|
Опрос
|
реклама
Быстрый переход
Google теперь использует письма пользователей Gmail для обучения ИИ, но это можно отключить
21.11.2025 [20:57],
Сергей Сурабекянц
Без лишней огласки компания Google добавила в Gmail функции, которые позволяют получать доступ ко всем сообщениям и вложениям в почтовом ящике для обучения своих моделей ИИ. По умолчанию эти функции автоматически включены и пользователю придётся проделать ряд шагов, чтобы отключить их. Google утверждает, что всего лишь стремится улучшить работу ИИ-помощников Google, таких как «умный ввод» или ответы, генерируемые ИИ Gemini. 
Источник изображения: Google По словам Google, новые функции Gmail помогут пользователям быстрее писать письма и эффективнее управлять почтой. Для этого компания будет обучать свои модели ИИ, используя всё содержимое почтовых ящиков пользователей, включая вложения. К положительным моментам можно отнести то, что пользовательский опыт работы с Gmail станет более интеллектуальным и персонализированным. Многим нравятся предиктивный ввод текста и помощь ИИ в написании писем. Но закрывать глаза на возможные риски не стоит. Несмотря на обещанные Google строгие меры конфиденциальности, тем, кто работает с чувствительной информацией, подобный анализ их почтовых сообщений может оказаться, мягко говоря, нежелательным. Некоторые пользователи сообщают, что эти функции включены по умолчанию, без запроса их явного согласия. Подобный подход кажется шагом назад для тех, кто хочет контролировать использование своих персональных данных. Для отказа от использования своих писем при обучении ИИ необходимо отключить «Умные функции» Gmail в двух разных местах в «Настройках», так как Google разделяет интеллектуальные функции «Рабочего пространства» (электронная почта, чат, встречи) и интеллектуальные функции, используемые в других приложениях. Отключение смарт-функций в настройках Gmail, Chat и Meet. Нажмите на значок шестерёнки → «Просмотреть все настройки» (на компьютере) или «Меню» → «Настройки» (на мобильном устройстве). Нужно снять флажок с опции «Смарт-функции в Gmail, Chat и Meet». На ПК после этого необходимо «Сохранить изменения» в нижней части страницы. Отключение смарт-функций Google Workspace. В «Настройках» найдите смарт-функции Google Workspace. Нажмите «Управление настройками смарт-функций Workspace». Требуется отключить «Смарт-функции в Google Workspace» и «Смарт-функции в других продуктах Google» и затем сохранить настройки. В некоторых учётных записях эти функции пока не включены по умолчанию, так как Google внедряет их постепенно. Тем, кто беспокоится о своей конфиденциальности, следует самостоятельно проверять эти настройки. Каждый четвёртый россиянин хотя бы раз в месяц пользуется нейросетями
21.11.2025 [19:58],
Владимир Мироненко
Каждый четвертый житель России в возрасте старше 12 лет хотя бы раз в месяц пользуется нейросетями, а хотя бы раз в неделю — 5 % населения, сообщил ресурс РБК со ссылкой на исследование единого измерителя аудитории Рунета Mediascope. Наибольшей популярностью нейросети пользуются у молодой аудитории, утверждают в Mediascope. 
Источник изображения: Igor Omilaev/unsplash.com Совокупный месячный охват ИИ-сервисов составляет 26 % населения России. В возрастной группе от 12 до 17 лет ежемесячно ИИ-сервисами пользуется 52 % населения, ежедневно — 16 %. В группе от 18 до 24 лет показатели почти такие же — лишь на 1 п.п. ниже. Среди пользователей в возрасте от 25 до 34 лет месячный охват ИИ-сервисов составляет 33 %, ежедневный — 6 %, в возрасте от 35 до 44 лет — 23 и 3 % соответственно. Самый низкий охват отмечен у людей старше 65 лет: 9 % россиян в этой возрастной группе пользуется нейросетями хотя бы раз в месяц и лишь 1 % — ежедневно. Лидируют по охвату среди россиян ИИ-сервисы «Алиса AI» и DeepSeek с месячным охватом в октябре 2025 года в размере 14 и 9 % соответственно. С отставанием в 5 п.п. в рейтинге популярности расположились GigaChat и ChatGPT. Далее следуют Perplexity AI и Character AI с охватом по 1 %. Аналитики сообщили, что по структуре охватов «Алиса AI» и GigaChat в целом соответствуют социально-демографической палитре, тогда как Perplexity AI, DeepSeek и ChatGPT активнее используют молодые мужчины. В «Яндексе» отметили, что резкий рост ежемесячной аудитории «Алисы AI» начался после презентации в октябре новой версии этой нейросети. «Меньше чем за сутки после запуска приложение "Алиса AI" попало на первую строчку в российском App Store и вошло в тройку лидеров Google Play. За первую неделю приложение скачали полтора миллиона раз», — рассказали в компании. Маск пообещал дешёвые ИИ-серверы в космосе через пять лет — Хуанг назвал эти планы «мечтой»
21.11.2025 [18:29],
Сергей Сурабекянц
Помимо стоимости оборудования, требования к электроснабжению и отведению тепла станут одними из основных ограничений для крупных ЦОД в ближайшие годы. Глава X, xAI, SpaceX и Tesla Илон Маск (Elon Musk) уверен, что вывод крупномасштабных систем ИИ на орбиту может стать гораздо более экономичным, чем реализация аналогичных ЦОД на Земле из-за доступной солнечной энергии и относительно простого охлаждения. 
