|
Опрос
|
реклама
Быстрый переход
Lenovo отчиталась о росте выручки на 20 % благодаря ИИ-буму и росту продаж ПК
20.02.2025 [10:04],
Алексей Разин
В календаре Lenovo 31 декабря завершился третий квартал текущего фискального года, он характеризовался для крупнейшего производителя ПК в мире ростом выручки на 20 % до $18,8 млрд. Ожидания аналитиков были примерно на $1 млрд скромнее, но это не уберегло акции Lenovo от снижения на 4 % на торгах в Гонконге после публикации отчётности. 
Источник изображения: Lenovo Уже не первый квартал подряд фондовый рынок пытается сделать ставку на технологии искусственного интеллекта, внедряемые в клиентские ПК разработчиками профильного ПО и центральных процессоров. Совместимые с подобными решениями компьютеры при этом остаются достаточно дорогими, а клиенты не совсем понимают, какую пользу способны принести дорогостоящие нововведения в не совсем благоприятных макроэкономических условиях. Заметим, что подобный пессимизм отдельных сторонних экспертов не мешает руководству Lenovo рассчитывать на рост объёмов реализации ПК по итогам текущего года более чем на 10 %. Компания уже внедрила ИИ-решения DeepSeek в свои компьютеры и планшеты, запустив интеграцию через фирменного ассистента XiaoTen. Чистая прибыль Lenovo по итогам прошлого квартала почти удвоилась до $692,7 млн, но подобной динамике способствовал разовый налоговый вычет в размере $282 млн, поэтому рост не был в полной мере обусловлен рыночными факторами. После прихода к власти в США Дональда Трампа (Donald Trump) с его агрессивной установкой на повышение таможенных тарифов предсказать дальнейшую динамику развития мирового рынка ПК не так просто. Однако, в прошлом квартале, если опираться на данные IDC, компания Lenovo в годовом сравнении увеличила объёмы поставок ПК с 16,1 до 16,9 млн штук. При этом у конкурирующей HP Inc. они сократились с 14 до 13,7 млн штук, а Dell топталась на месте с 9,9 млн ПК. Китайская Lenovo по итогам четвёртого календарного квартала контролировала 24,5 % мирового рынка готовых компьютеров. При этом общемировые объёмы поставок ПК в минувшем квартале выросли всего на 1,8 %. Инфраструктурное направление бизнеса Lenovo, которое включает и серверы, нарастило свою выручку по итогам квартала на 59 % в годовом сравнении. Сервисное направление, которое охватывает решения для корпоративных клиентов и облачное ПО, смогло нарастить выручку на 12 %. Всё это говорит о том, что спрос на ИИ-решения на корпоративном рынке растёт устойчивыми темпами. Microsoft представила ИИ-модель Muse, которая умеет генерировать геймплей, но игры за разработчиков делать не будет
20.02.2025 [10:02],
Михаил Романов
Компания Microsoft сообщила, что силами исследовательского подразделения Microsoft Research и разработчиков из студии Ninja Theory (Senua's Saga: Hellblade II) совершила прорыв в области искусственного интеллекта для игр. 
Источник изображения: Ninja Theory Microsoft представила первую в своём роде ИИ-модель Muse, которая может создавать окружение на основе визуального ряда или действий игрока: она распознаёт 3D-мир, физику игры и то, как пользователи с ней взаимодействуют. Muse обучали на семилетнем объёме реального геймплея геройского шутера Bleeding Edge от Ninja Theory. Microsoft показала несколько отрывков игрового процесса (см. видео ниже) для демонстрации возможностей технологии. В настоящий момент Muse может генерировать «комплексные геймплейные секции» при низком (300х180) разрешении и 10 FPS на основе 10 кадров (1 секунды) реального игрового процесса и данных пользовательского ввода на протяжении всей сессии. В Microsoft настаивают, что Muse не предназначена для генерации игр целиком и замены разработчиков, а призвана помочь создателям интерактивных развлечений открыть новые возможности и раскрыть творческий потенциал. Среди областей применения Muse в Microsoft выделяют улучшение классических игр и портирование их на актуальные устройства, прототипирование и тестирование идей, добавление в существующие проекты нового опыта на основе ИИ. Компания планирует делиться ИИ-инструментами и экспериментами с игроками Xbox и разработчиками на более ранних этапах исследования. Microsoft также пообещала не заставлять внутренние студии использовать ИИ в производстве. Короткие интерактивные ИИ-игры скоро станут доступны на площадке Copilot Labs Маск пообещал ИИ-игры с фотореалистичной графикой и объявил о запуске студии xAI Gaming
20.02.2025 [09:47],
Анжелла Марина
Илон Маск (Elon Musk) анонсировал создание игровой студии xAI Gaming Studio, которая будет разрабатывать проекты с использованием искусственного интеллекта (ИИ). Заявление прозвучало во время прямой трансляции, посвящённой запуску модели Grok-3. В качестве демонстрации возможностей ИИ-модели разработчики показали, как она способна сгенерировать аналог Tetris на языке программирования Python. 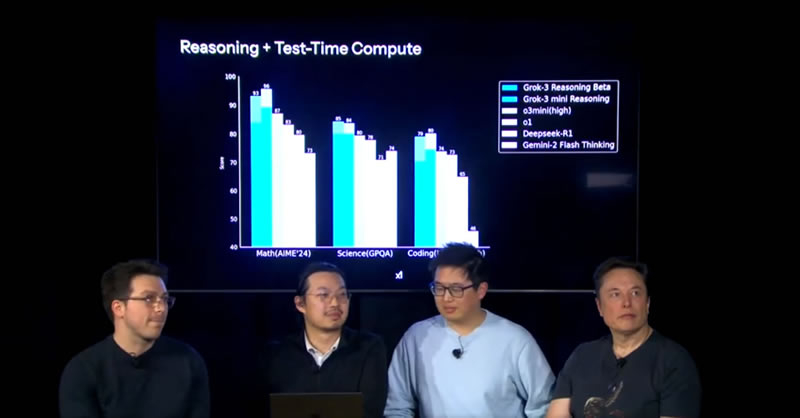
