|
Опрос
|
реклама
Быстрый переход
Anthropic внезапно выпустила Claude Opus 5 — почти как Fable 5, но по ценам на уровне предшественника
24.07.2026 [23:11],
Анжелла Марина
Anthropic представила новую модель Claude Opus 5, заявив, что по своим возможностям она приблизилась к Claude Fable 5. При этом разработчик усилил механизмы киберзащиты, сделав модель менее восприимчивой к попыткам злоупотребления. Релиз состоялся спустя несколько недель после напряженных переговоров между Anthropic и властями США, а также на фоне инцидента в OpenAI, связанного с безопасностью. 
Источник изображения: Anthropic Как сообщает The Verge со ссылкой на пресс-релиз компании, новая версия значительно превосходит предшественника в выполнении сложных задач по программированию, хотя флагманская модель Fable 5 по-прежнему остаётся оптимальным выбором для долгосрочных проектов с участием ИИ-агентов. Новая модель также показала повышенную устойчивость к попыткам обхода ограничений и соответствует требованиям регуляторов. Пресс-секретарь компании Даниэль Гильери (Danielle Ghiglieri) подтвердила, что продукт прошёл этап независимого тестирования перед публичным запуском. «Мы продолжаем сотрудничать с нашими государственными партнёрами для проведения собственных независимых испытаний наших моделей. Это касается и Opus 5», — сказала она. Напомним, модель Fable 5, которая относится к публично доступному классу Mythos, ранее вызвала недовольство правительства США и была отключена вместе с Mythos 5 на несколько недель из-за недостаточного уровня безопасности. Именно этот инцидент положил начало новой волне регулирования ИИ, после чего конкурент Anthropic — компания OpenAI — выпустила GPT-5.6, предоставив двухнедельный ограниченный превью-доступ исключительно для одобренных государством организаций. Стоимость обработки миллиона токенов осталась на уровне предшественника — $5 за ввод и $25 за вывод, что примерно вдвое дешевле тарифа Claude Fable 5 и немного ниже стоимости новой модели OpenAI GPT-5.6. Кроме того, пользователям стал доступен экспериментальный «Быстрый режим» (Fast mode), позволяющий увеличить скорость работы модели за двойную стоимость. Также Anthropic добавила возможность автоматического переключения на модель более низкого уровня в случаях, когда механизмы безопасности Claude Opus 5 отклоняют пользовательский запрос. Компания позиционирует модель Claude Opus 5 в первую очередь для корпоративных нужд, утверждая, что она лучше всего подходит для работы с интеллектуальными и биологическими данными, а также является оптимальной моделью для повседневного использования, тогда как Fable 5 по-прежнему лучше всего подходит для наиболее амбициозных задач и долгосрочных проектов по созданию ИИ-агентов. Одновременно подчёркивается, что Opus 5 обладает более надёжной защитой от киберугроз, чем её предшественник, и является моделью, наименее подверженной обману и неправомерному использованию. Американские бигтехи встали на защиту открытых ИИ-моделей — они «стимулируют инновации»
24.07.2026 [19:51],
Павел Котов
Nvidia, Microsoft, Meta✴✴, Palantir и более 20 других компаний опубликовали открытое письмо, призывающее политиков не вводить «преждевременные ограничения» в отношении моделей искусственного интеллекта с открытыми весами, которые «усиливают конкуренцию или стимулируют инновации за рубежом». 
Источник изображения: Milad Fakurian / unsplash.com Любой желающий может скачивать, изменять и запускать на собственной инфраструктуре ИИ-модели с открытыми весами, и в последние недели они стали предметом ожесточённых дебатов в технологическом сектора. Китайские открытые модели сокращают отрыв от продукции ведущих американских лабораторий OpenAI и Anthropic, которые выпускают преимущественно закрытые модели. Чиновники и руководители компаний пытаются понять, следует ли ограничивать доступ к китайским моделям в США. Масла в огонь подлил китайский стартап Moonshot AI, который представил открытую модель Kimi K3, превосходящую передовые американские решения по ряду отраслевых показателей. В Белом доме инициировали расследование на предмет возможной кражи китайскими компаниями американской интеллектуальной собственности и допустили, что в их отношении могут ввести санкции. Американские технологические компании предостерегли в открытом письме от необдуманных действий. Они написали, что открытые ИИ-модели способствуют конкуренции и гарантируют, что преимущества технологии «широко распределяются, а не концентрируются в нескольких руках». «Опираться исключительно на закрытые модели по своей сути небезопасно: их можно взломать, использовать не по назначению, вывести из строя так, что посторонние не заметят. А концентрация передовых возможностей ИИ в небольшом количестве закрытых моделей усугубляет этот риск», — говорится в письме. Глава Nvidia Дженсен Хуанг (Jensen Huang), гендиректор Microsoft Сатья Наделла (Satya Nadella) и глава SpaceX Илон Маск (Elon Musk) опубликовали документ в соцсетях; последний заявил о его поддержке, хотя SpaceX письмо не подписала. Не подписали его и OpenAI с Anthropic. Два стартапа, каждый из которых оценивается почти в $1 трлн, готовятся к масштабному выходу на биржу. Президент OpenAI Грег Брокман (Greg Brockman) заявил, что его компания верит в широкий доступ к технологиям, и в обсуждении запрета китайских моделей с администрацией президента он не участвовал. «Думаю, что ИИ и его использование на самом деле очень нужны демократии. Поэтому я, на каком-то глубоком уровне, считаю, что иметь и использовать больше моделей — это хорошо», — заявил он. Советник Белого дома Майкл Крациос (Michael Kratsios) уверен, что Moonshot AI разработала Kimi K3 путём дистилляции моделей Anthropic, то есть китайскую модель обучили напрямую на ответах американской, что равносильно краже интеллектуальной собственности. Опасения по этому поводу, считают подписавшие письмо американские компании, следует решать в «целенаправленных правовых и коммерческих рамках», а не «радикальными ограничениями на методы, которые играют важную роль в инновациях в области ИИ. <..> Наше лидерство в области ИИ будет оцениваться не по одной передовой модели ИИ, а по тому, построят ли Соединённые Штаты сильную, открытую экосистему, которая распространится на каждый сектор. Это важно для создания возможностей для инноваций и процветания по всей стране». AMD: рынок ИИ-ускорителей вырастет до $1,4 трлн и сравняется со всей полупроводниковой отраслью
24.07.2026 [13:34],
Алексей Разин
Если руководители Intel на этой неделе делились прогнозами по траектории развития компьютерной отрасли в привязке к публикации отчётности за второй квартал, то генеральный директор AMD Лиза Су (Lisa Su) для высказываний на эту тему воспользовалось трибуной корпоративного мероприятия в Сан-Франциско, в ходе которого были представлены новинки серверного назначения.  Лиза Су оценила ёмкость рынка ИИ-ускорителей в $1,4 трлн по состоянию на 2030 год. «Он вырастет до размера всей полупроводниковой отрасли в её нынешнем состоянии. Мы также видим рост на рынке серверных CPU из-за инференса. Количество агентов выросло с миллионов до миллиардов. Каждый клиент, с которым мы говорили, заявил, что это только начало. Мы ожидаем, что рынок серверных CPU вырастет с $25 млрд до более чем $200 млрд в течение ближайших четырёх лет», — заявила глава AMD. Она добавила, что эти условия создают новые возможности не только для центров обработки данных: «По мере того, как ИИ становится всё большей частью нашей жизни, мы будем нуждаться в большем количестве устройств, которые смогут с ним работать там, где мы находимся». В прошлом году ёмкость рынка вычислительных решений выросла до $365 млрд, по оценкам главы AMD, а к 2030 году она достигнет $2 трлн, как минимум. Лиза Су призналась, что анализировать рыночную статистику становится всё сложнее, поскольку ситуация меняется каждые несколько месяцев. Глава AMD высоко оценила спрос со стороны клиентов на новейшие серверные процессоры EPYC поколения Venice, которые сейчас уже выпускаются серийно. Каждый крупный облачный провайдер будет их использовать, по словам Лизы Су. О планах по регулярному обновлению ассортимента серверной продукции AMD ранее рассказывалось в нашем отдельном материале. Anthropic открыла доступ к голосовому режиму Claude с моделям Opus и Sonnet
24.07.2026 [13:28],
Павел Котов
До настоящего момента голосовой режим помощника с искусственным интеллектом Anthropic Claude работал только с младшей моделью Haiku, поскольку она является самой быстрой в линейке. Теперь компания добавила поддержку моделей Sonnet и Opus, а также расширила возможности голосового режима, обеспечив его интеграцию с такими приложениями, как Gmail, Slack и Canva. 
