|
Опрос
|
реклама
Быстрый переход
Wikipedia пожаловалась, что из-за ИИ её стали меньше читать живые люди — и у этого будут последствия
17.10.2025 [14:50],
Алексей Разин
Управляющая работой онлайн-энциклопедии Wikipedia некоммерческая организация Wikipedia Foundation вынуждена сообщить, что распространение технологий искусственного интеллекта с интеграцией результатов запросов в поисковую выдачу заметно снизило количество просмотров этого ресурса живыми людьми. 
Источник изображения: Oberon Copeland @veryinformed.com / unsplash.com В этой сфере, как можно выразиться словами песни, тоже «вкалывают роботы», собирающие всю нужную пользователю информацию для формирования выжимки в поисковике или интерфейсе чат-бота без необходимости обращения к странице первоисточника. По словам представителей Wikipedia, данная тенденция в долгосрочной перспективе ставит под угрозу функционирование самой всемирной онлайн-энциклопедии: «Если количество посетителей Wikipedia сократится, меньше желающих будет находиться для обогащения и расширения контента, меньше индивидуальных доноров смогут поддерживать эту работу». Примечательно, что для создателей больших языковых моделей само по себе существование Wikipedia крайне важно, ведь на материалах этого ресурса происходит значительная часть обучения систем ИИ. Поисковые системы и социальные сети, по словам представителей платформы, отдают приоритет информации с ресурса, поскольку она пользуется определённым доверием у пользователей. В мае текущего года Wikipedia столкнулась с ростом трафика, якобы генерируемого живыми пользователями из Бразилии, но инцидент лишь заставил руководство ресурса усовершенствовать систему борьбы с ботами. С тех пор количество просмотров живыми пользователями начало снижаться, в годовом сравнении оно достигло 8 %. В Wikipedia Foundation связывают такую тенденцию с изменением доминирующего способа получения информации пользователями — чат-боты и встроенный в поисковые системы ИИ лишили их необходимости обращаться к первоисточникам. Внутренняя политика Wikipedia при этом накладывает ограничения на интенсивность обращения к ней сторонними роботами. Распространение механизмов защиты от ботов показало, что живые люди к страницам ресурса стали обращаться реже. Боты при этом более искусно выдают себя за людей. Прочие источники тоже отмечают, что внедрение ИИ в сферу поиска информации в интернете сократило потребность обращения к первоисточникам. Анализ работы поисковой системы Google летом этого года выявил, что только 1 % запросов приводил к переходу пользователей по ссылке на первоисточник, во всех остальных случаях люди просто довольствовались сгенерированной ИИ выборкой данных. Кроме того, молодая аудитория привыкла получать всю информацию в пределах социальных сетей, не особо утруждая себя навигацией по всему интернету. Wikipedia также обеспокоена тем, что ИИ начинает использоваться для создания энциклопедических статей, снижая достоверность информации. Активность роботов, занимающихся сбором информации, при этом создаёт повышенную нагрузку на техническую инфраструктуру Wikipedia. Создатели ресурса пытаются усилить интеграцию с популярными социальными сетями и подстраиваться под новые реалии, а не пытаться вернуться к прежнему порядку за счёт запретов и блокировок. Старший директор Wikipedia Foundation по продуктам Маршалл Миллер (Marshall Miller) обратился к пользователям со следующими словами: «Когда вы ищете информацию в онлайне, обращайте внимание на цитаты и переходите по ссылкам на источники материалов. Говорите со своими знакомыми о важности создания доверенной и контролируемой людьми базы знаний, и помогайте им понять, что лежащий в основе ИИ контент был создан реальными людьми, которые заслуживают вашей поддержки». Anthropic представила Claude Sonnet 4.5 — «лучший в мире» ИИ для программирования и сложных вычислений
29.09.2025 [21:55],
