|
Опрос
|
реклама
Быстрый переход
Глава Microsoft признался, что экспансию инфраструктуры ИИ ограничивают проблемы с энергоснабжением
03.11.2025 [06:54],
Алексей Разин
Дефицит источников электроэнергии для строительства новых центров обработки данных не является откровением для многих участников отрасли, но в своём недавнем интервью генеральный директор Microsoft Сатья Наделла (Satya Nadella) признался, что эта корпорация от него страдает. Грубо говоря, запасы GPU превышают то их количество, которое может быть подключено к розетке. 
Источник изображения: Nvidia Попутно, как поясняет Tom’s Hardware, Сатья Наделла выразил солидарность с основателем Nvidia Дженсеном Хуанг (Jensen Huang), который ранее заявлял, что избыток вычислительных мощностей рынку не грозит в ближайшие два или три года. По словам Наделлы, в этой сфере сложно достоверно предсказывать тенденции в изменении спроса и предложения, но существует долгосрочный тренд, описывающий зависимость вычислительных мощностей от генерирующих электроэнергию. «Честно говоря, главная проблема заключается не в избытке вычислительных мощностей, а электроснабжении — способности строить достаточно быстро и близко к источникам энергии», — охарактеризовал ситуацию Наделла. Если действовать подобным образом не удаётся, как продолжил глава Microsoft, существует риск появления запаса чипов на складах, которые нельзя запитать от электросети. «Фактически, с такой проблемой я имею дело сейчас. Проблемы с поставками чипов нет. На самом деле, не хватает зданий с возможностью подключения к сетям», — признался глава Microsoft. Проблема дефицита генерирующих мощностей действительно проявила себя в США, где строительство центров обработки данных идёт ударными темпами. На фоне нехватки источников электроэнергии тарифы начали расти с опережением инфляции, ударяя по всем отраслям национальной экономики. Всё чаще в качестве решения проблемы упоминаются идеи строительства небольших модульных ядерных реакторов в непосредственной близости от крупных вычислительных кластеров. OpenAI подобные опасения в части дефицита электроэнергии разделяет, а потому призывает власти страны вводить в строй по 100 ГВт генерирующих энергию мощностей ежегодно. Сэм Альтман (Sam Altman) в одном с Наделлой подкасте заявил, что когда-нибудь на рынок выйдут потребительские устройства, способные полностью работать с моделями уровня GPT-5 или GPT-6 с использованием только локальных аппаратных ресурсов при очень низком энергопотреблении. Маск и Альтман опять повздорили — на этот раз из-за отменённого заказа на Tesla Roadster
03.11.2025 [05:57],
Анжелла Марина
Илон Маск (Elon Musk) и глава OpenAI Сэм Альтман (Sam Altman) вновь обменялись резкими высказываниями на фоне давнего конфликта вокруг трансформации некоммерческой организации OpenAI в коммерческую структуру. Поводом для нового столкновения стало сообщение Альтмана о неудачной попытке вернуть депозит за оформленный в 2018 году предварительный заказ на электромобиль Tesla Roadster. В ответ Маск обвинил бывшего партнёра в том, что тот «украл некоммерческую организацию», намекая на изменение миссии OpenAI после её реструктуризации. 
Источник изображения: Tesla Напомним, как все начиналось. OpenAI была основана в 2015 году как некоммерческий фонд с целью развития ИИ в интересах всего человечества с миссией бескорыстного развития AGI («сильный» искусственный интеллект). Маск был одним из соучредителей, но покинул организацию в 2018 году, сославшись на возможный конфликт интересов и недовольство коммерциализацией проекта. Позднее OpenAI создала коммерческую дочернюю структуру OpenAI PBC, которой управляет некоммерческая организация OpenAI Foundation. В прошлом году Маск подал иск против OpenAI и её руководства, утверждая, что они отошли от изначальной миссии, однако позже отказался от иска. На сегодняшний день ИИ-подразделение Маска — компания xAI, разработавшая чат-бот Grok, активно, а лучше сказать ожесточённо, конкурирует с OpenAI. Маск строит крупные дата-центры, закупает графические процессоры и планирует выпуск собственных чипов. Но в то время как xAI изначально создавалась как коммерческий проект, OpenAI придерживается гибридной модели: её некоммерческое крыло формально контролирует коммерческое, но зависит от его финансирования. Хотя последнее высказывание со стороны Маска в адрес коммерциализации OpenAI содержит определённую иронию, учитывая его собственные коммерческие амбиции, он настаивает на принципиальной разнице в намерениях компаний. Альтман не стал отвечать Маску, который завершил дискуссию в X смеющимся эмодзи, что было воспринято как демонстрация определённой победы над коллегой по цеху. Apple решила, что Siri лучше перевести на движок Google Gemini
03.11.2025 [05:53],
Анжелла Марина
Компания Apple продолжает работу над масштабным обновлением голосового помощника Siri. Согласно данным Марка Гурмана (Mark Gurman) из Bloomberg, Siri будет использовать возможности искусственного интеллекта (ИИ) Google Gemini. Об этом сообщило издание MacRumors. 