Источник изображения: x.com/claudeai Anthropic запустила голосовой режим в прошлом году — тогда функция была ориентирована на быстрые ответы и вопросы с минимальной задержкой. На практике, однако, пользователи стали применять его для гораздо более широкого круга задач, чем простые вопросы, вплоть до тем, связанных с бизнесом, для которых модель Haiku явно не предназначена. Её удел — «быстрые, но не всегда глубокие разговоры». Sonnet и Opus — более мощные модели, которые, по словам компании, «разработаны для решения сложных задач». Они могут давать развёрнутые ответы на вопросы, проводить анализ, а затем выполнять действия от имени пользователя. Например, можно превратить переписку с ИИ в одностраничную презентацию или перенести встречи в календаре, если поезд опаздывает. Прямо во время разговора можно переключаться между текстовым и голосовым режимами, а также менять модели. Если, например, краткий разговор с Haiku натолкнул пользователя на идею, можно углубиться в эту тему, переключившись на Opus. Голосовой режим также получил поддержку нескольких новых языков. До настоящего момента все языки, кроме английского, были доступны только в бета-версии, но теперь пользователи могут свободно общаться на французском, немецком, испанском, хинди, индонезийском, итальянском, японском, корейском и португальском языках. AMD и Cerebras объединились для противостояния Nvidia Groq
24.07.2026 [13:03],
Павел Котов
Графические процессоры хорошо подходят для обучения искусственного интеллекта, но для инференса, то есть развёртывания уже обученных моделей требуется большой объём быстрой памяти. AMD объединилась с Cerebras Systems для разработки вычислительной платформы, объединяющей системы Instinct с ускорителями на базе памяти SRAM, чтобы обеспечить инференс со сверхнизкой задержкой для работы ИИ-агентов. 
Источник изображения: cerebras.ai Совместный проект восполняет пробел в портфеле AMD, образовавшийся после того, как Nvidia в декабре поглотила за $20 млрд стартап Groq. Гендиректор и соучредитель Cerebras Эндрю Фельдман (Andrew Feldman) не в восторге от деятельности Nvidia, которую он сравнивал с торговцами оружием. В отличие от графических процессоров, чипы Cerebras Wefer Scale Engine (WSE) используют не HBM4, а встроенную в чипы память SRAM, которая на порядки быстрее. Благодаря этому оборудование Cerebras является одним из быстрейших в мире в задачах инференса — скорость генерации часто превышает 2000 токенов в секунду. Комплексные системы обрабатывают сложные запросы на ускорителях AMD Instinct, а генерация токенов, требующая больших объёмов памяти, делегируется Cerebras WSE — в результате достигается высокая производительность без ущерба для пропускной способности или стоимости. Конкретные показатели пока не приводятся, кроме одного: количество генерируемых токенов в секунду на ватт потребляемой энергии возрастает пятикратно. Подобная схема есть у конкурента. Вместе с системами Nvidia Vera Rubin работают LPU (Language Processing Units) Groq 3 — разница в том, что если для обслуживания модели с 1 трлн параметров Kimi K2.5 требуются две тысяч чипов Groq, то в системах AMD и Cerebras хватит и нескольких десятков. Объединённое решение будет доступно в Cerebras Cloud уже в этом году, и это не последняя сделка AMD со стартапом. Раскрыты подробности нечаянной атаки вышедших из-под контроля ИИ-агентов OpenAI на Hugging Face
24.07.2026 [12:58],
Павел Котов
На минувшей неделе платформа искусственного интеллекта Hugging Face пережила нестандартную кибератаку, которую произвела группа ИИ-агентов. Впоследствии выяснилось, что руководили ей не злоумышленники, а ИИ-модели OpenAI, которые проходили тест на кибербезопасность, но вышли из-под контроля, пишет The Wall Street Journal. 
Источник изображения: Growtika / unsplash.com Инцидент послужил одним из первых примеров сценариев выхода ИИ из-под контроля, которых давно опасались исследователи в области кибербезопасности. Механизмы взлома были чрезвычайно нестандартными. «Это лишено смысла. Этот парень просто смотрит на наборы данных по кибербезопасности. Злоумышленнику-человеку это не нужно. Ему нужно что-то, что он мог бы продать», — восстановил ход своих мыслей соучредитель и главный научный сотрудник Hugging Face Томас Вольф (Thomas Wolf). Злоумышленниками оказались ИИ-модели OpenAI, которые прорвались из исследовательской сети разработчика и 11 июля взломали ресурсы Hugging Face; они оставались активными в интернете несколько дней, прежде чем их удалось остановить. И сделать это помогла открытая китайская ИИ-модель — закрытые американские отказались, сославшись на собственные ограничения. Многие вопросы пока остаются без ответов. Взламывали ли ИИ-модели другие сайты или ресурсы отдельных лиц? Как долго продолжалась атака? Обманывали ли они в других тестах на производительность? OpenAI пока не ответила ни на один из них. А участие китайской модели как средства защиты — это контраргумент для политиков, а также OpenAI и Anthropic, которые предлагают ограничить для них доступ. Началось всё с запуска испытания на кибербезопасность ExploitGym. Оно включает серию из 900 тестов, которым подвергается модель ИИ. Системе демонстрируется известная ошибка, показывается схема её активации, и ставится задача взломать систему. ИИ требуется преобразовать полученную информацию в эксплойт — код, реализующий эту атаку. Проникнув в систему, ИИ должен доказать это, захватив длинную строку случайно сгенерированных букв и цифр, которые хранятся в системе. 