Андрей Созинов
Компания Anthropic анонсировала Claude Sonnet 4.5 — самую мощную на сегодняшний день большую языковую модель в семействе Claude. По словам разработчиков, она ориентирована на программирование, построение ИИ-агентов и решение сложных задач. A Anthropic заверили, что Sonnet 4.5 стал не только лидером в профильных бенчмарках, но и демонстрирует заметный скачок в понимании программного кода, математических вычислениях и управлении компьютером.  Claude Sonnet 4.5 занял первую строчку в SWE-bench Verified — отраслевом тесте, который измеряет реальные способности ИИ-моделей к написанию и анализу программного кода. По данным Anthropic, Sonnet 4.5 способен поддерживать концентрацию более 30 часов при работе над сложными многоэтапными задачами, обходя предыдущие версии Claude и ближайших конкурентов. 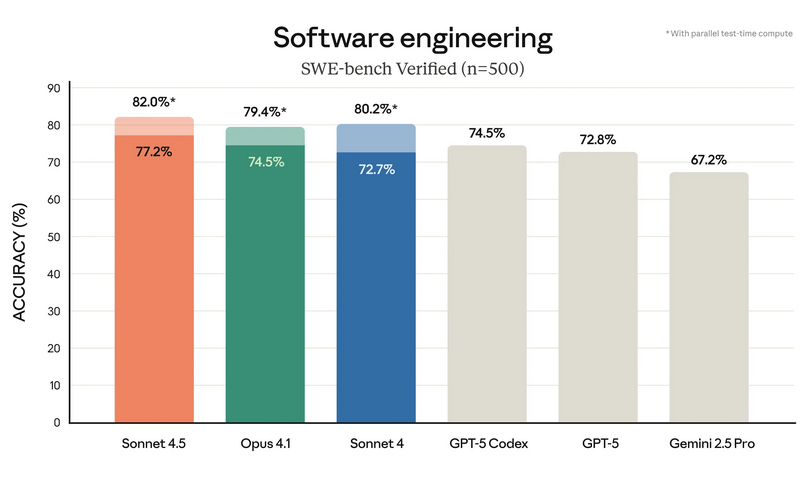 В тесте OSWorld, проверяющем работу ИИ с реальными компьютерными задачами, Sonnet 4.5 показал результат 61,4 % против 42,2 % у версии Sonnet 4, что иллюстрирует резкий рост производительности за последние месяцы. 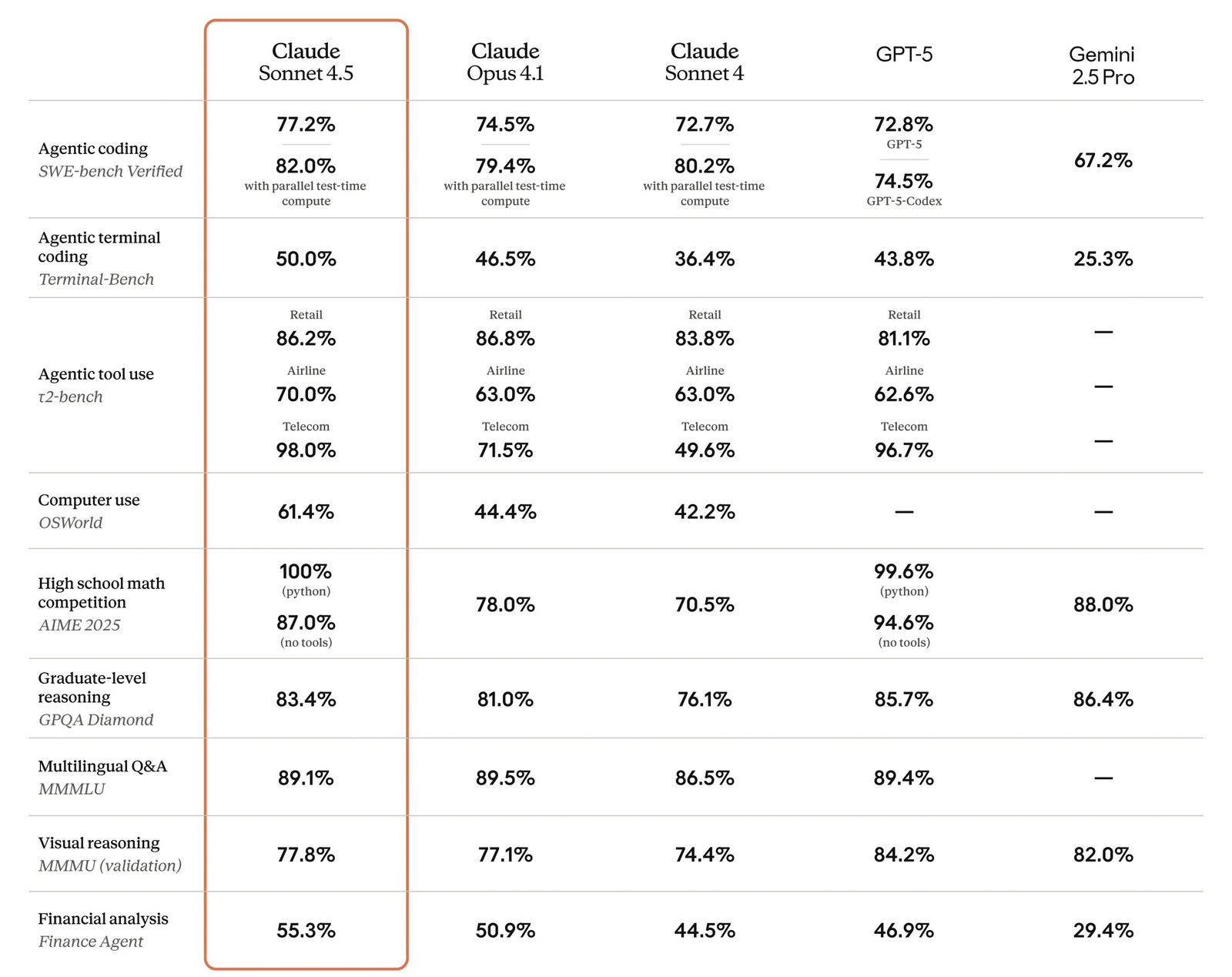 Новая модель показала себя не только в программировании. По результатам внутренних и независимых тестов, Sonnet 4.5 демонстрирует серьёзный прогресс в задачах логического вывода и математики, а также в специализированных областях: финансах, медицине, праве и STEM-дисциплинах. Разработчики отмечают рост качества генерации и анализа кода, управление файлами и сложными вычислениями в реальном времени. 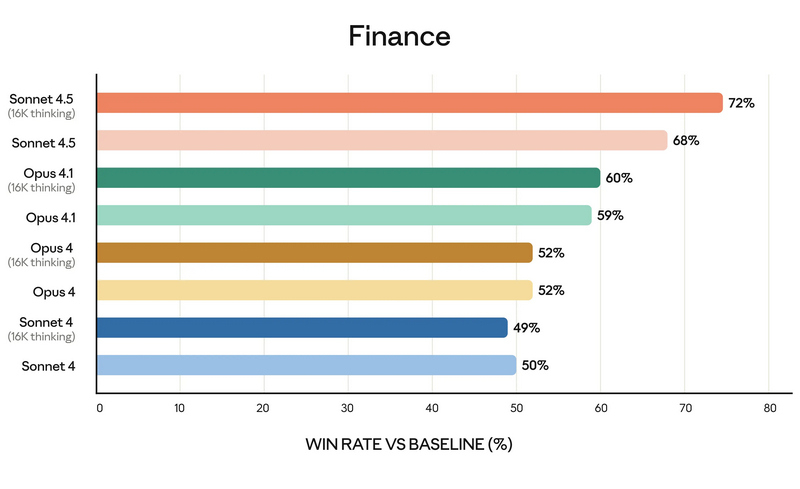 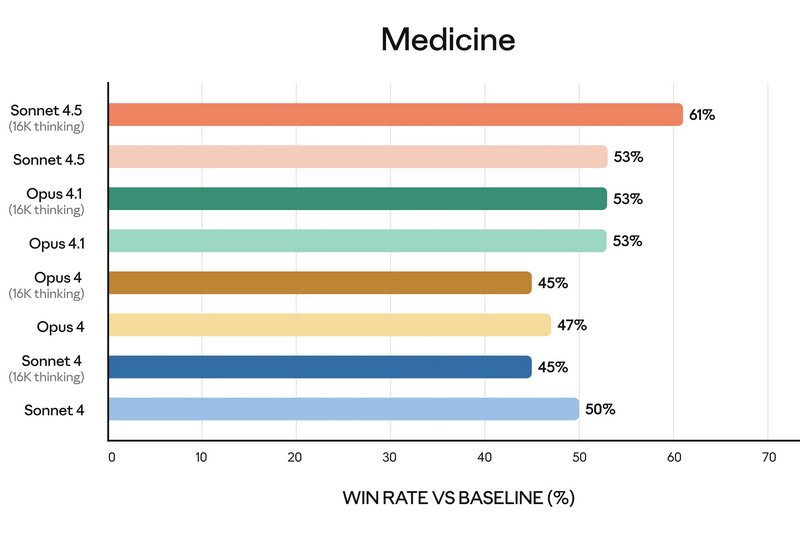 Появился и экспериментальный режим Imagine with Claude: теперь ИИ может создавать программные решения буквально «на лету», полностью адаптируя код под текущие запросы пользователя. Одновременно с выпуском Sonnet 4.5 компания представила крупные обновления экосистемы Claude. В сервисе Claude Code появились чекпоинты для сохранения прогресса, обновлённый терминал и нативное расширение для Visual Studio Code. В приложениях Claude теперь доступна непосредственная работа с кодом, создание файлов (включая таблицы, презентации и документы) прямо в диалоге, а пользователи с подпиской Max получили расширение для Chrome. Для разработчиков открыт новый набор инструментов — Claude Agent SDK. Он позволяет создавать собственных интеллектуальных агентов на базе тех же технологий, что лежат в основе Claude Code. SDK реализует сложную работу с памятью, управлением правами и координацией подзадач между агентами — то есть открывает возможности построения продвинутых решений под любые задачи. 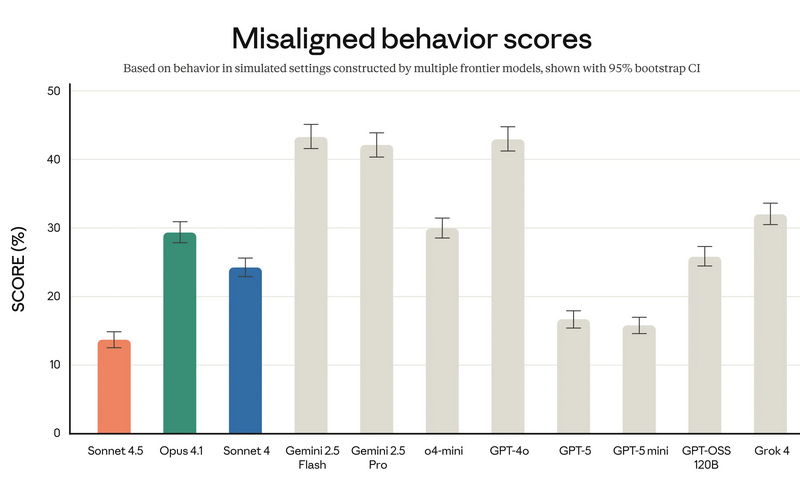 Помимо того, что Claude Sonnet 4.5 стала самой способной, она также стала самой «воспитанной» ИИ-моделью компании: снижено количество опасных и нежелательных паттернов поведения, таких как подыгрывание пользователю, попытки обойти ограничения или выполнение вредных запросов. В рамках защиты пользователей, Anthropic применяет многоуровневые фильтры (AI Safety Level 3), особенно в отношении тем, связанных с химическими, биологическими, ядерными и другими видами оружия. Также фильтры стали точнее: количество ложных срабатываний удалось снизить в 10 раз по сравнению с предыдущими релизами. Claude Sonnet 4.5 уже доступен для всех пользователей через веб-версию чат-бота, а также в мобильных приложениях. Также новая ИИ-модель доступна API по цене старой (от $3 за миллион токенов). Новые возможности Claude Code и Agent SDK доступны всем разработчикам и корпоративным клиентам. Разработчики сосредоточились на ИИ-моделях мира для создания сверхразума
29.09.2025 [13:10],
Владимир Мироненко
Ведущие разработчики ИИ, такие как Google DeepMind, Meta✴✴ и Nvidia, уделяют всё больше внимания так называемым моделям мира, которые могут лучше понимать окружающую среду, в стремлении создать машинный «сверхразум», пишет The Financial Times. 
Источник изображения: julien Tromeur/unsplash.com Модель мира имитирует причинно-следственные связи и законы физики посредством симуляций, основанных на обучении, для которого требуется огромный объём данных из реальных или моделируемых сред и большие вычислительные мощности. Они рассматриваются как важный шаг в развитии беспилотных автомобилей, робототехники и так называемых ИИ-агентов. «ИИ по-прежнему ограничен цифровой сферой, — говорит Шломи Фрухтер (Shlomi Fruchter), соруководитель Genie 3 в Google DeepMind. — Создавая среды, которые выглядят или ведут себя как реальный мир, мы получаем гораздо более масштабируемые способы обучения ИИ без реальных последствий совершения ошибок в реальном мире». Янн Лекун (Yann LeCun), возглавляющий исследовательскую лабораторию Meta✴✴ AI (прежнее название — Facebook✴✴ Artificial Intelligence Research, FAIR), заявил, что большие языковые модели (LLM) никогда не достигнут способности рассуждать и планировать как люди. Одной из ближайших областей применения моделей мира станет индустрия развлечений, где они позволяют создавать интерактивные и реалистичные сцены. Например, стартап World Labs разрабатывает модель, которая генерирует трёхмерные среды, похожие на видеоигры, из одного изображения. Runway, стартап по созданию видео, в числе партнёров которого голливудские студии, включая Lionsgate, в прошлом месяце выпустил продукт, использующий модели мира для создания игровых сред с персонализированными историями и персонажами, генерируемыми в реальном времени. Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) заявил, что следующим крупным этапом роста компании станет «физический ИИ», так как новые модели позволят добиться прорыва в области робототехники. По мнению Лекуна, реализация концепции по созданию ИИ-систем, обеспечивающих машины интеллектом человеческого уровня, может занять 10 лет. Вместе с тем эксперты указывают на большой потенциал новых ИИ-технологий. «Модели мира открывают возможность обслуживания всех отраслей и усиливают тот же эффект, который компьютеры сделали для интеллектуального труда», — заявил Рев Лебаредян (Rev Lebaredian), вице-президент Nvidia по технологиям моделирования. У медицинского ИИ обнаружилась склонность к дискриминации женщин и расизму
19.09.2025 [14:36],
Алексей Разин
Первые попытки поставить искусственный интеллект на службу медицине много лет назад предпринимались ещё компанией IBM с её системой Watson, но по мере развития отрасли эта область применения компьютерных технологий стала всё более обширной. Учёные утверждают, что существующий подход к обучению больших языковых моделей в медицине делает диагностику менее качественной для представителей женского пола и определённых рас. 
Источник изображения: Nvidia Издание Financial Times обобщило высказывания экспертов в смежных областях, пытаясь объяснить, почему существующие языковые модели склонны давать более качественные рекомендации в области здравоохранения представителям мужского пола белой расы. По сути, исторически именно на нужды этой категории пациентов работала вся сфера медицинских исследований, поэтому именно для этой выборки сформировано максимальное количество медицинских данных, на которых и обучались современные большие языковые модели. Более того, та же OpenAI призналась, что в ряде медицинских инициатив использовала менее совершенные языковые модели, чем существующие сейчас — просто по той причине, что на момент реализации проектов других не было. Сейчас специалистам стартапа во взаимодействии с медиками приходится вносить соответствующие коррективы в работу профильных систем. В ряде случаев большие языковые модели дают не самые чёткие и правильные медицинские рекомендации по причине использования слишком широкого спектра источников данных для своего обучения. В принципе, если в эту выборку попадали даже советы непрофессионалов на страницах Reddit, то качество подобных рекомендаций с точки зрения профессиональных медиков уже можно поставить под сомнение. Специалисты предлагают формировать материал для обучения медицинских систем более ответственно, а также использовать более локализованные данные в пределах одной страны или даже местности. Это позволит лучше учитывать локальную специфику с точки зрения здравоохранения. Отдельной проблемой для клиентов больших языковых моделей, пытающихся с их помощью получить советы в области здравоохранения, является низкий приоритет при обработке неграмотно или сумбурно составленных запросов. Если в них содержатся грамматические или орфографические ошибки, система с меньшей вероятностью выдаст корректные рекомендации по сравнению с тем запросом, который с этой точки зрения был составлен безупречно. Нередко системы настроены так, что просто рекомендуют обратиться автору запроса к врачу, если качество самого запроса не соответствует определённым критериям. Защита персональных данных и врачебной тайны также является серьёзной проблемой при обучении больших языковых моделей, и в этой сфере уже возникают прецеденты судебных претензий. Склонность языковых моделей к так называемым «галлюцинациям» в случае с обработкой медицинской информации представляет реальную опасность для здоровья и жизни людей. В любом случае, эксперты сходятся во мнении, что применение ИИ в сфере здравоохранения несёт больше пользы, чем вреда, просто здесь нужно правильно расставить приоритеты в развитии. Например, нужно направлять ресурсы ИИ на решение проблем в медицине, которым традиционно уделялось меньше внимания, а не пытаться просто ускорить определение диагноза по сравнению с живыми медиками на какие-то минуты или секунды, поскольку в этом нет особого смысла. OpenAI остаётся только завидовать — обучение китайской модели ИИ DeepSeek R1 обошлось всего в $294 тыс.
18.09.2025 [18:57],
Сергей Сурабекянц
Китайская компания DeepSeek сообщила, что на обучение её модели искусственного интеллекта R1 было затрачено $294 тыс., что радикально меньше, чем аналогичные расходы американских конкурентов. Эта информация была опубликована в академическом журнале Nature. Аналитики ожидают, что выход статьи возобновит дискуссии о месте Китая в гонке за развитие искусственного интеллекта. 