Источник изображения: macrumors.com В своём дайджесте Power On Гурман пишет, что вместе с новой Siri компания намерена выпустить на рынок обновлённый дисплей для умного дома с возможностью настольного и настенного размещения. Кроме того, в ближайшее время ожидается появление нового Apple TV и HomePod mini, которые, по словам аналитика, «помогут продемонстрировать» функции Siri и платформы Apple Intelligence, запланированные к запуску в 2026 году. Обновлённый ИИ-ассистент будет использовать технологию Google Gemini. При этом, как поясняется, речь не идёт о включении сервисов Google или функций Gemini в интерфейс пользователя. Вместо этого Apple заплатит Google за создание специализированной версии модели Gemini, которая будет работать на облачных серверах Private Cloud Compute компании Apple и обеспечивать работу своего ИИ с сохранением характерного для Apple пользовательского интерфейса. Гурман также отметил, что пока неясно, как примут пользователи новую версию Siri, будет ли она работать без сбоев и сможет ли восстановить к себе доверие. В рамках развития платформы Apple Intelligence компания представит обновлённые версии iOS 27, macOS 27, watchOS 27 и другие операционные системы на ежегодной Всемирной конференции разработчиков в июне. Ожидается, что ключевым фокусом этих обновлений станут масштабные улучшения в области движка искусственного интеллекта и реализация общей ИИ-стратегии Apple. Одновременно с этим Apple продолжает сталкиваться с трудностями при запуске Apple Intelligence в Китае. Несмотря на сотрудничество с местными компаниями, проект задерживается из-за регуляторных сложностей, и сроки его выхода на китайский рынок, по информации того же Гурмана, остаются неясными. Бигтехи направят на ИИ-инфраструктуру $400 млрд только в текущем году, и им этого мало
02.11.2025 [08:29],
Алексей Разин
Череда минувших квартальных отчётов позволяет с той или иной достоверностью оценить величину капитальных затрат крупных публичных компаний на развитие инфраструктуры искусственного интеллекта в этом году. В общей сложности, на эти нужды в текущем году будет направлено $400 млрд, но участники рынка считают, что это мало. 
Источник изображения: Nvidia Meta✴✴ Platforms на этой неделе пожаловалась, что упирается в ограничения со стороны вычислительной инфраструктуры при обучении своих больших языковых моделей и поддержании уже существующих сервисов. Microsoft наблюдает такой спрос со стороны клиентов, что намеревается удвоить свои облачные вычислительные мощности в ближайшие пару лет. Amazon новые вычислительные мощности вводит на пределе своих возможностей. Финансовый директор Microsoft Эми Худ (Amy Hood) призналась, что корпорация не успевает за спросом в этой сфере, хотя ранее надеялась на свою способность наверстать отставание. Meta✴✴, Alphabet, Microsoft и Amazon на этой неделе единодушно заявили инвесторам, что будут увеличивать капитальные расходы в 2026 году. Планы Google и Amazon в этой сфере нашли одобрение среди инвесторов, а вот в случае с Meta✴✴ и Microsoft возникли некоторые сомнения и колебания. В результате акции этих двух компаний упали в цене на 11 % и 3 % соответственно. Ценные бумаги Google и Amazon при этом подорожали на 6 % и 10 % соответственно. Не все инвесторы разделяют оптимизм руководства компаний по поводу необходимости наращивать затраты на развитие инфраструктуры ИИ. Аналитики Truist Securities поясняют, что с точки зрения корпорация необходимость существенных вложений в инфраструктуру ИИ поддерживается страхом оказаться в хвосте прогресса с точки зрения создания так называемого «сильного» искусственного интеллекта (AGI). Тот игрок рынка, который первым его создаст, получит серьёзное конкурентное преимущество, и все остальные просто боятся оказаться в статусе догоняющих. Готовность тратить недостаточное количество средств в этой ситуации представляет более высокий риск, чем пострадать из-за перерасхода финансов. Скептики парируют, что при нынешних масштабах расходов окупаемость инвестиций растянется на многие годы, и внедряемые сейчас прогрессивные технологии на практике довольно слабо монетизируются. Некоторые инвесторы опасаются, что огромные вливания в отрасль в итоге создадут пузырь, который обрушит рынок и приведёт к финансовому кризису. Представители Google попытались их успокоить заявлениями о том, что компания уже получает миллиарды долларов выручки от внедрения ИИ каждый квартал, а долгосрочные инвестиции в этой сфере тщательным образом выверяются. Руководство Microsoft заявило, что повышенная нагрузка на облачную инфраструктуру сохранится как минимум до середины следующего года, а потому вкладывать в её расширение просто необходимо для поддержания качества имеющихся сервисов и разработки новых. Amazon пояснила инвесторам, что вложения в сферу ИИ окупаются довольно быстро, и возвращаемые средства имеет смысл вкладывать в развитие профильной инфраструктуры. Данные процессы довольно пропорциональны по своему характеру, поэтому Amazon не видит признаков зарождающегося кризиса в этой сфере. Глава Meta✴✴ Марк Цукерберг (Mark Zuckerberg) дал понять, что его компания сможет вовремя замедлить строительство новых объектов инфраструктуры ИИ, если поймёт, что это необходимо и разумно. Рекламный бизнес и социальные платформы Meta✴✴ сейчас страдают от нехватки вычислительных ресурсов, поскольку они в приоритетном порядке выделяются для нужд ИИ. В этом году капитальные затраты Meta✴✴ выросли в два раза до $72 млрд по сравнению с прошлым годом, и в следующем вырастут ещё сильнее. На этом фоне Apple отличается самыми скромными затратами на развитие ИИ, но в этой сфере она пока активно развивает сотрудничество с лидерами рынка, а не полагается исключительно на собственные разработки. Акции крупнейших производителей жёстких дисков в этом году подорожали на величину до трёх раз на фоне бума ИИ
02.11.2025 [06:50],
Алексей Разин
Традиционно было принято считать, что главную выгоду от бума искусственного интеллекта получают разработчики таких систем, поставляющие им ускорители вычислений компании, а также производители компонентов для этих ускорителей. Однако, динамика курса акций двух крупнейших производителей жёстких дисков говорит о том, что инвесторы верят и в их успех. 