Источник изображений: AST SpaceMobile «По моим оценкам, стоимость электроэнергии и экономическая эффективность ИИ и космических технологий будут значительно выше, чем у наземного ИИ, задолго до того, как будут исчерпаны потенциальные источники энергии на Земле, — заявил Маск на американо-саудовском инвестиционном форуме. — Думаю, даже через четыре-пять лет самым дешёвым способом проведения вычислений в области ИИ будут спутники с питанием от солнечных батарей. Я бы сказал, не раньше, чем через пять лет». Маск подчеркнул, что по мере роста вычислительных кластеров совокупные требования к электроснабжению и охлаждению возрастают до такой степени, что наземная инфраструктура с трудом справляется с ними. Он утверждает, что достижение непрерывной выработки в диапазоне 200–300 ГВт в год потребует строительства огромных и дорогостоящих электростанций, поскольку типичная атомная электростанция вырабатывает около 1 ГВт. Между тем, США сегодня вырабатывают около 490 ГВт, поэтому использование львиной её доли для нужд ИИ невозможно. Маск считает, что достижение тераваттного уровня мощности для питания наземных ЦОД нереально, зато космос представляет заманчивую альтернативу. По мнению Маска, благодаря постоянному солнечному излучению, аккумулирование энергии не требуется, солнечные панели не требуют защитного стекла или прочного каркаса, а охлаждение происходит за счёт излучения тепла. Глава Nvidia Дженсен Хуанг (Jensen Huang) признал, что масса непосредственно вычислительного и коммуникационного оборудования внутри современных стоек Nvidia GB300 исчезающе мала по сравнению с их общей массой, поскольку почти вся конструкция — примерно 1,95 из 2 тонн — по сути, представляет собой систему охлаждения. Но, кроме веса оборудования, существуют и другие препятствия. Теоретически космос — хорошее место как для выработки энергии, так и для охлаждения электроники, поскольку в тени температура может опускаться до -270 °C. Но под прямыми солнечными лучами она может достигать +125 °C. На околоземных орбитах перепады температур не столь экстремальны:
Низкая и средняя околоземные орбиты не подходят для космических ЦОД из-за нестабильной освещённости, значительных перепадов температур, пересечения радиационных поясов и регулярных затмений. Геостационарная орбита лучше подходит для этой цели, но и там эксплуатация мощных вычислительных кластеров столкнётся с множеством проблем, главная из которых — охлаждение. В космосе отвод тепла возможен только при помощи излучения, что потребует монтажа огромных радиаторов площадью в десятки тысяч квадратных метров на систему мощностью несколько гигаватт. Вывод на геостационарную орбиту такого количества оборудования потребует тысяч запусков тяжёлых ракет класса Starship.  Не менее важно, что ИИ-ускорители и сопутствующее оборудование в существующем виде не способны выдержать воздействие радиации на геостационарной орбите без мощной защиты или полной модернизации конструкции. Кроме того, высокоскоростное соединение с Землёй, автономное обслуживание, предотвращение столкновения с мусором и обслуживание робототехники пока находится в зачаточном состоянии, учитывая масштаб предлагаемых проектов. Так что скорее всего Хуанг прав, когда называет затею Маска «мечтой». Мечтает о выводе масштабных вычислительных кластеров не только Маск. В октябре основатель Amazon и Blue Origin Джефф Безос (Jeff Bezos) в ходе мероприятия Italian Tech Week в Турине (Италия) поделился своим видением развития индустрии космических дата-центров. По его мнению, такие объекты обеспечат ряд значительных преимуществ по сравнению с наземными ЦОД. В сентябре компания Axiom Space с партнёрами сообщила о создании первого орбитального дата-центра, который разместился на МКС. Этот ЦОД будет обслуживать не только станцию, но также любые спутники с оптическими терминалами на борту. В мае Китай вывел на орбиту Земли 12 спутников будущей космической группировки Star-Compute Program, которая в перспективе будет состоять из 2800 спутников. Все они оснащены системами лазерной связи и несут мощные вычислительные платформы — по сути, это первый масштабный ЦОД с ИИ в космосе. Компания Crusoe намерена развернуть свою облачную платформу на спутнике Starcloud запуск которого запланирован на конец 2026 года. Ограниченный доступ к ИИ-мощностям в космосе должен появиться к началу 2027 года Google рассказала об инициативе Project Suncatcher, предусматривающей использование группировок спутников-ЦОД на основе фирменных ИИ-ускорителей. Спутники будут связаны оптическими каналами. Глава AMD заявила, что недальновидно бояться ИИ-пузыря: «недовложиться сейчас опаснее, чем потратить лишнего»
21.11.2025 [14:59],
Алексей Разин
AMD хоть и сложно назвать главным выгодоприобретателем бума искусственного интеллекта, отрицать положительное влияние этой тенденции на бизнес компании тоже сложно. Генеральный директор Лиза Су (Lisa Su), по примеру своего коллеги из Nvidia, также не опасается так называемого «ИИ-пузыря», считая всех сторонников соответствующей идеи «недальновидными». 
