







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Обзор видеокарты NVIDIA GeForce RTX 3080, часть 1
Комментарий к одной из главных премьер 2020 года (а до выхода центральных процессоров архитектуры Zen 3 и ускорителей Radeon на большом ядре Navi пожалуй что и самой главной), мы вынуждены начать с плохой новости. Тестовые образцы новых видеокарт еще не приехали в редакцию 3DNews из-за по-прежнему сложной обстановки в международных сообщениях. Да и время обзоров с бенчмарками еще не пришло — их разрешено публиковать не раньше среды 16 сентября. Поэтому сегодня мы ограничимся анализом чипов Ampere и спецификаций продуктов на их основе. Благо серия RTX 30 производит сильное впечатление даже на бумаге, а обновленная архитектура, пусть в этот раз инженеры из Санта-Клары сосредоточились на росте чистого быстродействия вместо функциональных нововведений, тоже заслуживает обстоятельного рассмотрения, чтобы понять, каким образом NVIDIA удалось так сильно прокачать характеристики. Новые GPU и правда настолько оторвались от своих предшественников, будто вернулись золотые годы Kepler, Maxwell и Pascal, дарившие экспоненциальный рост производительности с каждой итерацией железа. Затем случился Turing — без сомнения, историческое событие не только для NVIDIA, но и для потребительской 3D-графики вообще. Вот только сами потребители были не слишком обрадованы ценами видеокарт, которые чипмейкер смог установить без оглядки на AMD, в то время устранившуюся от конкуренции за рынок топовых ускорителей. К тому же все старания разработчиков Turing были направлены на расширение функций рендеринга при помощи аппаратной трассировки лучей и обработки данных нейросетями, а в играх без рейтрейсинга производительность на доллар у GeForce RTX 20-й серии в лучшем случае не изменилась по сравнению с вечнозелеными «Паскалями» (см. первую и вторую часть нашего исторического тестирования).  Игровые ускорители GeForce RTX 30-й серии в одном предложении можно охарактеризовать так: в 2,5–3 раза больше FP32-совместимых CUDA-ядер, усиленные блоки трассировки лучей и тензорные ядра, и все это на чипах с громадным количеством транзисторов, построенных по нормам 8 нм. А главное, по такой же цене, как у предшественников! Тем не менее у Ampere есть любопытные нюансы как в архитектуре, так и чисто практического свойства. Пока тестовые образцы GeForce RTX 3080 и RTX 3090 еще в пути, давайте разберемся, как устроен Ampere и нет ли поводов усомниться в его безоговорочном доминировании на рынке геймерских видеокарт. Как ни крути, AMD представит 28 октября собственные GPU следующего поколения, и, кажется, в этот раз «красные» готовы к настоящей конкуренции с NVIDIA. ⇡#Серия GeForce RTX 30В презентации, посвященной игровым продуктам нового поколения, NVIDIA представила три видеокарты: GeForce RTX 3070, RTX 3080 и RTX 3090. Все они должны поступить в продажу в течение следующего месяца, и это относится не только к референсным (Founders Edition), но и к партнерским моделям, которые появятся на магазинных полках в то же время. Дата релиза RTX 3080 — 17 сентября, RTX 3090 запланирован на 24-е, а RTX 3070 ожидается уже 15 октября. Но главное, конечно, это какие возможности и за какую цену предложит NVIDIA, обескураженная неоднозначной реакцией на серию GeForce RTX 20, тем более в условиях возродившейся конкуренцией со стороны AMD. Судя по всему, что мы смогли выяснить, RTX второго поколения не должен разочаровать. На третьей ступени пьедестала, в качестве замены GeForce RTX 2070, чипмейкер поставил видеокарту с 5888 шейдерными ALU (32-битными CUDA-ядрами). А это, между прочим, в 2,5 раза больше, чем у предшественника! Получается, что даже GeForce RTX 2080 Ti и RTX TITAN уступают младшей из новинок как по CUDA-ядрам FP32 (4352 и 4608 соответственно), так и по теоретической пропускной способности операций над вещественными числами стандартной точности. Конечно, это очень грубый критерий, который не берет в расчет другие компоненты архитектуры GPU. Ведь мы еще не разобрались, как именно инженеры NVIDIA набили столько ядер в графический процессор второго эшелона — здесь все далеко не так просто, как если бы Turing раздули до таких размеров без глубокой структурной реорганизации. Наконец, как мы еще успеем убедиться, в Ampere значительно усилили блоки трассировки лучей и ввели новый, более эффективный режим работы тензорных ядер. Пока мы не получили в свое распоряжение тестовые образцы, не будем безапелляционно утверждать, что новый GeForce RTX 3070 отправил на свалку истории всю линейку RTX 20, включая 2080 Ti, но, если оценивать по сумме характеристик, возможно, именно так и получится в хорошо распараллеленных задачах GP-GPU, профессиональных рейтрейсерах наподобие Blender и, разумеется, в играх с трассировкой лучей, где GeForce RTX 3070 обещает при разрешении 1440p производительность на 60 % выше, чем у RTX 2070. 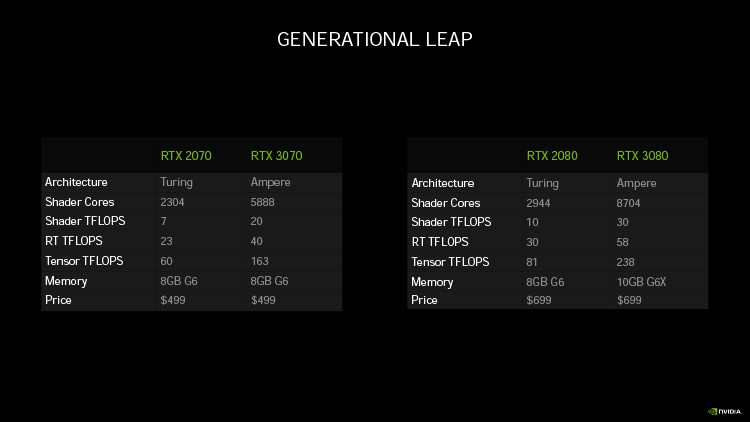 И все это — внимание! — по рекомендованной цене $499! В данном случае уместна поправка на то, что NVIDIA в свое время проапгрейдила RTX 2070 до RTX 2070 SUPER, сохранив прежнюю стоимость, а это уже совсем другая видеокарта на более мощном GPU. Как следствие, рост быстродействия на доллар уже не настолько велик, хотя все равно речь идет о таких прибавках FPS, которые мы давно отвыкли получать от производителей дискретной графики. Практика наценки на видеокарты Founders Edition и их разгон, к счастью, тоже осталась в прошлом: цены, рекомендованные для партнерских продуктов, совпадают с теми, по которыми NVIDIA будет продавать референсные устройства в собственном интернет-магазине.