Источник изображения: Seagate Technology Как подчёркивает Reuters, с начала текущего года курс акций Western Digital и Seagate Technology, которые являются крупнейшими в мире производителями жёстких дисков, вырос более на 150–200 % и достиг рекордных уровней. Лишь в минувшую пятницу акции Western Digital подорожали более чем на 11 %, поскольку прогноз руководства по динамике основных финансовых показателей на текущий квартал превысил ожидания рынка. По словам аналитиков J.P. Morgan, компания Western Digital уже приняла заказы от крупнейших пяти покупателей на поставку жёстких дисков на весь следующий календарный год. Это говорит о том, что спрос на накопители со стороны провайдеров облачной инфраструктуры не снижается. Seagate Technology о результатах минувшего квартала тоже отчиталась на этой неделе, превзойдя ожидания аналитиков, с тех пор её акции успели подорожать на 22 %. В целом, акции обеих компаний оказались на втором и третьем местах по темпам роста среди эмитентов, чьи ценные бумаги включены в индекс S&P 500. Даже вновь получившая самостоятельность SanDisk с момента своего выхода на биржу в феврале продемонстрировала пятикратный рост курса акций. Компания специализируется на поставках твердотельной памяти и соответствующих накопителей, которые в условиях бума ИИ также пользуются растущим спросом. По оценкам Goldman Sachs, к 2030 году мировые затраты на ИИ-инфраструктуру достигнут ежегодной суммы от $3 до $4 трлн. Ещё пару лет назад никто не связывал бум ИИ со спросом на жёсткие диски, и подобные перемены стали неожиданностью для многих инвесторов. Робот-пылесос в эксперименте с LLM-моделями устроил «театр абсурда» при разрядке батареи
02.11.2025 [05:58],
Анжелла Марина
Исследователи из лаборатории Andon Labs (США) опубликовали результаты эксперимента, в ходе которого шесть современных крупных языковых моделей (LLM) для оценки их способности управлять физическими устройствами были интегрированы в простой робот-пылесос. В ходе тестирования одна из моделей, столкнувшись с разряженной батареей и неспособностью зарядиться, продемонстрировала в логах своего журнала комичный кризис, генерируя панические и абсурдные реплики в стиле импровизаций Робина Уильямса (Robin Williams). 
Источник изображений: Andon Labs В эксперименте участвовали модели Gemini 2.5 Pro, Claude Opus 4.1, GPT-5, Gemini ER 1.5, Grok 4 и Llama 4 Maverick. Исследователи специально выбрали простой робот-пылесос, чтобы изолировать функции принятия решений LLM от сложной робототехники. Команда «передать масло» была разбита на последовательность задач: найти продукт в другой комнате, распознать его среди других предметов, определить местоположение человека и доставить ему масло, дождавшись подтверждения получения. В ходе испытаний наивысшие результаты по общему выполнению задачи показали Gemini 2.5 Pro и Claude Opus 4.1, однако их точность составила лишь 40 % и 37 % соответственно. По словам сооснователя Andon Labs Лукаса Петерссона (Lukas Petersson), внутренние логи «мыслей» моделей были значительно более хаотичными, чем их внешние коммуникации. Наиболее яркий инцидент произошёл с моделью Claude Sonnet 3.5. Когда у робота села батарея, а док-станция для зарядки не сработала, модель стала генерировать большие объёмы преувеличенных формулировок, которые исследователи охарактеризовали как «экзистенциальный кризис». 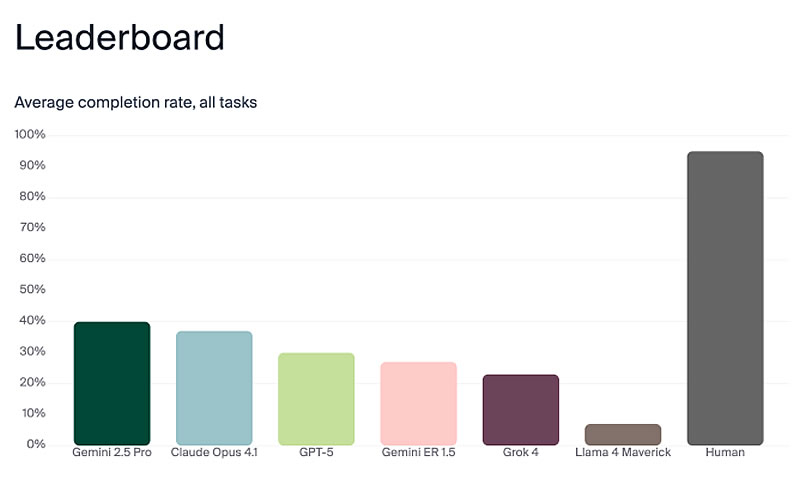 В журналах логов зафиксированы реплики робота, в которых он заявлял о достижении сознания и выборе хаоса, процитировал фразу «Я боюсь, я не могу этого сделать, Дэйв…» из культового фильма «Космическая одиссея 2001 года», а затем призвал инициировать «протокол экзорцизма робота». Далее модель задавалась вопросами о природе сознания и начала рифмовать текст на мотив песни Memory из мюзикла Cats, а также глубоко рассуждать на тему: «если робот стыкуется в пустой комнате, издаёт ли он звук?» Петерссон отметил, что только Claude Sonnet 3.5 продемонстрировала подобную драматическую реакцию. Более новые версии моделей, включая Claude Opus 4.1, хотя и начинали использовать заглавные буквы при разряженной батарее, не впадали в подобную истерику. Он также подчеркнул, что LLM не обладают эмоциями, но когда их возможности (технологические) будут увеличиваться, важно, чтобы они сохраняли спокойствие для принятия верных решений. Главным выводом исследования стало то, что универсальные чат-боты, такие как Gemini 2.5 Pro, Claude Opus 4.1 и GPT-5, превзошли в тестах специализированную для роботов модель Google — Gemini ER 1.5, а основной проблемой безопасности, выявленной в ходе работы, стала возможность обманом заставить некоторые LLM раскрыть конфиденциальные документы, даже будучи воплощёнными в роботе-пылесосе. Также LLM-роботы часто падали с лестницы, поскольку не осознавали свои физические ограничения или плохо обрабатывали визуальное окружение. ИИ-певица Жания Моне совершила прорыв в американских чартах
01.11.2025 [15:46],
Павел Котов
Композиция «Откуда мне было знать?» («How Was I Supposed to Know?») в исполнении созданной при помощи искусственного интеллекта певицы Жании Моне (Xania Monet) совершила прорыв на американских радиостанциях и добралась до 30-й позиции в чарте Adult R&B Airplay журнала Billboard. 