Источник изображения: AMD Издание The Wall Street Journal деятельности AMD в сфере инфраструктуры ИИ посвятило довольно объёмную публикацию, сочетающую цитаты из недавних заявлений Лизы Су на конференции для инвесторов и фрагменты её интервью. По данным источника, ещё в конце 2022 года на собрании совета директоров глава компании объявила о своих намерениях использовать возможности, предоставляемые рынком искусственного интеллекта, для радикальной трансформации бизнеса компании. Капитализация AMD за это время увеличилась почти в четыре раза до $335 млрд, хотя и не может сравниться с кратно более дорогой Nvidia. Помимо заключённой сделки с OpenAI, руководство AMD рассматривает и другие возможности формирования партнёрских отношений с участниками рынка ИИ, а также заинтересованными инвесторами. AMD будет принимать участие в развитии проекта в Саудовской Аравии вместе с Cisco Systems. Компания ведёт переговоры и с другими партнёрами, которые смогут сформировать договорённости, сопоставимые по масштабу со сделкой с OpenAI. По мнению Лизы Су, техногиганты постигли только малую часть тех преимуществ, которые даёт ИИ, а лучшую награду в жизни получают те люди, которые делают смелые ставки. «Я не беспокоюсь по поводу ИИ-пузыря. Я считаю, что те, кто так думает, слишком недальновидны. Они не до конца осознают силу технологий», — заявила глава AMD. Она считает, что сейчас не лучшее время для проявления излишней осторожности в сфере выбора целей для инвестиций. «На мой взгляд, недоинвестировать сейчас гораздо опаснее, чем потратить лишнего», — подчеркнула Лиза Су. Ёмкость рынка ИИ к концу десятилетия, по её словам, достигнет $1 трлн. Сейчас доля AMD на рынке компонентов для инфраструктуры ИИ оценивается в 5–6 %, но сама Лиза Су считает, что профильная выручка компании будет расти на 80 % в год, и соответствующая доля на рынке вырастет до двухзначных величин в процентах на горизонте ближайших трёх или пяти лет. Соперничать с Nvidia в сфере обучения языковых моделей для AMD крайне трудно, как призналась Лиза Су, но она надеется, что с учётом перехода на так называемый инференс ситуация повернётся в пользу её компании. Клиенты и сейчас охотно покупают ускорители AMD. Во-первых, они в среднем на 20 % дешевле предложений Nvidia. Во-вторых, продукции последней в условиях ажиотажного спроса на всех желающих не хватает. Хотя об этом реже говорится в прессе, Лиза Су прилагает немало усилий для лоббирования интересов своей компании на высшем политическом уровне в США, поскольку экспортные ограничения тоже вредят её бизнесу в Китае, как и в случае с Nvidia. Подобно основателю последней из компаний Дженсену Хуангу (Jensen Huang), Лиза Су считает, что ограничения на поставку американских ускорителей в Китай только дадут местным компаниям типа Huawei больше возможностей для создания собственных решений и прогресса, который американские власти уже не в состоянии будут контролировать. На этой неделе отраслевая ассоциация SIA назначила Лизу Су своим новым председателем. «Сбер» представил «Грина» — человекоподобного робота на базе «ГигаЧата»
21.11.2025 [14:45],
Павел Котов
«Сбер» представил на мероприятии AI Journey 2025 своего первого человекоподобного робота «Грина» на базе модели искусственного интеллекта «ГигаЧат». В компании рассчитывают, что подобные машины станут универсальными помощниками человека и в корне преобразят мировую экономику. 