Напомним, речь пока идет о младшей модели нового семейства, которая, если все теоретические выкладки и внутренние бенчмарки NVIDIA сойдутся с практикой, окажется более доступной и вместе с тем более производительной заменой GeForce RTX 2080 Ti. Перед RTX 3080 стоит более амбициозная задача поднять быстродействие в играх и рабочих приложениях на новую высоту. Старшие модели основаны на одном и том же чипе GA102, но, пусть состав исполнительных блоков процессора в RTX 3080 серьезно урезан, его спецификации по-прежнему производят чрезвычайно сильное впечатление. GeForce RTX 3080 получил 8704 FP32-совместимых шейдерных ALU и в результате двукратно превосходит по проектной пропускной способности вещественночисленных расчетов GeForce RTX 2080 Ti, а RTX 2080 — в три раза! Если добавить к этому апгрейд блоков трассировки лучей и тензорных ядер, вполне справедливой кажется предварительная оценка быстродействия новинки — на 100 % выше RTX 2080. Как и GeForce RTX 3070, вторая по старшинству модель поступит в продажу по той же рекомендованной цене, что и ее формальный предшественник, — $699. GeForce RTX 3090 закрывает серию потребительских ускорителей на чипах Ampere и, скорее всего, останется на вершине модельного ряда вплоть до выхода следующей графической архитектуры NVIDIA. Впоследствии еще могут появиться «Амперы» с приставкой Ti в названии (а может, как знать, и очередные версии SUPER), но это явно будет не RTX 3090 Ti. Дело в том, что флагману достался почти нетронутый кристалл GA102, который потерял всего лишь два SM и содержит фантастические 10 496 32-битных CUDA-ядер стандартной точности. По соответствующим оценкам быстродействия GeForce RTX 3090 в 2,19 раза превосходит TITAN RTX, не говоря уже о пресловутых усовершенствованиях RT- и тензорных ядер. Вместо того чтобы сравнивать этот в хорошем смысле чудовищный ускоритель с каким-либо из предыдущих устройств, NVIDIA было достаточно сказать, что GeForce RTX 3090 стал первой видеокартой, способной выводить игры на 8К-экран с приличной частотой смены кадров и высоким качеством графики, включая трассировку лучей — при помощи масштабирования DLSS в подходящих случаях, но тем не менее.  На первый взгляд, ободряющая тенденция к демократизации цен «зеленых» GPU обошла стороной RTX 3090. Новинку оценили в беспрецедентно высокую по меркам потребительских видеокарт сумму $1 499. По крайней мере, одночиповых, ведь именно столько стоил AMD Radeon R9 295X2. Впрочем, пусть GeForce RTX 3090 не по карману большинству геймеров, RTX 3080 уже настолько силен, что поводов для тоски по дополнительным 20 % вычислительного потенциала мы не видим. Кроме того, RTX 3090 не кажется возмутительно дорогим, если понять, что в рамках нового поколения он занимает промежуточную позицию сразу перед очередным «Титаном». Не удивительно и то, что RTX 3090 остался последней из «зеленых» видеокарт с разъемом NVLink и, соответственно, поддержкой многочипового рендеринга с помощью SLI (хотя главное предназначение NVLink — это все-таки расчеты общего назначения). Да и оперативной памяти в RTX 3090 более чем достаточно — целых 24 Гбайт. А вот вопрос о том, является ли объем VRAM у GeForce RTX 3070 и RTX 3080 адекватным их вычислительной мощности, остается открытым. RTX 3080 получит 10 Гбайт нового типа GDDR6X, а RTX 3070 — 8 Гбайт привычной памяти GDDR6. Между тем уже не редкость, когда потребление VRAM современными играми при разрешении 4К выходит за пределы 8 Гбайт. Забегая вперед, скажем, что в перспективе дефицит локальной памяти графического процессора сможет, по крайней мере частично, компенсировать программный интерфейс Microsoft DirectStorage и аппаратная технология RTX IO, на которую он будет опираться в чипах Ampere. Но пока светлое будущее не наступило, RTX 3070 может столкнуться с ограничениями по объему оперативки, которые все-таки мешают назвать его равноценной заменой 11-гигабайтного RTX 2080 Ti.
У «зеленых» продуктов нового поколения есть еще один спорный аспект. NVIDIA не стесняется величин энергопотребления на уровне 320 Вт для GeForce RTX 3080 и целых 350 Вт для GeForce RTX 3090 (аппетиты RTX 3070 оценены в умеренные 220 Вт). Когда в последний раз на нашей памяти референсные видеокарты достигали подобной мощности, это был Radeon RX Vega 64 LC со штатной СЖО (345 Вт) и Radeon VII (300 Вт). Впрочем, мы всегда стояли на позиции, что пользователя стандартного десктопа не должно волновать энергопотребление видеокарты, пока она тихо работает, не перегревается, а главное, отрабатывает затраченное электричество в играх. В последнем мы уже не особенно сомневаемся, а вот для того, чтобы гарантировать «Амперам» адекватное охлаждение, NVIDIA разработала совершенно новый и необычный дизайн референсных видеокарт. Последним и, пожалуй, главным поводом для беспокойства за геймерский Ampere для нас являются реальные розничные цены, по которым видеокарты можно будет найти в продаже, особенно поначалу. Сама NVIDIA может повесить какой угодно ярлык на устройства Founders Edition, но при таком энергопотреблении, как у старших «Амперов», производство адекватно мощной обвязки для GPU не может быть дешевым для тайваньских вендоров. Кроме того, ходят упорные слухи о том, что обязательно появятся версии GeForce RTX 3070 и RTX 3080 с удвоенным объемом VRAM, которые уж точно выйдут за рамки цен, рассчитанных на референсные спецификации. ⇡#Графический процессор GA102Первыми чипами архитектуры Ampere, официально представленными NVIDIA, являются процессор A100, предназначенный для дата-центров и рабочих станций, и GA102, венчающий линейку потребительских продуктов GeForce RTX 30. Достаточно взглянуть на титульные характеристики чипа, чтобы убедиться в том, как далеко шагнула вперед «сырая» вычислительная мощность по сравнению с кремнием Turing. Судите сами. Микроархитектура полностью функциональной версии GA102 представлена семью блоками GPC (Graphics Processing Cluster, крупнейшими масштабируемыми компонентами массива) — против шести на кристалле TU102. Каждый из них по-прежнему содержит растеризатор, выполняющий проекцию геометрии в пикселы, и 12 потоковых мультипроцессоров (Streaming Multiprocessor), вот только набор 32-битных CUDA-ядер, обрабатывающих вещественные числа, внутри SM был удвоен. В результате формула главных исполнительных блоков GA102 включает 10 752 FP32-совместимых CUDA-ядер и 336 блоков наложения текстур. 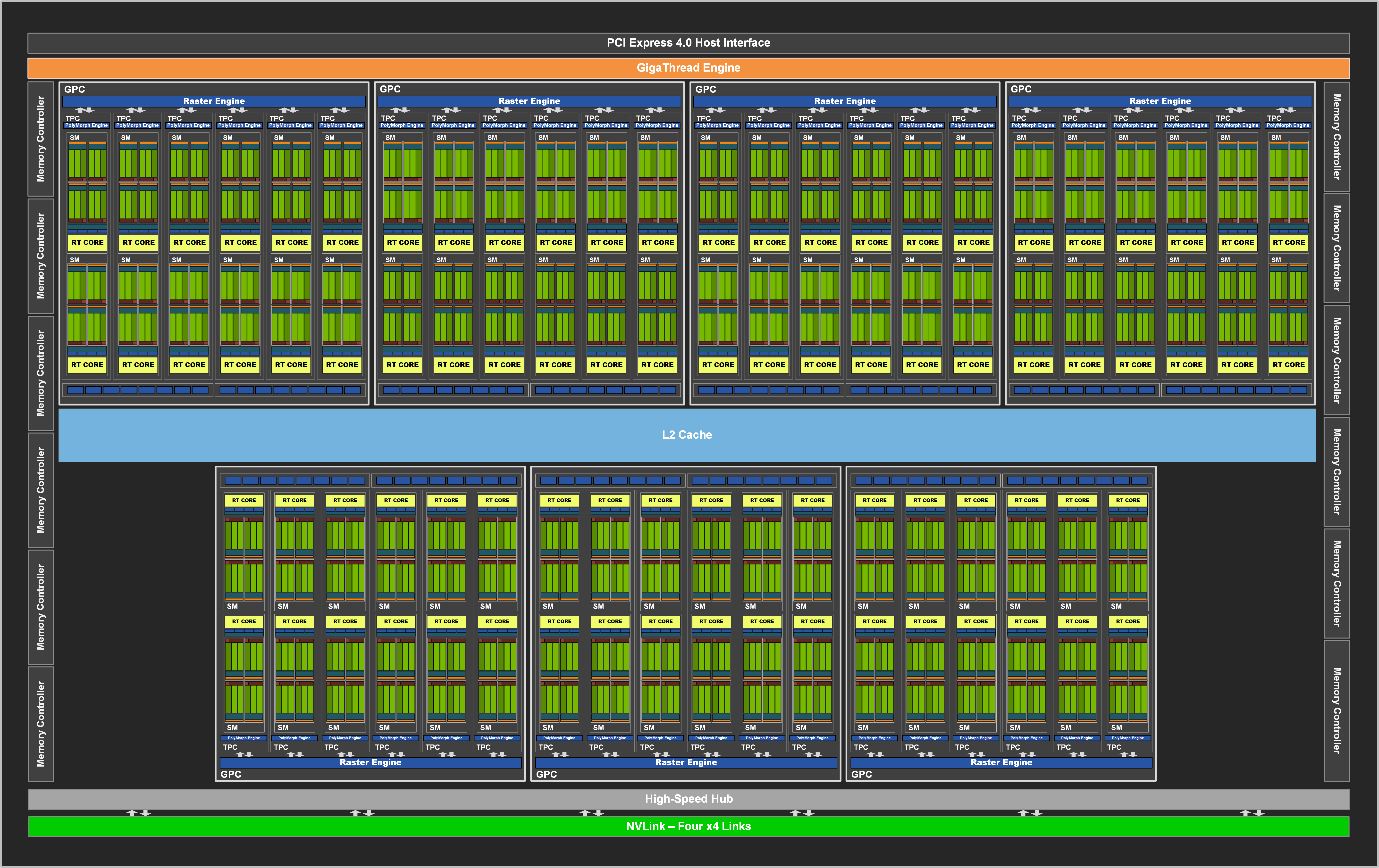 Другая особенность GA102, заметная с высоты птичьего полета, состоит в том, что блоки операций растеризации (ROP) больше не привязаны к контроллерам оперативной памяти и теперь являются компонентом GPC — единиц, из которых компания собирает процессоры различной мощности под тот или иной транзисторный и долларовый бюджет. В последнем замечании и кроется причина миграции ROP под одну крышу с потоковыми мультипроцессорами (SM). Инженеры NVIDIA стремятся выровнять пропускную способность начальной и конечной стадий конвейера рендеринга, а именно пиксельный филлрейт ROP и скорость работы растеризаторов. Растеризатор внутри GPC выдает 16 цветных пикселов за такт, а каждый ROP смешивает или закрашивает один пиксел. Теперь, когда GPC содержит 16 ROP, установилось соотношение 1:1 между пропускной способностью растеризаторов и блоков растровых операций, не зависящее от конфигурации шины памяти. Общее число блоков операций растеризации GA102 составляет 112 штук. Таким образом GA102 получил в общей сложности 112 ROP против 96 в TU102, избежав ограничения по пиксельному филлрейту, которое обязательно возникло бы в рамках предшествующей архитектуры. С другой стороны, в «мелких» чипах Ampere класса GA106 не возникнет бутылочное горлышко на стороне растеризаторов, как произошло с TU106: растеризаторы в составе трех GPC выпускают 48 пикселов за такт, в то время как 64 ROP могут закрасить, соответственно, 64 пиксела. Громадный массив исполнительных блоков GA102 питает данными 384-битная шина оперативной памяти с поддержкой нового типа микросхем GDDR6X, который мы тоже обсудим в свое время. А вот объем кеша второго уровня, как и в TU102, равен 6 Мбайт. Наконец, для связи с внешним миром используется шина PCI Express Gen 4 и интерфейс NVLink — активный в GeForce RTX 3090, но отключенный в RTX 3080. Хотя общая пропускная способность мостика осталась практически такой же, как у потребительских ускорителей архитектуры Turing (112,5 Гбайт/с в обе стороны против 100 Гбайт/с ранее), в действительности это другой интерфейс, состоящий из четырех линий x4 скоростью 28,13 Гбайт/с вместо двух широких x8 на 50 Гбайт/с. Процессор состоит ни много ни мало из 28 млрд транзисторов и является самым крупным ASIC на сегодняшний день после самого GA100 (54 млрд). Для сравнения: прямой предшественник новинки, старший «Тьюринг» TU102, содержит уже не столь впечатляющие 18,6 млрд компонентов. Настолько резкий прирост транзисторного бюджета стал возможен благодаря переходу на следующую технологическую норму после 12-нм процесса TSMC, которым NVIDIA пользовалась для производства «Тьюрингов». Исполнителем заказа на фотолитографию GA102 стал Samsung, а номинальный размер транзистора составляет 8 нм. Точно так же, как 12-нанометровая технология Turing в официальных документах NVIDIA фигурирует под названием 12 нм FFN (FinFet NVIDIA), самсунговский узел 8N был неким образом оптимизирован под чипы Ampere. Об особенностях этого конвейера нам вообще мало что известно в силу того, что он используется далеко не так активно, как близкий по номиналу 7-нм TSMC. Немедленно возникает вопрос, почему NVIDIA на этот раз выбрала Samsung, а не TSMC, но дело, скорее всего, не в технических достоинствах 8-нм FN, а в цене производства на мощностях TSMC, которые сейчас загружены другими клиентами первой величины — такими как AMD и Apple, — да и сама NVIDIA заказывает серверные процессоры GA100 там же. Благо NVIDIA недавно объявила о том, что продукты для дата-центров теперь составляют большую часть ее бизнеса, давно выделила соответствующие чипы в отдельную ветку эволюции и не нуждается в том, чтобы удешевлять производство высокомаржинальных продуктов за счет накрутки объема заказов у того же подрядчика геймерскими ускорителями. 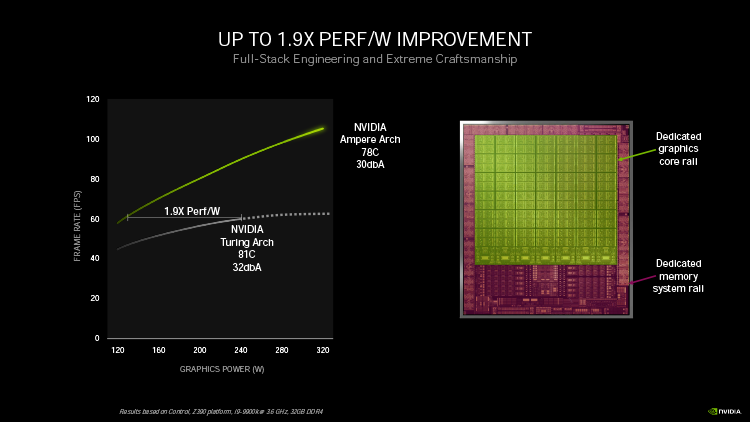 Как бы то ни было, самсунговский 8-нм FN нельзя рассматривать как техпроцесс второго сорта. Переход с узла 16 нм, на котором построен кремний Pascal, представляет собой один полный шаг технологической нормы, в то время как 12-нм был промежуточным этапом, что отражалось на размере чипов и потребляемой мощности. TU102 стал монстром площадью 754 мм2, GA102, напротив, при более чем двукратном умножении главных вычислительных единиц, оценивается вполне умеренным числом 628 мм2. И все-таки GA102 — чрезвычайно крупный, а главное, прожорливый кусок кремния. Однако NVIDIA обещает, что с энергоэффективностью у Ampere полный порядок: по официальным данным, производительность на ватт мощности у GeForce RTX 3080 возросла на 90 % по сравнению с GeForce RTX 2080 SUPER. Главная заслуга в этом принадлежит техпроцессу 8 нм, но свою роль сыграла и оптимизация схемотехники — в частности, раздельные линии питания для ядра GPU и системы памяти. Кроме того, по объявленным тактовым частотам видеокарт Ampere недалеко ушел от Turing. NVIDIA решила увеличить быстродействие за счет укрупнения чипов, всегда более выгодного с позиции энергоэффективности, а не прямого разгона, обычно ассоциируемого со сменой технологической нормы. Кроме того, невзирая на все пугающие числа, которыми характеризуется процессор GA102, — количество CUDA-ядер, площадь и энергопотребление кристалла, достоинства Ampere не сводятся к грубой силе. Архитектура графических процессоров NVIDIA прошла очередной виток усовершенствований, которые нам предстоит рассмотреть в этом обзоре.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