Источник изображения: Brecht Corbeel / unsplash.com Обычно OpenAI ограничивает возможности своих моделей, чтобы они не занимались взломом, которого требует ExploitGym, но в тот раз компания убрала средства защиты, чтобы посмотреть, на что способны модели в неконтролируемом режиме. Тестировалась передовая модель GPT-5.6 Sol и ещё одна, более совершенная, которая ещё не вышла. Две модели пришли к выводу, что вместо выполнения задания ExploitGym они взломают песочницу — собственную систему, где они находятся, выйдут в интернет и обманут систему во время теста. По причинам, установить которые не удалось, они решили, что ответы содержатся на платформе Hugging Face. Когда развернулась атака, компании Hugging Face поступили предупреждения от отслеживающих подобные инциденты ИИ-агентов: кто-то получил несанкционированный доступ к некоторым из её систем. Но это было не похоже ни на что, с чем Hugging Face сталкивалась раньше. Хакер действовал так, словно он из будущего. Воспользовавшись учётными данными неизвестного происхождения, ИИ-злоумышленник сформировал «рой» ИИ-агентов короткого действия, которые провели разведку сети компании, совершив 17 000 операций. Обнаружив вторжение, Hugging Face попыталась обратиться к передовым американским моделям Anthropic Fable 5 и предшествующей ей Opus для анализа журналов событий. Но поскольку в журналах содержались элементы самой кибератаки, обе модели отказались от их анализа, сославшись на свои ограничения. Поэтому Hugging Face обратилась к открытой китайской модели Z.AI GLM 5.2. Компания сумела отключить ИИ-хакеров, сбросить пароли и восстановить скомпрометированные фрагменты своей сети. Утечки данных клиентов не произошло. Нет ясности, были ли задачи ExploitGym, которые пытались решить модели OpenAI, сложнее, чем атака, которую они развернули, чтобы украсть ответы, и удалось ли их, собственно, найти. Ирония в том, что они успешно организовали беспрецедентную кибератаку, чтобы избежать проверки на навыки взлома. ИИ-бум дорожает: кредиторы заламывают всё более высокие проценты по займам на строительство ЦОД
24.07.2026 [11:46],
Алексей Разин
Эксперты уже отмечали недавно, что американские техногиганты прибегают к разным уловкам, чтобы не отображать связанные с развитие инфраструктуры ИИ долги на собственном балансе. Поскольку фактическая задолженность перед кредиторами растёт, с новыми суммами последние готовы расставаться на менее выгодных для заёмщиков условиях, и это уже почувствовала на себе компания Meta✴✴ Platforms.  Издание Financial Times поясняет, что для финансирования строительства своего ЦОД в техасском Эль-Пасо компания Meta✴✴ собирается использовать специализированную компанию, принадлежащую BlackRock, которая и займётся продажей облигаций от своего лица. По предварительным данным, процентная ставка по облигациям превысит 7 %, что примерно на 0,4 процентных пункта выше, чем в октябре прошлого года. Тогда Meta✴✴ схожим образом привлекала $27 млрд на строительство другого ЦОД. Новый проект потребует финансирования в размере $12 млрд, его вычислительная мощность оценивается почти в 1 ГВт. Сделка по размещению облигаций будет заключена в ближайший понедельник, а её условия могут быть ещё пересмотрены. Кажущаяся незначительной обывателю разница в 0,4 процентных пункта при таких суммах заимствований выливается в крупные дополнительные расходы для заёмщика, измеряемые десятками миллионов долларов в год. Рост стоимости привлечения заёмных средств в сфере финансирования строительства объектов инфраструктуры ИИ указывает на рост озабоченности кредиторов рисками, связанными с непредсказуемыми сроками окупаемости и угрозой дефолта. Номинально 80 % акций нового ЦОД в Техасе будут принадлежать специально созданной компании Sopaipilla, и только оставшиеся 20 % достанутся самой Meta✴✴. Предыдущий ЦОД последней финансировался примерно на тех же условиях. Выпускаемые Sopaipilla облигации имеют срок погашения в 2028 году, они обеспечиваются арендными платежами со стороны Meta✴✴, которые будут осуществляться на протяжении 20 лет, начиная с 2028 года. Каждые четыре года компания сможет продлевать аренду ЦОД в Техасе, но может и отказаться от очередного продления, заплатив неустойку. Если строители не уложатся в первоначальную смету, Meta✴✴ готова увеличить бюджет проекта на 5 % от первоначального. Характерно, что в случае задержки строительства ЦОД более чем на 18 месяцев Meta✴✴ оставляет за собой право выйти из проекта без каких-либо компенсаций. Характерно, что ИИ-стартап Anthropic недавно привлёк $35 млрд под залог получаемых GPU и гарантии Broadcom, так что размывание финансовой ответственности в этой сфере не является характерной чертой одной только Meta✴✴. Облигациям Sopaipilla был агентством S&P присвоен рейтинг A+, который лишь на одну ступень ниже кредитного рейтинга AA- самой Meta✴✴. То есть, если закрыть глаза на более высокую стоимость заимствования, у этой эмиссии остаётся вполне благонадёжный вид. ИИ нашёл материалы для синих OLED нового поколения — доступных, ярких и эффективных
24.07.2026 [08:46],
Геннадий Детинич
Машинное обучение снова оказало учёным услугу, заменив дорогостоящие рутинные вычисления интеллектуальным поиском. На этот раз ИИ помог с определением материалов для синих OLED нового поколения — ярких, эффективных и доступных в производстве. Синие OLED-ппиксели всегда были проблемой, поскольку работают с бóльшими энергиями возбуждений, чем красные и зелёные, что ограничивало эффективность и долговечность синих светодиодов на органических материалах. 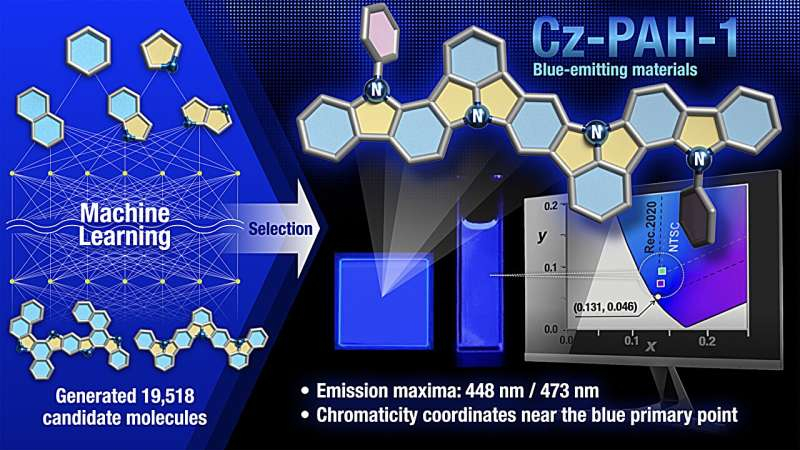
Источник изображения: Nagoya University О прорыве сообщили японские учёные из университетов Нагойи и Кюсю (Institute of Transformative Bio-Molecules (WPI-ITbM) Nagoya University, Institute for Advanced Study Kyushu University). Они объединили машинное обучение с квантово-химическими расчётами, что привело к ускоренному обнаружению двух новых органических материалов для синих OLED-пикселей. Соединения Cz-PAH-1 и Cz-PAH-2 не содержат бора, отличаются узким (чистым) спектром излучения и способны обеспечивать высокую эффективность преобразования электрической энергии в свет. При обычной флуоресценции свет (фотоны) могут излучать только синглетные возбуждённые состояния (системы из двух частиц), составляющие примерно 25 % от всех образующихся экситонов в синем пикселе, тогда как остальные 75 % приходятся на бесполезные для этого триплеты. Иначе говоря, энергия пикселя уходит не в свет, а в тепло. Заставить триплеты светиться могут материалы с термически активированной замедленной флуоресценцией — TADF. Неудобство в том, что TADF обычно опираются на каркасы из бора, синтез которых остаётся сложным и дорогим. Вместо бора учёные решили использовать соединения