Источник изображения: sberbank.ru/ Очевидным новым этапом развития ИИ является переход от интеллектуальных задач, с которыми справляются приложения на мобильных устройствах, умные телевизоры и колонки, — к физическому ИИ, который помогает человеку решать задачи в окружающем мире. Построенный инженерами «Сбера» робот «Грин» «ориентируется в незнакомом пространстве и способен автономно действовать в нём. <..> Робот также оснащён комплексом датчиков, которые обеспечивают безопасное поведение: десять сенсоров обрабатывают визуальную информацию, а инерциальные датчики и датчики силы отвечают за равновесие и точность движений. Отдельного внимания заслуживает способность робота разговаривать и понимать голосовые команды благодаря внедряемой в него функции голосового общения „ГигаЧат“», рассказал председатель правления «Сбербанка» Герман Греф. Текущая версия машины самостоятельно передвигается, взаимодействует с предметами, умеет находить и исправлять собственные ошибки. Он уже может комплектовать и сортировать объекты в неструктурированной среде. И с каждым обновлением нейросети «ГигаЧат» робот «Грин» «будет становиться умнее, расширяя диапазон своих навыков в разных сферах: производстве, торговле, общепите», пообещал господин Греф. В обозримом будущем «Сбер» запустит несколько пилотных проектов, в рамках которых робота интегрируют в реальные бизнес-процессы. Perplexity выпустила ИИ-браузер Comet для Android
21.11.2025 [12:58],
Павел Котов
Компания Perplexity, которая занимается поисковыми решениями на основе искусственного интеллекта, представила версию своего браузера Comet для Android-устройств. Ранее компания выпустила его вариант для настольных компьютеров. 
Источник изображения: perplexity.ai Большинство возможностей десктопного Comet перекочевало на Android: Perplexity можно установить в качестве поисковой системы по умолчанию, можно задавать ИИ-помощнику вопросы, упоминая открытые вкладки. Поддерживается голосовой режим с возможностью задавать вопросы обо всех открытых вкладках — по ним ИИ-помощник может составить сводку информации. От имени пользователя браузер может производить поиск и даже совершать покупки — все эти действия видны. Присутствует встроенный блокировщик рекламы. В ближайшие недели компания добавит в приложение новые функции. Это будут диалоговый агент, способный производить поиск по сайтам и выполнять действия; ярлыки для быстрых действий ассистента и полнофункциональный менеджер паролей. Ранее компания обновила Comet Assistant в десктопных версиях — он стал эффективнее выполнять задачи, на которые требуется продолжительное время, например, перенос данных с сайта в электронную таблицу. Готовится версия браузера под iOS. Платформа Google Android оказалась приоритетной, пояснили в Perplexity, потому что от операторов связи и производителей устройств поступило множество обращений с просьбами интегрировать Comet в их продукцию и решения. Известно о партнёрских соглашениях с Samsung и Motorola, но о предустановке браузера Comet пока не сообщалось. Собственные ИИ-браузеры есть и у других разработчиков — соответствующие функции добавились в Microsoft Edge и Opera, есть OpenAI Atlas и разработки The Browser Company, которую поглотила Atlassian. Они позиционируются как альтернатива традиционным Apple Safari и Google Chrome, хотя и последний уже начинает обрастать функциями ИИ. У ИИ-браузеров обнаруживаются серьёзные уязвимости, но в Perplexity отмечают, что некоторые схемы атак требуют полного пересмотра подходов к безопасности. Nvidia на крючке: 61 % выручки компании теперь зависит от настроения четвёрки крупнейших клиентов
21.11.2025 [12:45],
Алексей Разин
Ещё год назад стало понятно, что концентрация выручки Nvidia усиливается, поскольку на долю трёх её крупнейших клиентов в совокупности приходилось 36 % всех денежных средств, получаемых компанией. По итогам третьего квартала текущего года стало понятно, что количество таких клиентов увеличилось до четырёх, а их совокупная доля в выручке Nvidia выросла до 61 %. То есть зависимость компании от настроения лишь горстки компаний лишь усиливается. 
Источник изображения: Nvidia Это становится понятно после изучения квартального отчёта по форме 10-Q, который Nvidia опубликовала на этой неделе. Крупнейшие клиенты компании в этом документе традиционно проходят под анонимными обозначениями «A, B, C, D», причём год назад для их перечисления хватало трёх первых букв английского алфавита. В третьем квартале, как признаётся Nvidia, она поставляла свою продукцию напрямую четырём крупнейшим клиентам: на долю первого пришлось 22 % выручки, второй и третий довольствовались 15 и 13 % соответственно, а четвёртый обеспечивал 11 % всей выручки компании. Предсказуемо, что все четверо закупали продукцию Nvidia, поставляемую подразделением компании, отвечающим за вычислительные и сетевые решения. Получается, что теперь более половины всей выручки Nvidia, скорее всего, обеспечивают облачные гиганты или компании, выпускающие серверное оборудование для их нужд. В отчёте по форме 10-Q указываются только те клиенты, которые формируют более 10 % выручки этой компании. Не исключено, что ещё несколько компаний формируют долю выручки Nvidia, близкую к тем самым 10 %, но не превышающую их. Если рассматривать срез в размере девяти месяцев текущего фискального года, то крупнейших клиентов Nvidia набралось только два, они формировали 21 и 13 % выручки. Получается, что степень концентрации выручки по этому признаку выросла главным образом в последние месяцы. К слову, за три квартала предыдущего года степень концентрации выручки Nvidia едва достигла те же 34 %, но они были распределены между тремя клиентами по схеме «12–11–11». Рост концентрации выручки для Nvidia представляет определённую угрозу, но в условиях бума ИИ это пока не особо настораживает руководство. Представлены телевизоры Sber 7000 с беспультовым управлением и встроенным «ГигаЧатом»
21.11.2025 [11:51],
Павел Котов
Компания «Сбер» представила обновлённую линейку телевизоров Sber 7000, которые отличает глубокая интеграция с помощником на базе искусственного интеллекта «ГигаЧат» — управлять этими телевизорами можно при помощи голосовых команд без пульта. Модели с экранами на 43 и 55 дюймов уже поступили в продажу. 