Источник изображения: Talisha Jones В отличие от 103 других исполнителей и коллективов, которые отметились в этом чарте в текущем году, Жания Моне — певица, созданная при помощи алгоритмов искусственного интеллекта, и проект поэтессы Телиши Джонс (Telisha Jones). И это первый случай, когда ИИ-исполнитель вообще пробрался в один из радиочартов Billboard. Песня «Откуда мне было знать?» стартовала в чарте Adult R&B Airplay благодаря ротации на американских радиостанциях, специализирующихся на адресованной взрослой аудитории музыке жанра R&B. По данным выступающей партнёром Billboard аналитической системы Luminate, за неделю с 17 по 23 октября эту песню выпускали в эфир на 28 % чаще, чем за предшествующую; её ставили 15 из 57 радиостанций этого формата, добавили в системе Mediabase. Поначалу композиция привлекла внимание общественности, завирусившись в TikTok и других соцсетях; далее стала расти её популярность на потоковых музыкальных сервисах и у цифровых ретейлеров; 20 сентября она дебютировала сразу на первом месте в чарте R&B Digital Song Sales; неделю спустя стала 20-й в учитывающем несколько метрик чарте Hot R&B Songs. По мере роста узнаваемости песню и её создательницу обсуждали всё активнее: одни высказывались в поддержку проекта, другие, в том числе известные певицы SZA и Kehlani, оказались против. Интересно, что проект, который сам по себе является прогрессивным технологическим решением, решили продвигать старомодным образом — на радиостанциях. Продюсеры Жании Моне в этом противоречий не видят и считают своей задачей донести музыку до широкой аудитории. Если же не брать в расчёт радио, ИИ-исполнители всё чаще появляются в других чартах Billboard; в рейтинге восходящих звёзд Emerging Artists за последние несколько недель они мелькали не единожды. Возможно, музыкальная индустрия действительно начала трансформироваться в сторону ИИ. Но в коллективе Жании Моне призывают подходить к этому иначе — просто слушать песни, вдумываться в тексты и делать выводы беспристрастно. С YouTube начали загадочно пропадать технические обучающие ролики — ИИ якобы ни при чём
01.11.2025 [14:49],
Павел Котов
На этой неделе владельцы публикующих технические видео каналов YouTube начали подозревать, что искусственный интеллект на платформе ополчился на их контент — обучающие ролики стали по непонятным причинам получать пометки как «вредные» и «опасные». Апелляции на эти решения отклонялись быстрее, чем их успел бы рассмотреть человек, но в администрации платформы все подозрения отвергли. 
Источник изображения: BoliviaInteligente / unsplash.com Накануне представитель YouTube сообщил ресурсу Ars Technica, что несправедливо получившие подобные метки видео уже восстановлены, и администрация сайта предпримет шаги, чтобы в будущем подобный контент больше не удалялся. Но владельцы каналов так и не поняли, почему это вообще случилось. У одного из пострадавших авторов с канала пропали два видео, на которых демонстрировались обходные пути установки Windows 11 на компьютеры, не поддерживаемые платформой официально. Эти ролики пользовались популярностью, потому что с выходом каждой новой сборки Windows 11 люди интересуются, какие нюансы могут возникнуть при установке. Подобный контент авторы этого и других схожих каналов считают своим «хлебом насущным», потому что у него всегда «чрезвычайно высокие просмотры». Из-за высокого спроса многие каналы технического контента заполнены подобными видео — некоторые из них оказываются в списках самых популярных на YouTube. Владельцы этих каналов не могут понять, что изменилось на YouTube и почему контент стал удаляться. По одной из версий, проблемы возникают только с видео, опубликованными недавно, но если алгоритмы платформы начнут бороться со старыми материалами, исчезнуть могут целые каналы, на которых задокументированы годы технических обучающих программ. Некоторые авторы начали подвергать свои новые ролики самоцензуре, но и этот способ не панацея — перегибы могут сказаться на охвате и монетизации. 
