|
Опрос
|
реклама
Быстрый переход
Байден и Моди договорились о строительстве фабрики чипов в Индии
23.09.2024 [14:44],
Владимир Фетисов
США и Индия достигли соглашения, в рамках которого в южноазиатской стране будет построен новый завод по производству полупроводниковой продукции. Об этом сказано в официальном сообщении Белого дома, опубликованном после встречи президента США Джозефа Байдена (Joseph Biden) и премьер-министра Индии Нарендры Моди (Narendra Modi), которая прошла в минувшие выходные в штате Делавэр, США. 
Источник изображения: Brendan Smialowski/AFP/Getty Images В сообщении сказано, что новый завод будет выпускать полупроводниковую продукцию для использования в инфракрасных приборах, а также чипы на основе нитрида галлия и карбида кремния. Создание предприятия стало возможным благодаря «Индийской полупроводниковой миссии», а также «стратегическому технологическому партнёрству между Bharat Semi, 3rdiTech Inc. и Космическими силами США». Стратегическое геополитическое положении Индии в Азии привлекло внимание к стране и её возможностям в технологической индустрии. Последние годы Моди неоднократно позиционировал свою страну в качестве альтернативы Китаю, и это уже принесло определённые результаты. К примеру, Apple и Samsung перенесли часть производственных мощностей из Китая в Индию. На этом фоне Индия продолжает двигаться к тому, чтобы расширить свой сектор электроники до $500 млрд к концу десятилетия. В дополнение к этому страны объявили о планах по финансированию проектов, «катализирующих развитие внутренней цепочки поставок чистой энергии в Индии» на общую сумму в $1 млрд. В рамках своей поездки в США Моди примет участие в ежегодном саммите Quad, проведёт двусторонние переговорами с лидерами нескольких стран, а также выступит на Генеральной Ассамблее ООН и встретится с руководителями американских технологических компаний. Бывший тестировщик Half-Life нашёл у себя в гараже диск с бета-версией легендарного шутера Valve — в неё даже можно поиграть
23.09.2024 [14:05],
Михаил Романов
За более чем 25 лет с выхода оригинальной Half-Life игроки перепробовали множество сборок легендарного шутера Valve, однако недавно в открытый доступ попала предрелизная версия проекта. 
Источник изображения: Valve Бывший разработчик и тестировщик Чад Джессап (Chad Jessup) полторы недели назад взялся разбирать завалы у себя в гараже и среди артефактов своего игрового прошлого обнаружил диск с бета-версией Half-Life от 20 октября 1998 года. По словам Джессапа, он был одним из внешних тестировщиков Half-Life, и найденный им диск содержит сборку, которая вышла за несколько недель до официального релиза и содержит ряд «неожиданных отличий» от финальной. 
Источник изображения: X (ubahs1337) Архивариус Reagan (Frogsnatcher в X) задокументировал некоторые изменения в личном блоге: например, вторая половина карты из главы «Забудьте о Фримене!» в «бете» разительно отличается от финальной (см. видео ниже). В основном же различия не такие заметные (скрипты, ИИ, модели, текстуры), хотя торговый автомат с напитками Pepsi в глаза бросается — перед тем, как остановиться на выдуманном варианте, Valve перепробовала несколько реальных брендов. Благодаря Reagan найденная Джессапом бета-версия Half-Life образца второго сетевого тестирования была загружена в интернет-архив и доступна бесплатно. Однако заставить игру работать на современном ПК не так просто. Энтузиасты уже нашли обходные пути для решения проблем с установкой (вроде требования диска или истечения сроков запуска) и даже начали публиковать инструкции по инсталляции. Полностью беспилотные грузовики начали курсировать между Москвой и Санкт-Петербургом
23.09.2024 [13:26],
Владимир Мироненко
Сегодня состоялась торжественная церемония, посвящённая запуску движения полностью беспилотных грузовых автомобилей по трассе М-11 «Нева», соединяющей Москву и Санкт-Петербург, пишет ТАСС. В церемонии запуска, проведённой в рамках форума «Цифровая транспортация», принял участие вице-премьер РФ Виталий Савельев. 
Источник изображений: Минтранс России «В июне прошлого года мы начали беспилотные грузоперевозки между двумя столицами. На маршрут вышли автономные тягачи. Сначала на трассе работало три автомобиля, а за год их число увеличилось до 22. Они проехали более 3 млн км и перевезли свыше 330 тыс. м3 груза. К концу года автопарк вырастет до 43 машин, а в следующем году составит уже 93 автомобиля», — сообщил вице-премьер.  Как сообщает ТАСС, в рамках проекта осуществляется перевозка грузов таких компаний, как «Национальный перевозчик», «Глобалтрак», «ПЭК», Х5, «Магнит», «Газпромнефть-Снабжение» и Wildberries.  Беспилотные грузовики начали осуществлять перевозки по трассе М-11 «Нева» летом 2022 года, в рамках проекта «Беспилотные логистические коридоры», предложенного Минтрансом России и бизнесом весной 2021 года. Для запуска эксперимента правительство РФ одобрило введение экспериментального правового режима (ЭПР) на участке трассы М-11 «Нева» между Москвой и Санкт-Петербургом, который позволяет протестировать все аспекты внедрения технологий, нормативно-правовое регулирование и бизнес-модели. За рулём всё это время находились страхующие водители. В августе этого года действие ЭПР было распространено на трассы М-12 «Восток» и ЦКАД. Инсайдер раскрыл главный источник вдохновения для мультиплеерной Assassin's Creed Invictus — Fall Guys
23.09.2024 [12:46],
Михаил Романов
Французский блогер и датамайнер j0nathan поделился подробностями Assassin's Creed Invictus (кодовое название) — новой многопользовательской игры в серии псевдоисторических боевиков от Ubisoft. 
Источник изображения: Mediatonic По данным j0nathan, Assassin's Creed Invictus представляет собой аналог сетевой аркады Fall Guys: Ultimate Knockout от студии Mediatonic: 16 человек соревнуются друг с другом в нескольких режимах игры. Среди доступных форматов — командный бой на смерть, каждый сам за себя, игра на скорость (сбор светящихся точек). Проход в следующий раунд позволяет выбрать способности для использования в предстоящем матче. 
Источник изображения: Ubisoft Если верить j0nathan, Assassin's Creed Invictus позволит взять под контроль различных персонажей серии (блогер упомянул Эцио и Чезаре Борджиа) и предложит аркадный геймплей без реальной отдачи от ударов и с отдалённой от героев камерой. Карты в Invictus якобы будут вдохновлены разными играми серии: Багдад (Mirage), Япония (Shadows), тропический остров (вероятно, Black Flag). Планируется также локация на основе города Помпеи с поднимающимся уровнем лавы. 
Серия Assassin's Creed уже пересекалась с Fall Guys (источник изображения: Mediatonic) Официальных подробностей Assassin's Creed Invictus на данном этапе немного: известно, что игра создаётся командой ветеранов For Honor и войдёт в состав платформы Assassin’s Creed Infinity (она же теперь «Анимус»). Помимо Invictus, в составе Assassin’s Creed Infinity числится грядущая Assassin’s Creed Shadows. Боевик выходит уже 15 ноября, однако детали работы «Анимуса» до сих пор не раскрываются. Seasonic выпустила блок питания PRIME PX-2200 мощностью 2200 Вт за $500
23.09.2024 [12:42],
Николай Хижняк
Компания Seasonic выпустила блок питания PRIME PX-2200 мощностью 2200 Вт. Новинку впервые показывали на выставке Computex 2024 летом этого года. 
Источник изображений: Seasonic Производитель заявляет для PRIME PX-2200 соответствие стандартам питания ATX 3.1 и PCIe 5.1. Блок питания имеет сертификацию 80 Plus Platinum EU 230 V, указывающую на его высокую энергоэффективность.  В оснащение PRIME PX-2200 входят два разъёма питания 12V-2x6 для видеокарт. В БП используются высококачественные и надёжные японские алюминиевые электролитические конденсаторы, рассчитанные на работу при температурах до 105 °C. Компоненты блока питания охлаждаются 135-мм вентилятором.  Блок питания обладает защитой от превышения напряжения (OVP), превышения мощности (OPP), короткого замыкания (SCP), понижения напряжения в сети (UVP), перегрева (OTP), а также защитой от превышения силы тока (OCP).  PRIME PX-2200 поставляется с богатой комплектацией: в коробку производитель поместил множество кабелей питания, держателей кабелей, а также тестер и сумки для БП и для кабелей. На БП производитель предоставляет 12-летнюю гарантию. 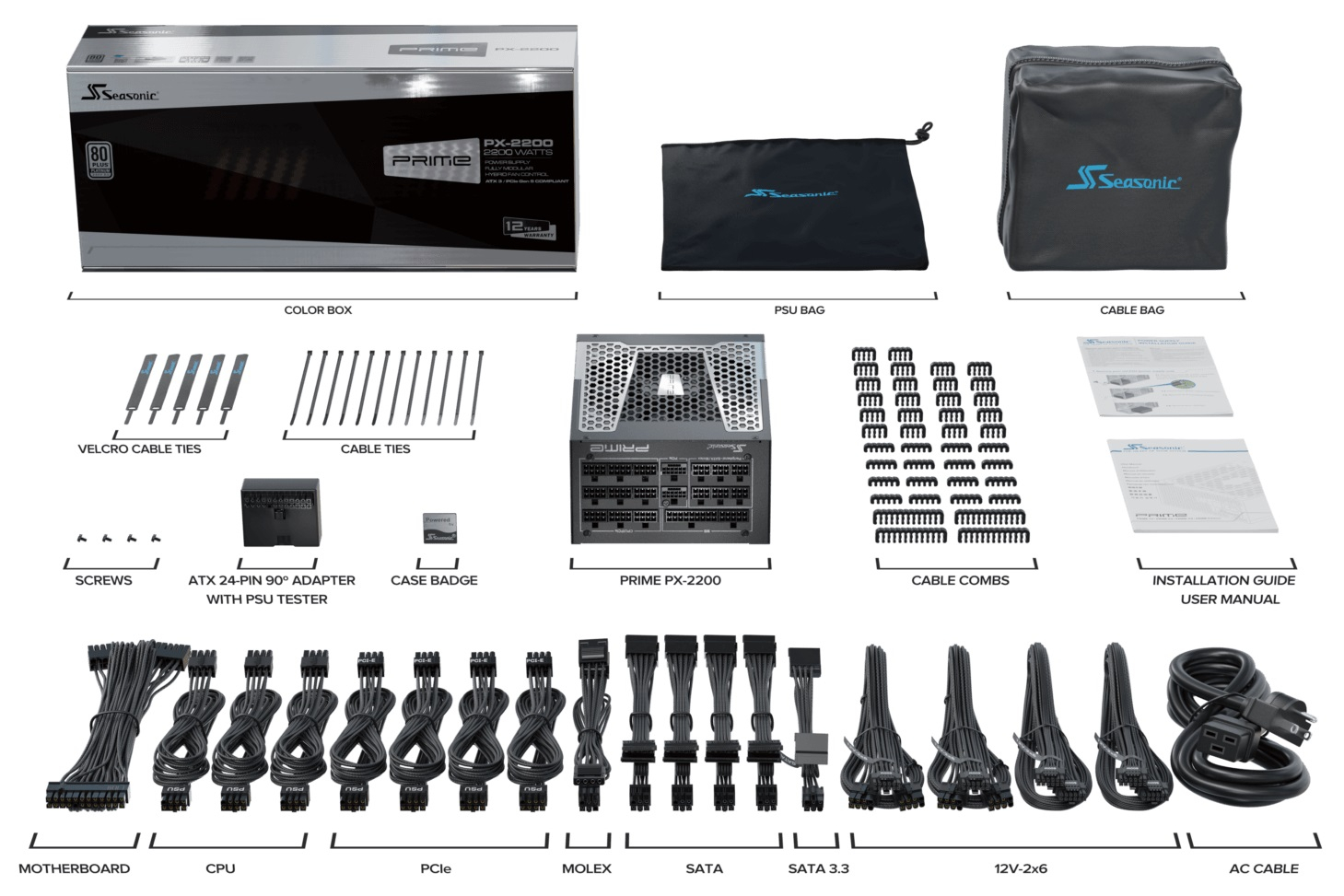 В Китае Seasonic PRIME PX-2200 уже доступен. Продажи новинки в Европе и остальном мире начнутся до конца текущего месяца, а в США он появится в октябре. Стоимость блока питания в Европе составит €579,90, в остальном мире — $499,99. Mercedes-Benz разогнал свой автопилот третьего уровня до 95 км/ч
23.09.2024 [12:34],
Алексей Разин
Способность современной автоматики управлять транспортными средствами без вмешательства человека ограничена рядом условий, и скорость движения является одним из них. Mercedes-Benz удалось поднять предел скорости при движении в автоматическом режиме с 60 до 95 км/ч, сняв требование на применение автопилота третьего уровня только в условиях городских пробок. 
Источник изображения: Mercedes-Benz По сути, как отмечает сайт ComputerBase.de, скоро системой Drive Pilot этого немецкого автопроизводителя можно будет пользоваться не только в пробках при движении со скоростью не более 60 км/ч в крайнем правом ряду. Во-первых, автоматика после обновления ПО способна управлять машиной на скорости до 95 км/ч. Во-вторых, автопилот третьего уровня по классификации SAE в исполнении Mercedes-Benz подразумевает, что водителю нет нужды при активации данной функции постоянно следить за дорогой или держать руки на руле. Ему и ранее дозволено было при движении в пробках откинуться для отдыха, играть на бортовом компьютере или просматривать видео. К концу текущего года Mercedes-Benz завершит испытания новой версии Drive Pilot, которая поднимет предел скорости до 95 км/ч в автоматическом режиме управления. После одобрения со стороны властей такое обновление начнёт распространяться на клиентских машинах в начале 2025 года. Правда, одно важное ограничение всё же сохраняется — перед пользователем такой системы должен двигаться другой автомобиль, играющий роль «ведущего». Расстояние до такой машины при движении по загородным шоссе должно измеряться сотнями метров, и активировать автопилот удастся только в крайней правой полосе. Кстати, рубеж в 95 км/ч выбран не случайно: специалисты Mercedes-Benz просто прибавили к типичной для грузовиков на немецких трассах скорости 80 км/ч погрешность в 15 км/ч, чтобы позволить автопилоту легковой машины следовать за таким «ведущим» в пределах одной полосы. К концу десятилетия Mercedes-Benz стремится поднять скорость движения на автопилоте до 130 км/ч. Обновление Drive Pilot достанется всем владельцам совместимых машин марки бесплатно и дистанционно, хотя при заказе машины сама такая опция стоит 5950 евро. Поскольку возможность её работы зависит от некоторых других особенностей комплектации, в реальности покупателю приходится за доступ к автопилоту переплачивать до 11 000 евро. Дорожные работы, туннели или сложные погодные условия являются ограничениями для работы системы, поэтому рассчитывать на активацию Drive Pilot в любой ситуации не приходится. Включение системы приводит к отображению символа «A» на приборной панели, если предельная скорость передвижения в автоматическом режиме достигает 60 км/ч, в случае её увеличения до 95 км/ч на панели будет высвечиваться символ «A+». Активировать систему можно клавишами на рулевом колесе. Автопилот третьего уровня в исполнении Mercedes-Benz подразумевает, что водителю не требуется следить за дорогой во время его активности или держать руки на руле. Однако, автопроизводитель при необходимости манипуляций в электронном устройстве рекомендует осуществлять их через интерфейс бортовой мультимедийной системы, поскольку держать смартфон между лицом и рулевым колесом небезопасно: при столкновении он может быть придавлен к лицу подушкой безопасности с большой силой. В случае необходимости взаимодействия со смартфоном его лучше держать справа в стороне. 
Источник изображения: ComputerBase.de При необходимости передачи управления обратно водителю бортовая автоматика Mercedes-Benz даёт ему 10 секунд на подтверждение готовности сделать это. Если требования системы игнорируются, машина будет издавать различные звуковые и визуальные сигналы, после чего подтянет ремень безопасности и плавно остановится в той же полосе движения, включив аварийную сигнализацию и вызвав экстренные службы. В такой ситуации автоматика будет считать, что водитель плохо себя чувствует и не в состоянии взять управление на себя. Кстати, об активности автоматики окружающим будут сигнализировать светодиодные полоски бирюзового цвета, продублированные в передней и задней светотехнике, а также боковых зеркалах. На уровне законодательства использование таких сигналов пока не утверждено, но Mercedes-Benz утверждает, что испытания подтвердили уместность подобной сигнализации. GPU ограничивают свободу программирования, поэтому в сфере ИИ появятся и другие чипы — Лиза Су
23.09.2024 [11:48],
Алексей Разин
Графические процессоры, первоначально созданные для построения трёхмерных изображений, неплохо проявили себя в сфере ускорения параллельных вычислений. В эпоху бурного развития систем искусственного интеллекта они оказались очень востребованы. Глава AMD Лиза Су (Lisa Su) ожидает, что лет через пять ситуация начнёт меняться, и достойное применение в сфере ИИ найдут не только GPU. 
Источник изображения: AMD Своими соображениями она поделилась с изданием The Wall Street Journal. «Сейчас GPU являются архитектурой выбора для больших языковых моделей, поскольку они весьма эффективны в параллельных вычислениях, но при этом они дают лишь ограниченную свободу программирования. Верю ли я, что они останутся предпочтительной архитектурой через пять с лишним лет? Думаю, что всё изменится», — заявила генеральный директор AMD. По её мнению, лет через пять от GPU никто отказываться не будет, но растущую популярность обретут компоненты для систем ИИ другого рода. Более узконаправленные чипы окажутся меньше, дешевле и продемонстрируют более высокую энергетическую эффективность. Примеры подобных чипов существуют уже сейчас. Облачные гиганты типа AWS (Amazon) и Google разрабатывают их для собственных нужд, используя в типовых сферах применения. GPU остаются более универсальными вычислительными средствами, но оптимизировать их энергопотребление и снизить себестоимость из-за постоянной необходимости увеличения производительности проблематично. Broadcom уже помогает Google создавать специализированные чипы, и таких примеров будет становиться только больше. Для разработчиков профильных ускорителей важно чувствовать конъюнктуру рынка и находить нужный баланс между гибкостью программирования и эффективностью работы чипов, а также обеспечивать совместимость с используемой программной экосистемой. Если специализация чипов станет узконаправленной преждевременно, это может принести разработчику большие убытки. Лиза Су добавила, что для вычислений нет универсальных решений, которые подошли бы всем. По её словам, с GPU в будущем станут соседствовать и другие архитектуры, всё просто будет зависеть от эволюции моделей. Metal Gear Solid Delta: Snake Eater получит перевод на русский язык — Konami незаметно обновила страницу ремейка MGS 3 в Steam
23.09.2024 [11:37],
Михаил Романов
Несмотря на советский антураж, оригинальная Metal Gear Solid 3: Snake Eater не имела поддержки русского языка, но грядущий ремейк культового стелс-экшена от Konami, похоже, готовится внести в историю коррективы. 
Источник изображения: Steam (Strife) Пользователи обратили внимание, что на странице Metal Gear Solid Delta: Snake Eater (именно так называется будущий ремейк) в сервисе цифровой дистрибуции Steam изменился список поддерживаемых языков. Напомним, с самого открытия прошлым летом на странице Metal Gear Solid Delta: Snake Eater в Steam упоминалась поддержка 11 языков, однако русского среди них до недавних пор не было. 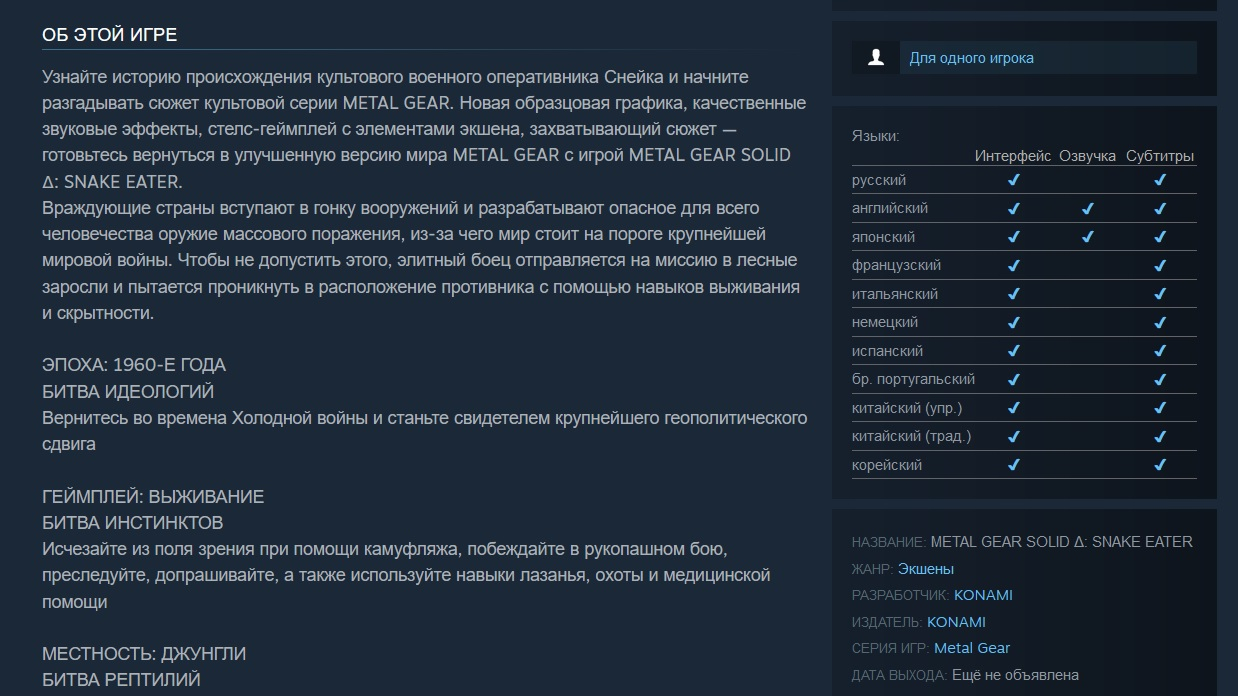
Источник изображения: Steam Судя по записи в SteamDB, в конце прошлой недели Konami удалила из списка поддерживаемых языков Metal Gear Solid Delta: Snake Eater в Steam польский и добавила вместо него русский. Как показал недавний пример Kingdom Come: Deliverance 2, пропажа языка из списка на странице в Steam не является приговором, так что польский ещё может вернуться в перечень локализаций. 
Источник изображения: Konami Помимо переработанной графики на Unreal Engine 5 и поддержки русского языка, серьёзных изменений ремейк не обещает: сюжет, гейм-дизайн, основные элементы геймплея, структура и даже озвучка останутся как в оригинальной игре. Metal Gear Solid Delta: Snake Eater создаётся для PC (Steam), PS5, Xbox Series X и S. По слухам, ремейк увидит свет лишь в 2025 году — Konami планирует объявить точную дату выхода до конца декабря. Samsung Display построит во Вьетнаме завод по производству OLED-дисплеев
23.09.2024 [11:34],
Владимир Мироненко
Южнокорейский производитель электроники Samsung Display планирует инвестировать в этом году $1,8 млрд в строительство завода по производству OLED-дисплеев для автомобилей и технологического оборудования, который будет расположен в промышленном парке Йенфонг в провинции Бакнинь на севере Вьетнама, пишет Reuters со ссылкой на заявление правительства Вьетнама, опубликованное в воскресенье. 
Источник изображения: Samsung Display Договорённость об инвестициях была достигнута в ходе встречи премьер-министра Вьетнама Фам Минь Чиня (Pham Minh Chinh) и генерального директора Samsung Vietnam Чой Джу Хо (Choi Joo Ho). Согласно местным СМИ, в воскресенье властями Бакниня и Samsung Display также был подписан меморандум о взаимопонимании по данному проекту, благодаря которому общий объём инвестиций Samsung в Бакнинь увеличится до $8,3 млрд с нынешних $6,5 млрд. За последнее десятилетие Вьетнам превратился в один из самых привлекательных производственных центров для компаний по производству электроники, отметило Reuters. По словам гендиректора Samsung Vietnam, южнокорейская компания открыла здесь шесть производственных предприятий, один научно-исследовательский центр и одно торговое представительство с совокупными инвестициями в размере $22,4 млрд. Ранее о планах разместить во Вьетнаме производство заявил американский поставщик оборудования для выпуска чипов Lam Research. Экран iPhone 16 Pro регулярно игнорирует некоторые касания и жесты, жалуются пользователи
23.09.2024 [10:28],
Владимир Фетисов
Всё больше пользователей жалуются на проблемы с отзывчивостью экрана iPhone 16 Pro. Они сталкиваются с тем, что сенсорный экран периодически не реагирует на нажатия и свайпы, что заметно при выполнении разных действий, таких как прокрутка экрана, нажатие кнопок или набор текста на виртуальной клавиатуре. 
Источник изображения: Apple Предполагается, что данная проблема связана с программной ошибкой и не является результатом какого-то аппаратного дефекта. По данным источника, причиной сбоя может являться алгоритм отклонения случайных нажатий, реализованный в iOS. По всей видимости, он настроен слишком чувствительно, из-за чего периодически отклоняет намеренные нажатия пользователя, принимая их за случайные. Некоторые владельцы iPhone 16 Pro отмечают, что проблема с отзывчивостью экрана возникает, когда один из пальцев руки находится рядом с элементом управления камерой в правой части экрана. Вероятно, проблема затрагивает все края экрана и усугубляется тем, что у новых iPhone 16 Pro как никогда тонкие рамки. Из-за этого чаще возникают ситуации, которые могут расцениваться алгоритмом, как случайное касание, после чего непродолжительное время отклоняются любые нажатия. Отмечается, что проблема может возникнуть, когда пользователь естественным образом держит телефон на ладони, обхватив пальцами боковые грани устройства. Чаще проблема с отзывчивостью экрана возникает при взаимодействии со смартфоном без чехла. По всей видимости, сбой возникает только когда устройство разблокировано, и пользователь взаимодействует с экраном. Жалобы поступают от владельцев iPhone 16 Pro с iOS 18 и бета-версией iOS 18.1. Скорее всего, Apple сумеет решить эту проблему с помощью обновления программного обеспечения. Поглощение Intel компанией Qualcomm вряд ли будет одобрено антимонопольщиками, особенно в Китае
23.09.2024 [10:24],
Алексей Разин
Желающих поверить в благополучный исход инициативы Qualcomm по приобретению активов Intel в эти выходные успокоила фраза о том, что сделка между двумя американскими компаниями не вызовет противодействия со стороны регуляторов в США. Между тем, она затрагивает интересы потребителей и на других рынках, и в том же Китае у чиновников наверняка найдутся причины заблокировать эту сделку. 
Источник изображения: Intel По крайней мере, такого мнения придерживаются аналитики Raymond James, на которых ссылается Seeking Alpha. Учитывая опыт предыдущих попыток американских компаний согласовать важные для себя сделки, рассчитывать на благосклонность китайских регуляторов в случае с Qualcomm не приходится, по мнению экспертов. В августе прошлого года именно китайские чиновники заблокировали сделку Intel по приобретению активов израильского контрактного производителя Tower Semiconductor. С точки зрения европейских регуляторов возможная сделка между Qualcomm и Intel также создаёт условия для доминирования как минимум в двух сегментах рынка: центральных процессоров для ПК и смартфонов соответственно, поскольку объединённая компания контролировала бы более 60 % того и другого. Как считают представители Raymond James, для Qualcomm имеет смысл покупка лишь части активов Intel, но не всей компании целиком, поскольку последний вариант создаёт риски регуляторного характера. Идеальным вариантом для Intel стала бы продажа дочерней компании Altera, но вопрос в том, нужен ли этот разработчик программируемых матриц компании Qualcomm. Сейчас активы Altera тянут на сумму от $18 до $22 млрд, а в 2015 году они достались Intel за $16,7 млрд. Кроме того, как считают аналитики Raymond James, активами Altera может интересоваться и компания Marvell Technology. Правда, как и в случае с Qualcomm, подобная сделка всё равно имеет шансы развалиться, встретив сопротивление китайских антимонопольных регуляторов. «Ещё один гвоздь в крышку гроба» игр по «Властелину колец»: душевный симулятор жизни хоббитов Tales of the Shire получил дату выхода и не впечатлил СМИ
23.09.2024 [10:23],
Михаил Романов
Новозеландская студия Weta Workshop при поддержке издательства Private Division провела обещанную презентацию и раскрыла дату выхода своей душевной игры о жизни хоббитов Tales of the Shire: A The Lord of the Rings Game. 
Источник изображений: Steam Напомним, Tales of the Shire: A The Lord of the Rings Game ожидалась к релизу на протяжении осени 2024 года, однако недавно разработчики объявили о переносе премьеры на начало 2025-го. Как стало известно, Tales of the Shire: A The Lord of the Rings Game выйдет 25 марта 2025 года на PC (Steam), PS5, Xbox Series X и S, Nintendo Switch и в Netflix Games. Анонс сопровождался коротким трейлером. События Tales of the Shire развернутся в ещё не получившем статус деревни местечке Байуотер на территории Шира. Игрокам предстоит создать собственного хоббита, изучать и украшать этот «идиллический уголок Средиземья». Основной сюжет будет двигать развитие отношений с жителями Байуотер. Игроки смогут обустраивать и расширять свою нору, приглашать в свой дом гостей и готовить для них, учитывая их предпочтения, свежесть и вкус продуктов. 
Певчие птицы будут указывать игрокам дорогу к цели Приуроченная ко Дню хоббита 19-минутная презентация включает много нового геймплея Tales of the Shire. Вслед за показом журналисты выложили предварительные обзоры, а IGN опубликовал первые 16 минут из игры. Судя по материалам PC Gamer и GamesRadar, Tales of the Shire не хватает очарования и глубины механик. Перенос должен позволить команде улучшить ситуацию, но пока проект видится «ещё одним гвоздём в крышку гроба» игр по «Властелину колец». AT&T с неохотой согласилась извлечь десятки тонн свинца со дна озера Тахо
23.09.2024 [09:13],
Руслан Авдеев
Американский телеком-оператор AT&T согласился изъять заброшенные кабели в свинцовой оболочке, приведшие к токсичному загрязнению озера Тахо (Tahoe). По данным Datacenter Dynamics, компания достигла судебного соглашения с природоохранной группой California Sportfishing Protection Alliance (CSPA), подавшей к ней иск в 2021 году. Кабели провели в воде не менее 60 лет. AT&T извлечёт со дна озера 107 тыс. фунтов (около 48,5 тонн) свинца, общая длина кабелей составляет около 8 миль (около 12,9 км). В CSPA празднуют победу, говоря о её важности для окружающей среды, местных жителей, получающих питьевую воду из озера, а таже миллионов посетителей берегов Тахо. Проведённое CSPA расследование выявило, что заброшенные кабели действительно отравляли воду озера. В частности, свинец обнаружили в водорослях, формирующих основу пищевых цепочек для местных рыб, некоторых моллюсках и раках. Доподлинно неизвестно, как долго кабели провели в озере. Вероятно, весьма долго, поскольку применение в США содержащей свинец кабельной инфраструктуры прекратилось в 1964 году. Зато известно, что использование свинцовых оболочек для кабелей в США началось в 1880-х. Когда стало применяться оптоволокно, старые кабели обычно просто бросали там, где они были проложены, а ВОЛС тянули параллельными маршрутами. 
Источник изображения: Rodrigo Soares/unsplash.com Изначально AT&T согласилась изъять кабели со дна в 2021 году, но практически сразу приостановила процесс и наняла девять экспертов, которые в один голос заявили, что никакой угрозы нет. Но в итоге AT&T решила не связываться с защитниками природы. Её представители заявили, что хотя компания уверена в безопасности кабелей, она всё же намерена придерживаться изначальных обещаний, касающихся озера Тахо. В прошлом году издание The Wall Street Journal провело расследование, выявившее, что AT&T, Verizon и другие американские телеком-компании загрязняют воды и земли США — их кабели со свинцовыми оболочками оставлены без присмотра как на суше, так и под водой. Всего исследователи собрали около 130 образцов с мест пролегания кабелей по всей стране. Оценка состояния почв и воды проводилась несколькими независимыми лабораториями — образцы были признаны токсичными. Всего было выявлено около 2 тыс. кабелей. Сами операторы утверждали, что многие кабели до сих пор используются, в том числе экстренными службами, и их эксплуатация не противоречит местным законам. Впоследствии против Verizon и AT&T были поданы коллективные иски, где операторов обвинили в сокрытии данных о принадлежащих им токсичных кабелях. А уже в 2024 года проблемой заинтересовалось Агентство по охране окружающей среды США (EPA). За два ближайших года Илон Маск собирается отправить на Марс пять беспилотных миссий SpaceX
23.09.2024 [08:19],
Алексей Разин
По традиции, минувшее воскресенье Илон Маск (Elon Musk) использовал для уведомления общественности о своих планах, на этот раз его откровения касались перспектив развития частной аэрокосмической компании SpaceX. До конца 2026 года она должна отправить на Марс пять беспилотных миссий, успех которых мог бы заложить фундамент для последующего полёта к этой планете космического корабля с экипажем на борту. 
Источник изображения: SpaceX Как уже отмечалось Маском ранее, выбор такого графика обусловлен благоприятными астрономическими условиями для полётов, поскольку в этот период Земля и Марс будут минимально удалены друг от друга. Если беспилотные миссии на Марс позволят отработать посадку на поверхность планеты, то пилотируемая миссия отправится через четыре года. Если же беспилотные миссии завершатся неудачей, запуск обитаемого космического корабля к Марсу компания SpaceX отложит ещё на два года. В этом году Маск уже заявлял, что посадка первого беспилотного космического аппарата на поверхность Марса должна состояться в ближайшие пять лет, а обитаемая миссия будет запущена через семь лет. Ракета-носитель Starship недавно продемонстрировала способность завершить облёт Земли с приводнением в Индийском океане. Однако, в этом году SpaceX приняла решение задержать запуск лунной миссии Artemis 3, которая подразумевала высадку людей на Луне, до сентября 2026 года. Ранее считалось, что осуществить этот полёт NASA сможет в конце 2025 года. Японский миллиардер Юсаку Маэдзава (Yusaku Maezawa) на этом фоне в июне текущего года отменил свой туристический полёт на Starship, который предусматривал облёт Луны и возвращение на Землю. ОАЭ готовы потратить $100 млрд на строительство предприятий Samsung или TSMC на своей территории
23.09.2024 [07:06],
Алексей Разин
Ранее уже появлялись слухи о стремлении главы OpenAI организовать производство чипов в странах Ближнего Востока для более эффективного решения проблемы дефицита ускорителей вычислений. Теперь The Wall Street Journal уточняет, что переговоры с властями ОАЭ уже ведут компании Samsung Electronics и TSMC. Совокупная стоимость предприятий, которые могут быть построены в этой стране, может достичь $100 млрд. 
Источник изображения: Samsung Electronics Высшее руководство TSMC, как отмечается, даже посетило ОАЭ для переговоров на эту тему. Тайваньская компания рассматривает возможность строительства в ОАЭ современного производственного комплекса, сопоставимого по величине с теми, которые есть на Тайване. Южнокорейская Samsung Electronics тоже направила в ОАЭ своих делегатов для аналогичных переговоров. Власти ОАЭ готовы через подконтрольные им инвестиционные компании субсидировать строительство предприятий по выпуску чипов, чтобы удержать уровень прибыли TSMC или Samsung на приемлемом уровне. Зарубежные предприятия обошлись бы обеим компаниям дороже в строительстве, поэтому эту разницу необходимо покрывать субсидиями, чтобы нивелировать разницу в расходах. Другой проблемой является доступ к запасам технической воды высокой степени очистки. ОАЭ основную часть воды получает из моря методом опреснения, но производство чипов требует использования очень чистой воды, и её добыча тоже обойдётся в копеечку при запуске производства чипов в ОАЭ. Зато с дешёвыми энергоресурсами проблем не будет, поскольку климатические условия позволяют добывать много электроэнергии через солнечные панели, а углеводородное топливо в регионе имеется в избытке. По слухам, интересы правительства ОАЭ в вероятных проектах с TSMC и Samsung будет представлять дочерняя компания той же Mubadala, которая является основным инвестором компании GlobalFoundries, основанной в 2009 году после отделения производственных активов от AMD. На первых порах Mubadala вынашивала планы по строительству предприятия GlobalFoundries в ОАЭ, но им не суждено было сбыться. Позже арабские инвесторы буквально «опустили руки» перед необходимостью тратить существенные суммы на освоение 7-нм технологии, и GlobalFoundries пришлось отказаться от её запуска в серийном производстве. Так или иначе, Mubadala управляет портфелем активов на общую сумму $300 млрд, поэтому частично профинансировать строительство комплекса предприятий стоимостью $100 млрд при наличии политической воли она бы смогла. Проект мог бы натолкнуться и на нехватку квалифицированных кадров для организации передового производства чипов на территории ОАЭ, но на примере американского предприятия TSMC в Аризоне уже понятно, что компания может завозить нужных специалистов с Тайваня, пока не будут подготовлены местные. Другой момент, который неизбежно возникает в свете контроля США за экспортом технологий на Ближний Восток, касается получения соответствующих экспортных лицензий компаниями TSMC и Samsung в случае готовности приступить к оснащению своих предприятий в ОАЭ технологическим оборудованием американского происхождения. Представители Совета по национальной безопасности США заявили WSJ, что они на протяжении двух последних лет работают с властями ОАЭ в части передовых технологий, и партнёрство развивается в нужном направлении. Источники отмечают, что без благословения властей США компании TSMC и Samsung не смогут начать строительство предприятий в ОАЭ, поскольку американское правительство опасается утечки передовых технологий и продукции в Китай. Apollo предложила спасти Intel от поглощения, инвестировав около $5 млрд
23.09.2024 [04:49],
Алексей Разин
После настойчивых слухов об интересе Qualcomm к активам Intel информация о прочих желающих получить доступ к ним стала поступать со страниц ресурса Bloomberg. Сперва агентство заявило, что интерес к Intel проявила компания Broadcom, а потом сообщило о готовности Apollo Global Management вложить в Intel около $5 млрд. 
Источник изображения: Intel Пока переговоры между процессорным гигантом и инвестиционным фондом только ведутся, и не факт, что они увенчаются успехом. Apollo не является новым для Intel инвестором, поскольку в июне первая купила долю в совместном предприятии с Intel, которое управляет деятельностью производственной площадки в Ирландии, тогда инвестору пришлось вложить $11 млрд. Если же вернуться к слухам об интересе Broadcom к активам Intel, то в данном случае препятствием к возможной сделке мог бы стать печальный опыт первой из компаний в части намерений приобрести Qualcomm в 2018 году. Тогдашний президент США Дональд Трамп (Donald Trump) заблокировал сделку, сославшись на интересы национальной безопасности. Убедить его Broadcom в своей лояльности так и не смогла, даже перенеся штаб-квартиру из Сингапура в США. Заменить батарею iPhone 16 поможет обычная 9-вольтовая батарейка, выяснили эксперты
23.09.2024 [00:55],
Анжелла Марина
С выходом iPhone 16 компания Apple внедрила усовершенствованный процесс замены батареи, который упростит самостоятельное проведение такой операции. Специалисты из iFixit продемонстрировали, как всего за 5 секунд можно удалить батарею с помощью электрического тока низкого напряжения. 
Источник изображения: Apple В этом году базовая модель iPhone 16 отличается от версий Pro не только внешне, но и внутренне — в более дешёвых моделях впервые для корпуса батареи используется электроотделяемый клей, упрощающий её замену, пишет The Verge. Используя официальную документацию Apple, вышедшую одновременно с выпуском смартфона, iFixit проверили, как это работает на практике и остались впечатлены. 
Источник изображения: iFixit После отключения батареи от платы к ней подключается источник питания, например, 9-вольтовая батарейка, на 90 секунд. Под воздействием тока клей теряет свои свойства, и батарея легко выпадает из корпуса под собственным весом. Для установки новой батареи достаточно просто прижать её к корпусу и клей под давлением самоактивируется. Отметим, что эксперты действовали по инструкции Apple, что также соответствовало техническим требованиями производителя инновационного клея Tesa. 
Источник изображения: Tesa В ходе разборки эксперты попутно обнаружили, что кнопка управления камерой на самом деле представляет из себя физическую кнопку, которая двигается, а гибкий кабель, скорее всего, предназначен для измерения силы нажатия. Также они обратили внимание на охлаждающий элемент, предназначенный, по всей видимости, для процессора A18, который весьма сильно греется при выполнении высокопроизводительных задач, в том числе связанных с искусственным интеллектом. 
Источник изображения: iFixit Apple отмечает, что со временем для отсоединения аккумулятора может потребоваться более долгое воздействие тока, однако на новых телефонах это может занять всего пять секунд (при использовании напряжения до 30 вольт). Новая статья: Обзор смартфона OPPO Reno 12 Pro: попытка выйти из тени
23.09.2024 [00:05],
3DNews Team
Amazon, Google и Microsoft снова пожаловались друг на друга британскому регулятору, который продлил антимонопольное расследование облачного рынка
22.09.2024 [23:40],
Владимир Мироненко
Управление по конкуренции и рынкам Великобритании (CMA) продлило сроки антимонопольного расследования положения дел на облачном рынке страны на четыре месяца — до 4 августа 2025 года. Ранее планировалось завершить его до 5 апреля следующего года, пишет DataCenter Dynamics. В своём заявлении, опубликованном 19 сентября, британский регулятор сообщил, что ведущая расследование группа считает невозможным завершить его в ранее объявленные сроки. Также указано, что несмотря на перенос крайнего срока на август, группа стремится завершить расследование «как можно скорее». Как предполагает ресурс Computer Weekly, продление расследования связано с необходимостью более подробного изучения практики лицензирования продуктов и сервисов Microsoft, которая может негативно отразиться на уровне конкуренции на облачном рынке Великобритании. Расследование CMA было начато в октябре 2023 года после публикации отчёта Ofcom, телеком-регулятора страны, в котором сообщалось о препятствиях, затрудняющим клиентам переключение между облачными провайдерами и/или одновременное использование услуг нескольких поставщиков облачных сервисов: плата за перенос данных, сборы за облачную репатриацию и скидки, стимулирующие клиентов использовать только одного поставщика, и т.д. Также поступали жалобы на практику лицензирования Microsoft, взимающую повышенную плату за запуск своего ПО в облаках конкурентов. 
Источник изображения: Vitaly Gariev / Unsplash Расследование проходит на фоне взаимных обвинений облачных провайдеров в антиконкурентном поведении. В декабре прошлого года Google, по данным источников, направила в CMA жалобу по этому поводу на Microsoft. Компания Amazon тоже сочла необходимым пожаловаться регулятору на используемую Microsoft практику лицензирования, которая усложняет переход клиентов к другим облачным провайдерам. CMA объявила о продлении расследования после того, как опубликовала отчёты о слушаниях Amazon Web Services (AWS), Google и Microsoft. Во время слушаний AWS, прошедших 2 июля, компания сообщила CMA, что она «считает конкуренцию между поставщиками ИТ-услуг хорошо функционирующей и что облачные сервисы отвечают потребностям клиентов как в Великобритании, так и во всем мире с точки зрения ценообразования, инноваций, выбора продуктов, разнообразия и качества». 
Источник изображения: Vitaly Gariev / Unsplash AWS сообщила, что считает конкурентами локальные ИТ-сервисы, отметив, что облачные сервисы составляют всего 15 % рынка ИТ-услуг Великобритании, и что представление о том, что как только клиенты переходят в облако, они никогда не возвращаются к локальным сервисам, неверно. Об этом сообщается в резюме регулятора, опубликованном 16 сентября. AWS также привела примеры клиентов, возвращающихся в локальные решения, что подчёркивает гибкость её подхода, и отметила, что «приветствует возможность» обсудить практику лицензирования Microsoft. «AWS заявила, что с 2019 года Microsoft ввела лицензионные ограничения, которые не позволяют клиентам использовать ранее приобретённые лицензии Microsoft в AWS (ограничения BYOL). AWS заявила, что это имело огромные финансовые последствия для клиентов и клиенты после покупки продукты Microsoft должны навсегда сохранить к ним доступ и иметь возможность использовать их у ИТ-провайдера по своему выбору», — сообщается в резюме CMA. Что касается сегмента ИИ, AWS указала на рост количества новых игроков, которые появились и составили дополнительную конкуренцию облачным провайдерам — вероятно, имея в виду CoreWeave и других поставщиков облачных ИИ-услуг. 
Источник изображения: Vitaly Gariev / Unsplash В свою очередь, Microsoft тоже отвергла наличие проблем с конкуренцией на рынке облачных сервисов Великобритании, добавив, что «возникшие суждения CMA о конкурентной среде и конъюнктуре рынка игнорируют реальные доказательства того, что рынок очень динамичен и быстро развивается, а степень удовлетворения потребностей клиентов высока». Компания сообщила, что на рынке Великобритании работают три гиперскейлера, и что хотя Google «не добилась такого же уровня успеха, как AWS и Azure на сегодняшний день», её не следует исключать из расследования. В ходе слушаний Microsoft заявила, что лицензионные сборы за её ПО «не столь существенно увеличивают расходы для её конкурентов», добавив, что AWS и Google имеют «достаточную маржу, чтобы конкурировать с Azure», и поэтому лицензионные сборы не приводят к ограничению доступа конкурентов к ключевым ресурсам. По словам Microsoft, соглашения об облачных услугах (CSA) со скидками на основе обязательств необходимы для конкуренции, и их отмена приведёт к более высоким ценам на рынке Великобритании. 
Источник изображения: Vitaly Gariev / Unsplash Google во время слушаний, прошедших 19 июля, а также в опубликованном ранее в этом месяце заявлении сообщила, что разделяет точку зрения CMA по поводу облачного рынка страны, в частности, о «значительной рыночной власти, которой обладают AWS и Microsoft». Для гиперскейлера с наименьшей долей рынка, эта позиция неудивительна, отметил ресурс Data Center Dynamics. Google также поддержала критику AWS в отношении практики лицензирования Microsoft, добавив, что «необходимы срочные и своевременные действия для решения проблемы политики Microsoft». Как и конкуренты, Google считает, что главную роль на рынке Великобритании играют локальные ИТ-решения, а не крупные облака. Новая статья: Warhammer 40,000: Space Marine 2 — резня и веселье во славу Императора. Рецензия
22.09.2024 [22:59],
3DNews Team
Данные берутся из публикации Warhammer 40,000: Space Marine 2 — резня и веселье во славу Императора. Рецензия Steam установил рекорд пикового онлайна — более 38 млн пользователей
22.09.2024 [19:25],
Игнатий Колыско
Сервис цифровой дистрибуции Steam от Valve обновил личный рекорд по количеству одновременно находящихся онлайн пользователей — в предыдущий раз это происходило 25 августа. 
Источник изображения: Valve SteamDB подсказывает, что 22 сентября приблизительно в 17:00 по московскому времени пиковый онлайн Steam достиг 38 367 277 человек. В играх при этом находилось менее 12,3 млн пользователей, что не дотягивает до нового рекорда (12,5 млн было в конце августа). Напомним, 25 августа пиковый онлайн Steam впервые превысил 37 млн человек. По мнению многих журналистов, тогда этому сильно поспособствовал релиз Black Myth: Wukong. Ролевой боевик даже спустя месяц продолжает оставаться в списке из 15 самых популярных игр по версии SteamDB. 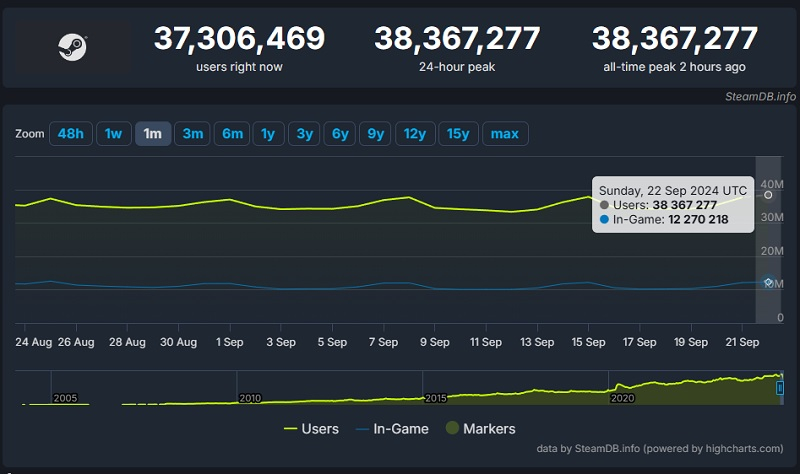
Источник изображения: SteamDB Steam в текущем году несколько раз обновлял свои рекордные показатели по количеству одновременно находящихся в системе геймеров. Как минимум, это случалось в августе, июле и несколько раз в марте. Легендарная игрушка Тамагочи опять входит в моду — мировые продажи удвоились
22.09.2024 [17:52],
Анжелла Марина
Культовая электронная игрушка 90-х Тамагочи оказалась снова на волне популярности. BBC сообщает о резком росте продаж устройств — интерес настолько высок, что в Великобритании открылся официальный магазин Тамагочи. Новая версия игрушки, которой заинтересовалась не только молодёжь, но и взрослые люди, предлагает новые технологии, такие как подключение по Wi-Fi и возможность взаимодействия с друзьями. 
Источник изображения: Cosmoh Love/Unsplash В мире, полном стрессов, люди ищут способы отвлечься и расслабиться. Виртуальные питомцы, такие как Тамагочи, предлагают простой и доступный способ хотя бы на время забыть о проблемах и погрузиться в мир приятной заботы и игры. После нескольких попыток вдохнуть новую жизнь в бренд, компания Bandai Namco, владелец Тамагочи, добилась таки успеха. «Глобальные продажи с 2022 по 2023 год выросли более чем в два раза», — сообщили представители компании BBC. Bandai Namco открыла свой первый магазин в Великобритании, чего не произошло даже в 1996 году, когда игрушка была на пике популярности. Конечно, современный Тамагочи отличается от своего предшественника из 90-х. Внешне он хоть и остался прежним — яркое яйцо с небольшим цифровым экраном и кнопками, однако функциональность игрушки значительно расширилась. «Теперь вы можете общаться с друзьями, соединяться по Wi-Fi и загружать различные предметы», — сказала Прия Джаджа (Priya Jadeja), бренд-менеджер Тамагочи. 
Источник изображения: bbc.com Напомним, виртуальный питомец официально вернулся в Великобританию в 2019 году и с тех пор набирает популярность среди игроков всех возрастов. «Когда мы перезапускали Тамагочи, мы думали, что он будет интересен в основном миллениалам, — говорит Джаджа. — Но его открывают для себя и дети, которые никогда раньше не сталкивались с подобными устройствами. Видеть, как они принимают его, очень приятно». В отличие от 1996 года, сейчас на рынке представлено множество других виртуальных питомцев. Например, Bitzee от Hatchimals с гибким дисплеем, реагирующим на прикосновения и наклоны. А осязаемый Punirunes от известной японской компании Takara Tomy, в свою очередь, предлагает популярную функцию, позволяющую «гладить» виртуального питомца на экране, помещая палец внутрь устройства. Ещё один привет из 90-х — это виртуальные питомцы DigiMon. Они также принадлежат Bandai Namco и изначально были задуманы как Тамагочи для мальчиков. Несмотря на гендерные различия, существовавшие в прошлом, Джаджа отмечает, что в настоящий момент нет никакой разницы в том, кто покупает эти игрушки. Дисплей iPhone 16 Pro Max не боится огня, а корпус выдержал тест на изгиб
22.09.2024 [17:23],
Владимир Мироненко
Автор YouTube-канала JerryRigEverything Зак Нельсон (Zach Nelson), известный своими роликами с проверками на прочность гаджетов, протестировал на устойчивость к внешнему воздействию смартфон iPhone 16 Pro Max с корпусом цвета Desert Titanium. 
Источник изображения: YouTube/JerryRigEverything Блогер отметил появление у смартфонов Apple новой сенсорной кнопки Camera Control для управления функциями камеры. Кнопка защищена от повреждений прочным сапфировым стеклом, которое он проверил на прочность. JerryRigEverything попытался нанести царапины на ней с помощью специального инструмента, с каждым шагом добавляя более твёрдый. При использовании инструмента с твёрдостью 7 по шкале Мооса на поверхности кнопки появились царапины, что подтверждает покрытие из сапфира. Вместе с тем блогер отметил, что это не чистый сапфир, о чем свидетельствует его неоднородная структура, проявляющаяся при попытке нанести царапины. JerryRigEverything также попытался определить чистоту используемого сапфира с помощью специального устройства, но это оказалось для него проблемой. Экран iPhone 16 Pro Max, а также покрытие объективов камер показали себя довольно устойчивыми к царапинам, чего не скажешь о корпусе смартфона из титанового сплава, на который нанести царапины также легко, как на изготовленный из анодированного алюминия. При этом экран показал высокую устойчивость к воздействию огнём зажигалки. Также смартфон оказался устойчивым к изгибу вне зависимости от точки приложения давления — со стороны фронтальной панели или задней. JerryRigEverything пообещал выполнить в дальнейшем разборку смартфона, чтобы выяснить причины такой повышенной устойчивости. «Образцовый ремастер»: игроки с восторгом приняли квест Broken Sword: Shadow of the Templars — Reforged
22.09.2024 [16:15],
Игнатий Колыско
Разработчики из британской студии Revolution Software выпустили обновлённую версию классического квеста Broken Sword: The Shadow of the Templars образца 1996 года. По такому случаю был представлен отдельный трейлер. 
Источник изображения: Revolution Software Доработанный вариант проекта, получивший название Broken Sword: Shadow of the Templars — Reforged, порадует поклонников жанра улучшенной графикой с поддержкой разрешения 4K. Авторы перерисовали все задники, улучшили анимацию спрайтов и снабдили игру более качественным звуком. Пользователи Steam встретили обновлённую версию квеста с теплотой, оставив на момент публикации материала 98 отзывов (рейтинг 97 %). Геймеры хвалят разработчиков за переработанную картинку и качественно сделанные анимации. А вот некоторые проблемы со звуком стали чуть ли не единственным поводом для недовольства. Вот избранные цитаты обладателей издания Reforged: «Образцовый ремастер квеста. По двадцать раз на каждом экране давил на TAB, чтобы увидеть, что перерисовали или дорисовали. […] Но в целом визуал — моё почтение. В сравнении с ним оригинал теперь выглядит очень старым», — написал некто Katarn. «Хвала создателям, точно буду проходить и смаковать эту забытую атмосферу, которая с первых кадров передана просто блестяще. Надеюсь на такой же ремейк Broken Sword 2: the Smoking Mirror», — восторженно отозвался QuinterGame. «Проблемы со звуком повсюду и это действительно раздражает. Диалоги звучат приглушённо, а уровни громкости везде разные. Когда вы разговариваете с полицейским возле кафе, вы едва можете что-либо услышать. Затем внезапно, когда Джордж разговаривает сам с собой, звук снова становится громким. Мне пришлось положиться на субтитры, чтобы просто следить за происходящим», — высказался ChallAcc. Broken Sword: Shadow of the Templars — Reforged доступна на ПК (Steam), PlayStation 5, Xbox Series X и S. Версия для Nintendo Switch выйдет в следующем месяце. Автопроизводители по всему миру стали снижать инвестиции в электромобили
22.09.2024 [14:29],
Анжелла Марина
Tesla, Ford, Mercedes-Benz и другие автогиганты корректируют свои планы в отношении производства электромобилей. На рынке наблюдается заметный сдвиг в сторону сокращения инвестиций в «зелёные» технологии, что, по заявлению экспертов отрасли, вызвано снижением спроса на этот вид транспорта. 
Источник изображения: Ernest Ojeh/Unsplash Как сообщает InsideEVs, согласно новому отчёту исследовательской компании BloombergNEF (BNEF), текущая ситуация может сказаться на количестве производимых электромобилей к концу текущего десятилетия. Ожидается, что 14 автопроизводителей, установивших цели по переходу на электромобили на 2030 год, выпустят 23,7 миллиона электромобилей, что значительно ниже первоначального прогноза в 27 миллионов. «Хотя каждый автопроизводитель устанавливает цели индивидуально, они могут коллективно трансформировать глобальный автопром, если эти цели будут успешно реализованы», — заявили аналитики BNEF. По мнению отраслевых экспертов, автопроизводители не могли предсказать, как будет развиваться рынок электрокаров. Несмотря на то что продажи автомобилей с традиционными двигателями начали снижаться с 2018 года, чёткой точки перелома, на которую надеялись компании, так и не произошло. Тем более, что инвестиции в различные типы приводов требуют значительных затрат времени и ресурсов, что создаёт существенные риски для компаний, не имеющих ясного представления о будущем. В 2024 году шесть крупных автопроизводителей пересмотрели свои прогнозы по продажам электромобилей на текущее десятилетие. В частности, Mercedes-Benz сократил свою цель по доле электромобилей в глобальных продажах с 100 % до 50 % к 2030 году. Ford также снизил свою цель по продаже электромобилей в Европе, что, вероятно, повлияет и на глобальные цели компании. Volvo отказалась от целевой установки продавать исключительно электромобили, заявив недавно, что по меньшей мере в 90 % всех её продаж войдут также гибриды. 
Источник изображения: Fer Troulik/Unsplash Volkswagen и Stellantis также не достигнут своих целей на 2030 год и, вероятно, пересмотрят свои планы в ближайшее время, считает BNEF. При этом не только долгосрочные, но и краткосрочные планы оказались под угрозой. General Motors недавно отказался от намерений произвести один миллион электромобилей в Северной Америке к 2025 году, а Toyota сократила свои прогнозы по продажам на 2026 год с 1,5 миллиона до 1 миллиона. BNEF проанализировал, как менялись заявления автопроизводителей о продажах электромобилей к 2025 году, и обнаружил, что совокупные цели достигли пика в 17,6 миллиона единиц (от 16 автопроизводителей), но на сегодняшний день составляют 11,9 миллиона (от 12 автопроизводителей). Все эти планы появились в начале десятилетия, когда в отрасли наблюдалась более оптимистичная атмосфера, что также влияло на рыночную капитализацию. Сейчас же компании стремятся продемонстрировать более взвешенный подход и, не в последнюю очередь, это связано с тем, что китайские автопроизводители начали отказываться от западных марок в пользу своих собственных моделей, повлияв тем самым на глобальные ожидания. Тем не менее, не все так плохо. Продажи электрокаров по всему миру, включая США, продолжают расти, а отраслевые эксперты ожидают долгосрочного расширения этого сегмента. По оценкам BNEF, продажи электромобилей и гибридов в США вырастут на 20 % в этом году. Оптимистичные новости приходят и от южнокорейских брендов Kia и Hyundai, которые демонстрируют устойчивый рост и не планируют значительных сокращений в производстве. Отмечается, что несмотря на текущие трудности, рынок электромобилей всё ещё имеет потенциал для роста. Ведущие игроки, такие как BYD и Tesla, продолжают активно развивать свои технологии, оставляя менее агрессивные компании позади. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