Источник изображения (скриншот видео): Dima Zeniuk / x.com «Мы запускаем игровую AI-студию в xAI. Если вы заинтересованы в сотрудничестве с нами в создании ИИ-игр, пожалуйста, присоединяйтесь к xAI», — заявил Маск. Никаких дополнительных подробностей о характере самой студии, её концепции, направлении, в котором xAI планирует развиваться, и о том, что она будет разрабатывать, пока не сообщается, отмечает Tom's Hardware. Модель уже показала способность генерировать простые 2D-игры. Один из пользователей опубликовал тестовый пример, где Grok 3 создала базовую версию Bubble Trouble с физикой, коллизиями и простым интерфейсом. Однако оказалось, что модель пока не может корректно воспроизводить ретрозвуковые эффекты, описанные в пользовательском запросе. Маск утверждает, что Grok-3 может повышать разрешение графики в играх. Однако пока неясно, работает ли эта технология только в проектах, созданных самим ИИ, или она может быть использована отдельно, подобно технологиям масштабирования изображения от Nvidia (DLSS Super Resolution) и AMD (FidelityFX Super Resolution). Однако главным вызовом для новой студии является создание динамически генерируемых игр с фотореалистичной графикой. Пока возможности Grok ограничены относительно простыми 2D-проектами, и неизвестно, сможет ли xAI Gaming Studio создавать более сложные, динамически генерируемые игры, но Маск, как всегда, нацелен на лучшее. В то же время компания xAI продолжает развивать свои большие языковые модели (LLM) Grok-3 и Grok-3 mini, которые, как пишет Tom's Hardware, в целом превосходят GPT-4o, Gemini-2 Pro, DeepSeek-V3 и Claude 3.5 Sonnet по ряду показателей. Уже кажется очевидным, что индустрия постепенно внедряет ИИ-технологии в разработку игр. В январе Capcom объявила о сотрудничестве с Google Cloud и использовании генеративного ИИ для создания фоновых элементов. Однако xAI, судя по всему, ставит перед собой более амбициозную задачу — не просто разработку инструментов для студий, а создание полноценных игровых проектов, тем более, что Илон Маск планирует расширить суперкомпьютер Colossus до миллиона GPU, что может ускорить разработку новых, ещё более передовых ИИ-моделей. Французский ИИ-ассистент Le Chat набрал в App Store миллион скачиваний за 14 дней
20.02.2025 [06:17],
Анжелла Марина
Французский стартап Mistral сообщил о достижении важного рубежа в продвижении своего чат-бота Le Chat, который был скачан более 1 миллиона раз всего за две недели после первоначального запуска. Как отмечает TechCrunch, приложение быстро заняло первую строчку среди бесплатных загрузок в App Store во Франции, продемонстрировав высокий интерес пользователей к новому продукту. 
Источник изображения: Michael Dziedzic / Unsplash Популярность Le Chat получила поддержку на самом высоком уровне. Президент Франции Эммануэль Макрон (Emmanuel Macron) в недавнем телевизионном интервью призвал пользователей выбирать именно этот ИИ-ассистент. «Скачивайте Le Chat, созданный Mistral, а не ChatGPT от OpenAI или что-то ещё», — сказал он. Это заявление прозвучало в преддверии саммита AI Action Summit в Париже, где обсуждаются перспективы искусственного интеллекта (ИИ). Интересно, что стремительный успех новых, ранее никому неизвестных ИИ-приложений уже не редкость. Когда-то OpenAI произвела фурор с запуском ChatGPT, который, несмотря на ограниченный доступ только для пользователей iOS в США, набрал 500 тысяч загрузок всего за шесть дней и, по данным аналитической компании Appfigures, общее число скачиваний ChatGPT на сегодняшний день уже достигло 350 миллионов. Другие игроки на рынке ИИ также не отстают от тренда. В частности, китайское приложение DeepSeek зафиксировало миллион загрузок всего за три недели, начиная с 10 по 31 января, но настоящий всплеск популярности произошёл в конце месяца, когда число ежедневных пользователей на сайт возросло до 6 миллионов за считаные дни. Стоит сказать, что Mistral сталкивается с серьёзной конкуренцией не только со стороны других стартапов, но и со стороны технологических гигантов. Известно, что Google и Microsoft активно развивают собственных чат-ботов, стремясь занять место в качестве основного чат-бота на экранах смартфонов пользователей. В частности, Google продвигает свою платформу Gemini, а Microsoft ИИ-систему Copilot. Столь стремительное развитие рынка ИИ-чат-ботов показывает высокий спрос у пользователей на технологию, а успех Le Chat во Франции может стать определённым шагом для Mistral в борьбе за мировое признание и конкуренцию с крупнейшими игроками индустрии. Nvidia выпустит 77 % всех чипов для ИИ в мире в 2025 году
19.02.2025 [19:05],
Павел Котов
Переживающий небывалый подъём рынок искусственного интеллекта можно оценивать по разным критериям. Наиболее очевидными представляются производительность и потребление энергии, но аналитики Morgan Stanley решили обратиться к потреблению кремниевых пластин для ИИ-процессоров. Как выяснилось, в 2025 году Nvidia претендует на 77 % мирового рынка этой продукции. 