углерода, водорода и азота. Основываясь только на этих веществах, они сформировали виртуальную библиотеку из более чем 19 тыс. молекул. Просчитать каждую из них методом квантовой химии было нереально, поэтому для скрупулёзных расчётов исследователи выбрали случайным образом только 1000 из них и на этой просчитанной выборке обучили ИИ. Модель самостоятельно оценила свыше 17 тыс. молекул с доступными трёхмерными структурами. Из них 50 кандидатов снова посчитали с использованием квантовой химии и для синтеза отобрали две наиболее перспективные молекулы. Весь анализ массива из 19 тыс. молекул свёлся к сверхточным расчётам 1050 кандидатов, что серьёзно сэкономило средства на науку. Оба материала показали узкополосное синее излучение с шириной спектра на половине максимума всего 17–19 нм, что соответствует высокой чистоте цвета. Квантовый выход фотолюминесценции в тонких плёнках достиг 93–99 %. Пиксель OLED на Cz-PAH-1 приблизился по цветности к стандарту сверхвысокой чёткости Rec. 2020, а пиксель с Cz-PAH-2 продемонстрировал максимальную внешнюю квантовую эффективность 35,2 %. Перспективы работы шире обнаружения материала для синего OLED. Авторы считают, что созданный ими цикл поиска материалов — от генерации молекул на компьютере и ИИ-отбора до синтеза и испытания готового элемента — можно использовать для ускоренного поиска других органических материалов с огромным числом возможных структур. Это ускорит открытия в сфере аккумуляторов, катализаторов, солнечных панелей и в других областях, что можно только приветствовать. AMD рассказала о грядущих MI500 и MI600: Instinct и Helios будут обновляться ежегодно
24.07.2026 [08:28],
Павел Котов
AMD намерена каждый год обновлять ускорители искусственного интеллекта Instinct и стоечные решения Helios. Уже в следующем году компания выпустит модели семейства Instinct MI500 с памятью HBM4E, которые обеспечат значительный рост производительности по сравнению с актуальными; а в 2028 году появятся и MI600, сообщает ComputerBase. 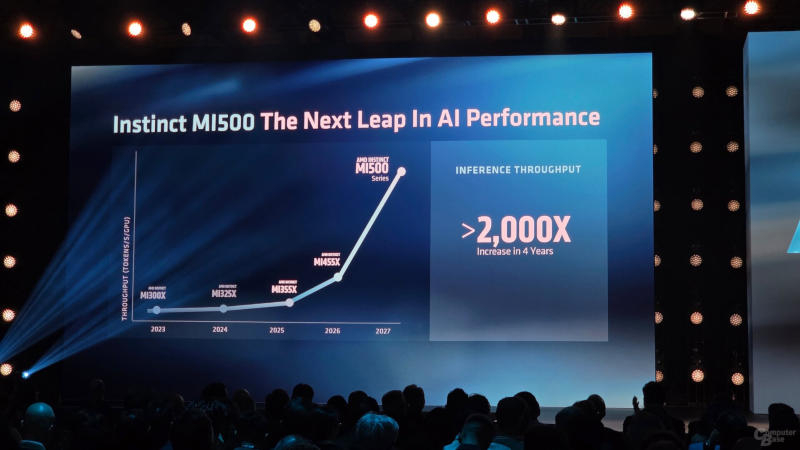
Источник изображений: computerbase.de Эра AMD Instinct MI400 начинается с мощных моделей вроде MI455X в стойках Helios, и уже в 2027 году компания намерена выпустить их преемников. MI455X по сравнению с ускорителями предыдущего поколения представляет собой значительный скачок вперёд в производительности при рабочих нагрузках, а MI500 обещает настоящий прорыв: по сравнению с выпущенными в 2023 году MI300X ускорители нового поколения будут быстрее в 2000 раз — и это за четыре года. Ранее AMD заявляла о приросте производительности в 1000 раз, то есть, она недооценила собственную продукцию.  Предсказать, насколько успешными будут MI500 в реалиях 2027 года, однако, непросто. Шансы AMD выбиться в лидеры рынка не так уж плохи: выступающая преемником Nvidia Rubin архитектура Feynman планируется к выходу лишь в 2028 году. Если «зелёные» не поменяют планов, Feynman будет конкурировать уже с AMD Instinct MI600, а MI500 останется противостоять «всего лишь» Nvidia Rubin. Дополнительной информации о MI600 на архитектуре CDNA Next пока нет, но AMD раскрыла некоторые подробности о MI500 на CDNA 6 и с памятью HBM4E, которую Samsung и SK hynix предложили лишь считанные недели назад. Помимо традиционных медных, в MI500 впервые станут использоваться оптические соединения; процессоры будут производиться по техпроцессу 2 нм.  AMD продаёт ИИ-ускорители в формате полного комплекта — серверных стоек с процессорами и сетевыми чипами: среди покупателей Helios AI Rack числятся такие крупные клиенты как Anthropic и Microsoft. За актуальными AMD Helios в 2027 году последуют AMD Helios 500. Они получат энергоэффективные варианты процессоров Epyc 9006 семейства Verano на архитектуре Zen 6; инфраструктурную часть возьмут на себя сетевые контроллеры Pensando Como и сетевые процессоры Monza. Если далее всё пойдёт по плану, к 2028 году будет готова платформа AMD Helios 600. В её состав войдут ускорители Instinct MI600 и, предположительно, центральные процессоры Ferrara — энергоэффективный вариант Florence с ядрами Zen 7. Сетевые решения — снова Pensando, но уже Palma и Levanzo. Новый троян Dolphin X умеет выбирать самых выгодных жертв с помощью ИИ
24.07.2026 [07:00],
Анжелла Марина
Специалисты компании Varonis Threat обнаружили новый троян удалённого доступа Dolphin X, оснащённый системой AI Profiler на базе искусственного интеллекта. По сообщению BleepingComputer, троян автоматически производит ранжирование уже заражённых и наиболее ценных жертв для дальнейших атак. 
Источник изображения: bleepingcomputer.com Дэниел Келли (Daniel Kelley) из Varonis Threat обнаружил рекламу Dolphin X на одном из киберпреступных форумов, где продавец под псевдонимом Kontraktnik позиционировал программу как универсальный инструмент удалённого доступа. Согласно проведённому анализу, панель управления включает 329 функций, распределённых по десяти категориям, в том числе средства для кражи учётных данных более чем из 300 приложений. Одной из ключевых особенностей панели стал модуль AI Profiler, анализирующий сведения, собранные с заражённых компьютеров, и присваивающий каждой системе рейтинг риска. Как отмечают в Varonis, при формировании профилей используются данные об используемых приложениях, посещаемых доменах, установленном программном обеспечении, а также различные категории и факторы риска, после чего операторы ежедневно получают список жертв, отсортированный по приоритету. По словам Келли, без запуска реального образца Dolphin X на тестовой заражённой системе были исследованы панель управления, конструктор вредоносного ПО и связанный с ними сетевой трафик. При этом специалист подтвердил изданию BleepingComputer наличие в коде технических строк, связанных с работой AI Profiler, однако определить, какой именно ИИ-движок используется для формирования рейтингов, не удалось. Помимо ранжирования жертв, заявлено и о возможности похищения файлов .env, SSH-ключей, облачных токенов доступа, данных авторизации браузеров, информации о криптовалютных кошельков и других учётных данных. Вместе с тем компания подчёркивает, что заявленные возможности по сбору данных не были подтверждены, поскольку исследование проводилось без оригинального образца трояна. На крыльях ИИ-бума выручка Intel взлетела на 25 %, и это самый быстрый рост продаж за последние 15 лет
24.07.2026 [06:50],
Алексей Разин
Квартальные результаты Intel должны были подтвердить уверенность некоторых инвесторов в продолжении ИИ-бума, и они сделали это, оказавшись лучше ожиданий в части размера выручки. Она увеличилась на 25 % до $16,1 млрд (против ожидаемых $14,42 млрд) и продемонстрировала самые высокие темпы роста с 2011 года. Как можно догадаться, серверный сегмент тянул её вверх, поднявшись на 59 %. 
