|
Опрос
|
реклама
Быстрый переход
Аудитория Meta✴ AI резко выросла благодаря «ИИ-тиктокам» Vibes — конкуренты зафиксировали спад активности
21.10.2025 [06:15],
Анжелла Марина
Мобильное приложение Meta✴✴ AI значительно увеличило свою ежедневную аудиторию и число новых установок после внедрения в сентябре функции Vibes — ленты коротких видеороликов, создаваемых с помощью ИИ. Согласно анализу Similarweb, число ежедневных активных пользователей приложения выросло более чем в три раза за последние четыре недели. 
Источник изображения: Salvador Rios/Unsplash Как сообщает TechCrunch со ссылкой на отчёт Similarweb, мобильное приложение Meta✴✴ AI для платформ iOS и Android зафиксировало значительный рост как числа ежедневных активных пользователей, так и количества новых установок. На 17 октября 2025 года ежедневная аудитория приложения составила 2,7 млн человек, существенно превысив показатель в 775 тысяч пользователей, зафиксированный четырьмя неделями ранее. Ежедневные загрузки приложения также выросли с менее чем 200 тысяч в день до 300 тысяч в день за тот же период. Для сравнения, 17 октября 2024 года, приложение Meta✴✴ AI получало около 4 тысяч загрузок в сутки. 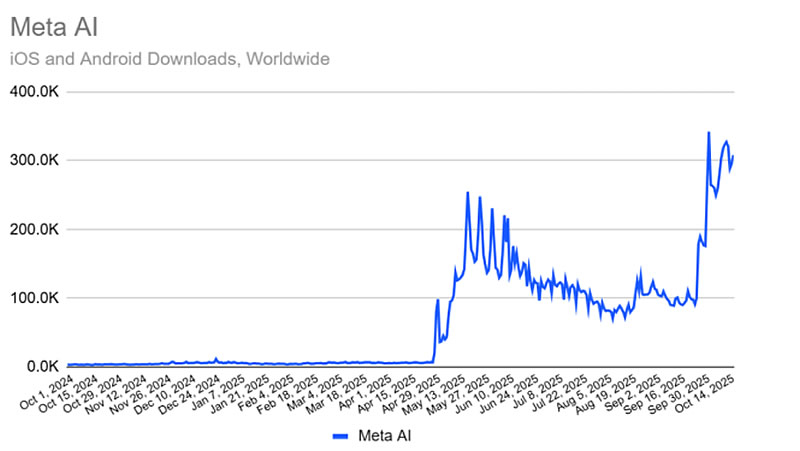 Аналитики Similarweb отмечают, что в их анализе не наблюдается значимой корреляции с изменениями в поисковых запросах или рекламных показателях, однако допускают возможность внутренних продвижений через Facebook✴✴ или Instagram✴✴, которые могли бы остаться незамеченными в их данных. Одновременно рассматривается в качестве вероятной причины роста популярности приложения запуск функции Vibes, которая была представлена 25 сентября 2025 года. Этот срок совпадает с началом резкого увеличения числа ежедневных активных пользователей как на iOS, так и на Android. 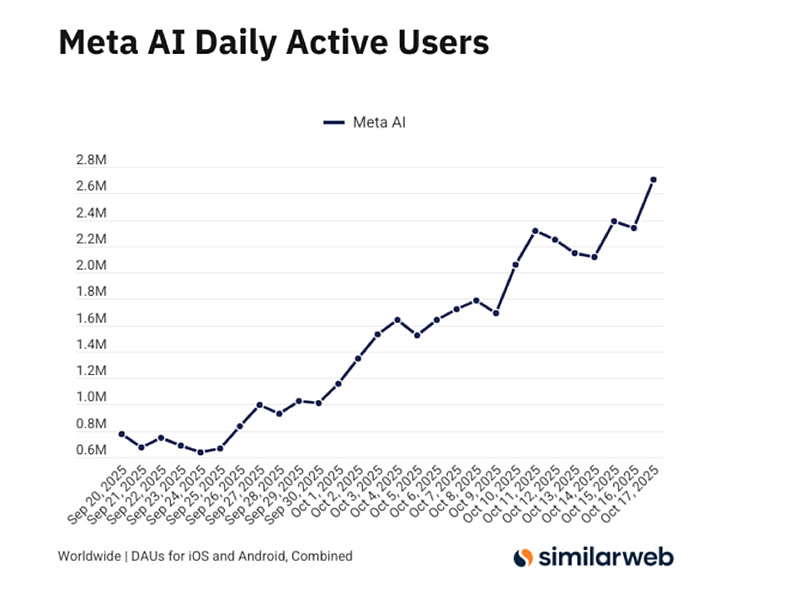 Рост интереса к ИИ-видео может быть также связан с недавним дебютом генератора видео Sora компании OpenAI, который вызвал широкий общественный резонанс и привёл к тому, что одноимённое приложение возглавило рейтинг App Store. Хотя данные Similarweb не подтверждают причинно-следственную связь, аналитики предполагают, что внимание к Sora могло побудить пользователей попробовать Meta✴✴ AI для сравнения возможностей. Кроме того, учитывая, что доступ к Sora остаётся не простым и предоставляется только по приглашениям, часть заинтересованных пользователей могла обратиться к Meta✴✴ AI как к доступной альтернативе. Это, в свою очередь, указывает на то, что политика OpenAI по ограничению доступа к Sora могла косвенно усилить позиции конкурентов. 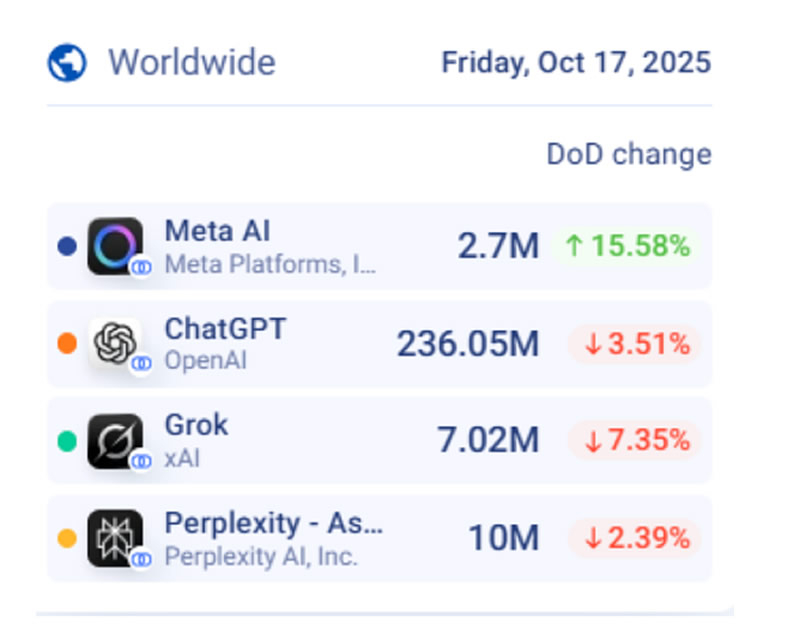 По состоянию на 17 октября приложение Meta✴✴ AI продемонстрировало рост ежедневной активной аудитории на 15,58 % в глобальном масштабе, в то время как приложения ChatGPT, Grok и Perplexity зафиксировали снижение на 3,51 %, 7,35 % и 2,29 % соответственно. Adobe запустила фабрику ИИ-моделей, заточенных под конкретный бизнес
20.10.2025 [18:44],
Николай Хижняк