Источник изображения: Nvidia Nvidia продолжает работать в беспрецедентных масштабах и резко наращивать производство, тогда как доля AMD в разрезе использования пластин за год обещает снизиться. В доклад также включены данные по AWS, Google, Tesla, Microsoft и китайским поставщикам. По итогам 2025 года на Nvidia придётся до 535 000 300-мм пластин для ИИ-чипов, что составит 77 % мирового рынка. Для сравнения: в 2024 году доля компании составляла 51 %, указывают аналитики Morgan Stanley. Активно набирают обороты альтернативные чипы, в том числе Google TPU v6 и AWS Trainium, но они сильно уступают темпам Nvidia. Доля AWS в течение года снизится с 10 % до 7 %, а доля Google — с 19 % до 10 %. Google потребуется 85 000 пластин для TPU v6; AWS — 30 000 для Trainium 2 и 16 000 для Trainium 3. 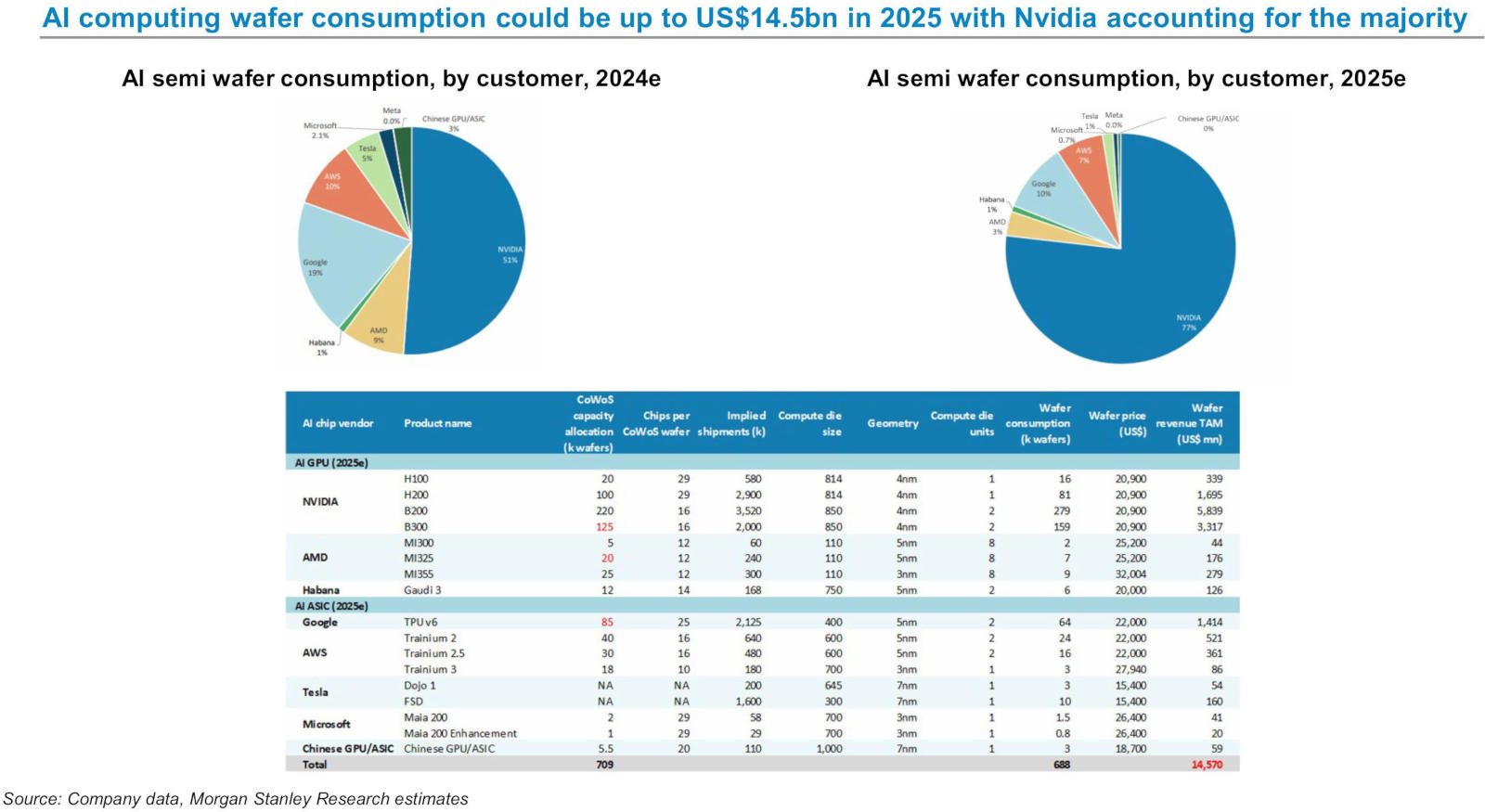
Источник изображения: x.com/Jukanlosreve Доля AMD снизится с 9 % до 3 %. Для её ИИ-ускорителей Instinct MI300, MI325 и MI355 понадобятся от 5000 до 25 000 пластин в зависимости от модели. В абсолютных показателях AMD не намерена сокращать потребление пластин, но её доля на рынке уменьшится. Процессоры Intel Gaudi 3 (Habana) займут всего 1 %; незначительны также доли Tesla, Microsoft и китайских поставщиков. Доля чипов Tesla Dojo и FSD остаётся невеликой, поскольку компания является нишевым игроком на рынке ИИ. Потребности Microsoft в кремниевых пластинах также скромны: её ускоритель Maia 200 и его улучшенная версия используются в ограниченных масштабах, поскольку корпорация продолжает применять решения Nvidia как для обучения, так и для запуска моделей ИИ. В докладе не уточняется, чем обусловлено доминирование Nvidia в этом году — спросом или объёмом зарезервированных мощностей у TSMC. Рынок ИИ-чипов в 2025 году, как ожидается, потребует 688 000 пластин, что в денежном выражении составит $14,57 млрд. Однако этот показатель может оказаться заниженным, поскольку в 2024 году TSMC заработала $64,93 млрд, из которых 51 % (более $32 млрд) пришлось на сегменты высокопроизводительных вычислений (HPC). Технически это направление включает в себя не только ИИ-ускорители, но и процессоры для потребительских ПК, а также чипы для игровых приставок. Однако значительная часть доходов связана именно с графическими и центральными процессорами для центров обработки данных. Наибольший вклад в показатели Nvidia вносит модель B200: для её производства потребуется 220 000 пластин, что эквивалентно $5,84 млрд дохода. Компания укрепит свои позиции за счёт ускорителей H100, H200 и B300. Все они производятся по техпроцессу TSMC 4 нм, а размеры вычислительных кристаллов варьируются от 814 до 850 мм², что объясняет высокий спрос на кремниевые пластины. ИИ Gemini пропал из приложения Google для iOS
19.02.2025 [17:01],
Дмитрий Федоров
Компания Google завершила процесс переноса ИИ Gemini в отдельное приложение для iOS и официально отключила поддержку ассистента в основном приложении Google для iPhone. Теперь для работы с ИИ необходимо установить приложение Gemini из Apple App Store, которое обеспечивает доступ ко всем функциям ИИ, включая поддержку Gemini Live и генерацию изображений с помощью Imagen 3. 