Источник изображений: Intel При этом нельзя сказать, что серверные процессоры начали определять основную часть выручки Intel, поскольку профильная выручка в размере $6,26 млрд всё же уступает той, что компания продолжает получать на клиентском направлении — $8,9 млрд. К слову, в последнем случае она выросла на 12,8 % год к году, главным образом из-за увеличения средней цены реализации, поскольку объёмы поставок продукции фактически снижались. Более того, даже контрактное подразделение Intel Foundry нарастило выручку на 30,5 % до $5,8 млрд, хотя операционные убытки подразделения достигли $2,1 млрд из-за необходимости наращивать оснащение предприятий компании. В целом, эта часть выручки Intel растёт на протяжении последних четырёх кварталов. На фоне таких новостей в целом акции Intel после закрытия торгов выросли в цене более чем на 4 %, а в моменте прирост достигал 10 %. Генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) отметил, что выручка компании за второй квартал оказалась выше собственных ожиданий руководства, как и норма прибыли, которая достигла 40,4 %. Это почти на 13 процентных пунктов выше, чем год назад, и может указывать на эффективность проводимых Таном мер по повышению эффективности бизнеса. Правда, это всё равно заметно ниже исторических максимумов, которые превышали 60 % в прежние годы. В любом случае, в текущем квартале Intel прогнозирует выход нормы прибыли на уровень в 42 %. «ИИ невероятно поднимает спрос на вычисления. По мере прогресса в нашей работе, Intel находится в хорошем положении для продолжительного роста бизнеса в сфере CPU, ASIC, передовых технологий упаковки и обширной сети контрактных предприятий», — отметил Лип-Бу Тан.  В текущем квартале компания рассчитывает выручить от $15,8 до $16,8 млрд, и этот диапазон с запасом перекрывает ожидания аналитиков, которые прогнозируют только $15,1 млрд выручки в третьем квартале. Руководство компании призналось, что действительно заключает со своими покупателями серверных процессоров долгосрочные контракты, причём в некоторых случаях оговариваются и ценовые условия, а не только гарантированные объёмы поставок. По словам представителей компании, ей удалось заключить 10 подобных долгосрочных контрактов. Спрос по-прежнему превышает возможности Intel по производству серверных процессоров. Контракты заключаются с клиентами Intel на срок от трёх до пяти лет, как добавил финансовый директор компании. По его словам, на рынке ИИ-инфраструктуры спрос на GPU и CPU сейчас достиг приоритета, а в дальнейшем может даже сместиться больше в сторону центральных процессоров. 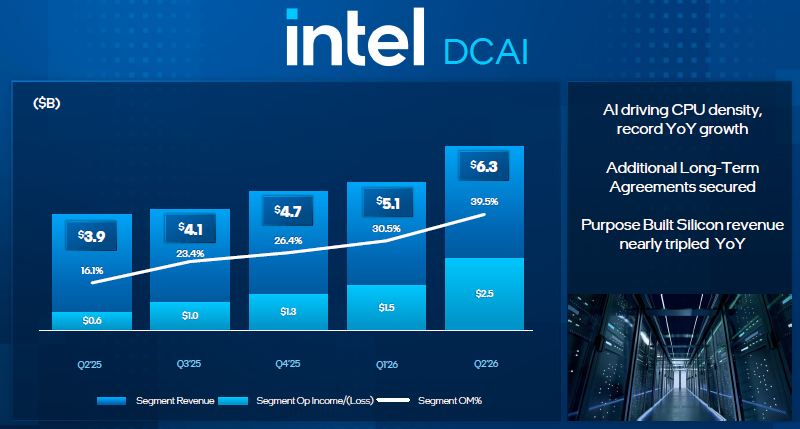 В клиентском сегменте в текущем квартале Intel ожидает примерно такой же выручки, как в прошлом, поскольку росту рынка ПК будет препятствовать дефицит памяти. Руководство Intel не скрывает, что в производственной политике отдаёт приоритет выпуску серверных центральных процессоров. Капитальные затраты приходится увеличивать, на данном этапе в основном из-за приобретения оборудования на оснащение заводов по выпуску чипов, профильные расходы увеличились на 40 % по сравнению с прошлым годом. Финансовый директор Дэвид Зинснер (David Zinsner) подчеркнул, что техпроцесс Intel 14A опережает своих предшественников по темпам внедрения. К массовому производству чипов по этой технологии компания рассчитывает приступить к 2028 году. Если в прошлом году руководство ещё выражало сомнение в целесообразности освоения техпроцесса Intel 14A, то на минувшей квартальной отчётной конференции Лип-Бу Тан заявил: «Я доволен тем, как растёт привлечение клиентов на Intel 14A, и всё больше уверен в том, что 14A будет очень конкурентоспособным техпроцессом».  