|
Опрос
|
реклама
Быстрый переход
Дисплей iPhone 16 Pro Max не боится огня, а корпус выдержал тест на изгиб
22.09.2024 [17:23],
Владимир Мироненко
Автор YouTube-канала JerryRigEverything Зак Нельсон (Zach Nelson), известный своими роликами с проверками на прочность гаджетов, протестировал на устойчивость к внешнему воздействию смартфон iPhone 16 Pro Max с корпусом цвета Desert Titanium. 
Источник изображения: YouTube/JerryRigEverything Блогер отметил появление у смартфонов Apple новой сенсорной кнопки Camera Control для управления функциями камеры. Кнопка защищена от повреждений прочным сапфировым стеклом, которое он проверил на прочность. JerryRigEverything попытался нанести царапины на ней с помощью специального инструмента, с каждым шагом добавляя более твёрдый. При использовании инструмента с твёрдостью 7 по шкале Мооса на поверхности кнопки появились царапины, что подтверждает покрытие из сапфира. Вместе с тем блогер отметил, что это не чистый сапфир, о чем свидетельствует его неоднородная структура, проявляющаяся при попытке нанести царапины. JerryRigEverything также попытался определить чистоту используемого сапфира с помощью специального устройства, но это оказалось для него проблемой. Экран iPhone 16 Pro Max, а также покрытие объективов камер показали себя довольно устойчивыми к царапинам, чего не скажешь о корпусе смартфона из титанового сплава, на который нанести царапины также легко, как на изготовленный из анодированного алюминия. При этом экран показал высокую устойчивость к воздействию огнём зажигалки. Также смартфон оказался устойчивым к изгибу вне зависимости от точки приложения давления — со стороны фронтальной панели или задней. JerryRigEverything пообещал выполнить в дальнейшем разборку смартфона, чтобы выяснить причины такой повышенной устойчивости. «Образцовый ремастер»: игроки с восторгом приняли квест Broken Sword: Shadow of the Templars — Reforged
22.09.2024 [16:15],
Игнатий Колыско
Разработчики из британской студии Revolution Software выпустили обновлённую версию классического квеста Broken Sword: The Shadow of the Templars образца 1996 года. По такому случаю был представлен отдельный трейлер. 
Источник изображения: Revolution Software Доработанный вариант проекта, получивший название Broken Sword: Shadow of the Templars — Reforged, порадует поклонников жанра улучшенной графикой с поддержкой разрешения 4K. Авторы перерисовали все задники, улучшили анимацию спрайтов и снабдили игру более качественным звуком. Пользователи Steam встретили обновлённую версию квеста с теплотой, оставив на момент публикации материала 98 отзывов (рейтинг 97 %). Геймеры хвалят разработчиков за переработанную картинку и качественно сделанные анимации. А вот некоторые проблемы со звуком стали чуть ли не единственным поводом для недовольства. Вот избранные цитаты обладателей издания Reforged: «Образцовый ремастер квеста. По двадцать раз на каждом экране давил на TAB, чтобы увидеть, что перерисовали или дорисовали. […] Но в целом визуал — моё почтение. В сравнении с ним оригинал теперь выглядит очень старым», — написал некто Katarn. «Хвала создателям, точно буду проходить и смаковать эту забытую атмосферу, которая с первых кадров передана просто блестяще. Надеюсь на такой же ремейк Broken Sword 2: the Smoking Mirror», — восторженно отозвался QuinterGame. «Проблемы со звуком повсюду и это действительно раздражает. Диалоги звучат приглушённо, а уровни громкости везде разные. Когда вы разговариваете с полицейским возле кафе, вы едва можете что-либо услышать. Затем внезапно, когда Джордж разговаривает сам с собой, звук снова становится громким. Мне пришлось положиться на субтитры, чтобы просто следить за происходящим», — высказался ChallAcc. Broken Sword: Shadow of the Templars — Reforged доступна на ПК (Steam), PlayStation 5, Xbox Series X и S. Версия для Nintendo Switch выйдет в следующем месяце. Автопроизводители по всему миру стали снижать инвестиции в электромобили
22.09.2024 [14:29],
Анжелла Марина
Tesla, Ford, Mercedes-Benz и другие автогиганты корректируют свои планы в отношении производства электромобилей. На рынке наблюдается заметный сдвиг в сторону сокращения инвестиций в «зелёные» технологии, что, по заявлению экспертов отрасли, вызвано снижением спроса на этот вид транспорта. 
Источник изображения: Ernest Ojeh/Unsplash Как сообщает InsideEVs, согласно новому отчёту исследовательской компании BloombergNEF (BNEF), текущая ситуация может сказаться на количестве производимых электромобилей к концу текущего десятилетия. Ожидается, что 14 автопроизводителей, установивших цели по переходу на электромобили на 2030 год, выпустят 23,7 миллиона электромобилей, что значительно ниже первоначального прогноза в 27 миллионов. «Хотя каждый автопроизводитель устанавливает цели индивидуально, они могут коллективно трансформировать глобальный автопром, если эти цели будут успешно реализованы», — заявили аналитики BNEF. По мнению отраслевых экспертов, автопроизводители не могли предсказать, как будет развиваться рынок электрокаров. Несмотря на то что продажи автомобилей с традиционными двигателями начали снижаться с 2018 года, чёткой точки перелома, на которую надеялись компании, так и не произошло. Тем более, что инвестиции в различные типы приводов требуют значительных затрат времени и ресурсов, что создаёт существенные риски для компаний, не имеющих ясного представления о будущем. В 2024 году шесть крупных автопроизводителей пересмотрели свои прогнозы по продажам электромобилей на текущее десятилетие. В частности, Mercedes-Benz сократил свою цель по доле электромобилей в глобальных продажах с 100 % до 50 % к 2030 году. Ford также снизил свою цель по продаже электромобилей в Европе, что, вероятно, повлияет и на глобальные цели компании. Volvo отказалась от целевой установки продавать исключительно электромобили, заявив недавно, что по меньшей мере в 90 % всех её продаж войдут также гибриды. 
Источник изображения: Fer Troulik/Unsplash Volkswagen и Stellantis также не достигнут своих целей на 2030 год и, вероятно, пересмотрят свои планы в ближайшее время, считает BNEF. При этом не только долгосрочные, но и краткосрочные планы оказались под угрозой. General Motors недавно отказался от намерений произвести один миллион электромобилей в Северной Америке к 2025 году, а Toyota сократила свои прогнозы по продажам на 2026 год с 1,5 миллиона до 1 миллиона. BNEF проанализировал, как менялись заявления автопроизводителей о продажах электромобилей к 2025 году, и обнаружил, что совокупные цели достигли пика в 17,6 миллиона единиц (от 16 автопроизводителей), но на сегодняшний день составляют 11,9 миллиона (от 12 автопроизводителей). Все эти планы появились в начале десятилетия, когда в отрасли наблюдалась более оптимистичная атмосфера, что также влияло на рыночную капитализацию. Сейчас же компании стремятся продемонстрировать более взвешенный подход и, не в последнюю очередь, это связано с тем, что китайские автопроизводители начали отказываться от западных марок в пользу своих собственных моделей, повлияв тем самым на глобальные ожидания. Тем не менее, не все так плохо. Продажи электрокаров по всему миру, включая США, продолжают расти, а отраслевые эксперты ожидают долгосрочного расширения этого сегмента. По оценкам BNEF, продажи электромобилей и гибридов в США вырастут на 20 % в этом году. Оптимистичные новости приходят и от южнокорейских брендов Kia и Hyundai, которые демонстрируют устойчивый рост и не планируют значительных сокращений в производстве. Отмечается, что несмотря на текущие трудности, рынок электромобилей всё ещё имеет потенциал для роста. Ведущие игроки, такие как BYD и Tesla, продолжают активно развивать свои технологии, оставляя менее агрессивные компании позади. Reverion привлекла $62 млн на выпуск контейнерных электростанций с «отрицательным» выбросом
22.09.2024 [14:16],
Руслан Авдеев
Немецкий стартап Reverion привлёк $62 млн в раунде финансирования серии A, передаёт Datacenter Dynamics. Reverion разрабатывает контейнерные микроэлектростанции с «отрицательным» углеродным выбросом и потратит полученные средства на запуск серийного производства своих продуктов. По словам компании, у неё уже есть предварительные заказы на более чем $100 млн. В ходе раунда A компания получила больше предложений, чем планировала. В том числе получены средства т.н. неразбавляющего финансирования, не влекущего уменьшения доли существующих инвесторов. Раунд возглавила Energy Impact Partners (EIP) при участии Honda и European Innovation Council Fund (EIC Fund). Также к ним присоединились и действующие инвесторы — Extantia Capital, UVC Partners, Green Generation Fund, Doral Energy-Tech Ventures и Possible Ventures. Reverion — детище Мюнхенского технического университета, превратившееся в самостоятельную бизнес-единицу в 2022 году. Заявляется, что его электростанции на твердооксидных топливных ячейках, работающих на биогазе, обеспечивают эффективность генерации энергии до 80 %. Это заметно лучше, чем у традиционных модулей. При этом при наличии избытка энергии в сети, например, от солнечных и ветряных источников, электростанция Reverion переключается на электролиз и сама производит «зелёный» водород или метан, которые сохраняются на будущее. 
