С тех пор, как NVIDIA представила первые чипы с аппаратной трассировкой лучей, эволюция «зеленых» видеокарт вернулась на путь роста чистой производительности, в то время как основы логики и функциональности GPU уже были заложены на годы вперед. Кремний Ampere привнес существенные корректировки в архитектуру, и все-таки по сравнению с предыдущим поколением чипов, Turing, изменения носили уже преимущественно экстенсивный характер. Что касается семейства Ada Lovelace, которое легло в основу ускорителей 40-й серии, то главные нововведения, реализованные в этих кристаллах, связаны со специализированными блоками графического процессора. Приоритетом вновь стала энергоэффективность, а главное — быстродействие в абсолютных величинах, которое зиждется на количественных параметрах GPU.
Благодаря тому, что NVIDIA вновь получила доступ к передовой фотолитографии TSMC, ей удалось выпустить чипы с ранее немыслимым компонентным бюджетом и тактовыми частотами, стремящимися к отметке 3 ГГц. Результат — межпоколенческая разница в производительности GPU по золотому стандарту GeForce GTX 1080 Ti. Кроме того, 40-я серия GeForce появилась в более благоприятное время, чем 30-я, которой пришлось выдержать тройной удар: от глобального дефицита полупроводников, пандемии и криптовалютного бума, а значит, кризис доступности видеокарт уже не повторится — по крайней мере, в таком же масштабе.

Всем существующим позициям 30-й серии рано или поздно предстоит замена 40-ми эквивалентами, но пока NVIDIA ограничилась двумя старшими моделями — GeForce RTX 4080 и RTX 4090, которые оценены в $1 199 и $1 599 соответственно. Даже RTX 4080 сулит ощутимо большую производительность по сравнению со старшими представителями GeForce 30, но его релиз состоится 16 ноября. А флагманский GeForce RTX 4090 уже здесь и готов к обзору, пусть и с изрядной задержкой после того, как новинку успели оценить наши зарубежные коллеги.