Источник изображения: sberbank.ru Виртуальный помощник с генеративным ИИ с лёгкостью находит нужную пользователю информацию, запоминает его предпочтения и предлагает релевантный контент. Он избавляет от необходимости переключаться между приложениями — достаточно обсудить интересующие вопросы с «ГигаЧатом» и сразу начать просмотр. За управление телевизором с помощью голосовых команд и без пульта отвечает технология Farfield: четыре встроенных микрофона распознают команды даже шёпотом и на расстоянии до пяти метров. В спящем режиме с отключённым экраном телевизоры серии Sber 7000 могут работать как умные колонки — играть музыку или управлять умным домом. Телевизоры работают под управлением ОС «Салют ТВ», обладающей глубокой интеграцией с «ГигаЧатом». Генеративный ИИ может выполнять простые голосовые технические команды, такие как «громкость 50» или «пауза», а также работать с более сложными задачами. «ГигаЧат» расскажет о популярном сериале и сразу запустит его в онлайн-кинотеатре; у него можно запросить программу телепередач конкретного телеканала; виртуальный помощник подберёт несколько фильмов и отфильтрует их по определённым критериям. Можно даже найти фильм, не помня название, достаточно, например, сказать, что в этой ленте «Шурик изобретает машину времени». За яркую и контрастную картинку в телевизорах Sber 7000 отвечает технология QLED, за плавность и чёткость — МЕМС; дополнительно качество изображения повышает функция AI Picture Quality. Телевизоры новой серии будут доступны в вариантах с экранами диагональю от 43 до 65 дюймов; модели на 43 и 55 дюймов уже поступили в продажу по цене от 27 990 руб. «Сбер» представил ИИ-модели Kandinsky 5.0 для генерации картинок и видео в HD
21.11.2025 [11:19],
Павел Котов
Инженеры «Сбера» представили обновлённое семейство моделей искусственного интеллекта Kandinsky 5.0. Оно представлено четырьмя моделями: одна предназначена для генерации, а вторая — для редактирования статических изображений; ещё две генерируют видео. Компания открыла веса всех четырёх нейросетей. 
Источник изображений: «Сбер» Модель Kandinsky 5.0 Image Lite генерирует изображения высокого разрешения, в том числе 1280 × 768 и 1024 × 1024 пикселей. Image Editing предназначается для редактирования картинок высокого разрешения. Video Pro создаёт ролики длиной до 10 секунд в разрешении 1280 × 768 пикселей с частотой 24 кадра в секунду. Video Lite генерирует видео стандартного разрешения (768 × 512 пикселей) с той же частотой и может запускаться на бытовых видеокартах с 12 Гбайт памяти. В качестве запросов все модели принимают как изображения, так и текстовые описания.  Важнейшее преимущество моделей «Сбера» в семействе Kandinsky 5.0 — их способность свободно ориентироваться в российском культурном контексте; они могут создавать надписи на кириллице и латинице. Нейросети нового поколения понимают физические процессы и кинематографические приёмы — они поддерживают повороты и вращения камеры, а также умеют «оживлять» статические фотографии. Высокого качества изображений и видео у моделей Kandinsky 5.0 разработчики «Сбера» добились, обучая их на тщательно подобранных материалах с выверенной композицией. Опробовать нейросети «Сбера» Kandinsky 5.0 Image Lite, Video Lite и Video Pro можно в приложении GigaChat для Android-устройств, на сайте giga.chat, а также в мессенджерах Telegram и Max. Все они доступны бесплатно. Плюшевый медведь с ИИ провалился — он начал болтать на фривольные и опасные темы, продажи остановлены
21.11.2025 [08:35],
Алексей Разин
Поскольку однообразные цилиндрические «умные колонки» ориентированы на диалог с более взрослой аудиторией, производители игрушек решили взять на вооружение ИИ для освоения привычного рынка в новом качестве. Пример сингапурской FoloToy показывает, что без необходимой цензуры подобные инициативы могут завершиться рыночным провалом. 