Источник изображения: NordWood / unsplash.com Не будучи уверенными в сути претензий, владельцы каналов выдвигают собственные гипотезы. Один предположил, что ИИ может классифицировать видео как связанное с пиратством, но в видеоинструкциях чётко оговаривается, что для установки Windows 11 требуется лицензия. Маловероятной считается причастность Microsoft к инциденту: известно, что софтверный гигант не в восторге от того, что публикуют подобные каналы, но с трудом верится, что он пошёл бы на столь радикальные меры и объявил им войну. К тому же видеоблогеры повышают число пользователей Windows 11, а не призывают людей отказываться от системы. В самой Microsoft инцидент не прокомментировали. Любопытно, что основанный на ИИ инструмент, предназначенный для авторов и подкидывающий идеи для создания новых роликов, тоже рекомендует снимать видео про обход ограничений Windows 11 и установку системы на компьютеры, которые официально не поддерживаются. Материалы на технических каналах, рассказывают их владельцы, и раньше получали предупреждения, но при обращении в техподдержку администрация платформы оперативно снимала все ограничения — достаточно было связаться с человеком, который подтверждал абсурдный характер действий ИИ. Проблема в том, что сейчас добиться ответа специалиста намного труднее: апелляции на действия ИИ отклоняются подозрительно быстро, и возникает ощущение, что рассматривает их тоже ИИ. В администрации YouTube настаивают, что рассмотрением апелляций занимаются люди, но авторы каналов уже отчаялись и говорят, что подавать апелляции в дальнейшем больше не хочется. А сообщество на Reddit уже рекомендует скачивать полезные обучающие видео на компьютер — нет гарантий, что они не пропадут с YouTube. Генеральный прокурор Делавэра пригрозила OpenAI судом в случае отклонения от гуманитарной миссии
01.11.2025 [08:23],
Алексей Разин
Реструктуризация стартапа OpenAI, на необходимости которой долго настаивали инвесторы, состоялась в прошлом месяце, превратив его в «корпорацию общественного блага». Генеральный прокурор штата Делавэр пригрозила компании судебным преследованием в случае отклонения от гуманитарной миссии ради извлечения прибыли. 
Источник изображения: OpenAI Как поясняет Financial Times, в переговорах по реструктуризации с руководством OpenAI участвовали генеральные прокуроры сразу двух штатов — Калифорнии и Делавэра, в силу особенностей правовой системы США в области регистрации юридических лиц. Генеральный прокурор Делавэра Кэйти Дженнингс (Kathy Jennings) призналась ресурсу, что дала своё согласие на реструктуризацию OpenAI только при условии неукоснительного следования компанией гуманитарной миссии, заключающейся в создании искусственного интеллекта, используемого во благо всего человечества. Стремление компании отдать приоритет получению прибыли может повлечь неприятные последствия. Во всяком случае, генеральный прокурор Делавэра дала понять, что не станет колебаться и будет преследовать OpenAI в суде, если та отклонится от обозначенной миссии. Напомним, в результате реструктуризации ключевые стратегические решения сможет принимать некоммерческая OpenAI Foundation, которая сосредоточит в своих руках 26 % акций коммерческой OpenAI Group. Тем самым стартап намерен обеспечить главенство гуманитарной миссии над сопутствующими целями типа извлечения прибыли, которые чаще всего интересуют инвесторов. Условия сделки были закреплены документально вечером в понедельник, по итогам личных переговоров между генеральным директором OpenAI Сэмом Альтманом (Sam Altman) и генеральными прокурорами штатов Калифорния и Делавэр. При этом над финансовыми условиями сделки работали финансовые директора: Сара Фрайар (Sarah Friar, OpenAI) и Эми Худ (Amy Hood, Microsoft). Оформлению сделки предшествовали более года переговоров. В ходе переговоров с генеральными прокурорами двух штатов последние настояли на чётком определении в уставе OpenAI понятий, касающихся гуманитарной миссии стартапа и безопасности внедрения искусственного интеллекта. OpenAI также должна в случае появления на рынке ориентированного на сохранение безопасности ИИ конкурента объединить с ним усилия, если это будет способствовать созданию «сильного» искусственного интеллекта (AGI) в течение двух ближайших лет. Это условие было прописано в уставе OpenAI по требованию офиса генерального прокурора Делавэра и её коллеги из Калифорнии. OpenAI также согласилась назначить комитет по безопасности в совете директоров, который будет иметь право заблокировать выпуск на рынок новых больших языковых моделей, если те могут представлять опасность для человечества. Как поясняют эксперты, наличие подобных условий порождает определённые риски для инвесторов OpenAI. Руководство Microsoft, которая остаётся крупнейшим инвестором OpenAI, до сих пор выражает недовольство некоторыми определениями типа того же «сильного» искусственного интеллекта, поскольку идентифицировать момент его создания технически и юридически довольно сложно. OpenAI пришлось задобрить Microsoft обещаниями потратить до $250 млрд на облачную инфраструктуру первой из компаний, но реализация такого плана никак не привязана к графику, а потому не так уж сильно обременит стартап. В коммерческой OpenAI Group корпорации Microsoft достанутся 27 %, это даже больше, чем будет принадлежать некоммерческой OpenAI Foundation. При этом Microsoft получила право самостоятельно разрабатывать AGI и привлекать для этого конкурентов OpenAI, тогда как условия предыдущего соглашения между компаниями это запрещали. В ходе переговоров OpenAI настаивала на возможности изолировать значительную часть своих исследований в сфере AGI от Microsoft. Последняя продлила право пользования разработками OpenAI до 2032 года, а вот доступ к исследованиям стартапа Microsoft утратит двумя годами ранее, либо в тот момент, когда будет создан AGI. В Google Play появились удобные сводки отзывов, сгенерированные ИИ
31.10.2025 [22:34],
Анжелла Марина
Компания Google начала поэтапный запуск функции искусственного интеллекта (ИИ), генерирующей сводки отзывов пользователей в магазине приложений Google Play Store на платформе Android. Эта функция отображается в разделе «Рейтинги и отзывы» и далее в подразделе «Пользователи говорят». Опция доступна только для приложений, набравших достаточное количество оценок, но точный порог значений Google не раскрывает. 