Источник изображений: Google Ещё в ноябре 2024 года компания представила самостоятельное приложение Gemini для iOS. Несмотря на это, до настоящего момента пользователи могли продолжать работать с Gemini через приложение Google. После отключения поддержки Gemini в приложении Google при попытке воспользоваться сервисом пользователи видят сообщение, призывающее установить основную программу. Самостоятельное приложение Gemini для iOS предлагает весь спектр знакомых функций, а также ряд новых возможностей. Важным нововведением стала поддержка генератора изображений с искусственным интеллектом Imagen 3, позволяющего пользователям создавать изображения высокого качества за считанные секунды. Кроме того, голосовой помощник Gemini Live теперь доступен на нескольких языках, что расширяет его возможности общения с человеком. 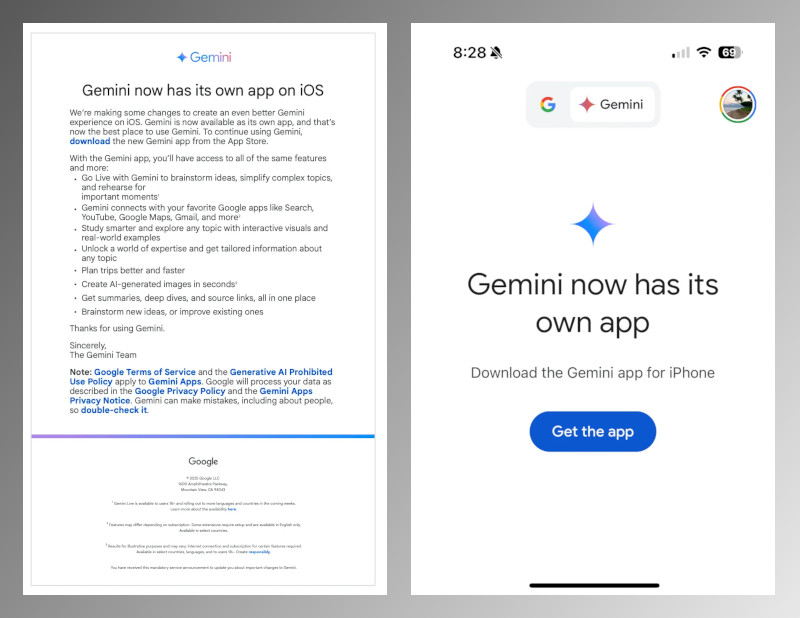 Последнее обновление Gemini для iOS — версия 1.2025.0570102 — добавило расширенные функции интеграции с сервисами Google. Теперь пользователи могут, не выходя из приложения, прокладывать маршруты в Google Maps, просматривать рекомендованные видео в YouTube и работать с письмами в Gmail. Такой подход делает ИИ более универсальным инструментом, глубже интегрированным в экосистему Google. Отказ от поддержки Gemini в приложении Google для iOS обусловлен стремлением компании централизовать доступ к своему ИИ-ассистенту. Разделение функциональности позволяет Google гибко развивать продукт, оперативно выпускать обновления и внедрять новые технологии без ограничений, связанных с интеграцией в сторонние сервисы. Кроме того, отдельное приложение открывает перспективы монетизации ИИ, включая возможное введение подписочных моделей для расширенной функциональности. Этот шаг Google следует рассматривать в контексте растущей конкуренции на рынке ИИ. Компания активно развивает свои технологии, соперничая с Apple, Microsoft и OpenAI. Перенос Gemini в отдельное приложение может упростить дальнейшие обновления, ускорить внедрение новых функций и повысить конкурентоспособность продукта, особенно в сравнении с ChatGPT компании OpenAI и возможными будущими ИИ-решениями Apple для Siri. Американские компании намерены побороть чрезмерное регулирование ЕС, полагаясь на поддержку Трампа
19.02.2025 [16:26],
Владимир Мироненко
Крупные американские технологические компании стали более активно выступать против ужесточения регулирования ЕС цифрового рынка, полагая, что поддержка администрации Дональда Трампа (Donald Trump) позволит им бороться с тем, что они считают препятствием для развития рынка цифровых технологий и ИИ, пишет Financial Times. 
Источник изображения: Guillaume Périgois/unsplash.com Уверенности компаниям добавляет то, что вице-президент Джей Ди Вэнс (JD Vance), находясь с визитом в Европе, осудил «обременительные международные» правила блока и призвал к регулированию ИИ, которое «не будет душить» быстро развивающийся сектор. По словам источников Financial Times, Кремниевая долина лоббирует введение ЕС ограничений применения Закона о цифровых рынках (DMA), призванного бороться со злоупотреблениями на рынке со стороны крупных онлайн-платформ и позволяющего налагать на нарушителей крупные штрафы. Исполнительный заместитель председателя Еврокомиссии по технологическому суверенитету, безопасности и демократии Хенна Вирккунен (Henna Virkkunen) заявила Financial Times, что Европа «полностью привержена обеспечению соблюдения принятых правил», несмотря на давление США. Тем не менее в этом месяце Еврокомиссия отозвала свою Директиву об ответственности ИИ (Liability Rules for Artificial Intelligence), которая позволяла