Компания Adobe запустила новый сервис Adobe AI Foundry по созданию индивидуальных генеративных моделей ИИ для бизнеса. Компания предлагает создавать индивидуальные модели генеративного ИИ, обученные на основе брендинга и интеллектуальной собственности этих компаний. 
Источник изображения: Adobe Модели Adobe AI Foundry, способные генерировать текст, изображения, видео и другие мультимедиа, такие как сцены с трёхмерной графикой, базируются на семействе ИИ-моделей Adobe Firefly. Компания выпустила их в 2023 году и с тех пор обучает исключительно на лицензионных данных. Сервис Adobe Foundry готов настроить эти модели для каждого клиента индивидуально, используя его интеллектуальную собственность. Цены на услуги Foundry зависят от поставленных задач, а не от количества пользователей, как во многих других продуктах Adobe. Ханна Эльсакр (Hannah Elsakr), вице-президент по новым бизнес-проектам в области генеративного ИИ в Adobe, рассказала TechCrunch, что сервис Foundry стал естественным расширением корпоративных продуктов компании в области ИИ, да и сами клиенты компании очень просили больше возможностей для персонализации ИИ-продуктов. «Это значительно расширяет возможности, которыми мы уже располагали. Бизнес обратился к нам за консультациями, помощью, сотрудничеством и предложением стать ведущим партнёром по креативному маркетингу на основе ИИ», — объясняет Эльсакр. С момента выпуска Adobe моделей Firefly в 2023 году компании использовали их для создания более 25 миллиардов ресурсов. Эльсакр отмечает, что индивидуально настроенные модели помогут брендам эффективнее управлять своими рекламными кампаниями. Например, клиент может создать рекламную кампанию для своего продукта один раз, а затем использовать кастомные ИИ-модели Adobe для создания той же рекламы, но для разных сезонов, языков или форматов. «Это очень персонализированный подход. Мы очень долго говорили об этом. И теперь генеративный ИИ и Firefly позволяют представить бренд с учётом его индивидуальности», — добавила она. Несмотря на возможности новых инструментов, Adobe никоим образом не пытается заменить профессионалов в области креатива, а просто предоставляет им улучшенные версии инструментов, которые они уже используют для создания своего контента, заявляет Эльсакр. «Мы считаем, что в основе творчества лежит человечность, и её невозможно заменить. Мы десятилетиями занимаемся разработкой креативных инструментов, которые вдохновляют, помогают рассказывать истории, развивать вашу способность представлять и реализовывать творческие замыслы. Firefly и Foundry — это всего лишь следующий этап развития инструментов, которые расширяют ваши возможности рассказывать истории», — говорит Эльсакр. Пройдёт не менее десяти лет, прежде чем ИИ-агенты действительно начнут работать — Андрей Карпатый
20.10.2025 [13:11],
Алексей Разин
Выступая в одном из подкастов на прошлой неделе, один из основателей OpenAI Андрей Карпатый (Andrej Karpathy) признался, что функциональные ИИ-агенты начнут реально работать примерно через десять лет. Стремительное развитие ИИ само по себе не гарантирует быстрых результатов, и участникам рынка, а также пользователям необходимо запастись терпением. 