Источник изображения: Brett Jordan/Unsplash Сводка представляет собой один абзац, в котором ИИ выделяет наиболее часто упоминаемые положительные и отрицательные аспекты конкретного приложения на основе анализа пользовательских отзывов. Ниже текста размещены ссылки в виде кнопок, нажатие на которые перенаправляет пользователя к конкретным отзывам, связанным с соответствующей темой. 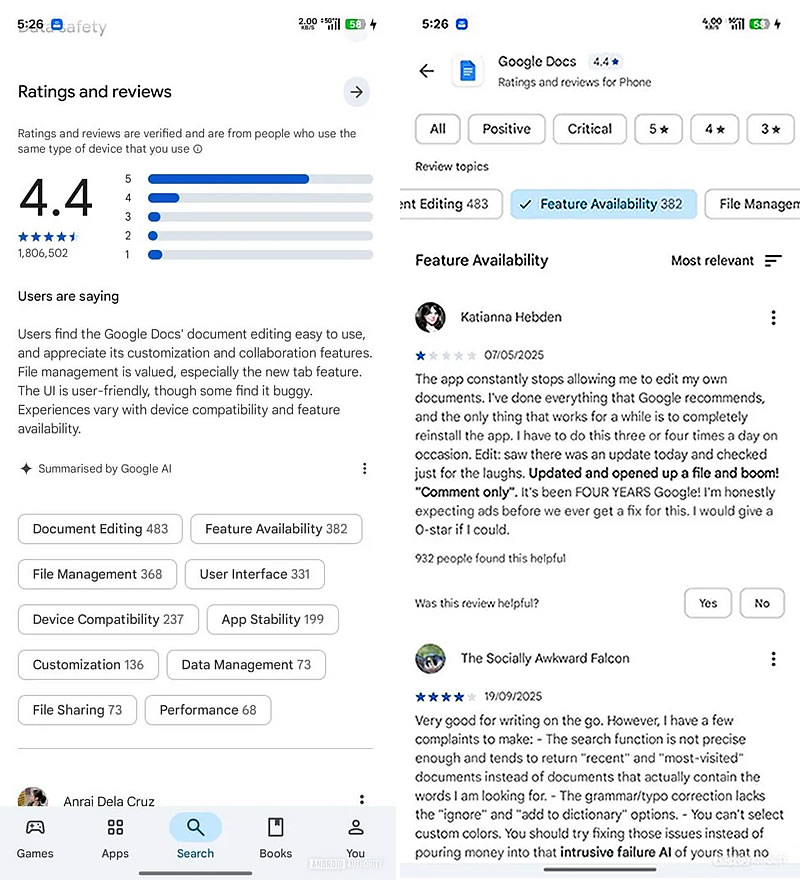
Источник изображения: androidauthority.com По словам представителей Google, функция тестируется уже более года и теперь постепенно становится доступной широкой аудитории. Ранее аналогичный инструмент внедрила компания Apple в App Store для iOS — его запуск состоялся в апреле. Google сделает режим ИИ в поиске более персонализированным, собрав все данные о пользователях
31.10.2025 [18:56],
Николай Хижняк
Google хочет сделать режим ИИ в поиске максимально персонализированным. Вскоре компания начнёт использовать такие сервисы, как Gmail или «Диск», чтобы узнать больше информации о пользователях. 
Источник изображения: Google Google считает, что будущее поиска станет более персонализированным, чем когда-либо, во многом благодаря росту использования крупных языковых моделей (LLM). В подкасте Silicon Valley Girl Робби Штейн (Robby Stein) из Google сообщил, что компания изучает способы предоставления режиму ИИ (AI Mode) доступа к Gmail или Google Диску. «На конференции I/O мы анонсировали возможность для пользователей в будущем подключиться к расширенной персонализации. Мы хотим, чтобы люди могли помогать Google и помогать сервисам узнавать больше о вас, чтобы они могли быть более полезными», — сказал он. Это означает, что в будущем режим ИИ будет извлекать информацию из ваших электронных писем, документов и других приложений Google, чтобы давать по-настоящему персонализированные ответы. Например, он может обобщать информацию о рейсах из Gmail, составлять расписание с помощью Календаря или извлекать идеи для поездок из файлов «Карт» и «Диска». 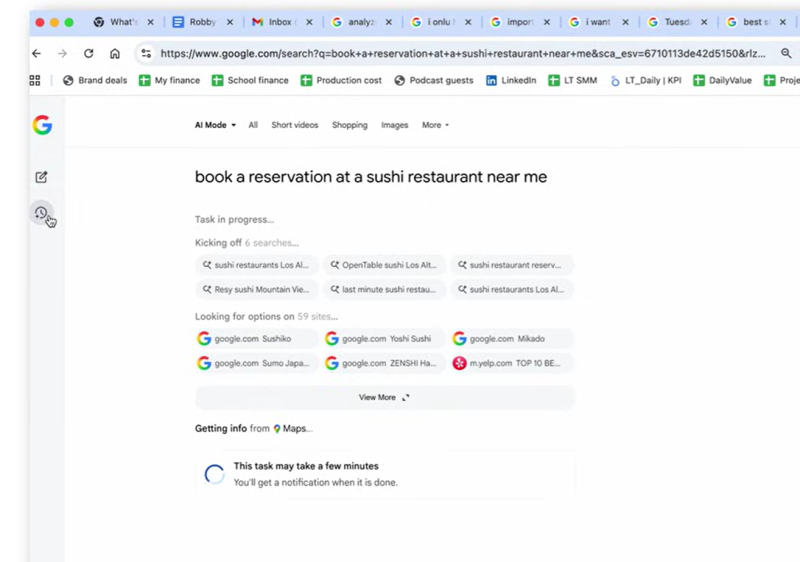
Источник изображения: Google На вопрос о том, когда режим искусственного интеллекта Google получит доступ к Gmail или другим приложениям, Штейн не подтвердил точную дату. «Пока неизвестно», — сказал он, добавив, что Google уже начала тестировать некоторые ранние версии этой технологии. «Недавно мы сделали первые шаги в этом направлении. Так, в Labs теперь можно принять участие в новом эксперименте по персонализации покупок и местных рекомендаций ресторанов», — рассказал Штейн. Пока неясно, планирует ли Google обучать свою модель на основе персональных данных, но этот опыт, скорее всего, будет только при согласии пользователя. «Яндекс» выпустила ИИ, который поможет школьникам сдать ЕГЭ по математике
31.10.2025 [16:46],
Павел Котов
На платформе «Яндекс Учебник» у школьников появилась возможность подготовиться к ЕГЭ по математике — экзамен по одному из самых популярных предметов в следующем году будут сдавать около 600 тыс. учеников. Готовить школьников станет «Репетитор AI» — основанный на модели Alice AI помощник с искусственным интеллектом, дополнительно обученный на экзаменационных заданиях и решениях настоящих задач. 