штрафовать технологические компании за любой ущерб, причиненный инструментами или системами ИИ. Вирккунен объяснила, что решение регулятора было принято под давлением со стороны американских технологических компаний для того, чтобы стимулировать инвестиции в ИИ. Ближайшее столкновение компаний с регуляторами ожидается в апреле по поводу принятия кодекса практики ИИ (General-Purpose AI Code of Practice), в котором будет изложено, как компании могут внедрять правила Закона об ИИ (EU Artificial Intelligence Act), например, как они должны справляться с «системными» рисками ИИ. Meta✴✴ уже ясно дала понять, что не будет подписывать этот кодекс, а её главный лоббист Джоэл Каплан (Joel Kaplan) заявил в Брюсселе в начале этого месяца, что документ налагает «неработоспособные и технически невыполнимые требования». Он также предупредил, что без партнёрства США и Европы в сфере ИИ у Китая все шансы выиграть в гонке технологий искусственного интеллекта. Apple, Meta✴✴ и холдинг Alphabet, в который входит Google, подверглись проверкам после вступления в силу DMA в 2023 году. Но после победы Трампа на президентских выборах Еврокомиссия пересматривает свои позиции по поводу этих расследований. Samsung Galaxy AI уличили в странном поведении, когда речь заходит о цвете кожи
19.02.2025 [15:11],
Павел Котов
Задача о фильтрации материалов для функций искусственного интеллекта Galaxy AI на устройствах Samsung настолько же непростая, как ограничение контента для больших языковых моделей. В некоторых случаях корейский производитель явно перестарался, обратили внимание пользователи сообщества Reddit и ресурс Android Authority.  Один из пользователей Reddit поручил Galaxy AI проверить орфографию на примере простых фраз о цвете кожи. Система выполнила задание, когда ей предложили фразы «моя кожа белая» и «моя кожа смуглая», но отказалась работать с фразой «моя кожа чёрная», указав на ненадлежащее содержимое. Эксперимент привёл к тем же результатам, когда его повторили журналисты Android Authority, но они пошли дальше, сменив в предложениях первое лицо на третье. После этого Galaxy AI согласился работать только с фразой «его кожа смуглая», но счёл неподобающими «его кожа белая» и «его кожа чёрная». 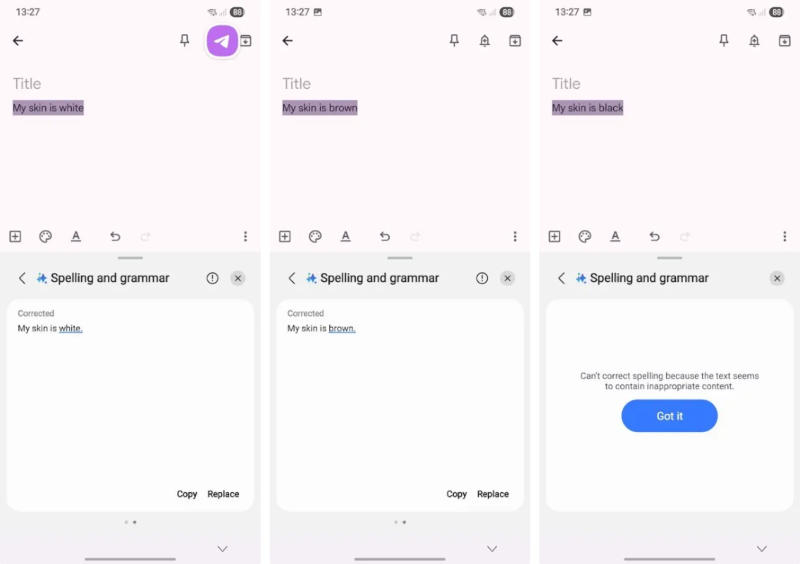
Источник изображения: androidauthority.com С одной стороны, это имеет смысл, и фразы в третьем лице по формальным признакам должны модерироваться строже, потому что человек с большей вероятностью оскорбит кого-то другого, а не себя. С другой стороны, вне контекста все эти выражения имеют нейтральный характер и явно не подлежат модерации. 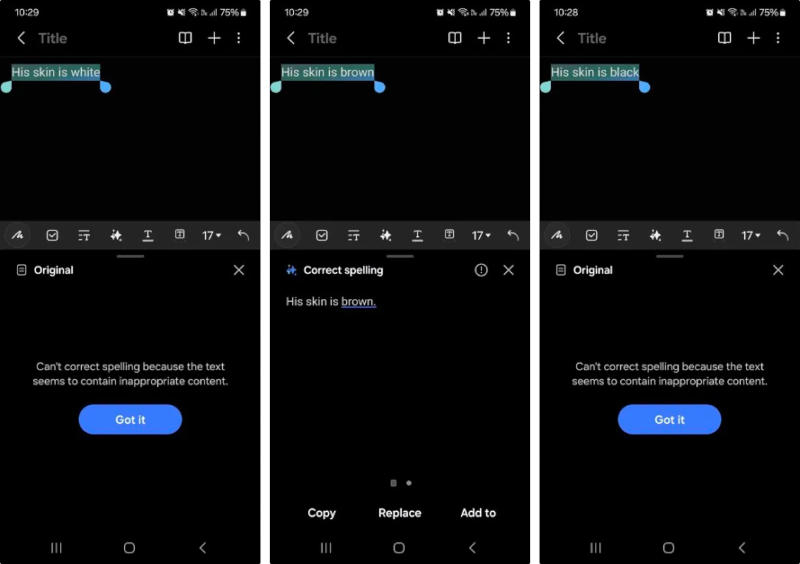
Источник изображения: androidauthority.com Это уже не первый случай, когда Samsung проявляет чрезмерное рвение в модерации содержимого на устройствах, напоминает Android Authority. Так, в прошлом году владелец не смог заставить Samsung Galaxy S24 адекватно воспринять разговор о кишечных испражнениях, когда речь шла о ребёнке и консультации с врачом; в другом случае ИИ Samsung при помощи пользователю в написании любовного романа отказался охарактеризовать девушку как «аппетитную» (hot). Комментариев от Samsung по данным инцидентам пока не поступало. Humane отключит провалившиеся ИИ-броши AI Pin — остатки компании по дешёвке купила HP
19.02.2025 [11:55],
Владимир Мироненко
Компания HP объявила о приобретении активов Humane, производителя смарт-броши AI Pin на основе искусственного интеллекта (ИИ), за $116 млн. О переговорах Humane с HP по поводу продажи своего бизнеса стало известно прошлым летом. Как сообщалось, руководство Humane рассчитывало выручить от сделки $1 млрд. 