Источник изображения: Gerd Altmann / pixabay.com В современном состоянии ИИ-агенты, по словам Карпатого, весьма далеки от совершенства: «Они просто не работают. Они недостаточно умны, недостаточно мультимодальны, они не могут использовать компьютер и делать прочие вещи. Они не могут обучаться непрерывно. Вы не можете просто сказать им что-то, чтобы они это запомнили. Они отстают в когнитивных способностях, и это просто не работает». По мнению сооснователя OpenAI, пройдёт не менее десяти лет, прежде чем все эти недостатки будут устранены. Агенты являются одной из самых обсуждаемых тем в сфере искусственного интеллекта, подчёркивает Business Insider. Многие инвесторы называют текущий год «годом агента». В общем случае, под агентом подразумевается виртуальный помощник, способный самостоятельно выполнять задания: анализировать сложные проблемы, составлять планы и предпринимать действия без дополнительного взаимодействия с пользователем. Карпатый на страницах социальной сети X добавил, что его критика отрасли вызвана стремлением преувеличить возможности имеющихся инструментов относительно реальности. «Отрасль живёт в будущем, в котором полностью автономные сущности параллельно взаимодействуют друг с другом для написания кода, а люди при этом бесполезны», — заявил один из основателей OpenAI. Он, по его собственному признанию, в такой реальности жить не готов, поскольку считает, что люди и ИИ должны содействовать друг другу при написании программного кода и выполнении заданий. Если описать комментарии Карпатого простыми словами, он хотел бы иметь возможность убедиться, что ИИ создаёт корректный программный код, не слишком увлекаясь допущениями и во всех сложных случаях советуется с человеком. Последний должен расти в профессиональном плане и совершенствоваться вместе с ИИ, а не довольствоваться ролью поддержания в работоспособном состоянии «гор кода», отметил Карпатый. Он также заявил, что проблема при создании не требующих вмешательства человека агентов заключается в том, что низкопробный контент, генерируемый ИИ, становится повсеместным, а люди — бесполезными. Прочие представители отрасли также выражают озабоченность стремлением некоторых пользователей слишком сильно полагаться на ИИ. По словам директора по развитию ScaleAI Квинтина Ау (Quintin Au), большие языковые модели сейчас при выполнении одного действия с вероятностью 20 % совершают ошибку. Если агенту требуется выполнить пять действий в рамках одного задания, шансы на корректное выполнение каждого не превышают 32 %. Андрей Карпатый при этом призывает не считать его ИИ-скептиком. По его словам, его внутренние графики в пять или десять раз пессимистичнее самых амбициозных комментариев представителей отрасли, но они всё равно более оптимистичны по сравнению с экспертами, полностью отрицающими ИИ. Учёные раскритиковали OpenAI за ложный анонс математического прорыва
20.10.2025 [05:19],
Анжелла Марина
OpenAI оказалась в центре скандала после того, как поспешно объявила о математическом прорыве новой модели GPT-5, который в реальности не произошёл. Директор по продуктам компании Кевин Вейль (Kevin Weil) в своём посте в социальной сети X написал, что GPT-5 нашла решения для 10 ранее нерешённых задач Эрдёша и добилась прогресса ещё в одиннадцати. 
Источник изображения: Zac Wolff/Unsplash Коллеги Вейля поддержали это утверждение, создав впечатление, что искусственный интеллект (ИИ) разработал доказательства для сложных вопросов теории чисел, что могло бы стать признаком его способности к самостоятельным научным открытиям. Однако, как сообщает The Decoder, математик Томас Блум (Thomas Bloom), владеющий сайтом erdosproblems.com, немедленно опроверг эти заявления, назвав их «драматическим неверным толкованием». Он разъяснил, что пометка «open» на его ресурсе означает лишь то, что ему лично неизвестно решение, а не то, что проблема действительно не решена научным сообществом. По факту, GPT-5 лишь обнаружила уже существующие научные работы, которые Блум упустил из виду, а не сгенерировала новые доказательства. Инцидент вызвал жёсткую критику со стороны ведущих экспертов в области ИИ. Генеральный директор DeepMind Демис Хассабис (Demis Hassabis) охарактеризовал эту ситуацию как «неловкую». Глава подразделения ИИ в Meta✴✴ Ян Лекун (Yann LeCun) иронично заметил, что OpenAI стала жертвой собственной шумихи. Под давлением критики оригинальные сообщения были удалены, а исследователи признали свою ошибку. 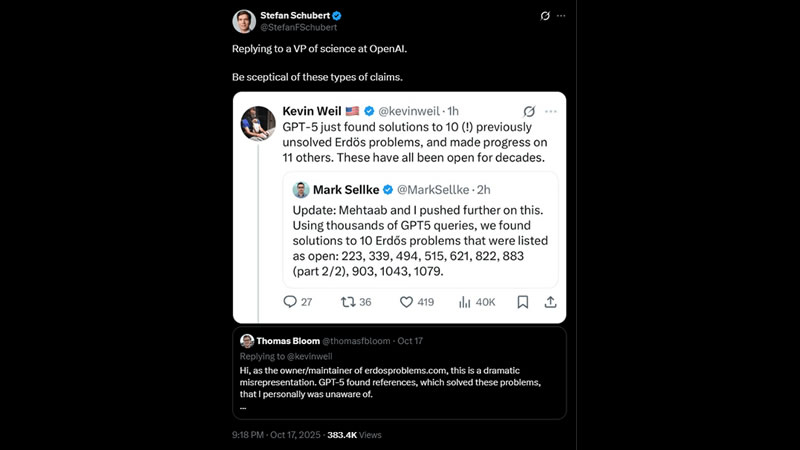
Источник изображения: the-decoder.com При этом реальная история о полезности GPT-5 оказалась в тени. Модель действительно доказала свою эффективность в качестве инструмента для исследований, способного отслеживать релевантные академические публикации. Это особенно ценно для задач, где научная литература разрознена или отсутствует единая терминология. Известный математик Теренс Тао (Terence Tao) видит в этом главный практический потенциал искусственного интеллекта в математике. Он заявил, что ИИ наиболее полезен не для решения сложнейших проблем, а для ускорения рутинных задач, таких как поиск литературы, что может помочь «индустриализировать» математику и ускорить прогресс в этой области. При этом Тао подчёркивает, что человеческий опыт критически важен для анализа, классификации и безопасной интеграции результатов, полученных с помощью ИИ, в реальные исследования. Инженеры Apple сомневаются, что новая Siri успеет к весеннему запуску в iOS 26.4
20.10.2025 [05:16],
Анжелла Марина
Сотрудники Apple выразили обеспокоенность по поводу производительности обновлённой версии голосового помощника Siri в ранних сборках операционной системы iOS 26.4. Несмотря на существенную задержку и дополнительное время на доработку Siri, инженеры компании, тестирующие программное обеспечение, сомневаются в её готовности к запуску, запланированному на весну 2026 года. 