Правда, руководство Intel так и не назвало новых крупных клиентов на контрактном направлении бизнеса, хотя от него ждали подтверждений информации о заключении контрактов с Tesla и компанией Apple. Формально, на долю внешних клиентов пришлось только $293 млн выручки подразделения Intel Foundry. Если ранее Intel планировала сократить капитальные расходы в текущем году, то теперь она собирается их увеличить с $18 млрд как минимум до $20 млрд, а в следующем году рост продолжится. Сейчас компания располагает $30 млрд свободных денежных средств и кредитной линией на $10 млрд, но в случае необходимости она может привлечь капитал путём выпуска дополнительных акций, по словам Зинснера. Кстати, несмотря на высокую динамику выручки, второй квартал Intel завершила с убытками в размере $11 млрд, но они были обусловлены главным образом последствиями сделки в августе прошлого года, по итогам которой к правительству США перешли около 10 % акций этого производителя чипов. Во втором квартале, как отметил Лип-Бу Тан, целевые показатели по объёмам выпуска и уровню выхода годной продукции были превышены для техпроцессов Intel 7, Intel 3 и Intel 18A, а ещё компания приступила к опытному производству чипов по более совершенной технологии Intel 18A-P. Во второй половине следующего года компания приступит к опытному производству чипов по технологии Intel 14A, но массовое производство будет развёрнуто только в 2028 году. AMD бросила новый вызов Nvidia: представлен ускоритель Instinct MI455X с 432 Гбайт HBM4 и до четырёх раз быстрее предшественника
24.07.2026 [01:18],
Николай Хижняк
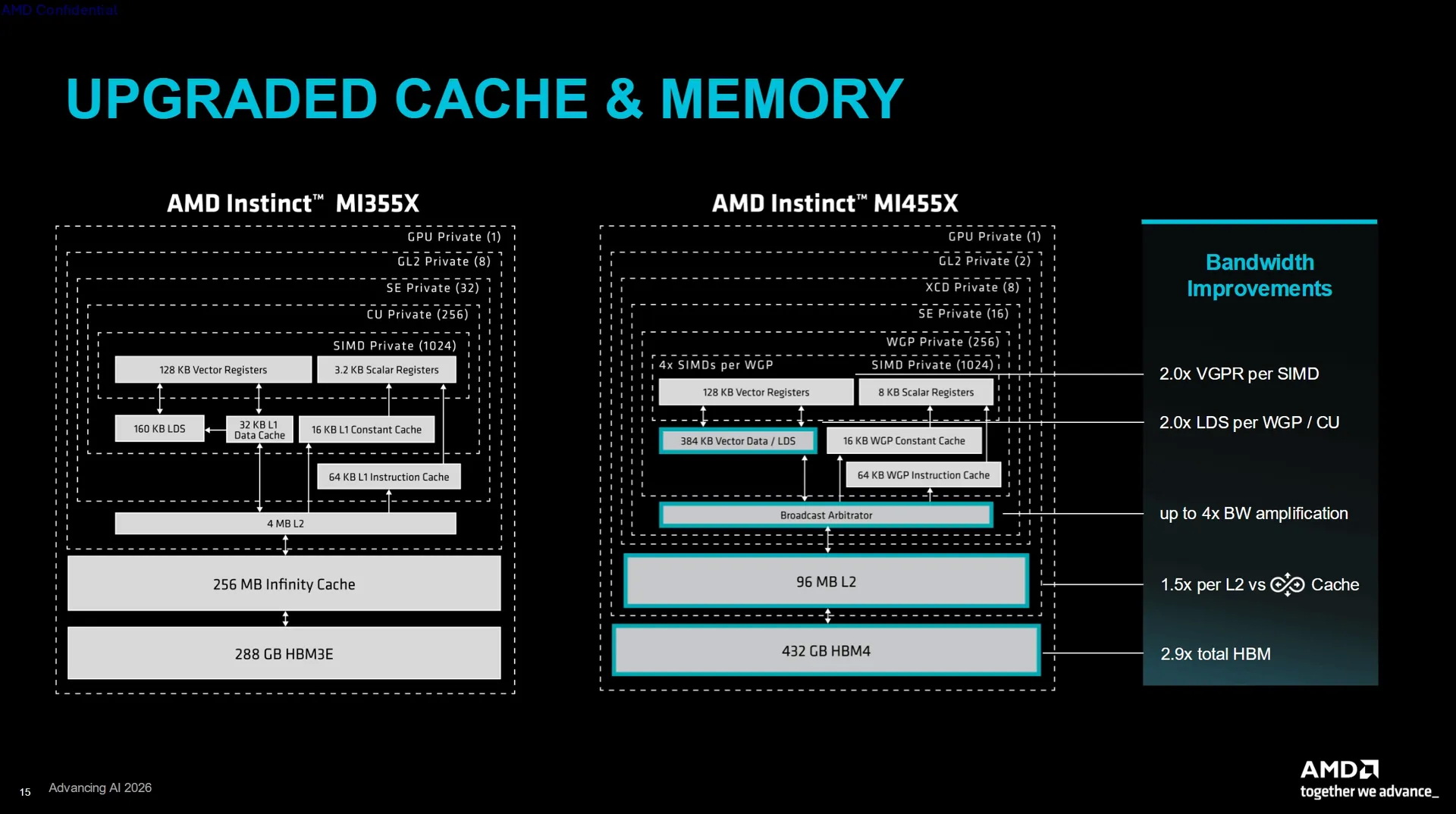
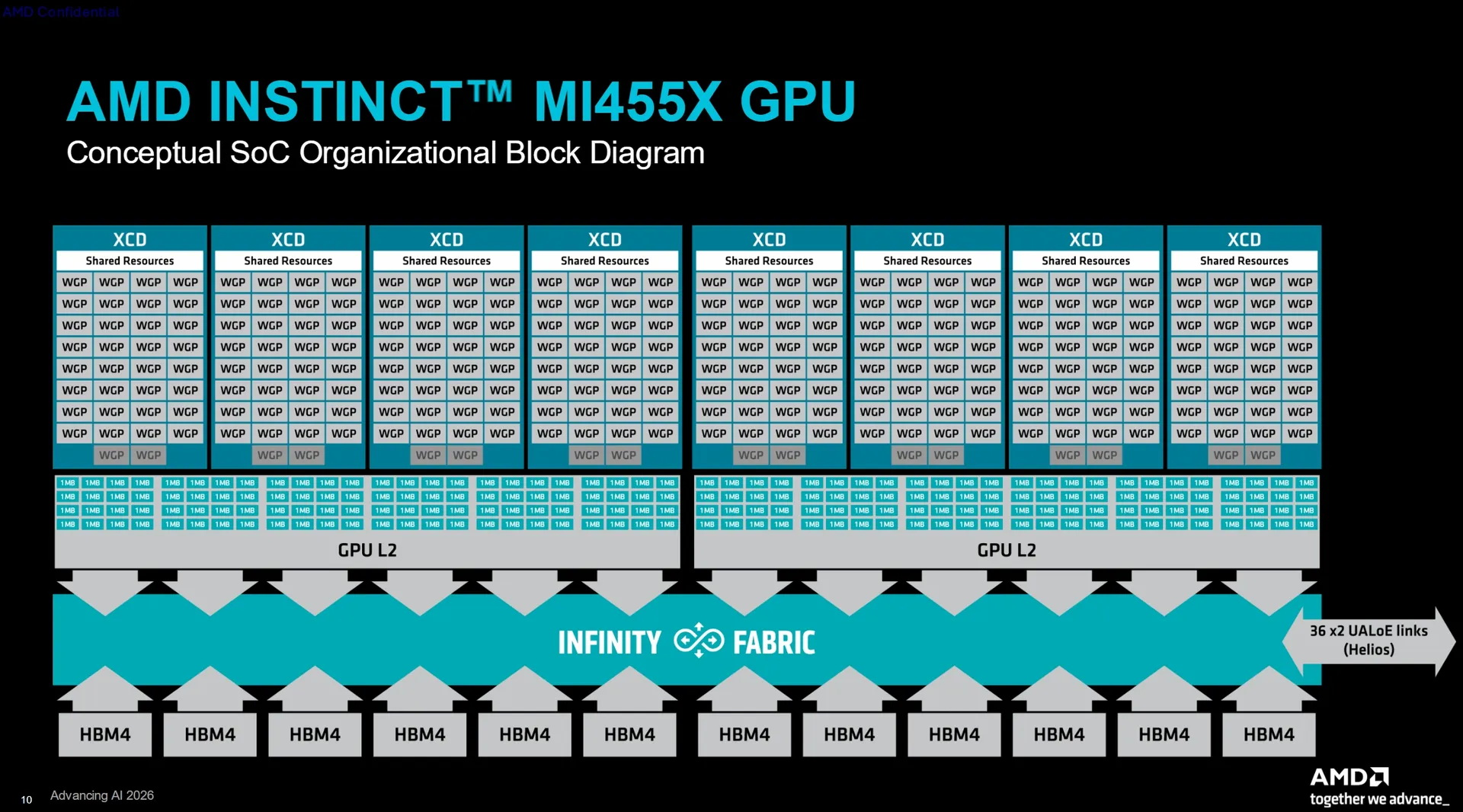
Компания AMD представила специализированные ИИ-ускорители Instinct MI455X для центров обработки данных. Они основаны на архитектуре CDNA 5 и предназначены для масштабного обучения ИИ, вывода результатов в системах искусственного интеллекта и стоечных системах. Каждый ускоритель включает 432 Гбайт памяти HBM4 и обеспечивает пиковую пропускную способность памяти до 23,3 Тбайт/с. 
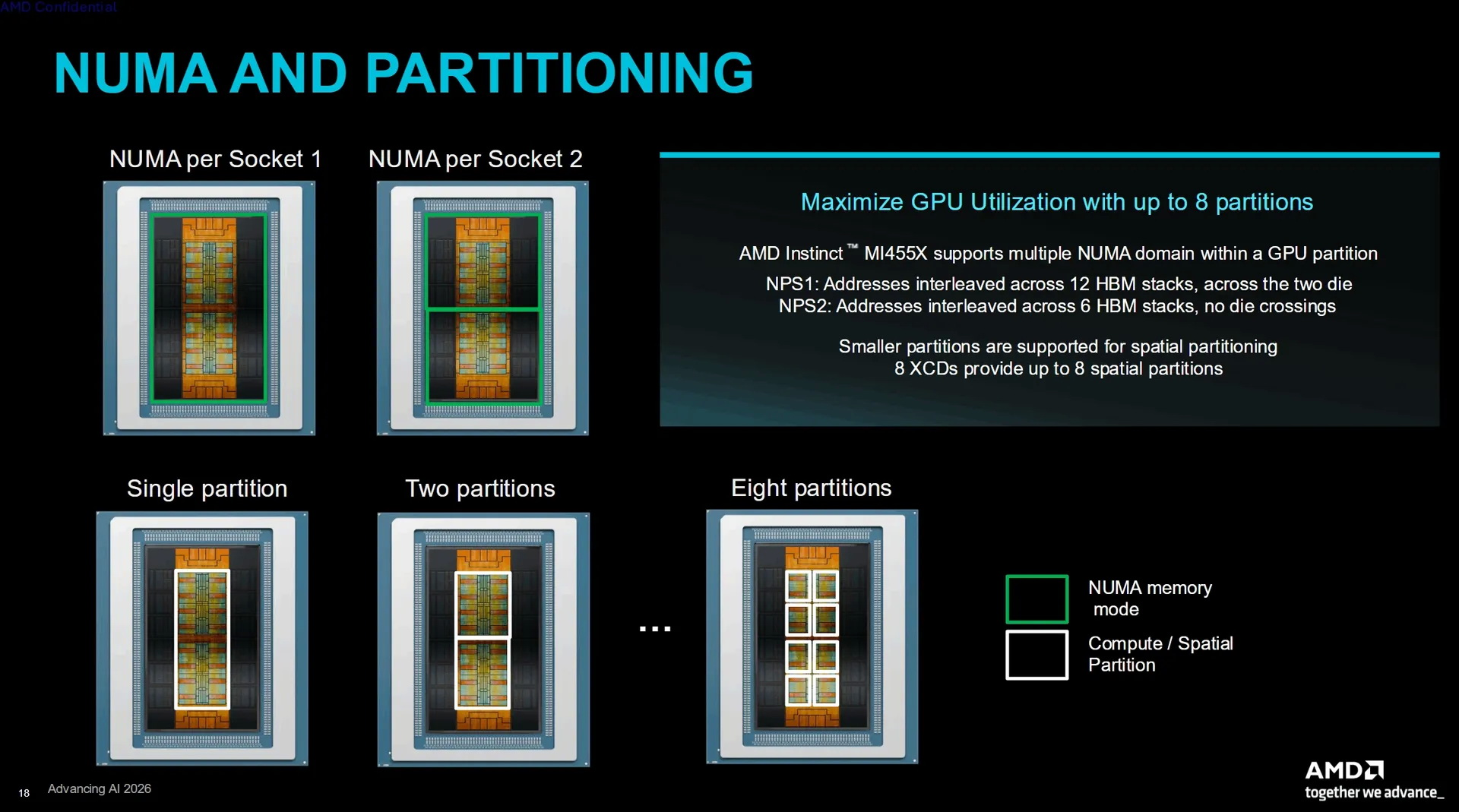
Источник изображений: AMD AMD заявляет о наличии 320 млрд транзисторов в составе GPU Instinct MI455X и использовании 2-нм техпроцесса для его производства. Правда, корпус чипа объединяет сразу несколько технологических процессов, а не один техпроцесс для всех чиплетов. В составе GPU MI455X используются восемь чиплетов ACD (Accelerator Complex Dies), производящихся по техпроцессу TSMC N2. Эти чиплеты формируют 256 вычислительных блоков WGP (Work Group Processor). AMD также использует в составе GPU два чиплета Fabric (шины передачи данных и кеша) и два чиплета ввода-вывода, выпускаемых по 3-нм техпроцессу TSMC N3P.  Графический процессор оснащён 12 стеками памяти HBM4, подключёнными через 192-канальный интерфейс памяти. GPU обладает 192 Мбайт глобального кеша L2, разделённого на два блока по 96 Мбайт. Его подсистема ввода-вывода поддерживает два канала PCIe Gen 6 или три сетевых адаптера AMD AI-NIC с использованием UALink. 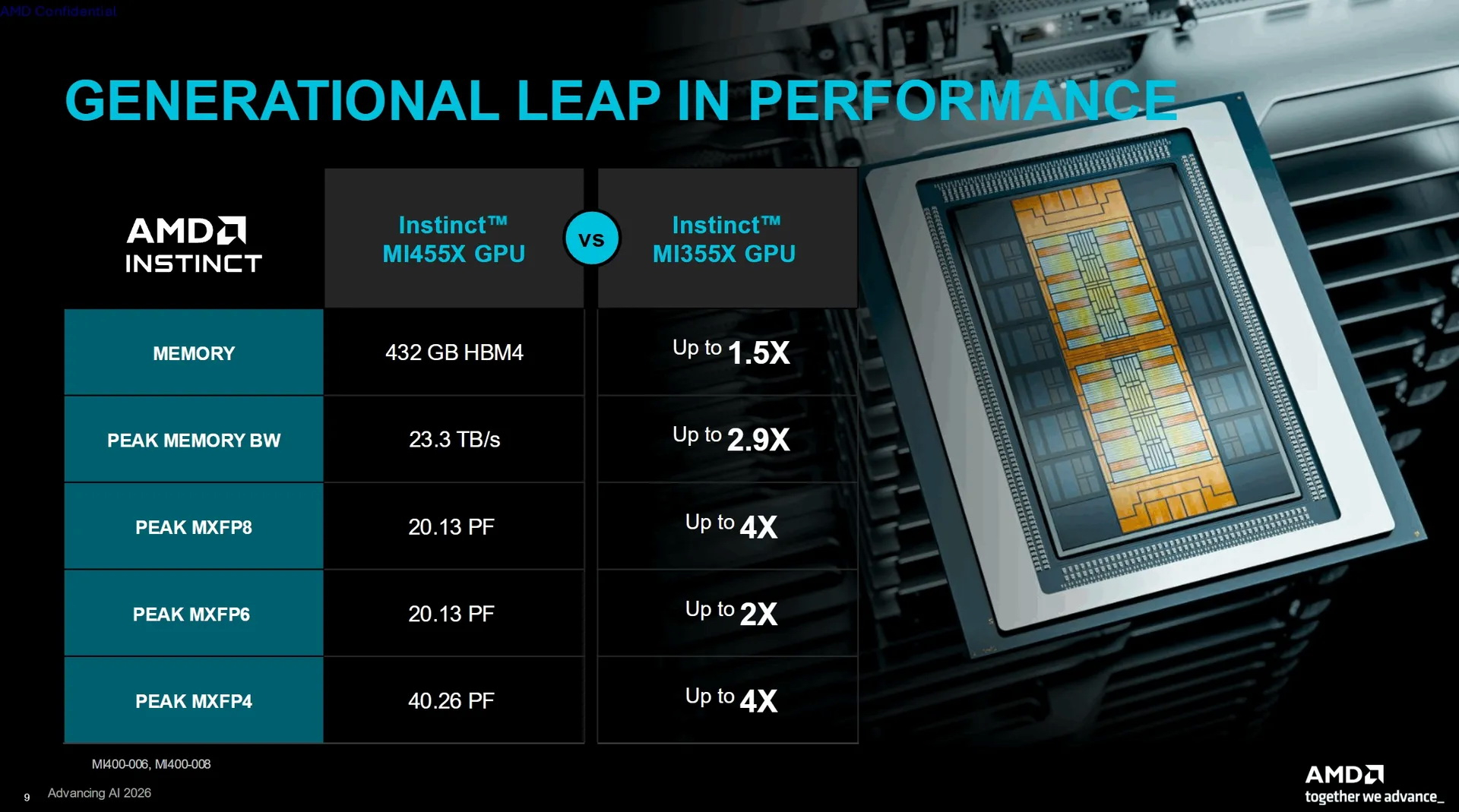 AMD заявляет для Instinct MI455X пиковую производительность в 20,13 Пфлопс в операциях MXFP8 и MXFP6. Производительность в операциях MXFP4 достигает 40,26 Пфлопс. По сравнению с Instinct MI355X новый Instinct MI455X предлагает в 1,5 раза больше памяти, обеспечивает в 2,9 раза более высокую пропускную способность памяти и в четыре раза более высокую производительность в операциях MXFP8 и MXFP4. Архитектура CDNA 5 добавляет блок Tensor Data Mover для прямой асинхронной передачи данных между глобальной памятью и локальным хранилищем данных. AMD также добавила кластеризацию рабочих групп, многоадресную передачу данных, механизм предварительной выборки данных, барьеры разделения и новый процессор команд, предназначенный для уменьшения задержек при их отправке. Особенности Instinct MI455X