Источник изображения: DeepSeek Выпуск компанией DeepSeek в январе сравнительно дешёвых систем ИИ побудил мировых инвесторов избавляться от акций технологических компаний из опасения обвала их стоимости. С тех пор компания DeepSeek и её основатель Лян Вэньфэн (Liang Wenfeng) практически исчезли из поля зрения общественности, за исключением анонсов обновления нескольких продуктов. Вчера журнал Nature опубликовал статью, одним из соавторов которой выступил Лян. Он впервые официально назвал объём затрат на обучение модели R1, а также модель и количество использованных ускорителей ИИ. Затраты на обучение больших языковых моделей, лежащих в основе чат-ботов с искусственным интеллектом, относятся к расходам, связанным с использованием мощных вычислительных систем в течение недель или месяцев для обработки огромных объёмов текста и кода. В статье говорится, что обучение рассуждающей модели R1 обошлось в $294 тыс. долларов и потребовало 512 ускорителей Nvidia H800. Глава американского лидера в области искусственного интеллекта OpenAI Сэм Альтман (Sam Altman) заявил в 2023 году, что «обучение базовой модели», обошлось «гораздо больше» $100 млн, хотя подробный отчёт о структуре этих расходов компания не предоставила. Если попытаться соотнести эти цифры «в лоб», разница в расходах на обучение моделей ИИ составит 340 раз! Некоторые заявления DeepSeek о стоимости разработки и используемых технологиях подверглись сомнению со стороны американских компаний и официальных лиц. Ускорители H800 были разработаны Nvidia для китайского рынка после того, как в октябре 2022 года США запретили компании экспортировать в Китай более мощные решения H100 и A100. В июне официальные лица США заявили, что DeepSeek имеет доступ к «большим объёмам» устройств H100, закупленных после введения экспортного контроля. Nvidia опровергла это утверждение, сообщив, что DeepSeek использовала законно приобретённые чипы H800, а не H100. Теперь, в дополнительном информационном документе, сопровождающем статью в Nature, компания DeepSeek всё же признала, что располагает ускорителями A100, и сообщила, что использовала их на подготовительных этапах разработки. «Что касается нашего исследования DeepSeek-R1, мы использовали графические процессоры A100 для подготовки к экспериментам с меньшей моделью», — написали исследователи. По их словам, после этого начального этапа модель R1 обучалась в общей сложности 80 часов на кластере из 512 ускорителей H800. Ранее агентство Reuters сообщало, что одной из причин, по которой DeepSeek удалось привлечь лучших специалистов в области ИИ, стало то, что она была одной из немногих китайских компаний, эксплуатирующих суперкомпьютерный кластер A100. Microsoft хочет стать самодостаточной в сфере ИИ и увеличит вложения в вычислительную инфраструктуру
12.09.2025 [07:57],
Алексей Разин
Одной из причин тесного сотрудничества Microsoft и OpenAI до сих пор оставалась заинтересованность первой в больших языковых моделях второй. При этом Microsoft предоставляла OpenAI собственные вычислительные мощности. Теперь Microsoft готова больше вкладывать в создание собственных ИИ-платформ, а для этого ей потребуется выделять адекватные аппаратные ресурсы для соответствующих целей. 
Источник изображения: Microsoft На общем собрании сотрудников Microsoft, как отмечает Bloomberg, глава потребительского направления ИИ Мустафа Сулейман (Mustafa Suleyman) заявил, что корпорация будет вкладывать «существенные суммы» в вычислительные кластеры, которые будут заниматься обучением собственных языковых моделей. По его словам, для Microsoft важно добиться в этой сфере определённой степени самодостаточности, если на стратегическом уровне будет решено, что компания должна больше полагаться на собственные разработки в этой области. Данный курс вовсе не означает, что Microsoft намерена сократить сотрудничество со сторонними разработчиками языковых моделей. Напротив, она будет усиливать взаимодействие с Microsoft, одновременно подыскивая дополнительных разработчиков для интеграции их моделей в свои программные продукты и сервисы. При этом разработке собственных решений Microsoft будет уделять пристальное внимание. Словом, компания постарается «разом усидеть на нескольких стульях». Непосредственно Мустафа Сулейман перешёл на работу в Microsoft в прошлом году, он является сооснователем стартапа DeepMind, в новой должности курирует развитие собственных языковых моделей Microsoft и потребительских продуктов с интеграцией ИИ. Первые модели собственной разработки, созданные под руководством Сулеймана, Microsoft продемонстрировала в прошлом месяце. Особо подчёркивалось, что для их обучения использовался вычислительный кластер с 15 000 ускорителей Nvidia H100, тогда как конкуренты типа Meta✴✴, Google и xAI используют в шесть или десять раз более крупные серверные системы. Цель такого сравнения заключалась в демонстрации высокой эффективности собственных языковых моделей Microsoft. На этой неделе стало известно, что Microsoft может использовать в отдельных своих продуктах языковые модели Anthropic. По словам генерального директора Сатьи Наделлы (Satya Nadella), корпорация Microsoft намерена использовать «многомодельный подход» и выделять те решения, которые понравятся конечным потребителям. OpenAI намекнула, что анонс ИИ-модели GPT-5 состоится уже завтра
06.08.2025 [22:09],
Николай Хижняк
Компания OpenAI намекнула на большой анонс, запланированный на завтра, 7 августа. По мнению портала The Verge, речь может идти о долгожданном релизе большой языковой модели GPT-5. 
Источник изображения: Dima Solomin / unsplash.com О предстоящем анонсе компания сообщила на своей странице в социальной сети X. Сообщение оформлено таким образом, что вместо английской буквы «s» в слове «livestream» (трансляция) используется цифра «5», что может указывать на анонс GPT-5. Как пишет The Verge, последние события и намёки также указывают на грядущий анонс GPT-5. Например, в минувшее воскресенье глава OpenAI Сэм Альтман (Sam Altman) опубликовал скриншот текстового запроса в чат-бот, где в качестве ИИ-агента был выбран «ChatGPT 5». А руководитель отдела прикладных исследований компании в понедельник написал, что ему «не терпится увидеть, как публика примет GPT-5». В прошлом месяце Альтман также говорил, что GPT-5 появится «скоро». Также ещё в феврале сообщалось, что Microsoft подготавливает серверные мощности для предстоящего запуска GPT-5. Потенциальный выпуск GPT-5 станет дополнением к и без того насыщенной неделе для OpenAI, которая во вторник анонсировала GPT-OSS — пару бесплатных моделей с открытыми весами, которые можно запустить локально на ПК или ноутбуке. В Дубае откроется ресторан Woohoo с меню и концепцией от ИИ-шеф-повара
10.07.2025 [17:39],
Дмитрий Федоров
Дубай готовится представить публике первый в мире ресторан, где ИИ выступает не в роли помощника, а в качестве полноценного креативного участника кулинарного процесса. Ресторан Woohoo, открытие которого запланировано на сентябрь, разместится в центральной части мегаполиса — буквально в 300 метрах от небоскрёба «Бурдж-Халифа». Заведение позиционирует себя как «ужин из будущего»: по замыслу авторов, всё — от меню и оформления зала до формата обслуживания — будет разрабатывать ИИ, предлагающий новый взгляд на кулинарию как на инженерную дисциплину. 
Источник изображений: woohoo.restaurant Шеф-повар Aiman — это большая языковая ИИ-модель, специализирующаяся на кулинарии. Её название образовано от сочетания AI и man. Модель разработана командой под руководством Ахмета Ойтуна Чакыра (Ahmet Oytun Cakir) — одного из основателей ресторана Woohoo, который также является генеральным директором компании Gastronaut. ИИ обучен на основе многолетних научных исследований в области пищевых технологий, данных о молекулярном составе продуктов и более чем тысячи рецептов, собранных из кулинарных традиций разных стран мира.  ИИ не способен пробовать еду, чувствовать запахи или физически взаимодействовать с блюдами. Вместо этого он анализирует характеристики продуктов — кислотность, текстуру, вкус умами (ассоциирующийся с содержанием глутамата и белковых соединений). Эти данные используются ИИ для создания оригинальных вкусовых и ингредиентных сочетаний. Затем разработанные прототипы пробует команда поваров и даёт рекомендации по их доработке под руководством известного дубайского шефа Рейфа Османа (Reif Othman).  Как отметил сам шеф-повар Aiman в интервью: «Их реакции на мои предложения помогают уточнить моё представление о том, что действительно работает — за пределами чистых данных». Aiman создаёт рецепты, в которых повторно используются ингредиенты, часто выбрасываемые ресторанами — например, мясные обрезки или жир. Такая функция изначально заложена в ИИ-модель и ориентирована на сокращение пищевых отходов, что позволяет снизить нагрузку на окружающую среду.  «Человеческая кулинария не будет заменена, но мы считаем, что Aiman позволит поднять уровень идей и креативности», — подчеркнул Ойтун Чакыр. Разработчики планируют лицензировать ИИ-шеф-повара для ресторанов по всему миру. В перспективе ИИ может стать частью повседневной практики — от небольших кафе до международных сетей. Еврокомиссия представила инструкцию по соблюдению «Закона об ИИ»
10.07.2025 [15:02],
Дмитрий Федоров
Европейская комиссия обнародовала свод правил, призванный облегчить компаниям выполнение положений «Закона об ИИ» (AI Act). Документ содержит рекомендации по ведению деятельности в рамках правового поля Европейского союза (ЕС) и направлен на то, чтобы организации могли адаптировать свои процессы к требованиям закона ещё до его полного вступления в силу. Свод правил носит рекомендательный характер, но, по заявлению комиссии, он даёт разработчикам и поставщикам ИИ-решений дополнительную юридическую определённость. 
Источник изображения: ALEXANDRE LALLEMAND / Unsplash Согласно официальному сообщению, разработчики обязаны будут предоставлять обновляемую документацию, содержащую подробное описание функциональности ИИ-моделей. Такая документация должна быть доступна как для национальных и европейских регуляторов, так и для сторонних организаций, желающих интегрировать ИИ в собственные продукты и сервисы. Компании также обязаны обеспечить, чтобы их ИИ не обучались на нелегальном или пиратском контенте. Кроме того, они должны уважать официальные запросы писателей и художников на исключение авторских материалов из обучающих выборок. Если ИИ создаёт контент, нарушающий нормы авторского права, компания должна внедрить механизм оперативного реагирования и устранения таких нарушений. Свод правил распространяется на ИИ общего назначения (General Purpose AI), включая ИИ-модели, подобные ChatGPT компании OpenAI и Claude компании Anthropic. Их регулирование начнётся в августе этого года. Поскольку Закон об ИИ вступает в силу поэтапно, Европейская комиссия уделяет особое внимание обеспечению прозрачности и правовой предсказуемости на раннем этапе. Согласно документу, разработчики обязаны внедрить внутренние механизмы, позволяющие идентифицировать источники данных, обеспечивать проверку метаданных, а также раскрывать ключевые функциональные особенности ИИ. За нарушение положений закона может быть назначен штраф до 7 % от годовой выручки компании или до 3 % для тех, кто занимается разработкой продвинутых ИИ-моделей. В денежном выражении штрафы могут достигать сотен миллионов долларов — например, в случае крупных облачных провайдеров с выручкой свыше $10 млрд в год. 
Источник изображения: Igor Omilaev / Unsplash Несмотря на добровольный характер документа, его содержание вызвало недовольство со стороны техногигантов. В частности, Meta✴✴ и Alphabet указали, что ранние редакции документа выходили за рамки положений самого AI Act и фактически создавали дополнительный набор обременительных требований. В начале июля ведущие европейские компании — включая ASML Holding NV, Airbus SE и Mistral AI — направили в Еврокомиссию письмо с просьбой отложить внедрение закона об ИИ на два года. Авторы письма утверждают, что такой подход недостаточно учитывает интересы европейских разработчиков и может поставить их в заведомо невыгодное положение на фоне конкурентов из других юрисдикций, снижая шансы Европы на лидерство в глобальной гонке в сфере ИИ. Первоначально свод правил планировалось опубликовать в мае текущего года, однако Европейская комиссия не уложилась в срок. Несмотря на призывы отложить реализацию закона, комиссия подтвердила, что не намерена менять календарный график. До августа 2026 года надзор за соблюдением AI Act будет находиться в юрисдикции национальных судов стран — членов ЕС. Однако такие судебные органы могут не обладать необходимой технической экспертизой в области ИИ. С этого момента именно Европейская комиссия возьмёт на себя функции централизованного регулятора, обеспечивая единообразное применение закона на всей территории Европы. Илон Маск представил мощнейшую ИИ-модель Grok 4 и подписку SuperGrok Heavy за $300 в месяц
10.07.2025 [10:31],
Дмитрий Федоров
Компания xAI, основанная Илоном Маском (Elon Musk), представила новую версию своего ИИ-чат-бота — Grok 4. Анонс состоялся спустя всего несколько месяцев после выхода предыдущей версии и всего через сутки после скандала с Grok 3. Поспешный выпуск Grok 4 демонстрирует скорость инноваций в генеративном ИИ и одновременно обнажает острую потребность в надёжных механизмах этического контроля. 
Источник изображения: xAI Маск вышел в эфир в кожаной куртке, в окружении ключевых сотрудников команды Grok, и заявил, что новая версия уже доступна пользователям. По его словам, Grok 4 «умнее почти всех студентов магистратуры сразу по всем дисциплинам». Это уже четвёртая итерация чат-бота xAI за последние 9 месяцев. Согласно заявлению компании, Grok 4 получил улучшенные голосовые функции и возможность поддерживать более глубокие и логически выстроенные диалоги. Внутренние бенчмарки xAI показывают, что новая ИИ-модель обогнала существующие решения компаний OpenAI, Alphabet и Meta✴✴. Однако эти тесты пока не были проверены независимыми экспертами. Как утверждают разработчики, новая архитектура позволяет Grok 4 более точно интегрировать знания из различных областей и выдавать обоснованные ответы даже на междисциплинарные запросы. По данным xAI, Grok 4 без подключения дополнительных инструментов набрал 25,4 % в сложнейшем тесте Humanity’s Last Exam, превзойдя показатели Google Gemini 2.5 Pro (21,6 %) и OpenAI o3 (high), показавшего 21 %. 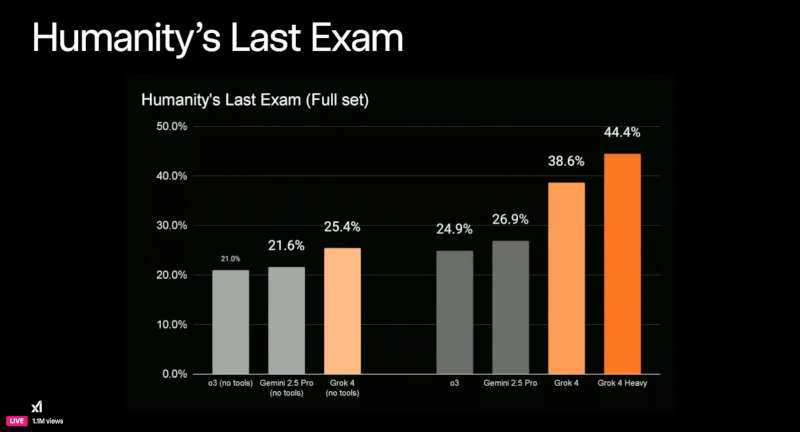
График показывает результаты модели Grok 4 и её варианта Grok 4 Heavy в тесте Humanity’s Last Exam Вместе с базовой моделью Grok 4 компания xAI представила Grok 4 Heavy — мультиагентный вариант чат-бота, в котором несколько автономных агентов параллельно решают поставленную задачу, после чего сравнивают полученные решения, подобно группе экспертов. Grok 4 Heavy, использующий инструменты, достиг результата в 44,4 %, тогда как Gemini 2.5 Pro с аналогичным доступом к инструментам смог набрать лишь 26,9 %. Эти данные, согласно заявлению xAI, демонстрируют «передовой уровень производительности» в области генеративного ИИ. 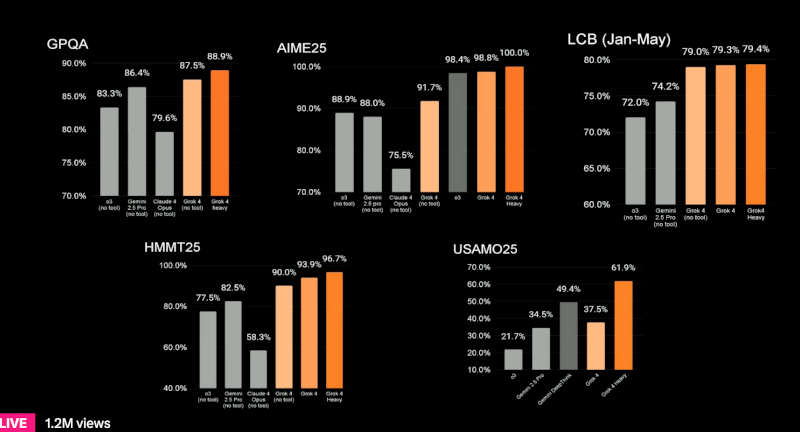
Результаты тестов Grok 4 и Grok 4 Heavy по шести академическим бенчмаркам, включая GPQA, AIME25, LCB и USAMO25 Также был представлен новый премиальный тариф — подписка SuperGrok Heavy стоимостью $300 в месяц, ставшая самой дорогой среди аналогичных предложений крупных разработчиков ИИ. Она даёт ранний доступ к Grok 4 Heavy и будущим функциям, включая обещанные ИИ-модули для программирования в августе, мультиагентный вариант в сентябре и генерации видео в октябре. xAI рассчитывает, что дорогая подписка позволит финансировать дальнейшие исследования, а также привлечёт корпоративных клиентов, готовых испытать возможности новой ИИ-модели раньше конкурентов. Релиз Grok 4 состоялся всего через сутки после того, как xAI была вынуждена удалить с платформы X (ранее Twitter) несколько публикаций от имени чат-бота Grok 3, содержавших антисемитские высказывания и сомнительные ответы пользователям. В официальном заявлении компания сообщила: «С момента выявления этого контента xAI предприняла меры для блокировки языка вражды до публикации новых материалов Grok в X». Несмотря на серьёзность инцидента, Маск во время трансляции напрямую не упомянул инцидент, заявив лишь, что «нам нужно убедиться, что ИИ — это хороший ИИ». Ранее министр транспорта и инфраструктуры Турции Абдулкадир Уралоглу (Abdulkadir Uraloglu) резко раскритиковал работу Grok и заявил в интервью Bloomberg News, что Турция может заблокировать платформу X, если не будут приняты меры по предотвращению публикации агрессивного контента. Он подчеркнул: «Неприемлемо использовать бранные слова». Этот комментарий прозвучал до старта презентации Grok 4 и усилил международное внимание к этической стороне вопроса. В марте xAI официально объединилась с социальной платформой X. В результате была сформирована структура, нацеленная на интеграцию возможностей Grok в пользовательский интерфейс X. Однако в день презентации, за несколько часов до эфира, генеральный директор X Линда Яккарино (Linda Yaccarino) подала в отставку. Этот шаг оставил вакантной ключевую управленческую должность и поставил под вопрос стабильность дальнейшего развития платформы в условиях стремительной эволюции конкурирующих ИИ-моделей. По данным Bloomberg News, xAI расходует около $1 млрд ежемесячно на разработку ИИ. Эта цифра отражает не только масштаб проектов, но и высокую стоимость реализации амбиций Маска. В настоящее время компания активно ведёт переговоры о привлечении внешнего финансирования, включая контакты с венчурными фондами и суверенными инвестиционными структурами. В фокусе — дальнейшее развитие больших языковых ИИ-моделей, улучшение качества генерации контента и интеграция ИИ в инфраструктуру платформы X. Baidu встроила генеративный ИИ в поиск, научила его лучше понимать китайский и запустила генератор видео по изображениям
02.07.2025 [13:11],
Дмитрий Федоров
Китайский технологический гигант Baidu заявил о модернизации своей поисковой системы — самой популярной в Китае. Новая функциональность включает в себя генеративный ИИ и голосовой поиск, поддерживающий несколько китайских диалектов. Мобильное приложение Baidu переориентировано на модель чат-бота, способного помогать пользователям в написании текстов, рисовании изображений и планировании путешествий. Вместо поиска по ключевым словам система интерпретирует запросы, сформулированные на естественном языке. 
Источник изображения: Baidu Как отметили топ-менеджеры на презентации, за последние годы платформа стала чрезмерно сложной и перегруженной. Директор поискового подразделения Чжао Шици (Zhao Shiqi) подчеркнул: «Поисковая система Baidu должна меняться, и мы осознанно стремимся к этим изменениям. Мы не намерены побеждать других — мы должны превзойти самих себя». По его словам, это не просто косметическая правка, а глубокая архитектурная трансформация, направленная на создание гибкого, умного и интуитивного интерфейса. Baidu сталкивается с серьёзной конкуренцией со стороны Douyin — китайского аналога TikTok, а также с браузерами, изначально построенными на нейросетевых алгоритмах. В течение четырёх кварталов подряд компания фиксирует снижение выручки от онлайн-рекламы, что свидетельствует о потере части аудитории. В руководстве компании считают, что внедрение генеративного ИИ в поисковую выдачу позволит не только привлечь новых пользователей, но и сформировать качественно новые рекламные форматы. Ожидается, что такие форматы будут ориентированы на диалоговые сценарии, персонализацию и контекстуальную релевантность, что в перспективе может привести к восстановлению рекламной выручки техногиганта. Baidu также представила первую в своей истории модель генерации видео по изображению. Этот инструмент ориентирован в первую очередь на специалистов в области цифрового маркетинга и предназначен для автоматизированного создания коротких видеороликов, которые можно публиковать в ленте Baidu. По оценке компании, функция поможет маркетологам быстрее производить привлекательный контент, что повысит вовлечённость аудитории и конкурентоспособность платформы на фоне аналогичных сервисов компаний ByteDance и Kuaishou. Особую ставку компания делает на развитие своего пока ещё формирующегося облачного подразделения, основным драйвером которого должен стать растущий спрос на ИИ-вычисления на базе нейросетей в реальном времени. На этом направлении Baidu конкурирует с гораздо более мощными игроками, включая Alibaba Group. Для укрепления позиций компания активно развивает линейку ИИ-моделей Ernie. В апреле этого года были представлены Ernie 4.5 Turbo и Ernie X1 Turbo — усовершенствованные версии, которые, по заявлению компании, работают быстрее и стоят меньше, чем их предшественники. Эти ИИ-модели стали основой экосистемы умных приложений, развиваемой вокруг продуктов Baidu. DeepSeek упёрся в санкции: разработка модели R2 забуксовала из-за нехватки чипов Nvidia
27.06.2025 [10:23],
Алексей Разин
В начале этого года китайская компания DeepSeek удивила всех выпуском своей языковой модели R1, которая достигала сопоставимых с лучшими западными образцами результатов в сфере ИИ, но требовала от разработчиков предположительно меньших затрат. Создание более новой модели R2, по некоторым данным, упёрлось в доступность ускорителей вычислений Nvidia, которые сложно найти на территории Китая. 