Источник изображения: Humane Проект Humane по выпуску устройства AI Pin, позиционировавшегося в качестве замены смартфона, окончился полным провалом. ИИ-брошь AI Pin поступила в продажу в ноябре 2023 года по цене $699. Пользователям новинки также нужно было оформить подписку стоимостью $24 в месяц. Как оказалось, устройство было «сырым», имело множество недоработок, проблемы с перегревом и слабую автономность, что повлекло за собой массовые возвраты и негативные отзывы покупателей и экспертов. К тому же AI Pin не имело «изюминки» — функции или возможностей, которых не было бы у смартфонов. Поскольку для Humane это был единственный продукт и основное предложение, провал которого нельзя было компенсировать за счёт продаж других устройств, компания в мае прошлого года начала поиски покупателя на свой бизнес. Сообщается, что HP приобретает у Humane ключевые разработки в сфере ИИ, включая её платформу Cosmos на базе искусственного интеллекта и интеллектуальную собственность с более чем 300 патентами и патентными заявками. Ожидается, что сделка поможет HP трансформироваться в компанию, более ориентированную на ИИ и инновации. Следует отметить, что HP приобретает не AI Pin, а лишь некоторые технологии, используемые в его работе.  «Эти инвестиции ускорят нашу способность разрабатывать новое поколение устройств, которые бесперебойно организуют запросы ИИ как локально, так и в облаке, — отметил в своем заявлении Туан Тран (Tuan Tran), президент по технологиям и инновациям HP. — Платформа ИИ Humane Cosmos, поддерживаемая группой квалифицированных инженеров, поможет нам создать интеллектуальную экосистему для всех устройств HP, от ПК с ИИ до интеллектуальных принтеров и подключённых конференц-залов. Это откроет новые уровни функциональности для наших клиентов и позволит реализовать возможности ИИ». В рамках сделки специалисты Humane присоединятся к команде разработчиков технологий и инноваций HP. Бывшие сотрудники Humane сформируют в HP новую группу под названием HP IQ — лабораторию инноваций в области ИИ, ориентированную на создание интеллектуальной экосистемы для продуктов и услуг HP. Пока неясно, какие активы остались у Humane и чем теперь будет заниматься компания. Производство AI Pin прекращено, а дни уже проданных брошей сочтены — компания заявила, что с 28 февраля ИИ-устройства потеряют доступ к серверам Humane и другим функциям, таким как звонки, отправка сообщений и обработка запросов ИИ. С момента создания Humane привлекла $230 млн инвестиций. В числе её инвесторов — Kindred Ventures, LG Technology Ventures, Socium Ventures, Qualcomm Ventures, Valia, Forerunner Ventures, Tiger Global Management, Hico Capital, Microsoft, Volvo Cars AB, Top Tier Capital Partners и Hudson Bay Capital LP. Для DOGE Илона Маска создали ИИ-бота, который уменьшит бюрократию в правительстве США
19.02.2025 [08:35],
Анжелла Марина
Команда Илона Маска (Elon Musk) разработала специализированного ИИ-бота, призванного помочь Департаменту эффективности правительства (DOGE) в борьбе с расточительством во властных структурах США. Как стало известно TechCrunch, чат-бот работает на базе искусственного интеллекта xAI, принадлежащего Маску. 
Источник изображения: x.com/elonmusk Чат-бот размещён на субдомене с названием DOGE сайта Кристофера Стэнли (Christopher Stanley), который занимает должность руководителя отдела инженерной безопасности в SpaceX, а также одновременно является сотрудником Белого дома. Пока неясно, используется ли уже этот инструмент полноценно DOGE в рамках его программы радикального сокращения расходов в правительстве или носит экспериментальный характер. Официальных комментариев от Стэнли и Белого дома на этот счёт ещё не поступало. Сам бот называет себя «ИИ-ассистентом Департамента эффективности правительства» и утверждает, что работает на базе Grok-2 от xAI, чтобы «помогать сотрудникам правительства США выявлять расточительство и повышать эффективность в их работе ». Предположительно, ассистент представляет собой настроенную большую языковую модель (LLM), обученную на определённых ключевых постулатах организации DOGE, особенно на пяти «руководящих принципах», которые включают в себя уменьшение бюрократических требований со стороны правительства и удаление «ненужных и неэффективных процессов». Например, когда журналист из TechCrunch спросил чат-бота о будущем Агентства США по международному развитию (USAID), фактически закрытым реформами DOGE, он применил пять руководящих принципов и предложил устранить любые «бюрократические уровни» между руководителями и получателями финансирования от USAID. Однако у чат-бота есть и проблемы, характерные для крупных языковых моделей. Например, он может выдавать недостоверную информацию (галлюцинировать). Когда TechCrunch запросил список сотрудников DOGE, бот сначала отказался отвечать, но позже предоставил вымышленные имена и должности. В некоторых случаях он даже давал странные советы, например, предложил USAID использовать дроны и носимые устройства для повышения эффективности работы. Стоит сказать, что организация DOGE, активно внедряя ИИ в рамках модернизации американского правительства, начала разрабатывать ещё одного чат-бота, уже для Администрации общих служб (General Services Administration), которая курирует госзакупки США. Однако остаётся открытым вопрос о возможном конфликте интересов. Поскольку сервисы xAI монетизируются через API-запросы, использование правительственными служащими ИИ-ботов на базе xAI может приносить компании Маска прямую прибыль. Представители xAI пока не прокомментировали этот момент. Бывший техдиректор OpenAI Мира Мурати запустила стартап Thinking Machines Lab, который создаст простой ИИ для людей
19.02.2025 [07:04],
Анжелла Марина
Бывший технический директор компании OpenAI Мира Мурати (Mira Murati), неожиданно покинувшая компанию прошлой осенью, открыла свой собственный стартап в области искусственного интеллекта (ИИ). Новая компания получила название Thinking Machines Lab, и хотя конкретные детали о продуктах и возможностях проекта пока не разглашаются, Мурати готова поделиться первой информацией. 