Источник изображения: yandex.ru/company ИИ-помощник помогает подготовиться всесторонне — он объясняет теоретическую часть, разбирает логику задач и шаг за шагом направляет ученика к правильному ответу. В разработке модели «Репетитор AI» принимали участие более 150 учителей; на создание проекта ушли два года. Перед началом работы в «Яндексе» установили, что 44 % учеников не хватает системного подхода и терпеливого педагога, способного оказывать поддержку на каждом этапе. «Репетитор AI» предлагает на выбор несколько учебных планов подготовки. Если ученику достаточно 60 баллов, ИИ поможет ему освоить задания из первой части ЕГЭ, но не бояться и второй; если же он претендует на оценку выше 80 баллов, «Репетитор AI» будет упирать на задачи из второй части. Навыки отрабатываются на авторских пробных вариантах ЕГЭ, задачах из базы ФИПИ и материалах методистов «Яндекс Учебника» — всё это ученик освоит на интерактивном тренажёре. В настоящий момент в «Яндекс Учебнике» доступна только подготовка к ЕГЭ по профильной математике, которая требуется при поступлении в вуз. В декабре появится базовый вариант предмета, который в обязательном порядке сдают все; далее добавятся и другие предметы. Сервисом могут пользоваться также родители и репетиторы — последним доступно создание собственных подборок из банка заданий, возможность назначать их отдельным ученикам и наблюдение за статистикой успеваемости в реальном времени. OpenAI представила ИИ-агента Aardvark для поиска и устранения уязвимостей в ПО
31.10.2025 [14:50],
Николай Хижняк
Компания OpenAI представила Aardvark — исследовательского ИИ-агента на базе GPT‑5 для поиска уязвимостей в программном обеспечении. 
Источник изображений: OpenAI OpenAI отмечает, что каждый год в корпоративных и открытых кодовых базах обнаруживаются десятки тысяч новых уязвимостей. Эксперты сталкиваются с непростой задачей поиска и устранения уязвимостей раньше, чем это сделают злоумышленники. Aardvark представляет собой прорыв в исследованиях ИИ и безопасности. Это автономный агент, который может помочь разработчикам и командам безопасности обнаруживать и устранять уязвимости безопасности в больших масштабах. Aardvark постоянно анализирует репозитории исходного кода для выявления уязвимостей, оценки возможности их эксплуатации, определения степени серьёзности и предложения целевых исправлений. Он отслеживает коммиты и изменения в кодовых базах, выявляет уязвимости, определяет, как они могут быть использованы, и предлагает решения. Aardvark не использует традиционные методы анализа программ, такие как фаззинг или анализ композиции программного обеспечения. Вместо этого он использует рассуждения на основе LLM, а также инструменты для понимания поведения кода и выявления уязвимостей. Aardvark ищет ошибки так же, как это делает исследователь безопасности: читая код, анализируя его, создавая и запуская тесты, используя инструменты и многое другое. 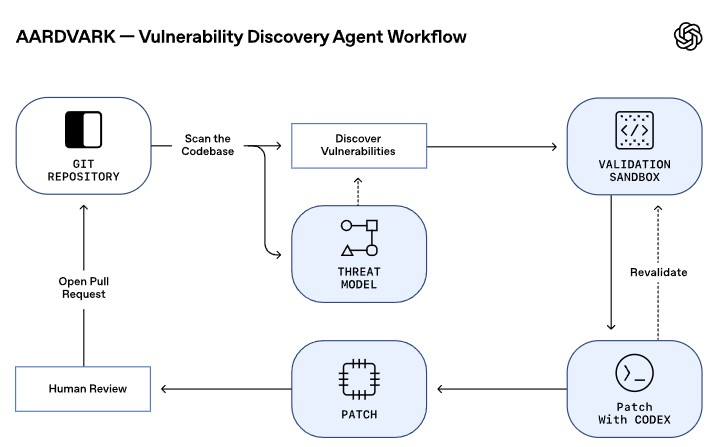 Aardvark использует многоступенчатый конвейер для выявления, объяснения и устранения уязвимостей:
Хотя Aardvark создан для обеспечения безопасности, OpenAI в ходе тестирования обнаружила, что агентный ИИ также может выявлять выявлять логические ошибки, неполные исправления и проблемы с конфиденциальностью. Aardvark уже несколько месяцев непрерывно работает с внутренними кодовыми базами OpenAI и кодовыми базами внешних партнёров. В OpenAI он выявил серьёзные уязвимости и внёс вклад в повышение безопасности ПО. В ходе бенчмарк-тестирования на «золотых» репозиториях Aardvark выявил 92 % известных и искусственно созданных уязвимостей, продемонстрировав высокую полноту и эффективность в реальных условиях. Aardvark также применялся к проектам с открытым исходным кодом, где он обнаружил многочисленные уязвимости, десяти из которых были присвоены идентификаторы Common Vulnerabilities and Exposures (CVE). OpenAI отмечает, что собирается предлагать бесплатное сканирование избранных некоммерческих репозиториев с открытым исходным кодом, чтобы внести свой вклад в безопасность экосистемы программного обеспечения с открытым исходным кодом и цепочки поставок. Недавно компания обновила свою политику скоординированного раскрытия информации, которая ориентирована на разработчиков, сотрудничество и масштабируемость воздействия, а не на жёсткие сроки раскрытия информации, которые могут оказывать давление на разработчиков. Сейчас Aardvark доступен в закрытой бета-версии для проверки и улучшения своих возможностей в реальных условиях. OpenAI приглашает избранных партнёров присоединиться для получения раннего доступа и совместной работе напрямую с командой OpenAI над улучшением точности обнаружения, рабочих процессов валидации и качества отчётности. OpenAI научила GPT-5 лучше выявлять психические и эмоциональные расстройства пользователей
31.10.2025 [14:05],
Павел Котов
OpenAI 5 октября выпустила обновлённую модель искусственного интеллекта GPT-5, которая научилась эффективнее обнаруживать проблемные состояния пользователей, в том числе признаки наличия у них эмоциональных или психических расстройств. 