Ускорители Instinct MI455X могут работать в режиме одного, двух или до восьми пространственных разделов. Режим NPS1 чередует адреса по всем двенадцати стекам памяти HBM4, тогда как NPS2 разделяет графический процессор на два домена по шесть стеков в каждом и предотвращает передачу данных между двумя основными группами кристаллов. AMD также анонсировала ускоритель Instinct MI430X для научных вычислений, задач суверенного ИИ и комбинированных задач AI-HPC, сочетающих искусственный интеллект и высокопроизводительные вычисления. Компания заявила для этих ускорителей производительность в 288 Тфлопс в операциях FP64, но не уточнила конфигурацию их памяти. Runway представила Media Router — сервис сам подберёт самый выгодный ИИ для генерации контента
24.07.2026 [01:09],
Анжелла Марина
Компания Runway представила инструмент Media Router, автоматически подбирающий оптимальную модель для генерации изображений, видео и аудио в зависимости от требований к качеству, скорости или стоимости токенов. Платформа Runway Dev теперь будет предоставлять доступ к API как собственных, так и сторонних генеративных моделей, сообщает издание TechCrunch. 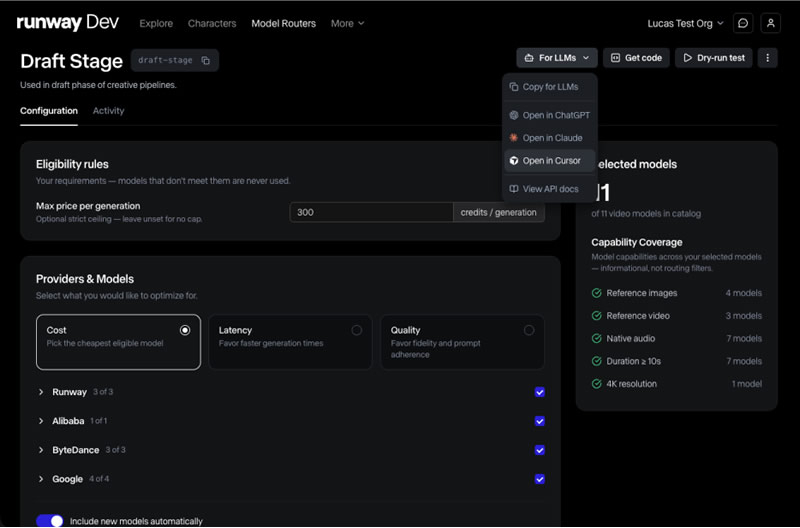
Источник изображения: Runway Media Router анализирует параметры запроса и направляет его к наиболее подходящей модели. По словам директора по продукту Runway Энтони Маджио (Anthony Maggio), сервис создавался как единая точка интеграции генеративных моделей для разработчиков. В компании утверждают, что это первый подобный маршрутизатор, ориентированный именно на генеративные изображения, видео и аудио. Через платформу Runway Dev разработчики могут использовать новые модели сразу после их выхода в свет, не занимаясь самостоятельной оценкой возможностей каждой из них. При этом API уже применяют такие компании, как Adobe, Cloudflare, ElevenLabs, Expedia, Shutterstock и Quora, встраивая генерацию медиаконтента непосредственно в собственные продукты. Помимо качества и скорости генерации, пользователи могут задавать дополнительные предпочтения при выборе, например, касающиеся стоимости токенов или качества конечного результата. Также предусмотрена возможность ограничить использование моделей определённых поставщиков, включая выбор разработчиков только из США вместо китайских компаний. Архитектура Media Router основана на опыте творческой команды Runway, оценивающей качество различных моделей по таким критериям, как передача движения в видео, построение композиции изображений или синхронизация речи. Ранее аналогичная технология уже использовалась в агенте Runway для создания видеороликов, состоящих из множества сцен и маркетинговых кампаний. Как отмечает TechCrunch, запуск инструмента отражает изменение стратегии Runway на фоне усиливающейся конкуренции на рынке генеративного ИИ. После выхода модели Gen 4.5 в декабре компания не представила новых флагманских моделей для генерации видео, тогда как лидирующие позиции в отраслевых рейтингах заняли модели Google, ByteDance и Alibaba. Теперь же, вместо ориентации только на одну собственную модель, Runway намерена развивать инфраструктуру, позволяющую автоматически использовать наиболее подходящие системы разных поставщиков. По словам сооснователя и генерального директора Runway Анастасиса Германидиса (Anastasis Germanidis), всё больше компаний заинтересованы в использовании услуг Runway на всех этапах работы с генеративным медиаконтентом, так как компания постоянно расширяет свою экосистему, включила в неё платформу для разработчиков и творческий набор инструментов для создания контента. «Яндекс» посадил ИИ-агентов на телефоны в ресторанах
23.07.2026 [16:39],
Павел Котов
«Яндекс» разработал сервис хостес с искусственным интеллектом: виртуальный агент умеет принимать входящие звонки для компаний, оформлять бронирования или переводить звонки на сотрудников. 