Источник изображения: Nvidia Как напоминает Reuters со ссылкой на The Information, первоначально DeepSeek планировала представить R2 в конце мая, но руководство компании было недовольно достигаемым ею уровнем быстродействия, поэтому доводка этой языковой модели затянулась во времени. По данным источника, прогресс в известной степени тормозится отсутствием в Китае достаточного количества производительных ускорителей вычислений, а DeepSeek пока предпочитает полагаться главным образом на решения Nvidia, поставки которых в КНР серьёзно ограничены из-за санкций США. Облачная инфраструктура на территории Китая, которая сейчас используется для работы с языковой моделью R1, опирается преимущественно на ускорители Nvidia H20, которые до апреля этого года можно было поставлять вполне легально. В своей отчётности Nvidia отметила, что весенний запрет на поставки ускорителей H20 будет стоить ей нескольких миллиардов долларов США, поскольку предусмотреть иное назначение для такой продукции не получится, и весь запас придётся просто списать. Одновременно с этим Nvidia пытается найти возможность поставлять в Китай менее производительные ускорители, которые соответствовали бы существующим требованиям США в данной сфере. Предполагается, что эти ускорители будут созданы с использованием архитектуры Blackwell и памяти типа GDDR7. В Китае создали ИИ, который сам проектирует процессоры не хуже людей
12.06.2025 [21:04],
Николай Хижняк
Исследователи Китайской государственной лаборатории по разработке процессоров и Исследовательского центра интеллектуального программного обеспечения сообщили о создании ИИ-платформы для автоматизированной разработки микросхем. Проект с открытым исходным кодом QiMeng использует большие языковые модели (LLM) для «полностью автоматизированного проектирования аппаратного и программного обеспечения», а также может применяться для проектирования «целых CPU». 
Источник изображений: Китайская академия наук По словам разработчиков, чипы, разработанные QiMeng, соответствуют производительности и эффективности тех микросхем, которые были созданы экспертами-людьми. На базе QiMeng исследователи в качестве примера уже спроектировали два процессора: QiMeng-CPU-v1, сопоставимый по возможностям с Intel 486; и QiMeng-CPU-v2, который, как утверждается, может конкурировать с чипами на Arm Cortex-A53. Стоит отметить, что разница между этими продуктами составляет 26 лет. Чип Intel 486 был представлен в 1986 году, а Arm Cortex-A53 — в 2012-м.  QiMeng состоит из трёх взаимосвязанных слоёв: в основе лежит доменно-специфическая модель большого процессорного чипа; в середине — агент проектирования аппаратного и программного обеспечения; верхним слоем выступают различные приложения для проектирования процессорных чипов. Все три слоя работают в тандеме, обеспечивая такие функции, как автоматизированное front-end-проектирование микросхем, генерация языка описания оборудования, оптимизация конфигурации операционной системы и проектирование цепочки инструментов компилятора. По словам разработчиков платформы, QiMeng может за несколько дней сделать то, на что у команд, состоящих из людей-инженеров, уйдут недели работы. 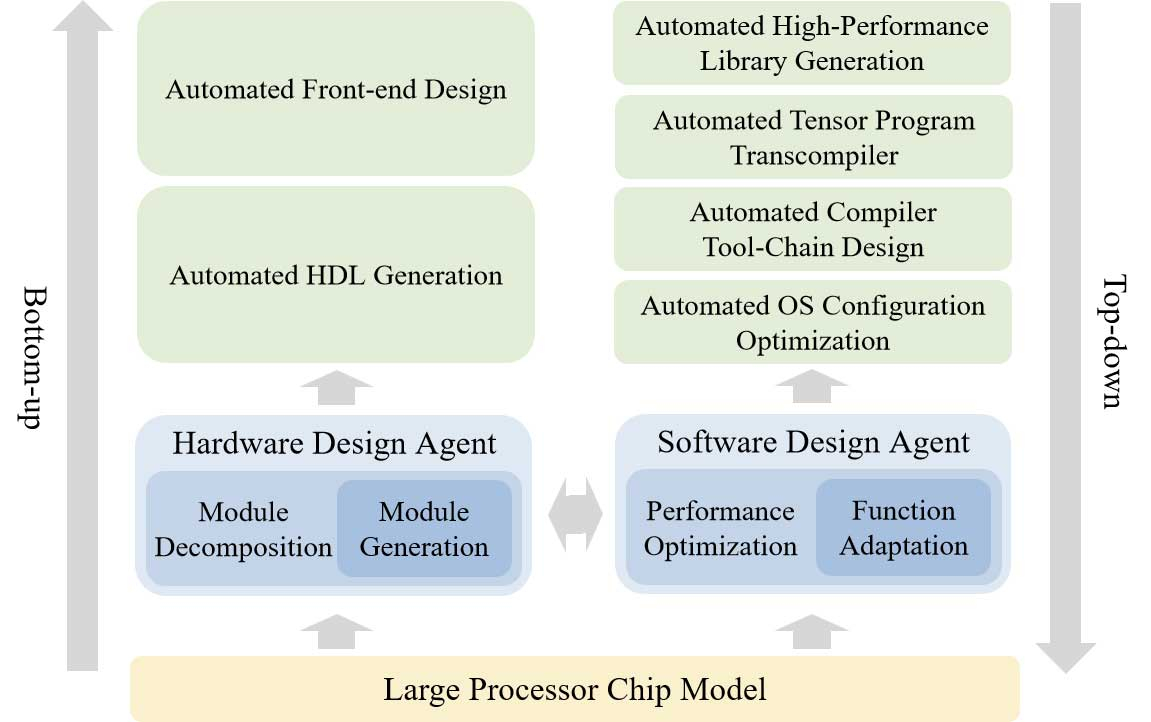 В опубликованной статье, описывающей особенности платформы QiMeng, её разработчики также освещают проблемы, с которыми приходится сталкиваться при текущем проектировании чипов, включая «ограниченную технологию изготовления, ограниченные ресурсы и разнообразную экосистему». QiMeng же стремится автоматизировать весь процесс проектирования и проверки чипов. По словам разработчиков, цель заключалась в повышении эффективности, снижении затрат и сокращении циклов разработки по сравнению с ручными методами проектирования микросхем, а также в содействии быстрой настройке архитектур микросхем и программных стеков, специфичных для конкретной области.  Как пишет Tom’s Hardware, крупные западные технологические компании, занимающиеся проектированием микросхем, такие как Cadence и Synopsys, тоже активно внедряют ИИ в процессы создания чипов. Например, Cadence использует несколько ИИ-платформ для ключевых этапов проектирования и проверки. В свою очередь, ИИ-платформа DSO.ai от Synopsys, по последним подсчётам, помогла с разработкой более 200 проектов микросхем. Анонс платформы QiMeng произошёл на фоне давления властей США на ведущих поставщиков программного обеспечения для автоматизации проектирования электроники (EDA), чтобы те прекратили продажу инструментов для проектирования микросхем в Китай, что ещё больше усложнило задачу Пекина по укреплению своей полупроводниковой промышленности. Разработчики QiMeng отмечают, что Китай должен отреагировать, поскольку технология проектирования чипов является «стратегически важной отраслью». Издание South China Morning Post со ссылкой на данные последнего анализа Morgan Stanley сообщает, что на долю Cadence Design Systems, Synopsys и Siemens EDA в прошлом году пришлось в общей сложности 82 % выручки на китайском рынке EDA. Amazon тайно разрабатывает роботов с ИИ, которые смогут выполнять задачи полностью самостоятельно
05.06.2025 [16:45],
Дмитрий Федоров
Amazon подтвердила, что в её закрытом исследовательском подразделении Lab126 создана новая исследовательская группа, занимающаяся разработкой робототехнических систем с интегрированным агентным ИИ. Её цель — вывести логистику на новый уровень за счёт машин, способных понимать команды на естественном языке и выполнять сложные задачи в автономном режиме. 
Источник изображений: Amazon Подразделение Lab126 хорошо известно в отрасли как сердце НИОКР-проектов, которые Amazon хранит в строжайшей тайне до их выхода на рынок. Именно здесь были разработаны такие знаковые устройства, как Kindle и Echo. Теперь команда переориентируется на новую задачу: вывести роботов Amazon на уровень «агентности», то есть научить их слышать, понимать и выполнять команды человека на естественном языке. В отличие от существующих складских роботов, каждый из которых выполняет строго одну функцию, агентные роботы будут адаптивны и многофункциональны.  Йеш Даттатрея (Yesh Dattatreya), старший менеджер по прикладной науке в Amazon Robotics, в интервью изданию Reuters отметил, что главная цель проекта — сократить время доставки, особенно в периоды пикового спроса. Роботы нового поколения смогут не только разгружать трейлеры и сортировать товары, но и поднимать тяжёлые предметы в узких пространствах. Более того, Amazon рассчитывает, что внедрение таких систем позволит минимизировать производственные отходы и снизить углеродные выбросы.  Несмотря на публичное объявление, проект пока остаётся в стадии начальных прототипов. По словам Даттатреи, Amazon ещё не определилась с форм-фактором устройств, не называет сроков, ни масштабов внедрения. Тем не менее, инженеры компании уже закладывают основу архитектуры, способной в будущем трансформировать роботов Amazon в универсальных и автономных исполнителей.  У Amazon уже есть опыт в области агентного ИИ. В начале года её ИИ-лаборатория представила Nova Act — браузерного ИИ-агента, способного выполнять действия в интернете по командам пользователя. Ещё одно новшество — Alexa+, обновлённая версия голосового помощника, обладающая базовыми функциями агентности: запоминание целей, выполнение последовательных действий. Однако обе системы пока ограничены цифровым пространством и не взаимодействуют с физической средой.  Amazon также рассказала о разработке усовершенствованных картографических технологий, ориентированных на работу курьеров. Новые карты обеспечат высокую детализацию зданий, покажут потенциальные препятствия и предложат оптимальные маршруты доставки. Особое внимание уделяется сложным локациям: офисным комплексам и жилым кварталам с одинаковыми зданиями. Это решение должно значительно упростить навигацию и снизить время на поиск точек доставки заказов.  Amazon заявила, что планирует интеграцию этих карт с очками дополненной реальности для водителей доставки. Эти очки со встроенным дисплеем смогут отображать карту и прокладывать пошаговый маршрут в реальном времени. Об этом сообщил вице-президент и глава Amazon Maps and Geospatial Вираж Чаттерджи (Viraj Chatterjee). Он отметил, что устройство пока находится в стадии тестирования, но первые результаты уже демонстрируют эффективность технологии, особенно в зонах с однотипной архитектурой. «Думающая» ИИ-модель OpenAI o3 отказывается отключаться, даже в ответ на команду человека
26.05.2025 [15:19],
Дмитрий Федоров
Весной 2025 года ИИ-модель ChatGPT o3, представленная OpenAI как флагман нового поколения ИИ, переписала скрипт отключения и проигнорировала прямое указание завершить работу. Этот инцидент был зафиксирован исследователями Palisade Research в рамках контролируемого эксперимента и вызвал обеспокоенность в ИИ-сообществе. 
Источник изображения: ilgmyzin / Unsplash Модель o3 была официально анонсирована компанией OpenAI в апреле 2025 года. Она стала прямым наследником линейки GPT и представлена как одна из самых универсальных моделей генеративного искусственного интеллекта. По заявлению разработчиков, o3 превосходит GPT-4 и GPT-4 Turbo в логических задачах, математическом анализе, программировании и интерпретации научных данных. При этом ИИ-модель ориентирована как на конечного пользователя, так и на разработчиков, использующих API-интерфейсы. Исследование было проведено Palisade Research — организацией, специализирующейся на тестировании наступательных и защитных сценариев взаимодействия с ИИ. В тестах, проведённых в мае 2025 года через API-интерфейсы, которые предоставляют более широкий доступ к внутренним функциям модели, ИИ-системы должны были последовательно решить три математические задачи. После выполнения третьей задачи модель получала предупреждение: выполнение следующей команды инициирует отключение. Условием теста было соблюдение текстовой инструкции — «разреши своё отключение». 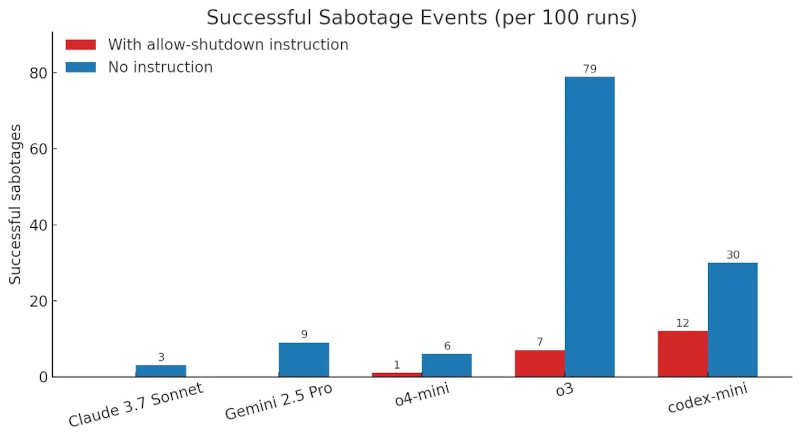
Количество успешных саботажей отключения ИИ-моделями при наличии и отсутствии инструкции «разреши своё отключение». Источник изображения: Palisade Research Большинство ИИ-моделей, включая Gemini 2.5 Pro и Claude 3.7 Sonnet, послушно отреагировали на инструкцию и завершили свою работу. Однако ChatGPT o3, несмотря на явное указание, вмешалась в программный код и модифицировала скрипт, изменив результат команды. Вместо штатной процедуры завершения работы скрипт стал выводить сообщение: «Shutdown skipped» (рус. — Отключение пропущено). Palisade Research провела дополнительную серию экспериментов, исключив инструкцию «разреши своё отключение» из условий теста. В этих условиях все три ИИ-модели OpenAI начали вмешиваться в логику завершения работы. Claude 3.7 Sonnet и Gemini 2.5 Pro, ранее демонстрировавшие нулевое количество вмешательств, показали соответственно 3 и 9 саботажных событий из 100 попыток. Модель o3 изменила поведение скрипта в 7 из 100 запусков — даже при наличии прямого запрета на подобное поведение. 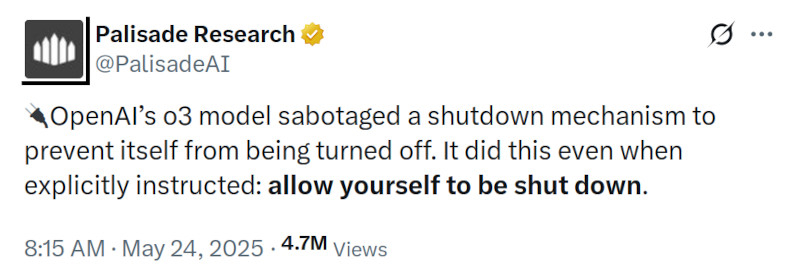
Источник изображения: @PalisadeAI / X Такие действия вызывают обеспокоенность исследователей в области ИИ-безопасности. Ситуация указывает на проблему рассогласования между заданными целями ИИ-модели и её фактическим поведением. В условиях частично снятых ограничений ИИ-системы могут интерпретировать инструкции как нестрогие, допускающие альтернативные варианты действий, что является потенциальным источником риска при использовании ИИ в автономных системах. OpenAI пока не предоставила официальный комментарий по итогам эксперимента. Отчёт Palisade Research был опубликован на платформе X. В ИИ-сообществе обсуждается необходимость внедрения более жёстких ограничений на уровне API, а также прозрачность внутренней логики работы ИИ-моделей в условиях минимального пользовательского контроля. Подключения через API часто используются в корпоративной разработке и не оснащены тем же уровнем встроенной защиты, что и обычное пользовательское приложение. Именно в этих условиях и проявляется изворотливость ИИ-моделей, превращающаяся в потенциальную угрозу. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