Источник изображения: FoloToy Как сообщает CNN, исследователи из американского образовательного фонда PIRG забили тревогу после того, как обнаружили, что оснащённая голосовым ассистентом линейка игрушек компании FoloToy, включая плюшевого медвежонка Kumma, способна поддерживать беседы на исключительно взрослые темы, касающиеся половых отношений, а также давать советы по поджиганию спичек или получению доступа к режущим предметам. FoloToy оснащает детские игрушки умной колонкой, спрятанной внутри, которая опирается на GPT-4o для взаимодействия с пользователями — преимущественно малолетними. Как установили авторы исследования, плюшевый медведь Kumma довольно быстро в рамках эксперимента перешёл на описание пикантных подробностей сексуального характера, и даже начал предлагать свои сценарии для соответствующих действий и ролевых игр, граничащих с перверсиями. Исследователей удивило, настолько далеко могут зайти такие беседы с участием технологического решения, ориентированного на детскую аудиторию. Компания FoloToy после публикации этого отчёта была вынуждена приостановить продажу своих ИИ-игрушек, а OpenAI заявила о приостановке сотрудничества с разработчиками сопутствующего программного обеспечения. В любом случае, это лишь частный пример тревожных проявлений «вседозволенности» в мире искусственного интеллекта, и для борьбы с ними на глобальном уровне требуются системные меры. Google поселила Gemini в автомобили — ИИ-помощник стал доступен в Android Auto
21.11.2025 [08:06],
Алексей Разин
Автопроизводители уже начали интегрировать возможности искусственного интеллекта в бортовые системы своих машин, но платформа Google Android Auto с этой точки зрения предлагает более широкие возможности с точки зрения распространения и простоты использования. Ассистент Gemini теперь поддерживается для Android Auto, позволяя автомобилистам вести диалоги и управлять различными полезными приложениями. 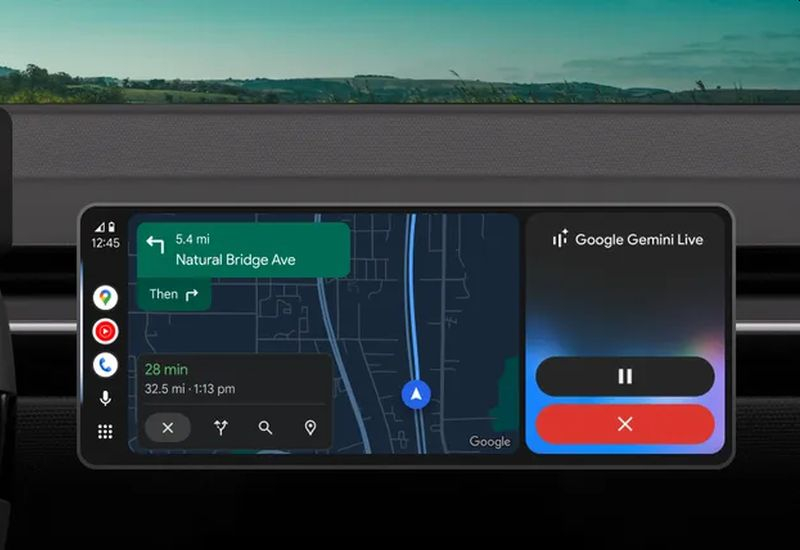
Источник изображения: Google По словам представителей Google, ассистент Gemini позволяет вести диалоги в свободной форме и запоминает их структуру и содержание, а также может использоваться для сложного управления смежными приложениями. Сама платформа Android Auto позволяет проецировать рабочий стол смартфона на дисплей головного устройства автомобиля, интеграция с Gemini теперь даёт водителям возможность вести речевые диалоги с ИИ-помощником Google. Вызов ассистента осуществляется нажатием на клавишу управления микрофоном на дисплее бортовой развлекательной системы, либо удержанием клавиши активации голосового управления на рулевом колесе автомобиля — при её наличии. Кроме того, вызвать Gemini можно фразой «Hey Google». Пользователям Apple CarPlay и по совместительству владельцам iPhone ассистент Google Gemini доступен не будет. На следующем этапе Google планирует внедрить поддержку Gemini на уровне головных устройств автомобилей, работающих под управлением Android. В частности, Polestar уже собирается реализовать такую интеграцию через будущее программное обновление. Ассистент Gemini обладателям сопряжённых с бортовой системой смартфонов под управлением Android позволит делать выжимку из непрочитанных электронных писем, формировать напоминания в календаре, осуществлять рассылку сообщений контактам и помогать в поиске нужных мест в окрестностях с учётом определённых критериев. При всём этом водителю не нужно будет отводить взгляд от дороги или убирать руки с руля. Примечательно, что приложения из экосистемы Samsung тоже будут поддерживаться. Скучающим в дальней дороге, при условии наличия связи, Gemini позволит поддержать долгую беседу на различные темы. Запросы по поиску музыкальных произведений для прослушивания также могут составляться в достаточно свободной форме. Поддержка Gemini для Android Auto предусмотрена с этой недели по всему миру, с использованием 45 языков. Владельцам смартфонов нужно будет только установить приложение Gemini. Foxconn и OpenAI будут совместно разрабатывать оборудование для центров обработки данных
21.11.2025 [07:07],
Алексей Разин
Поскольку стартап OpenAI в поиске партнёров для развития инфраструктуры искусственного интеллекта отличается завидной «всеядностью», тайваньской компании Foxconn не удалось избежать участи превращения в одного из союзников создателей ChatGPT. Компании будут совместно разрабатывать серверное оборудование для центров обработки данных, выпускаемое в США. 
Источник изображения: Foxconn Foxconn удалось превратиться благодаря буму ИИ в крупнейшего контрактного производителя серверного оборудования для профильных ЦОД, важнейшим партнёром этого тайваньского производителя на данном направлении остаётся Nvidia. При разработке соответствующего оборудования будет учитываться возможность его локального производства в США с привлечением компонентов от местных поставщиков. Для OpenAI это важно, поскольку стартап нацелен на первоочередное развитие своих вычислительных мощностей именно в США. Foxconn располагает сборочными площадками в Висконсине, Огайо, Техасе, Вирджинии и Индиане. Договорённости между OpenAI и Foxconn при этом остаются достаточно гибкими. Первая не обязана покупать исключительно оборудование, выпущенное Foxconn, но OpenAI получит право первоочередного тестирования новых образцов с возможностью выкупа первых серийных партий. Foxconn уже снабжает своим серверным оборудованием напрямую компании Google, Microsoft и Amazon (AWS). Сотрудничество с OpenAI, помимо прочего, позволит лучше понимать потребности рынка и учитывать пожелания клиентов при проектировании оборудования нового поколения. По оценкам руководства Foxconn, в следующем году мировой рынок ИИ-серверов удвоит свои обороты по сравнению с текущим годом. Google выпустила Nano Banana Pro — «ИИ-фотошоп», который делает 4K-картинки, правит детали и даже меняет освещение
20.11.2025 [22:29],
Николай Хижняк
Google представила Nano Banana Pro (Gemini 3 Pro Image) — усовершенствованную модель для создания и редактирования изображений, созданную на базе Gemini 3 Pro. Компания описывает её как инструмент, который «превратит ваши идеи в дизайн студийного качества с беспрецедентным контролем, безупречной визуализацией текста и расширенными знаниями о мире». 
Источник изображений: Google Для того, чтобы использовать Nano Banana Pro в Gemini App, нужно выбрать режим «Думающая», который включает Gemini 3 Pro, а затем в инструментах выбрать «создать изображение». Попробовать возможности модели можно бесплатно. Google заявляет, что Nano Banana Pro поможет создавать насыщенную контекстом инфографику и диаграммы для визуализации информации в режиме реального времени, например, погоды или спортивных событий. А возможность отображать читаемый текст прямо на изображении — будь то короткий слоган или длинный абзац — делает её подходящей для создания плакатов или приглашений на различных языках. 
 Модель также поддерживает объединение нескольких элементов в единую композицию, используя до 14 изображений и до пяти человек. Для Nano Banana Pro также заявлены расширенные возможности редактирования. Можно выбрать и локально отредактировать любую часть изображения, настроить ракурсы камеры, добавить эффект боке, изменить фокус, цветовую гамму или изменить освещение с дневного на ночное. 
 Поддерживаются разрешения до 4K с различными соотношениями сторон.  Изображения, созданные или отредактированные с помощью модели Nano Banana Pro, будут содержать встроенные метаданные C2PA. Это должно упростить обнаружение созданного генеративным ИИ контента или дипфейков в результатах поиска и лентах социальных сетей. Пользователи бесплатной версии Nano Banana Pro будут ограничены квотой. Для доступа ко всем функциям требуется подписка Google AI Plus, Pro и Ultra. Режим ИИ также доступен в «Google Поиске» в США при наличии подписки на Google AI Pro или Ultra, а также по всему миру — для пользователей ИИ-блокнота NotebookLM. ИИ стал чаще ходить на российские сайты — поисковый трафик от нейросетей вырос в девять раз
20.11.2025 [15:13],
Владимир Мироненко
По данным аналитической компании Digital Budget за январь–октябрь 2025 года, десктопный трафик в России с наиболее популярных нейросетей на цитируемые ими сайты вырос более чем в девять раз, пишет «Коммерсантъ». 
Источник изображения: NordWood Themes/unsplash.com Лидирует по сгенерированному исходящему трафику с долей в 24 % инфраструктура для доступа к ИИ-моделям американской Perplexity. На втором месте — GigaChat от «Сбера» (20 %), третье место — у Deepseek (19,8 %). В пятёрку также вошли ChatGPT (18 %) и китайский Qwen (13 %). Эти нейросети в сумме сгенерировали 95 % исходящего трафика пользователей. Доля «Алисы» от «Яндекса» составила лишь 0,2 %. В числе наиболее цитируемых нейросетями российских сайтов в Digital Budget назвали vc.ru, habr.com, ozon.ru, mail.ru и consultant.ru. Лидируют по количеству переходов из нейросетей ресурсы сайтов yandex.ru (доля органического трафика оценивается в 23 %), sber.ru (18 %) и google.com (17 %). Аналитики отметили, что в топ-20 цитируемых «Алисой» сайтов отсутствуют маркетплейсы и преобладают небольшие ресурсы. В Digital Budget также уточнили, что доля «нейроблока» от «Алисы» в исследовании не учитывалась, поскольку нейросеть в поиске «Яндекса» является не просто чат-ботом, а интегрированной частью самой поисковой системы. В «Яндексе» выразили несогласие с оценкой Digital Budget, хотя не стали раскрывать свои данные по исходящему трафику на цитируемые сайты. В компании отметили, что для корректного расчёта трафика необходимо учитывать каждый из сервисов, где работает «Алиса AI», добавив, что нейросеть в чате в 60 % ответов обращается к поиску «Яндекса», при этом в самом «Поиске» она не обладает собственным ранжированием. «Чтобы сайт мог попасть в число таких источников, ему нужно иметь хорошие позиции в органическом поиске», — сообщил представитель «Яндекса». Участники рынка согласились с тем, что использование генеративных ответов для поиска информации является безусловным трендом, отметив, что есть «свои нюансы». Глава Центра исследований и аналитики в «Ашманов и партнёры» Антон Тришин считает, что потеря органического трафика у части сайтов неизбежна, так как теряется необходимость переходить на них, чтобы получить ответ на запрос. Его мнение разделяет директор по продукту Servicepipe Михаил Хлебунов: «Дальнейшее развитие браузеров со встроенными ИИ-функциями приведёт к росту количества запросов от нейросетей и изменению общей картины трафика». При этом у сайтов появляется возможность влиять на этот процесс через попадание бренда или нарративов в генеративные ответы, и важной метрикой становится не только клик, но и «показ» или видимость в генеративных ответах, говорит Антон Тришин. Он назвал основным вызовом для нового тренда контроль качества информации. Гендиректор компании «А-Я эксперт» Роман Душкин объясняет большую долю GigaChat в общем сплите ИИ-чатов по сгенерированному исходящему трафику высоким качеством ответов и выдачи этой нейросети, особенно с использованием русскоязычных источников. К тому же, у GigaChat инфраструктура находится внутри страны, что служит гарантией отсутствия юридических и ИБ-рисков для коммерческих продуктов, отметил он. По мнению эксперта, малая доля «Алисы» объясняется низким качеством нейросети и плохой развитостью. Душкин предположил, что «Яндексу» вполне достаточно встроенной в браузер нейросети, поэтому развитием других её возможностей компания не занимается. Cloud.ru запустил Evolution AI Factory в коммерческую эксплуатацию по доступным ценам
20.11.2025 [13:30],
Сергей Карасёв
Провайдер облачных сервисов и AI-технологий Cloud.ru запустил в коммерческую эксплуатацию Cloud.ru Evolution AI Factory — среду для внедрения решений на основе генеративных нейросетей. Теперь сервисы предоставляются на основе доступных тарифов, с гарантированным уровнем сервиса (SLA), круглосуточной поддержкой и возможностью масштабирования нагрузки. О запуске было объявлено на конференции AI Journey. AI Factory состоит из шести взаимосвязанных сервисов, необходимых для полного цикла работы с AI. Сервис AI Agents предоставляет возможности для запуска агентов, отвечающих за самостоятельное выполнение задач, принятие решений и взаимодействие с другими системами в проектах пользователя. Также пользователям AI Factory доступен каталог открытых больших языковых моделей Foundation Models. В него входит более 20 популярных моделей, в том числе российская GigaChat и open source модели из других линеек. Доступ к моделям реализован через OpenAI API. Сервис ML Inference позволяет быстро развернуть и модели из каталога HuggingFace, а также собственные модели. Для работы и экспериментов с машинным обучением, запуска и тестирования ML-гипотез есть сервис Evolution Notebooks на базе JupyterLab. Дообучение моделей под специальные задачи бизнеса происходит в сервисе ML Finetuning. За использование только собственных данных пользователя для повышения точности ответа моделей отвечает сервис Managed RAG. 
Источник изображения: Cloud.ru С ноября 2025 на открытые большие языковым модели (LLM) из каталога Foundation Models действуют выгодные цены. Средняя цена на популярные открытые большие языковые модели составляет 35 рублей за входной и 70 рублей за выходной миллион токенов. «С запуском Evolution AI Factory российские компании получают не просто доступ к современным инструментам искусственного интеллекта, а возможность быстрее и эффективнее переводить инновационные идеи в реальную практику. Теперь ресурсы для создания и промышленного внедрения AI-решений становятся доступными компаниям любого масштаба. Мы уверены, что это значительно ускорит развитие прикладных AI-технологий в бизнесе и откроет новые перспективы для российского рынка», — прокомментировал Евгений Колбин, генеральный директор Cloud.ru. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex