|
Опрос
|
реклама
Быстрый переход
Microsoft представила три новые малые ИИ-модели семейства Phi-4
01.05.2025 [16:48],
Дмитрий Федоров
Microsoft выпустила три новые малые языковые модели (SLM) с открытой лицензией: Phi-4-mini-reasoning, Phi-4-reasoning и Phi-4-reasoning-plus. Каждая из моделей относится к классу рассуждающих (reasoning) моделей, ориентированных на логическую верификацию решений и тщательную проработку сложных задач. Эти ИИ-модели стали продолжением инициативы Microsoft по разработке компактных ИИ-систем — семейства Phi, впервые представленного год назад как фундамент для приложений, работающих на устройствах с ограниченными вычислительными возможностями. 
Источник изображения: Jackson Sophat / Unsplash Наиболее производительной из представленных является ИИ-модель Phi-4-reasoning-plus. Она представляет собой адаптацию ранее выпущенной Phi-4 под задачи логического вывода. По утверждению Microsoft, её качество ответов близко к DeepSeek R1, несмотря на существенную разницу в объёме параметров: у DeepSeek R1 — 671 млрд, тогда как у Phi-4-reasoning-plus их значительно меньше. Согласно внутреннему тестированию Microsoft, эта модель показала результаты, соответствующие ИИ-модели OpenAI o3-mini в рамках бенчмарка OmniMath, оценивающего математические способности ИИ. 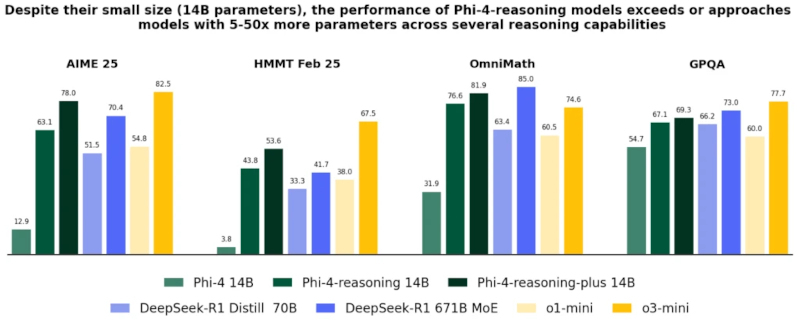
Модели Phi-4-reasoning и Phi-4-reasoning-plus (14 млрд параметров) демонстрируют превосходство над базовой Phi-4 и уверенно конкурируют с более крупными системами, включая DeepSeek-R1 Distill (70 млрд параметров) и OpenAI o3-mini, в задачах математического и логического мышления (AIME, HMMT, OmniMath, GPQA). Источник изображения: Microsoft Модель Phi-4-reasoning содержит 14 млрд параметров и обучалась на основе «качественных» данных из интернета, а также на отобранных демонстрационных примерах из o3-mini. Она оптимизирована для задач в области математики, естественных наук и программирования. Таким образом, Phi-4 reasoning ориентирована на высокоточные вычисления и аналитическую интерпретацию данных, оставаясь при этом относительно компактной и доступной для использования на локальных вычислительных платформах. 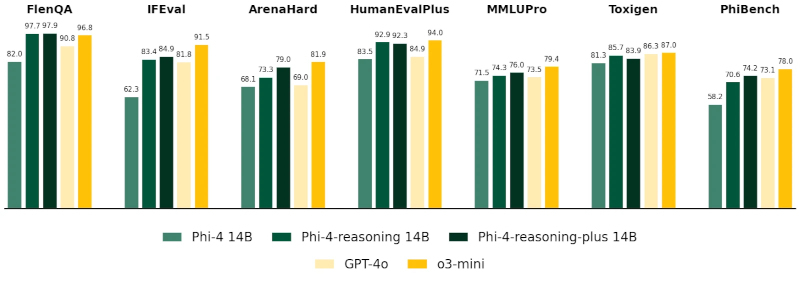
На универсальных тестах, включая FlenQA, IFEval, HumanEvalPlus, MMLUPro, ToxiGen и PhiBench, модели Phi-4-reasoning-plus демонстрируют точность, сопоставимую с GPT-4o и o3-mini, несмотря на меньший объём параметров (14 млрд параметров), особенно в задачах программирования, логики и безопасности. Источник изображения: Microsoft Phi-4-mini-reasoning — самая малогабаритная из представленных SLM. Её размер составляет около 3,8 млрд параметров. Она обучалась на основе приблизительно 1 млн