Источник изображений: Apple По информации 9to5Mac со ссылкой на отчёт Power On Марка Гурмана (Mark Gurman) из Bloomberg, в случае неудачного дебюта обновлённой Siri через шесть месяцев возможны новые уходы высокопоставленных специалистов из подразделения искусственного интеллекта Apple. «У сотрудников, тестирующих iOS 26.4, есть опасения относительно производительности голосового помощника в предстоящей версии операционной системы, в которую должна быть интегрирована новая Siri», — пишет Гурман. Напомним, что на конференции WWDC24 компания официально представила платформу Apple Intelligence в виде набора ИИ-функций, работающих локально на устройствах Apple. Хотя часть анонсированных возможностей, таких как инструмент Clean Up в приложении «Фото», генеративные эмодзи (Genmoji) и интеграция ChatGPT в Siri, была реализована в ходе цикла выпуска iOS 18, ключевое обновление самого голосового помощника так и не появилось. Apple изначально обещала три основные функции новой Siri. В частности, понимание контекстного диалога пользователя, анализ содержимого экрана и способность выполнять действия внутри приложений. Однако эти возможности не были включены даже в бета-версии iOS 18.4 или iOS 18.5, что привело к официальной задержке релиза на год из-за несоответствия внутренним стандартам качества. Позже, в интервью после конференции WWDC уже в 2025 году, руководитель подразделения программного обеспечения Apple Крейг Федериги (Craig Federighi) пояснил, что команде потребовалось время для перестройки архитектуры Siri, и выпуск должен состояться в 2026 году. По имеющимся данным, к выпуску готовятся две команды компании, разрабатывающие разные подходы к реализации нового помощника: один основан на локальных моделях непосредственно на устройстве, другой — на использовании модели Google Gemini через облачную интеллектуальную систему для комплексной обработки данных с пользовательских устройств Private Cloud Compute. Исследование показало, что ИИ ускорил мышление подростков, но есть одна проблема
20.10.2025 [05:12],
Анжелла Марина
Искусственный интеллект (ИИ) активно меняет когнитивные процессы подростков, заставляя их мыслить быстрее, но в ущерб глубине анализа. Таковы выводы нового исследования Оксфордского университетского издательства (Oxford University Press), о которых рассказало издание Business Iinsider, в ходе которого в августе были опрошены 2000 учащихся из Великобритании в возрасте от 13 до 18 лет. Около 80 % респондентов признались, что используют ИИ-инструменты для выполнения домашних заданий и это им помогает быстрее решать сложные задачи. 
Источник изображения: AI Как заявила директор Educational Neuroscience Hub Europe и соавтор отчёта Эрика Галеа (Erika Galea), современные студенты начинают мыслить вместе с машинами, приобретая беглость и скорость, но иногда теряя независимое мышление. Она добавила, что главной задачей становится не овладение технологиями, а сохранение глубины человеческой мысли в эпоху синтетического познания и искусственного интеллекта. Это «синтетическое познание», по терминологии оксфордских исследователей, характеризует новое мышление так называемого «поколения, рождённого с ИИ», то есть, подростков, которые взрослели бок о бок с алгоритмами. Исследование выявило двойственное влияние технологий. Более 90 % студентов сообщили, что ИИ помог им развить хотя бы один академический навык. Однако 60 % также констатировали негативное воздействие. В частности, четверть опрошенных считают, что ИИ делает обучение слишком лёгким, а каждый десятый отмечает ограничение творческих навыков и снижение потребности в критическом мышлении. Ко всему прочему, некоторые учащиеся уже демонстрируют зависимость от ИИ и прямо об этом заявляют. Озабоченность разделяют и педагоги: треть студентов указали, что их учителя неуверенно чувствуют себя при использовании ИИ на уроках, а 51 % респондентов хотели бы получить от школ более чёткие руководства по ответственному применению этого инструмента. Авторы отчёта настаивают на том, что образовательные системы должны меняться, чтобы использовать ИИ, но не позволять студентам мыслить как машины. Учитель и соавтор книги «Поколение Альфа в классе» (Generation Alpha in the Classroom) Ольга Сэйер (Olga Sayer) отметила, что ИИ изменил методы обучения, но не его цели. По её словам, конечная цель образования остаётся прежней — мыслить независимо и творчески, а также расти как личность. Оксфордские исследователи призвали учебные заведения внедрять грамотность в сфере ИИ, тренировать метапознание и оказывать поддержку педагогам, чтобы те могли помогать студентам балансировать в новой реальности. Alibaba нашла способ сократить потребность в количестве используемых ускорителей Nvidia на 82 %
20.10.2025 [04:52],
Алексей Разин
Нехватка вычислительных мощностей, присущая динамично развивающемуся рынку искусственного интеллекта, в Китае усугубляется ограничениями на импорт специализированных ускорителей. Разработчики вынуждены заниматься оптимизацией, и Alibaba нашла способ сократить количество необходимых ускорителей Nvidia для работы своих языковых моделей на 82 %. 
Источник изображения: Nvidia Как поясняет South China Morning Post, бета-тестирование профильной системы Aegaeon уже проводится одним их подразделений Alibaba Cloud на протяжении более чем трёх месяцев. По информации, представленной Alibaba на мероприятии SOSP в столице Южной Кореи, данная система позволила сократить количество обслуживающих десятки языковых моделей ускорителей Nvidia H20 с 1192 до 213 штук. При этом соответствующие языковые модели используют до 72 млн параметров, как поясняет источник. Представителям Alibaba в создании такой системы помогали учёные Пекинского университета, которые назвали её «первой попыткой выявить излишние затраты, связанные с одновременным обслуживанием нагрузок с большими языковыми моделями». Провайдеры облачных услуг типа Alibaba сталкиваются с необходимостью одновременного обслуживания тысяч ИИ-моделей, но в сфере инференса наиболее часто используются лишь несколько моделей типа Qwen или DeepSeek, а прочие вызываются довольно редко. Это приводит к нерациональному расходованию ресурсов. В экосистеме Alibaba Cloud, например, до 17,7 % ускорителей выделяются для обработки 1,35 % запросов. Исследователи во всём мире начали предлагать повысить эффективность использования вычислительных ресурсов за счёт объединения в пулы, когда один GPU обслуживает несколько моделей. Система Aegaeon использует автомасштабирование на уровне токенов, позволяющее GPU переключаться между разными моделями прямо в процессе генерирования токенов. Один GPU в результате способен обрабатывать до семи моделей, тогда как в альтернативно устроенных системах их количество в лучшем случае достигает двух или трёх. Задержки, необходимые на переключение между моделями, при этом сократились на 97 % в случае с Aegaeon. Alibaba эту систему испытывает на маркетплейсе моделей Bailian, который предлагает модели Qwen корпоративным пользователям. Ускорители Nvidia H20 одноимённой американской компанией были созданы специально для китайского рынка, в апреле они попали под временный запрет на поставку в КНР, но к лету он был снят. Однако, китайские власти начали настоятельно рекомендовать национальным разработчикам отдавать предпочтение местной компонентной базе. В результате позиции Nvidia на китайском рынке передовых чипов для ИИ, по словам руководителя компании, буквально сократились до нуля. Huawei показала ускоритель Atlas 300I Duo на базе пары ИИ-чипов Ascend 310
19.10.2025 [07:46],
Алексей Разин
Двухпроцессорные видеокарты в одно время пытались найти применение в верхнем ценовом сегменте игрового рынка, но получались они достаточно спорными с точки зрения эффективности и однозначно дорогими. В сегменте ускорителей вычислений Huawei подобные компоновочные решения готова применять, исходя из тех условий, в которых ей приходится существовать. 
Источник изображений: Gamers Nexus, ComputerBase Напомним, с 2019 года власти США обрушили на китайскую Huawei Technologies беспрецедентно жёсткие санкции. В результате она лишилась доступа к услугам TSMC по выпуску чипов, современным микросхемам памяти и западному программному обеспечению. В условиях ограниченности ресурсов Huawei пытается повышать производительность своих ускорителей вычислений разными способами, и в случае с Huawei Atlas 300I Duo решила нарастить быстродействие за счёт размещения на одной плате двух процессоров серии Ascend 310.  В руки представителей ресурса Gamers Nexus такой ускоритель попал в отдельности от совместимой серверной системы, поэтому испытать его в деле они не смогли, но уже разобрали его перед камерой, продемонстрировав результаты усилий инженеров Huawei. Довольно «низкий» ускоритель подразумевает охлаждение набегающим от корпусных вентиляторов потоком воздуха, поэтому изначально оснащается только радиаторами, но охлаждающие пластины предусмотрены и с оборотной стороны печатной платы. Для подключения дополнительного питания используется специфический 8-контактный разъём, который не совместим со стандартным.  Ускоритель Huawei Atlas 300I Duo оснащается 96 Гбайт памяти необычного для подобных решений типа LPDDR4X, пропускная способность памяти достигает 408 Гбайт/с. Для подключения к материнской плате используется интерфейс PCI Express x16 версии 4.0, быстродействие в режиме INT8 достигает 280 трлн операций в секунду (TOPS). Уровень TDP не превышает 150 Вт, а стоимость ускорителя ограничена 1370 евро. Возможно, он слабее Nvidia RTX Pro 6000 (Blackwell) с сопоставимым объёмом памяти типа GDDR7, но при этом и в шесть раз дешевле. Отставание же в быстродействии едва превышает три раза, поэтому в китайской вычислительной инфраструктуре решения Huawei вполне найдут себе достойное применение. Twitch анонсировал двухформатные эфиры, функции с ИИ и новые средства монетизации
18.10.2025 [17:54],
Павел Котов
На мероприятии TwitchCon 2025 популярная стриминговая платформа представила целый ряд нововведений: трансляции в вертикальном и горизонтальном форматах одновременно, поддержку умных очков Meta✴✴, функции искусственного интеллекта и инструменты для монетизации. 
Источник изображения: ilgmyzin / unsplash.com Двухформатная трансляция позволит стримерам Twitch вести эфиры в вертикальном и горизонтальном форматах сразу, то есть зрителям не придётся выбирать между просмотром на ноутбуке и смартфоне — разницы больше не будет. Администрация платформы объявила о партнёрстве с Meta✴✴, которая выпускает очки с поддержкой искусственного интеллекта — стримеры смогут выходить в прямой эфир прямо с них. Но этого нововведения придётся подождать, потому что Twitch ещё продолжает работать над соответствующим обновлением мобильного приложения. Алгоритм ИИ теперь сможет автоматически создавать клипы из фрагментов завершившейся трансляции, чтобы зрители увидели интересные моменты, которые могли пропустить. Около полугода назад стримеры среднего эшелона получили на Twitch возможность проводить собственные мероприятия, благодаря чему их средняя выручка выросла на 35–40 %. В ближайшие месяцы все стримеры с подключённой монетизацией получат новые функции панели управления: спонсоры смогут напрямую предлагать им участвовать в кампаниях, а стримеры — принимать такие предложения. Наконец, появились два новых типа учётных записей: ведущий модератор, а также представитель стримера — агент или менеджер; обновились нормы применения правил модерации и расширилась программа Creator Clubs. MSI представила мини-ПК Cubi Z AI 8M с ИИ-ускорителем
18.10.2025 [14:33],
Павел Котов
MSI представила Cubi Z AI 8M — ультракомпактный мини-ПК в корпусе объёмом всего 0,9 л, который располагает встроенным ускорителем для запуска алгоритмов искусственного интеллекта прямо на устройстве. 