⇡#Архитектура Ada Lovelace и графический процессор AD102
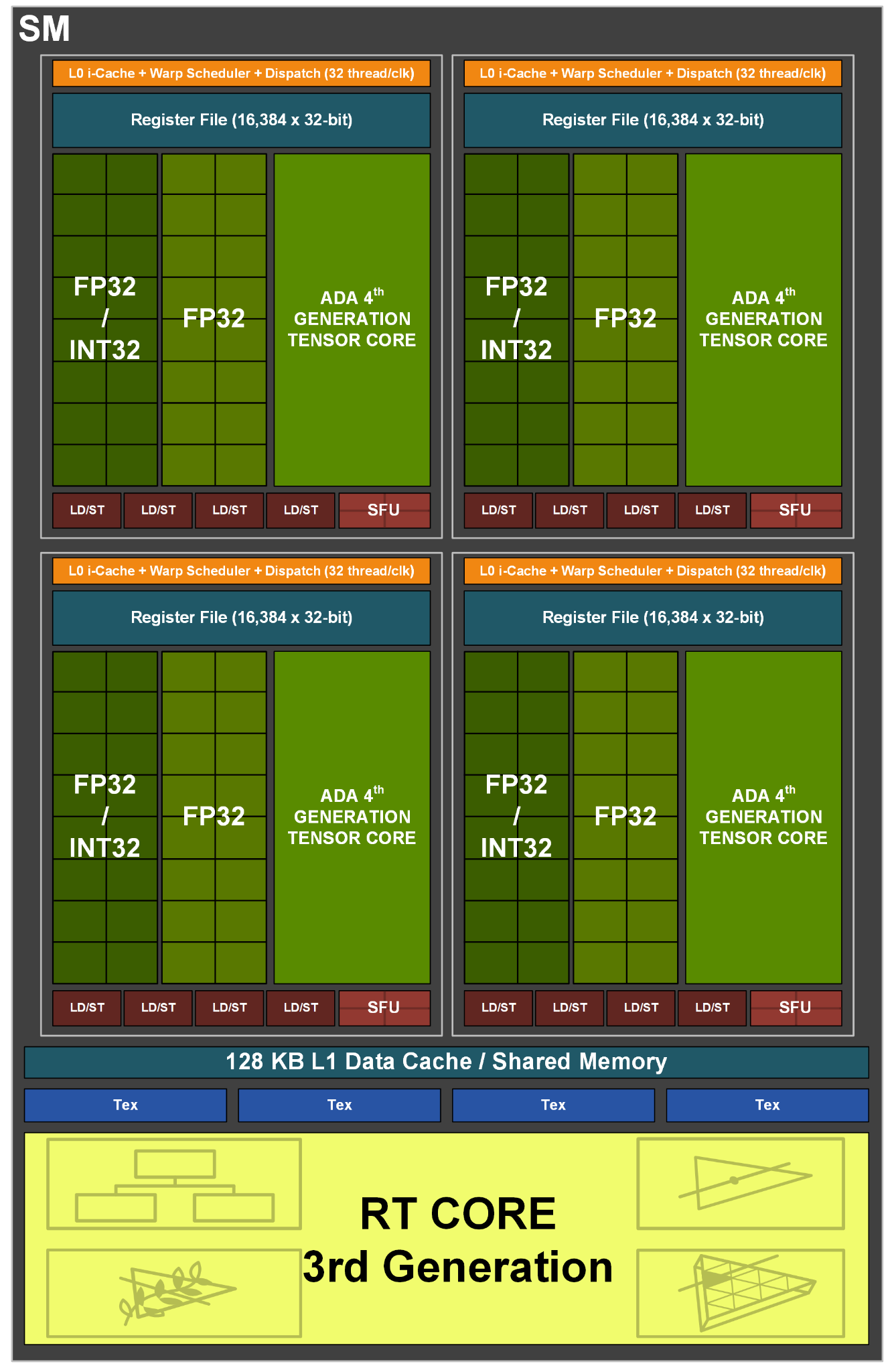
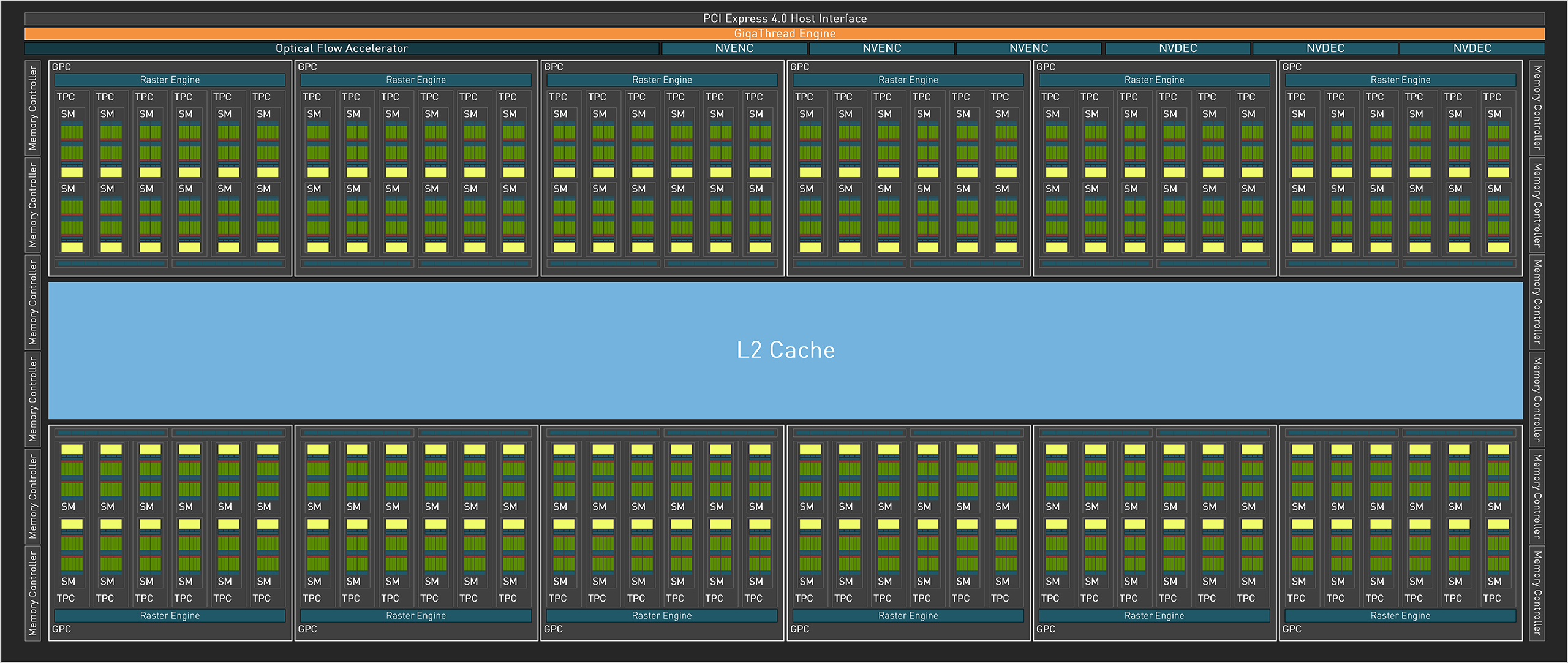
Структура чипов Ada, названных так в честь математика Ады Лавлейс, в общих чертах ничем не отличается от структуры Ampere. Крупнейшим блоком архитектуры, который позволяет масштабировать GPU в сторону большей или меньшей мощности, остается GPC (Graphics Processing Cluster): он состоит из растеризатора, выполняющего проекцию геометрии в пикселы, и 12 потоковых мультипроцессоров (SM), общее число которых издавна является наглядной характеристикой быстродействия «зеленых» чипов. Кроме того, начиная с Ampere частью GPC стали блоки операций растеризации (ROP) — благодаря этому пропускная способность растеризаторов и пиксельный филлрейт находятся в оптимальном соотношении 1:1.
Что касается потоковых мультипроцессоров, то в части работы с универсальным шейдерным кодом NVIDIA не сообщает о каких-либо изменениях по сравнению с логикой Ampere. Каждый SM содержит восемь секций по 16 FP32-совместимых CUDA-ядер, половина которых способна оперировать целочисленными данными INT32. Кроме того, в SM есть секция из четырех ALU специального назначения (SFU), предназначенных для выполнения тригонометрических операций, неопубликованное число скалярных ALU и пара CUDA-ядер двойной разрядности (FP64), которые гарантируют GPU базовую совместимость с подобным кодом. В свою очередь, операции над числами FP16 имеют значение не только в контексте вычислительных задач, но и для игрового рендеринга, когда шейдеру не требуется высокая точность данных. Они происходят в том же темпе, что и FP32-расчеты. Наконец, в состав SM входят четыре блока наложения текстур, четыре тензорных ядра и RT-блок. За более подробной информацией об основах архитектуры Ampere, которая полностью справедлива и в отношении Ada, рекомендуем обратиться к теоретической части нашего обзора GeForce RTX 3080.
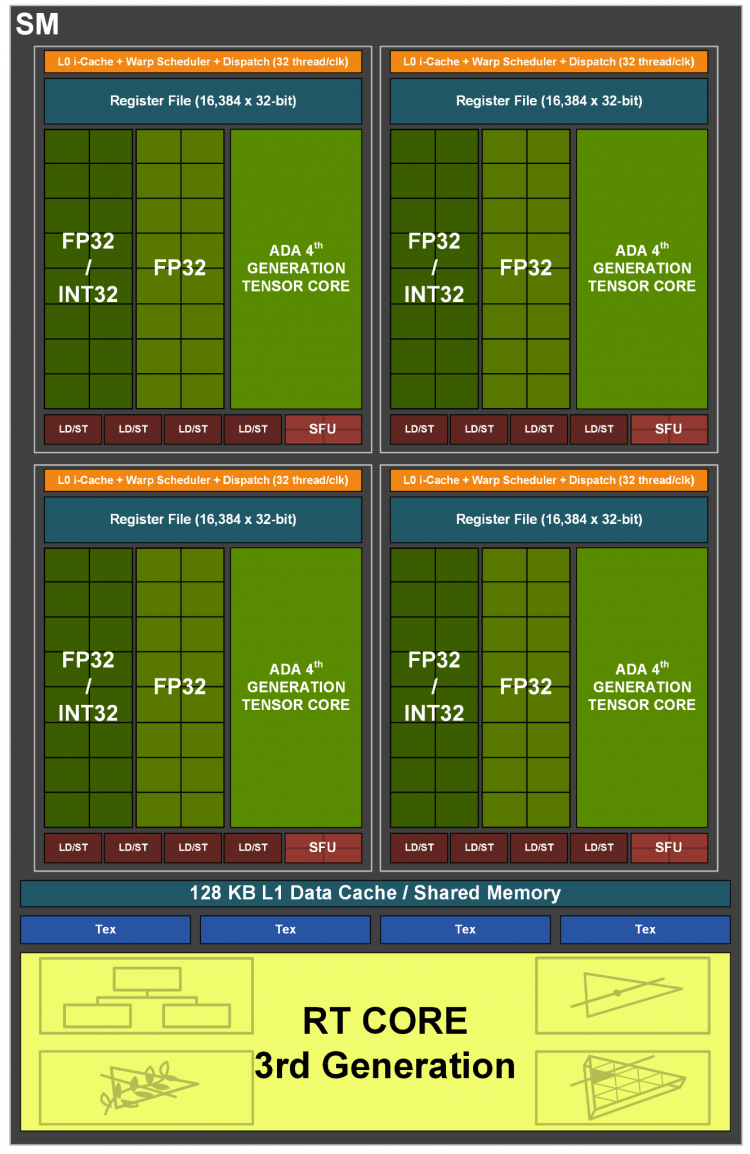
Таким образом, Ada ничего не изменила в теоретических оценках пропускной способности шейдерного массива по сравнению с конкурирующими архитектурами RDNA и RDNA 2 от AMD. NVIDIA сохраняет за собой главное преимущество в виде параллельного исполнения расчетов FP32 и INT32 или попросту вдвое большего числа инструкций FP32 за такт GPU, что, замечу справедливости ради, можно полностью реализовать лишь в условиях равномерной нагрузки рабочих приложений, но не игр. С другой стороны, Compute Unit «красных» графических процессоров, очевидно, является более экономной конструкцией с позиции транзисторного бюджета, но кого это волнует с тех пор, как NVIDIA получила в свое распоряжение передовой техпроцесс 4N на линиях TSMC?
Для выпуска консьюмерской ветки чипов Ampere NVIDIA пришлось воспользоваться мощностями Samsung, в то время как 7-нанометровый узел TSMC был занят другими крупными заказчиками (в первую очередь Apple и AMD) и продуктами самой NVIDIA для дата-центров. Чипы Ada вновь производятся силами TSMC, теперь по норме 5 нм. Формальная классификация процесса — 4N — вызвала путаницу в новостях, ведь у TSMC есть линия с похожим названием N4. В действительности фотолитография 4N представляет собой разновидность N5, заточенную специально под кремний NVIDIA. Как бы то ни было, и N4, и 4N принадлежат к узлу 5 нм. NVIDIA не сообщает никаких подробностей о геометрии техпроцесса, но даже если ориентироваться на параметры стандартного N5, миграция с самсунговских 8 нм позволяет рассчитывать на увеличение плотности транзисторов сразу в 3,1 раза!
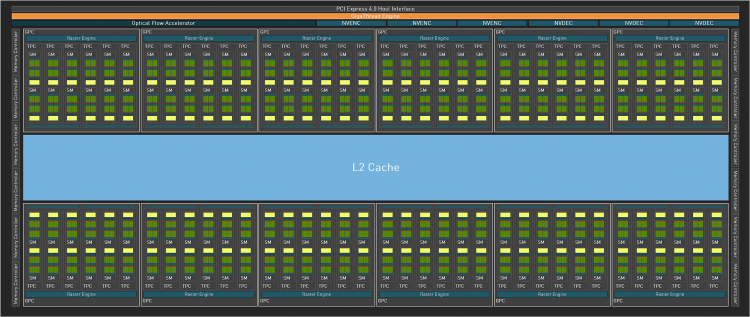
Если рассматривать флагманский процессор нового поколения, AD102, то при площади в 608,6 мм2 он является не самым крупным из «зеленых» кристаллов потребительской категории (первенство принадлежит TU102), однако его компонентный бюджет составляет ни много ни мало 76,3 млрд транзисторов. По этому параметру AD102 в данный момент уступает лишь родственному серверному чипу H100, который состоит из 80 млрд транзисторов, а флагманский чип Ampere, GA102, содержит уже не столь впечатляющие 28,3 млрд. Львиная доля новых транзисторов была потрачена на то, чтобы увеличить количество SM с 84 у GA102 до 144 штук, а полная формула чипа включает 18 432 FP32-совместимых шейдерных ALU, 576 текстурных блоков и 192 ROP.
