSI официально представит MEG Z890 Unify-X в следующем месяце, ближе к официальному анонсу новых настольных процессоров Core Ultra 200K, который ожидается 10 октября. Qualcomm предложила купить Intel целиком, но состоится ли «сделка века», пока неизвестно
20.09.2024 [23:42],
Николай Хижняк
Компания Qualcomm на днях обратилась к Intel с предложением её купить, пишет издание The Wall Street Journal, ссылаясь на источники, близкие к этому вопросу. В начале этого месяца сообщалось, что Qualcomm рассматривает возможность покупки части бизнеса Intel, а именно производства процессоров Core. Источники WSJ не уточнили, идёт ли речь о покупке всей компании Intel или только части её бизнеса. Продажа Intel, чья рыночная стоимость по состоянию на утро пятницы оценивалась примерно в $87 млрд, станет значительным событием для полупроводниковой индустрии. Как пишет WSJ, в настоящий момент Intel переживает один из самых значительных кризисов за свою пятидесятилетнюю историю. Источники издания отмечают, что вопрос о сделке далёк от определённости. Даже если Intel потенциально будет готова рассмотреть такое предложение, соглашение такого рода определённо привлечёт внимание регулирующих органов. С другой стороны, подобная сделка могла бы рассматриваться как возможность усилить конкурентное преимущество США в производстве микросхем на мировом рынке. А для одобрения подобной сделки со стороны регуляторов Qualcomm могла бы обязаться продать некоторые активы или части Intel другим заинтересованным сторонам. Intel, некогда самая дорогая компания по производству микросхем, стала свидетелем падения своих акций почти на 60 % с начала текущего года. На пике успеха рыночная капитализация компании составляла более $290 млрд. На фоне публикации The Wall Street Journal в пятницу акции Intel выросли на 7 %, а акции Qualcomm, которая на текущий момент оценивается примерно в $185 млрд, упали примерно на 4 %. Американская компания Qualcomm является одним из ведущих поставщиков чипов для смартфонов, а также компонентов, необходимых для работы сотовых базовых станций. Кроме того, это один из важнейших поставщиков компонентов для iPhone от Apple, а также для ряда других устройств от других производителей. Создатели Dead Cells показали 15 минут геймплея новой игры — молниеносного роглайт-экшена Windblown
20.09.2024 [22:15],
Михаил Романов
Разработчики из французской студии Motion Twin, наиболее известной по Dead Cells, устроили геймплейную демонстрацию альфа-версии своего стремительного кооперативного роглайт-экшена Windblown. 
Источник изображений: Motion Twin Игрокам в Windblown достанется роль воинов-прыгунов — защитников парящей вокруг смертоносного Вихря деревни Ковчег. В одиночку или в компании до трёх человек бойцам предстоит бросить вызов стражам и эмиссарам Вихря. Опубликованное 17-минутное видео, по словам авторов, включает 15 минут одиночного игрового процесса Windblown с начавшегося в феврале закрытого альфа-тестирования (записаться в добровольцы можно здесь). Создатели Windblown показали самое начало игры: пробуждение героя, обучение основным механикам, неминуемую первую смерть, знакомство со структурой игры и полноценную экспедицию. Игрок стремительно перемещается по воздушным островам, осваивает новые приёмы, поглощая воспоминания павших воинов, и расправляется со всё более сильными врагами (в том числе боссом), пока не становится чересчур самоуверенным.  Обещают молниеносное приключение в небесах, тяжёлые, но честные бои, простое в освоении и чёткое перемещение, вариативность стилей игры, полные тайн вылазки, коллекционных рыб (дают особые эффекты) и онлайн-кооператив на троих. Ранний доступ Windblown всё ещё запланирован к запуску до конца 2024 года на ПК (Steam). На старте будет пять биомов, 11 типов основного оружия, совместный режим и поддержка семи языков (русского среди них нет). От IoT до ЦОД: SiFive представила экономичные ИИ-ядра Intelligence XM
20.09.2024 [21:27],
Алексей Степин
Разработчик SiFive, известный своими процессорными ядрами с архитектурой RISC-V, решил подключиться к буму систем ИИ, анонсировав кластеры Intelligence XM — первые в индустрии RISC-V решения, оснащённые масштабируемым движком матричных вычислений для обработки ИИ-нагрузок. Как отмечает SiFive, новый дизайн должен помочь разработчикам чипов на базе RISC-V в создании кастомных ИИ-систем, в том числе для автономного транспорта, робототехники, БПЛА, IoT, периферийных вычислений и т.п., где роль таких нагрузок в последнее время серьёзно выросла, а требование к энергоэффективности никуда не делись. Но при желании можно создать и серверные ускорители, говорит компания. Каждый матричный блок в составе одного XM-кластера дополнен четырьмя ядрами X Core, каждое из которых имеет в своём составе два блока векторных вычислений и один блок скалярных вычислений. Все вместе они делят общий L2-кеш. XM-кластер располагает шиной с пропускной способностью 1 Тбайт/с и поддерживает подключение к памяти двух типов — когерентное через общую шину CHI, к которой подключается и внешняя память DDR/HBM, или высокоскоростной порт для SRAM. Производительность одного XM-кластера 8 Тфлопс в режиме BF16 и 16 Топс в режиме INT8 на каждый ГГц частоты. 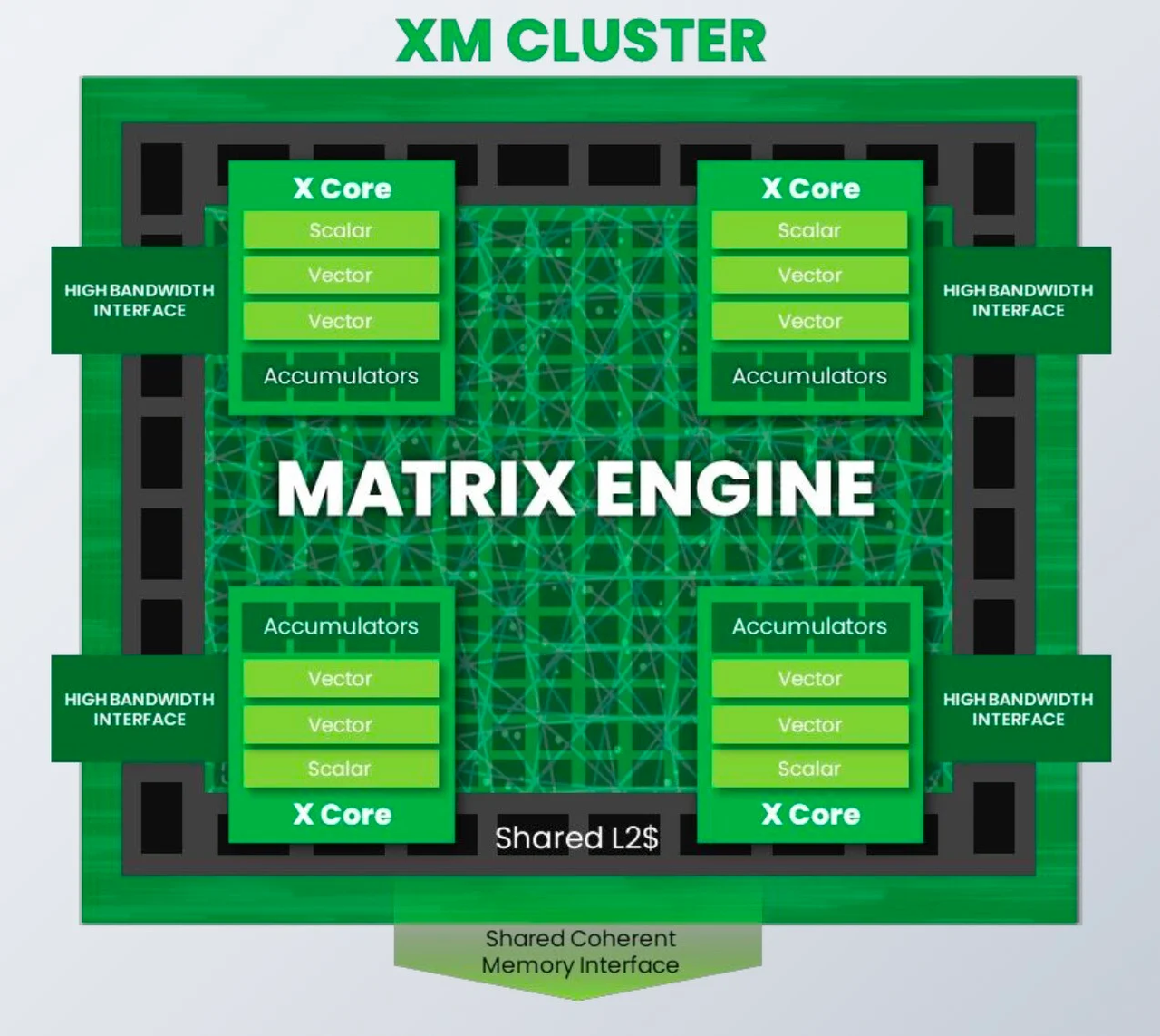
Источник здесь и далее: SiFive Тип хост-ядра не важен, это может быть RISC-V, Arm или даже x86. Впрочем, хост-ядра могут отсутствовать вовсе. Ожидается, что чипы на базе XM в среднем будут иметь от четырёх до восьми кластеров, что даст им до 8 Тбайт/с пропускной способности памяти и до 64 Тфлопс производительности в режиме BF16, и это лишь на частоте 1 ГГц при малом уровне энергопотребления. Но возможно и масштабирование до 512 XM-блоков, что даст уже 4 Пфлопс BF16. У NVIDIA Blackwell, например, в том же режиме производительность составляет 5 Пфлопс. 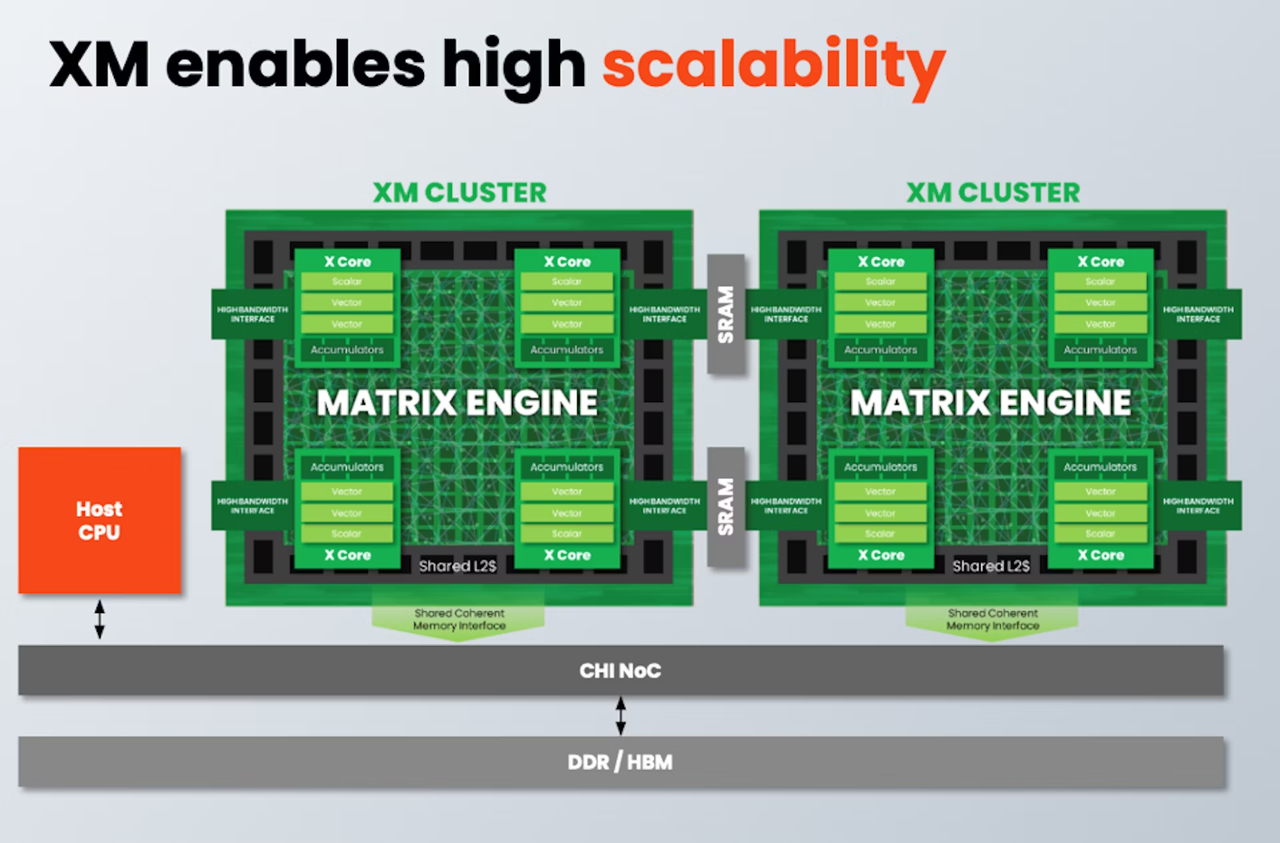 В целях дальнейшей популяризации архитектуры RISC-V компания также планирует сделать открытой (open source) референсную имплементацию SiFive Kernel Library (SKL). SKL включает оптимизированную для RISC-V ядер SiFive реализацю различных востребованных алгоритмов, в том числе для работы с нейронными сетями, обработки сигналов, линейной алгебры и т.д. 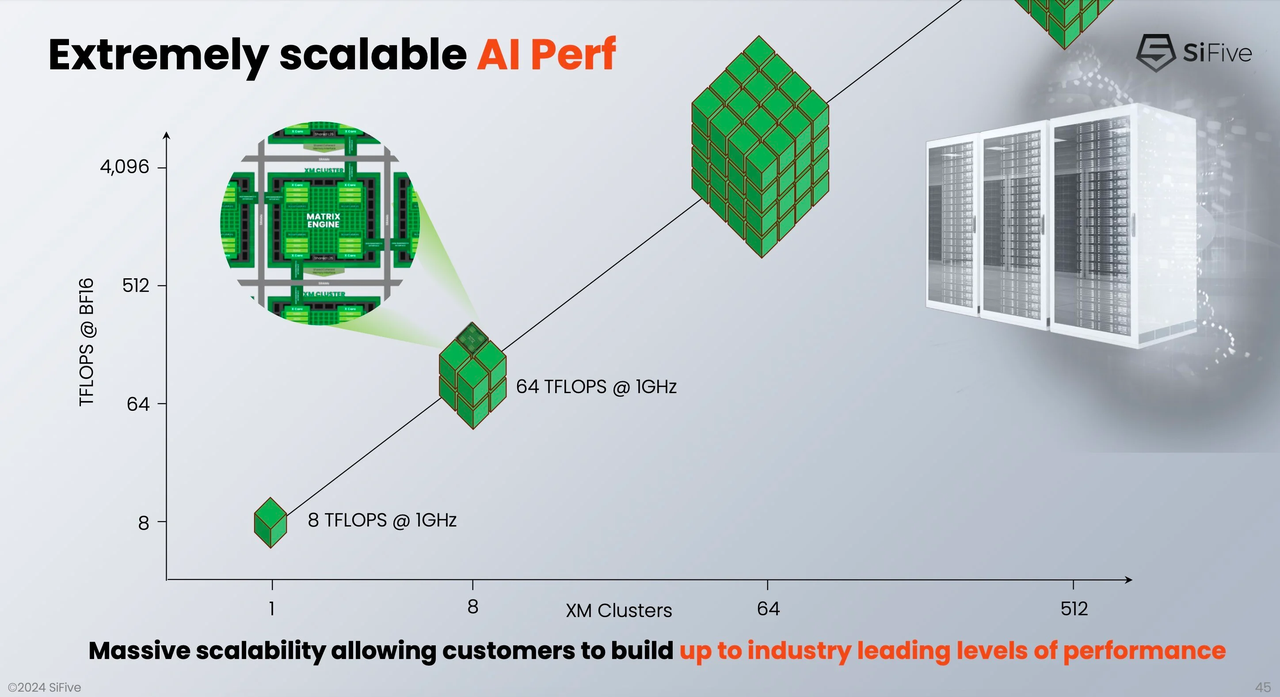 Дела у SiFive идут, судя по всему, неплохо, и, как отметил глава компании Патрик Литтл (Patrick Little), новые дизайны ядер помогут ей сохранить темпы роста и не отстать от эволюции ИИ, оставаясь в то же время поставщиком уникальных процессорных решений с открытой архитектурой. На данный момент решения SiFive уже поставляет свои решения таким гигантам, как Alphabet, Amazon, Apple, Meta✴✴, Microsoft, NVIDIA и Tesla. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex

