Источник изображения: Reverion Биогаз подаётся в систему, после чего из него устраняется сероводород и другие примеси. Газ предварительно нагревается и подаётся в топливную ячейку, где он окисляется для получения электроэнергии. Станция в стандартном 20-футовом контейнере обеспечивает до 100 кВт, а в 40-футовом — до 500 кВт. Параллельно она способна захватывать CO2, выделившийся в ходе генерации энергии. В Reverion заявляют, что фермеры с электростанциями на биогазе страдают от ужесточившихся требований регуляторов и ограничений, связанных с традиционными технологиями. Именно для этого сегмента рынка компания и предлагает свои решения. Некоторые эксперты предполагают, что компания способна стать лидером в своём сегменте не только в Европе, но и в мировых масштабах. Впрочем, у неё уже имеется немало конкурентов. Только в США Министерство энергетики выделило $750 млн на расширение производства водородных ячеек и электролизеров. Внедряют или намерены внедрять топливные элементы на газе многие операторы ЦОД, а некоторые компании вроде Plug Power уже занимаются их разработкой и изготовлением. Энтузиаст запустил ChatGPT на калькуляторе TI-84 — это мощнейший инструмент для списывания
22.09.2024 [14:09],
Дмитрий Федоров
Энтузиаст модифицировал популярный среди учащихся графический калькулятор Texas Instruments TI-84, встроив в него Wi-Fi-модуль для доступа к интернету и ChatGPT. Это является весьма впечатляющим с технической точки зрения, но в то же время подобное решение может использоваться для списывания на экзаменах. 
Источник изображения: ChromaLock / YouTube В субботу на YouTube-канале ChromaLock было опубликовано видео под названием I Made The Ultimate Cheating Device («Я создал идеальное устройство для списывания»). Автор подробно описал процесс модификации калькулятора Texas Instruments TI-84, способного строить графики математических функций. Модификация позволяет подключить калькулятор к интернету через Wi-Fi и получить доступ к ИИ-чат-боту ChatGPT. Пользователи могут вводить запросы с клавиатуры калькулятора и получать ответы на экране устройства в режиме реального времени. Сначала энтузиаст изучил порт связи калькулятора, который обычно используется для передачи образовательных программ между устройствами. Затем он спроектировал собственную печатную плату, названную TI-32. Ключевым компонентом платы стал миниатюрный Wi-Fi-контроллер Seed Studio ESP32-C3 стоимостью около $5. Также он установил дополнительные электронные компоненты для взаимодействия с системами калькулятора. Для воспроизведения работы ChromaLock потребуется приобрести калькулятор TI-84, микроконтроллер Seed Studio ESP32-C3 и ряд электронных компонентов. Кроме того, придётся изготовить печатную плату по схеме ChromaLock, которая доступна в интернете. Сложность процесса делает его малодоступным для обычных пользователей, но открывает возможности для энтузиастов. В ходе разработки ChromaLock столкнулся с рядом инженерных проблем, включая несовместимость напряжений и нарушения целостности сигнала. После создания нескольких прототипов ему удалось успешно интегрировать модифицированную плату в корпус калькулятора без видимых внешних изменений, что делает модификацию незаметной при визуальном осмотре. Помимо этого, энтузиаст разработал специальное программное обеспечение (ПО) как для микроконтроллера, так и для калькулятора. Исходный код проекта размещён в публичном репозитории на GitHub. Система эмулирует второй калькулятор TI-84, что позволяет использовать встроенные команды «send» и «get» для передачи файлов. Это даёт возможность легко загрузить программу запуска, обеспечивающую доступ к различным приложениям для списывания. Одним из таких приложений является ChatGPT, однако его эффективность ограничена из-за медленного ввода длинных буквенно-цифровых вопросов на клавиатуре калькулятора, что может существенно снизить практическую применимость ИИ в условиях ограниченного времени на экзамене. Помимо ChatGPT, устройство предлагает встроенный браузер изображений, открывающий доступ к заранее подготовленным наглядным пособиям, хранящимся на сервере. Также можно загружать текстовые шпаргалки, замаскированные под исходный код программ. Ещё ChromaLock упомянул о разработке функции камеры, детали которой пока не раскрываются. Энтузиаст утверждает, что его устройство способно обходить стандартные меры против списывания. Программа запуска может загружаться по требованию, что позволяет избежать её обнаружения при проверке или очистке памяти калькулятора преподавателем перед тестом. Более того, модификация якобы способна деактивировать «режим тестирования», предназначенный для предотвращения списывания. Несмотря на технические достоинства проекта, использование ChatGPT на калькуляторе во время экзамена представляет собой серьёзное нарушение академической этики. Такие действия могут привести к дисциплинарным взысканиям в большинстве учебных заведений США. Rocket Lab успешно запустила ракету Electron с пятью спутниками связи Kineis
22.09.2024 [12:36],
Дмитрий Федоров
Rocket Lab успешно запустила ракету-носитель Electron с пятью спутниками связи в субботу в 02:01 по московскому времени с площадки в Новой Зеландии. Этот запуск знаменует возвращение Rocket Lab к активной деятельности. Компания, являющаяся второй по числу пусков среди частных американских компаний после SpaceX, продолжает укреплять свои позиции на рынке, разрабатывая более крупную ракету для прямой конкуренции с фирмой Илона Маска (Elon Musk). 
Источник изображений: Rocket Lab На борту Electron находились пять спутников связи, изготовленных французским стартапом Kineis при поддержке Национального центра космических исследований (CNES) Франции. Запуску предшествовала отменённая попытка запуска в четверг, когда бортовой компьютер прервал старт после завершения обратного отсчёта из-за неполадок в наземных системах.  Компания, расположенная в Лонг-Бич (штат Калифорния), в этом году уже осуществила 11 успешных орбитальных миссий. Однако она по-прежнему значительно отстаёт от SpaceX, которая провела около 90 запусков за аналогичный период. Годом ранее Rocket Lab пережила серьёзную неудачу: ракета Electron и её полезная нагрузка были потеряны вскоре после старта, что привело к трёхмесячному прекращению полётов для тщательного расследования причин аварии. Несмотря на это, в 2023 году Rocket Lab сумела осуществить 10 запусков. Этот показатель вывел компанию на второе место по частоте запусков среди американских поставщиков услуг космических запусков.  Основанная в Новой Зеландии Питером Беком (Peter Beck), Rocket Lab активно развивает свои технологии, стремясь сократить отставание от бессменного лидера отрасли — SpaceX. Разработка более мощной ракеты-носителя — ключевой элемент стратегии компании по расширению своего присутствия на рынке коммерческих космических полётов. Акции Rocket Lab, торгующиеся на бирже Nasdaq, продемонстрировали впечатляющий рост на 35 % с начала года. Этот факт свидетельствует о позитивном восприятии стратегии компании финансовым сообществом и её способности конкурировать на высокотехнологичном рынке космических запусков.  В сентябре, в рамках стратегии по усилению своих позиций, Rocket Lab назначила нового операционного директора — Фрэнка Кляйна (Frank Klein), ранее работавшего в Rivian Automotive. Этот шаг отражает намерение Rocket Lab применить опыт автомобильного производства в космической индустрии, что может привести к оптимизации производственных процессов компании. Джони Айв и OpenAI создадут революционное ИИ-устройство
22.09.2024 [07:35],
Дмитрий Федоров
Джони Айв (Jony Ive), легендарный бывший главный дизайнер Apple, официально подтвердил своё участие в разработке нового ИИ-устройства совместно с OpenAI. Проект, находящийся на начальной стадии, может привлечь до $1 млрд инвестиций к концу года и обещает революцию во взаимодействии человека с ИИ. 
Источник изображения: Apple Сотрудничество Айва с Сэмом Альтманом (Sam Altman), генеральным директором OpenAI, впервые обсуждалось в СМИ почти год назад. Теперь эта информация получила официальное подтверждение в материале The New York Times о том, чем занимается бывший дизайнер после ухода из Apple. Проект объединяет экспертные знания в области ИИ и аппаратного обеспечения, что может привести к созданию принципиально нового класса вычислительных устройств. Концепция устройства основана на возможностях генеративного ИИ, который сможет делать для пользователей больше благодаря способности обрабатывать сложные запросы эффективнее, чем традиционное программное обеспечение (ПО). Детали проекта остаются тайной, однако известно, что Айва и Альтмана представил друг другу Брайан Чески (Brian Chesky), генеральный директор Airbnb. Финансирование проекта осуществляется Айвом и Emerson Collective — компанией Лорен Пауэлл Джобс (Laurene Powell Jobs). Ресурс The New York Times сообщает о возможности привлечения до $1 млрд инвестиций до конца 2024 года. Примечательно, что в публикации отсутствует упоминание о Масаёси Соне (Masayoshi Son), генеральном директоре SoftBank, который, по слухам, в прошлом году уже вложил в проект миллиард долларов. На данный момент в проекте заняты 10 сотрудников, включая ключевых специалистов, работавших с Айвом над Apple iPhone: Тэна Тана (Tang Tan) и Эванс Хэнки (Evans Hankey). Дизайном устройства занимается LoveFrom — компания, основанная Айвом. Команда располагается в офисе площадью 2 973 м2 в Сан-Франциско, являющемся частью приобретённого Айвом за $90 млн комплекса недвижимости. Марк Ньюсон (Marc Newson), соучредитель LoveFrom, в интервью The New York Times подтвердил, что спецификации продукта с генеративным ИИ и сроки его выхода на рынок находятся в процессе разработки. Это указывает на раннюю стадию проекта и возможные изменения в его концепции. США запретят российский и китайский софт в автомобилях, подключённых к интернету
22.09.2024 [07:31],
Алексей Разин
Стремление действующей администрации президента США Джозефа Байдена (Joseph Biden) утвердить как можно больше законов до ноябрьских выборов вполне объяснимо, но их характер может огорчить некоторых участников рынка систем активной помощи водителю. По крайней мере, уже в понедельник может быть введён запрет на использование на территории США программного и аппаратного обеспечения в автомобилях, имеющего китайское или российское происхождение. 
Источник изображения: Baidu, Apollo Go Речь идёт не только о системах автопилота как таковых, по данным Bloomberg, а о запрете и программного обеспечения или оборудования, используемых для передачи информации. Уклон сделан в сторону программного обеспечения, но номинально запрещается и аппаратное обеспечение. В последнем случае запрет больше коснётся китайских разработчиков, поскольку российские до сих пор специализировались на программном обеспечении такого типа. Запрет не будет внезапным, как этом может показаться, поскольку расследование в отношении китайского ПО для автономных транспортных средств было запущено в США ещё в марте этого года. Новейшая законодательная инициатива опирается на его итоги, как поясняет Bloomberg. Американские чиновники, как сообщается, опасаются возможности дистанционного перехвата управления транспортными средствами или сбора информации с их помощью. Даже если китайский автомобиль минимально автоматизирован в сфере управления, ему может быть закрыт путь на рынок США из-за использования китайской информационно-развлекательной системы с возможностью выхода в интернет. Напомним, что ещё в мае власти США приняли решение обложить 100-процентной пошлиной электромобили, импортируемые из Китая. Новые ограничения дополнительно снижают шансы китайских автопроизводителей закрепиться на рынке США, а также усложняют задачу тем западным автопроизводителям, которые разместили свои предприятия в Китае и рассчитывали экспортировать их продукцию в США. Предполагается, что новая инициатива также направлена против использования американскими автопроизводителями электронных систем китайского происхождения. Запрет будет внедряться в несколько этапов, сами правила вступят в силу с января следующего года после 30-дневного периода публичного обсуждения. Представители американской автомобильной промышленности уже заявили, что смена компонентной базы не может произойти моментально и потребует какого-то времени. Интересно, кстати, что предыдущие инициативы по запрету на импорт в США транспортных средств китайского производства не распространялись на сегмент сельскохозяйственной техники и горнодобывающего оборудования. Linux запустили на Intel 4004 — загрузка заняла пять дней
22.09.2024 [00:58],
Владимир Мироненко
Как передаёт OpenNet, разработчик Дмитрий Гринберг сумел запустить ядро Linux с rootfs-окружением из Debian на 10-мкм 4-бит процессоре Intel 4004, вышедшем в конце 1971 года и считающемся первым в мире коммерчески доступным однокристалльным микропроцессором. У Intel 4004 всего 2300 транзисторов. Процессор имел всего 46 инструкций, а его пиковая производительность достигала примерно 93 тыс. операций в секунду. Из-за невозможности напрямую портировать ядро на Intel 4004 и из-за ограничений самого CPU автор решил написать эмулятор процессора MIPS R3000, внутри которого уже запускался Linux. Для запуска процессора автор в несколько подходов создал плату Linux/4004 на базе компонентов 1970-х годов, которые, как выяснилось, не так уж дёшевы. Естественно, плата содержит и гораздо более современные компоненты, позволяющие, к примеру, использовать SD-карту в качестве постоянной памяти. 