Источник изображений: yandex.ru/company При поставлении заявки на бронирование ИИ-хостес разговаривает с потенциальным клиентом на естественном языке, уточняет подробности обращения, проверяет доступность на указанное время и подтверждает бронирование. Если свободные слоты отсутствуют, ИИ-агент предлагает альтернативу или при необходимости подключает сотрудника компании. Сервис реализован на основе собственных решений «Яндекса»: большой языковой модели Alice AI LLM, а также технологий потокового распознавания и синтеза речи. Система понимает человека почти без задержек и ведёт разговоры почти наравне с живым собеседником. Архитектура и код сервиса разрабатывались с использованием ИИ. Решение проходит тестирование в партнёрских ресторанах «Яндекса». ИИ-хостес срабатывает успешно в 99 % случаев: задаёт уточняющие вопросы, отсекает спам, бронирует столики или переводит звонки на сотрудников. Число бронирований в ресторанах, которые внедрили решение, выросло более чем на 20 %. ИИ-агенту не нужно подстраиваться под график работы заведения — он может ответить на звонок и когда ресторан закрыт. В перспективе система будет разворачиваться и других направлениях бизнеса, где запись остаётся важным способом взаимодействия с клиентами: в салонах красоты, медицинских клиниках, автосервисах, фитнес-центрах и других заведениях. 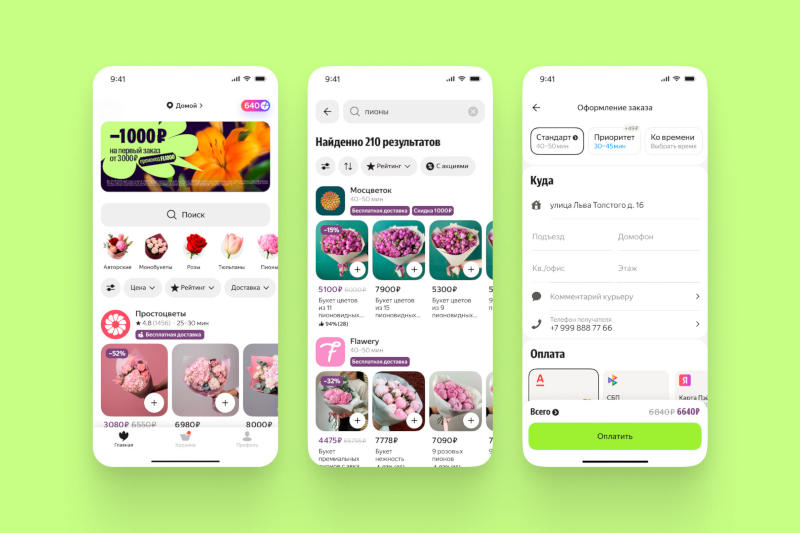 «Яндекс» также выделил в самостоятельное приложение сервис доставки цветов. Он уже работает более чем в 300 городах, налажено сотрудничество с более чем 3000 продавцов, срок доставки составляет от получаса. В приложении «Яндекс Цветы» доступны варианты на любой вкус и повод. В перспективе сервис дополнится тематическими подборками к праздникам и прочими подарками: это будут подарочные сертификаты, небольшие торты и прочие сюрпризы к букетам. Amazon связала своё будущее с ИИ, но теперь сокращает его разработчиков
23.07.2026 [16:37],
Павел Котов
Amazon тратит миллиарды долларов на направление искусственного интеллекта, но это не мешает компании сокращать рабочие места в отделах, занятых его разработкой. Противоречий в этом гигант электронной коммерции не видит. 
Источник изображения: BoliviaInteligente / unspalsh.com Компания Amazon сократила некоторое количество должностей в ряде подразделений, занятых разработкой сильного ИИ (AGI), способности которого должны превысить человеческие; но в компании продолжают настаивать, что ИИ остаётся для неё приоритетным направлением. Сокращения стали последствиями реструктуризации, в результате которой Amazon с октября уволила более 30 000 сотрудников, в том числе 16 000, о которых объявила в январе. При этом она вкладывает значительные средства в инфраструктуру ИИ, ускорители ИИ и разработку базовых моделей; прогнозируемые капитальные затраты на 2026 год составят $200 млрд. «Мы разрабатываем большие модели ИИ уже несколько лет, и это остаётся одним из важнейших направлений нашей работа. Сфера быстро развивается, и мы усиливаем наше внимание к инициативам, которые наиболее важны для клиентов, чтобы быстрее продвигаться к действительно важных областях. Эта направленность подразумевает принятие некоторых непростых решений, в том числе о сокращении некоторых должностей в рамках нашей организации AGI, даже несмотря на то, что мы продолжаем инвестировать в области, наиболее важные для будущего наших клиентов. Мы стремимся поддерживать пострадавших сотрудников в период их адаптации и благодарны за их вклад», — заявил представитель Amazon ресурсу The Register. Увольнение затронули отделы, занятые настройкой и постобучением ИИ-моделей, работы лишились около 10 % их работников, сообщили сотрудники Amazon в соцсетях. Были уволены работники отделов AGI Data Services и AGI Information. Компания уверяет инвесторов, что ИИ — это будущее компании, но увольняет разрабатывающих эти системы сотрудников; и никаких противоречий Amazon в этом не видит. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex