|
Опрос
|
реклама
Быстрый переход
Project Prometheus Безоса переманил из OpenAI сооснователя xAI для создания ИИ, понимающего физический мир
07.04.2026 [12:36],
Дмитрий Федоров
ИИ-стартап Project Prometheus Джеффа Безоса (Jeff Bezos) переманил из OpenAI сооснователя xAI Кайла Косича (Kyle Kosic), усилив команду закрытого проекта, который разрабатывает системы ИИ для промышленности и уже нанял сотни сотрудников в Сан-Франциско, Лондоне и Цюрихе. 
Источник изображения: bezosearthfund.org Косич был одним из сооснователей xAI вместе с Илоном Маском (Elon Musk). До возвращения в OpenAI в 2024 году он руководил группой, отвечавшей за вычислительную основу суперкомпьютера Colossus. В Project Prometheus он продолжит заниматься проектами, связанными с вычислительной базой для ИИ-систем. Project Prometheus («Прометей») — условное название новой компании, которой руководят Безос и бывший руководитель Google Викрам Баджадж (Vikram Bajaj). Компания разрабатывает системы ИИ, способные действовать в материальном мире и выходить за рамки решений, основанных прежде всего на обработке естественного языка, таких как ChatGPT и Claude. Основной ставкой Project Prometheus стали промышленные отрасли. По словам одного из источников, компания рассчитывает создать ИИ-модель, понимающую законы физики и обученную на данных из конкретных прикладных областей, включая проектирование реактивных двигателей. Тот же источник утверждает, что проект уже собрал «крупнейший массив данных по инженерному делу и по тому, как устроены такие системы». Project Prometheus планирует приобретать доли в капитале компаний из сфер технического проектирования, авиации, архитектуры и дизайна. Эти сделки должны дать проекту доступ к данным самих компаний, которые используют для улучшения собственной ИИ-модели. Безос и Баджадж лично привлекают для этой схемы десятки миллиардов долларов и более, а также обсуждают участие в инвестиционной структуре с суверенными фондами из Сингапура и стран Персидского залива. Средства направят в постоянно действующую инвестиционную структуру, которая будет покупать доли в компаниях, на деятельность, бизнес-модели и конкурентные позиции которых ИИ, по расчёту Project Prometheus, окажет радикальное влияние. Один из собеседников сравнил эту схему с холдинговой компанией по типу Berkshire Hathaway. Project Prometheus рассчитывает ускорить внедрение ИИ в этих отраслях и не растягивать этот процесс на 10 лет. Project Prometheus также намерен направлять сотрудников в компании, в которые будет вкладываться. Речь идёт об инженерах, работающих непосредственно на площадке заказчика. Проект рассчитывает, что их участие вместе с инвестициями поможет повысить прибыльность этих компаний и улучшить их текущую работу. Переход Косича произошёл на фоне жёсткой конкуренции за специалистов в сфере ИИ. По словам людей, знакомых с ситуацией, xAI уже покинули все 11 её сооснователей. Несколько из них ушли в последние месяцы, а часть бывших сотрудников жаловалась на стиль управления Маска. Последние двое, Мануэль Кройсс (Manuel Kroiss) и Росс Нордин (Ross Nordeen), покинули компанию в конце марта. Вокруг Сэма Альтмана разгорелся мощный скандал — расследование показало, что он социопат и патологический лжец
07.04.2026 [11:25],
Дмитрий Федоров
OpenAI вновь оказалась в центре скандала, связанного с вопросами доверия к руководству. Поводом стала новая публикация о главе компании Сэме Альтмане (Sam Altman), после которой обсуждение рисков ИИ сместилось от самой технологии к тем, кто принимает ключевые решения. В фокусе оказались старые претензии к откровенности Альтмана, новые свидетельства его бывших коллег и собственный доклад OpenAI о возможных тяжёлых последствиях широкого внедрения ИИ. 
Источник изображения: @sama / x.com Публикация Ронана Фэрроу (Ronan Farrow) и Эндрю Маранца (Andrew Marantz) в The New Yorker сводит претензии к Альтману к одному выводу: часть людей, работавших с ним, считает его уклончивым и ненадёжным. Один из бывших членов совета OpenAI формулирует это предельно резко: «Для него правда не является ограничением». Сам упрёк не нов. Осенью 2023 года совет директоров OpenAI уволил Альтмана, заявив, что он «не был неизменно откровенен в своих высказываниях и общении». Позднее Альтман вернулся на пост главы компании, а большинство его противников покинули OpenAI. Разногласия с бывшими коллегами после этого не исчезли. Несколько ИИ-стартапов создали люди, прежде работавшие с Альтманом, а затем ставшие его оппонентами. Самый заметный пример — компания Anthropic, которой руководит бывший топ-менеджер OpenAI Дарио Амодеи (Dario Amodei). Его неприязнь к Альтману давно стала частью публичного конфликта между выходцами из OpenAI. 
Источник изображения: Steve Johnson / unsplash.com Новые трения, как утверждает пресса, затронули и действующее руководство компании. The Information пишет, что у Альтмана не складываются отношения с финансовым директором Сарой Фрайар (Sarah Friar). Для OpenAI, которая готовится к выходу на биржу в 2026 году, такой конфликт имеет прямое значение. По данным издания, Фрайар ранее в 2026 году говорила коллегам, что не считает компанию готовой к первичному размещением акций (IPO). OpenAI оспорила сообщения о внутренних разногласиях. В ответ на публикацию The Information компания распространила совместное заявление Альтмана и Фрайар, в котором сказано, что оба в течение последнего года с лишним напрямую участвовали во всех значимых решениях по вычислительной инфраструктуре. Тем самым OpenAI попыталась опровергнуть вывод о том, что Фрайар была отстранена от обсуждения ключевых финансовых вопросов. Отдельно компания раскритиковала публикацию The New Yorker, заявив, что значительная часть текста пересказывает уже известные события через анонимные утверждения и выборочно подобранные свидетельства людей с явной заинтересованностью. 
Источник изображения: Nathan Kuczmarski / unsplash.com Спор о доверии к Альтману обострился в момент, когда сама OpenAI призвала обсуждать регулирование передовых ИИ-систем. В докладе Industrial Policy for the Intelligence Age: Ideas to Keep People First компания пишет, что ИИ способен принести значительные выгоды, но одновременно создаёт серьёзные риски. Среди них названы исчезновение рабочих мест и целых отраслей, злоупотребление технологией со стороны злоумышленников, выход ИИ из-под человеческого контроля, использование ИИ государствами и институтами в ущерб демократическим ценностям, а также усиление концентрации власти и богатства в руках корпораций. OpenAI связывает эти риски с собственной исходной миссией. Компания напоминает, что в 2015 году Альтман и его сооснователи создали некоммерческую структуру именно для того, чтобы помогать сдерживать такие угрозы. Сегодня у OpenAI действует гибридная структура, сочетающая коммерческую и некоммерческую модели управления. В том же докладе компания предлагает и практические меры: изменить налоговые правила, чтобы увеличить сборы с крупных компаний и богатых людей и компенсировать возможное сокращение поступлений от налогов в фонд оплаты труда, если ИИ вытеснит с рынка большое число работников, а также ввести дополнительные налоги для компаний, заменяющих людей ИИ. OpenAI потребовала от генеральных прокуроров Калифорнии и Делавэра заняться расследованием «неконкурентного поведения» Илона Маска
07.04.2026 [08:34],
Алексей Разин
В конце этого месяца должно состояться судебное заседание, на котором будут рассматриваться взаимные претензии Илона Маска (Elon Musk) и стартапа OpenAI, у истоков которого он стоял, но потом вступил в резкую конфронтацию с руководством. Сейчас OpenAI требует от прокуроров штатов Калифорния и Делавэр начать расследование «неконкуретного поведения» Илона Маска. 
Источник изображения: OpenAI Соответствующее обращение было направлено генеральным прокурорам штатов Делавэр и Калифорния директором OpenAI по стратегическому развитию Джейсоном Квоном (Jason Kwon). По его словам, Маск предпринимал попытки подорвать бизнес OpenAI своими атаками на компанию, и даже привлекал для этого основателя Meta✴✴ Platforms Марка Цукерберга (Mark Zuckerberg). Кроме того, руководство OpenAI обвиняет Маска в неоднократных попытках получить контроль над стартапом в собственных материальных интересах. Миллиардер, в свою очередь, требует от OpenAI и Microsoft до $134 млрд возмещения ущерба. Илон Маск, Сэм Альтман (Sam Altman) и ряд других компаньонов основали стартап OpenAI в 2015 году, считая его некоммерческой организацией, миссией которой является разработка систем искусственного интеллекта на благо всего человечества. Предприняв неудачную попытку объединить OpenAI с Tesla в 2018 году, Маск рассорился с сооснователями стартапа и покинул его. Создав конкурирующий стартап xAI, в 2024 году Маск направил судебный иск против OpenAI, утверждая, что руководство последнего усердно им манипулировало и вводило в заблуждение, пытаясь перевести стартап на коммерческие рельсы. Состав судебной коллегии для предстоящего заседания в Калифорнии начнёт формироваться 27 апреля. По мнению OpenAI, поведение Маска может оказать сдерживающее влияние на попытки стартапа создать «сильный» искусственный интеллект (AGI), который по своим когнитивным способностям как минимум не уступает человеческому. Руководство OpenAI считает, что стартап несёт законодательные обязательства по обеспечению использования AGI для общественного блага, а усилия Маска направлены на передачу сильного ИИ в руки конкурентов, которые подобными обязательствами не обременены и отвергают любую ответственность за его применение в небезопасных целях. OpenAI счёл нужным предупредить генеральных прокуроров двух указанных выше штатов по поводу способности Маска делать заявления об этом стартапе, которые не основаны на реальности и типичны для тактики домогательства, к которой он прибегал ранее. Руководство OpenAI утверждает, что Маск и его приспешники следили за генеральным директором стартапа Сэмом Альтманом, готовясь в случае необходимости обвинить его некорректном поведении в сфере половых взаимоотношений. Представители OpenAI считают, что Маск и Цукерберг совместными усилиями пытаются предотвратить дальнейшее развитие бизнеса стартапа. Если суд встанет на сторону Маска в споре с OpenAI, это может способствовать росту интереса пользователей к чат-боту Grok, как считают представители стартапа, напоминая генеральным прокурорам двух штатов, что именно на этой платформе xAI получили распространение откровенные изображения людей, сгенерированные ИИ без их согласия, включая несовершеннолетних. С властями штатов Делавэр и Калифорния у Илона Маска имеются давние противоречия, поэтому он даже перенёс штаб-квартиры своих компаний Tesla и SpaceX в Техас. OpenAI рассчитывает разогнать годовую выручку к $300 млрд уже через четыре года
06.04.2026 [11:23],
Алексей Разин
Из документов, подготовленных OpenAI и Anthropic для IPO, можно узнать много интересного об их текущем финансовом положении и планах на будущее. Получившее доступ к этим конфиденциальным документам издание The Wall Street Journal выяснило, что выйти на окупаемость OpenAI планирует к 2030 году, и к тому момент рассчитывает получать чуть менее $300 млрд выручки в год. 
Источник изображения: Anthropic Сейчас же этот стартап весьма активно тратит средства. Например, в 2028 году OpenAI собирается направить на содержание и расширение вычислительных мощностей, а также исследования $121 млрд. Это будет примерно в два раза больше, чем в 2027 году. В свою очередь, в 2027 году OpenAI примерно удвоит свои затраты на обучение больших языковых моделей. В период с 2026 по 2027 годы OpenAI планирует тратить 100 % своей выручки на соответствующие нужды. 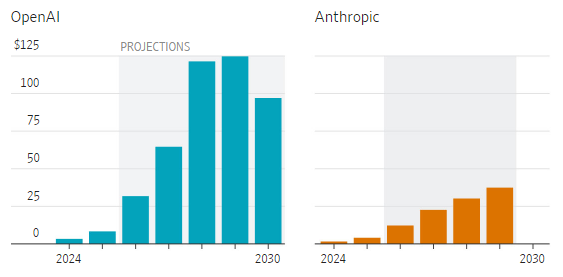
Источник изображений: The Wall Street Journal Anthropic расходы на обучение своих ИИ-моделей собирается увеличивать более плавно, даже к 2030 году они лишь превысят $30 млрд, но останутся в разы ниже, чем у OpenAI. Зато и первую прибыль, которую компания рассчитывает получить в 2030 году, OpenAI надеется сразу измерять суммой около $40 млрд. Кстати, если не учитывать расходы на обучение моделей, то OpenAI вышла бы на безубыточность уже в этом году, как и Anthropic. Первую прибыль в сумме около $5 млрд Anthropic надеется получить в 2029 году, а годом позже она уже может превысить $20 млрд. 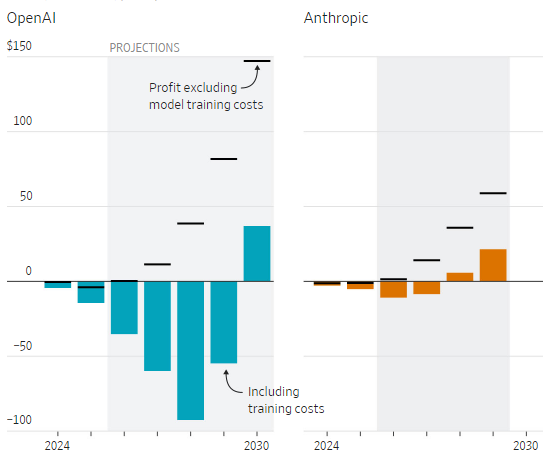 Напомним, в отличие от OpenAI которая многие свои услуги предоставляет в потребительском сегменте рынка и даже пока не получает за это денег от клиентов и рекламодателей, Anthropic сконцентрирована на корпоративном сегменте рынка, где денежные потоки формируются более исправно. Компания в этом году собирается более чем удвоить свою выручку, хотя на это же рассчитывает и OpenAI. 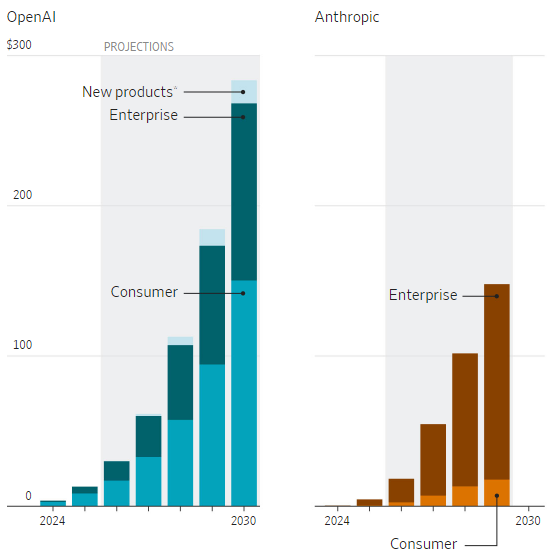 Где-то с 2028 года OpenAI собирается получать выручку не только от ИИ-моделей, но и от реализации прочих продуктов, среди которых будут и аппаратные решения. К концу десятилетия эта часть выручки компании будет измеряться миллиардами долларов, но всё равно основную часть выручки OpenAI будет получать в программном сегменте. Едва ли не $150 млрд выручки в 2030 году ей принесёт потребительский сегмент ИИ, чуть более $100 млрд обеспечит корпоративный сегмент. У Anthropic распределение выручки будет совсем иным, свои $150 млрд в 2030 году она получит главным образом от корпоративных клиентов, а потребительский сектор обеспечит не более $20 млрд выручки. В руководстве OpenAI провели очередные кадровые перестановки — частично вынужденные
04.04.2026 [14:05],
Владимир Мироненко
В OpenAI провели ряд кадровых изменений, сообщил Bloomberg со ссылкой на служебную записку компании. Это совпало с поворотным моментом в деятельности компании, готовящейся к первичному публичному размещению акций и стремящейся увеличить выручку, внедряя рекламу в ChatGPT, с целью повышения интереса потенциальных акционеров. 
Источник изображения: Levart_Photographer/unsplash.com Представитель OpenAI подтвердил ресурсу TechCrunch факт кадровых изменений. В служебной записке генерального директора по разработке искусственного интеллекта Фиджи Симо (Fidji Simo) сообщается, что Брэд Лайткэп (Brad Lightcap), операционный директор OpenAI, назначен руководителем «специальных проектов», которые будут включать «сложные сделки и инвестиции в масштабах всей компании». Он будет подчиняться непосредственно генеральному директору Сэму Альтману (Sam Altman) и курировать продажу программных продуктов обеспечения предприятиям через совместное предприятие с участием частных инвестиционных компаний. Часть его обязанностей возьмёт на себя Дениз Дрессер (Denise Dresser), недавно назначенная директором по доходам OpenAI. Директор по маркетингу Кейт Рауч (Kate Rouch) покидает свой пост, чтобы сосредоточиться на восстановлении после тяжёлого заболевания и после выздоровления вернётся к работе в OpenAI, но в «другой, более узкоспециализированной роли, когда позволит её здоровье». В связи с этим компания подыскивает кандидата на руководителя маркетинговой службы. Фиджи Симо также сообщила, что возьмёт медицинский отпуск на несколько недель для прохождения нового лечения от продолжающегося нейроиммунного заболевания и планирует вернуться на свою должность. «Время выбрано крайне неудачно, потому что у нас впереди захватывающий план действий, который команда успешно реализует, и я не хочу пропустить ни минуты», — отметила она в служебной записке. «У нас сильная команда руководителей, сосредоточенная на наших главных приоритетах: продвижении передовых исследований, расширении нашей глобальной пользовательской базы, насчитывающей почти 1 млрд пользователей, и обеспечении работы корпоративных сценариев использования», — указала OpenAI в заявлении для СМИ. — Мы хорошо подготовлены к тому, чтобы продолжать работу с сохранением преемственности и динамики». OpenAI внезапно решила потратить более сотни миллионов долларов на покупку популярного ток-шоу
03.04.2026 [07:37],
Алексей Разин
Казалось бы, отказ от второстепенных направлений развития, выразившийся и в прекращении поддержки генератора видео Sora, должен был повысить финансовую дисциплину OpenAI, но под конец этой недели появилась новость о покупке стартапом медийного актива TBPN ( Technology Business Programming Network) более чем за сотню миллионов долларов. 
Источник изображения: TBPN Как поясняет Financial Times, подкаст TBPN затрагивает технологическую сферу в своих беседах с приглашёнными экспертами, он весьма популярен в Кремниевой долине, но от OpenAI столь стремительных шагов по приобретению данного медийного актива никто не ожидал. Над созданием ток-шоу работает коллектив из 11 человек, ведущими являются Джорди Хейс (Jordi Hays) и Джон Куган (John Coogan), гостями студии уже побывали Марк Цукерберг (Mark Zuckerberg) и возглавляющий OpenAI Сэм Альтман (Sam Altman). Директор OpenAI по продуктам Фиджи Симо (Fidji Simo) отметила в своём обращении к персоналу стартапа, что «TBPN является одним из тех мест, где разговор об ИИ и его создателях ведётся на ежедневной основе». Руководству OpenAI импонирует подход ведущих TBPN к разговору о тех изменениях, которые приносит ИИ. Близкие к OpenAI источники отметили, что в компании не считают покупку TBPN отвлечением на второстепенные инициативы, поскольку она не потребует от исследователей и разработчиков распыления своих ресурсов. По некоторым оценкам, TBPN набирает по 70 000 просмотров ежедневно, в этом году данный канал вполне может выручить $30 млн, в основном от рекламы. Под крылом OpenAI ток-шоу сохранит независимость редакционной политики и будет базироваться в Лос-Анджелесе, как и прежде. Рекламодателями канала, что характерно, являются некоторые из конкурентов OpenAI. Редакция TPBN в структуре стартапа будет подчиняться директору по международному рынку Крису Лихейну (Chris Lehane). Руководители проекта смогут сами выбирать гостей, как и ранее. Сэм Альтман заявил, что не ожидает смягчения риторики в отношении OpenAI со стороны TBPN. Проект был запущен в прошлом году, его спонсорами уже являются Ramp, Plaid, Google и даже Нью-Йоркская фондовая биржа. По итогам нового раунда финансирования капитализация OpenAI выросла до $852 млрд
01.04.2026 [04:41],
Алексей Разин
Похоже, идеологическая задача достичь капитализации свыше $1 трлн по итогам IPO для OpenAI становится всё более доступной, поскольку ещё на этапе частного финансирования стартап смог выйти на оценку в $852 млрд и превысить собственные ожидания. Недавно компания привлекла $122 млрд вместо запланированных $110 млрд. 