Источник изображения: dmitry.gr Из-за малой производительности Intel 4004 эмулятор работал медленно — на обработку каждой виртуальной секунды в эмулируемом окружении уходило почти 4 часа реального времени. После усовершенствования платы и ПО загрузка Linux сократилась с почти 9 дней до примерно 5 дней. Автор даже смог разогнать CPU с базовых 740 кГц до 790 кГц. Желающие повторить эксперимент могут воспользоваться опубликованными спецификациями и схемой платы, а также ПО. Новая статья: Gamesblender № 692: чип AMD для PS6, «грандиозная» Battlefield 6 и никакой The Sims 5
21.09.2024 [23:34],
3DNews Team
Данные берутся из публикации Gamesblender № 692: чип AMD для PS6, «грандиозная» Battlefield 6 и никакой The Sims 5 Учёные разгадали одну из загадок сверхпроводимости
21.09.2024 [22:23],
Геннадий Детинич
Открытию сверхпроводимости 8 апреля этого года исполнилось 113 лет. Почтенный возраст, но загадка явления так и не отгадана. Первая внятная теория сверхпроводимости была создана только в 1957 году, но через 50 лет снова пошли сюрпризы. Так, в 2009 году обнаруженная к тому времени высокотемпературная сверхпроводимость (ВТСП) подкинула новую задачу — в сверхпроводниках выше критической температуры обнаружился необъяснимый теорией энергетический зазор. 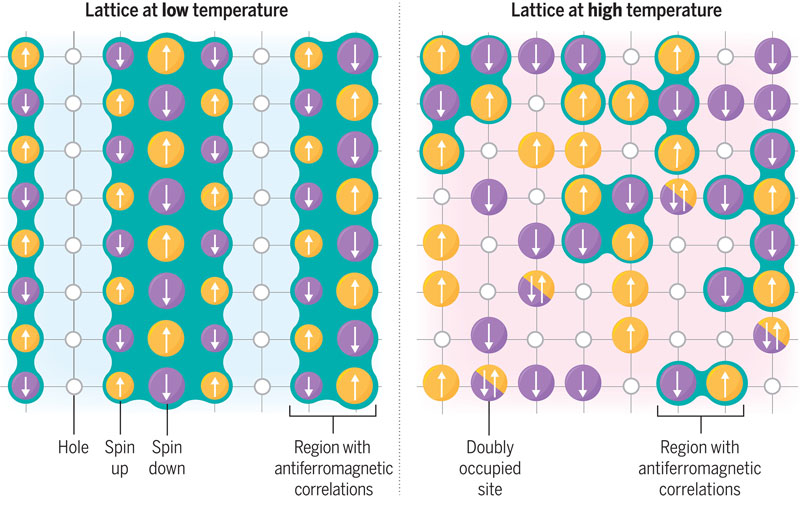
Слева показан режим нормальной энергетической щели в ВТСП, справа — положение электронов в режиме псевдощели. Источник изображения: Science Полное понимание физики сверхпроводимости и ВТСП в частности позволит искать нужные материалы буквально с открытыми глазами, тогда как сейчас (и все предыдущие 113 лет) учёные движутся в основном наугад. Созданная полвека назад учёными Джоном Бардиным, Леоном Купером и Робертом Шриффером «теория БКШ» объясняет сверхпроводимость когерентным поведением пар электронов — так называемых куперовских пар. Это явление квантового порядка, что делает анализ и моделирование сверхпроводимости архисложной и едва ли выполнимой задачей. По крайней мере, так было до появления новой работы. Группа учёных из Парижского политехнического института смогла разработать подход, который позволил бы моделировать поведение электронов и куперовских пар в ВТСП-материалах. По их словам, это прорыв, который трудно переоценить. Анализ вскрыл как минимум одну тайну, присущую ВТСП — как возникает в купратах (оксидах меди, обнаруживших сверхпроводимость в 1986 году) псевдощель. Это интересная и загадочная вещь, которой до сих пор не было внятного объяснения (были только две гипотезы). В классических сверхпроводниках энергетическая щель, в которой из электронов образуются квантово запутанные куперовские пары, возникает при температуре ниже критической (когда сверхпроводимость становится возможной). Для случаев ВТСП энергетическая щель может возникать при температуре выше критической. Это означает, что сверхпроводимость может проявляться при высоких температурах, включая комнатные. Надо ли объяснять, что понимание физики явления сулит чудесные открытия? Но с точки зрения теории БКШ эта щель необъяснима, за что она стала называться псевдощелью. Учёные из Франции и Швейцарии теперь готовы объяснить, как и почему она возникает. Для моделирования поведения электронов в ВТСП учёные воспользовались упрощённой моделью Хаббарда, к которой они применили статистический метод Монте-Карло. Модель Хаббарда представила электроны как пешки на шахматной доске, которые могут переходить с одной клетки на другую и выравниваются на ней (в материале) в зависимости от направления спина и даже могут располагаться на одной клетке в случае противоположно направленных спинов. Метод Монте-Карло позволил провести анализ всей «доски» единовременно, что приближает моделирование к естественному процессу. Переход к режиму псевдощели моделирование представило как перестройку электронов на «шахматной доске» от полосовой упорядоченной структуры к пустотам, расположенным как бы в шахматном порядке. Как только исчезала черезполосица, материал приобретал свойства псевдощели. «Наше открытие поможет учёным в их поисках сверхпроводимости при комнатной температуре, Святого Грааля физики конденсированных сред, который позволил бы передавать энергию без потерь, более быстрые аппараты МРТ и сверхбыстрые левитирующие поезда», — отмечают авторы исследования. AWS ищет главного инженера-атомщика, который поможет запитать ИИ ЦОД от АЭС и SMR
21.09.2024 [21:02],
Владимир Мироненко
После приобретения у Talen Energy Corporation кампуса ЦОД у АЭС Susquehanna в Пенсильвании (США) компания Amazon Web Services (AWS) разместила на сайте вакансию главного инженера-атомщика, который будет отвечать за развитие малых модульных реакторов и налаживание отношения с традиционными АЭС, пишет DatacenterDynamics (DCD). Претендент на эту должность должен иметь опыт проектирования и эксплуатации как АЭС для коммунальных нужд, так и малых модульных реакторов (SMR). Указано, что он будет разрабатывать «внутренние и внешние стратегические планы по ядерным продуктам и топливу» для дата-центров AWS. Также претендент должен уметь проводить комплексную проверку «конкретных энергетических проектов». В его обязанности будет входить выстраивание отношений с Министерством энергетики США и регулирующими органами, а также работа с внешними партнёрами в рамках проектирования «эксплуатационно эффективных и безопасных модульных атомных электростанций» для поддержки растущих потребностей в энергии. В связи с ростом потребности в электроэнергии для ИИ ЦОД, AWS и другие облачные провайдеры обратились к сектору атомной энергетики. 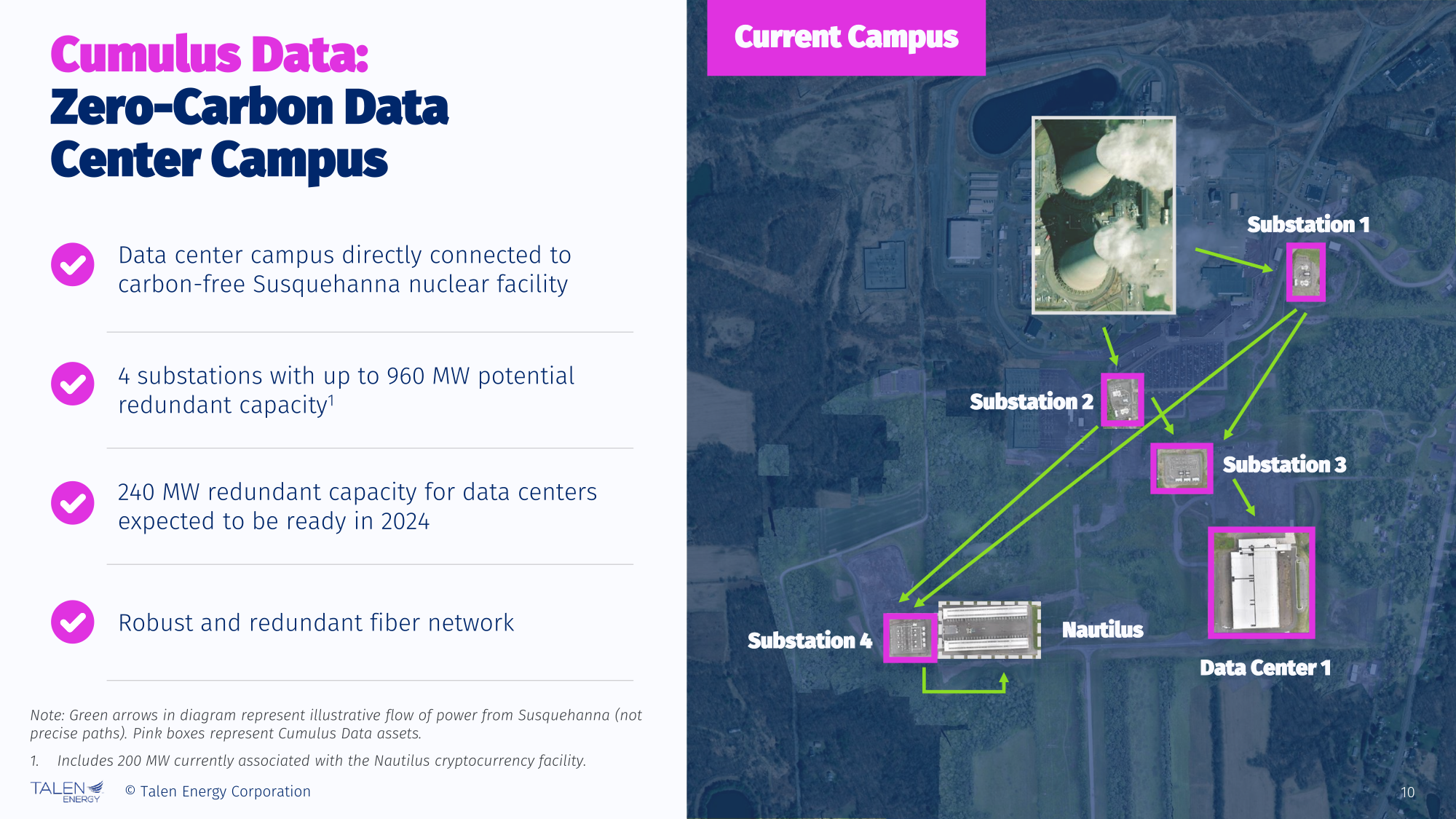
Источник: Talen Energy Как стало известно на днях, Microsoft заключила с крупнейшим оператором АЭС в США Constellation Energy 20-летний контракт на поставку электроэнергии (PPA) с АЭС Three Mile Island в Пенсильвании, которую вновь введут в эксплуатацию, а также сформировала целую команду по работе над атомной энергетикой и наняла целый ряд квалифицированных специалистов. По неофициальным данным, Microsoft будет платить за энергию порядка $800 млн/год. При этом начальные затраты только на восстановление работоспособности Three Mile Island составят $1,6 млрд. В апреле этого года Equinix подписала 20-летнее PPA-соглашение на поставку 500 МВт от модульных реакторов Oklo с возможностью его продления в дальнейшем. Спустя два месяца Wyoming Hyperscale (теперь Prometheus Hyperscale) подписала с Oklo PPA на 100 МВт. Кроме того, в этом месяце Oracle сообщила, что построит в США 1-ГВт кампус ЦОД с питанием от трёх малых модульных реакторов (SMR). Qualcomm хочет сначала «дружественно» поглотить Intel, а потом распродать её по частям
21.09.2024 [20:10],
Алексей Разин
Потенциальная «сделка века», по сценарию которой Qualcomm купит Intel целиком, является слишком важным информационным поводом, чтобы не возвращаться к нему несколько раз. Агентство Bloomberg по своим каналам добыло новые подробности вероятной сделки, подчеркнув, что поглощение будет дружественным и не вызовет беспокойства американских регуляторов, но часть активов Intel компания Qualcomm потом намерена распродать. 
Источник изображения: Intel Как отмечает источник, Qualcomm обратилась к Intel с предложением о дружественном поглощении несколько дней назад. Основной сценарий подразумевал покупку всей компании Intel целиком, но при наличии такой возможности Qualcomm не возражает против покупки отдельных активов Intel или их продажи после сделки. Как сообщается, представители Qualcomm консультировались с американскими регуляторами и убеждены, что сделка между двумя американскими компаниями не вызвала бы у властей серьёзной озабоченности. Самое интересное, что источникам Bloomberg удалось разузнать, как относится к подобной сделке генеральный директор Intel Патрик Гелсингер (Patrick Gelsinger), который почти четыре года назад занялся серьёзной реструктуризацией бизнеса процессорного гиганта. С одной стороны, Гелсингер уверен в способности Intel выйти из кризиса, опираясь на предложенный им совету директоров план, при этом оставаясь независимой компанией. С другой стороны, как отмечается, Гелсингер готов рассмотреть альтернативы, если они принесут компании реальную пользу. Обе компании советуются с различными консультантами по этим вопросам. За последние 12 месяцев курс акций Intel снизился на 37 %, уменьшив капитализацию компании до $93 млрд. За это время акции Qualcomm подорожали более чем на 50 % и увеличили капитализацию данной компании до $188 млрд. Если компании договорятся о слиянии, то это будет одна из крупнейших сделок в истории фондового рынка. Выручка Intel по итогам текущего года не превысит $52 млрд, как гласят прогнозы, и это лишь 70 % её выручки в 2021 году. На динамику курса акций Intel на текущей неделе повлияли новые подробности о плане выхода из кризиса. Компания собирается сильнее обособить своё производственное подразделение, чтобы не только привлечь клиентов на контрактный выпуск чипов из числа конкурентов, но и открыть возможность привлечения сторонних инвестиций в этот бизнес. Было объявлено о долгосрочной сделке с облачным подразделением Amazon, которая подразумевает выпуск компонентов на мощностях Intel по передовой технологии 18A. Кроме того, Intel провела оптимизацию своей организационной структуры, сосредоточив ресурсы на двух направлениях, связанных с разработкой и выпуском компонентов для ПК и серверного сегмента соответственно. Дочерняя компания Altera не будет продана целиком, как считалось, её Intel продолжить готовить к IPO. Дочернюю компанию Mobileye материнская Intel также продавать полностью не будет, но она уже вышла на американский фондовый рынок. Строительство предприятий в Германии и Польше Intel отложит на два года, а построенное предприятие в Малайзии не будет спешить вводить в строй. Мегаэкстремальные магнитные бури в истории Земли — не редкость, заявили учёные
21.09.2024 [18:09],
Геннадий Детинич
Первая задокументированная экстремальная солнечная магнитная буря в 1859 году была настолько сильной, что вывела из строя телеграфную связь в Северной Америке и Европе, вызвав местами даже пожары. Но в истории Земли такие катаклизмы были и намного мощнее — мегаэкстремальной интенсивности. Если бы такое произошло сегодня, это вызвало бы хаос во всём цивилизованном мире. Хуже всего, что оно рано или поздно произойдёт. Учёные хотят быть готовы к нему. 
Выброс корональной массы 31 августа 2012 года. Источник изображения: NASA/GFSC/SDO Можно ли подготовиться к солнечной буре невероятной интенсивности? По словам исследователей, да. Для этого необходимо, как минимум, искать признаки экстремальных солнечных бурь в прошлом, чтобы суметь верно оценить вероятность и даже признаки появления их в будущем. В 2012 году группа учёных под руководством Фуса Мияке (Fusa Miyake) из Университета Нагои в Японии обнаружила, что экстремальные солнечные бури могут вызывать резкие изменения концентрации радиоуглерода (C14), обнаруженного в кольцах деревьев. В сочетании с подсчётом годовых колец и используя другие методы определения возраста объектов можно обнаружить признаки сильных солнечных бурь на Земле и датировать их с большой точностью. Новое исследование не стало первой попыткой датирования солнечных бурь по годовым кольцам деревьев. Ранее группа Мияке показала, что одна из самых сильных солнечных бурь на Земле произошла в 774 году н.э., которая по своей интенсивности затмила бы геомагнитную бурю 1859 года. Связанные с этой бурей полярные сияния нашли отражения в письменных источниках того времени, что косвенно подтверждает правильность применяемой методики датирования. Другими датами наиболее интенсивных солнечных бурь назвали 993 год н.э., 660 год до н.э., 5259 год до н.э. и 7176 год до н.э. Но самая сильная солнечная буря произошла около 14 370 лет назад, ближе к концу последнего ледникового периода. Интенсивность её была такова, что практически всем спутникам на орбите Земли выше магнитосферы точно не поздоровилось бы. Справедливости ради следует признать, что некоторые из детектируемых событий могли быть вызваны также космическим излучением, например, гамма-вспышками от сверхновых или от других явлений. И всё же, учёные настаивают, что Солнце, как и подобные ему относительно холодные и спокойные звёзды, способно преподнести сюрприз технологически развитой цивилизации, а к такому надо готовиться заранее, чтобы минимизировать последствия. Падающие на головы спутники и тотальное отключение связи и электричества способны привести к хаосу на планете с далеко идущими последствиями. Запуск сервиса сотовой спутниковой связи Starlink и T-Mobile могут перенести на начало 2025 года
21.09.2024 [16:01],
Владимир Мироненко
Хотя SpaceX несколько месяцев назад обратилась в Федеральную комиссию по связи (FCC) США с просьбой разрешить запуск сервиса спутниковой сотовой связи Starlink нынешней осенью, эта услуга, скорее всего, появится у её партнёра, американского сотового оператора T-Mobile, только в следующем году. 
Источник изображения: Starlink Генеральный директор T-Mobile Майк Сиверт (Mike Sievert) сообщил в интервью телеканалу CNBC, что бета-программа по реализации спутниковой сотовой связи в партнёрстве со Starlink может начаться в конце этого года или в начале следующего. Причину отсрочки запуска сервиса Сиверт не указал, но упоминание о бета-программе предполагает, что T-Mobile сначала запустит услугу сотовой связи с использованием спутников Starlink в небольших масштабах прежде, чем приступить к более широкому развёртыванию сервиса. На официальном сайте SpaceX говорится, что в этом году компания предложит клиентам возможность обмена текстовыми сообщениями через спутники, а в 2025 году запустит поддержку голосовой связи и передачи данных. Ранее SpaceX сообщила, что для запуска сервиса спутниковой сотовой связи в США ей необходимо иметь на орбите около 300 спутников Starlink с поддержкой технологии Direct-to-Cell. В пятницу компания запустила очередную партию спутников с поддержкой Direct-to-Cell, в результате чего их общее число на орбите превысило 200 штук. Вполне возможно, что в этом году группировка спутников Starlink с Direct-to-Cell достигнет 300 единиц, но без разрешения FCC запуск сервиса не состоится. Кроме того, компания просит регулятора ослабить ограничения на радиоизлучение, чтобы улучшить покрытие и обеспечить осуществление видео- и голосовых вызовов в режиме реального времени. Против этого выступили операторы AT&T и Verizon, объясняя возражения тем, что это создаст помехи для мобильных наземных сетей. Немецкие правоохранительные органы взломали Tor
21.09.2024 [15:54],
Павел Котов
Tor является одним из важнейших интернет-сервисов, обеспечивающим анонимность пользователей. Он бесплатен и может использоваться любым желающим, кто стремится скрыть, например, публичный IP-адрес своего компьютера. Проектом, предназначенным для благих целей, злоупотребляют и преступники, которые стремятся остаться анонимными и уйти от правоохранительных органов. Конец этому решили положить правоохранительные органы Германии. 
Источник изображения: blog.torproject.org Немецкие правоохранительные органы в течение нескольких месяцев отслеживали серверы Tor, чтобы идентифицировать отдельных пользователей теневой сети. Им удалось идентифицировать сервер хакерской группировки Vanir Locker, который она использовала в сети Tor. Киберпреступники объявили, что опубликуют данные, похищенные в ходе одной из своих последних акций. Немецким властям удалось определить местоположение ресурса при помощи метода временного анализа. Временной анализ используется, чтобы связать подключения к сети Tor и локальные подключения к интернету. Для реализации этого метода производится мониторинг как можно большего числа узлов Tor, потому что это увеличивает вероятность идентификации. Таким образом, правоохранительные органы действительно отслеживают узлы Tor, и делается это не только в Германии. Немецкие специалисты перехватили контроль над адресом ресурса группы кибервымогателей в сети Tor и перенаправили его на свою страницу — в результате хакеры не смогли опубликовать данные на своём ресурсе. Репортёры государственной радиовещательной компании ARD ознакомились с документами, которые подтверждают, что в результате операции были успешно идентифицированы четверо лиц. Этот метод использовался также для идентификации участников платформы, на которой публиковались материалы, содержащие жестокое обращение с детьми. Администрация Tor Project подтвердила, что правоохранительным органам удалось лишить анонимности нескольких киберпреступников, но заявила, что для большинства интернет-пользователей Tor остаётся одним из лучших вариантов сохранения конфиденциальности. Наметился прорыв в изучении физики Солнца — учёные научились делать карты магнитных полей его атмосферы
21.09.2024 [15:52],
Геннадий Детинич
Учёные из Национальной солнечной обсерватории США (NSO) представили первые в мире детальные карты магнитных полей солнечной атмосферы (короны). Проделанная работа — это только начало тотального картирования магнитосферы короны. Это новый уровень в изучении физики нашей родной звезды, который позволит прогнозировать едва ли ни все явления на Солнце от пятен до корональных выбросов, а это путь к предсказанию космической погоды в нашей системе. 
Источник изображения: NASA/SDO Новаторские карты магнитных полей в атмосфере Солнца смог получить новый и самый большой в мире наземный солнечный телескоп им. Дэниела Иноуэ (Daniel K. Inouye Solar Telescope, DKIST). Он начал научную работу в феврале 2022 года и уже добыл самые детализированные снимки нашей звезды, где разрешение каждого пикселя соответствовало 20 км. Казалось бы, что нам искать фактически под микроскопом на Солнце? Тем не менее учёные имеют более-менее полное представление о масштабных физических процессах на нашей звезде, но в мелочах не способны разобраться даже сегодня. Для выявления магнитных линий (полей) в короне Солнца учёные воспользовались криогенно охлаждённым спектрометром, подключённым к телескопу DKIST. С помощью коронографа исследователи могли изолированно от поверхности наблюдать атмосферу Солнца и одновременно снимать её спектр в ближнем инфракрасном диапазоне. В частности, исследователей интересовал спектр железа в атмосфере звезды. Существует такое явление, как эффект Зеемана. Он описывает расщепление спектральных линий атомов в магнитном поле. 
Карта магнитных полей солнечной короны Спектрометр легко выявляет расщепление линий вплоть до определения поляризации линий магнитного поля. Всё это позволяет в подробностях увидеть распределение линий напряжённости в короне. Если мы знаем, как распределены линии магнитных полей в атмосфере Солнца, то можем предсказать появление, размеры и очертания пятен на Солнце, интенсивность вспышек и направления выбросов корональной массы. Солнце станет предсказуемым. Это будет своего рода победа над ним. «Картирование напряженности магнитного поля в короне — фундаментальный научный прорыв не только для исследований солнечной системы, но и для астрономии в целом, — говорят авторы исследования. — Это начало новой эры, когда мы поймем, как магнитные поля звёзд влияют на планеты здесь, в нашей собственной солнечной системе, и в тысячах экзопланетных систем, о которых мы теперь знаем». Смартфоны Samsung могут лишиться беспроводной зарядки после проигрыша в патентном споре
21.09.2024 [14:44],
Владимир Фетисов
Беспроводная зарядка является одной из популярных функций современных смартфонов. Однако в скором времени крупнейший производитель смартфонов в лице южнокорейской компании Samsung может отказаться от использования этой технологии в своих устройствах. Это связано с проигрышем в затянувшемся судебном разбирательстве по поводу нарушения нескольких патентов компании Mojo Mobility. 
Источник изображения: Samsung В 2022 году Mojo Mobility подала в суд на Samsung, обвинив производителя электроники в нарушении пяти патентов, связанных с технологией беспроводной зарядки, используемой в большинстве смартфонов, проданных с 2016 года по настоящее время. В прошлом году Samsung пыталась добиться признания этих патентов недействительными. Однако 13 сентября суд признал южнокорейскую компанию виновной в нарушении патентов и нанесении ущерба на сумму $192 136 029. Говоря проще, юридическое заключение сводится к тому, что Samsung украла разработки Mojo Mobility и использовала их в своих смартфонах, смарт-часах, наушниках и других устройствах. Если Samsung примет решение отказаться от выплаты штрафа, то, вероятно, ей придётся удалить беспроводную зарядку в своих будущих продуктах или же разработать новые способы беспроводной зарядки, которые не будут нарушать патенты Mojo Mobility. Также не исключен вариант, при котором Samsung обязуют отключить беспроводную зарядку в уже выпущенных устройствах, но это маловероятно. Samsung почти наверняка подаст апелляцию на это решение суда и попытается его оспорить. На самом деле южнокорейская компания не первый раз оказывается в подобной ситуации, причём именно в суде Восточного округа штата Техас, где происходило рассмотрение жалобы Mojo Mobility. По последним оценкам, патентные тролли в США подают иски против Samsung в среднем каждые пять дней. Для защиты от этих обвинений Samsung приходится задействовать целую армию адвокатов, а также патентовать любые собственные технологии в соответствии со всеми правилами. Если команда юристов Samsung не сможет решить данный вопрос в суде, то, наиболее вероятно, что Samsung попросту придётся оплатить штраф или заключить мировое соглашение с Mojo Mobility. В любом случае, до полного урегулирования спора по патентам на технологию беспроводной зарядки, вероятно, ещё далеко. Продажи трёхстворчатого смартфона Huawei Mate XT в Европе начнутся в первом квартале 2025 года
21.09.2024 [14:37],
Владимир Мироненко
Ресурсу AndroidAuthority стали известны сроки появления в глобальной продаже складного смартфона Huawei Mate XT с трёхсекционным гибким дисплеем, представленного в Китае на прошлой неделе. Как сообщает ресурс, чьи прогнозы не раз подтверждались, глобальный релиз Mate XT состоится в первом квартале 2025 года. 
Источник изображения: Huawei Несмотря на высокую стоимость — цена Mate XT начинается с 19 999 юаней (около $2800) за модель с 16/256 Гбайт памяти, число предзаказов на новинку бьёт рекорды — порядка 4,9 млн по состоянию на 11 сентября. Как правило, цена смартфонов китайских производителей в Европе значительно выше, чем в Китае. Поэтому нельзя исключать, что самая доступная модель Mate XT в Европе будет предлагаться за $3000 и дороже. Что касается российского рынка, то здесь ожидают появление Mate XT гораздо раньше — вполне возможно, что это произойдёт уже в следующем месяце. Такую возможность допускают в Inventive Retail Group Расим Лемберанский, развивающей сети Restore, Restore: Mix, а также монобрендовые магазины Samsung и Xiaomi. Также планируют начать продажи Huawei Mate XT в ближайшее время и в Wildberries. По словам исполнительного директора Huawei Юй Чэндуна (Yu Chengdong), также известного как Ричард Ю (Richard Yu), на разработку Mate XT ушло пять лет, но в итоге новинка отличается надёжностью и безотказной работой всех компонентов. Это подтверждают и первые обзоры блогеров. Акции Intel выросли на фоне сообщения о её возможном поглощении Qualcomm
21.09.2024 [14:34],
Дмитрий Федоров
Акции Intel выросли на 3,4 % после сообщения о её возможном поглощении компанией Qualcomm, что может стать крупнейшей сделкой в истории полупроводниковой отрасли. Однако, несмотря на краткосрочный рост, акции Intel остаются в минусе на 56 % с начала года. Это демонстрирует серьёзные проблемы, с которыми продолжает сталкиваться компания, в том числе потерю технологического лидерства и падение продаж. 
Источник изображений: Intel Intel переживает трудные времена. Компания столкнулась с падением продаж и растущими убытками, которые усугубляются утратой технологического преимущества. Рыночная капитализация Intel снизилась до $93,5 млрд, что составляет примерно половину стоимости Qualcomm. В попытке исправить ситуацию Intel анонсировала ряд стратегических изменений, включая многомиллиардную сделку с Amazon по разработке ИИ-чипа и план по преобразованию подразделения контрактного производства чипов в отдельную дочернюю компанию. Qualcomm является мировым лидером в разработке процессоров для смартфонов. Компания активно стремится расширить своё присутствие в других сегментах рынка, включая чипы для персональных компьютеров (ПК) — традиционной вотчины Intel. В отличие от Intel, Qualcomm не имеет собственных производственных мощностей, полагаясь на аутсорсинг производства у таких партнёров, как TSMC, которая также производит чипы для конкурентов Intel — Nvidia и AMD.  Потенциальное приобретение Intel могло бы предоставить Qualcomm доступ к производственным мощностям в США и контроль над ведущим брендом на рынке ПК и серверов. Однако эксперты полагают, что такая сделка автоматически не решит проблем Intel, ведь у Qualcomm отсутствует опыт управления производством и экспертиза в науке, лежащей в основе передовых производственных технологий, где TSMC превосходит конкурентов. Реакция рынка на новость была неоднозначной. Акции Qualcomm упали на 2,9 %, что отражает опасения инвесторов относительно рисков и сложностей, связанных с потенциальной сделкой такого масштаба. Эта ситуация напоминает о событиях более чем шестилетней давности, когда Qualcomm сама стала объектом попытки поглощения со стороны Broadcom. Тогда сделка была заблокирована президентом Дональдом Трампом (Donald Trump) из соображений национальной безопасности. Гибридные процессоры AMD Strix Point на Zen 5 оказались вдвое дороже, чем Hawk Point на Zen 4
21.09.2024 [14:32],
Павел Котов
Производитель портативных игровых компьютеров и ноутбуков GPD недавно объявил цены на новый лэптоп Duo с двумя OLED-дисплеями. Этот ПК обещает стать одним из первых устройств на базе нового гибридного процессора (APU) от AMD — речь идёт о модели Ryzen AI 9 HX 370 семейства Strix Point, цена которой оказалась неожиданно высокой. 
Источник изображения: gpd.hk Первоначально GPD сообщала, что Duo получит гибридный процессор Phoenix/Hawk Point на архитектуре Zen 4, но впоследствии спецификации компьютера обновились. Производитель решил не отказываться от первоначального варианта полностью, и тому нашлась причина: AMD решила продавать чипы Strix Point компании GPD по цене, вдвое превышающей стоимость процессора Hawk Point (Ryzen 7 8840U). Это заставило её пересмотреть вопрос о том, сможет ли продукт сохранить достаточную маржу для успешного запуска. GPD не является крупным игроком на рынке ноутбуков, но при наличии двух OLED-дисплеев стоимость варианта на чипе AMD Ryzen AI 9 HX 370 составит $1650 — для сравнения, версия с Ryzen 7 8840U оценена в $1270. Прямое их сравнение не вполне корректно: старшая модель имеет 32 Гбайт оперативной памяти против 16 Гбайт у младшей, и размер встроенного накопителя составляет 1 Тбайт по сравнению с 512 Гбайт у базового варианта. Но разница в цене Hawk Point и Strix Point вызывает опасения, что и долгожданные Strix Halo также значительно вырастут в цене, и это вытеснит ПК на них из диапазона доступных. И пока нет ясности, является ли цена на Strix Point окончательной, или у производителей остаётся пространство для переговоров. Возможно, более доступной окажется серия процессоров AMD Ryzen Z2, выход которой ожидается в будущем году. В противном случае следует ожидать подорожания портативных игровых компьютеров. AMD также работает над процессорами серии Kraken, которые получат восемь ядер Zen 5/5c и восемь вычислительных блоков RDNA 3.5. Наблюдения за вулканами на спутнике Юпитера Ио раскрыли секреты приливного нагрева лун планет-гигантов
21.09.2024 [14:31],
Геннадий Детинич
Исследователи Корнелльского университета смогли изучить фундаментальный процесс формирования и эволюции планет — приливный нагрев, наблюдая за вулканами самого вулканически активного тела Солнечной системы — спутником Юпитера Ио. Это не праздный интерес. Аналогичные явления происходят в глубинах глобальных океанов ряда других лун у Сатурна и Юпитера, а это шанс для возникновения там жизни, которую мы знаем по Земле. 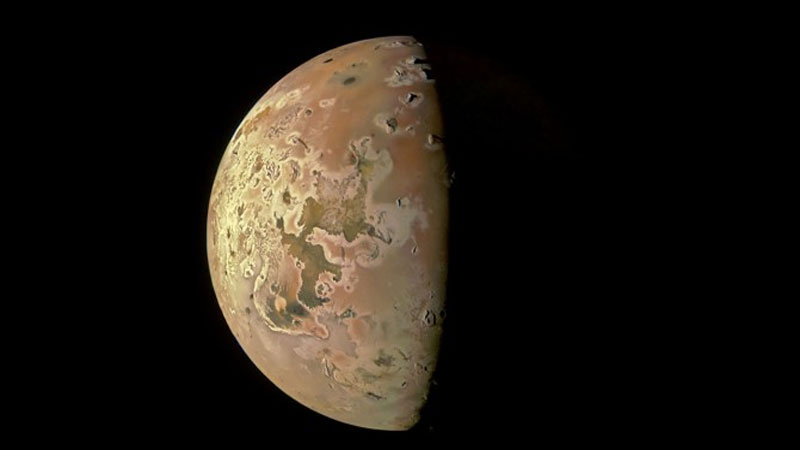
Спутник Юпитера Ио. Источник изображения: NASA Близкое расположение Ио к Юпитеру, а также пролёты сравнительно недалёких других спутников этой планеты-гиганта сминают и растягивают недра Ио приливной гравитацией. В результате напряжения и трения недра Ио чрезвычайно разогреты, а геология этой луны — активно-вулканическая. Одновременно на поверхности спутника активны до полутысячи вулканов и там же даже сегодня образуются новые вулканы. В какой-то мере вулканическая деятельность регулирует внутренне тепло спутника и также служит индикатором этого процесса. В последние годы данные о вулканах Ио исправно поставляет зонд NASA «Юнона» (Juno). Также стало возможным делать высокодетализированные снимки Ио прямо с Земли, что даёт массу данных для анализа. Работа астрономов из Корнелльского университета помогла систематизировать накопленные по вулканам Ио данные и позволила сделать интересные выводы. Так, учёные обнаружили неизвестную до этого деятельность вулканов в полярных областях спутника, тогда как раньше основной вклад в тепловой баланс планеты, как считалось, вносили вулканы экваториальной области. Более того, учёные засекли явно синхронную работу в группах полярных вулканов, которые одновременно разгорались и затухали. «Все они становились яркими, а затем тускнели с одинаковой скоростью, — говорят учёные. — Интересно наблюдать за вулканами и за тем, как они реагируют друг на друга». «Изучение негостеприимного ландшафта вулканов Ио действительно вдохновляет науку на поиски жизни, — пояснили свою главную цель учёные. — Приливный нагрев играет важную роль в нагревании и эволюции орбит небесных тел. Он обеспечивает тепло, необходимое для формирования и поддержания подповерхностных океанов на спутниках планет-гигантов, таких как Юпитер и Сатурн». Эксперты опасаются, что победа Google в суде с Минюстом США уничтожит открытый интернет
21.09.2024 [14:27],
Дмитрий Федоров
Судебное разбирательство Министерства юстиции (DOJ) США против Google вступило в активную фазу. Корпорации предъявлены обвинения в монопольном поведении на рынке онлайн-рекламы. Эксперты предупреждают, что победа Google может нанести сокрушительный удар по концепции открытого интернета, ущемив права пользователей и мелких онлайн-компаний. 