Легко заметить, что с учетом разницы между AD102 и GA102 в количестве SM компонентный бюджет увеличился непропорционально. Остальные транзисторы, не считая логики фиксированной функциональности и uncore-элементов, NVIDIA потратила на модификацию стека памяти. Дело в том, что уже в прошлом поколении графические процессоры столкнулись с дефицитом скорости VRAM, временным решением которого стали чипы GDDR6X, однако в масштабах AD102 и они едва ли обеспечивают достаточную пропускную способность. Ada пошла по такому же пути, как «красное» семейство Navi: задержку обращений к дальней памяти компенсирует раздувшаяся ближняя память, но в «зеленых» GPU идея реализована по-другому. AMD ввела третий уровень кеша, который уступает кешу L2 по совокупной пропускной способности каналов данных, но позволяет очень компактно упаковывать транзисторы. NVIDIA, в свою очередь, просто увеличила L2 с 6 Мбайт у GA102 до 96 Мбайт, что наверняка отразилось на площади кристалла, зато позволяет комбинировать высокий хитрейт массивного кеша с низкой латентностью.
Впрочем, опыт AMD показал, что, несмотря на большой кеш третьего уровня, чипы Navi все еще чувствительны к пропускной способности шины VRAM, а у младших моделей небольшой объем Infinity Cache является уязвимым местом при определенной вычислительной нагрузке (включая некоторые игры). NVIDIA застраховалась от этих проблем благодаря тому, что AD102 унаследовал от старшего Ampere 384-битную шину оперативной памяти. Заметим, что у чипа H100 родственной архитектуры Hopper объем L2 намного меньше, чем у AD100, — всего 50 Мбайт, однако Hopper использует несоизмеримо более производительную внешнюю память HBM3.
| Производитель | NVIDIA |
|---|
| Название |
AD104 |
AD103 |
AD102 |
| Где используется |
Н/Д |
GeForce RTX 4080 |
GeForce RTX 4090 |
| Микроархитектура |
Ada Lovelace |
Ada Lovelace |
Ada Lovelace |
| Техпроцесс, нм |
TSMC 4N |
TSMC 4N |
TSMC 4N |
| Число транзисторов, млрд |
35,8 |
45,9 |
76,3 |
| Площадь чипа, мм2 |
295 |
378,6 |
608,6 |
| Число SM/TPC/GPC |
| Streaming Multiprocessors (SM) |
60 |
80 |
144 |
| Thread Processing Clusters (TPC) |
30 |
40 |
72 |
| Graphics Processing Clusters (GPC) |
5 |
7 |
12 |
| Конфигурация потокового мультипроцессора (SM) |
| CUDA-ядра FP16 |
Нет |
Нет |
Нет |
| CUDA-ядра FP32 |
4 × 32 |
4 × 32 |
4 × 32 |
| CUDA-ядра FP64 |
2 |
2 |
2 |
| CUDA-ядра INT32 |
4 × 16 |
4 × 16 |
4 × 16 |
| ALU специального назначения (SFU) |
4 × 4 |
4 × 4 |
4 × 4 |
| Тензорные ядра |
4 × 1 |
4 × 1 |
4 × 1 |
| RT-ядра |
1 |
1 |
1 |
| Блоки наложения текстур (TMU) |
4 |
4 |
4 |
| Объем регистрового файла, Кбайт |
256 |
256 |
256 |
| Объем кеша L1/разделяемой памяти, Кбайт |
128 |
128 |
128 |
| Программируемые вычислительные блоки GPU |
| CUDA-ядра FP16 |
Нет |
Нет |
Нет |
| CUDA-ядра FP32 |
7 680 |
10 240 |
18 432 |
| CUDA-ядра FP64 |
120 |
160 |
288 |
| CUDA-ядра INT32 |
3 840 |
5 120 |
9 216 |
| ALU специального назначения (SFU) |
960 |
1 280 |
2 304 |
| Тензорные ядра |
240 |
320 |
576 |
| RT-ядра |
60 |
80 |
144 |
| Блоки GPU фиксированной функциональности |
| Блоки наложения текстур (TMU) |
240 |
320 |
576 |
| Блоки операций растеризации (ROP) |
80 |
112 |
192 |
| Конфигурация памяти |
| Объем кеша L2, Мбайт |
48 |
64 |
96 |
| Разрядность шины RAM, бит |
192 |
256 |
384 |
| Тип микросхем RAM |
GDDR6X SGRAM |
GDDR6X SGRAM |
GDDR6X SGRAM |
|
| Интерфейс NVLINK |
Нет |
Нет |
Нет |
| Интерфейс PCI Express |
4.0 x16 |
4.0 x16 |
4.0 x16 |
Помимо AD102, NVIDIA опубликовала спецификации графических процессоров второго и третьего эшелона — AD103 и AD104. AD103 по формуле основных вычислительных блоков близок к GA102, однако, в отличие от старого флагмана, пользуется 256-битной шиной VRAM и несет 64 Мбайт кеша L2. AD104, в свою очередь, содержит 60 SM и, таким образом, занимает по этой характеристике промежуточную позицию между GA102 и чипом GA104, на котором стоит вся середина 30-й серии GeForce от RTX 3060 Ti до RTX 3070 Ti, но довольствуется уже 192-битной шиной памяти, а объем L2 составляет 48 Мбайт.
⇡#Рейтрейсинг в чипах Ada
Чипы Ada Lovelace не могут похвастаться таким же списком функциональных нововведений, как Ampere и тем более Turing. Однако немногочисленные качественные изменения, которыми характеризуется кремний Ada, обещают существенно увеличить быстродействие GPU в приоритетных для NVIDIA задачах — рейтрейсинге, глубинном обучении и масштабировании кадров при помощи DLSS.
Так, архитектура Ampere представила RT-блоки второго поколения, которые способны в параллельном режиме находить точку пересечения одного луча с боксом BVH и другого луча — с поверхностью полигона. Последняя операция в Ampere выполняется дважды за такт, а в Ada — уже четырежды. Таким образом, логика рейтрейсинга архитектуры RDNA 2, так же как Intel Arc, по этому показателю в четыре раза уступает RT-блокам Ada.
Помимо роста чистой пропускной способности, у RT-блоков появился дополнительный механизм оптимизации при взаимодействии с альфа-каналом текстур. Прозрачные текстуры в общем случае усложняют рейтрейсинг из-за того, что каждое пересечение луча с полигоном вызывает шейдер, который определяет, что делать с лучом дальше (остановить трассировку или продолжить поиск дальнейших пересечений). В случае, если разработчик игры хочет обеспечить физически корректный рейтрейсинг текстуры с прозрачными участками (такой как листья деревьев или пламя), соответствующий полигон целиком помечают как прозрачный, что вызывает предсказуемый удар по быстродействию. Функция Opacity Micromesh Engine в чипах Ada позволяет снять часть нагрузки с шейдерных ALU путем разбивки примитива на сеть микротреугольников. Метка каждого микротреугольника идентифицирует его как непрозрачный либо прозрачный, а дальнейшее поведение луча после того, как обнаружено пересечение с микро-треугольником, определяется внутри RT-блока без вызова дополнительных шейдеров. В ином случае, когда микротреугольник имеет «неизвестное» состояние, задача решается программно на CUDA-ядрах SM.
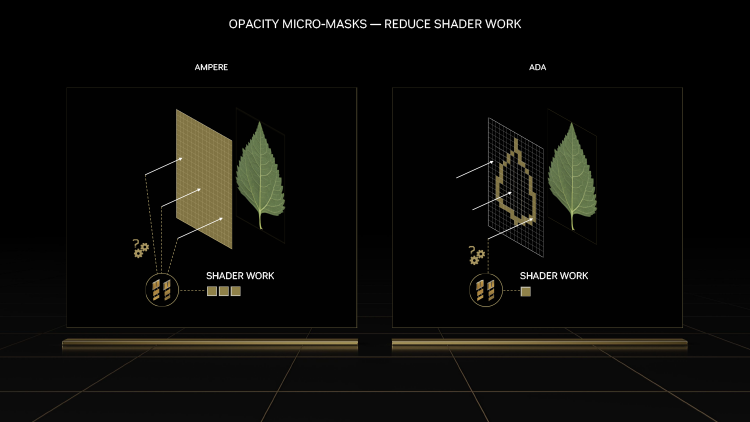
К сожалению, микрополигональные маски прозрачности, необходимые для работы OME, должны быть определены заранее, и подобная технология не является частью API Direct3D (впрочем, в последние годы Microsoft оперативно реагирует на появление новых функций GPU), а значит, вопрос применять ее или нет остается на усмотрение разработчиков игры. Пока OME используется только в трассированной модификации Portal.
Следующая аппаратная модификация RT-ядер Ada направлена на решение другой проблемы. Благодаря тому, как эффективно работают структуры BVH, многократное усложнение геометрии сцены несущественно увеличивает время, которое требуется для поиска пересечения луча с боксом BVH (кстати, в отличие от AMD и Intel, NVIDIA так и не раскрыла, сколько таких пересечений за такт GPU может найти один RT-блок). А вот время генерации BVH и объем, который она занимает в памяти, практически линейно зависит от количества полигонов в сцене. Чтобы сэкономить ресурсы видеокарты, NVIDIA предложила новый вид геометрического примитива (Displaced Micro-Mesh), который представляет собой единственный треугольник и ассоциированную с ним карту смещения. Последняя содержит барицентрические координаты множества дополнительных вершин, амплитуду их смещения относительно плоскости базового треугольника и, таким образом, выполняет компактное описание детализированной геометрии в пространстве отдельно взятого примитива, а не всей сцены. Как следствие, для трассировки сцены не требуется исчерпывающая предварительная тесселяция, переполняющая структуру BVH, а доступ к информации Displaced Micro-Mesh выполняется по требованию (при необходимости найти точку пересечения луча с поверхностью треугольника DMM дополнительная геометрия формируется на лету).
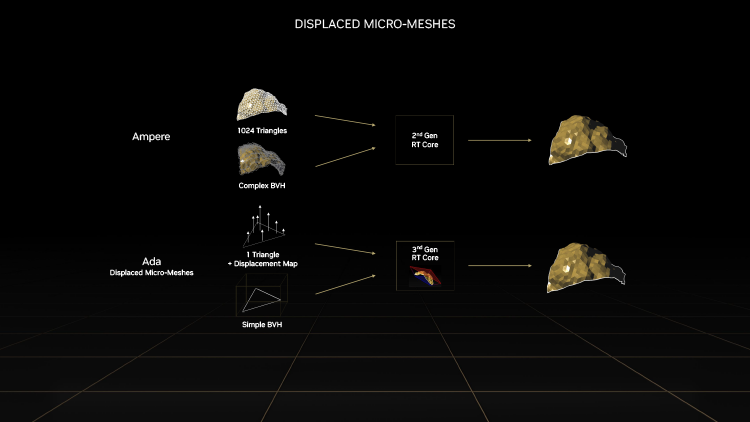
С таким же успехом Displaced Micro-Mesh можно использовать в контексте растеризации с произвольной точностью деталей при помощи вычислительных или mesh-шейдеров , которые появились в архитектуре Turing и с тех пор вошли в состав Direct3D. Алгоритм DMM также открыт для любых производителей софта и железа, хотя лишь чипы Ada в данный момент имеют аппаратные средства для его ускорения. Первыми партнерами NVIDIA, которые собираются внедрить DMM в собственных продуктах, стали Adobe и Simplygon (создатель одноименного инструментария для оптимизации 3D-графики).
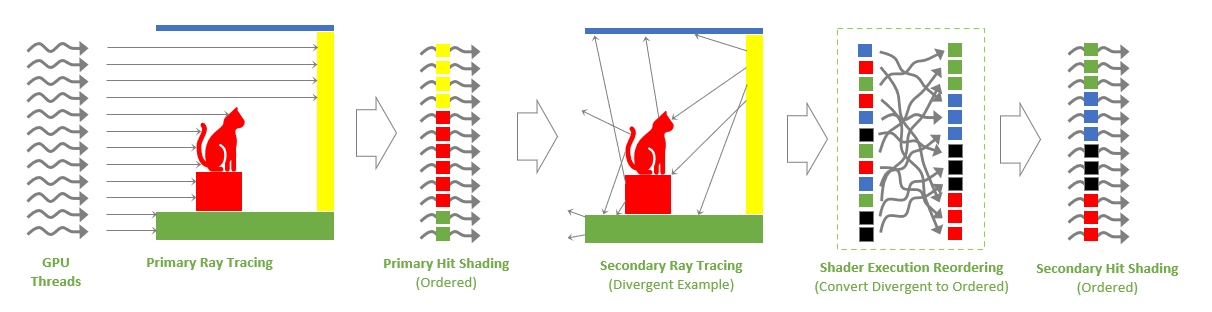
Наконец, в работе Ada с шейдерами для трассировки лучей произошло изменение на уровне планирования потоков инструкций. В типичной ситуации рейтрейсинга сцены первичные лучи от источника света представляют собой несколько потоков одной и той же шейдерной программы, что гарантирует идеальный параллелизм вычислений и тесную локализацию необходимых ресурсов в стеке памяти GPU. А вот на этапе вторичных, отраженных лучей граф вычислений разбивается на отличные друг от друга шейдеры, исполнение которых зачастую происходит последовательно. Кроме того, шейдеры вторичных лучей неизбежно обращаются к разрозненным адресам памяти, что усложняет кеширование.
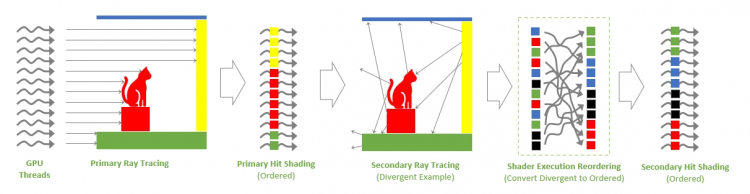
Чтобы компенсировать потерю быстродействия, вызванную расходящимися потоками инструкций, логика SM и памяти Ada подготовлена к возможности эффективно перегруппировывать потоки (Shader Execution Reordering) с целью повысить однородность вычислений. Впрочем, Ada — еще не настолько умный GPU, чтобы выполнять перегруппировку автоматически. Для этого разработчикам ПО придется использовать расширения проприетарного интерфейса NVAPI, хотя NVIDIA уже работает с Microsoft, чтобы стандартизировать SER в рамках Direct3D. По оценкам чипмейкера, в ситуациях с большим расхождением потоков (таких как Path Tracing) SER позволяет рассчитывать на двукратный рост производительности. Первой игрой с поддержкой SER станет Cyberpunk 2077. Грядущее обновление также принесет с собой режим RT: Overdrive, который увеличит плотность вычислений вплоть до 600 расчетов трассировки лучей на пиксель и больше, а главное DLSS 3.0.
⇡#Тензорные вычисления, DLSS 3.0 и кодирование видео
Процессоры Ada, как и серверные чипы Hopper, содержат массив тензорных ядер четвертого поколения, которые развивают вдвое большую пропускную способность за такт GPU по сравнению с тензорными ядрами Ampere. Кроме того, Ada позаимствовала у Hopper функцию Transformer Engine для ускорения тренировки т. н. трансформеров — разновидности нейросетей, получившей широкое распространение в таких задачах, как распознавание естественного языка и автореферирование, благодаря высокому параллелизму расчетов.
Однако в потребительских видеокартах главным потребителем тензорных вычислений было и остается масштабирование кадров с помощью DLSS. DLSS сам по себе является довольно ресурсоемким инструментом, которому пойдет на пользу высокая производительность тензорных ядер четвертого поколения, не говоря уже про общую массу тензорной логики в кристаллах Ada. Тем не менее наращивание вычислительной мощности в распоряжении DLSS не способно устранить фундаментальное ограничение всех существующих в играх методов апскейлинга. Дело в том, что, когда апскейлинг снимает нагрузку с GPU за счет рендеринга в пониженном разрешении, на первый план выходит быстродействие центрального процессора (это наглядно продемонстрируют тесты GeForce RTX 4090).

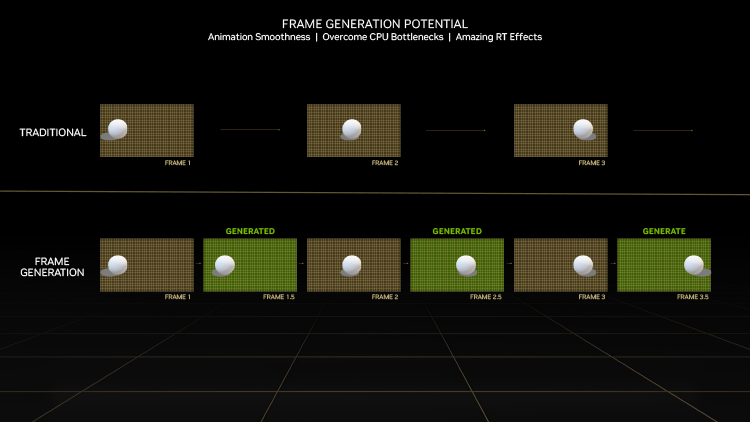
DLSS следующей, третьей версии решает эту проблему единственным возможным способом: теперь нейросеть не только выполняет масштабирование кадров, прошедших весь конвейер рендеринга, но и способна генерировать новые промежуточные кадры, опираясь на векторы движения внутри графического движка и Optical Flow. Последний представляет собой алгоритм аппроксимации движения пикселей, который издавна используется в обработке видео, VR/AR и машинном зрении. Графические процессоры Ampere как раз содержат аппаратный блок Optical Flow, отделенный от кодировщика видео NVENC, а в кремнии Ada его производительность возросла более чем вдвое. DLSS 3.0 также сулит вдвое большее быстродействие по сравнению с DLSS второй версии даже в условиях, когда фреймрейт ограничен ресурсами CPU.
Тот факт, что чипы Ampere умеют обрабатывать Optical Flow в железе, ставит под вопрос эксклюзивный характер DLSS 3.0, хотя формально третья версия алгоритма работает лишь на чипах Ada. Эксперименты моддеров с ранней версией грядущего патча Cypberpunk 2077 показали, что DLSS 3.0 с функцией генерации кадров можно запустить на видеокартах 30-й или даже 20-й серии и получить значительную прибавку фреймрейта. Однако апскейлинг работает нестабильно, так что ограничения, установленные NVIDIA, все-таки могут иметь под собой фактические основание. Как бы то ни было, DLSS 3.0 далеко не сразу приобретет широкую поддержку в играх.
Разумеется, интегрированным ASIC для вычислений Optical Flow может воспользоваться не только DLSS, но и рабочие приложения — в первую очередь связанные с обработкой видео. Кроме того, вслед за интеловскими графическими процессорами Arc, чипы NVIDIA научились кодировать в железе стандарт AV1. Чипы AD102 и AD103 и вовсе комплектуются двумя кодировщиками NVENC, однако пройдет какое-то время, прежде чем распространенные средства монтажа и конвертации видео получат доступ к этим функциям.
⇡#Технические характеристики видеокарт, цены
В данный момент линейка GeForce 40 представлена двумя моделями: RTX 4080 и RTX 4090. Флагманский ускоритель, о котором пойдет речь в данном обзоре, создан на основе чипа первого эшелона, AD102, но конфигурация GPU была урезана с целью увеличить поставки пригодных для эксплуатации кристаллов и оставить место для потенциального GeForce RTX 4090 Ti. Процессор утратил 16 SM, а общая формула чипа составляет 16 384 FP32-совместимых CUDA-ядра, 512 текстурных блоков и 176 ROP.
Старшая модель комплектуется 24 Гбайт памяти GDDR6X, работающей с пропускной способностью 21 Гбит/с на контакт 384-битной шины. Сам GPU по референсным спецификациям развивает тактовую частоту в 2 520 МГц при типичной игровой нагрузке, хотя, как покажут измерения, это весьма умеренная оценка. Даже исходя из референсных тактовых частот теоретическое быстродействие GeForce RTX 4090 оценивается в 2,3 раза выше по сравнению с GeForce RTX 3090 Ti, что, впрочем, является недостижимым ориентиром в реальных задачах (особенно играх). Как и GeForce RTX 3090 Ti, новый флагман рассчитан на энергопотребление вплоть до 450 Вт, однако NVIDIA наверняка не остановится на этом, если учесть, что полностью разблокированный AD102 еще не пошел в массы.

В свою очередь, GeForce RTX 4080, спроектирован по старой схеме NVIDIA, когда предтоповая видеокарта опирается на чип второго эшелона — в данном случае AD103. GPU также немного урезан (на 4 SM) и содержит 9 728 активных CUDA-ядер FP32, 304 блоков наложения текстур и 112 ROP. Шина памяти у RTX 4080 256-битная, но здесь используются микросхемы GDDR6X с общим объемом 16 Гбайт и пропускной способностью 22,4 Гбит/с на контакт. Хотя у GeForce RTX 4080 меньше шейдерных ALU, чем у GeForce RTX 3090 Ti, благодаря проектной тактовой частоте 2 505 МГц новинка на 33 % опережает бывший флагман по теоретическим оценкам быстродействия. Впрочем, при резерве мощности в 350 Вт аналогом RTX 4080 скорее является GeForce RTX 3080 Ti, а дистанция между этими устройствами по теоретической производительности составляет 43 %.
Изначально NVIDIA собиралась продолжить череду релизов 12-гигабайтной версией GeForce RTX 4080 на основе чипа GA104 с 192-битной шиной VRAM, но в ответ на критику релиз отменили. Эту видеокарту ждет ребрендинг и, возможно, коррекция спецификаций сообразно новому позиционированию.
До сих пор мы говорили о том, какими новшествами отличаются ускорители 40-й серии. Теперь перечислим функции, которых в Ada нет. Во-первых, потребительские GPU (как и ускорители для рабочих станций на базе Ada) окончательно лишились интерфейса NVLink, который стал прерогативой HPC-решений. Во-вторых, Ada, в отличие от Intel Arc, не поддерживает DisplayPort версии 2.0, что также вряд ли огорчит большинство пользователей. Наконец, хотя чипы Hopper уже освоили PCI Express пятого поколения, Ada довольствуется PCI Express 4.0 — вот это ограничение, может, и проявит себя в каких-то специфических задачах.
| Производитель | NVIDIA |
|---|
| Модель |
GeForce RTX 3080 Ti |
GeForce RTX 3090 Ti |
GeForce RTX 4080 |
GeForce RTX 4090 |
| Графический процессор |
| Название |
GA102 |
GA102 |
AD103 |
AD102 |
| Микроархитектура |
Ampere |
Ampere |
Ada Lovelace |
Ada Lovelace |
| Техпроцесс |
Samsung 8N |
Samsung 8N |
TSMC 4N |
TSMC 4N |
| Число транзисторов, млрд |
28,3 |
28,3 |
45,9 |
76,3 |
| Тактовая частота, МГц: Base Clock / Boost Clock |
1 365/1 665 |
1 395/1 695 |
2 210/2 505 |
2 230/2 520 |
| Шейдерные ALU FP32 |
10 240 |
10 752 |
9 728 |
16 384 |
| Блоки наложения текстур (TMU) |
320 |
336 |
304 |
512 |
| Блоки операций растеризации (ROP) |
112 |
112 |
112 |
176 |
| Тензорные ядра |
320 |
336 |
304 |
512 |
| RT-ядра |
80 |
84 |
76 |
128 |
| Оперативная память |
| Разрядность шины, бит |
384 |
384 |
256 |
384 |
| Тип микросхем |
GDDR6X SGRAM |
GDDR6X SGRAM |
GDDR6X SGRAM |
GDDR6X SGRAM |
| Тактовая частота, МГц (пропускная способность на контакт, Мбит/с) |
1 188 (19 000) |
1 313 (21 000) |
1 400 (22 400) |
1 313 (21 000) |
| Объем, Мбайт |
12 288 |
24 576 |
16 384 |
24 576 |
| Объем кеша L2, Мбайт |
6 |
6 |
64 |
96 |
| Шина ввода/вывода |
PCI Express 4.0 x16 |
PCI Express 4.0 x16 |
PCI Express 4.0 x16 |
PCI Express 4.0 x16 |
| Производительность |
| Пиковая производительность FP32, GFLOPS (из расчета максимальной указанной частоты) |
34 099 |
36 449 |
48 737 |
82 575 |
| Производительность FP64/FP32 |
1/64 |
1/64 |
1/64 |
1/64 |
| Производительность FP16/FP32 |
1/1 |
1/1 |
1/1 |
1/1 |
| Пропускная способность оперативной памяти, Гбайт/с |
912 |
1 008 |
717 |
1 008 |
| Вывод изображения |
| Интерфейсы вывода изображения |
DisplayPort 1.4a, HDMI 2.1 |
DisplayPort 1.4a, HDMI 2.1 |
DisplayPort 1.4a, HDMI 2.1 |
DisplayPort 1.4a, HDMI 2.1 |
| TBP/TDP, Вт |
350 |
450 |
320 |
450 |
| Розничная цена (США, без налога), $ |
1 199 (рекоменд. в момент выхода) |
1 999 (рекоменд. в момент выхода) |
1 199 (рекоменд. в момент выхода) |
1 599 (рекоменд. в момент выхода) |
| Розничная цена (Россия), руб. |
116 900 (рекоменд. в момент выхода) |
Н/Д |
Н/Д |
Н/Д |
Что касается цен старших моделей GeForce 40, то RTX 4080 назначили рекомендованную стоимость $1 199 (точно такую же, как у RTX 3080 Ti). Флагманский RTX 4090 оценивается в $1 599, что на $100 превышает релизную цену GeForce RTX 3090, однако RTX 3090 Ti стартовал с более высокой отметки $1 999.
В продажу пока поступил лишь GeForce RTX 4090, видеокарт сейчас не хватает на всех желающих, поэтому они продаются с большой накруткой. Так, на американских торговых площадках RTX 4090 отдают не меньше чем за $2 299, а у нас минимальная розничная цена составляет 156 232 руб.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex