|
Опрос
|
реклама
Быстрый переход
«Максимально правдивый ИИ»: xAI Илона Маска выпустила флагманскую ИИ-модель Grok 3
18.02.2025 [11:42],
Дмитрий Федоров
Компания xAI, основанная Илоном Маском (Elon Musk), представила флагманскую ИИ-модель Grok 3, а также обновления для iOS-приложения Grok и веб-версии. Разработка Grok 3 велась несколько месяцев, а её запуск, первоначально запланированный на 2024 год, был отложен. Для обучения Grok 3 были использованы вычислительные мощности, в 10 раз превышающие ресурсы его предшественника, что позволило существенно повысить точность и глубину анализа данных новой ИИ-моделью. 
Источник изображений: xAI Grok 3 представляет собой третье поколение семейства ИИ-моделей xAI, созданного в противовес таким разработкам, как GPT-4o компании OpenAI и Gemini корпорации Google. Новая ИИ-модель — серьёзный технологический шаг вперёд: усовершенствованные алгоритмы, увеличенные объёмы обучающих данных, возможность анализа изображений и даже интеграция ряда функций в социальной сети X. «Grok 3 на порядок мощнее Grok 2. Это максимально правдивый ИИ, даже если эта правда иногда расходится с политически корректной», — заявил Маск во время презентации. Для обучения Grok 3 xAI использовала один из крупнейших в мире дата-центров, расположенный в Мемфисе. В нём задействованы около 200 000 графических процессоров (GPU), что позволило обрабатывать более сложные массивы данных и выполнять вычисления с беспрецедентной скоростью. По словам Маска, ресурсы, использованные при обучении Grok 3, оказались в 10 раз больше, чем потребовалось для Grok 2. Кроме того, в обучающую выборку вошли не только общедоступные данные, но и материалы судебных дел, что потенциально расширяет возможности новой ИИ-модели в области анализа юридических документов. 
Дата-центр xAI, где обучался Grok 3, оснащён 200 000 GPU, причём расширение с 100 000 до 200 000 GPU заняло 92 дня
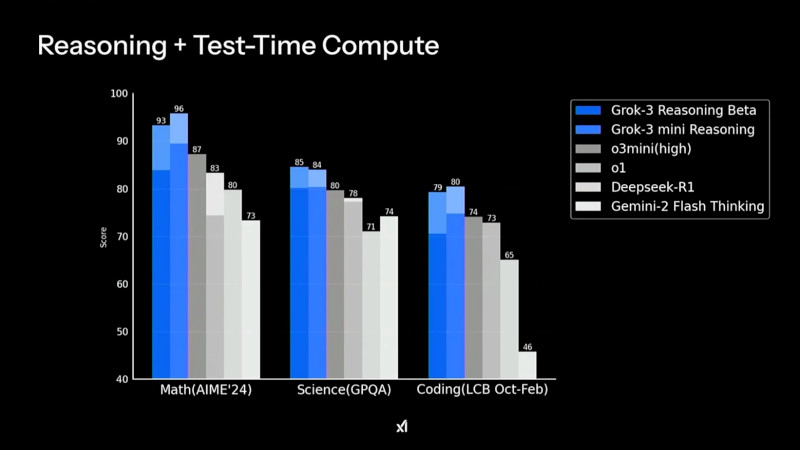
Grok 3 демонстрирует высокие результаты в тестах на математические, научные и задачи программирования, значительно опережая конкурентов в AIME'24, GPQA и LCB Компания xAI утверждает, что Grok 3 показывает превосходные результаты в тестах, в частности, опережая GPT-4o. В бенчмарке AIME, оценивающем математические способности, и GPQA, измеряющем уровень знаний в области физики, биологии и химии на уровне доктора наук, новинка демонстрирует выдающиеся показатели. Более того, ранняя версия Grok 3 заняла высокие позиции в Chatbot Arena (LMSYS) — платформе, где пользователи сравнивают ответы различных ИИ-моделей и голосуют за наиболее качественные. 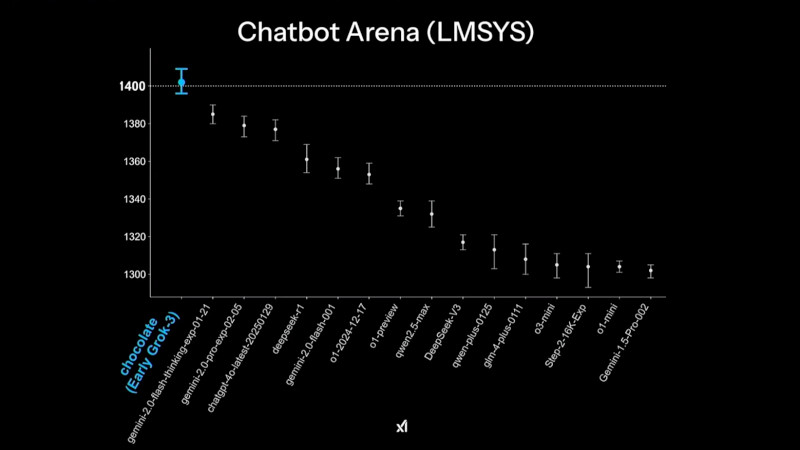
В рейтинге Chatbot Arena ранняя версия Grok 3 под кодовым названием Chocolate показала наивысший результат среди множества больших языковых ИИ-моделей Одним из ключевых нововведений стало появление Grok-3 Reasoning и Grok-3 mini Reasoning — специализированных ИИ-моделей, способных глубоко анализировать проблемы, подобно «рассуждающим» моделям, таким как o3-mini компании OpenAI и R1 китайской компании DeepSeek. Эти нейросети не просто дают ответы, но и тщательно проверяют факты перед их формулировкой, что позволяет значительно снизить вероятность ошибок. По данным xAI, Grok-3 Reasoning превзошёл o3-mini-high в ряде популярных бенчмарков, включая AIME 2025 Performance. 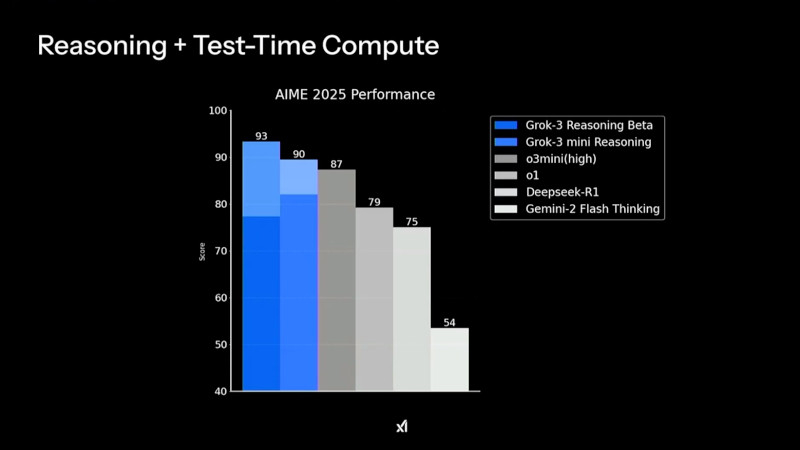
Производительность Grok 3 в тестах AIME 2025 показывает, что версия Grok-3 Reasoning Beta превосходит конкурентов, включая o3-mini-high и Deepseek-R1 Пользователи могут работать с Grok 3 через приложение Grok, в котором доступны два режима работы: Think — для стандартных запросов, и Big Brain — для сложных вычислений и логических задач. Режим Big Brain использует расширенные вычислительные мощности, что позволяет добиться более высокой точности ответов. Он оптимален для научных исследований, математического моделирования и программирования. По словам Маска, в приложении Grok некоторые «мысли» ИИ скрываются в процессе рассуждения, чтобы предотвратить дистилляцию — метод, используемый разработчиками конкурирующих ИИ-моделей для извлечения знаний из других нейросетей. 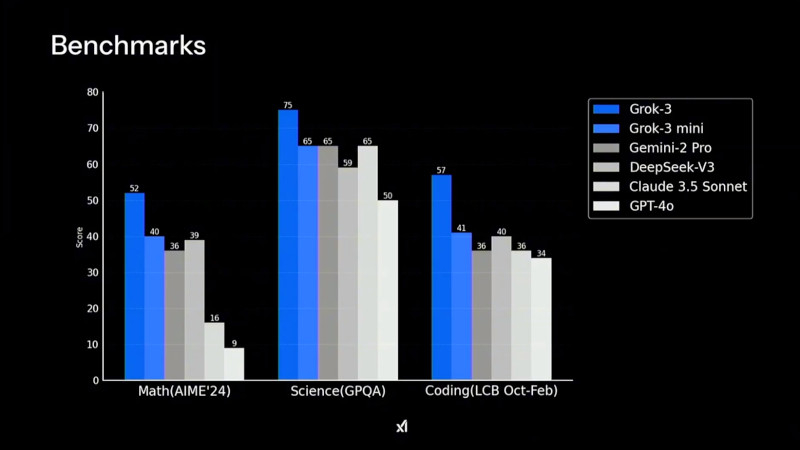
Grok 3 и его мини-версия превзошли конкурентов в тестах на математику, естественные науки и программирование, обогнав GPT-4o, Gemini-2 Pro и DeepSeek-V3 Ещё одной важной новацией стало появление DeepSearch — инструмента, построенного на базе «думающих» ИИ-моделей. Он выполняет интеллектуальный поиск по открытым источникам в интернете и данным социальной сети X, анализируя массивы информации и формируя сжатые аналитические сводки. Эта функциональность делает DeepSearch аналогом OpenAI Deep Research, но с более интегрированным подходом к обработке данных. На данный момент доступ к Grok 3 предоставляется подписчикам X Premium+, стоимость подписки составляет $22 в месяц. Дополнительно компания xAI запустила новый тариф SuperGrok, который стоит $30 в месяц или $300 в год. В него входят расширенные возможности reasoning-запросов, более глубокий анализ через DeepSearch и неограниченная генерация изображений. 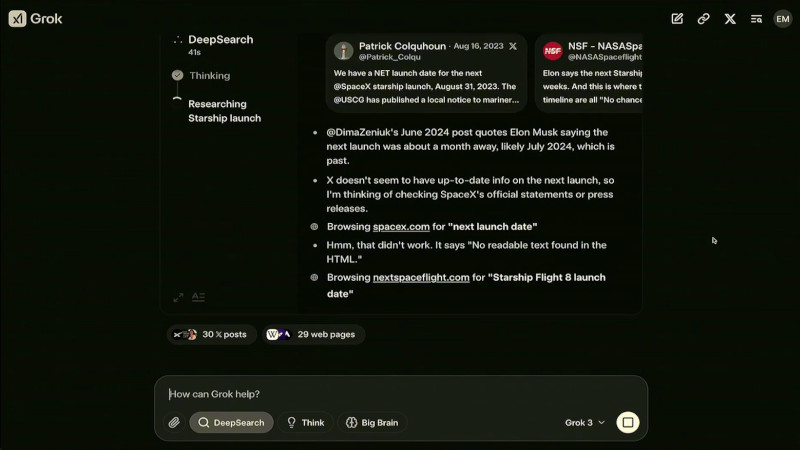
Работа DeepSearch в интерфейсе Grok 3, где система выполняет анализ и поиск актуальной информации о предстоящем запуске Starship от SpaceX В течение ближайшей недели приложение Grok получит обновление, которое добавит голосовой режим, позволяющий Grok общаться с пользователями синтезированным голосом. В дальнейшем, через несколько недель, Grok 3 станет доступен через корпоративный API xAI, что позволит компаниям интегрировать DeepSearch в свои бизнес-процессы. По словам Маска, его компания планирует открыть исходный код Grok 2: «Наш подход заключается в том, что мы выкладываем последнюю версию [Grok] в открытый доступ, когда следующая версия полностью готова. Когда Grok 3 станет зрелой и стабильной, что, вероятно, произойдёт в течение нескольких месяцев, тогда мы откроем исходный код Grok 2». Это означает, что после окончательной стабилизации работы Grok 3 разработчики смогут изучать исходный код его предшественника.  Первоначально Grok позиционировался как передовой и альтернативный ИИ, способный свободно обсуждать темы, которых избегают другие нейросети. Проведённые исследования показали, что до выхода Grok 3 ИИ-модель демонстрировала политический уклон, особенно в вопросах разнообразия и неравенства. Маск объяснил это тем, что обучающие данные включали общедоступные веб-страницы, отражающие определённые идеологические позиции. Маск пообещал, что Grok 3 будет более политически нейтральным, однако пока неясно, удалось ли xAI достичь этой цели. OpenAI внедрит защиту от враждебного поглощения на фоне деятельности Илона Маска
18.02.2025 [11:33],
Алексей Разин
Желание привлекать больше средств от инвесторов вынуждает стартап OpenAI менять свою структуру, поскольку сейчас во главе неё стоит некоммерческая организация. Инвесторам она кажется потенциальным источником неопределённости, поэтому OpenAI пытается приблизить свою структуру к классической. При этом совет директоров хочет защитить стартап от возможных враждебных поглощений. 
Источник изображения: Unsplash, Solen Feyissa Как отмечает Reuters со ссылкой на публикацию в Financial Times, в новой организационной структуре, более ориентированной на коммерческую деятельность и ответственность перед инвесторами, за советом директоров OpenAI предполагается закрепить право вето, которым его члены могут воспользоваться в случае угрозы недружественного поглощения. По всей видимости, подобные меры потребовались OpenAI в свете недавних попыток Илона Маска (Elon Musk) договориться о покупке OpenAI за $97,4 млрд. Совет директоров стартапа данное предложение отверг, но если компания будет переведена на коммерческие рельсы, подобных механизмов защиты в стандартной структуре правления предусмотрено не будет. Предполагается, что особые полномочия совета директоров при голосовании по стратегически важным вопросам позволят OpenAI оградить себя от давления мажоритарных акционеров типа Microsoft или SoftBank. Как сообщается, механизм защиты разрабатывается советом директоров во взаимодействии с генеральным директором Сэмом Альтманом (Sam Altman), который является одним из двух основателей OpenAI, приближённым к руководству компанией в настоящий момент. Илон Маск ещё несколько лет назад покинул компанию, и с тех пор упрекает её нынешнее руководство в отклонении от изначальной миссии. Попытку купить OpenAI за $97,4 млрд Маск обосновал необходимостью «спасения» стартапа, но отрицать коммерческий интерес миллиардера к теме искусственного интеллекта сложно. В 2023 году он основал собственный стартап xAI, который сейчас также активно развивается и привлекает средства инвесторов. «Блокнотом» в Windows 11 по-прежнему можно пользоваться без аккаунта Microsoft — если не запускать ИИ
18.02.2025 [11:25],
Владимир Фетисов
Последние несколько дней пользователи соцсети X обсуждают скриншот принудительной регистрации с учётной записью Microsoft, которую просит операционная система Windows 11. Автор публикации рассказал, что сообщение с требованием авторизации в аккаунте Microsoft появляется при запуске «Блокнота», но, похоже, что это не совсем так. 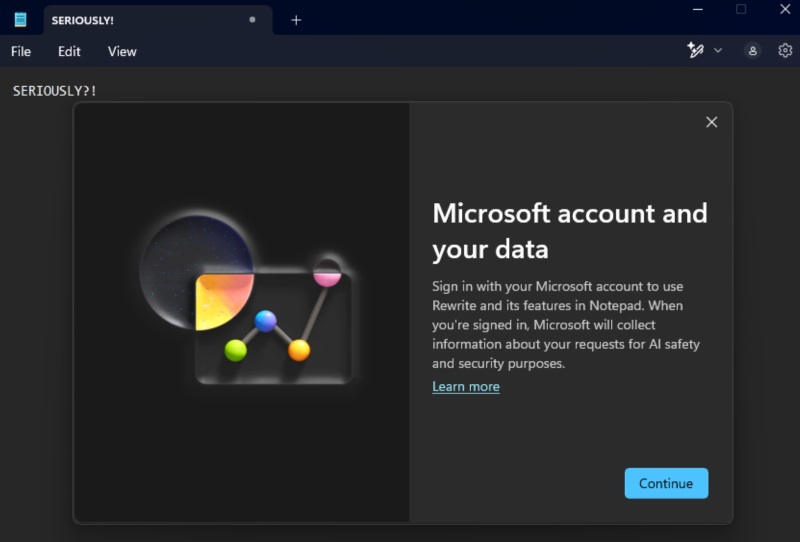
Источник изображения: @TheBobPony / X Хотя этот скриншот действительно реален, любой пользователь Windows 11 может взаимодействовать с обновлённым «Блокнотом» без необходимости авторизации с учётной записью Microsoft. В данном случае суть проблемы пользователя можно увидеть в описании всплывающего окна. Там сказано, что авторизация с учётной записью Microsoft требуется для использования ИИ-функции Rewrite. Очевидно, это сообщение появляется только на компьютерах Copilot Plus PC в момент, когда пользователь нажимает в «Блокноте» кнопку Rewrite. Не всем пользователям Windows нравится то, что Microsoft добавляет в свою операционную систему всё больше функций на основе нейросетей. Однако в данном случае споры выглядят чрезмерно раздутыми, поскольку пользователи Windows 11 всё ещё могут свободно взаимодействовать с «Блокнотом», не используя ИИ-функции. При этом далеко не всем может понравиться то, что Microsoft добавляет ИИ-инструменты в лёгкий и простой текстовый редактор, который сам по себе не подразумевает наличия функций на базе нейросетей. Интеграция ИИ DeepSeek в мессенджер WeChat спровоцировала рост акций Tencent и падение стоимости Baidu
17.02.2025 [18:47],
Сергей Сурабекянц
Китайский технологический гигант Tencent интегрировал ИИ-модель DeepSeek в свой мессенджер WeChat, тем самым пополнив ряды других китайских государственных органов и поставщиков услуг, также интегрировавших этот ИИ. Данный шаг помог инвесторам повысить уверенность в перспективах Tencent, особенно после нескольких успешных игровых релизов, в результате чего акции компании выросли более чем на 70 % за последний год. 
Источник изображения: unsplash.com Акции конкурента Tencent — компании Baidu, которая также встроила DeepSeek в свою поисковую систему, наоборот, упали на 8,8 % во второй половине дня отчасти из-за фиксации прибыли перед завтрашним отчётом о доходах. Рост акций Tencent вызван ажиотажем инвесторов вокруг китайских технологических компаний, вызванным сегодняшней встречей президента Китая Си Цзиньпина (Xi Jinping) с основателем гиганта интернет-коммерции Alibaba Джеком Ма (Jack Ma). Эта демонстрация поддержки частного сектора со стороны официального Китая наложилась на всплеск акций в Гонконге, вызванный растущими возможностями в области ИИ. 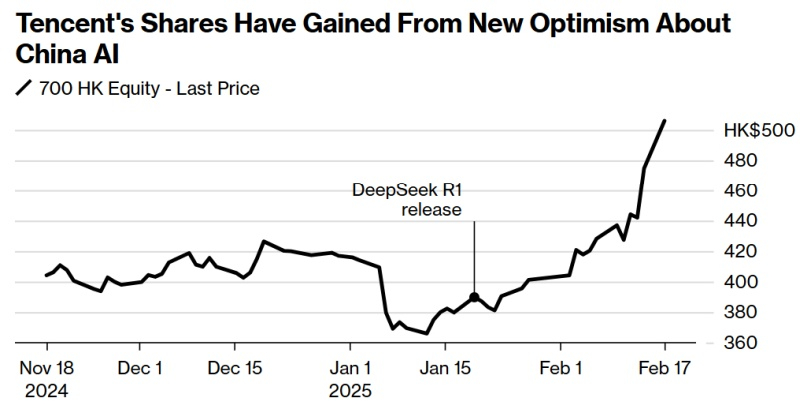
Источник изображения: Bloomberg «Широкое внедрение ИИ может увеличить EPS (прибыль на акцию — прим. ред.) Китая на 2,5 % в год в течение следующего десятилетия, — полагают аналитики Goldman Sachs. — Как бы многообещающе ИИ ни был для траектории роста Китая, мы считаем, что для решения глубоко укоренившихся макроэкономических проблем и обеспечения устойчивого прироста капитала по-прежнему необходимы мощные политические стимулы». Выпуск рассуждающей модели DeepSeek R1 20 января оказал шокирующее действие на мировые фондовые рынки, снизив стоимость самых передовых ИИ-компаний США на более чем триллион долларов. Одновременно это привело к росту акций китайских компании в размере 1,3 триллиона долларов, поскольку инвесторы поспешили «поменять лошадей на переправе». SSD подорожают во второй половине года из-за сокращения производства NAND и ажиотажа вокруг ИИ
17.02.2025 [17:38],
Сергей Сурабекянц
В настоящий момент рынок флеш-памяти (NAND) страдает от избыточного предложения, что приводит к снижению цен и финансовым затруднениям поставщиков. Тем не менее аналитическая компания TrendForce ожидает значительного улучшения баланса спроса и предложения во второй половине года. Ключевыми факторами, по мнению TrendForce, являются сокращение производства микросхем NAND, снижение складских запасов в секторе смартфонов и растущий спрос, вызванный развитием ИИ. 
Источник изображения: unsplash.com Производители флеш-памяти за последние два года осознали серьёзное влияние избыточного предложения на отрасль, особенно с учётом того, что годовые темпы роста спроса на флеш-память были пересмотрены с 30 % до 10–15 %. В результате они были вынуждены скорректировать свои производственные стратегии, чтобы смягчить столь длительное снижение цен. На рубеже 2025 года производители NAND приняли более решительные меры по сокращению производства, которые призваны оперативно снизить рыночный дисбаланс и заложить основу для восстановления цен. Кроме того, продолжающаяся политика субсидирования замены смартфонов в Китае эффективно стимулирует их продажи и ускоряет истощение запасов памяти NAND. 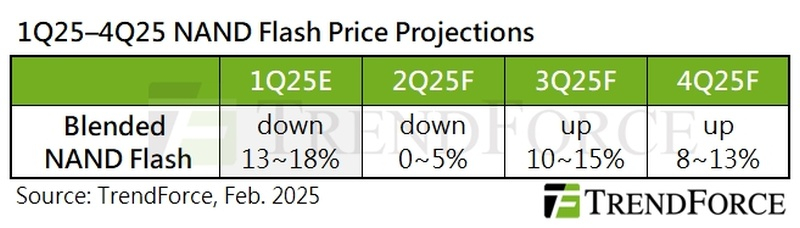
Источник изображения: TrendForce Nvidia намерена нарастить поставки своей продукции серии Blackwell во второй половине года, что значительно увеличит спрос на корпоративные SSD. Кроме того, достижения DeepSeek в снижении затрат на развёртывание серверов ИИ позволят предприятиям малого и среднего бизнеса активнее интегрировать ИИ, повышая свою конкурентоспособность. Ожидается, что SSD-накопители ёмкостью более 30 Тбайт станут предпочтительным решением для хранения данных благодаря их высокой производительности и низкой совокупной стоимости владения. Дополнительно появление ПК и рабочих станций с поддержкой ИИ будет способствовать более широкой интеграции искусственного интеллекта в повседневные приложения, что потенциально приведёт к долгосрочному росту ёмкости клиентских SSD для ПК. Снижение требований к вычислительной мощности, вероятно, ускорит проникновение на рынок бюджетных смартфонов с поддержкой ИИ, что дополнительно оживит спрос на флеш-память. Южная Корея закупит 10 000 ИИ-ускорителей, чтобы не отставать от остального мира
17.02.2025 [12:31],
Алексей Разин
Одним из главных событий в начале второго президентского срока Дональда Трампа (Donald Trump) стал анонс проекта Stargate, который подразумевает рекордные финансовые вливания в создание на территории США мощнейшей вычислительной инфраструктуры для ИИ. Южная Корея старается не отставать от заокеанского партнёра, а потому готова закупить 10 000 ускорителей вычислений в этом году. 
Источник изображения: Nvidia Об этом сообщает агентство Reuters со ссылкой на заявления южнокорейского президента Чхве Сан Мока (Choi Sang-mok): «Поскольку конкуренция за доминирование в отрасли ИИ усиливается, конкурентный ландшафт смещается от противостояний между компаниями к полномасштабному соперничеству между национальными экосистемами инноваций». По словам президента Южной Кореи, власти страны намереваются закупить к сентябрю этого года 10 000 GPU для использования в составе национального вычислительного центра, который будет работать над решением проблем в сфере искусственного интеллекта. Закупка ускорителей будет осуществляться в рамках частно-государственного партнёрства, но кто будет поставщиком этих GPU, не уточняется. Скорее всего, речь идёт о продукции Nvidia, ведь именно она контролирует не менее 80 % рынка данных изделий. Тем более, что Южной Корее посчастливилось оказаться в числе тех 18 стран, которые могут получать из США передовые ускорители вычислений для собственных нужд практически без ограничений. Подробные условия этой закупки будут определены к сентябрю текущего года. Высокий спрос на подобные ускорители заставляет рынок стремительно меняться. На прошлой неделе, например, стало известно о намерениях OpenAI завершить разработку собственного ИИ-чипа через несколько месяцев. Выпускать его по 3-нм технологии со следующего года может начать тайваньская компания TSMC. По меньшей мере, в рамках того же американского проекта Stargate такие ускорители OpenAI точно пригодятся. Google Chrome усилил защиту пользователей от мошенников и вирусов с помощью ИИ
17.02.2025 [12:09],
Дмитрий Федоров
Команда разработчиков Google Chrome интегрировала в браузер ИИ-функцию Enhanced Protection, предназначенную для обеспечения защиты пользователей в режиме реального времени от опасных сайтов, загрузок и расширений. Эта функция, являющаяся частью системы Safe Browsing, после трёхмесячного тестирования в канале Canary стала доступна на всех платформах. Однако при её активном использовании данные о посещаемых сайтах передаются Google. 
Источник изображения: Rubaitul Azad / Unsplash Ранее эта функция называлась Proactive Protection, однако её обновлённое название подчёркивает интеграцию ИИ в систему безопасности браузера. В настоящее время неясно, в чём именно заключается отличие новой функции, интегрированной с ИИ, от её предыдущей версии без ИИ. Тем не менее существует вероятность, что Google использует алгоритмы машинного обучения для анализа моделей поведения в режиме реального времени, что позволяет своевременно предупреждать о потенциально опасных сайтах, даже если они ранее не были зафиксированы. 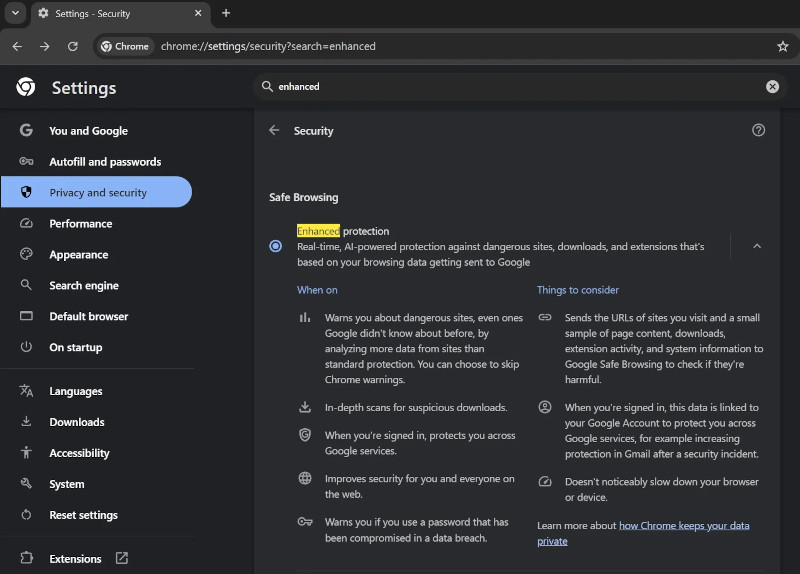
Усиленная защита с ИИ в стабильной версии Chrome. Источник изображения: BleepingComputer Согласно заявлению компании Google, система защиты, оснащённая современными ИИ-алгоритмами, проводит углублённое сканирование загружаемых файлов, что позволяет оперативно обнаруживать подозрительные загрузки, а также повышает точность и эффективность системы безопасности браузера. Усиленная защита с ИИ по умолчанию отключена, но пользователи могут включить её, перейдя в раздел «Settings → Privacy and security → Security» в Google Chrome на Windows, Android и iOS. В Южной Корее приложение DeepSeek запретили скачивать всем
17.02.2025 [06:43],
Алексей Разин
Ещё в начале месяца стало известно, что правительственным учреждениям Южной Кореи власти начали блокировать доступ к китайскому ИИ-приложению DeepSeek. Теперь запрет на скачивание этого приложения распространился на всех пользователей на территории Южной Кореи, поскольку методы работы DeepSeek с персональными данными не соответствуют требованиям местных законов. 
Источник изображения: Unsplash, Solen Feyissa Об этом сообщает Reuters со ссылкой на Комиссию по защите персональных данных Южной Кореи (PIPC). Расследование комиссию выявило, что DeepSeek не соблюдает ряд требований южнокорейских властей к обработке и хранению персональных данных, а также их защите. Как только китайская компания приведёт свои методы работы в соответствие с требованиями южнокорейского законодательства, запрет на скачивание приложения DeepSeek будет снят. Даже сейчас непосредственно доступ к инфраструктуре DeepSeek для большинства пользователей в Южной Корее не ограничен, нельзя лишь заново скачивать приложение. На прошлой неделе в Южной Корее начали работать законные представители DeepSeek, у них-то местные регуляторы и выяснили, что китайская компания пренебрегает рядом требований южнокорейского законодательства в части защиты персональных данных. Как известно, Италия заблокировала работу DeepSeek на своей территории ещё в прошлом месяце. При этом представители МИД КНР утверждают, что власти страны не принуждают частные компании или физических лиц собирать или хранить информацию в обход законов других стран, и никогда не стали бы этого делать. Власти Китая с большим уважением относятся к приватности данных и защищают их с помощью местных законов. ИИ научился распознавать эмоции животных по выражению морды
17.02.2025 [04:29],
Дмитрий Федоров
Учёные разработали ИИ-системы, способные выявлять боль, стресс и заболевания у животных посредством анализа фотографий их морды. Британский ИИ Intellipig распознаёт дискомфорт у свиней, а ИИ-алгоритмы Израильского университета в Хайфе (UH) обучены определять стресс у собак. В эксперименте, проведённом в Университете Сан-Паулу (USP), ИИ продемонстрировал точность до 88 % при выявлении болевых реакций у лошадей. Эти технологии могут преобразить ветеринарную диагностику и значительно повысить уровень благополучия животных. 
Источник изображения: Virginia Marinova / Unsplash Система Intellipig, разработанная английскими учёными из Университета Западной Англии в Бристоле (UWE Bristol) совместно с шотландскими исследователями из Шотландского сельскохозяйственного колледжа (SRUC), предназначена для мониторинга состояния свиней на фермах. ИИ анализирует фотографии морды животных, выявляя три ключевых маркера: боль, недомогание и эмоциональное расстройство. Фермеры получают автоматические уведомления, что позволяет оперативно реагировать на ухудшение состояния животных и повышать эффективность сельскохозяйственного производства. Параллельно исследовательская группа из UH адаптирует технологии машинного обучения для работы с собаками. Ранее учёные разработали ИИ-алгоритмы, используемые в системах распознавания лиц, для поиска потерявшихся питомцев. Теперь эти алгоритмы применяются для анализа мимики животных с целью выявления признаков дискомфорта. Выяснилось, что 38 % мимических движений у собак совпадает с человеческими, что открывает новые возможности для изучения их эмоционального состояния. Традиционно подобные ИИ-системы полагаются на человека, который выполняет предварительную работу по определению значений различных форм поведения животных, основываясь на длительных наблюдениях за ними в различных ситуациях. Однако недавно в USP был проведён эксперимент, в котором ИИ самостоятельно анализировал фотографии лошадей, сделанные до и после хирургического вмешательства, а также до и после приёма обезболивающих препаратов. ИИ изучал глаза, уши и рот лошадей, определяя наличие болевого синдрома. Согласно результатам исследования, ИИ сумел выявить признаки, указывающие на боль, с точностью 88 %, что подтверждает эффективность такого подхода и открывает перспективы для дальнейших исследований. Китайский фондовый рынок привлёк $1,3 трлн на волне успеха ИИ-стартапа DeepSeek
17.02.2025 [00:58],
Владимир Фетисов
В прошлом месяце китайская компания DeepSeek выпустила мощную нейросеть, которая быстрыми темпами набрала популярность по всему миру. Успех ИИ-стартапа способствовал наплыву на фондовый рынок Поднебесной инвесторов, которые активно вкладывают средства, в основном в акции представителей технологического сектора. Об этом пишет Bloomberg со ссылкой на данные осведомлённых экспертов. 
Источник изображения: Igor Omilaev/unsplash.com В сообщении сказано, что за счёт перераспределения средств инвесторов китайский рынок за последний месяц привлёк суммарно более $1,3 трлн. В это же время рынок Индии сократился более чем на $720 млрд. При этом индекс MSCI China уже третий месяц подряд опережает свой индийский аналог, что является самым продолжительным периодом лидерства за последние два года. «DeepSeek показала, что в Китае действительно есть компании, которые формируют жизненно важную часть всей экосистемы искусственного интеллекта», — считает аналитик Eastspring Investment Кен Вонг (Ken Wong). Он также добавил, что в последние месяцы его компания увеличивала объём вложений в китайские интернет-холдинги, одновременно сокращая инвестиции в акции индийских компаний, которые «выросли намного выше своих оценочных коэффициентов». Ротация капитала инвесторов знаменует собой отход от наблюдавшегося в последние несколько лет «поворота» к Индии. Эта тенденция была обусловлена ростом расходов на инфраструктуру в Индии и потенциалом страны в качестве производственного центра, альтернативного Китаю. Похоже, что Китай возвращает себе инвестиционную привлекательность благодаря фундаментальной переоценке своих инвестиционных возможностей, особенно в технологической сфере. Управляющий фондом Candriam Вивек Дхаван (Vivek Dhawan) считает, что связанные с DeepSeek события, скорее всего, помогут поднять экономику Китая, а также рынки страны, обеспечив длительный импульс. «Если сложить все части вместе, то в нынешних условиях с точки зрения соотношения риска и прибыли Китай становится более привлекательным, чем Индия», — считает Дхаван. Илон Маск объявил дату и время запуска «самого умного ИИ на Земле»
16.02.2025 [14:51],
Дмитрий Федоров
ИИ-компания xAI, принадлежащая Илону Маску (Elon Musk), представит и выпустит ИИ-чат-бот Grok 3 уже 18 февраля в 7:00 по московскому времени. Презентация передового ИИ-бота будет транслироваться в прямом эфире, что позволит сразу оценить функциональность чат-бота. Эксперты ожидают высокого интереса к новинке, а Маск уже поспешил назвать свой ИИ самым умным на Земле. 
Источник изображений: @elonmusk / X Стартап xAI был основан в 2023 году, а уже летом 2024 года на конференции Tesla Маск отметил потенциал собственной ИИ-технологии для беспилотного вождения. При этом Маск указал на возможность создания нового центра обработки данных и интеграции ИИ-чат-бота с программным обеспечением Tesla, что должно обеспечить синергию между ИИ и беспилотными электромобилями.  14 февраля издание Bloomberg, со ссылкой на источники, сообщило о намерении xAI привлечь инвестиции в размере $10 млрд, что потенциально может увеличить рыночную стоимость компании до $75 млрд. На этой неделе Маск подтвердил, что Grok 3 находится на завершающей стадии разработки и будет выпущен через одну-две недели. Perplexity запустила почти бесплатную альтернативу Deep Research от OpenAI и Google
15.02.2025 [11:07],
Анжелла Марина
Perplexity представила инструмент Deep Research, который позволяет создавать детализированные аналитические отчёты за считаные минуты. В отличие от конкурентов, сервис предлагает доступ к передовым возможностям искусственного интеллекта (ИИ) по значительно более низкой цене, что, по мнению экспертов, может перевернуть рынок ИИ-услуг. 
Источник изображения: Copilot Запуск Deep Research выявил «болезненную» правду о ценообразовании в сфере ИИ. В то время как Anthropic и OpenAI взимают тысячи долларов в месяц за свои услуги, Perplexity предлагает пять бесплатных запросов в день для всех пользователей, а для подписчиков Pro доступ расширен до 500 запросов в сутки за $20 в месяц. И как пишет VentureBeat, это может вынудить крупных игроков объяснить, почему их услуги стоят в 100 раз дороже. Одновременно корпоративные расходы на ИИ продолжают расти. Так, в 2025 году ожидается увеличение затрат на 5,7 %, несмотря на общий рост IT-бюджетов менее чем на 2 %. Некоторые компании планируют нарастить траты на ИИ более чем на 10 %, что в среднем составляет $3,4 млн платежей в этой сфере. Однако с появлением Deep Research такие вложения выглядят сомнительными, поскольку Perplexity предлагает схожие возможности по цене обычной пользовательской подписки. Да и с точки зрения технологий, Deep Research показывает высокие результаты, ставя под вопрос реальную ценность дорогих ИИ-решений. Модель Perplexity продемонстрировала 93,9 % точности в тесте SimpleQA и 20,5 % в Humanity’s Last Exam, обойдя Google Gemini Thinking и другие ведущие модели. При этом в компании отмечают, что инструмент выполняет большинство задач менее чем за три минуты, анализируя сотни источников и имитируя работу профессионального исследователя. Очевидно, что запуск Perplexity Deep Research меняет не только ценовую политику, но и доступность ИИ. Ранее передовые технологии были доступны лишь крупным корпорациям, а небольшие компании и независимые специалисты не могли позволить себе подписку за тысячи долларов. Теперь же с новым инструментом Deep Research можно выполнять сложные задачи, начиная от финансового анализа и маркетинговых исследований и заканчивая технической или медицинской документацией, и всё это за приемлимые деньги. Perplexity также планирует расширить доступность Deep Research, выпустив приложения для iOS, Android и Mac, так как это, по мнению компании, поможет ускорить распространение технологии среди пользователей, которые раньше считали продвинутый ИИ недоступным. Совет директоров OpenAI единогласно отверг предложение Маска о покупке стартапа за $97,4 млрд
15.02.2025 [05:43],
Алексей Разин
Ситуация с попыткой Илона Маска (Elon Musk) при поддержке консорциума инвесторов купить стартап OpenAI за $97,4 млрд к концу недели продолжила обрастать новыми подробностями. Председатель совета директоров OpenAI Брет Тейлор (Bret Taylor) признался в пятницу, что этот орган правления всё же получил предложение Маска и единогласно проголосовал против. 
Источник изображения: Unsplash, Faizi appshunter.io Ранее на этой неделе возникла путаница с порядком подачи подобных заявок, которая позволила представителям OpenAI до пятницы утверждать, что совет директоров стартапа официальных предложений от представителей Маска не получал. После того, как коммуникации были упорядочены, председатель совета директоров OpenAI написал на страницах социальной сети X: «OpenAI не продаётся, совет директоров единогласно отверг недавнюю попытку господина Маска подорвать конкуренцию». Тейлор также добавил, что любая предстоящая реорганизация OpenAI будет усиливать некоммерческую составляющую стартапа и её миссию достижения всеобщего блага для человечества при помощи сильного искусственного интеллекта (AGI). Напомним, что первоначальную реакцию на предложение Маска опубликовал ранее генеральный директор OpenAI Сэм Альтман (Sam Altman). Он отклонил предложение бывшего соратника, иронично отметив, что OpenAI вместо этого может купить за $9,74 млрд принадлежащую Маску социальную сеть X, ранее известную как Twitter. Успехи OpenAI, у истоков которого он стоял, но покинул к 2018 году, не дают покоя Маску как минимум с 2023 года. Он основал конкурирующую компанию xAI, а в 2024 году последовательно подал два иска к руководству OpenAI, которые в той или иной форме обвиняют его в отступлении от некоммерческой сути организации. Первый свой иск он отозвал после того, как представители OpenAI обнародовали переписку с Маском, в которой он соглашался с идеей о том, что стартапу потребуется серьёзное финансирование, и он должен как-то зарабатывать. На этой неделе Маск заявил, что воздержится от покупки OpenAI, если так откажется от намеченного плана реструктуризации с целью перехода на коммерческие рельсы. После формального отказа совета директоров OpenAI юрист Маска Марк Тоберофф (Marc Toberoff) упрекнул правление стартапа в нелогичности поведения. По его словам, совет директоров хочет продать OpenAI «сам себе» по цене в несколько раз меньшей той, что предлагает Маск. Каким образом это должно пойти на пользу «всему человечеству», адвокат Маска понимать отказывается. Google обновила Gemini: ИИ-помощник начал запоминать прошлые разговоры
14.02.2025 [05:13],
Дмитрий Федоров
Google представила новую функцию для своего ИИ-помощника Gemini, которая позволяет запоминать предыдущие беседы и использовать этот контекст в ответах. Обновление доступно подписчикам Google One AI Premium и даёт им возможность продолжать диалог c ИИ без необходимости напоминания деталей. Новая функция уже работает в веб-версии и мобильном приложении Gemini на английском языке, а поддержка других языков и интеграция с Google Workspace ожидаются в ближайшие недели. 
Источник изображения: Google Помимо запоминания контекста, новая функция позволяет пользователям запрашивать краткие итоги предыдущих бесед, что упрощает работу с информацией и делает Gemini более удобным инструментом для долгосрочных задач, требующих последовательного анализа данных. Например, пользователи могут отслеживать изменения в своих запросах или быстро восстанавливать в памяти обсуждённые ранее идеи. Ранее Google внедрила механизм запоминания пользовательских предпочтений, однако теперь ИИ-помощник способен учитывать не только разрозненные параметры, но и целостную структуру диалогов, что позволяет строить работу на основе накопленного контекста. Пользователи могут управлять историей взаимодействий с Gemini в любое время. Для этого достаточно открыть профиль в приложении, перейти в раздел «Gemini Apps Activity» и выбрать нужные параметры: просмотр, удаление или полную очистку сохранённых данных. Такой подход позволяет гибко контролировать, какие аспекты общения с ИИ остаются в памяти чат-бота, а какие подлежат удалению. Это не только повышает уровень персонализации, но и даёт возможность регулировать степень конфиденциальности данных. Функция запоминания уже доступна подписчикам Google One AI Premium, однако пока только на английском языке. В ближайшие недели Google планирует расширить её поддержку, добавив новые языки, а также интегрировать этот механизм в корпоративные тарифные планы Google Workspace Business и Enterprise. Хотя точные сроки запуска функции на других языках не называются, очевидно, что компания стремится сделать своего ИИ-помощника более универсальным и полезным для широкой аудитории. Подобные технологии уже применяются в других ИИ-чат-ботах, включая ChatGPT, который также способен запоминать детали прошлых разговоров и учитывать предпочтения пользователей. Однако подход Google сосредоточен на глубокой интеграции с экосистемой её сервисов, таких как Google Workspace. Это может дать дополнительные преимущества корпоративным клиентам, которым важны непрерывность рабочих процессов и возможность использования ИИ в структурированных деловых задачах. Конкуренция на рынке ИИ-ассистентов усиливается, и благодаря этому обновлению Gemini становится ещё более гибким инструментом для работы с накопленной информацией. Новая статья: ИИтоги января 2025 г.: смотрите, кто пришёл!
14.02.2025 [00:03],
3DNews Team
Данные берутся из публикации ИИтоги января 2025 г.: смотрите, кто пришёл! |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