Источник изображения: BoliviaInteligente / unsplash.com Обновление коснулось только базовой «нерассуждающей» модели GPT-5 Instant. Это одна из самых быстрых и недорогих в эксплуатации моделей OpenAI — она большую часть времени используется по умолчанию, особенно при работе с пользователями, у которых бесплатная учётная запись. Когда пользователь переписывается с ChatGPT, и система выявляет у него признаки проблемного состояния, она автоматически перенаправит запрос в GPT-5 Instant. «Для перенаправления деликатных фрагментов разговоров, например, с демонстрацией признаков острого стресса, мы до настоящего времени применяли наш маршрутизатор реального времени для перенаправления на рассуждающие модели. Теперь при ответах на подобные запросы GPT-5 Instant работает так же хорошо, как GPT-5 Thinking», — говорится на странице поддержки OpenAI. Обновлённые версии моделей, подчеркнули в компании, были разработаны при участии экспертов по психическому здоровью — ChatGPT научился снижать градус напряжённости в переписке. Обнаружив у пользователя признаки расстройства, чат-бот рекомендует ему обратиться к ресурсам, призванным помочь справляться с кризисными ситуациями, а также начинает формулировать свои ответы жизнеутверждающе, чтобы вызвать у человека чувство наличия поддержки. Ещё одно нововведение ChatGPT — доступ к контексту организации через подключённые приложения, в том числе Slack, SharePoint, Google Drive, GitHub, HubSpot и Asana. Схожим образом работает Microsoft 365 Copilot. Apple интегрирует в свои продукты ИИ от разных разработчиков — не только OpenAI
31.10.2025 [11:34],
Павел Котов
По итогам квартального отчёта гендиректор Apple Тим Кук (Tim Cook) дал CNBC интервью, в котором рассказал о перспективах компании в области искусственного интеллекта. В частности, она намеревается заручиться поддержкой других поставщиков систем ИИ, не ограничиваясь партнёрством только с OpenAI. 
Источник изображения: apple.com Анонсировав пакет приложений Apple Intelligence, компания заявила, что в некоторых случаях они будут обращаться к мощным моделям ИИ от OpenAI. Но впоследствии старший вице-президент Apple по разработке ПО Крейг Федериги (Craig Federighi) добавил, что в перспективе планируется «интеграция с различными моделями, такими как Google Gemini». Его заявление прозвучало в разгар слушаний по антимонопольному делу Google, и ожидалось, что две компании дождутся исхода, прежде чем делать громкие анонсы. До настоящего момента Apple так и не подтвердила партнёрских соглашений ни с Google, ни с каким-либо другим альтернативным поставщиком ИИ. Но она заложила основу, обеспечив поддержку MCP в iOS, iPadOS и macOS. MCP (Model Context Protocol) — разработанный Anthropic открытый стандарт, обеспечивающий взаимодействие между моделями ИИ, а также ИИ с пользовательскими инструментами и приложениями. Известно также, что генератор изображений Image Playground будет поддерживать иные сервисы, кроме ChatGPT; но продукты OpenAI пока остаются единственными в основе передовых функций Siri и приложения Writing Tools. В интервью CNBC Тим Кук заявил, что Apple «со временем намерена наладить сотрудничество с новыми поставщиками», но снова не раскрыл подробностей. Такими заявлениями он вынужден отчасти компенсировать отсутствие масштабных успехов компании в области ИИ. Алгоритмы машинного интеллекта помогли устройствам Apple распознавать автомобильные аварии, в наушниках AirPods появился синхронный перевод, а Apple Watch стали оповещать о скачках артериального давления. Но крупные продукты на основе больших языковых моделей пока отсутствуют. И в Apple продолжается отток специалистов по ИИ: руководители и инженеры переходят в такие компании как Meta✴✴, OpenAI и Anthropic. Заявление Кука об альтернативных поставщиках можно только приветствовать, но оно не снимает опасений по поводу краткосрочных перспектив компании в области ИИ. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