Источник изображения: Unsplash, Levart_Photographer Свежий раунд финансирования был анонсирован в феврале, ориентиром служила сумма $110 млрд, но к концу марта OpenAI смогла привлечь от инвесторов $122 млрд, как поясняет CNBC. Это позволяет оценить текущую капитализацию стартапа в $852 млрд. Основную часть нового транша обеспечили институциональные инвесторы во главе с SoftBank. В своём пресс-релизе по поводу завершения нового раунда финансирования OpenAI заявила: «ИИ влечёт рост производительности, ускоряет научные открытия и расширяет возможности людей и организаций. Эти средства обеспечивают нас ресурсами, позволяющими сохранить лидерство в том масштабе, которого требует момент». В последнее время OpenAI пришлось отказаться от некоторых направлений развития ради концентрации на главных и потенциально наиболее выгодных. В частности, от поддержки генератора видео Sora компания отказалась весьма неожиданно, но именно финансовые соображения легли в основу этого непростого решения. Кроме того, OpenAI стала более вдумчиво подходить к расширению вычислительной инфраструктуры ИИ, в Техасе один из ЦОД в рамках проекта Stargate теперь будет достраивать Microsoft, а не OpenAI и Oracle. В прошлом году выручка OpenAI составила $13,1 млрд, а сейчас компания получает до $2 млрд в месяц, но говорить о выходе на прибыльность преждевременно. В новейшем раунде финансирования трио стратегических инвесторов должно было обеспечить привлечение $110 млрд, из них Amazon предоставила $50 млрд, ещё $30 млрд обеспечила SoftBank, а Nvidia ограничилась $30 млрд, которые она наверняка вернёт себе в виде оплаты за поставки ускорителей вычислений. Оставшиеся $12 млрд были предоставлены более широким кругом инвесторов, причём OpenAI впервые привлекла $3 млрд от индивидуальных инвесторов через банковские каналы. Степень участия Microsoft в этом раунде финансирования не раскрывается, но оно подтверждено самой OpenAI. Представители стартапа выразили уверенность, что «вложенные инвесторами средства со временем потекут обратно в экономику, к компаниям, сообществам и всё более активно — к частным лицам». Стала известна причина закрытия ИИ-генератора видео OpenAI Sora и она весьма прозаична
30.03.2026 [11:15],
Алексей Разин
На прошлой неделе OpenAI внезапно отказалась от поддержания ИИ-генератора видео Sora в строю, тем самым подведя студию Disney, которая успела ранее заключить договор, затрагивающий условия использования этого сервиса. Издание The Wall Street Journal со ссылкой на собственные источники сообщило, что основной причиной принятия столь серьёзного решения стала банальная нехватка ресурсов. 
Источник изображения: OpenAI Характерно, что речь идёт не только о финансовых ресурсах, хотя энергоёмкий сервис действительно требовал от OpenAI довольно высоких затрат на генерацию видео. Из этих соображений на раннем этапе популярности Sora компания даже ограничила продолжительность создаваемых одним пользователем видео десятью секундами, чтобы инфраструктура могла справляться с вычислительной нагрузкой. Монетизировать Sora в сжатые сроки не представлялось возможным, а расходов на своё развитие и эксплуатацию генератор видео по текстовому запросу требовал серьёзных. По некоторым данным, эксплуатация Sora обходилась OpenAI примерно в $1 млн в день. Популярность Sora хоть и взлетела до 1 млн пользователей на начальном этапе, в последнее время откатилась до уровня в 500 000 пользователей. При этом каждый из них отнимал у OpenAI востребованные в других проектах вычислительные ресурсы в приличном объёме. Источник подчёркивает, что внутренняя система мониторинга позволяет OpenAI отслеживать, чем заняты используемые в инфраструктуре стартапа ускорители вычислений. Команда разработчиков Sora, которая исторически обладала в стартапе определённой самостоятельностью, получила весьма солидную часть вычислительных ресурсов, что в условиях их нехватки на других направлениях вызвало вопросы у руководства OpenAI. Прилично заработать на Sora компания вряд ли могла бы, а вот тратить приходилось много. Кроме того, из-за дефицита ресурсов страдали другие направления развития, которые были признаны приоритетными. От идеи предлагать платный доступ к Sora через ChatGPT стартап в конечном итоге отказался. Внезапность решения OpenAI о закрытии проекта Sora подтверждают и представители Disney, с которой у стартапа был заключён договор на $1 млрд. Он предусматривал, что Disney вложит соответствующую сумму в капитал OpenAI и позволит пользователям Sora использовать лицензированных персонажей из множества принадлежащих студии франшиз в своём творчестве по созданию роликов с помощью ИИ. Руководство Disney об отказе OpenAI от поддержки Sora в работоспособном состоянии узнало примерно на час быстрее общественности, что нельзя считать заблаговременным предупреждением. В принципе, после смены руководства Disney сейчас ведёт переговоры более чем с 10 возможными партнёрами, которые смогут предоставить студии различные ИИ-услуги. На официальном уровне Disney выражает признательность OpenAI за полученный опыт сотрудничества и с уважением относится к принятому решению отказаться от развития Sora. Microsoft приберёт к рукам ЦОД почти на 1 ГВт в Техасе, который не осилили построить Oracle и OpenAI
28.03.2026 [07:27],
Алексей Разин
В первые дни своего второго президентского срока Дональд Трамп (Donald Trump) принял участие в торжественной церемонии запуска проекта Stargate, который был призван за четыре года направить на строительство инфраструктуры ИИ в США до $500 млрд. Недавно стало известно, что от возведения части объектов в Техасе компании OpenAI и Oracle были вынуждены отказаться, но их место заняла Microsoft. 
Источник изображения: Oracle Ещё в начале марта стало известно, что флагманский ЦОД проекта в техасском Абилине будет построен в меньших масштабах, чем планировалось изначально, поскольку OpenAI и Oracle стали более трезво оценивать свои силы. Фактически, бурное развитие американской инфраструктуры вычислительных центров для ИИ в последние пару лет осуществляется на голословной уверенности руководства OpenAI в востребованности данных мощностей, но платить за это приходится партнёрам компании, среди которых в первых рядах стоят Oracle и SoftBank. Финансовые возможности последних не безграничны, они уже начали залезать в многомиллиардные долги, и вполне естественно, что от части проектов в сфере ИИ они вынуждены отказываться. Изначально считалось, что часть мощностей на техасской площадке за Oracle достроит Meta✴✴ Platforms, но теперь Bloomberg сообщает, что реализацией этой части проекта займётся корпорация Microsoft, которая является крупнейшим инвестором и давним партнёром OpenAI, которая как раз и способствует продвижению инициативы Stargate. К середине следующего года на указанной площадке в Техасе уже будет возведено и подключено к электросетям первое здание, а в перспективе здесь могут расположиться вычислительные системы совокупной мощностью до 900 МВт. Microsoft согласилась взять в аренду данный центр обработки данных. SoftBank одолжила $40 млрд на год, чтобы инвестировать их в OpenAI
27.03.2026 [22:43],
Анжелла Марина
Японская транснациональная холдинговая компания SoftBank Group — один из крупнейших в мире инвесторов в технологическом секторе — в пятницу объявила о привлечении промежуточного кредита на $40 млрд. Кредит предназначен для усиления инвестиций в компанию OpenAI, а также для общих корпоративных целей. 
Источник изображения: xAI Кредит, срок погашения которого наступает в марте 2027 года, является необеспеченным и был организован при участии в том числе JPMorgan Chase, Goldman Sachs, Mizuho Bank, Sumitomo Mitsui Banking Corp и MUFG Bank, сообщает Reuters. Ранее SoftBank уже договорился о вложении $30 млрд в разработчика ChatGPT через свой фонд Vision Fund 2. Данные шаги происходят на фоне растущего спроса на технологии генеративного искусственного интеллекта, где ключевую роль играет поддерживаемая Microsoft компания OpenAI. Одновременно кредитная сделка подчёркивает всё более агрессивную ставку на ИИ основателя SoftBank Масаёси Сона (Masayoshi Son), который в последние годы пережил периоды как рекордной прибыли, так и значительных убытков Vision Fund. Напомним, SoftBank и OpenAI совместно участвовали в прошлогоднем проекте Stargate, в рамках которого планируется инвестировать до $500 млрд в течение четырёх лет в создание инфраструктуры искусственного интеллекта на территории Соединённых Штатов. В декабре 2024 года Масаёси Сон и избранный на тот момент президент США Дональд Трамп (Donald Trump) анонсировали планы SoftBank по инвестированию $100 млрд в американские проекты в сфере ИИ и связанную с этой технологией инфраструктуру в США также в течение четырёх лет. OpenAI опробовала рекламу в ChatGPT — она уже может приносить более $100 млн в год
27.03.2026 [07:03],
Алексей Разин
Исчерпав возможности привлечения капитала в прежних объёмах, OpenAI начинает формировать более благопристойное впечатление о себе в глазах инвесторов. В поисках путей монетизации своих услуг, стартап пару месяцев назад запустил в США пилотный проект по демонстрации рекламы пользователям. Представители OpenAI говорят, что в годовом выражении выручка компании от рекламы уже может превышать $100 млн. 
Источник изображения: OpenAI Ещё в январе OpenAI начала демонстрировать рекламу подписчикам тарифа ChatGPT Go и пользователям бесплатного варианта этого чат-бота. По словам представителей OpenAI, на которые ссылается CNBC, компания работает с более чем 600 рекламодателями, не наблюдая каких-либо проблем, касающихся конфиденциальности передаваемых им данных о привычках и предпочтениях пользователей. Сейчас OpenAI рассматривает идею начала демонстрации рекламы пользователям ChatGPT в Австралии, Канаде и Новой Зеландии. Демонстрацию рекламы даже в подходящих для этого тарифах подписки OpenAI ограничивает определёнными правилами. Пользователям младше 18 лет она не демонстрируется, прочие видят её под ответом чат-бота с явной маркировкой. При обсуждении ряда тем типа политики и здоровья, включая ментальное, реклама также не демонстрируется в ChatGPT. На содержание ответа чат-бота реклама тоже не влияет, по словам представителей OpenAI. В США около 85 % пользователей бесплатного тарифа ChatGPT и версии Go являются аудиторией, которой демонстрируется реклама, но на ежедневной основе не более 20 % пользователей её просматривают. Медленное развёртывание рекламного бизнеса OpenAI в компании объясняют необходимостью тщательной проработки всех деталей. Как отмечают в OpenAI, «ранние сигналы от пользователей и участвующих брендов воодушевляют нас, мы продолжаем видеть сильную заинтересованность со стороны рекламодателей». OpenAI передумала развращать ChatGPT — проект ИИ-бота для взрослых отправили «в долгий ящик»
26.03.2026 [16:51],
Алексей Разин
Усилия руководства OpenAI по оптимизации бизнес-стратегии начинают определять те приоритетные направления развития стартапа, которые достойны запланированных многомиллиардных инвестиций. Вслед за неожиданным отказом от поддержки ИИ-генератора видео Sora, как отмечает Financial Times, компания решила отложить в «долгий ящик» и проект эротического чат-бота. 
Источник изображения: Unsplash, Brian Lawson Прошлая публикация на эту тему позволяет понять, что темой запуска эротических ИИ-сервисов OpenAI интересуется уже на протяжении нескольких лет, и после длительных колебаний воплотить эти планы в жизнь сперва было решено до конца первого квартала текущего года, но недавно стало известно, что в этой сфере возникает задержка как минимум на месяц. Теперь Financial Times со ссылкой на осведомлённые источники заявляет, что проект эротической направленности отложен в «долгий ящик» на неопределённое время, поскольку инвесторы и сами сотрудники OpenAI выражают глубокую озабоченность его вероятными социальными и экономическими последствиями. Внутри стартапа даже высказываются мнения о необходимости полностью отказаться от идеи запуска эротического чат-бота. Растёт беспокойство связанных с OpenAI лиц по поводу усиления нездоровой атмосферы вокруг чат-бота, а также последствий получения доступа к взрослому контенту со стороны несовершеннолетних пользователей. Представители OpenAI в комментариях Financial Times подтвердили, что эротическая ИИ-модель отложена по срокам реализации на неопределённое время. Прежде чем принять какие-то решения о жизнеспособности проекта, OpenAI хочет провести глубокое исследование по поводу его возможного влияния на общество. Каких-либо эмпирических данных на этот счёт до сих пор не существует, поэтому к изучению проблемы важно подойти досконально. Кроме того, распылять ресурсы на второстепенные инициативы OpenAI сейчас не желает, предпочитая сосредоточиться на разработке ИИ-инструментов для повышения производительности умственного труда и их монетизации. По некоторым данным, самые востребованные свои инструменты создатели ChatGPT намерены объединить в мощном настольном приложении. Выпуск платформы с эротическим уклоном мог бы вызвать неоднозначную реакцию аудитории в ближайшее время, поскольку на фоне скандала с «раздевающим» людей чат-ботом Grok компании xAI внимание регуляторов к этой теме резко возросло. Выход апеллирующего к теме эротики ИИ-решения OpenAI мог бы насторожить инвесторов с учётом планируемого IPO компании. Тем более, что перспективы серьёзной монетизации такого продукта многим из них тоже кажутся сомнительными. Наконец, создание такого продукта могло бы натолкнуться на чисто технические трудности. Годами ChatGPT развивался с учётом определённых этических ограничений, а для реализации «эротического проекта» их пришлось бы выборочно снимать, причём с сохранением категорической блокировки некоторых табуируемых в обществе тем. Сохранить оптимальный баланс между жизнеспособностью такой модели и её безопасностью было бы крайне сложно. Недавно модернизированная система верификации возраста пользователей по-прежнему даёт сбой в более чем 10 % случаев. Это означает, что миллионы несовершеннолетних могли бы получить доступ к контенту для взрослых, и подобные факты повлекли бы серьёзные юридические риски для OpenAI. Закрытие OpenAI ИИ-генератора видео Sora обрушило миллиардную сделку с Walt Disney
26.03.2026 [09:49],
Владимир Мироненко
В связи с закрытием OpenAI приложения для создания видео на основе искусственного интеллекта Sora компания Walt Disney, по данным The Hollywood Reporter, отказалась от сделки с OpenAI стоимостью около $1 млрд. 