Источник изображения: geralt / Pixabay В Вирджинии начался судебный процесс, в котором Google борется с Министерством юстиции США по поводу обвинений в том, что компания стала монополистом на рынке рекламных технологий, контролируя ключевые компоненты экосистемы цифровой рекламы, включая сети рекламодателей, рекламные серверы издателей и биржи рекламы. Министерство юстиции утверждает, что этот режим позволил компании оказывать неправомерное влияние на рынок, подавляя конкуренцию и нанося вред как издателям, так и рекламодателям. Недавно состоялась пресс-конференция с участием юристов, представителей некоммерческих организаций и экспертов по вопросам конфиденциальности. Они обсудили потенциальные последствия этого прецедентного дела. По их мнению, поражение DOJ может усугубить ситуацию в онлайн-пространстве как для рядовых пользователей, так и для компаний. «Победа Google способна подорвать сами основы открытого интернета», — заявил один из участников конференции. Концепция «открытого интернета» подразумевает свободную, децентрализованную и общедоступную информационную инфраструктуру. В идеале такая система функционирует без центральных органов управления или «привратников», контролирующих доступ к информации через стандартные веб-интерфейсы, такие как веб-браузеры. Однако реальность такова, что Google де-факто стал доминирующим «привратником» для большинства интернет-пользователей по всему миру. Ли Хепнер (Lee Hepner), калифорнийский адвокат по антимонопольным делам и юрисконсульт Американского проекта гражданских свобод (American Civil Liberties Project), утверждает, что если Google одержит победу в суде, деградация открытого интернета ускорится. Открытый интернет — это возможности для малого онлайн-бизнеса. Потеря этой экосистемы приведёт к централизации онлайн-рынка, который окажется в ловушке закрытых экосистем техногигантов. Саша Хаворт (Sacha Haworth), исполнительный директор проекта Tech Oversight, обвиняет Google в нежелании акцентировать внимание на очевидном вреде от своей хищнической бизнес-модели. По её словам, реклама, контролируемая Google, искажает цифровую экономику и существенно способствует росту инфляции. По данным экспертов, Google контролирует более 90 % рынка технологий поисковой рекламы. Аналитики утверждают, что отсутствие деструктивного влияния Google на рекламу привело бы к снижению потребительских цен на онлайн-товары. Элиз Филлипс (Elise Phillips), советник по вопросам политики организации Public Knowledge, подчёркивает, что демократизация ландшафта цифровой рекламы могла бы дать малому и среднему бизнесу шанс конкурировать за внимание онлайн-покупателей. Карина Монтойя (Karina Montoya), специалист по исследованию рынка, прогнозирует, что победа Google может привести к формированию практически непреодолимого разрыва между имущими и неимущими на онлайн-рынке. Процессор iPhone 17 не перейдёт на 2-нм техпроцесс — новые нормы внедрят лишь для iPhone 18 Pro
21.09.2024 [13:23],
Павел Котов
Телефоны серии iPhone 17 в следующем году получат процессоры, изготовленные TSMC с использованием усовершенствованной технологии N3P, а ожидаемые в 2026 году старшие модели iPhone 18 Pro получат чипы, вероятно, основанные на технологии нового поколения 2 нм. Ограничение их присутствия связано с проблемами со стоимостью, сообщает аналитик Мин-Чи Куо (Ming-Chi Kuo). 
Источник изображения: apple.com С прошлого года процессоры Apple для iPhone и Mac изготавливаются по технологии 3 нм — речь идёт о чипах A17 Pro в моделях iPhone 15 Pro и M3 для Mac; до этого процессоры Apple производились по технологии 5 нм. В этом году iPhone 16 получили процессоры A18 на основе технологии 3 нм второго поколения — они быстрее и эффективнее, чем A16 Bionic в базовых моделях iPhone 15. TSMC планирует начать производство 2-нм чипов в конце 2025 года, и Apple, как ожидается, станет первым клиентом, который получит процессоры, изготовленные с применением нового техпроцесса. Тайваньский подрядчик уже строит два новых завода для размещения производства 2-нм процессоров и ожидает разрешения на строительство третьего — компания обычно строит новые предприятия, когда ей нужно увеличить производственные мощности для работы с крупными заказами, и в преддверии запуска новых техпроцессов TSMC значительно расширяется. TSMC вкладывает миллиарды в эту новую технологию полупроводникового производства, а Apple предстоит соответствующим образом адаптировать проекты своих чипов. Будучи крупнейшим клиентом тайваньского подрядчика, американская компания традиционно получает приоритетный доступ к новейшим технологиям. Так, в 2023 году она выкупила все 3-нм мощности TSMC для своих iPhone, iPad и Mac. Это партнёрство помогает Apple внедрять передовые технологии раньше конкурентов. Между запусками поколений 3 и 2 нм TSMC развёртывает несколько промежуточных решений: компания уже наладила выпуск полупроводников по технологиям N3E и N3P, которые являются усовершенствованием базового решения 3 нм. В разработке значатся N3X для сегмента высокопроизводительных вычислений и N3AE для автопрома. С начала августа прямой российский трафик YouTube сократился вдвое
21.09.2024 [13:16],
Владимир Мироненко
По оценке компании CDN Video, с момента появления проблем с доступом в России к YouTube в августе, трафик видеосервиса упал на 50 %, пишет РБК со ссылкой на заявление гендиректора CDN Video Ярослава Городецкого, сделанное в минувшую пятницу на конференции MUSE. 
Источник изображения: Christian Wiediger/unsplash.com Как сообщил Городецкий, потерянный YouTube трафик частично перераспределился в VK Video (39 %), «Яндекс» (17 %), RuTube и «Иви» (по 8 %), Okko (6 %). Еще 22 % пользователей пока не определилось с выбором предпочитаемого видеосервиса. При этом значительная часть трафика перешла «на зарубежные хостинги», то есть VPN. По данным CDN Video, на фоне спада YouTube больше всего трафик вырос у Okko (+50 %), RuTube (+43,8 %), VK Video (+35 %), «Иви» (+30,4 %) и «Яндекса» (+21,4 %). По словам представителя RuTube, аудитория и трафик видеосервиса за последние два месяца «практически удвоились», хотя планировали достичь этого показателя только к концу года. Согласно прогнозу Городецкого, в России не будет платформы, способной подобно YouTube монополизировать рынок, поскольку на это место претендует много желающих. «Думаю, произойдёт некая фрагментация рынка: кто-то умеет хорошо монетизировать пользовательские видео, кто-то является частью больших медиахолдингов и т.д. В итоге будет несколько лидеров [в разных нишах]», — считает эксперт. Хотя проблемы с доступом в YouTube наблюдаются с августа, официальную причину этого пока не назвали. В «Ростелекоме» ещё раньше указывали на снижение качества работы видеосервиса в связи с уходом Google из России офиса и последовавшим за этим прекращением поддержки инфраструктуры своих кеширующих серверов на российских сетях связи. В Google, в свою очередь, утверждают, что нынешние проблемы не связаны с техническими вопросами или действиями компании. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