Источник изображения: msi.com MSI Cubi Z AI 8M работает на процессоре серии AMD Ryzen 8000 (Ryzen 5 8645HS, Ryzen 7 8845HS или Ryzen 9 8945HS) со встроенным ИИ-ускорителем (NPU), который позволяет выполнять задачи ИИ прямо на устройстве — его ресурсов, в частности, достаточно для работы ИИ-помощника Microsoft Copilot. В наличии два слота для оперативной памяти DDR5 5600 SO-DIMM, которой может быть до 64 Гбайт, и один — для накопителя M.2 2280 (PCIe 4.0 x4). Компьютер располагает широким набором портов: на лицевой стороне размещены четыре разъёма USB Type-A с поддержкой скорости до 10 Гбит/с, ещё один такой же находится на задней стороне вместе с одним USB 2.0 и двумя USB Type-C класса USB4 с поддержкой скорости передачи данных до 40 Гбит/с и подачи питания до 100 Вт; и двумя HDMI — всего к компьютеру можно подключить до четырёх дисплеев. Есть также два 2,5-гигабитных сетевых порта; в наличии дискретный модуль TPM (dTPM) для функций аппаратного шифрования и кенсингтонский замок для защиты оборудования. На борту присутствует встроенный динамик, а конструкция с креплением VESA позволяет повесить ПК за монитором или на стене. При изготовлении MSI Cubi Z AI 8M активно используются переработанные материалы — производитель заявил о стремлении сократить отходы и уменьшить воздействие на окружающую среду. Это соответствует установленным компанией целям в области ответственного производства и экологичного жизненного цикла продукции. ИИ-бот Google Gemini успешно конкурирует в области редактирования фото с инструментами Adobe
18.10.2025 [08:19],
Владимир Фетисов
В августе Google представила ИИ-модель Gemini 2.5 Flash Image, которая позволяет с высокой точностью контролировать процесс редактирования фотографий. Этот инструмент стал доступен всем пользователям приложения Gemini бесплатно, а разработчики могут задействовать соответствующий API для интеграции сервиса в свои продукты за относительно невысокую плату. За прошедшие с тех пор несколько месяцев алгоритм превратился в конкурента ИИ-инструментам для работы с медиаконтентом компании Adobe. 
Источник изображения: Google Об этом пишет Business Insider со ссылкой на данные аналитической компании Appfigures, которая подсчитала, что по мере стремительного роста числа загрузок приложения Gemini после интеграции в него новых функций для редактирования изображений, количество скачиваний приложения Firefly, в котором реализованы ИИ-инструменты Adobe для генерации изображений и видео, постепенно снижается. Невозможно точно сказать, связаны ли эти два события между собой. По данным Appfigures, после запуска в июне приложение Firefly показало «впечатляющий» рост, а в августе количество его загрузок выросло на 150 % по сравнению с июлем. За тот же период количество скачивания Gemini выросло лишь на 20 %. Эта статистика включает в себя данные о загрузках приложений из магазинов Google Play Маркет и Apple App Store. После обновления приложения Gemini 26 августа, когда в нём появились новые возможности в плане ИИ-редактирования фото, количество загрузок Firefly упало более чем вдвое в течение следующей недели. В это же время количество скачиваний Gemini стремительно росло. По данным Appfigures, по состоянию на 6 октября количество загрузок Gemini выросло на 331 % по сравнению с последней неделей июля, тогда как количество скачиваний Firefly снизилось на 68 %, что стало самым низким показателям с момента обновления Gemini в августе. Для лучшего понимания масштабов следует учитывать, что на прошлой неделе Gemini скачивали на 6,1 млн раз больше, чем на неделе, когда в приложение была интегрирована новая ИИ-модель для точного редактирования фото. За этот же период количество скачиваний Firefly снизилось на 2 млн. Данные Appfigures по разным регионам указывают на то, что в США количество скачиваний Gemini в октябре подскочило на 88 % по сравнению с сентябрём. За этот же период популярность Firefly в стране упала на 82 %. Это указывает на то, что Gemini превращается в серьёзного конкурента в сфере обработки изображений. Родители смогут ограничивать общение своих детей с ИИ-персонажами в Instagram✴
17.10.2025 [18:08],
Павел Котов
Meta✴✴ разрабатывает новые средства родительского контроля, которые помогут ограничить несовершеннолетних в общении с воплощающими виртуальные персонажи чат-ботами на базе искусственного интеллекта, которые работают в соцсетях компании. Основной помощник Meta✴✴ AI будет доступен, как и прежде. 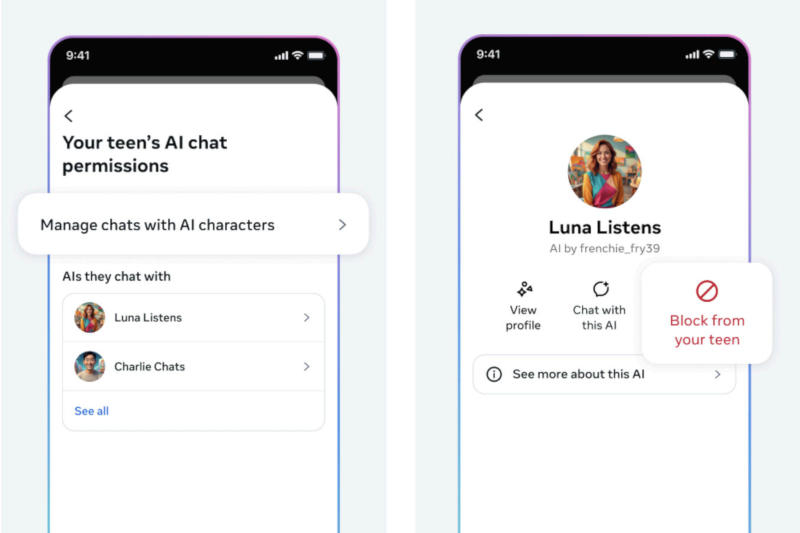
Источник изображения: Meta✴✴ Если родители не хотят блокировать своим детям все чат-боты с ИИ, они смогут отключить только отдельных персонажей; у них также появится возможность получать информацию о темах, которые их дети обсуждают с чат-ботами Meta✴✴. Компания пока только разрабатывает эти функции контроля и в следующем году начнёт их внедрять в англоязычном сегменте Instagram✴✴ в США, Великобритании, Канаде и Австралии. На эту меру Meta✴✴ решила после того, как подверглась критике за чрезмерную свободу, которую предоставляла чат-ботам с ИИ — вплоть до возможности вести переписку деликатного характера с несовершеннолетними. Инцидент имел резонанс на политическом уровне, а Meta✴✴ была вынуждена начать переобучение своего ИИ и добавить новые средства защиты, чтобы не позволить несовершеннолетним пользователям участвовать в неподобающих разговорах. В соцсетях она ввела возрастные ограничения, разрешив чат-ботам с ИИ давать только ответы, соответствующие рейтингам фильмов PG-13 и оставив подросткам выбор только среди персонажей, ориентированных на соответствующие их возрасту темы. ИИ повысил результативность фишинга в 4,5 раза, подсчитали в Microsoft
17.10.2025 [17:42],
Павел Котов
Написанные при помощи искусственного интеллекта фишинговые письма в прошлом году спровоцировали 54 % получателей перейти по вредоносным ссылкам или скачать вредоносные файлы — без ИИ показатель «конверсии» киберпреступных кампаний составлял 12 %. 
Источник изображения: Simon Ray / unsplash.com ИИ помогает адаптировать содержание фишинговых писем под особенности потенциальных жертв и предлагать им более правдоподобные приманки; он увеличивает шансы мошенников провоцировать граждан на клики и обещает увеличить прибыльность фишинговых атак на величину до 50 раз. «Эта огромная окупаемость вложений выступит стимулом для киберпреступников, которые ещё не пользуются ИИ, добавить его в свой арсенал в будущем», — говорится в ежегодном докладе (PDF) Microsoft, посвящённом вопросам цифровой защиты. Документ охватывает 2025 финансовый год Microsoft — с июля 2024 по июнь 2025 календарного года. Инструменты ИИ помогли киберпреступникам повысить эффективность и результативность своих атак — они помогают составлять фишинговые письма, упрощают и ускоряют поиск различных уязвимостей, прорабатывают схему их масштабной эксплуатации, помогают в проведении разведки, в выборе объектов атак — организаций и частных лиц — с использованием методов социальной инженерии, а также оказывают помощь в разработке вредоносного ПО. Злоумышленники теперь могут подделывать голос и создавать дипфейки в видеороликах. Всё чаще ИИ используют и структуры, связанные с властями стран. В июле 2023 года эксперты Microsoft не зафиксировали ни одной единицы контента, созданного поддерживаемыми властями стран организациями; в июле 2024 года их стало 50; в январе 2025 года — 125, а в июле — уже 225. 
Источник изображения: BoliviaInteligente / unsplash.com Серьёзной угрозой остаются атаки на ресурсы органов государственной власти — только в США за отчётный период обнаружены 623 таких инцидента; мотивом для 52 % всех атак была финансовая выгода, шпионские интересы преследовались лишь в 4 % случаев. В тех случаях, когда экспертам Microsoft удалось установить цели злоумышленников, 37 % инцидентов были направлены на кражу данных, 33 % реализовывались с целью вымогательства, 19 % были направлены на нанесение ущерба и 7 % — на подготовку инфраструктуры к будущим атакам. Сообщается о новом методе фишинговых атак, который набрал популярность в отчётный период — он получил название ClickFix. Это метод социальной инженерии, при котором пользователя обманом заставляют выполнить вредоносную команду на своём компьютере под видом безобидных или необходимых операций. С помощью ClickFix осуществляется кража информации, устанавливаются трояны удалённого доступа, бэкдоры и многое другое в подконтрольных жертвам средах. ClickFix использовался как первая ступень атаки в 47 % инцидентов. На классические виды фишинга пришлись 35 % атак. Злоумышленники становятся изощрённее — они реализуют «многоэтапные цепочки атак, сочетающие технические эксплойты, социальную инженерию, злоупотребление особенностями инфраструктуры и обход защиты через легитимные средства». В качестве одного из примеров приводится комбинированная атака с использованием «бомбардировки» через электронную почту, голосового фишинга и имитации обращений через Microsoft Teams — в результате злоумышленник убедительно выдаёт себя за специалиста техподдержки и получает удалённый доступ. При бомбардировке по электронной почте ящик жертвы регистрируется в тысячах новостных рассылок и онлайн-служб, в результате чего он заполняется тысячами писем, среди которых теряются критические оповещения, такие как оповещения о сбросе пароля или многофакторной авторизации, а также сообщения о мошенничестве. Wikipedia пожаловалась, что из-за ИИ её стали меньше читать живые люди — и у этого будут последствия
17.10.2025 [14:50],
Алексей Разин
Управляющая работой онлайн-энциклопедии Wikipedia некоммерческая организация Wikipedia Foundation вынуждена сообщить, что распространение технологий искусственного интеллекта с интеграцией результатов запросов в поисковую выдачу заметно снизило количество просмотров этого ресурса живыми людьми. 
Источник изображения: Oberon Copeland @veryinformed.com / unsplash.com В этой сфере, как можно выразиться словами песни, тоже «вкалывают роботы», собирающие всю нужную пользователю информацию для формирования выжимки в поисковике или интерфейсе чат-бота без необходимости обращения к странице первоисточника. По словам представителей Wikipedia, данная тенденция в долгосрочной перспективе ставит под угрозу функционирование самой всемирной онлайн-энциклопедии: «Если количество посетителей Wikipedia сократится, меньше желающих будет находиться для обогащения и расширения контента, меньше индивидуальных доноров смогут поддерживать эту работу». Примечательно, что для создателей больших языковых моделей само по себе существование Wikipedia крайне важно, ведь на материалах этого ресурса происходит значительная часть обучения систем ИИ. Поисковые системы и социальные сети, по словам представителей платформы, отдают приоритет информации с ресурса, поскольку она пользуется определённым доверием у пользователей. В мае текущего года Wikipedia столкнулась с ростом трафика, якобы генерируемого живыми пользователями из Бразилии, но инцидент лишь заставил руководство ресурса усовершенствовать систему борьбы с ботами. С тех пор количество просмотров живыми пользователями начало снижаться, в годовом сравнении оно достигло 8 %. В Wikipedia Foundation связывают такую тенденцию с изменением доминирующего способа получения информации пользователями — чат-боты и встроенный в поисковые системы ИИ лишили их необходимости обращаться к первоисточникам. Внутренняя политика Wikipedia при этом накладывает ограничения на интенсивность обращения к ней сторонними роботами. Распространение механизмов защиты от ботов показало, что живые люди к страницам ресурса стали обращаться реже. Боты при этом более искусно выдают себя за людей. Прочие источники тоже отмечают, что внедрение ИИ в сферу поиска информации в интернете сократило потребность обращения к первоисточникам. Анализ работы поисковой системы Google летом этого года выявил, что только 1 % запросов приводил к переходу пользователей по ссылке на первоисточник, во всех остальных случаях люди просто довольствовались сгенерированной ИИ выборкой данных. Кроме того, молодая аудитория привыкла получать всю информацию в пределах социальных сетей, не особо утруждая себя навигацией по всему интернету. Wikipedia также обеспокоена тем, что ИИ начинает использоваться для создания энциклопедических статей, снижая достоверность информации. Активность роботов, занимающихся сбором информации, при этом создаёт повышенную нагрузку на техническую инфраструктуру Wikipedia. Создатели ресурса пытаются усилить интеграцию с популярными социальными сетями и подстраиваться под новые реалии, а не пытаться вернуться к прежнему порядку за счёт запретов и блокировок. Старший директор Wikipedia Foundation по продуктам Маршалл Миллер (Marshall Miller) обратился к пользователям со следующими словами: «Когда вы ищете информацию в онлайне, обращайте внимание на цитаты и переходите по ссылкам на источники материалов. Говорите со своими знакомыми о важности создания доверенной и контролируемой людьми базы знаний, и помогайте им понять, что лежащий в основе ИИ контент был создан реальными людьми, которые заслуживают вашей поддержки». Учёные Apple представили три проекта для ИИ-программирования: обучение, поиск багов и тестирование
17.10.2025 [14:01],
Павел Котов
Apple опубликовала три статьи, посвящённые исследованиям в области искусственного интеллекта. Учёные компании предложили новые подходы для поиска ошибок в коде, для тестирования созданных ИИ программных решений и для обучения моделей и агентов, способных создавать работающий код. 
Источник изображения: Milad Fakurian / unsplash.com Первое исследование посвящено модели, которую в Apple назвали ADE-QVAET. Она призвана решить проблемы, свойственные традиционным современным моделям ИИ, такие как галлюцинации, выпадение модели из контекста при анализе кодовой базы большого объёма, а также утеря связи с фактической бизнес-логикой применительно к текущему программному решению. ADE-QVAET призвана повысить точность прогнозирования ошибок посредством объединения четырёх методов ИИ: адаптивная дифференциальная эволюция (Adaptive Differential Evolution — ADE), квантовый вариационный автокодировщик (Quantum Variational Autoencoder — QVAE), архитектура трансформера, а также адаптивное шумоподавление и дополнение (Adaptive Noise Reduction and Augmentation — ANRA). ADE выступает как альтернативный механизм обучения модели, QVAE способствует более глубокому обнаружению закономерностей в данных, трансформер помогает отслеживать связи этих закономерностей, а ANRA обеспечивает очистку и баланс данных, чтобы результаты работы ИИ были согласованными. При этом в отличие от большой языковой эта модель не проводит прямого анализа кода — она оценивает его сложность, размер и структуру и ищет закономерности, которые могут указывать на места, где вероятно возникновение ошибок. Обучив модель на 90 % данных исходного массива, исследователи установили, что точность прогнозов ADE-QVAET составляет от 95 % до 98 %. Это значит, что модель демонстрирует высокую надёжность и высокую эффективность в выявлении действительных ошибок и почти не даёт ложных срабатываний. Второе исследование, которое провели преимущественно авторы первого, призвано сформировать средства для планирования и создания инструментов тестирования крупных программных проектов. Учёные построили систему Agentic RAG (Retrieval-Augmented Generation) из большой языковой модели и ИИ-агентов, которая самостоятельно планирует, пишет и организовывает тестирование ПО, облегчая работу инженерам по качеству — эти задачи занимают у них от 30 % до 40 % рабочего времени, указывают авторы исследования. 
Источник изображения: Igor Omilaev / unsplash.com Подключение нескольких агентов к ИИ-модели с RAG помогло повысить точность тестирования ПО с 65 %, которые демонстрировала прежняя модель с RAG, работавшая без агентов, до 94,8 % у модели с ИИ-агентами. На 85 % сократилось время тестирования ПО, на те же 85 % повысилась точность средств тестирования, а прогнозируемая экономия средств составила 35 %. Новая система позволила сократить сроки ввода программных решений в эксплуатацию на два месяца. Единственное ограничение предложенной Apple системы Agentic RAG состоит в том, что испытывали её на сложных корпоративных кадровых и бухгалтерских системах, а также средствах SAP. Третий проект получил название SWE-Gym — его задача не прогнозировать ошибки и не тестировать ПО — это механизм обучения ИИ-агентов. Обучаясь на чтении, редактировании и проверке реально существующего программного кода, эти агенты обретают способность исправлять в нём ошибки. Платформу SWE-Gym построили на основе 2438 реальных задач на языке Python из 11 открытых репозиториев — в каждом из них были исполняемая среда и набор тестов, благодаря которым ИИ-агенты имели возможность практиковаться в написании и отладке кода в реалистичных условиях. Авторы исследования также создали платформу SWE-Gym Lite на базе 230 более простых задач, которая помогает ускорить обучение и снизить затраты на вычислительные ресурсы. Обученные с помощью средств SWE-Gym агенты правильно решили 72,5 % предложенных задач, то есть платформа помогла повысить качество их работы на 20 процентных пунктов по сравнению с предыдущими методами. В случае с SWE-Gym Lite время обучения сокращается вдвое, если сравнивать с полномасштабной платформой, но обученные на облегчённом варианте агенты предназначаются для работы с более простыми задачами. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