Источник изображения: Héctor Vásquez/unsplash.com «Поскольку зарождающаяся область искусственного интеллекта быстро развивается, мы уважаем решение OpenAI выйти из бизнеса по созданию видеороликов и переориентировать свои приоритеты на другие направления, — говорится в заявлении Disney, предоставленном СМИ. — Мы ценим конструктивное сотрудничество между нашими командами и то, чему мы научились благодаря ему, и мы продолжим взаимодействовать с платформами ИИ, чтобы находить новые способы взаимодействия с фанатами там, где они находятся, ответственно внедряя новые технологии, которые уважают интеллектуальную собственность и права создателей». В декабре Disney и OpenAI объявили о заключении трёхлетнего лицензионного соглашения, согласно которому более 200 персонажей, принадлежащих Disney, были бы доступны для использования в видеороликах, созданных с помощью приложения Sora. В рамках соглашения Disney обязалась инвестировать в ИИ-стартап $1 млрд. Хотя это соглашение представлялось практически свершившимся фактом, OpenAI указала тогда в заявлении, что оно «зависит от переговоров по окончательным соглашениям, необходимых корпоративных и советов директоров одобрений, а также стандартных условий закрытия сделки». Как сообщает Axios со ссылкой на источник, знакомый с ситуацией, деньги в рамках объявленной сделки так и не были перечислены. Ресурс Financial Times отметил, что сделка так и не состоялась, поскольку OpenAI изменила свою стратегическую направленность. Вместе с тем агентство Reuters утверждает, что Disney и OpenAI всё ещё обсуждают, есть ли другой способ сотрудничества или инвестирования между компаниями. Всё на нужды ИИ: OpenAI привлечёт ещё $10 млрд от мелких инвесторов
25.03.2026 [13:40],
Алексей Разин
Основную часть средств, необходимых OpenAI на развитие вычислительной инфраструктуры и обучение новых языковых моделей в краткосрочной перспективе, стартап недавно привлёк благодаря участию Amazon, Nvidia и SoftBank. Оставшиеся $10 млрд из $120 млрд, которые планируется привлечь в рамках текущего раунда, OpenAI получит от ряда более мелких институциональных инвесторов. 
Источник изображения: OpenAI Уточнение на этот счёт решило сделать агентство Bloomberg со ссылкой на CNBC. В своём интервью телеканалу финансовый директор OpenAI Сара Фрайар (Sarah Friar) пояснила, что стартап собирается привлечь к этой части раунда финансирования группу институциональных инвесторов во главе с Andreessen Horowitz, MGX из Абу-Даби, D.E. Shaw Ventures, TPG и T. Rowe Price. Сбор средств в размере $10 млрд планируется завершить на следующей неделе. Если учесть, что стратегические инвесторы в лице Amazon, Nvidia и SoftBank предоставили около $110 млрд, то общая сумма привлечения превысит $120 млрд. Это поднимает капитализацию OpenAI до $850 млрд, не говоря уже о рекордном масштабе привлечения финансовых ресурсов. Одновременно вложить в капитал OpenAI свои средства готовы Coatue Management, Thrive Capital и Altimeter Capital, как сообщает Bloomberg. К ним присоединится и Microsoft — самый опытный инвестор OpenAI, поддержку которого руководство стартапа по-прежнему высоко ценит. Для сравнения, капитализация конкурирующей Anthropic оценивается в $380 млрд после того, как в прошлом месяце стартапу удалось привлечь $30 млрд. OpenAI внезапно закрыла Sora — завоевавший вирусную популярность генератор ИИ-слопа
25.03.2026 [01:28],
Анжелла Марина
Компания OpenAI неожиданно приняла решение закрыть своё приложение для создания видео на основе искусственного интеллекта Sora. Нейросеть позволяла создавать видео различной тематики практически без ограничений, что делало процесс генерации из текстовых подсказок чрезвычайно простым. Продукт был выпущен в сентябре 2025 года и стал вторым приложением OpenAI для iPhone. 
Источник изображения: xAI Как выяснило издание 9to5Mac, в отличие от чат-бота ChatGPT, Sora не удалось завоевать такую же популярность. В результате, разработчики объявили о прекращении поддержки сервиса. Изначально запуск Sora сопровождался большим ажиотажем, включало в себя инструменты для генерации видеороликов, а также ленту социальных сетей для просмотра созданного контента. Функциональность сервиса позволяла создавать с лёгкостью любые видео, однако вскоре OpenAI ввела строгие ограничения, касающиеся использования интеллектуальной собственности без разрешения правообладателей. Этот шаг фактически и уничтожил на корню интерес пользователей к приложению. OpenAI объявила о прекращении поддержки Sora в сообщении на X: «Мы прощаемся с Sora. Всем, кто создавал что-то с помощью Sora, делился этим и создавал вокруг этого сообщество — спасибо. То, что вы делали с Sora, имело значение, и мы понимаем, что эта новость вас разочаровала. Вскоре мы поделимся дополнительной информацией, включая сроки разработки приложения и API, а также подробности о сохранении ваших работ», – Команда Sora Кроме того, издание The Wall Street Journal сообщает, что OpenAI сворачивает любые усилия, связанные с разработкой ИИ-моделей для генерации видео, какого бы это направления не касалось. Этот шаг объясняется ещё и тем, что компания намерена сосредоточить своё внимание на создании суперприложения. Новый продукт должен объединить в себе возможности ChatGPT, инструменты разработки Codex и веб-браузер Atlas, который на текущий момент испытывает серьёзные трудности, касающиеся безопасности и приватности. Эксперты отмечают, что Sora всегда воспринималась скорее как демонстрационная забава, а не профессиональный инструмент. Несмотря на это, проект успел заинтересовать выдающегося американского бизнесмена Боба Айгера (Bob Iger) в контексте потенциального сотрудничества с Disney. Однако проверить жизнеспособность идеи не удалось, сделка так и не состоялась. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



