







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexКитайские IT-компании с 2020 года запустили в стране 79 больших языковых моделей (Large Language Model, LLM), удвоив усилия по разработке алгоритмов ИИ. Согласно отчёту, подготовленному исследовательскими институтами Министерства науки и технологий Китая, разработка LLM, обученных с использованием методов глубокого обучения на огромных объёмах текстовых данных, вступила в «ускоренную» фазу.

Источник изображения: pixabay.com
В 2020 году китайские организации выпустили всего 2 LLM по сравнению с 11 в США, но в 2021 году в каждой стране было запущено по 30 LLM. В 2022 году в США было выпущено 37 LLM, а в Китае — 28. В этом году пока лидирует Китай с 19 LLM против 18 в США. «Судя по географии больших языковых моделей, выпущенных по всему миру, Китай и Соединённые Штаты лидируют с большим отрывом, на них приходится более 80 % рынка», — говорится в отчёте.
В отчёте проанализированы 79 больших языковых моделей, разработанных в Китае, и отмечено, что, хотя уже существуют 14 провинций и регионов, где такие технологии были разработаны, совместных проектов развития между академическими кругами и промышленностью на сегодняшний день «недостаточно».
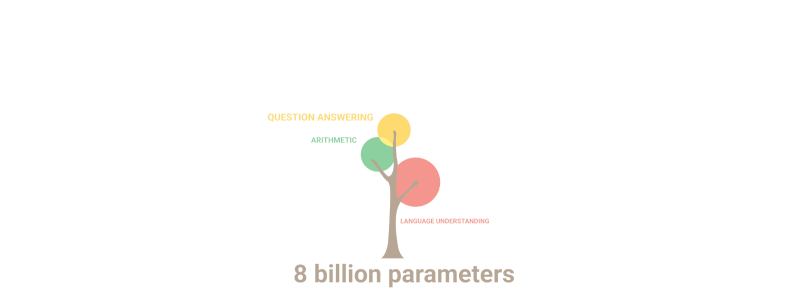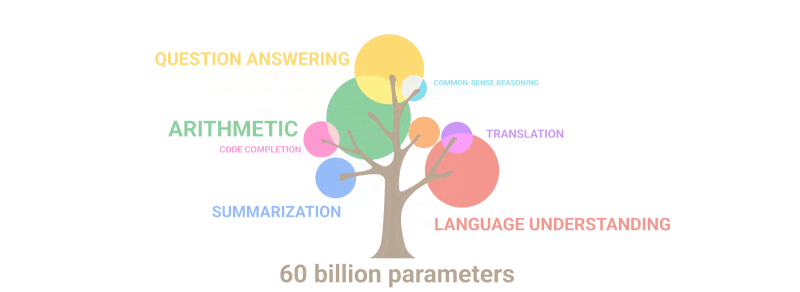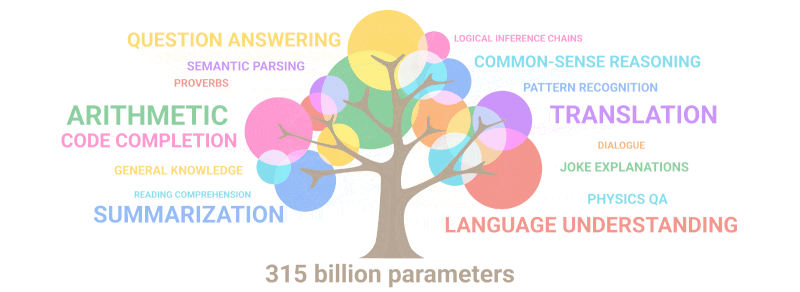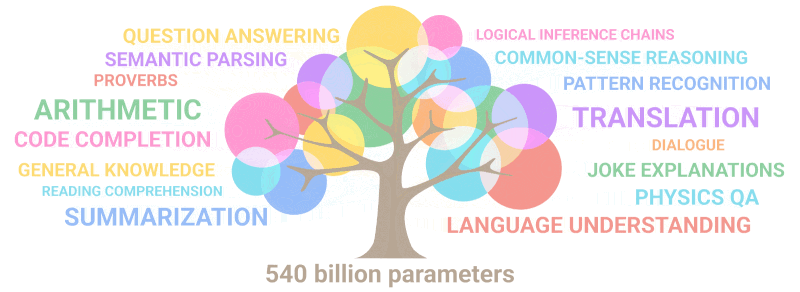
Индустрия ИИ в Китае сталкивается со значительными проблемами, поскольку экспортный контроль США ограничивает доступ китайских организаций к технологиям и полупроводникам, используемым для обучения LLM.
После того как OpenAI выпустила ChatGPT, китайские технологические гиганты, от Alibaba до производителя систем видеонаблюдения Sensetime и гиганта поисковых систем Baidu, запустили свои собственные версии чат-ботов на основе генеративного ИИ и LLM.
Источник:






 Подписаться
Подписаться