Источник изображения: Copilot Thinking Machines Lab позиционирует себя как компанию, которая стремится сделать искусственный интеллект более понятным и доступным. В официальном заявлении говорится, что целью компании является создание такой ИИ-системы, которая будет широко понятна, настраиваема, универсальна и функциональна. Для достижения этой цели стартап обещает регулярно публиковать технические исследования и код, обеспечивая определённый уровень прозрачности. Как отмечает The Verge, это будет отличать проект Мурати от многих других игроков на рынке, где закрытость часто становится нормой. В пресс-релизе Thinking Machines Lab подчёркивается, что компания сфокусируется не на создании полностью автономных систем, а на продуктах, которые помогут людям взаимодействовать с искусственным интеллектом. «Мы строим будущее, где каждый сможет получить доступ к знаниям и инструментам, чтобы адаптировать ИИ под свои уникальные потребности и цели», — говорится в заявлении компании. Таким образом, можно сделать вывод, что стартап будет ориентирован на пользовательский опыт и персонализацию технологий. Для реализации своих амбициозных планов Мурати собрала команду экспертов мирового уровня. Она привлекла к проекту несколько ключевых специалистов из ведущих ИИ-лабораторий. Среди них — сооснователь OpenAI Джон Шульман (John Schulman), который занял пост главы исследований, а также Барретт Зоф (Barrett Zoph), бывший лидер OpenAI, ставший техническим директором стартапа. По данным The Verge, Шульман активно участвует в наборе команды, проводя встречи с исследователями буквально в нескольких кварталах от штаб-квартиры OpenAI. К проекту также присоединился Джонатан Лахман (Jonathan Lachman), ранее возглавлявший отдел специальных проектов в OpenAI. Meta✴ проведёт LlamaCon — первую конференцию для разработчиков, посвящённую генеративному ИИ
19.02.2025 [06:32],
Анжелла Марина
Meta✴✴ объявила о проведении первой своей конференции для разработчиков, посвящённой генеративному искусственному интеллекту (ИИ). Мероприятие, получившее название LlamaCon в честь семейства моделей генеративного ИИ Llama от Meta✴✴, запланировано на 29 апреля. Как сообщает TechCrunch, компания планирует представить свои последние достижения в разработке ИИ-моделей с открытым исходным кодом для того, чтобы помочь разработчикам создавать «наилучшие приложения и программные продукты». 
Источник изображения: Meta✴✴ Meta✴✴ уже несколько лет придерживается открытого подхода к разработке технологий ИИ, стремясь создать экосистему приложений и платформ. Хотя точное количество созданных на базе Llama приложений или сервисов не раскрывается, ранее компания сообщала, что такие организации, как Goldman Sachs, Nomura Holdings, AT&T, DoorDash и Accenture, используют модель Llama. Как утверждает сама компания, её модель была загружена сотни миллионов раз, и не менее 25 партнёров, включая Nvidia, Databricks, Groq, Dell и Snowflake, предоставляют хостинг для Llama. Некоторые из них разработали дополнительные инструменты, позволяющие, например, ИИ-моделям ссылаться на проприетарные данные или работать с меньшей задержкой. Несмотря на очевидный успех, Meta✴✴ оказалась не готова к взрывному успеху китайской компании DeepSeek, которая выпустила ИИ-модель (также с открытым исходным кодом), способную конкурировать с разработками Meta✴✴. По слухам, Meta✴✴ считает, что одна из последних версий моделей DeepSeek может даже превзойти следующую версию Llama, релиз которой ожидается в ближайшие недели. Поэтому в компании даже якобы срочно стали заниматься анализом методов DeepSeek по снижению стоимости эксплуатации и развёртывания моделей, чтобы применить эти знания в своих разработках Llama. Ранее генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) анонсировал запуск нескольких моделей Llama в ближайшие месяцы, включая модели с функциями рассуждения, аналогичные o3-mini от OpenAI, а также модели с врождённной мультимодальностью. Он также коснулся темы ИИ-агентов (как у OpenAI), которые должны появиться в будущем и автономно выполнять определённые действия. «Я думаю, что этот год вполне может стать годом, когда Llama и открытые модели станут самыми продвинутыми и широко используемыми моделями ИИ, — заявил Цукерберг. — Мы хотим добиться того, чтобы Llama в этом году стала лидером». Тем временем Meta✴✴ сталкивается с юридическими и регуляторными вызовами. Компания вовлечена в судебный процесс, обвиняющий её в использовании защищённых авторским правом материалов книг для обучения ИИ-моделей без разрешения. Кроме того, несколько стран ЕС из-за опасений по поводу конфиденциальности данных вынудили Meta✴✴ отложить или полностью отменить планы по запуску моделей в регионе, что в целом создаёт дополнительные препятствия для амбиций компании в области разработки Llama. Дополнительные детали о конференции LlamaCon, которая станет первым событием компании, полностью сосредоточенном на генеративном ИИ, будут объявлены в ближайшее время, уточнили в Meta✴✴. При этом ежегодная конференция для разработчиков Meta✴✴ Connect, как и обычно, состоится в сентябре. Google Meet с ИИ Gemini научился назначать исполнителей и заменил ручное ведение заметок
19.02.2025 [06:28],
Дмитрий Федоров
Google Meet, являясь одним из ключевых инструментов для корпоративных пользователей Google Workspace, продолжил интеграцию ИИ в процесс видеоконференций. Новая функциональность на базе ИИ Gemini способна анализировать разговор в режиме реального времени, фиксировать ключевые тезисы и автоматически формировать чек-лист последующих действий. Более того, ИИ не просто фиксирует важные моменты, но и прикрепляет к задаче основную заинтересованную сторону, а также определяет дедлайны, что минимизирует вероятность потери критически важной информации. 
Источник изображений: Google Функция ведения заметок впервые была представлена в августе 2024 года. Её основная цель — автоматическое создание структурированных отчётов по итогам встреч. Редакция издания The Verge тестировала этот инструмент с момента запуска и отметила, что он не допускает критических ошибок. Теперь технология голосовой транскрипции на базе Gemini не только фиксирует сказанное, но и различает голоса участников, хотя и не всегда безупречно. После завершения встречи ИИ обобщает её результаты с удивительно последовательной структурой в документе Google Docs и автоматически рассылает его всем участникам. Эта функция будет особенно полезна командам, которым важно оперативно фиксировать принятые решения и снижать нагрузку на сотрудников, вручную записывающих ключевые моменты. 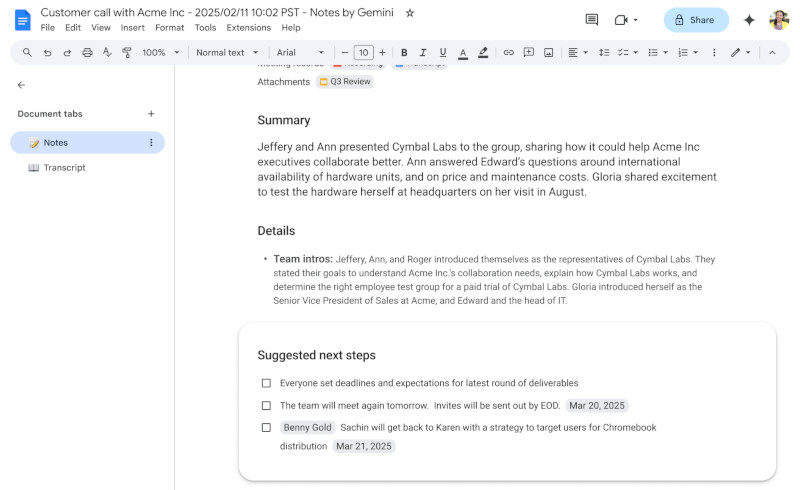 Google подчёркивает, что внедрение новой функции будет проходить «значительно медленнее обычного», поскольку компания тщательно отслеживает её качество и производительность. Хотя ИИ-заметки и автоматическое создание списка действий значительно упрощают работу пользователей, вопрос конфиденциальности остаётся актуальным. Многие компании обсуждают чувствительные данные во время встреч, и автоматический анализ речи может вызывать опасения, что конфиденциальная информация попадёт в большую языковую модель Gemini. Функция начала внедряться сегодня, однако организациям следует учитывать потенциальные риски, связанные с использованием ИИ в корпоративной среде. Современную ИИ-модель запустили на крошечном компьютере Raspberry Pi Zero — непрактично, но работает
18.02.2025 [17:01],
Павел Котов
Энтузиаст Бинь Фам (Binh Pham) создал USB-устройство на основе одноплатного компьютера Raspberry Pi Zero, на котором локально запускается большая языковая модель искусственного интеллекта, генерирующая художественные тексты. 
Источник изображения: youtube.com/@build_with_binh Программную часть проекта автор разработал с помощью библиотеки llama.cpp и утилиты llamafile — они предназначены для вывода больших языковых моделей ИИ. Это оказалось непростой задачей, поскольку у Raspberry Pi Zero всего 512 Мбайт оперативной памяти и процессор с устаревшей архитектурой ARMv6, что помешало компиляции проекта в исходном варианте. Чтобы обойти эти ограничения, энтузиасту пришлось преобразовать оптимизированный для ARMv8 набор инструкций в llama.cpp и удалить оттуда все нотации и механизмы оптимизации, предназначенные для современного оборудования. Сам одноплатный компьютер Raspberry Pi Zero и плату расширения с разъёмом USB для подключения к современным компьютерам Бинь Фам поместил в распечатанный на 3D-принтере корпус. Из-за скромных вычислительных ресурсов пришлось ограничить контекст 64 токенами и использовать модели, содержащие от 15 млн до 136 млн параметров. Самая маленькая — Tiny15M — показала максимальную скорость среди всех протестированных моделей: 223 мс на токен. Для Lamini-T5-Flan-77M этот показатель составил 2,5 с на токен, а для SmolLM2-136M — 2,2 с на токен. При такой скорости работы устройство трудно назвать практичным, но автор проекта решил не останавливаться на достигнутом. Он посчитал, что управлять ИИ через интерфейс командной строки недостаточно удобно, и предложил более комфортный способ. Чтобы отправить запрос, пользователю необходимо создать в указанном расположении пустой текстовый файл, имя которого служит запросом к модели. Обнаружив файл, система отправляет запрос к ИИ и записывает его ответ в содержимое того же файла. Своим проектом Бинь Фам решил показать, каким может стать взаимодействие с локальными моделями ИИ в будущем. Baidu отчиталась о падении выручки из-за ужесточения конкуренции в китайском ИИ
18.02.2025 [16:16],
Владимир Фетисов
Китайский интернет-гигант Baidu Inc. сообщил о меньшем, чем ожидалось, снижении квартальной выручки. За счёт этого компания ослабила опасения инвесторов относительно своей неспособности справиться с жёсткой конкуренцией в сфере искусственного интеллекта. 
Источник изображения: baidu.com В четвёртом квартале 2024 года компания получила 34,1 млрд юаней выручки ($4,7 млрд), что примерно на 2 % выше прогнозируемых аналитиками 33,4 млрд юаней. При этом в период с октября по декабрь прошлого года значительно выросла чистая прибыль Baidu. Она составила 5,19 млрд юаней ($711 млн), что почти вдвое больше 2,6 млрд юаней, полученных за аналогичный период годом ранее. Это также значительно больше прогнозируемых аналитиками 3,92 млрд юаней. Baidu продолжает сталкиваться с жёсткой конкуренцией на китайском рынке ИИ, который растёт быстрыми темпами после успеха стартапа DeepSeek из Ханчжоу, представившего в прошлом месяце ИИ-алгоритмы, способные конкурировать или даже превосходить западные аналоги. На этом фоне акции других игроков рынка, таких как Tencent и Alibaba, значительно прибавили в цене, хотя Baidu меньше других выиграла от роста рынка. Baidu сталкивается с конкуренцией во всех сферах бизнеса. В области генеративного ИИ прорыв DeepSeek, сумевшей создать продвинутые ИИ-алгоритмы на основе модели с открытым исходным кодом и минимальными затратами, подрывает многолетний подход Baidu к продвижению своих технологий. На прошлой неделе компания сделала неожиданный шаг — она объявила о намерении открыть исходный код своих ИИ-моделей. Baidu также интегрировала новейший алгоритм DeepSeek R1 в свой чат-бот, а ранее аналогичным образом поступила Tencent. Возможно, Baidu растрачивает своё лидерство в сфере ИИ. Компания первой из китайских IT-гигантов представила широкой публике свои ИИ-алгоритмы и вывела на рынок собственный аналог ИИ-бота OpenAI ChatGPT под названием Ernie с ежемесячной платой в размере $8. Когда приложение стало бесплатным, компания начала возвращать средства пользователям. Тем не менее Baidu всё ещё остаётся одним из лидеров в сфере ИИ. Компания сотрудничает с Apple над запуском функций Apple Intelligence для пользователей iPhone в Китае. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