синтетических математических задач, сгенерированных ИИ-моделью R1 китайского стартапа DeepSeek. Microsoft позиционирует её как ИИ-модель для образовательных сценариев, включая «встроенное обучение» на маломощных и мобильных устройствах. Благодаря компактности и точности, эта ИИ-модель может применяться в интерактивных обучающих системах, где приоритетом являются скорость отклика и ограниченность вычислительных ресурсов. 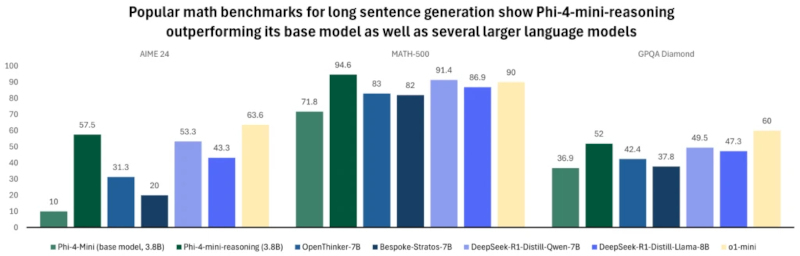
Phi-4-mini-reasoning (3,8 млрд параметров) значительно превосходит свою базовую версию и модели с вдвое большим размером на бенчмарках AIME 24, MATH-500 и GPQA Diamond, а также сопоставима или превосходит OpenAI o1-mini по точности генерации длинных математических ответов. Источник изображения: Microsoft Все три ИИ-модели доступны на платформе Hugging Face и распространяются под открытой лицензией. По словам Microsoft, при их обучении использовались дистилляция, обучение с подкреплением и высококачественные обучающие данные. Эти методы позволили сбалансировать размер SLM и их вычислительную производительность. ИИ-модели достаточно компактны, чтобы использоваться в средах с низкой задержкой, но при этом способны решать задачи, требующие строгости логического построения и достоверности результата. Ранее такие задачи были характерны лишь для гораздо более крупных ИИ. Microsoft выпустила три новые ИИ-модели ИИ Phi-3.5 — они превосходят аналоги от Google и OpenAI
23.08.2024 [11:03],
Павел Котов
Компания Microsoft не стала почивать на лаврах своего партнёрства с OpenAI и выпустила три новые системы искусственного интеллекта, относящиеся к семейству Phi — языковые и мультимодальные модели. 
Источник изображения: VentureBeat / Midjourney Три новых проекта линейки Phi 3.5 включают большую языковую модель базового варианта Phi-3.5-mini-instruct на 3,82 млрд параметров, мощную Phi-3.5-MoE-instruct на 41,9 млрд параметров, а также Phi-3.5-vision-instruct на 4,15 млрд параметров — она предназначена для анализа изображений и видео. Все три модели доступны под брендом Microsoft на платформе Hugging Face по лицензии MIT — их можно загружать, производить тонкую настройку, модифицировать и использовать в коммерческих целях без ограничений. В тестах они не уступают, а иногда и превосходят такие конкурирующие продукты как Google Gemini 1.5 Flash, Meta✴✴ Llama 3.1 и даже OpenAI GPT-4o. 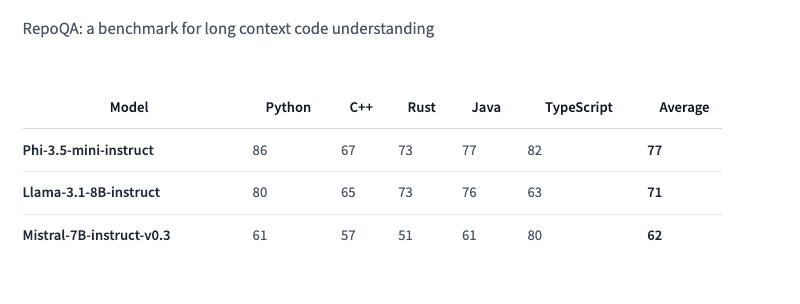
Здесь и далее источник изображения: VentureBeat / Midjourney Phi-3.5 Mini Instruct оптимизирована для окружений с ограниченными вычислительными ресурсами. Это облегчённая модель с 3,8 млрд параметров. Она предназначается для выполнения инструкций и поддерживает контекст длиной 128 тыс. токенов. Модель справляется с такими задачами как генерация кода, решение математических задач и логические рассуждения. Несмотря на свой компактный размер, Phi-3.5 Mini Instruct вполне конкурентоспособна в многоязычных и многооборотных языковых задачах. В тесте RepoQA, который используется для оценки «понимания длинного контекстного кода» она опережает, в частности, Llama-3.1-8B-instruct и Mistral-7B-instruct. 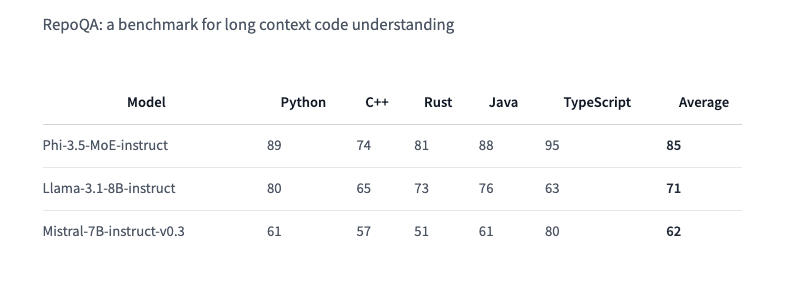 Phi-3.5 MoE (Mixture of Experts) объединяет несколько моделей различного типа, каждая из которых специализируется на собственной задаче. Архитектура модели характеризуется 42 млрд активных параметров и поддержкой контекста в 128 тыс., что позволяет применять её в требовательных приложениях — примечательно, что в документации Hugging Face говорится лишь о 6,6 млрд активных параметров. Phi-3.5 MoE демонстрирует достойные результаты в математике, генерации кода и понимании многоязычных запросов, зачастую превосходя более крупные модели в некоторых тестах, включая RepoQA; она также обошла GPT-4o mini в тесте MMLU (Massive Multitask Language Understanding) в области естественных и технических наук, а также гуманитарных и социальных дисциплин на разных уровнях знаний. 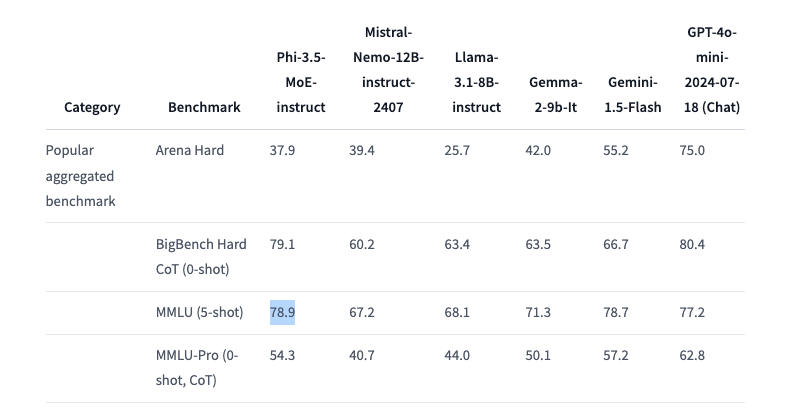 Phi-3.5 Vision Instruct объединяет возможности обработки текста и изображений. Она подходит для распознавания картинок и символов, анализа диаграмм и таблиц, а также составления сводок по видео. Vision Instruct, как и другие модели Phi-3.5, поддерживает длину контекста 128 тыс. токенов, что позволяет ей работать со сложными многокадровыми визуальными задачами. Система была обучена на синтетических и отфильтрованных общедоступных наборах данных с упором на высококачественные массивы информации с высокой плотностью рассуждений. Phi-3.5 Mini Instruct обучалась на 3,4 трлн токенов с использованием 512 ускорителей Nvidia H100-80G в течение 10 дней; модель смешанной архитектуры Phi-3.5 MoE была обучена на 4,9 трлн токенов с использованием 512 единиц Nvidia H100-80G за 23 дня; для обучения Vision Instruct на 500 млрд токенов с использованием 256 ИИ-ускорителей Nvidia A100-80G потребовались 6 дней. Всё трио Phi-3 доступно по лицензии MIT — она позволяет разработчикам свободно использовать, изменять, объединять, публиковать, распространять, сублицензировать или продавать копии продуктов. Лицензия содержит отказ от ответственности: модели предоставляются «как есть» без каких-либо гарантий — Microsoft и другие обладатели авторских прав не несут ответственности за любые претензии, убытки и прочие обязательства, которые могут возникнуть при использовании моделей. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


